MessagePack for C#におけるオートマトンベースの文字列探索によるデシリアライズ速度の高速化
- 2017-08-28
MessagePack for C# 1.6.0出しました。目玉機能というか、かなり気合い入れて実装したのは文字列キー(Map)時のデシリアライズ速度の高速化です。なんと前バージョンに比べて2.5倍も速くなっています!!!

他のシリアライザと比較してみましょう。

IntKey, StringKey, Typeless_IntKey, Typeless_StringKeyがMessagePack for C#です。MessagePack for C#はどのオプションにおいても、デシリアライズのプロセスにおいてメモリを一切消費しません。(56Bはデシリアライズ後の戻り値のサイズのみです)
JSONの二種はStringからとbyte[]からStreamReaderの2つの計測を入れてます。これは、通常byte[]でデータは届くので、計測的にはそこも入れないとダメですよね、ということで。StreamReader通すとオーバーヘッドがデカくなりすぎて(UTF8デコードが必要というのもある)、どうしてもかなり速度が落ちてしまうんですよね。なので、JSONは、バイナリ系に比べると現実的なケースではかなり遅くなりがちなのは避けられません。見慣れないHyperionはAkka.NETのためのシリアライザでWireのForkです。この辺はシリアライザマニアしか知らないものなのでどうでもいいでしょう(
さて、MessagePack for C#の数字キー(Array)が一番速いです。文字列キーの3倍速い、ただしこれは数字キーのケースがヤバいぐらいむしろ速すぎなんで、別に文字列キーが遅いわけじゃあないというのは、他と比べれば分かるでしょう(文字列キー時ですらprotobuf-netより高速!)。数字キーのほうが高速になるのは、原理を考えると当然の話で、数字キーはMessagePackのArray、文字列キーはMapを使ってシリアライズするのですが、デシリアライズ時にArrayの場合は read array length, for(array length) { binary decode } という感じのデシリアライズを試みます。Mapの場合は read map length, for(map length) { decode key, lookup by key, binary decode } という具合に、キーのデコードと、どのメンバーに対してデシリアライズすればいいのかのルックアップの、2つの余計なコストがかかってくるので、どうしても遅くなってしまいます。
とはいえ、文字列キーは中々に有用で、コントラクトレス(属性つけなくていお手軽エディション)やJSONの気楽な置き換え、より固い他言語との相互通信やバージョニング耐性、より自己記述的なスキーマあたりのメリットがあり、割と使われてます。実際、結構使われているっぽいです。もともと数字キーはエクストリームにチューニングされていて激速だったんですが、文字列キーはそれほどでもなかったので、文字列キーのデシリアライズ速度の高速化が急務でした。
最終的にはオートマトンベースの文字列探索をIL生成時インライン化で埋め込むことにより高速化を達成したのですが(インライン化が効果あるのはMicroResolver - C#最速のDIコンテナライブラリと、最速を支えるメタプログラミングテクニックの実装時に分かっていたので、そのアイディアを転用してます)、とりあえずそこに至るまでのステップを見ていきましょうでしょう。
文字列のデコードを避ける
素朴な実装、MessagePack for C#のついこないだまで(前の前のバージョン)の実装では、文字列キーをStringにデコードしていました。そこから引っ張ってくる、という。
// 文字列をキーにしたDictionaryをキャッシュとして持つというのはあるあよくある。
static Dictionary<string, TValue> cache = new Dictionary<string, TValue>();
// ネットワークからデータが来る場合はUTF8Stringのbyte[]の場合が非常に多い
// で、キャッシュからデータを引くためにstringにデコードしなければらない
var key = Encoding.UTF8.GetString(bytes, offset, count);
var v1 = d1[key];
// この場合、keyは無駄 of 無駄で、デコードなしに辞書が引けたら
// デコードコストがなくなってパフォーマンスも良くなる&一時ゴミを作らないので全面的にハッピー
ということです。シチュエーションとして、なくはないんじゃないでしょうか?実際具体的なところとしては、MessagePack for C#の文字列キーオブジェクトのデコードでは、このケースにとても当てはまります。Fooというプロパティがあったら Dictionary<string, MemberInfo> にTryGetValue("Foo")でMemberInfoを取り出す。みたいな感じです。
public class MyClassFormatter : IMessagePackFormatter<MyClass>
{
Dictionary<string, int> jumpTable;
public MyClassFormatter()
{
// MyProperty1, 2, 3の3つのプロパティのあるクラスのためのプロパティ名 -> ジャンプ番号のテーブル
jumpTable = new Dictionary<string, int>(3)
{
{ "MyProperty1", 0 },
{ "MyProperty2", 1 },
{ "MyProperty3", 2 },
};
}
public MyClass Deserialize(byte[] bytes, int offset, IFormatterResolver formatterResolver, out int readSize)
{
// ---省略
// 中では Encoding.UTF8.GetString(bytes, offset, count)
var key = MessagePackBinary.ReadString(bytes, offset, out readSize);
if (!jumpTable.TryGetValue(key, out var jumpNo)) jumpNo = -1;
// 以下それ使ってデシリアライズ...
