Microsoft MVP for Developer Technologies(.NET)を再々々々々々々々々々々々々々受賞しました
- 2025-07-14
Microsoft MVPは一年ごとに再審査されるのですが、今年も更新しました。2011年から初めて15回目です。昨今の予算の事情を考えると、席も少なくなっているのではないかという気配があるので、いつまでも居座るのはどうなのかという気もしますが、まぁ実績出してるから、しょうがないね……?
毎年新しいOSSでヒット作を出すのも大変ですよ、と思いつつ去年はR3、今年はZLinqを出しました。これは文句なしでいいんじゃないかと。ZLinqは本当に作るの大変だったんで報われたい(?)
今回の審査期間中の対外的な発表は以下の3つがありました。
2025年に入ってからは何もやっていないので、何か機会があれば、と伺ってはいるのですが中々どうして。今年はAI関連に力を入れたいと思っているので、まずはOSSで何か出してから、というのがいつもの自分のパターンなので、それは近々出します……!あとはZLinqに関してはアーキテクチャを話す場が作れるといいんですが、まぁそのうちどこかで。今のところ予定は完全に未定です。
自社のタイトルではないので私のほうから大きく言えることはないのですが、先日は大きなタイトルがリリースされたというのもあるので、そういったところからもC#(クライアント/サーバー)の力を世の中にアピールできるといいな、とは思っています。
というわけで引き続き、C#の推進やっていきます!
ゼロアロケーションLINQライブラリ「ZLinq」のリリースとアーキテクチャ解説
- 2025-05-05
ZLinq v1を先月リリースしました!structとgenericsベースで構築することによりゼロアロケーションを達成しています。またLINQ to Span, LINQ to SIMD, LINQ to Tree(FileSystem, JSON, GameObject, etc.)といった拡張要素と、任意の型のDrop-in replacement Source Generator。そして.NET Standard 2.0, Unity, Godotなどの多くのプラットフォームサポートまで含めた大型のライブラリとなっています!現在GitHub Starsも2000を超えました。
structベースのLINQそのものは珍しいものではなく、昔から多くの実装が挑戦してきました。しかし、真に実用的と言えるものはこれまでありませんでした。極度なアセンブリサイズの肥大化、オペレーターの網羅の不足、最適化不足で性能が劣るなど、実験的な代物を抜け切れていないものばかりでした。ZLinqでは実用的に使えるものを目指し、.NET 10(Shuffle, RightJoin, LeftJoinなど新しいものも含む)に含まれる全てのメソッドとオーバーロードの100%のカバーと、99%の挙動の互換性の確保、そしてアロケーションだけではなく、SIMD化も含めて、多くのケースにおける性能面で勝てるように実装しました。
それが出来るのは、そもそも私のLINQ実装の経験はものすごく長くて、2009年4月にlinq.jsというJavaScript用のLINQ to Objectsライブラリを公開しています(linq.jsは現在もForkした人が今もメンテナンスされているようです、素晴らしい!)。他にもUnityで広く使われているReactive ExtensionsライブラリUniRxを実装し、直近ではそれの進化版であるR3を公開したばかりです。バリエーションとしてもLINQ to GameObject、LINQ to BigQuery、SimdLinqといったものを作っていました。これらに、ゼロアロケーション関連ライブラリ(ZString, ZLogger)やハイパフォーマンスシリアライザー(MessagePack-CSharp, MemoryPack)の知見を掛け合わせることで、標準ライブラリの上位互換という野心的目標を達成できました。

これはシンプルなベンチマークで、Where, Where.Take, Where.Take.Selectとメソッドチェーンを重ねれば重ねるほど、通常はアロケーションが増えていきますがZLinqはずっとゼロです。
性能は元のソース、個数、値の型、そしてメソッドの繋げ方によって変わってきます。多くのケースで性能面で有利なことを確認するために、ZLinqでは様々なケースのベンチマークを用意し、GitHub Actions上で走らせています。ZLinq/actions/Benchmark。構造上どうしても負けてしまうケースも存在はするのですが、現実的なケースではほとんど勝っています。
ベンチマーク上極端に差が出るものでいえば、シンプルにSelectを複数回繰り返したものは、SystemLinqもZLinqも特殊な最適化が入っていないケースになりますが、大きな性能差が出ています。
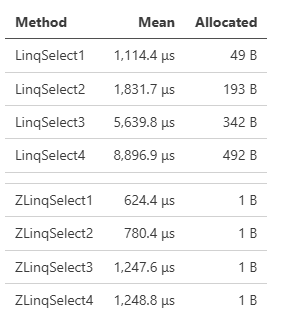
シンプルなケースでは、DistinctやOrderByなど中間バッファを必要とするものは、積極的なプーリングによりアロケーションを大きく抑えているため、差が大きくなります(ZLinqは原則ref strcutであり短寿命が期待できるため、プーリング利用はややアグレッシブにしています)。例えばこのベンチマークはDistinctです。
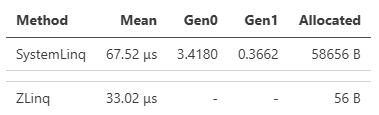
LINQはメソッド呼び出しのパターンにより特殊な最適化がかかるなど、アロケーションを抑えるだけでは性能面で常に勝てるわけではありません。そうしてオペレーターの繋がりによる最適化に関しても、これは.NET 9で最適化されたパターンとしてPerformance Improvements in .NET 9で紹介されている例ですが、ZLinqではそれらの最適化を全て実装し、より高いパフォーマンスを引き出しています。
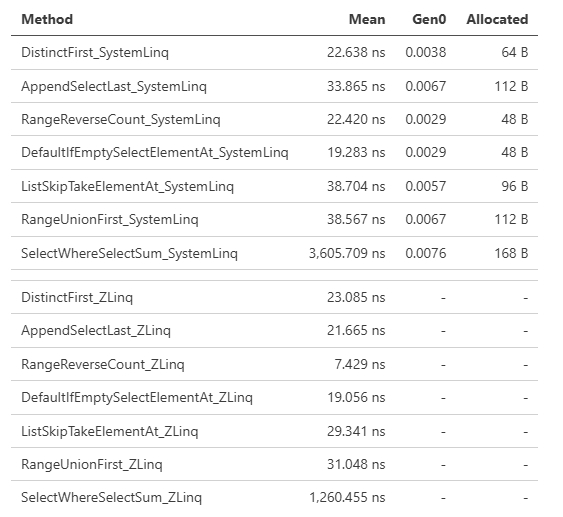
ZLinqの良いところとして、これらLINQの進化による最適化の恩恵を、最新の.NETだけではなく、全ての世代の.NET(.NET Frameworkも含む)が得られることでもあります。
利用法はシンプルに、AsValueEnumerable()呼び出しを追加するだけです。オペレーターに関しては100%網羅しているので、既存コードからの置き換えも全て問題なくコンパイルが通り、動作します。
using ZLinq;
var seq = source
.AsValueEnumerable() // only add this line
.Where(x => x % 2 == 0)
.Select(x => x * 3);
foreach (var item in seq) { }
ZLinqでは挙動の互換性を保証するために、dotnet/runtimeのSystem.Linq.Testsを移植して ZLinq/System.Linq.Tests 常に走らせています。

9000件のテストケースのカバーにより、動作を保証しています(Skipしているケースはref structであるため、同一テストコードを動かせない場合によるものなど)
また、 AsValueEnumerable() すら省略したDrop-In Replacementを任意で有効化するSource Generatorも提供しています。
[assembly: ZLinq.ZLinqDropInAttribute("", ZLinq.DropInGenerateTypes.Everything)]

この仕組みにより、Drop-In Replacementの範囲を自由にコントロールすることができます。ZLinq/System.Linq.Tests自体がDrop-In Replacementにより、既存テストコードを変えずにZLinqで動作するようになっています。
ValueEnumerableのアーキテクチャと最適化
使い方などはReadMeを参照してもらえればいいので、ここでは最適化の話を深堀します。ただたんなるシーケンスを遅延実行するだけ、ではないところが、アーキテクチャ上の特色であり、他の言語のコレクション処理ライブラリと比べても、多くの工夫が詰まっています。
連鎖のベースとなるValueEnumerable<T>の定義はこうなっています。
public readonly ref struct ValueEnumerable<TEnumerator, T>(TEnumerator enumerator)
where TEnumerator : struct, IValueEnumerator<T>, allows ref struct // allows ref structは.NET 9以上の場合のみ
{
public readonly TEnumerator Enumerator = enumerator;
}
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current); // as MoveNext + Current
// Optimization helper
bool TryGetNonEnumeratedCount(out int count);
bool TryGetSpan(out ReadOnlySpan<T> span);
bool TryCopyTo(scoped Span<T> destination, Index offset);
}
これを基にして、例えばWhereなどのオペレーターはこうした連鎖が続きます。
public static ValueEnumerable<Where<TEnumerator, TSource>, TSource> Where<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Func<TSource, Boolean> predicate)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
IValueEnumerable<T>ではなくてこのようなアプローチを取ったのは、(this TEnumerable source) where TEnumerable : struct, IValueEnumerable<TSource>のような定義にすると、TSourceへの型推論が効かなくなります。これはC#が型引数の制約からは型推論をしないという言語仕様上の制限(dotnet/csharplang#6930)があるためで、もしそのような定義のまま実装をすると、インスタンスメソッドとして大量の組み合わせを定義することになります。それをやったのがLinqAFであり、その結果100,000+ methods and massive assembly sizesということで、あまり良い結果をもたらしていません。
LINQにおいては実装は全てIValueEnumerator<T>側にあり、また、全てのEnumeratorはstructのため、GetEnumerator()ではなくて、共通でEnumeratorのコピー渡しするだけで、それぞれのEnumeratorが独立したステートで処理できることに気付いたので、IValueEnumerator<T>をValueEnumerable<TEnumerator, T>でラップするだけ、という構成に最終的になりました。これにより型が制約側ではなくて型宣言側に現れるので、型推論での問題もありません。
- TryGetNext
次にイテレートの本体であるMoveNextについて詳しく見ていきましょう。
// Traditional interface
public interface IEnumerator<out T> : IDisposable
{
bool MoveNext();
T Current { get; }
}
// iterate example
while (e.MoveNext())
{
var item = e.Current; // invoke get_Current()
}
// ZLinq interface
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current);
}
// iterate example
while (e.TryGetNext(out var item))
{
}
C#の foreach は MoveNext() + Current に展開されるわけですが、問題が二点あります。一つはメソッド呼び出し回数で、イテレート毎にMoveNextとget_Currentの2回必要です。もう一つはCurrentのために、変数を保持する必要があること。そこで、それらをbool TryGetNext(out T current)にまとめました。これによりメソッド呼び出し回数が一度で済みパフォーマンス上有利です。
なお、この bool TryGetNext(out T current) 方式は、例えばRustのイテレーターで採用されています。
pub trait Iterator {
type Item;
// Required method
fn next(&mut self) -> Option<Self::Item>;
}
変数の保持に関してはピンとこないと思うので、例としてSelectの実装を見てください。
public sealed class LinqSelect<TSource, TResult>(IEnumerator<TSource> source, Func<TSource, TResult> selector) : IEnumerator<TResult>
{
// フィールドが3つ
IEnumerator<TSource> source = source;
Func<TSource, TResult> selector = selector;
TResult current = default!;
public TResult Current => current;
public bool MoveNext()
{
if (source.MoveNext())
{
current = selector(source.Current);
return true;
}
return false;
}
}
public ref struct ZLinqSelect<TEnumerator, TSource, TResult>(TEnumerator source, Func<TSource, TResult> selector) : IValueEnumerator<TResult>
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
// フィールドが2つ
TEnumerator source = source;
Func<TSource, TResult> selector = selector;
public bool TryGetNext(out TResult current)
{
if (source.TryGetNext(out var value))
{
current = selector(value);
return true;
}
current = default!;
return false;
}
}
IEnumerator<T>はMoveNext()で進めてCurrentで返す、という都合上、Currentのフィールドが必要です。ところがZLinqでは進めると同時に値を返すため、フィールドに保持する必要がありません。これは、全体がstructベースで構築されているZLinqではかなり大きな違いがあります。ZLinqではメソッドチェーンの度に、以前のstructを丸ごと抱える(TEnumeratorがstruct)構造になるため、メソッドチェーンを重ねる度に構造体のサイズが肥大化していきます。常識的な範囲内でメソッドチェーンを重ねる限りは、パフォーマンス上も問題にはなっていなかったのですが、それでも小さければ小さいほどコピーコストが小さくなり性能面で有利にはなります。1バイトでも構造体を小さくする、ためにもTryGetNextの採用は必然でした。
TryGetNextの欠点は、共変・反変をサポートできないことです。ただし私は、そもそもイテレーターや配列から共変・反変のサポートは撤廃すべきだと思っています。Span<T>との相性が悪いため、メリット・デメリットを天秤にかけると、時代遅れの概念だと言えます。具体例を出すと、配列のSpan化は失敗する可能性があり、それはコンパイル時には検出できず実行時エラーとなります。
// ジェネリクスの変性によりDerived[]をBase[]で受け取る。
Base[] array = new Derived[] { new Derived(), new Derived() };
// その場合、Span<T>へのキャストやAsSpan()は実行時エラーになる!
// System.ArrayTypeMismatchException: Attempted to access an element as a type incompatible with the array.
Span<Base> foo = array;
class Base;
class Derived : Base;
Span<T>以前に追加された機能のため、もうどうにもならないとは思いますが、現代の.NETはあらゆるところでSpanが活用されるようになっているので、それが実行時エラーになる可能性をはらんでいる時点で、使い物にならないと考えてもいいはずです。
- TryGetNonEnumeratedCount / TryGetSpan / TryCopyTo
全てを愚直に列挙するだけだと、パフォーマンスは最大化されません。例えばToArrayするときに、もしサイズの変動がないなら(array.Select().ToArray())、new T[count]のように固定長配列を作ることができます。SystemLinqでも、そうした最適化を実現するために、内部的にはIterator<T>型が使われているのですが、引数はIEnumerable<T>のため、必ず if (source is Iterator<TSource> iterator) のようなコードが必要になっています。
ZLinqでは最初からLINQのための定義を前提にできるため、すべて織り込み済みで用意しています。ただし、むやみやたらに増やすのはアセンブリサイズの肥大化を招くため、必要最小限の定義で、最大限の効果を生み出すように調整したのが、この3つのメソッドとなっています。
TryGetNonEnumeratedCount(out int count)は、元のソースが有限の個数であり、途中にフィルタリング系メソッド(WhereやDistinctなど。TakeやSkipは算出可能なため含まない)が挟まらない場合は成功します。ToArrayなどのほか、OrderByやShuffleなど中間バッファが必要な時に効果が出るケースもあります。
TryGetSpan(out ReadOnlySpan<T> span)は、元ソースが連続的なメモリとして取得できる場合には、オペレーターによってはSIMDが適用されて劇的なパフォーマンス向上に繋がったり、Spanによるループ処理によって集計パフォーマンスが高まるなど、性能面で大きな違いをもたらす可能性があります。
TryCopyTo(scoped Span<T> destination, Index offset)は内部イテレーターによってパフォーマンスを向上させる仕組みです。外部イテレーターと内部イテレーターについて説明すると、例えばList<T>はforeachとForEachの両方が選べます。
// external iterator
foreach (var item in list) { Do(item); }
// internal iterator
list.ForEach(Do);
見た目は似ていますが、性能面で違いがあります。foreachは素直な構文で書けている。ForEachはデリゲート渡し。処理の実体まで分解すると
// external iterator
List<T>.Enumerator e = list.GetEnumerator();
while (e.MoveNext())
{
var item = e.Current;
Do(item);
}
// internal iterator
for (int i = 0; i < _size; i++)
{
action(_items[i]);
}
これはデリゲート呼び出し(+デリゲート生成アロケーション)のオーバーヘッド vs イテレーターのMoveNext + Current呼び出しの対決になっていて、イテレート速度自体は内部イテレーターのほうが速い。この場合デリゲート呼び出しのほうが軽量な場合があり、ベンチマーク的に内部イテレーターのほうが有利な可能性があります。
もちろん、ケースバイケースであることと、ラムダ式にキャプチャが発生したり、普通の制御構文が使えない(continueなど)ことから、私としてはForEachは使うべきではないし、拡張メソッドでForEachのようなものを独自定義すべきではない、とも思っていますが、原理的にはこのような違いが存在します。
TryCopyTo(scoped Span<T> destination, Index offset)は、デリゲートではなくSpanを受け取ることで限定的に内部イテレーター化しました。
これもSelectを例に出すと、ToArrayの場合にCountが取れているとSpanを渡して内部イテレーターで処理します。
public ref struct Select
{
public bool TryCopyTo(Span<TResult> destination, Index offset)
{
if (source.TryGetSpan(out var span))
{
if (EnumeratorHelper.TryGetSlice(span, offset, destination.Length, out var slice))
{
// loop inlining
for (var i = 0; i < slice.Length; i++)
{
destination[i] = selector(slice[i]);
}
return true;
}
}
return false;
}
}
// ToArray
if (enumerator.TryGetNonEnumeratedCount(out var count))
{
var array = GC.AllocateUninitializedArray<TSource>(count);
// try internal iterator
if (enumerator.TryCopyTo(array.AsSpan(), 0))
{
return array;
}
// otherwise, use external iterator
var i = 0;
while (enumerator.TryGetNext(out var item))
{
array[i] = item;
i++;
}
return array;
}
のように、SelectはSpanは作れませんが、元ソースがSpanを作れるなら、内部イテレーターとして処理することでループ処理を高速化することが可能です。
TryCopyToの定義は普通のCopyToと違って、Index offsetを持っています。また、destinationはソースサイズよりも小さいことを許しています(通常の.NETのCopyToはdestinationが小さいと失敗する)。これによって、destinationのサイズが1の場合、IndexによってElementAtが表現できます。そして0ならFirstだし^1の場合はLastになります。IValueEnumerator<T>自体にFirst, Last, ElementAtを持たせると、クラス定義として無駄が多くなってしまいますが(アセンブリサイズにも影響が出る)、小さいdestinationとIndexを持たせることにより、一つのメソッドでより多くの最適化ケースをカバーできるようになりました。
public static TSource ElementAt<TEnumerator, TSource>(this ValueEnumerable<TEnumerator, TSource> source, Index index)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
using var enumerator = source.Enumerator;
var value = default(TSource)!;
var span = new Span<T>(ref value); // create single span
if (enumerator.TryCopyTo(span, index))
{
return value;
}
// else...
}
ところで、このTryGetNextや内部イテレーターに関しては、2007年の時点で https://nyaruru.hatenablog.com/entry/20070818/p1 で紹介されていました。この記事はずっと頭に残っていて、ようやくこうして20年経って理屈通りの実現ができました。という点でも少し感慨深いです。2008年前後はLINQ登場前後ということで、このあたりの話がアツかった時代なんですよねー。
LINQ to Span
ZLinqは .NET 9 以上であれば、Span<T>やReadOnlySpan<T>に対しても、全てのLINQオペレーターを繋げることができます。
using ZLinq;
// Can also be applied to Span (only in .NET 9/C# 13 environments that support allows ref struct)
Span<int> span = stackalloc int[5] { 1, 2, 3, 4, 5 };
var seq1 = span.AsValueEnumerable().Select(x => x * x);
// If enables Drop-in replacement, you can call LINQ operator directly.
var seq2 = span.Select(x => x);
Span対応のLINQを謳ったライブラリも、世の中には多少ありますが、それらはSpan<T>にだけ拡張メソッドを定義する、といったようなものであり、汎用的な仕組みではありませんでした。網羅されるオペレーターも制約があり、一部のものに限られていました。それは言語的にもSpan<T>をジェネリクス引数として受け取ることができなかったためで、汎用的に処理できるようになったのは .NET 9でallows ref structが登場してくれたおかげです。
ZLinqではIEnumerable<T>とSpan<T>に何の区別もありません、全て平等に取り扱われます。
ただし、allows ref structの言語/ランタイムサポートが必要なため、ZLinq自体は.NET Standard 2.0以上の全ての.NETをサポートしていますが、Span<T>対応に関してのみ.NET 9以上限定の機能となっています。また、これにより.NET 9以上の場合は、全てのオペレーターがref structになっている、という違いがあります。
LINQ to SIMD
System.Linqでは、一部の集計メソッドがSIMDによって高速化されています。例えば一部のプリミティブ型の配列に直接SumやMaxを呼び出すと高速化されています。これらの呼び出しはforで処理するよりも遥かに高速化されます。とはいえ、IEnumerbale<T>がベースであるため、適用可能な型が限定的であるなどの欠点を感じています。ZLinqではIValueEnumeartor.TryGetSpanによってSpan<T>が取得できる場合が対象となるコレクションとなるため、より汎用的になっています(もちろんSpan<T>に適用することもできます)。
対応するメソッドは以下のようなものになっています。
- Range to ToArray/ToList/CopyTo/etc...
- Repeat for
unmanaged structandsize is power of 2to ToArray/ToList/CopyTo/etc... - Sum for
sbyte,short,int,long,byte,ushort,uint,ulong,double - SumUnchecked for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Average for
sbyte,short,int,long,byte,ushort,uint,ulong,double - Max for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Min for
byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128 - Contains for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint - SequenceEqual for
byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint
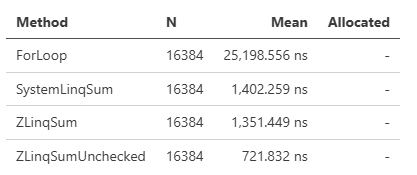
Sumはオーバーフローをチェックします。これは処理においてオーバーヘッドとなっているため、独自にSumUncheckedというメソッドも追加しています。性能差は以下のようになり、Uncheckedのほうがより高速です。
これらメソッドは条件がマッチした場合に暗黙的に適用されるということであり、SIMDを狙って適用させるには内部パイプラインへの理解が必要とされています。そこでT[] or Span<T> or ReadOnlySpan<T>には.AsVectorizable()というメソッドを用意しました。SIMD適用可能なSum, SumUnchecked, Average, Max, Min, Contains, and SequenceEqualを明示的に呼び出すことができます(ただしVector.IsHardwareAccelerated && Vector<T>.IsSupportedではない場合は通常の処理にフォールバックされるため、必ずしもSIMDが適用されることを保証するわけではありません)。
int[] or Span<int>にはVectorizedFillRangeというメソッドが追加されます。これはValueEunmerable.Range().CopyTo()と同じ処理で、連番で埋める処理がSIMDで高速化されます。連番が必要になる局面で、forで埋めるよりも遥かに高速なので、覚えておくといいかもしれません。
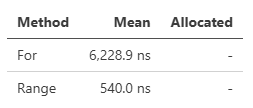
- Vectorizable Methods
SIMDによるループ処理を手書きするのは、慣れが必要で少し手間がいります。そこでFuncを引数に与えることでカジュアルに使えるヘルパーをいくつか用意しました。デリゲートを経由するオーバーヘッドが発生するためインラインで書くよりもパフォーマンスは劣りますが、カジュアルにSIMD処理できるという点では便利かもしれません。これらは引数にFunc<Vector<T>, Vector<T>> vectorFuncとFunc<T, T> funcを受け取り、ループの埋められるところまでVector<T>で処理し、残りをFunc<T>で処理します。
T[], Span<T>にはVectorizedUpdateというメソッドが用意されています。
using ZLinq.Simd; // needs using
int[] source = Enumerable.Range(0, 10000).ToArray();
[Benchmark]
public void For()
{
for (int i = 0; i < source.Length; i++)
{
source[i] = source[i] * 10;
}
}
[Benchmark]
public void VectorizedUpdate()
{
// arg1: Vector<int> => Vector<int>
// arg2: int => int
source.VectorizedUpdate(static x => x * 10, static x => x * 10);
}
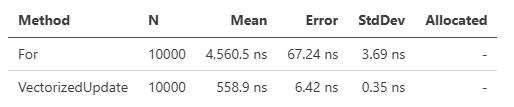
forよりも高速、ですが、パフォーマンスはマシン環境やサイズによって変わるので、盲目的に使うのではなくて、都度検証することをお薦めします。
AsVectorizable()にはAggregate, All, Any, Count, Select, and Zipが用意されています。
source.AsVectorizable().Aggregate((x, y) => Vector.Min(x, y), (x, y) => Math.Min(x, y))
source.AsVectorizable().All(x => Vector.GreaterThanAll(x, new(5000)), x => x > 5000);
source.AsVectorizable().Any(x => Vector.LessThanAll(x, new(5000)), x => x < 5000);
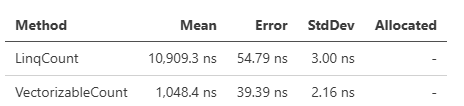
source.AsVectorizable().Count(x => Vector.GreaterThan(x, new(5000)), x => x > 5000);
パフォーマンスは、データ次第ではありますが一例としてはCountで、このぐらいの差が出ることもあります。
Select, Zipに関しては、後続にToArrayかCopyToを選びます。
// Select
source.AsVectorizable().Select(x => x * 3, x => x * 3).ToArray();
source.AsVectorizable().Select(x => x * 3, x => x * 3).CopyTo(destination);
// Zip2
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).CopyTo(destination);
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).ToArray();
// Zip3
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).CopyTo(destination);
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).ToArray();
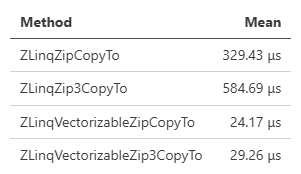
Zipなんかは結構面白い&ちゃんと高速なので、使いどころあるかもしれません(2つのVec3のマージとか)。
LINQ to Tree
皆さんLINQ to XMLを使ったことはありますか? LINQの登場した2008年は、まだまだXML全盛期で、LINQ to XMLのあまりにも使いやすいAPIには衝撃を受けました。しかし、すっかり時代はJSONでありLINQ to XMLを使うことはすっかりなくなりました。
しかし、LINQ to XMLの良さというのは、ツリー構造に対するLINQ的操作のリファレンスデザインだと捉えることができます。ツリー構造がLINQになる、そのガイドライン。LINQ to Objectsと非常に相性の良い探索の抽象化。その代表例がRoslynのSyntaxTreeに対する操作で、AnalyzerやSource Generatorを書くのにDescendantsなどのメソッドを日常的に利用しています。
そこでZLinqはそのコンセプトを拡張し、ツリー構造に対して汎用的に Ancestors, Children, Descendants, BeforeSelf, and AfterSelf が適用できるインターフェイスを定義しました。

これはUnityのGameObjectへの走査の図ですが、標準でFileSystem(DirectoryTreeはツリー構造)やJSON(System.Text.JsonのJsonNodeに対してLINQ to XML的な操作を可能にする)を用意しています。もちろん、任意にインターフェイスを実装することで追加することもできます。
public interface ITraverser<TTraverser, T> : IDisposable
where TTraverser : struct, ITraverser<TTraverser, T> // self
{
T Origin { get; }
TTraverser ConvertToTraverser(T next); // for Descendants
bool TryGetHasChild(out bool hasChild); // optional: optimize use for Descendants
bool TryGetChildCount(out int count); // optional: optimize use for Children
bool TryGetParent(out T parent); // for Ancestors
bool TryGetNextChild(out T child); // for Children | Descendants
bool TryGetNextSibling(out T next); // for AfterSelf
bool TryGetPreviousSibling(out T previous); // BeforeSelf
}
例えばJSONに対しては
var json = JsonNode.Parse("""
// snip...
""");
// JsonNode
var origin = json!["nesting"]!["level1"]!["level2"]!;
// JsonNode axis, Children, Descendants, Anestors, BeforeSelf, AfterSelf and ***Self.
foreach (var item in origin.Descendants().Select(x => x.Node).OfType<JsonArray>())
{
// [true, false, true], ["fast", "accurate", "balanced"], [1, 1, 2, 3, 5, 8, 13]
Console.WriteLine(item.ToJsonString(JsonSerializerOptions.Web));
}
といったように書くことができます。
UnityにはGameObjectやTransform、GodotにはNodeへのLINQ to Treeを標準で用意しました。アロケーションや走査のパフォーマンスにかなり気を使って書かれているので、手動でループを回すよりも、もしかしたら高速かもしれません。
OSSと私
ここ数ヶ月で.NET関連のOSSには幾つか事件がありました。名のしれたOSSの商業ライセンス化、など……。私は、github/Cysharpで出しているOSSの数は40を超え、個人やMessagePack organizationなどのものも含めると、総スター数では50000を超えるなど.NET周りのサードパーティーとしては最大規模でのOSS提供者なのではないかと思います。
商業化、に関しては予定はありません、が、メンテナンスに関しては規模が大きくなってきたため、追いつかなくなっている面が多々あります。OSSが批判を覚悟で商業化を試みるの要因として、メンテナーに対する精神的な負荷というのが大きい(時間に対しての報酬が全く見合っていない)のですが、私も、まぁ、大変です!
