C#の高速なMySQLのドライバを書こうかという話、或いはパフォーマンス向上のためのアプローチについて
- 2017-08-07
割とずっと公式のC# MySQL Driverは性能的にビミョいのではと思っていて、それがSQL Serverと比較してもパフォーマンス面で足を引っ張るなー、と思っていたんですが、いよいよもって最近はシリアライザも延々と書いてたりで、その手の処理に自信もあるし、いっちょやったるかと思い至ったのであった。つまり、データベースドライバをシリアライゼーションの問題として捉えたわけです。あと会社のプログラム(黒騎士と白の魔王)のサーバー側の性能的にもう少し飛躍させたくて、ボトルネックはいっぱいあるんですが、根本から変えれればそれなりにコスパもいいのでは、みたいな。

中間結果としては、コスパがいいというには微妙な感じというか、Mean下がってなくてダメじゃんという形になって、割と想定と外れてしまってアチャー感が相当否めなくて困ったのですが(ほんとにね!)、まぁそこはおいおいなんとかするとして(します)、メモリ確保だけは確実にめちゃくちゃ減らしました。1/70も減ってるのだから相当中々だと思いたい、ということで、スタート地点としては上等じゃないでしょふか。
↑のベンチマークはBenchmarkDotNetで出していまして、使い方はこないだ別ブログに書いた C#でTypeをキーにしたDictionaryのパフォーマンス比較と最速コードの実装 ので、そちらを参照のことこと。
まだふいんき程度ですが、コードも公開しています。
まだα版とすらいえない状態なので、そこはおいおい。
性能向上のためのアプローチ
競合として、公式のMySQL Connectorと非公式のAsync MySQL Connectorというのがあります。非公式のは、名前空間どころか名前まで被せてきて紛らわしさ超絶大なので、この非公式のやつのやり方は好きじゃありません。
それはさておき、まず非同期の扱いについてなんですが、別に非同期にしたからFastなわけでもありません。だいたいどうせASP.NETの時点でスレッドいっぱいぶちまけてるんちゃうんちゃうん?みたいなところもあるし。むしろ同期に比べてオーバーヘッドが多くなりがち(実装を頑張る必要大!)なので、素朴にやるとむしろ性能低下に繋がります。
さて、で、パフォーマンスを意識したうえで、どう実装していけば良いのか、ですが、MySqlSharpでは以下のものを方針としています。
- 同期と非同期は別物でどちらかがどちらかのラッパーだと遅い。両方、個別の実装を提供し、最適化する必要がある
- 禁忌のMutableなStructをReaderとして用意することでGCメモリ確保を低減する
- テキストプロトコルにおいて数値変換に文字列変換+パースのコストを直接変換処理を書くことでなくす
- ADO.NET抽象を避けて、プリミティブなMySQL APIを提供する。ADO.NETをはそのラッパーとする
- 特化したDapper的なMicro ORMを用意する、それは上記プリミティブMySQL APIを叩く
- Npgsql 3.2のようなプリペアドステートメントの活用を目指す
といったメニューになっていまして、実装したものもあれば妄想の段階のものもあります。
Mutable Struct Reader
structはMutableにしちゃいけない、というのが世間の常識で実際そうなのですが、最近のC#はstruct絡みが延々と強化され続けていて(まだ続いてます - C# Language Design Notes for Jul 5, 2017によるとC# 7.2でrefなんとかが大量投下される)、structについて真剣に考え、活用しなければならない時が来ています。
ところでMySQLのプロトコルはバイナリストリームは、更にPacketという単位で切り分けられて届くようになっています。これを素朴に実装すると
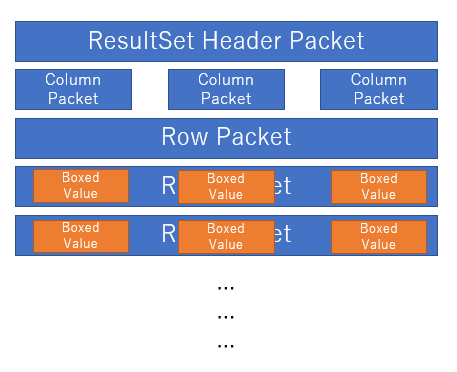
Packet単位にクラスを作っちゃって、無駄一時オブジェクトがボコボコできちゃうんですね。
// ふつーのパターンだとこういう風にネストしていくようにする
using (var packetReader = new PacketReader())
using (var protocolReader = new ProtocolReader(packetReader))
{
var set = protocolReader.ReadTextResultSet();
}
かといって、Packet単位で区切って扱えるようにしないと実装できなかったりなので、悩ましいところです。そこで解決策として Mutable Struct Reader を投下しました。
// MySqlSharpはこういうパターンを作った
var reader = new PacketReader(); // struct but mutable, has reading(offset) state
var set = ProtocolReader.ReadTextResultSet(ref reader); // (ref PacketReader)
PacketReaderはstructでbyte[]とoffsetを抱えていて、Readするとoffsetが進んでいく。というよくあるXxxReader。しかしstruct。それを触って実際にオブジェクトを組み立てる高レベルなリーダーはstaticメソッド、そしてrefで渡して回る(structなのでうかつに変数に入れたりするとコピーされて内部のoffsetが進まない!)。
奇妙なようでいて、実際見かけないやり方で些か奇妙ではあるのですが、この組み合わせは、意外と良かったですね、APIの触り心地もそこまで悪くないですし。もちろんノーアロケーションですし。というわけで、いつになくrefだらけになっています。時代はref。
数値変換を文字列変換を介さず直接行う
クエリ結果の行データは、MySQLは通常テキストプロトコルで行われています(サーバーサイドプリペアドステートメント時のみバイナリプロトコル)。どういうことかというと、1999は "1999" という形で受け取ります。実際にはbyte[]の"1999" ですね。これをintに変換する場合、素朴に書くとこうなります(実際、MySQL Connectorはこう実装されてます)
// 一度、文字列に変換してからint.Parse
int.Parse(Encoding.UTF8.GetString(binary));
これにより一時文字列を作るというゴミ製造が発生します、ついでにint.Parseだって文字列を解析するのでタダな操作じゃない。んで、UTF8で、文字数の長さもわかっている状態で、中身が数字なのが確定しているのだから、直接変換できるんじゃないか、というのがMySqlSharpで導入したNumberConverterです。
