2012年を振り返る。
- 2012-12-30
12/30は私の誕生日でして(どうでもいい)、まだかろうじて20代です。 というわけで、今年を振り返りますかー。今年は1/1から動きがありましたから、というか転職でしたね、gloopsに入社しました。入社するまでドッキドキでしたねえ、正月とかあんま落ち着かない感じで過ごしてたのを思い出しました。 2011年の振り返りでは
ここで言うことか?という話ではありますが、12月で会社を退職し(て)ました。1月からは新しい会社で働くことになります。次の会社でもC#をメインにやっていきます(ということで雇われるわけでもありますので)。しっかり成果を出していきたいし、事例やコードなんかも、出せるならガシガシ出したいと思っています。その辺のことは追々。
と言ってましたが、結果はどうだったかしらん。C#とLINQとVisual Studioの社内布教には尽力できたし、割とよくやれたとは思います。コードは出せなかったけれど、事例は、うーん、事例というほどではないですが、割とよく露出して会社と関係なくC#のことを喋るお仕事はしてた気がします。Windows Developer Daysへの登壇とかね。LINQ to Everything : データソース・言語を超える LINQ の未来だってお!とかまあ、色々それなりにそこそこよくやってたんじゃないでしょーか。
7月頃に海外勤務の話が上がったというか、実際に1か月ほどシンガポールに行ってまして、そのまま割と長めにいるはずだったのが、色々あってお流れに!ぐぬぬぬ。ここが一番ぐぬぬぬだったり、ピー(禁則事項です)。まあ、特に面白い話はありません!
そんなわけで10/19にgloopsを退職して、今はニート。ではなく、謎社にいます。謎社ってなんだよというか伏せる意味は特にないんですが、まぁまだ伏せておきます。実際のとこ出来たばかりの会社でして、だいたいほぼほぼ創立メンバーとして働いてます。そして現在のところPHPが95%でC#が5%といったところですが(私もPHP書いてますよ!毎日吐き気が!)、直近の目標はC#比率を高めることです(笑)
プログラミング
gloopsがASP.NETな会社だから、というのもあって、ブログネタが急速にうぇぶけーに傾いた気がします。エクストリームWebFormsとかね。Advent CalendarネタのMemcachedTranscoderなども、まさに仕事ネタでした。LINQネタはちょいちょい、Rxネタは、今年は非同期と合わせたのが少しというだけで、ほとんどなかった……。などなど、やっぱ仕事成分多くなるとshoganaiのかなあとか思いつつも、shomonaiですねえ。
gloopsで割と忙しかったというのもあって、ライブラリ類のメンテナンスが完全に止まってましたね、うわぁ。Pull Requestの放置に定評のある私です(キリッ とか言ってる場合ではない。
LINQ
2011年から続いてLinQはかなりメジャー感が増して全国的な知名度も高くなりTwitterの検索が完全に役立たなくなるなど素晴らしい躍進でした、まる。
linq.js ver.3のプロジェクトを本格的に動かして、延々とやった割には、いまだBeta 4という状況がとてもアレ。来年の初頭にはリリースしたいです。各方面にも絶賛ご迷惑おかけ、というかver.2とver.3では何もかもが違うので、ver.2が普及すればするほど、いくない状況になってしまうので、早いところ手を打ちたいのは本当です。linq.js ver.3のスライドは10000viewを超えていて、まあそれなりに期待されてるのかなあ、なんて、ね。思いますので。
そういえばLINQ to XML for JavaScriptの登場も大きなトピックでした。BetaということもあってDL数も思ったよりも全然伸びてないのですが、Betaな理由は私が悪いので、もう本当に申し訳なすぎる……。
あと、実はRxのオープンソース化にともなってRxチームのボスであるErik Meijer氏からメールを貰ったものの、一度返信しただけで、その後の返信は一切放置という失礼極まりない態度を取ってしまって激しく後悔中。英語で返事考えるの大変だなー、と置いておいたら、なんかもう出すに出せなくなってしまい……。
講演
講演というか勉強会の発表側ですが、今年は今までになくやった気がする。gloopsでの発表もそうだし、ふつーに勉強会のとしても。C#次世代非同期処理概観 - Task vs Reactive Extensionsなんかは20000view行ってるし、テーマがキャッチーだとその後の資料の閲覧の伸びもいい。というのは至極当たり前にゃ。
メールの放置にも定評のある私なのですが、来年はちゃんとした応対を取れるまっとうな人間になろう、と心がけたいところです。そんなメール対応でタイトルが仮だった第1回 業開中心会議 .NET技術の断捨離も、ちゃんとタイトル決まりましたので、来年早々の2013年1月26日(土)にはよろしくおねがいします。もう定員埋まっちゃいましたが!