金銭面は置いておいて、お願い事としては、メンテナンスが滞ることがあることは多少受け入れて欲しい!今回のZLinqのような大きなライブラリを仕込んでいる最中は、集中する時間が必要なため、他のライブラリのIssueやPRへの応答が数ヶ月音信不通になります。意識的に全く見ないようにしています、タイトルすら見てません(ダッシュボードや通知のメールなども一切目にしないようにしています)。そうした不義理を働くことで創造的なライブラリを生み出すことができるのだ、これは必要な犠牲なのです……!
また、そうじゃなくても、面倒見てるライブラリの数が多すぎるのでローテートでも数ヶ月の遅延が発生することは、あります。もうこれは絶対的なマンパワーが不足しているため、しょうがないじゃないですかー、というわけで、そのしょうがないを受け入れて、ちょっと返事が遅れるだけでthis library is dead的なこと言わないで欲しいなあ、というのが正直なところです!言われると辛い!なるべく努力はしたいんですが、特に新しいライブラリの創造は時間をめちゃくちゃ取られて大量の遅延が発生して、その遅延が更に遅延を呼んで泥沼になって精神を削っていくのですよー。
あとはMicrosoft関連でイラッとさせられてモチベーションを削られるとか、この辺はC#関連のOSSあるあるが発生したりしたりしながらも、なるべく末永く続けていきたいとは思っています。
かなり危機感は持っているので、AIによってどこまで負荷の軽減ができるのか、というところをテーマに、ある程度実験場として色々やっていきたいなあ、と思っています。うまくいけば、よりコアに集中できる環境になってくれるわけですしね。
まとめ
ZLinqの構造は最初のプレビュー版公開後のフィードバックで結構変わっていて、@Akeit0さんにはコアとなるValueEnumerable<TEnumerator, T>という定義やTryCopyToへのIndexの追加など、パフォーマンスに重要なコア部分の提案を多く頂きました!また、@filzrevさんからは多大なテスト・ベンチマークのインフラストラクチャーを提供してもらいました。互換性確保やパフォーマンス向上は、この貢献がなければ成しえませんでした。お二人には深く感謝します。
改めて、ゼロアロケーションLINQライブラリというコンセプト自体はそこまで珍しいものでもなく、今までもライブラリが死屍累々と転がっていたわけですが、ZLinqは徹底度合いが違う。経験と知識があるうえで、精神論で気合で、全メソッド実装、テストケースも全部流して完全互換、最適化類もSIMD含めて全部実装する、をやり切ったのが立派なところなのではないかな、と。いや、ほんとこれめっちゃ大変だったのです……。
タイミングとしても.NET 9/C# 13が、フルセットでやりたいことが全部やれる言語機能となったことは、やる気を後押ししてくれました。と、同時に、Unityや.NET Standard 2.0対応も大事にできたのもいいことです。
ただのゼロアロケーションLINQというだけではなく、LINQ to Treeはお気に入りの機能なので是非使ってみて欲しいですね……!そもそもに元々は、10年前に作っていたLINQ to GameObjectをモダン化しよう、というのが出発点でした。昔のコードだったのでかなりベタ書きだったのですが、もうちょっと抽象化したほうがいいかな、と弄っているうちに、だったらゼロアロケーションLINQとしての抽象化まで進化させてしまったほうがいいのでは、という思いつきに至ったのでした。
ところで、LINQのパフォーマンスのネックの一つとしてはデリゲートがあり、一部のライブラリはstructでFuncのようなものを模写するValueDelegateというアプローチがあるのですが、それはあえて採用していません。というのも、それらの定義はかなり手間なので、現実的にはやってられないはずです。そこまでやるなら普通にインラインで書いたほうがマシなので、LINQでValueDelegate構造を使う意味はありません。そんなベンチマークハックのためだけに内部構造の複雑化とアセンブリサイズの肥大化を招くのは無駄なので、System.Linqと互換のFuncのみを受け入れるスタイルにしています。
R3が.NET標準のSystem.Reactiveを置き換えるものという野心的ライブラリでしたが、System.Linqの置き換えはそれよりも遥かに大きな、あるいは大袈裟すぎる代物なので、採用に抵抗感はあるんじゃないかなー、と思います。ですが、置き換えるだけのメリットは掲示できていると思うので、是非とも試してみてくれると嬉しいです!
2024年を振り返る
- 2024-12-30
今年もCysharpはちゃんと生存していて良きかな、というわけでサイトが相変わらずペライチなのでそろそろリニューアルしたいと思って幾星霜。
そんなわけで今年もC#をやりこみ(?)していました……!
新規:
大型アップデート
うーん、十分でしょ!割といつも年の中で浮き沈みはあって、調子でないなあ、ここ数ヶ月ダメだぁ、みたいな気持ちになることが割とあるのですが、振り返ってみれば十分すぎるでしょ!むしろやりすぎでしょ!というわけで、C#最前線キープとしては全く問題ないでしょう。
ハイライトとしてはやはり年初のR3 - C#用のReactive Extensionsの新しい現代的再実装ですかね……!これは、めちゃくちゃ大変でした。物量とかそのものの実装難易度とかもそうなのですが、スタンダードとなっているインターフェイスや仕様を変えるという判断を通しているんですよね。これが、ちゃんと成り立たせられるのか、それで普及させられるのか、という悩みもあり、また、インターフェイスも作りながら割とクルクル最後まで変えながらやってたので、完成して良かったし、1年弱経って、ちゃんと受け入れられているのを見てようやくホッと一息です。Unityにおいても、今年はNuGet化を強烈に推進していったわけですが、なんだかんだで受け入れてもらえってるような気がしますがどうでしょう……?
Claudiaや、なんかブログに書く機会を逸して書いてない気がするのですがUtf8StreamReaderなんかも中々いい感じではあったと思います。
そして大型アップデート系はSource Generator祭り。まずConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークは傑作かと!これは自信作ですねー、めちゃくちゃいいものが出来たと思ってます。直近のConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、などで完全に仕上がりました。
MessagePack for C#は長年懸案だったSource Generator化をついに果たしました。そして色々あって共同メンテナーが離脱したことにより、再度主導権が私の方に戻っています。この辺のことは思うところは割とあるのですが、まぁ結果的には良かったかな、と思ってます。再びやれることの幅も広がったので、MemoryPackともどもで来年は強化していきたいと思っています。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベースも、ずっとSource Generator化したいと思って2年ぐらい放置していた案件なので、ようやく解消できて嬉しい話ですね。しかもやってたら想像通りにめちゃくちゃDX(Developer Experience)よくなってるので、やっと理想が実現できた、というかむしろ時代がやっと追いついた(なんせこの辺の仕組みはSource Generator以前に構築していたパターンなので)という気持ちです。
Cysharpの提供しているライブラリから単独コードジェネレーターは消滅して全てSource Generator化し、そして.NETプロジェクトとUnityプロジェクトのソースコード共有最新手法でも書いたようにUnityとのコードシェアもかなりやりやすい手法が確立できたので、まさにこれはC#大統一理論元年……!「出来ない」よりは「出来たほうがいい」ので、別に今までのやり方が悪かったとは思いませんが、ようやく理想形に到達できた、という感じではあります。来年初頭にはMagicOnionのMessagePack for C# v3対応を出す予定で、これで全てのパーツが揃います!
なんとか of the Year
今年一番大きかった変化として、メモ環境にObsidianを全面導入したのですが、これは超絶良いですね。Daily Notesの有用性というのをようやく理解しました。有料課金して同期することで更に便利、プラグインもマシマシで便利、まぁ入れすぎてもしょうがないので適度に絞ってますよ、と思ったんですが、意外と結構はいってるかも……。
TODOもObsidianに寄せるようにしていますが、特にTODOプラグインなどは使わずにDaily Notesで表現できるように若干工夫しています(TemplaterでJavaScript書いてDaily Notesの生成時にチェック済みのTODOタスクは自動で消すようにしてる&未チェックのTODOタスクは引き継ぐようにしている)。TODOアプリは無限に彷徨って毎年違うものに変えてたりするのですが、これが一番手に馴染んでるので決定版ということでいいかなー。
もう一つ革命的に良かったと思うのはHUAWEI FreeClip。これはとんでもなく良くてビックリした。HUAWEI製品のクオリティの高さにもビビッた。オープンイヤー型のイヤホンなわけですが、付け心地も良いし細かいところも良く出来てるし音質もしっかりしてる。言う事無し。オープンイヤーは、外音取り込みとは耳への圧迫感が自然さが全然違うんですよねえ、これだと1日中付けっぱなしとまではしないけど、割と頻繁に耳につけといて、音を聞くことが増えました。講演動画とか英語のリスニングとか日常生活に流せるといい感じ度が上がります。あとダラダラYouTube見る頻度が相当上がってしまった……。あまり使い分けとかは出来ないタイプの人間なので今まで使っていたAirPods Proはお蔵入りしてFreeClip一本使いになってます。ノイズキャンセリング性能がーというのと真逆なわけですが、外音と混じった音楽も、それはそれで心地よいのでいい感じなので、騒音環境下でもそこまで気にならず使えてる気がします。
あとは、家のキーボードをRealforce RC1に変更しました。HHKBにF1-12キーが追加されたようなレイアウトなわけですが、まず、キーボードにF1-F12は必須なんですよね!Visual Studio的に!あとは、日本語キーボードレイアウトじゃないとダメ人間なので、ずっとコンパクト配列にしたいなあと思いつつも選択肢がなくてなあ、と、テンキーレスぐらいで我慢していたので、満を持しての本命というわけでした。
それとFnキーとの組み合わせによるハードウェアキーレイアウト変更が柔軟かつ安定性が高いことに気づいた!昔から無変換+ESDFを十字キーとして使う癖があって、AutoHotKeyなどソフトウェアでフックするやつを使って実現していたのですが、挙動的に不安定(抜けが出たりするのが辛い)なのが気になってました。が、Realforceの設定で無変換と変換をFnキーにしてしまって、Fnキーとの組み合わせでESDFを十字キーにしてしまえば完璧だった……!というわけで現在のレイアウトがこちら。
そんなにキーボードから手を離さないで全部操作出来ないと!みたいな感じではなく、右手はマウス行きしちゃうので、左手側に詰め込みがちです。とにかくESDFでの十字キー化が安定したのがめっちゃ嬉しい。これ、WSDFじゃないんですか?というところなのですが、主に使うシチュエーションはテキストエディタでの十字移動なので、ESDFはホームポジションから手を動かさずに十字キーになるのがWSDFに比べての圧倒的利点です。それとQAZが空くので、そこにもキーを詰め込めるのも嬉しい。
というわけでQ, AはHome/End(ちなみに私はHomeめちゃくちゃよく使います)。Z, CにShift + Home/End。XにShift + @(つまり```)。VにWin + V。それと1, 2, 3にはAlt + 1, 2, 3を入れています、というのも私はArcというブラウザを使っているのですが、これのスペースの切り替えがAltになっていて、AltよりもFn(元の無変換)を使うことが多いので、そのまま切り替えられるようにしたほうが便利かな、と。
そしてFn + 半角/全角にCtrl + Shift + Alt + Eを割り当てて、これはWindowsのアプリケーションへのグローバルショートカットキーでEverythingを宛ててます。あまりキーをフックするようなのをソフトウェア側で仕込みたくはないのですが、Windows標準機能ならまぁ良いでしょう、ということで。
マクロが欲しいとかショートカットキー登録数が少ないとか思うところもありますが、全体的にはかなり相当良いです!
キーボードといえば、iPad Pro用にlogicool Keys-To-Go 2 for iPadを買ったのですが、これもかなり良くて体験変わりました。今までモバイルキーボード難民で全然しっくり来るものがなかったのですが、これが一番アリだなあ、という感じですね……!
iPadにはprendre タブレットスタンド iPadを貼り付けてキックスタンドにしてます。たった17g追加するだけで自立する!これは超便利。軽量化したとはいえ、重たいiPadなのでケースとか入れてこれ以上重たくしたくはない。が、自立してくれないと不便、で、色々探して買ったのがこれでした。
横はもちろん、縦でもちゃんと安定してくれる。粘着テープで貼り付けるタイプは剥がれる危険性があるわけですが、iPad Proが軽量化してくれたおかげもあってそこそこ安定しています。ただし両面テープは付属のは剥がして、色々試した結果スリーエム(3M) 3M 両面テープ 超強力 スーパー多用途 薄手 幅12mmに落ち着きました。あまり強力すぎると、それはそれで剥がしにくくて売るときとかに泣いちゃう(本当に剥がれない……!)ので、粘着力が基本なのですが、その上でいざというときに剥がれてくれるかどうかのバランスも大事……。
というわけかでiPad Pro 13インチも買ったのですが、これは満足感高いです。違いは、やっぱ有機ELディスプレイですかねー、今までのiPadの画質って割と不満足というか、どう見てもiPhoneよりも画質悪いじゃん!という感じで萎え萎えだった(のであまり使わなくなっていった……)のですが、今回の画質ならOKです!というわけで利用頻度上がりました。ちなみにNano-textureガラスではありません。いや、最初Nano-textureガラスのやつを買っちゃったんですが、これ普通に画質めちゃくちゃ悪いんですよ。インターネットマンが画質は大して変わらないとか言うから信じたのにめっちゃ悪くて……。耐えられなかったのですみませんがの返品からの買い直しコンボさせていただきました……。
そして、povo。ずっとauだったのですが、povoに乗り換えました。で、これがめちゃくちゃいい、というかiPadでの利用にとてもいい。SIM付きモデル買ったのですが、auでのデータ共有がうまくできず(難易度高すぎ&なんかバグってると思う……)塩漬けだったのです。が、povoで単独での契約だと、当たり前ですがスムーズに通信できて快適。iPadもテザリングがそこそこiPhoneとスムーズにつながるからなくてもいいじゃん、とか思ってなくもなかったのですが、単独で通信できる快適さはぜんぜん違う!そして、私の用途的に別にそんなに毎日通信するわけでもないので、あんまりギガはいらないんですが、povoだとプロモーションと合わせると実質0円運用できるのが、とてもいい感じです。例えばローソン500円購入券がpovoで500円で買えて0.3GBの通信料がついてくる、とかだと、どうせ500円買うんだしpovoで買ってiPadに0.3GBチャージしとくかあ、みたいな。
最後に、Game of the Yearは今更グランツーリスモ7ということで(?)。というのもLogicoolのPROレーシングホイール + PRO RACING PEDALSを買ったのですが、これが抜群にいい……!今まで(G923)とは桁違い、というか実際桁違いで、G923が2.4nmというフィードバック力しか出せていないのですが、PROレーシングホイール11nm出る!11nmって別に全くピンと来ないのですが、触ってみると2.4nmはスカスカで、逆に11nmをフルに出すと重くて曲げられないレベル(実際、筋肉痛になった……)。そんなわけで一気に楽しくなったので、今年は一番グランツーリスモ7をやってた気がします。はい。
来年
C#でSaaS作りたい欲求はずっとあるので、OSSメンテナンス業が重くのしかかりつつも、来年はそっち側でも進展を見せたいと思ってます……!Cysharpももう少し大きくしたいとは思っているので、引き続きよろしくおねがいします。
MasterMemory v3 - Source Generator化したC#用の高速な読み込み専用インメモリデータベース
- 2024-12-20
MasterMemory v3出しました!ついにSource Generator化されました!
MasterMemoryはC#のインメモリデータベースで、高速で、メモリ消費量が少なく、タイプセーフ。というライブラリです。SQLiteを素朴に使うよりも 4700倍高速だぞ、と。
もともとMasterMemoryはC#コードからC#コードを生成するという、Source Generatorのなかった時代にSource Generatorのようなことをやる先進的な設計思想を持ったシステムでした。今回移植してみて、あまりにもスムーズに移植できるし、旧来のコードも全く手を付けずにそのまま動いたので我ながら感心しました。やっと時代が追い付いたか……。
というわけで、以下のようなC#定義からデータベース構築のためのコードと、クエリ部分がSource Generatorによって自動生成されます。
[MemoryTable("person"), MessagePackObject(true)]
public record Person
{
[PrimaryKey]
public required int PersonId { get; init; }
[SecondaryKey(0), NonUnique]
[SecondaryKey(1, keyOrder: 1), NonUnique]
public required int Age { get; init; }
[SecondaryKey(2), NonUnique]
[SecondaryKey(1, keyOrder: 0), NonUnique]
public required Gender Gender { get; init; }
public required string Name { get; init; }
}

C#コードとして生成されるので、クエリが全て入力補完も効くし戻り値も型付けされていてタイプセーフなのはもちろん、パフォーマンスの良さにも寄与しています。
読み取り専用データベースとして使うので、クラス定義はイミュータブルのほうがいいわけですが、最近のC#は record, init, required といった機能が提供されているので、Readonly Databaseとしての使い勝手が更に上がりました。Unityではrequiredは使えませんがrecordとinitは使えるので、Unityでも問題ありません。
なお、Unity版は今回からNuGetForUnityでの提供となります。また、MessagePack for C#もSource Generator対応のv3を要求します。
Next
MasterMemory、実は結構使われています。ゲームでも採用されているものを割と見かけるようになりました。なので、外部ツール由来のコード生成の面倒さにはだいぶ心を痛めていたので、ようやく解消できて本当に嬉しい!
v2からv3へのマイグレーションもそんなに大変ではない、はずです。あえて生成コードの品質や、コアの関数、メソッドシグネチャなどには一切手を加えていないので、今までコマンドラインツールを叩いていた部分を削除するだけで、そのまま動き出すぐらいの代物になっています。名前空間の設定だけ、アセンブリ属性で行ってください。
そのうえでrecord対応(今までしてなかった!)や#nullable enable対応(今までしてなかった!)を追加しているので、生成部分以外の使い勝手も上がっているはずです。
今後はMemoryPack対応や、そもそものAPIの更なるモダン化(現状はnetstandard2.0なので古い)、全体的に改修したいところ(ImmutableBuilderなど生成コードの差し替え部分)、などなどやれること自体はめっちゃありますので、折を見て手を入れていけるといいかなあ、と思っています。
ConsoleAppFramework v5.3.0 - NuGet参照状況からのメソッド自動生成によるDI統合の強化、など
- 2024-12-16
ConsoleAppFramework v5の比較的アップデートをしました!v5自体の詳細は以前に書いたConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワークを参照ください。v5はかなり面白いコンセプトになっていて、そして支持されたと思っているのですが、幾つか使い勝手を犠牲にした点があったので、今回それらをケアしました。というわけで使い勝手がかなり上がった、と思います……!
名前の自動変換を無効にする
コマンドネームとオプションネームは、デフォルトでは自動的にkebab-caseに変換されます。これはコマンドラインツールの標準的な命名規則に従うものですが、内部アプリケーションで使うバッチファイルの作成に使ったりする場合などには、変換されるほうが煩わしく感じるかもしれません。そこで、アセンブリ単位でオフにする機能を今回追加しました。
using ConsoleAppFramework;
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]
var app = ConsoleApp.Create();
app.Add<MyProjectCommand>();
app.Run(args);
public class MyProjectCommand
{
public void Execute(string fooBarBaz)
{
Console.WriteLine(fooBarBaz);
}
}
[assembly: ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion = true)]によって自動変換が無効になります。この例では ExecuteCommand --fooBarBaz がコマンドとなります。
実装面でいうと、Source Generatorにコンフィグを与えるのはAdditionalFilesにjsonや独自書式のファイル(例えばBannedApiAnalyzersのBannedSymbols.txt)を置くパターンが多いですが、ファイルを使うのは結構手間が多くて面倒なんですよね。boolの1つや2つを設定するぐらいなら、アセンブリ属性を使うのが一番楽だと思います。
実装手法としてはCompilationProviderからAssembly.GetAttributesで引っ張ってこれます。
var generatorOptions = context.CompilationProvider.Select((compilation, token) =>
{
foreach (var attr in compilation.Assembly.GetAttributes())
{
if (attr.AttributeClass?.Name == "ConsoleAppFrameworkGeneratorOptionsAttribute")
{
var args = attr.NamedArguments;
var disableNamingConversion = args.FirstOrDefault(x => x.Key == "DisableNamingConversion").Value.Value as bool? ?? false;
return new ConsoleAppFrameworkGeneratorOptions(disableNamingConversion);
}
}
return new ConsoleAppFrameworkGeneratorOptions(DisableNamingConversion: false);
});
これを他のSyntaxProviderからのSourceとCombineしてやれば、生成時に属性の値を参照できるようになります。
ConfigureServices/ConfigureLogging/ConfigureConfiguration
ゼロディペンデンシーを掲げている都合上、特定のライブラリに依存したコードを生成することができないという制約がConsoleAppFramework v5にはありました。そのため、DIとの統合時に自分でServiceProviderをビルドしなければならないなの、利用には一手間必要でした。そこで、NuGetでのDLLの参照状況を解析し、Microsoft.Extensions.DependencyInjectionが参照されていると、ConfigureServicesメソッドがConsoleAppBuilderから使えるという実装を追加しました。
var app = ConsoleApp.Create()
.ConfigureServices(service =>
{
service.AddTransient<MyService>();
});
app.Add("", ([FromServices] MyService service, int x, int y) => Console.WriteLine(x + y));
app.Run(args);
これによりフレームワークそのものはゼロディペンデンシーでありながら、ライブラリ依存のコードも生成することができるという、新しい体験を提供します。これはMetadataReferencesProviderから引っ張ってきて生成処理に回すことで実現しました。
var hasDependencyInjection = context.MetadataReferencesProvider
.Collect()
.Select((xs, _) =>
{
var hasDependencyInjection = false;
foreach (var x in xs)
{
var name = x.Display;
if (name == null) continue;
if (!hasDependencyInjection && name.EndsWith("Microsoft.Extensions.DependencyInjection.dll"))
{
hasDependencyInjection = true;
continue;
}
// etc...
}
return new DllReference(hasDependencyInjection, hasLogging, hasConfiguration, hasJsonConfiguration, hasHost);
});
context.RegisterSourceOutput(hasDependencyInjection, EmitConsoleAppConfigure);
参照の解析は複数のものに対して行っていて、他にもMicrosoft.Extensions.Loggingが参照されていればConfigureLoggingが使えるようになります。なのでZLoggerと組み合わせれば
// Package Import: ZLogger
var app = ConsoleApp.Create()
.ConfigureLogging(x =>
{
x.ClearProviders();
x.SetMinimumLevel(LogLevel.Trace);
x.AddZLoggerConsole();
x.AddZLoggerFile("log.txt");
});
app.Add<MyCommand>();
app.Run(args);
// inject logger to constructor
public class MyCommand(ILogger<MyCommand> logger)
{
public void Echo(string msg)
{
logger.ZLogInformation($"Message is {msg}");
}
}
といったように、比較的すっきりと設定が統合できます。
appsettings.jsonから設定ファイルを引っ張ってくるというのも最近では定番パターンですが、これもMicrosoft.Extensions.Configuration.Jsonを参照しているとConfigureDefaultConfigurationが使えるようになり、これはSetBasePath(System.IO.Directory.GetCurrentDirectory())とAddJsonFile("appsettings.json", optional: true)を自動的に行います(追加でActionでconfigureすることも可能、また、ConfigureEmptyConfigurationもあります)。
なのでコンフィグを読み込んでクラスにバインドしてコマンドにDIで渡す、などといった処理もシンプルに書けるようになりました。
// Package Import: Microsoft.Extensions.Configuration.Json
var app = ConsoleApp.Create()
.ConfigureDefaultConfiguration()
.ConfigureServices((configuration, services) =>
{
// Package Import: Microsoft.Extensions.Options.ConfigurationExtensions
services.Configure<PositionOptions>(configuration.GetSection("Position"));
});
app.Add<MyCommand>();
app.Run(args);
// inject options
public class MyCommand(IOptions<PositionOptions> options)
{
public void Echo(string msg)
{
ConsoleApp.Log($"Binded Option: {options.Value.Title} {options.Value.Name}");
}
}
Microsoft.Extensions.Hostingでビルドしたい場合は、ToConsoleAppBuilderが、これもMicrosoft.Externsions.Hostingを参照すると追加されるようになっています。
// Package Import: Microsoft.Extensions.Hosting
var app = Host.CreateApplicationBuilder()
.ToConsoleAppBuilder();
また、今回から設定されているIServiceProviderはRunまたはRunAsync終了後に自動的にDisposeするようになりました。
RegisterCommands from Attribute
コマンドの追加はAddまたはAdd<T>が必要でしたが、クラスに属性を付与することで自動的に追加される機能をいれました。
[RegisterCommands]
public class Foo
{
public void Baz(int x)
{
Console.Write(x);
}
}
[RegisterCommands("bar")]
public class Bar
{
public void Baz(int x)
{
Console.Write(x);
}
}
これらは自動で追加されています。
var app = ConsoleApp.Create();
// Commands:
// baz
// bar baz
app.Run(args);
これらとは別に追加でAdd, Add<T>することも可能です。
なお、実装の当初予定では任意の属性を使えるようにする予定だったのですが、IncrementalGeneratorのAPIの都合上難しくて、固定のRegisterCommands属性のみを対象としています。また、継承することもできません……。なので独自の処理用属性がある場合は、組み合わせてもらう必要があります。例えば以下のように。
[RegisterCommands, Batch("0 10 * * *")]
public class MyCommands
{
}
この辺はConsoleAppFrameworkとAWS CDKで爆速バッチ開発を読んで、うーん、v5を使ってもらいたい!なんとかしたい!と思って色々考えたのですが、この辺が現状の限界でした……。名前変換オフりたいのもわかるー、とか今回の更新内容はこの記事での利用例を参考にさせていただきました、ありがとうございます!
まとめ
v5のリリース以降もフィルターを外部アセンブリに定義できるようになったり、Incremental Generatorの実装を見直して高速化するなど、Improvmentは続いています!非常に良いフレームワークに仕上がってきました!
ところでSystem.CommandLine、現状うまくいってないからResettting System.CommandLineだ!と言ったのが今年の3月。例によって想像通り進捗は無です。知ってた。そうなると思ってた。何も期待しないほうがいいし、普通にConsoleAppFramework使っていくで良いでしょう。
SourceGenerator対応のMessagePack for C# v3リリースと今後について
- 2024-12-06
先月MessagePack for C#プロジェクトは .NET Foundationに参加しました!より安定した視点で利用していただけるという一助になればいいと思っています。
そして、長く開発を続けていたメジャーバージョンアップ、v3がリリースされました。コア部分はv2とはほぼ変わらずですが、Source Generatorを全面的に導入しています。引き続きIL動的生成も存在するため、IL動的生成とSource Generatorのハイブリッドなシリアライザーとなります。v3にはSource GeneratorとAnalyzerがビルトインで同梱されていて、今までのコードはv3でコンパイルするだけで自動的にSource Generator化されます。v2 -> v3アップデートでSource Generator対応するために追加でユーザーがコードを記述する必要はありません!
