LINQ to BigQuery - C#による型付きDSLとLINQPadによるDumpと可視化
- 2014-09-24
と、いうものを作りました。BigQueryはGoogleのビッグデータサービスで、最近非常に脚光を浴びていて、何度もほってんとりやTwitterに上がってきたりしてますね。詳細はGoogle BigQuery の話とかGoogleの虎の子「BigQuery」をFluentdユーザーが使わない理由がなくなった理由あたりがいいかな、超でかいデータをGoogleパワーで数千台のサーバー並べてフルスキャンするから、超速くて最強ね、という話。で、実際凄い。超凄い。しかも嬉しいのが手間いらずなところで、最初Amazon RedShiftを検討して試していたのですが、列圧縮エンコードとか考えるのすっごく大変だし、容量やパワーもインスタンスタイプと睨めっこする必要がある。それがBigQueryだと容量は格安だから大量に格納できる、チューニング設定もなし、この手軽さ!おまけにウェブインターフェイスが中々優れていてクエリが見やすい。Query Referenceもしっかり書かれてて非常に分かりやすい。もう非の打ち所なし!
触ってすぐに気に入った、んですが、C#ドライバがプリミティブすぎてデシリアライズすらしてくれないので、何か作る必要がある。せっかく作るならSQLっぽいクエリ言語なのでLINQだろう、と。それとIQueryableは幻想だと思っていたので、じゃあ代替を作るならどうするのか、を現実的に示したくて、ちょうど格好の題材が出現!ということで、LINQで書けるようなライブラリを作りました。
- GitHub - LINQ-to-BigQuery
- PM> Install-Package LINQ-to-BigQuery
ダウンロードは例によってNuGetからできます。今年はそこそこ大きめのライブラリを作ってきていますが、LINQ to BigQueryは特に初回にしては大きめで割と充実、非常に気合入ってます!是非使ってみてねー。GitHubのReadMe.mdはこのブログ記事で力尽きたので適当です、あとでちゃんと書く……。
簡単なDEMO
BigQueryの良い所にサンプルデータが豊富というところがあります、というわけでGitHubのデータを扱って色々集計してみましょう。データは[publicdata:samples.github_timeline]を使ってもいいのですが、それは2011年時点のスナップショットでちょっとツマラナイ。GitHub Archiveから公開データを引っ張ってくれば、現時点での最新の、今ついさっきのリアルタイムの情報が扱えて非常に素敵(あとBigQueryはこういうpublicなDataSetが幾つかあるのが本当に最高に熱い)。ひっぱてくるやり方は書いてありますが(超簡単)、テーブル名は[githubarchive:github.timeline]です。
まずは単純なクエリということで、プログラミング言語だけでグループ化して個数を表示してみます。github.timelineは、例えばPushしたとかBranch作ったとか、雑多な情報が大量に入っているので、別にリポジトリ数のランキングではなくて、どちらかといえばアクティビティのランキング、ぐらいに捉えてもらえれば良さそうです。とりあえずトップ5で。
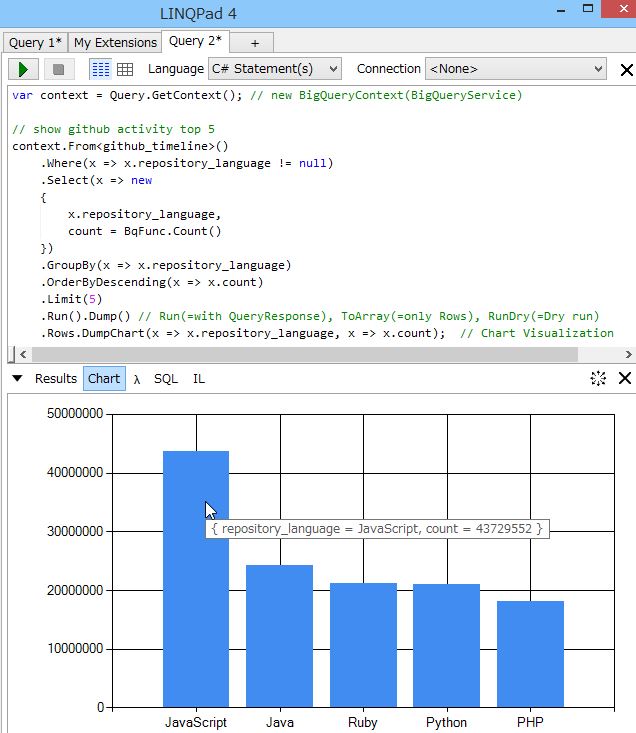