switch (jumpNo)
{
case 0:
break;
default:
break;
}
}
}
ちなみにswitch(string)はC#のswitch文のコンパイラ最適化についてに書きましたが、コンパイラがバイナリサーチに変換するだけなので、そこまで夢ある速度は出ません(こういうケースでバイナリサーチとハッシュテーブル、どっちが速いかは微妙なラインというかむしろハッシュテーブルのほうが速い)。あとIL生成でそれやるのは面倒なので、現実的な実装では辞書引きが落とし所になります。
とはいえまぁ、そのデコードって無駄なんですよね。byte[]で届いてくるのを、辞書から引くためだけにデコードしてる。byte[]のまま比較すればデコードコストはかからないのに!
そこで、byte[]のまま辞書引きができるようなEqualityComparerを実装しましょう。そうすると
// 別に辞書のKeyとして引くだけなら、 byte[]そのもので構わないので、こうする。
Dictionary<ArraySegment<byte>, TValue> d2;
// そのためにはArraySegment<byte>のEqualityComparerが必要
d2 = new Dictionary<ArraySegment<byte>, TValue>(new ByteArraySegmentEqualityComparer());
// すると、byte[] + offset + countだけでキーを引ける。
var v2 = d2[new ArraySegment<byte>(bytes, offset, count)];
ハッピーっぽい。さて、実はこれ、ようするにC#で入る入る詐欺中のUTF8Stringです。Dictionary<UTF8String>で持てばデコード不要でマッチできますよね、という。しかし、残念ながらUTF8Stringの実装は中途半端な状態で、ぶっちけ使いものにならないレベルなので、存在は無視しておきましょう(少なくとも辞書のキーとして使うにはGetHashCodeのコードが仮すぎて話にならないんで、絶対にやめるべき、ていうかいくら仮でもあの実装はない)。いつか正式に入った時は、そちらを使えば大丈夫ということになるとは思います。まぁ、まだ当分は先ですね。
ByteArraySegmentEqualityComparerを実装する
Dictionaryの仕組みとしてはGetHashCodeでオブジェクトが入ってる可能性がありそうな連結リストを引いて、その後にEqualsで正確な比較をする。という感じになっています。二段構え。なので、Equalsをオーバーライドする時は必ずGetHashCodeもオーバーライドしなければならない、の理由はその辺この辺ということです。
public class ByteArraySegmentEqualityComparer : IEqualityComparer<ArraySegment<byte>>
{
public int GetHashCode(ArraySegment<byte> obj)
{
throw new NotImplementedException();
}
public bool Equals(ArraySegment<byte> x, ArraySegment<byte> y)
{
throw new NotImplementedException();
}
}
さて、GetHashCodeはどうしましょう。アルゴリズムは色々ありますが、素朴に実装するならFNV1-a Hashというのがよく使われます。
public int GetHashCode(ArraySegment<byte> obj)
{
var x = obj.Array;
var offset = obj.Offset;
var count = obj.Count;
uint hash = 0;
if (x != null)
{
var max = offset + count;
hash = 2166136261;
for (int i = offset; i < max; i++)
{
hash = unchecked((x[i] ^ hash) * 16777619);
}
}
return unchecked((int)hash);
}
先に出たswitch(string)の中でのハッシュコード算出でもこのアルゴリズムが使われています(つまりC#コンパイラの中にこれの生成コードが埋まってます)。
素朴にそれを実装してもいいんですが、見た通り、なんか別にそんな速くなさそうなんですよね、見た通り!ハッシュコード算出のアルゴリズムは実は色々あるんですが、もっと良いのはないのか、ということで色々と調べて試して回ったのですが、最終的にFarmHashが良さそうでした。これは一応Googleで実装され使われているという謳い文句になっていて、できたのが2014年と比較的新しめです。詳細はその前身のCityHashのスライドを読んで下さい。
一応特性としては特に文字列に対してイケてるっていうのと、短めの文字列にたいしても最適化されているというのが、良いところです。
何故なら、今回のターゲットは文字列、そしてメンバー名は通常4~12あたりが最も多いからです。実際にFarmHashのコードの一部を引いてくると、こんな感じです。
static unsafe ulong Hash64(byte* s, uint len)
{
if (len <= 16)
{
if (len >= 8)
{
ulong mul = k2 + len * 2;
ulong a = Fetch64(s) + k2;
ulong b = Fetch64(s + len - 8);
ulong c = Rotate64(b, 37) * mul + a;
ulong d = (Rotate64(a, 25) + b) * mul;
return HashLen16(c, d, mul); // 中身はMurmurっぽいの(^ * mulを4回ぐらいやる)
}
// if(len >= 4, len > 0)
}
// if(len <= 32, 64, 128...)
