2024年を振り返る
- 2024-12-30
今年もCysharpはちゃんと生存していて良きかな、というわけでサイトが相変わらずペライチなのでそろそろリニューアルしたいと思って幾星霜。
そんなわけで今年もC#をやりこみ(?)していました……!
新規:
大型アップデート
うーん、十分でしょ!割といつも年の中で浮き沈みはあって、調子でないなあ、ここ数ヶ月ダメだぁ、みたいな気持ちになることが割とあるのですが、振り返ってみれば十分すぎるでしょ!むしろやりすぎでしょ!というわけで、C#最前線キープとしては全く問題ないでしょう。
ハイライトとしてはやはり年初のR3 - C#用のReactive Extensionsの新しい現代的再実装ですかね……!これは、めちゃくちゃ大変でした。物量とかそのものの実装難易度とかもそうなのですが、スタンダードとなっているインターフェイスや仕様を変えるという判断を通しているんですよね。これが、ちゃんと成り立たせられるのか、それで普及させられるのか、という悩みもあり、また、インターフェイスも作りながら割とクルクル最後まで変えながらやってたので、完成して良かったし、1年弱経って、ちゃんと受け入れられているのを見てようやくホッと一息です。Unityにおいても、今年はNuGet化を強烈に推進していったわけですが、なんだかんだで受け入れてもらえってるような気がしますがどうでしょう……?
Claudiaや、なんかブログに書く機会を逸して書いてない気がするのですがUtf8StreamReaderなんかも中々いい感じではあったと思います。
そして大型アップデート系はSource Generator祭り。まずConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークは傑作かと!これは自信作ですねー、めちゃくちゃいいものが出来たと思ってます。直近のConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、などで完全に仕上がりました。
MessagePack for C#は長年懸案だったSource Generator化をついに果たしました。そして色々あって共同メンテナーが離脱したことにより、再度主導権が私の方に戻っています。この辺のことは思うところは割とあるのですが、まぁ結果的には良かったかな、と思ってます。再びやれることの幅も広がったので、MemoryPackともどもで来年は強化していきたいと思っています。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベースも、ずっとSource Generator化したいと思って2年ぐらい放置していた案件なので、ようやく解消できて嬉しい話ですね。しかもやってたら想像通りにめちゃくちゃDX(Developer Experience)よくなってるので、やっと理想が実現できた、というかむしろ時代がやっと追いついた(なんせこの辺の仕組みはSource Generator以前に構築していたパターンなので)という気持ちです。
Cysharpの提供しているライブラリから単独コードジェネレーターは消滅して全てSource Generator化し、そして.NETプロジェクトとUnityプロジェクトのソースコード共有最新手法でも書いたようにUnityとのコードシェアもかなりやりやすい手法が確立できたので、まさにこれはC#大統一理論元年……!「出来ない」よりは「出来たほうがいい」ので、別に今までのやり方が悪かったとは思いませんが、ようやく理想形に到達できた、という感じではあります。来年初頭にはMagicOnionのMessagePack for C# v3対応を出す予定で、これで全てのパーツが揃います!
なんとか of the Year
今年一番大きかった変化として、メモ環境にObsidianを全面導入したのですが、これは超絶良いですね。Daily Notesの有用性というのをようやく理解しました。有料課金して同期することで更に便利、プラグインもマシマシで便利、まぁ入れすぎてもしょうがないので適度に絞ってますよ、と思ったんですが、意外と結構はいってるかも……。
TODOもObsidianに寄せるようにしていますが、特にTODOプラグインなどは使わずにDaily Notesで表現できるように若干工夫しています(TemplaterでJavaScript書いてDaily Notesの生成時にチェック済みのTODOタスクは自動で消すようにしてる&未チェックのTODOタスクは引き継ぐようにしている)。TODOアプリは無限に彷徨って毎年違うものに変えてたりするのですが、これが一番手に馴染んでるので決定版ということでいいかなー。
もう一つ革命的に良かったと思うのはHUAWEI FreeClip。これはとんでもなく良くてビックリした。HUAWEI製品のクオリティの高さにもビビッた。オープンイヤー型のイヤホンなわけですが、付け心地も良いし細かいところも良く出来てるし音質もしっかりしてる。言う事無し。オープンイヤーは、外音取り込みとは耳への圧迫感が自然さが全然違うんですよねえ、これだと1日中付けっぱなしとまではしないけど、割と頻繁に耳につけといて、音を聞くことが増えました。講演動画とか英語のリスニングとか日常生活に流せるといい感じ度が上がります。あとダラダラYouTube見る頻度が相当上がってしまった……。あまり使い分けとかは出来ないタイプの人間なので今まで使っていたAirPods Proはお蔵入りしてFreeClip一本使いになってます。ノイズキャンセリング性能がーというのと真逆なわけですが、外音と混じった音楽も、それはそれで心地よいのでいい感じなので、騒音環境下でもそこまで気にならず使えてる気がします。
あとは、家のキーボードをRealforce RC1に変更しました。HHKBにF1-12キーが追加されたようなレイアウトなわけですが、まず、キーボードにF1-F12は必須なんですよね!Visual Studio的に!あとは、日本語キーボードレイアウトじゃないとダメ人間なので、ずっとコンパクト配列にしたいなあと思いつつも選択肢がなくてなあ、と、テンキーレスぐらいで我慢していたので、満を持しての本命というわけでした。
それとFnキーとの組み合わせによるハードウェアキーレイアウト変更が柔軟かつ安定性が高いことに気づいた!昔から無変換+ESDFを十字キーとして使う癖があって、AutoHotKeyなどソフトウェアでフックするやつを使って実現していたのですが、挙動的に不安定(抜けが出たりするのが辛い)なのが気になってました。が、Realforceの設定で無変換と変換をFnキーにしてしまって、Fnキーとの組み合わせでESDFを十字キーにしてしまえば完璧だった……!というわけで現在のレイアウトがこちら。
そんなにキーボードから手を離さないで全部操作出来ないと!みたいな感じではなく、右手はマウス行きしちゃうので、左手側に詰め込みがちです。とにかくESDFでの十字キー化が安定したのがめっちゃ嬉しい。これ、WSDFじゃないんですか?というところなのですが、主に使うシチュエーションはテキストエディタでの十字移動なので、ESDFはホームポジションから手を動かさずに十字キーになるのがWSDFに比べての圧倒的利点です。それとQAZが空くので、そこにもキーを詰め込めるのも嬉しい。
というわけでQ, AはHome/End(ちなみに私はHomeめちゃくちゃよく使います)。Z, CにShift + Home/End。XにShift + @(つまり```)。VにWin + V。それと1, 2, 3にはAlt + 1, 2, 3を入れています、というのも私はArcというブラウザを使っているのですが、これのスペースの切り替えがAltになっていて、AltよりもFn(元の無変換)を使うことが多いので、そのまま切り替えられるようにしたほうが便利かな、と。
そしてFn + 半角/全角にCtrl + Shift + Alt + Eを割り当てて、これはWindowsのアプリケーションへのグローバルショートカットキーでEverythingを宛ててます。あまりキーをフックするようなのをソフトウェア側で仕込みたくはないのですが、Windows標準機能ならまぁ良いでしょう、ということで。
マクロが欲しいとかショートカットキー登録数が少ないとか思うところもありますが、全体的にはかなり相当良いです!