この例では記述と表示はLINQPadで行っています。LINQPadは非常に優れていて、C#コードが入力補完付きでサクッと書けるほか、実行結果をDumpして色々表示させることも可能です。DumpChartはLINQ to BigQueryのために独自に作ったDumpなのですが、それにより結果のグラフ化がXとYを指定するだけのたった一行
.DumpChart(x => x.repository_language, x => x.count)
だけで出来てしまう優れものです。描画は.NET標準のチャートライブラリを使っているため、棒グラフの他にも円グラフでも折れ線グラフでも、SeriesChartTypeにある35個の表示形式が選べます。見たとおり、Tooltip表示もあるので個数が大量にあっても全然確認できるといった、チャートに求められる基本的な機能は満たしているので、ちょっとしたサクッと書いて確認する用途ならば上等でしょう。
(DumpChartやQuery.GetContextのコードはこの記事の末尾にコード貼り付けてあるので、それで使ってください)
Resultsタブのほうを開けば、クエリ結果の詳細が見れます。
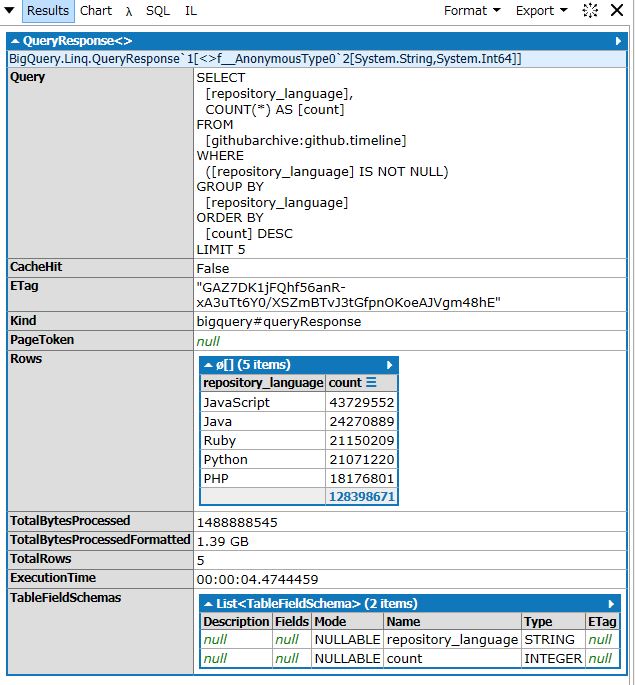
クエリ文字列はBigQueryの性質上、色々なところで使うはずです。そうした他所で使える可搬性のために、生成結果を人間の読める綺麗なものにする事にこだわりました(TypeScript的な)。純粋なクエリビルダとして使う(ちなみにToString()すればRunしなくてもクエリを取り出せます)ことも十分可能でしょう。Rowsに関しては切り離してグリッド表示も可能で、そうすれば簡単なソートやCSVへの書き出しといった、データベース用IDEに求められる基本的な機能も満たしています。
TotalBytesProcessedが読みづらかったのでひゅーまんりーだぶるな形に直してあるのも用意してあるところが優しさ(普通に自分が使ってて困ったので足しただけですが)。
BigQueryはウェブインターフェイスが非常に優れている、これは正直感動ポイントでした。いやぁ、RedShift、データベース管理用のIDEがろくすっぽなくて(PostgreSQL互換といいつつ違う部分で引っかかって動かないものが非常に多い)どうしたもんか、と苦労してたんですが、BigQueryはそもそも標準ウェブインターフェイスが超使いやすい。スキーマも見やすいしクエリも書きやすい。まさに神。
てわけでウェブインターフェイスには割と満足してるんですが、表示件数をドバッと表示したかったり、グラフ化もサクッとしたいし(何気にGoogle SpreadSheet連携は面倒くさい!)、日頃からデータベースもSQL Server Management StudioやHeidi SQLといったデスクトップツールを使って操作するWindows野郎としては、デスクトップで使えるIDE欲しいですね、と。それに分析やる以上、結構複雑なクエリも書くわけで、そういう時に型が欲しいなーとは思ってしまったり。LINQ to BigQueryはAlt BigQuery Query、Better BigQuery Queryとして、ただたんにC#で書けます以上のものを追求しました。そして、LINQPadとの組み合わせは、現存するBigQuery用のIDEとして最も良いはずです(そもそもBigQuery用のIDEは標準ウェブインターフェイス以外にあるのかどうか説もあるけれど)。日常使い、カジュアルな分析にも欠かせない代物となることでしょう。
Why LINQ?
