2011年を振り返る
- 2011-12-30
一年、ありがとうございました。何とか生き延びれました。ブログも冬眠せず続けられましたし、よきかなよきかな。
今年は色々ありました。やはり一番大きかったのはMicrosoft MVP for Visual C#の受賞ですね。と、いっても、今まで通りブログを書いてライブラリを書いて、というわけで、別に今までと何が変わったわけでもありません。ただ、肩書きとして威力があったりなかったり、というのはあります。あと、出す情報に関してはある程度は責任というか、適当すぎることは書けないかな、という意識は持ちました。
良くも悪くもといえば、やはりラベルが貼られると、ラベルに沿って動いてしまうというのが人の性かもしれません。少しC#贔屓が強くなりすぎたかもねー、とか。ちょっと反省。それと、他の言語を全然学べなかったなあ、というのもよくなかった。今年はちょっと色々なことに追われすぎたというかRx-WP7-Async-Roslynと、C#だけでいっぱいいっぱいだったのです……。結局Roslynはあまり追えてないし。
@ITでの連載 Reactive Extensions(Rx)入門 - @IT がスタートしたり、C#ユーザー会で基礎からのCode Contracts、すまべんでReactive Extensionsで非同期処理を簡単に、Silverlight SquareでReactiveProperty - slintokyo4といった、幾つかの勉強会で発表させて頂いたりなど、結構動き出した年でもありました。
ゲーム
死ぬほどプレイ、しなかった……。積みゲーどころか買ったけど封すら開けなかったり。こんな私は想像できなかったなあ。しかも別に時間がないわけじゃなくてさあ、だらだらとネット見てTwitter見てるだけなんですよ。ただ無駄に時間を捨てているだけで。楽しみだったはずのSkyrimにすら手を出していない。ふぅー、来年はちゃんとメリハリつけて付き合いたいものです。ねえ、だらだらネット見てるだけって、だらだらTV見てるだけと何も違わないぢゃあないか。
C#
ライブラリも色々作りました。その時の関心ごとに応じて、徹底的に調べて、不満をライブラリ作って解消する、というのが基本的なスタイルでした。ユニットテストの書き方が気に入らないからChaining Assertionを作り、DBへの生クエリ周りが気に入らないからDbExecutorを作り、INotifyPropertyChangedが気に入らないからReactivePropertyを作った。関心ごとが見つかったら、深くダイブして、新しいやり方を見つけ出す。なんていうとご立派ですが、本当に新しいこと、なんてないのですよね。既存の断片は幾らでも見つかる。だから、それらもまた徹底的に調査して、そして、自分の気にいるように融和させていく。
ずっとlinq.js - LINQ for JavaScriptをlowerCamelCaseに変更する!と思ってたのですが未だにできてはいなくて。よくないですね。ちょうど今日、新しいReactive Extensions for JavaScriptが出ました。詳しくは年明け早々に紹介したいと思いますが、これはちゃんとlowerCamelCaseになってます。いつまでも遅れていちゃマズい。
来年
ここで言うことか?という話ではありますが、12月で会社を退職し(て)ました。1月からは新しい会社で働くことになります。次の会社でもC#をメインにやっていきます(ということで雇われるわけでもありますので)。しっかり成果を出していきたいし、事例やコードなんかも、出せるならガシガシ出したいと思っています。その辺のことは追々。
来年は、MVP絡みで米MS本社でのMVP Global Summitもあり、新しい会社で働く(初めての転職です)ことにもなるしで、私としてもかなり転機な年になるのではという予感がしています。不安もありますが、同時に楽しみでもあります。2010年を振り返るで、来年には更なる成長のために動き出したい、などと言っていましたが、一応はしっかりとスタートを踏み出せたようです。
そんな感じですが、来年もよろしくお願いします。
RxとパフォーマンスとユニットテストとMoles再び
- 2011-12-21
C# Advent Calendar 2011、順調に進んでいますね。どのエントリも力作で大変素晴らしいです。私はこないだModern C# Programming Style Guideというものを書きました。はてブ数は現段階で45、うーん、あまり振るわない……。私の力不足はともかくとしても、他の言語だったらもっと伸びてるだろうに、と思うと、日本のC#の現状はそんなものかなあ、はぁ、という感じではあります。はてブが全てではない(むしろ斜陽?)とはいえ、Twitterでの言及数などを見ても、やっぱまだまだまだまだまだまだ厳しいかなあ、といったところ。Unityなどもあって、見ている限りだと人口自体は着実に増えている感じではありますけれど、もっともっと、関心持ってくれる人が増えるといいな。私も微力ながら尽力したいところです。
ところで、id:ZOETROPEさんのAdvent Calendarの記事、Reactive Extensionsでセンサプログラミングが大変素晴らしい!センサー、というと私だとWindows Phone 7から引っ張ってくるぐらいしか浮かばないのですが(最近だとKinectもHotですか、私は全然触れてませんが……)おお、USB接続のレンジセンサ!完全に門外漢な私としては、そういうのもあるのか!といったぐらいなわけですが、こうしてコード見させていただくと、実践的に使うRxといった感じでとてもいいです。
記事中で扱われているトピックも幅広いわけですが、まず、パフォーマンスに関しては少し補足を。@okazukiさんの見せてもらおうじゃないかReactive Extensionsの性能とやらを! その2のコメント欄でもちょっと言及したのですが、この測り方の場合、Observable.Rangeに引っ張られているので、ベンチマークの値はちょっと不正確かな、と思います。
// 1000回イベントが発火(発火の度に長さ3000のbyte配列が得られる)を模写
static IObservable<byte[]> DummyEventsRaised()
{
return Observable.Repeat(new byte[3000], 1000, Scheduler.Immediate);
}
// 配列をバラす処理にObservable.Rangeを用いた場合
static IObservable<byte> TestObservableRange()
{
return Observable.Create<byte>(observer =>
{
return DummyEventsRaised()
.Subscribe(xs =>
{
Observable.Range(0, xs.Length, Scheduler.Immediate).ForEach(x => observer.OnNext(xs[x]));
});
});
}
// 配列をバラす処理にEnumerable.Rangeを用いた場合(ForEachはIxのもの)
static IObservable<byte> TestEnumerableRange()
{
return Observable.Create<byte>(observer =>
{
return DummyEventsRaised()
.Subscribe(xs =>
{
Enumerable.Range(0, xs.Length).ForEach(x => observer.OnNext(xs[x]));
});
});
}
// SelectManyでバラす場合
static IObservable<byte> TestSelectMany()
{
return DummyEventsRaised().SelectMany(xs => xs);
}
static void Main(string[] args)
{
// ベンチマーク補助関数
Action<Action, string> bench = (action, label) =>
{
var sw = Stopwatch.StartNew();
action();
Console.WriteLine("{0,-12}{1}", label, sw.Elapsed);
};
// 配列をばらすケースは再度連結する(ToList)
bench(() => TestObservableRange().ToList().Subscribe(), "Ob.Range");
bench(() => TestEnumerableRange().ToList().Subscribe(), "En.Range");
bench(() => TestSelectMany().ToList().Subscribe(), "SelectMany");
// 配列をばらして連結せず直接処理する場合
bench(() => TestSelectMany().Subscribe(), "DirectRx");
// byte[]をばらさず直接処理する場合
bench(() => DummyEventsRaised().Subscribe(xs => { foreach (var x in xs);}), "DirectLoop");
// 実行結果
// Ob.Range 00:00:02.2619670
// En.Range 00:00:00.2600460
// SelectMany 00:00:00.2701137
// DirectRx 00:00:00.0852836
// DirectLoop 00:00:00.0152816
}
得られる配列をダイレクトに処理するとして、Observable.Rangeで配列のループを回すと論外なほど遅い。のですが、しかし、この場合ですとEnumerable.Rangeで十分なわけで、そうすれば速度は全然変わってきます(もっと言えば、ここではEnumerable.Rangeではなくforeachを使えば更に若干速くなります)。更に、これは配列を平坦化している処理とみなすことができるので、observerを直に触らず、SelectManyを使うこともできますね。そうすれば速度はほとんど変わらず、コードはよりすっきり仕上がります。
と、いうわけで、遅さの原因はObservable.Rangeです。Rangeが遅いということはRepeatやGenerateなども同様に遅いです。遅い理由は、値の一つ一つをISchedulerを通して流しているから。スケジューラ経由であることは大きな柔軟性をもたらしていますが、直にforeachするよりもずっとずっと遅くなる。なので、Enumerableで処理出来る局面ならば、Enumerableを使わなければなりません。これは、使うほうがいい、とかではなくて、圧倒的な速度差となるので、絶対に、Enumerableのほうを使いましょう。
また、一旦配列をバラして、再度連結というのは、無駄極まりなく、大きな速度差にも現れてきます。もし再度連結しないでそのまま利用(ベンチ結果:DirectRx)すれば直接ループを回す(ベンチ結果:DirectLoop)よりも5倍程度の遅さで済んでいます。このぐらいなら許容範囲と言えないでしょうか?とはいえ、それでも、遅さには違いないわけで、避けれるのならば避けたほうがよいでしょう。
ZOETROPEさんの記事にあるように、ここはばらさないほうが良い、というのが結論かなあ、と思います。正しくは上流ではばらさない。一旦バラしたものは復元不可能です。LINQで、パイプラインで処理を接続することが可能という性質を活かすのならば、なるべく後続で自由の効く形で流してあげたほうがいい。アプリケーション側でバラす必要があるなら、それこそSelectMany一発でばらせるのだから。
例えばWebRequestで配列状態のXMLを取ってくるとします。要素は20個あるとしましょう。最初の文字列状態だけを送られてもあまり意味はないので、XElement.Parseして、実際のクラスへのマッピングまではやります。例えばここではPersonにマッピングするとして、長さ1のIObservable<Person[]>です。しかし、それをSelectManyして長さ20のIObservable<Person>にはしないほうがいい。ここでバラしてしまうと長さという情報は消滅してしまうし、一回のリクエスト単位ではなくなるのも不都合が生じやすい。もしアプリケーション的にフラットになっていたほうが都合が良いのなら、それはまたそれで別のメソッドとして切り分けましょう。
