LINQ to GameObject 2.1 - 手書き列挙子による性能向上と追加系をより使いやすく
- 2016-08-11
(前回の1.3から)1年ぶりの更新です!2.0は諸事情でスキップされました。アセットストアには出したんですが内容的にもう少しやりたかったのでなかったこと扱いで。LINQ to GameObject自体の説明はVer 1.0リリース時のブログLINQ to GameObjectによるUnityでのLINQの活用を参照ください。
今回はパフォーマンスチューニングを徹底的にやりました。というのも以前の素朴な実装は、素朴な通りの性能で、いいとか悪いとかじゃなく素朴なので、やるのならいっそギチギチにやってみたらどうかな、と。性能面でここまでやってるものは絶対にないはず。
もう一つは追加系をより使いやすく。のためにガッツリと破壊的変更を入れています。破壊的変更が入った理由は、使いにくかったからです。うぇぇ……。使いにくいポイントは概ね分かっていたし、プルリク等も貰っていたのですが、API的にイマイチなもので乗り気になれず、かといってAPIを維持しているとオーバーロードの解決などの問題でうまく処理できなくて、モニョモニョしている間に一年が経ってしまった。互換性は残したくはあったんですが、使いにくいままであったり、微妙なオーバーロードの追加とかで解決するよりは良いかな、と。いう決断です。
Traverse系
APIはほとんど変わってないです(但しnameでフィルターかけるオーバーロードは消しました、HTMLやXMLと違って名前でのフィルタの重要性がかなり低いので、むしろないほうがいいかな、と)。
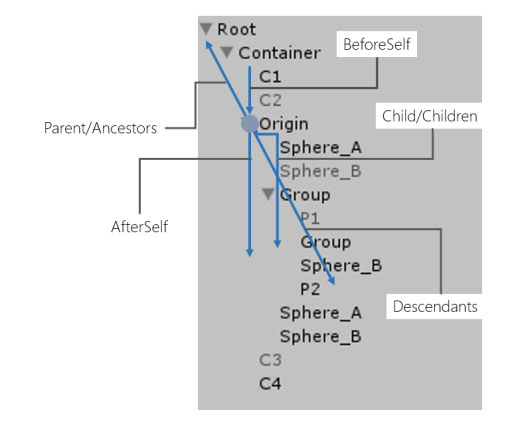
ヒエラルキーをツリーに見立てて、「軸」の概念を元にして、必要となる全方向での列挙を満たしています。今回、コードを劇的に書き換えたパフォーマンスチューニングを施しました。一点目は、yield returnによるコードを、全部手書きの構造体の列挙子に書き換えてます。これにより列挙に伴うゴミ発生が理想的にはなくなっています、理想的には:)
残念ながら、そのままforeachに流すと C#のGCゴミとUnity(5.5)のコンパイラアップデートによるListのforeach問題解決について によりboxingが発生しますが(ゴミ化)、それでも構造体のサイズや再帰的に処理される場合での内部処理は気を配っているので(特にDescendantsはエクストリームにチューニングしたコードに変えた(再帰を特化Stackで置き換えたり……))、以前よりも良くなっているのは間違いないです。
ちなみに、基本的にはmutableなstructは避けたほうがいいです。Enumeratorはまさにそれで、実装にも注意が必要なら、利用にも注意を要するため(これはList<T>.Enumeratorも同様で、直接触ろうとすると罠にはまるケースが出てくる)なんでもかんでもstructで、というのは止めたほうがいいでしょう、どうしてもということでなければ原則やらないほうがいい事案です。struct enumeratorを返すテクニック自体は今は亡きXNAでも使われていたので(EffectPassCollectionやModelMeshCollectionなど各種コレクションがstruct Enumeratorを返す)、まぁ最終テクニックとしては有効(但し現状Unityではどうせforeachではボックス化されるのでそこまで有効ではないので、基本やらなくていいでしょう)
LINQで繋げたら、当然普通にLINQの消費フローに入るので、そんな意味ないんですけどね!というだけなのもアレなので、改善二点目、頻出パターンについて特化した最適化を入れてます。(+ OfComponent) + First, FirstOrDefault, ToArray に関しては通常のLINQではなく、この構造体Enumeratorに特化した呼び出しをするため、所謂LINQで想像する性能劣化を受けません。社内調べによると、割と FirstOrDefault や ToArray が直接接続されてる場合が多いので、それだけでも6~7割はカバーできているのではないかな、と。
更に三点目、ToArrayNonAllocというメモリ節約/GC防止メソッドが追加されています(IEnumerable<T>にも生やしてあるのでLINQ to GameObject関係ないシーンでも使えないこともない)
GameObject[] array = new GameObject[0];
// 毎フレーム走査していても余計なメモリ確保はしない!
