.NET(C#)におけるシリアライザのパフォーマンス比較
- 2010-05-29
ちょっとしたログ解析(細々としたのを結合して全部で10万件ぐらい)に書き捨てコンソールアプリケーションを使って行っていたのですが(データ解析はC#でLinqでコリっと書くのが楽だと思うんです、出力するまでもなく色々な条件を書いておいてデバッガで確認とか出来るし)、実行の度に毎回読んでパースして整形して、などの初期化に時間がかかってどうにも宜しくない。そこで、データ丸ごとシリアライズしてしまえばいいんじゃね?と思い至り、とりあえずそれならバイナリが速いだろうとBinaryFormatterを使ってみたら異常に時間がかかってあらあら……。
というしょうもない用途から始まっているので状況としては非現実的な感じではありますが、標準/非標準問わず.NET上で実装されている各シリアライザで、割と巨大なオブジェクトをシリアライズ/デシリアライズした時間を計測しました。そんなヘンテコな状況のパフォーマンスなんてどうでもいー、という人は、各シリアライザの基本的な使いかたの参考にでもしてください(いやまあ、どれもnewしてSerializeメソッド呼ぶだけですが)。ソースは後で出しますが、具体的に計測に使ったオブジェクトはテスト用クラスが10万件含まれたListです。まずは結果のほうを。
Serialize BinaryFormatter
00:00:06.4701421
53MB
Serialize XmlSerializer
00:00:07.7035246
59MB
Serialize DataContractSerializer
00:00:02.1545153
149MB
Serialize DataContractSerializer Binary
00:00:01.4706517
78MB
Serialize DataContractJsonSerializer
00:00:02.6021908
47MB
Serialize DataContractJsonSerializer Binary
00:00:02.5019512
75MB
Serialize NetDataContractSerializer
00:00:09.1802584
183MB
Serialize NetDataContractSerializer Binary
00:00:08.1960399
99MB
Serialize Formatter`1 - Protocol Buffers
00:00:00.7043000
13MB
Serialize MsgPackFormatter - MessagePack
00:01:33.3844083
46MB
Serialize JsonSerializer - JSON.NET
00:00:07.4997295
38MB
Serialize JsonSerializer - JSON.NET BSON
00:00:11.7767353
44MB
Deserialize BinaryFormatter
00:00:59.1693980
Check => OK
Deserialize XmlSerializer
00:00:02.7073623
Check => NG
Deserialize DataContractSerializer
00:00:06.3459340
Check => OK
Deserialize DataContractSerializer Binary
00:00:03.5622500
Check => OK
Deserialize DataContractJsonSerializer
00:00:10.5392504
Check => OK
Deserialize DataContractJsonSerializer Binary
00:00:07.2658857
Check => OK
Deserialize NetDataContractSerializer
00:00:09.1020073
Check => OK
Deserialize NetDataContractSerializer Binary
00:00:07.4024345
Check => OK
Deserialize Formatter`1 - Protocol Buffers
00:00:00.9176016
Check => OK
Deserialize MsgPackFormatter - MessagePack
00:00:29.8292134
Check => OK
Deserialize JsonSerializer - JSON.NET
00:00:11.7517757
Check => OK
Deserialize JsonSerializer - JSON.NET BSON
00:00:12.0099519
Check => OK
対象シリアライザ、かかった時間、シリアライズ時は出力ファイルサイズ、デシリアライズ時は正しく復元できたかを表示しています。
