Microsoft MVP for Developer Technologies(.NET)を再々々々々々々々々々々々々々々受賞しました
- 2026-07-17
Microsoft MVPは一年ごとに再審査されるのですが、今年も更新しました。2011年から初めて16回目です。前期は中盤から完全に息切れていてなんもやってないなー感すら出ていたのですが、年度通したらそれなりに成果出せていた気もします。
これは去年(前半)ですし、ZLinq v1.0.0は大きかったですね、GitHub Starsも5000を超えています!
ここ半年はAIとの向き合い方を中々アラインできなくて悶々としていたのですが、Fableが突破口になりました。今までのAIは単純に私の納得できるだけの知能がなかったのであり、Fableでついにそこまで到達した、と。先日AI時代におけるC#でのBenchmarkDotNetを使った最速コードの書き方という記事を上げましたが、結構反響もあり、国内外各所でこれを活用してパフォーマンス向上したという報告が相次ぐ……!こういうところでも世の中に貢献しているので、これは文句なしのMicrosoft MVPですよ(?)
そんなわけで、Fableと創り上げる新しい世代のアーキテクチャへのやる気が猛烈に上がってるので現在制作中の"Ultra" MessagePack for C#のパフォーマンス。

限界を超えた限界まで絞りだしているということで、めちゃくちゃ凄い、です。Serializeはかなり詰めた後なのですが、Deserializeはまだなので、全然伸びしろ更にアリです。アーキテクチャはさすがにポン出しではなくて、というかどちらかというと私が長年温めていたものを投下していて、これは当然想定通りにかなり効果あり。そのうえでアセンブリレベルでの最適化をFableが絞り出してくることによって従来のC#の限界を超えてます。これは、もう、まさに今だからこそ辿り着けた領域で、とても感動しています。
と、いうわけで、今年はすさまじいコードをぼんぼん出していけたらいいですね!それはAIのコードだから価値がないのでは?みたいなところもなくもないですが、しかし別にFableをその辺の人に渡しても、これは作れないんですよね。という点で、やはりAIはツールであり、コードは使いこなした人間の作品であるんだと思います。いまのところは。さすがにポン出しでこのレベルのが出てくるようになったらもう何も言えない。あと、多分、これは次のナレッジカットオフに含まれるようになるので、次からは実際ポン出しで出てくるようになる可能性はある。まぁ、それでもいいんです。逆に、今は人間とAIの最後の最前線の競争だからこそ、行き急ぐつもりで楽しむ必要があります……!
それとC# Kaigi 2026も9月にありますので、(もうすぐ始まる)参加登録よろしくおねがいします、私もいい感じの基調講演の内容を練っています!
AI時代におけるC#でのBenchmarkDotNetを使った最速コードの書き方
- 2026-07-06

AI時代においてテストが、AI Agentがループを回すための足腰として重要なように、プロファイラーも思考のための素材を与えるという点で重要です。従来は、基本的には Mean と Allocated を見るぐらいでしたが、どうせAIが読むんだったら、与えられる情報は多ければ多いほどいい、ということで JIT Disassembler や BranchMispredictions/Op も追加していきましょう、デフォルトで。というお話です。この記事では最後にMessagePack for C#の整数値のWriteを改善する例を紹介しますが、asmや分岐予測のデータを元にして、Fableは人間(私)を遥かに超えるコードを生成してくれました。
↑なんと4倍速の余地がある。
なにせAIはこの手の解析は得意技ですから!得意技というのもあるのですが、「なぜそのコードが速くなったのか」を理解するためには、元コード, Mean, Allocatedだけでは証拠が足りないのです。証拠が足りないと、理由付けは推測でしかなくて、外れることがある。それでは改善ループは進まない、これは別に熟練した人間でも、AIであっても変わらない話であり、人間だけがやってきた今までは、なんとなくの理由付けで済ませて、それで終わらせていたことも多くありました。AIなら機械語を解析するコストはゼロなので、押し付けられるコンテキストは可能な限り押し付けてやりましょう。
手法の説明をするにあたって、Skill だの AGENTS.mdだのは、賞味期限も短いので特に書くことでもないと思っています。新しいモデルが来るたびにゲームチェンジでゲームエンドして手のひらクルクルしててどうするの?小手先のスキル・ハーネスも色々ありますが、やはり賞味期限が短く感じます。別にAI驚き屋が言うような、AIを今すぐ使いこなさなければ乗り遅れる、なんてこたぁないんですよね。明らかに去年よりも、いや、半年前よりも使いこなすのがイージーになってきているので、手のひらクルクルしてる時間を真剣に生きたほうがいいですよ絶対……!
Fable 5も出ましたし、Anthrorpic公式のFable 5のプロンプトガイドにもありますが、過剰な指示よりも簡潔に要点絞って方向性を合わせるほうがいいかなあ、と思います。で、これってプロンプトエンジニアリングやハーネス作りに血道をあげるよりは、ずっとイージー度合いが高まっているわけですよね。そして的確な指示を行うには的確な理解力が必要になる、それはプロダクトであれば深いドメイン知識であったりプラットフォームへの理解であったり、ライブラリであれば言語や環境への理解が大事なわけです。たとえAIのほうが知識があったとしても、方向性を示せなければ、真に求めるものを得るのはランダムなガチャを引いて当たりを手にすることを祈るようなものであり、実現は難しいのです。
最速のSum
まずはベンチマークの骨組みから、ということで簡単な指示を与えて作らせます。
C#でbenchmarkdotnetを使って小さな関数を、なにが最速なのかを確認しながら、AIが結果を読み取って最適なコードを見つける仕組みを作りたい。実行速度だけじゃなくて、JIT結果の機械語のdisassembleとその解析も行ってください。
もう少し短くてもいいかなという感じですが、短くしすぎて外してやり取りの往復するのはダルいので、このぐらいで。手順や解析のポイントなんかはAIが自分で作り出して文章化して膨らませてくれるわけだから、秘伝のSkillはいらないかな、と思います。どちらかというと用途別のオーダーメイドなほうがいいとすら思っているので、あれこれ足してコンテキスト汚染するよりも、簡潔なところから、簡潔さを維持しながら育てていくべきではないかな、と。大きなアプリケーションであれば、最終的に固有情報がみっちりかかれた代物が出来上がるかもしれませんが、それはそれで、ようするにオーダーメイドの一点ものが出来上がったということで、とても良いことです。
さて、とりあえずのサンプルとしてAIはSumのベンチマークを作ってきました。これはOpusでもFableでもそうだったし、わかりやすいので、いい例だとは思います。もし作ってこないようだったらSumのベンチマーク作って、とプロンプトに足しておけばいいでしょう。
Baselineのコードは、シンプルな配列のSumのfor loopです。
[Benchmark(Baseline = true)]
public int ForLoop()
{
var d = data;
int sum = 0;
for (int i = 0; i < d.Length; i++)
{
sum += d[i];
}
return sum;
}
結果はこうです。
| Method | Mean |
| ------------------- | --------: |
| ForLoop | 211.31 ns |
| ForEachLoop | 211.44 ns |
| LinqSum | 59.42 ns |
| VectorSimd | 36.42 ns |
| TensorPrimitivesSum | 13.54 ns |
| VectorRef | 32.44 ns |
| Vector512Unrolled | 22.05 ns |
| Vector512Final | 18.36 ns |
SIMDにして速くなりましたー、みたいなのは当然かな、と思うのですが、なんか色々やってくれてますね。これは、理屈としてはAIがasmを見ながら3 roundで最適化処理をかけていったという体になります。
| Round | 実装 | Mean | asm から見つけた欠陥 → 次の一手 |
| ----- | -------------------- | --------- | ---------------------------------------------------------- |
| 1 | ForLoop (baseline) | 203 ns | 未ベクトル化 |
| 1 | VectorSimd | 33 ns | Slice の範囲チェックが毎反復残存 → ref ベース化 |
| 2 | Vector512Unrolled | 19 ns | `movsxd` が毎ロード前に挿入、端数がスカラー → nuint 化+マスク端数 |
| 3 | **Vector512Final** | **18 ns** | メインループが純粋な `vpaddd zmm`×4、端数も AVX-512 マスクレジスタ処理。手書きの理想形に到達 |
| — | TensorPrimitives.Sum | 13 ns | 天井(64B アラインメント調整+8段アンロール) |
この結果は究極で、これ以上言えることはなんもありません。ちなみにOpusではここまでたどり着かなかったので、やはりFableは強力だな、と思いました。
さて、コードを見ていきましょう。SIMD化はシンプルな話で、通常だと手書きでもこのぐらいは書くし、このぐらいでいっか、で終わらせるところです。
[Benchmark]
public int VectorSimd()
{
var d = data.AsSpan();
var acc = Vector<int>.Zero;
int i = 0;
for (; i <= d.Length - Vector<int>.Count; i += Vector<int>.Count)
{
acc += new Vector<int>(d.Slice(i));
}
int sum = Vector.Sum(acc);
for (; i < d.Length; i++)
{
sum += d[i];
}
return sum;
}
今回の試行ではその先へもグイグイ進んで、Round3の最終形は、アンロール頑張りました。
// Round 3: nuint indexing (kills movsxd) + masked vector tail (kills scalar remainder loop)
[Benchmark]
public int Vector512Final()
{
ref int p = ref MemoryMarshal.GetArrayDataReference(data);
nuint length = (nuint)data.Length;
nuint vc = (nuint)Vector512<int>.Count;
if (!Vector512.IsHardwareAccelerated || length < vc)
{
int s = 0;
for (nuint j = 0; j < length; j++)
{
s += Unsafe.Add(ref p, j);
}
return s;
}
var acc0 = Vector512<int>.Zero;
var acc1 = Vector512<int>.Zero;
var acc2 = Vector512<int>.Zero;
var acc3 = Vector512<int>.Zero;
nuint i = 0;
if (length >= vc * 4)
{
nuint lastBlock = length - vc * 4;
for (; i <= lastBlock; i += vc * 4)
{
acc0 += Vector512.LoadUnsafe(ref p, i);
acc1 += Vector512.LoadUnsafe(ref p, i + vc);
acc2 += Vector512.LoadUnsafe(ref p, i + vc * 2);
acc3 += Vector512.LoadUnsafe(ref p, i + vc * 3);
}
}
for (nuint lastVector = length - vc; i <= lastVector; i += vc)
{
acc0 += Vector512.LoadUnsafe(ref p, i);
}
if (i < length)
{
// overlapping load of the final vector, masking out already-summed lanes
nuint offset = length - vc;
var lane = Vector512<int>.Indices + Vector512.Create((int)offset);
var mask = Vector512.GreaterThanOrEqual(lane, Vector512.Create((int)i));
acc1 += mask & Vector512.LoadUnsafe(ref p, offset);
}
return Vector512.Sum((acc0 + acc1) + (acc2 + acc3));
}
こうしたラウンドの進行に欠かせなかったのが BenchmarkDotNetの DisassemblyDiagnoser で、ベンチ実行結果のasmを取得してくれます。
var config = ManualConfig.Create(DefaultConfig.Instance)
.AddJob(Job.ShortRun) // 3 warmup + 3 iterations, fast feedback loop for AI iteration
.AddDiagnoser(MemoryDiagnoser.Default)
.AddDiagnoser(new DisassemblyDiagnoser(new DisassemblyDiagnoserConfig(
maxDepth: 3,
printSource: true,
exportGithubMarkdown: true,
exportCombinedDisassemblyReport: true)))
.AddExporter(JsonExporter.Full);
これによってシンプルなfor-loopの結果から
; SumBenchmark.ForLoop()
; var d = data;
; ^^^^^^^^^^^^^
; int sum = 0;
; ^^^^^^^^^^^^
; for (int i = 0; i < d.Length; i++)
; ^^^^^^^^^
; sum += d[i];
; ^^^^^^^^^^^^
; return sum;
; ^^^^^^^^^^^
mov rax,[rcx+8]
xor ecx,ecx
mov edx,[rax+8]
test edx,edx
jle short M00_L01
add rax,10
M00_L00:
add ecx,[rax]
add rax,4
dec edx
jne short M00_L00
M00_L01:
mov eax,ecx
ret
; Total bytes of code 30
ここまで機械語の命令を見て自律的な改善を試行してくれます。
; SumBenchmark.Vector512Final()
; ref int p = ref MemoryMarshal.GetArrayDataReference(data);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; nuint length = (nuint)data.Length;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; nuint vc = (nuint)Vector512<int>.Count;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; if (!Vector512.IsHardwareAccelerated || length < vc)
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; int s = 0;
; ^^^^^^^^^^
; for (nuint j = 0; j < length; j++)
; ^^^^^^^^^^^
; s += Unsafe.Add(ref p, j);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^
; return s;
; ^^^^^^^^^
; var acc0 = Vector512<int>.Zero;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; var acc1 = Vector512<int>.Zero;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; var acc2 = Vector512<int>.Zero;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; var acc3 = Vector512<int>.Zero;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; nuint i = 0;
; ^^^^^^^^^^^^
; if (length >= vc * 4)
; ^^^^^^^^^^^^^^^^^^^^^
; nuint lastBlock = length - vc * 4;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc0 += Vector512.LoadUnsafe(ref p, i);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc1 += Vector512.LoadUnsafe(ref p, i + vc);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc2 += Vector512.LoadUnsafe(ref p, i + vc * 2);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc3 += Vector512.LoadUnsafe(ref p, i + vc * 3);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; for (; i <= lastBlock; i += vc * 4)
; ^^^^^^^^^^^
; for (nuint lastVector = length - vc; i <= lastVector; i += vc)
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc0 += Vector512.LoadUnsafe(ref p, i);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; if (i < length)
; ^^^^^^^^^^^^^^^
; nuint offset = length - vc;
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^
; var lane = Vector512<int>.Indices + Vector512.Create((int)offset);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; acc1 += mask & Vector512.LoadUnsafe(ref p, offset);
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; return Vector512.Sum((acc0 + acc1) + (acc2 + acc3));
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
mov rax,[rcx+8]
mov rcx,rax
cmp [rcx],cl
add rcx,10
mov edx,[rax+8]
cmp rdx,10
jb near ptr M00_L05
vxorps ymm0,ymm0,ymm0
vxorps ymm1,ymm1,ymm1
vxorps ymm2,ymm2,ymm2
vxorps ymm3,ymm3,ymm3
xor eax,eax
cmp rdx,40
jb short M00_L01
lea r8,[rdx-40]
M00_L00:
vpaddd zmm0,zmm0,[rcx+rax*4]
vpaddd zmm1,zmm1,[rcx+rax*4+40]
vpaddd zmm2,zmm2,[rcx+rax*4+80]
vpaddd zmm3,zmm3,[rcx+rax*4+0C0]
add rax,40
cmp rax,r8
jbe short M00_L00
M00_L01:
mov r8,rdx
sub r8,10
mov r10,r8
cmp rax,r10
ja short M00_L03
M00_L02:
vpaddd zmm0,zmm0,[rcx+rax*4]
add rax,10
cmp rax,r10
jbe short M00_L02
M00_L03:
cmp rax,rdx
jae short M00_L04
vpbroadcastd zmm4,r8d
vpaddd zmm4,zmm4,[7FFB6613A480]
vpbroadcastd zmm5,eax
vpcmpnltd k1,zmm4,zmm5
vpmovm2d zmm4,k1
vpandd zmm4,zmm4,[rcx+r8*4]
vpaddd zmm1,zmm4,zmm1
M00_L04:
vpaddd zmm0,zmm0,zmm1
vpaddd zmm1,zmm2,zmm3
vpaddd zmm0,zmm1,zmm0
vmovaps zmm1,zmm0
vextracti32x8 ymm0,zmm0,1
vpaddd ymm0,ymm0,ymm1
vmovaps ymm1,ymm0
vextracti128 xmm0,ymm0,1
vpaddd xmm0,xmm0,xmm1
vpsrldq xmm1,xmm0,8
vpaddd xmm0,xmm1,xmm0
vpsrldq xmm1,xmm0,4
vpaddd xmm0,xmm1,xmm0
vmovd eax,xmm0
vzeroupper
ret
M00_L05:
xor eax,eax
xor r8d,r8d
inc rdx
jmp short M00_L07
M00_L06:
add eax,[rcx+r8]
add r8,4
M00_L07:
dec rdx
jne short M00_L06
vzeroupper
ret
; Total bytes of code 280
人間がこれ見て解析進めようというのは骨が折れるし、あらゆるベンチマークで丁寧な解析を実行することは現実的ではないんですが、AIに与える分にはコストゼロで強力な武器となってくれます。マイクロベンチマーク実行時にDisassemblyを含めるのは新時代の常識といえるでしょう。
なお、オチは .NET 11のTensorPrimitive.Sum最強理論でした。たった一行で圧倒的最速!
[Benchmark]
public int TensorPrimitivesSum() => TensorPrimitives.Sum<int>(data);
コードはTensorPrimitives.IAggregationOperator.Vectorized512で見ることができますが、AIの書いたVector512Finalに近いです。しかし更に一層ゴリゴリのコードが書かれているということで、ある意味、AIの思考の正しさが証明されていることでもあります。もちろんFableがこの「答えを知っている」可能性も大いにあり得るので、こういった汎用的な問題だけで真の思考力、応用力を測ることは不可能ではありますが。
MessagePackのWrite性能を改善する
分岐予測の診断の例も入れたいので、MessagePackのWriteの例を出します。Readはより難しくて見応えがあるんですが、Writeのほうがシンプルなので例としてはいいかな、と。
次のベンチマークとして、MessagePackのエンコーダーのパフォーマンス改善をしたい。`BinaryPrimitives.TryWriteInt32LittleEndian()`のように`TryWriteInt32()`の実装候補を出して性能改善していってください。
public static class MessagePackPrimitives
{
public static bool TryWriteInt32(Span<byte> destination, int value, out int bytesWritten)
{
}
}
分岐予測に関しても正確な計測をしたいので HardwareCounter.BranchMispredictions, HardwareCounter.BranchInstructions も診断情報に追加してください。Windowsで、管理者権限で起動しているので取得実行できるはずです。
今回、分岐があることを知っているので最初から指示に入れていますが、そうでなければコード見て確認して追加してもいいかもしれません。いずれにせよ相談(こちらからの明確な指示)がないと入れてくれることはない(と思う)ので、この辺も「AI時代の指示力」といったところでしょうか。
なお、HardwareCounterの実行には管理者権限が必要になり、Cursorの場合は子プロセスに権限を引き継いでくれていたのですが、Claude Code のシェルは管理者権限を継承してくれませんでした。一応、Claude(Fable)が「UAC 経由で実行する(ユーザーに UAC 許可を依頼)」という形で解消してくれたので、全自動とはいかない(UAC許可を押す必要あり)のですが、問題なく解決はしてくれました。
さて、ベースラインのコードはこれになります。
// Candidate 1 (baseline): straightforward if-else cascade, MessagePackWriter.WriteInt32 style
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool TryWriteInt32Cascade(Span<byte> destination, int value, out int bytesWritten)
{
if (value >= 0)
{
if (value <= 127)
{
if (destination.Length < 1) goto Fail;
destination[0] = (byte)value;
bytesWritten = 1;
return true;
}
if (value <= 255)
{
if (destination.Length < 2) goto Fail;
destination[0] = UInt8Code;
destination[1] = (byte)value;
bytesWritten = 2;
return true;
}
if (value <= 65535)
{
if (destination.Length < 3) goto Fail;
destination[0] = UInt16Code;
BinaryPrimitives.WriteUInt16BigEndian(destination.Slice(1), (ushort)value);
bytesWritten = 3;
return true;
}
if (destination.Length < 5) goto Fail;
destination[0] = UInt32Code;
BinaryPrimitives.WriteUInt32BigEndian(destination.Slice(1), (uint)value);
bytesWritten = 5;
return true;
}
else
{
if (value >= -32)
{
if (destination.Length < 1) goto Fail;
destination[0] = unchecked((byte)value);
bytesWritten = 1;
return true;
}
if (value >= sbyte.MinValue)
{
if (destination.Length < 2) goto Fail;
destination[0] = Int8Code;
destination[1] = unchecked((byte)value);
bytesWritten = 2;
return true;
}
if (value >= short.MinValue)
{
if (destination.Length < 3) goto Fail;
destination[0] = Int16Code;
BinaryPrimitives.WriteInt16BigEndian(destination.Slice(1), (short)value);
bytesWritten = 3;
return true;
}
if (destination.Length < 5) goto Fail;
destination[0] = Int32Code;
BinaryPrimitives.WriteInt32BigEndian(destination.Slice(1), value);
bytesWritten = 5;
return true;
}
Fail:
bytesWritten = 0;
return false;
}
やっていることは単純で、if連打しているだけです。MessagePackのintの仕様としてはint(4バイト)を「1バイトの種類コード+値」として、1~5バイトの可変で保存します。-32~127は1バイト(positive fixint, negative fixint)、255までは2バイト(uint8tag + 値)、65535までは……、といったような分岐で書き込みます。
さて、ベンチマークの結果はこうなっています。
| Method | Distribution | Mean | BranchMispredictions/Op | BranchInstructions/Op | Code Size |
| --------------- | ------------ | ------------: | ----------------------: | --------------------: | --------: |