void Update()
{
var size = origin.Children().ToArrayNonAlloc(ref array);
for (int i = 0; i < size; i++)
{
var element = array[i];
}
}
Physics.RaycastNonAllocやGetComponentsInChildren[T](List[T] results) のようなものですね。どうしても走査頻度が高くて、という場合には使えるんじゃないかと思います。まぁ、Find系は極力使わないように、というのと同じ話で、走査系を頻繁にやること自体が全然よくはないのですけれど。
また、ToArray/ToArrayNonAlloc/Destroyには(Func<GameObject, T> selector), (Func<GameObject, bool> filter), (Func<GameObject, bool> filter, Func<GameObject, T> selector), (Func<GameObject, TState> let, Func<TState, bool> filter, Func<TState, T> selector) といった、Where().Select().ToArray() のような割とよくある状況に対する最適化オーバーロードを入れてます。
この辺を活用してもらえば、単純にインラインで自前実装するよりも、むしろ速い/効率的なことのほうが多いでしょう。
特化したものを速くなるのはある種当たり前で、しかしそうするとメソッドが雪だるま式に増えるのが良くなくて、そしてLINQのいいところは合成可能なことにより特化させずとも無限の組み合わせで機能を実現できるところにある。しかし、まぁ勿論、柔軟性とパフォーマンスが幾ばくかトレードオフなのは当然の話なわけで、LINQの雰囲気を保ったまま、裏側だけ特化実装にこっそり差し替わってる。というあたりが落とし所としては良いのかな、と思ってますし、なのでそういう風に実装しました。
再帰的なイテレータの罠
Children(子要素列挙)なんかは数が大したことないので問題はそんなないんですが、Descendants(子孫要素列挙)は性能差が大きく出てきます。そして、利用頻度で言ってもDescendants系が基本多い。これのパフォーマンスを改善することは、非常に意味のあることです。さて、これはシンプルなDescendantsの実装です。
static IEnumerable<GameObject> Descendants(GameObject root)
{
yield return root;
foreach (Transform item in root.transform)
{
foreach (var child in Descendants(item.gameObject))
{
yield return child.gameObject;
}
}
}
このコードには大きな問題があります!再帰的なイテレータ、つまり foreach (var child in Descendants(item.gameObject)) は危険です。Baaaaad Practice、デス。要警戒です。これ、子孫にあるGameObjectの数だけ、イテレータ作ってます。GetEnumerator祭り!これは、LINQがどうのとかそういう次元を超えています。LINQのコストというのはメソッドチェーン分のGetEnumeratorの加算とMoveNextの連鎖による一回の呼び出しコストの増加が基本的な話で、ようするに2~3増えるという話で大したことあるといえば大したことあるし、大したことないといえば大したことない。が、さすがに要素数分だけ無駄にEnumerator作るとなったら話は別だ。ちょっとね、かなり気になるよね。
解決策は2つあります。一つはstruct enumeratorで、struct生成コストはあるもののゴミにはなりません。↑で書いたように実装済みです。
もう一点は、内部イテレーター化。イテレーターには概ね二種類、内部イテレーターと外部イテレーターがあります。外部イテレーターはforeachで使える、つまりGetEnumerator経由のもので、内部イテレーターはListのForEachなどクラスに直接生えてるもの。それぞれ利点と欠点があります。外部イテレーターの利点は柔軟性(LINQ)と言語サポート(foreach/generator)、よって基本的にはこちらを選べばOKです。欠点はパフォーマンスが内部イテレーターほど稼げない。どうしても一つシーケンスを進めるのにMoveNextとCurrentの2つのメソッド呼び出しが必要になるので。内部イテレーターの利点はパフォーマンスで、内部構造に最適化したループを回せるので、基本最速です。欠点は柔軟性がないのと、それぞれのコレクションで独自実装になること。
LINQ to GameObjectでは両方実装しています。外部イテレーターは手書きで最適化したstruct enumerator(とStackPoolと、その他諸々の仕掛け)によって、遅延実行やLINQサポートなどの柔軟性を維持したまま、パフォーマンスとGC行きのゴミを全く出さないようにしています。内部イテレーターに関してはForEachとToArray(NonAlloc)に関しては、外部イテレーター版と全く異なる実行パスを通ることにより、最速を維持します。
ところで、Unityネイティブに用意されているものがある場合は、それを使ったほうが速くなります。例えば DescendantsAndSelf().OfComponent().ToArray() は GetComponentsInChildren(includeInactive:true) に概ね等しく(一つのオブジェクトに複数コンポーネントが貼り付けてある場合、LINQ to GameObjectではそれぞれのGameObjectに一つのみ、GetComponentsInChildrenは複数と、正確には挙動が異なります)、後者を使ったほうが断然速い。一応ですが、ネイティブだから常に速いとか、そういうことはなくて、ネイティブ-マネージド間の変換コストのほうが勝る場合もあります(たとえばUnityにおけるコルーチンの省メモリと高速化について、或いはUniRx 5.3.0でのその反映のような話)。けれど、この場合は、C#だけで走査すると、GameObject毎でのGetComponentが避けられません(GetComponentのコストはタダではないのだ)。なので、一発でネイティブ内でかき集めてきたほうが絶対的に速くなります。子孫を辿るだけならほとんど遜色ない、むしろ速いといっていいぐらいなので、本当にこれはGetComponentに対する処理効率の差だけですね。これだけはどうにもできませんでした。
追加系
変わってます。使い勝手的にはこっちの対応がメインです。