}
と、文字列の長さ毎に、算出コードに細かい分岐が入っていて、なんかいい感じです。Fetch64というのはlongで引っ張ってくるとこなので、8~16文字の時の処理は Fetch, Fetch, Rotate, Rotate, MulMul。まぁ、細かい話はおいておいて、FNV1-aより計算回数は少なそうです。
そんなFarmHash、使いたければFarmhash.SharpというC#移植があるので、それを使えばいいでしょう。ただ、MessagePack for C#の場合は微妙にそれではダメだったので(Farmhash.SharpはOffsetが0から前提だった……)、自分で必要な分だけ移植しました。そのバージョンはMessagePack.Internal.FarmHashの中にInternalという名に反してpublicで置いてあるので、MessagePack for C#を引っ張ってくれば使えます。
GetHashCodeについてはそのぐらいにしておいて、Equalsについてですが、ようはmemcmp。なのですがC#にはありません。最近だとSystem.Memoryに入っているReadOnlySpanを使ってSequenceEqualを使うと、それっぽい実装が入っているので割と良いのですが、まだpreviewなので自前実装にしておきましょう。ここは素朴にループ回してもよいのですが、unsafeにしてlong単位で引っ張ってやったほうが高速といえば高速です。
public unsafe class ByteArraySegmentEqualityComparer : IEqualityComparer<ArraySegment<byte>>
{
static readonly bool Is64Bit = sizeof(IntPtr) == 8;
public int GetHashCode(ArraySegment<byte> obj)
{
// 特に文字列が前提のシナリオでFarmHashは高速
if (Is64Bit)
{
return unchecked((int)MessagePack.Internal.FarmHash.Hash64(obj.Array, obj.Offset, obj.Count));
}
else
{
return unchecked((int)MessagePack.Internal.FarmHash.Hash32(obj.Array, obj.Offset, obj.Count));
}
}
public unsafe bool Equals(ArraySegment<byte> left, ArraySegment<byte> right)
{
var xs = left.Array;
var xsOffset = left.Offset;
var xsCount = left.Count;
var ys = right.Array;
var ysOffset = right.Offset;
var ysCount = right.Count;
if (xs == null || ys == null || xsCount != ysCount)
{
return false;
}
fixed (byte* px = xs)
fixed (byte* py = ys)
{
var x = px + xsOffset;
var y = py + ysOffset;
var length = xsCount;
var loooCount = length / 8;
// 8byte毎に比較
for (var i = 0; i < loooCount; i++, x += 8, y += 8)
{
if (*(long*)x != *(long*)y)
{
return false;
}
}
// あまったら4byte比較
if ((length & 4) != 0)
{
if (*(int*)x != *(int*)y)
{
return false;
}
x += 4;
y += 4;
}
// あまったら2byte比較
if ((length & 2) != 0)
{
if (*(short*)x != *(short*)y)
{
return false;
}
x += 2;
y += 2;
}
// 最後1byte比較
if ((length & 1) != 0)
{
if (*x != *y)
{
return false;
}
}
return true;
}
}
}
まぁこんなもんでしょう。これらのコードはMessagePack.Internal.ByteArrayComparerに埋まっているので、internalだけどpublicなので、MessagePack for C#を入れてもらえればコピペせずとも使えます。
実際、これでStringデコードしてくるよりも高速になりました!素晴らしい!終了!
