BigQueryで数列生成とC#クラスからのTable生成とデータインサート
- 2014-10-05
連番を作りましょう!突然!SQL的なものを見ると、まず連番を作りたくなるのはSQLで数列を扱うからなのですが、というわけでBigQueryでも作りますし作れます。実際、Enumerable.Rangeはダイジですからね?また、地味にLINQ to BigQueryもver 0.3.3になってました。ひっそり。そんなわけで、LINQで書くと何が嬉しいのかPart2です。
LINQ to BigQuery(やBigQuery)については、最初の記事LINQ to BigQuery - C#による型付きDSLとLINQPadによるDumpと可視化をどーぞ。
0-9を作る
TempTableにInsertというわけにもいかないので、まずは愚直にUNION ALLで並べましょう。BigQueryのUNION ALLはFromをカンマで並べること(ふつーのSQLとそこが違います)で、また、Subqueryも突っ込めます。ド単純に書くとこうなる。
// 以下contextとでてきたらコレのこと
var context = new BigQueryContext(/* BigqueryService */, /* projectId */);
var seq = Enumerable.Range(0, 10).Select(x => context.Select(() => new { num = x }));
context.From(seq)
.Select(x => new { x.num })
.Run()
.Dump(); // DumpはLINQPadのDumpね。
// ↓で、こんなクエリが出てくる
/*
SELECT
[num]
FROM
(
SELECT
0 AS [num]
),
(
SELECT
1 AS [num]
),
// 以下9まで続くので(略) */
普通に動きはしますが、馬鹿っぽいですね!少しだけカッコヨク書いてみましょうか。どうやって列を増やすか、が割と課題なのですが、BigQueryではSplitを使って増やせます。
// LINQPadでRun().Dump()って書くの面倒いのでまとめちゃう:)
public static class MyExtensions
{
public static QueryResponse<T> DumpRun<T>(this IExecutableBigQueryable<T> source)
{
return source.Run().Dump();
}
}
// SELECT query which references non constant fields or uses aggregation functions
// or has one or more of WHERE, OMIT IF, GROUP BY, ORDER BY clauses must have FROM clause.
context.Select(() => new { digit = BqFunc.Integer(BqFunc.Split("0123456789", ""))}).DumpRun();
怒られました!FROM句を含めないとSplitが使えないそーですなので、wordはサブクエリに分離しましょう。この辺は覚えられないので怒られたらそーいうものなんだ、って感じに対応していきましょふ。案外エラーメッセージは(親切な時は)親切です。親切じゃない時は何言ってるのか分からないエラーメッセージを吐いてきますが、まぁ7割ぐらいは分かりやすいエラーメッセージを吐いてくれます、偉い。
context
.Select(() => new { word = "0123456789" })
.AsSubquery()
.Select(x => new { digit = BqFunc.Integer(BqFunc.Split(x.word, ""))})
.DumpRun();
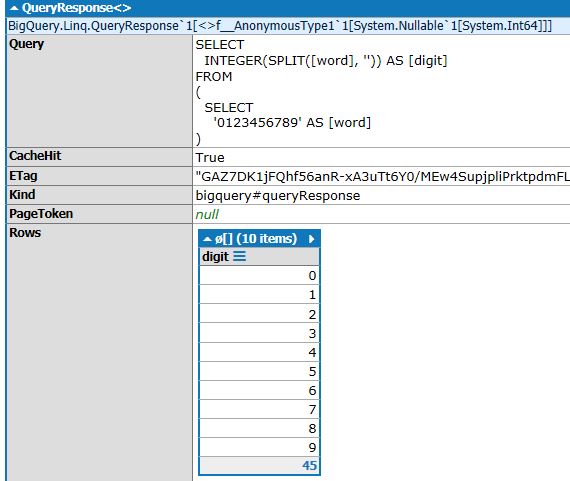
さすがにFROM句に並べまくるよりは、綺麗に書けてる感が出てる気がします!