諸事情あって見返したいというわけでもないですが、来年はむしろ増量したい感があったりなかったり。そしてC#を布教する!実際、つい一昨日ぐらいにはぴーHPの会社に行ってC#ばんざーいしてきたりとか、野良だからこそできる不躾気味な野良活動も色々やってきたいですねー。まあ、会社が落ち着いたらの話ですががが。
ネット
Twitter廃人度が増した。いや、別にフォローもフォロワーも並程度でしかないし発言数もさして多いわけじゃあないんですが、四六時中眺めててストリームが常に更新されている程度にはフォロワーがいて、でも頑張れば全部読めちゃう程度で、つまり、全てを漏らさず眺めようとしてしまい……。時間ドブに捨ててる度ヤバすぎる。これねえ、よくなさすぎるねえ。どうにかしなければ……。
ゲーム
ソーシャルゲームをつまむ程度にプレイしてたぐらいで、ぜーんぜんやってない。待ちに待ったSkyrimすら未開封なのでゲーマーとして完全にオワタオワタオワタ……。いや、やりたいんですよ、というかですね、やってないとゲーム的な感覚が完全に抜けてしまっててすっごく良くない。ゲームに対してどこがいいとか悪いとか、感性抜けきってて何も考えられないの。ムは無関心のム、ですよ。昔はあんなに文句たらしまくって感想だの書きたくってたのにねえ(このサイトの前身はXboxゲームの攻略サイトでした)、むしろ意図的に考えないようにしてる(キリッ とか言ってたら感性が完全に死んじゃったのね、笑えない。内心では、やればちゃんとゲームについて評価できるもん!とか思ってても、実際はもう出来やしないのね。という現実。と向き合わなきゃ。
というわけで、来年はゲームリハビリ元年にしたいかな。割と本気で。
来年
今年が今まで生きてきた中で、一番変化のあった年でした。来年は変化というよりは進化、↑で書いたとおりにゲームを、じゃあなくて会社を前身させるのに全力で突き進む、というわっかりやすい目標があるんで、そのとーりに邁進しましょう。C#といったら謎社!みたいな、C#を使う人が憧れるぐらいな立ち位置の会社にできればいいなと思っています。ただ、それは一従業員の私の思いであって会社の方針とは何ら関係ありません!が、結構本気なので期待してください。興味ある人は今からでも私にコソッと言ってくだしあ、です。いやほんと。
ともあれ、来年はより面白い感じにすごせそーなので、いいことです。
Micro-ORMとC#(とDapperカスタマイズ)
- 2012-12-11
C#に続き、ASP.NET Advent Calendar 2012です。前日は84zumeさんのWebFormっぽいコントロールベスト3でした。私はC#ではMemcachedTranscoder - C#のMemcached用シリアライザライブラリを書きまして、ああ!これこそむしろASP.NETじゃねえか!と悶絶したりなどして、日付逆にすれば良かったよー、困ったよー。しかもあんまし手持ちの札にASP.NETネタがない!というわけで、ASP.NETなのかビミョーですが押し通せば大丈夫だろう、ということでMicro-ORMについて。
Micro-ORM?
最近タイムリーなことに、またORM論争が起こっていて。で、O/R Mapperですが、私としては割と否定派だったりして。C#にはLINQ(to SQL/Entities)があります!はい、色々な言語のORMを見ても、LINQ(to SQL/Entities)の完成度はかなり高いほうに入ると思われます。それもこれもC#の言語機能(Expression Tree, 匿名型, その他その他)のお陰です。言語は実現できる機能にあんま関係ないとかいう人が割とたまにじゃばにいますが、んなことは、ないでしょ。
で、ORMと一口に言うとややこしいので、分解しよう、分解。一つはクエリビルダ。SQL文を組み立てるところです。ORMといったら、まず浮かぶのはここでしょう、そして実際、ここの部分の色々のもやもやを振り払うために、世の中のORMは色々腐心しているのではかと思います。
残りは、クエリを発行してDBに投げつける実行部分。コネクション作ってコマンド作ってパラメータ作って、とかがお仕事。最後に、結果セットをマッピングするところ。この2つは地味ですね、ORMという時に、特に意識されることはないでしょう。
で、Micro-ORMはクエリビルダはないです。あるのは実行とマッピングだけです。生SQL書いてオブジェクトにマッピングされたのが返ってくる。つまり、ORMと言ったときにまず浮かべる部分が欠けてます。だからORMって、RelationalとはMappingしてないんならもうDataMapperとかTableMapperとか言ったほうがいいのでは、感もありますが、つまるところそういうわけでMicro-ORMはORMじゃないですね。
ORM or その他、といった時に、ORM(DataSet, NHibernate, LINQ to SQL, Entity Framework)を使わない、となると、その次が生ADO.NETに吹っ飛ぶんですよね、選択肢。それ、えっ?って。生ADO.NETとか人間が直に触るものじゃあない、けど、まあ昔からちょっとしたお手製ヘルパぐらいは存在していたけれど、それだけというのもなんだかなー。という隙間に登場したのがMicro-ORMです。
Not ORM
つまりORMじゃあない。LINQという素敵な完成系があるのに、違うのを選びたくなる。何故?LINQという素敵なもので夢を見させてくれた、それでなお、ダメかもね、という結論に至ってしまう。じゃあもうORMって無理じゃない?
SQLは全然肯定できません。30年前のしょっぱい構文、の上にダラダラ足されていく独自拡張。じゃあ標準万歳かといえば、全然そんなことはないのでにっちもさっちもいかずだし、そもそもその標準の時点で相当しょっぱいっつーの。でも、それでも、ORMにまつわる面倒ごとであったり制限を押しのけてまで欲しいかい?と言われると、いらない。になる。
結局、データベースはデータベースであり、オブジェクトはオブジェクトであり。
EF CodeFirstって凄く滑稽。オブジェクトをそのまんまDBに投げ込むのなんて幻想で。だからデータベースを意識させて、クラスじゃないクラスを作る。リレーションを手でコードで張っていく、そんな、おかしいよ!まともなクラスじゃないクラスを手で書かされるぐらいなら、SQL Server Management Studioでペトペト作って、DBからクラス生成するほうがずっといい(勿論EFはそれできます)。
オブジェクト入れたいならさ、Redisとかも検討できる、そっちのほうがずっと素直に入る。勿論、データベースをやめよう、じゃないよ。ただ、データベースはデータベースである、というだけなんだ。
SQLだってすごく進化しているのに(書きやすさは置いておいてね)、ORMの抽象はそれらに完璧に対応できない。だって、データベース毎に、違うんだものね、同じ機能なかったりするものね。RDBMSは同じだ、というのが、まず、違うんじゃないかな、って。
良い面がいっぱいあるのは分かるよ!where句を文字列で捏ね捏ねするよりもオブジェクト合成したいし、LINQのタイプセーフなところは凄く魅力的なんだ!それでもね、厄介な挙動と複雑な学習コスト、パフォーマンスの問題、その他諸々。それらとは付き合わない、という選択もね、あっていいよね。
Dapper
具体例としてDapperを扱います。もっともポピュラーだから。速いしね。で、チマッとした具体例は、出してもつまらないので省略。それは↑の公式サイトで見ればいいでしょ。
拡張しよう
基本的にマッピングはプロパティ名とDBのカラム名が一致してないとダメです。ダメ絶対。しかし、世の中往々にして一致してるとは限らないケースが少なくもない。例えばDBのカラム名はsnake_caseでつけられていたりね。勿論、その場合C#のプロパティ名もsnake_caseにすりゃあいんですが、きんもーっ。嫌なんだよね、それ。
というわけでDapperには救済策が用意されていて、マッピングルールを型毎に設定することが可能です。この辺はリリース時にはなかったんですが後から追加されてます。そしてドキュメントが一向に更新されないため、何が追加されてるのとか、はためにはさっぱり分かりません。何気に初期リリースから地味に随分と機能が強化されていたりなかったりするんですんが、この辺は定期的にSourceとTest見れってとこですねー、shoganai。
