31
- 2009-03-31
今月はゲームについて絶対に書かない月間を完遂おめでとう!誰得!誰得!書かないついでに、ほとんどプレイもしてなかったのは普通にどうかと思う。来月からは普通のペースに戻したいかなあ、と思ってはいるんですがどうでしょう。先週から作り直してるjs用linqライブラリが出来上がったらパーッとやりたいのですけど。中途半端な状態だと気持ち悪くて。
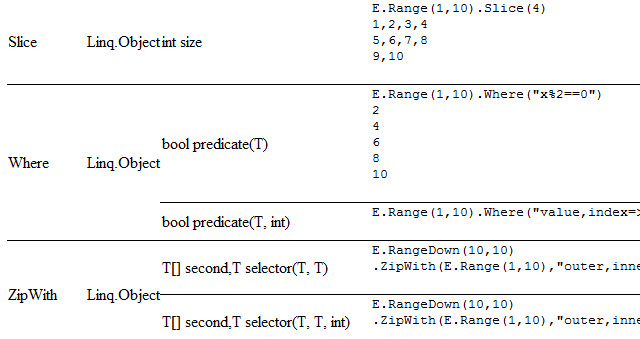
一応出来上がりました。で、必死にリファレンス書いてます。英語で解説するのは無理だと諦めたので(笑) 例題コードをクリックするとその場で実行されるようにしました。実行結果はコードの真下に出てくる。これなら見たまんまな結果なので文字による解説が一つもなくても、それなりに分かりやすいでしょう。まあ、そもそもC#のLINQの丸々コピーなのでMSDNの親切なヘルプを見るのが一番なのですが。で、そうそう、一応はC#のLINQの丸々コピーになっているので、このリファレンスを見ることでC#のLINQのメソッドの動きの確認もしやすい、ような代物になればいいなぁ、と。
画像だとwidth640に縮めたので何がなんだか分かりませんね。カラムはメソッド名・戻り値・引数・コードです。フルサイズだとこんな感じ、な予定。進行状況1/3ぐらい。
{kind=link}
ラムダ式モドキは、どうせ文字列から生成してるんだからと調子に乗って略記法を多めに搭載しました。引数一個なら=>を省くとxをデフォルトの引数変数名として使える、とか。なので本家LINQよりもサクサク書けます。サクサク書けるのはともかくとして実行効率は……そんなこと気にしたら負けかなと思っている。実用的にどうなのかはともかく、結構楽しく書き進められました(リファレンス書きは苦痛ですけど!) 作っただけで自分で使わないというのも寂しいので、これが終わったらFirefoxのアドオン作成でもして、それに使おうかなあ……。
JavaScriptでLINQ
- 2009-03-23
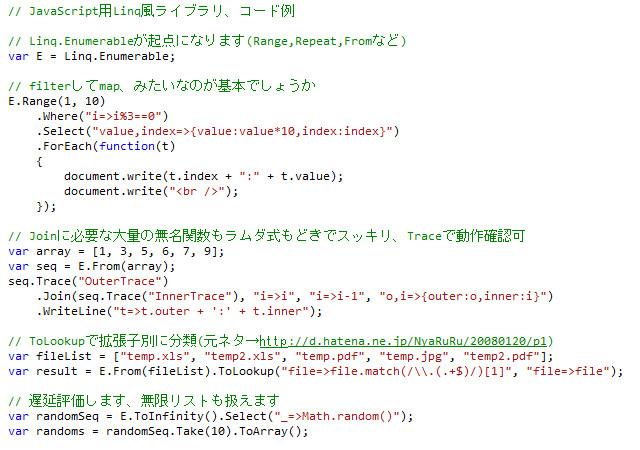
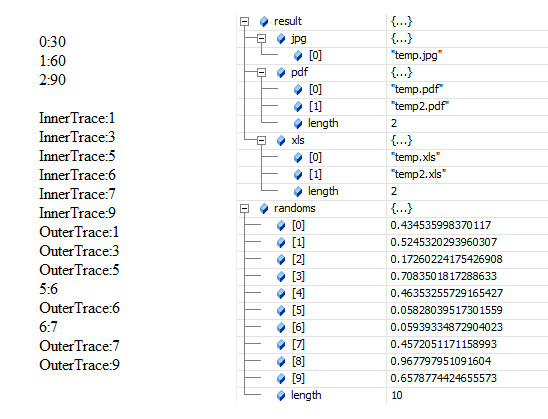
あまりJavaScriptっぽく見えませんが、JavaScript用のLINQライブラリを制作中です。1月頃に一応完成はしていたのだけど、あまり良い出来ではなかったので放置していました。けど、ふと思い立って昨日から改修を始めました。
- C#のLINQとの95%の互換性(メソッドオーバーロードの関係上、一部が無理)
- Achiralからパク……参考にさせていただいた標準LINQ外の拡張メソッド群
- ラムダ式もどきによる簡潔な記述
- C#の拡張メソッドのように簡単に俺俺メソッドを追加可能
という4つの特徴を持ちます予定。4番目は微妙かも。yield returnがないのでコードがゴチャついちゃってて。C#にないFromメソッドは、Array.prototypeを拡張するのはお行儀悪いので、配列をメソッドチェーン可能にさせるための苦肉の策。若干面倒くさいですが勘弁してやってください。Fromは連想配列を放り込んでも動作します。その場合、以降キーは.Key、値は.Valueで取り出すことになります。この辺もC#を模してます。あと、TraceメソッドはFirebugのコンソールに流せるようにしたりする予定。
この手のものは珍しくないし、LINQ風JavaScriptライブラリもそれなりな数があるんですが、ラムダ式もどきで簡潔に記述出来ることもあってわりかし使い勝手が良いほうに入るんじゃないかと思います。実際問題何が便利なのか、というと、IEでfilterやmapやreduceが使えるとでも思ってくれればどーでしょう。もしくはPerl のリスト操作を Ruby 風に的な。
4月中ごろまでには公開出来たらいいなあ……。
追記:完成しました - neue cc - linq.js - JavaScript用LINQライブラリ
Scan?
- 2009-03-16
いつかの記事が、何とNyaRuRuさんに取り上げて頂いて 前後の値も利用したシーケンス処理 - NyaRuRuの日記 嬉しさのあまり卒倒しつつ恥ずかしさでいっぱいな今日この頃。
int[] array = { 1, 2, 4, 4, 3, 3, 4, 0, 0 };
var result = array
.OfType<Nullable<int>>()
.Scan(new Tuple<int?, int?>(), (t, x) => Make.Tuple(t.Item2, x))
.Skip(1)
.Where(t => t.Item1 != t.Item2)
.Select(t => t.Item2.Value);