.NET標準ライブラリからはBinaryFormatter, XmlSerializer, DataContractSerializerとそのバイナリ出力, DataContractJsonSerializerとそのバイナリ出力, NetDataContractSerializerとそのバイナリ出力。オープンソースライブラリからは、GoogleのProtocol Buffersの.NET移植protobuf-net、国産のMessagePackのC#実装、Json.NETのJSONシリアライズとBSON(Mong DBで使われているバイナリ形式のJSON)のシリアライズを出力しました。
BinaryFormatter遅くね?が発端であり裏付けるように、BinaryFormatterのデシリアライズが異常に遅い。他が数秒なのに1分かかってます。テスト用データの詳細は後で述べますが、どうもObjectの配列が含まれていると遅くなるようです。テストデータにはKeyValuePair[]を含んでいるので、それが引っかかって激遅に。シリアライザする対象によって速度が変化するのは分かりますが、幾らなんでも限度を超えた速度低下。バグじゃないかしら?と言いたい。DataContractSerializerでもバイナリが吐ける昨今、もはやObsoleteにしてもいい雰囲気すら漂う。
XmlSerializerが速い・サイズ少ないという感じですがデシリアライズでCheck => NGと表記されているように、シリアライズに失敗しています。テストデータにKeyValuePair[]が含まれているのですが、それがシリアライズ出来なくて空配列になってしまったため。Dictionaryがシリアライズ出来なかったりと、XmlSerializerは割と使いにくいところがあります。今だとガイドライン的にも、XmlのAttributeの設定とか出力するXMLを細かく制御するならXmlSerializer、そうでないならDataContractSerializerのほうを推奨、とのことです。
そのDataContractSerializerはファイルサイズが嵩んでいるのが難点。属性などを付与していないため、テストデータ中の自動プロパティが <_x003C_MyProperty1_x003E_k__BackingField>hoge1</_x003C_MyProperty1_x003E_k__BackingField> といったような、とんでもなく長ったらしいタグになってしまっているのが原因。DataMember属性で名前を振ってあげればマシになりますが、今回は属性未使用で計測としました。そんなDataContractSerializerですが、バイナリXMLとして保存するとファイルサイズが縮むので気になる場合はそちらを使えばいいのかも。パフォーマンスも良くなります。
DataContractJsonSerializerは、シリアライズ・デシリアライズの速度はXMLよりも劣っていますが、ファイルサイズに関しては(JSONなので当然とはいえ)比較にならないほど小さい。バイナリXMLよりも小さくて、中々優秀のようです。しかし、バイナリ化して保存すると逆にファイルサイズが膨らむという罠が。
NetDataContractSerializerはシリアライザ作る時に型指定がいらなかったりと利便性はちょびっと○。また、循環参照が含まれていても問題なくシリアライズ出来たりと、DataContractSerializer(素の状態だと循環参照が含まれると例外)とは若干毛色が違います。といった点から言っても、BinaryFormatterの後継はこれになるのでしょう。
Protocol Buffersは爆速な上に非常に縮んで素晴らしい!さすがGoogle。ということだけじゃなく、protobuf-netの実装も良いのでしょうね。APIも非常に練られていて使いやすいし、C#でのクラスから.protoファイルの生成とかも出来て大変便利。Silverlightで使えるし、Windows Phone 7でも動かせるよう調整中、とのことでかなり気に入りました。
MsgPackFormatterはシリアライズ、デシリアライズ共にかなり時間が……。これは、MessagePackが、というよりも、実装の方でオブジェクトグラフの生成に時間がかかってるようです。
JSON.NETは中々優秀な結果を出しています。しかし、Performance ComparisonでDataContractSerializerよりも速いぜ!と謳っていたけれど、そんなことはなく。こういうのは計測する内容によって変わってくるので一概にどうこう言えないんですねー、というのを知るなど。バイナリ化で逆にサイズが膨らむのはDataContractJsonSerializerと同様。なお、JSON.NETはAPIが正直使いにくくてどうにかならないのかねー、と思うので個人的には好きじゃありません。使いやすいAPI設計ってセンスが必要ですよね……。
コード
割と長ったらしいので、分割して。追試したい方はこちらに元ソース置いておくので使ってみてください。VS2010用。ライブラリ全部揃えるのも大変だと思うので、測定を省きたい項目はMainメソッドのリスト初期化子の部分で該当するものをコメントアウトすれば省けます。
[ProtoContract]
[Serializable]
public class TestClass : IEquatable<TestClass>
{
[ProtoMember(1)]