LINQ to BigQueryで書く場合の良い点。一つは型が効いているので、間違っていたらコンパイルエラーで(Visual Studioで書けばリアルタイムにエラー通知で)弾かれること。別にカラム名の名前間違いなどといったことだけじゃなくて、文字列であったりタイムスタンプであったりといった型も厳密に見えているので、型の合わない関数を書いてしまうといったミスもなくせます。例えばDate and time functionsの引数が文字列なのかタイムスタンプなのかUNIX秒なのか、そして戻り値もまた文字列なのかタイムスタンプなのかUNIX秒なのか、ってのは全く覚えてられないんですが、そんな苦痛とはオサラバです。
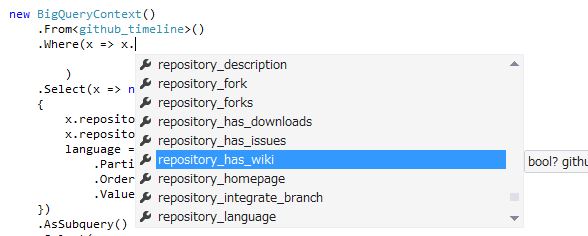
github_timelineのカラム数はなんと200個。さすがに覚えてられませんし、それの型だってあやふやってものです(例えばboolであって欲しいフォークされたリポジトリなのかを判定するrepository_forkというカラムには"false"といったような文字列でやってくるんですぜ!?)。
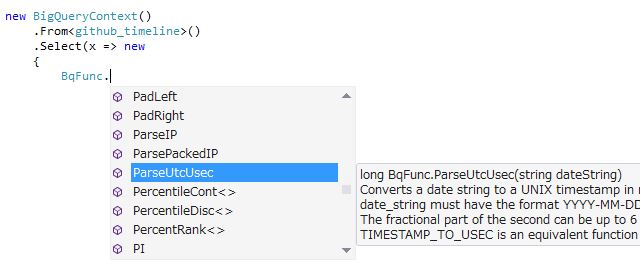
全ての関数はBqFuncの下にぶら下がっていて、引数と戻り値、それにドキュメント付きです。これなら覚えてなくても大丈夫!ちなみに、ということはクエリ中の全ての関数呼び出しにBqFunc.がついてきて見た目がウザいという問題があるのですが、それはC# 6.0のusing staticを使えば解決します。
// C# 6.0 Using Static
using BigQuery.Linq.BqFunc;
楽しみに待ちましょう(C# 6.0は多分2015年には登場するんじゃないかな?)。
LINQ to BigQueryはO/Rマッパーじゃありません。いや、もちろんクエリの構築やC#オブジェクトへのマッピングは行いますが、リレーションの管理はしません。かわりに、書いたクエリがほとんどそのままの見た目のクエリ文字列になります。なので意図しない酷いクエリが発行されてるぞー、というありがちななことは起きません。そして、LINQ to BigQueryで99%のクエリが記述できます、LINQで書けないから文字列でやらなきゃー、というシチュエーションはほぼほぼ起きません。LINQとクエリ文字列を1:1に、あえてほぼ直訳調にしているのはそのためです。
また、順序を強く規制してあります、無効なクエリ順序での記述(例えばGroupBy使わずにHaving書くとかLimitの後にWhere書いてしまうとか)やSelectなしの実行はコンパイルエラーで、そもそも書けないようにしています。
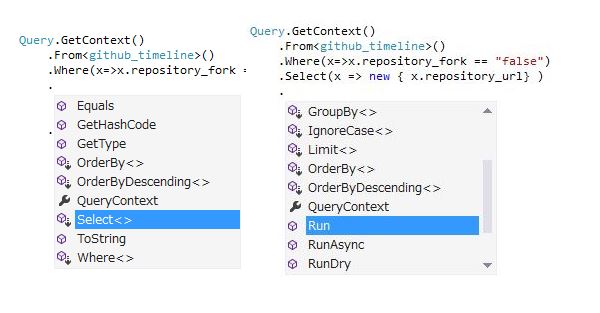
左はWhereの後のメソッド、これが全部でSelectとOrderByとWhere(ANDで連結される)しか使えない。右はSelect後で、GroupBy(奇妙に思えるかもしれませんが、GroupByの中でSelectの型が使えることを考えるとこの順序が適正)やLimit、そしてRunなどの実行系のメソッドが使えるようになっています。
これらにより、LINQ to BigQueryで書いたクエリは一発で実行可能なことが期待できるものが作れます(文字列で書くと、カラムの参照周りとかで案外つまづいてエラりやすい)。さすがにExpressionの中身は検査できないんですが、概ね大丈夫で、"守られてる感"はあるかと思います。ちなみにこんな順序で書けます。
From(+TableDecorate) -> Join -> Where -| -> OrderBy(ThenBy) -> Select -> | -> Limit -> IgnoreCase
| -> Select | -> GroupBy -> Having -> OrderBy(ThenBy) | -> IgnoreCase
| -> OrderBy(ThenBy) -> |
そういうの実現するためにLINQ to BigQueryはIQueryableじゃないんですが、そのことはこの長いブログ記事の後ろのほうでたっぷりポエム書いてるので読んでね!あと、こんな割とザルな構成でもしっかり機能しているように見えるのは、BigQueryのSQLがかなりシンプルなSQLだから。標準SQLにできることは、あんま出来ないんですね。で、私はそこが気に入ってます。好きです、BigQueryのSQL。別に標準SQLにがっつし寄せる必要はあんまないんじゃないかなー、SQL自体は複雑怪奇に近いですから、あんまり良くはない。とはいえ、ある程度の語彙は共用されていたほうが親しめるので、そういったバランス的にもBigQueryのSQLはいい塩梅。