方法としてはCustomPropertyTypeMapを作って、SqlMapper.SetTypeMapに渡してやればOK。CustomPropertyTypeMapではTypeとDBのカラム名が引数にくるので、そこからPropertyInfoを返してやればOK。一度定義されたマッピングファイルは初回のクエリ実行時にIL生成&キャッシュされ、二度呼ばれることはないので高速に動作します。
例えばsnake_caseをPascalCaseにマッピングさせてやるには
// こーいう関数を用意してやると
static void SetSnakeToPascal<T>()
{
var mapper = new CustomPropertyTypeMap(typeof(T), (type, columnName) =>
{
//snake_caseをPascalCaseに変換
var propName = Regex.Replace(columnName, @"^(.)|_(\w)", x => x.Groups[1].Value.ToUpper() + x.Groups[2].Value.ToUpper());
return type.GetProperty(propName);
});
SqlMapper.SetTypeMap(typeof(T), mapper);
}
// こんなクラスがあるとして
public class Person
{
// DBではid, first_name, last_name, created_at
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime CreatedAt { get; set; }
}
static void Main()
{
// MyClassをカラム名snake_cake → プロパティ名PascalCaseにマッピングするようセット
SetSnakeToPascal<Person>();
using (var conn = new MySqlConnection("せつぞくもじれつ"))
{
conn.Open();
var result = conn.Query<Person>("select * from people"); // 無事マッピングできてる
}
}
といった感じ。SqlMapper.SetTypeMapをどこで呼ばせるか&管理面倒くせー、という問題は無きにしも非ずですが、まあその辺はやりようは幾らでもあるので(例えばクラスに専用の属性でも貼り付けておいてApplication_Startでリフレクションで全部舐めて登録してしまうとか)、大した問題ではないでしょう。
Dapperは何もかもの面倒は見てくれません。必要なものは随時、自分で足す。作る。でも、それでいいんじゃない?どうせ、出来あいの代物が自分達の要求に100%合致するなんてことはなくて、大なり小なり、自分達で足回り部分は作るでしょう。なら、そのついでです。大したことじゃあない。むしろ余計な面倒がなくていい。
ところでちなみに何でMySqlConnectionなのかというと、手元にあるDBが諸事情でMySQLだからです。諸事情!そこはdoudemoiiとして、DapperならMySQLでも繋げやすいという利点がありますね。DB選びません。C#はSQL Server専用みたいなものでしょ?なんてことはないのです。
Query Builder for Dapper
Dapperは純粋な実行とマッピングのみとなるように作られています、というのが設計やIssueの返信などからも見て取れます。生ADO.NETの一つ上の層として存在する、混じり気なしの代物にするのが目標だ、と。つまり、Dapper自身に、ちょっとしたPKで取ってくるだけのもの、Findとかよく言われるようなヘルパメソッドが乗ったりすることはありません。が、欲しいですよね、それ、そういうの。生で使ってもいいんですが、もう一枚、ほんの少しだけ、薄いの、被せたい。
そんなわけで、そのDapperの更に一枚上にのった、ちょっとしたCRUDヘルパーがDapperExtensionsやDapper.Rainbowなのですけれど、ビミョー。しょーじきビミョー。なので、作りましょう。自分で。例えばこういうのよくなくないですか?
// これで↓のクエリに変換される
// select * from Person p where p.FirstName = @0 && p.CreatedAt <= @1
var sato = conn.Find<Person>(x => x.FirstName == "佐藤" && x.CreatedAt <= new DateTime(2012, 10, 10));
// updateもこんな感じで update .... values ... が生成、実行される
conn.Update(sato, x => x.Id == 10)
Expression Treeから、タイプセーフなクエリ生成をする。select-where程度の、PKで取ってきたり、ちょっとした条件程度のものならさくっと書ける。InsertやUpdateも、そんまんまぶん投げて条件入れるだけなので単純明快。ところで、このまま拡張していくと、事前のマッピングクラス生成が不要な即席Queryable、LINQ to DBみたいなものができなくない?たとえばconn.AsQueryable().Where().OrderBy().Select() といったように。
結論を言えば、できる。が、やらないほうがいいと思ってます。一つは、どこかでQueryableのクエリ抽象の限界に突き当たること。生SQLで書いたほうがいいのか、Queryableで頑張ればいいのか。もしくは、これはQueryableでちゃんとサポートしているのか。そういう悩み、無駄だし意味ないし。select-whereならヘルパある、それ以外は生SQL書け。それぐらい単純明快なルールが敷けたほうが、シンプルでいいんじゃないかな。どうでもいい悩みを減らすためにやっているのに、また変な悩みを増やすようじゃやってられない。
もう一つは、Queryableを重ねれば重ねるほどパフォーマンスロスが無視できなくなっていくこと。たった一つの、↑のFindみたいなExpression Treeの生成/解析なんてたかがしれていて、無視できる範囲に収まっています。あ、これはちゃんと検証して言ってますよん。遅くなるといえば遅くなってますが、Entity Frameworkのクエリ自動コンパイルは勿論、手動コンパイルよりも速いです、逐次解析であっても。
Queryableを重ねれば重ねるほど遅くなるので、手動コンパイル(&キャッシュ)させなければならなくて、しかし手動コンパイルはかなり手間で滑稽なのでやりたくない。EFの自動コンパイルは悪くない!のですが、やっぱ相応に、そこまで速くはなくて、ね……。
実際に実装すると、こんな風になります。
// Expression Treeをなめなめする下準備
public static class ExpressionHelper
{
// Visitorで舐めてx => x.Hoge == xxという形式のExpression Treeから値と演算子のペアを取り出す
public static PredicatePair[] GetPredicatePairs<T>(Expression<Func<T, bool>> predicate)
{
return PredicateExtractVisitor.VisitAndGetPairs(predicate);
}
class PredicateExtractVisitor : ExpressionVisitor
{
readonly ParameterExpression parameterExpression; // x => ...のxなのかを比較判定するため保持
List<PredicatePair> result = new List<PredicatePair>(); // 抽出結果保持
public static PredicatePair[] VisitAndGetPairs<T>(Expression<Func<T, bool>> predicate)
{
var visitor = new PredicateExtractVisitor(predicate.Parameters[0]); // x => ... の"x"
visitor.Visit(predicate);
return visitor.result.ToArray();
}
public PredicateExtractVisitor(ParameterExpression parameterExpression)
