ReactiveProperty : Rx + MVVMへの試み
- 2011-08-26
Reactive Extensionsといったら非同期、じゃなくて、その前にイベントですよ!イベント!というわけで、随分手薄になっていたイベント周りの話を増強したいこの頃です。イベントと一口に言っても色々あります。UI(クリックやマウスムーブ)、センサー、変更通知(INotifyPropertyChanged)などなど。中でも一番よく使うのは、UI周りのイベントでしょう。
しかし、UIの持つTextChangedイベントだのから直接FromEventPatternで変換してしまったら、Viewと密接に結びついてしまってよろしくない。ここはMVVM的にやりましょう。でも、どうやって?
View(UI)が持つネイティブなイベントを、ViewModelの持つ更新通知付きのプロパティに変換します。これはバインディングにより可能です。そこはWPF/SLの仕組みに任せましょう。ということで、RxでUIに対してプログラミングするというのは、ViewModelの通知に対してプログラミングするという形になります。
テキストボックスの変更に反応して、1秒ディレイをかけた後に表示する、という簡単な例を(何の面白みもありません、すみません)
public class ToaruViewModel : INotifyPropertyChanged
{
private string input;
public string Input
{
get { return input; }
set { input = value; RaiseEvent("Input"); }
}
private string output;
public string Output
{
get { return output; }
set { output = value; RaiseEvent("Output"); }
}
public ToaruViewModel()
{
Observable.FromEvent<PropertyChangedEventHandler, PropertyChangedEventArgs>(
h => (sender, e) => h(e),
h => this.PropertyChanged += h, h => this.PropertyChanged -= h)
.Where(e => e.PropertyName == "Input") // Inputが更新されたら
.Select(_ => Input) // Inputの値を
.Delay(TimeSpan.FromSeconds(1)) // 1秒遅らせて
.ObserveOnDispatcher() // Dispatcherで(Silverlightではこれ必要・WPFでは不要)
.Subscribe(s => Output = "入力が1秒後に表示される:" + s); // Outputへ代入
}
// この辺は別途、ライブラリを使って持ってくるほうが良いかも
public void RaiseEvent(string propertyName)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
public event PropertyChangedEventHandler PropertyChanged;
}
// xaml.csはInitializeだけ、xamlのバインディングは各プロパティへ当てるだけ。
// ただしSL/WP7はUpdateSourceTrigger=PropertyChangedに対応してないので別途Behaviorの適用が必要
// 詳しくは、最後にソース配布(WPF/SL/WP7全て含む)URLを置いているのでそちらを見てください
……実にダサい。はい。全くいけてないです。バインディング可能なのはプロパティなので、そういった中間レイヤへの中継が発生していて、冗長だし、美味しさがかなり損なわれています。わかりきったINotifyPropertyChangedのWhere, Selectは無駄そのもので。勿論、簡単にDelayを混ぜられるといった時間の扱いの容易さはRxならでは、ではあるのですけれど。
ReactiveProperty
中継が手間ならば、中間レイヤだけを抜き出してやればいい。通知処理を内包したIObservable<T>があれば解決する。というわけで、ReactivePropertyと名付けたものを作りました。それを使うと、こうなります。
public class SampleViewModel : INotifyPropertyChanged
{
public ReactiveProperty<string> ReactiveIn { get; private set; }
public ReactiveProperty<string> ReactiveOut { get; private set; }
public SampleViewModel()
{
// UIから入力されるものはnewで作成、デフォルト値も同時に指定出来る。
ReactiveIn = new ReactiveProperty<string>(_ => RaiseEvent("ReactiveIn"), "でふぉると");
// UIへ出力するIO<T>はToReactivePropertyで、初期値での発火も自動的にされます。
ReactiveOut = ReactiveIn
.Delay(TimeSpan.FromSeconds(1))
.Select(s => "入力が1秒後に表示される:" + s)
.ToReactiveProperty(_ => RaiseEvent("ReactiveOut"));
}
// 通常は、他のMVVMフレームワークなりを使い、それの更新通知システムを利用するといいでしょう
// Rxを使ったからって、決してMVVMフレームワークと競合するわけではなく、むしろ協調すると考えてください
public void RaiseEvent(string propertyName)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
public event PropertyChangedEventHandler PropertyChanged;
}
// これはWPF版のもの
<Window x:Class="ReactiveProperty.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:l="clr-namespace:ReactiveProperty"
Title="MainWindow" Height="350" Width="525">
<Window.DataContext>
<l:SampleViewModel />
</Window.DataContext>
<StackPanel>
<TextBox Text="{Binding ReactiveIn.Value, UpdateSourceTrigger=PropertyChanged}" />
<TextBlock Text="{Binding ReactiveOut.Value}" />
</StackPanel>
</Window>
XAMLではPathに必ず.Valueまで指定します。これによりGetが求められれば最新の値を返し、値をSetされればPushするようになります。
今回はUI->ReactiveProperty->クエリ演算->ReactiveProperty->UIという風に戻してやりましたが、勿論、UIからの入力をModelに流してそれで止めてもいいし、Modelからの値をUIに流すだけでもいいし、トリガーはタイマーであってもいいし、その辺は完全に自由です。普通の通知プロパティと何も変わりません。また普通のプロパティとして使いたい時は.Valueで値を取り出す/セットできます。
かなりシンプルに仕上がります。通知付きプロパティは、本質的に値の変更毎に通知される無限長のIObservable<T>と見なせるので、そのことにより表現がより自然になっています。書き味も、リアクティブプログラミング(といわれてパッと浮かばれる値が自動更新されるという奴)にかなり近い感じの風合い。XAMLでのバインドも簡単ですし、VMの実装も自動実装プロパティだけで書けるので記述が楽チン。