以前のAPIの何が不便かって、引数にGameObjectしか受け付けなかった!そして戻り値がGameObject!大抵の場合はComponentを入れてComponentを受け取りたいのに!これは酷い!いやほんと酷すぎでした……。なんでそうなってたかというと言い訳はそれなりにあって、まずGameObjectとComponentって継承階層が別のとこにいるんですよねー、のが困る。それをオーバーロードとして分けると、IEnumerableを受け取るオーバーロードが存在していたため、どうやってもうまく型が解決できなかったのだ……。
もうどうにもならなかったので、API変えてます。IEnumerableを受け取るオーバーロードはXxxRangeという名前に分離。また、基本的には<T>を返すように、そして T:UnityEngine.Object を受け取れるようにしたので、引数としてやっとMonoBehaviourなComponentを素直に流し込めるようになりましたー。万歳。継承階層が別のとこにいて困ります問題は、UnityEngine.Objectを受け取った上で、動的にGameObjectとComponentに仕分けすることで解決。
というわけで、やっと自信持って普通に使えるようになりました。単純な話なんですが、まず破壊的変更にする、ということに腰が重かったことと、それを踏まえても、うまいAPIを構築するのに手間取った。のせいでこんなに遅れてしまって、いやはや……。
その他、あとDestroyでデフォルトでヒエラルキから外さなくしました。このヒエラルキから外すというのは最低のアイディアで、配列ではなく列挙しながら(LINQ to GameObjectでやるような!)Destroyする場合に、ヒエラルキから外すせいで位置がずれて死ぬ。というのを防ぐためにToArrayでキャッシュしなければならない(無駄なオーバーヘッド!)。というしょうもない自体に陥りがちなので、やめました。わざわざ外すコストだってゼロじゃないので、二重に悪い。
まとめ
GameObjectBuilderというものがあったのですが、イラナイ子なので消しました。LINQ to XMLのFunctional Constructionを模した――ものなのですが、そういう、コピーに一生懸命なだけなのって悪趣味なんですよね。大事なのは、概念(LINQ to Tree)を対象環境(Unity)に最適化することであって、コピーすることではない。そういうの、分かっているつもりではいたのですが、やり始めるとついついやってしまうところがある。随時見切って、バッサリ切り落とせるようにならないとですね。
LINQ to GameObjectのオリジナルのデザインは2014/10/28だったんですが、その頃は今よりは全然遥かにUnityへの習熟度、知識が欠けていたなぁ、というのを改めて痛感しました。思い上がる、ということはないですが、環境への理解力が足らないとどこかイマイチなものになってしまうわけで、C#云々抜きに、常にUnityに真摯に向き合ってかないとダメですね。実際問題、愛情を持って突き詰めて考えられないと、本当の理想のところまでは行けない。小手先の知識だけで処理したようなライブラリは、まぁ使いたくないですねえ、そういうの実際どうしてもどこか独りよがりのしょうもないものになってしまうので。
LINQは遅い/GCキツくなるというのは絶対的な事実ではあるのですけれど、極力書き味を失わないようにしつつ、6, 7割ぐらいのシチュエーションには特化した最適化を施し、何も考えずともむしろ普通に書くよりも速くなる。それ以外のシチュエーションでも、速さを意識した使い方をすれば、やはり普通に書くよりも速くなる。という、私的には理想的かな、というところで表現できたので、是非是非、機能を気にする人も、性能を気にする人も使ってみてください。どちらも満たせるものになっているはずです。
ところでしつこいですが、9/13にPhoton勉強会で「Photon Server Deep Dive - PhotonWireの実装から見つめるPhoton Serverの基礎と応用」というタイトルで話しますので、Photon興味ある人も、そうでなくてもUniRx興味ある人もどうぞ。LINQ to GameObject、或いはUnityとLINQについての話は、さすがにあんま関係ないのでセッション内容には含まれませんが懇親会ででも掴まえてもらえば何でも答えます。
C#のGCゴミとUnity(5.5)のコンパイラアップデートによるListのforeach問題解決について
- 2016-08-05
UnityにおいてList<T>のforeachは厳禁という定説から幾数年。しかしなんと現在Unityが取組中のコンパイラアップデートによって解決されるのだ!ついに!というわけで、実際どういう問題があって、どのように解決されるのかを詳しく見ていきます。
現状でのArrayのforeachとListのforeach
まずは現状確認。を、Unityのプロファイラで見てみます。以下の様なコードを書いて計測すると……。
var array = new int[] { 1, 2, 3, 4, 5 };
var list = new List<int> { 1, 2, 3, 4, 5 };
// ボタンを叩いて計測開始
button.OnClickAsObservable().Subscribe(_ =>
{
Profiler.BeginSample("GCAllocCheck:Array");
foreach (var item in array) { }
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:List");
foreach (var item in list) { }
Profiler.EndSample();
// プロファイラでそこ見たいのでサッと止める。
Observable.NextFrame(FrameCountType.EndOfFrame).Subscribe(__ =>
{
EditorApplication.isPaused = true;
});
});

Unityのプロファイラは使いやすくて便利。というのはともかく、なるほどListは40B消費している(注:Unity上でコンパイラした時のみの話で、普通のC#アプリなどでは0Bになります。詳しくは後述)。おうふ……。ともあれ、なぜListのforeachでは40Bの消費があるのか。ってところですよね。foreach、つまりGetEnumeratorのせいに違いない!というのは、半分合ってて半分間違ってます。つまり100%間違ってます。
GetEnumeratorとforeach
foreachはコンパイラによってGetEnumerator経由のコードに展開されます。
// このコードは
foreach(var item in list)
{
}
// こう展開される
using (var e = list.GetEnumerator())
{
while (e.MoveNext())
{
var item = e.Current;
}
}
GetEnumerator、つまり IEnumerator<T> はクラスなので、ヒープに突っ込まれてるに違いない。はい。いえ。だったらArrayだって突っ込まれてるはずじゃないですかー?