0-99を作る
0-9が出来たら、あとは簡単に増やせます。ここはCROSS JOINです。0-9と0-9の直積を取ればおk。LINQでBigQueryを書くことの利点に変数にクエリを渡せて、合成可能という点が挙げられます(また、合成可能というのはLINQらしい感じさせるための重要な要素でもある)。0-9を変数に置いてやれば、コピペで同じSQLを書かないでも済みます。
var digit = context.Select(() => new { word = "0123456789" })
.Into()
.Select(x => new { digit = BqFunc.Integer(BqFunc.Split(x.word, ""))});
// これは動かないけどネ
// Cannot query the cross product of repeated fields
digit.Into()
.JoinCross(digit, (d1, d2) => new { d1, d2 })
.Select(x => new { seq = x.d1.digit + x.d2.digit * 10 })
.DumpRun();
ネ。まぁこれは動かないんですけどネ。例によってエラーメッセージが出てから対処すればいいんですが、これはSplitで生成したカラムがrepeated fieldになってるのでcross joinできないよ、とのこと。FLATTENを使えば解決します。あとOrderByを忘れてるのでOrderByも足してやりましょうか。
var digit = context.Select(() => new { word = "0123456789" })
.Into()
.Select(x => new { digit = BqFunc.Integer(BqFunc.Split(x.word, ""))})
.Into()
.Flatten(x => x.digit);
digit.JoinCross(digit, (d1, d2) => new { d1, d2 })
.Select(x => new { seq = x.d1.digit + x.d2.digit * 10 })
.OrderBy(x => x.seq)
.DumpRun();
SELECT
([d1.digit] + ([d2.digit] * 10)) AS [seq]
FROM FLATTEN(
(
SELECT
INTEGER(SPLIT([word], '')) AS [digit]
FROM
(
SELECT
'0123456789' AS [word]
)
), [digit]) AS [d1]
CROSS JOIN FLATTEN(
(
SELECT
INTEGER(SPLIT([word], '')) AS [digit]
FROM
(
SELECT
'0123456789' AS [word]
)
), [digit]) AS [d2]
ORDER BY
[seq]

この辺まで来ると、圧倒的に手書きよりも捗るのではないでしょうか。というか、LINQならサクサク書けますが(エラー来たら、ああはいはいIntoね、みたいに対処するだけだし)、手書きSQLはシンドイ。むしろ無理。その上で、別に意図と全然違うクエリが吐かれるわけではない、というラインはキープされてると思います。
それとネストが深くなるクエリはどう整形したらいいか悩ましいものなのですが(Stackoverflowには可読性ゼロのめちゃくちゃなインデントのBigQueryのクエリの質問が沢山転がっている!実際きちんと書くのむつかしい)、LINQ to BigQueryは、まぁまぁ読みやすい感じにきっちりフォーマットして出してくれます。若干冗長に思えるところもあるかもですが、まぁそこはルールなのだと思ってもらえれば。見やすいフォーマットといえるものにするため、微調整を繰り返したコダワリがあります。
パラメータを使う
もう一個LINQ to BigQueryのいいとこは、パラメータが使えるとこです。パラメータというか、クエリ文字列にたいして値を埋め込めるの。例えば
// こんなメソッドを作るじゃろ
Task<string[]> GetTitleBetweenRevision(int revisionIdFrom, int revisionIdTo, int limit)
{
return context.From<wikipedia>()
.Where(x => BqFunc.Between(x.revision_id, revisionIdFrom, revisionIdTo))
.Select(x => x.title)
.Limit(limit)
.ToArrayAsync();
}
// こういうふうに使いますね、的な
var rows = await GetTitleBetweenRevision(1, 200, 100);
-- 1と200が文字列置換なくSQLに埋め込まれる
SELECT
[title]
FROM
[publicdata:samples.wikipedia]
WHERE
([revision_id] BETWEEN 1 AND 200)
LIMIT 100
その場でのクエリ書きには使いませんが、プログラムに埋め込んで発行する場合なんかは当然ながらあるといいですよね、と。文字列置換や組み立てはかなり手間かかるので、ずっとぐっと遥かに楽になれるかと思います。LINQなら条件によってWhereを足したり足さなかったり、みたいな書き方も簡単です。
(この機能は0.3.1から入れました!アタリマエのように見えて、ExpressionTreeを操作する上で、地味に微妙に面倒くさいのですよー。とはいえ実用性考えるとこういうのないとアリエナイというか私が使ってて不便したんでようやっと入れました)
クエリ書きに使うのに便利といえば日付の操作は圧倒的に楽になります。例えば昨日の20時というのをBigQueryだけでやると……
context // 走査範囲を狭くするために適当に5日前ぐらいからのRangeにしてる
.From<github_timeline>("[githubarchive:github.timeline]").WithRange(TimeSpan.FromDays(5))
.Where(x => x.type=="CreateEvent"
&& BqFunc.ParseUtcUsec(x.repository_created_at) >= BqFunc.ParseUtcUsec(BqFunc.StrftimeUtcUsec(BqFunc.TimestampToUsec(BqFunc.DateAdd(BqFunc.UsecToTimestamp(BqFunc.Now()), -1, IntervalUnit.Day)), "%Y-%m-%d 20:00:00"))
&& x.repository_fork == "false"
&& x.payload_ref_type == "repository")
.Select(x => x.repository_name)
.DumpRun();
// SQL
SELECT
[repository_name]
FROM
[githubarchive:github.timeline@-432000000-]
WHERE
(((([type] = 'CreateEvent') AND (PARSE_UTC_USEC([repository_created_at]) >= PARSE_UTC_USEC(STRFTIME_UTC_USEC(TIMESTAMP_TO_USEC(DATE_ADD(USEC_TO_TIMESTAMP(NOW()), -1, 'DAY')), '%Y-%m-%d 20:00:00')))) AND ([repository_fork] = 'false')) AND ([payload_ref_type] = 'repository'))
結構しんどいです。厄介な日付部分を取り出すと
PARSE_UTC_USEC(STRFTIME_UTC_USEC(TIMESTAMP_TO_USEC(DATE_ADD(USEC_TO_TIMESTAMP(NOW, -1, 'DAY')), '%Y-%m-%d 20:00:00'))))
ですからね!結構かなり絶望的……。これをC#のDateTimeで操作すれば
// 今日から一日引いてその日付のみのほうを取って20時間足す
var yesterday = DateTime.UtcNow.AddDays(-1).Date.AddHours(20);
context
.From<github_timeline>("[githubarchive:github.timeline]").WithRange(TimeSpan.FromDays(5))
.Where(x => x.type=="CreateEvent"
&& BqFunc.Timestamp(x.repository_created_at) >= yesterday // ほら超スッキリに!