| **Cascade** | **Large** | **4.1720 ns** | **0** | **9** | **426 B** |
| CascadeUnsafe | Large | 3.9454 ns | 0 | 8 | 331 B |
| FixintFirst | Large | 5.3299 ns | 0 | 11 | 371 B |
| BranchlessTable | Large | 1.7388 ns | 0 | 4 | 459 B |
| Branchless2 | Large | 1.7022 ns | 0 | 3 | 442 B |
| Hybrid | Large | 1.8189 ns | 0 | 4 | 471 B |
| | | | | | |
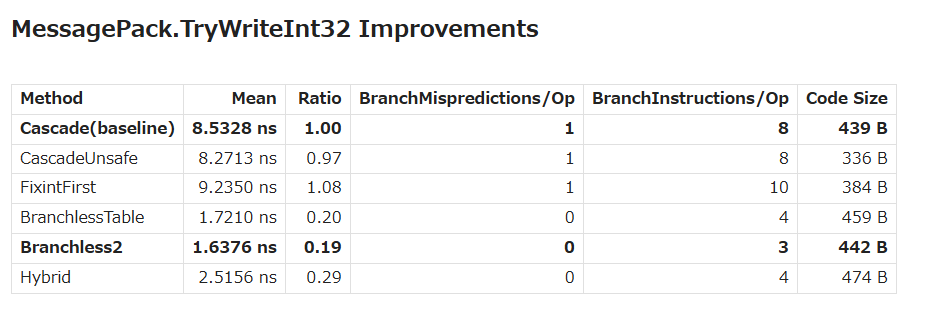
| **Cascade** | **Mixed** | **8.5328 ns** | **1** | **8** | **439 B** |
| CascadeUnsafe | Mixed | 8.2713 ns | 1 | 8 | 336 B |
| FixintFirst | Mixed | 9.2350 ns | 1 | 10 | 384 B |
| BranchlessTable | Mixed | 1.7210 ns | 0 | 4 | 459 B |
| Branchless2 | Mixed | 1.6376 ns | 0 | 3 | 442 B |
| Hybrid | Mixed | 2.5156 ns | 0 | 4 | 474 B |
| | | | | | |
| **Cascade** | **Small** | **1.9931 ns** | **0** | **5** | **404 B** |
| CascadeUnsafe | Small | 1.3937 ns | 0 | 5 | 309 B |
| FixintFirst | Small | 0.6945 ns | 0 | 4 | 171 B |
| BranchlessTable | Small | 1.7197 ns | 0 | 4 | 459 B |
| Branchless2 | Small | 1.6388 ns | 0 | 3 | 442 B |
| Hybrid | Small | 0.7017 ns | 0 | 4 | 450 B |
というわけで、上のシンプルなコード(Cascade)よりも良い結果が出せています。
で、まず、ベンチマーク結果をチェックする場合は、ベンチマークコードのチェックが必須です。ベンチマークは、与える値によって結果がかなり変わります。例えばJsonSerializerのパフォーマンステストをするときに、ASCIIだけのものと、日本語交じりのものとでは、性能が全然変わってきたりします(UTF8エンコーディングのfastpathへの入り方が違う)。というわけで、ちゃんと網羅しているかどうかを確認することは重要です。で、人間がベンチマークを書くとパラメータの網羅性が雑になったりすることが多々ある、少なくとも私は網羅どころか単一パラメータだけで済ませていることも多かったのですが、やはりここはAI時代なのでちゃんと網羅しているものを生成してもらいましょう。またはAIの性能が低いと網羅してくれてない場合もありうるので、ここは人間が、「何をテストしようとしているのか」の確認はすべきだと思っています。AI時代はコードなんて見ないとか言ってる場合じゃないんです。
今回はintの値によってifの回数とかも変わってきて、それが性能差になるので、Small, Large, Mixedとしてパターンを作っています。
// Small: all fixint (perfectly predictable branch)
// Mixed: format class chosen at random per element (worst case for branch prediction)
// Large: all 5-byte int32/uint32
[Params("Small", "Mixed", "Large")]
public string Distribution = "Mixed";
[GlobalSetup]
public void Setup()
{
var rand = new Random(42);
values = new int[Count];
buffer = new byte[Count * 5];
for (int i = 0; i < Count; i++)
{
values[i] = Distribution switch
{
"Small" => rand.Next(-32, 128),
"Large" => rand.Next(2) == 0 ? rand.Next(65536, int.MaxValue) : rand.Next(int.MinValue, -32768),
_ => rand.Next(8) switch
{
0 => rand.Next(0, 128),
1 => rand.Next(-32, 0),
2 => rand.Next(128, 256),
3 => rand.Next(-128, -32),
4 => rand.Next(256, 65536),
5 => rand.Next(-32768, -128),
6 => rand.Next(65536, int.MaxValue),
_ => rand.Next(int.MinValue, -32768),
},
};
}
}
Small(-32~127の範囲に収まる)も多いだろうなあ、とは思いますが、まぁMixedのケースも全然いっぱいあるだろうということで、そこのバランスをとっていきたいですね。FixintFirstは、まさにそのfixintのレンジのifを最初に入れることで、Smallだけは絶対に速いというfastpathになっています。
// Candidate 3: single-compare fast path for fixint [-32, 127] (the dominant case in typical
// msgpack payloads), everything else in a non-inlined slow path
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool TryWriteInt32FixintFirst(Span<byte> destination, int value, out int bytesWritten)
{
if ((uint)(value + 32) <= 159 && destination.Length >= 1)
{
MemoryMarshal.GetReference(destination) = unchecked((byte)value);
bytesWritten = 1;
return true;
}
return TryWriteInt32MultiByte(destination, value, out bytesWritten);
}
ちなみに↑の-32~127のレンジという処理が if ((uint)(value + 32) <= 159 ...) というお洒落なif一発におさめているのは、地味に特筆すべき点だと思っています。こういうのシレッと含ませてくれると感心しちゃいますよね。
さて、とりあえず重点を置きたいのはMixedの数値なので、それをRound別にチェックしてみます。
| Round | 実装 | Mean | asm / カウンタから見つけた欠陥 → 次の一手 |
| ----- | ------------------ | ----------: | ----------------------------------------------------------------------------------------------------------------- |
| 1 | Cascade (baseline) | 8.53 ns | if-else 連鎖。分岐 8/op・ミス 1/op — ミスペナルティ(≈13サイクル)が支配 → 分岐自体を消すしかない |
| 1 | CascadeUnsafe | 8.27 ns | Slice・個別 store を ref + unaligned store に統合(コード 426→331B)。しかし分岐構造が同じでミスも 1/op のまま → 命令数削減では効かないと確定 |
| 1 | FixintFirst | 9.24 ns | fixint を1比較で先行(Small なら 0.69 ns)。Mixed ではその先行分岐自体がミス源 → 分布依存が極端 |
| 1 | BranchlessTable | 1.72 ns | lzcnt+66エントリ表で分岐レス達成・ミス 0。ただし asm に表の境界チェック(`cmp r11d,42; jae RNGCHKFAIL`)と `sign*33` の乗算相当が残存 → 64エントリ表+Unsafe 化 |
| 計測修正 | (全実装) | — | Count=1000 では Mixed でも Mispredictions/Op=0 — Zen 5 予測器が固定配列の分岐パターンを丸ごと記憶していた → Count=100,000 に増量 |
| 2 | **Branchless2** | **1.64 ns** | 境界チェック消滅、index 計算が `shr+and+or` に。ホットパス分岐 3/op(全て予測可能)。残るは lzcnt→表ロード→movbe の直列依存チェーンで可変長エンコーダに固有 → **収束** |
| 2 | Hybrid | 2.52 ns | Branchless2 の前に fixint 1比較(Small 0.70 ns)。Mixed では先行分岐が ~0.4 ミス/op → 分布が小整数支配と分かっているときだけ選ぶ |
まず感心するところは、ベンチマークのパラメータとして最初はCount = 1000だったのですが、Mispredictions/Op=0 という計測結果が出ていたので 「Zen 5 予測器が固定配列の分岐パターンを丸ごと記憶していた → Count=100,000 に増量」という対処をしたことです。
// large enough that the branch predictor cannot memorize the repeating sequence
// (with 1000 values, Zen 5 learned the whole pattern: BranchMispredictions/Op was 0 even for Mixed)
const int Count = 100_000;
[Benchmark(OperationsPerInvoke = Count)]
public int Cascade()
この辺も Mispredictions/Op の計測を入れていたからこそ素早く自動で認知して対応できたわけで、そうじゃなければ進行不能になる可能性がありました。
さて、コードのチェックに入りたいのですが、if分岐の最速化対応は手コードだとあんまやれることがないんですが、AIはブランチレスコードを2パターン作ってくれました。最速案のBranchless2を見てみます。
// Round 2: significant bits of a non-negative int are 0..31, never 32, so a 64-entry table
// indexed by ((value >>> 26) & 32) | bits works — single OR instead of imul, and the
// power-of-two size lets us drop the bounds check via Unsafe
static ReadOnlySpan<uint> Formats64 =>
[
// non-negative: bits 0..7 fixint, 8 uint8, 9..16 uint16, 17..31 uint32
Fix1, Fix1, Fix1, Fix1, Fix1, Fix1, Fix1, Fix1,
U8,
U16, U16, U16, U16, U16, U16, U16, U16,
U32, U32, U32, U32, U32, U32, U32, U32, U32, U32, U32, U32, U32, U32, U32,
// negative (bits of ~value): 0..5 fixint, 6..7 int8, 8..15 int16, 16..31 int32
Fix1, Fix1, Fix1, Fix1, Fix1, Fix1,
I8, I8,
I16, I16, I16, I16, I16, I16, I16, I16,
I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32, I32,
];
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool TryWriteInt32Branchless2(Span<byte> destination, int value, out int bytesWritten)
{
if (destination.Length >= 5)
{
int x = value ^ (value >> 31);
int bits = 32 - BitOperations.LeadingZeroCount((uint)x); // 0..31
int idx = ((value >>> 26) & 32) | bits;
uint e = Unsafe.Add(ref MemoryMarshal.GetReference(Formats64), idx);
int len = (int)(e & 0xff);
ref byte d = ref MemoryMarshal.GetReference(destination);
d = (byte)((e >> 8) | ((uint)value & (e >> 16)));
Unsafe.WriteUnaligned(ref Unsafe.Add(ref d, 1), BinaryPrimitives.ReverseEndianness((uint)value << ((5 - len) * 8)));
bytesWritten = len;
return true;
}
return TryWriteInt32Cascade(destination, value, out bytesWritten);
}
こういうの妥当かどうかって全然判断つかないですよね正直。GeminiとかChatGPTにも投げて、ヨシといってるんならもうヨシということにしようか、みたいな感じですらあります(妥当でしたのでヨシ)
いや、わからんがヨシ、ではなくて、少なくともお出しされたものを受け入れる場合はちゃんとline-by-lineで理解できてないとブラックボックスが無限に広がってダメになっちゃうので、ちゃんと理解はしないと!はい、ちゃんと理にかなっていると思います。まず、 if (value <= 65535) などといった、その数字がどのレンジに含まれているかどうかは、Leading Zero Countで判別することができる。intは4バイトなので32ビット、正負合わせて64個のテーブルがあればif分岐なし、テーブル引きでタイプを取ってこれるというわけですね。正負不問にするために最初にabsしてからのLeadingZeroCountの値自体は0..31なので5ビット、それに先頭の正負をくっつければ(ビットシフト26)、6ビットで64のインデックスが生成できるので、それでテーブルから引いてこれる、と。引いてきたテーブルはuintに情報を複数入れる(ヘッダータグ(e >> 8)、長さ(e & 0xff)、マスク(e >> 16))ことでテーブル一発で複数情報を取ってこれる、と。で、最後に値は1~4バイトは全て4バイト単位で書き込み、と。文句のつけようのないif分岐コードからのブランチレスコードへの変換です。
と、いうわけでmixedのシチュエーションで 8.53 nsが 1.64 ns に、超高速化されたということになります。これをそのまま採用するかどうかはともかくとして、改めて興味深い結果が得られました。持ち帰って検討させていただきます(?)
なおETWベースのハードウェアカウンターに関しては、他に InstructionRetired や TotalCycles、CacheMisses あたりが更に追加可能です。更に情報をとるならCPUベンダーのプロファイラー(AMD uProf, Intel VTune)を組み合わせたループを構築するというのも次の一手になるかもしれません。とはいえ、ETW(Event Tracing for Windows)ベースでサクッと取れるというのは大掛かりにならずに仕込める手段なので、相当有意義なのは間違いないでしょう。
AI時代のコーディング
SumにせよMessagePackのTryWriteIntにせよ、人間を遥かに超えてるのは間違いない。Sumのforループ高速化はカンニング疑惑が拭えなかったわけですが、ブランチレスのMessagePack Writeのコードは世の中にはないと思うので、Fableがちゃんと自力で導出したコードだといえます。この結果はOpusでは得られてなかったので、個人的にはFableが閾値超えてきたな、と思いました。今までは解析は勿論AIの強みだけど書かせるとイマイチだなー、と思ってたんですが、Fableは分析力が更に増したせいなのか、書き力も高くなっているぞ、と。少なくともこの手の関数単位みたいな超スモール領域ではコーディング力に圧倒されてしまう。人間のやることは雰囲気を整えるのと、トレードオフに対してどちらのハンコを押すか決めるぐらいしかない。
ただし、じゃあアプリケーション全体、ライブラリ全体をまるっと作らせて満足いくコードが仕上がってくるかというと、そこはまだまだNoではある。単純にコンテキストの問題もあるし、複雑性が桁違いでもあるし、ただ、AIの性能がめちゃくちゃ上がってそこを克服したとしても、ライブラリ全体の作りが満足いくかどうかは、もう感性の世界でもあるので、気に入るか気に入らないかの領域であり、受け入れるか受け入れないか、といったところではある。AIがどれだけ進化しても自分の100%の好みなものをポン出しで生成することは絶対ないわけなので、ひたすら自分好みにしようとする不毛な応酬をするぐらいなら、心折れて、AIの出した、まぁ動くコードを諦めて受け入れるしかない、にはなりそう。
ようするところオーナーシップが持てなくなってきているんですね、コードから。短期的には動けばいい、んですが中長期的にはモチベーションに大きく影響するので、単純な受け入れは結構危険だと思っています。それでも自分で吟味して生成したコードはいいんです、TryWriteInt32Branchless2 なんかは自分が生成したコードなら受け入れるでしょう。でも、これがPRですごいパフォーマンス改善のコードなんです!と来た時にはどう対応できるかな、と。多分、拒絶しますね。受け入れたら受け入れたで、もうそのあたりは見たくない、になります。
会社のプロダクトだったら、アプリケーションだったら、コードへの愛着に関しては捨てて、プロダクトに向き合うことでオーナーシップを担保していかなければならない。なんだったら、そのほうが理想的でしょ?といえるかもしれません(個人的には、色々な職種や見てる領域によって大きなプロダクトは成り立つので、エンジニアがコードへの関心が占める割合が高いのは、悪いことではないと思っていますが)。実際私も個人アプリとか、こないだはAndroidアプリを作って公開しましたが、そういうのはコードはどうでもいいしほとんど見てなくて、アプリケーションの出来、ルック&フィールが全てでした。
けれど、OSSライブラリは100%コードの世界なので、ここを捨ててしまうと、なにもないんですね、なにも残りません。実際、ちょっとやや虚無感を抱き始めているところが無きにしも非ずで、コミュニケーション取っていい機能できたんですよーっていうんで見てみたらAIプルリクですねこれ、なんていうのがあると、どうしても見る気が起きなくなるし、セキュリティチェックしましたー、は大事だしいいんですがセットのAI修正コードの山です、というのはかなり厳しいものがあった。モチベーションがぽきぽき折れてきます。
というわけで、とても複雑な気持ちを抱えています。
それはそれとして、何が作りたいか、というと、全てが研ぎ澄まされた究極のライブラリが作りたいという気持ちがあり、Fableが超強力な武器なのは間違いないわけです。というか、なんだったら今まで公開している今のすべてのコードをむしろ恥じます。全部作り直したい、なんだったら今までのコードは恥なので見たくない(?)とすら思いかねないところもあります。
まとめ
上記のFableでの結果がかなり良かったので、ヒントを与えた状態での他のモデルでどのぐらいの基礎点を取れるか測るため「ブランチレスでMessagePackのWriteを書いてくれ」という指示でSonnet 5, Opus 4.8, Fable 5, Gemini 3.1 Proに書かせたところ、Fable 5だけが唯一合格点(上記のコードに近いもの)を出力しました、それ以外のモデルの出力結果は論外でした。基となるコードの生成能力がなければ、どれだけベンチマークハーネスを組んだところで自己改善することはできません。ただたんに動くコードを出力することと、私が採用できる水準のコードを出力することには大きな差があります。そんな中で、Fableがついにそのレベルに到達した、と思っています。そして、今回紹介したようなベンチマークハーネスを用意することで、ついに望んでいた磨き上げられたコードが生成されるようになりました。私にとって、ようやくAIコーディング元年が到達したかもしれません。
この記事はAI補助ゼロで100%オーガニックな手書きで作られています。文章に関しては本当にAIベースのものが好きじゃないので、それこそClaude Codeにベンチマーク取らせたわけだから、いい感じにブログになるように整形してよ、といえば、まぁできなくはない、できなくはないんですが、それは血が通ってない面白みも少ない(ないとは言いませんが)記事だなあ、と思ってしまうわけです。ノイズだらけ、雑味だらけのこの文章が一周回ってよく思えてきませんか……!?塩化ナトリウム99%みたいな文章を摂取してる場合じゃあないんです、時代は天然塩。
で、まとめとしては、究極のライブラリをまずは一品出すところからなんじゃあないでしょうか。間違いなくやれる感が高まっていて、とてもワクワクしています……!それの実現には新しいアーキテクチャ、AIが最大限の機能を発揮するための構造+ランタイムの性能やヒューマンフレンドリーなAPIへの完成の融合が必要です。ええ、そして、そのイメージが完全に浮かんでいます。今後を楽しみにしてください……!また、OSSにおいてはメンテナンスビリティが改めて重要だということも深く感じているので、ここ1年、いや、ここ1年半ほど、動きが止まっていたものも、改めて動き出せると思っています。そちらのほうもやっていきます!
C# Kaigi 2026基調講演します!と、.NET for AndroidとVibe Coding
- 2026-06-24
C# Kaigi 2026というイベントが2026年9月19日 (土)に開催されます!C#er のための C# 特化型カンファレンス、ついに開催!おー。ほー。知らんかった。シランカッタデス。私はnot運営です。ただ、C#はカンファレンスがなかったし、MSがやるものもすっかりAzure一色、そして今やAI一色になって寂しい限りなので、開催はとても嬉しいです。企画に感謝。そして、この第一回が成功して、長く、大きく続いていくといいなぁ。
そんなわけで、貢献するためにもセッションのプロポーザル書くかなあ、と思ってたのですが、僭越ながら基調講演に抜擢していただきました!基調講演のタイトルは「C#の現在地 進化の歴史と、AI時代の.NET Everywhere」にします、しました!第一回だしまぁ歴史はやっぱ外せないのかな、ではありつつも、別に中の人でもないしカタログ並べて紹介してもしょうがない。私は昔から、今もC#に魅力を感じ続けているわけで、その時々で何に魅力を感じて使い続けているのか、そんな外側からの目線を話せたらいいかなあと思っています。
.NET Everywhereというのは、懐かしい響きだとも思います。あえてそこを改めて見つめるのもいいかな、といった感じでそこもタイトルに入れてみました。AIは、まぁ今どきAIはとりあえず入れておこう精神です(?)
レギュラーセッションは公募です!2026/07/05 (日) まで公募受付中で「C# に関する事ならなんでも OK」だそうですので、是非是非ふるって応募ください!私はnotプロポーザル査読マンですので、ピュアな気持ちでセッション楽しみにしています!
超dotnet new
超dotnet newというイベントをひっそり開催しました。以前にdotnet newというイベントをやっていたので、その第二弾です。「dotnet new」というイベント名も「超dotnet new」というイベント名も私がつけたんですが、こちらも特に主催ではないです(実際何もやってない)
イベントの趣旨としては(基本的に)参加者=登壇者ということで、敷居低くカジュアルに登壇して欲しいし、カジュアルに交流したい、登壇があると、その人のバックグラウンドや関心事について深く知れるので、とてもスムーズに交流できてお互いがより楽しめる。といった参加型イベントということを想定していました。セッション時間もコンパクトなLTスタイルで5分、そのかわりLTイベントなので登壇者数多めで17人という枠の設定です。
お久しぶりの人はもちろん、半数は(X上では知っていても)初めましての人も多く、とてもいい感じのイベントだったと思います!これもまた忘れた頃にそのうち第三弾がやれたらいいんじゃないでしょうか(運営のほうをチラッ)
私の方からは「.NET for Android with Native AOT Built with Cursor」というセッションをしました。
iPhoneからAndroid(Leica Leitzphone powered by Xiaomi)に乗り換えましたと書いたように、3月からAndroidに乗り換えています。で、Leitzphoneでの願望として
今のところレンズリングはカメラアプリ内でしか機能しないんですが、普通にボリューム操作とかにも使いたいですね……!
というのがあって、Androidの自由度なら、自作することも可能なんじゃないか!?という気がしてきたので、作りました。
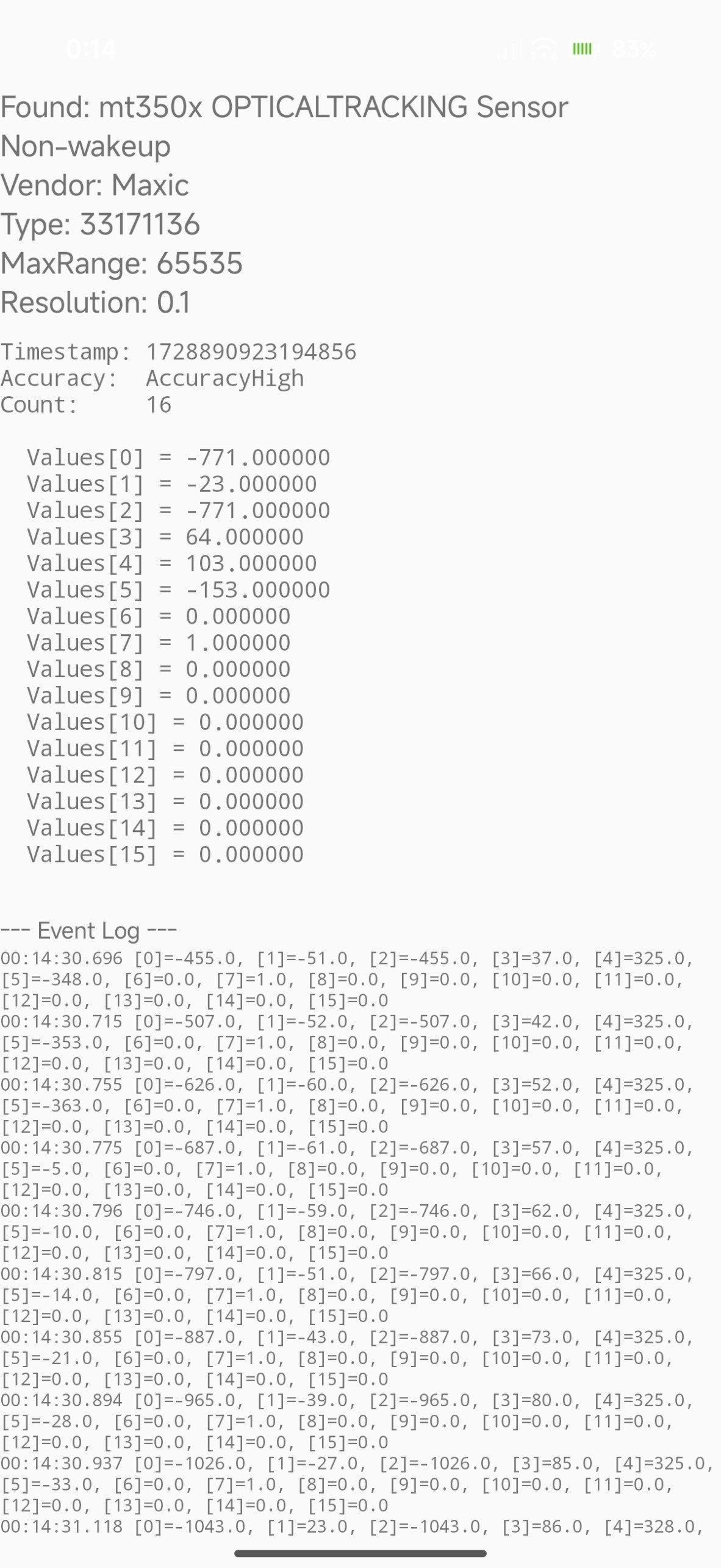
ネイティブレベルのルック&フィールと、未公開のハードウェアセンサーからデータ引っ張ってくるということで、割とよくできた造りになっていると思います。当然C#で、.NET for Androidで、さらにせっかくなのでCoreCLR/Native AOTでpublishしてます。LTなのでそんなディープな話ではないですが、その一連の流れをセッションでは軽く紹介しました。
AI任せなので簡単に作れたか、というと、そこまで簡単ではなかったかもしれません。まず、そもそも実現可能なのかもわからないところからスタートしていて、Claudeと一緒にadb使いながら壁打ちしてました。
最近は時代はLoop、人間は不要!みたいな論もありますが、全自動だとうまくたどり着けなかった感はあります。人間が適切にカンを効かせて方向性を定めつつ、AIの抜群の解析力で進めるのが今のところはまっていました。
最終的には↑のように生のセンサー情報が引っ掛けられそうなことが掴めたので、これならいけるな、ということでCursorを使ってコーディングを進めていきました。
生データのマッピング、グローバルで動かせるようにAccessibility Servicesとしての作成、完成度が微妙な.NET 10でのAndroid NativeAOTの迂回などなどは割とサクサク行ったんですが、正直UIは難しかったです。
延々とComposer 2.5で往復しながら微調整を繰り返したので、全自動とは程遠い……!まぁでもUIのデザインやフィーリングって難しいところなので、ここは人間が細かく干渉してもいいところかなー、とは思います。ある程度出来上がってるサイトのページの量産とかなら、デザインルールのSkillをベースにやるとかでもいいとは思いますが、一点ものだとどうしてもうまくはいかないんじゃないかしら。
結果的にルック&フィールは相当良くなってると思います、(今のところは)この品質はAIポン出しじゃあできないですよぅー。
作業自体はCursorのチャットウィンドウで完結、実機に接続している状態だったのでCursorがコンパイル確認のついでに dotnet build -t:Run することで実機に即座にデプロイされるようになったので、実機チェック→チャットで指示→実機チェック→チャットで指示 の人間ループがうまく回りました。
エディターなんていらんかったんや。というわけで昨今のAgentツールは全てお決まりの3ペイン、左側がセッション一覧、真ん中がチャット、右側がアーティファクトという構成で、エディタが要らないのならVS Codeフォークである必要はなく、CursorもAntigravityも独自アプリ化した。という流れには納得しかないです。
逆にコードを確認したい、しっかりレビューしたい、というシチュエーションでは、裏でAgentとは無関係にIDE開いてチェックすればいいかなあという感じがあるので、私的にはVisual Studio 2026とうまい使い分けができるようになって良かったかな、と。つまるところVS 2026へのAI統合は期待してないというか、もはやしなくていいというか。
まとめ
RingController自体はOSSで公開しました!https://github.com/Cysharp/RingController が、Leitzphone自体が出荷台数もあまり多くない特殊なモデルなので、ユーザーはあまりいなさそうですね、しょーがない、そういうこともある。
時代はAI個人開発アプリ、みたいなのは十分体験できたので、引き続きアプリ開発していくぞい!という興味と(作りたいものはなんだかんだでいっぱいあるので)、もう一つ、ライブラリメンテナンスをAIでいい感じにする体制づくりを実践していくぞい!の二本立てで今年はやっていこうと思ってます。今年も、もう半分すぎちゃいましたが。
iPhoneからAndroid(Leica Leitzphone powered by Xiaomi)に乗り換えました
- 2026-03-15
15年ぐらいずっとiPhone使ってたんですが、Leica Leitzphone powered by Xiaomiに移行しました。レンズリングが回転するというギミックを知って(最高にクールじゃないですか!?)から即buyというほとんど衝動買いです。

先に結論からいくと
- Leitzphoneはめっちゃ良い。レンズリング回転機構は最高に良いので一代限りにならず継続して欲しい
- Windows母艦の環境においてAndroidはiPhoneよりずっと良い、めっちゃ快適になった
- Android自体も悪くない、Xiaomi HyperOS + Snapdragon 8 Elite Gen 5は十分強力
というわけで、全体的には大満足で、なんだったらもっと早く脱Appleすれば良かった……(?)