キーボードといえば、iPad Pro用にlogicool Keys-To-Go 2 for iPadを買ったのですが、これもかなり良くて体験変わりました。今までモバイルキーボード難民で全然しっくり来るものがなかったのですが、これが一番アリだなあ、という感じですね……!
iPadにはprendre タブレットスタンド iPadを貼り付けてキックスタンドにしてます。たった17g追加するだけで自立する!これは超便利。軽量化したとはいえ、重たいiPadなのでケースとか入れてこれ以上重たくしたくはない。が、自立してくれないと不便、で、色々探して買ったのがこれでした。
横はもちろん、縦でもちゃんと安定してくれる。粘着テープで貼り付けるタイプは剥がれる危険性があるわけですが、iPad Proが軽量化してくれたおかげもあってそこそこ安定しています。ただし両面テープは付属のは剥がして、色々試した結果スリーエム(3M) 3M 両面テープ 超強力 スーパー多用途 薄手 幅12mmに落ち着きました。あまり強力すぎると、それはそれで剥がしにくくて売るときとかに泣いちゃう(本当に剥がれない……!)ので、粘着力が基本なのですが、その上でいざというときに剥がれてくれるかどうかのバランスも大事……。
というわけかでiPad Pro 13インチも買ったのですが、これは満足感高いです。違いは、やっぱ有機ELディスプレイですかねー、今までのiPadの画質って割と不満足というか、どう見てもiPhoneよりも画質悪いじゃん!という感じで萎え萎えだった(のであまり使わなくなっていった……)のですが、今回の画質ならOKです!というわけで利用頻度上がりました。ちなみにNano-textureガラスではありません。いや、最初Nano-textureガラスのやつを買っちゃったんですが、これ普通に画質めちゃくちゃ悪いんですよ。インターネットマンが画質は大して変わらないとか言うから信じたのにめっちゃ悪くて……。耐えられなかったのですみませんがの返品からの買い直しコンボさせていただきました……。
そして、povo。ずっとauだったのですが、povoに乗り換えました。で、これがめちゃくちゃいい、というかiPadでの利用にとてもいい。SIM付きモデル買ったのですが、auでのデータ共有がうまくできず(難易度高すぎ&なんかバグってると思う……)塩漬けだったのです。が、povoで単独での契約だと、当たり前ですがスムーズに通信できて快適。iPadもテザリングがそこそこiPhoneとスムーズにつながるからなくてもいいじゃん、とか思ってなくもなかったのですが、単独で通信できる快適さはぜんぜん違う!そして、私の用途的に別にそんなに毎日通信するわけでもないので、あんまりギガはいらないんですが、povoだとプロモーションと合わせると実質0円運用できるのが、とてもいい感じです。例えばローソン500円購入券がpovoで500円で買えて0.3GBの通信料がついてくる、とかだと、どうせ500円買うんだしpovoで買ってiPadに0.3GBチャージしとくかあ、みたいな。
最後に、Game of the Yearは今更グランツーリスモ7ということで(?)。というのもLogicoolのPROレーシングホイール + PRO RACING PEDALSを買ったのですが、これが抜群にいい……!今まで(G923)とは桁違い、というか実際桁違いで、G923が2.4nmというフィードバック力しか出せていないのですが、PROレーシングホイール11nm出る!11nmって別に全くピンと来ないのですが、触ってみると2.4nmはスカスカで、逆に11nmをフルに出すと重くて曲げられないレベル(実際、筋肉痛になった……)。そんなわけで一気に楽しくなったので、今年は一番グランツーリスモ7をやってた気がします。はい。
来年
C#でSaaS作りたい欲求はずっとあるので、OSSメンテナンス業が重くのしかかりつつも、来年はそっち側でも進展を見せたいと思ってます……!Cysharpももう少し大きくしたいとは思っているので、引き続きよろしくおねがいします。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベース
- 2024-12-20
MasterMemory v3出しました!ついにSource Generator化されました!