public string MyProperty1 { get; set; }
[ProtoMember(2)]
public int MyProperty2 { get; set; }
[ProtoMember(3)]
public DateTime MyProperty3 { get; set; }
[ProtoMember(4)]
public bool MyProperty4 { get; set; }
[ProtoMember(5)]
public KeyValuePair<string, string>[] MyProperty5 { get; set; }
public bool Equals(TestClass other)
{
return this.MyProperty1 == other.MyProperty1
&& this.MyProperty2 == other.MyProperty2
&& this.MyProperty3 == other.MyProperty3
&& this.MyProperty4 == other.MyProperty4
&& this.MyProperty5.SequenceEqual(other.MyProperty5);
}
public override int GetHashCode()
{
return this.MyProperty1.GetHashCode() + this.MyProperty2.GetHashCode();
}
}
これがテスト用クラスの中身です。string, int, DateTime, bool, KeyValuePair<string,string>[] とそこそこ満遍なく散りばめて、それとデシリアライズがちゃんと出来たか確認出来るようIEquatable<TestClass>を実装して値比較出来るようにしています。&&や||や三項演算子の:は前置にする派。綺麗に揃う感じが好き。属性はProtocol Buffersはつけないと動かないのでProtoMemberを指定していますが、それ以外は無指定です。指定した方が縮んだりとかありそうですが、私的には無指定の状態で調べたいなあ、と思ったのでなし。最適じゃない状態からのそれぞれのシリアライズ形式への生成、書き戻しの具合を見たいと思ったので。いや、単純に各実装で使う属性を調べるのが面倒だったという手抜きな理由もありますが。
public abstract class SerializerBenchmark
{
public static readonly List<TestClass> TestData;
static SerializerBenchmark()
{
TestData = Enumerable.Range(1, 100000)
.Select(i => new TestClass
{
MyProperty1 = "hoge" + i,
MyProperty2 = i,
MyProperty3 = new DateTime(1999, 12, 11).AddDays(i),
MyProperty4 = i % 2 == 0,
MyProperty5 = Enumerable.Range(1, 10)
.ToDictionary(x => x.ToString(), _ => i.ToString()).ToArray()
})
.ToList();
}
public static SerializerBenchmark<T> Create<T>(T serializer, Func<T, Action<Stream, Object>> serializeSelector, Func<T, Func<Stream, Object>> deserializeSelector, string optional = null)
{
return new SerializerBenchmark<T>(serializer, serializeSelector, deserializeSelector, optional);
}
public abstract void Serialize();
public abstract void Deserialize();
}
ベンチマークで重複コードのコピペ(ストップウォッチを前後に挟んだり)を省くために抽象クラスを作りました。このList<TestClass> TestDataが実際にシリアライズ/デシリアライズに使ったデータになります。Enumerable.Range(1, 100000)のToListで10万件のリスト生成。KeyValuePairの配列は、全て長さ10で、DictionaryのToArrayで作っています。
public class SerializerBenchmark<T> : SerializerBenchmark
{
private T serializer;
private string name;
Action<Stream, Object> serialize;
Func<Stream, Object> deserialize;
private string FileName { get { return name + ".temp"; } }