{
this.parameterExpression = parameterExpression;
}
// Visitぐるぐるの入り口
protected override Expression VisitBinary(BinaryExpression node)
{
// && と || はスルー、 <, <=, >, >=, !=, == なら左右の解析
PredicatePair pair;
switch (node.NodeType)
{
case ExpressionType.AndAlso:
pair = null;
break;
case ExpressionType.OrElse:
pair = null;
break;
case ExpressionType.LessThan:
pair = ExtractBinary(node, PredicateOperator.LessThan);
break;
case ExpressionType.LessThanOrEqual:
pair = ExtractBinary(node, PredicateOperator.LessThanOrEqual);
break;
case ExpressionType.GreaterThan:
pair = ExtractBinary(node, PredicateOperator.GreaterThan);
break;
case ExpressionType.GreaterThanOrEqual:
pair = ExtractBinary(node, PredicateOperator.GreaterThanOrEqual);
break;
case ExpressionType.Equal:
pair = ExtractBinary(node, PredicateOperator.Equal);
break;
case ExpressionType.NotEqual:
pair = ExtractBinary(node, PredicateOperator.NotEqual);
break;
default:
throw new InvalidOperationException();
}
if (pair != null) result.Add(pair);
return base.VisitBinary(node);
}
// 左右ノードから抽出
PredicatePair ExtractBinary(BinaryExpression node, PredicateOperator predicateOperator)
{
// x.hoge == xx形式なら左がメンバ名
var memberName = ExtractMemberName(node.Left);
if (memberName != null)
{
var value = GetValue(node.Right);
return new PredicatePair(memberName, value, predicateOperator);
}
// xx == x.hoge形式なら右がメンバ名
memberName = ExtractMemberName(node.Right);
if (memberName != null)
{
var value = GetValue(node.Left);
return new PredicatePair(memberName, value, predicateOperator.Flip()); // >, >= と <, <= を統一して扱うため演算子は左右反転
}
throw new InvalidOperationException();
}
string ExtractMemberName(Expression expression)
{
var member = expression as MemberExpression;
// ストレートにMemberExpressionじゃないとUnaryExpressionの可能性あり
if (member == null)
{
var unary = (expression as UnaryExpression);
if (unary != null && unary.NodeType == ExpressionType.Convert)
{
member = unary.Operand as MemberExpression;
}
}
// x => xのxと一致してるかチェック
if (member != null && member.Expression == parameterExpression)
{
var memberName = member.Member.Name;
return memberName;
}
return null;
}
// 式から値取り出すほげもげ色々、階層が深いと面倒なのね対応
static object GetValue(Expression expression)
{
if (expression is ConstantExpression) return ((ConstantExpression)expression).Value;
if (expression is NewExpression)
{
var expr = (NewExpression)expression;
var parameters = expr.Arguments.Select(x => GetValue(x)).ToArray();
return expr.Constructor.Invoke(parameters); // newしてるけどアクセサ生成で高速云々
}
var memberNames = new List<string>();
while (!(expression is ConstantExpression))
{
if ((expression is UnaryExpression) && (expression.NodeType == ExpressionType.Convert))
{
expression = ((UnaryExpression)expression).Operand;
continue;
}
var memberExpression = (MemberExpression)expression;
memberNames.Add(memberExpression.Member.Name);
expression = memberExpression.Expression;
}
var value = ((ConstantExpression)expression).Value;
for (int i = memberNames.Count - 1; i >= 0; i--)
{
var memberName = memberNames[i];
// とりまリフレクションだけど、ここはアクセサを生成してキャッシュして高速可しよー
dynamic info = value.GetType().GetMember(memberName)[0];
value = info.GetValue(value);
}
return value;
}
}
}
// ExpressionTypeだと範囲広すぎなので縮めたものを
public enum PredicateOperator
{
Equal,
NotEqual,
LessThan,
LessThanOrEqual,
GreaterThan,
GreaterThanOrEqual
}
// x.Hoge == 10 みたいなのの左と右のペアを保持
public class PredicatePair
{
public PredicateOperator Operator { get; private set; }
public string MemberName { get; private set; }
public object Value { get; private set; }
public PredicatePair(string name, object value, PredicateOperator predicateOperator)
{
this.MemberName = name;
this.Value = value;
this.Operator = predicateOperator;
}
}
public static class PredicatePairsExtensions