MasterMemoryはC#のインメモリデータベースで、高速で、メモリ消費量が少なく、タイプセーフ。というライブラリです。SQLiteを素朴に使うよりも 4700倍高速だぞ、と。
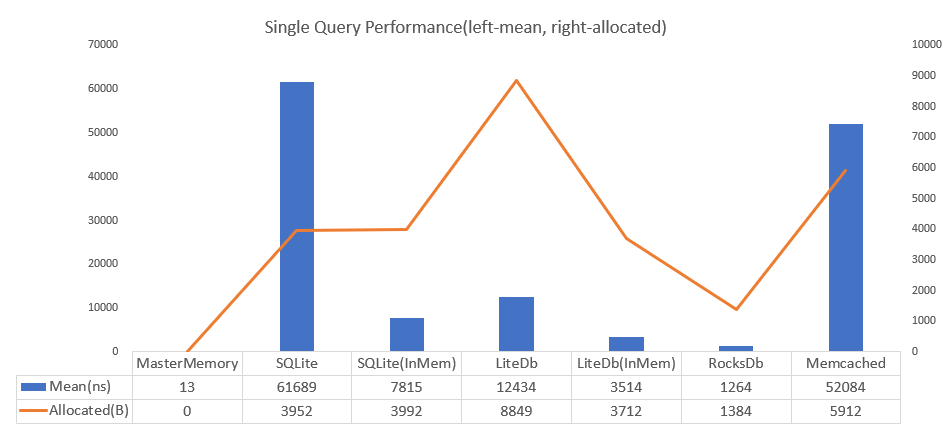
もともとMasterMemoryはC#コードからC#コードを生成するという、Source Generatorのなかった時代にSource Generatorのようなことをやる先進的な設計思想を持ったシステムでした。今回移植してみて、あまりにもスムーズに移植できるし、旧来のコードも全く手を付けずにそのまま動いたので我ながら感心しました。やっと時代が追い付いたか……。
というわけで、以下のようなC#定義からデータベース構築のためのコードと、クエリ部分がSource Generatorによって自動生成されます。
[MemoryTable("person"), MessagePackObject(true)]
public record Person
{
[PrimaryKey]
public required int PersonId { get; init; }
[SecondaryKey(0), NonUnique]
[SecondaryKey(1, keyOrder: 1), NonUnique]
public required int Age { get; init; }
[SecondaryKey(2), NonUnique]
[SecondaryKey(1, keyOrder: 0), NonUnique]
public required Gender Gender { get; init; }
public required string Name { get; init; }
}

C#コードとして生成されるので、クエリが全て入力補完も効くし戻り値も型付けされていてタイプセーフなのはもちろん、パフォーマンスの良さにも寄与しています。
読み取り専用データベースとして使うので、クラス定義はイミュータブルのほうがいいわけですが、最近のC#は record, init, required といった機能が提供されているので、Readonly Databaseとしての使い勝手が更に上がりました。Unityではrequiredは使えませんがrecordとinitは使えるので、Unityでも問題ありません。
なお、Unity版は今回からNuGetForUnityでの提供となります。また、MessagePack for C#もSource Generator対応のv3を要求します。
Next
MasterMemory、実は結構使われています。ゲームでも採用されているものを割と見かけるようになりました。なので、外部ツール由来のコード生成の面倒さにはだいぶ心を痛めていたので、ようやく解消できて本当に嬉しい!
v2からv3へのマイグレーションもそんなに大変ではない、はずです。あえて生成コードの品質や、コアの関数、メソッドシグネチャなどには一切手を加えていないので、今までコマンドラインツールを叩いていた部分を削除するだけで、そのまま動き出すぐらいの代物になっています。名前空間の設定だけ、アセンブリ属性で行ってください。
そのうえでrecord対応(今までしてなかった!)や#nullable enable対応(今までしてなかった!)を追加しているので、生成部分以外の使い勝手も上がっているはずです。
今後はMemoryPack対応や、そもそものAPIの更なるモダン化(現状はnetstandard2.0なので古い)、全体的に改修したいところ(ImmutableBuilderなど生成コードの差し替え部分)、などなどやれること自体はめっちゃありますので、折を見て手を入れていけるといいかなあ、と思っています。
ConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、など
- 2024-12-16
ConsoleAppFramework v5の比較的アップデートをしました!v5自体の詳細は以前に書いたConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークを参照ください。v5はかなり面白いコンセプトになっていて、そして支持されたと思っているのですが、幾つか使い勝手を犠牲にした点があったので、今回それらをケアしました。というわけで使い勝手がかなり上がった、と思います……!
名前の自動変換を無効にする
コマンドネームとオプションネームは、デフォルトでは自動的にkebab-caseに変換されます。これはコマンドラインツールの標準的な命名規則に従うものですが、内部アプリケーションで使うバッチファイルの作成に使ったりする場合などには、変換されるほうが煩わしく感じるかもしれません。そこで、アセンブリ単位でオフにする機能を今回追加しました。
using ConsoleAppFramework;
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]
var app = ConsoleApp.Create();
app.Add<MyProjectCommand>();
app.Run(args);
public class MyProjectCommand
{
public void Execute(string fooBarBaz)
{
Console.WriteLine(fooBarBaz);
}
}
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]によって自動変換が無効になります。この例では ExecuteCommand --fooBarBaz がコマンドとなります。
実装面でいうと、Source Generatorにコンフィグを与えるのはAdditionalFilesにjsonや独自書式のファイル(例えばBannedApiAnalyzersのBannedSymbols.txt)を置くパターンが多いですが、ファイルを使うのは結構手間が多くて面倒なんですよね。boolの1つや2つを設定するぐらいなら、アセンブリ属性を使うのが一番楽だと思います。
実装手法としてはCompilationProviderからAssembly.GetAttributesで引っ張ってこれます。
var generatorOptions = context.CompilationProvider.Select((compilation, token) =>
{
foreach (var attr in compilation.Assembly.GetAttributes())
{
if (attr.AttributeClass?.Name == "ConsoleAppFrameworkGeneratorOptionsAttribute")
{
var args = attr.NamedArguments;
var disableNamingConversion = args.FirstOrDefault(x => x.Key == "DisableNamingConversion").Value.Value as bool? ?? false;
return new ConsoleAppFrameworkGeneratorOptions(disableNamingConversion);
}
}
return new ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion: false);
});
これを他のSyntaxProviderからのSourceとCombineしてやれば、生成時に属性の値を参照できるようになります。
ConfigureServices/ConfigureLogging/ConfigureConfiguration
ゼロディペンデンシーを掲げている都合上、特定のライブラリに依存したコードを生成することができないという制約がConsoleAppFramework v5にはありました。そのため、DIとの統合時に自分でServiceProviderをビルドしなければならないなの、利用には一手間必要でした。そこで、NuGetでのDLLの参照状況を解析し、Microsoft.Extensions.DependencyInjectionが参照されていると、ConfigureServicesメソッドがConsoleAppBuilderから使えるという実装を追加しました。
var app = ConsoleApp.Create()
.ConfigureServices(service =>
{
service.AddTransient<MyService>();
});
app.Add("", ([FromServices] MyService service, int x, int y) => Console.WriteLine(x + y));
app.Run(args);
これによりフレームワークそのものはゼロディペンデンシーでありながら、ライブラリ依存のコードも生成することができるという、新しい体験を提供します。これはMetadataReferencesProviderから引っ張ってきて生成処理に回すことで実現しました。
var hasDependencyInjection = context.MetadataReferencesProvider
.Collect()
.Select((xs, _) =>
{
var hasDependencyInjection = false;
foreach (var x in xs)
{
var name = x.Display;
if (name == null) continue;
if (!hasDependencyInjection && name.EndsWith("Microsoft.Extensions.DependencyInjection.dll"))
{
hasDependencyInjection = true;
continue;
}
// etc...
