ゼロアロケーションLINQライブラリ「ZLinq」のリリースとアーキテクチャ解説
- 2025-05-05
ZLinq v1を先月リリースしました!structとgenericsベースで構築することによりゼロアロケーションを達成しています。またLINQ to Span, LINQ to SIMD, LINQ to Tree(FileSystem, JSON, GameObject, etc.)といった拡張要素と、任意の型のDrop-in replacement Source Generator。そして.NET Standard 2.0, Unity, Godotなどの多くのプラットフォームサポートまで含めた大型のライブラリとなっています!現在GitHub Starsも2000を超えました。
structベースのLINQそのものは珍しいものではなく、昔から多くの実装が挑戦してきました。しかし、真に実用的と言えるものはこれまでありませんでした。極度なアセンブリサイズの肥大化、オペレーターの網羅の不足、最適化不足で性能が劣るなど、実験的な代物を抜け切れていないものばかりでした。ZLinqでは実用的に使えるものを目指し、.NET 10(Shuffle, RightJoin, LeftJoinなど新しいものも含む)に含まれる全てのメソッドとオーバーロードの100%のカバーと、99%の挙動の互換性の確保、そしてアロケーションだけではなく、SIMD化も含めて、多くのケースにおける性能面で勝てるように実装しました。
それが出来るのは、そもそも私のLINQ実装の経験はものすごく長くて、2009年4月にlinq.jsというJavaScript用のLINQ to Objectsライブラリを公開しています(linq.jsは現在もForkした人が今もメンテナンスされているようです、素晴らしい!)。他にもUnityで広く使われているReactive ExtensionsライブラリUniRxを実装し、直近ではそれの進化版であるR3を公開したばかりです。バリエーションとしてもLINQ to GameObject、LINQ to BigQuery、SimdLinqといったものを作っていました。これらに、ゼロアロケーション関連ライブラリ(ZString, ZLogger)やハイパフォーマンスシリアライザー(MessagePack-CSharp, MemoryPack)の知見を掛け合わせることで、標準ライブラリの上位互換という野心的目標を達成できました。

これはシンプルなベンチマークで、Where, Where.Take, Where.Take.Selectとメソッドチェーンを重ねれば重ねるほど、通常はアロケーションが増えていきますがZLinqはずっとゼロです。
性能は元のソース、個数、値の型、そしてメソッドの繋げ方によって変わってきます。多くのケースで性能面で有利なことを確認するために、ZLinqでは様々なケースのベンチマークを用意し、GitHub Actions上で走らせています。ZLinq/actions/Benchmark。構造上どうしても負けてしまうケースも存在はするのですが、現実的なケースではほとんど勝っています。
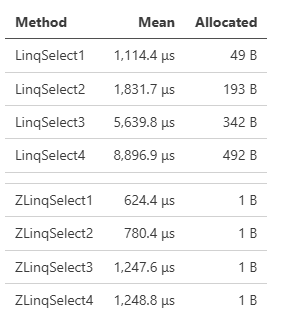
ベンチマーク上極端に差が出るものでいえば、シンプルにSelectを複数回繰り返したものは、SystemLinqもZLinqも特殊な最適化が入っていないケースになりますが、大きな性能差が出ています。
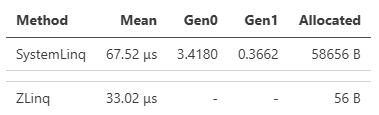
シンプルなケースでは、DistinctやOrderByなど中間バッファを必要とするものは、積極的なプーリングによりアロケーションを大きく抑えているため、差が大きくなります(ZLinqは原則ref strcutであり短寿命が期待できるため、プーリング利用はややアグレッシブにしています)。例えばこのベンチマークはDistinctです。
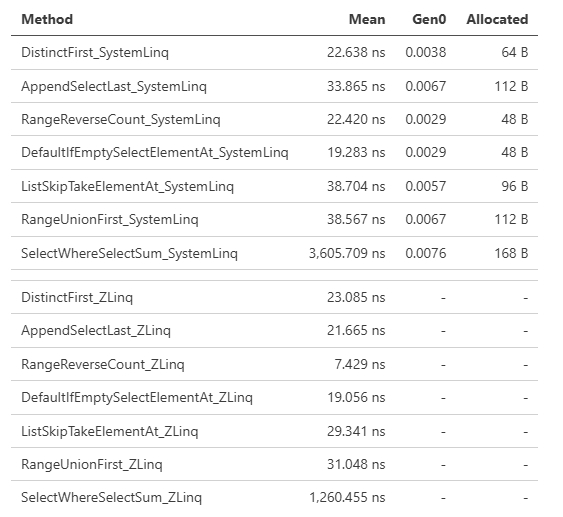
LINQはメソッド呼び出しのパターンにより特殊な最適化がかかるなど、アロケーションを抑えるだけでは性能面で常に勝てるわけではありません。そうしてオペレーターの繋がりによる最適化に関しても、これは.NET 9で最適化されたパターンとしてPerformance Improvements in .NET 9で紹介されている例ですが、ZLinqではそれらの最適化を全て実装し、より高いパフォーマンスを引き出しています。
ZLinqの良いところとして、これらLINQの進化による最適化の恩恵を、最新の.NETだけではなく、全ての世代の.NET(.NET Frameworkも含む)が得られることでもあります。
利用法はシンプルに、AsValueEnumerable()呼び出しを追加するだけです。オペレーターに関しては100%網羅しているので、既存コードからの置き換えも全て問題なくコンパイルが通り、動作します。
using ZLinq;
var seq = source
.AsValueEnumerable() // only add this line
.Where(x => x % 2 == 0)
.Select(x => x * 3);