オートマトンによる文字列探索
と思って、実際実装もしたんですが、そしてまぁ確かに速くはなったんですが、しかし満足行くほど速くはならなかったのです。いや、別に遅くはないんですが、それでもなんというかすっごく不満。もっと速くできるだろうという感じで。
んで、こうしてGetHashCodeとEqualsを全部手実装して思ったのは、GetHashCodeを消し去りたい。しょーがないんですが、Equals含めるとこれbyte[]を二度読みしてることになってるわけで。DictionaryはO(1)かもしれんがbyte[n]に対して、O(n * 2)じゃん、的な。しかもデシリアライズって全プロパティを見るので、クラス単位でDictionaryを作ると、というか作るわけですが、普通は一個か二個はハッシュテーブルの原理的に衝突します。衝突するので、Equalsはもう少し何度か呼ばれることになる。なんかもういけてない!ていうかそれがIntKeyに対しての速度が出ない要因なわけです。
これをなんとかするための案として出てきたのがオートマトンで探索かけること。これはもともとJilの最適化トリックで言及されていたので、いつかやりたいなあ、と前々から思っていたので、今しかないかな、と。ついでにオートマトン化して探索を埋め込めるようになると、IL的なインライン化もより進められるので一石二鳥。MicroResolverの実装時にILインライン化が効果あったのは分かっていたので、もはややはりやるしかない。
具体的にはこんなイメージです。

"MyProperty1"という文字列はUTF8だと"77 121 80 114 111 112 101 114 116 121 49"というbyte[]。で、それを1byteずつ比較するのはアレなので、long(8 byte)単位で取り出すと"8243118316933118285, 3242356"になる(8byteに足りない部分は0埋めします、UTF8文字列前提ならその処理でもコンフリクトはなく大丈夫、多分……)。で、それで分岐かけた探索に変換する、と。オートマトンといいつつも、一方向の割と単純なツリー(ようするところトライ木)ではある。
これによって、long単位でのFetch二回と、比較二回だけでメンバー検索処理が済む!実際にジェネレートされるコードは以下のような感じです。

定数は実行時に生成されて埋め込まれるので、実行マシンのエンディアンの影響は受けません。メンバー数が多くなっている場合は、そこは二分検索コードを生成してILで埋め込みます。実際のシチュエーションだと、最初の8byteのところに集中するので、そこが二分検索、あとは普通は一本道なのでひたすらlongで取り出して比較、ですね。通常メンバ名は16文字以下なので、1回の二分検索と1回の比較で済むはずです。仮に多くなっても文字数 / 8の比較程度なので、そこまで大きくはならないでしょう。
完全に手書きじゃ無理な最適化ということで、いい感じです。さて、mpc.exe(事前コード生成)による生成は、ここまでの対応はしていないので、Unityだとここまで速くはなってないです、しょぼん(ただDictionary likeなオートマトン検索は行います、インライン化されないということなんで、いうてそこそこ悪くはないです)。事前生成で定数を埋め込むことに日和ってるので、まぁ別にLittleEndianだしいいじゃん、に倒してもいいかもしれないし、いくないかもしれないしでなんともかんともというところ。
まとめ
オートマトン化のIL実装は結構苦戦して、今回の土日は延々と試行錯誤してました。土曜だけで終わらせるはずが……。まぁ、結果としてできてよかった。
というわけでエクストリーム高速化されました。ここまで徹底的にやってるシリアライザは存在しないので、そりゃ速いよね。性能面では文句ないわけですが、機能面でも既に他を凌駕しています。目標は性能面でも機能面でも究極のシリアライザを作る、ということになってきたので以下ロードマップとか、私の考えているシリアライザの機能とはこういうのです、というラインナップ。
- Generics - 普通の。最初から実装済み。
- NonGenerics - フレームワークから要求されることが多い。最初から実装済み。
- Dynamic - Dynamicで受け取れるデシリアライズ、Ver 1.2.0から実装済み。
- Object Serialize - シリアライズ時はObject型を具象型でシリアライズする必要がある。Ver 1.5.0から実装済み(実はつい最近ようやく!)
