linq.js ver.2.2.0.0 - 配列最適化, QUnitテスト, RxJSバインディング
- 2010-06-29
CodePlex - linq.js - LINQ for JavaScript
linq.jsをver 2.2に更新しました。変更事項は、メソッドの追加、配列ラッピング時の動作最適化、ユニットテストのQUnitへの移行、RxJSバインディング追加の4つです(あと、若干のバグフィックスと、RxJS用vsdoc生成プログラムの同梱)。まずは、追加した二つのメソッドについて。
var seq = Enumerable.From([1, 5, 10, 4, 3, 2, 99]);
// TakeFromLastは末尾からn個の値を取得する
var r1 = seq.TakeFromLast(3).ToArray(); // [3, 2, 99]
// 2.0から追加されているTakeExceptLast(末尾からn個を除く)と対になっています
var r2 = seq.TakeExceptLast(3).ToArray(); // [1, 5, 10, 4]
// ToJSONはjson文字列化します(列挙をJSON化なので必ず配列の形になります)
// JSON.stringifyによるJSON化のため、
// ネイティブJSON対応ブラウザ(IE8以降, Firefox, Chrome, Opera...)
// もしくはjson2.jsをインポートしていないと動作しません
var objs = [{ hoge: "huga" }, { tako: 3}];
var json = Enumerable.From(objs).ToJSON(); // [{"hoge":"huga"},{"tako":3}]
TakeFromLast/TakeExceptLastはRxからの移植です(Rxについては後でまた少し書きます)。RxではTakeLast, SkipLastという名前ですが、諸般の都合により名前は異なります。より説明的なので悪くはないかな、と。
もう一つはToJSONの復活。ver 1.xにはあったのですが、2.xでばっさり削ってたました。復活といっても、実装は大きく違います。1.xでは自前でシリアライズしていたのですが、今回はJSON.stringifyに丸投げしています。と、いうのも、IE8やそれ以外のブラウザはJSONのネイティブ実装があるので、それに投げた方が速いし安全。ネイティブ実装はjson2.jsと互換性があるので、IE6とかネイティブ実装に対応していないブラウザに対しては、json2.jsを読み込んでおくことでToJSONは動作します。
json2.jsはネイティブ実装がある場合は上書きせずネイティブ実装を優先するようになっているので、JSON使う場合は何も考えずとりあえず読み込んでおくといいですね。
配列ラップ時の最適化
Any, Count, ElementAt, ElementAtOrDefault, First, FirstOrDefault, Last, LastOrDefault, Skip, SequenceEqual, TakeExceptLast, TakeFromLast, Reverse, ToString。
Enumerable.From(array)の直後に、以上のメソッドを呼んだ際は最適化された挙動を取るように変更しました。各メソッドに共通するのは、lengthが使えるメソッドということです。Linqは基本的に長さの情報を持っていない(無限リストとか扱えるから)ため、例えばCountだったら最後まで列挙して長さを取っていました。しかし、lengthが分かっているのならば、Countはlengthに置き換えられるし、Reverseは[length - 1]から逆順に列挙すればいい。ElementAt(n)はまんま[n]だしLastは[length - 1]だし、などなど、lengthを使うことで計算量が大幅に低減されます。
C#でも同様のことをやっている(ということは以前にLinqとCountの効率という記事で書いてあったりはする)のですが、今になってようやく再現。先の記事にあるように、C#では中でisやasを使ってIEnumerableの型を調べて分岐させてますが、linq.jsでは Enumerable.FromでEnumerableを生成する際に、今まではEnumerableを返していたところを、ArrayEnumerable(継承して配列用にメソッドをオーバーライドしたもの)を返す、という形を取っています。
これが嬉しいかどうかというと、そこまで気にするほどではありません。C#では array.Last() のように使えますが、linq.jsではわざわざ Enumerable.From(array).Last() と、ラップしなきゃいけませんから、それならarray[array.length - 1]でいいよ、という。ちなみに当然ですがFrom(array).Where().Count()とか、他のLinqメソッドを挟むと、ArrayEnumerableじゃなくEnumerableになるため最適化的なものは消滅します。
でもまあ、意味はあるといえばあります。配列を包んだだけのEnumerableは割と色々なところで出てきます。例えばGroupJoin。これのresultSelectorの引数のEnumerableは、配列をラップしただけです。又は、ToLookup。Lookupを生成後、Getで取得した際の戻り値のEnumerableは配列を包んだだけです。GroupByの列挙(Grouping)もそう。特にGroupingで、グループの個数を使うってシーンは多いように思います。そこで今まではCount()で全件列挙が廻っていたのが、一度も列挙せずに値が取れるというのは精神衛生上喜ばしい。
パフォーマンス?