const byte Minus = 45;
public static Int32 ToInt32(byte[] bytes, int offset, int count)
{
// Min: -2147483648
// Max: 2147483647
// Digits: 10
if (bytes[offset] != Minus)
{
switch (count)
{
case 1:
return (System.Int32)(((Int32)(bytes[offset] - Zero)));
case 2:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 10) + ((Int32)(bytes[offset + 1] - Zero)));
case 3:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 100) + ((Int32)(bytes[offset + 1] - Zero) * 10) + ((Int32)(bytes[offset + 2] - Zero)));
// snip case 4..9
case 10:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 1000000000) + ((Int32)(bytes[offset + 1] - Zero) * 100000000) + ((Int32)(bytes[offset + 2] - Zero) * 10000000) + ((Int32)(bytes[offset + 3] - Zero) * 1000000) + ((Int32)(bytes[offset + 4] - Zero) * 100000) + ((Int32)(bytes[offset + 5] - Zero) * 10000) + ((Int32)(bytes[offset + 6] - Zero) * 1000) + ((Int32)(bytes[offset + 7] - Zero) * 100) + ((Int32)(bytes[offset + 8] - Zero) * 10) + ((Int32)(bytes[offset + 9] - Zero)));
default:
throw new ArgumentException("Int32 out of range count");
}
}
else
{
// snip... * -1
}
}
ASCIIコードでベタにやってくるので、じゃあベタに45引けば数字作れますよね、という。UTF-8以外のエンコーディングのときどーすんねん?というと
- 対応しない
- そん時は int.Parse(Encoding.UTF8.GetString(binary)) を使う
のどっちかでいいかな、と。今のところ面倒なので対応しない、が有力。
Primitive API for MySQL
MySQL Protocolには本来、もっと色々なコマンドがあります。COM_QUIT, COM_QUERY, COM_PING, などなど。まぁ、そうじゃなくても、COM_QUERYを流すのにADO.NET抽象を被せる必要はなくダイレクトに投下できればいいんじゃない?とは思わなくもない?
// Driver Direct
var driver = new MySqlDriver(option);
driver.Open();
var reader = driver.Query("selct 1"); // COM_QUERY
while (reader.Read())
{
var v = reader.GetInt32(0);
}
// you can use other native APIs
driver.Ping(); // COM_PING
driver.Statistics(); // COM_STATISTICS
// ADO.NET Wrapper
var conn = new MySqlConnection("connStr");
conn.Open();
var cmd = conn.CreateCommand();
cmd.CommandText = "select 1";
var reader = cmd.ExecuteReader();
while (reader.Read())
{
var v = reader.GetInt32(0);
}
APIはADO.NETに似せるようにしてはいますが、余計な中間オブジェクトも一切なく直接叩けるのでオーバーヘッドがなくなります。もちろん、実用的にはADO.NETを挟まないと色々な周辺ツールが使えなくなるので、殆どの場合はADO.NET抽象経由になるとは思いますが。
とはいえ、DapperのようなORMをMySqlSharp専用で作ることにより、直接MySqlSharpのPrimitive APIを叩いて更なるパフォーマンスのブーストが可能です。理屈上は。まだ未実装なので知らんけど。恐らくいけてる想定です、脳内では。
まとめ
実装は、むしろMySQL公式からドキュメントが消滅している - Chapter 14 MySQL Client/Server Protocolせいで、Web Archivesから拾ってきたり謎クローンから拾ってきたりMariaDBのから拾ってきたりと、とにかく参照が面倒で、それが一番捗らないところですね。もはやほんとどういうこっちゃ。
MySQLには最近X-Protocolという新しいプロトコルが搭載されていて、こちらを通すと明らかに良好な気配が見えます。これはProtocol Buffersでやり取りするため、各言語のドライバのシリアライゼーションの出来不出来に、性能が左右されなくなるというのも良いところですね。
が、Amazon AuroraではX-Protocolは使えないし、あまり使えるようになる気配も見えないので、あえて書く意味は、それなりにあるんじゃないかしらん。ちゃんと完成すればね……!それと.NET CoreなどLinux環境下などでも.NET使ってくぞー、みたいな流れだと、当然データベースはMySQL(やPostgreSQL)のほうが多くなるだろう、というのは自然なことですが、そこでDBなども含めたトータルなパフォーマンスでは.NET、遅いっすね!ってなるのはめっちゃ悔しいじゃないですか。でも実際そうなるでしょう。だから、高速なMySQLドライバーというのは、これからの時代に必要なもののはずなのです。
公開しないほうがお蔵入りになる可能性が高いので、公開しました。あとは私の頑張りにご期待下さい。