- Union(Polymorphism, Surrogate, Oneof) - 複数型がぶら下がるシリアライズ。最初から実装済み。
- Configuration - Resolverで概ね賄えるけれど、一部のプリミティブが最適化のためオミットされるので、そこの調整が必要。
- Extensibility - 拡張性。Resolverにより最初から実装済み。Ver 1.3.0から MessagePackFormatterAttribute により簡易的な拡張も可能。
- Compression - 圧縮。LZ4で最初から実装済み。
- Stream - ストリーミングデシリアライズ。Ver 1.3.3から限定サポート(readStrict:trueでサイズ計算して必要な分だけStreamから読み取れる)。
- Async - 現状だとむしろ遅くなるのでやる気あんまなし、System.IO.Pipelinesが来たら考える。ただStream APIに関しては入れてもいいかも入れよう。
- Reader/Writer - Primitive API(MessagePackBinary)として最初から実装済み。ちょいちょいAPIは足していて、あらゆるユースケースに対応できる状態に整備されたはず。
- JSON - JSONとの相互変換。ToJson, FromJsonがVer 1.3.1から実装済み。
- Private - プライベートフィールドへのアクセス。コード生成的にひとひねり必要なのでまだ未実装。
- Circular reference - 循環参照。ID振って色々やる俺々拡張実装が必要で一手間なので当分未実装。
- IDL(Schema) - MessagePack自体に存在しないのでないが、C#クラス定義がそれになるような形で最初から実装済み。
- Pre Code Generation - シリアライザ事前生成。最初から実装済み。ただしWindowsのみでMacはまだ未対応。
- Typeless(self-describing) - 型がバイナリに埋まってるBinaryFormatter的なもの。ver 1.4.0から実装済み。
- Overwrite(Merge) - デシリアライズ時に生成せず上書き、Protobufにはある。現在実装中。
- Deferred - デシリアライズを遅延する。FlatBuffersやZeroFormatterのそれ。コンセプト実装中。
Overwriteは結構面白いと思っていて、例えばUnityだとMonoBehaviourに直接デシリアライズを投げ込むとかが可能になります。デシリアライズのための中間オブジェクトを作らなくて済むのでメモリ節約度がかなり上がるので、普通のAPI通信だと大したことないんですが、リアルタイム通信で頻度が多いようだと、かなりいけてるかなー、と思います。構造体を使うといっても、レスポンス型が大きい場合は構造体は逆に不利ですからね(巨大な構造体はコピーコストが嵩むので)。
DeferredはZeroFormatterアゲイン。アゲインってなんだよって感じですが。なんですかね。
とはいえ、やってると本当にキリがないので、ちょっと一端は実装は後回しにしたいので、もう少し先になります。というのも、UniRx(放置中!)とかMagicOnion(放置中!)とか、先にやるべきことがアリアリなので……!現実逃避してる場合ではない……!
C#のベンチマークドリブンで同一プロジェクトの性能向上を比較する方法
- 2017-08-20
ある日のこと、MessagePack for C#のTypeless Serializerがふつーのと比べて10倍遅いぞ、というIssueが来た。なるほど遅い。Typelessはあんま乗り気じゃなくて、そもそも実装も私はコンセプト出しただけでフィニッシュまでやったのは他の人で私はプルリクマージしただけだしぃ、とかいうダサい言い訳がなくもないのですが、本筋のラインで使われるものでないとはいえ、実装が乗ってるものが遅いってのは頂けない。直しましょう直しましょう。
速くするのは、コード見りゃあどの辺がネックで手癖だけで何をどうやりゃよくて、どの程度速くなるかはイメージできるんで割とどうでもいいんですが(実際それで8倍高速化した)、とはいえ経過は計測して見ていきたいよね。ってことで、Before, Afterをどう調べていきましょうか、というのが本題。
基本的にはBenchmarkDotNetを使っていきます。詳しい使い方はC#でTypeをキーにしたDictionaryのパフォーマンス比較と最速コードの実装で紹介しているので、そちらを見てくださいね、というわけでベンチマークをセットアップ。
class Program
{
static void Main(string[] args)
{
var switcher = new BenchmarkSwitcher(new[]
{
typeof(TypelessSerializeBenchmark),
typeof(TypelessDeserializeBenchmark),
});
switcher.Run(args);
}
}
internal class BenchmarkConfig : ManualConfig
{
public BenchmarkConfig()
{
Add(MarkdownExporter.GitHub);
Add(MemoryDiagnoser.Default);
// ダルいのでShortRunどころか1回, 1回でやる
Add(Job.ShortRun.With(BenchmarkDotNet.Environments.Platform.X64).WithWarmupCount(1).WithTargetCount(1));
}
}
[Config(typeof(BenchmarkConfig))]
public class TypelessSerializeBenchmark
{
private TypelessPrimitiveType TestTypelessComplexType = new TypelessPrimitiveType("John", new TypelessPrimitiveType("John", null));
[Benchmark]