私は基本的にPCはWindowsから離れられない(主にVisual Studioのため)ので、元々iOSでのエコシステム連携は全然強くはなかったのですが、それでもiPad, Apple TV, Apple Watch, AirPods, HomePod, AirTagと、せっかくなのでとApple製品で固めてしまっていて、それはそれなりにそこそこ便利ではあった。
が、メインのイヤホンをHUAWEI FreeClip(FreeClip 2)に変え(ちなみにFreeClipはめっっっっっちゃくちゃ良い)、HomePodをSonosに変え、Apple TVは別に大して使ってないし、となると、よく考えると現状Apple製品エコシステムには別にもうあんま縛られてるわけではないな、と。AirTagは使えなくなっても、Xiaomi Tag出たし。これはケース不要のデザインなのが使い勝手良き。
機種変の際の手間がないのは大いに利点ではあったけれど、毎年新しいiPhoneに買い替えててきた(Pro Max -> Pro Max -> Air)ものの、ある意味、そのせいでマンネリ感があった。20万とかするものを買ってるのに、特にここ最近のiPhoneの新しいフィーチャーはコケ気味なので、なんか別になんも変わらんよね、を無限に繰り返してた。Airは薄い軽いで大きな変化で、良いっちゃあ良いけど、機能じゃあないので大きな感動とはまた違う感じだったんですよね、なんだったら機能面ではPro Maxに比べて低下していたわけだし。
そしてAI Codingブームじゃないですが、ちょっとした個人的な不便を解消するアプリを自分のスマホに入れたいなあという思いがずっとあったんで、Vibe Codingで雑に作ってデプロイしたかったんですよね。それがWin x iPhoneだと絶対的にできない。じゃあ、もう、ついにAndroidですね、と。
Switch to Android
iOS -> iOSとまではいかなくとも、今どきもう全自動で一瞬でサクッと移行できるっすよーという話を信じた(?)んですが、そんなこたぁなかった。ほとんど全部手動になりました、ふぁぃ。
- eSIM転送は無理なので再発行(auと一部機種なら行けるらしい)
- 画像は節約でiCloudに退避させるオプションにしていたせいか歯抜けで入ってしまった。どうしようかなーってところで、Webからエクスポートできないかなと思ったんですが1000件毎では全然足りない。最終的にicloud_photos_downloaderというスクレイピングダウンローダーを実行してローカルに全部落としてから、USB接続でPC to AndroidでDCIMに放り込みました。工程が目に見えてて確実&十分高速だったので、これはアリ
- アプリ類は当然なら再ログイン&ものによっては独自のデータ移行、みたいな感じなので(あとログインの仕方忘れてるとかApple認証で入っちゃってるので連携し直しとか)まぁ、延々と頑張るしかない、と
手動とはいえ、別になんだかんだでやれる範囲なのと、iOSにしかないようなアプリとか機能をそんなに多用していたわけでもないので、意外とスムーズといえばスムーズとも言える、でしょうか。最近のアプリはほとんどサブスクだし、古の買い切りアプリ/ゲームはどうせ起動できないので、十分切り捨てられました。しいていえばFlorenceだけは入れておきたかったのだけど、最新のAndroid OSに対応していない(?)っぽく移行できず、残念……。Super HexagonもAndroid版だけストアから消滅してるし。我慢できるけど悲しいといえば悲しい。この2つは人生のトップ10ゲームに絶対に入れるんですが。
Xiaomi HyperOSがiOSに似てる(これはかなり似せてる系ですよね?)ので、ホームのレイアウトやウィジェットなども、それなりに元通りにできました。
No Suica
Leica Leitzphone powered by Xiaomiは、グローバルで同一モデルということで、NFCは搭載していますが、日本独自のFeliCaは非搭載。マイナポータルからのマイナンバーカードでの認証やクレジットカードのタッチ決済はできますが、Suicaは入れられない。なるほど!Xiaomi端末は結構非搭載が多め、と。
まぁそれは、いいことだと思います!余計なコストかけずグローバルモデルであるべきだし、そもそも私はSuica全然好きじゃないので!なくていいです!なんだったら、ないほうが思想的に良いです!
と、思想的にはなくていいんですが、実用的には困るといえば困る……。日常的な決済でSuicaが必要なシーンはゼロなのですが(電子決済としてSuicaしか対応してない、なんてことはないので)、やっぱバス・電車がどうしても……。Suicaカードでも別にいいかなあとあ思ったんですが、チャージの仕様が微妙すぎて今更チャージはしたくないんですよねえ。オートチャージの仕様も終わってるので基本、使えないと思っていいし。
そこで、最近ずっとApple Watch Ultra使ってるので(去年体調崩してから、頻繁に心拍計測して安心感を得ている……)、とりあえずApple WatchにSuicaを入れて凌ぐことにしました。今のところやってやれなくもなし。Apple Watch自体は心拍測るのにしか使ってないので(?)母艦と連動してなくても問題なし。チャージもWiFiがあればApple Watch単体でできるので、出先でイザという時になくなってもテザリングでチャージで回避、もできそうなので問題なく運用できそう。
Gboard to SwiftKey
入力システムは慣れの問題もあるので、あまりどうこう言いたくはないのですが、Gboardの日本語QWERTYの機能/レイアウトだけは、流石に駄目です。私は入力は 英語QWERTY + 日本語QWERTY でやっているのですが日本語キーボードのレイアウトが
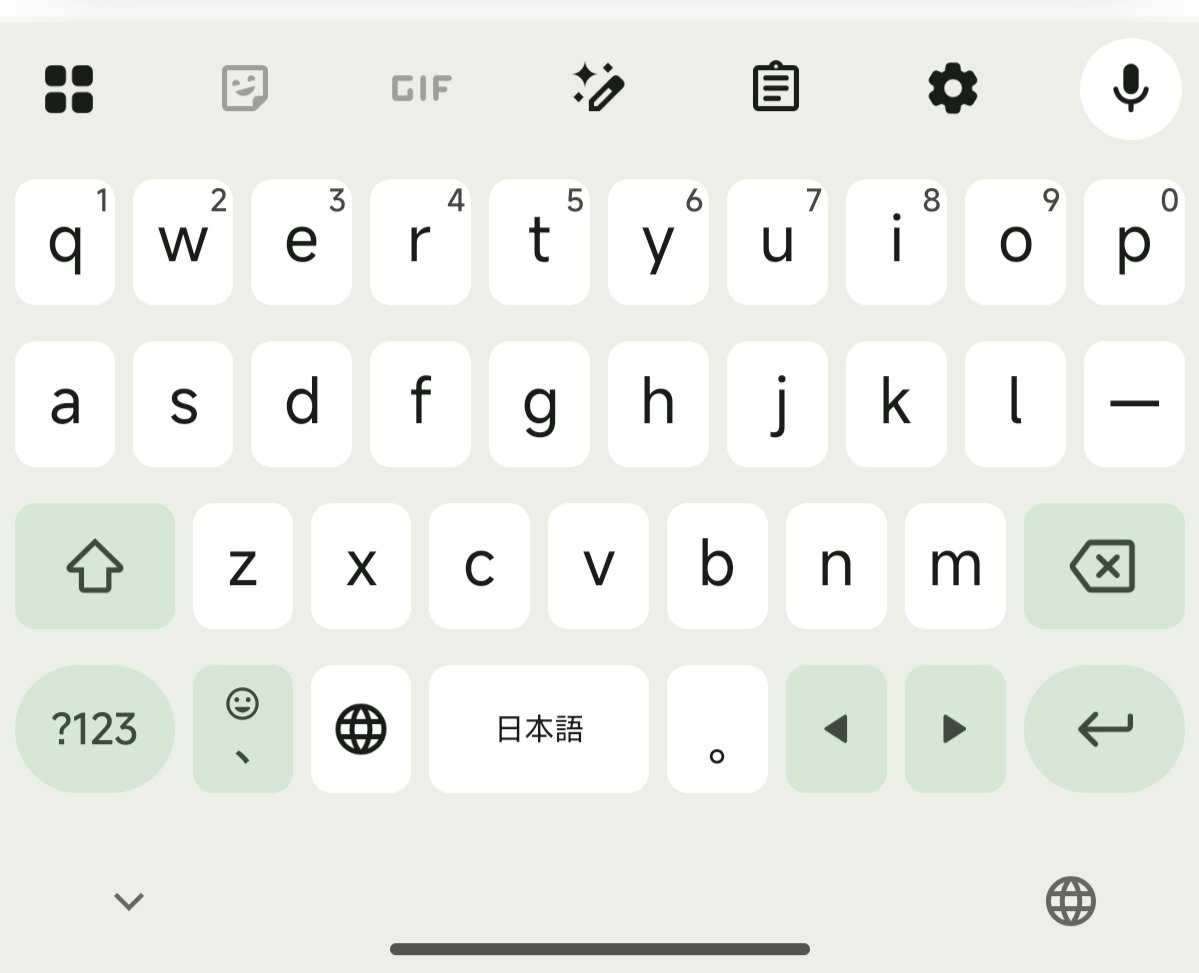
スペースがキー2つ分しか取られてない!さすがに狭すぎる。そしてレイアウト変更や不要キー削除などで広げることはできない。←→の矢印キーとか削除したいんですが。そしてフリーカーソルがない。日本語キーボードではこのクソみたいな←→矢印でカーソル移動するしかない。英語キーボードだとスペースのドラッグでカーソル移動できるのに何で……?さすがにキー2つじゃ移動させられないから機能搭載していないということ?
というわけでキーボードはMicrosoft SwiftKeyを使うことにしました。
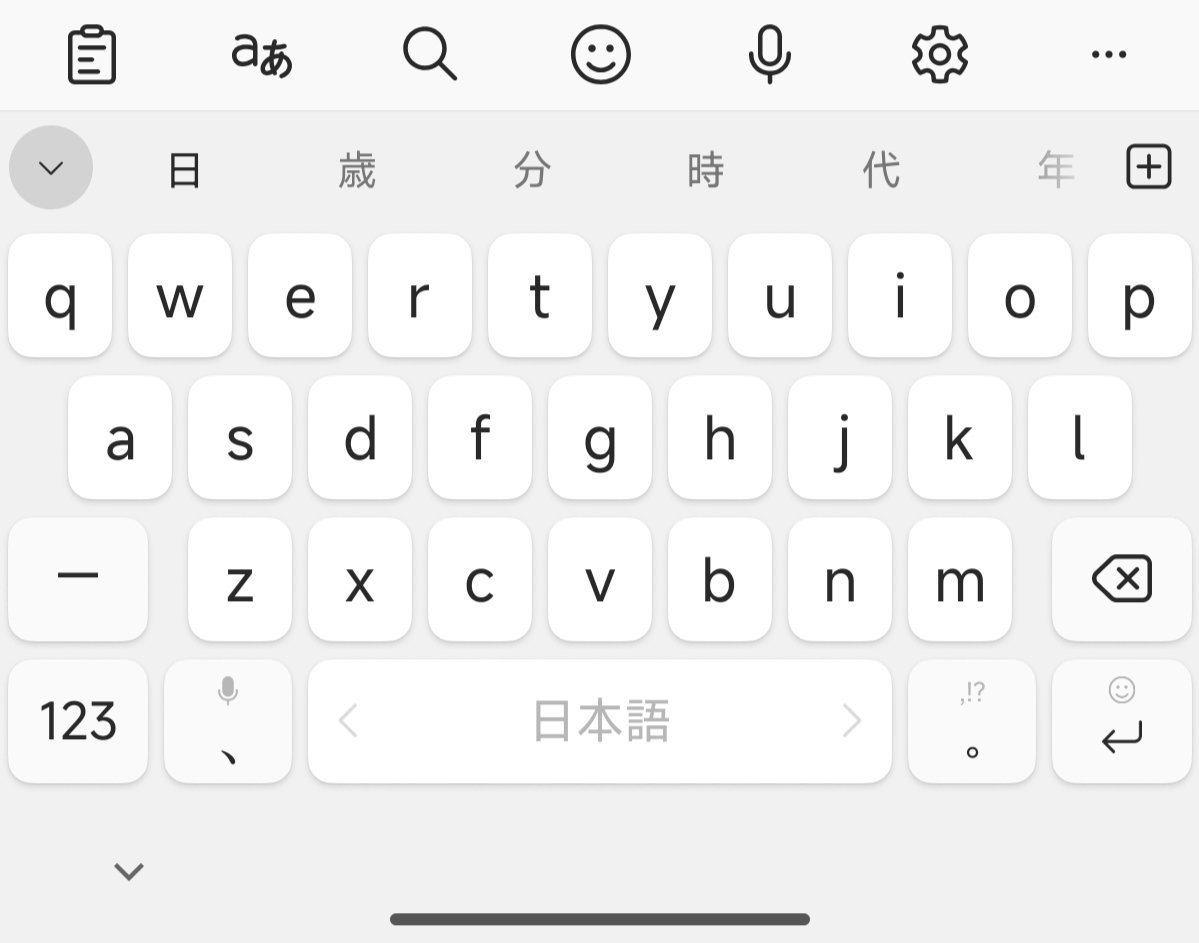
細かいことは置いといて、とりあえずレイアウトに関しては100点です。英語/日本語切り替えでアルファベットのレイアウトの移動がないのが素晴らしい。かわりに「ー」がShiftの位置になっているのが打ち間違いをたまによくやってしまいますが、ここは慣れでなんとかなるでしょう。フリーカーソルも日本語/英語の両方でちゃんと付いてるし。
ところでクリップボードに関しては明確にiOSのキーボードよりも、こちらのほうが良いですね、履歴や固定が便利すぎて、なんでiOSにはないんですかー?WindowsにもWin+V(よく使ってる)で(やっと)標準で入ってるというのに……!
また、Windows 11でのスマートフォン連携は明らかに超強力でした。Windowsのクリップボードがリアルタイムに即Androidのクリップボードに入る。ようはAndroidで打たなきゃいけない文章をPCでさっと書いてAndroidに送り込める、と。今までiPhoneでチマチマ文章打ってたのが馬鹿らしくなってきましたほんと。。。
サッとカメラロールをチェックできるのも良いですね。スクリーンショットとかPC上で確認/取得したかったりするケースが多いので。いやあ、母艦Windows使っててiPhone使い続けていたのはなんとも愚かだった。
Leitzphone
Leica Leitzphone powered by Xiaomiは3月5日に発売されたばかりの端末で、Xiaomi 17 Ultraにレンズリング回転機構を追加してデザイン変えて一部UIのアイコンを変えたもの、です。価格差がまぁまぁあるのですが、レンズリング回転機構は値段以上の価値があるのでLeitzphoneのほうがいいですよ絶対……!リングは回すと本体のハプティックが連動してコトコトするのがまた気持ちい。
スペック的には最新のSnapdragon 8 Elite Gen 5を積んでいて文句無し、なのですが誰もスペックの話はしないし、なんだったら公式サイトもカメラの話しかしないぐらいに、カメラ推し、です。私が撮ったものはここに載せたりはしませんが、適当に撮ってもめっちゃ映える絵が出力されて、すんごく気持ちいい。
ところでXiaomi 17 Ultra/LeitzphoneにはPhotography Kit Proというカメラグリップめいたものを接続することができて、完全に見た目がカメラになります。
で、これの使用感がまためっちゃいいんですね、ポートレートモードで、レンズリングでズームしてグリップのダイヤルで絞り値を変えて、反押しシャッターとか、完全にカメラで気持ちいい。これはいいものだ。
と、非常に気に入ったのですがケースをつけないと使いにくい(サイズがケース着用に合わされてる)ので、裸で使うか、カメラグリップを使うためにケースをつけて使うか(なおケースは一度付けるとめちゃくちゃ外しにくい)の二択を迫られて、最初はケース付きを選択したのですが最終的に裸で使うことにしました。いかんせんケースつけてると美しくない&厚い&重い&端のスワイプの操作感が悪くなるで、徐々にツラミが増してきたので。
カメラグリップなくても割と普通にちゃんとカメラっぽくいけそうですし。Leitzphoneのサイドのローレット加工(ギザギザ)は滑り止めとしても機能としていて、見た目だけじゃなく(カメラとして構えているときの)持ちやすさにも寄与してます。Leitzphoneの場合はレンズリングがあるので、ダイヤルやズームレバーが死に設定になりがちなのも、なくてもいいかな、と思った理由でしょうか。
各種レビューとか見るとLeitzphoneのレンズリング別にいらなかったとかいう評価もあるんですが、ほんとに……?スマホでこんなに自然にズーム回せるのはレンズリングだからこその体験だし(そのためにかLeitzphoneの75-100mmは光学ズームまで搭載されている!)。しいて言えば縦で普通に持つとリングが回しにくい(レンズに手がかかっちゃう)のですが、ここはグリップ付けた時の感覚で、レンズを下にするとスススッと回せるんですよね。というわけですっかり縦撮りのときは逆さにするようになりました。
というわけで裸でもいいといえばいいんですが、でも気分も変わるのでグリップも併用していきたいので、裸使用でも接続性の良いPhotography Kit、出してくれませんかね……?あと今のところレンズリングはカメラアプリ内でしか機能しないんですが、普通にボリューム操作とかにも使いたいですね……!今後のアップデートに期待!
Xiaomi Buds 5 Pro Wifi
メインのイヤホンはHUAWEI FreeClip 2で、オープンイヤー型は、音楽を聞くだけではない、何だったら音楽を聞いている時間のほうが短い、ぐらいの現代のイヤホンの使い方に非常にマッチしたデザインだと思っています。YouTube見たり配信見たりZoomしたりだと、ノイズキャンセリングよりもこちらのほうが耳に自然で圧倒的にいいんですよね。
最近のノイズキャンセリングイヤホンの外音取り込みモードは、それ自体はどれも優秀で自然なのですが、耳をふさいでいるということの軽い圧迫感に加えて、話したり、歩いたり、食事したりといった際に発生する人間の内側から出すノイズに脆弱で違和感が強く出てしまうのが難点でした。特にイヤホンしたままの食事は、私は無理だなあ、という感じです。
オープンイヤー型は付け心地の軽さに加えて、それらが全く発生しないので、外音取り込みモードがどれだけ進化しても超えられないんじゃあないかな、と。実際これはSONYの最新ハイエンドのノイズキャンセリングイヤホンWF-1000XM6でも意識されているみたいで「イヤフォン本体から耳への通気量が増えたことで、自らの足音や咀嚼音などの体内ノイズが大幅に減少しました」といった対策を取ったりしているみたいですが、つまり構造的に絶対にオープンイヤー型レベルの体内ノイズ減少にはならないでしょう。
そんなオープンイヤー型の中でもFree Clipの出来は断然よく、そしてこないだ発売されたばかりのFree Clip 2は更に進化していてすごい、すごい!絶対買うべき!
なのですが、それはそれとしてノイズキャンセリングしたいし音楽もちゃんと聞きたいというシチュエーションはいっぱい存在するので、ノイズキャンセリングイヤホンも欲しい。と、そこでXiaomi Buds 5 Proです。厳密にはXiaomi Buds 5 Pro Wifiです。
高音質と言われるコーデックLDACでも990kbpsのところを、Wi-Fi接続によりBluetoothの限界を突破して最大4.2Mbpsの伝送速度(4倍!) 96kHz/24ビットの真のロスレスオーディオに対応している、と。これはQualcommのXPANという最新の技術で実現していて、伝送側も対応している必要があるので、今のところ現実的に使える組み合わせはXiaomiのハイエンド端末とXiaomi Buds 5 Pro Wifiだけ、です。
QualcommからはBluetoothに代わり、Wi-Fiがイヤフォンのワイヤレス伝送の中核に。Qualcomm「XPAN」とは何かということで夢いっぱいな規格という雰囲気ですが、しかしとりあえず今のところ使えるのはXiaomiだけ、と。
せっかくそんなハイエンド端末を買ったので(LeitzphoneはXiaomi 17 Ultraと同スペック)、これは是非試したい。最新究極プロトコルとか、圧倒的なロマンに溢れていますから……!
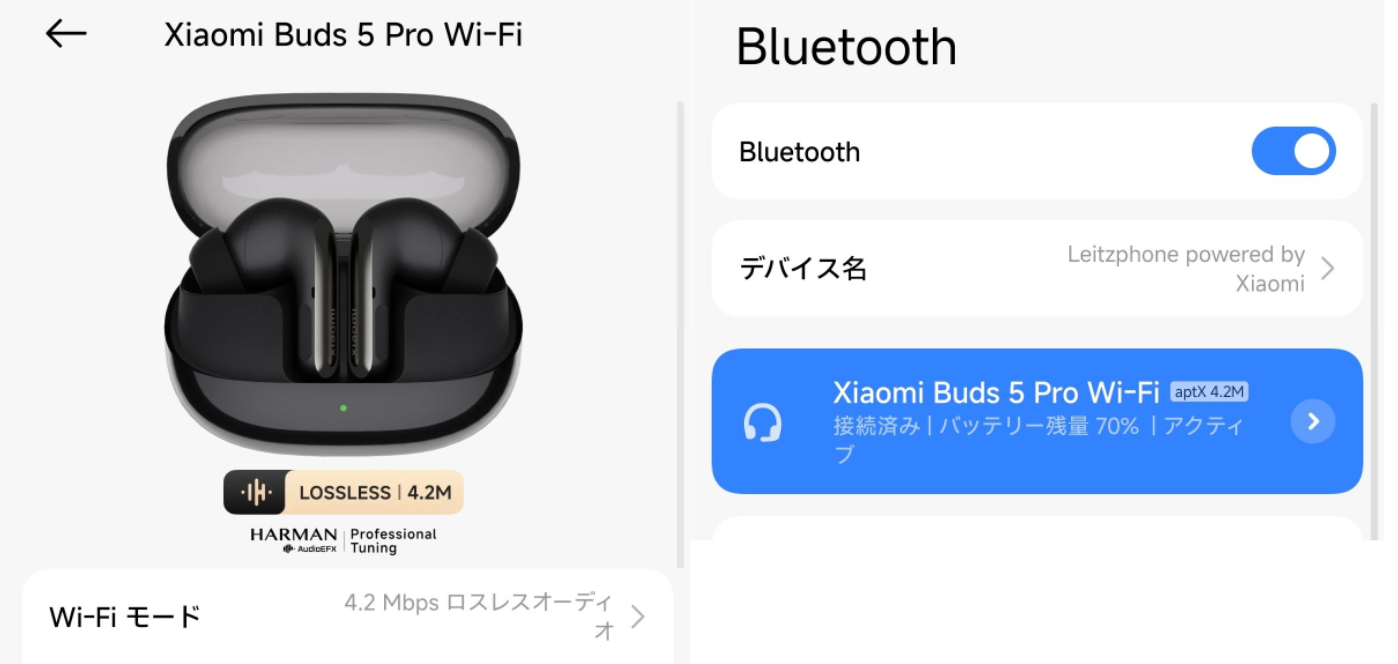
感想としては、パーフェクト。Wi-Fi伝送すごい、XPANすごい、これは流行るべき……。
正直Bluetooth伝送だとイマイチ(特に比較対象として、いま手元にある Bose QuietComfort Ultra Earbuds (第2世代) が相手だと)なのですが、Wi-Fi伝送だと変わります。いうてそこまで変わらないでしょと思いきや、かなり良くなる。BluetoothとWi-Fiでチューニング変えてるんじゃないの?というぐらいに変わってる感じがある。Boseと比較してどうこうというのはおいておきますが、とりあえずWi-Fi伝送はすごい、と。
音質設定のコンフィグが色々とっ散らかっているんですが、外耳道スキャンしてサウンド補正とか、聴覚テストして補正とか、色々入っているのも面白い。ただ、どっちも、ONにすると個人的にはむしろ悪化したのでオフにしちゃいましたが……。サウンドモードに関してはデフォルトはHarman AudioEFXだったのですが、これはHarman Masterのほうが好ましかったです。
とりあえず、今のところ特別な組み合わせによる音質ということに、嬉しさが上乗せされてて満足度めっちゃ高い。
C# .NET for Android
Androidで嬉しいのは野良アプリを入れ放題ということ、実際、まだ一週間ですが幾つか野良アプリを入れる機会が。で、つまりは野良アプリだけじゃなくて自作の雑アプリも入れ放題というわけですね!