挙動を詳しく見ていきましょう。例えば、
[MessagePackObject]
public class MyTestClass
{
[Key(0)]
public int MyProperty { get; set; }
}
というコードを書くと、自動的に以下のコードがSource Generatorによって内部的に生成されます。
partial class GeneratedMessagePackResolver
{
internal sealed class MyTestClassFormatter : IMessagePackFormatter<MyTestClass>
{
public void Serialize(ref MessagePackWriter writer, MyTestClass value, MessagePackSerializerOptions options)
{
if (value == null)
{
writer.WriteNil();
return;
}
writer.WriteArrayHeader(1);
writer.Write(value.MyProperty);
}
public MyTestClass Deserialize(ref MessagePackReader reader, MessagePackSerializerOptions options)
{
if (reader.TryReadNil())
{
return null;
}
options.Security.DepthStep(ref reader);
var length = reader.ReadArrayHeader();
var ____result = new MyTestClass();
for (int i = 0; i < length; i++)
{
switch (i)
{
case 0:
____result.MyProperty = reader.ReadInt32();
break;
default:
reader.Skip();
break;
}
}
reader.Depth--;
return ____result;
}
}
}
また、このGeneratedMessagePackResolverはデフォルトのオプション(StandardResolverなど)に最初から登録されているため、
public static readonly IFormatterResolver[] DefaultResolvers = [
BuiltinResolver.Instance,
AttributeFormatterResolver.Instance,
SourceGeneratedFormatterResolver.Instance, // here
ImmutableCollection.ImmutableCollectionResolver.Instance,
CompositeResolver.Create(ExpandoObjectFormatter.Instance),
DynamicGenericResolver.Instance, // only enable for RuntimeFeature.IsDynamicCodeSupported
DynamicUnionResolver.Instance];
ユーザーコードのアセンブリに含まれているシリアライズ対象クラスは、Source Generatorによって生成されたコードが優先的に使われることになります。GeneratedMessagePackResolverは既定の名前空間や名前を変えたり、生成フォーマッターをmapベースに変更するなど、幾つかのカスタマイズポイントも用意されています。より詳しくは新しいドキュメントを見てください。また、v2 -> v3の変更箇所の詳細を知りたい人はMigration Guide v2 -> v3をチェックしてください。
Unityにおいては導入方法が大きく変わりました。コアライブラリは .NET 版と共通になりNuGetからのインストールが必要となります。そのうえでUPMでUnity用の追加コードをダウンロードする必要があります。詳しくはMessagePack-CSharp#unity-supportのセクションを確認してください。
.unitypackageの提供は廃止されています。また、IL2CPP対応のために要求していたmpcはなくなりました。完全にSource Generatorに移行されます。そのため、Unityのサポートバージョンは 2022.3.12f1 からとなります。Source Generatorに関してはNuGetForUnityでのコアライブラリインストール時に自動的に有効化されるため、追加の作業は必要ありません。
History and Next
MessagePack for C#のオリジナル(v1)は私(Yoshifumi Kawai/@neuecc)によって、2017年にリリースしました。当時開発していたゲームのパフォーマンス問題を解決するために、2016年時点で存在していた(バイナリ)シリアライザーでは需要を満たせなかったため、パフォーマンスを最重要視したバイナリシリアライザーとして作成しました。合わせて、同じくネットワークシステムとして作成したgRPCベースのRPCフレームワークMagicOnionもリリースしています。
v1リリース当時はbyte[]のみを対象としていましたが、Span<T>やIBufferWriter<T>など、.NETには次々と新しいI/O系のAPIが追加されていったため、v2ではそれらに焦点を当てた新しいデザインが導入されました。この実装はMicrosoftのEngineerであるAndrew Arnott / @AArnott氏によって主導され、リリースしています。
以降、共同のメンテナンス体制として、そして私の個人リポジトリ(neuecc/MessagePack-CSharp)からオーガナイゼーション(MessagePack-CSharp/MessagePack-CSharp)して今に至ります。Visual Studio内部での利用やSignalRのバイナリープロトコル、Blazor Serverのプロトコルなど大きなMicrosoftのプロダクトでも使用され、GitHubでのスター数は.NETのバイナリーシリアライザーとしては最も大きなスターを集めています。.NET 9で廃止されたBinaryFormatterの移行先の一つとしても推奨されています。
v3ではSource Generatorに対応することで、より高いパフォーマンスと柔軟性、AOT対応への第一段階に踏み出すことができました。
MessagePack for C#プロジェクトは大きな成功を収めたと考えていますが、しかし現在、AArnott氏は個人の新しいMessagePackプロジェクトの開発を開始しています。私もその間、MemoryPackという異なるフォーマットのシリアライザーをリリースしています。そのため、MessagePack for C#の今後と、その特性について、ある程度説明する必要があると思います。
引き続きメンテナンス体制は2人だと考えていますが、アクティブな活動に関しては、再び私が担うことになるかもしれません。私はMessagePackとMemoryPackとでは異なる性質を持ったフォーマットであるため、どちらも重要であるという認識で動いています。オリジナルの実装であるMessagePack for C#も気に入ってますし、現在においても決して引けを取ることのないものだと思っています。
AArnott氏の別のMessagePackシリアライザーとは根本的な哲学が若干異なります。その点で、私はそれはより良く改善されたシリアライザーではなく、別の個性のシリアライザーだと認識しています。そこで、違いについて説明させてください。
Binary spec, default settings and performance
シリアライザーのパフォーマンスに重要なのは、「仕様と実装」の両方です。例えばテキストフォーマットのJSONよりもバイナリフォーマットのほうが一般的には速いでしょう。しかし、よくできたJSONシリアライザーは、中途半端な実装のバイナリシリアライザーよりも高速です(私はそれをUtf8Jsonというシリアライザーを作成することで実証したことがあります)。なので、仕様も大事だし、実装も大事です。どちらも兼ねることができれば、それがベストなパフォーマンスのシリアライザーとなります。
MessagePackのバイナリ仕様は "It's like JSON. but fast and small." を標語にしている通り、JSONのバイナリ化としてあらわされています。ところが、MessagePack for C#のデフォルトは必ずしもJSON likeを狙っているわけではありません。
[MessagePackObject]
public class MsgPackSchema
{
[Key(0)]
public bool Compact { get; set; }
[Key(1)]
public int Schema { get; set; }
}
このクラスをシリアライズした場合は、JSONで表現すると[true, 0]のようになります。これはオブジェクトをarrayベースでシリアライズしているからで、mapベースでシリアライズすると{"Compact":true,"Schema":0}のような表現になります。
arrayベースの利点は見た通りに、バイナリ容量として、よりコンパクトになります。容量がコンパクトなことは処理量が少なくなるためシリアライズの速度にも良い影響を与えます。また、デシリアライズにおいては、文字列を比較してデシリアライズするプロパティを探索する必要がなくなるため、より高速なデシリアライズ速度が期待できます。
なお、arrayベースのシリアライズはMessagePackの仕様策定者である Sadayuki Furuhashi 氏によるリファレンス実装であるmsgpack-javaなどでも採用されているため、決して異端のやり方というわけではありません。
MessagePack-CSharpではJSONライクなmapベースでシリアライズしたい場合は[MessagePackObject(true)]と記述することができます。また、Source Generatorの場合はResolver単位でオーバーライドして強制的にmapベースにすることも可能です。
[MessagePackObject(keyAsPropertyName: true)]
public class MsgPackSchema
{
public bool Compact { get; set; }
public int Schema { get; set; }
}
mapの利点は、柔軟なスキーマエボリューションの実現と、他言語との疎通する際にコミュニケーションが取りやすいこと、バイナリそのものの自己記述性が高いことです。デメリットは容量とパフォーマンスへの悪影響、特にオブジェクトの配列においては一要素毎にプロパティ名が含まれることになってしまい、かなりの無駄となります。
デフォルトをarrayにしているのは、コンパクトさとパフォーマンスの追求のためです。私はMessagePackをJSON likeの前に、高いパフォーマンスを実現可能なバイナリ仕様として考えました。もちろん、mapも重要なので、その上で比較的簡単にmapモードを実現するために属性に(true)を追加するだけで可能にしました。
arrayモードの場合はKey属性を全てのプロパティに付与する必要があります。これは、例えばProtocol Buffersなどでも数値タグを必要とするように、プロパティ名そのものをキーとするわけではなければ、必須だと考えています。もちろん、連番で自動採番させることも可能ですが、バイナリフォーマットのキーを暗黙的に処理するのはリスクが大きすぎる(順番を弄ったりするだけでバイナリ互換性が壊れることになる)と判断しています。つまり、明示的がデフォルト、ということです。大きなプロジェクト開発ではシニアメンバーからジュニアメンバーまでコードを触ることになるでしょう、全てを理解している人だけがコードを触るわけではありません。なので、暗黙的な挙動は避けるべきで、明示的にすべきだという強い意志で、この設計を選んでいます。
ただしKeyを全てのプロパティに付与する作業はとても苦痛です(私はMessagePack-CSharp開発以前には、DataContractやprotobuf-netで辛い思いをしました)。そこで、Analyzer + Code Fixによって、自動的に付与する機能を用意しました。これにより明示的であることの苦痛は和らげられ、良いとこどりができているのだと考えています。
別のMessagePackシリアライザーのデフォルトはmapのようです。これはPolyTypeというSource Generatorベースのライブラリ作成のための抽象化ライブラリがベースとしているためでもあり、また、そちらのほうを好んでいるという明示的な判断でもあるようです。
「デフォルト」はライブラリで一つしか選べません。どちらのモードで処理することができたとしても、「デフォルト」はただ一つです。改めて言うと、私はバイナリフォーマットとしての「コンパクトとパフォーマンス」を好み、優先しています。
皆さんはPolyTypeについて初めて知ったかもしれません。私はPolyTypeはあまり好意的には考えていません。ちょっとしたものを作るには非常に便利だとは思いますが、ベストなパフォーマンスを狙ったり、ベストなアイディアを表現するには、抽象層であることの制限が大きすぎると考えています。なので、MessagePack for C#で採用することはありませんし、他の何かを作る際にも採用することはないでしょう。
Unity(multiplatform) Support
MessagePack for C#ではv1の時代からゲームエンジンUnityの1st classのサポートを実行してきました。これは私がCygamesという日本のゲーム会社の関連会社(Cysharp)のCEOを務めていて、ビデオゲームインダストリーと関係性が深いという都合もあります。自分たちで実際にUnityで動くものを作り、使ってきました。もちろん、サーバーサイドやデスクトップアプリケーションでも使っています。
UnityにはIL2CPPという独自のAOTシステムがあり、特にiOSなどモバイルプラットフォームでのリリースには必須なのですが、それもSource Generatorが存在しなかった時代から、mpcというRoslynを使ったコードジェネレートツールを作り、提供してきました。数百のモバイルゲームでMessagePackが使われているのは、これら私の熱心なサポートのお陰といっても過言ではないでしょう。v3ではついにSource Generatorベースになったことにより、ワークフローが大きく簡易化されることとなります!
一般的に、.NETコミュニティにおいてはUnityサポートはかなり軽視されていました。また、外から見ているとMicrosoftやMicrosoftの従業員もそのようで、自社のプラットフォーム以外への関心は薄そうです。こうした態度は、あまり好ましいとは思っていませんし、せっかくの .NET の可能性を狭めていることにもなっています。Xamarinがうまく成長軌道に乗らなかったのも、そのようなMicrosoft自体の冷たい視線のせいだとも思っています。
私は、私の作るライブラリはなるべくUnityにもしっかり対応できるように気を付けて作っています(最新は新しいReactive ExtensionsライブラリーであるCysharp/R3)。別のMessagePackシリアライザーに関しては、あまりしっかりした対応はされなさそうですが……。
Beyond v3
v3のNative AOT Supportは完全ではありません。Source Generatorにするだけでは完全なNative AOT対応とはならないのは難しいところです。これはUnityのAOTであるIL2CPPでは完璧に動作しているだけに、正直不可解なことでもあり、また、Microsoftのよくない癖が出ているな、とも思っています。つまり、完璧な対応をするために、複雑なものを提供している。それが現在のNative AOTです。複雑怪奇な属性やフローは、理解できるところもありますが、もう少し簡略化すべきだったと思います。まぁ、もう修正されることもないのでしょうが……。
パフォーマンス面でもv1からv2で退化してしまった点もあるので、最新の知見を元に、実装面での改善を施す必要があります。特にReadOnlySequenceの利用幅が大きいことは、かなりの制約を生み出していて、不満があります。
.NET 9でPipeReader/PipeWriterが標準化されたことによる、より良い非同期APIや、パフォーマンスを両立したストリーミング対応というのも、大きなトピックとなるかもしれません。
MessagePack for C#は広く使われているが故に、破壊的変更はしづらいし、互換性の維持は最重要トピックスです。しかし、世の中が変わっていく以上、進化しないことを選んだら、それは滅びる道でしかありません。やれることはまだまだあると思っていますので、.NETにおける最先端の、最高のバイナリシリアライザーであり続けたいと思っています(MemoryPackもね……!)
まずは、v3のSource Generatorをぜひ試してみてください。皆の力でより良いものを作っていけるというのも、OSSの良さだと思っています。
Fuzzing in .NET: Introducing SharpFuzz
- 2024-12-03
この記事はC# Advent Calendar 2024に参加しています。また、先月開催されたdotnet newというイベントでの発表のフォローアップ、のつもりだったのですがコロナ感染につき登壇断念……。というわけで、セッション資料はないので普通にブログ記事とします!
dotnet/runtime と Fuzzing
今年に入ってからdotnet/runtimeにFuzzingテストが追加されています。dotnet/runtime/Fuzzing。というわけで、実はfuzzingは非常に最近のトピックスなのです……!
ファジングとはなんなのか、ザックリとはランダムな入力値を大量に投げつけることによって不具合や脆弱性を発見するためのテストツールです。エッジケースのテスト、やはりどうしても抜けちゃいがちだし、ましてや脆弱性になりうる絶妙な不正データを人為的に作るのも難しいので、ここはツール頼みで行きましょう。
Goでは1.18(2022年)から標準でgo fuzzコマンドとして追加されたらしいので、 Go1.18から追加されたFuzzingとはのような解説記事を読むのもイメージを掴みやすいです。
さて、dotnet/runtimeのFuzzingでは現状
- AssemblyNameInfoFuzzer
- Base64Fuzzer
- Base64UrlFuzzer
- HttpHeadersFuzzer
- JsonDocumentFuzzer
- NrbfDecoderFuzzer
- SearchValuesByteCharFuzzer
- SearchValuesStringFuzzer
- TextEncodingFuzzer
- TypeNameFuzzer
- UTF8Fuzzer
というのものが用意されてます。わかるようなわからないような。だいたいデータのパース系によく使われるものなので、その通りのところに用意されています。一番わかりやすいJsonDocumentFuzzerを見てみましょう。
internal sealed class JsonDocumentFuzzer : IFuzzer
{
public string[] TargetAssemblies { get; } = ["System.Text.Json"];
public string[] TargetCoreLibPrefixes => [];
public string Dictionary => "json.dict";
// fuzzerからのランダムなバイト列が入力
public void FuzzTarget(ReadOnlySpan<byte> bytes)
{
if (bytes.IsEmpty)
{
return;
}
// The first byte is used to select various options.
// The rest of the input is used as the UTF-8 JSON payload.
byte optionsByte = bytes[0];
bytes = bytes.Slice(1);
var options = new JsonDocumentOptions
{
AllowTrailingCommas = (optionsByte & 1) != 0,
CommentHandling = (optionsByte & 2) != 0 ? JsonCommentHandling.Skip : JsonCommentHandling.Disallow,
};
using var poisonAfter = PooledBoundedMemory<byte>.Rent(bytes, PoisonPagePlacement.After);
try
{
// それをParseに投げて、もし不正な例外が来たらなんかバグっていたということで
JsonDocument.Parse(poisonAfter.Memory, options);
}
catch (JsonException) { }
}
}
ようは想定外のデータ入力でJsonDocument.Parseが失敗しないことを祈る、といったものですね。正常に認識しているinvalidな値ならJsonExceptionをthrowするはずですが、ArgumentExceptionとかStackOverflowExceptionとかが出てきちゃった場合は認識できていない不正パターンなので、ちゃんとしたハンドリングが必要になってきます。
では、これを参考にやっていきましょう、とはなりません。えー。まず、dotnet/runtimeのFuzzingではSharpFuzz, libFuzzer, そしてOneFuzzが使用されていると書いてあるのですが、OneFuzzはMicrosoft内部ツールなので外部では使用できません。正確には2020年にオープンソース公開したものの、2023年にはクローズドに戻している状態です。まぁ事情は色々ある。しょーがない。
というわけで、これはMicrosoft内部で動かすためのOneFuzzや、dotnet/runtimeで動かすために調整してあるIFuzzerといったフレームワーク部分が含まれているので、小規模な自分たちのコードをfuzzingするにあたっては、不要ですし、ぶっちゃけあまり参考にはなりません!解散!
Introducing SharpFuzz
そんなわけでdotnet/runtimeのFuzzingでも使われているMetalnem/sharpfuzz: AFL-based fuzz testing for .NETを直接使っていきます。sharpfuzzはafl-fuzzと連動して動くように作られている .NETライブラリです。3rd Partyライブラリですが作者はMicrosoftの人です(dotnet/runtimeで採用されている理由でもあるでしょう)。ReadMeのTrophiesでは色々なもののバグを見つけてやったぜ、と書いてあります。AngleSharpとかGoogle.ProtobufとかGraphQL-ParserとかMarkdigとかMessagePack for C#とImageSharpとか。まぁ、やはり用途としてはパーサーのバグを見つけるのには適切、という感じです。
AFL(American Fuzzy Lop)ってなに?ということなのですが、そもそもファジングの「ランダムな入力値を大量に投げつける」行為は、完全なランダムデータを投げつけていくわけではありません。完全ランダムだとあまりにも時間がかかりすぎるため、脆弱性発見において実用的とは言えない。そこでAFLはシード値からのミューテーションと、カバレッジをトレースしながら効率よくデータを生成していきます。Wikipediaから引用すると
テスト対象のプログラム(テスト項目)のソースコードをインストルメント化することにより、afl-fuzzは、ソフトウェアのどのブロックが特定のテスト刺激で実行されたかを後で確認できる。そのため、AFLはグレーボックステストに使用することができる。遺伝的手法による検査データの生成に関連して、ファザーはテストデータをより適切に生成できるため、このメソッドを使用しない他のファザーよりも、処理中に以前は使用されていなかったコードブロックが実行される。その結果、コードカバレッジは比較的短い時間で比較的高い結果が得られる。この方法は、生成されたデータ内の構造を独立して(つまり、事前の情報なしで)生成することができる。このプロパティは、テストカバレッジの高いテストコーパス(テストケースのコレクション)を生成するためにも使用される。
というわけでdotnet testのようにテストコードを渡したら全自動でやってくれる、というほど甘くはなくて、多少の下準備が必要になってきます。SharpFuzzは一連の処理をある程度やってくれるようにはなっていますが、そもそもに実行までに二段階の処理が必要になっています。
- sharpfazzコマンド(dotnet tool)でdllにトレースポイントを注入する
- その注入されたdll(とexe)をネイティブのfuzzing実行プロセス(afl-fuzzなど)に渡す
dllにトレースポイントを注入はお馴染みのCecilでビルド済みのDLLのILを弄ってトレースポイントを仕込みます。
これは注入済みのdllですが、Trace.SharedMemとかTrace.PrevLocationとか、分岐点に対して明らかに注入している様が見えます。そうしたトレースポイントとの通信や実行データ生成などは外部プロセスが行うので、SharpFuzzというライブラリは、それ自体は実行ツールではなくて、それらとの橋渡しをするためのシステムということです。
ではやっていきましょう!色々なシステムが絡んでくる分、ちょっとややこしく面倒くさいのと、ReadMeの例をそのままやると罠が多いので、少しアレンジしていきます。
まずはRequirementsですが、実行機であるAFLがWindowsでは動きません(Linux, macOSでは動く)。なのでWSL上で動かしましょうという話になってくるのですが、それはあんまりにもやりづらいので、libFuzzerというLLVMが開発しているAFL互換のFuzzingツールを使っていくことにします。これはWindowsでビルドできます。
自分でビルドする必要はなく、SharpFuzzの作者が連携して使うことを意識して用意してくれているlibfuzzer-dotnetのReleasesページから、バイナリを直接落としてきましょう。libfuzzer-dotnet-windows.exeです。
次に、IL書き換えを行うツールSharpFuzz.CommandLineを .NET toolで入れていきましょう。これはglobalでいいかな、と思います。
dotnet tool install --global SharpFuzz.CommandLine
次に、今回はJilという、今はもうあまり使われることもないJsonシリアライザーをターゲットとしてやっていこうということなので、JilとSharpFuzzをインストールします。
dotnet add package Jil --version 2.15.4
dotnet add package SharpFuzz
ここで注意が必要なのは、Jilの最新バージョンはSharpFuzzにより発見されたバグが修正されているので、最新版を入れるとチュートリアルにはなりません!というわけでここは必ずバージョン下げて入れましょう。
新規のConsoleApplicationで、コードは以下のようにします。
using Jil;
using SharpFuzz;
// 実行機としてlibFuzzerを使う(引数はReadOnlySpan<byte>)
Fuzzer.LibFuzzer.Run(span =>
{
try
{
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader); // このメソッドが正しく動作してくれるかをテスト
}
catch (Jil.DeserializationException)
{
// Jil.DeserializationExceptionは既知の例外(正しくハンドリングできてる)なので握り潰し
// それ以外の例外が発生したらルート側にthrowされて問題が検知される
}
});
今度はベースになるテストデータを用意します。名前とかはなんでもいいんですが、TestcasesフォルダにTest.jsonを追加しました。
{"menu":{"id":1,"val":"X","pop":{"a":[{"click":"Open()"},{"click":"Close()"}]}}}
このデータを元にしてfuzzerは値を変形させていくことになります。
では実行しましょう!実行するためには、ビルドしてILポストプロセスしてlibFuzzer経由で動かす……。という一連の定型の流れが必要になるため、作者の用意してくれているPowerShellスクリプトfuzz-libfuzzer.ps1をダウンロードしてきて使いましょう。
とりあえずfuzz-libfuzzer.ps1とlibfuzzer-dotnet-windows.exeをcsprojと同じディレクトリに配置して、以下のコマンドを実行します。ConsoleApp24.csprojの部分だけ適当に変えてください。
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases"
動かすと、見つかった場合はいい感じに止まってくれます。
なお、見つからなかった場合は無限に探し続けるので、なんとなくもう見つかりそうにないなあ、と思ったら途中で自分でとめる(Ctrl+C)必要があります。
Testcasesには途中の残骸と、クラッシュした場合はcrash-idでクラッシュ時のデータが拾えます。
今回見つかったクラッシュデータは
{"menu":{"id":1,"val":"X","popid":1,"val":"X","pop":{"a":[{"click":"Open()"},{"c
でした。実際このデータを使って再現できます。
using Jil;
// クラッシュファイルのプロパティでデータはCopy to Output Directoryしてしまう
// <None Update="crash-c57462e70fb60e86e8c41cd18b70624bd1e89822">
// <CopyToOutputDirectory>Always</CopyToOutputDirectory>
// </None>
var crash = File.ReadAllBytes("crash-c57462e70fb60e86e8c41cd18b70624bd1e89822");
var span = crash.AsSpan();
// Fuzzing時と同じコード
using var stream = new MemoryStream(span.ToArray());
using var reader = new StreamReader(stream);
JSON.DeserializeDynamic(reader);
以上!完璧!便利!一度手順を理解してしまえば、そこまで難しいことではないので、是非ハンズオンでやってみることをお薦めします。なお、ps1のスクリプトは実行対象自身へのインジェクトは除外されるようになっているので、小規模な自分のコードでfuzzingを試してみたいと思った場合は、対象コードはexeとは異なるプロジェクトに分離しておく必要があります。
ところで、AFLにはdictionaryという仕組みがあり、既知のキーワード集がある場合は生成速度を大幅に上昇させることが可能です。例えばjson.dictを使う場合は
PowerShell -ExecutionPolicy Bypass ./fuzz-libfuzzer.ps1 -libFuzzer "./libfuzzer-dotnet-windows.exe" -project "ConsoleApp24.csproj" -corpus "Testcases" -dict ./json.dict
のように指定します。JSONとかYAMLとかXMLとかZipとか、一般的な形式はAFLplusplus/dictionariesなどに沢山転がっています。独自に作ることも可能で、例えばdotnet/runtimeのFuzzingではBinaryFormatterのテストが置いてありますが、これはNRBF(.NET Remoting Binary Format)の辞書、nrbfdecoder.dictを用意しているようでした。
もちろん、なしでも動かすことはできますが、用意できそうなら用意しておくとよいでしょう。
まとめ
MemoryPackでも実際バグ見つかってたりするので、この手のライブラリを作る人だったら覚えておいて損はないです。シリアライザーに限らずパーサーに関わるものだったらネットワークプロトコルでも、なんでも適用可能です。ただし現状、入力がbyte[]に制限されているので、応用性自体はあるようで、なかったりはします。これがintとか受け入れてくれると、様々なメソッドに対してカジュアルに使えて、より便利な気もしますが……(実際go fuzzはbyte[]だけじゃなくて基本的なプリミティブの生成に対応している)
byte[]列から適当に切り出してintとして使う、といったような処理だと、ミューテーションやカバレッジの関係上、適切な値を取得しにくいので、あまりうまくやれません。libFuzzerではStructure-Aware Fuzzing with libFuzzerといったような手法が考案されていて、protocol buffersの構造を与えるとか、gRPCの構造を与えるとかでうまく活用している事例はあるようです。この辺はSharpFuzzの対応次第となります(いつかやりたい、とは書いてありましたが、現実的にいつ来るかというと、あまり期待しないほうが良いでしょう)
Rustにもcargo fuzzといったcrateがあり、それなりに使われているようです。
Fuzzingは適用範囲が限定的であることと下準備の手間などがあり、一般的なアプリケーション開発者においては、あまりメジャーなテスト手法ではないというのが現状だと思いますが、使えるところはないようで意外とあるとも思うので、ぜひぜひ試してみてください。
CysharpのOSS Top10まとめ / Ulid vs .NET 9 UUID v7 / MagicOnion
- 2024-11-19
「CysharpのOSS群から見るModern C#の現在地」というタイトルでセッションしてきました。
作りっぱなし、というわけではないですが(比較的メンテナンスしてるとは思います!)、リリースから年月が経ったライブラリをどう思っているかは見えないところありますよね、というわけで、その辺を軽く伝えられたのは良かったのではないかと思います。
この中だと非推奨に近くなっているのがZStringとUlidでしょうか。
Ulid vs .NET 9 UUID v7
スライドにも書きましたが、ULIDをそこそこ使ってきての感想としては、「Guidではないこと」が辛いな、と。独自文字列形式とか要らないし。そんなわけで私はむしろUUID v7のほうを薦めたいレベルだったりはします。.NET 9からGuid.CreateVersion7()という形で、標準で生成できるようになりました。
パフォーマンス的なところは些細なことなので問題ないのですが、 .NET 9未満との互換性が取れないのは厳しいところかもしれません。というわけで、自作のV7実装を用意してあげるといいでしょう。以下に置いておきますのでどうぞ(コードのベースはdotnet/runtimeのCCreateVersion7です)
public static class GuidEx
{
private const byte Variant10xxMask = 0xC0;
private const byte Variant10xxValue = 0x80;
private const ushort VersionMask = 0xF000;
private const ushort Version7Value = 0x7000;
public static Guid CreateVersion7() => CreateVersion7(DateTimeOffset.UtcNow);
public static Guid CreateVersion7(DateTimeOffset timestamp)
{
// 普通にGUIDを作る
Guid result = Guid.NewGuid();
// 先頭48bitをいい感じに埋める
var unix_ts_ms = timestamp.ToUnixTimeMilliseconds();
// GUID layout is int _a; short _b; short _c, byte _d;
Unsafe.As<Guid, int>(ref Unsafe.AsRef(ref result)) = (int)(unix_ts_ms >> 16); // _a
Unsafe.Add(ref Unsafe.As<Guid, short>(ref Unsafe.AsRef(ref result)), 2) = (short)(unix_ts_ms); // _b
ref var c = ref Unsafe.Add(ref Unsafe.As<Guid, short>(ref Unsafe.AsRef(ref result)), 3);
c = (short)((c & ~VersionMask) | Version7Value);
ref var d = ref Unsafe.Add(ref Unsafe.As<Guid, byte>(ref Unsafe.AsRef(ref result)), 8);
d = (byte)((d & ~Variant10xxMask) | Variant10xxValue);
return result;
}
// GuidにはTimestamp部分を取り出すメソッドがないので、これも用意してあげると便利
public static DateTimeOffset GetTimestamp(in Guid guid)
{
// エンディアンについては特に考慮してません
ref var p = ref Unsafe.As<Guid, byte>(ref Unsafe.AsRef(in guid));
var lower = Unsafe.ReadUnaligned<uint>(ref p);
var upper = Unsafe.ReadUnaligned<ushort>(ref Unsafe.Add(ref p, 4));
var time = (long)upper + (((long)lower) << 16);
return DateTimeOffset.FromUnixTimeMilliseconds(time);
}
}
UUID v7のよくあるユースケースはDBの主キーにGUID(UUID v4)の代わりに使う、ということです。UUID v4だとランダムに配置されるので断片化して、auto incrementの主キーに比べると色々と遅くなる。それがv7だとランダムの性質を持ちつつも配置場所はタイムスタンプベースなのでauto incrementと同様になるため性能劣化がない。
という理屈を踏まえたうえで、.NETのUUID v7事情を踏まえると単純に置き換えるだけで良い、とはなりません。
GUIDは内部的なバイナリデータとしてはリトルエンディアンで保持していて、出力時に切り分けるというデザインになっています(無指定の場合はlittleEndianでの出力)。
public readonly struct Guid
{
public byte[] ToByteArray()
public byte[] ToByteArray(bool bigEndian)
public bool TryWriteBytes(Span<byte> destination)
public bool TryWriteBytes(Span<byte> destination, bool bigEndian, out int bytesWritten)
}
String(char36)として格納するなら気にしなくてもいいのですが、GUID型やバイナリ型としてデータベースに格納する時は、UUID v7に関してはビッグエンディアンで書き出さないと、ソート可能にならない非常に都合が悪い。これのハンドリングは言語のデータベースドライバーライブラリの責務となっています。
代表的なライブラリを見ていくと、MySQLのmysqlconnector-netはコネクションストリングで GuidFormat=Binary16 を指定することでbig-endianでBINARY(16)に書き込む設定となります。
PostgreSQLの場合、npgsqlのGuidUuidConverterが常にbigEndianとして処理するようになっているようです。
ではMicrosoft SQL Serverはどうかというと、ばっちしlittle-endianです。ダメです。というわけで、性能を期待してCreateVersion7を使うと、逆に断片化して遅くなるような憂き目にあいます。
こちらはdotnet/SqlClientのdiscussions#2999で議論されているようなので、成り行きに注目ということで。今までとの互換性などを考えると一括でbigにしてしまえばいいじゃん、というわけにもいかないしで、中々素直にはいかないかもしれませんね……。
なお、このことは別に.NET 9がリリースされる前にもわかっていたことなのに(私でもダメだという状況は把握していた)、リリースされるまでアクションが全く起きないというところに、今のSQL Serverへのやる気を感じたりなかったり。
MagicOnion
イベントではCysharpの @mayuki さんからMagicOnionの入門セッションもありました!