public SerializerBenchmark(T serializer, Func<T, Action<Stream, Object>> serializeSelector, Func<T, Func<Stream, Object>> deserializeSelector, string optional = null)
{
this.serializer = serializer;
this.name = serializer.GetType().Name + ((optional == null) ? "" : " " + optional);
this.serialize = serializeSelector(serializer);
this.deserialize = deserializeSelector(serializer);
}
private void Bench(string label, Action action)
{
GC.Collect();
Console.WriteLine(label + " " + name);
var sw = Stopwatch.StartNew();
action();
Console.WriteLine(sw.Elapsed);
}
private void OpenAndExecute(string path, Action<FileStream> action)
{
using (var fs = File.Open(path, FileMode.OpenOrCreate))
{
action(fs);
}
}
public override void Serialize()
{
Bench("Serialize", () => OpenAndExecute(FileName, fs => serialize(fs, TestData)));
Console.WriteLine(new FileInfo(FileName).Length / 1024 / 1024 + "MB");
}
public override void Deserialize()
{
List<TestClass> data = null;
Bench("Deserialize", () => OpenAndExecute(FileName, fs => data = (List<TestClass>)deserialize(fs)));
Console.Write("Check => ");
Console.WriteLine(TestData.SequenceEqual(data) ? "OK" : "NG");
}
}
こちらがベンチマークの中身。処理を共通化したかったのですが、各シリアライザがIFormatter(Serialize,Deserializeメソッドを持つインターフェイス)を実装している、なんてことは全くなくて共通化しようがなくてうぎゃー。せめてメソッド名が全てSerializeならdynamic使うという最終手段もあるけれど、DataContractSerializerのメソッド名はWriteObjectだし、ダメだこりゃ。
で、気づいたのがSerializeはAction<Stream, Object>、DeserializeはFunc<Stream, Object>だということ。というわけで、各メソッドそのものをコンストラクタで渡してあげる形にすることで共通化できた。めでたしめでたし。もはやFuncやActionのない世界は考えられませんね!え、Javaのことですか知りません。
Deserialize時には、正しくデシリアライズ出来たかのチェックを仕込んでいます。データがListなのでLinqのSequenceEqualで元データと値比較。Listの要素であるTestClassもIEquatableなので、全部値比較で確認。
static class Program
{
static void Main(string[] args)
{
var bench = new List<SerializerBenchmark>
{
SerializerBenchmark.Create(new BinaryFormatter(), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new XmlSerializer(typeof(List<TestClass>)), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new DataContractSerializer(typeof(List<TestClass>)), x => x.WriteObject, x => x.ReadObject),
SerializerBenchmark.Create(new DataContractSerializer(typeof(List<TestClass>)),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(new DataContractJsonSerializer(typeof(List<TestClass>)), x => x.WriteObject, x => x.ReadObject),