このArrayへの最適化は勿論パフォーマンスのためなのですが、じゃあ全体的にlinq.jsのパフォーマンスはどうなの?というと、遅いよ!少し列挙するだけで山のように関数呼び出しが間に入りますから、速そうな要素が一つもない。ただ、遅さがクリティカルに影響するほどのものかは、場合によりけりなので分かりません。遅い遅いと言っても、jQueryでセレクタ使って抽出してDOM弄りするのとどちらが重いかといったら、(データ量にもよりますが)圧倒的にDOM弄りですよね?的な。
JavaScriptは、どうでもいいようなレベルの高速化記事がはてブなんかにも良く上がってくるんですが、つまらない目先に囚われず、全体を見てボトルネックをしっかり掴んでそこを直すべきだと思うんですよね。「1万回の要素追加で9msの高速化」とか、意味無いだろそれ絶対と思うのですが……。
ただ、アプリケーションとライブラリだと話は別で、ライブラリならば1msでも速いにこしたことはないのは事実です。linq.jsは仕組み的には遅いの確定なのはしょうがないとしても、もう少しぐらいは、速度に気を使って努力すべきな気はとてもします。今後の課題。
コードスニペット
無名関数書くのに、毎回function(x) { return って書くの、面倒くさいですよね。ということで、Visual Studio用のコードスニペットを同梱しました。func1->Tab->Tabで、linq.jsで頻繁に使う一行の無名関数 function(x){ return /* キャレットここ */ } を生成してくれます。これは激しく便利で、C#の快適さの3割ぐらいを占めていると言っても過言ではないぐらいに便利なのですが、動画じゃないと伝わらないー、けれど動画撮ってる体力的余裕がないので省略。
func0, func1, func2, action0, action1, action2を定義しています。0だの1だのは引数の数。funcはreturn付き、actionはreturn無しのスニペットです。また、Enumerable.RangeとEnumerable.Fromにもスニペットを用意しました。erange, efromで展開されます。jQueryプラグイン版の場合はjqrange, jqfromになります。
インストールは、Visual Studio 2010でツール→コードスニペットマネージャーを開いてインポートでsnipetts/.snippetを全部インポート。
binding for RxJS
RxJS -Reactive Extensions for JavaScriptと接続出来るようになりました。ToObservableとToEnumerableです(jQuery版のTojQueryとtoEnumerableと同じ感覚)。
// enumerable sequence to observable
var source = Enumerable.Range(1, 10)
.Shuffle()
.ToObservable()
.Publish();
source.Where(function (x) { return x % 2 == 0 })
.Subscribe(function (x) { document.writeln("Even:" + x + "<br>") });
source.Where(function (x) { return x % 2 != 0 })
.Subscribe(function (x) { document.writeln("Odd:" + x + "<br>") });
source.Connect();
// observable to enumerable
var subject = new Rx.ReplaySubject();
subject.OnNext("I");
subject.OnNext(4);
subject.OnNext("B");
subject.OnNext(2);
subject.OnNext("M");
var result = subject.ToEnumerable()
.OfType(String)
.Select(function (x) { return x.charCodeAt() - 1 })
.Select(function (x) { return String.fromCharCode(x) })
.ToString("-");
alert(result); // H-A-L
ToObservableでは、こないだ例に出したPublishによる分配を。ToEnumerableは、例が全然浮かばなかったので適当にOnNextを発火させた奴をEnumerable化出来ますねー、と。なお、cold限定です。hotに対して適用すると空シーケンスが返ってくるだけです(ちなみにC#版のRxでhotに対してToEnumerableするとスレッドをロックして無限待機になる)
それと、RxVSDocGeneratorの最新版を同梱してあります。以前に公開していたのは、RxJSのバージョンアップと同時に動かなくなっちゃってたのよね。というわけで、修正したうえで同梱商法してみました。
プレースホルダの拡張
無名関数のプレースホルダが少し拡張されました。今までは引数が一つの時のみ$が使えたのですが、今回から二引数目は$$、三引数目は$$$、四引数目は$$$$が使えるようになりました。
// 連続した重複がある場合最初の値だけを取る
// (RxのDistinctUntilChangedをlinq.jsでやる場合)
// 1, 5, 4, 3, 4
Enumerable.From([1, 1, 5, 4, 4, 3, 4, 4])
.PartitionBy("", "", "key,group=>group.First()")
// $$でニ引数目も指定出来るようになった
Enumerable.From([1, 1, 5, 4, 4, 3, 4, 4])
.PartitionBy("", "", "$$.First()")
便利といえば便利ですが、あまりやりすぎると見た目がヤバくなるので適度に抑えながらでどうぞ。なお、以前からある機能ですが""は"x=>x"の省略形です。PartitionByでは、それぞれkeySelectorとelementSelector。