MagicOnionも2016年の初リリース、2018年のリブート(v2)、googleのgRPC C Coreからgrpc-dotnetベースへの変更、クライアントのHttpClientベースへの変更など、内部的には色々変わってきたし機能面でも磨かれてきています。まだまだ次のアップデートが控えている、最前線で戦える強力なフレームワークとなっています!
.NET 9 AlternateLookup によるC# 13時代のUTF8文字列の高速なDictionary参照
- 2024-08-29
.NET 9 から辞書系のクラス、Dictionary, ConcurrentDictionary, HashSet, FrozenDictionary, FrozenSetに GetAlternateLookup<TKey, TValue, TAlternate>() というメソッドが追加されました。今までDictionaryの操作はTKey経由でしかできませんでした。それは当たり前、なのですが、困るのが文字列キーで、これはstringでも操作したいし、ReadOnlySpan<char>でも操作したくなります。今まではReadOnlySpan<char>しか手元にない場合はToStringでstring化が必須でした、ただたんにDictionaryの値を参照したいだけなのに!
その問題も、.NET 9から追加されたGetAlternateLookupを使うと、辞書に別の検索キーを持たせることが出来るようになりました。
var dict = new Dictionary<string, int>
{
{ "foo", 10 },
{ "bar", 20 },
{ "baz", 30 }
};
var lookup = dict.GetAlternateLookup<ReadOnlySpan<char>>();
var keys = "foo, bar, baz";
// .NET 9 SpanSplitEnumerator
foreach (Range range in keys.AsSpan().Split(','))
{
ReadOnlySpan<char> key = keys.AsSpan(range).Trim();
// ReadOnlySpan<char>でstring keyの辞書のGet/Add/Removeできる
int value = lookup[key];
Console.WriteLine(value);
}
ところでSplitは、通常のstringのSplitは配列とそれぞれ区切られたstringをアロケーションしてしまいますが、.NET 8から、ReadOnlySpan<char>に対して固定個数のSplitができるMemoryExtensions.Splitが追加されました。.NET 9では、更にSpanSplitEnumeratorを返すSplitが新たに追加されています。これにより一切の追加のアロケーションなく、元の文字列からReadOnlySpan<char>を切り出すことができます。
そうして取り出したReadOnlySpan<char>のキーで参照するために、GetAlternateLookupが必要になってくるわけです。
使い道としては、例えばシリアライザーは頻繁にキーと値のルックアップが必要になります。私の開発しているMessagePack for C#では、高速でアロケーションフリーなデシリアライズのために、複数の戦略を採用しています。その一つはUTF8の文字列を8バイトずつのオートマトンとして扱うAutomataDictionary、この部分は更にIL EmitやSource Generatorではインライン化して埋め込まれて辞書検索もなくしています。もう一つはAsymmetricKeyHashTableという機構で、これは同一の対象を表す2つのキーで検索可能にしようというもので、内部的には byte[] と ArraySegment<byte> で検索できるような辞書を作っていました。
// MessagePack for C#のもの
internal interface IAsymmetricEqualityComparer<TKey1, TKey2>
{
int GetHashCode(TKey1 key1);
int GetHashCode(TKey2 key2);
bool Equals(TKey1 x, TKey1 y);
bool Equals(TKey1 x, TKey2 y); // TKey1とTKey2での比較
}
つまり、今までは、こうした別の検索キーを持った辞書が必要なシチュエーションでは、辞書そのものの自作が必要だったし、パフォーマンスのためには基礎的なデータ構造すら自作を厭わない必要がありましたが、.NET 9からはついに標準でそれが実現するようになりました。
AlternateLookupでも必要なのはIAlternateEqualityComparer<in TAlternate, T>で、以下のような定義になっています。(IAsymmetricEqualityComparerと似たような定義なので、また時代を10年先取りしてしまったか)
public interface IAlternateEqualityComparer<in TAlternate, T>
where TAlternate : allows ref struct
where T : allows ref struct
{
bool Equals(TAlternate alternate, T other);
int GetHashCode(TAlternate alternate);
T Create(TAlternate alternate);
}
C# 13から追加された言語機能 allows ref struct によってref struct、つまりSpan<T>などをジェネリクスの型引数にすることができるようになりました。
基本的にはこれはIEqualityComparer<T>とセットで実装する必要があります。実際、Dictionary.GetAlternateLookupではDictionaryのIEqualityComparerがIAlternateEqualityComparerを実装していないと実行時例外が出ます(コンパイル時チェックではありません!)また、EqualityComparerなのにCreateがあるのが少し奇妙ですが、これはAdd操作のために必要だからです。
現状、標準ではIAlternateEqualityComparerはstring用しかありません。stringで標準的に使われるEqualityComparerはIAlternateEqualityComparerを実装していて、ReadOnlySpan<char>で操作できますが、それ以外は用意されていません。
しかし、現代において現実的に必要なのはUTF8です、ReadOnlySpan<byte>です。シリアライザーのルックアップで使う、と言いましたが、現代のシリアライザーの入力はUTF8です。ReadOnlySpan<char>の出番なんてありません。というわけで、以下のようなIAlternateEqualityComparerを用意しましょう!
public sealed class Utf8StringEqualityComparer : IEqualityComparer<byte[]>, IAlternateEqualityComparer<ReadOnlySpan<byte>, byte[]>
{
public static IEqualityComparer<byte[]> Default { get; } = new Utf8StringEqualityComparer();
// IEqualityComparer
public bool Equals(byte[]? x, byte[]? y)
{
if (x == null && y == null) return true;
if (x == null || y == null) return false;
return x.AsSpan().SequenceEqual(y);
}
public int GetHashCode([DisallowNull] byte[] obj)
{
return GetHashCode(obj.AsSpan());
}
// IAlternateEqualityComparer
public byte[] Create(ReadOnlySpan<byte> alternate)
{
return alternate.ToArray();
}
public bool Equals(ReadOnlySpan<byte> alternate, byte[] other)
{
return other.AsSpan().SequenceEqual(alternate);
}
public int GetHashCode(ReadOnlySpan<byte> alternate)
{
// System.IO.Hashing package, cast to int is safe for hashing
return unchecked((int)XxHash3.HashToUInt64(alternate));
}
}
byte[]は標準では参照比較になってしまいますが、データの一致で比較したいので、ReadOnlySpan<T>.SequenceEqual を使います。これは、特にTが幾つかのプリミティブの場合はSIMDを活用して高速な比較が実現されています。ハッシュコードの算出は、高速なアルゴリズムxxHashシリーズの最新版であるXXH3の.NET実装であるXxHash3を用いるのがベストでしょう。これはNuGetからSystem.IO.Hashingをインポートする必要があります。64ビットで算出するため戻り値はulongですが、32ビット値が必要な場合はxxHashの作者より、ただたんに切り落とすだけで問題ないと言明されているため、intにキャストするだけで済まします。
使う場合の例は、こんな感じです。
// Utf8StringEqualityComparerを設定した辞書を作る
var dict = new Dictionary<byte[], bool>(Utf8StringEqualityComparer.Default)
{
{ "foo"u8.ToArray(), true },
{ "bar"u8.ToArray(), false },
{ "baz"u8.ToArray(), false }
};
var lookup = dict.GetAlternateLookup<ReadOnlySpan<byte>>();
// こんな入力があるとする
ReadOnlySpan<byte> json = """
{
"foo": 0,
"bar": 0,
"baz": 0
}
"""u8;
// System.Text.Json
var reader = new Utf8JsonReader(json);
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.PropertyName)
{
// 切り出したKeyで検索できる
ReadOnlySpan<byte> key = reader.ValueSpan;
var flag = lookup[key];
Console.WriteLine(flag);
}
}
一つ注意なのは、stringとReadOnlySpan<byte>でAlternateKeyを作ろうとするのはやめたほうが良いでしょう。それだと、常にエンコードが必要になり、悪いとこどりのようになってしまいます(Runeを使ってアロケーションレスで処理するにしても、どちらにせよバイナリ比較だけで済ませられるbyte[]キーとは比較になりません)。どうしても両方の検索が必要なら、辞書を二つ用意するほうがマシです。
ともあれ、これは私にとっては念願の機能です!色々なバリエーションで、Span対応のためにジェネリクスにもできずに決め打ちで辞書を何度も作ってきました、汎用的に使えるようになったのは大歓迎です。allows ref structはジェネリクス定義での煩わしさもありますが(自動判定での付与でも良かったような?)、言語としては重要な進歩です。.NET 9, C# 13、使っていきましょう。現状はまだプレビューですが、11月に正式版がリリースされるはずです。
Microsoft MVP for Developer Technologies(.NET)を再々々々々々々々々々々々々受賞しました
- 2024-07-11
Microsoft MVPは一年ごとに再審査されるのですが、今年も更新しました。2011年から初めて14回目ということで、長い!のですが、引き続きC#の最前線に立ち続けられていると思います。以下、審査用書類に出した、審査期間での実績一覧です。
OSS New
- MagicPhysX
.NET PhysX 5 binding to all platforms(win, osx, linux) for 3D engine, deep learning, dedicated server of gaming. - PrivateProxy
Source Generator and .NET 8 UnsafeAccessor based high-performance strongly-typed private accessor for unit testing and runtime. - Utf8StringInterpolation
Successor of ZString; UTF8 based zero allocation high-peformance String Interpolation and StringBuilder. - R3
The new future of dotnet/reactive and UniRx. - Claudia
Unofficial Anthropic Claude API client for .NET. - Utf8StreamReader
Utf8 based StreamReader for high performance text processing.
OSS Update
- StructureOfArraysGenerator
Structure of arrays source generator to make CPU Cache and SIMD friendly data structure for high-performance code in .NET and Unity. - Ulid
Fast .NET C# Implementation of ULID for .NET and Unity. - ZLogger
Zero Allocation Text/Structured Logger for .NET with StringInterpolation and Source Generator, built on top of a Microsoft.Extensions.Logging. - ZString
Zero Allocation StringBuilder for .NET and Unity. - MessagePack-CSharp
Extremely Fast MessagePack Serializer for C#(.NET, .NET Core, Unity, Xamarin). - ObservableCollections
High performance observable collections and synchronized views, for WPF, Blazor, Unity. - UnitGenerator
C# Source Generator to create value-object, inspired by units of measure. - MemoryPack
Zero encoding extreme performance binary serializer for C# and Unity. - csbindgen
Generate C# FFI from Rust for automatically brings native code and C native library to .NET and Unity. - DFrame
Distributed load testing framework for .NET and Unity. - MessagePipe
High performance in-memory/distributed messaging pipeline for .NET and Unity. - UniTask
Provides an efficient allocation free async/await integration for Unity.
Speaker
- CEDEC 2023 モダンハイパフォーマンスC# 2023 Edition - Speaker Deck
- メタバースプラットフォーム 「INSPIX WORLD」はPHPもC++もまとめてC#に統一! ~MagicOnionが支えるバックエンド最適化手法~ - Speaker Deck
- 他言語がメインの場合のRustの活用法 - csbindgenによるC# x Rust FFI実践事例 - Speaker Deck
Book
世界中見てもこんだけ叩き出してる人間いないので、これだけやってれば、満場一致で更新でいいでしょう。はい。自分で言うのもあれですが。あれ。
期間中で言うとR3が大型タイトル(?)です。また、Updateのほうも大型リニューアルとしてZLogger v2は相当力の入ったものになっています。今年の範囲だと、こないだ出したConsoleAppFramework v5や、近いうちにリリースされる(はず)のMessagePack for C# v3といった計画も控えています。なお、MagicOnionは現在メンテナーじゃないので実績に含めてはいないのですが、引き続きアクティブに開発されています!
ところで、このサイトも地味に更新されていて(自作のC#製静的サイトジェネレーターで作られています、ハンドメイド!)、ついに全文検索が搭載されました!上のほうのインプットボックスがそれになっているので、ぜひ試してみてください。ちょっと引っ掛かり方が変な可能性も高いですが、そこは検索ライブラリの仕様なので、いつか改善されるでしょう。多分きっと。
ConsoleAppFramework v5 - ゼロオーバーヘッド・Native AOT対応のC#用CLIフレームワーク
- 2024-06-13
ConsoleAppFrameworkの完全に新しいバージョンをリリースしました。完全に設計しなおして実装も完全に作り直された、何もかもが新しいフレームワークになっています。設計指針として「Zero Dependency, Zero Overhead, Zero Reflection, Zero Allocation, AOT Safe」を掲げ、もちろん、他を圧倒的に引き離すパフォーマンスを実現しています。
これはコールドスタートアップ・ウォームアップなしでのベンチマークとなっていて、CLIアプリケーションでの実際での利用に最も即したものだと考えています。System.CommandLineと比較すれば280倍!メモリアロケーション量もほかのフレームワークの100~1000倍少なくなっています(表示されている400Bはほぼシステム自体のallocなのでフレームワーク自体は0です)。
このパフォーマンスは、全てをSource Generatorで生成することで実現しました。例えば以下のようなコード。
using ConsoleAppFramework;
// args: ./cmd --foo 10 --bar 20
ConsoleApp.Run(args, (int foo, int bar) => Console.WriteLine($"Sum: {foo + bar}"));
ConsoleAppFrameworkはSource GeneratorがRunで与えられているラムダ式の引数を解析して、Runメソッドそのものを生成します。
internal static partial class ConsoleApp
{
// Generate the Run method itself with arguments and body to match the lambda expression
public static void Run(string[] args, Action<int, int> command)
{
// code body
}
}
通常C#のSource Generatorは属性をクラスかメソッドに与えて、それを元に生成されますが、ConsoleAppFrameworkはメソッドの呼び出しを監視して生成のキーにしています。これはRustのマクロから発想を得ていて、RustにはAttribute-like macros and Function-like macrosといったような分類がありますが、今回のやりかたはFunction-likeなスタイルと言えるでしょう。
実際の生成されるコード全体は以下のようなものになります。
internal static partial class ConsoleApp
{
public static void Run(string[] args, Action<int, int> command)
{
if (TryShowHelpOrVersion(args, 2, -1)) return;
var arg0 = default(int);
var arg0Parsed = false;
var arg1 = default(int);
var arg1Parsed = false;
try
{
for (int i = 0; i < args.Length; i++)
{
var name = args[i];
switch (name)
{
case "--foo":
{
if (!TryIncrementIndex(ref i, args.Length) || !int.TryParse(args[i], out arg0)) { ThrowArgumentParseFailed("foo", args[i]); }
arg0Parsed = true;
break;
}
case "--bar":
{
if (!TryIncrementIndex(ref i, args.Length) || !int.TryParse(args[i], out arg1)) { ThrowArgumentParseFailed("bar", args[i]); }
arg1Parsed = true;
break;
}
default:
// omit...(case-insensitive compare codes)
ThrowArgumentNameNotFound(name);
break;
}
}
if (!arg0Parsed) ThrowRequiredArgumentNotParsed("foo");
if (!arg1Parsed) ThrowRequiredArgumentNotParsed("bar");
command(arg0!, arg1!);
}
catch (Exception ex)
{
Environment.ExitCode = 1;
if (ex is ValidationException or ArgumentParseFailedException)
{
LogError(ex.Message);
}
else
{
LogError(ex.ToString());
}
}
}
static partial void ShowHelp(int helpId)
{
Log("""
Usage: [options...] [-h|--help] [--version]
Options:
--foo <int> (Required)
--bar <int> (Required)
""");
}
}
特にひねりもなさそうなド直球ドシンプルなコードに見えるのではないでしょうか。それが大事です!単純なコードであればあるほど速い!フレームワークなのに単純、だから速い。というのが目指している姿です。余計なコードはいっさいなく、メソッド本体に全ての処理が集約されているので、フレームワークとしてゼロ・オーバーヘッド、最適化した手書きコードと同等の速度を実現しました。
CLIアプリケーションは通常、コールドスタートからの単発の実行になるため、動的コード生成(IL.EmitやExpression.Compile)やキャッシュ(ArrayPoolやDictionary生成による以降のマッチング高速化)が効きにくい分野です。それらを作ったほうがオーバーヘッドが大きいですから。かといってリフレクションなどをそのまま使うのは、それはそれで低速です。ConsoleAppFrameworkは全ての必要な処理をインライン生成することによって、単発実行での速度が圧倒的に高速化されています。
リフレクションもないのでNative AOTとの親和性も圧倒的に高く、コールドスタートアップ速度におけるC#の欠点は一切なくなります。
もう一つ特徴として、ConsoleAppクラスを含めて、全てがSource Generatorによって生成されるために、ConsoleAppFramework自体も含めて依存が全くありません。
コンソールアプリケーションを作るシチュエーションは多用です。多数の依存を持った大きなバッチアプリケーションの場合もあれば、超単機能の小さなコマンドの場合もあります。小さなコマンドを作りたい時には、少しも追加の依存を入れたくはないでしょう。それこそ Microsoft.Extensions.Hosting を参照すると、それだけで数十個の依存DLLが追加されてしまいます!ConsoleAppFrameworkなら、自身も含めて依存ゼロです。
依存ゼロの良いところは明らかにバイナリサイズが小さくなることです。特にNative AOTではバイナリサイズは気になるところですが、ConsoleAppFrameworkなら追加のコストはほぼゼロです。
そしてもちろん、単機能ではフレームワークとしては物足りない、ということで以下のような機能が実現されています。十分に充実した機能群は、他のフレームワークと比べても全く見劣りしないはずです。
- SIGINT/SIGTERM(Ctrl+C) handling with gracefully shutdown via
CancellationToken - Filter(middleware) pipeline to intercept before/after execution
- Exit code management
- Support for async commands
- Registration of multiple commands
- Registration of nested commands
- Setting option aliases and descriptions from code document comment
System.ComponentModel.DataAnnotationsattribute-based Validation- Dependency Injection for command registration by type and public methods
Microsoft.Extensions(Logging, Configuration, etc...) integration- High performance value parsing via
ISpanParsable<T> - Parsing of params arrays
- Parsing of JSON arguments
- Help(
-h|--help) option builder - Default show version(
--version) option
生成されるコードはモジュール化されていて、コードが使用する機能によって変化し、常にその機能の実現において最小のコードが生成されるようになっています。それにより多機能と高速さを両立しています。また、どの機能も最速で実行できるよう念入りに調整してあるため、全機能が有効化されてもなお、他とは比較にならないほどに高速です。
余談ですが、デリゲートはデリゲート生成というアロケーションがあります。つまり真のゼロアロケーション・ゼロオーバーヘッドじゃないじゃん、と言うことができます。しかし、ちゃんとConsoleAppFrameworkは真のゼロアロケーションを実現する仕組みもちゃんと用意されています。以下のように静的関数をfunction pointerとして渡してください。
unsafe
{
ConsoleApp.Run(args, &Sum);
}
static void Sum(int x, int y) => Console.Write(x + y);
すると、以下のような delegate* managed<> (あまり見慣れないと思いますが、managed function pointerという言語機能がC#には追加されているのです)の引数を持ったメソッドの実体を生成します。
public static unsafe void Run(string[] args, delegate* managed<int, int, void> command)
これならもう完全に文句なくゼロアロケーション・ゼロオーバーヘッドです!
実用的には別にデリゲートでも全く関係ないレベルですが、完全に完璧を目指す執拗な姿勢により、対応を入れました。これでどの角度からも絶対に文句は付けられないでしょう。
高速な値変換
文字列からC#の値に変換する最速の手段はなんでしょうか?intだったら int.TryParse ですよね。では、他は?intは決め打ちだからいいとして、string -> T(あるいはobject)を汎用的にするには?というと少し難しい話になってきて、昔はTypeConverterというものが使われてきました。もちろん、パフォーマンスは悪いです。
あるいは最近はJsonSerializerが標準搭載されているから、それに丸投げしてみるというのもアリでしょう。もちろん、パフォーマンスは決して良くはありません。特にコールドスタートアップで考えるとJsonSerializerのキャッシュ処理が必要になってきて、単発実行においてはかなりのオーバーヘッドが足されてしまいます。
ConsoleAppFrameworkではIParsable, ISpanParsableを採用しています。これは .NET 7から追加され、C# 11で追加されたstatic abstract interfaceが使用されています。
public interface IParsable<TSelf> where TSelf : IParsable<TSelf>?
{
static abstract TSelf Parse(string s, IFormatProvider? provider);
static abstract bool TryParse([NotNullWhen(true)] string? s, IFormatProvider? provider, [MaybeNullWhen(returnValue: false)] out TSelf result);
}
C# 11になってようやく汎用的な 「文字列 -> 値」変換処理が実現するようになったのです! ConsoleAppFrameworkでは .NET 8/C# 12 を最小実行可能環境としているため、問答無用で採用しました。HalfやInt128などの .NET 8で登場した新しい型や、自分で定義する方もIParsable<T>を実装すればそれを使って高速に処理されます!
とはいえ、intなどの基本型はそもそもSource Generatorがintであることを知っているので、直接int.TryParseのように直接実行されるようになっていたりはします。
なお、値のバインディングに関してはparams arrayやデフォルト値にも対応しています。
ConsoleApp.Run(args, (
[Argument]DateTime dateTime, // Argument
[Argument]Guid guidvalue, //
int intVar, // required
bool boolFlag, // flag
MyEnum enumValue, // enum
int[] array, // array
MyClass obj, // object
string optional = "abcde", // optional
double? nullableValue = null, // nullable
params string[] paramsArray
) => { });
ちょうどC# 12からラムダ式にデフォルト値やparamsが使用できるようになりました、ということが反映されています。
ドキュメントコメントによる定義
DescriptionやAliasの追加は、今までは、あるいは他のフレームワークでは属性を使って記述していました。しかし、それは少しメソッドの各パラメーターに属性、更にかなり長めの文字列を付与するのは、メソッドとしてかなり読みづらくなります。
そこでConsoleAppFrameworkではドキュメントコメントを活用することにしました。
class Commands
{
/// <summary>
/// Display Hello.
/// </summary>
/// <param name="message">-m, Message to show.</param>
public static void Hello(string message) => Console.Write($"Hello, {message}");
}
これは
Usage: [options...] [-h|--help] [--version]
Display Hello.
Options:
-m|--message <string> Message to show. (Required)
というコマンドになります。ドキュメントコメントであれば、多くの引数があっても自然な見た目を保つことが可能です。この手法が取れるのはSource Generatorで生成するため.xmlは不要でコードから直接読み取れることの強みでもありますね。(ただしSource Generatorでドキュメントコメントをあらゆる環境で読み取れるようにするには若干のハックが必要でした)
複数コマンドの追加
ConsoleApp.Runは単独コマンドのためのショートカットでしたが、複数のコマンドやネストされているサブコマンドの追加も可能です。例えば以下のような設定を行った場合の生成を例を見ていきます。
var app = ConsoleApp.Create();
app.Add("foo", () => { });
app.Add("foo bar", (int x, int y) => { });
app.Add("foo bar barbaz", (DateTime dateTime) => { });
app.Add("foo baz", async (string foo = "test", CancellationToken cancellationToken = default) => { });
app.Run(args);
このコードのAddは、まず以下のように展開されます。Source Generatorが全てのAddされるラムダ式の型を知っているので、それぞれ固有の型を持ったフィールドに割り当てます。
partial struct ConsoleAppBuilder
{
Action command0 = default!;
Action<int, int> command1 = default!;
Action<global::System.DateTime> command2 = default!;
Func<string, global::System.Threading.CancellationToken, Task> command3 = default!;
partial void AddCore(string commandName, Delegate command)
{
switch (commandName)
{
case "foo":
this.command0 = Unsafe.As<Action>(command);
break;
case "foo bar":
this.command1 = Unsafe.As<Action<int, int>>(command);
break;
case "foo bar barbaz":
this.command2 = Unsafe.As<Action<global::System.DateTime>>(command);
break;
case "foo baz":
this.command3 = Unsafe.As<Func<string, global::System.Threading.CancellationToken, Task>>(command);
break;
default:
break;
}
}
}
これによりDelegateを保持しておくための配列や、DelegateのままInvokeするリフレクション/ボクシングが防げています。
Runでは、string[] argsからコマンドを選択するために定数文字列のswitchが埋め込まれます。
partial void RunCore(string[] args)
{
if (args.Length == 0)
{
ShowHelp(-1);
return;
}
switch (args[0])
{
case "foo":
if (args.Length == 1)
{
RunCommand0(args, args.AsSpan(1), command0);
return;
}
switch (args[1])
{
case "bar":
if (args.Length == 2)
{
RunCommand1(args, args.AsSpan(2), command1);
return;
}
switch (args[2])
{
case "barbaz":
RunCommand2(args, args.AsSpan(3), command2);
break;
default:
RunCommand1(args, args.AsSpan(2), command1);
break;
}
break;
case "baz":
RunCommand3(args, args.AsSpan(2), command3);
break;
default:
RunCommand0(args, args.AsSpan(1), command0);
break;
}
break;
default:
ShowHelp(-1);
break;
}
}
C#で文字列から特定のコードにジャンプする最速の手段は、switchで文字列定数を使うことです。展開されるアルゴリズムは何度か修正されていて、C# 12ではPerformance: faster switch over string objects · Issue #56374 · dotnet/roslynとして、まず長さをチェックした後に、差が存在する1文字だけを絞るといった形でマッチさせます。
Dictionary<string, T>からのマッチなどよりも高速で初期化時間もアロケーションもないのが、C#コンパイラの助けを借りれる強みであり、そうした処理ができるのはC#コードそのものを出力するSource Generator方式だけです。なので絶対に最速なわけです。
DIとCancellationTokenとライフタイム
引数にはコマンドのパラメーターとして有効になるもの以外に、DI経由で渡したいもの(例えばILogger<T>やOption<T>など)や、特別扱いする型としてConsoleAppContextとCancellationTokenを定義することができます。
DIによる受取は、コンソールアプリケーションがASP.NETのプロジェクトなどと設定ファイルを共有したいようなシチュエーションで有効でしょう。そうした場合のために、 Microsoft.Extensions.Hosting と連動させることが可能です。
また、CancellationTokenを渡した場合は、SIGINT/SIGTERM/SIGKILL(Ctrl+C)をフックするコンソールアプリケーションとしてのライフタイム管理が働くようになります。
await ConsoleApp.RunAsync(args, async (int foo, CancellationToken cancellationToken) =>
{
await Task.Delay(TimeSpan.FromSeconds(5), cancellationToken);
Console.WriteLine($"Foo: {foo}");
});
上記のコードは以下のように展開されます。
using var posixSignalHandler = PosixSignalHandler.Register(ConsoleApp.Timeout);
var arg0 = posixSignalHandler.Token;
await Task.Run(() => command(arg0!)).WaitAsync(posixSignalHandler.TimeoutToken);
.NET 6から追加されたPosixSignalRegistrationを使って、SIGINT/SIGTERM/SIGKILLがフックし、CancellationTokenをキャンセルの状態にします。と同時に、即時終了を抑制します(通常Ctrl + Cを押すと即座にAbortされますが、Abortされなくなります)。
それによりアプリケーションがCancellationTokenを正常にハンドリングする余地を残しています。
ただしCancellationTokenをハンドリングしないと終了命令を無視するだけになってしまい、それはそれで困るので、強制的に終了するタイムアウト時間が設けられています。デフォルトでは5秒に設定されていますが、これは ConsoleApp.Timeout プロパティで自由に変更できます。もし強制終了をオフにしたい場合は ConsoleApp.Timeout = Timeout.InfiniteTimeSpan を指定すると良いでしょう。
Task.WaitAsyncは .NET 6 からです。TimeSpanを渡す以外に、CancellationTokenを渡すことも可能なので、単純な数秒後ではなく、WaitAsyncの発火するタイミングをPosixSignalRegistrationが発火した後にTimeout後、といった条件を作ることができました。
フィルターパイプライン
実行の前後をフックする仕組みとしてConsoleAppFrameworkではFilterを採用しています。ミドルウェアパターンとも呼ばれて、特にasync/awaitが使える言語ではよく見かけるパターンだと思います。
internal class NopFilter(ConsoleAppFilter next) : ConsoleAppFilter(next) // ctor needs `ConsoleAppFilter next` and call base(next)
{
// implement InvokeAsync as filter body
public override async Task InvokeAsync(ConsoleAppContext context, CancellationToken cancellationToken)
{
try
{
/* on before */
await Next.InvokeAsync(context, cancellationToken); // invoke next filter or command body
/* on after */
}
catch
{
/* on error */
throw;
}
finally
{
/* on finally */
}
}
}
この設計パターンは本当に優れていて、実行をフックしたいような仕組みを用意したい場合は、このパターンを採用することを絶対にお薦めします。GoFの時代にasync/awaitがあったら、重要なデザインパターンとして載っていたことでしょう。
ReadMeにはフィルターでできることとして、実行時間のロギング・ExitCodeのカスタマイズ・多重実行禁止・認証処理などを紹介しています。Task InvokeAsync一つで様々な処理を実現できる素晴らしさ。誰がこのパターンを最初に発見したんでしょうね?