成功と失敗の一本化
ZOETROPEさんの記事の素晴らしいのは、通常のルート(DataReceived)と失敗のルート(ErrorReceived)を混ぜあわせているところ!これもまたイベントの合成の一つの形なわけなんですねー。こういう事例はWebClientのDownloadStringAsyncのような、EAP(Eventbased Asynchronous Programming)をTaskCompletionSourceでラップしてTaskに変換する 方法: タスクに EAP パターンをラップする←なんかゴチャゴチャしていますが、TrySetCanceled, TrySetException, TrySetResultで結果を包んでいます、というのと似た話だと見なせます。
WebClientではEventArgsがCancelledやErrorといったステータスを持っているのでずっと単純ですが、SerialPortではエラーは別のイベントでやってくるのですね。というわけで、私もラップしてみました。
public static class SerialPortExtensions
{
// 面倒くさいけれど単純なFromEventでのイベントのRx化
public static IObservable<SerialDataReceivedEventArgs> DataReceivedAsObservable(this SerialPort serialPort)
{
return Observable.FromEvent<SerialDataReceivedEventHandler, SerialDataReceivedEventArgs>(
h => (sender, e) => h(e), h => serialPort.DataReceived += h, h => serialPort.DataReceived -= h);
}
public static IObservable<SerialErrorReceivedEventArgs> ErrorReceivedAsObservable(this SerialPort serialPort)
{
return Observable.FromEvent<SerialErrorReceivedEventHandler, SerialErrorReceivedEventArgs>(
h => (sender, e) => h(e), h => serialPort.ErrorReceived += h, h => serialPort.ErrorReceived -= h);
}
// DataReceived(プラスbyte[]化)とErrorReceivedを合成する
public static IObservable<byte[]> ObserveReceiveBytes(this SerialPort serialPort)
{
var received = serialPort.DataReceivedAsObservable()
.TakeWhile(e => e.EventType != SerialData.Eof) // これでOnCompletedを出す
.Select(e =>
{
var buf = new byte[serialPort.BytesToRead];
serialPort.Read(buf, 0, buf.Length);
return buf;
});
var error = serialPort.ErrorReceivedAsObservable()
.Take(1) // 届いたらすぐに例外だすので長さ1として扱う(どうせthrowするなら関係ないけど一応)
.Do(x => { throw new Exception(x.EventType.ToString()); });
return received.TakeUntil(error); // receivedが完了した時に同時にerrorをデタッチする必要があるのでMergeではダメ
}
}
成功例と失敗例を合成して一本のストリーム化。また、DataReceivedはそのままじゃデータすっからかんなので、Selectでbyte[]に変換してあげています。これで、ObserveReceiveBytes拡張メソッドを呼び出すだけで、かなり扱いやすい形になっている、と言えるでしょう。パフォーマンスも、これなら全く問題ありません。
MolesとRx
と、ドヤ顔しながら書いていたのですが、とーぜんセンサーの実物なんて持ってませんので動作確認しようにもできないし。ま、まあ、そういう時はモックとか用意して、ってSerialDataReceivedEventArgsはパブリックなコンストラクタないし、ああもうどうすればー。と、そこで出てくるのがMoles - Isolation framework。以前にRx + MolesによるC#での次世代非同期モックテスト考察という記事で紹介したのですが、めちゃくちゃ強力なモックライブラリです。パブリックなコンストラクタがないとか関係なくダミーのインスタンスを生成可能だし、センサーのイベントだから作り出せないし、なんてこともなく自由にダミーのイベントを発行しまくれます。
[TestClass]
public class SerialPortExtensionsTest : ReactiveTest
{
[TestMethod, HostType("Moles")]
public void ObserveReceiveBytesOnCompleted()
{
// EventArgsを捏造!
var chars = new MSerialDataReceivedEventArgs() { EventTypeGet = () => SerialData.Chars };
var eof = new MSerialDataReceivedEventArgs() { EventTypeGet = () => SerialData.Eof };
// SerialPort::BytesToRead/SerialPort::Readで何もしない
MSerialPort.AllInstances.BytesToReadGet = (self) => 0;
MSerialPort.AllInstances.ReadByteArrayInt32Int32 = (self, buffer, offset, count) => 0;
var scheduler = new TestScheduler();
// 時間10, 20, 30, 40でSerialData.Charsのイベントを、時間50でEofのイベントを発行
MSerialPortExtensions.DataReceivedAsObservableSerialPort = _ => scheduler.CreateHotObservable(
OnNext(10, chars),
OnNext(20, chars),
OnNext(30, chars),
OnNext(40, chars),
OnNext(50, eof))
.Select(x => (SerialDataReceivedEventArgs)x);
// 走らせる(戻り値のbyte[]はどうでもいいので無視するためUnitに変換)
var result = scheduler.Start(() => new SerialPort().ObserveReceiveBytes().Select(_ => Unit.Default), 0, 0, 100);
result.Messages.Is(
OnNext(10, Unit.Default),
OnNext(20, Unit.Default),
OnNext(30, Unit.Default),
OnNext(40, Unit.Default),
OnCompleted<Unit>(50));
}
[TestMethod, HostType("Moles")]
public void ObserveReceiveBytesOnError()
{
// EventArgsを捏造!
var chars = new MSerialDataReceivedEventArgs() { EventTypeGet = () => SerialData.Chars };
var eof = new MSerialDataReceivedEventArgs() { EventTypeGet = () => SerialData.Eof };
// SerialPort::BytesToRead/SerialPort::Readで何もしない
MSerialPort.AllInstances.BytesToReadGet = (self) => 0;
MSerialPort.AllInstances.ReadByteArrayInt32Int32 = (self, buffer, offset, count) => 0;
var scheduler = new TestScheduler();
// 時間10, 20, 30, 40でSerialData.Charsのイベントを、時間50でEofのイベントを発行
MSerialPortExtensions.DataReceivedAsObservableSerialPort = _ => scheduler.CreateHotObservable(
OnNext(10, chars),
OnNext(20, chars),
OnNext(30, chars),
OnNext(40, chars),
OnNext(50, eof))
.Select(x => (SerialDataReceivedEventArgs)x);
/* ↑までOnCompletedのものと共通 */
// 時間35でErrorのイベントを発行
MSerialPortExtensions.ErrorReceivedAsObservableSerialPort = _ => scheduler.CreateHotObservable(
OnNext<SerialErrorReceivedEventArgs>(35, new MSerialErrorReceivedEventArgs()));
// 走らせる(戻り値のbyte[]はどうでもいいので無視するためUnitに変換)
var result = scheduler.Start(() => new SerialPort().ObserveReceiveBytes().Select(_ => Unit.Default), 0, 0, 100);
// Exceptionの等値比較ができないので、バラしてAssertする
result.Messages.Count.Is(4);
result.Messages[0].Is(OnNext(10, Unit.Default));
result.Messages[1].Is(OnNext(20, Unit.Default));
result.Messages[2].Is(OnNext(30, Unit.Default));
result.Messages[3].Value.Kind.Is(NotificationKind.OnError);
result.Messages[3].Time.Is(35);
}
}
アサーションに使っているIsメソッドは、いつも通りChaining Assertionです。
Molesがいくら強力だとは言っても、イベントをそのまま乗っ取るのはデリゲートの差し替えなどで、割と面倒だったりします。しかし、FromEventでラップしただけのIObservable<T>を用意しておくと…… それを差し替えるだけで済むので超簡単になります。イベント発行については、TestScheduler(Rx-Testingを参照しておく)で、仮想時間で発行する値を作ってしまうと楽です。こういう、任意の時間で任意の値、というダミーの用意もFromEventでラップしただけのIObservable<T>があると、非常に簡単になります。
あとは、scheduler.Startで走らせると(3つの引数はそれぞれcreated, subscribed, disposedの仮想時間、何も指定しないと…… 実は0始まり「ではない」ことに注意。100,200,1000がデフォなので、0はすっ飛ばされています)、その戻り値で結果を受け取って、Messagesに記録されているので、それにたいしてアサートメソッドをしかける。
実に簡単ですね!Molesの力とRxの力が組み合わさると、イベントのテストが恐ろしく簡単になります。素敵じゃないでしょうか?