そして、Rxを使うことによる最大の利点である、他のイベント(他の変更通知プロパティ)と合成しやすかったり、時間が扱いやすくなったり、非同期と混ぜても同じように扱えたり、スレッドの切り替えが簡単であったり、などを最大限に甘受できます。VMとして独立している、かつ全てがRxに乗っているため、単体テストも非常に作成しやすい状態です(時間軸を扱う処理のテストは通常難しいのですが、Rxの場合は自分で時間をコントロール可能なSchedulerを中間に挟むと、好きなように時間を進められるようになります、イベントのテストも、この状態ならばプロパティを変更するだけで生成されますし)。また、決して他のMVVMフレームワークと競合が起こるわけではない(多分……)のも見逃せない利点です。
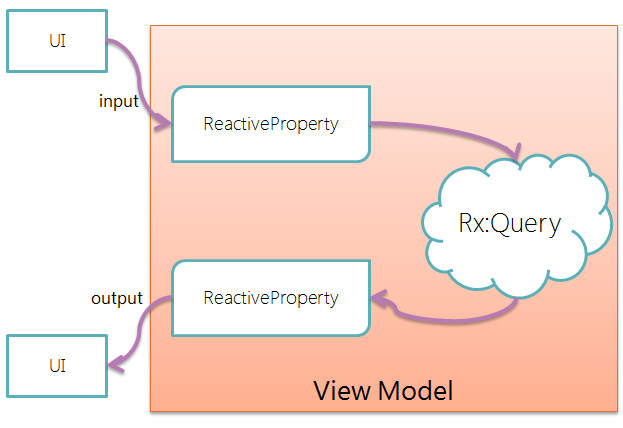
単純な例なのでModelがありませんが、まあこんな感じ?(それと今はコマンドがないので単純なデータバインドのみの図です)。Modelへのアクセスは通常恐らくRx:Query内で行い、Modelの形態は色々だと思いますが、通信してデータを処理して返す、みたいなものはRxになっているとVMのReactiveProperty側での合成処理が容易なので、非同期にしてIObservable<T>で返すと良いのではかと思います。自身が通知を持つReactivePropertyになっていてもいいですね。そうなると、コードのほとんどがLINQになるという素敵な夢が見れる気がしますが気のせいです。
実装
ReactivePropertyの実装はこんな感じです。ご自由にコピペって使ってみてください。
using System;
#if WINDOWS_PHONE
using Microsoft.Phone.Reactive;
#else
using System.Reactive.Linq;
using System.Reactive.Subjects;
#endif
public class ReactiveProperty<T> : IObservable<T>, IDisposable
{
T latestValue;
IObservable<T> source;
Subject<T> anotherTrigger = new Subject<T>();
IDisposable sourceDisposable;
public ReactiveProperty(Action<T> propertyChanged, T initialValue = default(T))
: this(Observable.Never<T>(), propertyChanged, initialValue)
{ }
public ReactiveProperty(IObservable<T> source, Action<T> propertyChanged, T initialValue = default(T))
{
this.latestValue = initialValue;
var merge = source.Merge(anotherTrigger)
.DistinctUntilChanged()
.Publish(initialValue);
this.sourceDisposable = merge.Connect();
// PropertyChangedの発火はUIスレッドで行うことにする
// UIへの反映の際に、WPFでは問題ないが、SL/WP7ではUIスレッドから発行しないと例外が出るため
merge.ObserveOnDispatcher().Subscribe(x =>
{
latestValue = x;
propertyChanged(x);
});
this.source = merge;
}
public T Value
{
get
{
return latestValue;
}
set
{
latestValue = value;
anotherTrigger.OnNext(value);
}
}
public IDisposable Subscribe(IObserver<T> observer)
{
return source.Subscribe(observer);
}
public void Dispose()
{
sourceDisposable.Dispose();
}
}
// 拡張メソッド
public static class ObservableExtensions
{
public static ReactiveProperty<T> ToReactiveProperty<T>(this IObservable<T> source, Action<T> propertyChanged, T initialValue = default(T))
{
return new ReactiveProperty<T>(source, propertyChanged, initialValue);
}
}
Valueで値の中継をしているという、それだけです。Publish(value)はBehaviorSubjectというものを使った分配で、必ず最新の値一つをキャッシュとして持っていて、Subscribeされると同時に、まずその値で通知してくれます。これにより「初期値での自動発火」が自然に行える、という仕組みになっています。また、プロパティの変更時に同値の場合は変更通知をしない、というよくあるほぼ必須処理も、ここでDistinctUntilChangedを挟んで行っています(オプションで選択制にしてもいいかもしれない)。
それReactiveUI?
ReactiveUIというRxを前提にしたMVVMフレームワークがあって、それに用意されているObservableAsPropertyHelperと、ReactivePropertyはかなり近いです(ということにプロトタイプ作ってから気づいた、ReactiveUIはこれまで名前は知ってたけど中身完全ノーチェックだったので)。ただ、機能的にはOAPHは双方向バインディングに対応していないので、ReactivePropertyのほうが上です。また、OAPHは使い勝手もあまり良くないし、名前がダサい(ObservableAsPropertyHelperは長すぎるし型名として宣言させるにはイマイチに思える……)などなどで、あまり気に入るものではなかったです。
ReactiveUIは全体的には軽く眺めた程度なのですが、今ひとつ私には合わない。ちょっと、いや、かなり気にいらない。なので、私としてはそのうち他のMVVMライブラリをベースに置いた上での拡張として、Rx用のUI周りライブラリを作りたい。独自に上から下まで面倒を見るフレームワーク、という指針は今一つに思えるので、Rxならではの特異な部分だけを、最初から他のMVVMフレームワークの拡張として用意していく、という方向性のほうが良いものが作れると思っています。素のままのRxでは辛いので、何かしらの中間層が必要なのは間違いないので。
次は、ReactiveCommandを!あー、あとReactiveCollectionも必要かしら。Validationとかも……。まあ、そういうところは普通に書けばいいんですよ、何も全部Rxでやる必要はないですからね。
まとめ
WPFのバインディングの美味しさをRxで更に美味しくする、ということでした。世の中的には弱参照が~などなどというお話もありますが、それには全然追いついてませんので、おいおいちかぢかそのうち。
今回のコードの全体(WPF/SL/WP7)はneuecc / ReactiveProperty /Bitbucketに置いてありますので、好きに見てください。例が単純すぎると美味しさもよくわからないので、もう少し複雑な例で、サンプル準備中なのでしばしお待ちを。
ところで9/15にいよいよRx本が出ます。
オライリーで出ているProgramming C#の著者と、ReactiveUIの作者(元Microsoft Office Labs、つい最近Githubに転職した模様)の共著です。私も買いますので、うーん、読書会とかやったら来てくれる方います?
linq.js LT資料
- 2011-08-22
LTで簡単にlinq.jsの紹介をしましたので、その資料を。といっても、資料は全く使わないでLTの場では完全にデモ一本にしました。ええ、こういう場では、やっぱデモ優先のほうがいいかなー、と。資料は資料で、要素がきっちりまとまって紹介という感じなので、見てもらえればと思います。
スライドのテンプレは同じの使っていてそろそろ飽きたので、新しいのに変えたいところ。基本的にはテンプレのテーマまんまですが、やっぱ細かいところでスライドマスタの調整は必要なので、面倒くさー、と思ってしまい中々に気力が。むしろデザイン変更は一年に一回でいいかしらいいかしら?