Pairwiseを使う、などの発想が全くなかったので確認のためAchiralを使って書き直し。ただ、何だか怪しい。Scanを使うと、seedの分が一つ余計なのでSkip(1)はしょうがない、はず。一つズらすのでペアが出来ないところをNullableで補うのも必要、な、はず。はずなんだけど何だか違和感が拭えない。うーん。
intという、型を明示していくのが非常に書きにくい。これが違和感の元なのかな、普通にLINQで書くときはあまりないシチュエーションなので。ただ、こればっかりはしょうがない気がする。Nullableでなくても、空のTuple作るときに型が必要だから。んー、そもそも、Nullableにしなければもう少し綺麗になるような。ScanのseedをMake.Tuple(int.MinValue,int.MinValue)にでもすれば……。でもそれはそれで納得が行かない気がする。うーん、すっきりしない。
C#でカリー化
- 2009-03-15
LINQハァハァ→関数型言語?→Haskell!という感じに辿ってHaskellを勉強中なので、カリー化について。Haskell、の前にまずはC#で考える。例えば、たまーに見かける「a => b => c => a + b + c」のようなものがパッと見意味分からない。Haskellでも型定義Int->Int->Intみたいことやるので、それと同じなわけっぽいですけれど。
ゆっくり分解すると、「=>」の左が引数、右が戻り値なのでa =>( b => c => a + b + c) つまり Func<int,???>。???の部分もカッコでくくって b =>( c => a + b + c) つまりFunc<int,Func<int,???>>。c=>a+b+cは、見たまんまなのでFunc<int,Func<int,Func<int,int>>>ということになる。
冷静に解きほぐせばそんな難しくない。というわけで準備運動が済んだので、カリー化関数を作ろう。
// カリー化する関数
static Func<T, Func<U, V>> Currying<T, U, V>(Func<T, U, V> func)
{
return t => u => func(t, u);
}
// 非カリー化する関数
static Func<T, U, V> UnCurrying<T, U, V>(Func<T, Func<U, V>> func)
{
return (t, u) => func(t)(u);
}
// 例として使うx+yを返す関数
static int Sum(int x, int y)
{
return x + y;
}
static void Main()
{
int num1 = Sum(3, 5); // 普通に、8
// Sumをカリー化する、関数はデリゲートに包む必要がある
var CurriedSum = Currying((Func<int, int, int>)Sum);
int num2 = CurriedSum(3)(5); // 当然、8
var BindedSum = CurriedSum(3); // 3を部分適用する
int num3 = BindedSum(5); // 勿論、8
var UnCurriedSum = UnCurrying(CurriedSum); // 非カリー化
int num4 = UnCurriedSum(3, 5); // 当然、Sum関数と一緒
}
多分、あってる、と思いたい。カリー化とは大雑把に言って「f(x,y) = g(x)(y)」ということのようなので、そうなるようバラしたり戻したり。そういえばで気付いたのですが、関数/ラムダ式をデリゲートに包む方法は
Func<int> test1 = () => 1;
var test2 = (Func<int>)(() => 2);
var test3 = new Func<int>(() => 3);
意外とバリエーションがある、気がする。ようは省略出来るだけでしょって話っぽいけど。単独で定義するときは1番を用いるかなー。癖でとりあえずvar、って書いてから、あー、これはnewするのダルいケースだった、varじゃなくてちゃんと書かなきゃ、と後ろに戻ったりするのがよくあって笑えない。
クロージャ
関数を返す関数繋がりでついでに、関数型言語って何がすごいんですか - Gemmaの日記からロケットのコードのC#版を。
static void Main()
{
Func<int, Action> Rocket = n => () => Console.WriteLine((n > 0) ? (n--).ToString() : "liftoff");
var F = Rocket(3);
var G = Rocket(3);