まとめ
テストなしで書いてたコードは、Molesでテスト走らせたら間違ってました。TakeWhileの条件が==だったのと、Mergeで結合していたり……。はっはっは、ちゃんとユニットテストは書かないとダメですね!そして、Molesのお陰でちゃんと動作するコードが書けたので恥を欠かなくてすみました、やったね。
Modern C# Programming Style Guide
- 2011-12-16
C# Advent Calendar 2011、ということで、C# 4.0時代のプログラミングスタイルについて説明してみます。モダン、というけれど、某書のように変態的なことじゃなくて、むしろ基本的な話のほうです。こういったものはナマモノなので、5.0になればまた変わる、6.0になればまた変わる。変わります。古い話を間に受けすぎないこと(歴史を知るのは大事だけど、そのまま信じるのは別の話)、常に知識をリフレッシュするようにすること。そういうのが大事よね。でも、だからってモダンに書けなきゃダメ!なんてことはありません。ただ、知ること、少しずつ変えていくこと、そういうのは大事よね、って。
ところでしかし、私の主観がかなり入っているので、その辺は差っ引いてください。
- varを使う
C# 3.0から搭載された型推論での宣言。出た当初には散々議論があって、今もたまに否の意見が出てきたりもしますが、varは使いましょう。積極的に。何にでも。国内的にも世界的にもMicrosoft的にも、var積極利用の方向で傾いているように見えます。また、最近流行りの関数型言語(Haskell, Scala, F#)は、少なくともC#のvarで可能な範囲は全て推論を使いますね←C#のvarはそれらに比べれば遥かに貧弱ですからね。そういったこともあるので、使わない理由もないでしょう。
var person = new Person();
var dict = new Dictionary<string, Tuple<int, Person>>();
var query = Enumerable.Range(1, 10).Select(x => x * 10);
varの利点は、何といっても書いていて楽なことです。はい、圧倒的に楽です。そして、型宣言の長さが一致するので「実は見やすい」というのもポイント高し。たった3文字の短さと相まって、ソースコードが綺麗になります。また、必ず変数の初期化を伴う、というのも良いことです。
欠点は「メソッドの戻り値などは宣言を見ても型が分からない」「インターフェイスで宣言できない」の二つが代表的でしょうか。前者は、Visual Studioを使えばマウスオーバーで型が表示されるので、コーディング上では支障はない。メールやBlogやWikiなど、Visual Studioのサポートのない完全にコードのみの状態だとサッパリなのは確かに難点ではありますが、逆にその程度の部分的な範囲なら、括り出されている目的が明確なわけなので、適切な変数名がついているのなら、正確な型名とまではいかずとも何に使うもののか大体分かるのではないでしょうか?なので、大きな問題だとは私は思いません。もし変数名がテキトーで型名ぐらいしかヒントが得られないんだよ!ということならば、varよりも前にまともな変数名をつけるようにしたほうがいいです。
インターフェイスで宣言できないことは、私は何の問題もないと思っています。具象型やメソッドの返す型でそのまま受けることに何の不都合が?むしろインターフェイスで宣言すると、アップキャスト可能という怪しい状態を作り出しているだけです。
ちなみにintやstring、配列などの基本的なものぐらいは型を書くという流儀もなくはないようですが、それは意味無いのでやめたほうがいいでしょう。
var num = 100;
var text = "hogehoge";
var array = new[] { 1, 2, 3, 4, 5 };
だって、こういうのこそ、見れば一発で分かるほど自明なので。
- オプション引数を使う(使いすぎない)
害悪もあるわけですが、割と積極的に使ってもいいような気がします。実際Roslyn CTPなどでは結構派手に使われていますし、オーバーロード地獄よりはIntelliSense的にも分かりやすいかな、って。思います。enumなど使うと、明確に何が使われるか見えるんですね、これはとても嬉しくて。やっぱC#としてはIntelliSenseで分かりやすい、というのはとても大事かと。

さて、分かりやすく使いすぎに注意な点としては、引数なしコンストラクタが消滅してしまう可能性があげられます。引数なしコンストラクタがないと、色々なところで弊害が起こります。
// こんなオプション引数なコンストラクタしかないクラスがあるとして
public class ToaruClass
{
public ToaruClass(int defaultValue = -1)
{
}
}
class Program
{
static T New<T>() where T : new()
{
return new T();
}
static void Main(string[] args)
{
// 使うときは引数なしでnewできるけど
var _ = new ToaruClass();
// 実態は違うので、ジェネリックのnew制約が不可能になる
New<ToaruClass>(); // コンパイル通らない
// 引数なしコンストラクタを要求するシリアライザの利用も不可能に
new XmlSerializer(typeof(ToaruClass)).Serialize();
}
}
シリアライズできなかったりジェネリックのnew制約がきかなくなってしまったり。ご利用は計画的に。シリアライズに関しては、DataContractSerializerならばコンストラクタを無視するので使えはしますが……。その辺の話はneue cc - .NETの標準シリアライザ(XML/JSON)の使い分けまとめで。
Roslyn CTPのAPIはオプション引数が激しく使われているのですが、中でもこれは面白いと思いました。Mindscape Blog » Blog Archive » In bed with Roslynから引用します。
PropertyDeclarationSyntax newProperty = Syntax.PropertyDeclaration(
modifiers: Syntax.TokenList(Syntax.Token(SyntaxKind.PublicKeyword)),
type: node.Type,
identifier: node.Identifier,
accessorList: Syntax.AccessorList(
accessors: Syntax.List(
Syntax.AccessorDeclaration(
kind: SyntaxKind.GetAccessorDeclaration,
bodyOpt: Syntax.Block(
statements: Syntax.List(
getter
)
)
),
Syntax.AccessorDeclaration(
kind: SyntaxKind.SetAccessorDeclaration,
bodyOpt: Syntax.Block(
statements: Syntax.List(
setter
)
)
)
)
)
);
そう、名前付き引数でツリー作ってるんですね。LINQ to XMLの関数型構築も面白いやり方だと思いましたが、この名前付き引数を使った構築も、かなり素敵です。流行るかも!
- ジェネリックを使う
もしお持ちの本がArrayListやHashTableを使っているコードが例示されていたら、窓から投げ捨てましょう。Silverlightでは廃止されていますし、WinRT(Windows 8)でも、勿論そんな産廃はありません。もはやどこにもそんなものを使う理由はありません。どうしても何でも入れられるListが欲しければ、List<object>を使えばいいぢゃない。
- ジェネリックデリゲート(Func, Action)を使う
これも賛否両論ではあるのですが、私は断然ジェネリックデリゲート派です。ちなみにその反対は野良デリゲート量産派でしょうか(悪意のある言い方!)。ジェネリックデリゲートを使うと良い点は、デリゲートの型違い(同じ引数・戻り値のデリゲートでも型が違うとキャストが必要)に悩まされなくてすむ、定義しなくていいので楽、そして、なにより分かりやすい。例えば、「MatchEvaluator」というだけじゃ、何なのかさっぱり分かりません。正規表現のReplaceで使われるデリゲートなのですけどね。Func<Match, string>のほうが、ずっと分かりやすい。
では良くない点は、というと、引数に変数名で意味をつけられない。例えばLINQのSelectメソッドのFunc<TSource, int, TResult>。このintはインデックスですが、そのことはドキュメントコメントからしか分かりません。その点、野良デリゲートを作れば
public delegate TR ConverterWithIndex<T, TR>(T value, int index);
という形で、明示できます。なんて素晴らしい?そう?実のところそんなでもなくて、これ、IntelliSenseからじゃあ分からないんですよね。

F12なりなんなりで型定義まで飛ばないと見えないのです、デリゲートの変数名は。その点Func<Match, string>なら引数の型、戻り値の型がIntelliSenseで見えるわけでして。C#的にはIntelliSenseで見えないと価値は9割減です。というわけで、天秤にかければ、圧倒的にFuncの大勝利。引数ずらずらでイミフになるならドキュメントコメントに書くことで補う、でもいいぢゃない。
ちなみにoutやrefのジェネリックデリゲートは存在しないので、その場合のみ自作デリゲートを立てる必要があります。それ以外、つまるところ99%ぐらいはFunc, Action, EventHandler<T>でいいと思います。LINQだってPredicateじゃなくてFunc<T, bool>だしね。
- ラムダ式を使う
ラムダ式(C# 3.0)を使わなければ何を使うのって話ですが、ラムダ式の登場により割を食った匿名メソッド(C# 2.0)は産廃です。唯一の利点は、匿名メソッドは引数を使わない場合は省略して書けます。
// 引数省略して書けるぞ!