入門QUnit
今までlinq.jsのユニットテストはJSUnitを使用していたんですが、相当使いにくくてやってられなかったため、QUnitに移しました。QUnitはjQueryの作者、John Resigの作成したテストフレームワークで、流石としか言いようがない出来です。物凄く書きやすい。JSUnitだとテストが書きづらくて、だから苦痛でしかなかった。テストドリブンとか言うなら、まずはテストが書きやすい環境じゃないとダメだ。
JSUnitのダメな点―― 導入が非常に面倒。大量のファイルを抱えたテスト実行環境が必要だし、クエリストリングでファイル名を渡さなければならなかったり、しかも素ではFirefox3で動かなかったりと(Firefox側のオプションを調整)下準備が大変。面倒くささには面倒くささなりのメリット(Java系の開発環境との連携とかあるらしいけど知らない)があるようですが、俺はただテスト書いて実行したいだけなんだよ!というには些か重たすぎる。一方、QUnitはCSSとJSとHTMLだけで済む。
また、JSUnitはアサーションのメソッドが微妙。大量にあるんだけど、逆に何が何だか分からない。assertObjectEqualsとかassertArrayEqualsとか。ArrayEqualsはオブジェクトの配列を値比較してくれない上に、それならせめて失敗してくれればいいものの成功として出されるから役に立たなかったり、ね……。QUnitは基本、equal(参照比較)とdeepEqual(値比較)だけという分かりやすさ。deepEqualはしっかりオブジェクト/配列をバラして再帰的に比較してくれるという信頼感があります。
テスト結果画面の分かりやすさもQUnitに軍配が上がる。というかJSUnitは致命的に分かりづらい。一つのテスト関数の中に複数のアサートを入れると、どれが失敗したか分からないという有様。なのでJSUnitではtestHoge1, testHoge2といった形にせざるを得ないのだけど、大変面倒。更に、JSUnitのテスト実行は遅くて数百件あるとイライラする。
そもそもJSUnitはコードベースが古いし最近更新されてるかも微妙(GitHubに移って開発は進んでるようですが)。というわけで今からJavaScriptでユニットテストやるならQUnitがいいよ!残念ながらか、ネットを見ると古い紹介記事ばかりが見当たるので、ていうかオフィシャルのドキュメントまで古かったりしてアレゲなので、簡単に解説します。と、思ってたのですが、一月程前に素晴らしいQUnitの記事が出ていました。なので基本無用なのですが、文章を書いてしまってあったので(これ書いてたのは4月頃なのです)出します、とほほ。
まず、QUnit - jQuery JavaScript LibraryのUsing QUnitのところにあるqunit.jsとqunit.cssを落とし、下記のテンプレHTMLは自前で作る。ファイル名はなんでもいいんですが、私はtestrunner.htmとでもしておきました。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>linq.js test</title>
<link href="qunit.css" rel="stylesheet" type="text/css" />
<script src="qunit.js" type="text/javascript"></script>
<!-- テストに必要な外部ライブラリは好きに読み込む -->
<script src="linq.js" type="text/javascript"></script>
<!-- ここにテスト直書きもアリだし -->
<script type="text/javascript">
test("Range", function()
{
deepEqual(Enumerable.Range(1, 3).ToArray(), [1, 2, 3]);
});
// 自動的にロード後に実行されるので、これも問題なく動く
test("hoge", function ()
{
var h2 = document.getElementsByTagName("h2");
equal(h2.length, 2);
});
</script>
<!-- 外部jsファイルにして読み込むのもアリ -->
<script src="testEnumerable.js" type="text/javascript"></script>
<script src="testProjection.js" type="text/javascript"></script>
</head>
<body>
<h1 id="qunit-header">linq.js test</h1>
<h2 id="qunit-banner"></h2>
<h2 id="qunit-userAgent"></h2>
<ol id="qunit-tests"></ol>
</body>
</html>
実行用のHTMLにqunit.jsとqunit.cssを読み込み、body以下の4行を記述すれば準備は完了(bodyの4行はid決め打ちで面倒だし、どうせ空なので、qunit.js側で動的に生成してくれてもいいような気がする、というか昔はそうだった気がするけどjQuery依存をなくした際になくしたのかしらん)。
あとは、test("テスト名", 実行される関数) を書いていけばいいだけ。そうそう、test関数はHTMLが全てロードされてから実行が始まるので、jQuery読み込んでjQuery.readyで囲む必要とかは特にありません。testProjection.jsは大体↓のような感じ。
/// <reference path="testrunner.htm"/>
module("Projection");
test("Select", function ()
{
actual = Enumerable.Range(1, 10).Select("i=>i*10").ToArray();