}
return new DllReference(hasDependencyInjection, hasLogging, hasConfiguration, hasJsonConfiguration, hasHost);
});
context.RegisterSourceOutput(hasDependencyInjection, EmitConsoleAppConfigure);
参照の解析は複数のものに対して行っていて、他にもMicrosoft.Extensions.Loggingが参照されていればConfigureLoggingが使えるようになります。なのでZLoggerと組み合わせれば
// Package Import: ZLogger
var app = ConsoleApp.Create()
.ConfigureLogging(x =>
{
x.ClearProviders();
x.SetMinimumLevel(LogLevel.Trace);
x.AddZLoggerConsole();
x.AddZLoggerFile("log.txt");
});
app.Add<MyCommand>();
app.Run(args);
// inject logger to constructor
public class MyCommand(ILogger<MyCommand> logger)
{
public void Echo(string msg)
{
logger.ZLogInformation($"Message is {msg}");
}
}
といったように、比較的すっきりと設定が統合できます。
appsettings.jsonから設定ファイルを引っ張ってくるというのも最近では定番パターンですが、これもMicrosoft.Extensions.Configuration.Jsonを参照しているとConfigureDefaultConfigurationが使えるようになり、これはSetBasePath(System.IO.Directory.GetCurrentDirectory())とAddJsonFile("appsettings.json", optional: true)を自動的に行います(追加でActionでconfigureすることも可能、また、ConfigureEmptyConfigurationもあります)。
なのでコンフィグを読み込んでクラスにバインドしてコマンドにDIで渡す、などといった処理もシンプルに書けるようになりました。
// Package Import: Microsoft.Extensions.Configuration.Json
var app = ConsoleApp.Create()
.ConfigureDefaultConfiguration()
.ConfigureServices((configuration, services) =>
{
// Package Import: Microsoft.Extensions.Options.ConfigurationExtensions
services.Configure<PositionOptions>(configuration.GetSection("Position"));
});
app.Add<MyCommand>();
app.Run(args);
// inject options
public class MyCommand(IOptions<PositionOptions> options)
{
public void Echo(string msg)
{
ConsoleApp.Log($"Binded Option: {options.Value.Title} {options.Value.Name}");
}
}
Microsoft.Extensions.Hostingでビルドしたい場合は、ToConsoleAppBuilderが、これもMicrosoft.Externsions.Hostingを参照すると追加されるようになっています。
// Package Import: Microsoft.Extensions.Hosting
var app = Host.CreateApplicationBuilder()
.ToConsoleAppBuilder();
また、今回から設定されているIServiceProviderはRunまたはRunAsync終了後に自動的にDisposeするようになりました。
RegisterCommands from Attribute
コマンドの追加はAddまたはAdd<T>が必要でしたが、クラスに属性を付与することで自動的に追加される機能をいれました。
[RegisterCommands]
public class Foo
{
public void Baz(int x)
{
Console.Write(x);
}
}
[RegisterCommands("bar")]
public class Bar
{
public void Baz(int x)
{
Console.Write(x);
}
}
これらは自動で追加されています。
var app = ConsoleApp.Create();
// Commands:
// baz
// bar baz
app.Run(args);
これらとは別に追加でAdd, Add<T>することも可能です。
なお、実装の当初予定では任意の属性を使えるようにする予定だったのですが、IncrementalGeneratorのAPIの都合上難しくて、固定のRegisterCommands属性のみを対象としています。また、継承することもできません……。なので独自の処理用属性がある場合は、組み合わせてもらう必要があります。例えば以下のように。
[RegisterCommands, Batch("0 10 * * *")]
public class MyCommands
{
}
この辺はConsoleAppFrameworkとAWS CDKで爆速バッチ開発を読んで、うーん、v5を使ってもらいたい!なんとかしたい!と思って色々考えたのですが、この辺が現状の限界でした……。名前変換オフりたいのもわかるー、とか今回の更新内容はこの記事での利用例を参考にさせていただきました、ありがとうございます!
まとめ
v5のリリース以降もフィルターを外部アセンブリに定義できるようになったり、Incremental Generatorの実装を見直して高速化するなど、Improvmentは続いています!非常に良いフレームワークに仕上がってきました!
ところでSystem.CommandLine、現状うまくいってないからResettting System.CommandLineだ!と言ったのが今年の3月。例によって想像通り進捗は無です。知ってた。そうなると思ってた。何も期待しないほうがいいし、普通にConsoleAppFramework使っていくで良いでしょう。
SourceGenerator対応のMessagePack for C# v3リリースと今後について
- 2024-12-06
先月MessagePack for C#プロジェクトは .NET Foundationに参加しました!より安定した視点で利用していただけるという一助になればいいと思っています。
そして、長く開発を続けていたメジャーバージョンアップ、v3がリリースされました。コア部分はv2とはほぼ変わらずですが、Source Generatorを全面的に導入しています。引き続きIL動的生成も存在するため、IL動的生成とSource Generatorのハイブリッドなシリアライザーとなります。v3にはSource GeneratorとAnalyzerがビルトインで同梱されていて、今までのコードはv3でコンパイルするだけで自動的にSource Generator化されます。v2 -> v3アップデートでSource Generator対応するために追加でユーザーがコードを記述する必要はありません!