フィルターの設計にも色々な手法があるのですが、ConsoleAppFrameworkでは最もパフォーマンスの出る方法を選びました。コンストラクターでNextを受け取ることと、コードジェネレート時に静的に全ての利用するフィルターが決定するので(動的な追加は許可していません)、全てを埋め込んで組み立てています。
app.UseFilter<NopFilter>();
app.UseFilter<NopFilter>();
app.UseFilter<NopFilter>();
app.UseFilter<NopFilter>();
app.UseFilter<NopFilter>();
// The above code will generate the following code:
sealed class Command0Invoker(string[] args, Action command) : ConsoleAppFilter(null!)
{
public ConsoleAppFilter BuildFilter()
{
var filter0 = new NopFilter(this);
var filter1 = new NopFilter(filter0);
var filter2 = new NopFilter(filter1);
var filter3 = new NopFilter(filter2);
var filter4 = new NopFilter(filter3);
return filter4;
}
public override Task InvokeAsync(ConsoleAppContext context, CancellationToken cancellationToken)
{
return RunCommand0Async(context.Arguments, args, command, context, cancellationToken);
}
}
これにより、中間の配列のアロケーションや、ラムダ式のキャプチャのアロケーションは発生せず、フィルターの個数 + 1(メソッド本体のラップ)の追加のアロケーションのみが追加のコストとなります。また、戻り値のTaskは、同期的に完了する場合はTask.Completed相当のものが使われることになるため、これをValueTaskにする必要はありません。
コンストラクターでNextを受け取ってbaseに渡すだけのコードも、primary constructorのお陰で簡単に書けるようになりました。
コマンドライン引数の構文について
コマンドライン引数はスペース区切りでstring[] argsに渡されるということ以外は、完全に自由です。なんとなく --や-がパラメーター識別子だと思われていますが、実際はなんでもいいし、なんだったらWindowsは/が使われることも多かった。
とはいえ、ある程度標準的なルールは存在します。代表的なものはPOSIX規格と、その拡張であるGNU Coding Standardsでしょうか。ConsoleAppFrameworkでも、POSIX規格にある程度は従いつつ、GNU Coding Stadardsで定義されている --version と --help を組み込みのオプションとしています。名前も --lower-kebab-case がデフォルトです。
「ある程度」というのは、つまり、完全に従っているというわけではありません。規格にせよ伝統的な慣習にせよ、古いルールは現代的な観点から許容すべきでないルールも少なくありません。例えば-xと-Xが区別されて異なる挙動をするというのは絶対にナシでしょう。あるいは広く使われているものでもバンドリング、-fdxは-f, -d, -xと解釈されるといったものも、あまり良いとは思えません。バンドリングに関しては、パフォーマンス上でも、パース処理を複雑化させるため問題があります。
ConsoleAppFrameworkで優先しているのはパフォーマンスであるため、パフォーマンス上問題を引き起こす可能性のあるルールに関しては採用していません。大文字小文字の区別はしないようにしていますが、これは小文字のマッチングを先に行った後、フォールバックとしてcase-insensitiveのマッチングを行うため、実用上のパフォーマンスの低下は起こらないと考えています。
System.CommandLine のコマンド ライン構文の概要 - .NET | Microsoft Learnを見ると、System.CommandLineがかなり柔軟な構文解釈を可能にしていることがわかるでしょう。それはとても良いことです!良いことではあるのですが、パフォーマンス劣化を引き起こしているなら問題です。そして実際、System.CommandLineの性能はベンチマーク結果から明らかなとおり、非常に悪い。これはちょっといただけません。
迷走を続けているSystem.CommandLineは、どうやら再度分解されて実装を変更するようです。Resetting System.CommandLineということで、POSIX規格のパーサーとしての小さなコアを.NET 9 あるいは .NET 10で標準採用されることを目指している、ようです。
もしそれらが標準採用されたとしても、パフォーマンスの観点からは、ConsoleAppFrameworkを超えることは絶対にないでしょう。
v4からの互換性について
破壊的変更!破壊的変更を厭わないことはいいことです、イノベーションを妨げない、常に先端的であり続けるために必要なことです。C#の先端を走り続けるのはCysharpのアイデンティティでもあります。と、同時に、もちろん大迷惑なことです。今回の v4 -> v5 に関しては .NET Frameworkから.NET Coreに変わったような、 ASP.NET から ASP.NET Coreに変わったような、そんな変革なのでしょうがない、どうしても必要な変化だったのだ……。
ただし、実際のところは別にそこまで大きく変わっているわけではなかったりもします。名前変換処理(lower-kebab-case)のロジックは同じものを使っているため、名前がズレてしまうといったこともないので、コンパイルエラー出たメソッド名をマッピングするだけ、ではあります。そのぐらいのことはよくある、よね?
var app = ConsoleApp.Create(args); app.Run(); -> var app = ConsoleApp.Create(); app.Run(args);
app.AddCommand/AddSubCommand -> app.Add(string commandName)
app.AddRootCommand -> app.Add("")
app.AddCommands<T> -> app.Add<T>
app.AddSubCommands<T> -> app.Add<T>(string commandPath)
app.AddAllCommandType -> NotSupported(use Add<T> manually)
[Option(int index)] -> [Argument]
[Option(string shortName, string description)] -> Xml Document Comment
ConsoleAppFilter.Order -> NotSupported(global -> class -> method declrative order)
ConsoleAppOptions.GlobalFilters -> app.UseFilter<T>
全体的には、より単純化された、ようするに「良くなった」と思ってもらえる仕様変更だとは思います。
また、標準で Microsoft.Extensions.Hosting に乗っからなくなったというのは大きな違いですが、これは一行追加するだけで解決します。Hostingの上に乗っかるというのは、つまりはHostingで生成するServiceProviderを使う、それだけのことなのだ、と。実際はLifetime管理もありますが、それはConsoleAppFrameworkが自前でやっているので、DIのためのServiceProviderだけ渡してやれば実用上の違いはありません。
using var host = Host.CreateDefaultBuilder().Build(); // use using for host lifetime
ConsoleApp.ServiceProvider = host.ServiceProvider;
v4ではConsoleAppBaseを継承させていましたが、v5ではPOCOでよくなりました。代わりにConsoleAppContextやCancellationTokenに関してはコンストラクタインジェクションで受け取ってください。これも、C# 12のprimary constructorのお陰でそんなに手間じゃなくなりました。これもベースクラスを必要とする仕組みをやめた理由の一つになります。
真のIncremental Generator
Incremental Generatorって、ただたんに何も考えずに作るとIncrementalにならないのです。というのは知識として知ってはいたのですが、今まで見て見ぬふりをしていました!ありがたいことに指摘が入ったので、重い腰を上げてちゃんと抜本的な対応を取ることにしました。
まず最初にやらなければならないのは、Incrementalであるかどうかを視認できるようにすることです。普通に動かしていても内部状態は全く見えないので、ユニットテストで状態をチェックできるようにすることが大事です。例えばこんなユニットテストが書かれています。
[Fact]
public void RunLambda()
{
var step1 = """
using ConsoleAppFramework;
ConsoleApp.Run(args, int () => 0);
""";
var step2 = """
using ConsoleAppFramework;
ConsoleApp.Run(args, int () => 100); // body change
Console.WriteLine("foo"); // unrelated line
""";
var step3 = """
using ConsoleAppFramework;
ConsoleApp.Run(args, int (int x, int y) => 100); // change signature
Console.WriteLine("foo");
""";
var reasons = CSharpGeneratorRunner.GetIncrementalGeneratorTrackedStepsReasons("ConsoleApp.Run.", step1, step2, step3);
reasons[0][0].Reasons.Should().Be("New");
reasons[1][0].Reasons.Should().Be("Unchanged");
reasons[2][0].Reasons.Should().Be("Modified");
VerifySourceOutputReasonIsCached(reasons[1]);
VerifySourceOutputReasonIsNotCached(reasons[2]);
}
Incremental Generatorは trackIncrementalGeneratorSteps: true というオプションを渡してDriverを動かすと、各ステップの状態の結果が見えるようになります。IncrementalStepRunReasonにはNew, Unchanged, Modified, Cached, Removed という状態があり、最終出力の手前がUnchangedかCachedなら、出力処理がスキップされます。
上のユニットテストではstep2では出力コードに変更のない箇所に変更が加わっただけなので、Unchangedです。なので最終段ではCachedになっていました。step3は再生成が必要な変更が加わっているのでModifiedとなり、ソースコード生成処理まで走ります。
IncrementalStepRunReasonはTrackedStepsから取り出すことが出来るのですが、そのままだとちょっと読みづらすぎるので、確認しやすいように整形しています、というのがGetIncrementalGeneratorTrackedStepsReasonsというユーティリティメソッドです。
public static (string Key, string Reasons)[][] GetIncrementalGeneratorTrackedStepsReasons(string keyPrefixFilter, params string[] sources)
{
var parseOptions = new CSharpParseOptions(LanguageVersion.CSharp12); // 12
var driver = CSharpGeneratorDriver.Create(
[new ConsoleAppGenerator().AsSourceGenerator()],
driverOptions: new GeneratorDriverOptions(IncrementalGeneratorOutputKind.None, trackIncrementalGeneratorSteps: true))
.WithUpdatedParseOptions(parseOptions);
var generatorResults = sources
.Select(source =>
{
var compilation = baseCompilation.AddSyntaxTrees(CSharpSyntaxTree.ParseText(source, parseOptions));
driver = driver.RunGenerators(compilation);
return driver.GetRunResult().Results[0];
})
.ToArray();
var reasons = generatorResults
.Select(x => x.TrackedSteps
.Where(x => x.Key.StartsWith(keyPrefixFilter) || x.Key == "SourceOutput")
.Select(x =>
{
if (x.Key == "SourceOutput")
{
var values = x.Value.Where(x => x.Inputs[0].Source.Name?.StartsWith(keyPrefixFilter) ?? false);
return (
x.Key,
Reasons: string.Join(", ", values.SelectMany(x => x.Outputs).Select(x => x.Reason).ToArray())
);
}
else
{
return (
Key: x.Key.Substring(keyPrefixFilter.Length),
Reasons: string.Join(", ", x.Value.SelectMany(x => x.Outputs).Select(x => x.Reason).ToArray())
);
}
})
.OrderBy(x => x.Key)
.ToArray())
.ToArray();
return reasons;
}
ごちゃごちゃしてよくわからないという感じですが、つまりそのままだと本当によくわからない代物ということで。Keyに関しては各ステップで .WithTrackingName("ConsoleApp.Run.0_CreateSyntaxProvider") のような命名規則で付与しています。TrackedStepsがImmutableDictionaryのため列挙の順番が順不同でイマイチ確認しづらいので、番号振ってソートするようにしました。また、複数のRegisterSourceOutputが走っていると(ConsoleAppFrameworkではRun系とBuilder系の2種が動いてる)混線してわかりづらくなるため、keyPrefixとしてフィルタリングするようにしています。
注意すべき点とか、いい感じに作る方法とか、色々説明しておかなければならないことが多いのですが、めちゃくちゃ長くなるので、それはまたの機会ということで……!
まとめ
もともとConsoleAppFrameworkはCysharpの製品ラインでは珍しく、パフォーマンスを重視していたわけではない、という成り立ちがあります。どちらかというと機能面、当時それなりに珍しかったHostingと融合してCLIフレームワークを作るといったコンセプトの立証を主軸に作り上げ、そして一定の成果を挙げました。何回かの改修でHelpがリッチになったりMinimal APIっぽく書けるようになったりもしましたが、どうしても古くささが目立ってきました。
特にCoconaは、ConsoleAppFrameworkの影響を受けつつも、より柔軟で、より強力な機能を備えていてとても素晴らしいライブラリです。このままではConsoleAppFrameworkはただの劣化版ではないか、という意識もありました。自信をもってベストであると薦められないのは心苦しい。というかCoconaを作っているのはCysharpの同僚ですしですの。
なので、今回APIの幾つかは逆にCoconaからの影響を受けつつ([Argument]など)、全く異なるキャラクターを持ったフレームワークとなるように腐心しました。パースについての項目で説明したように、ConsoleAppFramework v5は柔軟性をある程度犠牲にしているため、豊富な機能が必要ならば、System.CommandLineやCoconaを使用することをお薦めします。
また、パフォーマンスの観点から言うと、本体の実行時間が長ければ長いほどフレームワークのオーバーヘッドなんてどうでもよくはなります。10分、1分、いや、10秒ぐらいかかる処理であるなら、フレームワーク部分が1msだろうと50msだろうと誤差みたいなものでしょう。それはそもそもJITコンパイルにも言えることではありますが。とはいえ、Native AOTだのコールドスタートアップ速度だのがやいやい言われる昨今では、別にそんなもの無視できる程度の話だろう、と一刀両断できるわけでもなく、早いに越したことはないのは間違いないとも言えます。
パフォーマンスや依存性なしといったメリットはもちろんですが、アプローチや設計面でも特異で面白いものになっていると思いますので、是非お試しください!もちろん、実用性もめちゃくちゃ高く、文句なしに必須ライブラリと考えてもらってもいいのではないでしょうか!
R3のコードから見るC#パフォーマンス最適化技法実例とTimeProviderについて
- 2024-05-01
4/27に大阪で開催されたC#パフォーマンス勉強会で「R3のコードから見る実践LINQ実装最適化・コンカレントプログラミング実例」という題でセッションしてきました!
タイトル的にあまりLINQでもコンカレントでもなかったかな、とは思いますが、R3を題材に、具体的なコードをもとにした最適化技法の紹介という点では面白みはあったのではないかと思います。
Rxの定義
R3は、やや挑発的な内容を掲げていることもあり、R3は「Rxではない」みたいなことを言われることもあります。なるほど!では、そもそも何をもってRxと呼ぶのか、呼べるのか。私は「Push型でLINQ風のオペレーターが適用できればRx」というぐらいの温度感で考えています。もちろん、R3はそれを満たしています。
mutable structの扱いと同じく、あまり教条主義的にならず、時代に合わせて、柔軟により良いシステムを考えていきましょう。コンピュータープログラミングにおいて、伝統や歴史を守ることは別に大して重要なことではないはずです。
TimeProvider DeepDive
TimeProviderについて、セッションでも話しましたが、大事なことなのでもう少し詳しくいきましょう。TimeProviderにまず期待するところとしては、ほとんどがSystemClock.Now、つまりオレオレDateTime.Now生成器の代わりを求めているでしょう。それを期待しているとTimeProviderの定義は無駄に複雑に見えます。しかしTimeProviderを分解してみると、これは4つの時間を司るクラスの抽象層になっています。
public abstract class TimeProvider
{
// TimeZoneInfo
public virtual TimeZoneInfo LocalTimeZone => TimeZoneInfo.Local;
// DateTimeOffset
public virtual DateTimeOffset GetUtcNow() => DateTimeOffset.UtcNow;
public DateTimeOffset GetLocalNow() =>
// Stopwatch
public virtual long TimestampFrequency => Stopwatch.Frequency;
public virtual long GetTimestamp() => Stopwatch.GetTimestamp();
public TimeSpan GetElapsedTime(long startingTimestamp, long endingTimestamp) =>
public TimeSpan GetElapsedTime(long startingTimestamp) => GetElapsedTime(startingTimestamp, GetTimestamp());
// System.Threading.Timer
public virtual ITimer CreateTimer(TimerCallback callback, object? state, TimeSpan dueTime, TimeSpan period) =>
}
public interface ITimer : IDisposable, IAsyncDisposable
{
bool Change(TimeSpan dueTime, TimeSpan period);
}
4つの時間を司るクラス、すなわちTimeZoneInfo、DateTimeOffset、Stopwatch、System.Threading.Timer。
この造りになっているからこそ、あらゆる時間にまつわる挙動を任意に変更することができるのです。
挙動を任意に変更するというとユニットテストでの時間のモックにばかり意識が向きますが(実際、FakeTimeProviderはとても有益です)、別にユニットテストに限らず、優れた時間の抽象化層として使うことができます。ということを実装とともに証明したのがR3で、特にR3ではCreateTimerをかなり弄っていて、WPFではDispatcherTimerを使うことで自動的にUIスレッドにディスパッチしたり、UnityではPlayerLoopベースのタイマーとしてScaledとUnsacledでTimescaleの影響を受けるタイマー・受けないタイマーなどといった実行時のカスタマイズ性を実現しました。
セッションではStopwatchについてフォーカスしました。二点の時刻の経過時間を求めるのにDateTimeの引き算、つまり
DateTime now = DateTime.UtcNow;
/* do something... */
TimeSpan elapesed = DateTime.UtcNow - now;
といったコードを書くのはよくあることですが、これはバッドプラクティスです。DateTimeの取得はタダではありません。では、なるほどStopwatchですね?ということで
Stopwatch sw = Stopwatch.StartNew();
/* do something... */
TimeSpan elapsed = sw.Elapsed;
これは、Stopwatchがclassなのでアロケーションがあります。うまく使いまわしてあげる必要があります。 使いまわしができないシチュエーションのために、アロケーションを避けるためにstructのStopwatch、ValueStopwatchといったカスタム型を作ることもありますが、待ってください、そもそもStopwatchが不要です。
二点の経過時間を求めるなら、時計による時刻も不要で、その地点の何らかのタイムスタンプが取れればそれで十分なのです。
// .NET 7以降での手法(GetElapsedTimeが追加された)
long timestamp = Stopwatch.GetTimestamp();
/* do something... */
TimeSpan elapsed = Stopwatch.GetElapsedTime(timestamp);
このlongは、通常は高解像度タイムスタンプ、WindowsではQueryPerformanceCounterが使われています。TimeSpanでよく使うTicksではないことに注意してください。
ベンチマークを取ってみましょう。
using BenchmarkDotNet.Attributes;
using System.Diagnostics;
BenchmarkDotNet.Running.BenchmarkRunner.Run<TimestampBenchmark>();
public class TimestampBenchmark
{
[Benchmark]
public long Stopwatch_GetTimestamp()
{
return Stopwatch.GetTimestamp();
}
[Benchmark]
public DateTime DateTime_UtcNow()
{
return DateTime.UtcNow;
}
[Benchmark]
public DateTime DateTime_Now()
{
return DateTime.Now;
}
}
NowではUtcNowに加えてTimeZoneからのオフセット算出が入るために更にもう一段遅くなります。
ちなみに、2点間の時間の算出にDateTimeではなくTimestampを使うもう一つの利点としては、システム時間の変更の影響を受けないという点があります。dotnet/reactiveではISchedulerがDateTimeOffsetベースで作られていたため、ISchedulerインターフェイスそのものがこの問題の影響を避けられないために、内部的にゴチャゴチャしたハックが繰り返され、パフォーマンスの大幅な劣化にも繋がっていました。
なお、マイクロベンチマークを取るときは必ずBenchmarkDotNetを使ってください。(micro)benchmark is hard、です。Stopwatchで測られても、あらゆる要因から誤差が出まくるし、そもそも指標もよくわからないしで、数字を見ても何もわかりません。私はそういう数字の記事とかを見た場合、役に立たないと判断して無視します。
まとめ
セッション資料に盛り込めた最適化技法の紹介は極一部ではありますが、R3がどれだけ気合い入れて作られているかが伝わりましたでしょうか?10年の時を経て、私自身の成長とC#の成長が合わさり、UniRxからクオリティが桁違いです。
これからも足を止めずにやっていきますし、みなさんも是非モダンC#やっていきましょう……!(Unityも十分モダンC#の仲間入りで良いです!)
そういえばブログに貼り付けるのを忘れてたのですが3月末にはこんなセッションもしていました。
ええ、ええ。Unityもモダンですよ!大丈夫!
Redis互換の超高速インメモリデータストア「Garnet」にC# CustomCommandを実装してコマンドを拡張する
- 2024-03-19
MicrosoftからIntroducing Garnet – an open-source, next-generation, faster cache-store for accelerating applications and servicesという記事が今日公開されて、Garnetという新しいインメモリデータストアがOSSとして公開されました。Microsoft ResearchでFASTERを手掛けていたチームによるもので、FASTERはC#実装の高速なキーバリューストアでした。今回のGarnetはその発展形のようなもので、FASTERベースのストレージと、Redis互換のプロトコルによる、インメモリデータストアになっています。詳しくはGarnetのほうのブログA Brief History of Garnetで。GarnetもC#で作られています。
ベンチマークによると、Redisはもちろんのこと、DragonflyというRedis互換の世界最速のインメモリデータストア(を公式で謳ってる)Dragonflyよりも高速、だそうで。
このグラフ、そこまで大きな差がないように見えますが対数グラフになっていて、Redisが1,000.00 kops/sec に対して、100,000.00 kops/secって言ってます。100倍です!えー。
そもそもRedisの速度に関していうと、シングルスレッドベースであることなどから、たまによくそこまで速くはないというのは言われてきていて、先述のDragonflyはRedis互換で25倍高速とする「Dragonfly」が登場。2022年の最新技術でインメモリデータストアを実装などというリリースとともに、現代の技術で作り直せばもっともっと速くなる、とはされてきました。とはいえ、単純なGET/SETだけのメモリキャッシュとは比較にならない豊富なデータ型など利便性がとても高く、いうて別にそこまで遅いというわけでもないので、特に気にすることなく使われ続けているのではないでしょうか。
GarnetはC#で作られていますが、当然ながらC#専用ではなく、汎用的なRedisサーバーとして動作するため、既存のRedisクライアントで直接繋げることができます。RedisはそのプロトコルRedis serialization protocol(RESP)の仕様を公開しているため、互換サーバーが作りやすいというわけですね、素晴らしい……!
C#から使う場合はStackExchange.Redisと、Garnet同梱のGarent Clientのどちらかが使えます。パッとGarnet Clientを見た限り、現状現実的に使うならStackExchange.Redisですね。最低限は用意されているけれど、Redisクライアントとして使うには、しんどみがありそうです。ただ、性能面ではGarnet Clientのほうが良さそうです。StackExchange.Redisも、前身のBookSleeveから数えると初期設計が10年以上前のものになっているので、現代の観点から見ると設計は古く、パフォーマンス的にも、この実装は悪そうだな、と思えるところがかなりあります。なのでロマンを追いかけるならGarnet Clientを使うのも面白くはあります……!
C#でカスタムコマンドを実装する
普通にRedis互換サーバーとして立てて使うのもいいのですが、C#使いなら面白い点があって、Garnetをライブラリとして参照して(NuGet: Microsoft.Garnet)、アプリケーションに組み込んでのセルフホストができます。例えばロガーとしてZLoggerを差し込んでVerboseでログを出してみたりとか、ちょっと使いやすくていい感じです。ローカル開発とかだったらDockerでRedis動かして、などではなく、ソリューションにGarnetをそのまま組み込んで.NET Aspireで同時起動させるとかもいい感じでしょう。RedisはWindowsでは動かないので(大昔にMicrosoftがForkして動かせるようにしたプロジェクトがありましたが!)、ちゃんと動く互換サーバーが出てきたこと自体がとても嬉しかったりもします。
using Garnet;
using Microsoft.Extensions.Logging;
using ZLogger;
try
{
var loggerFactory = LoggerFactory.Create(x =>
{
x.ClearProviders();
x.SetMinimumLevel(LogLevel.Trace);
x.AddZLoggerConsole(options =>
{
options.UsePlainTextFormatter(formatter =>
{
formatter.SetPrefixFormatter($"[{0}]", (in MessageTemplate template, in LogInfo info) => template.Format(info.Category));
});
});
});
using var server = new GarnetServer(args, loggerFactory);
// Optional: register custom extensions
RegisterExtensions(server);
// Start the server
server.Start();
Thread.Sleep(Timeout.Infinite);
}
catch (Exception ex)
{
Console.WriteLine($"Unable to initialize server due to exception: {ex.Message}");
}
もう一つは、カスタムコマンドを実装できることです……!C#で……!