foreach (var item in seq) { }
ZLinqでは挙動の互換性を保証するために、dotnet/runtimeのSystem.Linq.Testsを移植して ZLinq/System.Linq.Tests 常に走らせています。

9000件のテストケースのカバーにより、動作を保証しています(Skipしているケースはref structであるため、同一テストコードを動かせない場合によるものなど)
また、 AsValueEnumerable() すら省略したDrop-In Replacementを任意で有効化するSource Generatorも提供しています。
[assembly: ZLinq.ZLinqDropInAttribute("", ZLinq.DropInGenerateTypes.Everything)]

この仕組みにより、Drop-In Replacementの範囲を自由にコントロールすることができます。ZLinq/System.Linq.Tests自体がDrop-In Replacementにより、既存テストコードを変えずにZLinqで動作するようになっています。
ValueEnumerableのアーキテクチャと最適化
使い方などはReadMeを参照してもらえればいいので、ここでは最適化の話を深堀します。ただたんなるシーケンスを遅延実行するだけ、ではないところが、アーキテクチャ上の特色であり、他の言語のコレクション処理ライブラリと比べても、多くの工夫が詰まっています。
連鎖のベースとなるValueEnumerable<T>の定義はこうなっています。
public readonly ref struct ValueEnumerable<TEnumerator, T>(TEnumerator enumerator)
where TEnumerator : struct, IValueEnumerator<T>, allows ref struct // allows ref structは.NET 9以上の場合のみ
{
public readonly TEnumerator Enumerator = enumerator;
}
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current); // as MoveNext + Current
// Optimization helper
bool TryGetNonEnumeratedCount(out int count);
bool TryGetSpan(out ReadOnlySpan<T> span);
bool TryCopyTo(scoped Span<T> destination, Index offset);
}
これを基にして、例えばWhereなどのオペレーターはこうした連鎖が続きます。
public static ValueEnumerable<Where<TEnumerator, TSource>, TSource> Where<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Func<TSource, Boolean> predicate)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
IValueEnumerable<T>ではなくてこのようなアプローチを取ったのは、(this TEnumerable source) where TEnumerable : struct, IValueEnumerable<TSource>のような定義にすると、TSourceへの型推論が効かなくなります。これはC#が型引数の制約からは型推論をしないという言語仕様上の制限(dotnet/csharplang#6930)があるためで、もしそのような定義のまま実装をすると、インスタンスメソッドとして大量の組み合わせを定義することになります。それをやったのがLinqAFであり、その結果100,000+ methods and massive assembly sizesということで、あまり良い結果をもたらしていません。
LINQにおいては実装は全てIValueEnumerator<T>側にあり、また、全てのEnumeratorはstructのため、GetEnumerator()ではなくて、共通でEnumeratorのコピー渡しするだけで、それぞれのEnumeratorが独立したステートで処理できることに気付いたので、IValueEnumerator<T>をValueEnumerable<TEnumerator, T>でラップするだけ、という構成に最終的になりました。これにより型が制約側ではなくて型宣言側に現れるので、型推論での問題もありません。
- TryGetNext
次にイテレートの本体であるMoveNextについて詳しく見ていきましょう。
// Traditional interface
public interface IEnumerator<out T> : IDisposable
{
bool MoveNext();
T Current { get; }
}
// iterate example
while (e.MoveNext())
{