最後に、Table DecoratorsやTable wildcard functionsが圧倒的に記述しやすいのも利点です。
// Table Decorators - WithRange(relative or absolute), WithSnapshot
// FROM [githubarchive:github.timeline@-900000-]
.From<github_timeline>().WithRange(TimeSpan.FromMinutes(15))
// FROM [githubarchive:github.timeline@1411398000000000]
.From<github_timeline>().WithSnapshot(DateTimeOffset.Parse("2014-09-23"))
// Table wildcard functions - FromDateRange, FromDateRangeStrict, FromTableQuery
// FROM (TABLE_DATE_RANGE([mydata], TIMESTAMP('2013-11-10'), TIMESTAMP('2013-12-01')))
.FromDateRange<mydata>("mydata", DateTimeOffset.Parse("2013-11-10"), DateTimeOffset.Parse("2013-12-1"))
// FROM (TABLE_QUERY([mydata], "([table_id] CONTAINS 'oo' AND (LENGTH([table_id]) >= 4))"))
.FromTableQuery<mydata>("mydata", x => x.table_id.Contains("oo") && BqFunc.Length(x.table_id) >= 4)
// FROM (TABLE_QUERY([mydata], "REGEXP_MATCH([table_id], r'^boo[\d]{3,5}')"))
.FromTableQuery<mydata>("mydata", x => BqFunc.RegexpMatch(x.table_id, "^boo[\\d]{3,5}"))
Table decoratorは、例えばログ系を突っ込んでる場合は障害対応や監視で、直近1時間から引き出したいとか普通にあるはずで、そういう場合に走査範囲を簡単に制御できる非常に有益な機能です。が、しかし、普通に書くとUNIXタイムスタンプで記述しろということで、ちょっとムリゲーです。それがC#のTimeSpanやDateTime、DateTimeOffsetが使えるので比較にならないほど書きやすい。
FromTableQueryも文字列指定だったりtable_idってどこから来てるんだよ!?という感じであんま書きやすくないのですが、LINQ to BigQueryでは型付けされたメタテーブル情報が渡ってくるので超書きやすい。(ところでCONTAINSだけ、BqFuncじゃなくてstring.Containsが使えます、これはCONTAINSの見た目がこれだけ関数じゃないので、ちょっと特別扱いしてあげました、他の関数は全部BqFuncのみです)
Table DecoratorsとTable wildcard functionsは非常に有益なので、テーブル名の設計にも強く影響を及ぼします。これらが有効に使える設計である必要があります。TABLE_DATE_RANGEのために(垂直分割するなら)末尾はYYYYMMDDである必要があるし、Range decoratorsを有効に使うためには極力、水平シャーディングは避けたほうが良いでしょう。そこのところを無視して、ただ単にシャーディング、シャーディングって言ってたりするのは、ちょっと、ないなー。
複雑なDEMO
ひと通り紹介は終わったので、より複雑なクエリを一つ。同じく最新のGitHubのデータを扱って、一ヶ月毎に、新しく作られたリポジトリを言語毎で集計して表示してみます。まずはグラフ化の結果から。
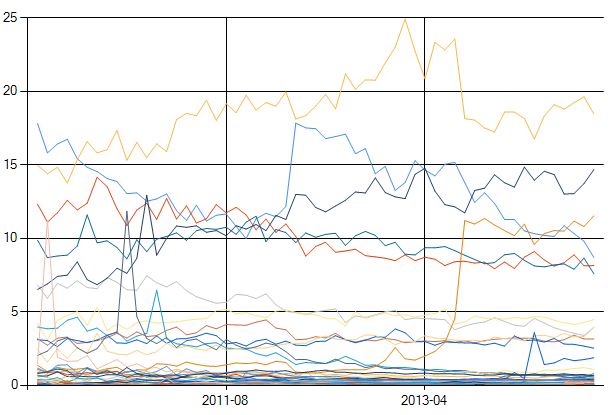
LINQPadではちゃんと多重グラフもメソッド一発で書けるようにしてます。コードは後で載せるとしてグラフの説明ですが、縦がパーセント、横が日付、それぞれの折れ線グラフが言語。一番上はJavaScriptで今月は43000件の新規リポジトリが立ち上がっていて全体の19%を占めてるようです。2位はJava、3位はCSS、そしてRuby、Python、PHPと続いて、この辺りまでが上位組ですね。C#はその後のC++、Cと来た次の9位で9251件・全体の4%でした。
コードは、ちょっと長いよ!