そういえばどうでもよくないのですが、SlideshareをBlogに埋め込む時はlargeサイズを選んで欲しい。文字潰れてしまうもの、わざわざ小さいサイズで埋め込む必要はどこにもなくて。
文字列を先頭から見て同じところまで除去をlinq.jsとC#で解いてみた
- 2011-08-19
JavaScript で「文字列を先頭から見て同じところまで除去」をやってみました。という記事を見て、「linq.js を使いたかったのですが使いどころがパッと思い浮かびませんでした」とのことなので、linq.js - LINQ for JavaScriptで答えてみます。お題の元はお題:文字列を先頭から見て同じところまで除去からです。解き方も色々あると思いますが、最長の一致する文字を見つけて、それを元に文字列を削除していく、という方法を取ることにしました。
function dropStartsSame(array)
{
var seq = Enumerable.From(array);
return Enumerable.From(seq.First())
.Scan("$+$$")
.TakeWhile(function (x) { return seq.All(function (y) { return y.indexOf(x) == 0 }) })
.Insert(0, [""]) // 一つもマッチしなかった場合のため
.TakeFromLast(1)
.SelectMany(function (x) { return seq.Select(function (y) { return y.substring(x.length) }) });
}
dropStartsSame(["abcdef", "abc123"]).WriteLine();
dropStartsSame(["あいうえお", "あいさんさん", "あいどる"]).WriteLine();
dropStartsSame(["12345", "67890", "12abc"]).WriteLine();
はい、ワンライナーで書けました、って何だか意味不明ですね!まず、例えば"abcdef"から["a","ab","abc","abcd","abcde","abcdef"]を作ります。これはものすごく簡単で、Scanを使うだけです。
// ["a","ab","abc","abcd","abcde","abcdef"]
Enumerable.From("abcdef").Scan("$+$$")
素晴らしい!そうして比較のタネができたら、あとは全てのindexOfが0(先頭に一致する)の間だけ取得(TakeWhile)します。["abcdef","abc123"]だとシーケンスは["a","ab","abc"]に絞られます。必要なのは最長のもの一つだけなのでTakeFromLast(1)で最後のものだけを取得。もし一つもマッチしなかった場合は代わりに""が通るようにInsertで事前に先頭にさしてやってます。あとは、その"abc"を元にして文字列を置換したシーケンスを返してやるようにすればいい、というわけです、はい。
少し修正
SelectManyで繋げるのは悪趣味なので、ちょっと変えましょう。
function dropStartsSame(array)
{
var seq = Enumerable.From(array);
var pre = Enumerable.From(seq.First())
.Scan("$+$$")
.TakeWhile(function (x) { return seq.All(function (y) { return y.indexOf(x) == 0 }) })
.LastOrDefault("");
return seq.Select(function (x) { return x.substring(pre.length) });
}
変数を一つ置いてやるだけで随分とすっきり。無理に全部繋げるのはよくないね、という当たり前の話でした。
C# + Ix
C#とIxで書くとこうなるかな?基本的には同じです。(Ixって何?という人はneue cc - LINQ to Objects & Interactive Extensions & linq.js 全メソッド概説を参照ください)
static IEnumerable<string> DropStartsSame(params string[] args)
{
var pre = args.First()
.Scan("", (x, y) => x + y)
.TakeWhile(x => args.All(y => y.StartsWith(x)))
.LastOrDefault() ?? "";
return args.Select(x => x.Substring(pre.Length));
}
static void Main()
{
var x = DropStartsSame("abcdef", "abc123").SequenceEqual(new[] { "def", "123" });
var y = DropStartsSame("あいうえお", "あいさんさん", "あいどる").SequenceEqual(new[] { "うえお", "さんさん", "どる" });
var z = DropStartsSame("12345", "67890", "12abc").SequenceEqual(new[] { "12345", "67890", "12abc" });
Console.WriteLine(x == y == z == true);
}
Ixで使ってるのはScanだけですけれど。
Deferの使い道
ところで、上のコードは遅延評価なのか遅延評価でないのか、微妙な感じです。preの計算までは即時で、その後は遅延されています。まるごと遅延したい場合はIxのDeferというメソッドが使えます。
// Deferで生成を遅延する
static IEnumerable<string> DropStartsSame2(params string[] args)
{
return EnumerableEx.Defer(() =>
{
var pre = args.First()
.Scan("", (x, y) => x + y)
.TakeWhile(x => args.All(y => y.StartsWith(x)))
.LastOrDefault() ?? "";
return args.Select(x => x.Substring(pre.Length));
});
}
// もしくはyield returnを使ってしまうという手も私はよく使っていました
static IEnumerable<string> DropStartsSame3(params string[] args)
{
var pre = args.First()
.Scan("", (x, y) => x + y)
.TakeWhile(x => args.All(y => y.StartsWith(x)))
.LastOrDefault() ?? "";
var query = args.Select(x => x.Substring(pre.Length));
foreach (var item in query) yield return item;
}
// 勿論、全部LINQで組んでしまってもOK
static IEnumerable<string> DropStartsSame4(params string[] args)
{
return args.First()
.Scan("", (x, y) => x + y)
.TakeWhile(x => args.All(y => y.StartsWith(x)))
.StartWith("") // linq.jsではInsert(0, [])でした
.TakeLast(1) // linq.jsではTakeFromLastでした
.SelectMany(x => args.Select(y => y.Substring(x.Length)));
}
私はIx以前はyield returnを結構よく使ってました。今は、Deferのほうが、例えば if(args == null) throw new ArgumentNullException(); とかがそのまま書けるのでDeferを選びたいかも。この辺の評価タイミングの話は前回、詳説Ix Share/Memoize/Publish編(もしくはyield returnの注意点)で書きました。
まとめ
というわけで、Scanの使い方でした。Scan可愛いよScan。ようするにAggregateの計算途中も列挙する版なわけなので、これ、標準クエリ演算子にも入って欲しかったなあ。結構使えるシーン多いです。
ああ、あとJavaScriptでもforなんて使いません(キリッ。linq.jsは真面目に普通に多機能なので遅い、じゃなくて、いや、それはまあ事実なんですが、便利には違いないです。他の普通のコレクションライブラリじゃ出来ないことも平然と出来ます。でもかわりに(ry
詳説Ix Share/Memoize/Publish編(もしくはyield returnの注意点)
- 2011-08-15
LINQ to Objects & Interactive Extensions & linq.js 全メソッド概説でのIxのPublishの説明がおざなりだったので、一族について詳しく説明したいと思います(Ixの詳細・入手方法などは先の全メソッド概説のほうを参照ください)。ええ、これらはIBuffer<T>を返すという一族郎党だという共通点があります。なので、並べてみれば分かりやすい、かも?挙動を検証するためのコードは後で出しますので、ひとまず先に図をどうぞ。星がGetEnumerator、丸がMoveNext(+Current)、矢印線が二つ目の列挙子を取得したタイミングを表しています。
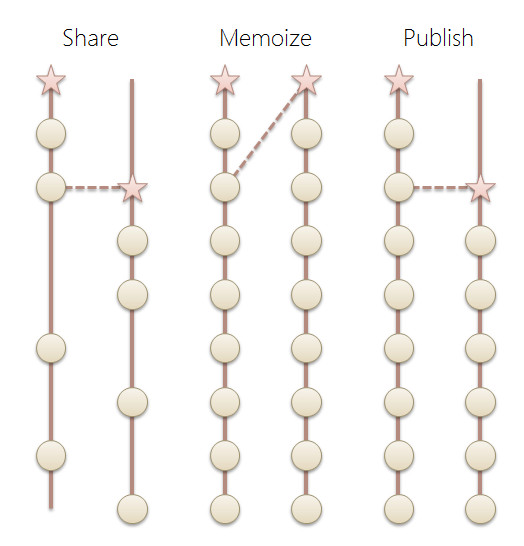
これだけじゃよく分かりません。と、いうわけで、少しだけ上の図を頭に入れて、以下の解説をどうぞ。
Memoize
Memoizeはメモ化。メモイズ。メモライズじゃないっぽいです。二度目三度目の列挙時は値をキャッシュから返すので、前段がリソースから取得したり複雑な計算処理をしていたりで重たい場合に有効、という使い道が考えられます。とりあえずEnumeratorを取ってきて、それでじっくり動きを観察してみましょう。
// ShareやMemoizeやPublishの戻り値の型はIBuffer<T>で、これはIDisposableです。
// もしリソースを抱えるものに適用するなら、usingしたほうがいいかも?