var item = e.Current; // invoke get_Current()
}
// ZLinq interface
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current);
}
// iterate example
while (e.TryGetNext(out var item))
{
}
C#の foreach は MoveNext() + Current に展開されるわけですが、問題が二点あります。一つはメソッド呼び出し回数で、イテレート毎にMoveNextとget_Currentの2回必要です。もう一つはCurrentのために、変数を保持する必要があること。そこで、それらをbool TryGetNext(out T current)にまとめました。これによりメソッド呼び出し回数が一度で済みパフォーマンス上有利です。
なお、この bool TryGetNext(out T current) 方式は、例えばRustのイテレーターで採用されています。
pub trait Iterator {
type Item;
// Required method
fn next(&mut self) -> Option<Self::Item>;
}
変数の保持に関してはピンとこないと思うので、例としてSelectの実装を見てください。
public sealed class LinqSelect<TSource, TResult>(IEnumerator<TSource> source, Func<TSource, TResult> selector) : IEnumerator<TResult>
{
// フィールドが3つ
IEnumerator<TSource> source = source;
Func<TSource, TResult> selector = selector;
TResult current = default!;
public TResult Current => current;
public bool MoveNext()
{
if (source.MoveNext())
{
current = selector(source.Current);
return true;
}
return false;
}
}
public ref struct ZLinqSelect<TEnumerator, TSource, TResult>(TEnumerator source, Func<TSource, TResult> selector) : IValueEnumerator<TResult>
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
// フィールドが2つ
TEnumerator source = source;
Func<TSource, TResult> selector = selector;
public bool TryGetNext(out TResult current)
{
if (source.TryGetNext(out var value))
{
current = selector(value);
return true;
}
current = default!;
return false;
}
}
IEnumerator<T>はMoveNext()で進めてCurrentで返す、という都合上、Currentのフィールドが必要です。ところがZLinqでは進めると同時に値を返すため、フィールドに保持する必要がありません。これは、全体がstructベースで構築されているZLinqではかなり大きな違いがあります。ZLinqではメソッドチェーンの度に、以前のstructを丸ごと抱える(TEnumeratorがstruct)構造になるため、メソッドチェーンを重ねる度に構造体のサイズが肥大化していきます。常識的な範囲内でメソッドチェーンを重ねる限りは、パフォーマンス上も問題にはなっていなかったのですが、それでも小さければ小さいほどコピーコストが小さくなり性能面で有利にはなります。1バイトでも構造体を小さくする、ためにもTryGetNextの採用は必然でした。
TryGetNextの欠点は、共変・反変をサポートできないことです。ただし私は、そもそもイテレーターや配列から共変・反変のサポートは撤廃すべきだと思っています。Span<T>との相性が悪いため、メリット・デメリットを天秤にかけると、時代遅れの概念だと言えます。具体例を出すと、配列のSpan化は失敗する可能性があり、それはコンパイル時には検出できず実行時エラーとなります。
// ジェネリクスの変性によりDerived[]をBase[]で受け取る。
Base[] array = new Derived[] { new Derived(), new Derived() };
// その場合、Span<T>へのキャストやAsSpan()は実行時エラーになる!
// System.ArrayTypeMismatchException: Attempted to access an element as a type incompatible with the array.