public byte[] Serialize()
{
return MessagePackSerializer.Serialize(TestTypelessComplexType, TypelessContractlessStandardResolver.Instance);
}
}
// Deserializeも同じようなコードなので省略。
ベンチマークコードは本体のライブラリからプロジェクト参照によって繋がっています。こんな感じ。

というわけで、これでコード書き換えてけば、グングンとパフォーマンスが向上してくことは分かるんですが、これだと値をメモらなきゃダメじゃん。Before, Afterを同列に比較したいじゃん、という至極当然の欲求が生まれるのであった。そうじゃないと面倒くさいし。
2つのアセンブリ参照
古いバージョンをReleaseビルドでビルドしちゃって、そちらはDLLとして参照しちゃいましょう。とやると、うまくいきません。

同一アセンブリ名のものは2つ参照できないからです。ということで、どうするかといったら、まぁプロジェクトは自分自身で持ってるので、ここはシンプルにアセンブリ名だけ変えたものをビルドしましょう。

これを参照してやれば、一旦はOK。
extern alias
2つ、同じMessagePackライブラリが参照できたわけですが、今度はコード上でそれを使い分けられなければなりません。そのままでは出し分けできないので(同一ネームスペース、同一クラス名ですからね!)、次にaliasを設定します。

対象アセンブリのプロパティで、Aliasesのところに任意のエイリアスをつけます。今回は1_4_4にはoldmsgpack, プロジェクト参照している最新のものにはnewmsgpackとつけてみました。
あとはコード上で、extern aliasとoldmsgpack::といった::によるフル修飾で、共存した指定が可能です。
// 最上段でextern aliasを指定
extern alias oldmsgpack;
extern alias newmsgpack;
[Config(typeof(BenchmarkConfig))]
public class TypelessSerializeBenchmark
{
private TypelessPrimitiveType TestTypelessComplexType = new TypelessPrimitiveType("John", new TypelessPrimitiveType("John", null));
[Benchmark]
public byte[] OldSerialize()
{
// フル修飾で書かなきゃいけないのがダルい
return oldmsgpack::MessagePack.MessagePackSerializer.Serialize(TestTypelessComplexType, oldmsgpack::MessagePack.Resolvers.TypelessContractlessStandardResolver.Instance);
}
[Benchmark(Baseline = true)]
public byte[] NewSerialize()
{
return newmsgpack::MessagePack.MessagePackSerializer.Serialize(TestTypelessComplexType, newmsgpack::MessagePack.Resolvers.TypelessContractlessStandardResolver.Instance);
}
}
これで完成。実行すれば

最終的に、以前と比較して9倍ほど速くなりました。実際には、何度か実行していって、速くなったことを確認しながらやっています。
クソ遅かったのね!って話なのですが、Typelessは実際クソ遅かったのですが、それ以外の普通のは普通にちゃんと速かったので、一応、大丈夫です、はい、あくまでTypelessだけです、すみません……。
まとめ
ある程度完成している状態になっているならば、ベンチマークドリブンデベロップメントは割とかなり効果的ですね。改善はまずは計測から、とかいっても、結局、その数値が速いのか遅いのかの肌感覚がないとクソほども役に立たないわけですが(ただたんに漠然と眺めるだけの計測には本当に何の意味もないし、数値についての肌感覚を持っているかいないかの経験値は、ツールが充実している今でもなお重要だと思います。肌感覚に繋げていくことを意識して、経験を積みましょう)、さすがにBefore, Afterだととてもわかりやすくて、導入としてもいい感じです。
MessagePack for C#は、昨日ver 1.5.0を出しまして、最速モード(Object-Array)以外の部分(Object-Map)でも性能的にかなり向上したのと、object型のシリアライズがみんなの想像する通りのシリアライズをしてくれるようにようやくなりまして、本気で死角なし、になりました。Typelessの性能向上は次のアップデート。それと、もう一つ大型の機能追加(とても役に立ちます!特にUnityで!)を予定しているので、まだまだ良くなっていきますので期待しといてください。
C#の高速なMySQLのドライバを書こうかという話、或いはパフォーマンス向上のためのアプローチについて
- 2017-08-07
割とずっと公式のC# MySQL Driverは性能的にビミョいのではと思っていて、それがSQL Serverと比較してもパフォーマンス面で足を引っ張るなー、と思っていたんですが、いよいよもって最近はシリアライザも延々と書いてたりで、その手の処理に自信もあるし、いっちょやったるかと思い至ったのであった。つまり、データベースドライバをシリアライゼーションの問題として捉えたわけです。あと会社のプログラム(黒騎士と白の魔王)のサーバー側の性能的にもう少し飛躍させたくて、ボトルネックはいっぱいあるんですが、根本から変えれればそれなりにコスパもいいのでは、みたいな。