挙動を詳しく見ていきましょう。例えば、
[MessagePackObject]
public class MyTestClass
{
[Key(0)]
public int MyProperty { get; set; }
}
というコードを書くと、自動的に以下のコードがSource Generatorによって内部的に生成されます。
partial class GeneratedMessagePackResolver
{
internal sealed class MyTestClassFormatter : IMessagePackFormatter<MyTestClass>
{
public void Serialize(ref MessagePackWriter writer, MyTestClass value, MessagePackSerializerOptions options)
{
if (value == null)
{
writer.WriteNil();
return;
}
writer.WriteArrayHeader(1);
writer.Write(value.MyProperty);
}
public MyTestClass Deserialize(ref MessagePackReader reader, MessagePackSerializerOptions options)
{
if (reader.TryReadNil())
{
return null;
}
options.Security.DepthStep(ref reader);
var length = reader.ReadArrayHeader();
var ____result = new MyTestClass();
for (int i = 0; i < length; i++)
{
switch (i)
{
case 0:
____result.MyProperty = reader.ReadInt32();
break;
default:
reader.Skip();
break;
}
}
reader.Depth--;
return ____result;
}
}
}
また、このGeneratedMessagePackResolverはデフォルトのオプション(StandardResolverなど)に最初から登録されているため、
public static readonly IFormatterResolver[] DefaultResolvers = [
BuiltinResolver.Instance,
AttributeFormatterResolver.Instance,
SourceGeneratedFormatterResolver.Instance, // here
ImmutableCollection.ImmutableCollectionResolver.Instance,
CompositeResolver.Create(ExpandoObjectFormatter.Instance),
DynamicGenericResolver.Instance, // only enable for RuntimeFeature.IsDynamicCodeSupported
DynamicUnionResolver.Instance];
ユーザーコードのアセンブリに含まれているシリアライズ対象クラスは、Source Generatorによって生成されたコードが優先的に使われることになります。GeneratedMessagePackResolverは既定の名前空間や名前を変えたり、生成フォーマッターをmapベースに変更するなど、幾つかのカスタマイズポイントも用意されています。より詳しくは新しいドキュメントを見てください。また、v2 -> v3の変更箇所の詳細を知りたい人はMigration Guide v2 -> v3をチェックしてください。
Unityにおいては導入方法が大きく変わりました。コアライブラリは .NET 版と共通になりNuGetからのインストールが必要となります。そのうえでUPMでUnity用の追加コードをダウンロードする必要があります。詳しくはMessagePack-CSharp#unity-supportのセクションを確認してください。
.unitypackageの提供は廃止されています。また、IL2CPP対応のために要求していたmpcはなくなりました。完全にSource Generatorに移行されます。そのため、Unityのサポートバージョンは 2022.3.12f1 からとなります。Source Generatorに関してはNuGetForUnityでのコアライブラリインストール時に自動的に有効化されるため、追加の作業は必要ありません。
History and Next
MessagePack for C#のオリジナル(v1)は私(Yoshifumi Kawai/@neuecc)によって、2017年にリリースしました。当時開発していたゲームのパフォーマンス問題を解決するために、2016年時点で存在していた(バイナリ)シリアライザーでは需要を満たせなかったため、パフォーマンスを最重要視したバイナリシリアライザーとして作成しました。合わせて、同じくネットワークシステムとして作成したgRPCベースのRPCフレームワークMagicOnionもリリースしています。
v1リリース当時はbyte[]のみを対象としていましたが、Span<T>やIBufferWriter<T>など、.NETには次々と新しいI/O系のAPIが追加されていったため、v2ではそれらに焦点を当てた新しいデザインが導入されました。この実装はMicrosoftのEngineerであるAndrew Arnott / @AArnott氏によって主導され、リリースしています。
以降、共同のメンテナンス体制として、そして私の個人リポジトリ(neuecc/MessagePack-CSharp)からオーガナイゼーション(MessagePack-CSharp/MessagePack-CSharp)して今に至ります。Visual Studio内部での利用やSignalRのバイナリープロトコル、Blazor Serverのプロトコルなど大きなMicrosoftのプロダクトでも使用され、GitHubでのスター数は.NETのバイナリーシリアライザーとしては最も大きなスターを集めています。.NET 9で廃止されたBinaryFormatterの移行先の一つとしても推奨されています。
v3ではSource Generatorに対応することで、より高いパフォーマンスと柔軟性、AOT対応への第一段階に踏み出すことができました。
MessagePack for C#プロジェクトは大きな成功を収めたと考えていますが、しかし現在、AArnott氏は個人の新しいMessagePackプロジェクトの開発を開始しています。私もその間、MemoryPackという異なるフォーマットのシリアライザーをリリースしています。そのため、MessagePack for C#の今後と、その特性について、ある程度説明する必要があると思います。
引き続きメンテナンス体制は2人だと考えていますが、アクティブな活動に関しては、再び私が担うことになるかもしれません。私はMessagePackとMemoryPackとでは異なる性質を持ったフォーマットであるため、どちらも重要であるという認識で動いています。オリジナルの実装であるMessagePack for C#も気に入ってますし、現在においても決して引けを取ることのないものだと思っています。
AArnott氏の別のMessagePackシリアライザーとは根本的な哲学が若干異なります。その点で、私はそれはより良く改善されたシリアライザーではなく、別の個性のシリアライザーだと認識しています。そこで、違いについて説明させてください。
Binary spec, default settings and performance
シリアライザーのパフォーマンスに重要なのは、「仕様と実装」の両方です。例えばテキストフォーマットのJSONよりもバイナリフォーマットのほうが一般的には速いでしょう。しかし、よくできたJSONシリアライザーは、中途半端な実装のバイナリシリアライザーよりも高速です(私はそれをUtf8Jsonというシリアライザーを作成することで実証したことがあります)。なので、仕様も大事だし、実装も大事です。どちらも兼ねることができれば、それがベストなパフォーマンスのシリアライザーとなります。
MessagePackのバイナリ仕様は "It's like JSON. but fast and small." を標語にしている通り、JSONのバイナリ化としてあらわされています。ところが、MessagePack for C#のデフォルトは必ずしもJSON likeを狙っているわけではありません。
[MessagePackObject]
public class MsgPackSchema
{
[Key(0)]
public bool Compact { get; set; }
[Key(1)]
public int Schema { get; set; }
}