button.Click += delegate { MessageBox.Show("hoge"); };
// ラムダ式の場合は省略できないんだ(棒)
button.Click += (_, __) => MessageBox.Show("hoge");
こんなことは実にどうでもいいので、匿名メソッドを使うのはやめましょう。もしラムダ式が先にあれば、匿名メソッドはなかったと思います。ジェネリックが最初からあれば非ジェネリックコレクションクラスがなかっただろう、ということな程度には。あとジェネリックが先にあれば野良デリゲートもなかった気がする。なので、多少どうでもいい利点があったとしても、素直に使わないのが一番。
ところでラムダ式の引数の名前ですが、どうしていますか?私は、昔は型名から取っていました、例えばintだったらi、stringだったらs。でも最近は全てxにしています。理由は、面倒くさいし適切な名前が出てこない場合もあるし修正漏れが起こったりする(ハンガリアンみたいなもんですしねえ)などなどで、メリットを感じなかったので。
ちなみに、ラムダ式で長い名前を使うのは反対です。「名前はしっかりつけなきゃダメ!」が原則論のはずなのにxってなんだよそれって感じですが、逆に、小さい範囲のものは小さいほうがいいのです。名前をつけないことで、他の名前のついているものを強調します。なんでもかんでも名前をつけていると五月蝿くて、木を森に隠す、のようになってしまいます。LINQやRxでラムダ式だらけになると、なおそうです。勿論、ラムダ式だからって全てxにするわけではありません。中でネストしてネスト内でも使われたり、式ではなく文になってスコープが長くなっている場合などは、ちゃんと名前をつけます。また、(分かりやすさのため)強く意味を持たせたい場合も名前をつけます。型名以上の意味を持たせられないのなら、あえて名前をつける必要性を感じないのでxです。
そういうわけで、多少崩すこともありますが、原則的に私の命名規則は「ただの変数 = x, 配列などコレクション = xs, 引数を使わない = アンダースコア」としています。xのかわりにアンダースコアを使う流儀もあるようですが、私は嫌いですね……。Scalaのアンダースコアとは意味が違う感じもあるし、同じ.NETファミリーならばF#が引数を使わないという意味でアンダースコアを使っているので、それに合わせたほうがいいと思っています。xだと座標のxと被る、という場合は座標のxにつける変数名をpointXだかpxだかに変えます。
Exceptionはexにしたり、イベントの場合は(sender, e)にしたりはしますけれど、このへんは慣習ですし、わざわざ崩すほうが変かな。あとLINQでのGroupingはgを使ったりしますね。
- LINQを使う(主にメソッド構文を使う、クエリ構文もたまには使う)
LINQはデータベースのためだけじゃなく、むしろ通常のコレクションへの適用(LINQ to Objects)のほうが多い。そんなにコレクション操作することなんてない、わけがない、はず。
// 配列の中のYから始まるものの名前(スペースできった最後のもの)を取り出す
new[] { "Yamada Tarou", "Yamamoto Jirou", "Suzuki Saburou" }
.Where(x => x.StartsWith("Y"))
.Select(x => x.Split(' ').Last());
上の例のような、Where(フィルタリング)+ Select(射影)は特に良く使うパターンです。Pythonなどでもリスト内包表記としてパッケージされるぐらいには。やはり、この手の処理を持っていないと、重苦しい。しかし、C# 3.0はLINQを手にしたので、お陰で軽快に飛び回れるようになりました。しかもただのフィルタ+射影だけではなく、ありとあらゆる汎用コレクション処理を、チェーンで組み合わせることで、無限のパターンを手にしました。
LINQにはメソッド構文とクエリ構文があり、どちらも同じですがメソッド構文のほうが機能豊富だし、分かりやすいです。なのでメソッド構文でメソッドチェーンハァハァしましょう。linq.js - LINQ for JavaScriptで同様の記法でJavaScriptでも使えますし!
じゃあクエリ構文に利点はないのかというと当然そんなことはなく、多重from(SelectManyに変換される)が多く出現する場合はクエリ構文のほうがいいですね。また、Joinなどもクエリ構文のほうが書きやすいし、GroupJoinと合わせた左外部結合を記述したりなど複雑化する場合はクエリ構文じゃないと手に負えません(書けなくはないんですけどねえ)
それと、LINQ to SQLなどExpression Treeをそれぞれの独自プロパイダが解釈するタイプのものは、メソッド構文の豊富な記述可能性が逆に、プロパイダの解釈不能外に飛び出しがちなので、適度に制約の効いたクエリ構文だけで書いたほうがスムーズにいく可能性があります。
また、XMLはC#ではXmlReader/Writer, XmlDocument(DOM), XDocument(LINQ to XML)がありますが、そのうちDOMのXmlDocumentは産廃です。DOMって使いづらいのよね、それにSilverlightにはないし。メモリ内にツリーを持つタイプではXDocument(XElement)でLINQでハァハァするのが主流です。ちなみにXmlReader/Writerはストリーミング型なので別枠、ただ、生で使うことはあまりないと思います。特にWriterは、XStreamingElementを使えば省メモリなストリーミングで、Writeできる、しかもずっと簡単に。なので、使うことはないかと思います。
- Taskを使う(生スレッドを使わない)
マルチスレッドプログラミングしなきゃ!Threadを使おう?デリゲートのBeginInvokeがある?それともThreadPool?BackgroundWorkerもあるぞ!古い記事はこれらの使用方法が解説されてきました。そうです、今まではそれらしかなかったので。けれど、全部ゴミ箱に投げ捨てましょう。.NET 4.0からは基本的原則的にTaskを使うべきです。豊富な待ち合わせ処理・継続・例外処理・キャンセルなどをサポートしつつ、同じスレッドを使いまわそうとするなど実行効率も配慮されています。もはや生スレッドを使う理由はないし、デリゲートのBeginInvokeなどともさよなら。BackgroundWorkerは、もう少しは出番あるかも(UIへの通知周りが今のTaskだけだと少し面倒、RxやC# 5.0のAsyncなら簡単にこなせるのですが)。
CPUを使う処理を並列に実行をしたいのなら、PLINQやParallel.ForEachなどが手軽かつ超強力です。
また、C# 5.0からはTaskの言語サポートが入り、awaitキーワードによりコード上では待機したように見せかけ同期的のように書けつつ中身は非同期で動く、といったことが可能になります。
async Task<string> GetBingHtml()
{
var wc = new WebClient();
var html = await wc.DownloadStringTaskAsync(new Uri("http://bing.com/"));
return html;
}
awaitするだけで同期的のように非同期が書けるなんて魔法のよう!
また、非同期といっても二つあります。CPUを沢山使って重たい処理と、I/O待ち(ネットワークやファイルアクセス)が重たい処理。これらへの対処は、別です。I/O待ちにスレッドを立てて対処することも可能ではありますが、あまり褒められた話ではありません。と、C#たんが非同期I/O待ちで言ってました。非同期I/Oは優れているのは分かったとしても、記述が面倒なのがネックだったのですね。しかし、C# 5.0からならばawaitが入るのでかなりサクッと書ける。非同期だって、node.jsにばかりは負けてられない!
なお、現在SilverlightやWindows Phone 7にはTaskがない(Silverlight 5にはTask入りました)ですが、将来的には間違いなく入るので、期待して待ちましょう。そして、分かりやすく書けるC# 5.0もwktkして待ちましょう。待ちきればければAsync CTPとして公開されているので、試すことが可能です。
- Rxを使う
C# 5.0はCTPだし、現実問題として非同期に困ってるんだよ!という場合は、変化球としてReactive Extensionsが使えます。詳しくはReactive Extensions(Rx)入門 - @ITで連載しているので読んでね!第二回がいつまでたっても始まらないのは何故なのでしょう、はい、私が原稿を送っていないからです、ごめんなさい……。これ書いてないで原稿書けやゴルァという感じですはい。いえ、もうすぐもう少しなので、ちょっと待ってください。
RxはTaskとは全く別の次元からやってきつつ、機能的にはある程度代替可能です。C# 5.0が来た時に共存できるのか、というと、非同期面ではTaskに譲るでしょう。けれど、非同期の生成をTaskで行なって、コントロールをawaitも使いつつRxでメインに使うとかも可能です。基本的に、コントロール周りはawaitサポートを除けばRxのほうが強力で柔軟です(代償として効率を若干犠牲にしているけれど)。ただまあ、基本的には非同期処理はTaskに絞られていくだろうと考えています。少し寂しいけど、全体としてより美しく書けるなら全然いいです、むしろ大歓迎なので早くC#5.0来ないかなあ。
ちなみに、Rxは別に非同期のためだけじゃなくて、イベントと、そしてあらゆるソースを合成するという点も見逃せないわけなので、決してAsync来たからRxさようなら、ではないです。その辺のことも連載であうあう。
- Expressionを使う(そしてEmitしない)
Expressionの簡単な基本ですが、Expressionとして宣言します。Funcとほとんど同じで、違うのは型宣言だけです。
// 同じラムダ式だけれど
Expression<Func<int, int>> expr = x => x * x;
Func<int, int> func = x => x * x;
// Expressionで宣言すると実態は以下のものになる(コンパイラが自動生成する)
var paramX = Expression.Parameter(typeof(int), "x");
var expr = Expression.Lambda<Func<int, int>>(
Expression.Multiply(paramX, paramX),
new[] { paramX });
Expressionで宣言するとコンパイラがコンパイル時に式木生成コードに変換してくれるのですね。自分で宣言しなくても、メソッドの引数の型がExpressionならば同じです。例えばQueryable.SelectのselectorはExpression型の引数なので、Queryableで連鎖を書いているということは同様に↑のようなコードが吐かれています。
Expressionの仕事は色々ありますが、概ね二つ。式がデータとして取り出せること。簡単な所ではINotifyPropertyChangedの実装なので話題沸騰したりしなかったりした、文字列ではなくプロパティを渡して、そこから引数名を取り出すことができること。
public class MyClass
{
public string MyProperty { get; set; }
}
// これ
public static string GetPropertyName<T>(Expression<Func<T>> propertyExpression)
{
return (propertyExpression.Body as MemberExpression).Member.Name;
}
static void Main(string[] args)
{
var mc = new MyClass();
var propName = GetPropertyName(() => mc.MyProperty);
}
こんな形で推し進めたのが、LINQ to SQLなど、式木の塊を解釈してSQLに変換するといった、QueryProviderですね。
そしてもう一つはILビルダー。式木はCompileすることでFuncに変換することが可能です。
// (object target, object value) => ((T)target).memberName = (U)value
static Action<object, object> CreateSetDelegate(Type type, string memberName)
{
var target = Expression.Parameter(typeof(object), "target");
var value = Expression.Parameter(typeof(object), "value");
var left =
Expression.PropertyOrField(
Expression.Convert(target, type), memberName);
var right = Expression.Convert(value, left.Type);
var lambda = Expression.Lambda<Action<object, object>>(
Expression.Assign(left, right),
target, value);
return lambda.Compile();
}
// Test
static void Main(string[] args)
{
var target = new MyClass { MyProperty = 200 };
var accessor = CreateSetDelegate(typeof(MyClass), "MyProperty");
accessor(target, 1000); // set
Console.WriteLine(target.MyProperty); // 1000
}
少なくとも、自前でILを書くよりは圧倒的に簡単に、動的コード生成を可能にしました。動的コード生成はCompileは重いものの、一度生成したデリゲートをキャッシュすることで二度目以降は超高速になります。単純なリフレクションよりはずっと速く。といったようなことをneue cc - Expression Treeのこね方・入門編 - 動的にデリゲートを生成してリフレクションを高速化で書いたので読んでね!