Query.GetContext()
.From<github_timeline>()
.Where(x => x.repository_language != null && x.repository_fork == "false")
.Select(x => new
{
x.repository_url,
x.repository_created_at,
language = BqFunc.LastValue(x, y => y.repository_language)
.PartitionBy(y => y.repository_url)
.OrderBy(y => y.created_at)
.Value
})
.Into()
.Select(x => new
{
x.language,
yyyymm = BqFunc.StrftimeUtcUsec(BqFunc.ParseUtcUsec(x.repository_created_at), "%Y-%m"),
count = BqFunc.CountDistinct(x.repository_url)
})
.GroupBy(x => new { x.language, x.yyyymm })
.Having(x => BqFunc.GreaterThanEqual(x.yyyymm, "2010-01"))
.Into()
.Select(x => new
{
x.language,
x.yyyymm,
x.count,
ratio = BqFunc.RatioToReport(x, y => y.count)
.PartitionBy(y => y.yyyymm)
.OrderBy(y => y.count)
.Value
})
.Into()
.Select(x => new
{
x.language,
x.count,
x.yyyymm,
percentage = BqFunc.Round(x.ratio * 100, 2)
})
.OrderBy(x => x.yyyymm)
.ThenByDescending(x => x.percentage)
.Run() // ↑BigQuery
.Dump() // ↓LINQ to Objects(and LINQPad)
.Rows
.GroupBy(x => x.language)
.DumpGroupChart(x => x.yyyymm, x => x.percentage);
規模感は全体で153GBで行数が2億5千万行ぐらいだけど、この程度は10秒ちょいで返してきますね、速い速い(多分)。
メソッドチェーンがやたら続いているのですが、実際のところこれはサブクエリで入れ子になってます。随所に挟まれてるIntoメソッドで入れ子を平らにしてます。入れ子の形で書くこともできるんですが、フラットのほうが直感的で圧倒的に書きやすいく、(慣れれば)読みやすくもあります。こういう書き方が出来るのもLINQ to BigQueryの大きなメリットだとは、書いてればすぐに実感できます。
(BqFunc.GreaterThanEqualが奇妙に思えるかもしれないのですが、これは文字列だけの特例です。数値やタイムスタンプの場合は記号で書けるようにしてあるのですが、文字列はそもそもC#自体に演算子オーバーロードが定義されていないのでコンパイラに弾かれる、けどBigQuery的には書きたい時がある、というのの苦肉の策でLessThan(Equal)/GreaterThan(Equal)を用意してあります)
チャート化はGroupBy.DumpGroupChartを叩くだけなんですが、ちょっと面白いのは、ここのGroupByはLINQ to Objects(C#で結果を受け取った後にインメモリで処理)のGroupByなんですよね。
.Run() // ↑BigQuery
.Dump() // ↓LINQ to Objects(and LINQPad)
.Rows
.GroupBy(x => x.language)
.DumpGroupChart(x => x.yyyymm, x => x.percentage);
二次元のクエリ結果を、シームレスに三次元に起こし直せるってのもLINQの面白いところだし、強いところです。モノによっては無理にSQLでこねくり回さなくてもインメモリに持ってきてから弄ればいいじゃない?という手が簡単に打てるのが嬉しい(もちろん全件持ってこれるわけがないのでBigQuery側で処理できるものは基本処理しておくのは前提として、ね)。
例えば、実のところこれの結果は、言語-日付という軸だと歯抜けがあって、全ての月に1つは言語がないと、チャートが揃いません。グラフの見た目の都合上、今回は2010-01以降にHAVINGしてありますが、その後に新しく登場した言語(例えばSwift)なんかはうまく表示できません。まぁ主要言語は大丈夫なので今回スルーしてますが、厳密にやるため、その辺の処理を、しかしSQLのままやるのは存外面倒くさい。でも、こういう処理、C#でインメモリでやる分には簡単なんですよね。なんで、一旦ローカルコンピューター側に持ってきてから、少しだけC#で処理書くか、みたいなのがカジュアルにできちゃうのもLINQ to BigQuery + LINQPadのちょっと良いところ。
さて、実際に吐かれるSQLは以下。
SELECT
[language],
[count],
[yyyymm],
ROUND(([ratio] * 100), 2) AS [percentage]
FROM
(
SELECT
[language],
[yyyymm],
[count],
RATIO_TO_REPORT([count]) OVER (PARTITION BY [yyyymm] ORDER BY [count]) AS [ratio]
FROM
(
SELECT
[language],
STRFTIME_UTC_USEC(PARSE_UTC_USEC([repository_created_at]), '%Y-%m') AS [yyyymm],
COUNT(DISTINCT [repository_url]) AS [count]
FROM
(
SELECT
[repository_url],
[repository_created_at],
LAST_VALUE([repository_language]) OVER (PARTITION BY [repository_url] ORDER BY [created_at]) AS [language]
FROM
[githubarchive:github.timeline]
WHERE
(([repository_language] IS NOT NULL) AND ([repository_fork] = 'false'))
)
GROUP BY
[language],
[yyyymm]
HAVING
[yyyymm] >= '2010-01'
)
)
ORDER BY
[yyyymm], [percentage] DESC
まず、ちゃんと読めるクエリを吐いてくれるでしょ?というのと、これぐらいになってくると手書きだと結構しんどいです、少なくとも私は。ウィンドウ関数もあんま手で書きたくないし、日付の処理の連鎖は型が欲しい。それと、サブクエリ使うとプロパティを外側に伝搬していく必要がありますが、それがLINQだと入力補完が効くのでとっても楽。Into()ですぐにサブクエリ化できるので、すごくカジュアルに、とりあえず困ったらサブクエリ、とぶん投げることが可能でめちゃくちゃ捗る。大抵のことはとりあえずサブクエリにして書くと解決しますからね!処理効率とかはどうせBigQueryなので何とかしてくれるだろうから、ふつーのMySQLとかで書く時のように気遣わなくていいので、めっちゃカジュアルに使っちゃう。
ところでどうでもいい余談ですが、LAST_VALUEウィンドウ関数はリファレンスに載ってません。他にも載ってない関数は幾つかあったりして(追加された時にブログでチラッと告知はされてるようなんですけどね、リファレンスにもちゃんと書いてくださいよ……)。LINQ to BigQueryならそういうアンドキュメントな関数もちゃんと網羅したんでひじょーにお薦めです!