このクラスをシリアライズした場合は、JSONで表現すると[true, 0]のようになります。これはオブジェクトをarrayベースでシリアライズしているからで、mapベースでシリアライズすると{"Compact":true,"Schema":0}のような表現になります。
arrayベースの利点は見た通りに、バイナリ容量として、よりコンパクトになります。容量がコンパクトなことは処理量が少なくなるためシリアライズの速度にも良い影響を与えます。また、デシリアライズにおいては、文字列を比較してデシリアライズするプロパティを探索する必要がなくなるため、より高速なデシリアライズ速度が期待できます。
なお、arrayベースのシリアライズはMessagePackの仕様策定者である Sadayuki Furuhashi 氏によるリファレンス実装であるmsgpack-javaなどでも採用されているため、決して異端のやり方というわけではありません。
MessagePack-CSharpではJSONライクなmapベースでシリアライズしたい場合は[MessagePackObject(true)]と記述することができます。また、Source Generatorの場合はResolver単位でオーバーライドして強制的にmapベースにすることも可能です。
[MessagePackObject(keyAsPropertyName: true)]
public class MsgPackSchema
{
public bool Compact { get; set; }
public int Schema { get; set; }
}
mapの利点は、柔軟なスキーマエボリューションの実現と、他言語との疎通する際にコミュニケーションが取りやすいこと、バイナリそのものの自己記述性が高いことです。デメリットは容量とパフォーマンスへの悪影響、特にオブジェクトの配列においては一要素毎にプロパティ名が含まれることになってしまい、かなりの無駄となります。
デフォルトをarrayにしているのは、コンパクトさとパフォーマンスの追求のためです。私はMessagePackをJSON likeの前に、高いパフォーマンスを実現可能なバイナリ仕様として考えました。もちろん、mapも重要なので、その上で比較的簡単にmapモードを実現するために属性に(true)を追加するだけで可能にしました。
arrayモードの場合はKey属性を全てのプロパティに付与する必要があります。これは、例えばProtocol Buffersなどでも数値タグを必要とするように、プロパティ名そのものをキーとするわけではなければ、必須だと考えています。もちろん、連番で自動採番させることも可能ですが、バイナリフォーマットのキーを暗黙的に処理するのはリスクが大きすぎる(順番を弄ったりするだけでバイナリ互換性が壊れることになる)と判断しています。つまり、明示的がデフォルト、ということです。大きなプロジェクト開発ではシニアメンバーからジュニアメンバーまでコードを触ることになるでしょう、全てを理解している人だけがコードを触るわけではありません。なので、暗黙的な挙動は避けるべきで、明示的にすべきだという強い意志で、この設計を選んでいます。
ただしKeyを全てのプロパティに付与する作業はとても苦痛です(私はMessagePack-CSharp開発以前には、DataContractやprotobuf-netで辛い思いをしました)。そこで、Analyzer + Code Fixによって、自動的に付与する機能を用意しました。これにより明示的であることの苦痛は和らげられ、良いとこどりができているのだと考えています。
別のMessagePackシリアライザーのデフォルトはmapのようです。これはPolyTypeというSource Generatorベースのライブラリ作成のための抽象化ライブラリがベースとしているためでもあり、また、そちらのほうを好んでいるという明示的な判断でもあるようです。
「デフォルト」はライブラリで一つしか選べません。どちらのモードで処理することができたとしても、「デフォルト」はただ一つです。改めて言うと、私はバイナリフォーマットとしての「コンパクトとパフォーマンス」を好み、優先しています。
皆さんはPolyTypeについて初めて知ったかもしれません。私はPolyTypeはあまり好意的には考えていません。ちょっとしたものを作るには非常に便利だとは思いますが、ベストなパフォーマンスを狙ったり、ベストなアイディアを表現するには、抽象層であることの制限が大きすぎると考えています。なので、MessagePack for C#で採用することはありませんし、他の何かを作る際にも採用することはないでしょう。
Unity(multiplatform) Support
MessagePack for C#ではv1の時代からゲームエンジンUnityの1st classのサポートを実行してきました。これは私がCygamesという日本のゲーム会社の関連会社(Cysharp)のCEOを務めていて、ビデオゲームインダストリーと関係性が深いという都合もあります。自分たちで実際にUnityで動くものを作り、使ってきました。もちろん、サーバーサイドやデスクトップアプリケーションでも使っています。
UnityにはIL2CPPという独自のAOTシステムがあり、特にiOSなどモバイルプラットフォームでのリリースには必須なのですが、それもSource Generatorが存在しなかった時代から、mpcというRoslynを使ったコードジェネレートツールを作り、提供してきました。数百のモバイルゲームでMessagePackが使われているのは、これら私の熱心なサポートのお陰といっても過言ではないでしょう。v3ではついにSource Generatorベースになったことにより、ワークフローが大きく簡易化されることとなります!
一般的に、.NETコミュニティにおいてはUnityサポートはかなり軽視されていました。また、外から見ているとMicrosoftやMicrosoftの従業員もそのようで、自社のプラットフォーム以外への関心は薄そうです。こうした態度は、あまり好ましいとは思っていませんし、せっかくの .NET の可能性を狭めていることにもなっています。Xamarinがうまく成長軌道に乗らなかったのも、そのようなMicrosoft自体の冷たい視線のせいだとも思っています。
私は、私の作るライブラリはなるべくUnityにもしっかり対応できるように気を付けて作っています(最新は新しいReactive ExtensionsライブラリーであるCysharp/R3)。別のMessagePackシリアライザーに関しては、あまりしっかりした対応はされなさそうですが……。
Beyond v3
v3のNative AOT Supportは完全ではありません。Source Generatorにするだけでは完全なNative AOT対応とはならないのは難しいところです。これはUnityのAOTであるIL2CPPでは完璧に動作しているだけに、正直不可解なことでもあり、また、Microsoftのよくない癖が出ているな、とも思っています。つまり、完璧な対応をするために、複雑なものを提供している。それが現在のNative AOTです。複雑怪奇な属性やフローは、理解できるところもありますが、もう少し簡略化すべきだったと思います。まぁ、もう修正されることもないのでしょうが……。
パフォーマンス面でもv1からv2で退化してしまった点もあるので、最新の知見を元に、実装面での改善を施す必要があります。特にReadOnlySequenceの利用幅が大きいことは、かなりの制約を生み出していて、不満があります。
.NET 9でPipeReader/PipeWriterが標準化されたことによる、より良い非同期APIや、パフォーマンスを両立したストリーミング対応というのも、大きなトピックとなるかもしれません。
MessagePack for C#は広く使われているが故に、破壊的変更はしづらいし、互換性の維持は最重要トピックスです。しかし、世の中が変わっていく以上、進化しないことを選んだら、それは滅びる道でしかありません。やれることはまだまだあると思っていますので、.NETにおける最先端の、最高のバイナリシリアライザーであり続けたいと思っています(MemoryPackもね……!)
まずは、v3のSource Generatorをぜひ試してみてください。皆の力でより良いものを作っていけるというのも、OSSの良さだと思っています。
Fuzzing in .NET: Introducing SharpFuzz
- 2024-12-03
この記事はC# Advent Calendar 2024に参加しています。また、先月開催されたdotnet newというイベントでの発表のフォローアップ、のつもりだったのですがコロナ感染につき登壇断念……。というわけで、セッション資料はないので普通にブログ記事とします!
dotnet/runtime と Fuzzing
今年に入ってからdotnet/runtimeにFuzzingテストが追加されています。dotnet/runtime/Fuzzing。というわけで、実はfuzzingは非常に最近のトピックスなのです……!