SerializerBenchmark.Create(new DataContractJsonSerializer(typeof(List<TestClass>)),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(new NetDataContractSerializer(), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new NetDataContractSerializer(),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(ProtoBuf.Serializer.CreateFormatter<List<TestClass>>(), x => x.Serialize, x => x.Deserialize, "- Protocol Buffers"),
SerializerBenchmark.Create(new MsgPackFormatter(), x => x.Serialize, x => x.Deserialize, "- MessagePack"),
SerializerBenchmark.Create(new JsonSerializer(),
x => (s, data) => new StreamWriter(s).Using(sw => new JsonTextWriter(sw).Using(tw=> x.Serialize(tw, data))),
x => s => new StreamReader(s).Using(sr => new JsonTextReader(sr).Using(tr=> x.Deserialize<List<TestClass>>(tr))),
"- JSON.NET"),
SerializerBenchmark.Create(new JsonSerializer(),
x => (s, data) => new BsonWriter(s).Using(bw => x.Serialize(bw, data)),
x => s => new BsonReader(s){ReadRootValueAsArray = true}.Using(br => x.Deserialize<List<TestClass>>(br)),
"- JSON.NET BSON")
};
bench.ForEach(b => b.Serialize());
Console.WriteLine();
bench.ForEach(b => b.Deserialize());
Console.ReadKey();
}
// IDisposable extensions
static void Using<T>(this T disposable, Action<T> action) where T : IDisposable
{
using (disposable) action(disposable);
}
static TR Using<T, TR>(this T disposable, Func<T, TR> func) where T : IDisposable
{
using (disposable) return func(disposable);
}
}
Listに突っ込んで、まとめてForEachで計測。でも何だかゴチャゴチャしててキタナイですね……。Listの最初の3つまでは良いんです。それぞれ一行で。SerializeとDeserialize登録するだけで。その次から想定外でして……。そう、Serializeは決して必ずしもAction<Stream, Object>じゃあなかった!例えばDataContractSerializerでバイナリXML化を行うには、WriteObjectにStreamじゃなくてXmlDictionaryWriterを渡さなきゃいけない。と、いうわけで、そういった特別対応が必要なメソッドには入れ子のラムダ式を作って処理しています。そのせいでゴチャゴチャと。もはや可読性の欠片もない。がくり。入れ子のラムダが出てくると読むのシンドイんですよね、可能な限り避けたいとは思ってるんですが……。
Using拡張メソッドは、using構文使うと式じゃなくて文になってラムダ式で書きづらくてウザいので無理やり式にするためのシロモノ。そのせいで入れ子が更に入れ子になって可読性落としてる気がする。何事もやりすぎはいけない。
まとめ
DataContractSerializer良いよね。XmlDictionaryWriter.CreateBinaryWriter突っ込めばバイナリ化も出来るし。あとprotobuf-netはこうして数字見ると本当に凄いね。と、いったことことぐらいしか言うことがなく。
それとは関係あったりなかったりで、Twitter素晴らしい。毎回思うけれど、やっぱTwitterは素晴らしい。もともとBinaryFormatterなんか遅くね?とTwitterに愚痴ったところからスタートして、色々な人にアドバイスを受けて最終的にこんな記事(斜め上なだけな気はする)になったわけで、Twitterなかったら「遅くね?以上終了」で終わってた。