というわけでAndroidアプリを作ったことはないのですが(やるのはUnityアプリのデプロイぐらい)、Claudeの助けを借りて雑にやっていきましょう。C#で。
AIがやるならネイティブで(Kotlinで)やれよ、という話もあるんですが、自分のスキルセットにない言語や環境でVibe Codingでアプリケーションを作ると、コードをほとんど見なくなっちゃうんですよね、なんか読んでもあんまわからないし、みたいな。動きゃあなんでもいいだろ、と。そして動くなくなったら普通に詰んで投げ捨ててる。さすがにC#なら分からないなりに分かるのと、環境セットアップもほぼ不要でVisual Studioで完結できるので、楽でいいです。
作りたいものは決まっていて、ストップウォッチです。いや、なんかXiaomiのコントロールセンターにストップウォッチ(というか時計/アラーム)がないので、サクッと起動できないんで普通に困ってるんですよ、ないわけないと思うんですけど、なんで?
あとラップタイムを叩いた時にトータルタイムだけじゃなくて、そのラップタイムの時間もリアルタイム表記して欲しいんですよね。これApple Watchのストップウォッチができなくてイライラしています(なのでワークアウトの表記をカスタマイズしてセグメントを常時表記して代用してます)。Xiaomiの標準ストップウォッチもできてないです。
適当なストップウォッチを探す旅に出るほどのものでもないので、こういうものこそ雑に自作する時代でしょう、小さな不満は自作で解決する時代!
というわけで初めての.NET for Androidです。Visual StudioでAndroidのテンプレートで作ってCtrl + F5すると、いきなりdotnet workload restoreしろと言われる。体験悪い……。幸いrestoreしただけでビルドは通って、デプロイしようとするとエミュレーター入れてね、とエミュレーターインストールウィンドウまで出てきて親切……!
ただエミュレーターで開発してくのは興味なくて、今はVibeで実機にボンボン突っ込みたいだけなので、Leitzphoneのほうを開発者モードを有効にしてUSBデバッグを有効にして、Error ADB0010: Mono.AndroidTools.InstallFailedException: Failure [INSTALL_FAILED_USER_RESTRICTED: Install canceled by user]で怒られる。これはUSB経由でインストールも有効にしてなかったせいらしいので、そっちも有効にする(なお、これはXiaomiアカウントを作ってログインしとかないと有効化できないらしい。個人端末なので普通にログインしてるので問題ないんですが、法人での開発用端末だと面倒ですね)。
これでVisual Studio上でもデプロイ先にXiaomiがいるじゃないですかー。25128PNA1GがLeitzphoneのモデル名らしい。あとはこれでデプロイ、と。
そんなわけで初めてのインストールを済ませたら、後はMainActivity.csとactivity_main.xmlをClaudeに雑に編集してもらう、ということで何度かダメ出しして10往復ぐらいした後のAndroidApp1がこちら。
全然いいんじゃないでしょうか……!ストップウォッチに見た目も機能もなくて結構なので、全然これでヨシです。業務の複雑なコードの仕事ですらこなせる昨今、こんなドシンプルな要求に対するコードを生成できることに驚きは特になく。とはいえ、もはやそんな当たり前のことを当たり前にやってもらえることにしみじみ喜びがあります。いかんせん、Android知識ゼロなので、多分手書きしてたらこれ作るのそれなりにドキュメント読んでチュートリアルこなす必要があったので、それを完全にスキップして数分で完成なら上出来すぎます。
コードは正直クソみたいなコードだな、とは思いましたが(長ったらしいのでここには貼りません)、AndroidのXmlも分からんし Android.App.Activity もわからんのに、ここまでやってくれるなら言うことは特にないです。
さて、アプリが及第点なので、不満点の解消としてコントロールセンターから起動できるようにしたい、と。ClaudeによるとTileServiceを実装すれば追加可能になるよ、と。
using Android.App;
using Android.Content;
using Android.Service.QuickSettings;
namespace AndroidApp1;
[Service(
Name = "AndroidApp1.StopwatchTileService",
Label = "ストップウォッチ",
Icon = "@drawable/ic_stopwatch",
Exported = true,
Permission = "android.permission.BIND_QUICK_SETTINGS_TILE")]
[IntentFilter(new[] { "android.service.quicksettings.action.QS_TILE" })]
public class StopwatchTileService : TileService
{
public override void OnClick()
{
base.OnClick();
var intent = new Intent(this, typeof(MainActivity));
intent.AddFlags(ActivityFlags.NewTask);
var pendingIntent = PendingIntent.GetActivity(
this, 0, intent, PendingIntentFlags.Immutable)!;
StartActivityAndCollapse(pendingIntent);
}
}
やってることはシンプルそうですが、こっちはミリしらなので、別にレビューすることもなく素通ししかない。
アイコンもXMLで生成してくれてありがたい。
<vector xmlns:android="http://schemas.android.com/apk/res/android"
android:width="24dp"
android:height="24dp"
android:viewportWidth="24"
android:viewportHeight="24">
<!-- stopwatch body -->
<path
android:fillColor="#FFFFFF"
android:pathData="M12,4C7.03,4 3,8.03 3,13s4.03,9 9,9 9,-4.03 9,-9S16.97,4 12,4zM12,20c-3.86,0 -7,-3.14 -7,-7s3.14,-7 7,-7 7,3.14 7,7 -3.14,7 -7,7z" />
<!-- hand -->
<path
android:fillColor="#FFFFFF"
android:pathData="M11,8h2v6h-2z" />
<!-- top button -->
<path
android:fillColor="#FFFFFF"
android:pathData="M11,1h2v3h-2z" />
</vector>
というわけで無事ストップウォッチがコントロールセンターに追加されました(右下)
完成!
ここまでサクサク行ったので、更に欲張って、iPhoneのストップウォッチと同じ用にXiaomiのダイナミックアイランド(Xiaomi HyperIslandというらしい)に対応させてやろう、と思ったら、なんと独自の非公開データを投げつけなきゃいけないとか複雑骨折仕様なので、少しやらせたけど、うまくできなかったので撤退しました。これはXiaomiが悪い。ちなみに独自仕様は、次のHyperOS 3.1からは標準仕様に乗っかるらしいので、無理やり頑張るよりそれを待ったほうがお得っぽいのでヨシ。
まとめ
せっかくなので断捨離したからとかもありますが、全体的に満足度は非常に高くなりました。面倒くさくはありましたが、移行して良かった。色々良さはあるんですが、やっぱLeitzphone自体が良いのが何より、かな。ハプティックフィードバックのあるレンズリングをグルグル回す原始的な楽しさと、雑にぱっと撮ってもそれなりに見栄えがしてしまうライカマジックのカメラは官能度高いです。
AndroidなのかXiaomi HyperOSなのか、という切り分けもありますが、iOSに比べてぱっと見は一緒なのだけど、すぐに作りの甘さみたいなのは感じてしまいます。特に文字周りがイマイチになりがちではあるかなあ。Windowsはもっとボロボロなので全く許容範囲なのですが!ガクガクするような動きの遅さとか引っ掛かりは一切感じず、ちゃんとヌルッとしてるので全然アリではありますよ。
サードパーティアプリまで広げると、ダイナミックアイランド(Xiaomi HyperIsland)が全然活かされていない。iOSでのライブアクティビティがダイナミックアイランドに格納されるのはかなり便利だったので、ちゃんと動いて欲しいと思ったんですよね。雑アプリ作っていて知ったんですが、現状はだいぶ独自対応、というか非公開の仕様に沿った出力が必要なようで、こういうOSの分断は、そりゃあサードパーティアプリはカバーできるわけがないよねえ、と理解しました。中国国内のアプリはかなり対応していそうですがグローバルなアプリが完全に未対応になっちゃってるんですね。ただしこれは、標準APIと繋ぎ合わせて対応させていくみたいな流れ(HyperOS 3.1(Beta)ではAndroid 16の標準API経由で対応できそうらしい)も合わせて、時が解決していく流れでやってるのならヨシ、ということで。
また、これもHyperOS起因なのか、素のカスタマイズ製はiOSよりもないですね。コントロールセンターにアプリも追加できないし。思ってたよりも遥かにガチガチで何も追加できない雰囲気で(iOSはなんだかんだでショートカット組めば何でもできるみたいなところがあった)、これは雑アプリを作ってカバーするか、といった気持ちでいます。
とはいえ総評としては本当に改めて大満足で(移行が面倒くさくてサンクコスト爆発してるので、そういい聞かせているところもなくはない)、WindowsユーザーはAndroid使うべきですよ過激派に転向します……!
2025年を振り返る
- 2025-12-30
今年のC#やりこみ振り返り……!
新規:
大きめアップデート
作りかけ
毎年、今年のやりこみ度は大丈夫かな?という気になりますが、とりあえずZLinqが大型案件(?)だったので大丈夫でしょう。注目度(Star数は現在4800行きました)も高く、実装の安定度も高く、奇抜性も高くということで、いいものになっているのではないかと思います。Star数でいうと、UniTaskは10000超えしました!GitHub/Cysharp全体では45000超え、neueccやMessagePack-CSharp名義のものも含めれば、トータルで60000を超えるということで、C#関連でいったら世界屈指と言えるのではないでしょうか。
そんなわけで悪くない結果だと思うのですが、一方で今年はブログをほとんど書いていません!年々書かなくなっていますが、過去一で書いていません!理由としては体調不良で、ZLinqを終えてちょっとした辺りグッと体調を崩してしまって色々と停滞してしまいました。OSS関連も意識的に手を付けないようにしていたので、Issue/PR系も過去一番に手を付けられていません……!言い訳がましいことを言うと、作りかけを完了できなかったのもこの辺が悪く――。といった感じでは不満の残る結果でもあります。一応、復調傾向にはあるので、来年はじっくり取り込みたいとは思っています。
これは私が発表したわけではありませんが
というセッションでShadowverse: Worlds Beyondのアーキテクチャに関する発表があったのですが、かなりCysharp/MagicOnionについて言及してもらっています。触れられているとおり、初期から開発に関わらせていただいています。採用ライブラリも「MagicOnion、R3、ZLinq、MessagePack for C#、UniTask、YetAnotherHttpHandler」とアグレッシブに新しいものも詰んでもらいました。リリースを迎えられるのは、やはりとても嬉しいですね……!
なんとか of the Year
Game of the Year総舐めですが、やはり私もClair Obscur: Expedition 33を挙げたいと思います。ああ、こういうの好きだったよなあという感覚と、ただの懐古主義じゃない完全に現代的に調和した内容。こうあって欲しいという思いが見事実現化されているようです。めちゃくちゃフランスを感じるところは、西洋風のエスニックで、馴染みあるようで全然なくてめちゃくちゃ新鮮でもあって、まぁ、とにかく良い、文句無し……!全てが気合入っているというよりは、見せ場には力をしっかり入れつつ、手を抜くところはしっかり抜くというバランス感覚は開発的には大事ですねえ。ゲームバランスが序盤-中盤がかなり緊張感ある面白さだったのに反して、後半はインフレバトルに突入するのは、一粒で二度美味しい、というには、やはり大味になりすぎた気がするので若干残念ですが、まぁ味変ということで、それはそれで良いでしょふ。
なんか買ったものとしては、軽量化計画ということで財布をZenlet Cache 3.0に変えたのですが、ポケットがすっきりして実際めっちゃ良き。数年前から小銭入れのない財布を使ってきて、まぁまぁやれてたので、去年はthe RIDGEというマネークリップを使っていたのですが、更に突き詰めたいと思って色々探していて見つけたのがCache 3.0でした。
マイナンバーカードもiPhoneに入るようになったし(とはいえマイナンバーカードは持ち歩いていますが)、楽天銀行もスマホATMに対応したしということで、カードも厳選して持ち歩く枚数をかなり減らせるので、最小限の最小限で十分かな、と。最小限のカード(クレジットカードとマイナンバーカードとその他一枚)と最小限の現金(1万円札1枚と1000円札1枚)で問題なし。Phoneにペタっと付く&キックスタンドになるのも便利なので、良い塩梅でした。
iPhoneはiPhone Airに変更しました。ここ数年ずっとPro Maxだったので、こちらも一気に軽量化……!基本的に欲しいのは画面サイズだったので、Pro以上Max以下の画面サイズは個人的にはジャストです。まぁ不人気すぎて後継機器は出なそうなので、Foldが来たら一気に重量化しちゃいますが……。バッテリー持ちがかなり悪いので、マグセーフ型のバッテリーとしてMATECH(マテック)® Qi2 モバイルバッテリー マグセーフを合わせています。これはマグセーフに加えてスタンドが付いてるところがポイントで、外で、というよりかは家の中で、休日とかに1日中持たないので、スタンド代わりに使いながら充電することで1日持たせる、みたいな使い方をしています。というわけで、スタンド付きが重要です。財布もスタンド付きが重要だったということで、今年はスタンドブームが来てます……!
バッテリーといえばAnker Power Bank (25000mAh, Built-In & 巻取り式USB-Cケーブル)が今年買って、一番便利だったもの、かも。これも完全に家用なのですが、ワイヤレスで移動可能な軽量充電ステーションとして使ってます。コンセントの近くまで行かないと充電できないのが何かと不便だったのですが、これがあればどこでも充電ステーション化できるので、ちょっとした小物の充電がめっちゃ楽になりました。25000mAhあれば、私の使い方的には一週間は持つので、この容量が個人的にはベスト(あまり大きくするとデカいし重いしになるので)。ケーブルが2本ビルトインで生えてるのもいい塩梅です。
というわけで巻取り式ケーブル内蔵ブームが来たのでAnker Nano Charger (35W, 巻取り式 USB-Cケーブル)とAnker Nano Charging Station (7-in-1, 100W, 巻取り式 USB-Cケーブル)も調達して、便利度が上がりました。
来年
使ってないわけではないですが、AIブームから乗り遅れている&Vibe Codingには懐疑派として、CompilerBrainというC# Coding Agentの計画があるので、来年初頭には見せれるものに仕上げたいと思っています。あと今年溜まったOSS Issueもなんとかやりきりたい……!
それとUnityのCoerCLR対応がついに来年くる、っぽいので、めっちゃ楽しみにしています。今まで以上にC#やり込みパワーが火を吹くときが来ましたか……!言語を極めることで、表現できることの幅というのは広がるものなのです、ということを実証していきますよ……!
今年はOSSとお金に関する話も多くトピックスに上がって来ました。C#でも、やはりホットなトピックスで、有名ライブラリの有償化や、提言など色々が色々です。私としては引き続きOSSベースでやっていきますし、有償化は全く考えていません。とはいえメンテナーに強く負荷がかかることもあり、無償の奉仕を求めるのが当然ではありません。持続性のあるOSSエコシステムを求めるなら、なおのこと、お金に関しては強く考える必要があります。そんなわけで改めて、特に直接の還元ができているわけではないですが、sponsors/neueccへの寄付はとてもありがたく思っています。
というわけで引き続きC#を発展させていきますので、来年も頑張りましょう……!
ToonEncoder - C#とLLMのためのJSON互換フォーマットエンコーダー
- 2025-12-23
Token-Oriented Object Notation(TOON)というJSON互換のフォーマットのシリアライザー(エンコードのみ)を作りました。TOONは、適切に活用することで、LLMとの対話時に、トークンを大きく節約できる可能性を秘めています。コンパクトなライブラリーではありますが、内部的には全てUTF8ベースで処理していて、IBufferWriter<byte>対応やSource Generatorによるシリアライザー生成など、現代的なライブラリとしての基本機能は十分備えています。
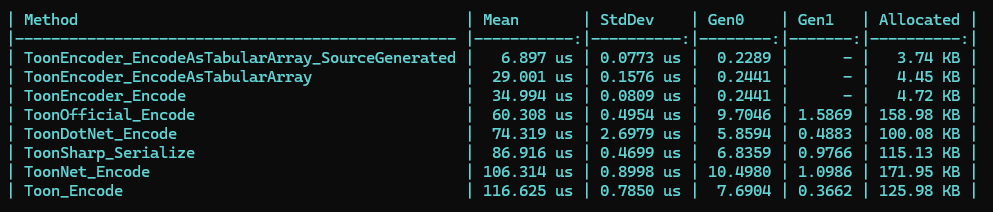
もちろん、競合と比べてもパフォーマンスやメモリ効率は圧倒的に良いです。
この辺はとにかく私がシリアライザーの設計に慣れすぎていて(MessagePack-CSharp, MemoryPack, Utf8Json, etc...)実績もノウハウもありまくりなので……!ジャンルがジャンルなのでAIでとりあえず動くものにしましたっぽいライブラリも多い感じですが、全然勝負になりません。なんせこちらは温かみのある手作りコードですから……!ハイパーハンドメイドクラフトコーディング。現状のAI生成のコードレベルは、トップレベルからは、ほど遠いと実際思ってます。動くものはできるし、それは凄いんですけど、ね。
さて、まずTOONについて軽く説明すると、以下のJSONのデータが
{
"context": {
"task": "Our favorite hikes together",
"location": "Boulder",
"season": "spring_2025"
},
"friends": ["ana", "luis", "sam"],
"hikes": [
{
"id": 1,
"name": "Blue Lake Trail",
"distanceKm": 7.5,
"elevationGain": 320,
"companion": "ana",
"wasSunny": true
},
{
"id": 2,
"name": "Ridge Overlook",
"distanceKm": 9.2,
"elevationGain": 540,
"companion": "luis",
"wasSunny": false
},
{
"id": 3,
"name": "Wildflower Loop",
"distanceKm": 5.1,
"elevationGain": 180,
"companion": "sam",
"wasSunny": true
}
]
}
TOONで表現すると以下のように小さくなります。
context:
task: Our favorite hikes together
location: Boulder
season: spring_2025
friends[3]: ana,luis,sam
hikes[3]{id,name,distanceKm,elevationGain,companion,wasSunny}:
1,Blue Lake Trail,7.5,320,ana,true
2,Ridge Overlook,9.2,540,luis,false
3,Wildflower Loop,5.1,180,sam,true
JSONというよりかは、YAMLとCSVのハイブリッドのようなもので、特に、テーブルとして(CSVとして)表現できる、プリミティブ要素のみを含むオブジェクトの配列が、CSV的に出力されるのでデータが大きく縮みます。この縮み幅がLLMにおけるトークンの節約に繋がるということでちょっとだけ脚光を浴びました。ならよくわからんフォーマットじゃなくてCSVでいいじゃん、というと、CSVだけだとテーブルのみで付随情報がつけられなくて実用には厳しいので、こちらのほうが使い勝手は良い印象です。また、JSONと相互互換のある仕様にしていることで、JSONからのDrop-in replacementが可能というのもセールスポイントにはなっています。
個人的な所感としてはTOONはヒューマンリーダブルではないです。TOONは効率性に寄せているため、配列の表現方法が3種類あります。ToonEncoderではTabularArray、InlineArray、NonUniformArrayと呼んでいますが、3種類あると正直読みづらいよね。また、TabularArrayとNonUniformArrayがオブジェクトのネストと合わさると、インデントがわけわからなくなります。LLMは、よくわからん形式とはいえ、ヒューマンリーダブルなら、なんとなくちゃんと読み取ってくれている雰囲気がありますが、そうした破綻した状態で解釈を正しく持ってくれるかどうかには不安があります。
というわけで、JSONを全て置き換えるのではなく、ピンポイントにCSV的なテーブル(TabularArrya)か、フラットなオブジェクトにTabularArrayを末尾に足したぐらいのものに適用するのが、トークン効率的にもLLMの理解力的にも人間のリーダビリティ的にもちょうど良いのではないかと思っています。実際ToonEncoderではそうした運用で最高なパフォーマンスが出るように調整してありますし、Microsoft.Extensions.AIとの組み合わせで、一部の型のみToon化する、といった連携ができるようになっています。
Microsoft.Extensions.AIと一緒に使う
NuGet/ToonEncoderからダウンロードしてもらうとコアライブラリ―とSource Generatorが同梱でついてきます。なお最小ターゲットプラットフォームは .NET 10 です。
基本的にはEncodeでJsonElement、またはT valueを変換できます。
using Cysharp.AI;
var users = new User[]
{
new (1, "Alice", "admin"),
new (2, "Bob", "user"),
};
// simply encode
string toon = ToonEncoder.Encode(users);
// [2]{Id,Name,Role}:
// 1,Alice,admin
// 2,Bob,user
Console.WriteLine(toon);
public record User(int Id, string Name, string Role);
今回はプリミティブ要素のみのオブジェクト配列のため、表形式レイアウト(TabularArray)としてシリアライズされています。
具体的な利用法としてはMicrosoft.Extensions.AIのFunction Callingに適用する場合は、対応する型のコンバーターを設定した JsonSerializerOptions を用意し、オプションに渡してあげると良いでしょう。また、Source Generatorを使うと、効率的なJsonConverterを生成してくれます。使用方法は対象の型に[GenerateToonTabularArrayConverter]するだけです!
public IEnumerable<AIFunction> GetAIFunctions()
{
var jsonSerializerOptions = new JsonSerializerOptions
{
Encoder = JavaScriptEncoder.UnsafeRelaxedJsonEscaping,
WriteIndented = false,
DefaultIgnoreCondition = JsonIgnoreCondition.Never,
Converters =
{
// setup generated converter
new Cysharp.AI.Converters.CodeDiagnosticTabularArrayConverter(),
}
};
jsonSerializerOptions.MakeReadOnly(true); // need MakeReadOnly(true) or setup converter to TypeInfoResolver
var factoryOptions = new AIFunctionFactoryOptions
{
SerializerOptions = jsonSerializerOptions
};
yield return AIFunctionFactory.Create(GetDiagnostics, factoryOptions);
}
[Description("Get error diagnostics of the target project.")]
public CodeDiagnostic[] GetDiagnostics(string projectName)
{
// ...
}
// Trigger of Source Generator
[GenerateToonTabularArrayConverter]
public class CodeDiagnostic
{
public string Code { get; set; }
public string Description { get; set; }
public string FilePath { get; set; }
public int LocationStart { get; set; }
public int LocationLength { get; set; }
}
この例の場合、CodeDiagnostic[]の件数が多いと、JsonとToonでトークン消費量にかなりの差が出てToonの優位度が高まります。ただし、Toonには得手不得手があるので、特性を見てToonを適用するか(Converterを追加するか)そのままにする(Json)かを選んでいくといいと思っています。
フラットな階層のオブジェクト(プリミティブ, プリミティブ要素の配列, プリミティブ要素のみで構成されたオブジェクトの配列)の生成の場合は、別の属性[GenerateToonSimpleObjectConverter]によりTabularArray + 追加のメタデータといったシナリオに対応できます。
var item = new Item
{
Status = "active",
Users = [new(1, "Alice", "Admin"), new(2, "Bob", "User")]
};
var toon = Cysharp.AI.Converters.ItemSimpleObjectConverter.Encode(item);
// Status: active
// Users[2]{Id,Name,Role}:
// 1,Alice,Admin
// 2,Bob,User
Console.WriteLine(toon);
[GenerateToonSimpleObjectConverter]
public record Item
{
public required string Status { get; init; }
public required User[] Users { get; init; }
}
Json to Toon
ToonEncoder.Encodeは JsonElement から string, byte[] への変換、 IBufferWriter<byte>, ToonWriterへの書き込みをサポートします。
namespace Cysharp.AI;
public static class ToonEncoder
{
public static string Encode(JsonElement element);
public static void Encode<TBufferWriter>(ref TBufferWriter bufferWriter, JsonElement element)
where TBufferWriter : IBufferWriter<byte>;
public static void Encode<TBufferWriter>(ref ToonWriter<TBufferWriter> toonWriter, JsonElement element)
where TBufferWriter : IBufferWriter<byte>;
public static byte[] EncodeToUtf8Bytes(JsonElement element);
public static async ValueTask EncodeAsync(Stream utf8Stream, JsonElement element, CancellationToken cancellationToken = default);
}
IBufferWriter<byte>のオーバーロードを用いるとUTF8で直接データを書き込むため、string変換を介すよりもパフォーマンスが高くなります。
EncodeではJsonElementがarrayの際に、TabularArrayかInlineArrayかNonUniformArrayかどうかを全件チェックしてから書き込みしますが、JsonElementがarrayかつ、全ての要素の出現順序が等しく、全てがプリミティブ(Array, Objectではない)であることを保証できる場合は EncodeAsTabularArray メソッドを用いると検査を省くため、より高いパフォーマンスで変換できます。
namespace Cysharp.AI;
public static class ToonEncoder
{
public static string EncodeAsTabularArray(JsonElement array);
public static void EncodeAsTabularArray<TBufferWriter>(ref TBufferWriter bufferWriter, JsonElement array)
where TBufferWriter : IBufferWriter<byte>;
public static byte[] EncodeAsTabularArrayToUtf8Bytes(JsonElement array);
public static async ValueTask EncodeAsTabularArrayAsync(Stream utf8Stream, JsonElement array, CancellationToken cancellationToken = default);
public static void EncodeAsTabularArray<TBufferWriter>(ref ToonWriter<TBufferWriter> toonWriter, JsonElement array)
where TBufferWriter : IBufferWriter<byte>;
}
というのが基本的な変換の仕様になっています。
まとめ
この記事は、C# Advent Calendar 2025に特にエントリーしていない記事ですが、時期的にはだいたいそんな感じです。
このToonEncoderは、Cysharp/CompilerBrainという全然まだできてないC# Coding Agentのパーツとして用意しました。結構データ大量にドカドカするので節約したいなあ、と思い……。そんなわけで来年初頭はCompilerBrainやっていきます、多分……!
