linq.js ver 1.3.0.0 - Unfold, Matches, etc...
- 2009-05-24
今回は本体も含めて大量更新です。生成子にUnfoldとMatchesを追加しました。Unfoldは応用範囲がとても広く(広すぎて逆に使い道が思いつかない)、Matchesは正規表現がより使いやすくなるので、実用度が非常に高いと思われます。そして、FromにStringを入れたときの動作を一文字毎に分解するよう変更。更に操作用メソッドにも、Insert, IndexOf, LastIndexOfを追加しました。あと、その他色々。
Unfold
UnfoldはAggregateの反対、といっても良くわからないのですが、引数と戻り値の型が同一の関数を無限に適用し続ける、という感じです。例えばE.Unfold(0, "$+3")は、初期値が0で、適用する関数が+3。というわけで、0,3,6,9....と無限に3ずつ増幅していく値が取り出せます。これだけでは終了しないので、終了条件はTakeかTakeWhileで別に与えます。
// フィボナッチ数列の無限リスト
var fib = E.Unfold({ a: 1, b: 1 }, "{a:$.b, b:$.a + $.b}").Select("$.a");
// 10個分だけ画面に出力 - 1,1,2,3,5,8,13,21,34,55
fib.Take(10).WriteLine();
// abcdefを一文字ずつ削っていく- abcdef,bcdef,cdef,def,ef,f
E.Unfold("abcdef", "$.substr(1)").TakeWhile("$.length>0").WriteLine();
例はフィボナッチ数列で、これは熟練した C# 使いは再帰を書かない? - NyaRuRuの日記の丸コピです。タプルの片方を計算用の一時領域として使う、という感じでしょうか?
static void Main(string[] args)
{
// 16進の文字列をByte配列に変換する
var str16 = "FF-04-F2 B3 05 16F3";
var regex = new Regex(@"[abcdef\d]{2}", RegexOptions.IgnoreCase);
// 全部マッチさせてから変換
var byteArray1 = regex.Matches(str16)
.Cast<Match>()
.Select(m => Convert.ToByte(m.Value, 16));
// Unfold使って一つずつ変換
var byteArray2 = Unfold(regex.Match(str16), m => m.NextMatch())
.TakeWhile(m => m.Success)
.Select(m => Convert.ToByte(m.Value, 16));
}
static IEnumerable<T> Unfold<T>(T seed, Func<T, T> func)
{
while (true)
{
yield return seed;
seed = func(seed);
}
}
UnfoldをC#で正規表現のマッチに使ってみた。あまり意味はない。これをJavaScriptでやると、マッチオブジェクトにNextMatch()がないので、lastIndexの変化したRegExpにexec()し続ける必要がある。というわけで、Timesを使えば同じことができます。E.Times("regex.exec(input)").TakeWhile("$ != null") です。String.match(オプションはglobal)を使って配列を取得したほうが楽なのですが、それだと文字列配列(みたいな何か)であって、個々のマッチオブジェクトが取れないので、個々のindex(一致した位置)やキャプチャが必要な場合はRegExp.execを使う、という使い分けかなー、と私は思っています。
Matches
そんなことを考えていたら、やっぱRegExp.execのglobalって使いづらいね、と思ったのでE.Matchesを追加しました。C#のRegex.Matchesと同じようにマッチオブジェクト全てを返します。配列で欲しい場合はToArray()を。そのまま処理を加えたい場合は、Linqのメソッド群全てが使えます。マッチのうち先頭だけが欲しいけど射影処理もしたい場合はMatches().Select().First()という手が使えます。
var input = "abcdefgABzDefabgdg";
E.Matches(input, "ab(.)d", "i").ForEach(function(match)
{
for (var prop in match)
{
document.write(prop + " : " + match[prop] + "<br />");
}
document.write("toString() : " + match.toString() + "<br />");
document.write("<br />");
});
E.Matches(input, /ab(.)/i); // こうも書ける、gフラグはつけなくていい
E.Matches(input, "ab(.)d"); // 大文字小文字を区別するならflag無しで
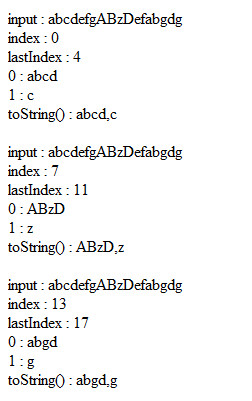
E.Matches(input, pattern, flags)で、patternは文字列でも正規表現オブジェクトでも、どちらでも可能。flagsは省略可、与える場合は仕様通り"i", "m", "im"が使えます。gフラグを明示的に与える必要はありません。与えても与えなくても関係なくglobalで検索します。
中に入るマッチオブジェクトなのですが、[0]にマッチした文字列全体、キャプチャがある場合は[1]以降にキャプチャした文字列が入ります。あとは.indexと.input。IEだと.lastIndexも取れてますが、IE以外のブラウザではlastIndexは使えません(undefinedでした)
From(String)
今までE.From("hoge").ToArray()とすると[0]="hoge"になっていました。つまりE.Repeat("hoge",1)というわけです。これは、何というか、意味ないですよね。C#だと['h','o','g','e']というように、Charに分解します。というわけで、E.From("hoge").ToArray()の結果が["h","o","g","e"]になるように動作を変更しました。
var input = "こんにちは みなさん おげんき ですか? わたしは げんき です。\
この ぶんしょう は いぎりすの ケンブリッジ だいがく の けんきゅう の けっか\
いかりゃく"
var result = E.From(input.split(/[\s\t\n]/))
.Select(function(s)
{
return (s.length > 3)
? s.charAt(0)
+ E.From(s).Skip(1).Take(s.length - 2).Shuffle().ToString()
+ s.charAt(s.length - 1)
: s;
})
.ToString(" ");
alert(result);
サンプルとして、流行から100歩遅れてケブンッリジ変換をlinq.jsで。
真ん中の、「E.From(s).Skip(1).Take(s.length - 2).Shuffle().ToString()」という部分が「こんにちは」を「こんちには」に変換する部分です。E.From(s)で文字列を一文字ずつにバラしているわけです。Skip(1).Take(s.length-2)が、「最初と最後の文字を除く」です。実際の実行例は下のURLからどうぞ。
↑で動かしているものは、必ずシャッフルされるようにしたり、「、。!?」が末尾の時には別の処理をしていたりと、例に出しているコードとはちょっと違いますけれど。詳しくはソースを見てください。
その他
他に追加したメソッドはぶっちゃけ全然使い道ないのでササッと書き流します。まずInsertですが、これはConcatの場所自由版という感じにシーケンスを特定場所に挿入。IndexOf, LastIndexOfは位置の発見で見つからない場合は-1を返すというお馴染みな動作をします。他にlinq.tools.jsにHashSetを追加しました。これはC#のHashSetに似たようなもので、詳しくはリファレンス見てください。そして、Stopwatchに静的メソッドBenchを追加。これは、どうせStopwatch使うのはベンチマークの時だけでしょ?ということで。
var result = Linq.Tools.Stopwatch.Bench(1000, function()
{
E.Range(1,100).Where("$%2==0").Select("$*$").Force();
});
document.write(result + 'ms')
第一引数に繰り返し回数、第二引数に実行する関数。わざわざDateの引き算をすることなく、気楽に計れるので、便利といえば便利。というか、この手のものは手間がかかるとついつい避けてしまうので、サクッと計れないとダメですものね。