私がTwitterをはじめたのはTwitterはじめましたとかいう記事で確認出来るところでは2008/01/04(CoD4について書いてますけど、CoD4のシングルはあんま好きじゃなかった、でもその後マルチプレイヤーにはまったので結局MW2買ってますね!)。しかも、この後も当分は何もポストしないままでいて、同年9月の三度目の正直とかいう記事でTwitter→はてダへの転送ツールを作ってからようやく始めてました。コードの一部が載ってますけど、postList.Addとかいうのが初々しいなあ。今だとforeach使ったら負け、.ToList()だろ常識的に考えて。ですね。あと、TrimStartの使い方を間違えてるという。1年半前の私のド素人っぷりが伺えて面白い。ていうか、考えてみると物凄く成長しましたね……。
そして今ではすっかりTwitter中毒です。あらあらうふふ。
アドバイス受けてばかりというのもアレですので、私でも応えられそうなのがTLに流れてきたり検索(キーワード「Linq」を割と頻繁に眺めてる)にかかった時は答えるようにしています。いや、あんましてないかも。積極的に答えるようにしていきたいなあ、と。そんなわけで、@neueccでTwitterやってるので気が向いたらフォローしてやってください。
JavaScriptエディタとしてのVisual Studioの使い方入門
- 2010-05-24
linq.jsってデバッグしにくいかも……。いや、やり方が分かればむしろやりやすいぐらい。という解説を動画で。HDなので文字が見えない場合はフルスクリーンなどなどでどうぞ。中身の見えないEnumerableは、デバッガで止めてウォッチウィンドウでToArrayすれば見えます。ウォッチウィンドウ内でメソッドチェーンを繋げて表示出来るというのは、ループが抽象化されているLinqならではの利点。sortしようが何しようが、immutableなので元シーケンスに影響を与えません。ラムダ式もどきでインタラクティブに条件を変えて確認出来たりするのも楽ちん。
ところで、JavaScript開発でもIDE無しは考えられません。デバッグというだけならFirebugもアリではありますが、入力補完や整形が可能な高機能エディタと密接に結びついている、という点でIDEに軍配があがるんじゃないかと私は思っています。動画中ではVisual Studioの無料版、Visual Web Developerを使っています。Visual Studioというと、何か敷居が高く感じられるかもしれませんが、使う部分を絞ってみれば、超高性能なHTML/JavaScriptエディタとして使えちゃいます。有料版の最高級エディションは170万円ですからね(MSDNという何でも使えるライセンスがセットなので比較は不公平ですが)、機能限定版とはいえ、その実力は推して知るべし、です(機能限定部分は、主にC#でのASP.NET開発部分に絡むものなのでJavaScript周りでは全く関係ありません)。
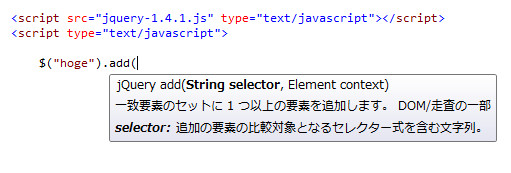
VSを使うと何が嬉しいのでしょう?JavaScriptでの強力な入力補完、自動整形、使いやすいデバッガ、リアルタイムエラー通知。そしてこっそり地味に大切なことですが、jQueryの完璧な日本語ドキュメント付き入力補完が同梱されています。と、嬉しいことはいっぱいあるのですが、ASP.NETの開発用ではあるので、JS開発には不要なメニューが多くて戸惑う部分も多いのは事実。分かれば不要部分はスルーするだけなので簡単なのですが、そこまでが大変かもしれない。なので、JavaScript開発で使うVisualStudio、という観点に絞って、何が必要で不要なのかを解説していきます。
インストール
何はともあれまずはインストール。Microsoft Visual Studio ExpressからVisual Web Developerを選び、リンク先のWeb Platform Installerとかいうのをダウンロード&実行。
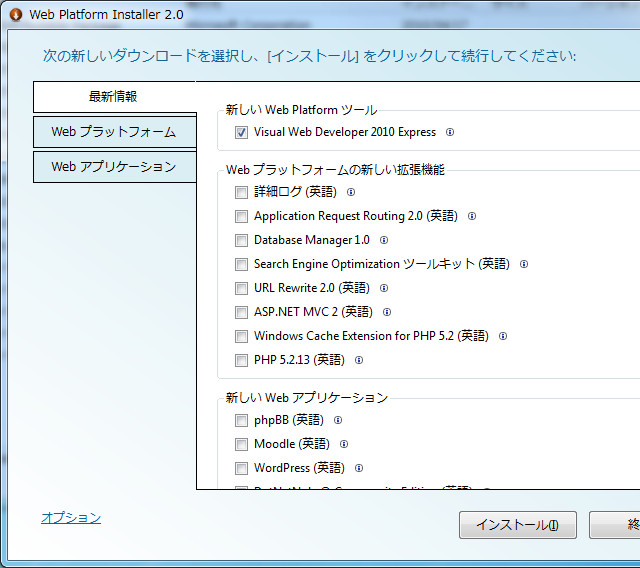
PHPとかWordPressとか色々ありますがどうでもいいので、Visual Web Developer 2010 Expressだけ入れましょう。クリックして指示に従って適当に待つだけ、10分ぐらいあれば終わるはず。10分は短くはないですが、インストール自体は非常に簡単です。
プロジェクト作成
実行すると初回起動時はイニシャライズが若干長いですが、それを超えれば新しいプロジェクトと新しいWebサイトの違いが分からねえええええ。で、ここは新しいWebサイトです。プロジェクトのほうはC#でASP.NETが基本なので関係ありません。スタートページから、もしくはファイル→新規作成→Webサイト。
![]()
更に項目があって分からねえ、けどここはASP.NET空のウェブサイトを選びます。次にソリューションエクスプローラーウィンドウを見ます(なければ表示→ソリューションエクスプローラー)。web.configとかいうゴミがありますが、それはスルーしておきましょう(消してもいいですが復活します)。空なので、ルートを右クリックして新しい項目の追加。
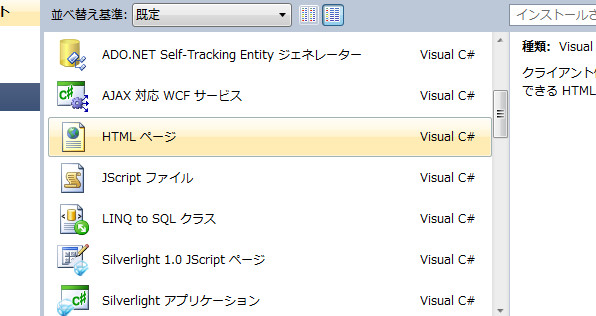