{
// SQL文作るー、のでValueのほうは無視気味。
public static string ToSqlString(this PredicatePair[] pairs, string parameterPrefix)
{
var sb = new StringBuilder();
var isFirst = true;
foreach (var pair in pairs)
{
if (isFirst) isFirst = false;
else sb.Append(" && "); // 今は&&連結だけ。||対応は面倒なのよ。。。
sb.Append(pair.MemberName);
switch (pair.Operator)
{
case PredicateOperator.Equal:
if (pair.Value == null)
{
sb.Append(" is null ");
continue;
}
sb.Append(" = ").Append(parameterPrefix + pair.MemberName);
break;
case PredicateOperator.NotEqual:
if (pair.Value == null)
{
sb.Append(" is not null ");
continue;
}
sb.Append(" <> ").Append(parameterPrefix + pair.MemberName);
break;
case PredicateOperator.LessThan:
if (pair.Value == null) throw new InvalidOperationException();
sb.Append(" < ").Append(parameterPrefix + pair.MemberName);
break;
case PredicateOperator.LessThanOrEqual:
if (pair.Value == null) throw new InvalidOperationException();
sb.Append(" <= ").Append(parameterPrefix + pair.MemberName);
break;
case PredicateOperator.GreaterThan:
if (pair.Value == null) throw new InvalidOperationException();
sb.Append(" > ").Append(parameterPrefix + pair.MemberName);
break;
case PredicateOperator.GreaterThanOrEqual:
if (pair.Value == null) throw new InvalidOperationException();
sb.Append(" >= ").Append(parameterPrefix + pair.MemberName);
break;
default:
throw new InvalidOperationException();
}
}
return sb.ToString();
}
}
public static class PredicateOperatorExtensions
{
// 演算子を反転させる、 <= と >= の違いを吸収するため
public static PredicateOperator Flip(this PredicateOperator predicateOperator)
{
switch (predicateOperator)
{
case PredicateOperator.LessThan:
return PredicateOperator.GreaterThan;
case PredicateOperator.LessThanOrEqual:
return PredicateOperator.GreaterThanOrEqual;
case PredicateOperator.GreaterThan:
return PredicateOperator.LessThan;
case PredicateOperator.GreaterThanOrEqual:
return PredicateOperator.LessThanOrEqual;
default:
return predicateOperator;
}
}
}
public static T Find<T>(this IDbConnection conn, Expression<Func<T, bool>> predicate)
{
var pairs = ExpressionHelper.GetPredicatePairs(predicate);
// とりあえずテーブル名はクラス名で
var className = typeof(T).Name;
var condition = pairs.ToSqlString("@"); // とりま@に決めうってるけどDBによっては違いますなー
var query = string.Format("select * from {0} where {1}", className, condition);
// 匿名型でなく動的にパラメータ作る時はDynamicParameterを使う
var parameter = new DynamicParameters();
foreach (var pair in pairs)
{
parameter.Add(pair.MemberName, pair.Value);
}
// Dapperで実行. 勿論、FirstではないFindAllも別途用意するとヨシ。
return conn.Query<T>(sql: query, param: parameter, buffered: false).First();
}
static void Main(string[] args)
{
using (var conn = new MySqlConnection("せつぞくもじれつ"))
{
conn.Open();
// ↓のようなクエリ文になる
// select * from Person where FirstName = @FirstName && CreatedAt <= @CreatedAt
var sato = conn.Find<Person>(x => x.FirstName == "佐藤" && x.CreatedAt <= new DateTime(2012, 10, 10));
}
といった、Expression TreeベースのタイプセーフなMicro Query Builderを中心にしたMicro-ORMが、DbExecutor ver.3で、実際に作っていました。水面下で。そしてお蔵入りしました!お蔵入りした理由は色々お察し下さい。まぁまぁ悪くないセンは行ってたかなー、とは思うのでお蔵入りはMottainai感が若干あるものの、全体的には今一つだったなあ、というのが正直なところで、"今"だったら違う感じになったかな、と思っちゃったりだから、あんまし後悔はなく没でいいかな。某g社の方々へは申し訳ありません、と思ってます。
そんなわけでMicro Query Builderというコンセプトを継いで、マッピング部分はDapperを使うDapper拡張として作り直したものは、近日中にお目見え!はしません。しませんけれど(タスクが山積みすぎてヤバい)、そのうちに出したいというか、絶対に出しますので、乞うご期待。謎社の今後にも乞うご期待。
まとめ
あんましFull ORM使わなきゃー、とか悩む必要はないです。XXが便利で使いたいんだ!というなら使えばいいですし、逆にXXがあってちょっと嫌なんだよなー、というならば、使わない、が選択肢に入っていいです。.NETだって選択の自由はあるんですよ?そこ勘違いしちゃダメですよ?自由度を決めるのは、Microsoftでもコミュニティーの空気でもなく、自分達ですから。
さて、ASP.NET Advent Calendar 2012、次はMicrosoft MVP for Windows Azureの割と普通さんです。AzureとWeb Sitesについて聞けるようですよ!wktk!
MemcachedTranscoder - C#のMemcached用シリアライザライブラリ
- 2012-12-03
