詳説Ix Share/Memoize/Publish編(もしくはyield returnの注意点)
- 2011-08-15
LINQ to Objects & Interactive Extensions & linq.js 全メソッド概説でのIxのPublishの説明がおざなりだったので、一族について詳しく説明したいと思います(Ixの詳細・入手方法などは先の全メソッド概説のほうを参照ください)。ええ、これらはIBuffer<T>を返すという一族郎党だという共通点があります。なので、並べてみれば分かりやすい、かも?挙動を検証するためのコードは後で出しますので、ひとまず先に図をどうぞ。星がGetEnumerator、丸がMoveNext(+Current)、矢印線が二つ目の列挙子を取得したタイミングを表しています。
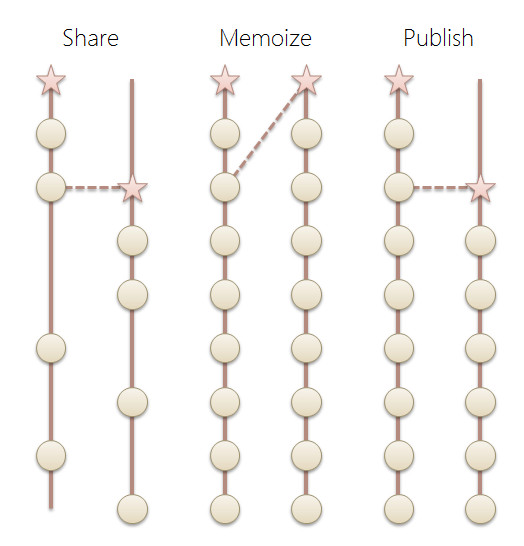
これだけじゃよく分かりません。と、いうわけで、少しだけ上の図を頭に入れて、以下の解説をどうぞ。
Memoize
Memoizeはメモ化。メモイズ。メモライズじゃないっぽいです。二度目三度目の列挙時は値をキャッシュから返すので、前段がリソースから取得したり複雑な計算処理をしていたりで重たい場合に有効、という使い道が考えられます。とりあえずEnumeratorを取ってきて、それでじっくり動きを観察してみましょう。
// ShareやMemoizeやPublishの戻り値の型はIBuffer<T>で、これはIDisposableです。
// もしリソースを抱えるものに適用するなら、usingしたほうがいいかも?
using (var m = Enumerable.Range(1, int.MaxValue)
.Do(x => Console.WriteLine("spy:" + x)) // 元シーケンスが列挙される確認
.Memoize())
{
var e1 = m.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); // spy:1,spy:2,spy:3
Console.WriteLine(e1.Current); // 3
var e2 = m.GetEnumerator();
e2.MoveNext(); // キャッシュから返されるので元シーケンスは不動
Console.WriteLine(e2.Current); // 1
e2.MoveNext(); e2.MoveNext(); e2.MoveNext(); // spy:4
Console.WriteLine(e2.Current); // 4
e1.MoveNext(); // 今度はe2が先行したので、こちらもキャッシュから
Console.WriteLine(e1.Current); // 4
}
特に考える必要もなく分かりやすい内容です。オーバーロードにはreaderCountを受けるものがありますが、それの挙動は以下のようになります。
// Memoizeの第二引数はreaderCount(省略した場合は無限個)
using (var m = Enumerable.Range(1, int.MaxValue).Memoize(2))
{
// readerCountはEnumeratorの取得可能数を表す
var e1 = m.GetEnumerator();
e1.MoveNext(); // MoveNextするとMemoizeに登録される
var e2 = m.GetEnumerator();
var e3 = m.GetEnumerator();
e3.MoveNext();
e2.MoveNext(); // 3つめはNGなので例外が飛んで来る
}
これを使うと、キャッシュから値が随時削除されていくので、メモ化しつつ巨大なシーケンスを取り扱いたい場合には、メモリ節約で有効なこともあるかもしれません。とはいっても、普段はあまり考えなくてもいいかな?毎回削除処理が入るので、実行時間は当然ながら遅くなります。
Share
Shareは列挙子を共有します。
using (var s = Enumerable.Range(1, int.MaxValue).Share())
{
var e1 = s.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 3
var e2 = s.GetEnumerator(); // 列挙子が共有されているので3からスタート
Console.WriteLine(e2.Current); // 0。共有されるといっても、MoveNext前の値は不定です
e2.MoveNext();
Console.WriteLine(e2.Current); // 4。正しく初期値といえるのはここ
Console.WriteLine(e1.Current); // 3。e1とe2は同じものを共有していますが、Currentの値はMoveNextしない限りは変わらない
e1.MoveNext();
Console.WriteLine(e1.Current); // 5。列挙子を共有しているので、e2の続き
}
といった形です。これの何が美味しいの?というと、例えば自分自身と結合させると、隣り合った値とくっつけられます。
// Share, Memoize, Publishにはselectorを受けるオーバーロードがある
// このselectorには var xs = source.Share() の xsが渡される
// つまり、一度外部変数に置かなくてもよいという仕組み、Zipなどと相性が良い
// 結果は {x = 1, y = 2}, { x = 3, y = 4}, { x = 5, y = 6}