deepEqual(actual, [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]);
actual = Enumerable.Range(1, 10).Select("i,index=>i*10+index").ToArray();
deepEqual(actual,[10, 21, 32, 43, 54, 65, 76, 87, 98, 109]);
});
reference pathはVisualStudio用のパスなのであんま気にせずにー。詳細はJavaScriptエディタとしてのVisual Studioの使い方入門のほうで。読み込み元のHTMLを指定しておくとIntelliSenseが効いて、書くのが楽になります。
actual(実行結果)は私は別変数で受けてますが、当然、直書きでも構いません。アサーション関数は、基本は(actual, expected(期待する結果), message(省略可能)) の順番になっています。
equal(1, "1"); // okay - 参照比較(==)
notEqual
strictEqual(1, "1"); // failed - 厳密な比較(===)
notStrictEqual
deepEqual([1], [1]); // okay - 値比較
notDeepEqual
ok(1 == "1"); // okay - boolean
ok(1 !== "1"); // okay - notの場合は!で
基本的に使う関数はこれらだけです。ドキュメントへの記載はないのですが、以前にあったequalsとsameはequalとdeepEqualに置き換わっています。後方互換性のためにequals/sameは残っていますが、notと対称が取れるという点で、equal/deepEqualを使ったほうが良いんじゃないかと思います。
非同期テストとかは、またそのうちに。
まとめ
linq.js ver.2出したときには、もう当分更新することなんてないよなあ、なんて思っていたのですが、普通にポコポコと見つかったり。でもさすがに、もうないと思いたい。C#との挙動互換性も、私の知る限りでは今回の配列最適化が最後で、やり残しはない。そして今回がラストだー、とばかりに思いつく要素を全部突っ込んでやりました。
そんなわけなので、使ってやってください。私がVisualStudio使いなのでVS関連の補助が多めですが、別にVS必須というわけじゃなくプラスアルファ的なもの(入力補完ドキュメントだのコードスニペットだの)でしかないので、エディタ書きでも何ら問題なく使える、かな、きっと。
Reactive Extensions for .NET (Rx) メソッド探訪第7回:IEnumerable vs IObservable
- 2010-06-24
物凄く期間を開けてしまいましたが、Reactive Extensions for .NET (Rx)紹介を再開していきます。もはやRxってなんだっけ?という感じなので、今回は最も基本である、IObservableについて扱います。ボケーッとしている間にIQbservable(IQueryableのデュアル)とか出てきてて置いてかれちゃってるし。
そんなこんなで、IObservableはIEnumerableのデュアルなんだよ、とか言われてもぶっちゃけさっぱり分かりません。なので、その辺のことはスルーして普通にコードで対比させながら見ていくことにします。
// IEnumerable (RunはForEachです、ようするに)
Enumerable.Range(1, 10)
.Where(i => i % 2 == 0)
.Select(i => i * 2)
.Run(Console.WriteLine, () => Console.WriteLine("completed!"));
// IObservable
Observable.Range(1, 10)
.Where(i => i % 2 == 0)
.Select(i => i * 2)
.Subscribe(Console.WriteLine, () => Console.WriteLine("completed!"));
ボタンを押して確認する、までもなく同じ結果です。1から10までを偶数だけ通して二倍して出力。見た目は同じですが、中身は丸っきり違います。見た目が一緒すぎて言葉で表現出来ないので図に表してみました。
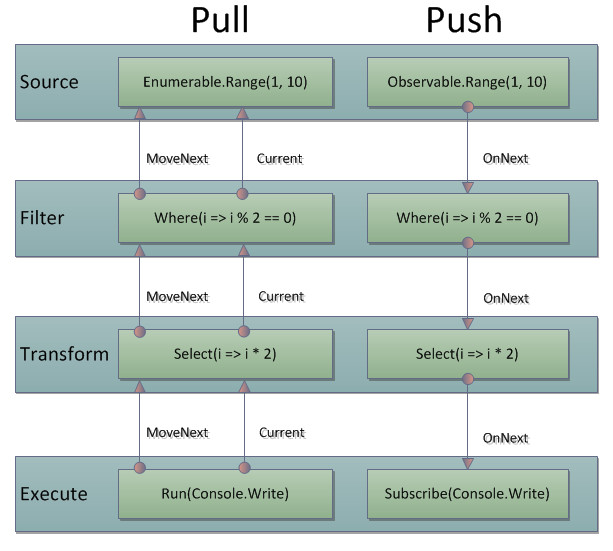
何という下手っぴな図、さっぱり伝わらん。……。というのはおいておいて、矢印の向きに注目。IEnumerableの連鎖は、列挙を消費する時にIEnumeratorの伝搬に変わります。Run->Select->Where->RangeとMoveNextが駆け上がったら、今度はRange->Where->Select->RunとCurrentが降りていきます。末尾(Run)が値を要求(MoveNext)して値(Current)を取り出すという連鎖。末端から根元の値を引っ張ってくる(Pull)ようなイメージ。
IObservableは、根元自体が値を押し出していく(Push)ようなイメージ。こちらはIObserverの連鎖になっていて、根元からOnNextで値を伝えていきます。
Pushのメリット
Observable.Rangeのような、もしくはEunmerableに対してToObservableした時のような、普通のPull型シーケンスをPush型に変換することのメリットは?イベントや非同期など、他の形式から生成されたIObservableと連携出来る、というのは当然一番の話ですが、もう一つ、要素を分配出来るようになります。
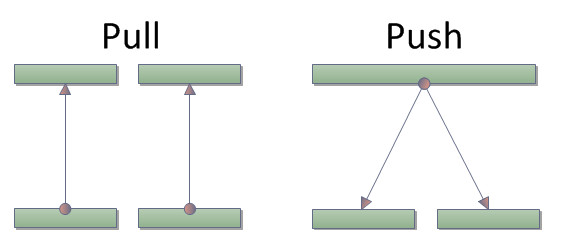
このイミフな図の言わんとしていることが伝わる、わけはないので説明。Pull型はソースと1対1の関係である必要があるため、複数の列挙の消費者(RunだったりCountだったりSumだったりLastだったり)がいる場合、接続した回数だけ列挙が最初から回ることになります。かたやPush型は、1対多の関係を持つことが出来るため、一度の列挙で全ての消費者に値を配分することが可能です。