// こんなコードを動かしてみると
Profiler.BeginSample("GCAllocCheck:Array.GetEnumerator");
array.GetEnumerator();
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:List.GetEnumerator");
list.GetEnumerator();
Profiler.EndSample();

そう、むしろArrayは32B確保していてListはむしろ0なのだ。どっちも直感的には変てこ。
配列とforeachの最適化
配列をforeachで回すとコンパイラが、forループに展開します。
// このコードは
foreach (var item in array)
{
}
// こうなる
for (int i = 0; i < array.Length; i++)
{
var item = array[i];
}
ちなみに配列のループを回すときは明確にLengthを使うと良いです。というのも、配列の境界チェック(自動で入る)が実行時に消せます。
// こっちよりも
var len = array.Length;
for (int i = 0; i < len; i++)
{
var item = array[i];
}
// こっちのほうが速い
for (int i = 0; i < array.Length; i++)
{
var item = array[i];
}
詳しくはArray Bounds Check Elimination in the CLRをどうぞ。ようするに基本的には配列はforeachで回しておけばおk、indexを別途使う場合があるなら、Lengthで回すことを心がけるとベター。というところでしょうか。(もっというと配列の要素は構造体であると、更にベターなパフォーマンスになります。また、配列は色々特別なので、配列 vs Listで回す速度を比較すれば配列のほうがベタベターです)
List<T>のGetEnumeratorへの最適化
list.GetEnumeratorが0Bの理由は、ここにクラスライブラリ側で最適化が入っているからです。と、いうのも、List<T>.GetEnumeratorの戻り値はIEnumerator<T>ではなくて、List<T>.Enumeratorという構造体になっています。そう、特化して用意された素敵構造体なのでGCゴミ行きしないのだ。なので、これをわざとらしくtry-finallyを使ったコードで回してみると
Profiler.BeginSample("GCAllocCheck:HandConsumeEnumerator");
var e = list.GetEnumerator();
try
{
while (e.MoveNext())
{
var item = e.Current;
}
}
finally
{
e.Dispose();
}
Profiler.EndSample();

0Bです。そう、理屈的にはforeachでも問題ないはずなんですが……。ここでちゃんと正しくforeachで「展開された」後のコードを書いてみると
using (var e = list.GetEnumerator())
{
while (e.MoveNext())
{
var item = e.Current;
}
}

40B。なんとなくわかってきました!?
using展開のコンパイラバグ
「List<T>をforeachで回すとGCゴミが出るのはUnityのコンパイラが古いせいでバグッてるから」というのが良く知られている話ですが、より正しい理解に変えると、「構造体のIDisposableに対するusingの展開結果が最適化されていない(仕様に基づいていない)」ということになります。この辺の話はECMA-334 C# Language Specificationにも乗っているので、C#コンパイラの仕様に対するバグと言ってしまうのは全然良いのかな?
どういうことかというと、現状のUnityのコンパイラはこういうコードになります。
var e = list.GetEnumerator();
try
{
while (e.MoveNext())
{
var item = e.Current;
}
}
finally
{
var d = (IDisposable)e; // ここでBoxing
d.Dispose(); // 本来は直接 e.Dispose() というコードでなければならない
}
そう、全体的に良い感じなのに、最後の最後、Disposeする時にIDisposableにボックス化してしまうので、そこでGCゴミが発生するというのが結論です。そして、これは最新のmonoコンパイラなどでは直っています、というか2010年の時点で直ってます。どんだけ古いねん、Unityのコンパイラ……。
40Bの出処
ゴミ発生箇所は分かったけれど、せっかくなのでもう少し。サイズが40Bの根拠はなんなの?というところについて。まずは色々なもののサイズを見ていきましょうー。
// こんなのも用意した上で
struct EmptyStruct
{
}
struct RefStruct
{
public object o;
}
class BigClass
{
public long X;
public long Y;
public long Z;
}
---
// 色々チェックしてみる
Profiler.BeginSample("GCAllocCheck:object");
var _0 = new object();
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:class");
var _1 = new BigClass();
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:int");
var _2 = 99;
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:int.boxing");
object _3 = 99;
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:emptyStruct");
var _4 = new EmptyStruct();
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:emptyStruct.boxing");
object _5 = new EmptyStruct();
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:bool.boxing");
object _6 = true;
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:float.boxing");
object _7 = 0.1f;
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:double.boxing");
object _8 = 0.1;
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:refStruct.boxing");
object _9 = new RefStruct();
Profiler.EndSample();

なるほどなるほど。当たり前ですがstructのままのは0B。EmptyStructやboolなど最小1バイトのboxingは17B(ほえ?)、int(4バイト)が20Bでdouble(8バイト)や参照を一個持たせた(IntPtr - 64bit環境において8バイト)構造体が24B。classにlongを3つめたのが40B。そしてobjectが16B。つまり。つまり、最小が16Bで、そこからフィールドのそれぞれの要素のサイズが加算されるということです。
この16 bytesがどこから来ているかというと、オブジェクトのヘッダです。ああ、なるほどそういう……。
さて、これを踏まえてListのEnumeratorのフィールドを見てみると
public struct Enumerator : IEnumerator, IDisposable, IEnumerator<T>
{
private List<T> l;
private int next;
private int ver;
private T current;
ヘッダ16B + IntPtrの8B + intの4B + intの4B + Tがintの場合は4B = 36B。40じゃないじゃん、ってところは、32以降は8Bずつ埋まってくっぽ、実質33Bだと40B, 41Bだと48Bという感じ。といったところから40Bの消費になっていたということですね!