// 列挙子を共有して自分自身と結合するので、隣り合った値とくっつく
Enumerable.Range(1, 6)
.Share(xs => xs.Zip(xs, (x, y) => new { x, y }))
.ForEach(x => Console.WriteLine(x));
なんだか、へぇー、という感じの動き。このShareを使うとstringの配列からDictionary<string, string>への変換 まとめ - かずきのBlog@Hatenaのコードは
// {"1":"one"}, {"2":"two"}
var array = new[] { "1", "one", "2", "two" };
var dict = array.Share(xs => xs.Zip(xs, Tuple.Create))
.ToDictionary(t => t.Item1, t => t.Item2);
物凄くシンプルになります。ループを回すなんて、やはり原始人のやることでしたね!
Publish
PublishはRxでは値を分散させましたが、Ixでも分散です。ただ、挙動にはかなりクセがあり、あまりお薦め出来ないというか……。動きとしては、取得時には共有された列挙子から流れてくるのでShareのようであり、列挙子取得後は全て必ず同じ値が返ってくることからMemoizeのようでもある。
using (var p = Enumerable.Range(1, int.MaxValue).Publish())
{
var e1 = p.GetEnumerator();
e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 3
var e2 = p.GetEnumerator(); // 取得時は列挙子の状態が共有されているので3からスタート
Console.WriteLine(e2.Current); // 0。 共有されるといっても、MoveNext前の値はやはり不定
e2.MoveNext();
Console.WriteLine(e2.Current); // 4。正しく初期値といえるのはここ
e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); e1.MoveNext(); e1.MoveNext();
Console.WriteLine(e1.Current); // 8
e2.MoveNext(); // 取得後の状態はそれぞれ別、またキャッシュから返される
Console.WriteLine(e2.Current); // 5
}
このPublish、こうして生イテレータを操作している分には理解できますが、普通に使うように演算子を組み合わせると予測不能の挙動になります。例えば
// 自分自身と結合、GetEnumeratorのタイミングが同じなので同値で結合される
// {1,1},{2,2},{3,3},{4,4},{5,5}
Enumerable.Range(1, 5)
.Publish(xs => xs.Zip(xs, (x, y) => new { x, y }))
.ForEach(a => Console.WriteLine(a));
// もし後者のほうをSkip(1)したらこうなります
// {1,3},{2,4},{3,5}
Enumerable.Range(1, 5)
.Publish(xs => xs.Zip(xs.Skip(1), (x, y) => new { x, y }))
.ForEach(a => Console.WriteLine(a));
Skip(1)すると {1,2},{2,3}... ではなくて {1,3},{2,4}... になる理由、すぐにティンと来ますか?正直私はわけがわかりませんでした。Zipの実装を見ながら考えると、少し分かりやすくなります。
static IEnumerable<TR> Zip<T1, T2, TR>(this IEnumerable<T1> source1, IEnumerable<T2> source2, Func<T1, T2, TR> selector)
{
using (var e1 = source1.GetEnumerator())
using (var e2 = source2.GetEnumerator())
{
while (e1.MoveNext() && e2.MoveNext())
{
yield return selector(e1.Current, e2.Current);
}
}
}
Skip(1)のない、そのままZipで結合したものはEnumeratorを取得するタイミングは同じなので、 {1,1},{2,2}... になるのは妥当です。では、source2がSkip(1)である場合は、というと、source2.GetEnumeratorの時点で取得されるのはSkip(1)のEnumeratorであり、Publishで分配されているEnumeratorはまだ取得開始されていません。では、いつPublishされているEnumeratorを取得するか、というと、これは最初にe2.MoveNextが呼ばれたときになります。なので、e1.MoveNextにより一回列挙されているから、e2の(MoveNext済みでの)初期値は2。更にSkip(1)するので、{1,3},{2,4}... という結果が導かれます。