Generate Schema
型付けされてるのがイイのは分かったけれど、それの定義が面倒なのよねー。と、そこで耳寄りな情報。まず、全部のテーブルのちょっとした情報(table_idとかサイズとか)はGetAllTableInfoという便利メソッドで取ってこれるようにしてます(実際便利!)。で、そこから更にテーブルスキーマが取り出せるようになってます。更にそこからオマケでC#コードをstringで吐き出せるようになってます。
var context = new BigQueryContext(/* BigqueryService, projectId */);
// Get All tableinfo(table_id, creation_time, row_count, size_bytes, etc...)
var tableInfos = context.GetAllTableInfo("mydataset");
// ToString - Human readable info
tableInfos.Select(x => x.ToString()).Dump();
// Get TableSchema
var schema = tableInfos[0].GetTableSchema(context.BigQueryService);
// Build C# class definition
schema.BuildCSharpClass().Dump();
まあ、そんなに洗練されたソリューションじゃないんでアレですが、一時凌ぎには良いでしょふ。publicdataとか自分のプロジェクト下にないものは直接MetaTableクラスを作ってからスキーマ取れるようになってます。
new MetaTable("publicdata", "samples", "github_timeline")
.GetTableSchema(Query.GetContext().BigQueryService)
.BuildCSharpClass();
// =>
[TableName("[publicdata:samples.github_timeline]")]
public class github_timeline
{
public string repository_url { get; set; }
public bool? repository_has_downloads { get; set; }
public string repository_created_at { get; set; }
public bool? repository_has_issues { get; set; }
// snip...(200 lines)
public string url { get; set; }
public string type { get; set; }
}
TableName属性がついたクラスはFrom句でテーブル名を指定しなくてもそこから読み取る、っていう風になってます(今までのコードでテーブル名を指定してなかったのはそのお陰)
リアルタイムストリーミングクエリ
Streaming Insertによりリアルタイムにログを送りつけてリアルタイムに表示することが可能に!というのがBigQuery超イカス。今までうちの会社は監視系のログはSumo Logicを使っていたのですが、もう全部BigQueryでいいね、といった状態になりました、さようなら、Sumo……。
で、リアルタイムなんですが、リアルタイム度によりけりですが、1分ぐらいの遅延やそれ以上のウィンドウを取るクエリならBigQueryで十分賄えますね。Range decoratorsが最高に使えるので、定期的にそれで叩いてやればいい。そして最近流行りのReactive ProgrammingがC#でも使えるというかむしろC#はReactive Programmingの第一人者みたいなもんなので、Reactiveに書きましょふ。Rxの説明は……しないよ?
// まぁgithub.timelineがリアルタイムじゃないからコレに関しては意味ないヨ、ただの例
// [githubarchive:github.timeline@1411511274158000-1411511574167000]
// [githubarchive:github.timeline@1411511574167000-1411511874174000]
// [githubarchive:github.timeline@1411511874174000-1411512174175000]
// ...
Observable.Timer(TimeSpan.Zero, TimeSpan.FromMinutes(5))
.Timestamp()
.Buffer(2, 1) // Buffer Window
.SelectMany(xs =>
{
var context = Query.GetContext();
context.UseQueryCache = false;
return context.From<github_timeline>().WithRange(xs[0].Timestamp, xs[1].Timestamp)
.Select(x => new { x.repository_name, x.created_at })
.ToArrayAsync();
})
.Dump();
アプリケーション側のStreaming Insertの間隔(バッファとかもするだろうし本当のリアルタイムじゃあないでしょう?)と、そしてBigQueryのクエリ時間(数秒)の絡みがあるので、まぁ1分ぐらいからでしょうかねー、でもまぁ、多くのシチュエーションでは十分許容できるんじゃないかと思います、障害調査で今すぐログが欲しい!とかってシチュエーションであっても間に合う時間だし。
よほどの超リアルタイム(バッファもほとんど取らず数秒がマスト)でなければ、もはやAmazon Kinesisのような土管すらもイラナイ感じですね。ストレージとしてもBigQueryは激安なので、Streaming Insertが安定するならば、もうBigQuery自体を土管として使って、各アプリはBigQueryから取り出して配信、みたいな形でも良いというかむしろそれでいい。Range decoratorsが効いてるなら走査範囲も小さいんで速度も従量課金も全く問題ないしねぇ。BigQuery最強すぎる……。
データ転送
本筋じゃないのでちょっとだけ話ますが、C#ってことは基本Windows Server(AWS上に立ってる)で、データをどうやってBigQueryに送るのー?と。もちろんFluentdは動かないし、(Windowsブランチあるって?あー、うーん、そもそも動かしたい気がない)、どうしますかね、と。ストレージに突っ込んでコピーは簡単明快でいいんですが、まぁ↑に書いたようにStreamingやりたいね、というわけで、うちの会社((株)グラニ。gihyoに書いた神獄のヴァルハラゲートの裏側をCTOが語り尽くす!とか読んでくださいな)では基本的にStreaming Insertのみです。ETW/EventSource(簡単な説明はWindows high speed logging: ETW in C#/.NET using System.Diagnostics.Tracing.EventSourceを)経由でログを送って、Semantic Logging Application Block(SLAB)のOut-of-process Serviceで拾って、自家製のSink(ここは今のところ手作りする必要あり、そのうちうちの会社から公開するでしょふ)でStreaming Insert(AWS->BigQueryでHTTP経由)。という構成。
今のとこリトライは入ってますが完全インメモリなんでまるごと死んだらログはロスト。といった、Fluentdが解決している幾つかの要素は解決されてないんですが、それなりに十二分に実用には使えるところかな、と。速さとかの性能面は全く問題ありません、ETWがとにかく強いし、そっから先もasync/awaitを活かした並列インサートが使えるので他のでやるよりはずっと良いはずきっと。
TODO:
実はまだRecord型に対応してません!なのでそれに関係するFLATTENやWITHIN句も使えません!99%のクエリが再現できる、とか言っておきながら未対応……。おうふ、ま、まぁ世の中のほとんどは入れ子な型なんて使ってませんよね……?そんなことはないか、そうですね、さすがに対応は必須だと思ってるので、早めに入れたいとは思ってます。
あと、LINQPadにはDataExplorerがあって、ちゃんとスキーマ情報の表示やコネクション保持とか出来るんですねー。というわけで、真面目にそのLINQPadドライバは作りたいです、というか作ろうとしていましたし、割と作れる感触は掴んだんです、が、大きな障壁が。LINQPadドライバは署名付きであることを要求するのですが、Google APIs Client Library for .NETが、署名されてない……。署名付きDLLは全部の参照DLLが署名付きであること必要があって、肝心要のGoogleライブラリが使えないという事態に。俺々署名してもInternalVisibleToがどうのこうのとかエラーの嵐で一歩も進めないよー。Googleが署名さえしてくれてれば全部解決なのに!だいたい著名なライブラリで署名されてないのなんかGoogleぐらいだよ!もはやむしろありえないレベル!なんとかして!