Span<Base> foo = array;
class Base;
class Derived : Base;
Span<T>以前に追加された機能のため、もうどうにもならないとは思いますが、現代の.NETはあらゆるところでSpanが活用されるようになっているので、それが実行時エラーになる可能性をはらんでいる時点で、使い物にならないと考えてもいいはずです。
- TryGetNonEnumeratedCount / TryGetSpan / TryCopyTo
全てを愚直に列挙するだけだと、パフォーマンスは最大化されません。例えばToArrayするときに、もしサイズの変動がないなら(array.Select().ToArray())、new T[count]のように固定長配列を作ることができます。SystemLinqでも、そうした最適化を実現するために、内部的にはIterator<T>型が使われているのですが、引数はIEnumerable<T>のため、必ず if (source is Iterator<TSource> iterator) のようなコードが必要になっています。
ZLinqでは最初からLINQのための定義を前提にできるため、すべて織り込み済みで用意しています。ただし、むやみやたらに増やすのはアセンブリサイズの肥大化を招くため、必要最小限の定義で、最大限の効果を生み出すように調整したのが、この3つのメソッドとなっています。
TryGetNonEnumeratedCount(out int count)は、元のソースが有限の個数であり、途中にフィルタリング系メソッド(WhereやDistinctなど。TakeやSkipは算出可能なため含まない)が挟まらない場合は成功します。ToArrayなどのほか、OrderByやShuffleなど中間バッファが必要な時に効果が出るケースもあります。
TryGetSpan(out ReadOnlySpan<T> span)は、元ソースが連続的なメモリとして取得できる場合には、オペレーターによってはSIMDが適用されて劇的なパフォーマンス向上に繋がったり、Spanによるループ処理によって集計パフォーマンスが高まるなど、性能面で大きな違いをもたらす可能性があります。
TryCopyTo(scoped Span<T> destination, Index offset)は内部イテレーターによってパフォーマンスを向上させる仕組みです。外部イテレーターと内部イテレーターについて説明すると、例えばList<T>はforeachとForEachの両方が選べます。
// external iterator
foreach (var item in list) { Do(item); }
// internal iterator
list.ForEach(Do);
見た目は似ていますが、性能面で違いがあります。foreachは素直な構文で書けている。ForEachはデリゲート渡し。処理の実体まで分解すると
// external iterator
List<T>.Enumerator e = list.GetEnumerator();
while (e.MoveNext())
{
var item = e.Current;
Do(item);
}
// internal iterator
for (int i = 0; i < _size; i++)
{
action(_items[i]);
}
これはデリゲート呼び出し(+デリゲート生成アロケーション)のオーバーヘッド vs イテレーターのMoveNext + Current呼び出しの対決になっていて、イテレート速度自体は内部イテレーターのほうが速い。この場合デリゲート呼び出しのほうが軽量な場合があり、ベンチマーク的に内部イテレーターのほうが有利な可能性があります。
もちろん、ケースバイケースであることと、ラムダ式にキャプチャが発生したり、普通の制御構文が使えない(continueなど)ことから、私としてはForEachは使うべきではないし、拡張メソッドでForEachのようなものを独自定義すべきではない、とも思っていますが、原理的にはこのような違いが存在します。
TryCopyTo(scoped Span<T> destination, Index offset)は、デリゲートではなくSpanを受け取ることで限定的に内部イテレーター化しました。
これもSelectを例に出すと、ToArrayの場合にCountが取れているとSpanを渡して内部イテレーターで処理します。
public ref struct Select
{
public bool TryCopyTo(Span<TResult> destination, Index offset)
{
if (source.TryGetSpan(out var span))
{
if (EnumeratorHelper.TryGetSlice(span, offset, destination.Length, out var slice))
{
// loop inlining
for (var i = 0; i < slice.Length; i++)
{
destination[i] = selector(slice[i]);
}
return true;
}
}
return false;
}
}
// ToArray
if (enumerator.TryGetNonEnumeratedCount(out var count))
{
var array = GC.AllocateUninitializedArray<TSource>(count);