Experimental Scripting Previews
ついにコンパイラアップデートのPreviewがやってきた!Experimental Scripting Previewsにて、コンパイラのアップデートプロジェクトも始まっています。そして今のところ5.3.5p8-csharp-compiler-upgradeが配られています。
というわけで早速、冒頭の配列とListのforeachをかけてみると……
Profiler.BeginSample("GCAllocCheck:Array");
foreach (var item in array) { }
Profiler.EndSample();
Profiler.BeginSample("GCAllocCheck:List");
foreach (var item in list) { }
Profiler.EndSample();

やった!これで問題nothingですね!(実際は計測時は初回にListのほうに32B取られててあれれ?となったんですが、コンパイル後のIL見ても正常だし、まぁ二回以降叩いたのは↑画像の通りになったので、よしとしておこ……)
まとめ
で、現状はList<T>の列挙はどうすればいいのか、というと、まぁforでindexerでアクセスが安心の鉄板ではある。ForEachが内部配列に直接アクセスされるので速い説はなくはないですが、ForEachだとラムダ式のキャプチャに気を使わないと逆効果なので(詳しくはUnityでのボクシングの殺し方、或いはラムダ式における見えないnewの見極め方)、基本的には普通にforがいいと思います(なお、キャプチャのないように気を使えば、ForEachのほうが速度を稼げる余地はあります。理論上、正常になったforeachよりも良い場合があるため)
理想的にはforeachであるべきだし、改革の時はまもなく!(5.5に↑のコンパイラアップグレードは入るっぽいですよ)。ちなみに、あくまでコンパイラのアップグレードなだけで、フレームワークのアップデートや言語バージョンのアップデートは今は含まれてはいない。段階的にやっていく話だと思うので、とりあえずはコンパイラがより良くなる、というだけでも良いと思ってます。というか全然良いです。素晴らしい。
UniRx 5.4.0 - Unity 5.4対応とまだまだ最適化
- 2016-08-03
UniRx 5.4.0をリリースしました!ちょうどUnity 5.4もリリースされたので、5.4向けの修正(Warning取り除いただけですが)を出せて良かった。というわけで5.4正式対応です。リリースは前回が5月だったので3ヶ月ぶりです。5.2 -> 5.3も3ヶ月だったので、今のとこ3ヶ月スパンになってますが偶然です。
何が変わったのかというと
Add: Observable.FrameInterval
Add: Observable.FrameTimeInterval
Add: Observable.BatchFrame
Add: Observable.Debug(under UniRx.Diagnostics namespace)
Add: ObservableParticleTrigger and OnParticleCollisionAsObservable, OnParticleTriggerAsObservabl(after Unity 5.4) extension methods
Add: UniRx.AsyncReactiveCommand
Add: ReactiveCommand.BindToOnClick, `IObservable<bool>.BindToButtonOnClick`
Add: UniRx.Toolkit.ObjectPool, AsyncObjectPool
Add: UniRx.AsyncMessageBroker, asynchronous variation of MessageBroker
Add: ObserveEveryValueChanged(IEqualityComparer) overload
Add: `Observable.FromCoroutine(Func<CancellationToken, IEnumerator>)` overload
Add: ObservableYieldInstruction.IsDone property
Add: IPresenter.ForceInitialize(object argument)
Improvement: Where().Select(), Select().Where() peformance was optimized that combine funcs at internal
Improvement: MicroCoroutine performance was optimized that prevent refresh spike
Improvement: Observable.Return performance was optimized that reduced memory cost
Improvement: Observable.Return(bool) was optimzied perofmrance that allocate zero memory
Improvement: Observable.ReturnUnit was optimzied perofmrance that allocate zero memory
Improvement: Observable.Empty was optimzied perofmrance that allocate zero memory
Improvement: Observable.Never was optimzied perofmrance that allocate zero memory
Improvement: Observable.DelayFrame performance was optimized
Improvement: UnityEqualityComparer.GetDefault peformance was optimized
Improvement: AddTo(gameObject) dispose when ObservableTrigger is not activated
Improvement: AddTo(gameObject/component) performance was optimized by use inner CompositeDisposable of ObservableDestroyTrigger
Improvement: `FromCoroutine<T>(Func<IObserver<T>, IEnumerator>)` stops coroutine when subscription was disposed
Improvement: ReactiveCollection, ReactiveDictionary implements dispose pattern
Fix: ToYieldInstruction throws exception on MoveNext when reThrowOnError and has error
Fix: ObserveEveryValueChanged publish value immediately(this is degraded from UniRx 5.3)
Fix: Prevent warning on Unity 5.4 at ObservableMonoBehaviour/TypedMonoBehaviour.OnLevelWasLoaded
Fix: Remove indexer.set of IReadOnlyReactiveDictionary