F(); F(); F(); F(); // 行数使うのもアレなので横に並べます
G(); G();
}
中々なスッキリ具合。function retrunが必要ない、というのがC#ラムダ式の強みですねえ。JavaScriptは(IEのせいもあって)function{return}が必須なのがカッタルイ。そんなことを思うと、C#はとても身軽で、個人的にはある意味とてもLightweightだと感じてしまったりする。
インテリセンスがりがり、コードスニペットがりがり、コードフォーマッタがりがりな上に乗っかっているので、軽快というか、Lightweight Languageが短距離走選手のようだとしたら、VS2008+C#は重武装+ロケットブースターで、それ自体は鈍重であっても、結果的にブースター付きのは強烈なスピードだよね、みたいな。軽快に書き進められるの自分の力じゃなくてVisualStudioの力でしょ、と思わないときもないけれど。
LINQとeach_sliceと匿名Enum
- 2009-03-12
ToLookupで思ったのは、匿名Enumが欲しい。わざわざ外に定義するほどでもないけれど、ただの文字列で区分けするのは嫌だ。なんて思ったのは、以前ジオメトリのランキングを引っ張ってくる際にGroupByを使った時に思ったんだった。それにしても、改めて眺めてみると酷い、Firstの連発とか。しかし、昔とは違うんです、昔とは。冷静に問題を考えればきっと分かる。
ようするに配列を3つ刻みで分割したい。{3, 4, 631, 671, 7, 5, 82, 1, 2}とあったら、{[3,4,631],[671,7,5],[82,1,2]}に分けたい。一次元→二次元、ということかな?phpのarray_chunkやRubyのEnumerable#each_sliceがそれに相当する、っぽい。
しかし延々と考えてもさっぱり思い浮かばない。自分で思い浮かばない時は検索しよう、と検索したらすぐ出てきた。Eric White's Blog : Chunking a Collection into Groups of Three。 3つ区切りでグループ分け、とはまさに考えている問題と同じ話。ただ、あの、このFirstの連打は私とやってること同じじゃん。
私のようなタコならともかく、他の人も似たようなことやってるし、もしくは拡張メソッドでループ回している例しか見つからないから、しょうがないかな、と諦め。きれない。ようはSkip().First()にせよFirst(predicate)にせよ、IEnumerable<T>状態だからいけない。何らかのキーで直接アクセス出来ればいいわけですよね? お、ToLookupぢゃん!でも今回は中に入るのが一個であること確定なので、ToDictionaryが良いですね。そして、ふふ、滅多に出番のないGroupByのresultSelectorを使うときがついにきたようだ……。
// 3つ区切りで、[商品名,値段,売ってる場所]となっている配列を分解したい
string[] array = { "大根", "100", "八百屋", "豚肉", "300", "肉屋", "イカ", "150", "魚屋" };
// enumモドキの匿名型
var Key = new
{
Name = Guid.NewGuid(),
Price = Guid.NewGuid(),
Shop = Guid.NewGuid()
};
var result = array.Select((value, index) => new
{
value,
chunk = index / 3,
attr = (index % 3 == 0) ? Key.Name :
(index % 3 == 1) ? Key.Price :
Key.Shop
}).GroupBy(t => t.chunk, t => t, (k, g) => g.ToDictionary(t => t.attr, t => t.value))
.Select(d => new
{
Name = d[Key.Name],
Price = d[Key.Price],
Shop = d[Key.Shop]
});
できたー。最初のSelect時にバラしているので行数がSkip().First()より増えているのは突っ込みどころだけど、満足。あと、元の配列がきっかり3で割りきれないと、Dictionaryなので存在しないキーにアクセスしました例外が出て死んでしまいます。対策としてはToLookupにして[Key.Name].FirstOrDefault()を使う、というのがすぐに浮かんだけど、スッキリしないのは否めない。ていうかその辺も踏まえてもSkip().FirstOrDefault()のほうが賢いやり方な気がする……。