IQueryable is Dead. Long live Expression!
ちょっとだけC#の話もしよふ。以下、LINQ好きだからポエム書くよ!
LINQ to BigQueryはIQueryableじゃあ、ありません。この手のクエリ系のLINQはIQueryableでQuery Providerである必要が……、あるの?IQueryableは確かにその手のインフラを提供してくれるし、確実にLINQになる。けれど、絶対条件、なの?
私がLINQ to BigQueryで絶対譲れない最優先の事項として考えたのは、LINQで書けないクエリをなくすこと。全てのクエリがLINQで書ける、絶対に文字列クエリを必要としないようにする。そのためにはIQueryableの範囲を逸脱する必要があった。そして同時に強く制約したかった、順序も規定したいし、不要なクエリは(NotSupported!)そもそも書けないようにしたかった。これらはIQueryableに従っていては絶対に実現できないことだった。
LINQがLINQであるためにはクエリ構文はいらない。Query Providerもいらない。LINQ to XMLがLINQなのは何故?Parallel LINQがLINQであるのは何故?Reactive ExtensionsがLINQであるのは何故?linq.jsがLINQであるのは何故?そこにあるのは……、空気と文化。
LINQと名乗ること自体はマーケティングのようなもので、形はない。使う人が納得さえすれば、LINQでしょう。そこにルールを求めたがる人がいても、ないものはないのだから規定しようがないよ?LINQらしく感じさせる要素をある程度満たしてればいい。FuncもしくはExpressionを使ってWhereでフィルタしSelectで射影する(そうすればクエリ構文もある程度は使えるしね)。OrderBy系の構文はOrderBy/OrderByDescending/ThenBy/ThenByDescendingで適用される。基本的な戻り値がシーケンスっぽい何かである。うん、だんだん満たせてくる。別に100%満たさなくても、70%ぐらい満たせばLINQらしいんだよ。SelectManyがなくたって、いい。どうせNotSupportedExceptionが投げられるのなら、最初からないのと何が違うというの?
LINQ to BigQueryからはLINQらしさを感じられると思っています。最優先事項の全てのBigQueryのクエリを書けるようにすることやNotSupportedを投げないことなどを持ちつつも、可能な限りLINQらしさを感じさせるよう細心の注意を払ってデザインしました。極論言えば私がLINQだって言ってるんだからLINQなのですが(何か文句ある?)、多くの人には十分納得してもらえると考えています。LimitをTakeで"書けない"とかね、BigQueryらしくすることも使いやすさだし、LINQらしくすることも使いやすさ。この辺は私の匙加減。
と、いうわけでIQueryableは、データベース系クエリの抽象化というのが幻想で、無用の長物と化してしまったのだけど、しかし役に立たなかったかといえば、そうじゃあない。LINQだと感じさせるための文化を作る一翼をIQueryableは担っていたから。データベース系へのクエリはこのように定義されていると"らしい"感じになる。その意識の統一にはIQueryableは必要だった、間違いなく。しかし時は流れて、もう登場から6年も経ってる。もう、同時にかかった呪いからは解放されていいんじゃないかな?みんなでIQueryableを埋葬しよう。
と、いうのがIQueryableを使ってない理由。死にました。殺しました。IQueryableは死んだのですが、しかしExpressionは生きています!LINQ to BigQueryも当然Expressionで構成されています。空前のExpression Tree再評価の機運が!で、まぁしかしだからってふつーのアプリのクエリをExpression Treeでやりたいかは別の話ね。やっぱ構築コストとか、そもそもBigQueryは比較的シンプルなSQLだから表現しきれたけどふつーのSQLは複雑怪奇で表現できないだろー、とか、色々ありますからね。まぁ、あんま好ましく思ってないのは変わりません。
コストの話は、BigQueryの場合は完全に無視できるのよね。クエリのレスポンスが普通のDBだったら数msだけど、BigQueryは数千~数万msと桁が4つも5つも違う。リクエスト数もふつーのクエリは大量だけどBigQueryはほとんどない(一般ユーザーが叩くものじゃないからね)。なので、ほんとうの意味でExpression Treeの構築や解釈のコストは無視できちゃう。そういう、相当富豪的にやっても何の問題もないというコンテキストに立っています。だからLINQ to BigQueryはあらゆる点で完全無欠に有益。
LINQPad用お土産一式
Query.GetContextとかDumpChartとかは、LINQPadの左下のMy Extensionsのとこに以下のコードをコピペってください。それで有効になります。本当はLINQPad Driver作ってそれ入れれば有効になるようにしたかったんですが、とりあえず今のところはこんなんで勘弁してくだしあ。こんなんでも、十分使えますので。
// Import this namespaces
BigQuery.Linq
System.Windows.Forms.DataVisualization.Charting
Google.Apis.Auth.OAuth2
Google.Apis.Bigquery.v2
Google.Apis.Util.Store
Google.Apis.Services
public static class Query
{
public static BigQueryContext GetContext()
{
BigQueryContext context;
// Replace this JSON. OAuth2 JSON Generate from GCP Management Page.