Breaking Changes: Does not guaranty MicroCoroutine action on same frame
Breaking Changes: UniRx.Diagnostics.LogEntry was changed from class to struct for performance improvement
相変わらずへっぽこな英語はおいといてもらえるとして、基本的にはパフォーマンス改善、です。
前回紹介したMicroCoroutineを改良して、配列をお掃除しながら走査する(かつ配列走査速度は極力最高速を維持する)ようになったので、より安定感もましたかな、と。その他メモリ確保しないで済みそうなものは徹底的に確保しないようになど、しつっこく性能改善に努めました。あと新規実装オペレータに関しては性能に対する執拗度がかなり上がっていて、今回でいうとBatchFrameはギチギチに最適化した実装です。既存オペレータも実装甘いものも残ってはいるので、見直せるものは見なおしてみたいですねえ。
また、9/13日にPhoton勉強会【Photon Server Deep Dive - PhotonWireの実装から見つめるPhoton Serverの基礎と応用、ほか】で登壇するので、PhotonWireではUniRxもクライアント側でかなり使っているので、その辺もちょっと話したいなと思っていますので、Photonに興味ある方もない方も是非是非。Photon固有の話も勿論しますが、普通にUnityとリアルタイム通信エンジンについての考えや、UniRx固有の話なども含めていきますので。
Debug
Debugという直球な名前のオペレータが追加されました。標準では有効化されていなくて、UniRx.Diagnosticsというマイナーな名前空間をusingするようで使えるようになります。実際どんな効果が得られるのかというと
using UniRx.Diagnostics;
---
// [DebugDump, Normal]OnSubscribe
// [DebugDump, Normal]OnNext(1)
// [DebugDump, Normal]OnNext(10)
// [DebugDump, Normal]OnCompleted()
{
var subject = new Subject<int>();
subject.Debug("DebugDump, Normal").Subscribe();
subject.OnNext(1);
subject.OnNext(10);
subject.OnCompleted();
}
// [DebugDump, Cancel]OnSubscribe
// [DebugDump, Cancel]OnNext(1)
// [DebugDump, Cancel]OnCancel
{
var subject = new Subject<int>();
var d = subject.Debug("DebugDump, Cancel").Subscribe();
subject.OnNext(1);
d.Dispose();
}
// [DebugDump, Error]OnSubscribe
// [DebugDump, Error]OnNext(1)
// [DebugDump, Error]OnError(System.Exception)
{
var subject = new Subject<int>();
subject.Debug("DebugDump, Error").Subscribe();
subject.OnNext(1);
subject.OnError(new Exception());
}
シーケンス内で検出可能なアクション(OnNext, OnError, OnCompleted, OnSubscribe, OnCancel)が全てコンソールに出力されます。よくあるのが、何か値が流れてこなくなったんだけど→どこかで誰かがDispose済み(OnCompleted)とか、OnCompletedが実は呼ばれてたとかが見えるようになります。
超絶ベンリな可視化!ってほどではないんですが、こんなものがあるだけでも、Rxで困ったときのデバッグの足しにはなるかなー、と。
BatchFrame
BatchFrameは特定タイミング後(例えばEndOfFrameまでコマンドまとめるとか)にまとめて発火するという、Buffer(Frame)のバリエーションみたいなものです。都度処理ではなくてまとめてから発火というのは、パフォーマンス的に有利になるケースが多いので、そのための仕組みです。Bufferでも代用できなくもなかったのですが、Bufferとは、タイマーの回るタイミングがBufferが空の時にスタートして、出力したら止まるというのが大きな違いですね。その挙動に合わせて最適化されています。
// BatchFrame特定タイミング後にまとめられて発火
// デフォルトは0フレーム, EndOfFrameのタイミング
var s1 = new Subject<Unit>();
var s2 = new Subject<Unit>();
Observable.Merge(s1, s2)
.BatchFrame()
.Subscribe(_ => Debug.Log(Time.frameCount));
Debug.Log("Before BatchFrame:" + Time.frameCount);
s1.OnNext(Unit.Default);
s2.OnNext(Unit.Default);
実装的には、まとめる&発火のTimerはコルーチンで待つようにしているのですが、今回はそのIEnumeratorを手実装して、適宜Resetかけて再利用することで、パイプライン構築後は一切の追加メモリ消費がない状態にしてます。
Optimize Combination
オペレータの組み合わせには、幾つかメジャーなものがあります。特に代表的なのはWhere().Select()でしょう。これはリスト内包表記などでも固有記法として存在するように、フィルタして射影。よくありすぎるパターンです。また、Where().Where()などのフィルタの連打やSelect().Select()などの射影の連打、そして射影してフィルタSelect().Where()などもよくみかけます(特にWhere(x => x != null)みたいなのは頻出すぎる!)。これらは、内部的に一つのオペレータとして最適化した合成が可能です。
// Select().Select()
onNext(selector1(selector2(x)));
// Where().Where()
if(predicate1(x) && predicate2(x))
{
onNext(x);
}
// Where().Select()
if(predicate(x))
{
onNext(selector(x));
}
// Select().Where()
var v = selector(x);
if(predicate(v))
{
onNext(v);
}
と、いうわけで、今回からそれらの結合を検出した場合に、内部的には自動的にデリゲートをまとめた一つのオペレータに変換して返すようになっています。
MessageBroker, AsyncMessageBroker
MessageBrokerはRxベースのインメモリPubSubです。AndroidでOttoからRxJavaへの移行ガイドのような記事があるように、PubSubをRxベースで作るのは珍しいことではなく、それのUniRx版となってます。
UniRxのMessageBrokerは「型」でグルーピングされて分配される仕組みにしています。
// こんな型があるとして
public class TestArgs
{
public int Value { get; set; }
}
---
// Subscribe message on global-scope.