で、冒頭の匿名Enum云々は、匿名型を使って実現?してみました。値は、絶対に被らないもの、ということでGUIDを使ってみた。ただ、定義時に全部にGuid.NewGuid()というのがダルい。というか若干ヤケくそ気味なのは否めない。こちらも上手いやり方が思い浮かばず、ってそればっか。そもそもEnumモドキなら、intでいいし、もしくは"商品名"とか文字列を使えば普通に便利なので、GUIDは全く意味ないですね。しょうもな。というわけで、実際に使う場合(あるかなあ?)はGUIDじゃなくて文字列でやります……。
回数サンドイッチ
- 2009-03-07
class Program
{
static void Main()
{
// 何でもいい配列
var array = Enumerable.Repeat("a", 10);
// foreachで素直っぽくindexを付ける
foreach (var item in array.Select((value, index) => new { value, index }))
{
Console.WriteLine("{0}:{1}", item.index, item.value);
}
// 拡張メソッドにしちゃう
foreach (var item in array.WithIndex())
{
Console.WriteLine("{0}:{1}", item.Key, item.Value);
}
// foreachで使う場合は普通に外側にcount用の変数置いた方が……
// indexの取れない拡張メソッド(ToLookupとか)へのチェイン時には便利に使えるかも
var splittedArray = array.WithIndex().ToLookup(kvp => kvp.Key < 5, kvp => kvp.Value);
}
}
public static class ExtMethods
{
public static IEnumerable<KeyValuePair<int, T>> WithIndex<T>(this IEnumerable<T> source)
{
int index = 0;
foreach (var item in source)
{
yield return new KeyValuePair<int, T>(index++, item);
}
}
}
最近は、どこにでもあるゲーム雑感サイト→どこにでもあるプログラミング雑感サイト、に無理矢理シフトしようとして浮ついた無理無理感が漂っていますが、別に特にシフトしたいわけでもなく、せっかくなので3月は集中的に書いてみようかな、と思っただけですが空気的に不評な雰囲気を感じちゃってたりしなかったりは、とりあえず無視黙殺で進めようかと思うこの頃ですがいかがお過ごしでしょうか。
前々回、前回からまだ続いて、Selectでindexを取る話。[C#]何度目の動きを見て、便利便利と思ったので簡単に使えるように拡張メソッドに放り込んでみた。KeyValuePairなんて名前じゃなくてIndexValuePairが良いんですが(笑) あるものは、そのまんま使うということで。
それ自体は別にforeachの外側にカウント用の変数置けばいいぢゃーん、という気がしなくもなくて困ったので、言い訳として、幾つかのメソッドがインデックス取れないから中間に挟む用として便利!と思うことにした。SelectとかWhereとか、大抵のものはFunc<T,int,TResult>も用意されているんだけどね。ToLookupとか、一部のものには無いんだね。
C# LINQで左外部自己結合
- 2009-03-06
static void Main(string[] args)
{
// 連続して同じ値が来る箇所だけを省いて取得する
// この場合だと1,2,4,3,4,0が取れることを目指す
int[] array = { 1, 2, 4, 4, 3, 3, 4, 0, 0 };
var arrayWithIndex = array.Select((value, index) => new { value, index });
var result =
from orig in arrayWithIndex
join alias in arrayWithIndex on orig.index equals alias.index - 1 into _
from alias in _.DefaultIfEmpty()
where alias == null || orig.value != alias.value
select orig.value;
}