using (var m = Enumerable.Range(1, int.MaxValue)
.Do(x => Console.WriteLine("spy:" + x)) // 元シーケンスが列挙される確認
.Memoize())
{
var e1 = m.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); // spy:1,spy:2,spy:3
Console.WriteLine(e1.Current); // 3
var e2 = m.GetEnumerator();
e2.MoveNext(); // キャッシュから返されるので元シーケンスは不動
Console.WriteLine(e2.Current); // 1
e2.MoveNext(); e2.MoveNext(); e2.MoveNext(); // spy:4
Console.WriteLine(e2.Current); // 4
e1.MoveNext(); // 今度はe2が先行したので、こちらもキャッシュから
Console.WriteLine(e1.Current); // 4
}
特に考える必要もなく分かりやすい内容です。オーバーロードにはreaderCountを受けるものがありますが、それの挙動は以下のようになります。
// Memoizeの第二引数はreaderCount(省略した場合は無限個)
using (var m = Enumerable.Range(1, int.MaxValue).Memoize(2))
{
// readerCountはEnumeratorの取得可能数を表す
var e1 = m.GetEnumerator();
e1.MoveNext(); // MoveNextするとMemoizeに登録される
var e2 = m.GetEnumerator();
var e3 = m.GetEnumerator();
e3.MoveNext();
e2.MoveNext(); // 3つめはNGなので例外が飛んで来る
}
これを使うと、キャッシュから値が随時削除されていくので、メモ化しつつ巨大なシーケンスを取り扱いたい場合には、メモリ節約で有効なこともあるかもしれません。とはいっても、普段はあまり考えなくてもいいかな?毎回削除処理が入るので、実行時間は当然ながら遅くなります。
Share
Shareは列挙子を共有します。
using (var s = Enumerable.Range(1, int.MaxValue).Share())
{
var e1 = s.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 3
var e2 = s.GetEnumerator(); // 列挙子が共有されているので3からスタート
Console.WriteLine(e2.Current); // 0。共有されるといっても、MoveNext前の値は不定です
e2.MoveNext();
Console.WriteLine(e2.Current); // 4。正しく初期値といえるのはここ
Console.WriteLine(e1.Current); // 3。e1とe2は同じものを共有していますが、Currentの値はMoveNextしない限りは変わらない
e1.MoveNext();
Console.WriteLine(e1.Current); // 5。列挙子を共有しているので、e2の続き
}
といった形です。これの何が美味しいの?というと、例えば自分自身と結合させると、隣り合った値とくっつけられます。
// Share, Memoize, Publishにはselectorを受けるオーバーロードがある
// このselectorには var xs = source.Share() の xsが渡される
// つまり、一度外部変数に置かなくてもよいという仕組み、Zipなどと相性が良い
// 結果は {x = 1, y = 2}, { x = 3, y = 4}, { x = 5, y = 6}
// 列挙子を共有して自分自身と結合するので、隣り合った値とくっつく
Enumerable.Range(1, 6)
.Share(xs => xs.Zip(xs, (x, y) => new { x, y }))
.ForEach(x => Console.WriteLine(x));
なんだか、へぇー、という感じの動き。このShareを使うとstringの配列からDictionary<string, string>への変換 まとめ - かずきのBlog@Hatenaのコードは
// {"1":"one"}, {"2":"two"}
var array = new[] { "1", "one", "2", "two" };
var dict = array.Share(xs => xs.Zip(xs, Tuple.Create))
.ToDictionary(t => t.Item1, t => t.Item2);
物凄くシンプルになります。ループを回すなんて、やはり原始人のやることでしたね!
Publish
PublishはRxでは値を分散させましたが、Ixでも分散です。ただ、挙動にはかなりクセがあり、あまりお薦め出来ないというか……。動きとしては、取得時には共有された列挙子から流れてくるのでShareのようであり、列挙子取得後は全て必ず同じ値が返ってくることからMemoizeのようでもある。
using (var p = Enumerable.Range(1, int.MaxValue).Publish())
{
var e1 = p.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 3
var e2 = p.GetEnumerator(); // 取得時は列挙子の状態が共有されているので3からスタート
Console.WriteLine(e2.Current); // 0。 共有されるといっても、MoveNext前の値はやはり不定
e2.MoveNext();
Console.WriteLine(e2.Current); // 4。正しく初期値といえるのはここ
e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 8
e2.MoveNext(); // 取得後の状態はそれぞれ別、またキャッシュから返される
Console.WriteLine(e2.Current); // 5
}
このPublish、こうして生イテレータを操作している分には理解できますが、普通に使うように演算子を組み合わせると予測不能の挙動になります。例えば
// 自分自身と結合、GetEnumeratorのタイミングが同じなので同値で結合される
// {1,1},{2,2},{3,3},{4,4},{5,5}
Enumerable.Range(1, 5)
.Publish(xs => xs.Zip(xs, (x, y) => new { x, y }))
.ForEach(a => Console.WriteLine(a));
// もし後者のほうをSkip(1)したらこうなります
// {1,3},{2,4},{3,5}
Enumerable.Range(1, 5)
.Publish(xs => xs.Zip(xs.Skip(1), (x, y) => new { x, y }))
.ForEach(a => Console.WriteLine(a));
Skip(1)すると {1,2},{2,3}... ではなくて {1,3},{2,4}... になる理由、すぐにティンと来ますか?正直私はわけがわかりませんでした。Zipの実装を見ながら考えると、少し分かりやすくなります。
static IEnumerable<TR> Zip<T1, T2, TR>(this IEnumerable<T1> source1, IEnumerable<T2> source2, Func<T1, T2, TR> selector)
{
using (var e1 = source1.GetEnumerator())