中間結果としては、コスパがいいというには微妙な感じというか、Mean下がってなくてダメじゃんという形になって、割と想定と外れてしまってアチャー感が相当否めなくて困ったのですが(ほんとにね!)、まぁそこはおいおいなんとかするとして(します)、メモリ確保だけは確実にめちゃくちゃ減らしました。1/70も減ってるのだから相当中々だと思いたい、ということで、スタート地点としては上等じゃないでしょふか。
↑のベンチマークはBenchmarkDotNetで出していまして、使い方はこないだ別ブログに書いた C#でTypeをキーにしたDictionaryのパフォーマンス比較と最速コードの実装 ので、そちらを参照のことこと。
まだふいんき程度ですが、コードも公開しています。
まだα版とすらいえない状態なので、そこはおいおい。
性能向上のためのアプローチ
競合として、公式のMySQL Connectorと非公式のAsync MySQL Connectorというのがあります。非公式のは、名前空間どころか名前まで被せてきて紛らわしさ超絶大なので、この非公式のやつのやり方は好きじゃありません。
それはさておき、まず非同期の扱いについてなんですが、別に非同期にしたからFastなわけでもありません。だいたいどうせASP.NETの時点でスレッドいっぱいぶちまけてるんちゃうんちゃうん?みたいなところもあるし。むしろ同期に比べてオーバーヘッドが多くなりがち(実装を頑張る必要大!)なので、素朴にやるとむしろ性能低下に繋がります。
さて、で、パフォーマンスを意識したうえで、どう実装していけば良いのか、ですが、MySqlSharpでは以下のものを方針としています。
- 同期と非同期は別物でどちらかがどちらかのラッパーだと遅い。両方、個別の実装を提供し、最適化する必要がある
- 禁忌のMutableなStructをReaderとして用意することでGCメモリ確保を低減する
- テキストプロトコルにおいて数値変換に文字列変換+パースのコストを直接変換処理を書くことでなくす
- ADO.NET抽象を避けて、プリミティブなMySQL APIを提供する。ADO.NETをはそのラッパーとする
- 特化したDapper的なMicro ORMを用意する、それは上記プリミティブMySQL APIを叩く
- Npgsql 3.2のようなプリペアドステートメントの活用を目指す
といったメニューになっていまして、実装したものもあれば妄想の段階のものもあります。
Mutable Struct Reader
structはMutableにしちゃいけない、というのが世間の常識で実際そうなのですが、最近のC#はstruct絡みが延々と強化され続けていて(まだ続いてます - C# Language Design Notes for Jul 5, 2017によるとC# 7.2でrefなんとかが大量投下される)、structについて真剣に考え、活用しなければならない時が来ています。
ところでMySQLのプロトコルはバイナリストリームは、更にPacketという単位で切り分けられて届くようになっています。これを素朴に実装すると
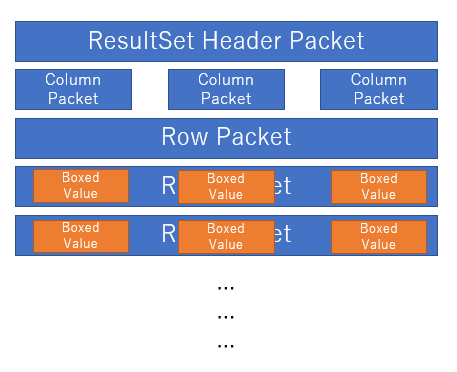
Packet単位にクラスを作っちゃって、無駄一時オブジェクトがボコボコできちゃうんですね。
// ふつーのパターンだとこういう風にネストしていくようにする
using (var packetReader = new PacketReader())
using (var protocolReader = new ProtocolReader(packetReader))
{
var set = protocolReader.ReadTextResultSet();
}
かといって、Packet単位で区切って扱えるようにしないと実装できなかったりなので、悩ましいところです。そこで解決策として Mutable Struct Reader を投下しました。
// MySqlSharpはこういうパターンを作った
var reader = new PacketReader(); // struct but mutable, has reading(offset) state
var set = ProtocolReader.ReadTextResultSet(ref reader); // (ref PacketReader)
PacketReaderはstructでbyte[]とoffsetを抱えていて、Readするとoffsetが進んでいく。というよくあるXxxReader。しかしstruct。それを触って実際にオブジェクトを組み立てる高レベルなリーダーはstaticメソッド、そしてrefで渡して回る(structなのでうかつに変数に入れたりするとコピーされて内部のoffsetが進まない!)。
奇妙なようでいて、実際見かけないやり方で些か奇妙ではあるのですが、この組み合わせは、意外と良かったですね、APIの触り心地もそこまで悪くないですし。もちろんノーアロケーションですし。というわけで、いつになくrefだらけになっています。時代はref。
数値変換を文字列変換を介さず直接行う
クエリ結果の行データは、MySQLは通常テキストプロトコルで行われています(サーバーサイドプリペアドステートメント時のみバイナリプロトコル)。どういうことかというと、1999は "1999" という形で受け取ります。実際にはbyte[]の"1999" ですね。これをintに変換する場合、素朴に書くとこうなります(実際、MySQL Connectorはこう実装されてます)
// 一度、文字列に変換してからint.Parse
int.Parse(Encoding.UTF8.GetString(binary));
これにより一時文字列を作るというゴミ製造が発生します、ついでにint.Parseだって文字列を解析するのでタダな操作じゃない。んで、UTF8で、文字数の長さもわかっている状態で、中身が数字なのが確定しているのだから、直接変換できるんじゃないか、というのがMySqlSharpで導入したNumberConverterです。
const byte Minus = 45;
public static Int32 ToInt32(byte[] bytes, int offset, int count)
{
// Min: -2147483648
// Max: 2147483647
// Digits: 10
if (bytes[offset] != Minus)