MessageBroker.Default.Receive<TestArgs>().Subscribe(x => UnityEngine.Debug.Log(x));
// Publish message
MessageBroker.Default.Publish(new TestArgs { Value = 1000 });
// AsyncMessageBroker is variation of MessageBroker, can await Publish call.
AsyncMessageBroker.Default.Subscribe<TestArgs>(x =>
{
// show after 3 seconds.
return Observable.Timer(TimeSpan.FromSeconds(3))
.ForEachAsync(_ =>
{
UnityEngine.Debug.Log(x);
});
});
AsyncMessageBroker.Default.PublishAsync(new TestArgs { Value = 3000 })
.Subscribe(_ =>
{
UnityEngine.Debug.Log("called all subscriber completed");
});
AsyncMessageBrokerはMessageBrokerの非同期のバリエーションで、Publish時に全てのSubscriberに届いて完了したことを待つことができます。例えばアニメーション発行をPublishで投げて、Subscribe側ではそれの完了を単一のObservableで返す、Publish側はObservableになっているので、全ての完了を待ってSubscribe可能。みたいな。文字だけだとちょっと分かりにくいですが、使ってみれば結構簡単です。
UniRx.Toolkit.ObjectPool/AsyncObjectPool
UniRx.Toolkit名前空間は、本体とはあんま関係ないけれど、Rx的にベンリな小物置き場という感じのイメージでたまに増やすかもしれません。こういうのはあまり本体に置くべき「ではない」とも思っているのですが、Rxの内部を考慮した最適化を施したコードを書くのはそこそこ難易度が高いので、実用的なサンプル、のような意味合いも込めて、名前空間を隔離したうえで用意していってもいいのかな、と思いました。
というわけで、最初の追加はObjectPoolです。ObjectPoolはどこまで機能を持たせ、どこまで汎用的で、どこまで特化させるべきかという範囲がかなり広くて、実装難易度が高いわけではないですが、好みのものに仕上げるのは難しいところです。なのでまぁプロジェクト毎に作りゃあいいじゃん、と思いつつもそれはそれで面倒だしねー、の微妙なラインなのでちょっと考えつくも入れてみました。
// こんなクラスがあるとして
public class Foobar : MonoBehaviour
{
public IObservable<Unit> ActionAsync()
{
// heavy, heavy, action...