今年もAdvent Calendarの季節がやってきました。というわけで、この記事はC# Advent Calendar 2012用の話となります。去年はModern C# Programming Style Guideという記事を書きまして、結構好評でした。また、去年は他Silverlight Advent Calendar 2011で.NETの標準シリアライザ(XML/JSON)の使い分けまとめというシリアライザの話をしました。今年も路線は引き続きで、モダンなシリアライザの話をしましょう。
MemcachedTranscoder
そんなわけで、表題のものを作りました。dllのインストールはNuGet経由でお願いします。
Memcachedは言わずと知れた分散キャッシュ。C#で最もメジャーなMemcachedのライブラリはEnyim.Memcachedです。これを使って、オブジェクトをGet、Setするわけだー。さて、オブジェクトをSetするというのは、最終的にbyte[]に落とす必要があります。ただたんにポーンとオブジェクト投げたらSetできたー、にはなりませんですのよ。では、どうやってbyte[]に変換しているの?というと、シリアライザが内部で動いてます。
シリアライザについては以前に.NET(C#)におけるシリアライザのパフォーマンス比較という記事も書いたりしていて、結構うるさいんで割と気にするほうです。さて、そんなEnyim.Memcachedのシリアライザは、デフォルトではBinaryFormatterです。はい、これは、あまり速くないしファイルサイズも結構かさんでゲンニョリ系シリアライザ。
ただしEnyim.MemcachedはそれらをTranscoderと呼んでいて、自由に差し替えが可能になっています。つまりBinaryFormatterがゲンニョリならば自分で差し替えればいいじゃない!ちなみに純正オプションとしてNetDataContractSerializerも用意されているのですが、これは……話にならないぐらいサイズがデカくなるので、ないわー。
そんなわけで.NET最速シリアライザのProtobuf-netと、やっぱ時代はJSONよねということで、.NETで最もスタンダードなJSONライブラリであるJSON.NETと、新進気鋭のMsgPack-Cliの3種のTranscoderを作りました。
使い方
app.configかweb.configのMemcachedのTranscoderの設定行に、それぞれ使いたいTranscoderのものを指定して、dllを実行ファイルと同ディレクトリにでも置いてください。
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<sectionGroup name="enyim.com">
<section name="memcached" type="Enyim.Caching.Configuration.MemcachedClientSection, Enyim.Caching" />
</sectionGroup>
</configSections>
<enyim.com>
<memcached protocol="Binary">
<servers>
<add address="127.0.0.1" port="11211"/>
</servers>
<transcoder type="MemcachedTranscoder.ProtoTranscoder, ProtoTranscoder" />
</memcached>
</enyim.com>
</configuration>
Transcoderのバリエーションは以下の感じ。
<transcoder type="MemcachedTranscoder.ProtoTranscoder, ProtoTranscoder" />
<transcoder type="MemcachedTranscoder.JsonTranscoder, JsonTranscoder" />
<transcoder type="MemcachedTranscoder.MessagePackTranscoder, MessagePackTranscoder" />
<transcoder type="MemcachedTranscoder.MessagePackMapTranscoder, MessagePackMapTranscoder" />
ProtoTranscoderはProtocol Buffers、JsonTranscoderはJSON、MessagePackTranscoderはMsgPackをArrayモードで、MessagePackMapTranscoderはMsgPackをMapモードでオブジェクトを変換します。
型とデシリアライズ
使い方を説明して終わり、というのもつまらないので、もっと深く見ていきましょう。Enyim.MemcachedはGetもSetもobjectでしかできません。ジェネリックなのもあるように見せかけて、最終的にはobjectに落ちます。ITranscoderのところには型が伝達されないのです。以下のがITranscoderインターフェイスね。
public interface ITranscoder
{
object Deserialize(CacheItem item);
CacheItem Serialize(object value);
}
何が困るって?シリアライザは型が必要なんですよ!デシリアライズの時に!DataContractSerialize作るのにtypeofで型を渡しているでしょう?Protobuf.Serialize<T>でしょう?MessagePackSerializer.Create<T>でしょう?(JsonConvert.DeserializeObjectは、一見デシリアライズ可能にみえて、それJObjectが帰ってくるから意味ないです)
例えばMyClassクラスというint MyProperty{get;set;}だけがある、なんてことのないクラスがあるとして、ふつーにJSONにシリアライズした結果は
{"MyProperty":100}
こんな感じになります。が、これだとこれがMyClassという情報は一切ありません。HogeClassかもしれないしHugaClassかもしれない。つまりデシリアライズ不能です。よって、外から型を与える必要があります。Deserialize<MyClass>、といったように。これがもし
{
"Type" : "MyClass",
"Properties" : [
{"MyProperty":100}
]
}
このように、値が型情報も持っていれば、型がMyClassだと分かるので、型を渡すのは不要になります。BinaryFormatterやNetDataContractSeiralizerが型不要でSerialize/Deserializeできているのは何故か、というと、シリアライズした後の形に型が付与されているからなのです。そして、なぜEnyim.Memcachedが標準でBinaryFormatterとNetDataContractSerializerを用意しているのか、あるいは何故他のものが用意できないのか、というと、型情報が必要だからです。
じゃあ型入れとけばいいじゃーん、といったところですが、こうすると型情報の分だけファイルサイズが嵩んでしまいます。また、.NET固有の型を埋め込むというのは、他の言語と通信するのにあたっては、かなりビミョウです。
だから、理想的には型は外から与えられるといいな、って思うのです。とはいえ、実際問題、Transcoderは型の渡せないインターフェイスなので、どうにかしなきゃあいけません。
型を埋める
そんなわけで、解法は、手動で型を埋める、になります。(他には全てのAPIを型付きにラップしてそれ経由でしかアクセスさせないで、Serializeを呼ぶときはbyte[]に崩してから呼ぶとかいう方法もあるですかしらん)。どういうこっちゃ、というと、伝わりやすいであろうJSON版のTranscoderで見てみましょうか。
protected override ArraySegment<byte> SerializeObject(object value)
{
var type = value.GetType();
var typeName = writeCache.GetOrAdd(type, TypeHelper.BuildTypeName); // Get type or Register type