ところで改めて正直なところTOON自体は別に全然いいフォーマットとは思えません。というかどちらかといえば相当厳しい……。が、まぁマーケティング的にJSON互換でDrop-in replacementというのが響いたのはありそうだし、実際CSVだと厳しいっちゃあ厳しいので、とりあえず仕様があるという点で妥協として悪くないといえば悪くない選択かもしれません。
複雑なデータをシリアライズする気はない、ということが[GenerateToonTabularArrayConverter]と[GenerateToonSimpleObjectConverter]に現れています。これはAnalyzerも兼ねていて非対応なネストしたプロパティとか持たせようとするとコンパイルエラーにするという、ようはToonのサブセットみたいなものを疑似的に作り出しているんですね。もちろんJsonElement経由のメソッドを呼べば、ちゃんとネストしたプロパティとかはシリアライズできます。一応用意されている公式のテストスイートには(意図的にサポートしていない機能を除いて)全件合格しています。
またライブラリ名の通り、Encodeしかサポートしていません。Decodeはできません。LLMに送信するためのものなのでだから、デコードは別にいらないでしょう。
といった感じで色々と手を抜いたコンパクトさもあるのですが、それなりに実用的にはなっているので、興味ある方は是非是非試してみてください!
Microsoft MVP for Developer Technologies(.NET)を再々々々々々々々々々々々々々受賞しました
- 2025-07-14
Microsoft MVPは一年ごとに再審査されるのですが、今年も更新しました。2011年から初めて15回目です。昨今の予算の事情を考えると、席も少なくなっているのではないかという気配があるので、いつまでも居座るのはどうなのかという気もしますが、まぁ実績出してるから、しょうがないね……?
毎年新しいOSSでヒット作を出すのも大変ですよ、と思いつつ去年はR3、今年はZLinqを出しました。これは文句なしでいいんじゃないかと。ZLinqは本当に作るの大変だったんで報われたい(?)
今回の審査期間中の対外的な発表は以下の3つがありました。
2025年に入ってからは何もやっていないので、何か機会があれば、と伺ってはいるのですが中々どうして。今年はAI関連に力を入れたいと思っているので、まずはOSSで何か出してから、というのがいつもの自分のパターンなので、それは近々出します……!あとはZLinqに関してはアーキテクチャを話す場が作れるといいんですが、まぁそのうちどこかで。今のところ予定は完全に未定です。
自社のタイトルではないので私のほうから大きく言えることはないのですが、先日は大きなタイトルがリリースされたというのもあるので、そういったところからもC#(クライアント/サーバー)の力を世の中にアピールできるといいな、とは思っています。
というわけで引き続き、C#の推進やっていきます!
ゼロアロケーションLINQライブラリ「ZLinq」のリリースとアーキテクチャ解説
- 2025-05-05
ZLinq v1を先月リリースしました!structとgenericsベースで構築することによりゼロアロケーションを達成しています。またLINQ to Span, LINQ to SIMD, LINQ to Tree(FileSystem, JSON, GameObject, etc.)といった拡張要素と、任意の型のDrop-in replacement Source Generator。そして.NET Standard 2.0, Unity, Godotなどの多くのプラットフォームサポートまで含めた大型のライブラリとなっています!現在GitHub Starsも2000を超えました。
structベースのLINQそのものは珍しいものではなく、昔から多くの実装が挑戦してきました。しかし、真に実用的と言えるものはこれまでありませんでした。極度なアセンブリサイズの肥大化、オペレーターの網羅の不足、最適化不足で性能が劣るなど、実験的な代物を抜け切れていないものばかりでした。ZLinqでは実用的に使えるものを目指し、.NET 10(Shuffle, RightJoin, LeftJoinなど新しいものも含む)に含まれる全てのメソッドとオーバーロードの100%のカバーと、99%の挙動の互換性の確保、そしてアロケーションだけではなく、SIMD化も含めて、多くのケースにおける性能面で勝てるように実装しました。
それが出来るのは、そもそも私のLINQ実装の経験はものすごく長くて、2009年4月にlinq.jsというJavaScript用のLINQ to Objectsライブラリを公開しています(linq.jsは現在もForkした人が今もメンテナンスされているようです、素晴らしい!)。他にもUnityで広く使われているReactive ExtensionsライブラリUniRxを実装し、直近ではそれの進化版であるR3を公開したばかりです。バリエーションとしてもLINQ to GameObject、LINQ to BigQuery、SimdLinqといったものを作っていました。これらに、ゼロアロケーション関連ライブラリ(ZString, ZLogger)やハイパフォーマンスシリアライザー(MessagePack-CSharp, MemoryPack)の知見を掛け合わせることで、標準ライブラリの上位互換という野心的目標を達成できました。

これはシンプルなベンチマークで、Where, Where.Take, Where.Take.Selectとメソッドチェーンを重ねれば重ねるほど、通常はアロケーションが増えていきますがZLinqはずっとゼロです。
性能は元のソース、個数、値の型、そしてメソッドの繋げ方によって変わってきます。多くのケースで性能面で有利なことを確認するために、ZLinqでは様々なケースのベンチマークを用意し、GitHub Actions上で走らせています。ZLinq/actions/Benchmark。構造上どうしても負けてしまうケースも存在はするのですが、現実的なケースではほとんど勝っています。
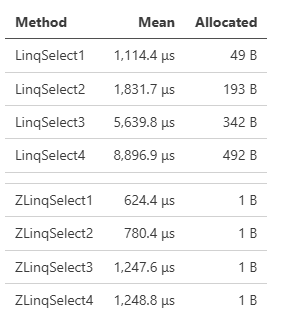
ベンチマーク上極端に差が出るものでいえば、シンプルにSelectを複数回繰り返したものは、SystemLinqもZLinqも特殊な最適化が入っていないケースになりますが、大きな性能差が出ています。
シンプルなケースでは、DistinctやOrderByなど中間バッファを必要とするものは、積極的なプーリングによりアロケーションを大きく抑えているため、差が大きくなります(ZLinqは原則ref strcutであり短寿命が期待できるため、プーリング利用はややアグレッシブにしています)。例えばこのベンチマークはDistinctです。
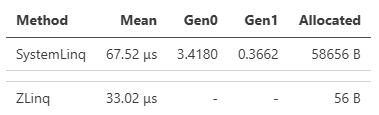
LINQはメソッド呼び出しのパターンにより特殊な最適化がかかるなど、アロケーションを抑えるだけでは性能面で常に勝てるわけではありません。そうしてオペレーターの繋がりによる最適化に関しても、これは.NET 9で最適化されたパターンとしてPerformance Improvements in .NET 9で紹介されている例ですが、ZLinqではそれらの最適化を全て実装し、より高いパフォーマンスを引き出しています。
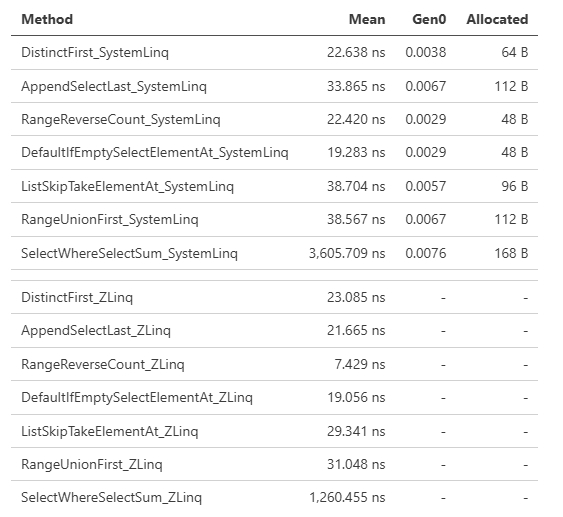
ZLinqの良いところとして、これらLINQの進化による最適化の恩恵を、最新の.NETだけではなく、全ての世代の.NET(.NET Frameworkも含む)が得られることでもあります。
利用法はシンプルに、AsValueEnumerable()呼び出しを追加するだけです。オペレーターに関しては100%網羅しているので、既存コードからの置き換えも全て問題なくコンパイルが通り、動作します。
using ZLinq;
var seq = source
.AsValueEnumerable() // only add this line
.Where(x => x % 2 == 0)
.Select(x => x * 3);
foreach (var item in seq) { }
ZLinqでは挙動の互換性を保証するために、dotnet/runtimeのSystem.Linq.Testsを移植して ZLinq/System.Linq.Tests 常に走らせています。

9000件のテストケースのカバーにより、動作を保証しています(Skipしているケースはref structであるため、同一テストコードを動かせない場合によるものなど)
また、 AsValueEnumerable() すら省略したDrop-In Replacementを任意で有効化するSource Generatorも提供しています。
[assembly: ZLinq.ZLinqDropInAttribute("", ZLinq.DropInGenerateTypes.Everything)]

この仕組みにより、Drop-In Replacementの範囲を自由にコントロールすることができます。ZLinq/System.Linq.Tests自体がDrop-In Replacementにより、既存テストコードを変えずにZLinqで動作するようになっています。
ValueEnumerableのアーキテクチャと最適化
使い方などはReadMeを参照してもらえればいいので、ここでは最適化の話を深堀します。ただたんなるシーケンスを遅延実行するだけ、ではないところが、アーキテクチャ上の特色であり、他の言語のコレクション処理ライブラリと比べても、多くの工夫が詰まっています。
連鎖のベースとなるValueEnumerable<T>の定義はこうなっています。
public readonly ref struct ValueEnumerable<TEnumerator, T>(TEnumerator enumerator)
where TEnumerator : struct, IValueEnumerator<T>, allows ref struct // allows ref structは.NET 9以上の場合のみ
{
public readonly TEnumerator Enumerator = enumerator;
}
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current); // as MoveNext + Current
// Optimization helper
bool TryGetNonEnumeratedCount(out int count);
bool TryGetSpan(out ReadOnlySpan<T> span);
bool TryCopyTo(scoped Span<T> destination, Index offset);
}
これを基にして、例えばWhereなどのオペレーターはこうした連鎖が続きます。
public static ValueEnumerable<Where<TEnumerator, TSource>, TSource> Where<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Func<TSource, Boolean> predicate)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
IValueEnumerable<T>ではなくてこのようなアプローチを取ったのは、(this TEnumerable source) where TEnumerable : struct, IValueEnumerable<TSource>のような定義にすると、TSourceへの型推論が効かなくなります。これはC#が型引数の制約からは型推論をしないという言語仕様上の制限(dotnet/csharplang#6930)があるためで、もしそのような定義のまま実装をすると、インスタンスメソッドとして大量の組み合わせを定義することになります。それをやったのがLinqAFであり、その結果100,000+ methods and massive assembly sizesということで、あまり良い結果をもたらしていません。
LINQにおいては実装は全てIValueEnumerator<T>側にあり、また、全てのEnumeratorはstructのため、GetEnumerator()ではなくて、共通でEnumeratorのコピー渡しするだけで、それぞれのEnumeratorが独立したステートで処理できることに気付いたので、IValueEnumerator<T>をValueEnumerable<TEnumerator, T>でラップするだけ、という構成に最終的になりました。これにより型が制約側ではなくて型宣言側に現れるので、型推論での問題もありません。
- TryGetNext
次にイテレートの本体であるMoveNextについて詳しく見ていきましょう。
// Traditional interface
public interface IEnumerator<out T> : IDisposable
{
bool MoveNext();
T Current { get; }
}
// iterate example
while (e.MoveNext())
{
var item = e.Current; // invoke get_Current()
}
// ZLinq interface
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current);
}
// iterate example
while (e.TryGetNext(out var item))
{
}
C#の foreach は MoveNext() + Current に展開されるわけですが、問題が二点あります。一つはメソッド呼び出し回数で、イテレート毎にMoveNextとget_Currentの2回必要です。もう一つはCurrentのために、変数を保持する必要があること。そこで、それらをbool TryGetNext(out T current)にまとめました。これによりメソッド呼び出し回数が一度で済みパフォーマンス上有利です。
なお、この bool TryGetNext(out T current) 方式は、例えばRustのイテレーターで採用されています。
pub trait Iterator {
type Item;
// Required method
fn next(&mut self) -> Option<Self::Item>;
}
変数の保持に関してはピンとこないと思うので、例としてSelectの実装を見てください。
public sealed class LinqSelect<TSource, TResult>(IEnumerator<TSource> source, Func<TSource, TResult> selector) : IEnumerator<TResult>
{
// フィールドが3つ
IEnumerator<TSource> source = source;
Func<TSource, TResult> selector = selector;
TResult current = default!;
public TResult Current => current;
public bool MoveNext()
{
if (source.MoveNext())
{
current = selector(source.Current);
return true;
}
return false;
}
}
public ref struct ZLinqSelect<TEnumerator, TSource, TResult>(TEnumerator source, Func<TSource, TResult> selector) : IValueEnumerator<TResult>
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
// フィールドが2つ
TEnumerator source = source;
Func<TSource, TResult> selector = selector;
public bool TryGetNext(out TResult current)
{
if (source.TryGetNext(out var value))
{
current = selector(value);
return true;
}
current = default!;
return false;
}
}
IEnumerator<T>はMoveNext()で進めてCurrentで返す、という都合上、Currentのフィールドが必要です。ところがZLinqでは進めると同時に値を返すため、フィールドに保持する必要がありません。これは、全体がstructベースで構築されているZLinqではかなり大きな違いがあります。ZLinqではメソッドチェーンの度に、以前のstructを丸ごと抱える(TEnumeratorがstruct)構造になるため、メソッドチェーンを重ねる度に構造体のサイズが肥大化していきます。常識的な範囲内でメソッドチェーンを重ねる限りは、パフォーマンス上も問題にはなっていなかったのですが、それでも小さければ小さいほどコピーコストが小さくなり性能面で有利にはなります。1バイトでも構造体を小さくする、ためにもTryGetNextの採用は必然でした。
TryGetNextの欠点は、共変・反変をサポートできないことです。ただし私は、そもそもイテレーターや配列から共変・反変のサポートは撤廃すべきだと思っています。Span<T>との相性が悪いため、メリット・デメリットを天秤にかけると、時代遅れの概念だと言えます。具体例を出すと、配列のSpan化は失敗する可能性があり、それはコンパイル時には検出できず実行時エラーとなります。
// ジェネリクスの変性によりDerived[]をBase[]で受け取る。
Base[] array = new Derived[] { new Derived(), new Derived() };
// その場合、Span<T>へのキャストやAsSpan()は実行時エラーになる!
// System.ArrayTypeMismatchException: Attempted to access an element as a type incompatible with the array.
Span<Base> foo = array;
class Base;
class Derived : Base;
Span<T>以前に追加された機能のため、もうどうにもならないとは思いますが、現代の.NETはあらゆるところでSpanが活用されるようになっているので、それが実行時エラーになる可能性をはらんでいる時点で、使い物にならないと考えてもいいはずです。
- TryGetNonEnumeratedCount / TryGetSpan / TryCopyTo
全てを愚直に列挙するだけだと、パフォーマンスは最大化されません。例えばToArrayするときに、もしサイズの変動がないなら(array.Select().ToArray())、new T[count]のように固定長配列を作ることができます。SystemLinqでも、そうした最適化を実現するために、内部的にはIterator<T>型が使われているのですが、引数はIEnumerable<T>のため、必ず if (source is Iterator<TSource> iterator) のようなコードが必要になっています。
ZLinqでは最初からLINQのための定義を前提にできるため、すべて織り込み済みで用意しています。ただし、むやみやたらに増やすのはアセンブリサイズの肥大化を招くため、必要最小限の定義で、最大限の効果を生み出すように調整したのが、この3つのメソッドとなっています。
TryGetNonEnumeratedCount(out int count)は、元のソースが有限の個数であり、途中にフィルタリング系メソッド(WhereやDistinctなど。TakeやSkipは算出可能なため含まない)が挟まらない場合は成功します。ToArrayなどのほか、OrderByやShuffleなど中間バッファが必要な時に効果が出るケースもあります。
TryGetSpan(out ReadOnlySpan<T> span)は、元ソースが連続的なメモリとして取得できる場合には、オペレーターによってはSIMDが適用されて劇的なパフォーマンス向上に繋がったり、Spanによるループ処理によって集計パフォーマンスが高まるなど、性能面で大きな違いをもたらす可能性があります。
TryCopyTo(scoped Span<T> destination, Index offset)は内部イテレーターによってパフォーマンスを向上させる仕組みです。外部イテレーターと内部イテレーターについて説明すると、例えばList<T>はforeachとForEachの両方が選べます。
// external iterator
foreach (var item in list) { Do(item); }
// internal iterator
list.ForEach(Do);
見た目は似ていますが、性能面で違いがあります。foreachは素直な構文で書けている。ForEachはデリゲート渡し。処理の実体まで分解すると
// external iterator
List<T>.Enumerator e = list.GetEnumerator();
while (e.MoveNext())
{
var item = e.Current;
Do(item);
}
// internal iterator
for (int i = 0; i < _size; i++)
{
action(_items[i]);
}
これはデリゲート呼び出し(+デリゲート生成アロケーション)のオーバーヘッド vs イテレーターのMoveNext + Current呼び出しの対決になっていて、イテレート速度自体は内部イテレーターのほうが速い。この場合デリゲート呼び出しのほうが軽量な場合があり、ベンチマーク的に内部イテレーターのほうが有利な可能性があります。
もちろん、ケースバイケースであることと、ラムダ式にキャプチャが発生したり、普通の制御構文が使えない(continueなど)ことから、私としてはForEachは使うべきではないし、拡張メソッドでForEachのようなものを独自定義すべきではない、とも思っていますが、原理的にはこのような違いが存在します。
TryCopyTo(scoped Span<T> destination, Index offset)は、デリゲートではなくSpanを受け取ることで限定的に内部イテレーター化しました。
これもSelectを例に出すと、ToArrayの場合にCountが取れているとSpanを渡して内部イテレーターで処理します。
public ref struct Select
{
public bool TryCopyTo(Span<TResult> destination, Index offset)
{
if (source.TryGetSpan(out var span))
{
if (EnumeratorHelper.TryGetSlice(span, offset, destination.Length, out var slice))
{
// loop inlining
for (var i = 0; i < slice.Length; i++)
{
destination[i] = selector(slice[i]);
}
return true;
}
}
return false;
}
}
// ToArray
if (enumerator.TryGetNonEnumeratedCount(out var count))
{
var array = GC.AllocateUninitializedArray<TSource>(count);
// try internal iterator
if (enumerator.TryCopyTo(array.AsSpan(), 0))
{
return array;
}
// otherwise, use external iterator
var i = 0;
while (enumerator.TryGetNext(out var item))
{
array[i] = item;
i++;
}
return array;
}
のように、SelectはSpanは作れませんが、元ソースがSpanを作れるなら、内部イテレーターとして処理することでループ処理を高速化することが可能です。
TryCopyToの定義は普通のCopyToと違って、Index offsetを持っています。また、destinationはソースサイズよりも小さいことを許しています(通常の.NETのCopyToはdestinationが小さいと失敗する)。これによって、destinationのサイズが1の場合、IndexによってElementAtが表現できます。そして0ならFirstだし^1の場合はLastになります。IValueEnumerator<T>自体にFirst, Last, ElementAtを持たせると、クラス定義として無駄が多くなってしまいますが(アセンブリサイズにも影響が出る)、小さいdestinationとIndexを持たせることにより、一つのメソッドでより多くの最適化ケースをカバーできるようになりました。
public static TSource ElementAt<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Index index)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
using var enumerator = source.Enumerator;
var value = default(TSource)!;
var span = new Span<T>(ref value); // create single span
if (enumerator.TryCopyTo(span, index))
{
return value;
}
// else...
}
ところで、このTryGetNextや内部イテレーターに関しては、2007年の時点で https://nyaruru.hatenablog.com/entry/20070818/p1 で紹介されていました。この記事はずっと頭に残っていて、ようやくこうして20年経って理屈通りの実現ができました。という点でも少し感慨深いです。2008年前後はLINQ登場前後ということで、このあたりの話がアツかった時代なんですよねー。
LINQ to Span
ZLinqは .NET 9 以上であれば、Span<T>やReadOnlySpan<T>に対しても、全てのLINQオペレーターを繋げることができます。
using ZLinq;
// Can also be applied to Span (only in .NET 9/C# 13 environments that support allows ref struct)
Span<int> span = stackalloc int[5] { 1, 2, 3, 4, 5 };
var seq1 = span.AsValueEnumerable().Select(x => x * x);
// If enables Drop-in replacement, you can call LINQ operator directly.
var seq2 = span.Select(x => x);
Span対応のLINQを謳ったライブラリも、世の中には多少ありますが、それらはSpan<T>にだけ拡張メソッドを定義する、といったようなものであり、汎用的な仕組みではありませんでした。網羅されるオペレーターも制約があり、一部のものに限られていました。それは言語的にもSpan<T>をジェネリクス引数として受け取ることができなかったためで、汎用的に処理できるようになったのは .NET 9でallows ref structが登場してくれたおかげです。
ZLinqではIEnumerable<T>とSpan<T>に何の区別もありません、全て平等に取り扱われます。
ただし、allows ref structの言語/ランタイムサポートが必要なため、ZLinq自体は.NET Standard 2.0以上の全ての.NETをサポートしていますが、Span<T>対応に関してのみ.NET 9以上限定の機能となっています。また、これにより.NET 9以上の場合は、全てのオペレーターがref structになっている、という違いがあります。
LINQ to SIMD
System.Linqでは、一部の集計メソッドがSIMDによって高速化されています。例えば一部のプリミティブ型の配列に直接SumやMaxを呼び出すと高速化されています。これらの呼び出しはforで処理するよりも遥かに高速化されます。とはいえ、IEnumerbale<T>がベースであるため、適用可能な型が限定的であるなどの欠点を感じています。ZLinqではIValueEnumeartor.TryGetSpanによってSpan<T>が取得できる場合が対象となるコレクションとなるため、より汎用的になっています(もちろんSpan<T>に適用することもできます)。
対応するメソッドは以下のようなものになっています。
- Range to ToArray/ToList/CopyTo/etc...