- dynamicを使わない(部分的に使う)
一時期、LLブームで動的言語が持て囃されましたが、今は(静的型付けの)関数型言語ブームで、静的型付けへ寄り戻しが来ています。なので、C#もdynamicあって動的だよねひゃっほーい、なんてことはなく、むしろvarで型推論です(キリッ のほうが正しくて。そんなわけで、dynamicはあまり使いません。ですが、使うとより素敵な場所も幾つかあります。それは、本質的に動的なところに対して。動的なのってどこ?というと、アプリケーションの管理範囲外。
例えばJSONはスキーマレス。DBも、自動生成しなければアプリケーションの外側で見えない。.NETはDLRがあるのでIronPythonなどスクリプト言語との連携などもそう。DynamicJsonを例にだすと、スキーマレスなJSONに対して、そのまま、JSONをJavaScriptで扱うのと同じように使えます。
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
var r1 = json.foo; // "json" - dynamic(string)
var r2 = json.bar; // 100 - dynamic(double)
var r3 = json.nest.foobar; // true - dynamic(bool)
また、動的な存在であるDBへのIDataRecordも、DbExecutorを例に出すと
var products = DbExecutor.ExecuteReaderDynamic(new SqlConnection(connStr), @"
select ProductName, QuantityPerUnit from Products
where SupplierID = @SupplierID and UnitPrice > @UnitPrice
", new { SupplierID = 1, UnitPrice = 10 })
.Select(d => new Product
{
ProductName = d.ProductName,
QuantityPerUnit = d.QuantityPerUnit
})
.ToArray();
ドットで自然に参照可能なことと、また、dynamicが自動でキャストしてくれるので明示的なキャストが不要なため、取り回しの面倒な手動DBアクセスが随分と簡単になります。(が、DBのアクセス結果を決まったクラスにマッピングするのなら、9で紹介している動的コード生成でアクセサを作ったほうが更に楽々になるのでそこまで出番はないかも。DbExecutorは両方を搭載しているので、必要に応じて選ぶことが可能です)
- 自動プロパティを使う
自動プロパティ vs パブリックフィールド。同じです。はい、同じです。じゃあパブリックフィールドでいいぢゃん?という話が度々ありますが、いえ、そんなことはありません。プロパティにするとカプセル化が云々、変更した場合に云々、などは割とどうでもいいのですが、重要な違いはちゃんとあります。
WPFとかASP.NETとかのバインディングがプロパティ大前提だったりしてパブリックフィールドだと動かないことがある。
なので、黙って自動プロパティにしておきましょう。それに関連してですが、リフレクションでの扱い易さがプロパティとフィールドでは全然違って、プロパティだと断然楽だったりします。そういう面でサードパーティのライブラリでも、プロパティだけをサポート、なものも割とあるのではかと思います。具体例はあげられませんが私は自分で作るちょろっとリフレクションもにょもにょ系の小粒なライブラリは面倒なのでプロパティだけサポート、にすることが結構あります。
あと自動プロパティの定義はコードスニペットを使って一行でやりましょう。prop->Tab->Tabです。
public int MyProperty { get; set; }
get, setで改行して5行使ったりするのはコードの可読性が落ちるので、好きじゃありません。コードスニペットで一行のものが生成されるわけなので、それに従うという意味でも、一行で書くのがベストと思います。
まとめ
C#は言語がちゃんと進化を続けてきた。進化って無用な複雑化!ではなくて、基本的には今までよくなかった、やりづらいことを改善するために進化するんですよね。だから、素直にその良さを甘受したい。そしてまた、進化するということは、歴史の都合上で廃棄物が出てきてしまうというのもまた隣合わせ。C#は巧妙に、多量の廃棄物が出現するのを避けてきていると思います。ヘジたんの手腕が光ります。しかし、やはりどうしても幾つかの廃棄物に関しては致し方ないところです。それに関しては、ノウハウとして、自分で避けるしかなくて。
この手の話だったら、.NETのクラスライブラリ設計が良いです。もしお持ちでなければ、今すぐ買いましょう!いますぐ!超おすすめです。
また、この手の本だったらEffective C# 4.0もかしら。第一版は(翻訳が出たのが既にC# 4.0の頃で1.0の内容)古くてう~ん、といった感だったのですが、第二版(C# 4.0対応)はかなり良かったです。More Effective C#のほうはLINQ前夜といった感じの内容で若干微妙なのですが、LINQ的な考えが必要な理由を抑える、という点では悪くないかもしれません。また、決定版的な内容を求めるならば、読み通す必要はなく気になるところつまみ読みで良いので、プログラミング.NET Frameworkがお薦めです。
これらに加えて、自分のやりたいことの対象フレームワークの本(ASP.NET/ASP.NET MVC/Win Forms/WPF/WCF/Silverlight/Windows Phone 7/Unity)を一冊用意すれば、導入としては準備万端で素敵ではないかしらん。まあ、今時フレームワークとかの先端の部分だと、フレームワークの進化の速度が速すぎて本だと情報の鮮度が落ちる(特に日本だと)ので、基本は本でサッと抑えて、深い部分はネットの記事を見たほうが良いのではかと思います。ソースコードが公開されていたりフレームワークの制作陣や第一人者が情報出していたりしますしね。本こそが情報の基本にして全て、という時代でもないのだなぁ、と。学習の仕方というのも、時代で変わっていくものだと思います。
Voidインスタンスの作り方、或いはシリアライザとコンストラクタについて
- 2011-12-13
voidといったら、特別扱いされる構造体です。default(void)なんてない。インスタンスは絶対作れない。作れない。本当に?
var v = System.Runtime.Serialization.FormatterServices.GetUninitializedObject(typeof(void));
Console.WriteLine(v); // System.Void
作れました。というわけで、GetUninitializedObjectはその名前のとおり、コンストラクタをスルーしてオブジェクトを生成します。そのため、voidですら生成できてしまうわけです、恐ろしい。こないだ.NETの標準シリアライザ(XML/JSON)の使い分けまとめという記事でシリアライザ特集をして少し触れましたが、DataContractSerializerで激しく使われています。よって、シリアライズ対象のクラスがコンストラクタ内で激しく色々なところで作用しているようならば、それが呼び出されることはないので注意が必要です。
ただし、DataContractSerializerを使ったからって、必ずしも呼ばれるわけではないです。DataContract属性がついていなければ普通にコンストラクタを呼ぶ。DataContract属性がついていれば、引数のないコンストラクタがあったとしても、コンストラクタを無視する。という挙動になっているようです。ちょっと紛らわしいので、以下のコードは(参照設定があれば)そのままペーストして動くので、是非試してみてください。
using System;
using System.IO;
using System.Linq.Expressions;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Json;
using System.Text;
using System.Xml.Serialization;
public class EmptyClass
{
public EmptyClass()
{
Console.WriteLine("BANG!");
}
}
[DataContract]
public class ContractEmptyClass
{
public ContractEmptyClass()
{
Console.WriteLine("BANG!BANG!");
}
}
[DataContract]
public class NoEmptyConstructorClass
{
public NoEmptyConstructorClass(int dummy)
{
Console.WriteLine("BANG!BANG!BANG!");
}
}
class Program
{
static void Main(string[] args)
{
// 普通にnewするとBANG!
Console.WriteLine("New:");
var e1 = new EmptyClass();
// Activator.CreateInstanceでnewするのもBANG!
Console.WriteLine("Activator.CreateInstance:");
var e2 = Activator.CreateInstance<EmptyClass>();
// ExpressionTreeでCompileしてもBANG!