using (var e2 = source2.GetEnumerator())
{
while (e1.MoveNext() && e2.MoveNext())
{
yield return selector(e1.Current, e2.Current);
}
}
}
Skip(1)のない、そのままZipで結合したものはEnumeratorを取得するタイミングは同じなので、 {1,1},{2,2}... になるのは妥当です。では、source2がSkip(1)である場合は、というと、source2.GetEnumeratorの時点で取得されるのはSkip(1)のEnumeratorであり、Publishで分配されているEnumeratorはまだ取得開始されていません。では、いつPublishされているEnumeratorを取得するか、というと、これは最初にe2.MoveNextが呼ばれたときになります。なので、e1.MoveNextにより一回列挙されているから、e2の(MoveNext済みでの)初期値は2。更にSkip(1)するので、{1,3},{2,4}... という結果が導かれます。
ZipやSkipなど、他のメソッドを組み合わせるなら、それらの内部をきっちり知らなければ挙動が導けないという、ものすごく危うさを抱えているので、Publishを上手く活用するのは難しい印象です、今のところ、私には。もともとPublishはRxに分配のためのメソッドとして存在して、その鏡としてIxにも移植されているという出自なのですが、どうしてもPull型で実現するには不向きなため、不自然な挙動となってしまっています。分配はPull(Ix)じゃなくてPush(Rx)のほうが向いている、というわけで、分配したいのならToObservableして、Observable側のPublishを使ったほうが、素直な動きをして良いと思います。
yield returnを突っつく
MemoizeのreaderCountの例でもそうでしたが、Publish/Memoizeされている列挙子を取得するのがGetEnumerator時ではなくて最初のMoveNextの時、になるのはyield returnを使うとそういう挙動で実装されるからです。例えば
static IEnumerable<T> Hide<T>(this IEnumerable<T> source)
{
Console.WriteLine("列挙前");
using (var e = source.GetEnumerator()) // 通常は、foreachを使いますが。
{
while (e.MoveNext()) yield return e.Current;
}
Console.WriteLine("Dispose済み");
} // yield break
static void Main(string[] args)
{
var e = Enumerable.Repeat("hoge", 1).Hide().GetEnumerator(); // ここではまだ何も起こらない
e.MoveNext(); // 列挙前 ← ここでメソッド冒頭からyield return e.Currentのところまで移動
Console.WriteLine(e.Current); // hoge
e.MoveNext(); // Dispose済み ← 最終行まで到達して終了
}
イテレータの自動実装でメソッド本文を動きだすのは、最初のMoveNextから、というわけです。また、イテレータ内でusingなどリソースを掴む実装をしている場合は、普通にブロックを(using,lock,try-finally)超えた時に解放されます。ただし、ちゃんとブロックを超えるまでMoveNextを呼びきれる保証なんてない(例外が発生したり)ので、GetEnumeratorする時はusingも忘れずに、は大原則です。using、つまりEnumeratorをDisposeすると、using,lock,finallyがメソッド本文中で呼ばれていなかった場合は、呼ぶようになってます。
ところで、本文が動き出すのは最初のMoveNextから、であることが困る場合もあります。例えば引数チェック。
public static IEnumerable<string> Hoge(string arg)
{
if (arg == null) throw new ArgumentNullException();
yield return arg;
}
void Main(string[] args)
{
var hoge = Hoge(null); // ここでは何も起こらない!
hoge.GetEnumerator().MoveNext(); // ArgumentNullException発生
}
nullチェックはメソッドに渡したその時にチェックして欲しいわけで、これではタイミングが違って良くない。これを回避するにはどうすればいいか、というと
// 先にnullチェックを済ませて普通にreturn
public static IEnumerable<string> Hoge(string arg)
{
if (arg == null) throw new ArgumentNullException();
return HogeCore(arg);
}
// privateなメソッドで、こちらにyield returnで本体を書く
private static IEnumerable<string> HogeCore(string arg)
{
yield return arg;
}
static void Main(string[] args)
{
var hoge = Hoge(null); // 例外発生!
}
こうすれば、完璧な引数チェックの完成。実際に、LINQ to Objectsの実装はそうなっています。この時のprivateメソッドの命名には若干困りますが、私は今のところXxxCoreという形で書くようにしてます。MicrosoftのEnumerable.csではXxxIteratorという命名のようですね。また、Ixを覗くとXxx_という名前を使っている感じ。みんなバラバラなので好きな命名でいいのではかと。
なお、こんなことのためだけにメソッドを分割しなければならないというのは、無駄だしバッドノウハウ的な話なので、かなり嫌いです。インラインにラムダ式でyield returnが使えればこんなことにはならないんだけれどなー、チラチラ(次期C#に期待)
まとめ
再度、冒頭の図を眺め直してもらうと、ああ、なるほどそういうことね、と分かりますでしょうか?
とはいえ、ShareもMemoizeもPublishもあんま使うことはないかと思いますぶっちゃけ!Memoizeは、使いたいシチュエーションは確かに多いのですけれど、しかし事前にToArrayしちゃってたりしちゃうことのほうが多いかなー、と。Shareは面白いんだけど使いどころを選ぶ。Publishは挙動が読みきれなくなりがちなので、避けたほうがいいと思います。
LINQ to Objects & Interactive Extensions & linq.js 全メソッド概説
- 2011-08-10
@ITに以前書いたLINQの基礎知識の話が載りました -> LINQの仕組み&遅延評価の正しい基礎知識 - @IT。ああ、もっとしっかり書いていれば(図もへっぽこだし)、と思ったり思わなかったり。それでも校正していただいたのと、細部は修正してあるので、元のものよりも随分と読みやすいはずです。そういえばで1月頭の話なんですね、姉妹編としてRxの基礎知識もやるつもりだったのにまだやってないよ!
ところでそもそも基礎知識といったら標準クエリ演算子が何をできるかではないのでしょうか?知ってるようで知らない標準クエリ演算子。101 LINQ SamplesもあるしMSDNのリファレンスは十分に充実していますが、しかし意外と見逃しもあるかもしれません。また、Interactive Extensionsで何が拡張されているのかは知っていますか?ついでにJS実装のlinq.jsには何があるのか知っていますか?