var json = @"{""installed"":{""auth_uri"":""https://accounts.google.com/o/oauth2/auth"",""client_secret"":"""",""token_uri"":""https://accounts.google.com/o/oauth2/token"",""client_email"":"""",""redirect_uris"":[""urn:ietf:wg:oauth:2.0:oob"",""oob""],""client_x509_cert_url"":"""",""client_id"":"""",""auth_provider_x509_cert_url"":""https://www.googleapis.com/oauth2/v1/certs""}}";
using (var ms = new MemoryStream(Encoding.UTF8.GetBytes(json)))
{
// Open Browser, Accept Auth
var userCredential = GoogleWebAuthorizationBroker.AuthorizeAsync(ms,
new[] { BigqueryService.Scope.Bigquery },
"user",
CancellationToken.None, new FileDataStore(@"LINQ-to-BigQuery")) // localcache
.Result;
var bigquery = new BigqueryService(new BaseClientService.Initializer
{
ApplicationName = "LINQ to BigQuery",
HttpClientInitializer = userCredential
});
context = new BigQueryContext(bigquery, "write your project id");
}
// Timeout or other options
context.TimeoutMs = (long)TimeSpan.FromMinutes(1).TotalMilliseconds;
return context;
}
}
public static class MyExtensions
{
public static IEnumerable<T> DumpChart<T>(this IEnumerable<T> source, Func<T, object> xSelector, Func<T, object> ySelector, SeriesChartType chartType = SeriesChartType.Column, bool isShowXLabel = false)
{
var chart = new Chart();
chart.ChartAreas.Add(new ChartArea());
var series = new Series { ChartType = chartType };
foreach (var item in source)
{
var x = xSelector(item);
var y = ySelector(item);
var index = series.Points.AddXY(x, y);
series.Points[index].ToolTip = item.ToString();
if (isShowXLabel) series.Points[index].Label = x.ToString();
}
chart.Series.Add(series);
chart.Dump("Chart");
return source;
}
public static IEnumerable<IGrouping<TKey, T>> DumpGroupChart<TKey, T>(this IEnumerable<IGrouping<TKey, T>> source, Func<T, object> xSelector, Func<T, object> ySelector, SeriesChartType chartType = SeriesChartType.Line)
{
var chart = new Chart();
chart.ChartAreas.Add(new ChartArea());
foreach (var g in source)
{
var series = new Series { ChartType = chartType };
foreach (var item in g)
{
var x = xSelector(item);
var y = ySelector(item);
var index = series.Points.AddXY(x, y);
series.Points[index].ToolTip = item.ToString();
}
chart.Series.Add(series);
}
chart.Dump("Chart");
return source;
}
}
GCPの管理ページからOAuth2認証用のJSONをベタ貼りするのとプロジェクトIDだけ書いてもらえれば使えるかと。最初にブラウザ立ち上がって認証されます、2回目以降はローカルフォルダにキャッシュされてるので不要。まぁ色々ザルなんですが、軽く使う分にはいいかな、と。
まとめ
いやもう本当に、この手のソリューションではBigQueryが群を抜いて凄い。Azure使ってる人もAWS使ってる人(実際、うちのプロダクトはAWS上で動かしてますがデータはBigQueryに投げてます)もオンプレミスの人もBigQuery使うべきだし、他のものを使う意味が分からないレベル。とにかく試せ、であり、そして試すのは皆Googleアカウントは絶対持ってるはずだからワンポチするだけで立ち上がってるし、最初から膨大なサンプルデータがあるので簡単に遊べるし、一発で気にいるはず、間違いない。
そしてWindows(C#)の人には、LINQ to BigQuery + LINQPadがベストなツールとなってくれるはず。むしろあらゆるBigQueryを扱う環境の中でC#こそが最高といえるものになってくれるよう、色々やっていきたいですね。