Hot vs Cold
同じように見えるIObservableにも、HotとColdという性質があります。それはyield returnで作る遅延評価のIEnumerableと、配列のように既に値が生成済みのIEnumerableとの違い、のようなものかもしれません。
var seq = Observable.Range(1, 5)
.Do(i => Console.WriteLine("source -> " + i));
button1.Click += (sender, e) =>
seq.Subscribe(i => Console.WriteLine("button1 -> " + i));
button2.Click += (sender, e) =>
seq.Subscribe(i => Console.WriteLine("button2 -> " + i));
Doは、列挙に通ったものを取り出しつつも素通しします。つまり、 Select(i => { action(i); return i; }) です。今回は列挙がその箇所を通ったかどうかを書き出しています。余談ですが、IEnumerableならNyaRuRuさんの作成されたAchiralにはHookというメソッドがあって、細かい列挙中のモニタリングが出来るようになっています。
実行結果を見てみると、ボタンを押す=Subsribeを繋げると、即座に列挙が開始されていて、これだとIEnumerableのforeachと何も変わません。よって、このIObservableはColdです。もう値は生成され終わっているので。Subscribeの度に即座に全ての値をPushします。
ではHotは?
// FromEvent(canvas,"MouseMove")は手軽ですが、丁寧にこう書くほうが理想的かしら
Func<IObservable<Point>> GetMouseMovePosition = () =>
Observable.FromEvent<MouseEventHandler, MouseEventArgs>(
h => (sender, e) => h(sender, e),
h => canvas.MouseMove += h,
h => canvas.MouseMove -= h)
.Select(e => e.EventArgs.GetPosition(canvas));
// ICollection<IDisposable>です。
var disposables = new CompositeDisposable();
evenButton.Click += (sender, e) =>
{
disposables.Add(
GetMouseMovePosition()
.Where(p => p.X % 2 == 0 && p.Y % 2 == 0)
.Subscribe(p => Console.WriteLine("Even -> " + p.X + ":" + p.Y)));
};
oddButton.Click += (sender, e) =>
{
disposables.Add(
GetMouseMovePosition()
.Where(p => p.X % 2 != 0 && p.Y % 2 != 0)
.Subscribe(p => Console.WriteLine("Odd -> " + p.X + ":" + p.Y)));
};
disposeButton.Click += (sender, e) =>
{
// Disposeでイベントのデタッチ + 再登録不可
// Clearでイベントのデタッチ + 再登録可
disposables.Clear();
};
例えばマウスイベント。クリックの度にOnNextに値を送る、ムーブの度に値を送るといったイベントをIObservable化するFromEventはHot。無限リスト状態になっているものは、接続しただけでは値が送られてこないとも言えるので、幾つでもSubscribeすることが出来ます。サンプルでは、ボタンをクリックすればしただけ、右側のログ表示に同内容のものが連続して表示されるのが確認出来ます。
両者が混ざったような挙動をするIObservableもあります(例えばReplaySubject)ので、HotなのかColdなのか両方なのか。というのを意識してみると理解が深まるかもしれません。また、メソッドの動作確認などの際にHotとColdを区別せずにいると、思わぬ挙動で混乱するかもしれないので注意。というか、私はよくやります……。Observable.Rangeばかりで確認していてイミフ!と思ったら、FromEventでチェックしたら何て分かりやすいこと!というのが何度も。
CompositeDisposable
本題と離れますがTips。イベントのデタッチが簡単なのもRxのメリットの一つです。さて、複数イベントをデタッチする場合はどうしましょうか?List<IDisposable>に格納してforeachで列挙してDispose、というのも悪くないですが、そういう用途で使うためのCompositeDisposableというICollection<IDisposable>なクラスが用意されているので、そちらを使ったほうがよりスマートに書けます。
上のSilverlightのHotのサンプルコードでは、ボタンを押す(=Subscribeする=イベントを登録する)度にCompositeDisposableにAdd。そしてDisposeAllボタンでまとめてデタッチしています。
var subject = new Subject<int>();
var d1 = subject.Subscribe(i => Console.WriteLine(i));
var d2 = subject.Subscribe(i => Console.WriteLine(i * i));
using (new CompositeDisposable(d1, d2))
{
subject.OnNext(2); // 2, 4
subject.OnNext(3); // 3, 9