{
switch (count)
{
case 1:
return (System.Int32)(((Int32)(bytes[offset] - Zero)));
case 2:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 10) + ((Int32)(bytes[offset + 1] - Zero)));
case 3:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 100) + ((Int32)(bytes[offset + 1] - Zero) * 10) + ((Int32)(bytes[offset + 2] - Zero)));
// snip case 4..9
case 10:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 1000000000) + ((Int32)(bytes[offset + 1] - Zero) * 100000000) + ((Int32)(bytes[offset + 2] - Zero) * 10000000) + ((Int32)(bytes[offset + 3] - Zero) * 1000000) + ((Int32)(bytes[offset + 4] - Zero) * 100000) + ((Int32)(bytes[offset + 5] - Zero) * 10000) + ((Int32)(bytes[offset + 6] - Zero) * 1000) + ((Int32)(bytes[offset + 7] - Zero) * 100) + ((Int32)(bytes[offset + 8] - Zero) * 10) + ((Int32)(bytes[offset + 9] - Zero)));
default:
throw new ArgumentException("Int32 out of range count");
}
}
else
{
// snip... * -1
}
}
ASCIIコードでベタにやってくるので、じゃあベタに45引けば数字作れますよね、という。UTF-8以外のエンコーディングのときどーすんねん?というと
- 対応しない
- そん時は int.Parse(Encoding.UTF8.GetString(binary)) を使う
のどっちかでいいかな、と。今のところ面倒なので対応しない、が有力。
Primitive API for MySQL
MySQL Protocolには本来、もっと色々なコマンドがあります。COM_QUIT, COM_QUERY, COM_PING, などなど。まぁ、そうじゃなくても、COM_QUERYを流すのにADO.NET抽象を被せる必要はなくダイレクトに投下できればいいんじゃない?とは思わなくもない?
// Driver Direct
var driver = new MySqlDriver(option);
driver.Open();
var reader = driver.Query("selct 1"); // COM_QUERY
while (reader.Read())
{
var v = reader.GetInt32(0);
}
// you can use other native APIs
driver.Ping(); // COM_PING
driver.Statistics(); // COM_STATISTICS
// ADO.NET Wrapper
var conn = new MySqlConnection("connStr");
conn.Open();
var cmd = conn.CreateCommand();
cmd.CommandText = "select 1";
var reader = cmd.ExecuteReader();
while (reader.Read())
{
var v = reader.GetInt32(0);
}
APIはADO.NETに似せるようにしてはいますが、余計な中間オブジェクトも一切なく直接叩けるのでオーバーヘッドがなくなります。もちろん、実用的にはADO.NETを挟まないと色々な周辺ツールが使えなくなるので、殆どの場合はADO.NET抽象経由になるとは思いますが。
とはいえ、DapperのようなORMをMySqlSharp専用で作ることにより、直接MySqlSharpのPrimitive APIを叩いて更なるパフォーマンスのブーストが可能です。理屈上は。まだ未実装なので知らんけど。恐らくいけてる想定です、脳内では。
まとめ
実装は、むしろMySQL公式からドキュメントが消滅している - Chapter 14 MySQL Client/Server Protocolせいで、Web Archivesから拾ってきたり謎クローンから拾ってきたりMariaDBのから拾ってきたりと、とにかく参照が面倒で、それが一番捗らないところですね。もはやほんとどういうこっちゃ。
MySQLには最近X-Protocolという新しいプロトコルが搭載されていて、こちらを通すと明らかに良好な気配が見えます。これはProtocol Buffersでやり取りするため、各言語のドライバのシリアライゼーションの出来不出来に、性能が左右されなくなるというのも良いところですね。
が、Amazon AuroraではX-Protocolは使えないし、あまり使えるようになる気配も見えないので、あえて書く意味は、それなりにあるんじゃないかしらん。ちゃんと完成すればね……!それと.NET CoreなどLinux環境下などでも.NET使ってくぞー、みたいな流れだと、当然データベースはMySQL(やPostgreSQL)のほうが多くなるだろう、というのは自然なことですが、そこでDBなども含めたトータルなパフォーマンスでは.NET、遅いっすね!ってなるのはめっちゃ悔しいじゃないですか。でも実際そうなるでしょう。だから、高速なMySQLドライバーというのは、これからの時代に必要なもののはずなのです。
公開しないほうがお蔵入りになる可能性が高いので、公開しました。あとは私の頑張りにご期待下さい。