そんなわけで、LINQ to Objects、Ix、linq.jsの全メソッドを一行解説したいと思います。
LINQ to Objects
いわゆる、標準クエリ演算子。.NET 3.5から使えます。.NET4.0からはZipメソッドが追加されました。なお、サンプルと実行例はlinq.js Referenceに「完全に」同じ挙動をするJS実装での例がありますので、そちらを参照にどうぞ。こういう場合はJS実装だと便利ですね。
| Aggregate | 汎用的な値算出 |
| All | 条件に全て一致するか |
| Any | 条件に一つでも一致するか、引数なしの場合は空かどうか |
| AsEnumerable | IEnumerable<T>へアップキャスト |
| Average | 平均 |
| Cast | 値のダウンキャスト、主な用途はIEnumerableからIEnumerable<T>への変換 |
| Concat | 引数のシーケンスを後ろに連結 |
| Contains | 値が含まれているか、いわばAnyの簡易版 |
| Count | シーケンスの件数 |
| DefaultIfEmpty | シーケンスが空の場合、デフォルト値を返す(つまり長さ1) |
| Distinct | 重複除去 |
| ElementAt | 指定インデックスの要素の取得 |
| ElementAtOrDefault | 指定インデックスの要素の取得、なければデフォルト値を返す |
| Empty | 空シーケンスの生成 |
| Except | 差集合・差分だけ、集合なので重複は除去される |
| First | 最初の値の取得、ない場合は例外が発生 |
| FirstOrDefault | 最初の値を取得、ない場合はデフォルト値を返す |
| GroupBy | グループ化、ToLookupの遅延評価版(ただしストリーミングでの遅延評価ではない) |
| GroupJoin | 右辺をグループにして結合、外部結合をしたい時にDefaultIfEmptyと合わせて使ったりもする |
| Intersect | 積集合・共通の値だけ、集合なので重複は除去される |
| Join | 内部結合 |
| Last | 最後の値を取得、ない場合は例外が発生 |
| LastOrDefault | 最後の値を取得、ない場合はデフォルト値を返す |
| LongCount | シーケンスの件数、longなので長い日も安心 |
| Max | 最大値 |
| Min | 最小値 |
| OfType | 指定した型の値だけを返す、つまりWhereとisが組み合わさったようなもの |
| OrderBy | 昇順に並び替え |
| OrderByDescending | 降順に並び替え |
| Range | 指定個数のintシーケンスの生成 |
| Repeat | 一つの値を繰り返すシーケンスの生成 |
| Reverse | 逆から列挙 |
| Select | 射影、関数の第二引数はインデックス |
| SelectMany | シーケンスを一段階平らにする、モナドでいうbind |
| SequenceEqual | 二つのシーケンスを値で比較 |
| Single | 唯一の値を取得、複数ある場合は例外が発生 |
| SingleOrDefault | 唯一の値を取得、複数ある場合はデフォルト値を返す |
| Skip | 指定個数だけ飛ばす |
| SkipWhile | 条件が正のあいだ飛ばす |
| Sum | 合計 |
| Take | 指定個数列挙、シーケンスの個数より多く指定した場合はシーケンスの個数分だけ |
| TakeWhile | 条件が正のあいだ列挙 |
| ThenBy | 同順の場合のソートキーの指定、昇順に並び替え |
| ThenByDescending | 同順の場合のソートキーの指定、降順に並び替え |
| ToArray | 配列に変換 |
| ToDictionary | 辞書に変換 |
| ToList | リストに変換 |
| ToLookup | 不変のマルチ辞書(一つのキーに複数の値を持つ)に変換 |
| Union | 和集合・両方の値全て、集合なので重複は除去される |
| Where | フィルタ |
| Zip | 二つのシーケンスの結合、長さが異なる場合短いほうに合わされる |
暗記する必要はなくて、なんとなくこういうのがあってこんな名前だったかなー、とぐらいに覚えておけば、IntelliSenseにお任せできるので、それで十分です。
リスト処理という観点からみるとLINQはかなり充実しているわけですが、更に他の言語と比較した場合の特色は、やはりクエリ構文。SelectManyへの構文は多くの言語が備えていますが(モナドの驚異を参照のこと、LINQはLINM:言語統合モナドである、というお話)、SQLの構文をベースにしたJoin、GroupBy、OrderByへの専用記法は、意外と、というか普通に便利。
特にJoinはあってよかったな、と思います、インメモリで色々なところからデータ引っ張ってきて結合などすると特に。一つぐらいの結合なら別にメソッド構文でいいのですが、フツーのSQLと同じように大量のjoinを並べる場合に、クエリ構文じゃないとシンドい。インメモリからデータベースまで統一的な記法で扱える、ということの凄さを実感するところ。
といっても、普段はほとんどメソッド構文で書いてるんですけどねー。あくまで、込み入った状況になるときだけクエリ構文にしています。クエリ構文では表現できないものが結構多いわけで、わざわざ、これはクエリ構文だけで表現できるからクエリ構文にするかー、とか考えるのもカッタルイので。あと、単純にIntelliSenseでポコポコ打ってるほうが快適、というのもあります。
クエリ構文は、モナドへの記法というよりも、強力なリスト内包表記といった印象も、HaskellへのOrder By, Group Byのペーパー見て思ったりなんかしたりして。
Ix
Ix(Interactive Extensions)はReactive Extensionsで、現在は実験的なものとして提供されている、Enumerableの拡張メソッド群。NuGetのIx_Experimental-Mainで入れるのが使いやすい感じ。InfoQ: LINQ to Objectsのためのインタラクティブエクステンションに解説が少し出ていましたが、少し不足していたり、間違っていたり(DoWhileとTakeWhileは一見似ていますが、挙動は全然異なるし、Forは別に全く興味深くなくSelectManyと同じです)したので、こちらの方が正しいです(キリッ
| Buffer | 指定個数分に区切って配列で値を列挙 |
| Case | 引数のIDictionaryを元に列挙するシーケンスを決める、辞書に存在しない場合はEmpty |
| Catch | 例外発生時に代わりに後続のシーケンスを返す |
| Concat | 可変長引数を受け入れて連結する生成子、拡張メソッド版はシーケンスのシーケンスを平らにする |
| Create | getEnumeratorを渡し任意のIEnumerableを生成する、といってもEnumerator.Createがないため、あまり意味がない |
| Defer | シーケンスの生成をGetEumerator時まで遅延 |
| Distinct | 比較キーを受け入れるオーバーロード |
| DistinctUntilChanged | 同じ値が続くものを除去 |
| Do | 副作用として各値にActionを適用し、値をそのまま列挙 |
| DoWhile | 一度列挙後に条件判定し、合致すれば再列挙 |
| Expand | 幅優先探索でシーケンスを再帰的に平らにする |
| Finally | 列挙完了時に指定したActionを実行 |
| For | SelectManyと一緒なので存在意義はない(Rxと鏡にするためだけに存在) |
| ForEach | foreach、関数の第二引数はインデックス |
| Generate | forループを模した初期値、終了判定、増加関数、値成形関数を指定する生成子 |
| Hide | IEnumerable<T>に変換、具象型を隠す |
| If | 条件が正なら指定したシーケンスを、負なら指定したシーケンス、もしくはEmptyで列挙する |
| IgnoreElements | 後に続くメソッドに何の値も流さない |
| IsEmpty | シーケンスが空か、!Any()と等しい |