Console.WriteLine("Expression.New");
var e3 = Expression.Lambda<Func<EmptyClass>>(Expression.New(typeof(EmptyClass))).Compile().Invoke();
// 何も起こらない(コンストラクタを無視するのでね)
Console.WriteLine("GetUninitializedObject:");
var e4 = System.Runtime.Serialization.FormatterServices.GetUninitializedObject(typeof(EmptyClass));
// XmlSerializerでのデシリアライズはBANG!
Console.WriteLine("XmlSerializer:");
var e5 = new XmlSerializer(typeof(EmptyClass)).Deserialize(new MemoryStream(Encoding.UTF8.GetBytes("<EmptyClass />")));
// DataContractSerializerでもBANGって起こるよ!
Console.WriteLine("DataContractSerializer:");
var e6 = new DataContractSerializer(typeof(EmptyClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("<EmptyClass xmlns=\"http://schemas.datacontract.org/2004/07/\" />")));
// DataContractJsonSerializerでも起こるんだ!
Console.WriteLine("DataContractJsonSerializer:");
var e7 = new DataContractJsonSerializer(typeof(EmptyClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("{}")));
// DataContract属性をつけたクラスだと何も起こらない
Console.WriteLine("DataContract + DataContractSerializer:");
var e8 = new DataContractSerializer(typeof(ContractEmptyClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("<ContractEmptyClass xmlns=\"http://schemas.datacontract.org/2004/07/\" />")));
// DataContract属性をつけたクラスだとJsonSerializerのほうも当然何も起こらない
Console.WriteLine("DataContract + DataContractJsonSerializer:");
var e9 = new DataContractJsonSerializer(typeof(ContractEmptyClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("{}")));
// 空コンストラクタのないもの+DataContractSerializerだと何も起こらない
Console.WriteLine("NoEmptyConstructor + DataContractSerializer:");
var e10 = new DataContractSerializer(typeof(NoEmptyConstructorClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("<NoEmptyConstructorClass xmlns=\"http://schemas.datacontract.org/2004/07/\" />")));
// 空コンストラクタのないもの+DataContractJsonSerializerでも何も起こらない
Console.WriteLine("NoEmptyConstructor + DataContractJsonSerializer:");
var e11 = new DataContractJsonSerializer(typeof(NoEmptyConstructorClass)).ReadObject(new MemoryStream(Encoding.UTF8.GetBytes("{}")));
}
}
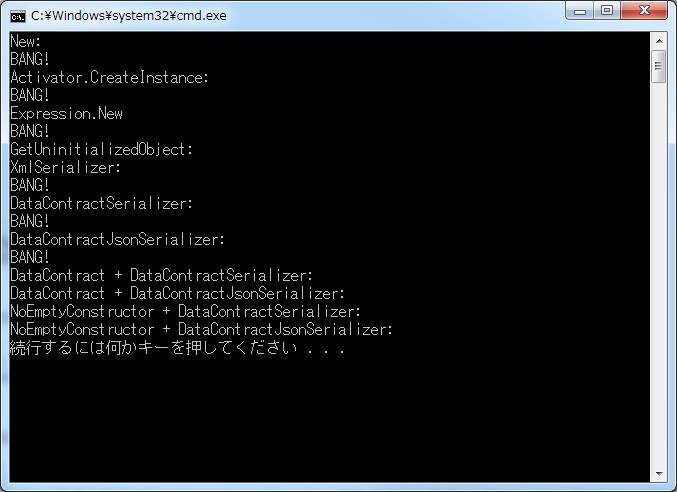
.NET 4でもSilverlightでも共通です。この挙動は妥当だと思います。DataContract属性を付けた時点で、そのクラスはシリアライズに関して特別な意識を持つ必要がある。コンストラクタ内でシリアライズで復元できない副作用のある処理をすべきではない。逆に、何も付いていない場合は特に意識しなくても大丈夫。
.NETの標準シリアライザ(XML/JSON)の使い分けまとめ
- 2011-12-10
今年もAdvent Calendarの季節がやってきましたね。去年は私はC#とJavaScriptで書きましたが、今年はC#とSilverlightでやります。というわけで、この記事はSilverlight Advent Calendar 2011用のエントリです。前日は@posauneさんのSilverlightのListBoxでつくるいんちきHorizontalTextBlock でした。
今回の記事中のサンプルはSilverlight 4で書いています。が、Silverlight用という体裁を持つためにDebug.WriteLineで書いているというだけで、Silverlightらしさは皆無です!えー。.NET 4でもWindows Phone 7でも関係なく通じる話ですねん。
シリアライザを使う場面
概ね3つではないでしょうか。外部で公開されているデータ(APIをネット経由で叩くとか)をクラスに変換する。これは 自分の管理外→プログラム での片方向です。内部で持っているデータ(クラスのインスタンス)を保存用・復元用に相互変換する。これは プログラム←→自分の管理内 での双方向です。最後に、内部で持っているデータを公開用に変換する。これは プログラム→外部 での片方向。
目的に応じてベストな選択は変わってきます。こっから延々と長ったらしいので、まず先に結論のほうを。
- 外部APIを叩く→XML/XmlSerializer, JSON/DataContractJsonSerializer
- オブジェクトの保存・復元用→DataContractSerializer
- 外部公開→さあ?
外部公開のは、Silverlightの話じゃないので今回はスルーだ!XStreamingElementで組み上げてもいいし、何でもいいよ!WCFのテンプレにでも従えばいいんぢゃないでしょーか。
XmlSerializer
古くからあるので、シリアライザといったらこれ!という印象な方も多いのではないでしょうか。その名の通り、素直にXMLの相互変換をしてくれます。
// こんなクラスがあるとして
// (以降、断り書きなくPersonが出てきたらこいつを使ってると思ってください)
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
// データ準備
var data = new Person { Name = "山本山", Age = 99 };
var serializer = new XmlSerializer(typeof(Person));
using (var ms = new MemoryStream())
{
serializer.Serialize(ms, data); // シリアライズ
// 結果確認出力
var xml = Encoding.UTF8.GetString(ms.ToArray(), 0, (int)ms.Length);
Debug.WriteLine(xml);
ms.Position = 0; // 巻き戻して……
var value = (Person)serializer.Deserialize(ms); // デシリアライズ
Debug.WriteLine(value.Name + ":" + value.Age); // 山本山:99
}
// 出力結果のXML
<?xml version="1.0" encoding="utf-8"?>
<Person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Name>山本山</Name>
<Age>99</Age>
</Person>
素直な使い勝手、素直な出力。いいですね。さて、しかし特に外部APIを叩いて手に入るXMLは名前PascalCaseじゃねーよ、とか属性の場合どうすんだよ、という場合も多いでしょう。細かい制御にはXmlAttributeを使います。
[XmlRoot("people")]
public class People
{
[XmlElement("count")]
public int Count { get; set; }
[XmlArray("persons")]
[XmlArrayItem("person")]
public Person[] Persons { get; set; }
}
[XmlRoot("person")]
public class Person
{
[XmlElement("name")]
public string Name { get; set; }
[XmlAttribute("age")]
public int Age { get; set; }
}
// データ準備
var data = new People
{
Count = 2,
Persons = new[]
{
new Person { Name = "山本山", Age = 99 },
new Person { Name = "トマト", Age = 19 }
}
};
var xml = @"
<people>
<count>2</count>
<persons>
<person age=""14"">
<name>ほむ</name>
</person>
<person age=""999"">
<name>いか</name>
</person>
</persons>
</people>";
var serializer = new XmlSerializer(typeof(People));
// シリアライズ
using (var ms = new MemoryStream())
{
serializer.Serialize(ms, data);
Debug.WriteLine(Encoding.UTF8.GetString(ms.ToArray(), 0, (int)ms.Length));
}
// デシリアライズ
using (var sr = new StringReader(xml))
{
var value = (People)serializer.Deserialize(sr);
foreach (var item in value.Persons)
{
Debug.WriteLine(item.Name + ":" + item.Age);
}
}
// 出力結果のXMLは↑に書いたXMLと同じようなものなので割愛
ちょっと属性制御が面倒ですが、それなりに分かりやすく書けます。他によく使うのは無視して欲しいプロパティを指定するXmlIgnoreかしら。さて、そんな便利なXmlSerializerですが、XML化するクラスに制限があります。有名所ではDictionaryがシリアライズできねえええええ!とか。小細工して回避することは一応可能ですが、そんな無理するぐらいなら使うのやめたほうがいいでしょう、シリアライザは別にXmlSerializerだけじゃないのだから。
というわけで、XmlSerializerの利用シーンのお薦めは、ネットワークから外部APIを叩いて手に入るXMLをクラスにマッピングするところです。柔軟な属性制御により、マッピングできないケースは(多分)ないでしょう。いや、分かりませんが。まあ、ほとんどのケースでは大丈夫でしょう!しかし、LINQ to XMLの登場により、手書きで変換するのも十分お手軽なってしまったので、こうして分かりにくい属性制御するぐらいならXElement使うよ、というケースのほうが多いかもしれません。結局、XML構造をそのまま映すことしかできないので、より細かく変換できたほうが良い場合もずっとあって。
実際、私はもう長いことXmlSerializer使ってない感じ。LINQ to XMLは偉大。
DataContractSerializer
割と新顔ですが、もう十分古株と言ってよいでしょう(どっちだよ)。XmlSerializerと同じくオブジェクトをXMLに変換するのですが、その機能はずっと強力です。Dictionaryだってなんだってシリアライズできますよ、というわけで、現在では.NETの標準シリアライザはこいつです。
// データ準備
var data = new Person { Name = "山本山", Age = 99 };
var serializer = new DataContractSerializer(typeof(Person));
using (var ms = new MemoryStream())
{
serializer.WriteObject(ms, data); // シリアライズ
// 結果確認出力
var xml = Encoding.UTF8.GetString(ms.ToArray(), 0, (int)ms.Length);
Debug.WriteLine(xml);
ms.Position = 0; // 巻き戻して……
var value = (Person)serializer.ReadObject(ms); // デシリアライズ
Debug.WriteLine(value.Name + ":" + value.Age); // 山本山:99
}
<Person xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.datacontract.org/2004/07/SilverlightApplication34"><Age>99</Age><Name>山本山</Name></Person>
とまあ、使い勝手はXmlSerializerと似たようなものです。おお、出力されるXMLは整形されていません。整形して出力したい場合は
// 出力を整形したい場合はXmlWriter/XmlWriterSettingsを挟む
using (var ms = new MemoryStream())
using (var xw = XmlWriter.Create(ms, new XmlWriterSettings { Indent = true }))
{
serializer.WriteObject(xw, data);
xw.Flush();
var xml = Encoding.UTF8.GetString(ms.ToArray(), 0, (int)ms.Length);
Debug.WriteLine(xml);
}
<?xml version="1.0" encoding="utf-8"?>
<Person xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.datacontract.org/2004/07/SilverlightApplication34">
<Age>99</Age>
<Name>山本山</Name>
</Person>
さて、結果をXmlSerializerと見比べてみるとどうでしょう。名前空間が違います。SilverlightApplication34ってありますね。これは、私がこのXMLを出力するのに使ったSilverlightプロジェクトの名前空間です。ワシのConsoleApplicationは221まであるぞ(整理しろ)。さて、ではこのXMLをデシリアライズするのに、別のアプリケーション・別のクラスで使ってみるとどうでしょう?