// try internal iterator
if (enumerator.TryCopyTo(array.AsSpan(), 0))
{
return array;
}
// otherwise, use external iterator
var i = 0;
while (enumerator.TryGetNext(out var item))
{
array[i] = item;
i++;
}
return array;
}
のように、SelectはSpanは作れませんが、元ソースがSpanを作れるなら、内部イテレーターとして処理することでループ処理を高速化することが可能です。
TryCopyToの定義は普通のCopyToと違って、Index offsetを持っています。また、destinationはソースサイズよりも小さいことを許しています(通常の.NETのCopyToはdestinationが小さいと失敗する)。これによって、destinationのサイズが1の場合、IndexによってElementAtが表現できます。そして0ならFirstだし^1の場合はLastになります。IValueEnumerator<T>自体にFirst, Last, ElementAtを持たせると、クラス定義として無駄が多くなってしまいますが(アセンブリサイズにも影響が出る)、小さいdestinationとIndexを持たせることにより、一つのメソッドでより多くの最適化ケースをカバーできるようになりました。
public static TSource ElementAt<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Index index)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
using var enumerator = source.Enumerator;
var value = default(TSource)!;
var span = new Span<T>(ref value); // create single span
if (enumerator.TryCopyTo(span, index))
{
return value;
}
// else...
}
ところで、このTryGetNextや内部イテレーターに関しては、2007年の時点で https://nyaruru.hatenablog.com/entry/20070818/p1 で紹介されていました。この記事はずっと頭に残っていて、ようやくこうして20年経って理屈通りの実現ができました。という点でも少し感慨深いです。2008年前後はLINQ登場前後ということで、このあたりの話がアツかった時代なんですよねー。
LINQ to Span
ZLinqは .NET 9 以上であれば、Span<T>やReadOnlySpan<T>に対しても、全てのLINQオペレーターを繋げることができます。
using ZLinq;
// Can also be applied to Span (only in .NET 9/C# 13 environments that support allows ref struct)
Span<int> span = stackalloc int[5] { 1, 2, 3, 4, 5 };
var seq1 = span.AsValueEnumerable().Select(x => x * x);
// If enables Drop-in replacement, you can call LINQ operator directly.
var seq2 = span.Select(x => x);
Span対応のLINQを謳ったライブラリも、世の中には多少ありますが、それらはSpan<T>にだけ拡張メソッドを定義する、といったようなものであり、汎用的な仕組みではありませんでした。網羅されるオペレーターも制約があり、一部のものに限られていました。それは言語的にもSpan<T>をジェネリクス引数として受け取ることができなかったためで、汎用的に処理できるようになったのは .NET 9でallows ref structが登場してくれたおかげです。
ZLinqではIEnumerable<T>とSpan<T>に何の区別もありません、全て平等に取り扱われます。
ただし、allows ref structの言語/ランタイムサポートが必要なため、ZLinq自体は.NET Standard 2.0以上の全ての.NETをサポートしていますが、Span<T>対応に関してのみ.NET 9以上限定の機能となっています。また、これにより.NET 9以上の場合は、全てのオペレーターがref structになっている、という違いがあります。
LINQ to SIMD
System.Linqでは、一部の集計メソッドがSIMDによって高速化されています。例えば一部のプリミティブ型の配列に直接SumやMaxを呼び出すと高速化されています。これらの呼び出しはforで処理するよりも遥かに高速化されます。とはいえ、IEnumerbale<T>がベースであるため、適用可能な型が限定的であるなどの欠点を感じています。ZLinqではIValueEnumeartor.TryGetSpanによってSpan<T>が取得できる場合が対象となるコレクションとなるため、より汎用的になっています(もちろんSpan<T>に適用することもできます)。
対応するメソッドは以下のようなものになっています。
- Range to ToArray/ToList/CopyTo/etc...