Redis上でちょっと複雑な実行をしたいことはよくあり、Redisの場合はLua Scriptで処理していましたが、GarnetではC#でカスタムコマンドを実装して組み込むことができます。LUAだとパフォーマンス上どうか、あるいはLUAではできないかなり複雑なことをしたい、といった場合に、パフォーマンス上のデメリットなく使えます。もっとさらに嬉しい点としては、サーバー側で用意した拡張コマンドは、RESPに従っているので、クライアントはC#専用ではなく、PHPからでもGoからでも呼べます。
というわけで、サンプルということで単純な、「SETLCLAMP」というSET時にclampするカスタムコマンドを早速作っていきましょう。作る前に、先に↑のコードで欠けてるRegisterExtensionsの部分を。
static void RegisterExtensions(GarnetServer server)
{
// ClampLongCustomCommandというカスタムコマンドをSETLCLAMPというコマンド名で登録する。
// これはMath.Clampを呼び出すので、パラメーター数は3(long value, long min, long max)
server.Register.NewCommand("SETLCLAMP", 3, CommandType.ReadModifyWrite, new ClampLongCustomCommand());
}
カスタムコマンドの登録自体は非常に簡単で、CustomRawStringFunctions, CustomTransactionProcedure または CustomObjectFactory を実装したクラスをコマンド名と共に追加するだけです。
カスタムコマンドの実装も簡単……?まぁ、理解すればそれなりぐらいに。
using Garnet.server;
using System.Buffers;
using System.Buffers.Binary;
using Tsavorite.core;
sealed class ClampLongCustomCommand : CustomRawStringFunctions
{
// trueの場合はKeyが空の時の動作(GetInitialLength, InitilUpdate)を呼びに行く
public override bool NeedInitialUpdate(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, ref (IMemoryOwner<byte>, int) output) => true;
// UpdaterのSpan<byte> value(書き込みたいメモリデータ)の長さを決める
public override int GetInitialLength(ReadOnlySpan<byte> input)
{
// 今回はlongだけなので決め打ち8
return 8;
}
public override bool InitialUpdater(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, Span<byte> value, ref (IMemoryOwner<byte>, int) output, ref RMWInfo rmwInfo)
{
// inputに対してGetNextArgを連続して呼ぶとパラメーターの取得。これは定型句。
int offset = 0;
var arg1 = GetNextArg(input, ref offset);
var arg2 = GetNextArg(input, ref offset);
var arg3 = GetNextArg(input, ref offset);
// ClientはWriteInt64LittleEndianでシリアライズしてきてるので、Readでデシリアライズ
var v = BinaryPrimitives.ReadInt64LittleEndian(arg1);
var min = BinaryPrimitives.ReadInt64LittleEndian(arg2);
var max = BinaryPrimitives.ReadInt64LittleEndian(arg3);
var result = Math.Clamp(v, min, max);
// valueに対して値を書くことで値のセットになる
BinaryPrimitives.WriteInt64LittleEndian(value, result);
// 戻り値とかエラーを書きたい場合はoutputを使う(RespWriteUtilsに色々Utilityが揃ってる)
// WriteIntegerAsBulkStringなどを使うと"String"としての結果になることに注意
// 今回はlongをバイナリとして出力する
unsafe
{
var len = 8 + 6; // $8\r\n{value}\r\n
var pool = MemoryPool.Rent(len);
using var memory = pool.Memory.Pin();
var begin = (byte*)memory.Pointer;
var end = begin + len;
RespWriteUtils.WriteBulkString(value, ref begin, end);
output = (pool, len);
}
return true;
}
// 同じメモリ領域を再利用する(置換する値の長さが同値なら再利用可能)かどうかを決める
public override bool NeedCopyUpdate(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, ReadOnlySpan<byte> oldValue, ref (IMemoryOwner<byte>, int) output) => false;
// 置換時に再利用する場合
public override bool InPlaceUpdater(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, Span<byte> value, ref int valueLength, ref (IMemoryOwner<byte>, int) output, ref RMWInfo rmwInfo)
{
// 置換するvalueの長さが一緒(あるいは小さい)の場合は
// valueにはoldValueが入ってきてる。
// 今回は特に考慮しないのでそのまんま書く。
int offset = 0;
var v = BinaryPrimitives.ReadInt64LittleEndian(GetNextArg(input, ref offset));
var min = BinaryPrimitives.ReadInt64LittleEndian(GetNextArg(input, ref offset));
var max = BinaryPrimitives.ReadInt64LittleEndian(GetNextArg(input, ref offset));
var result = Math.Clamp(v, min, max);
BinaryPrimitives.WriteInt64LittleEndian(value, result);
unsafe
{
var len = 8 + 6; // $8\r\n{value}\r\n
var pool = MemoryPool.Rent(len);
using var memory = pool.Memory.Pin();
var begin = (byte*)memory.Pointer;
var end = begin + len;
RespWriteUtils.WriteBulkString(value, ref begin, end);
output = (pool, len);
}
return true;
}
// 置換時に別のメモリ領域を確保する場合
public override int GetLength(ReadOnlySpan<byte> value, ReadOnlySpan<byte> input) => 8;
public override bool CopyUpdater(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, ReadOnlySpan<byte> oldValue, Span<byte> newValue, ref (IMemoryOwner<byte>, int) output, ref RMWInfo rmwInfo) => throw new NotImplementedException();
// 読み込み処理用
public override bool Reader(ReadOnlySpan<byte> key, ReadOnlySpan<byte> input, ReadOnlySpan<byte> value, ref (IMemoryOwner<byte>, int) output, ref ReadInfo readInfo) => throw new NotImplementedException();
}
今回はRedisでいうところのStringベースで作るので CustomRawStringFunctions を使います。RedisのStringは文字列型じゃなくて、どちらかというとバイナリ型で、バイナリシリアライズできるものなら、なんでも突っ込めるイメージです。私もゲームサーバーを作っていたときはMessagePackのバイナリを突っ込みまくってましたし、開発時には雑に画像データのバイナリを投げ込んで画像DB代わりに使ったりとかもありました。
オーバーライドするメソッドの数が多いことと、パラメーターがSpan<byte>だらけで一瞬圧倒されちゃうんですが、冷静に追ってみるとそこまで難しいことは言ってないことに気づきます。追加時(Add)・置換時(Replace)が、最適化のため同じサイズか違うサイズかで2択、それとRead時用。といった別れ方をしています。
key, input, valueが全てReadOnlySpan<byte>なのは、まぁそりゃそうでしょう(ここでstringとか出てきたら逆に良くない!)
inputをパラメーターに分解するのはGetNextArgというヘルパーメソッドを使います。当然それも出てくるのはReadOnlySpan<byte>なので、あとは適当に、もしJSONとかMessagePackとかMemoryPackでシリアライズしたデータだったらシリアライザを使って戻すのもいいし、プリミティブの値だったらBinaryPrimitivesが恐らく適役です。MemoryPackでValueTupleにまとめちゃうのがArgumentが分かれないので最速かつ簡単かもしれません。
結果はSpan<byte> valueに書きます。この出力先のSpanの長さは事前にGetLengthまたはGetInitialLengthで求めておく必要があります。outputはクライアント側に戻すときの値で、RESPに則った形式で出力する必要があるので色々注意がいります。まずはRESPの仕様を簡単にでも頭に入れたほうがつまずかないで済むかもしれません、ここを分かってないとイマイチ書きづらいと思います。
と、いうわけで、バイナリ操作がそこそこ混ざることを除けば、それなりに素直に書けるのではないでしょうか。雰囲気は理解しました!ある程度なんでもは出来ますが(CustomTransactionProcedure や CustomObjectFactory でもまた色々出来る)、同期メソッドしかないように、DB呼んだりHTTP通信したりはご法度です。当たり前ですが。当たり前ですが。計算量もGarnetサーバーのCPUにストレートに影響を与えるので、そんなに無茶なことを書くことはないと思いますがお気をつけを。それでも、LUAを走らせるよりもずっと軽いんじゃないかなという予感はさせてくれます。実際これただのC#のメソッドそのものですしね。
クライアントから呼び出す場合は、こんなメソッドを用意してみます。
public static class GarnetClientExtensions
{
// RESPプロトコルにのっとってOpCodeを用意する
// RESPのBlukStringの仕様: https://redis.io/docs/reference/protocol-spec/#bulk-strings
// $<length>\r\n<data>\r\n
readonly static Memory<byte> OpCode_SETLCLAMP = Encoding.ASCII.GetBytes("$9\r\nSETLCLAMP\r\n");
public static async Task<long> ClampAsync(this GarnetClient client, Memory<byte> key, long value, long min, long max, CancellationToken cancellationToken = default)
{
var parameters = new byte[24];
var valSpan = parameters[0..8];
var minSpan = parameters[8..16];
var maxSpan = parameters[16..24];
BinaryPrimitives.WriteInt64LittleEndian(valSpan, value);
BinaryPrimitives.WriteInt64LittleEndian(minSpan, min);
BinaryPrimitives.WriteInt64LittleEndian(maxSpan, max);
// key + (value, min, max)
// 戻り値のMemoryResultはArrayPoolから借りてる状態なのでDisposeでReturnする
using var result = await client.ExecuteForMemoryResultWithCancellationAsync(OpCode_SETLCLAMP, new Memory<byte>[] { key, valSpan, minSpan, maxSpan }, cancellationToken);
return BinaryPrimitives.ReadInt64LittleEndian(result.Span);
}
}
サーバー側で用意した拡張コマンドは、ちゃんとRESPに従っているので、クライアントはC#専用ではありませんし、Garnet Client専用でもありません。StackExchange.Redisであれば、db.Execute("SETLCLAMP", ...) で呼べます。
実際に動かしてみるとこんな感じです。
static async Task RunClientAsync(ILoggerFactory loggerFactory)
{
var logger = loggerFactory.CreateLogger("Client");
var client = new GarnetClient("localhost", 3278, logger: logger);
logger.ZLogInformation($"Client Connecting.");
await client.ConnectAsync();
logger.ZLogInformation($"Success Connect.");
var key = Encoding.UTF8.GetBytes("foo");
var v1 = await client.ClampAsync(key, 12345, min: 0, max: 100);
Console.WriteLine(v1); // 100
// String系のGET/SET/DELなどは普通に呼べる
using var v2 = await client.StringGetAsMemoryAsync(key);
Console.WriteLine(BinaryPrimitives.ReadInt64LittleEndian(v2.Span)); // 100
var isDelete = await client.KeyDeleteAsync(key);
Console.WriteLine(isDelete); // True
}
いいですね!
まとめ
さすがに公開されてまだ10時間経ってないぐらいなのでザックリとした理解なのですが、かなりいいんじゃないかと!
どうしてもMemachedとかRedisとかは、クラウドのマネージドサービスが用意されてないと嫌だー、という思考に陥りがちなのですが、C#でガリガリ拡張できるとなれば、まぁマネージドがなくてもしょうがないな!という気持ちになれ、る、でしょうかね……?
まぁそうじゃなくても、あまりマネージド指向になりすぎるのも良くないかな、とは思っています。私は最近はPubSubにNATSをお薦めしてクライアントも作ったりしてたわけですが、もちろんマネージドサービスはありません。で、だから、諦めます、というのは違うかな、と。もったいないと思うんですよね。
なので、必要あれば、いや、必要じゃなくても(?)気持ちがあるなら、自前に立てるというのも否定しちゃあいけないと思ってます。特にC#アプリケーションを作ったことがある人なら、C#で組み込んでホスティングすること自体は別に難しくもない、なんだったらいつもやってることの延長線上でいけますし。もちろん、そこからインフラ安定させるとかデータどうするなとかリカバリどうするとか、そういうのは別問題の話ではありますが……!
ともあれかなり面白いし使える予感があるので、やっていきましょう!
Claudia - Anthropic ClaudeのC# SDKと現代的なC#によるウェブAPIクライアントの作り方
- 2024-03-18
AI関連、競合は現れども、性能的にやはりOpenAI一強なのかなぁというところに現れたAnthropic Claude 3は、確かに明らかに性能がいい、GPT-4を凌駕している……!というわけで大いに気に入った(ついでに最近のOpenAIのムーブが気に入らない)ので、C#で使い倒していきたい!そこで、まずはSDKがないので非公式SDKを作りました。こないだまでプレビュー版を流していたのですが、今回v1.0.0として出します。ライブラリ名は、Claudeだから、Claudiaです!.NET全般で使えるのと、Unity(Runtime/Editor双方)でも動作確認をしているので、アイディア次第で色々活用できると思います。
今回のSDKを作るにあたっての設計指針の一番目は、公式のPython SDKやTypeScript SDKと限りなく似せること、です。というのもドキュメント類の解説はこれら公式SDKベースになるし、世の中的にもブログなどには公式SDKベースの記事が多く出回るでしょう。公式の充実したプロンプトライブラリも、APIリクエストで叩き込みたくなるかもしれない。
そんな時に、APIのスタイルが違うと、変換の認知負荷がかかります。些細なことですが、そういうところがすごく大事で引っ掛かってしまうので、徹底的に取り除きます。そのうえで、無理に動的な要素を入れず、C#らしさを崩さないというバランス取りが設計において重要です。
C#クライアントの見た目はこうです。
// C#
using Claudia;
var anthropic = new Anthropic();
var message = await anthropic.Messages.CreateAsync(new()
{
Model = "claude-3-opus-20240229",
MaxTokens = 1024,
Messages = [new() { Role = "user", Content = "Hello, Claude" }]
});
Console.WriteLine(message);
比較してTypeScriptの見た目はこうなっています。
// TypeScript
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic();
const message = await anthropic.messages.create({
model: 'claude-3-opus-20240229',
max_tokens: 1024,
messages: [{ role: 'user', content: 'Hello, Claude' }],
});
console.log(message.content);
かなり近い!でしょう。そのうえで、C#版はdynamicやDictionary<string, object>などは使わず、全て型付けされたものが指定されます。上記の例で使用しているC# 9.0で追加されたTarget-typed new expressionsや、C# 12で追加されたCollection expressionsの存在を前提として、うまくAPIを合わせています。
もともと、動的型付け言語のAPIのほうが(見た目は)簡潔で使いやすそう、という印象を抱くことは多いので、それと同レベルの簡潔さで、しっかりと型付けが効いて書けるというのは、現代のC#の大きな強みです。(そもそもTypeScriptの公式SDKに合わせようと思ったのは、私から見ても公式SDKのAPIスタイルはよくできていると思ったからです、仮にあまりにも酷かった場合は合わせようとはしなかったでしょう)
いかにも古典的なC#やJavaみたいな冗長な設計のAPIクライアントは、反省しましょう。現代のC#はここまでやれるのだから。
Streaming and Blazor
StreamingのAPIも用意されていて、Blazorと組み合わせれば簡単にリアルタイムに更新されるChat UIが作れます。コードは本当にたったのこれだけ、メソッド本体なんて10行ちょい!
[Inject]
public required Anthropic Anthropic { get; init; }
double temperature = 1.0;
string textInput = "";
string systemInput = SystemPrompts.Claude3;
List<Message> chatMessages = new();
async Task SendClick()
{
chatMessages.Add(new() { Role = Roles.User, Content = textInput });
var stream = Anthropic.Messages.CreateStreamAsync(new()
{
Model = Models.Claude3Opus,
MaxTokens = 1024,
Temperature = temperature,
System = string.IsNullOrWhiteSpace(systemInput) ? null : systemInput,
Messages = chatMessages.ToArray()
});
var currentMessage = new Message { Role = Roles.Assistant, Content = "" };
chatMessages.Add(currentMessage);
textInput = "";
StateHasChanged();
await foreach (var messageStreamEvent in stream)
{
if (messageStreamEvent is ContentBlockDelta content)
{
currentMessage.Content[0].Text += content.Delta.Text;
StateHasChanged();
}
}
}
全てのリクエスト/レスポンス型はSystem.Text.Json.JsonSerializerでシリアライズ可能なため、このList<Message>をそのままシリアライズすれば保存、デシリアライズすれば読み込みになります。
Function Calling
ClaudiaはただのREST APIを叩くだけのSDK、ではありません。Source Generatorを活用して、Function Callingを簡単に定義するための仕組みを用意しました。
Function Callingができると何がいいか、というと、現状のLLMは単体だとできないことが幾つかあります。例えば計算は、それっぽい答えを返してくれる場合も多いし、Step-by-Stepで考えさせるなど、それっぽさの精度を上げることはできるけれど、正確な計算はできないという苦手分野だったりします(複雑な計算を投げると正しそうで間違ってる答えを出しやすい)。それなら計算が必要なら普通に計算機で計算して、その答えをもとに文章を作ればいいじゃん、と。あるいは現在日時を答えることもできません。ウェブページを指定して要約したり翻訳して欲しいとお願いしても、中身を見ることはできませんと言われます。それらを解決するのがFunction Callingです。
まずは一例ということで、指定したURLのウェブページをClaudeに返す関数を定義してみましょう。
public static partial class FunctionTools
{
/// <summary>
/// Retrieves the HTML from the specified URL.
/// </summary>
/// <param name="url">The URL to retrieve the HTML from.</param>
[ClaudiaFunction]
static async Task<string> GetHtmlFromWeb(string url)
{
using var client = new HttpClient();
return await client.GetStringAsync(url);
}
}
[ClaudiaFunction]で定義した関数がSource Generatorによって色々生成されます。これを利用する場合、以下のようになります。
var input = new Message
{
Role = Roles.User,
Content = """
Could you summarize this page in three lines?
https://docs.anthropic.com/claude/docs/intro-to-claude
"""
};
var message = await anthropic.Messages.CreateAsync(new()
{
Model = Models.Claude3Haiku,
MaxTokens = 1024,
System = FunctionTools.SystemPrompt, // set generated prompt
StopSequences = [StopSequnces.CloseFunctionCalls], // set </function_calls> as stop sequence
Messages = [input],
});
var partialAssistantMessage = await FunctionTools.InvokeAsync(message);
var callResult = await anthropic.Messages.CreateAsync(new()
{
Model = Models.Claude3Haiku,
MaxTokens = 1024,
System = FunctionTools.SystemPrompt,
Messages = [
input,
new() { Role = Roles.Assistant, Content = partialAssistantMessage! } // set as Assistant
],
});
// The page can be summarized in three lines:
// 1. Claude is a family of large language models developed by Anthropic designed to revolutionize the way you interact with AI.
// 2. This documentation is designed to help you get the most out of Claude, with clear explanations, examples, best practices, and links to additional resources.
// 3. Claude excels at a wide variety of tasks involving language, reasoning, analysis, coding, and more, and the documentation covers key capabilities, getting started with prompting, and using the API.
Console.WriteLine(callResult);
Claudeへは二回のリクエストを行っています。まず、最初のClaudeへのリクエストでは、質問と共に利用可能な関数の一覧と説明を送り、関数を実行するのが最適だと判断されると、実行したい関数名とパラメーターが返されます。それを下に、手元で関数を実行し、結果をClaudeに渡すことで最終的に求める結果を得られます。
ではSource Generatorは何をやっているのかというと、まずはClaudeのシステム文に渡しているFunctionTools.SystemPromptを生成しているわけですが、その中身はこれです(一部省略)。
// ...前文は省略
<tools>
<tool_description>
<tool_name>GetHtmlFromWeb</tool_name>
<description>Retrieves the HTML from the specified URL.</description>
<parameters>
<parameter>
<name>url</name>
<type>string</type>
<description>The URL to retrieve the HTML from.</description>
</parameter>
</parameters>
</tool_description>
</tools>
XMLです。ClaudeはXMLタグを認識するようになっていて、システム的に明確に情報を与えたい場合はXMLタグを活用することがベストプラクティスとなっています。そこで、C#の関数からClaudeに渡すためのXMLを自動生成しています。これを手書きは、したくないでしょう……?
そしてClaudeはそのリクエストに対して、以下のような結果を返します。
<function_calls>
<invoke>
<tool_name>GetHtmlFromWeb</tool_name>
<parameters>
<url>https://docs.anthropic.com/claude/docs/intro-to-claude</url>
</parameters>
</invoke>
やはりXMLです(閉じタグが欠けているのはStopSequencesで止めているため。関数を呼びたい場合はこれ以上の情報は不要なので打ち止めておく)。これをパースして、関数(GetHtmlFromWeb)を実行し、Claudeに渡すためのメソッド FunctionTools.InvokeAsync がSource Generatorによって生成されています。実際生成されているInvokeAsyncメソッドは以下のようなものです。
#pragma warning disable CS1998
public static async ValueTask<string?> InvokeAsync(MessageResponse message)
{
var content = message.Content.FirstOrDefault(x => x.Text != null);
if (content == null) return null;
var text = content.Text;
var tagStart = text .IndexOf("<function_calls>");
if (tagStart == -1) return null;
var functionCalls = text.Substring(tagStart) + "</function_calls>";
var xmlResult = XElement.Parse(functionCalls);
var sb = new StringBuilder();
sb.AppendLine(functionCalls);
sb.AppendLine("<function_results>");
foreach (var item in xmlResult.Elements("invoke"))
{
var name = (string)item.Element("tool_name")!;
switch (name)
{
case "GetHtmlFromWeb":
{
var parameters = item.Element("parameters")!;
var _0 = (string)parameters.Element("url")!;
BuildResult(sb, "GetHtmlFromWeb", await GetHtmlFromWeb(_0).ConfigureAwait(false));
break;
}
default:
break;
}
}
sb.Append("</function_results>"); // final assistant content cannot end with trailing whitespace
return sb.ToString();
static void BuildResult<T>(StringBuilder sb, string toolName, T result)
{
sb.AppendLine(@$" <result>
<tool_name>{toolName}</tool_name>
<stdout>{result}</stdout>
</result>");
}
}
#pragma warning restore CS1998
}
これを手書きは、あまりしたくはないでしょう。特に呼び出したい関数が増えれば増えるほど大変ですし。
これで呼び出し&生成したXMLを再度Claudeに、Assistantによる先頭の出力結果だと渡すことによって、望む答えを得ることができます。このテクニックはPrefill Claude's responseとして公式でもベストプラクティスの一つとして案内されているもので、Claudeによる返答を望む方向に導くのに有益です。例えば{をprefill responseとして返すと、Claudeが結果をJSONとして出力する確率が飛躍的に上昇します。
API vs LangChain, SemanticKernel
大規模言語モデルを触るなら、生で使うよりもLangChainや、特にC#だとSemantic Kernelを使うというのを入り口にするのも定説ではありますが、やや疑問はあります。最近でもLangChainを使わないやLangChain は LLM アプリケーションの開発に採用すべきではないといった記事のようにLangChain不要論も出てきています。
そもそも、まぁこの記事はエンジニア向けに書いてるわけですが、一部の機能はあきらかに過剰でいらないんじゃないかと、保存用のプラグインとか。Semantic Kernelの大量にあるコネクターパッケージとかぞっとする感じで、コード書けないデータサイエンティストが継ぎ接ぎでやるならともかく、エンジニアは保存ぐらい自前でやったほうが絶対いいでしょ。TimePluginだのHttpPluginだのFileIOPluginだのも、正直馬鹿らしい、という感じしかないのでは。
どうせ最後に叩くのは生APIなら、真摯にAPIドキュメントを読め、と。ClaudeのAPIドキュメントのUser Guidesは分かりやすく素晴らしく、それもまたClaudeを支持したい理由の一つになります。しょうもない抽象化を通すぐらいならClaudeに特化して、特徴的なXMLによる指示の活かしかたを考えろ、と。
特にC#の人はSemantic Kernel至上主義になってると思われるので、いったんまずそっから離れて考えていくといいんじゃないです?
モダンウェブAPIクライアントの作り方
ここからはClaudiaの設計から見る現代的なAPIクライアントの設計方法の話をします。
まず、通信の基盤はHttpClientを使います。一択です。異論を挟む余地はない。Grpc.Net.ClientだってHTTP/2 gRPC通信にHttpClientを使っていますし、好むと好まざると全てのHTTP系の通信の基盤はHttpClientです。
ここでは、外からHttpMessageHandlerを受け取れるようにしておくといいでしょう。
public class Anthropic : IMessages, IDisposable
{
readonly HttpClient httpClient;
// DefaultRequestHeadersやBaseAddressを変更させてあげるためにpublicで公開しておく
public HttpClient HttpClient => httpClient;
public Anthropic()
: this(new HttpClientHandler(), true)
{
}
public Anthropic(HttpMessageHandler handler)
: this(handler, true)
{
}
public Anthropic(HttpMessageHandler handler, bool disposeHandler)
{
this.httpClient = new HttpClient(handler, disposeHandler);
}
public void Dispose()
{
httpClient.Dispose();
}
}
HttpClientというのは実はガワでしかなくて、実体はHttpMessageHandlerです。HttpMessageHandlerにはやれることが色々あって、DelegatingHandlerを実装してリクエストの前後をフックするような機能を仕込んだりも出来るし、Cysharp/YetAnotherHttpHandlerはHttpMessageHandlerの実装という形で通信処理を丸ごとRust実装に差し替えています。Unityでは.NETランタイムの通信実装じゃなくてUnityWebRequestを使いたいんだよなあ、といったような場合にはUnityWebRequestHttpMessageHandler.csを使えば、やはり通信処理が全てUnityによるものに差し替わります。
インターフェイスの切り方も工夫していきましょう。
client.Messages.CreateAsync のように、MVCでいったら.Controller.Methodのように、2階層に整理された呼び出し方は直感的で使いやすい設計です。特に、入力補完に優しいのが嬉しい。そのためには、まずインターフェイスを切りますが、工夫として、それを明示的なインターフェイスの実装にして、インターフェイス自体はreturn this;で返してやりましょう。
public interface IMessages
{
Task<MessageResponse> CreateAsync(MessageRequest request, RequestOptions? overrideOptions = null, CancellationToken cancellationToken = default);
IAsyncEnumerable<IMessageStreamEvent> CreateStreamAsync(MessageRequest request, RequestOptions? overrideOptions = null, CancellationToken cancellationToken = default);
}
public class Anthropic : IMessages, IDisposable
{
public IMessages Messages => this;
async Task<MessageResponse> IMessages.CreateAsync(MessageRequest request, RequestOptions? overrideOptions, CancellationToken cancellationToken)
{
// ...
}
async IAsyncEnumerable<IMessageStreamEvent> IMessages.CreateStreamAsync(MessageRequest request, RequestOptions? overrideOptions, [EnumeratorCancellation] CancellationToken cancellationToken)
{
// ...
}
}
これによって一個階層を下がる際のアロケーションがない(thisを返すため)ですし、明示的な実装になっているのでトップ階層では入力補完には現れないので、使いやすさと性能、ついでにいえば実装のしやすさ(全てのクライアントのフィールドにそのままアクセスできるため)の全てが満たされます。
ユーザーフレンドリーなリクエスト型生成
Anthropicのリクエスト型はかなり整理されて、型有り言語に優しい仕様になっているのですが、一部、single string or an array of content blocksというものがあります。どっちか、とかそういうの微妙に困るわけですが、しかし、じゃあOption<Either<List<>>>かなー、とか、そういうことではありません。そんな定義にしたらAPIクライアントの手触りは最悪になるでしょう。よく考えてみると、Anthropic APIのこの場合のstringは、長さ1のstring contentと同一です。
// こうじゃなくて
Content = [ new() { Type = "text", Text = "Hello, Claude" }]
// こう書きたい
Content = "Hello, Claude"
これは、良い仕様だと思います。杓子定規に Type = "text", Text = "..." と書かせるのはダルいでしょう。利用時の95%ぐらいはsingle string contentでしょうし(Typeはimageの場合もある、その場合はSourceにバイナリのbase64文字列を設定する。arrayなのは、画像とテキストを両方渡したりするため)。
その仕様をC#で実現しましょう。今回の場合、正規化するようなイメージでいいので、暗黙的変換で実装しました。
public record class Message
{
/// <summary>
/// user or assistant.
/// </summary>
[JsonPropertyName("role")]
public required string Role { get; set; }
/// <summary>
/// single string or an array of content blocks.
/// </summary>
[JsonPropertyName("content")]
public required Contents Content { get; set; }
}
public class Contents : Collection<Content>
{
public static implicit operator Contents(string text)
{
var content = new Content
{
Type = ContentTypes.Text,
Text = text
};
return new Contents { content };
}
}
Content[]ではなくて独自のコレクションにして、それの文字列からの暗黙的変換でsingle string contentを生成する形にしました。別に最新のC#仕様でもなんでもなく昔からある手法ですし、闇雲な利用は厳禁ですが、こうしたところに利用するのはAPIクライアントの手触り向上に効果的です。
タイムアウト
タイムアウトは定番の処理なので、APIクライアントで簡単にユーザーが設定できるようにしておいたほうがいいでしょう。といっても、HttpClientがTimeoutプロパティを持っているので、通常はそれにセットしてあげるだけで十分です。しかし、Claudiaではあえて無効にしています。
public class Anthropic : IMessages, IDisposable
{
public TimeSpan Timeout { get; init; } = TimeSpan.FromMinutes(10);
public Anthropic(HttpMessageHandler handler, bool disposeHandler)
{
this.httpClient = new HttpClient(handler, disposeHandler);
this.httpClient.Timeout = System.Threading.Timeout.InfiniteTimeSpan;
}
}
Anthropicの公式クライアントがメソッド呼び出し毎にTimeout設定をオーバーライドできるという仕様を持っているため、それにならってオーバーライド可能に必要があったためです。HttpClientやそれに準ずるもの呼び出しはスレッドセーフであるべき(実際APIクライアントはSingletonで登録されたりする場合がある)なので、SendAsyncでHttpCleintのプロパティの値を弄るのはよくない。ので、HttpClientが持つTimeoutは無効にして、手動で処理するようにしています。
実装方法は、LinkedTokenSourceを生成し、CancelAfterによってタイムアウト時間後にキャンセルされるCancellationTokenを作り、HttpClient.SendAsyncに渡すだけです。なお、これはHttpClient.Timeoutがタイムアウト時間を持つ場合の内部実装と同じです。
// 実際のコードはリトライ処理と混ざっているため、若干異なります
async Task<TResult> RequestWithAsync<TResult>(HttpRequestMessage message, CancellationToken cancellationToken, RequestOptions? overrideOptions)
{
var timeout = overrideOptions?.Timeout ?? Timeout;
using (var cts = CancellationTokenSource.CreateLinkedTokenSource(cancellationToken))
{
cts.CancelAfter(timeout);
try
{
var result = await httpClient.SendAsync(message, HttpCompletionOption.ResponseHeadersRead, cancellationToken).ConfigureAwait(ConfigureAwait);
return result;
}
catch (OperationCanceledException ex) when (ex.CancellationToken == cts.Token)
{
if (cancellationToken.IsCancellationRequested)
{
throw new OperationCanceledException(ex.Message, ex, cancellationToken);
}
else
{
throw new TimeoutException($"The request was canceled due to the configured Timeout of {Timeout.TotalSeconds} seconds elapsing.", ex);
}
throw;
}
}
}
実際にキャンセルされた場合(OperationCanceledExceptionが投げられる)のエラーハンドリングには注意しましょう。まず、LinkedTokenを剥がす必要があります。素通しだとOperationCanceledExceptionのTokenがLinkedTokenのままですが、これだと上流側でキャンセル原因の判定に使うことができません。キャンセル原因が渡されているCancellationTokenのキャンセルだった場合は、OperationCanceledExceptionを作り直してキャンセル理由のTokenを変更します。
タイムアウトだった場合はOperationCanceledExceptionではなく、TimeoutExceptionを投げてあげるのが良いでしょう。なお、HttpClientのタイムアウト実装を使った場合は歴史的事情でTaskCanceledExceptionを投げてくるようになっています(互換性のため変更したくても、もう変更できない、とのこと。あまり良い設計ではないと言えるので、そこは見習わなくていいでしょう)
リトライ
リトライをAPIクライアント自身が持つべきかどうかに関しては、少し議論があるかもしれません。しかし、単純に例外が出たらcatchしてリトライかければいいというものではなく、リトライ可なものと不可のものの判別がまず必要です。例えば認証に失敗しているとか、リクエストに投げるJSONが腐ってるといった場合は何度リトライしても無駄なのでリトライすべきものではないのですが、そうした細かい条件は、APIクライアント自身しか知り得ないので、リトライ処理を内蔵してしまうのは良いと思います。
Claudiaでは公式クライアントに準拠する形で、具体的には408 Request Timeout, 409 Conflict, 429 Rate Limit, and >=500 Internal errorsをリトライ対象にしています。認証失敗のPermissionError(403)やリクエスト内容が不正(InvalidRequestError(400))はリトライされません。たまによくあるOverloadedError(過負荷状態なので結果返せまんでしたエラー)は529で、これは何度か叩き直せば解消されるやつなのでリトライして欲しい、といったものはリトライされます。
リトライロジックも公式クライアントに準拠していて、レスポンスヘッダにretry-after-msやretry-afterがあればそれに従いつつ、ない場合(やretry-afterが規定よりも大きい場合)はジッター付きのExponential Backoffで間隔を制御しています。
キャンセル
クライアント側に.Cancel()メソッドなどは持たせません。というのも、HttpClientと準拠させるとクライアントそのものは、ほぼシングルトンで使えて、各呼び出しに対して共有されることになります(場合によってはDIでシングルトンでインジェクトするかもしれませんし)。なので、全てに影響を与える.Cancel()ではなくて、各呼び出しそれぞれにCancellationTokenを渡してね、という形を取ります。
Server Sent Eventsの超高速パース
Streamingでレスポンスを取得するAPIは、server-sent eventsという仕様で、ストリーミングで送信されてきます。具体的には以下のようなテキストメッセージが届きます。
event: message_start
data: {"type":"message_start","message":...}
event: content_block_start
data: {"type":"content_block_start","index":...}
event: イベント名, data: JSON, ...。といったことの繰り返しです。さて、改行区切りのテキストメッセージといったらStreamReaderでReadLine、というのは正解、ではあるのですがモダンC#的には不正解です。
ReadLineは文字列を生成します。イベント名の判定のために、あるいは最終的にdataのJSONはデシリアライズしてオブジェクトに変換するのですが、UTF8のデータから直接変換できるはずです。というわけで、ここは(ユーザーに渡すオブジェクトの生成以外は)ゼロアロケーションが狙えます。文字列を通しさえしなければ。というわけでStreamReaderの出番はありません。
具体的なコードを見ていきましょう。前半部(下準備)と後半部(パース部分)で分けます。
internal class StreamMessageReader
{
readonly PipeReader reader;
readonly bool configureAwait;
MessageStreamEventKind currentEvent;
public StreamMessageReader(Stream stream, bool configureAwait)
{
this.reader = PipeReader.Create(stream);
this.configureAwait = configureAwait;
}
public async IAsyncEnumerable<IMessageStreamEvent> ReadMessagesAsync([EnumeratorCancellation] CancellationToken cancellationToken)
{
READ_AGAIN:
var readResult = await reader.ReadAsync(cancellationToken).ConfigureAwait(configureAwait);
if (!(readResult.IsCompleted | readResult.IsCanceled))
{
var buffer = readResult.Buffer;
while (TryReadData(ref buffer, out var streamEvent))
{
yield return streamEvent;
if (streamEvent.TypeKind == MessageStreamEventKind.MessageStop)
{
yield break;
}
}
reader.AdvanceTo(buffer.Start, buffer.End);
goto READ_AGAIN;
}
}
まず、Streamは、System.IO.Pipelines.PipeReaderに渡しておきます。今回のStreamはネットワークからサーバー側がストリーミングで返してくる不安定なStreamなので、バッファ管理が大変です。PipeReader/PipeWriterは、若干癖がありますが、その辺の管理をよしなにやってくれるもので、現代のC#ではかなり重要なライブラリです。
基本の流れはバッファを読み込み(ReadAsync)、そのバッファでパース可能(行の末尾までないとパースできないので、改行コードが含まれているかどうか)な状態なら、1行毎にパース(TryReadData)してyield returnでオブジェクトを返す。バッファが足りなかったらAdvanceToで読み取った部分までマークしてから、再度ReadAsync、といった流れになります。
利用側はBlazorのサンプルで出していたのですが、await foreachで列挙するのが基本になります。
await foreach (var messageStreamEvent in Anthropic.Messages.CreateStreamAsync())
{
}
こういったネットワークの絡む処理のストリーミング処理にはIAsyncEnumerableが非常に向いていますし、データソース側も、非同期シーケンスをyield returnで返せるというのは、とても楽になりました。これがない時代には、もう戻るのは無理でしょう……。
次に後半部、PipeReaderによって分解されたバッファからパースする処理になります。
[SkipLocalsInit]
bool TryReadData(ref ReadOnlySequence<byte> buffer, [NotNullWhen(true)] out IMessageStreamEvent? streamEvent)
{
var reader = new SequenceReader<byte>(buffer);
Span<byte> tempBytes = stackalloc byte[64]; // alloc temp
while (reader.TryReadTo(out ReadOnlySequence<byte> line, (byte)'\n', advancePastDelimiter: true))
{
if (line.Length == 0)
{
continue; // next.