}
subject.OnNext(2); // usingを抜けデタッチ済みなので何も起こらない
List<IDisposable>に対するCompositeDisposableのメリットは、Disposeで解除出来るということ。つまり、using構文に放りこむことが可能です。多段Usingよりも綺麗に見えるのでお薦め。
上の例にコソッと出したSubjectクラスはPush型シーケンスの大本で、OnNextやOnCompletedを後続に送ることが出来ます。イベントのラップじゃなく、Rxネイティブなクラスを作る場合に使います。Subjectはちゃんと詳しく書かなきゃいけない大事なクラスの一つなので、また次にでもきっちり紹介する予定は未定。
列挙の分配
Pushのメリットとして分配可能なことを挙げたのに、Coldなので分配出来ません。以上終了。で終わるわけは当然ないわけで、Cold to Hot変換メソッドが使えます。Publishです。Publishの戻り値はIConnectableObservable。
public interface IConnectableObservable<out T> : IObservable<T>
{
IDisposable Connect();
}
IObservableなのでメソッドチェインを繋げることが出来ます。そして、Subscribeしても列挙は始まりません。Connectを呼んだ時に、一度だけ列挙することが出来ます(二度以降Connectを呼んでも何もしない)
私はダムの堰止をイメージしています。何もしないとドバドバと水が流れてしまうのでPublishで一時的に止めて、Connectで放水。放水後は空っぽ。みたいな。
Max/Sumなど集計系
インターフェイスを挙げただけじゃよく分からないので実例を。SumやMaxといった集計系メソッドと合わせて使ってみます。そこら中にモニタリング用のDoが入っていてコードが若干分かりづらいですが、実行結果で、どのタイミングで値が通過するのかを確認してみてください。
var source = Enumerable.Range(1, 5)
.Do(i => Console.WriteLine("Source -> " + i));
enumerableButton.Click += (sender, e) =>
{
var sum = source.Sum();
var max = source.Max();
var all = source.All(i => i < 3);
Console.WriteLine("sum = " + sum);
Console.WriteLine("max = " + max);
Console.WriteLine("all = " + all);
};
observableButton.Click += (sender, e) =>
{
var connectable = source.ToObservable().Publish();
connectable.Subscribe(_ => { }, () => Console.WriteLine("OnCompleted"));
var sum = default(int);
connectable
.Do(i => Console.WriteLine("BeforeSum -> " + i))
.Sum()
.Do(i => Console.WriteLine("AfterSum -> " + i))
.Subscribe(i => sum = i);
var max = default(int);
connectable
.Do(i => Console.WriteLine("BeforeMax -> " + i))
.Max()
.Do(i => Console.WriteLine("AfterMax -> " + i))
.Subscribe(i => max = i);
var all = default(bool);
connectable
.Do(i => Console.WriteLine("BeforeAll -> " + i))
.All(i => i < 3)
.Do(b => Console.WriteLine("AfterAll -> " + b))
.Subscribe(b => all = b);
connectable.Connect();
Console.WriteLine("sum = " + sum);
Console.WriteLine("max = " + max);
Console.WriteLine("all = " + all);
};
値が確定した時、Allならば全ての列挙が完了した(OnCompletedを受信する)か、条件がfalseのものが見つかったときに、1つだけSubscribeに値が届きます。SumやMaxは、全ての列挙が完了しないと算出出来ないので、全て完了したとき。こういった結果の確定するタイミングは、Enumerableでの場合と変わりません。
このような動作(戻り値が長さ1のIObservable)をするものには、 Aggreagte, Count, Any... 、ようするにIEnumerableにもあって戻り値がIEnumerableじゃないメソッドは全てそうです。全部似たりよったりなので具体的な紹介は省きます。
Pushのデメリット
IObservable便利すぎてIEnumerableいらなくネ? と、言いたいところですが、例えばこれら集計系メソッドは全て長さ1のIObservableになります。Sumの場合、欲しいのはintであってIObservableではありません。長さ1のIObservableは、いつConnectされるか分からないのでSubscribeで外の値に受け渡してやらなければならないわけですが、見た目が美しくなく宣言も冗長になる。
また、集計するのに複数回列挙は確かに格好悪いな!よし、そういう場合はRx使おう。と思った場合はとりあえず待った。ただの配列からの列挙程度の場合は、ふつーに複数回列挙したほうがPublishで分岐させるよりも遥かに速かったりします。元ソースが複雑にLinqで繋いであって重たかったり、ファイルやネットワーク経由だったりで複数呼び出しを避けたい、副作用があって複数回呼びだすと内容が変化している、という場合はRxです。が、一旦ToListしてキャッシュすれば済むシーンならば、キャッシュした方が分かりやすく速い場合が多かったりします。