- Repeat for
unmanaged structandsize is power of 2to ToArray/ToList/CopyTo/etc... - Sum for
sbyte,short,int,long,byte,ushort,uint,ulong,double - SumUnchecked for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Average for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Max for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Min for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Contains for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint - SequenceEqual for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint
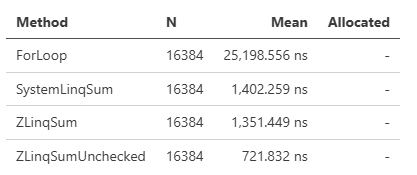
Sumはオーバーフローをチェックします。これは処理においてオーバーヘッドとなっているため、独自にSumUncheckedというメソッドも追加しています。性能差は以下のようになり、Uncheckedのほうがより高速です。
これらメソッドは条件がマッチした場合に暗黙的に適用されるということであり、SIMDを狙って適用させるには内部パイプラインへの理解が必要とされています。そこでT[] or Span<T> or ReadOnlySpan<T>には.AsVectorizable()というメソッドを用意しました。SIMD適用可能なSum, SumUnchecked, Average, Max, Min, Contains, and SequenceEqualを明示的に呼び出すことができます(ただしVector.IsHardwareAccelerated && Vector<T>.IsSupportedではない場合は通常の処理にフォールバックされるため、必ずしもSIMDが適用されることを保証するわけではありません)。
int[] or Span<int>にはVectorizedFillRangeというメソッドが追加されます。これはValueEunmerable.Range().CopyTo()と同じ処理で、連番で埋める処理がSIMDで高速化されます。連番が必要になる局面で、forで埋めるよりも遥かに高速なので、覚えておくといいかもしれません。
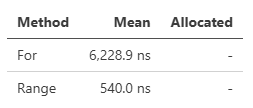
- Vectorizable Methods
SIMDによるループ処理を手書きするのは、慣れが必要で少し手間がいります。そこでFuncを引数に与えることでカジュアルに使えるヘルパーをいくつか用意しました。デリゲートを経由するオーバーヘッドが発生するためインラインで書くよりもパフォーマンスは劣りますが、カジュアルにSIMD処理できるという点では便利かもしれません。これらは引数にFunc<Vector<T>, Vector<T>> vectorFuncとFunc<T, T> funcを受け取り、ループの埋められるところまでVector<T>で処理し、残りをFunc<T>で処理します。
T[], Span<T>にはVectorizedUpdateというメソッドが用意されています。
using ZLinq.Simd; // needs using
int[] source = Enumerable.Range(0, 10000).ToArray();
[Benchmark]
public void For()
{
for (int i = 0; i < source.Length; i++)
{
source[i] = source[i] * 10;
}
}
[Benchmark]
public void VectorizedUpdate()
{
// arg1: Vector<int> => Vector<int>
// arg2: int => int
source.VectorizedUpdate(static x => x * 10, static x => x * 10);
}
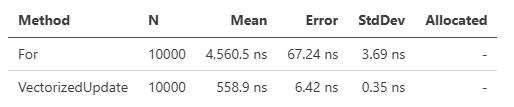
forよりも高速、ですが、パフォーマンスはマシン環境やサイズによって変わるので、盲目的に使うのではなくて、都度検証することをお薦めします。
AsVectorizable()にはAggregate, All, Any, Count, Select, and Zipが用意されています。
source.AsVectorizable().Aggregate((x, y) => Vector.Min(x, y), (x, y) => Math.Min(x, y))
source.AsVectorizable().All(x => Vector.GreaterThanAll(x, new(5000)), x => x > 5000);
source.AsVectorizable().Any(x => Vector.LessThanAll(x, new(5000)), x => x < 5000);
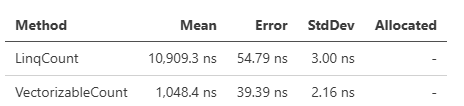
source.AsVectorizable().Count(x => Vector.GreaterThan(x, new(5000)), x => x > 5000);
パフォーマンスは、データ次第ではありますが一例としてはCountで、このぐらいの差が出ることもあります。
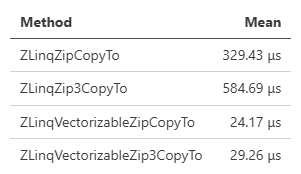
Select, Zipに関しては、後続にToArrayかCopyToを選びます。
// Select