- Repeat for
unmanaged structandsize is power of 2to ToArray/ToList/CopyTo/etc... - Sum for
sbyte,short,int,long,byte,ushort,uint,ulong,double - SumUnchecked for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Average for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Max for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Min for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Contains for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint - SequenceEqual for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint
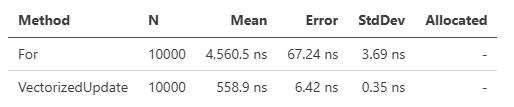
Sumはオーバーフローをチェックします。これは処理においてオーバーヘッドとなっているため、独自にSumUncheckedというメソッドも追加しています。性能差は以下のようになり、Uncheckedのほうがより高速です。
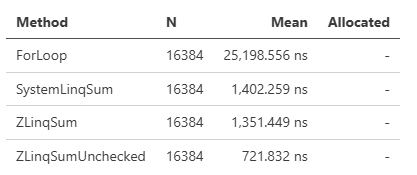
これらメソッドは条件がマッチした場合に暗黙的に適用されるということであり、SIMDを狙って適用させるには内部パイプラインへの理解が必要とされています。そこでT[] or Span<T> or ReadOnlySpan<T>には.AsVectorizable()というメソッドを用意しました。SIMD適用可能なSum, SumUnchecked, Average, Max, Min, Contains, and SequenceEqualを明示的に呼び出すことができます(ただしVector.IsHardwareAccelerated && Vector<T>.IsSupportedではない場合は通常の処理にフォールバックされるため、必ずしもSIMDが適用されることを保証するわけではありません)。
int[] or Span<int>にはVectorizedFillRangeというメソッドが追加されます。これはValueEunmerable.Range().CopyTo()と同じ処理で、連番で埋める処理がSIMDで高速化されます。連番が必要になる局面で、forで埋めるよりも遥かに高速なので、覚えておくといいかもしれません。
- Vectorizable Methods
SIMDによるループ処理を手書きするのは、慣れが必要で少し手間がいります。そこでFuncを引数に与えることでカジュアルに使えるヘルパーをいくつか用意しました。デリゲートを経由するオーバーヘッドが発生するためインラインで書くよりもパフォーマンスは劣りますが、カジュアルにSIMD処理できるという点では便利かもしれません。これらは引数にFunc<Vector<T>, Vector<T>> vectorFuncとFunc<T, T> funcを受け取り、ループの埋められるところまでVector<T>で処理し、残りをFunc<T>で処理します。
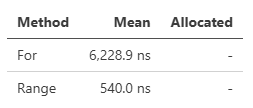
T[], Span<T>にはVectorizedUpdateというメソッドが用意されています。
using ZLinq.Simd; // needs using
int[] source = Enumerable.Range(0, 10000).ToArray();
[Benchmark]
public void For()
{
for (int i = 0; i < source.Length; i++)
{
source[i] = source[i] * 10;
}
}
[Benchmark]
public void VectorizedUpdate()
{
// arg1: Vector<int> => Vector<int>
// arg2: int => int
source.VectorizedUpdate(static x => x * 10, static x => x * 10);
}
forよりも高速、ですが、パフォーマンスはマシン環境やサイズによって変わるので、盲目的に使うのではなくて、都度検証することをお薦めします。
AsVectorizable()にはAggregate, All, Any, Count, Select, and Zipが用意されています。
source.AsVectorizable().Aggregate((x, y) => Vector.Min(x, y), (x, y) => Math.Min(x, y))
source.AsVectorizable().All(x => Vector.GreaterThanAll(x, new(5000)), x => x > 5000);
source.AsVectorizable().Any(x => Vector.LessThanAll(x, new(5000)), x => x < 5000);
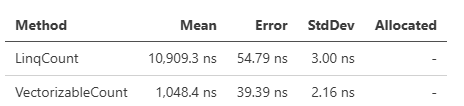
source.AsVectorizable().Count(x => Vector.GreaterThan(x, new(5000)), x => x > 5000);
パフォーマンスは、データ次第ではありますが一例としてはCountで、このぐらいの差が出ることもあります。
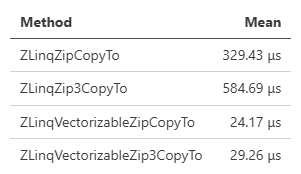
Select, Zipに関しては、後続にToArrayかCopyToを選びます。
// Select
source.AsVectorizable().Select(x => x * 3, x => x * 3).ToArray();
source.AsVectorizable().Select(x => x * 3, x => x * 3).CopyTo(destination);
// Zip2
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).CopyTo(destination);
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).ToArray();
// Zip3
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).CopyTo(destination);
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).ToArray();
Zipなんかは結構面白い&ちゃんと高速なので、使いどころあるかもしれません(2つのVec3のマージとか)。
LINQ to Tree
皆さんLINQ to XMLを使ったことはありますか? LINQの登場した2008年は、まだまだXML全盛期で、LINQ to XMLのあまりにも使いやすいAPIには衝撃を受けました。しかし、すっかり時代はJSONでありLINQ to XMLを使うことはすっかりなくなりました。
しかし、LINQ to XMLの良さというのは、ツリー構造に対するLINQ的操作のリファレンスデザインだと捉えることができます。ツリー構造がLINQになる、そのガイドライン。LINQ to Objectsと非常に相性の良い探索の抽象化。その代表例がRoslynのSyntaxTreeに対する操作で、AnalyzerやSource Generatorを書くのにDescendantsなどのメソッドを日常的に利用しています。
そこでZLinqはそのコンセプトを拡張し、ツリー構造に対して汎用的に Ancestors, Children, Descendants, BeforeSelf, and AfterSelf が適用できるインターフェイスを定義しました。

これはUnityのGameObjectへの走査の図ですが、標準でFileSystem(DirectoryTreeはツリー構造)やJSON(System.Text.JsonのJsonNodeに対してLINQ to XML的な操作を可能にする)を用意しています。もちろん、任意にインターフェイスを実装することで追加することもできます。
public interface ITraverser<TTraverser, T> : IDisposable
where TTraverser : struct, ITraverser<TTraverser, T> // self
{
T Origin { get; }
TTraverser ConvertToTraverser(T next); // for Descendants
bool TryGetHasChild(out bool hasChild); // optional: optimize use for Descendants
bool TryGetChildCount(out int count); // optional: optimize use for Children
bool TryGetParent(out T parent); // for Ancestors
bool TryGetNextChild(out T child); // for Children | Descendants
bool TryGetNextSibling(out T next); // for AfterSelf
bool TryGetPreviousSibling(out T previous); // BeforeSelf
}
例えばJSONに対しては
var json = JsonNode.Parse("""
// snip...
""");
// JsonNode
var origin = json!["nesting"]!["level1"]!["level2"]!;
// JsonNode axis, Children, Descendants, Anestors, BeforeSelf, AfterSelf and ***Self.
foreach (var item in origin.Descendants().Select(x => x.Node).OfType<JsonArray>())
{
// [true, false, true], ["fast", "accurate", "balanced"], [1, 1, 2, 3, 5, 8, 13]
Console.WriteLine(item.ToJsonString(JsonSerializerOptions.Web));
}
といったように書くことができます。
UnityにはGameObjectやTransform、GodotにはNodeへのLINQ to Treeを標準で用意しました。アロケーションや走査のパフォーマンスにかなり気を使って書かれているので、手動でループを回すよりも、もしかしたら高速かもしれません。
OSSと私
ここ数ヶ月で.NET関連のOSSには幾つか事件がありました。名のしれたOSSの商業ライセンス化、など……。私は、github/Cysharpで出しているOSSの数は40を超え、個人やMessagePack organizationなどのものも含めると、総スター数では50000を超えるなど.NET周りのサードパーティーとしては最大規模でのOSS提供者なのではないかと思います。
商業化、に関しては予定はありません、が、メンテナンスに関しては規模が大きくなってきたため、追いつかなくなっている面が多々あります。OSSが批判を覚悟で商業化を試みるの要因として、メンテナーに対する精神的な負荷というのが大きい(時間に対しての報酬が全く見合っていない)のですが、私も、まぁ、大変です!
金銭面は置いておいて、お願い事としては、メンテナンスが滞ることがあることは多少受け入れて欲しい!今回のZLinqのような大きなライブラリを仕込んでいる最中は、集中する時間が必要なため、他のライブラリのIssueやPRへの応答が数ヶ月音信不通になります。意識的に全く見ないようにしています、タイトルすら見てません(ダッシュボードや通知のメールなども一切目にしないようにしています)。そうした不義理を働くことで創造的なライブラリを生み出すことができるのだ、これは必要な犠牲なのです……!
また、そうじゃなくても、面倒見てるライブラリの数が多すぎるのでローテートでも数ヶ月の遅延が発生することは、あります。もうこれは絶対的なマンパワーが不足しているため、しょうがないじゃないですかー、というわけで、そのしょうがないを受け入れて、ちょっと返事が遅れるだけでthis library is dead的なこと言わないで欲しいなあ、というのが正直なところです!言われると辛い!なるべく努力はしたいんですが、特に新しいライブラリの創造は時間をめちゃくちゃ取られて大量の遅延が発生して、その遅延が更に遅延を呼んで泥沼になって精神を削っていくのですよー。
あとはMicrosoft関連でイラッとさせられてモチベーションを削られるとか、この辺はC#関連のOSSあるあるが発生したりしたりしながらも、なるべく末永く続けていきたいとは思っています。
かなり危機感は持っているので、AIによってどこまで負荷の軽減ができるのか、というところをテーマに、ある程度実験場として色々やっていきたいなあ、と思っています。うまくいけば、よりコアに集中できる環境になってくれるわけですしね。
まとめ
ZLinqの構造は最初のプレビュー版公開後のフィードバックで結構変わっていて、@Akeit0さんにはコアとなるValueEnumerable<TEnumerator, T>という定義やTryCopyToへのIndexの追加など、パフォーマンスに重要なコア部分の提案を多く頂きました!また、@filzrevさんからは多大なテスト・ベンチマークのインフラストラクチャーを提供してもらいました。互換性確保やパフォーマンス向上は、この貢献がなければ成しえませんでした。お二人には深く感謝します。
改めて、ゼロアロケーションLINQライブラリというコンセプト自体はそこまで珍しいものでもなく、今までもライブラリが死屍累々と転がっていたわけですが、ZLinqは徹底度合いが違う。経験と知識があるうえで、精神論で気合で、全メソッド実装、テストケースも全部流して完全互換、最適化類もSIMD含めて全部実装する、をやり切ったのが立派なところなのではないかな、と。いや、ほんとこれめっちゃ大変だったのです……。
タイミングとしても.NET 9/C# 13が、フルセットでやりたいことが全部やれる言語機能となったことは、やる気を後押ししてくれました。と、同時に、Unityや.NET Standard 2.0対応も大事にできたのもいいことです。
ただのゼロアロケーションLINQというだけではなく、LINQ to Treeはお気に入りの機能なので是非使ってみて欲しいですね……!そもそもに元々は、10年前に作っていたLINQ to GameObjectをモダン化しよう、というのが出発点でした。昔のコードだったのでかなりベタ書きだったのですが、もうちょっと抽象化したほうがいいかな、と弄っているうちに、だったらゼロアロケーションLINQとしての抽象化まで進化させてしまったほうがいいのでは、という思いつきに至ったのでした。
ところで、LINQのパフォーマンスのネックの一つとしてはデリゲートがあり、一部のライブラリはstructでFuncのようなものを模写するValueDelegateというアプローチがあるのですが、それはあえて採用していません。というのも、それらの定義はかなり手間なので、現実的にはやってられないはずです。そこまでやるなら普通にインラインで書いたほうがマシなので、LINQでValueDelegate構造を使う意味はありません。そんなベンチマークハックのためだけに内部構造の複雑化とアセンブリサイズの肥大化を招くのは無駄なので、System.Linqと互換のFuncのみを受け入れるスタイルにしています。
R3が.NET標準のSystem.Reactiveを置き換えるものという野心的ライブラリでしたが、System.Linqの置き換えはそれよりも遥かに大きな、あるいは大袈裟すぎる代物なので、採用に抵抗感はあるんじゃないかなー、と思います。ですが、置き換えるだけのメリットは掲示できていると思うので、是非とも試してみてくれると嬉しいです!
2024年を振り返る
- 2024-12-30
今年もCysharpはちゃんと生存していて良きかな、というわけでサイトが相変わらずペライチなのでそろそろリニューアルしたいと思って幾星霜。
そんなわけで今年もC#をやりこみ(?)していました……!
新規:
大型アップデート
うーん、十分でしょ!割といつも年の中で浮き沈みはあって、調子でないなあ、ここ数ヶ月ダメだぁ、みたいな気持ちになることが割とあるのですが、振り返ってみれば十分すぎるでしょ!むしろやりすぎでしょ!というわけで、C#最前線キープとしては全く問題ないでしょう。
ハイライトとしてはやはり年初のR3 - C#用のReactive Extensionsの新しい現代的再実装ですかね……!これは、めちゃくちゃ大変でした。物量とかそのものの実装難易度とかもそうなのですが、スタンダードとなっているインターフェイスや仕様を変えるという判断を通しているんですよね。これが、ちゃんと成り立たせられるのか、それで普及させられるのか、という悩みもあり、また、インターフェイスも作りながら割とクルクル最後まで変えながらやってたので、完成して良かったし、1年弱経って、ちゃんと受け入れられているのを見てようやくホッと一息です。Unityにおいても、今年はNuGet化を強烈に推進していったわけですが、なんだかんだで受け入れてもらえってるような気がしますがどうでしょう……?
Claudiaや、なんかブログに書く機会を逸して書いてない気がするのですがUtf8StreamReaderなんかも中々いい感じではあったと思います。
そして大型アップデート系はSource Generator祭り。まずConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークは傑作かと!これは自信作ですねー、めちゃくちゃいいものが出来たと思ってます。直近のConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、などで完全に仕上がりました。
MessagePack for C#は長年懸案だったSource Generator化をついに果たしました。そして色々あって共同メンテナーが離脱したことにより、再度主導権が私の方に戻っています。この辺のことは思うところは割とあるのですが、まぁ結果的には良かったかな、と思ってます。再びやれることの幅も広がったので、MemoryPackともどもで来年は強化していきたいと思っています。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベースも、ずっとSource Generator化したいと思って2年ぐらい放置していた案件なので、ようやく解消できて嬉しい話ですね。しかもやってたら想像通りにめちゃくちゃDX(Developer Experience)よくなってるので、やっと理想が実現できた、というかむしろ時代がやっと追いついた(なんせこの辺の仕組みはSource Generator以前に構築していたパターンなので)という気持ちです。
Cysharpの提供しているライブラリから単独コードジェネレーターは消滅して全てSource Generator化し、そして.NETプロジェクトとUnityプロジェクトのソースコード共有最新手法でも書いたようにUnityとのコードシェアもかなりやりやすい手法が確立できたので、まさにこれはC#大統一理論元年……!「出来ない」よりは「出来たほうがいい」ので、別に今までのやり方が悪かったとは思いませんが、ようやく理想形に到達できた、という感じではあります。来年初頭にはMagicOnionのMessagePack for C# v3対応を出す予定で、これで全てのパーツが揃います!
なんとか of the Year
今年一番大きかった変化として、メモ環境にObsidianを全面導入したのですが、これは超絶良いですね。Daily Notesの有用性というのをようやく理解しました。有料課金して同期することで更に便利、プラグインもマシマシで便利、まぁ入れすぎてもしょうがないので適度に絞ってますよ、と思ったんですが、意外と結構はいってるかも……。
TODOもObsidianに寄せるようにしていますが、特にTODOプラグインなどは使わずにDaily Notesで表現できるように若干工夫しています(TemplaterでJavaScript書いてDaily Notesの生成時にチェック済みのTODOタスクは自動で消すようにしてる&未チェックのTODOタスクは引き継ぐようにしている)。TODOアプリは無限に彷徨って毎年違うものに変えてたりするのですが、これが一番手に馴染んでるので決定版ということでいいかなー。
もう一つ革命的に良かったと思うのはHUAWEI FreeClip。これはとんでもなく良くてビックリした。HUAWEI製品のクオリティの高さにもビビッた。オープンイヤー型のイヤホンなわけですが、付け心地も良いし細かいところも良く出来てるし音質もしっかりしてる。言う事無し。オープンイヤーは、外音取り込みとは耳への圧迫感が自然さが全然違うんですよねえ、これだと1日中付けっぱなしとまではしないけど、割と頻繁に耳につけといて、音を聞くことが増えました。講演動画とか英語のリスニングとか日常生活に流せるといい感じ度が上がります。あとダラダラYouTube見る頻度が相当上がってしまった……。あまり使い分けとかは出来ないタイプの人間なので今まで使っていたAirPods Proはお蔵入りしてFreeClip一本使いになってます。ノイズキャンセリング性能がーというのと真逆なわけですが、外音と混じった音楽も、それはそれで心地よいのでいい感じなので、騒音環境下でもそこまで気にならず使えてる気がします。
あとは、家のキーボードをRealforce RC1に変更しました。HHKBにF1-12キーが追加されたようなレイアウトなわけですが、まず、キーボードにF1-F12は必須なんですよね!Visual Studio的に!あとは、日本語キーボードレイアウトじゃないとダメ人間なので、ずっとコンパクト配列にしたいなあと思いつつも選択肢がなくてなあ、と、テンキーレスぐらいで我慢していたので、満を持しての本命というわけでした。
それとFnキーとの組み合わせによるハードウェアキーレイアウト変更が柔軟かつ安定性が高いことに気づいた!昔から無変換+ESDFを十字キーとして使う癖があって、AutoHotKeyなどソフトウェアでフックするやつを使って実現していたのですが、挙動的に不安定(抜けが出たりするのが辛い)なのが気になってました。が、Realforceの設定で無変換と変換をFnキーにしてしまって、Fnキーとの組み合わせでESDFを十字キーにしてしまえば完璧だった……!というわけで現在のレイアウトがこちら。
そんなにキーボードから手を離さないで全部操作出来ないと!みたいな感じではなく、右手はマウス行きしちゃうので、左手側に詰め込みがちです。とにかくESDFでの十字キー化が安定したのがめっちゃ嬉しい。これ、WSDFじゃないんですか?というところなのですが、主に使うシチュエーションはテキストエディタでの十字移動なので、ESDFはホームポジションから手を動かさずに十字キーになるのがWSDFに比べての圧倒的利点です。それとQAZが空くので、そこにもキーを詰め込めるのも嬉しい。
というわけでQ, AはHome/End(ちなみに私はHomeめちゃくちゃよく使います)。Z, CにShift + Home/End。XにShift + @(つまり```)。VにWin + V。それと1, 2, 3にはAlt + 1, 2, 3を入れています、というのも私はArcというブラウザを使っているのですが、これのスペースの切り替えがAltになっていて、AltよりもFn(元の無変換)を使うことが多いので、そのまま切り替えられるようにしたほうが便利かな、と。
そしてFn + 半角/全角にCtrl + Shift + Alt + Eを割り当てて、これはWindowsのアプリケーションへのグローバルショートカットキーでEverythingを宛ててます。あまりキーをフックするようなのをソフトウェア側で仕込みたくはないのですが、Windows標準機能ならまぁ良いでしょう、ということで。
マクロが欲しいとかショートカットキー登録数が少ないとか思うところもありますが、全体的にはかなり相当良いです!
キーボードといえば、iPad Pro用にlogicool Keys-To-Go 2 for iPadを買ったのですが、これもかなり良くて体験変わりました。今までモバイルキーボード難民で全然しっくり来るものがなかったのですが、これが一番アリだなあ、という感じですね……!
iPadにはprendre タブレットスタンド iPadを貼り付けてキックスタンドにしてます。たった17g追加するだけで自立する!これは超便利。軽量化したとはいえ、重たいiPadなのでケースとか入れてこれ以上重たくしたくはない。が、自立してくれないと不便、で、色々探して買ったのがこれでした。
横はもちろん、縦でもちゃんと安定してくれる。粘着テープで貼り付けるタイプは剥がれる危険性があるわけですが、iPad Proが軽量化してくれたおかげもあってそこそこ安定しています。ただし両面テープは付属のは剥がして、色々試した結果スリーエム(3M) 3M 両面テープ 超強力 スーパー多用途 薄手 幅12mmに落ち着きました。あまり強力すぎると、それはそれで剥がしにくくて売るときとかに泣いちゃう(本当に剥がれない……!)ので、粘着力が基本なのですが、その上でいざというときに剥がれてくれるかどうかのバランスも大事……。
というわけかでiPad Pro 13インチも買ったのですが、これは満足感高いです。違いは、やっぱ有機ELディスプレイですかねー、今までのiPadの画質って割と不満足というか、どう見てもiPhoneよりも画質悪いじゃん!という感じで萎え萎えだった(のであまり使わなくなっていった……)のですが、今回の画質ならOKです!というわけで利用頻度上がりました。ちなみにNano-textureガラスではありません。いや、最初Nano-textureガラスのやつを買っちゃったんですが、これ普通に画質めちゃくちゃ悪いんですよ。インターネットマンが画質は大して変わらないとか言うから信じたのにめっちゃ悪くて……。耐えられなかったのですみませんがの返品からの買い直しコンボさせていただきました……。
そして、povo。ずっとauだったのですが、povoに乗り換えました。で、これがめちゃくちゃいい、というかiPadでの利用にとてもいい。SIM付きモデル買ったのですが、auでのデータ共有がうまくできず(難易度高すぎ&なんかバグってると思う……)塩漬けだったのです。が、povoで単独での契約だと、当たり前ですがスムーズに通信できて快適。iPadもテザリングがそこそこiPhoneとスムーズにつながるからなくてもいいじゃん、とか思ってなくもなかったのですが、単独で通信できる快適さはぜんぜん違う!そして、私の用途的に別にそんなに毎日通信するわけでもないので、あんまりギガはいらないんですが、povoだとプロモーションと合わせると実質0円運用できるのが、とてもいい感じです。例えばローソン500円購入券がpovoで500円で買えて0.3GBの通信料がついてくる、とかだと、どうせ500円買うんだしpovoで買ってiPadに0.3GBチャージしとくかあ、みたいな。
最後に、Game of the Yearは今更グランツーリスモ7ということで(?)。というのもLogicoolのPROレーシングホイール + PRO RACING PEDALSを買ったのですが、これが抜群にいい……!今まで(G923)とは桁違い、というか実際桁違いで、G923が2.4nmというフィードバック力しか出せていないのですが、PROレーシングホイール11nm出る!11nmって別に全くピンと来ないのですが、触ってみると2.4nmはスカスカで、逆に11nmをフルに出すと重くて曲げられないレベル(実際、筋肉痛になった……)。そんなわけで一気に楽しくなったので、今年は一番グランツーリスモ7をやってた気がします。はい。
来年
C#でSaaS作りたい欲求はずっとあるので、OSSメンテナンス業が重くのしかかりつつも、来年はそっち側でも進展を見せたいと思ってます……!Cysharpももう少し大きくしたいとは思っているので、引き続きよろしくおねがいします。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベース
- 2024-12-20
MasterMemory v3出しました!ついにSource Generator化されました!
MasterMemoryはC#のインメモリデータベースで、高速で、メモリ消費量が少なく、タイプセーフ。というライブラリです。SQLiteを素朴に使うよりも 4700倍高速だぞ、と。
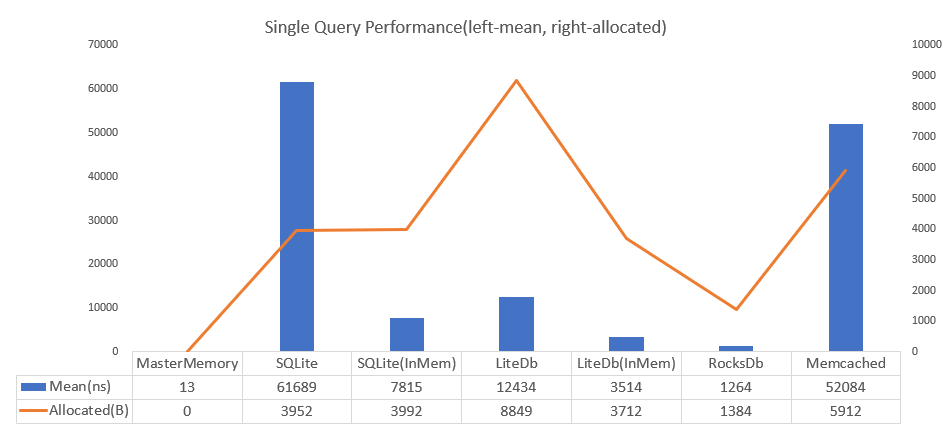
もともとMasterMemoryはC#コードからC#コードを生成するという、Source Generatorのなかった時代にSource Generatorのようなことをやる先進的な設計思想を持ったシステムでした。今回移植してみて、あまりにもスムーズに移植できるし、旧来のコードも全く手を付けずにそのまま動いたので我ながら感心しました。やっと時代が追い付いたか……。
というわけで、以下のようなC#定義からデータベース構築のためのコードと、クエリ部分がSource Generatorによって自動生成されます。
[MemoryTable("person"), MessagePackObject(true)]
public record Person
{
[PrimaryKey]
public required int PersonId { get; init; }
[SecondaryKey(0), NonUnique]
[SecondaryKey(1, keyOrder: 1), NonUnique]
public required int Age { get; init; }
[SecondaryKey(2), NonUnique]
[SecondaryKey(1, keyOrder: 0), NonUnique]
public required Gender Gender { get; init; }
public required string Name { get; init; }
}

C#コードとして生成されるので、クエリが全て入力補完も効くし戻り値も型付けされていてタイプセーフなのはもちろん、パフォーマンスの良さにも寄与しています。
読み取り専用データベースとして使うので、クラス定義はイミュータブルのほうがいいわけですが、最近のC#は record, init, required といった機能が提供されているので、Readonly Databaseとしての使い勝手が更に上がりました。Unityではrequiredは使えませんがrecordとinitは使えるので、Unityでも問題ありません。
なお、Unity版は今回からNuGetForUnityでの提供となります。また、MessagePack for C#もSource Generator対応のv3を要求します。
Next
MasterMemory、実は結構使われています。ゲームでも採用されているものを割と見かけるようになりました。なので、外部ツール由来のコード生成の面倒さにはだいぶ心を痛めていたので、ようやく解消できて本当に嬉しい!
v2からv3へのマイグレーションもそんなに大変ではない、はずです。あえて生成コードの品質や、コアの関数、メソッドシグネチャなどには一切手を加えていないので、今までコマンドラインツールを叩いていた部分を削除するだけで、そのまま動き出すぐらいの代物になっています。名前空間の設定だけ、アセンブリ属性で行ってください。
そのうえでrecord対応(今までしてなかった!)や#nullable enable対応(今までしてなかった!)を追加しているので、生成部分以外の使い勝手も上がっているはずです。
今後はMemoryPack対応や、そもそものAPIの更なるモダン化(現状はnetstandard2.0なので古い)、全体的に改修したいところ(ImmutableBuilderなど生成コードの差し替え部分)、などなどやれること自体はめっちゃありますので、折を見て手を入れていけるといいかなあ、と思っています。
ConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、など
- 2024-12-16
ConsoleAppFramework v5の比較的アップデートをしました!v5自体の詳細は以前に書いたConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークを参照ください。v5はかなり面白いコンセプトになっていて、そして支持されたと思っているのですが、幾つか使い勝手を犠牲にした点があったので、今回それらをケアしました。というわけで使い勝手がかなり上がった、と思います……!