いっぱいあると思いますが、ほとんど関係ありません、ノイズです。真ん中ぐらいにあるHTMLページかJScriptファイルを選びましょう。あとは、エディタでガリガリと書いたら、Ctrl+F5を押せば簡易サーバーが立ち上がり、ブラウザ上に現在編集中のHTMLが表示されます。
以上が基本です。手順は簡単なので一度覚えればすんなり行くはずです。最初は如何せんHTML/JS用としてはダミー項目が多いのがやや難点。なお、保存時はデフォルトではMy DocumentのVS2010のWebSites下にHTMLとかが、Projects下に.slnファイル(プロジェクトを束ねている設定とかが書かれたファイル)が置かれています。以後プロジェクトをVSで開くときは.slnのほうをダブルクリック、もしくはスタートページの最近使ったプロジェクトから。
では、Visual Studioを使ってJavaScriptを書いて嬉しい!機能を幾つか挙げていきます。
エラー表示
小括弧が、波括弧が、足らなかったり足しすぎだったりを見落とすことは割とあります。そして起こる実行時エラー。こんなのコンパイルエラーで弾かれてくれ、あばばばば。と思うときはいっぱいあります。そこでVisual Studioのリアルタイムエラー検出。
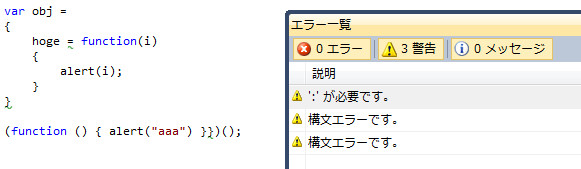
hoge = functionではなくhoge : function。下のは波括弧が一個多い。というのを、リアルタイムで検出してくれて、疑わしいところには波線を敷いてくれます。エラー一覧にも表示されるので、このウィンドウは常時表示させておくと書くのが楽になります。私は縦置きにしてエディタの左側にサイドバーとして常時表示。カラムはカテゴリと説明だけにしています。
エラー通知のためのコード走査はバックグラウンドで定期的に動いているようですが、任意に発動させたい場合はCtrl + Shift + Jで行えます。修正結果が正しいのかとっとと確認したいんだよ馬鹿やろー、って時に便利。というか普通に押しまくります、私は。
コードフォーマット
コード整形は大事な機能だと思っています。手動でスペース入れていくとか面倒くさいし。かといって整形が汚いコードは萎えます。

ショートカットはCtrl+K、で、Ctrlを押しながら続けてD。微妙に覚えにくいショートカット。ちなみに選択範囲のコメント化はCtrl+K, Cで、非コメント化はCtrl+K, U。ようするに整形系はCtrl+K始まりで、DはDocumentFormat、CはComment、UはUncommentの意味になるようです。フォーマットのルール(改行をどこに入れるか、とか)は設定で変えられます。
デバッグ
当然のようにブレークポイントの設定、ステップイン、ステップアウトなどのデバッグをサポートしています。

F9でブレークポイントを設定してF5でデバッグ実行。が基本です。ローカルウィンドウで変数の値表示、そして便利なのがウォッチウィンドウで、見たい値を好きに記述出来ます。式も書けるので平気で副作用かませます。で、デバッガで良いのはthisが見れるところですねー。JavaScriptはthisが不定で、いったいこの中のthisは何を指しているんだ!と悩んでしまうわけですが、そんなものデバッガで見れば一発で分かりますね、はは。考えるより前にとりあえずデバッグ実行。
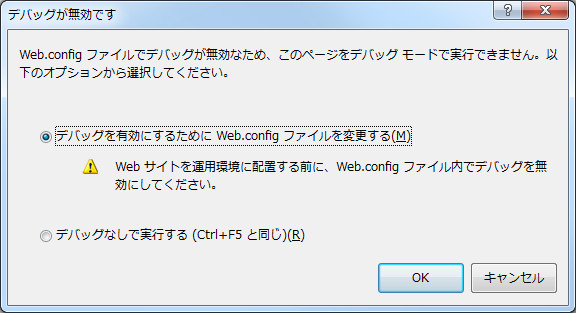
さて、そんなデバッグですが、初回時には何やら怪しげなダイアログが上がります。ここはYESで。そして、デバッグ出来ましたか?出来なかった人も多いかもしれません。実は、IEじゃないとデバッガ動かないのです。というわけで、ソリューションエクスプローラーからプロジェクトのルート部分を右クリックしてブラウザの選択を選ぶ。
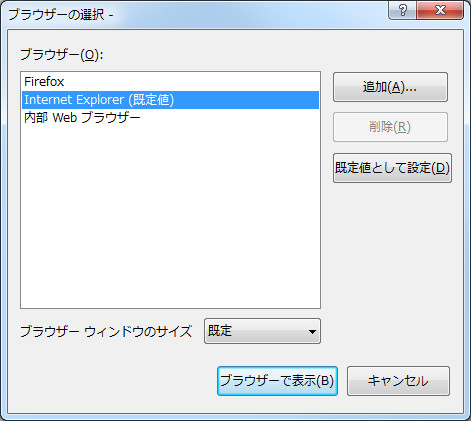
IEをデフォルトにしてください。一度設定すれば、以降はこの設定が継続されます。IEとか冗談じゃない。と思うかもしれませんが、えーと、IEで常に書くことで、IEで動かないスクリプトを書くことを避けられるのです、とかいうどうでもいい効用はあります。でもまあ、Firefox拡張とかChrome拡張を書くのにはデバッガが使えなくなるも同然なのは不便ですね。その時はデバッグは当然ブラウザ固有のデバッガを使い(デバッガを使わないと言う選択肢はないよ!)、エディタとしてだけに使えばいいぢゃない。
入力補完/日本語jQuery
入力補完(IntelliSense)は素敵。ローカル変数があればそれが出てくる。もう変数名打ち間違えで動かない、とかない。ドットを打てば、補完候補に文字列であればreplaceとか、配列であればjoinとか、DOMであればappendChildとか出てくる。メソッド名を暗記する必要もなければ、打ち間違えることもない。
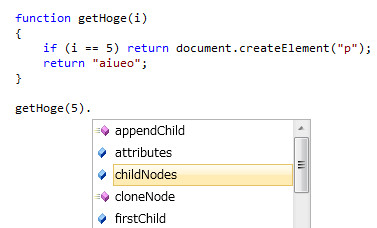
補完は割と賢くて、関数では引数を見て(というか裏でインタプリタ走ってるんですね、きっと)、ちゃんと返す値を判別してくれます。
ところでですが、最初の釣り画像にあるjQueryの日本語化ドキュメントはどこにあるのでしょうか?