}
else if (line.FirstSpan[0] == 'e') // event
{
// Parse Event.
if (!line.IsSingleSegment)
{
line.CopyTo(tempBytes);
}
var span = line.IsSingleSegment ? line.FirstSpan : tempBytes.Slice(0, (int)line.Length);
var first = span[7]; // "event: [c|m|p|e]"
if (first == 'c') // content_block_start/delta/stop
{
switch (span[23]) // event: content_block_..[]
{
case (byte)'a': // st[a]rt
currentEvent = MessageStreamEventKind.ContentBlockStart;
break;
case (byte)'o': // st[o]p
currentEvent = MessageStreamEventKind.ContentBlockStop;
break;
case (byte)'l': // de[l]ta
currentEvent = MessageStreamEventKind.ContentBlockDelta;
break;
default:
break;
}
}
else if (first == 'm') // message_start/delta/stop
{
switch (span[17]) // event: message_..[]
{
case (byte)'a': // st[a]rt
currentEvent = MessageStreamEventKind.MessageStart;
break;
case (byte)'o': // st[o]p
currentEvent = MessageStreamEventKind.MessageStop;
break;
case (byte)'l': // de[l]ta
currentEvent = MessageStreamEventKind.MessageDelta;
break;
default:
break;
}
}
else if (first == 'p')
{
currentEvent = MessageStreamEventKind.Ping;
}
else if (first == 'e')
{
currentEvent = (MessageStreamEventKind)(-1);
}
else
{
// Unknown Event, Skip.
// throw new InvalidOperationException("Unknown Event. Line:" + Encoding.UTF8.GetString(line.ToArray()));
currentEvent = (MessageStreamEventKind)(-2);
}
continue;
}
else if (line.FirstSpan[0] == 'd') // data
{
// Parse Data.
Utf8JsonReader jsonReader;
if (line.IsSingleSegment)
{
jsonReader = new Utf8JsonReader(line.FirstSpan.Slice(6)); // skip data:
}
else
{
jsonReader = new Utf8JsonReader(line.Slice(6)); // ReadOnlySequence.Slice is slightly slow
}
switch (currentEvent)
{
case MessageStreamEventKind.Ping:
streamEvent = JsonSerializer.Deserialize<Ping>(ref jsonReader, AnthropicJsonSerialzierContext.Default.Options)!;
break;
case MessageStreamEventKind.MessageStart:
streamEvent = JsonSerializer.Deserialize<MessageStart>(ref jsonReader, AnthropicJsonSerialzierContext.Default.Options)!;
break;
// 中略(MessageDela, MessageStop, ContentBlockStart, ContentBlockDelta, ContentBlockStop, errorに対して同じようなDeserialize<T>
default:
// unknown event, skip
goto END;
}
buffer = buffer.Slice(reader.Consumed);
return true;
}
}
END:
streamEvent = default;
buffer = buffer.Slice(reader.Consumed);
return false;
}
event, dataの二行から、dataのJSONをデシリアライズしてオブジェクトを返したい。というのが処理のやりたいことです。bufferには必ずしも都合よくevent, dataの二行が入っているわけでもなくeventだけかもしれない、dataだけかもしれない、あるいはdataも途中で切れてる(そのままだと不完全なJSON)かもしれない。といったことを考慮して、中断・再開できる構造にしておく必要があります。
といっても、基本的には改行コードが存在してれば一行分のバッファは十分あるだろうということで、 while (reader.TryReadTo(out ReadOnlySequence<byte> line, (byte)'\n', advancePastDelimiter: true)) といったループを回して、これをStreamReader.ReadLineの代わりにしています。このreaderはSequenceReaderというReadOnlySequenceからの読み取りをサポートするユーティリティで、ref structのため、それ自体のアロケーションはありません。ReadOnlySequenceは性能良く正しく使うには、かなり落とし穴の多いクラスなので、こうしたユーティリティベースに実装したほうがお手軽かつ安全です。
まずeventのパースで、ここからdataがどの種類化を読み取っています。正攻法でやると if (span.SequenceEqual("content_block_start")) といったように判定していくことになります。Span<byte>へのSequenceEqualは高速な実装になっているので、まぁ悪くないといえば悪くないのですが、とはいえifの連打は如何なものか……。そこで、Claudiaでは実際には以下のような判定に簡略化しています。
var first = span[7]; // "event: [c|m|p|e]"
if (first == 'c') // content_block_start/delta/stop
{
switch (span[23]) // event: content_block_..[]
{
case (byte)'a': // st[a]rt
currentEvent = MessageStreamEventKind.ContentBlockStart;
break;
case (byte)'o': // st[o]p
currentEvent = MessageStreamEventKind.ContentBlockStop;
break;
case (byte)'l': // de[l]ta
currentEvent = MessageStreamEventKind.ContentBlockDelta;
break;
default:
break;
}
}
else if (first == 'm') // message_start/delta/stop
{
switch (span[17]) // event: message_..[]
{
case (byte)'a': // st[a]rt
currentEvent = MessageStreamEventKind.MessageStart;
break;
case (byte)'o': // st[o]p
currentEvent = MessageStreamEventKind.MessageStop;
break;
case (byte)'l': // de[l]ta
currentEvent = MessageStreamEventKind.MessageDelta;
break;
default:
break;
}
}
メッセージの種類はcontent_block_start/delta/stop, message_start/delta/stop, ping, errorの8種類。まず、先頭1文字でcontent系かmessage系かその他か判定できる。start/delta/stopに関しては3文字目を見ると判定できる。というわけで、1byteのチェックを2回行うだけで分類可能です。明らかに高速!なお、今後のメッセージ種類の追加でチェックが壊れる可能性がゼロではない(例えばcontent_block_ffowardとかが来るとcontent_block_stopと誤判定される)、という問題があることは留意する必要があります。Claudiaではいうて大丈夫だろ、という楽観視してますが。
なお、これは以前に発表したモダンハイパフォーマンスC# 2023でのコードのバリエーションと言えるでしょうか。
テキストプロトコルを見るとなんとかして判定をちょろまかしたいという欲求に抗うのは難しい……。なお、もし厳密な判定をしつつもif連打を避けたい場合は、まず長さチェックをいれます。長さで大雑把な分岐をかけてからSequenceEqualで正確なチェックをします。ようするところ、C#のstringへのswtichの最適化(コンパイラがそういう処理に変換している!)と同じことをやろうという話なだけですが。分岐数が多い場合はハッシュコードを取って分岐かけるとか、ようするにインラインDictionaryのようなものを実装するのもアリでしょう。
最後に、data行はJSON Deserializeです。ReadOnlySpan<byte>またはReadOnlySequence<byte>のままデシリアライズするにはUtf8JsonReaderを通す必要があります。なお、Utf8JsonReaderもref structなのでアロケーションには含めません。
これで、Stringを一切通さない処理ができました!StreamReaderを使えば超単純になるのに!という気はしなくもないですが、文字列化したら負けだと思っている病に罹患しているのでしょーがない……。
Source Generator vs Reflection
Function Callingの実装に、ClaudiaではSource Generatorを採用しました。リフレクションベースで作成することも可能では有りましたが、今回に関してはSource Generatorのほうが望ましい結果が得られました。まず、仮にリフレクションで実装したらどんな関数定義を要求されるだろうか、というところを、Semantic Kernel実装の場合との比較で見てください。
public static partial class FunctionTools
{
// Claudia Source Generator
/// <summary>
/// Retrieve the current time of day in Hour-Minute-Second format for a specified time zone. Time zones should be written in standard formats such as UTC, US/Pacific, Europe/London.
/// </summary>
/// <param name="timeZone">The time zone to get the current time for, such as UTC, US/Pacific, Europe/London.</param>
[ClaudiaFunction]
public static string TimeOfDay(string timeZone)
{
var time = TimeZoneInfo.ConvertTimeBySystemTimeZoneId(DateTime.UtcNow, timeZone);
return time.ToString("HH:mm:ss");
}
// Semantic Kernel
[KernelFunction]
[Description("Retrieve the current time of day in Hour-Minute-Second format for a specified time zone. Time zones should be written in standard formats such as UTC, US/Pacific, Europe/London.")]
public static string TimeOfDay([Description("The time zone to get the current time for, such as UTC, US/Pacific, Europe/London.")]string timeZone)
{
var time = TimeZoneInfo.ConvertTimeBySystemTimeZoneId(DateTime.UtcNow, timeZone);
return time.ToString("HH:mm:ss");
}
}
Function Callingでは、Claudeに関数の情報を与えなければならないので、メソッド・パラメーター共に説明が必須です。ClaudiaのSource Generator実装ではそれをドキュメントコメントから取得するようにしました。Semantic KernelではDescription属性から取ってきています。これはドキュメントコメントのほうが自然で書きやすいはずです。特にパラメーターへの属性は、書きやすさだけじゃなく、複数パラメーターがある場合にかなり読みづらくなります。
また、Source Generatorではアナライザーとして不足がある際にはコンパイルエラーにできます。
全てのパラメーターにドキュメントコメントが書かれていなければならない・対応していない型を利用している、などのチェックが全てコンパイル時どころかエディット時にリアルタイムに分かります。
難点は実装難易度がSource Generatorのほうが高いことと、ドキュメントコメントの利用にはかなり注意が必要です。
Roslyn上でドキュメントコメントを取得するには、ISymbol.GetDocumentationCommtentXml()が最もお手軽なのですが、これが取得できるかどうかは<GenerateDocumentaionFile>に左右されます。falseの場合は常にnullを返します。それだと使いにくすぎるので、ClaudiaではSyntaxNodeから取得しようとしたのですが、それも同じく<GenerateDocumentaionFile>の影響を受けていました。
そこでしょうがなく、以下のような拡張メソッドを用意することで全ての状況でドキュメントコメントを取得することに成功しました(Triviaベースなので少し扱いづらいですが、取れないよりも遥かにマシ)
public static DocumentationCommentTriviaSyntax? GetDocumentationCommentTriviaSyntax(this SyntaxNode node)
{
if (node.SyntaxTree.Options.DocumentationMode == DocumentationMode.None)
{
var withDocumentationComment = node.SyntaxTree.Options.WithDocumentationMode(DocumentationMode.Parse);
var code = node.ToFullString();
var newTree = CSharpSyntaxTree.ParseText(code, (CSharpParseOptions)withDocumentationComment);
node = newTree.GetRoot();
}
foreach (var leadingTrivia in node.GetLeadingTrivia())
{
if (leadingTrivia.GetStructure() is DocumentationCommentTriviaSyntax structure)
{
return structure;
}
}
return null;
}
DocumentationModeの状態によってDocumentationCommentTriviaSyntaxが取れるかどうかが変わる(GenerateDocumentaionFile=falseの場合はNoneになる)ので、Noneの場合はDocumentationMode.Parseをつけたうえでパースし直すことで取得できました。SyntaxNodeのままオプションを渡してCSharpSyntaxTreeを生成しても、パースし直してくれないのかDocumentationModeを変更しても無駄だったので、文字列化してからParseTextするようにしています。
JSON Serializer
リクエストもレスポンスもJSONです、今の世の中。そして、使うライブラリはSystem.Text.Json.JsonSerializer一択です。異論を挟む余地は、ありますが、ない。好むと好まざると、もはや使わなければならないわけです。
System.Text.Jsonの特徴としてはUTF8ベースで処理ができることなので、極力文字列を通さないようにしてあげると高い性能が見込めます。ReadOnlySpan<byte>またはReadOnlySequence<byte>をデシリアライズするには Utf8JsonReaderを通す必要があります。これはref structだからアロケーションがないので、そのままnewして使っていきましょう。ではWriterは?というと、Utf8JsonWriterはclassです。どうして……?なので、Writerに関してはアプリケーションの作りによりますが、フィールドに持って使い回せるのならフィールドに持っての使いまわし(Resetがあります)、持てない場合は[ThreadStatic]から引っ張ってくるようにしましょう。
ライブラリで用意する場合は、利用する型が全て決まっているのでソース生成してあげると、パフォーマンスもよく、AOTセーフ度も上がるので望ましいはずです。Claudiaでも生成しています。
[JsonSourceGenerationOptions(
GenerationMode = JsonSourceGenerationMode.Default,
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull,
WriteIndented = false)]
[JsonSerializable(typeof(MessageRequest))]
[JsonSerializable(typeof(Message))]
[JsonSerializable(typeof(Contents))]
[JsonSerializable(typeof(Content))]
[JsonSerializable(typeof(Metadata))]
[JsonSerializable(typeof(Source))]
[JsonSerializable(typeof(MessageResponse))]
[JsonSerializable(typeof(Usage))]
[JsonSerializable(typeof(ErrorResponseShape))]
[JsonSerializable(typeof(ErrorResponse))]
[JsonSerializable(typeof(Ping))]
[JsonSerializable(typeof(MessageStart))]
[JsonSerializable(typeof(MessageDelta))]
[JsonSerializable(typeof(MessageStop))]
[JsonSerializable(typeof(ContentBlockStart))]
[JsonSerializable(typeof(ContentBlockDelta))]
[JsonSerializable(typeof(ContentBlockStop))]
[JsonSerializable(typeof(MessageStartBody))]
[JsonSerializable(typeof(MessageDeltaBody))]
public partial class AnthropicJsonSerialzierContext : JsonSerializerContext
{
}
// 内部での利用時は全てこのJsonSerializerContextを指定している
JsonSerializer.SerializeToUtf8Bytes(request, AnthropicJsonSerialzierContext.Default.Options)
一つ引っ掛かったのが、JsonIgnoreCondition.WhenWritingNullが、通常(リフレクションベース)だとNullable<T>にも効いていたのですが、Source Generatorだと効かなくなってnullの時に無視してくれなくなったという挙動の差異がありました。しょうがないので、全ての対象の型のNullable<T>プロパティに直接[JsonIgnore(Condition = JsonIgnoreCondition.WhenWritingDefault)]を付与することで回避しました。
public record class MessageRequest
{
// ...
[JsonPropertyName("temperature")]
[JsonIgnore(Condition = JsonIgnoreCondition.WhenWritingDefault)]
public double? Temperature { get; set; }
}
正直Source Generator版の実装漏れの気がするんですが、まぁ回避できたので、とりあえずはいっか。。。
まとめ
OpenAI APIに対するAzure OpenAI Serviceのように、AWS環境の人はAmazon Bedrock経由のほうが使いやすい、というのがあるかもしれません。というわけで本日の先ほどのリリース(v1.0.1)でBedrock対応もしました!より一層利用しやすくなったはずです。
Anthorpic APIを使うにあたって、このClaudiaが、公式SDKや各言語の非公式SDKも含めて、最も使いやすいSDKになっているんじゃないかと自負します。ということは、C#が最もClaudeをAPI経由で使うのに捗る言語ということです!これはC#やるしかない!あるいはClaudeやるしかない!ということで、やっていきましょう……!
R3 - C#用のReactive Extensionsの新しい現代的再実装
- 2024-02-27
先日、新しいC#用のReactive Extensionsの実装としてR3を正式公開しました!R3はRx for .NETを第一世代、UniRxを第二世代とした場合の、第三世代のRxという意味で命名しています。Rxとしてのコア部分(ほぼdotnet/reactiveと同様)は.NET共通のライブラリとして提供し、各プラットフォーム特化のカスタムスケジューラーやオペレーターは別ライブラリに分けるという形により、全ての.NETプラットフォーム向けのコアライブラリと、各種フレームワーク Unity, Godot, Avalonia, WPF, WinForms, WinUI3, Stride, LogicLooper, MAUI, MonoGame 向けの拡張ライブラリを提供しています。
幾つかの破壊的変更を含むため、ドロップインリプレースメントではないですが、dotnet/reactiveやUniRxからの移行も現実的に可能な範囲に収めてあります。この辺は語彙や操作がLINQ的に共通化されているというRxの良いところで、そこのところは大きく変わりはありません。思ったよりも何も変わっていない、といったような印象すら抱けるかもしれませんが、そう思っていただければ、それはそれでR3の設計としては大成功ということになります。
なので基本的なところはRxですし、使えるところも変わりないです。よって、押さえておくべきことは、なぜ今R3という新たな実装が必要になったかということと、Rx for .NET, UniRxとの違いはどこかということです。(新規の人は何も考えず使ってください……!)
機能とか移行とかの話は、toRisouPさんにより既に優れた記事が上がっているので、今回は概念的なところを中心に紹介します……!
Rxの歴史と vs async/await
Rx使ってますか?という問いに、使ってません、と答える人も増えてきました。別にこれは.NETやUnityだけの話ではなく、JavaでもSwiftでもKotlinでも。明らかにプレゼンスが低下しています。なぜか?というと、それはもう簡単です。async/awaitが登場したから。.NETのReactive Extensionsが初登場したのは2009年。C# 3.0, .NET Framework 3.5の頃であり、対応プラットフォームもSilverlightやWindows Phoneといった、今はもう消滅したプラットフォームも並んでくるような時代。もちろん、async/await(初登場はC# 5.0, 2012年)も存在していません。まだTaskすら導入されていなかった頃です。余談ですがReactive Extensionsの"Extensions"は、先行して開発されていたParallel Extensions(Parallel LINQやTask Parallel Library, .NET Framework 4.0で追加された)から名前が取られたとされています。
Rxは、まず、言語サポートのない場合の非同期処理の決定版として、あらゆる言語に普及し一世を風靡しました。単機能なTaskやPromiseよりも、豊富なオペレーターを備えたRxのほうが使いやすいし遥かに強力!私も当時はTPLいらね、とRxに夢中になったものです。しかしasync/awaitが言語に追加されて以降の結果はご存じの通り。async/awaitこそが非同期処理の決定版として、これまたC#からあらゆる言語に普及し、非同期処理におけるスタンダードとなりました。(ちなみにF#こそが発祥だって言う人もいますが、国内海外問わず当時のF#コミュニティのC# async/awaitへの反発と難癖の数々はよーく覚えているので、あ、そうですか、ぐらいの感じです。awaitないしね)
async/awaitが普及したことにより、とりあえず非同期処理のためにRxを入れるという需要はなくなり、Rxの採用率は下がっていったのであった。UnityにおいてのRxのスタンダードであったUniRxの開発者である私も、別にそれに固執することはなく、むしろゲームエンジン(Unity)に特化したasync/awaitランタイムが必要であると素早く認知し、Unityにおいて必要な条件(C# 7.0)が揃ったタイミングで即座にUniTaskを開発し、今ではUniTaskは絶対に入れるけどUniRxは入れない、といった開発者も増えてきました。そしてそれは悪いことではなく、むしろ正しい感覚であると思います。
Rxの価値の再発見
そもそもRxって別に非同期処理のためだけのシステムではないですよね?LINQ to Everythingではあったけれど、むしろEverythingというのはノイズで、分離するものは分離したほうがいい、最適なものはそれを使ったほうがいい。Rxを非同期処理のために使うべきではないし、長さ1のObservableはTaskで表現したほうが、分かりやすさにおいてもパフォーマンスにおいても利点がある。そうなるとRxにはasync/awaitと統合されたAPIが必要で、それはObservableはモナドだからSelectManyにTaskを渡せることもできるだとか、そんなどうでもいいことではない。真剣にasync/awaitと共存するRxを考えてみると、手を加えなければならないAPIは多数ある。
単純にawaitできるだけでは現実のアプリケーション開発には少し足りない。そこで非同期/並列処理に関しては様々なライブラリが考案されてきました、RxだけではなくTPL Dataflowなど色々ありましたが、それらを好んで今から使おうとする人もいないでしょう。そして今は2024年、勝者は決まりました。言語サポートのIAsyncEnumerableとSystem.Threading.Channelsがベストです。また、これらはバックプレッシャーの性質も内包しているため、RxJavaなどにあるバックプレッシャーに関するオペレーターは.NETには不要でしょう。もう少し具体的なI/Oに関する処理が必要ならSystem.IO.Pipelinesを選べば、最大のパフォーマンスを発揮できます。
非同期LINQはあってもいいけれど、実際の非同期ストリームのシナリオからするとLINQ to Objectsと違い利用頻度も少ないので、別に積極的に導入したいというほどの代物ではない(なお、これは私はUniTaskにUniTaskAsyncEnumerableとLINQを自分で実装して提供している上での発言です)。Rxの夢の一つとして分散クエリ(IQbservable)がありましたが、それも、現代での勝者はGraphQLになるでしょう。分散システムという点ではKubernetesが普及し、RPCとしてはgRPCがスタンダードとして君臨し、Orleans, Akka.NET, SignalR, MagicOnionといったような選択肢のバリエーションもあります。
今は様々なテクノロジーが覇権を争った2009年ではない。現代でService Fabricを選ぶ人などいないように、今からそこに乗り出して勝ち筋を見出すのは難しい。そうした分散処理に進むことはRxの未来ではない。と、私は考えています。Rxを生み出したのがCloud Programmability Teamであるからといって、Cloudで活用できるようにすることが原点で正しいなどということもないだろう。もちろん、未来は複数あってもいいので、私が示すRxの未来の選択肢の一つがR3だと思ってもらえればよいです。
ではRxの価値はどこにあるのか、というと、原点に立ち返ってインメモリのメッセージングをLINQで処理するLINQ to Eventsにあると考えます。特にクライアントサイド、UIに対する処理は、現代でもRxが評価されているポイントであり、Rx Likeな、しかしより言語に寄り添い最適化されているKotlin FlowやSwift Combineといった選択肢が現役で存在しています。UIだけではなく、複雑で大量のイベントが飛び交うゲームアプリケーションにおいても、ゲームエンジン(Unity)で使われているUniRxの開発者として、非常に有益であることを実感しています。オブザーバーパターンやeventの有意義さは疑う余地のないところですし、そこでRxがbetter event、オブザーパーパターンの決定版として使えることもまた変わらないわけです。
R3での再構築
最初に、Rxとしてのインターフェイスを100%維持しながらレガシーAPIの削除や新APIの追加をすべきか、それとも根本から変更すべきかを悩みました。しかし(私が問題だと考えている)すべての問題を解決するには抜本的な変更が必要だし、Kotlin FlowやSwift Combineの成功事例もあるので、旧来のRxとの互換性に囚われず、.NET 8, C# 12という現代のC#環境に合わせて再構築された、完全に新しいRxであるべきという路線に決めました。
といっても、最終的にはインターフェイスにそこまで大きな違いはありません。
public abstract class Observable<T>
{
public IDisposable Subscribe(Observer<T> observer);
}
public abstract class Observer<T> : IDisposable
{
public void OnNext(T value);
public void OnErrorResume(Exception error);
public void OnCompleted(Result result); // Result is (Success | Failure)
}
パッと見だとOnErrorがOnErrorResumeになったことと、interfaceではなくてabstract classになったこと、ぐらいでしょうか。どうしても変更したかった点の一つがOnErrorで、パイプライン上で例外が起きると購読解除されるという挙動はRxにおけるbillion-dollar mistakeだと思っています。R3では例外はOnErrorResumeに流れて、購読解除されません。かわりにOnCompletedに、SuccessまたはFailureを表すResultが渡ってくるようになっていて、こちらでパイプラインの終了が表されています。
IObservable<T>/IObserver<T>の定義はIEnumerble<T>/IEnumerator<T>と密接に関わっていて、数学的双対であると称しているのですが、実用上不便なところがあり、その最たるものがOnErrorで停止することです。なぜ不便かというと、IEnumerable<T>のforeachの例外発生とIObservable<T>の例外発生では、ライフタイムが異なることに起因します。foreachの例外発生はそこでイテレーターの消化が終わり、必要があればtry-catchで処理して、大抵はリトライすることもないですが、ObservableのSubscribeは違います。イベントの購読の寿命は長く、例外発生でも停止しないで欲しいと思うことは不自然ではありません。通常のeventで例外が発生したとて停止することはないですが、Rxの場合はオペレーターチェーンの都合上、パイプライン中に例外が発生する可能性が常にあります(SelectやWhereすればFuncが例外を出す可能性がある)。イベントの代替、あるいは上位互換として考えると、例外で停止するほうが不自然になってしまいます。
そして、必要があればCatchしてRetryすればいい、というものではない!Rxにおいて停止したイベントを再購読するというのは非常に難しい!Observableにはeventと異なり、完了するという概念があります。完了したIObservableを購読すると即座にOnError | OnCompletedが呼ばれる、それにより自動的な再購読は、完了済みのシーケンスを再購読しにかかる危険性があります。もちろんそうなれば無限ループであり、それを判定し正しくハンドリングする術もない。Stack OverflowにはRx/Combine/FlowのUI購読で再購読するにはどうすればいいですか?のような質問が多数あり、そしてその回答は非常に複雑なコードの記述を要求していたりします。現実はRepeat/Retryだけで解決していない!