ファジングとはなんなのか、ザックリとはランダムな入力値を大量に投げつけることによって不具合や脆弱性を発見するためのテストツールです。エッジケースのテスト、やはりどうしても抜けちゃいがちだし、ましてや脆弱性になりうる絶妙な不正データを人為的に作るのも難しいので、ここはツール頼みで行きましょう。
Goでは1.18(2022年)から標準でgo fuzzコマンドとして追加されたらしいので、 Go1.18から追加されたFuzzingとはのような解説記事を読むのもイメージを掴みやすいです。
さて、dotnet/runtimeのFuzzingでは現状
- AssemblyNameInfoFuzzer
- Base64Fuzzer
- Base64UrlFuzzer
- HttpHeadersFuzzer
- JsonDocumentFuzzer
- NrbfDecoderFuzzer
- SearchValuesByteCharFuzzer
- SearchValuesStringFuzzer
- TextEncodingFuzzer
- TypeNameFuzzer
- UTF8Fuzzer
というのものが用意されてます。わかるようなわからないような。だいたいデータのパース系によく使われるものなので、その通りのところに用意されています。一番わかりやすいJsonDocumentFuzzerを見てみましょう。
internal sealed class JsonDocumentFuzzer : IFuzzer
{
public string[] TargetAssemblies { get; } = ["System.Text.Json"];
public string[] TargetCoreLibPrefixes => [];
public string Dictionary => "json.dict";
// fuzzerからのランダムなバイト列が入力
public void FuzzTarget(ReadOnlySpan<byte> bytes)
{
if (bytes.IsEmpty)
{
return;
}
// The first byte is used to select various options.
// The rest of the input is used as the UTF-8 JSON payload.
byte optionsByte = bytes[0];
bytes = bytes.Slice(1);
var options = new JsonDocumentOptions
{
AllowTrailingCommas = (optionsByte & 1) != 0,
CommentHandling = (optionsByte & 2) != 0 ? JsonCommentHandling.Skip : JsonCommentHandling.Disallow,
};
using var poisonAfter = PooledBoundedMemory<byte>.Rent(bytes, PoisonPagePlacement.After);
try
{
// それをParseに投げて、もし不正な例外が来たらなんかバグっていたということで
JsonDocument.Parse(poisonAfter.Memory, options);
}
catch (JsonException) { }
}
}
ようは想定外のデータ入力でJsonDocument.Parseが失敗しないことを祈る、といったものですね。正常に認識しているinvalidな値ならJsonExceptionをthrowするはずですが、ArgumentExceptionとかStackOverflowExceptionとかが出てきちゃった場合は認識できていない不正パターンなので、ちゃんとしたハンドリングが必要になってきます。
では、これを参考にやっていきましょう、とはなりません。えー。まず、dotnet/runtimeのFuzzingではSharpFuzz, libFuzzer, そしてOneFuzzが使用されていると書いてあるのですが、OneFuzzはMicrosoft内部ツールなので外部では使用できません。正確には2020年にオープンソース公開したものの、2023年にはクローズドに戻している状態です。まぁ事情は色々ある。しょーがない。
というわけで、これはMicrosoft内部で動かすためのOneFuzzや、dotnet/runtimeで動かすために調整してあるIFuzzerといったフレームワーク部分が含まれているので、小規模な自分たちのコードをfuzzingするにあたっては、不要ですし、ぶっちゃけあまり参考にはなりません!解散!
Introducing SharpFuzz
そんなわけでdotnet/runtimeのFuzzingでも使われているMetalnem/sharpfuzz: AFL-based fuzz testing for .NETを直接使っていきます。sharpfuzzはafl-fuzzと連動して動くように作られている .NETライブラリです。3rd Partyライブラリですが作者はMicrosoftの人です(dotnet/runtimeで採用されている理由でもあるでしょう)。ReadMeのTrophiesでは色々なもののバグを見つけてやったぜ、と書いてあります。AngleSharpとかGoogle.ProtobufとかGraphQL-ParserとかMarkdigとかMessagePack for C#とImageSharpとか。まぁ、やはり用途としてはパーサーのバグを見つけるのには適切、という感じです。
AFL(American Fuzzy Lop)ってなに?ということなのですが、そもそもファジングの「ランダムな入力値を大量に投げつける」行為は、完全なランダムデータを投げつけていくわけではありません。完全ランダムだとあまりにも時間がかかりすぎるため、脆弱性発見において実用的とは言えない。そこでAFLはシード値からのミューテーションと、カバレッジをトレースしながら効率よくデータを生成していきます。Wikipediaから引用すると
テスト対象のプログラム(テスト項目)のソースコードをインストルメント化することにより、afl-fuzzは、ソフトウェアのどのブロックが特定のテスト刺激で実行されたかを後で確認できる。そのため、AFLはグレーボックステストに使用することができる。遺伝的手法による検査データの生成に関連して、ファザーはテストデータをより適切に生成できるため、このメソッドを使用しない他のファザーよりも、処理中に以前は使用されていなかったコードブロックが実行される。その結果、コードカバレッジは比較的短い時間で比較的高い結果が得られる。この方法は、生成されたデータ内の構造を独立して(つまり、事前の情報なしで)生成することができる。このプロパティは、テストカバレッジの高いテストコーパス(テストケースのコレクション)を生成するためにも使用される。
というわけでdotnet testのようにテストコードを渡したら全自動でやってくれる、というほど甘くはなくて、多少の下準備が必要になってきます。SharpFuzzは一連の処理をある程度やってくれるようにはなっていますが、そもそもに実行までに二段階の処理が必要になっています。
- sharpfazzコマンド(dotnet tool)でdllにトレースポイントを注入する
- その注入されたdll(とexe)をネイティブのfuzzing実行プロセス(afl-fuzzなど)に渡す
dllにトレースポイントを注入はお馴染みのCecilでビルド済みのDLLのILを弄ってトレースポイントを仕込みます。
これは注入済みのdllですが、Trace.SharedMemとかTrace.PrevLocationとか、分岐点に対して明らかに注入している様が見えます。そうしたトレースポイントとの通信や実行データ生成などは外部プロセスが行うので、SharpFuzzというライブラリは、それ自体は実行ツールではなくて、それらとの橋渡しをするためのシステムということです。
ではやっていきましょう!色々なシステムが絡んでくる分、ちょっとややこしく面倒くさいのと、ReadMeの例をそのままやると罠が多いので、少しアレンジしていきます。