&& x.repository_fork == "false"
&& x.payload_ref_type == "repository")
.Select(x => x.repository_name)
.DumpRun();
// 日付比較部分のSQLはこう出力される
TIMESTAMP([repository_created_at]) >= '2014-10-03 20:00:00.000000')
その場で書いてクエリ実行する分には、別に日付が埋め込まれようとNOW()からSQLで全部操作しようと変わらない話ですからね。楽な方でやればいいし、日付操作は圧倒的にC#で操作して持ってたほうが楽でしょう、明らかに。
Tableを作る、データを投げる
サンプルデータを扱ってるのもいいんですが、やっぱ自分でデータ入れたいですね、テーブル作りたいですね。基本的には(Google API SDKの)BigqueryServiceを使え!っていう感じなのですが、それはそれでやっぱりそれもプリミティブな感じなので、テーブル作成に関してはちょっとしたユーティリティ用意してみました。以下の様な感じで作れます。
// DataTypeUtility.ToTableFieldSchemaでTableFieldSchema[]を定義から作れる
// 匿名型を渡す以外に既存クラスだったら<T>やtypeof(T)を渡すのもOK
// もちろん手でTableFieldSchema[]を作って渡すのも構わない
new MetaTable("project_id", "mydata", "people")
.CreateTable(service, DataTypeUtility.ToTableFieldSchema(new
{
firstName = default(string), // STRING REQUIRED
lastName = default(string), // STRING REQUIRED
age = default(int?), // INTEGER NULLABLE
birth = default(DateTimeOffset) // TIMESTAMP REQUIRED
}));
Web Interfaceから作ると、「空のテーブルが作れない」「スキーマはなんかカンマ定義で指定してかなきゃいけなくてダルい」という点があって存外ダルいです。bqも同様。やはり時代はLINQPad、で作る。ちなみにSTRING NULLABLEはクラス定義から抽出するのが不可能だったので(こういうところが不便なのよね……)、まあTableFieldSchema[]を作ってから schemas[1].Mode = "NULLABLE" とでも書いてください。
データの投下も同じようにMetaTableを作ってInsertAllAsyncで。
// ExponentialBackOffを渡した場合はそれにのっとってリトライをかける
await new MetaTable("project_id", "mydata", "people")
.InsertAllAsync(service, new[]
{
new { firstName = "hoge", lastName = "huga", age = 20, birth = new DateTime(2010,1,1,12,13,14, DateTimeKind.Utc)},
new { firstName = "tako", lastName = "bcbc", age = 30, birth = new DateTime(1983,3,1,10,33,24, DateTimeKind.Utc)},
new { firstName = "oooo", lastName = "zzzz", age = 45, birth = new DateTime(2043,1,3,11,4,43, DateTimeKind.Utc)},
}, new Google.Apis.Util.ExponentialBackOff(TimeSpan.FromMilliseconds(250), 5));
これでBigQueryのStreming Insertになります。ひどーきなので別テーブルに並走して書きたい場合は複数書いてWhenAllすれば高速で良いでしょふ。Streaming Insertはそんな頻繁、ではないですけれどそれなりに失敗することもあるので、引数にExponentialBackOff(これ自体はGoogle API SDKに含まれている)を渡せばExponential backoffでリトライを試みます。
まとめ
基本的な機能は完全に実装完了したかなあ、という感じ。0.1 ~ 0.3.3の間に自分で使っててイラッとした細かい部分をチクチク修正してきましたが、そろそろ完全に満足!といったところです。不満ない!完璧!パーフェクち!というわけで、残るはRECORD型サポートに向けて改装すれば敵なし、LINQったらサイキョーね!
な、わけですが、まぁ.NET + BigQueryというニッチに二乗かけたようなアレなので、興味関心、はあっても使ってみた!という人は少ないでしょう、というかいないでしょう、残念無念。でもBigQueryは本当に凄く良いので使ってみて欲しいんだなー。ビッグデータなんてアタクシには無縁、と思ってる人も、実は使い出、使いドコロって、絶対あります。まずはログを片っ端から突っ込んでみましょう、から始めてみませんか?