Publishの具体的な使い処としては、以前に、TwitterのStreamAPIをRxを使って分配するという記事で紹介しました。
まとめ
PullとPushは、むしろ動作的にはPushのほうが素直で分かりやすい雰囲気。難解だと思って避けていたそこのアナタ、さあ、Rxを使おう! しかしColdとHotは大いなる罠。初見ではきっとつまづく。この区別は本当に大事。Rxが難解っぽいとしたら、Cold/Hotのせい。挙動がまるっと変わるんだもの。でも、ゆっくり紐解けば全然大丈夫。さあ、Rxを使おう!Publishや集計系はそんなには使わないかもですが、覚えておくと便利な時も割とある。さあ、Rxを(ry
個人的にRxの特色・使いどころは「イベントの合成」「タイマー・ネットワーク・スレッドなど非同期処理の一元化」「シーケンスの分配」の3つだと思っているのですが、このブログでは、延々とシーケンス分配という、3つの中で一番どうでもいい機能しか紹介していない!という酷い事実に気がつきました。そんなんじゃRxのポテンシャルを全然伝えられない。
というわけで、次回はタイマー辺りを紹介したいと思います予定は未定。というか計画ではObservableの合流周りとMarble Diagramについてを書く予定。Rxの知名度も徐々に上がってきているようなので、しっかり紹介していきたいですし、他の人も書いて欲すぃ。
Linq雑話
- 2010-06-08
ここ数日Twitterで見た/出したLinqネタまとめ。私の広くない観測範囲(@neuecc)での話ですが。
SelectManyとクエリ構文でUsing
ネタ元、コード元はCode, code and more code.: SelectMany; combining IDisposable and LINQから。
static void Main(string[] args)
{
var firstLines =
from path in new[] { "foo.txt", "bar.txt" }
from stream in File.OpenRead(path)
from reader in new StreamReader(stream)
select path + "\t" + reader.ReadLine();
}
public static IEnumerable<TResult> SelectMany<TSource, TDisposable, TResult>(
this IEnumerable<TSource> source,
Func<TSource, TDisposable> disposableSelector,
Func<TSource, TDisposable, TResult> resultSelector) where TDisposable : IDisposable
{
foreach (var item in source)
{
using (var disposableItem = disposableSelector(item))
yield return resultSelector(item, disposableItem);
}
}
自前定義の拡張メソッドはメソッド構文だけのものと思っていませんでしたか?私はそう思っていました。でも、クエリ構文でも同名のものがあれば拡張メソッドが使用されるんです、というお話。それを利用してusingのネストをクエリ構文で華麗に表現してやったぜー、というサンプルで、確かにこれはクール!素晴らしすぎる。
でも、クエリ構文使いたいかというと、そんなことはなく変わらずメソッド構文派です、私は。クエリ構文自体は悪いとは思わないし、良さがあるのも分かるんですが、他の拡張メソッドに繋げる時に前後にカッコで括ると途端に書き/読みにくくなることと、拡張性の乏しさが如何ともし難い。クエリ構文とメソッド構文のちゃんぽんになるぐらいなら、メソッド構文だけで書いたほうが美しいよね、と思ってしまう。あと、クエリ構文の存在が「LINQ = SQLみたいなの」という図式を産んでしまっているくさいのも、憎んでしまいますね……。
ラムダ式の引数の名前とシャッフルについて
お馴染み感溢れるOrderByでのシャッフル。
var rand = new Random();
var shuffle = Enumerable.Range(1, 10).OrderBy(_ => rand.Next());
それはそれとして、ラムダ式の引数の名前どうする?というお話が。私は、引数を使わない場合は _ を、使う場合は型の1~2文字(i(Int32)とかs(String)とかa(AnonymousType)とか、考えるの面倒なときはx、配列系はarかxs)という自分ルールを敷いています。以前にラムダ式の引数の名前という記事を書いたのですが、その時から変わっていません。ですが、最近ネットで見かけるコードでは全部_でまかなう例もよく見るね、と。Scalaでは匿名関数の引数として_が使える(プレースホルダ構文って言うんですね、名前知らなかった)ようなので、_をダメとは言い辛いのですけど、私はちょち苦手(linq.jsで$をゴリゴリ使ってるくせに、って話ではあるけど) 。
C#にもプレースホルダ構文みたいなの欲しいね、というのは、若干ある。プロパティの「value」とか最初からそこにある良く分からない変数、みたいなのはあるし。ただ、IntelliSenseとの兼ね合いもあるし、そういうのが入れられるか、入って本当に幸せになれるのかどうかの判断は保留。短絡的に欲しい!って言うのは簡単だけど、それの及ぼす影響となると分からないものだ。
それともう一つ。OrderByの引数は比較関数ではなくキーセレクターにすぎないのでちゃんとシャッフルされる、とか言ったりなどした私ですが、そうじゃなくてシャッフルの精度はランダムの範囲に影響されるね(実際上は問題ないとしても)、という話が。完全に頭から抜け落ちていて、かつ、全くもってその通りで恥ずかしかったりしたのですが確認できてよかったです、感謝。