名前の自動変換を無効にする
コマンドネームとオプションネームは、デフォルトでは自動的にkebab-caseに変換されます。これはコマンドラインツールの標準的な命名規則に従うものですが、内部アプリケーションで使うバッチファイルの作成に使ったりする場合などには、変換されるほうが煩わしく感じるかもしれません。そこで、アセンブリ単位でオフにする機能を今回追加しました。
using ConsoleAppFramework;
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]
var app = ConsoleApp.Create();
app.Add<MyProjectCommand>();
app.Run(args);
public class MyProjectCommand
{
public void Execute(string fooBarBaz)
{
Console.WriteLine(fooBarBaz);
}
}
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]によって自動変換が無効になります。この例では ExecuteCommand --fooBarBaz がコマンドとなります。
実装面でいうと、Source Generatorにコンフィグを与えるのはAdditionalFilesにjsonや独自書式のファイル(例えばBannedApiAnalyzersのBannedSymbols.txt)を置くパターンが多いですが、ファイルを使うのは結構手間が多くて面倒なんですよね。boolの1つや2つを設定するぐらいなら、アセンブリ属性を使うのが一番楽だと思います。
実装手法としてはCompilationProviderからAssembly.GetAttributesで引っ張ってこれます。
var generatorOptions = context.CompilationProvider.Select((compilation, token) =>
{
foreach (var attr in compilation.Assembly.GetAttributes())
{
if (attr.AttributeClass?.Name == "ConsoleAppFrameworkGeneratorOptionsAttribute")
{
var args = attr.NamedArguments;
var disableNamingConversion = args.FirstOrDefault(x => x.Key == "DisableNamingConversion").Value.Value as bool? ?? false;
return new ConsoleAppFrameworkGeneratorOptions(disableNamingConversion);
}
}
return new ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion: false);
});
これを他のSyntaxProviderからのSourceとCombineしてやれば、生成時に属性の値を参照できるようになります。
ConfigureServices/ConfigureLogging/ConfigureConfiguration
ゼロディペンデンシーを掲げている都合上、特定のライブラリに依存したコードを生成することができないという制約がConsoleAppFramework v5にはありました。そのため、DIとの統合時に自分でServiceProviderをビルドしなければならないなの、利用には一手間必要でした。そこで、NuGetでのDLLの参照状況を解析し、Microsoft.Extensions.DependencyInjectionが参照されていると、ConfigureServicesメソッドがConsoleAppBuilderから使えるという実装を追加しました。
var app = ConsoleApp.Create()
.ConfigureServices(service =>
{
service.AddTransient<MyService>();
});
app.Add("", ([FromServices] MyService service, int x, int y) => Console.WriteLine(x + y));
app.Run(args);
これによりフレームワークそのものはゼロディペンデンシーでありながら、ライブラリ依存のコードも生成することができるという、新しい体験を提供します。これはMetadataReferencesProviderから引っ張ってきて生成処理に回すことで実現しました。
var hasDependencyInjection = context.MetadataReferencesProvider
.Collect()
.Select((xs, _) =>
{
var hasDependencyInjection = false;
foreach (var x in xs)
{
var name = x.Display;
if (name == null) continue;
if (!hasDependencyInjection && name.EndsWith("Microsoft.Extensions.DependencyInjection.dll"))
{
hasDependencyInjection = true;
continue;
}
// etc...
}
return new DllReference(hasDependencyInjection, hasLogging, hasConfiguration, hasJsonConfiguration, hasHost);
});
context.RegisterSourceOutput(hasDependencyInjection, EmitConsoleAppConfigure);
参照の解析は複数のものに対して行っていて、他にもMicrosoft.Extensions.Loggingが参照されていればConfigureLoggingが使えるようになります。なのでZLoggerと組み合わせれば
// Package Import: ZLogger
var app = ConsoleApp.Create()
.ConfigureLogging(x =>
{
x.ClearProviders();
x.SetMinimumLevel(LogLevel.Trace);
x.AddZLoggerConsole();
x.AddZLoggerFile("log.txt");
});
app.Add<MyCommand>();
app.Run(args);
// inject logger to constructor
public class MyCommand(ILogger<MyCommand> logger)
{
public void Echo(string msg)
{
logger.ZLogInformation($"Message is {msg}");
}
}
といったように、比較的すっきりと設定が統合できます。
appsettings.jsonから設定ファイルを引っ張ってくるというのも最近では定番パターンですが、これもMicrosoft.Extensions.Configuration.Jsonを参照しているとConfigureDefaultConfigurationが使えるようになり、これはSetBasePath(System.IO.Directory.GetCurrentDirectory())とAddJsonFile("appsettings.json", optional: true)を自動的に行います(追加でActionでconfigureすることも可能、また、ConfigureEmptyConfigurationもあります)。
なのでコンフィグを読み込んでクラスにバインドしてコマンドにDIで渡す、などといった処理もシンプルに書けるようになりました。
// Package Import: Microsoft.Extensions.Configuration.Json
var app = ConsoleApp.Create()
.ConfigureDefaultConfiguration()
.ConfigureServices((configuration, services) =>
{
// Package Import: Microsoft.Extensions.Options.ConfigurationExtensions
services.Configure<PositionOptions>(configuration.GetSection("Position"));
});
app.Add<MyCommand>();
app.Run(args);
// inject options
public class MyCommand(IOptions<PositionOptions> options)
{
public void Echo(string msg)
{
ConsoleApp.Log($"Binded Option: {options.Value.Title} {options.Value.Name}");
}
}
Microsoft.Extensions.Hostingでビルドしたい場合は、ToConsoleAppBuilderが、これもMicrosoft.Externsions.Hostingを参照すると追加されるようになっています。
// Package Import: Microsoft.Extensions.Hosting
var app = Host.CreateApplicationBuilder()
.ToConsoleAppBuilder();
また、今回から設定されているIServiceProviderはRunまたはRunAsync終了後に自動的にDisposeするようになりました。
RegisterCommands from Attribute
コマンドの追加はAddまたはAdd<T>が必要でしたが、クラスに属性を付与することで自動的に追加される機能をいれました。
[RegisterCommands]
public class Foo
{
public void Baz(int x)
{
Console.Write(x);
}
}
[RegisterCommands("bar")]
public class Bar
{
public void Baz(int x)
{
Console.Write(x);
}
}
これらは自動で追加されています。
var app = ConsoleApp.Create();
// Commands:
// baz
// bar baz
app.Run(args);
これらとは別に追加でAdd, Add<T>することも可能です。
なお、実装の当初予定では任意の属性を使えるようにする予定だったのですが、IncrementalGeneratorのAPIの都合上難しくて、固定のRegisterCommands属性のみを対象としています。また、継承することもできません……。なので独自の処理用属性がある場合は、組み合わせてもらう必要があります。例えば以下のように。
[RegisterCommands, Batch("0 10 * * *")]
public class MyCommands
{
}
この辺はConsoleAppFrameworkとAWS CDKで爆速バッチ開発を読んで、うーん、v5を使ってもらいたい!なんとかしたい!と思って色々考えたのですが、この辺が現状の限界でした……。名前変換オフりたいのもわかるー、とか今回の更新内容はこの記事での利用例を参考にさせていただきました、ありがとうございます!
まとめ
v5のリリース以降もフィルターを外部アセンブリに定義できるようになったり、Incremental Generatorの実装を見直して高速化するなど、Improvmentは続いています!非常に良いフレームワークに仕上がってきました!
ところでSystem.CommandLine、現状うまくいってないからResettting System.CommandLineだ!と言ったのが今年の3月。例によって想像通り進捗は無です。知ってた。そうなると思ってた。何も期待しないほうがいいし、普通にConsoleAppFramework使っていくで良いでしょう。
SourceGenerator対応のMessagePack for C# v3リリースと今後について
- 2024-12-06
先月MessagePack for C#プロジェクトは .NET Foundationに参加しました!より安定した視点で利用していただけるという一助になればいいと思っています。
そして、長く開発を続けていたメジャーバージョンアップ、v3がリリースされました。コア部分はv2とはほぼ変わらずですが、Source Generatorを全面的に導入しています。引き続きIL動的生成も存在するため、IL動的生成とSource Generatorのハイブリッドなシリアライザーとなります。v3にはSource GeneratorとAnalyzerがビルトインで同梱されていて、今までのコードはv3でコンパイルするだけで自動的にSource Generator化されます。v2 -> v3アップデートでSource Generator対応するために追加でユーザーがコードを記述する必要はありません!
挙動を詳しく見ていきましょう。例えば、
[MessagePackObject]
public class MyTestClass
{
[Key(0)]
public int MyProperty { get; set; }
}
というコードを書くと、自動的に以下のコードがSource Generatorによって内部的に生成されます。
partial class GeneratedMessagePackResolver
{
internal sealed class MyTestClassFormatter : IMessagePackFormatter<MyTestClass>
{
public void Serialize(ref MessagePackWriter writer, MyTestClass value, MessagePackSerializerOptions options)
{
if (value == null)
{
writer.WriteNil();
return;
}
writer.WriteArrayHeader(1);
writer.Write(value.MyProperty);
}
public MyTestClass Deserialize(ref MessagePackReader reader, MessagePackSerializerOptions options)
{
if (reader.TryReadNil())
{
return null;
}
options.Security.DepthStep(ref reader);
var length = reader.ReadArrayHeader();
var ____result = new MyTestClass();
for (int i = 0; i < length; i++)
{
switch (i)
{
case 0:
____result.MyProperty = reader.ReadInt32();
break;
default:
reader.Skip();
break;
}
}
reader.Depth--;
return ____result;
}
}
}
また、このGeneratedMessagePackResolverはデフォルトのオプション(StandardResolverなど)に最初から登録されているため、
public static readonly IFormatterResolver[] DefaultResolvers = [
BuiltinResolver.Instance,
AttributeFormatterResolver.Instance,
SourceGeneratedFormatterResolver.Instance, // here
ImmutableCollection.ImmutableCollectionResolver.Instance,
CompositeResolver.Create(ExpandoObjectFormatter.Instance),
DynamicGenericResolver.Instance, // only enable for RuntimeFeature.IsDynamicCodeSupported
DynamicUnionResolver.Instance];
ユーザーコードのアセンブリに含まれているシリアライズ対象クラスは、Source Generatorによって生成されたコードが優先的に使われることになります。GeneratedMessagePackResolverは既定の名前空間や名前を変えたり、生成フォーマッターをmapベースに変更するなど、幾つかのカスタマイズポイントも用意されています。より詳しくは新しいドキュメントを見てください。また、v2 -> v3の変更箇所の詳細を知りたい人はMigration Guide v2 -> v3をチェックしてください。
Unityにおいては導入方法が大きく変わりました。コアライブラリは .NET 版と共通になりNuGetからのインストールが必要となります。そのうえでUPMでUnity用の追加コードをダウンロードする必要があります。詳しくはMessagePack-CSharp#unity-supportのセクションを確認してください。
.unitypackageの提供は廃止されています。また、IL2CPP対応のために要求していたmpcはなくなりました。完全にSource Generatorに移行されます。そのため、Unityのサポートバージョンは 2022.3.12f1 からとなります。Source Generatorに関してはNuGetForUnityでのコアライブラリインストール時に自動的に有効化されるため、追加の作業は必要ありません。
History and Next
MessagePack for C#のオリジナル(v1)は私(Yoshifumi Kawai/@neuecc)によって、2017年にリリースしました。当時開発していたゲームのパフォーマンス問題を解決するために、2016年時点で存在していた(バイナリ)シリアライザーでは需要を満たせなかったため、パフォーマンスを最重要視したバイナリシリアライザーとして作成しました。合わせて、同じくネットワークシステムとして作成したgRPCベースのRPCフレームワークMagicOnionもリリースしています。
v1リリース当時はbyte[]のみを対象としていましたが、Span<T>やIBufferWriter<T>など、.NETには次々と新しいI/O系のAPIが追加されていったため、v2ではそれらに焦点を当てた新しいデザインが導入されました。この実装はMicrosoftのEngineerであるAndrew Arnott / @AArnott氏によって主導され、リリースしています。
以降、共同のメンテナンス体制として、そして私の個人リポジトリ(neuecc/MessagePack-CSharp)からオーガナイゼーション(MessagePack-CSharp/MessagePack-CSharp)して今に至ります。Visual Studio内部での利用やSignalRのバイナリープロトコル、Blazor Serverのプロトコルなど大きなMicrosoftのプロダクトでも使用され、GitHubでのスター数は.NETのバイナリーシリアライザーとしては最も大きなスターを集めています。.NET 9で廃止されたBinaryFormatterの移行先の一つとしても推奨されています。
v3ではSource Generatorに対応することで、より高いパフォーマンスと柔軟性、AOT対応への第一段階に踏み出すことができました。
MessagePack for C#プロジェクトは大きな成功を収めたと考えていますが、しかし現在、AArnott氏は個人の新しいMessagePackプロジェクトの開発を開始しています。私もその間、MemoryPackという異なるフォーマットのシリアライザーをリリースしています。そのため、MessagePack for C#の今後と、その特性について、ある程度説明する必要があると思います。
引き続きメンテナンス体制は2人だと考えていますが、アクティブな活動に関しては、再び私が担うことになるかもしれません。私はMessagePackとMemoryPackとでは異なる性質を持ったフォーマットであるため、どちらも重要であるという認識で動いています。オリジナルの実装であるMessagePack for C#も気に入ってますし、現在においても決して引けを取ることのないものだと思っています。
AArnott氏の別のMessagePackシリアライザーとは根本的な哲学が若干異なります。その点で、私はそれはより良く改善されたシリアライザーではなく、別の個性のシリアライザーだと認識しています。そこで、違いについて説明させてください。
Binary spec, default settings and performance
シリアライザーのパフォーマンスに重要なのは、「仕様と実装」の両方です。例えばテキストフォーマットのJSONよりもバイナリフォーマットのほうが一般的には速いでしょう。しかし、よくできたJSONシリアライザーは、中途半端な実装のバイナリシリアライザーよりも高速です(私はそれをUtf8Jsonというシリアライザーを作成することで実証したことがあります)。なので、仕様も大事だし、実装も大事です。どちらも兼ねることができれば、それがベストなパフォーマンスのシリアライザーとなります。
MessagePackのバイナリ仕様は "It's like JSON. but fast and small." を標語にしている通り、JSONのバイナリ化としてあらわされています。ところが、MessagePack for C#のデフォルトは必ずしもJSON likeを狙っているわけではありません。
[MessagePackObject]
public class MsgPackSchema
{
[Key(0)]
public bool Compact { get; set; }
[Key(1)]
public int Schema { get; set; }
}
このクラスをシリアライズした場合は、JSONで表現すると[true, 0]のようになります。これはオブジェクトをarrayベースでシリアライズしているからで、mapベースでシリアライズすると{"Compact":true,"Schema":0}のような表現になります。
arrayベースの利点は見た通りに、バイナリ容量として、よりコンパクトになります。容量がコンパクトなことは処理量が少なくなるためシリアライズの速度にも良い影響を与えます。また、デシリアライズにおいては、文字列を比較してデシリアライズするプロパティを探索する必要がなくなるため、より高速なデシリアライズ速度が期待できます。
なお、arrayベースのシリアライズはMessagePackの仕様策定者である Sadayuki Furuhashi 氏によるリファレンス実装であるmsgpack-javaなどでも採用されているため、決して異端のやり方というわけではありません。
MessagePack-CSharpではJSONライクなmapベースでシリアライズしたい場合は[MessagePackObject(true)]と記述することができます。また、Source Generatorの場合はResolver単位でオーバーライドして強制的にmapベースにすることも可能です。
[MessagePackObject(keyAsPropertyName: true)]
public class MsgPackSchema
{
public bool Compact { get; set; }
public int Schema { get; set; }
}
mapの利点は、柔軟なスキーマエボリューションの実現と、他言語との疎通する際にコミュニケーションが取りやすいこと、バイナリそのものの自己記述性が高いことです。デメリットは容量とパフォーマンスへの悪影響、特にオブジェクトの配列においては一要素毎にプロパティ名が含まれることになってしまい、かなりの無駄となります。
デフォルトをarrayにしているのは、コンパクトさとパフォーマンスの追求のためです。私はMessagePackをJSON likeの前に、高いパフォーマンスを実現可能なバイナリ仕様として考えました。もちろん、mapも重要なので、その上で比較的簡単にmapモードを実現するために属性に(true)を追加するだけで可能にしました。
arrayモードの場合はKey属性を全てのプロパティに付与する必要があります。これは、例えばProtocol Buffersなどでも数値タグを必要とするように、プロパティ名そのものをキーとするわけではなければ、必須だと考えています。もちろん、連番で自動採番させることも可能ですが、バイナリフォーマットのキーを暗黙的に処理するのはリスクが大きすぎる(順番を弄ったりするだけでバイナリ互換性が壊れることになる)と判断しています。つまり、明示的がデフォルト、ということです。大きなプロジェクト開発ではシニアメンバーからジュニアメンバーまでコードを触ることになるでしょう、全てを理解している人だけがコードを触るわけではありません。なので、暗黙的な挙動は避けるべきで、明示的にすべきだという強い意志で、この設計を選んでいます。
ただしKeyを全てのプロパティに付与する作業はとても苦痛です(私はMessagePack-CSharp開発以前には、DataContractやprotobuf-netで辛い思いをしました)。そこで、Analyzer + Code Fixによって、自動的に付与する機能を用意しました。これにより明示的であることの苦痛は和らげられ、良いとこどりができているのだと考えています。
別のMessagePackシリアライザーのデフォルトはmapのようです。これはPolyTypeというSource Generatorベースのライブラリ作成のための抽象化ライブラリがベースとしているためでもあり、また、そちらのほうを好んでいるという明示的な判断でもあるようです。
「デフォルト」はライブラリで一つしか選べません。どちらのモードで処理することができたとしても、「デフォルト」はただ一つです。改めて言うと、私はバイナリフォーマットとしての「コンパクトとパフォーマンス」を好み、優先しています。
皆さんはPolyTypeについて初めて知ったかもしれません。私はPolyTypeはあまり好意的には考えていません。ちょっとしたものを作るには非常に便利だとは思いますが、ベストなパフォーマンスを狙ったり、ベストなアイディアを表現するには、抽象層であることの制限が大きすぎると考えています。なので、MessagePack for C#で採用することはありませんし、他の何かを作る際にも採用することはないでしょう。
Unity(multiplatform) Support
MessagePack for C#ではv1の時代からゲームエンジンUnityの1st classのサポートを実行してきました。これは私がCygamesという日本のゲーム会社の関連会社(Cysharp)のCEOを務めていて、ビデオゲームインダストリーと関係性が深いという都合もあります。自分たちで実際にUnityで動くものを作り、使ってきました。もちろん、サーバーサイドやデスクトップアプリケーションでも使っています。
UnityにはIL2CPPという独自のAOTシステムがあり、特にiOSなどモバイルプラットフォームでのリリースには必須なのですが、それもSource Generatorが存在しなかった時代から、mpcというRoslynを使ったコードジェネレートツールを作り、提供してきました。数百のモバイルゲームでMessagePackが使われているのは、これら私の熱心なサポートのお陰といっても過言ではないでしょう。v3ではついにSource Generatorベースになったことにより、ワークフローが大きく簡易化されることとなります!
一般的に、.NETコミュニティにおいてはUnityサポートはかなり軽視されていました。また、外から見ているとMicrosoftやMicrosoftの従業員もそのようで、自社のプラットフォーム以外への関心は薄そうです。こうした態度は、あまり好ましいとは思っていませんし、せっかくの .NET の可能性を狭めていることにもなっています。Xamarinがうまく成長軌道に乗らなかったのも、そのようなMicrosoft自体の冷たい視線のせいだとも思っています。
私は、私の作るライブラリはなるべくUnityにもしっかり対応できるように気を付けて作っています(最新は新しいReactive ExtensionsライブラリーであるCysharp/R3)。別のMessagePackシリアライザーに関しては、あまりしっかりした対応はされなさそうですが……。
Beyond v3
v3のNative AOT Supportは完全ではありません。Source Generatorにするだけでは完全なNative AOT対応とはならないのは難しいところです。これはUnityのAOTであるIL2CPPでは完璧に動作しているだけに、正直不可解なことでもあり、また、Microsoftのよくない癖が出ているな、とも思っています。つまり、完璧な対応をするために、複雑なものを提供している。それが現在のNative AOTです。複雑怪奇な属性やフローは、理解できるところもありますが、もう少し簡略化すべきだったと思います。まぁ、もう修正されることもないのでしょうが……。
パフォーマンス面でもv1からv2で退化してしまった点もあるので、最新の知見を元に、実装面での改善を施す必要があります。特にReadOnlySequenceの利用幅が大きいことは、かなりの制約を生み出していて、不満があります。
.NET 9でPipeReader/PipeWriterが標準化されたことによる、より良い非同期APIや、パフォーマンスを両立したストリーミング対応というのも、大きなトピックとなるかもしれません。
MessagePack for C#は広く使われているが故に、破壊的変更はしづらいし、互換性の維持は最重要トピックスです。しかし、世の中が変わっていく以上、進化しないことを選んだら、それは滅びる道でしかありません。やれることはまだまだあると思っていますので、.NETにおける最先端の、最高のバイナリシリアライザーであり続けたいと思っています(MemoryPackもね……!)
まずは、v3のSource Generatorをぜひ試してみてください。皆の力でより良いものを作っていけるというのも、OSSの良さだと思っています。
Fuzzing in .NET: Introducing SharpFuzz
- 2024-12-03
この記事はC# Advent Calendar 2024に参加しています。また、先月開催されたdotnet newというイベントでの発表のフォローアップ、のつもりだったのですがコロナ感染につき登壇断念……。というわけで、セッション資料はないので普通にブログ記事とします!
dotnet/runtime と Fuzzing
今年に入ってからdotnet/runtimeにFuzzingテストが追加されています。dotnet/runtime/Fuzzing。というわけで、実はfuzzingは非常に最近のトピックスなのです……!
ファジングとはなんなのか、ザックリとはランダムな入力値を大量に投げつけることによって不具合や脆弱性を発見するためのテストツールです。エッジケースのテスト、やはりどうしても抜けちゃいがちだし、ましてや脆弱性になりうる絶妙な不正データを人為的に作るのも難しいので、ここはツール頼みで行きましょう。
Goでは1.18(2022年)から標準でgo fuzzコマンドとして追加されたらしいので、 Go1.18から追加されたFuzzingとはのような解説記事を読むのもイメージを掴みやすいです。
さて、dotnet/runtimeのFuzzingでは現状
- AssemblyNameInfoFuzzer
- Base64Fuzzer
- Base64UrlFuzzer
- HttpHeadersFuzzer
- JsonDocumentFuzzer
- NrbfDecoderFuzzer
- SearchValuesByteCharFuzzer
- SearchValuesStringFuzzer
- TextEncodingFuzzer
- TypeNameFuzzer
- UTF8Fuzzer
というのものが用意されてます。わかるようなわからないような。だいたいデータのパース系によく使われるものなので、その通りのところに用意されています。一番わかりやすいJsonDocumentFuzzerを見てみましょう。
internal sealed class JsonDocumentFuzzer : IFuzzer
{
public string[] TargetAssemblies { get; } = ["System.Text.Json"];
public string[] TargetCoreLibPrefixes => [];
public string Dictionary => "json.dict";
// fuzzerからのランダムなバイト列が入力
public void FuzzTarget(ReadOnlySpan<byte> bytes)
{
if (bytes.IsEmpty)
{
return;
}
// The first byte is used to select various options.