using (var ms = new MemoryStream())
using (var tw = new StreamWriter(ms))
using (var jw = new Newtonsoft.Json.JsonTextWriter(tw))
{
jw.WriteStartArray(); // [
jw.WriteValue(typeName); // "type",
jsonSerializer.Serialize(jw, value); // obj
jw.WriteEndArray(); // ]
jw.Flush();
return new ArraySegment<byte>(ms.ToArray(), 0, (int)ms.Length);
}
}
["型名", {objectのシリアライズ結果}]といった風に埋めてます。長さ2の配列で決め打ち!0番目は型名の文字列!1番目が実態!これなら、まあ他の言語で触るのも問題ないし(多少は不恰好ですけどね)、ファイルサイズ増大もほぼほぼ型名だけで抑えられています。MessagePack用のTranscoderも同じような実装です。このアイディアはMsgPack-Cli作者の @yfakariyaさんから頂きました。
JSON, MsgPackはそうなのですけれど、Protocol Buffers版は……違います。
ProtoTranscoder
Enyim.Memcached用のProtocol BuffersなTranscoderは、もともとprotobuf-net作者のMarc Gravell氏が作成し公開しています。Distributed caching with protobuf-net。
しかし、幾つかの理由により、このコードを使用することはお薦めしません、というかやめたほうがいいです。
- 1.対応しているProtobufやEnyim.Memcachedが古いので若干手直しが必要
- 2.配列や辞書など、効果の高いコレクション系に対してシリアライズしてくれない(BinaryFormatterが使われる)
- 3.そもそもバグっていて、ジェネリックなクラスを突っ込むと壊れる
1はそのまま。2は、そういうif文が入っているからです。別にコレクションだけ避けるようになっている、というわけじゃなくて、ある種の保険でそういう条件分岐があるのですが、結果としてコレクションが避けられることになってしまっていて、効果が薄くなってしまうな、と。そして3ですが、これは致命的です。どこがバグってるかというと、以下のところ。
string typeName = type.AssemblyQualifiedName;
int i = typeName.IndexOf(','); // first split
if (i >= 0) { i = typeName.IndexOf(',', i + 1); } // second split
if (i >= 0) { typeName = typeName.Substring(0, i); } // extract type/assembly only
型情報を埋め込む、つまりは型から型情報の文字列を取ってこなければなりません。それ自体はAssemblyQualifiedNameを呼ぶだけの、造作もないことなのですけれど
// System.Int32, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089
Console.WriteLine(typeof(int).AssemblyQualifiedName);
Versionとか、Cultureとか、PublicKeyTokenとか、いらないね。型名とアセンブリ名、それだけ分かればそれでいい、それがいい。なので、それら無駄な情報を除去しようとしているのが↑↑のコードです。
実際うまくいきます。ジェネリックを含まなければ。
var type = typeof(List<int>);
string typeName = type.AssemblyQualifiedName;
int i = typeName.IndexOf(','); // first split
if (i >= 0) { i = typeName.IndexOf(',', i + 1); } // second split
if (i >= 0) { typeName = typeName.Substring(0, i); } // extract type/assembly only
// ↓のtypeNameは壊れてる
// System.Collections.Generic.List`1[[System.Int32, mscorlib
Console.WriteLine(typeName);
見事に欠落してしまいます。AssemblyQualifiedNameが、ジェネリックを含むクラスだと形が若干変わるので、この決め打ちSubstringでは対応しきれてません。
でもバグってるから使えない、というだけじゃ勿体ない!.NET最速シリアライザが使えないとか!というわけかで、私の作成したProtoTranscoder半分は氏のコードをベースにしています。また、型情報を埋め込むといったことの元ネタもこのコードからです。
んで、このバグッてた型情報を削るところですが、AssemblyQualifiedNameが実際どういう形を取るのか、もしくはどういう形が読み込めるものなのか、というのはMSDNのType.GetTypeメソッド解説に例付きで詳しく書いてあります。非常に複雑で正面からきっちりパースしようとすると苦戦します。なので、正規表現でサクッと削ることにしました。
internal static class TypeHelper
{
static readonly Regex SubtractFullNameRegex = new Regex(@", Version=\d+.\d+.\d+.\d+, Culture=\w+, PublicKeyToken=\w+", RegexOptions.Compiled);
internal static string BuildTypeName(Type type)
{
return SubtractFullNameRegex.Replace(type.AssemblyQualifiedName, "");
}
}
一応テストは書いてありまして、TypeHelperTest.cs、色々並べたてた限り問題ないようなので、問題ないと思われます。
あと、型情報の埋め込みですが、JsonTranscoderは配列にして型情報を入れていましたが、ProtoTranscoderはbyte[]の先頭に直接埋め込んでいます。先頭4バイトが型情報の長さを表し(int)、その後に続く長さの分だけ型情報の文字列(UTF8)があり、その後ろが実体。配列がどうこうとかないので、サイズ的にも処理的にも有利です。ただ、Memcachedに格納された値自体は不正なProtocol Buffersの値となるわけで、相互運用性には難ありといったところ(他のデシリアライズするもの側でもストリーム先頭の型情報部分をスキップするようにすれば、回避できるといえばできます)。最初から相互運用性ゼロのBinaryFormatter(他の言語ではこれでシリアライズされた後の形を解釈できない)よりは遥かにマシ、ではありますね。
Memcached is dead. Long live Redis!
バグってるとか、いーのかよー、という感じですが、そもそも、使われてないんですよね。Stackoverflowのキャッシュ層はRedisですので。完全にノーメンテ。(StackoverflowのアーキテクチャはStack Overflow Architecture Update - Now At 95 Million Page Views A Monthで。これも2011/3のものなので、今は更に進化してるんだろうねえ。StackoverflowはかなりRedis好きみたいで、Memcached is dead. Long live Redis!ってStackoverflowのエンジニア(Marc氏ではない)が言ってた。
私もRedis好きですね。超好き。アレは超良いものだ……。ちなみにRedisのライブラリはBookSleeveとServiceStack.Redisがありまして、この辺に関して詳しくは、そのうち書きましょう。いや、ほんとRedis良いしC#との相性もいいし、たまらんです。