まずはRequirementsですが、実行機であるAFLがWindowsでは動きません(Linux, macOSでは動く)。なのでWSL上で動かしましょうという話になってくるのですが、それはあんまりにもやりづらいので、libFuzzerというLLVMが開発しているAFL互換のFuzzingツールを使っていくことにします。これはWindowsでビルドできます。
自分でビルドする必要はなく、SharpFuzzの作者が連携して使うことを意識して用意してくれているlibfuzzer-dotnetのReleasesページから、バイナリを直接落としてきましょう。libfuzzer-dotnet-windows.exeです。
次に、IL書き換えを行うツールSharpFuzz.CommandLineを .NET toolで入れていきましょう。これはglobalでいいかな、と思います。
dotnet tool install --global SharpFuzz.CommandLine
次に、今回はJilという、今はもうあまり使われることもないJsonシリアライザーをターゲットとしてやっていこうということなので、JilとSharpFuzzをインストールします。
dotnet add package Jil --version 2.15.4
dotnet add package SharpFuzz
ここで注意が必要なのは、Jilの最新バージョンはSharpFuzzにより発見されたバグが修正されているので、最新版を入れるとチュートリアルにはなりません!というわけでここは必ずバージョン下げて入れましょう。
新規のConsoleApplicationで、コードは以下のようにします。
using Jil;
using SharpFuzz;
// 実行機としてlibFuzzerを使う(引数はReadOnlySpan<byte>)
Fuzzer.LibFuzzer.Run(span =>
{
try
{
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader); // このメソッドが正しく動作してくれるかをテスト
}
catch (Jil.DeserializationException)
{
// Jil.DeserializationExceptionは既知の例外(正しくハンドリングできてる)なので握り潰し
// それ以外の例外が発生したらルート側にthrowされて問題が検知される
}
});
今度はベースになるテストデータを用意します。名前とかはなんでもいいんですが、TestcasesフォルダにTest.jsonを追加しました。
{"menu":{"id":1,"val":"X","pop":{"a":[{"click":"Open()"},{"click":"Close()"}]}}}
このデータを元にしてfuzzerは値を変形させていくことになります。
では実行しましょう!実行するためには、ビルドしてILポストプロセスしてlibFuzzer経由で動かす……。という一連の定型の流れが必要になるため、作者の用意してくれているPowerShellスクリプトfuzz-libfuzzer.ps1をダウンロードしてきて使いましょう。
とりあえずfuzz-libfuzzer.ps1とlibfuzzer-dotnet-windows.exeをcsprojと同じディレクトリに配置して、以下のコマンドを実行します。ConsoleApp24.csprojの部分だけ適当に変えてください。
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases"
動かすと、見つかった場合はいい感じに止まってくれます。
なお、見つからなかった場合は無限に探し続けるので、なんとなくもう見つかりそうにないなあ、と思ったら途中で自分でとめる(Ctrl+C)必要があります。
Testcasesには途中の残骸と、クラッシュした場合はcrash-idでクラッシュ時のデータが拾えます。
今回見つかったクラッシュデータは
{"menu":{"id":1,"val":"X","popid":1,"val":"X","pop":{"a":[{"click":"Open()"},{"c
でした。実際このデータを使って再現できます。
using Jil;
// クラッシュファイルのプロパティでデータはCopy to Output Directoryしてしまう
// <None Update="crash-c57462e70fb60e86e8c41cd18b70624bd1e89822">
// <CopyToOutputDirectory>Always</CopyToOutputDirectory>
// </None>
var crash = File.ReadAllBytes("crash-c57462e70fb60e86e8c41cd18b70624bd1e89822");
var span = crash.AsSpan();
// Fuzzing時と同じコード
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader);
以上!完璧!便利!一度手順を理解してしまえば、そこまで難しいことではないので、是非ハンズオンでやってみることをお薦めします。なお、ps1のスクリプトは実行対象自身へのインジェクトは除外されるようになっているので、小規模な自分のコードでfuzzingを試してみたいと思った場合は、対象コードはexeとは異なるプロジェクトに分離しておく必要があります。
ところで、AFLにはdictionaryという仕組みがあり、既知のキーワード集がある場合は生成速度を大幅に上昇させることが可能です。例えばjson.dictを使う場合は
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases" -dict ./json.dict
のように指定します。JSONとかYAMLとかXMLとかZipとか、一般的な形式はAFLplusplus/dictionariesなどに沢山転がっています。独自に作ることも可能で、例えばdotnet/runtimeのFuzzingではBinaryFormatterのテストが置いてありますが、これはNRBF(.NET Remoting Binary Format)の辞書、nrbfdecoder.dictを用意しているようでした。
もちろん、なしでも動かすことはできますが、用意できそうなら用意しておくとよいでしょう。
まとめ
MemoryPackでも実際バグ見つかってたりするので、この手のライブラリを作る人だったら覚えておいて損はないです。シリアライザーに限らずパーサーに関わるものだったらネットワークプロトコルでも、なんでも適用可能です。ただし現状、入力がbyte[]に制限されているので、応用性自体はあるようで、なかったりはします。これがintとか受け入れてくれると、様々なメソッドに対してカジュアルに使えて、より便利な気もしますが……(実際go fuzzはbyte[]だけじゃなくて基本的なプリミティブの生成に対応している)
byte[]列から適当に切り出してintとして使う、といったような処理だと、ミューテーションやカバレッジの関係上、適切な値を取得しにくいので、あまりうまくやれません。libFuzzerではStructure-Aware Fuzzing with libFuzzerといったような手法が考案されていて、protocol buffersの構造を与えるとか、gRPCの構造を与えるとかでうまく活用している事例はあるようです。この辺はSharpFuzzの対応次第となります(いつかやりたい、とは書いてありましたが、現実的にいつ来るかというと、あまり期待しないほうが良いでしょう)
Rustにもcargo fuzzといったcrateがあり、それなりに使われているようです。
Fuzzingは適用範囲が限定的であることと下準備の手間などがあり、一般的なアプリケーション開発者においては、あまりメジャーなテスト手法ではないというのが現状だと思いますが、使えるところはないようで意外とあるとも思うので、ぜひぜひ試してみてください。