// The rest of the input is used as the UTF-8 JSON payload.
byte optionsByte = bytes[0];
bytes = bytes.Slice(1);
var options = new JsonDocumentOptions
{
AllowTrailingCommas = (optionsByte & 1) != 0,
CommentHandling = (optionsByte & 2) != 0 ? JsonCommentHandling.Skip : JsonCommentHandling.Disallow,
};
using var poisonAfter = PooledBoundedMemory<byte>.Rent(bytes, PoisonPagePlacement.After);
try
{
// それをParseに投げて、もし不正な例外が来たらなんかバグっていたということで
JsonDocument.Parse(poisonAfter.Memory, options);
}
catch (JsonException) { }
}
}
ようは想定外のデータ入力でJsonDocument.Parseが失敗しないことを祈る、といったものですね。正常に認識しているinvalidな値ならJsonExceptionをthrowするはずですが、ArgumentExceptionとかStackOverflowExceptionとかが出てきちゃった場合は認識できていない不正パターンなので、ちゃんとしたハンドリングが必要になってきます。
では、これを参考にやっていきましょう、とはなりません。えー。まず、dotnet/runtimeのFuzzingではSharpFuzz, libFuzzer, そしてOneFuzzが使用されていると書いてあるのですが、OneFuzzはMicrosoft内部ツールなので外部では使用できません。正確には2020年にオープンソース公開したものの、2023年にはクローズドに戻している状態です。まぁ事情は色々ある。しょーがない。
というわけで、これはMicrosoft内部で動かすためのOneFuzzや、dotnet/runtimeで動かすために調整してあるIFuzzerといったフレームワーク部分が含まれているので、小規模な自分たちのコードをfuzzingするにあたっては、不要ですし、ぶっちゃけあまり参考にはなりません!解散!
Introducing SharpFuzz
そんなわけでdotnet/runtimeのFuzzingでも使われているMetalnem/sharpfuzz: AFL-based fuzz testing for .NETを直接使っていきます。sharpfuzzはafl-fuzzと連動して動くように作られている .NETライブラリです。3rd Partyライブラリですが作者はMicrosoftの人です(dotnet/runtimeで採用されている理由でもあるでしょう)。ReadMeのTrophiesでは色々なもののバグを見つけてやったぜ、と書いてあります。AngleSharpとかGoogle.ProtobufとかGraphQL-ParserとかMarkdigとかMessagePack for C#とImageSharpとか。まぁ、やはり用途としてはパーサーのバグを見つけるのには適切、という感じです。
AFL(American Fuzzy Lop)ってなに?ということなのですが、そもそもファジングの「ランダムな入力値を大量に投げつける」行為は、完全なランダムデータを投げつけていくわけではありません。完全ランダムだとあまりにも時間がかかりすぎるため、脆弱性発見において実用的とは言えない。そこでAFLはシード値からのミューテーションと、カバレッジをトレースしながら効率よくデータを生成していきます。Wikipediaから引用すると
テスト対象のプログラム(テスト項目)のソースコードをインストルメント化することにより、afl-fuzzは、ソフトウェアのどのブロックが特定のテスト刺激で実行されたかを後で確認できる。そのため、AFLはグレーボックステストに使用することができる。遺伝的手法による検査データの生成に関連して、ファザーはテストデータをより適切に生成できるため、このメソッドを使用しない他のファザーよりも、処理中に以前は使用されていなかったコードブロックが実行される。その結果、コードカバレッジは比較的短い時間で比較的高い結果が得られる。この方法は、生成されたデータ内の構造を独立して(つまり、事前の情報なしで)生成することができる。このプロパティは、テストカバレッジの高いテストコーパス(テストケースのコレクション)を生成するためにも使用される。
というわけでdotnet testのようにテストコードを渡したら全自動でやってくれる、というほど甘くはなくて、多少の下準備が必要になってきます。SharpFuzzは一連の処理をある程度やってくれるようにはなっていますが、そもそもに実行までに二段階の処理が必要になっています。
- sharpfazzコマンド(dotnet tool)でdllにトレースポイントを注入する
- その注入されたdll(とexe)をネイティブのfuzzing実行プロセス(afl-fuzzなど)に渡す
dllにトレースポイントを注入はお馴染みのCecilでビルド済みのDLLのILを弄ってトレースポイントを仕込みます。
これは注入済みのdllですが、Trace.SharedMemとかTrace.PrevLocationとか、分岐点に対して明らかに注入している様が見えます。そうしたトレースポイントとの通信や実行データ生成などは外部プロセスが行うので、SharpFuzzというライブラリは、それ自体は実行ツールではなくて、それらとの橋渡しをするためのシステムということです。
ではやっていきましょう!色々なシステムが絡んでくる分、ちょっとややこしく面倒くさいのと、ReadMeの例をそのままやると罠が多いので、少しアレンジしていきます。
まずはRequirementsですが、実行機であるAFLがWindowsでは動きません(Linux, macOSでは動く)。なのでWSL上で動かしましょうという話になってくるのですが、それはあんまりにもやりづらいので、libFuzzerというLLVMが開発しているAFL互換のFuzzingツールを使っていくことにします。これはWindowsでビルドできます。
自分でビルドする必要はなく、SharpFuzzの作者が連携して使うことを意識して用意してくれているlibfuzzer-dotnetのReleasesページから、バイナリを直接落としてきましょう。libfuzzer-dotnet-windows.exeです。
次に、IL書き換えを行うツールSharpFuzz.CommandLineを .NET toolで入れていきましょう。これはglobalでいいかな、と思います。
dotnet tool install --global SharpFuzz.CommandLine
次に、今回はJilという、今はもうあまり使われることもないJsonシリアライザーをターゲットとしてやっていこうということなので、JilとSharpFuzzをインストールします。
dotnet add package Jil --version 2.15.4
dotnet add package SharpFuzz
ここで注意が必要なのは、Jilの最新バージョンはSharpFuzzにより発見されたバグが修正されているので、最新版を入れるとチュートリアルにはなりません!というわけでここは必ずバージョン下げて入れましょう。
新規のConsoleApplicationで、コードは以下のようにします。
using Jil;
using SharpFuzz;
// 実行機としてlibFuzzerを使う(引数はReadOnlySpan<byte>)
Fuzzer.LibFuzzer.Run(span =>
{
try
{
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader); // このメソッドが正しく動作してくれるかをテスト
}
catch (Jil.DeserializationException)
{
// Jil.DeserializationExceptionは既知の例外(正しくハンドリングできてる)なので握り潰し
// それ以外の例外が発生したらルート側にthrowされて問題が検知される
}
});
今度はベースになるテストデータを用意します。名前とかはなんでもいいんですが、TestcasesフォルダにTest.jsonを追加しました。
{"menu":{"id":1,"val":"X","pop":{"a":[{"click":"Open()"},{"click":"Close()"}]}}}
このデータを元にしてfuzzerは値を変形させていくことになります。
では実行しましょう!実行するためには、ビルドしてILポストプロセスしてlibFuzzer経由で動かす……。という一連の定型の流れが必要になるため、作者の用意してくれているPowerShellスクリプトfuzz-libfuzzer.ps1をダウンロードしてきて使いましょう。
とりあえずfuzz-libfuzzer.ps1とlibfuzzer-dotnet-windows.exeをcsprojと同じディレクトリに配置して、以下のコマンドを実行します。ConsoleApp24.csprojの部分だけ適当に変えてください。
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases"
動かすと、見つかった場合はいい感じに止まってくれます。
なお、見つからなかった場合は無限に探し続けるので、なんとなくもう見つかりそうにないなあ、と思ったら途中で自分でとめる(Ctrl+C)必要があります。
Testcasesには途中の残骸と、クラッシュした場合はcrash-idでクラッシュ時のデータが拾えます。
今回見つかったクラッシュデータは
{"menu":{"id":1,"val":"X","popid":1,"val":"X","pop":{"a":[{"click":"Open()"},{"c
でした。実際このデータを使って再現できます。
using Jil;
// クラッシュファイルのプロパティでデータはCopy to Output Directoryしてしまう
// <None Update="crash-c57462e70fb60e86e8c41cd18b70624bd1e89822">
// <CopyToOutputDirectory>Always</CopyToOutputDirectory>
// </None>
var crash = File.ReadAllBytes("crash-c57462e70fb60e86e8c41cd18b70624bd1e89822");
var span = crash.AsSpan();
// Fuzzing時と同じコード
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader);
以上!完璧!便利!一度手順を理解してしまえば、そこまで難しいことではないので、是非ハンズオンでやってみることをお薦めします。なお、ps1のスクリプトは実行対象自身へのインジェクトは除外されるようになっているので、小規模な自分のコードでfuzzingを試してみたいと思った場合は、対象コードはexeとは異なるプロジェクトに分離しておく必要があります。
ところで、AFLにはdictionaryという仕組みがあり、既知のキーワード集がある場合は生成速度を大幅に上昇させることが可能です。例えばjson.dictを使う場合は
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases" -dict ./json.dict
のように指定します。JSONとかYAMLとかXMLとかZipとか、一般的な形式はAFLplusplus/dictionariesなどに沢山転がっています。独自に作ることも可能で、例えばdotnet/runtimeのFuzzingではBinaryFormatterのテストが置いてありますが、これはNRBF(.NET Remoting Binary Format)の辞書、nrbfdecoder.dictを用意しているようでした。
もちろん、なしでも動かすことはできますが、用意できそうなら用意しておくとよいでしょう。
まとめ
MemoryPackでも実際バグ見つかってたりするので、この手のライブラリを作る人だったら覚えておいて損はないです。シリアライザーに限らずパーサーに関わるものだったらネットワークプロトコルでも、なんでも適用可能です。ただし現状、入力がbyte[]に制限されているので、応用性自体はあるようで、なかったりはします。これがintとか受け入れてくれると、様々なメソッドに対してカジュアルに使えて、より便利な気もしますが……(実際go fuzzはbyte[]だけじゃなくて基本的なプリミティブの生成に対応している)
byte[]列から適当に切り出してintとして使う、といったような処理だと、ミューテーションやカバレッジの関係上、適切な値を取得しにくいので、あまりうまくやれません。libFuzzerではStructure-Aware Fuzzing with libFuzzerといったような手法が考案されていて、protocol buffersの構造を与えるとか、gRPCの構造を与えるとかでうまく活用している事例はあるようです。この辺はSharpFuzzの対応次第となります(いつかやりたい、とは書いてありましたが、現実的にいつ来るかというと、あまり期待しないほうが良いでしょう)
Rustにもcargo fuzzといったcrateがあり、それなりに使われているようです。
Fuzzingは適用範囲が限定的であることと下準備の手間などがあり、一般的なアプリケーション開発者においては、あまりメジャーなテスト手法ではないというのが現状だと思いますが、使えるところはないようで意外とあるとも思うので、ぜひぜひ試してみてください。
CysharpのOSS Top10まとめ / Ulid vs .NET 9 UUID v7 / MagicOnion
- 2024-11-19
「CysharpのOSS群から見るModern C#の現在地」というタイトルでセッションしてきました。
作りっぱなし、というわけではないですが(比較的メンテナンスしてるとは思います!)、リリースから年月が経ったライブラリをどう思っているかは見えないところありますよね、というわけで、その辺を軽く伝えられたのは良かったのではないかと思います。
この中だと非推奨に近くなっているのがZStringとUlidでしょうか。
Ulid vs .NET 9 UUID v7
スライドにも書きましたが、ULIDをそこそこ使ってきての感想としては、「Guidではないこと」が辛いな、と。独自文字列形式とか要らないし。そんなわけで私はむしろUUID v7のほうを薦めたいレベルだったりはします。.NET 9からGuid.CreateVersion7()という形で、標準で生成できるようになりました。
パフォーマンス的なところは些細なことなので問題ないのですが、 .NET 9未満との互換性が取れないのは厳しいところかもしれません。というわけで、自作のV7実装を用意してあげるといいでしょう。以下に置いておきますのでどうぞ(コードのベースはdotnet/runtimeのCCreateVersion7です)
public static class GuidEx
{
private const byte Variant10xxMask = 0xC0;
private const byte Variant10xxValue = 0x80;
private const ushort VersionMask = 0xF000;
private const ushort Version7Value = 0x7000;
public static Guid CreateVersion7() => CreateVersion7(DateTimeOffset.UtcNow);
public static Guid CreateVersion7(DateTimeOffset timestamp)
{
// 普通にGUIDを作る
Guid result = Guid.NewGuid();
// 先頭48bitをいい感じに埋める
var unix_ts_ms = timestamp.ToUnixTimeMilliseconds();
// GUID layout is int _a; short _b; short _c, byte _d;
Unsafe.As<Guid, int>(ref Unsafe.AsRef(ref result)) = (int)(unix_ts_ms >> 16); // _a
Unsafe.Add(ref Unsafe.As<Guid, short>(ref Unsafe.AsRef(ref result)), 2) = (short)(unix_ts_ms); // _b
ref var c = ref Unsafe.Add(ref Unsafe.As<Guid, short>(ref Unsafe.AsRef(ref result)), 3);
c = (short)((c & ~VersionMask) | Version7Value);
ref var d = ref Unsafe.Add(ref Unsafe.As<Guid, byte>(ref Unsafe.AsRef(ref result)), 8);
d = (byte)((d & ~Variant10xxMask) | Variant10xxValue);
return result;
}
// GuidにはTimestamp部分を取り出すメソッドがないので、これも用意してあげると便利
public static DateTimeOffset GetTimestamp(in Guid guid)
{
// エンディアンについては特に考慮してません
ref var p = ref Unsafe.As<Guid, byte>(ref Unsafe.AsRef(in guid));
var lower = Unsafe.ReadUnaligned<uint>(ref p);
var upper = Unsafe.ReadUnaligned<ushort>(ref Unsafe.Add(ref p, 4));
var time = (long)upper + (((long)lower) << 16);
return DateTimeOffset.FromUnixTimeMilliseconds(time);
}
}
UUID v7のよくあるユースケースはDBの主キーにGUID(UUID v4)の代わりに使う、ということです。UUID v4だとランダムに配置されるので断片化して、auto incrementの主キーに比べると色々と遅くなる。それがv7だとランダムの性質を持ちつつも配置場所はタイムスタンプベースなのでauto incrementと同様になるため性能劣化がない。
という理屈を踏まえたうえで、.NETのUUID v7事情を踏まえると単純に置き換えるだけで良い、とはなりません。
GUIDは内部的なバイナリデータとしてはリトルエンディアンで保持していて、出力時に切り分けるというデザインになっています(無指定の場合はlittleEndianでの出力)。
public readonly struct Guid
{
public byte[] ToByteArray()
public byte[] ToByteArray(bool bigEndian)
public bool TryWriteBytes(Span<byte> destination)
public bool TryWriteBytes(Span<byte> destination, bool bigEndian, out int bytesWritten)
}
String(char36)として格納するなら気にしなくてもいいのですが、GUID型やバイナリ型としてデータベースに格納する時は、UUID v7に関してはビッグエンディアンで書き出さないと、ソート可能にならない非常に都合が悪い。これのハンドリングは言語のデータベースドライバーライブラリの責務となっています。
代表的なライブラリを見ていくと、MySQLのmysqlconnector-netはコネクションストリングで GuidFormat=Binary16 を指定することでbig-endianでBINARY(16)に書き込む設定となります。
PostgreSQLの場合、npgsqlのGuidUuidConverterが常にbigEndianとして処理するようになっているようです。
ではMicrosoft SQL Serverはどうかというと、ばっちしlittle-endianです。ダメです。というわけで、性能を期待してCreateVersion7を使うと、逆に断片化して遅くなるような憂き目にあいます。
こちらはdotnet/SqlClientのdiscussions#2999で議論されているようなので、成り行きに注目ということで。今までとの互換性などを考えると一括でbigにしてしまえばいいじゃん、というわけにもいかないしで、中々素直にはいかないかもしれませんね……。
なお、このことは別に.NET 9がリリースされる前にもわかっていたことなのに(私でもダメだという状況は把握していた)、リリースされるまでアクションが全く起きないというところに、今のSQL Serverへのやる気を感じたりなかったり。
MagicOnion
イベントではCysharpの @mayuki さんからMagicOnionの入門セッションもありました!
MagicOnionも2016年の初リリース、2018年のリブート(v2)、googleのgRPC C Coreからgrpc-dotnetベースへの変更、クライアントのHttpClientベースへの変更など、内部的には色々変わってきたし機能面でも磨かれてきています。まだまだ次のアップデートが控えている、最前線で戦える強力なフレームワークとなっています!
.NET 9 AlternateLookup によるC# 13時代のUTF8文字列の高速なDictionary参照
- 2024-08-29
.NET 9 から辞書系のクラス、Dictionary, ConcurrentDictionary, HashSet, FrozenDictionary, FrozenSetに GetAlternateLookup<TKey, TValue, TAlternate>() というメソッドが追加されました。今までDictionaryの操作はTKey経由でしかできませんでした。それは当たり前、なのですが、困るのが文字列キーで、これはstringでも操作したいし、ReadOnlySpan<char>でも操作したくなります。今まではReadOnlySpan<char>しか手元にない場合はToStringでstring化が必須でした、ただたんにDictionaryの値を参照したいだけなのに!
その問題も、.NET 9から追加されたGetAlternateLookupを使うと、辞書に別の検索キーを持たせることが出来るようになりました。
var dict = new Dictionary<string, int>
{
{ "foo", 10 },
{ "bar", 20 },
{ "baz", 30 }
};
var lookup = dict.GetAlternateLookup<ReadOnlySpan<char>>();
var keys = "foo, bar, baz";
// .NET 9 SpanSplitEnumerator
foreach (Range range in keys.AsSpan().Split(','))
{
ReadOnlySpan<char> key = keys.AsSpan(range).Trim();
// ReadOnlySpan<char>でstring keyの辞書のGet/Add/Removeできる
int value = lookup[key];
Console.WriteLine(value);
}
ところでSplitは、通常のstringのSplitは配列とそれぞれ区切られたstringをアロケーションしてしまいますが、.NET 8から、ReadOnlySpan<char>に対して固定個数のSplitができるMemoryExtensions.Splitが追加されました。.NET 9では、更にSpanSplitEnumeratorを返すSplitが新たに追加されています。これにより一切の追加のアロケーションなく、元の文字列からReadOnlySpan<char>を切り出すことができます。
そうして取り出したReadOnlySpan<char>のキーで参照するために、GetAlternateLookupが必要になってくるわけです。
使い道としては、例えばシリアライザーは頻繁にキーと値のルックアップが必要になります。私の開発しているMessagePack for C#では、高速でアロケーションフリーなデシリアライズのために、複数の戦略を採用しています。その一つはUTF8の文字列を8バイトずつのオートマトンとして扱うAutomataDictionary、この部分は更にIL EmitやSource Generatorではインライン化して埋め込まれて辞書検索もなくしています。もう一つはAsymmetricKeyHashTableという機構で、これは同一の対象を表す2つのキーで検索可能にしようというもので、内部的には byte[] と ArraySegment<byte> で検索できるような辞書を作っていました。
// MessagePack for C#のもの
internal interface IAsymmetricEqualityComparer<TKey1, TKey2>
{
int GetHashCode(TKey1 key1);
int GetHashCode(TKey2 key2);
bool Equals(TKey1 x, TKey1 y);
bool Equals(TKey1 x, TKey2 y); // TKey1とTKey2での比較
}
つまり、今までは、こうした別の検索キーを持った辞書が必要なシチュエーションでは、辞書そのものの自作が必要だったし、パフォーマンスのためには基礎的なデータ構造すら自作を厭わない必要がありましたが、.NET 9からはついに標準でそれが実現するようになりました。
AlternateLookupでも必要なのはIAlternateEqualityComparer<in TAlternate, T>で、以下のような定義になっています。(IAsymmetricEqualityComparerと似たような定義なので、また時代を10年先取りしてしまったか)
public interface IAlternateEqualityComparer<in TAlternate, T>
where TAlternate : allows ref struct
where T : allows ref struct
{
bool Equals(TAlternate alternate, T other);
int GetHashCode(TAlternate alternate);
T Create(TAlternate alternate);
}
C# 13から追加された言語機能 allows ref struct によってref struct、つまりSpan<T>などをジェネリクスの型引数にすることができるようになりました。
基本的にはこれはIEqualityComparer<T>とセットで実装する必要があります。実際、Dictionary.GetAlternateLookupではDictionaryのIEqualityComparerがIAlternateEqualityComparerを実装していないと実行時例外が出ます(コンパイル時チェックではありません!)また、EqualityComparerなのにCreateがあるのが少し奇妙ですが、これはAdd操作のために必要だからです。
現状、標準ではIAlternateEqualityComparerはstring用しかありません。stringで標準的に使われるEqualityComparerはIAlternateEqualityComparerを実装していて、ReadOnlySpan<char>で操作できますが、それ以外は用意されていません。
しかし、現代において現実的に必要なのはUTF8です、ReadOnlySpan<byte>です。シリアライザーのルックアップで使う、と言いましたが、現代のシリアライザーの入力はUTF8です。ReadOnlySpan<char>の出番なんてありません。というわけで、以下のようなIAlternateEqualityComparerを用意しましょう!
public sealed class Utf8StringEqualityComparer : IEqualityComparer<byte[]>, IAlternateEqualityComparer<ReadOnlySpan<byte>, byte[]>
{
public static IEqualityComparer<byte[]> Default { get; } = new Utf8StringEqualityComparer();
// IEqualityComparer
public bool Equals(byte[]? x, byte[]? y)
{
if (x == null && y == null) return true;
if (x == null || y == null) return false;
return x.AsSpan().SequenceEqual(y);
}
public int GetHashCode([DisallowNull] byte[] obj)
{
return GetHashCode(obj.AsSpan());
}
// IAlternateEqualityComparer
public byte[] Create(ReadOnlySpan<byte> alternate)
{
return alternate.ToArray();
}
public bool Equals(ReadOnlySpan<byte> alternate, byte[] other)
{
return other.AsSpan().SequenceEqual(alternate);
}
public int GetHashCode(ReadOnlySpan<byte> alternate)
{
// System.IO.Hashing package, cast to int is safe for hashing
return unchecked((int)XxHash3.HashToUInt64(alternate));
}
}
byte[]は標準では参照比較になってしまいますが、データの一致で比較したいので、ReadOnlySpan<T>.SequenceEqual を使います。これは、特にTが幾つかのプリミティブの場合はSIMDを活用して高速な比較が実現されています。ハッシュコードの算出は、高速なアルゴリズムxxHashシリーズの最新版であるXXH3の.NET実装であるXxHash3を用いるのがベストでしょう。これはNuGetからSystem.IO.Hashingをインポートする必要があります。64ビットで算出するため戻り値はulongですが、32ビット値が必要な場合はxxHashの作者より、ただたんに切り落とすだけで問題ないと言明されているため、intにキャストするだけで済まします。
使う場合の例は、こんな感じです。
// Utf8StringEqualityComparerを設定した辞書を作る
var dict = new Dictionary<byte[], bool>(Utf8StringEqualityComparer.Default)
{
{ "foo"u8.ToArray(), true },
{ "bar"u8.ToArray(), false },
{ "baz"u8.ToArray(), false }
};
var lookup = dict.GetAlternateLookup<ReadOnlySpan<byte>>();
// こんな入力があるとする
ReadOnlySpan<byte> json = """
{
"foo": 0,
"bar": 0,
"baz": 0
}
"""u8;
// System.Text.Json
var reader = new Utf8JsonReader(json);
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.PropertyName)
{
// 切り出したKeyで検索できる
ReadOnlySpan<byte> key = reader.ValueSpan;
var flag = lookup[key];
Console.WriteLine(flag);
}
}
一つ注意なのは、stringとReadOnlySpan<byte>でAlternateKeyを作ろうとするのはやめたほうが良いでしょう。それだと、常にエンコードが必要になり、悪いとこどりのようになってしまいます(Runeを使ってアロケーションレスで処理するにしても、どちらにせよバイナリ比較だけで済ませられるbyte[]キーとは比較になりません)。どうしても両方の検索が必要なら、辞書を二つ用意するほうがマシです。
ともあれ、これは私にとっては念願の機能です!色々なバリエーションで、Span対応のためにジェネリクスにもできずに決め打ちで辞書を何度も作ってきました、汎用的に使えるようになったのは大歓迎です。allows ref structはジェネリクス定義での煩わしさもありますが(自動判定での付与でも良かったような?)、言語としては重要な進歩です。.NET 9, C# 13、使っていきましょう。現状はまだプレビューですが、11月に正式版がリリースされるはずです。