return Observable.Timer(TimeSpan.FromSeconds(3)).AsUnitObservable();
}
}
// それ専用のPoolを<T>で作る
public class FoobarPool : ObjectPool<Foobar>
{
readonly Foobar prefab;
readonly Transform hierarchyParent;
public FoobarPool(Foobar prefab, Transform hierarchyParent)
{
this.prefab = prefab;
this.hierarchyParent = hierarchyParent;
}
// 基本的にはこれだけオーバーロード。
// 初回のインスタンス化の際の処理を書く(特定のtransformに下げたりとかその他色々あるでしょふ)
protected override Foobar CreateInstance()
{
var foobar = GameObject.Instantiate<Foobar>(prefab);
foobar.transform.SetParent(hierarchyParent);
return foobar;
}
// 他カスタマイズする際はOnBeforeRent, OnBeforeReturn, OnClearをオーバーロードすればおk
// デフォルトでは OnBeforeRent = SetActive(true), OnBeforeReturn = SetActive(false) が実行されます
// protected override void OnBeforeRent(Foobar instance)
// protected override void OnBeforeReturn(Foobar instance)
// protected override void OnClear(Foobar instance)
}
public class Presenter : MonoBehaviour
{
FoobarPool pool = null;
public Foobar prefab;
public Button rentButton;
void Start()
{
pool = new FoobarPool(prefab, this.transform);
rentButton.OnClickAsObservable().Subscribe(_ =>
{
// プールから借りて
var foobar = pool.Rent();
foobar.ActionAsync().Subscribe(__ =>
{
// 終わったらマニュアルで返す
pool.Return(foobar);
});
});
}
}
基本的に手動で返しますし、貸し借りの型には何の手も入ってません!Rent後のトラッキングは一切されてなくて、手でReturnしろ、と。まあ、9割のシチュエーションでそんなんでいいと思うんですよね。賢くやろうとすると基底クラスがばら撒かれることになって、あまり良い兆候とは言えません。パフォーマンス的にも複雑性が増す分、どんどん下がっていきますし。
どこがRxなのかというと、PreloadAsyncというメソッドが用意されていて、事前にプールを広げておくことができます。フリーズを避けるために毎フレームx個ずつ、みたいな指定が可能になっているので、その完了がRxで待機可能ってとこがRxなとこです。
それと同期版の他に非同期版も用意されていて、それは CreateInstance/Rent が非同期になってます。
MessageBrokerと同じくAsyncとそうでないのが分かれているのは、Asyncに統一すべき「ではない」から。統一自体は可能で、というのも同期はObservable.Returnでラップすることで非同期と同じインターフェイスで扱えるから。そのこと自体はいいんですが、パフォーマンス上のペナルティと、そもそもの扱いづらさ(さすがにTのほうがIObservable[T]より遙かに扱いやすい!)を抱えます。
sync over asyncは、UniRx的にはバッドプラクティスになるかなあ。なので、同期版と非同期版とは、あえて分けて用意する。使い分ける。使う場合は極力同期に寄せる。ほうがいいんじゃないかな、というのが最近の見解です。
なお、Rent, Returnというメソッド名はdotnet/corefxのSystem.Buffersから取っています。
AsyncReactiveCommand
というわけでこちらもsync/asyncの別分けパターンで非同期版のReactiveCommandです。ReactiveCommandは何がベンリなのか分からないって話なのですが、実はこっちのAsyncReactiveCommandはかなりベンリです!
public class Presenter : MonoBehaviour
{
public UnityEngine.UI.Button button;
void Start()
{
var command = new AsyncReactiveCommand();
command.Subscribe(_ =>
{
// heavy, heavy, heavy method....
return Observable.Timer(TimeSpan.FromSeconds(3)).AsUnitObservable();
});
// after clicked, button shows disable for 3 seconds
command.BindTo(button);
// Note:shortcut extension, bind aync onclick directly
button.BindToOnClick(_ =>
{
return Observable.Timer(TimeSpan.FromSeconds(3)).AsUnitObservable();
});
}
}
interactableの状態をコード実行中、というかつまりIO<T>が返されるまでfalseにします。連打防止でThrottleFirstがよく使われますが、それをより正確にコントロールしたり、また、引数にIReactiveProperty[bool]を渡せて、それを複数のAsyncReactiveCommandで共有することで、特定のボタンを実行中は他のボタンも実行できない、のような実行可否のグルーピングが可能になります(例えばグローバルでUI用に一個持っておけば、ゲーム中でUIは単一の実行しか許可されない、的なことが可能になる)
PresenterBase再考
PresenterBase、Obsoleteはつけてないのですけれど、GitHub上のReadMeで非推奨の明言を入れました。賢い基底クラスは悪。なのです。POCO。それはUnityにおいても何事においても例外ではない。その原則からするとPresenterBaseは賢すぎたのでナシ of the Year。動きはする、動きはするんですが……。
Model-View-Presenterパターン自体の否定ではなくて(それ自体は機能するとは思っています、ただし関心がModelにばかり向きがちですが、Viewは何か、Presenterは何か、についてもきちんと向き合わないとPresenterが奇形化するかなー、というのは実感としてある。ViewであるものをPresenterとして表現してアレゲになる、とか)、PresenterBaseというフレームワークのミスかな、とは。です。
とりあえずいったん初期化順序が気になるシーンは手でInitializeメソッド立てて、それをAwake, Startの代わりにして、呼ばせる。いじょ。みたいな素朴な奴で十二分かなー、とオモッテマス。結局。メリットよりもデメリットのほうが大きすぎたかな。反省。
この辺りに関してはアイディアはあるので、形にするまで、むー、ちょっと味噌汁で顔洗って出直してきます。
まとめ
あんまり大きな機能追加はなく細々とした変化なんですが、着々と良くはなっているかな、と!
Rxに関してもバッドプラクティスを色々考えられるというか反省できる(おうふ……)ようになっては来たので、どっかでまとめておきたいですね。油断するとすぐリアクティブスパゲティ化するのはいくないところではある。強力なツールではあるんですが、やりすぎて自爆するというのは、どんなツールを使っても避けられないことではあるけれど、Rxがその傾向はかなり強くはある。
まぁ、sync over asyncはいくないです。ほんと(思うところいっぱいある)。
というわけかで繰り返しますが、9/13日にPhoton勉強会【Photon Server Deep Dive - PhotonWireの実装から見つめるPhoton Serverの基礎と応用、ほか】で登壇するので、よければそちらも是非是非です。