そんなわけで放置されていたんですが、昨日の今日で、新しいのがリリースされました。protobuf-net.Enyim。そして、バグはそのままでした……。というわけで、そのことはTwitterで伝えたので、そのうち直るでしょう(Twitterは連絡手段として非常に気楽でいいですなあ)。でも、プリミティブ型の配列などにProtobufが使われない、とかTypeCacheからのTypeの取得部分がforeachぐるぐるるーぷ、などはそのままなので、私の作ったもののほうが良いです。多分ね。
パフォーマンス
性能ですが、まず、シリアライザはシリアライズする対象によって速度は変わります。だから、一概にどれが速いとか遅いとか言いにくいところはあります。そのうえで、以下のクラスと、それの配列(長さ10)を用意しました。
[ProtoContract]
[Serializable]
public class TestClass
{
[ProtoMember(1)]
[MessagePackMember(0)]
public string MyProperty1 { get; set; }
[ProtoMember(2)]
[MessagePackMember(1)]
public int MyProperty2 { get; set; }
[ProtoMember(3)]
[MessagePackMember(2)]
public DateTime MyProperty3 { get; set; }
[ProtoMember(4)]
[MessagePackMember(3)]
public bool MyProperty4 { get; set; }
}
// シンプルなPOCOとしての対象
var obj = new TestClass
{
MyProperty1 = "hoge",
MyProperty2 = 1,
MyProperty3 = new DateTime(1999, 12, 11),
MyProperty4 = true
};
// オブジェクト配列としての対象
var array = Enumerable.Range(1, 10)
.Select(i => new TestClass
{
MyProperty1 = "hoge" + i,
MyProperty2 = i,
MyProperty3 = new DateTime(1999, 12, 11).AddDays(i),
MyProperty4 = i % 2 == 0
})
.ToArray();
これを100000回シリアライズ/デシリアライズした速度と、一個のファイルサイズの検証結果が以下になります。あと、これはTranscoderを介した速度検証であって、決してシリアライザ単体での速度測定ではないことには留意してください。
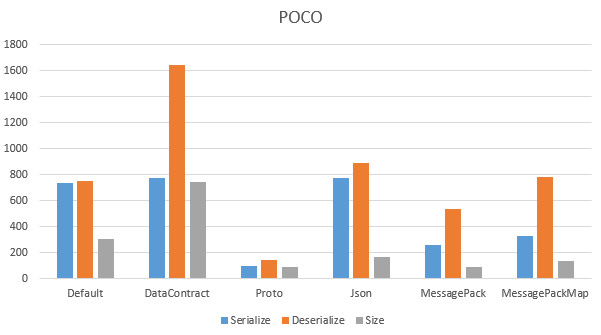
Simple POCO************************
S DefaultTranscoder:735
D DefaultTranscoder:750
Size:305
S DataContractTranscoder:775
D DataContractTranscoder:1642
Size:746
S ProtoTranscoder:99
D ProtoTranscoder:142
Size:88
S JsonTranscoder:772
D JsonTranscoder:892
Size:167
S MessagePackTranscoder:256
D MessagePackTranscoder:535
Size:89
S MessagePackMapTranscoder:327
D MessagePackMapTranscoder:783
Size:137
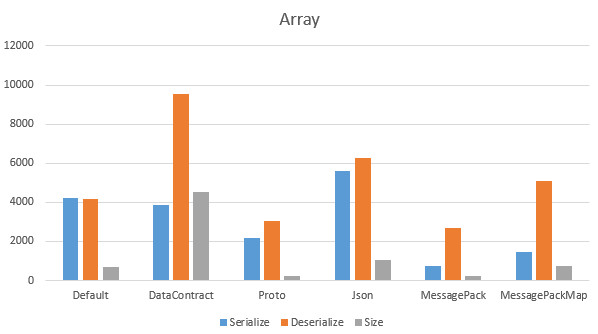
Array******************************
S DefaultTranscoder:4234
D DefaultTranscoder:4186
Size:712
S DataContractTranscoder:3874
D DataContractTranscoder:9532
Size:4525
S ProtoTranscoder:2189
D ProtoTranscoder:3040
Size:255
S JsonTranscoder:5618
D JsonTranscoder:6275
Size:1043
S MessagePackTranscoder:752
D MessagePackTranscoder:2696
Size:256
S MessagePackMapTranscoder:1453
D MessagePackMapTranscoder:5088
Size:736
単体ではProtobufが最速。これは予想通り。配列にすると、MsgPack-Cliが爆速。ほええー。理由は分かりません!また、BinaryFormatterが決して悪くないのね。速度もそうだし、サイズも、特に配列にしたときにそんなにサイズが膨れないのは偉い、結果的にJSONより小さくなってるしね。これは、JSONは律儀に全部の配列の値に対してプロパティ名を入れますが、BinaryFormatterは先頭に型情報を一つ定義し、あとはその定義への参照という形で廻しているから、でしょうね。BinaryFormatterのデータ構造の仕様は.NET Remoting: Binary Format Data Structureにありますが、別に読まなくてもいいと思いますん。
私はバイナリアンじゃないのでバイナリと睨めっこはあんましたくないですね、前々職でTrueType Fontの仕様と睨めっこしてバイナリほじほじした時は、それはそれで楽しくはあったけれど、好んでやりたくない感はあったり。ゆるふわゆとり世代ですものー。
Azure Caching
Windows Azure CachingもMemcachedプロトコルをサポートということなので、今回の話はまんま使えますね!まあ、既存のものの移し替え、とかでなければ、Enyim... よりもAzure Cachingのライブラリ使ったほうがいいとは思いますが。「Enyim cache client API で入れたデータを Windows Azure caching API (Client Api) で取得すると、例外が発生します。(その逆も同様です。)」というのは、書いてある通りにシリアライザが違うからですねー。デフォルトはNetDataContractSerializerということで、まあ、アレですね、悲しいですね、Azure Caching使うならCustom Serializer作ったほうがいいんじゃないですかね(これがEnyim...のTranscoderにあたる)。まあ、Memcached ProtocolにしてEnyim... を使ってもいいでしょうけれど、Enyim...もビミョいといえばビミョいので、その辺は何とも。
まあ、私はAzureは知らないので、きっとAzureの誰かが言ってくれるでせう。あ、 Azure Cachingのシリアライズコストが発生しない云々は ローカルキャッシュのみの話で、外側に行くなら原理的にシリアライズ/デシリアライズが発生するのは当たり前です、というのは一応。
まとめ
NetDataContractSerializerは論外として、BinaryFormatterは決して悪くはないので、エクストリームなパフォーマンスを求めないなら、そのまんまでいい気がしました。求めるんなら、やっぱProtobufに安定感ありますねえ。しかしMsgPackも良いんですね。可搬性ならJSONにしちゃうのも良いかなー。結局、アレだ、好きなもの選ぶのがいいと思いますですよ、と。
ところで、これはもともと、前職のgloopsで使うつもりで用意していたのですが、辞めちゃったとかあったので、投入するところまでは行きませんでした。というわけで今のところ利用実績はないです!まあ、多分大丈夫だと思うんですがその辺は投下してみてもらわないと何とも言えません。要は勇気が自己責任。ともあれ、コードの公開を許可してくれたgloopsに感謝します。
そんなこんなで、謎社でもC#でエクストリームな性能を求めたい方を求めております。パブリックに詳しく言えるのは予定は未定なので、そういったことをやりたいという方は、こっそり私のほうに聞いてくれると嬉しいですね。あ、これは割とマジな話ですよ。それとAzureの営業かけるなら今のうちなのでそれも私のほうまで(謎)