OrderByのComparison
全然使わないけどOrderByの第二引数。
class MyClass
{
public int Hoge { get; set; }
public int Fuga { get; set; }
}
static void Main(string[] args)
{
var array = new[] { new MyClass(), new MyClass() };
// コンパイルは通るけど例外出る
var ordered = array.OrderBy(x => x).ToArray();
// 上のはこれに等しい(当然、例外出る)
array.OrderBy(x => x, Comparer<MyClass>.Default);
// AnonymousComparerを使えばComparisonを使った比較が出来る
array.OrderBy(x => x, (x, y) => x.Fuga - y.Hoge);
}
OrderByついでですが、キーセレクターは制約かかってないので別にIComparableじゃなくても動いたりします。そういう時はComparer<T>.Defaultが指定されることになって、例外出て死ぬだけです。意味ナイネ。
DescendingとThenByがあるので滅多に使わないであろう第二引数はIComparer。一々クラス作ってnewですってよ、C#らしくないですね。Comparisonじゃないなんて!大変ウザい。そんな人のためのAnonymousComparer。ラムダ式でIEqualityComparer/IComparerを作ることが出来ます。また、Linq標準演算子への拡張メソッドとしてOrderBy/ThenByのオーバーロードとしてComparisonが使えるようになります。便利ですね!是非使ってください、という宣伝。
Empty -> Sum
Empty.Sum()は0。言われてみれば当たり前といえば当たり前なのですが……。
// SumはAggregateで表現出来る
var sum = Enumerable.Range(1, 10).Aggregate((x, y) => x + y); // 55
// でもEmptyで例外出るから表現出来ない(キリッ
sum = Enumerable.Empty<int>().Sum(); // 0
sum = Enumerable.Empty<int>().Aggregate((x, y) => x + y); // 例外
// 実はseed与えればおk
sum = Enumerable.Empty<int>().Aggregate(0, (x, y) => x + y); // 0
SumやMax, Minなどは全てAggregateで表現出来ます。でも、Sumは空シーケンスの時はゼロ出すけど(MaxやAverageは例外)Aggregateを使うと例外が出てしまうので表現出来ない、とか言ったのですが0を最初に与えとけばいいよね、という話が。ぬお、そうでした!
発端はlinq.jsでこの問題(というかC#と互換が取れてないこと)に気づいたことで、linq.jsではAggregateでやってるため、AggregateはScan.LastだからScan.LastOrDefault(0)にするー、なんて考えてたんですが、初項0で済むというシンプルさを完全に失念。標準演算子外のメソッドを大量に用意してあるので、そっち側で解決しちゃおうとしてしまう姿勢は、ちょっと頭硬直化しちゃってる、全くもってよろしくない。
シャッフルの話といい、Aggregateの話といい、最近はLinqに慣れすぎて逆に見方が定型的になりすぎていると実感したので、少し気を引き締めないと。あ、で、そんなこんなでlinq.jsの空シーケンスでのSumの問題は次のリリースで直します。他にもバグがあったり(MemoizeAllが少しマズい)、加えたいことが数点あったりするので、もう少し先になりますが。
世の中の主流はまだVS2005ですか?
開発言語としてのJavaとC#を10の視点から比較
共通点が多いが、今後は違いが大きくなるかも
しかし近年のC#はLINQ(Language Integrated Query:言語統合クエリ)プロジェクトが重視されています。これはクエリ、集合操作、変換、および型推測などのデータ指向機能の多くを直接的にC#言語に統合しようとするものです。今後は違いがさらに大きくなっていくかもしれません。
プログラマが知っておきたいJavaと.NETの違い (3/4) - @IT
Linqは、VS2008出たのは3年前だよね(プレビュー版から言えばどれだけ前なのかしら)。今後は違いが大きくなるかも、じゃなくて既に違いは大きすぎるような。そして10の比較というけれど、最大の違いはデリゲートの有無では?特に、匿名メソッド/ラムダ式の有無。A.R.N [ Top > 書庫 > Microsoftの「Delegate」について ]にある、Javaには無名クラスがあるからdelegateは不要、とは10年以上前のSunの言で、さすがに10年以上も前のを持ち出してどうこう言ってもしょうがないのですが(比較対象に匿名メソッドないし)、価値観は移り変わっていくものなのだと思わずにはいられない。匿名クラスで代用出来るって、いやまあ出来なくもないのは分かりますがUglyすぎ。今、クロージャなんて不要、とか言ったらフルボッコなはず。
言語面で見ると、Java5から進化の足を止めている(そしてJava7延期しすぎ)ように見えるJavaと、ひたすら貪欲に(無節操に)取り込み続けるC#。スタート時には似たようなものだったとして、今はもうコードの見た目からして全然似てるようには見えない。Java畑の人は、今でもC#はJavaに似たようなもの、という認識なのかしら。
確かに、古典的に書けば似てますが……。そして、他の言語を考えれば、やっぱ似てるといえば似てるのですが。しかし……。ふむ。そろそろModern C# Designが出版されるべき。 Bart De Smetが書くC# 4.0 Unleashed
には超期待。