source.AsVectorizable().Select(x => x * 3, x => x * 3).ToArray();
source.AsVectorizable().Select(x => x * 3, x => x * 3).CopyTo(destination);
// Zip2
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).CopyTo(destination);
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).ToArray();
// Zip3
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).CopyTo(destination);
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).ToArray();
Zipなんかは結構面白い&ちゃんと高速なので、使いどころあるかもしれません(2つのVec3のマージとか)。
LINQ to Tree
皆さんLINQ to XMLを使ったことはありますか? LINQの登場した2008年は、まだまだXML全盛期で、LINQ to XMLのあまりにも使いやすいAPIには衝撃を受けました。しかし、すっかり時代はJSONでありLINQ to XMLを使うことはすっかりなくなりました。
しかし、LINQ to XMLの良さというのは、ツリー構造に対するLINQ的操作のリファレンスデザインだと捉えることができます。ツリー構造がLINQになる、そのガイドライン。LINQ to Objectsと非常に相性の良い探索の抽象化。その代表例がRoslynのSyntaxTreeに対する操作で、AnalyzerやSource Generatorを書くのにDescendantsなどのメソッドを日常的に利用しています。
そこでZLinqはそのコンセプトを拡張し、ツリー構造に対して汎用的に Ancestors, Children, Descendants, BeforeSelf, and AfterSelf が適用できるインターフェイスを定義しました。

これはUnityのGameObjectへの走査の図ですが、標準でFileSystem(DirectoryTreeはツリー構造)やJSON(System.Text.JsonのJsonNodeに対してLINQ to XML的な操作を可能にする)を用意しています。もちろん、任意にインターフェイスを実装することで追加することもできます。
public interface ITraverser<TTraverser, T> : IDisposable
where TTraverser : struct, ITraverser<TTraverser, T> // self
{
T Origin { get; }
TTraverser ConvertToTraverser(T next); // for Descendants
bool TryGetHasChild(out bool hasChild); // optional: optimize use for Descendants
bool TryGetChildCount(out int count); // optional: optimize use for Children
bool TryGetParent(out T parent); // for Ancestors
bool TryGetNextChild(out T child); // for Children | Descendants
bool TryGetNextSibling(out T next); // for AfterSelf
bool TryGetPreviousSibling(out T previous); // BeforeSelf
}
例えばJSONに対しては
var json = JsonNode.Parse("""
// snip...
""");
// JsonNode
var origin = json!["nesting"]!["level1"]!["level2"]!;
// JsonNode axis, Children, Descendants, Anestors, BeforeSelf, AfterSelf and ***Self.
foreach (var item in origin.Descendants().Select(x => x.Node).OfType<JsonArray>())
{
// [true, false, true], ["fast", "accurate", "balanced"], [1, 1, 2, 3, 5, 8, 13]
Console.WriteLine(item.ToJsonString(JsonSerializerOptions.Web));
}
といったように書くことができます。
UnityにはGameObjectやTransform、GodotにはNodeへのLINQ to Treeを標準で用意しました。アロケーションや走査のパフォーマンスにかなり気を使って書かれているので、手動でループを回すよりも、もしかしたら高速かもしれません。
OSSと私
ここ数ヶ月で.NET関連のOSSには幾つか事件がありました。名のしれたOSSの商業ライセンス化、など……。私は、github/Cysharpで出しているOSSの数は40を超え、個人やMessagePack organizationなどのものも含めると、総スター数では50000を超えるなど.NET周りのサードパーティーとしては最大規模でのOSS提供者なのではないかと思います。
商業化、に関しては予定はありません、が、メンテナンスに関しては規模が大きくなってきたため、追いつかなくなっている面が多々あります。OSSが批判を覚悟で商業化を試みるの要因として、メンテナーに対する精神的な負荷というのが大きい(時間に対しての報酬が全く見合っていない)のですが、私も、まぁ、大変です!
