C#でスクレイピング:HTMLパース(Linq to Html)のためのSGMLReader利用法
- 2010-03-02
Linq to XmlがあるならLinq to Htmlもあればいいのに!と思った皆様こんばんは。まあ、DOMでしょ?ツリーでしょ?XHTMLならそのままXDocument.Loadで行けるよね?XDocument.Parseで行けるよね? ええ、ええ、行けますとも。XHTMLなら、ね、ValidなXHTMLならね。世の中のXHTML詐称の99.99%がそのまま解析出来るわけがなく普通に落ちてくれるので、XDocumentにそのまま流しこむことは出来ないわけです(もちろん、うちのサイトも詐称ですよ!ていうかこのサイトのHTMLは酷すぎるのでそのうち何とかしたい……)。
そこでHtmlを整形してXmlに変換するツールの出番なわけですが、まず名前が上がるのがTidy、の.NET移植であるTidy.NETで、これは論外。とにかく面倒くさい上に、パースしきれてなくてXDocumentに流すと平然と落ちたりする。おまけにXDocumentに入れるには文字列にしてから入れる必要があって二度手間感がある、などなど全くお薦めできません。XboxInfoTwitはTidy使ってますが、後悔してますよ……。
次にHtml Agility Packで、これは中々良いです。Linq to Xml風で大変使いやすい。のですが、あくまで風味であって、なんで本物のLinq to Xmlが目の前にあるのに、それっぽく模したものを覚えなきゃいけないの?二度手間で面倒くさいよ。
そこで、第三の選択としてSGMLReaderを使うという方法を提案します。SGML Reader自体は古くからあるのですが、日本語での情報はあまりないみたいだしLinq to Xmlと組み合わせたスクレイピング用途、に至っては皆無のようなので、ここで紹介しましょう。とりあえず例を。
// たったこれだけのメソッドを用意しておけば
static XDocument ParseHtml(TextReader reader)
{
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower })
{
sgmlReader.InputStream = reader; // ↑の初期化子にくっつけても構いません
return XDocument.Load(sgmlReader);
}
}
static void Main(string[] args)
{
using (var stream = new WebClient().OpenRead("http://www.bing.com/search?cc=jp&q=linq"))
using (var sr = new StreamReader(stream, Encoding.UTF8))
{
var xml = ParseHtml(sr); // これだけでHtml to Xml完了。あとはLinq to Xmlで操作。
XNamespace ns = "http://www.w3.org/1999/xhtml";
foreach (var item in xml.Descendants(ns + "h3"))
{
Console.WriteLine(item.Value); // bingでlinqを検索した結果のタイトルを列挙
}
}
}
見たとおり、信じられないほど簡単です。SgmlReaderはXmlReaderを継承しているため、XDocument.Load(xmlReader)にそのまま流し込めます。また、SgmlReader自体もDocTypeとInputStreamを設定するだけという超簡単設計になっているため、楽にHtml to Xmlが実現。HtmlはXDocumentになってしまえさえすれば、あとは慣れ親しんだLinq to Xmlの操作で抽出していけます。
例では、BingでLinqを検索した結果の検索結果見出し部分を抽出しています。見出しはh3で囲まれているので、Descendants(ns + "h3")。以上。超簡単。C#のスクレイピングの簡単さはRubyも超えたね!