前回に引き続いてindex生成してゴニョゴニョするネタを考えたい。というわけで、SQL的な自己結合。これで前後の値との比較が可能になるわけですね! 自己結合自体は普通にjoinで同じソースを置くだけ。例では、「連続して同じ値が入っている箇所」を省くため、インデックスを1つずらして結合。ただ、普通に結合すると最後の値が無いので、結合から抜け落ちてしまう。というわけで、内部結合ではなく外部結合にする。外部結合はDefaultIfEmptyを使って、MSDNに記事があるのをそのまんまな方向で。
var list = new List<int>();
list.Add(array[0]);
for (int i = 1; i < array.Length; i++)
{
if (array[i] != array[i - 1]) list.Add(array[i]);
}
……でも結局、こんな例ならばList使った方が遥かにスッキリなのであった。意味ないねー。とても。少しはまともな例題が考え出せやしないものなのかしらん。
リストの分割
- 2009-03-03
// リスト自体は何だっていいので適当に生成
var list = Enumerable.Repeat("a", 50);
// 25以下をtrue、それ以上をfalseとするkeyでグループ分け
var result = list
.Select((value, index) => new { value, index })
.GroupBy(t => t.index <= 25, t => t.value);
// 多分、こんな感じに取り出す……?
var first = result.Single(g => g.Key == true);
var second = result.Single(g => g.Key == false);
2ch見てたら、要素数50のリストを0-25と26-50に分割するのどーするの、という質問が出てたのでごにゃごにゃ考えた。最初、list.GroupBy(i => i < 25);なんて答えたのだけど、即座に値じゃなくて添え字で分けたいんでしょーがボケ、と突っ込みが入ったので書き換えたのが↑のもの。微妙な長さと無駄手間感が何とも言えない、ただのLINQ遊びでしかない状態になってしまった。うーん。これはこれで面白いと思うのだけど。ただ、もう少し短くできないかな……?グループ化が挟まると、その後がどうしても長ったらしく。ていうか、あと、trueとfalseしかないんだから、First()とLast()でいいよね、という話ではある。
// 条件ばかりが無駄に多くて限りなく微妙
var alphabet = Enumerable.Range('A', 'z' + 1 - 'A')
.Where(c => c <= 'Z' || c >= 'a')
.GroupBy(c => c <= 'Z', c => (char)c);
// ていうか、意味ないよね、これ、全く
var upper = alphabet.First();
var lower = alphabet.Last();
何だか悔しいので、もう少し考えてみた。例えばアルファベットの大文字と小文字とか!……意味ない。死ぬほど意味がない。少なくとも、これだけを考えるならEnumerable.Range('a', 26).Select(i => ((char)i).ToString());でいいし。ダメだこりゃ。
追記
あ、違う、こういう場合はGroupByじゃなくてToLookup使えばいいんだった。GroupByと違ってキーでアクセス出来るようになるから、SingleだのFirstだのといった微妙なアクセスじゃなく(しかも、これらを使うと毎回走査してるってことだよね!) result[true]とかalphabet[true]とかでアクセス出来る。これで遙かにスッキリ。Lookupは素晴らしい。けど、ついつい忘れてしまう。
var result = list
.Select((value, index) => new { value, index })
.ToLookup(t => (t.index <= 25) ? "以下" : "より上", t => t.value);
var ika = result["以下"]; // こんな感じで
var tako = result["より上"]; // 取り出せるわけです!
これならすっきり。めでたしめでたし。キーは日本語でもboolでもenumでも好きなモノを使うといいさあー。
追追記
さっそく Enumerable.ToLookup が役立った - NyaRuRuの日記
つまりこういうことなのであった。間違いなく昔読んだはずなのに、すっかり忘れていたという事実が何よりも悲しい。あと、ToLookupで検索しても全然引っかからないというのが、限りなく人気無いメソッドのようで悲しい。私も忘れてたけどね!