| Max | IComparer<T>を受け入れるオーバーロード |
| MaxBy | 指定されたキーで比較し最大値だった値を返す |
| Memoize | メモ化、複数回列挙する際にキャッシュされた値を返す |
| Min | IComparer<T>を受け入れるオーバーロード |
| MinBy | 指定されたキーで比較し最小値だった値を返す |
| OnErrorResumeNext | 例外が発生してもしなくても後続のシーケンスを返す |
| Publish | ShareとMemoizeが合わさったような何か |
| Repeat | 無限リピート生成子、拡張メソッドのほうは列挙後に無限/指定回数最列挙 |
| Retry | 例外発生時に再度列挙する |
| Return | 単一シーケンス生成子 |
| Scan | Aggregateの算出途中の値も列挙する版 |
| SelectMany | 引数を使わず別のシーケンスに差し替えるオーバーロード |
| Share | 列挙子を共有 |
| SkipLast | 後ろからn個の値をスキップ |
| StartWith | 先頭に値を連結 |
| TakeLast | 後ろからn個の値だけを列挙 |
| Throw | 例外が発生するシーケンス生成子 |
| Using | 列挙完了後にDisposeするためのシーケンス生成子 |
| While | 列挙前に条件判定し合致したら列挙し、終了後再度条件判定を繰り返す生成子 |
みんな実装したことあるForEachが載っているのが一番大きいのではないでしょうか。別に自分で実装するのは簡単ですが、公式に(といってもExperimental Releaseですが)あると、全然違いますから。なお、何故ForEachが標準クエリ演算子にないのか、というのは、“foreach” vs “ForEach” - Fabulous Adventures In Codingによれば副作用ダメ絶対とのことで。納得は……しない。
Ixに含まれるメソッドは標準クエリ演算子では「できない」もしくは「面倒くさい」。Ixを知ることは標準だけでは何ができないのかを知ること。何ができないのかを知っていれば、必要な局面でIxを使うなり自前実装するなりといった対応がすぐに取れます、無理に標準クエリ演算子をこねくり回すことなく。例えばBufferやExpandは非常に有益で、使いたいシチュエーションはいっぱいあるんですが、標準クエリ演算子ではできないことです。
While, DoWhileとTakeWhileの違いは条件判定する箇所。While,DoWhileは列挙完了前/後に判定し、判定がtrueならシーケンスを再び全て列挙する。TakeWhileは通る値で毎回判定する。
PublishとMemoizeの違いは難解です。Memoizeは直球そのままなメモ化なんですが、Publishが凄く説明しづらくて……。Enumerator取得まではShareと同じく列挙子の状態は共有されてるんですが、取得後はMemoizeのようにキャッシュした値を返すので値の順番は保証される、といった感じです。うまく説明できません。
存在意義が微妙なものも、それなりにありますね。例えばIfとCaseとForなどは、正直、使うことはないでしょう。Usingも、これを使うなら別メソッドに分けて、普通にusing + yield returnで書いてしまうほうが良いと私は考えています。
Ixを加えると、ほとんど全てをLINQで表現出来るようになりますが、やりすぎて解読困難に陥ったりしがちなのには少し注意を。複雑になるようならベタベタ書かずに、一定の塊にしたものを別メソッドに分ければいいし、分けた先では、メソッドを組み合わせるよりも、yield returnで書いたほうが素直に表現出来るかもしれません。
適切なバランス感覚を持って、よきLINQ生活を!
linq.js
LINQ to ObjectsのJavaScript実装であるlinq.jsにも、標準クエリ演算子の他に(作者の私の趣味で)大量のメソッドが仕込んであるので、せっかくなのでそれの解説も。標準クエリ演算子にあるものは省きます(挙動は同一なので)。また、C#でIEqualityComparer<T>を受け取るオーバーロードは、全てキーセレクター関数のオーバーロードに置き換えられています。
一行サンプルと実行はlinq.js Referenceのほうをどうぞ。
| Alternate | 値の間にセパレーターを織り込む、HaskellのIntersperseと同じ |
| BufferWithCount | IxのBufferと同じ、次のアップデートでBufferに改称予定 |
| CascadeBreadthFirst | 幅優先探索でシーケンスを再帰的に平らにする、IxのExpandと同じ |
| CascadeDepthFirst | 深さ優先探索でシーケンスを再帰的に平らにする |
| Catch | IxのCatchと同じ |
| Choice | 引数の配列、もしくは可変長引数をランダムに無限に列挙する生成子 |
| Cycle | 引数の配列、もしくは可変長引数を無限に繰り返す生成子 |
| Do | IxのDoと同じ |
| Finally | IxのFinallyと同じ |
| Flatten | ネストされた配列を平らにする |
| Force | シーケンスを列挙する |
| ForEach | IxのForEachと同じ |
| From | 配列やDOMなど長さを持つオブジェクトをEnumerableに変換、linq.jsの要の生成子 |
| Generate | ファクトリ関数を毎回実行して値を作る無限シーケンス生成子、IxのGenerateとは違う(IxのGenerateはUnfoldで代用可) |
| IndexOf | 指定した値を含む最初のインデックス値を返す |
| Insert | 指定したインデックスの箇所に値を挿入、Insert(0, value)とすればIxのStartWithと同じ |
| LastIndexOf | 指定した値を含む最後のインデックス値を返す |
| Let | 自分自身を引数に渡し、一時変数を使わず自分自身に変化を加えられる |
| Matches | 正規表現のマッチ結果をシーケンスとして列挙する生成子 |
| MaxBy | IxのMaxByと同じ |
| MemoizeAll | IxのMemoizeと同じ、次のアップデートでMemoizeに改称予定 |
| MinBy | IxのMinByと同じ |
| Pairwise | 隣り合う要素とのペアを列挙 |
| PartitionBy | キーで指定した同じ値が続いているものをグループ化する |
| RangeDown | 指定個数のマイナス方向数値シーケンス生成子 |
| RangeTo | 指定した値まで(プラス方向、マイナス方向)の数値シーケンス生成子 |
| RepeatWithFinalize | 単一要素の無限リピート、列挙完了時にその要素を受け取る指定した関数を実行 |
| Return | IxのReturnと同じ |
| Scan | IxのScanと同じ |
| Share | IxのShareと同じ |
| Shuffle | シーケンスをランダム順に列挙する |
| TakeExceptLast | IxのSkipLastと同じ |
| TakeFromLast | IxのTakeLastと同じ |
| ToInfinity | 無限大までの数値シーケンス生成子 |
| ToJSON | シーケンスをJSON文字列に変換(組み込みのJSON関数のあるブラウザかjson2.jsの読み込みが必要) |
| ToNegativeInfinity | マイナス無限大までの数値シーケンス生成子 |
| ToObject | JSのオブジェクトに変換 |
| ToString | 文字列として値を連結 |
| Trace | console.logで値をモニタ |
| Unfold | Aggregateの逆、関数を連続適用する無限シーケンス生成子 |
| Write | document.writelnで値を出力 |
| WriteLine | document.writeln + <br />で値を出力 |
| TojQuery | シーケンスをjQueryオブジェクトに変換 |
| toEnumerable | jQueryの選択している複数の要素を単一要素のjQueryオブジェクトにしてEnumerableへ変換 |