残る問題は、日本語を扱う際はエンコーディング周りの設定が面倒くさい(間違ったエンコーディングだと文字化けする)、ということなのですが、そのWebClientのエンコーディング問題は、.NET Framework 4.0から修正された System.Net.WebClient は、HTTP ヘッダーから Encoding を自動的に認識してほしい | Microsoft Connect らしいです。素晴らしい!提案して頂いたbiacさんに感謝。
追記(2014/3/26)
いつのバージョンからか、TimeoutでWebExceptionが出るようになってたかもしれません。これはdtdを読みに行こうとしているのが原因のようなので、 IgnoreDtd = true を足してやれば回避できます。
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower, IgnoreDtd = true })
ということです。
追記(より簡単に)
上の記事を書いてから気づいたのですが、HrefプロパティにURLを指定するだけで、中でStream類を作って自動的にHtmlだと判別してくれるようです。更には、エンコーディングもContentTypeを見て自動調整してくれます(詳しくはSgmlParser.csのOpenメソッドを参照)。よって、もっとずっと簡単に書けます。
static void Main(string[] args)
{
XDocument xml;
using (var sgml = new SgmlReader() { Href = "http://www.xbox.com/ja-JP/games/calendar.aspx" })
{
xml = XDocument.Load(sgml); // たった3行でHtml to Xml
}
// Xboxの発売スケジュールからタイトルと発売日を抜き出してみる
var ns = xml.Root.Name.Namespace;
var query = xml.Descendants(ns + "table")
.Last()
.Descendants(ns + "tr")
.Skip(1) // テーブル一行目は項目説明なので飛ばす
.Select(e => e.Elements(ns + "td").ToList())
.Select(es => new
{
Title = es.First().Value,
ReleaseDate = es.Last().Value
});
// 書き出し
foreach (var item in query)
{
Console.WriteLine(item.Title + " - " + item.ReleaseDate);
}
}
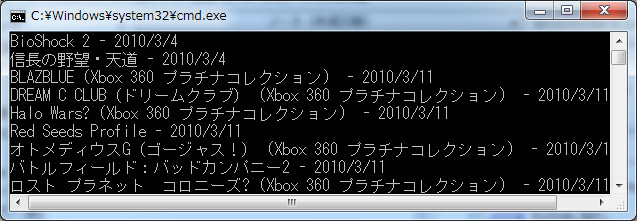
usingの辺りが若干鬱陶しいので、最初の例のようにメソッドに切り出してもいいかもしれません(CaseFolding.ToLowerも付けたいし)。Loadし終わったらストリームはもう不要です。XDocumentはメモリ内に全部構築するタイプのもので、実質XmlDocument(DOMツリー)の代替となっています。抽出時のXml名前空間ですが、サイトによってついていたりついていなかったりするので、var ns = xml.Root.Name.Namespaceとしておくと、全てのサイトに対応出来ます。
抽出のテクニック
上の例は Xbox.com | Xbox ゲームソフト 発売スケジュールからタイトルと発売日を抽出するというものです。定期的にページを監視して、更新されたらTwitterに投稿するXbox発売予定BOTとか作れますね!Xmlで取れるAPIさえあれば……なんてことはなくなりました!これからは 全てのサイトが易々とスクレイピング可能な代物として浮き上がってきますな。
ただし、元がHTMLのものはAPIとして用意されているXMLと違って、抽出に優しくない構造をしています。 Descendants一発でOk、というわけにもいかないので若干の慣れは必要かもしれません。今回の例の抽出コードが何やってるかよくわからない、という人はHTMLソースと見比べてみてください。目的のTableに辿り着くにも、いくつかの方法があります。決め打ち成分が入ってしまうのはどうにもならないのですが、何を決め打ちにするのがスッキリ書けるのか、となると色々です。今回はTableがLastである、という点を使いましたが、他の方法を考えてみると
var case2 = xml.Descendants(ns + "div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1")
.SelectMany(e => e.Descendants(ns + "tr"));
var case3 = xml.Descendants(ns + "table")
.First(x => x.Ancestors().Any(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1"))
.Descendants(ns + "tr");
目的のTableを囲むdivのclassが XbcWpFreeForm1であり、XbcWpFreeForm1が適用されているdivは一つしかない、ということに着目するとこうなります。case2は、divを全て列挙して探し出す方法。First(predicate)ではなくWhere.SelectManyにすることで、目的のTableが複数個ある場合でも対応出来ます。case3はTableに絞った上で、そのTableの上位階層(Ancestors)にXbcWpFreeForm1が含まれるかを探し当てる方法。Last、という決め打ちが難しい(場合により変動するケース)場合には有効でしょう。この、上位階層(Ancestors)や下位階層(Descendants)の要素に特異な要素はないか(Any)、と探す手法は、ターゲット自体に特徴がなく抽出し難い場合に活用出来ます。
そもそもDescendantsなんて富豪すぎて許せん、実行効率命!という人はElement("body").Element("div")....とトップから掘っていってもいいわけですが、さすがにElementの連続はダルいのでXPathを使うのもよいでしょう。Linq to XmlでのXPathの利用法は、以前neue cc - そしてXPathに戻るに書きました。XPathは、複雑なことを書こうとすると暗号めいた感じになるから余りすきじゃないですね。私は多少冗長なぐらいでもLinqで書くのが好きだなあ。