namespace TestSilverlightApp
{
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
public partial class MainPage : UserControl
{
public MainPage()
{
InitializeComponent();
var xml = @"<?xml version=""1.0"" encoding=""utf-8""?>
<Person xmlns:i=""http://www.w3.org/2001/XMLSchema-instance"" xmlns=""http://schemas.datacontract.org/2004/07/SilverlightApplication34"">
<Age>99</Age>
<Name>山本山</Name>
</Person>";
var serializer = new DataContractSerializer(typeof(Person));
using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(xml)))
{
// System.Runtime.Serialization.SerializationExceptionが起こってデシリアライズできない
// 名前空間 'http://schemas.datacontract.org/2004/07/TestSilverlightApp' の要素 'Person' が必要です。
// 名前が 'Person' で名前空間が 'http://schemas.datacontract.org/2004/07/SilverlightApplication34' の 'Element' が検出されました。
var value = (Person)serializer.ReadObject(ms);
}
}
}
}
デシリアライズ出来ません。対象オブジェクトが名前空間によって厳密に区別されるからです。じゃあどうするのよ!というと、属性で名前空間を空、という指示を与えます。
// DataContract属性をクラスにつけた場合は
// そのクラス内のDataMember属性をつけていないプロパティは無視される
[DataContract(Namespace = "", Name = "person")]
public class Person
{
[DataMember(Name = "name")]
public string Name { get; set; }
[DataMember(Name = "age")]
public int Age { get; set; }
}
// こんなプレーンなXMLも読み込める
var xml = @"
<person>
<age>99</age>
<name>山本山</name>
</person>";
var serializer = new DataContractSerializer(typeof(Person));
using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(xml)))
{
var value = (Person)serializer.ReadObject(ms);
Debug.WriteLine(value.Name + ":" + value.Age);
}
属性面倒くせー、ですけれど、まあしょうがない。そうすれば外部からのXMLも読み込めるし、と思っていた時もありました。以下のようなケースではどうなるでしょうか?Personクラスは↑のものを使うとして。
// こんなさっきと少しだけ違うXMLがあるとして
var xml = @"
<person>
<name>山本山</name>
<age>99</age>
</person>";
var serializer = new DataContractSerializer(typeof(Person));
using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(xml)))
{
var value = (Person)serializer.ReadObject(ms);
Debug.WriteLine(value.Name + ":" + value.Age); // 結果は???
}
これは出力結果は「山本山:0」になります。Ageが0、つまり復元されませんでした。なぜかというと、XMLを見てください。nameが先で、ageが、後。DataContractSerializerは規程された順序に強く従います。DataMember属性のOrderプロパティで順序を与えるか、与えない場合はアルファベット順(つまりAgeが先でNameが後)となります。この辺はデータ メンバーの順序に書かれています。
と、いうような事情から、DataContractSerializerを外部XMLからの受け取りに使うのはお薦めしません。XmlSerializerなら順序無視なので大丈夫です。いや、普通は順序が変わったりなどしないだろう!と思わなくもなくもないけれど、意外とデタラメなのじゃないか、基本的にはお外からのデータが何もかも信用できるわけなどないのだ、とうがってしまい(TwitterのAPIとか胡散臭さいのを日常的に触っていると!)、厳しいかなって、思ってしまうのです。
しかし、オブジェクトの保存・復元用にはDataContractSerializerは無類の強さを発揮します。例えば設定用のクラスを丸ごとシリアライズ・デシリアライズとかね。iniにして、じゃなくてフツーはXMLにすると思いますが、それです、それ。Dictionaryだってシリアライズできるし、引数なしコントラクタがないクラスだってシリアライズできちゃうんですよ?
// とある引数なしコンストラクタがないクラス
[DataContract]
public class ToaruClass
{
[DataMember]
public string Name { get; set; }
public ToaruClass(string name)
{
Name = name;
}
}
var toaru = new ToaruClass("たこやき");
var serializer = new DataContractSerializer(typeof(ToaruClass));
using (var ms = new MemoryStream())
{
serializer.WriteObject(ms, toaru); // シリアライズできるし
ms.Position = 0;
var value = (ToaruClass)serializer.ReadObject(ms); // デシリアライズできる
Debug.WriteLine(value.Name); // たこやき
}
ただし、対象クラスにDataContract属性をつけてあげる必要はあります。つけてないとシリアライズもデシリアライズもできません。
ちなみに何でコンストラクタがないのにインスタンス化出来るんだよ!というと、System.Runtime.Serialization.FormatterServices.GetUninitializedObjectを使ってインスタンス化しているからです(Silverlightの場合はアクセス不可能)。こいつはコンストラクタをスルーしてオブジェクトを生成する反則スレスレな存在です、というか反則です。チートであるがゆえに、対象クラスにはDataContract属性をつける必要があります。コンストラクタ無視してもいいよ、ということを保証してあげないとおっかない、というわけです。(GetUninitializedObjectメソッド自体は別に属性は不要で何でもインスタンス化できます、typeof(void)ですらインスタンス化できます、無茶苦茶である)
なお、このGetUninitializedObjectが使われるのはDataContract属性がついているクラスのみです。DataContract属性がついていなければ、普通のコンストラクタが呼ばれるし、逆にDataContract属性がついていると、例え引数をうけないコンストラクタがあったとしても、GetUninitializedObject経由となりコンストラクタは無視されます。DataContract属性を付ける時はコンストラクタ内でシリアライズで復元できない副作用のある処理をすべきではない。ということに注意してください。
また、.NET 4版ではprivateプロパティの値も復元できるのですが、Silverlightの場合は無理のようです。ということでフル.NETなら不変オブジェクトでもサクサク大勝利、と思ってたのですが、Silverlightでの不変オブジェクトのシリアライズ・デシリアライズは不可能のようです。保存したいなら、保存専用の代理のオブジェクトを立ててやるしかない感じでしょうかね。
そんなわけで微妙な点も若干残りはしますが、オブジェクトを保存するのにはDataContractSerializerがお薦めです。
DataContractとSerializable
シリアライズ可能なクラス、の意味でDataContract属性をつけているわけですが、じゃあSerializable属性は?というと、えーと、SerializableはSilverlightでは入っていなかったりするとおり、過去の遺物ですね。なかったということで気にしないようにしましょう。
DataContractJsonSerializer
今時の言語はJSONが簡単に扱えなきゃダメです。XMLだけ扱えればいい、なんて時代は過ぎ去りました。しかしC#は悲しいことに標準では……。いや、いや、SilverlightにはSystem.Jsonがありますね。しかし.NET 4にはありません(.NET 4.5とWinRTには入ります)。いや、しかし.NET 4にはDynamicJsonがあります(それ出していいならJSON.NETがあるよ、で終わりなんですけどね)。が、Windows Phone 7には何もありません。ああ……。
とはいえ、シリアライザならば用意されています。DataContractJsonSerializerです。
// データ準備
var data = new Person { Name = "山本山", Age = 99 };
var serializer = new DataContractJsonSerializer(typeof(Person));
using (var ms = new MemoryStream())
{
serializer.WriteObject(ms, data); // シリアライズ
// 結果確認出力
var xml = Encoding.UTF8.GetString(ms.ToArray(), 0, (int)ms.Length);
Debug.WriteLine(xml); // {"Age":99,"Name":"山本山"}
ms.Position = 0; // 巻き戻して……
var value = (Person)serializer.ReadObject(ms); // デシリアライズ
Debug.WriteLine(value.Name + ":" + value.Age); // 山本山:99
}
使い勝手はDataContractSerializerと完全に一緒です。ただし、違う点が幾つか。名前空間が(そもそもJSONで表現不可能なので)なくなったのと、順序も関係なく復元可能です。
var json1 = @"{""Name"":""山本山"",""Age"":99}";