ZipやSkipなど、他のメソッドを組み合わせるなら、それらの内部をきっちり知らなければ挙動が導けないという、ものすごく危うさを抱えているので、Publishを上手く活用するのは難しい印象です、今のところ、私には。もともとPublishはRxに分配のためのメソッドとして存在して、その鏡としてIxにも移植されているという出自なのですが、どうしてもPull型で実現するには不向きなため、不自然な挙動となってしまっています。分配はPull(Ix)じゃなくてPush(Rx)のほうが向いている、というわけで、分配したいのならToObservableして、Observable側のPublishを使ったほうが、素直な動きをして良いと思います。
yield returnを突っつく
MemoizeのreaderCountの例でもそうでしたが、Publish/Memoizeされている列挙子を取得するのがGetEnumerator時ではなくて最初のMoveNextの時、になるのはyield returnを使うとそういう挙動で実装されるからです。例えば
static IEnumerable<T> Hide<T>(this IEnumerable<T> source)
{
Console.WriteLine("列挙前");
using (var e = source.GetEnumerator()) // 通常は、foreachを使いますが。
{
while (e.MoveNext()) yield return e.Current;
}
Console.WriteLine("Dispose済み");
} // yield break
static void Main(string[] args)
{
var e = Enumerable.Repeat("hoge", 1).Hide().GetEnumerator(); // ここではまだ何も起こらない
e.MoveNext(); // 列挙前 ← ここでメソッド冒頭からyield return e.Currentのところまで移動
Console.WriteLine(e.Current); // hoge
e.MoveNext(); // Dispose済み ← 最終行まで到達して終了
}
イテレータの自動実装でメソッド本文を動きだすのは、最初のMoveNextから、というわけです。また、イテレータ内でusingなどリソースを掴む実装をしている場合は、普通にブロックを(using,lock,try-finally)超えた時に解放されます。ただし、ちゃんとブロックを超えるまでMoveNextを呼びきれる保証なんてない(例外が発生したり)ので、GetEnumeratorする時はusingも忘れずに、は大原則です。using、つまりEnumeratorをDisposeすると、using,lock,finallyがメソッド本文中で呼ばれていなかった場合は、呼ぶようになってます。
ところで、本文が動き出すのは最初のMoveNextから、であることが困る場合もあります。例えば引数チェック。
public static IEnumerable<string> Hoge(string arg)
{
if (arg == null) throw new ArgumentNullException();
yield return arg;
}
void Main(string[] args)
{
var hoge = Hoge(null); // ここでは何も起こらない!
hoge.GetEnumerator().MoveNext(); // ArgumentNullException発生
}
nullチェックはメソッドに渡したその時にチェックして欲しいわけで、これではタイミングが違って良くない。これを回避するにはどうすればいいか、というと
// 先にnullチェックを済ませて普通にreturn
public static IEnumerable<string> Hoge(string arg)
{
if (arg == null) throw new ArgumentNullException();
return HogeCore(arg);
}
// privateなメソッドで、こちらにyield returnで本体を書く
private static IEnumerable<string> HogeCore(string arg)
{
yield return arg;
}
static void Main(string[] args)
{
var hoge = Hoge(null); // 例外発生!
}
こうすれば、完璧な引数チェックの完成。実際に、LINQ to Objectsの実装はそうなっています。この時のprivateメソッドの命名には若干困りますが、私は今のところXxxCoreという形で書くようにしてます。MicrosoftのEnumerable.csではXxxIteratorという命名のようですね。また、Ixを覗くとXxx_という名前を使っている感じ。みんなバラバラなので好きな命名でいいのではかと。
なお、こんなことのためだけにメソッドを分割しなければならないというのは、無駄だしバッドノウハウ的な話なので、かなり嫌いです。インラインにラムダ式でyield returnが使えればこんなことにはならないんだけれどなー、チラチラ(次期C#に期待)
まとめ
再度、冒頭の図を眺め直してもらうと、ああ、なるほどそういうことね、と分かりますでしょうか?
とはいえ、ShareもMemoizeもPublishもあんま使うことはないかと思いますぶっちゃけ!Memoizeは、使いたいシチュエーションは確かに多いのですけれど、しかし事前にToArrayしちゃってたりしちゃうことのほうが多いかなー、と。Shareは面白いんだけど使いどころを選ぶ。Publishは挙動が読みきれなくなりがちなので、避けたほうがいいと思います。