そこで、そもそも例外で停止しないように変更しました。OnErrorという命名のままでは従来の停止する動作と混同する可能性があるため、かわりにOnErrorResumeという名前に変えています。これで再購読に関する問題は全て解決します。更にこの変更には利点があり、停止する→停止しないの挙動変更は不可能ですが(Disposeチェーンが走ってしまうので状態を復元できないので全体の再購読以外に手段がない)、停止しない→停止するへの挙動変更は非常に簡単でパフォーマンスもよく実装できます。OnErrorResumeが来たらOnCompleted(Result.Failure)に変換するオペレーターを用意するだけですから(標準でOnErrorResumeAsFailureというオペレーターを追加してあります)。
Rx自体が複雑なコントラクトを持つ(OnErrorかOnCompletedはどちらか一つしか発行されない、など)わりに、インターフェースは実装上の保証がないので、従来のRxは正しく実装するのが難しいという問題がありました。SourceのSubscribeが遅延される場合は、先行して返却されるDisposableを正しくハンドリングする必要がある(SingleAssignmentDisposableを使う)などといったことも、正しく理解することは難しいでしょう。SubscribeのonNextで発生した例外はどこに行くのか、onErrorに行ってDisposeされるのか継続されるのか。その動作は特に規定されていないため実装次第で挙動はバラバラの場合もあります。R3ではasbtract class化することにより大部分のコントラクトを保証し、挙動の統一と、独自実装を容易にしました。
そしてabstract classにした最大の理由は、全ての購読を中央管理できるようにしたことです。全てのSubscribeは必ず基底クラスのSubscribe実装を通ります。これにより、購読のトラッキングが可能になりました。例えば以下のような形で表示できます。
これはUnity向けの拡張Windowですが、Godot用にも存在するほか、APIとして提供しているためログに出したり任意のタイミングで取得したり、独自の可視化を作ることも可能です
TaskにはParallel Debuggerがありますが(これもTaskが基底クラス側でs_asyncDebuggingEnabledの時に中央管理している)、Rxの購読の可視化は、それよりも遥かに重要でしょう。イベントの購読リークはつきもので、開発終盤に必死に探し回る羽目になりますが、R3ならもう不要です!圧倒的開発効率アップ!
R3ではこうした購読の管理、リーク防止については最重要視していて、Observable Trackerによる全ての購読の追跡の他に、概念として「全てのObservableは完了することができる」ようにしました。
Rxにおける購読の管理の基本はIDisposableをDisposeすることです。が、購読を解除する方法は実はそれだけではなく、OnError | OnCompletedが流れることでも解除されるようになっています(IObservableのコントラクトが保証しているわけではないですが実装上そうなっている、R3では必ずそうなるように基底クラス側で保証するようにした)。つまりシーケンスの上流(OnError | OnCompletedの発行)と下流(Dispose)、両面からハンドリングすることでリークをより確実に防ぐことができます。
対応として過剰に思うかもしれませんが、実際のアプリケーションを開発してきた経験からいうと、購読管理は過剰なぐらいがちょうどいい。そうした思想から、R3では、今までOnCompletedを発行する手段のなかったObservable.FromEventやObservable.Timer、EveryUpdateなども、OnCompletedを発行可能にしました。なお、発行方法はCancellationTokenを渡すことで、これもasync/await以降に多用(あるいは濫用)されるようになったCancellationTokenを活用する現代的なAPI設計です。また、こうした全てのObservableは完了する、という思想があるため、SubjectのDisposeも標準でOnCompletedを発行するように変更しました。
ISchedulerを再考する
Rxの時空を移動するマジックを実現する機構がISchedulerです。TimerやObserveOnに渡すことで、任意の場所(ThreadやDispatcher、PlayerLoopなど)・時間に値を移動させることができます。
public interface IScheduler
{
DateTimeOffset Now { get; }
IDisposable Schedule<TState>(TState state, Func<IScheduler, TState, IDisposable> action);
IDisposable Schedule<TState>(TState state, TimeSpan dueTime, Func<IScheduler, TState, IDisposable> action);
IDisposable Schedule<TState>(TState state, DateTimeOffset dueTime, Func<IScheduler, TState, IDisposable> action);
}
そして、実は破綻しています。Rxのソースコードを見たことがあるなら気づいているかもしれませんが、初期のうちから追加の別の定義が用意されています。例えばThreadPoolSchedulerは以下のようなインターフェイスを実装しています。
public interface ISchedulerLongRunning
{
IDisposable ScheduleLongRunning<TState>(TState state, Action<TState, ICancelable> action);
}
public interface ISchedulerPeriodic
{
IDisposable SchedulePeriodic<TState>(TState state, TimeSpan period, Func<TState, TState> action);
}
public interface IStopwatchProvider
{
IStopwatch StartStopwatch();
}
public abstract partial class LocalScheduler : IScheduler, IStopwatchProvider, IServiceProvider
{
}
public sealed class ThreadPoolScheduler : LocalScheduler, ISchedulerLongRunning, ISchedulerPeriodic
{
}
そして、以下のような呼び出しがなされています。
public static IStopwatch StartStopwatch(this IScheduler scheduler)
{
var swp = scheduler.AsStopwatchProvider();
if (swp != null)
{
return swp.StartStopwatch();
}
return new EmulatedStopwatch(scheduler);
}
private static IDisposable SchedulePeriodic_<TState>(IScheduler scheduler, TState state, TimeSpan period, Func<TState, TState> action)
{
var periodic = scheduler.AsPeriodic();
if (periodic != null)
{
return periodic.SchedulePeriodic(state, period, action);
}
var swp = scheduler.AsStopwatchProvider();
if (swp != null)
{
var spr = new SchedulePeriodicStopwatch<TState>(scheduler, state, period, action, swp);
return spr.Start();
}
else
{
var spr = new SchedulePeriodicRecursive<TState>(scheduler, state, period, action);
return spr.Start();
}
}
ようは生のISchedulerを使わないケースがそれなりにあります。なぜ使われないのか、というと、パフォーマンス上の問題で、IScheduler.Scheduleは単発の実行しか定義されていなくて、複数回の呼び出しは再帰的にScheduleを呼べばいいじゃんという発想なわけですが、都度IDisposableを生成するなどパフォーマンス的に問題がある。ので、それを回避するためにISchedulerPeriodicなどが用意されたのでした。
それなら、もうISchedulerではなく、実態をまともに反映されたものを使ったほうがいいんじゃないか?と思ったときに出てきたのが.NET 8で追加されたTimeProviderで、これならISchedulerが行っていたことをより効率的にできることを発見しました。
public abstract class TimeProvider
{
// use these.
public virtual ITimer CreateTimer(TimerCallback callback, object? state, TimeSpan dueTime, TimeSpan period);
public virtual long GetTimestamp();
}
CreateTimerで生成されるITimerはISchedulerPeriodicで行える機能を十分持っているほか、ワンタイムの実行を繰り返す(Schedule<TState>(TState state, TimeSpan dueTime, Func<IScheduler, TState, IDisposable> action))のシナリオにおいても、ITimerを使いまわせるため、dotnet/reactiveのThreadPoolSchedulerよりも効率的です(ThreadPoolSchedulerは都度new Timer()している)。
現在時間の取得に関しては、DateTimeOffset IScheduler.NowのようにTimeProviderもDateTimeOffset TimeProvider.GetUtcNow()がありますが、使っているのはlong GetTimestampだけです。というのも、オペレーターの実装に必要なのはTicksだけなので、わざわざDateTimeOffsetに包むようなオーバーヘッドはないほうが良いので、生のTicksを扱って時間を計算します。
DateTimeOffset.UtcNowはOSのシステム時刻の変更の影響を受ける可能性もあるので、そういう点でもDateTimeOffsetを介さないGetTimestamp(標準ではStopwatch.GetTimestamp()からの高解像度タイマーが利用される)経由が良いでしょう。
ISchedulerのもう一つの問題として、同期的な処理を行うImmediateSchedulerやCurrentSchedulerがいます。これらにTimerやDelayなど時間系の処理を任せるとThread.Sleepするという、使うべきではない非同期コードのエミュレーションをするので、つまり、同期的なSchedulerは存在が悪なのでないほうがいいでしょう。R3では完全に消し、TimeProviderを指定するということは必ず非同期的な呼び出しであるということを徹底しました。
ImmediateSchedulerやCurrentSchedulerの問題はそれだけじゃなくて、そもそもパフォーマンスが致命的に悪いという問題があります。
Observable.Range(1, 10000).Subscribe()の結果
CurrentSchedulerはともかく、ImmediateSchedulerの結果が悪いのは直観に反するかもしれません。dotnet/reactiveのImmediateSchedulerは、Scheduleされるたびにnew AsyncLockScheduler()し、AsyncLockSchedulerが呼び出す基底クラスLocalSchedulerのコンストラクターがSystemClock.Registerし、それはlockしnew WeakReference<LocalScheduler>(scheduler)し、HashSet.Addします。パフォーマンスが悪いのも当然です(ただし再帰的な呼び出し時には都度SingleAssignmentDisposableを生成するだけに抑えられてはいます、それでも多いですが)
Rangeなんてめったに使わないから大丈夫と思いきや、実は意外なところでImmediateSchedulerはちょくちょく使われています。代表的なのがMergeで、これはISchedulerが無指定の場合はImmediateSchedulerを使うため、頻繁な購読を繰り返す作りになっていると、かなりの呼び出す回数になる可能性があります。実際、dotnet/reactiveをサーバーアプリケーションで使用した際に、MergeとImmediateSchedulerが原因でサーバーのメモリ使用量のかなりを占めたことがありました。その時はカスタムの軽量なスケジューラーを作成し、直接指定することで徹底的にImmediateSchedulerを避けることで何とかしました。Next dotnet/reactiveがあるなら、ImmediateSchedulerのパフォーマンスの改善は真っ先に行う必要があります。
SystemClock.Registerをしている理由としては、DateTimeOffset.UtcNowとシステム時刻の変更の監視のためのようです。つまり、最初からDateTimeOffsetではなくlongを使えば、このような致命的なパフォーマンス低下も招きませんでした。これもまたISchedulerのインターフェイス定義の失敗理由の一つです。
ところで、TimeProviderの採用によって、Microsoft.Extensions.Time.Testing.FakeTimeProviderを使い、標準的な手法でユニットテストが容易になったことも嬉しいところでしょう。
FrameProvider
他のRxでは見かけないがUniRxで絶大な効果を発揮したものとして、フレームベースのオペレーター郡があります。一定フレーム後に実行するDelayFrameや次フレームで実行するNextFrame、毎フレーム発行するファクトリーであるEveryUpdateや、毎フレーム値を監視するEveryValueChangedなど、ゲームエンジンで利用するにあたって便利なオペレーターが揃っています。
そこで気づいたのが、時間とフレームは概念的には似たものであり、ゲームエンジンだけでなく、UI処理ではメッセージループやレンダリングループという形で、様々なフレームワークに存在している。そこで、R3では新しくTimerProviderと対になるFrameProviderという形でフレームベースの処理を抽象化しました。これによってUnityだけに提供されていたフレームベースのオペレーターが、C#が動作するあらゆるフレームワーク(WinForms, WPF, WinUI3, MAUI, Godot, Avalonia, Stride, etc...)で動作せることができるようになりました。
public abstract class FrameProvider
{
public abstract long GetFrameCount();
public abstract void Register(IFrameRunnerWorkItem callback);
}
public interface IFrameRunnerWorkItem
{
// true, continue
bool MoveNext(long frameCount);
}
R3ではTimeProviderを要求するオペレーターがある場合、全てに対となる***Frameオペレーターを実装しました。
- Return <-> ReturnFrame
- Yield <-> YieldFrame
- Interval <-> IntervalFrame
- Timer <-> TimerFrame
- Chunk <-> ChunkFrame
- Debounce <-> DebounceFrame
- Delay <-> DelayFrame
- DelaySubscription <-> DelaySubscriptionFrame
- ObserveOn(TimeProvider) <-> ObserveOn(FrameProvider)
- Replay <-> ReplayFrame
- Skip <-> SkipFrame
- SkipLast <-> SkipLastFrame
- SubscribeOn(TimeProvider) <-> SubscribeOn(FrameProvider)
- Take <-> TakeFrame
- TakeLast <-> TakeLastFrame
- ThrottleFirst <-> ThrottleFirstFrame
- ThrottleFirstLast <-> ThrottleFirstLastFrame
- ThrottleLast <-> ThrottleLastFrame
- Timeout <-> TimeoutFrame
async/await Integration
まず、既存のRxにおいて良くない点である単一の値を返すObservableを徹底的に排除しました。これらはasync/awaitを使うべきで、単一の値を返したり、単一の値を期待して合成するようなオペレーターはバッドプラクティスに誘うノイズです。FirstはFirstAsyncになり、Task<T>を返します。AsyncSubjectはなくなり、TaskCompletionSourceを使ってください。
そのうえで、現在のC#コードは日常的に非同期のコードが返ってきます、が、基本的にはRxは同期コードしか受け取りません。うっかりすればFireAndForget状態になるし、SelectManyに混ぜるだけでは十分とはいえません。そこで、Where/Select/Subscribeに特殊なメソッド群を用意しました。
- SelectAwait(this
Observable<T>source,Func<T, CancellationToken, ValueTask<TResult>>selector,AwaitOperationawaitOperation = Sequential, ...) - WhereAwait(this
Observable<T>source,Func<T, CancellationToken, ValueTask<Boolean>>predicate,AwaitOperationawaitOperation = Sequential, ...) - SubscribeAwait(this
Observable<T>source,Func<T, CancellationToken, ValueTask>onNextAsync,AwaitOperationawaitOperation = Sequential, ...) - SubscribeAwait(this
Observable<T>source,Func<T, CancellationToken, ValueTask>onNextAsync,Action<Result>onCompleted,AwaitOperationawaitOperation = Sequential, ...) - SubscribeAwait(this
Observable<T>source,Func<T, CancellationToken, ValueTask>onNextAsync,Action<Exception>onErrorResume,Action<Result>onCompleted,AwaitOperationawaitOperation = Sequential, ...)
public enum AwaitOperation
{
/// <summary>All values are queued, and the next value waits for the completion of the asynchronous method.</summary>
Sequential,
/// <summary>Drop new value when async operation is running.</summary>
Drop,
/// <summary>If the previous asynchronous method is running, it is cancelled and the next asynchronous method is executed.</summary>
Switch,
/// <summary>All values are sent immediately to the asynchronous method.</summary>
Parallel,
/// <summary>All values are sent immediately to the asynchronous method, but the results are queued and passed to the next operator in order.</summary>
SequentialParallel,
/// <summary>Send the first value and the last value while the asynchronous method is running.</summary>
ThrottleFirstLast
}
SelectAwait, WhereAwait, SubscribeAwaitは非同期メソッドを受け取り、その非同期メソッドが実行されている間に届く値に対する処理のパターンを6パターン用意しました。Sequentialはいったんキューにためて非同期メソッドが完了したら新しい値を送ります。Dropは実行中に届いた値は全て捨てます、これはイベントハンドリングで多重Submit防止などに使えます。SwitchはObservable<Observable>.Switchと同様、Parallelは並列実行するものでObservable<Observable>.Mergeと同様、ですがわかりやすいでしょう。並列実行数も指定できます。SequentialParallelは並列実行しつつ、後続に流す値は届いた順序で保証します。ThrottleFirstLastは非同期メソッド実行中の最初の値と最後の値を送ります。
更に、以下の時間系のフィルタリングメソッドなども非同期メソッドを受け取るようになっています。
- Debounce(this
Observable<T>source,Func<T, CancellationToken, ValueTask>throttleDurationSelector, ...) - ThrottleFirst(this
Observable<T>source,Func<T, CancellationToken, ValueTask>sampler, ...) - ThrottleLast(this
Observable<T>source,Func<T, CancellationToken, ValueTask>sampler, ...) - ThrottleFirstLast(this
Observable<T>source,Func<T, CancellationToken, ValueTask>sampler, ...)
また、Chunkも同様に非同期メソッドを受け取るほか、SkipUntilには非同期メソッドと、Task, CancellationTokenを受け取れるようになっています。
- SkipUntil(this
Observable<T>source,CancellationTokencancellationToken) - SkipUntil(this
Observable<T>source,Tasktask) - SkipUntil(this
Observable<T>source,Func<T, CancellationToken, ValueTask>asyncFunc, ...) - TakeUntil(this
Observable<T>source,CancellationTokencancellationToken) - TakeUntil(this
Observable<T>source,Tasktask) - TakeUntil(this
Observable<T>source,Func<T, CancellationToken, ValueTask>asyncFunc, ...) - Chunk(this Observable
source, Func<T, CancellationToken, ValueTask> asyncWindow, ...)
例えばChunkの非同期関数版を使えば、固定時間ではなくてランダム時間でチャンクを生成するといった複雑な処理を、自然に簡単に書けるようになります。
Observable.Interval(TimeSpan.FromSeconds(1))
.Index()
.Chunk(async (_, ct) =>
{
await Task.Delay(TimeSpan.FromSeconds(Random.Shared.Next(0, 5)), ct);
})
.Subscribe(xs =>
{
Console.WriteLine(string.Join(", ", xs));
});
async/awaitは現代のC#に欠かせないコードですが、可能な限りスムーズにRxと統合されるように腐心しました。
Retry関連もasync/awaitを活用することで、よりベターなハンドリングができます。まず、以前のRxはパイプライン丸ごとのリトライしか出来ませんでしたが、async/awaitを受け入れられるR3なら、非同期メソッド実行単位でのリトライができます。
button.OnClickAsObservable()
.SelectAwait(async (_, ct) =>
{
var retry = 0;
AGAIN:
try
{
var req = await UnityWebRequest.Get("https://google.com/").SendWebRequest().WithCancellation(ct);
return req.downloadHandler.text;
}
catch
{
if (retry++ < 3) goto AGAIN;
throw;
}
}, AwaitOperation.Drop)
.SubscribeToText(text);
Repeatもasync/awaitと組み合わせることで実装できます。この場合、Repeatの条件に関する複雑なハンドリングがRxだけで完結させるよりも、容易にできるでしょう。
while (!ct.IsCancellationRequested)
{
await button.OnClickAsObservable()
.Take(1)
.ForEachAsync(_ =>
{
// do something
});
}
手続き的なコードは決して悪いことではないですし、場合によりRxのオペレーターだけで完結させるよりも可読性が高くなります。コーディングにおいて優先すべきは可読性の高さ(とパフォーマンス)です。より良いコードのためにも、Rxとasync/awaitをうまく連携させていきましょう。
CreateやCreateFromなどで、非同期メソッドからObservableを生成することもできます。ここから生成することで、オペレーターを無理やりこねくり回すよりも簡潔に記述することが可能かもしれません。
Create(Func<Observer<T>, CancellationToken, ValueTask> subscribe, ...)CreateFrom(Func<CancellationToken, IAsyncEnumerable<T>> factory)
名前付けのルール
R3では幾つかのメソッドの名前がdotnet/rectiveやUniRxから変更されています。例えば以下のものです。
Buffer->ChunkStartWith->PrependDistinct(selector)->DistinctByThrottle->DebounceSample->ThrottleLast
この変更の理由について説明しましょう。
まず、.NETにおいてLINQスタイルのライブラリを作成する場合に最優先すべき名前はLINQ to Objects(Enumerable)に実装されているメソッド名です。BufferがなぜChunkに変更されたかというと、.NET 6からEnumerable.Chunkが追加され、その機能がBufferと同じだからです。RxのほうがChunkの登場より遥か前なので、名前が違うのはどうにもならないのですが、何のしがらみもないのなら名称はLINQ to Objectsに合わせなければならない。よって、Chunk一択です。PrependやDistinctByも同様です。
ThrottleがDebounceに変更されたことには抵抗があるかもしれません。これは、そもそも世の中のスタンダードはDebounceだからです。Rx系でDebounceをThrottleという名前でやってるのはdotnet/reactiveだけです。世の中のRxの始祖はRxNetなのだから変えなきゃいけない謂われはない、と突っぱねることも正義ではあるんですが、もはや多勢に無勢の少数派なので、長いものに巻かれることもまた正しい。
Debounceに変えた理由はそれだけではなく、ThrottleFirst / ThrottleLastの存在もあります。これらはサンプリング期間の最初の値を採用する、または最後の値を採用する、というもので対になっています。で、(dotnet/reactiveの)Throttleは全然違う挙動なわけです、なのにThrottleという名前は混乱するでしょう。そももそもdotnet/reactiveにはThrottleFirstが存在せず、ThrottleLastに相当するSampleのみが存在するので大丈夫なのですが、ThrottleFirst/ThrottleLastを採用するなら、必然的に名前はDebounceにせざるを得ません。どちらかというとdotnet/reactiveの機能不足が悪い。
Sampleに関してはFirst/Lastという名前と機能の対称性からThrottleLastという名前に変更しました。dotnet/reactiveではFirstが存在しないのでSampleでも良かったのですが、ThrottleFirstを採用するなら、必然的に名前はThrottleLastになります。
Sampleの名前は残してThrottleLastのエイリアスにするという折衷案もあるのですが(RxJavaなどはそうなっています)、同じ機能の別名があるとユーザーは混乱します。世の中にはsampleとthrottleLastの違いってなんですか?みたいな質問がそれなりにあります。ただでさえ複雑なRx、無用な混乱を避けるためにもエイリアスは絶対にやめるべき。SelectをMap、WhereをFilterにマッピングするみたいなエイリアスは愚かの極みです。
プラットフォーム向けデフォルトスケジューラー
dotnet/reactiveにおいてデフォルトのスケジューラーはほとんど固定です。正確にはIPlatformEnlightenmentProviderやIConcurrencyAbstractionLayerというのものを適切に実装すれば、ある程度挙動を差し替えることも可能なのですが、無駄に複雑なうえに[EditorBrowsable(EditorBrowsableState.Never)]で隠されているしで、まともに使うことはほとんど想定されていないように見えます。
しかし、TimerやDelayなどはWPFであればDispatcherTimerで、UnityではPlayerLoop上のTimerで動くと、自動的にメインスレッドにディスパッチしてくれるので、ほとんどの場合でObserveOnが不要になるので便利ですしパフォーマンス上も有利に働きます。
R3ではシンプルにデフォルトのTimeProvider/FrameProviderを差し替えられるようにしました。
public static class ObservableSystem
{
public static TimeProvider DefaultTimeProvider { get; set; } = TimeProvider.System;
public static FrameProvider DefaultFrameProvider { get; set; } = new NotSupportedFrameProvider();
}
アプリケーション起動時に差し替えれば、そのアプリケーション上でベストなスケジューラーがデフォルト利用されます。
// 例えばWPFの場合はDispatcher系がセットされるので自動的にUIスレッドに戻ってくる
public static class WpfProviderInitializer
{
public static void SetDefaultObservableSystem(Action<Exception> unhandledExceptionHandler)
{
ObservableSystem.RegisterUnhandledExceptionHandler(unhandledExceptionHandler);
ObservableSystem.DefaultTimeProvider = new WpfDispatcherTimerProvider();
ObservableSystem.DefaultFrameProvider = new WpfRenderingFrameProvider();
}
}
// Unityの場合はPlayerLoopベースのものが使用されるのでThreadPoolを避けれる
public static class UnityProviderInitializer
{
[RuntimeInitializeOnLoadMethod(RuntimeInitializeLoadType.AfterAssembliesLoaded)]
public static void SetDefaultObservableSystem()
{
SetDefaultObservableSystem(static ex => UnityEngine.Debug.LogException(ex));
}
public static void SetDefaultObservableSystem(Action<Exception> unhandledExceptionHandler)
{
ObservableSystem.RegisterUnhandledExceptionHandler(unhandledExceptionHandler);
ObservableSystem.DefaultTimeProvider = UnityTimeProvider.Update;
ObservableSystem.DefaultFrameProvider = UnityFrameProvider.Update;
}
}
dotnet/reactiveがデフォルトスケジューラーを変更できないのは、あまり、多種のプラットフォームをサポートしているとは言い難いでしょう。
internal static class SchedulerDefaults
{
internal static IScheduler ConstantTimeOperations => ImmediateScheduler.Instance;
internal static IScheduler TailRecursion => ImmediateScheduler.Instance;
internal static IScheduler Iteration => CurrentThreadScheduler.Instance;
internal static IScheduler TimeBasedOperations => DefaultScheduler.Instance;
internal static IScheduler AsyncConversions => DefaultScheduler.Instance;
}
特にAOTのシナリオやWeb向けパブリッシュ(WASM)では、ThreadPoolが使えなくて絶対に避けたいという状況もあります。そこでSchedulerDefaults.TimeBasedOperationsが実質ThreadPoolSchedulerに固定されているのは厳しいと言わざるを得ません。
Pull IAsyncEnumerable vs Push Observable
IAsyncEnumerable(またはUniTaskのIUniTaskAsyncEnumerable)は、Pullベースの非同期シーケンス。RxはPushベースの非同期シーケンス。似てます。LINQ的なことができるのも似てます。どちらを使うべきかがケースバイケースなのは当然だとして、じゃあそのケースってのはなんなのか、いつどちらを使えばいいのか。という判断基準は欲しいところです。
基本的には裏にバッファー(キュー)があるものはPullベースが向いていると思うので、ネットワーク系のシナリオなんかはIAsyncEnumerableを使っていくといいんじゃないでしょーか。で、実際、System.IO.PipelinesやSystem.Threading.Channelsによって自然と使う機会が出てきます。
Rxを使うべきところは、やはりイベント関連です。
どちらを使うべきかの判断の決め手は、源流のソースにとって自然な表現を選ぶべき、ということです。生のイベント、OnMoveであったりOnClickであったりなどは、完全にPushで、そこにバッファーはありません。ということは、Rxで扱うほうが自然です。間にキューを挟んでIAsyncEnumerableで扱うこともできますが、不自然ですよね。あるいはキューを介さないことにより意図的に値をDropするという表現をすることもできますが、やはりそれも不自然です。不自然ということはたいていはパフォーマンスも良くないし、分かりやすくもない。つまり、良くない。だから、イベント関連はRxで扱いましょう。R3ならasync/awaitとの統合によって、非同期処理中のバッファリングや値のドロップなどは明示的にオペレーターで指定することができます。それは、分かりやすく、パフォーマンスも良い。R3を使っていきましょう。
C#パフォーマンス勉強会
ところで4/27にC#パフォーマンス勉強会という勉強会が大阪で(大阪で!)開催されます。私は「R3のコードから見る実践LINQ実装最適化・コンカレントプログラミング実例」というタイトルで、R3の!実装の!パフォーマンス上の工夫を!徹底的に解説しようと思っているので、参加できる方はぜひぜひです。関西へは滅多に行かないので貴重な機会ということなのでよろしくお願いします!
まとめ
色々言いましたが、オリジナルのRx.NETの作者達には感謝しかありません。改めて、やはりRxのアイディアの素晴らしさや、各種オペレーターの整理された機能には目を見張るものがあります。幾つかの部分の実装は古くなってしまっていますが、実装クオリティも高いと思います。私自身も最初期から使ってきたし、熱狂してきました。そして、現在のメンテナーにも感謝します。常に変わっていく環境の中で、多く使われているライブラリを維持することはとても大変なことです。
しかし、だからこそ、Rxの価値を復活させたかった。そして、再構築するならば、できるのは私しかいないと思った。最初期からのRxの歴史と実装を知っていて、自分でRxそのものの実装(UniRx)を行い、それが世の中に広く使われることで多くのユースケースや問題点を知り、自分自身もゲームタイトルの実装で大規模に使われるRxのアプリケーション側にも関わり、Rxと対となるasync/awaitの独自ランタイム(UniTask)を実装し、それも世の中に広く使われていることで、この領域に関してのあらゆる知見がある。
上のほうでも言いましたが、未来は複数あってもいいので、私が示すRxの未来の一つがR3だと思ってもらえればよいです。dotnet/reactiveにもまた別の進化と未来がある。かもしれません。
そのうえでR3は置き換えられるだけのポテンシャルと、可能性を見せることができたと思っています。実装には自信あり、です。今回UniRxの実績があったからというのもあり、プレビュー公開時から多くのフィードバックがもらえたことは嬉しかったです(UniTask初公開時は、Unityのコンパイラを実験的コンパイラに差し替える必要があるとかいうエクストリーム仕様だったせいか、しばらくの間は誰も使ってくれなかったというか意義を分かってくれなかったので……)。
移行に関するシナリオも最大限配慮したつもりではあるので、是非使ってみてください……!