| ToObservable | 引数のSchduler上で(デフォルトはCurrentThread)Observableへ変換 |
| ToEnumerable | Cold ObservableのみEnumerableへ変換 |
Ixと被るものもあれば、そうでもないものも。ToStringなどは分かりやすく便利でよく使うのではかと。ToJSONもいいですね。Fromは拡張メソッドのない/prototype汚染をしないための、JavaScriptだけのためのメソッド。Matchesは地味に便利です、JSの正規表現は使いやすいようでいて、マッチの列挙はかなり面倒くさいので、そこを解消してくれます。linq.jsは移植しただけ、ではあるんですが、同時に移植しただけではなくて、JavaScriptでLINQはどうあるべきか、どうあると便利なのか、という考えに基づいて調整されています。
JavaScriptにはyield returnがないので(Firefoxにはyieldありますが)、シーケンスは全て演算子の組み合わせだけで表現できなければならない。というのが、手厚くメソッドを用意している理由でもあります。これだけあれば何だって作れるでしょう、きっと多分恐らく。
まとめ
これで今日からLINQ to Objectsマスター。Rx版もそのうち書きます(以前にReactive Extensions入門 + メソッド早見解説表を書きましたが、今は結構変わってしまいましたからね)。
ToArray vs ToList
- 2011-08-03
LINQの結果は遅延評価なので、その場で全部評価して欲しかったりする場合などに使うToArrayとToList。どちらを使っていますか?私はToArrayのほうが好みです。と、いうのも、LINQで書く以上、長さは決まったようなものなので、これ以上AddやRemoveしたいことなんてほとんどない。勿論、必ずないとは言いませんので、その場合だけToListを使いますが、そうでない場合は、長さが固定だという意図を示すためにもToArrayが好ましい。
パフォーマンス
T[]やList<T>に変換されたあとだと、T[]のほうが、大体においてパフォーマンスは良い。という点でもToArrayがいいかなあ、と思うわけですが、それはさておき、ではToArrayとToListメソッドそれ自体のパフォーマンスはどちらのほうが良いでしょうか?理屈の上ではToListのほうが上です。というのも、変換処理は下記の図のようになっているからです。
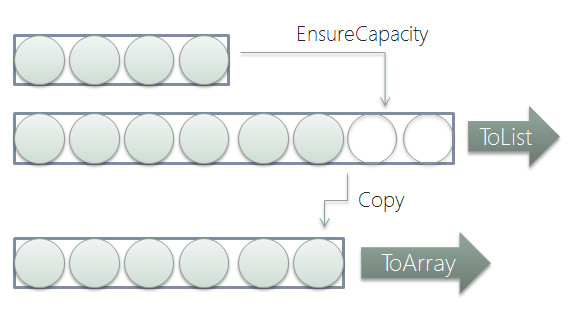
元ソースがIEnumerable<T>である以上、長さは分からないので、ToArrayでも動的配列としていっぱいになったら二倍に拡大する、という動作を行うのはToListと変わりありません。この辺の話は動的配列への追加コストはなぜ O(1)?や、2倍だけじゃないを参考に。.NETは2倍です。そして、最後に拡大された配列の長さを整えるためコピーするのがToArray、そのまま渡すのがToList。つまり、ToArrayのほうが最後の一回のコピー動作が増えているわけです。
でも、ベンチマークをとると、ToArrayのほうが速かったりします。
// 適当さ溢れている(若干恣意的な)測り方なので、それはそれとしてくだしあ
// ToArray:00:00:01.5002685
// ToList :00:00:01.8124284
var source = Enumerable.Range(1, 100000000);
var sw = Stopwatch.StartNew();
source.ToArray();
Console.WriteLine("ToArray:" + sw.Elapsed);
GC.Collect();
sw.Restart();
source.ToList();
Console.WriteLine("ToList:" + sw.Elapsed);
へー、ToArrayのほうが速いんだー、ではなくて、要素数1億件でこの程度しかでないので、どうでもいい程度の差でしかないということです。ここ注意。こういう適当なマイクロベンチのマイクロな差で、こっちのほうが速いからこうしなければならない、これが最適化のための10箇条、みたいなことをやるのは間抜けだと思います。JavaScriptにはそういう記事があまりにも多すぎるとも思っています。
それはともかく、何で理屈の上ではコピーが多いToArrayのほうが"速い"のか。それは中身をゴニョゴニョしてみてみれば分かりますが
public static List<T> ToList<T>(this IEnumerable<T> source)
{
// ICollection<T>の場合はnew List<T>(source)の中で最適化されてます
// 最適化されない場合はforach(var item in source) this.Add(item) という感じ
return new List<T>(source)
}
// 実際のコードとは違います、あくまでイメージです
public static T[] ToArray<T>(this IEnumerable<T> source)
{
// ICollection<T>の場合はCopyToで最適化
var collection = source as ICollection<T>;
if (collection!= null)
{
var dest = new T[collection.Count];
collection.CopyTo(dest, 0);
return dest;
}
// そうでないなら列挙して配列を伸ばしながら作る
var array = new T[4];
var count = 0;
foreach (var item in source)
{
if (array.Length == count)
{
var dest = new T[count * 2];
Array.Copy(array, dest, count);
array = dest;
}
array[count++] = item;
}
// 生成したものと長さが同じならそのまま返す
if (array.Length == count) return array;
// そうでないなら長さを整えてから返す
var result = new T[count];
Array.Copy(array, result, count);
return result;
}
これだけだとよくわからない?うーん、そうですね。ToArrayの場合は配列を作る、それだけに最適化されていて余計なコードが一切ありません。反面、ToList、というかnew List<T>(source)は、内部では少し色々なものの呼び出し回数が多かったりしています。その辺のことが、コピー回数以上に「ほんの少しだけ」速度の差を生んでいるのではないかな、ということのようです。
// パフォーマンスを一切考えないのならこれでいいのよね
public static T[] ToArray<T>(this IEnumerable<T> source)
{
// 実際はreturn new Buffer<T>(source).ToArray();
return new List<T>(source).ToArray();
}
理屈的にはこれでいいわけですが、実際はBuffer<T>クラスというものをinternalでもっていて、それはLINQで使うためだけに余計なものが一切ない動的配列で、LINQ to Objectsの各メソッドは、動的配列が必要な場合ではList<T>ではなく、そのBuffer<T>クラスを使っています。DRYはどうした、という気は少しだけしますが、まあ、ユーザーとしては速いに越したことはないです。
Array.Copy
ところで、Array.CopyやICollection<T>のCopyToって面倒くさいですよね、長さを持った空の配列を作って、渡さなければならないって。と、Array Copy - Memo+の記事を見て改めて思いましたが、しかし、一番よくあるケースである一次元配列のコピーならToArrayを使えばOKです。↑の実装イメージであるように、ちゃんとis asで判定して最適化してくれているので、LINQだとforeachで全部舐めるから遅いんじゃないかなー、と考えなくても大丈夫。
まとめ
今日、Twitterで間違ったこと投稿しちゃって恥ずかすぃかったので反省して書いた。まる。とりあえずToArray使えばいいです。