var json2 = @"{""Age"":99,""Name"":""山本山""}";
var serializer = new DataContractJsonSerializer(typeof(Person));
using (var ms1 = new MemoryStream(Encoding.UTF8.GetBytes(json1)))
using (var ms2 = new MemoryStream(Encoding.UTF8.GetBytes(json2)))
{
var value1 = (Person)serializer.ReadObject(ms1);
var value2 = (Person)serializer.ReadObject(ms2);
Debug.WriteLine(value1.Name + ":" + value2.Age);
Debug.WriteLine(value2.Name + ":" + value2.Age);
}
というわけで、随分とDataContractSerializerよりも使い勝手が良い模様。いい話だなー。さて、難点は出力されるJSONの整形が不可能です。DataContractSerializerではXmlWriterSettingsで行えましたが、DataContractJsonSerializerではそれに相当するものがありません。というわけでヒューマンリーダブルな形で出力、とはならず、一行にドバーっとまとめて吐かれるのでかなり苦しい。
もう一つ、これは本当に大したことない差なのでどうでもいいのですが、DataContractSerializerのほうが速いです。理由は単純でDataContractSerializerに一枚被せる形でDataContractJsonSerializerが実装されているから。その辺の絡みで.NET 4にはJsonReaderWriterFactoryなどがあって、これを直に触ってJSON→XML変換をするとLINQ to XMLを通したJSONの直接操作が標準ライブラリのみで可能なのですが、Silverlight/Windows Phone 7では残念なことに触ることができません。
外部APIを叩いて変換する際に、シリアライズはお手軽で便利であると同時に、完全に同一の形のオブジェクトを用意しなければならなくて、かったるい側面もあります。LINQ to XML慣れしていると特に。そういった形でJSONを扱いたい場合、WP7ではJson.NETを使う、しかありません。使えばいいんぢゃないかな、どうせNuGetでサクッと入れられるのだし。
とはいえまあ、そう言うほど使いづらいわけでもないので、標準のみでJSONを扱いたいという場合は、DataContractJsonSerializerが第一にして唯一の選択肢になります。
JavaScriptSerializer
.NET Framework 4.0 Client Profileでは使えないのですが、FullならばSystem.Web.Extensionを参照することでJavaScriptSerializerが使えます。もはや完全にSilverlightと関係ないのでアレですが、少し見てみましょう。
var serializer = new JavaScriptSerializer();
var target = new { Name = "ほむほむ", Age = 14 };
var json = serializer.Serialize(target); // stringを返す
Serializeで文字列としてのJSONを返す、というのがポイントです。それと、シリアライザ作成時にtypeを指定しません。また、匿名型もJSON化することが可能です(これはDataContractSerializerでは絶対無理)。ただし、コンストラクタのないクラスのデシリアライズは不可能です。
中々使い勝手がいいですね!で、これは、リフレクションベースの非常に素朴な実装です。だから匿名型でもOKなんですねー。ちょっとした用途には非常に楽なのですが、Client Profileでは使えないこともありますし(ASP.NETで使うために用意されてる)、あまり積極的に使うべきものではないと思います。ちなみに、一時期ではObsoleteになっていてDataContractJsonSerializer使え、と出ていたのですが、またObsoleteが外され普通に使えるようになりました。やはり標準シリアライザとしてはDataContractJsonSerializerだけだと重すぎる、ということでしょうか。
バイナリとか
別にシリアライズってXMLやJSONだけじゃあないのですね。サードパーティ製に目を向ければ、色々なものがあります。特に私がお薦めなのはprotobuf-net。これはGoogleが公開しているProtocol Buffersという仕様を.NETで実装したものなのですが、とにかく速い。めちゃくちゃ速い。稀代のILマスターが書いているだけある恐ろしい出来栄えです。SilverlightやWP7版もあるので、Protocol Buffersの本来の用途というだけなく、幅広く使えるのではかとも思います。
もう一つは国内だと最近目にすることの多いMessagePack。以前に.NET(C#)におけるシリアライザのパフォーマンス比較を書いたときは振るわないスコアでしたが、最近別のC#実装が公開されまして、それは作者によるベンチMessagePack for .NET (C#) を書いたによると、protobuf-netよりも速いそうです。
Next
というわけでSilverlight枠でいいのか怪しかったですが、シリアライザの話でした。次は@ugaya40さんのWeakEventの話です。引き続きチェックを。あ、あと、Silverlight Advent Calendarはまだ埋まってない(!)ので、是非是非参加して、埋めてやってください。申し込みはSilverlight Advent Calendar 2011から。皆さんのエントリ、待ってます。どうやらちょうど今日Silverlight 5がリリースされたようなので、SL5の新機能ネタとかいいんじゃないでしょうか。
自家製拡張メソッド制作のすすめ だいx回 BufferWithPadding
- 2011-12-09
Ix(Interactive Extensions)は使っていますか?Rxから逆移植されてきている(IxのNuGet上のアイコンはRxのアイコンの逆向きなのですね)、LINQ to Objectsを更に拡張するメソッド群です。みんな大好きForEachなど、色々入っています。その中でも、私はBufferというものをよく使っています。Ixが参照できない場合は何度も何度も自作するぐらいに使いどころいっぱいあって、便利です。こんなの。
// 指定個数分をまとめたIList<T>を返します
// 第二引数を使うとずらす個数を指定することもできます
// これの結果は
// 0123
// 4567
// 89
foreach (var xs in Enumerable.Range(0, 10).Buffer(4))
{
xs.ForEach(Console.Write);
Console.WriteLine();
}
標準でこういうのできないのー?というと、できないんですよねえ、残念なことに。
さて、ところで、この場合、指定個数に足りなかった場合はその分縮められたものが帰ってきます。上の例だと返ってくるListの長さは4, 4, 2でした。でも、埋めて欲しい場合ってあります。足りない分は0で埋めて長さは4, 4, 4であって欲しい、と。そこはLINQなので、創意工夫で頑張りましょう。例えば
// EnumerableEx.Repeatは指定の値の無限リピート
// それと結合して、Takeで詰めることで足りない場合だけ右を埋めることが出来る
// 0123
// 4567
// 8900
foreach (var xs in Enumerable.Range(0, 10).Buffer(4))
{
xs.Concat(EnumerableEx.Repeat(0)).Take(4).ForEach(Console.Write);
Console.WriteLine();
}
EnumerableEx.RepeatはIxにある無限リピート。Ixを参照しない場合は Enumerable.Repeat(value, int.MaxValue) で代用することも一応可能です。
さて、しかしこれも面倒なので、自家製拡張メソッドを作りましょう。拡張メソッドはばんばん作るべきなのです。
// 指定した値で埋めるように。これの結果は
// 0123
// 4567
// 89-1-1
foreach (var xs in Enumerable.Range(0, 10).BufferWithPadding(4, -1))
{
xs.ForEach(Console.Write);
Console.WriteLine();
}
public static class EnumerableExtensions
{
public static IEnumerable<T[]> BufferWithPadding<T>(this IEnumerable<T> source, int count, T paddingValue = default(T))
{
if (source == null) throw new ArgumentNullException("source");
if (count <= 0) throw new ArgumentOutOfRangeException("count");
return BufferWithPaddingCore(source, count, paddingValue);
}
static IEnumerable<T[]> BufferWithPaddingCore<T>(this IEnumerable<T> source, int count, T paddingValue)
{
var buffer = new T[count];
var index = 0;
foreach (var item in source)
{
buffer[index++] = item;
if (index == count)
{
yield return buffer;
index = 0;
buffer = new T[count];
}
}
if (index != 0)
{
for (; index < count; index++)
{
buffer[index] = paddingValue;
}
yield return buffer;
}
}
}
すっきりしますね!Emptyの時は何も列挙しないようにしていますが、Emptyの時は埋めたのを一つ欲しい、と思う場合は最後のifの囲みを外せばOK。あと、最後のif...for...yieldの部分を var dest = new T[index]; Array.Copy(buffer, dest, index); yield return dest; に変えればパディングしないBufferになります。Ix参照したくないけどBuffer欲しいなあ、と思ったときにコピペってどうぞ。
本体のコードと引数チェックを分けているのは、yield returnは本体が丸ごと遅延評価されるため、引数チェックのタイミング的によろしくないからです。少し面倒ですが、分割するのが良い書き方。詳しくはneue cc - 詳説Ix Share/Memoize/Publish編(もしくはyield returnの注意点)で書いていますので見てください。