金銭面は置いておいて、お願い事としては、メンテナンスが滞ることがあることは多少受け入れて欲しい!今回のZLinqのような大きなライブラリを仕込んでいる最中は、集中する時間が必要なため、他のライブラリのIssueやPRへの応答が数ヶ月音信不通になります。意識的に全く見ないようにしています、タイトルすら見てません(ダッシュボードや通知のメールなども一切目にしないようにしています)。そうした不義理を働くことで創造的なライブラリを生み出すことができるのだ、これは必要な犠牲なのです……!
また、そうじゃなくても、面倒見てるライブラリの数が多すぎるのでローテートでも数ヶ月の遅延が発生することは、あります。もうこれは絶対的なマンパワーが不足しているため、しょうがないじゃないですかー、というわけで、そのしょうがないを受け入れて、ちょっと返事が遅れるだけでthis library is dead的なこと言わないで欲しいなあ、というのが正直なところです!言われると辛い!なるべく努力はしたいんですが、特に新しいライブラリの創造は時間をめちゃくちゃ取られて大量の遅延が発生して、その遅延が更に遅延を呼んで泥沼になって精神を削っていくのですよー。
あとはMicrosoft関連でイラッとさせられてモチベーションを削られるとか、この辺はC#関連のOSSあるあるが発生したりしたりしながらも、なるべく末永く続けていきたいとは思っています。
かなり危機感は持っているので、AIによってどこまで負荷の軽減ができるのか、というところをテーマに、ある程度実験場として色々やっていきたいなあ、と思っています。うまくいけば、よりコアに集中できる環境になってくれるわけですしね。
まとめ
ZLinqの構造は最初のプレビュー版公開後のフィードバックで結構変わっていて、@Akeit0さんにはコアとなるValueEnumerable<TEnumerator, T>という定義やTryCopyToへのIndexの追加など、パフォーマンスに重要なコア部分の提案を多く頂きました!また、@filzrevさんからは多大なテスト・ベンチマークのインフラストラクチャーを提供してもらいました。互換性確保やパフォーマンス向上は、この貢献がなければ成しえませんでした。お二人には深く感謝します。
改めて、ゼロアロケーションLINQライブラリというコンセプト自体はそこまで珍しいものでもなく、今までもライブラリが死屍累々と転がっていたわけですが、ZLinqは徹底度合いが違う。経験と知識があるうえで、精神論で気合で、全メソッド実装、テストケースも全部流して完全互換、最適化類もSIMD含めて全部実装する、をやり切ったのが立派なところなのではないかな、と。いや、ほんとこれめっちゃ大変だったのです……。
タイミングとしても.NET 9/C# 13が、フルセットでやりたいことが全部やれる言語機能となったことは、やる気を後押ししてくれました。と、同時に、Unityや.NET Standard 2.0対応も大事にできたのもいいことです。
ただのゼロアロケーションLINQというだけではなく、LINQ to Treeはお気に入りの機能なので是非使ってみて欲しいですね……!そもそもに元々は、10年前に作っていたLINQ to GameObjectをモダン化しよう、というのが出発点でした。昔のコードだったのでかなりベタ書きだったのですが、もうちょっと抽象化したほうがいいかな、と弄っているうちに、だったらゼロアロケーションLINQとしての抽象化まで進化させてしまったほうがいいのでは、という思いつきに至ったのでした。
ところで、LINQのパフォーマンスのネックの一つとしてはデリゲートがあり、一部のライブラリはstructでFuncのようなものを模写するValueDelegateというアプローチがあるのですが、それはあえて採用していません。というのも、それらの定義はかなり手間なので、現実的にはやってられないはずです。そこまでやるなら普通にインラインで書いたほうがマシなので、LINQでValueDelegate構造を使う意味はありません。そんなベンチマークハックのためだけに内部構造の複雑化とアセンブリサイズの肥大化を招くのは無駄なので、System.Linqと互換のFuncのみを受け入れるスタイルにしています。
R3が.NET標準のSystem.Reactiveを置き換えるものという野心的ライブラリでしたが、System.Linqの置き換えはそれよりも遥かに大きな、あるいは大袈裟すぎる代物なので、採用に抵抗感はあるんじゃないかなー、と思います。ですが、置き換えるだけのメリットは掲示できていると思うので、是非とも試してみてくれると嬉しいです!