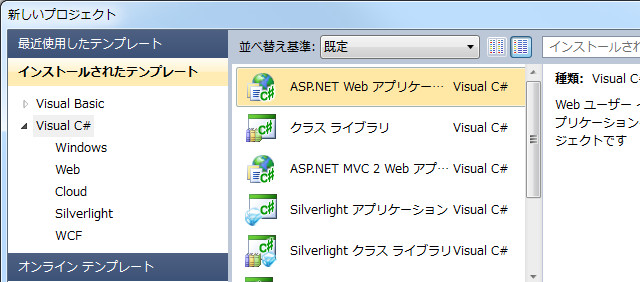
ファイル→新規作成→プロジェクトからASP.NET Webアプリケーションを選びます。すると、Scriptsフォルダの下にjquery-1.4.1-vsdoc.jsとかいうものが!こいつを、コピペって頂いてしまいましょう。ASP.NET Web Application自体はどうでもいいので破棄です、破棄。でもせっかくなので、Default.aspxを開いてCtrl+F5で実行してみてください。出来た!ウェブアプリが出来た!そう、C#+ASP.NETは驚くほど簡単にウェブアプリが作れるんです。あとは安レンタルサーバーさえ普及してくれれば……。
vsdocについて
-vsdoc自体は<script src>で読み込む必要はありませんし、実際にサーバーにアップロードする必要もありません。仕組みとしてはhoge.jsとhoge-vsdoc.jsが同じ階層にあると、VisualStudioの入力補完解析はhoge-vsdoc.jsを見に行く、といった感じになっています。なので、jquery-1.4.1.jsだけを読み込めばOKです。
HTMLファイルに記述する場合はscript srcで読み込めて補完が効くのは分かるけど、単独JSファイルの場合は読み込みの依存関係をどう指定すればよいでしょうか。答えは、ファイルの先頭にreference pathを記載します。
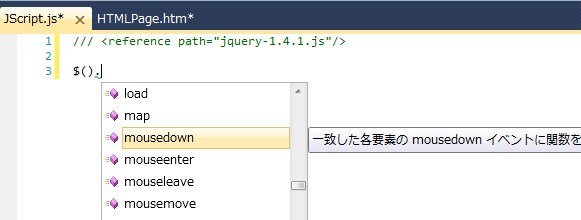
これで、JScript1.jsという単独JSファイルでもjQueryの補完が効かせられるようになりました。reference pathというのはVSだけで効果のあるタグで、ブラウザの解釈上はコメントに過ぎないので、ブラウザ表示時に問題が出ることもありません。
なお、このreference pathというのを覚えている必要はありません。refと記述してTabを二回押すとこのタグが展開されるはずです。コードスニペットというコード挿入の仕組みに予め用意されているわけです。なお、コードスニペットは、この他にもfor->Tab x2でforが展開されたりなど色々あって便利です(自分で作成することも出来る)。
その他設定など
その他、好みもありますが設定など。ツール→オプションから。
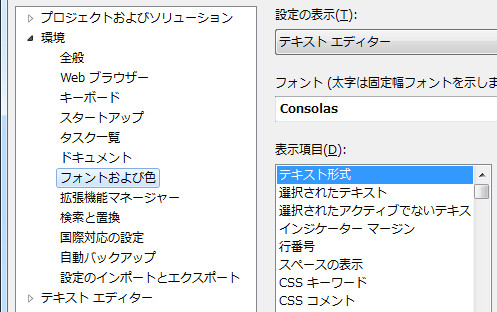
何はともかくフォントの変更。MSゴシックとかありえん。フォントをConsolasにしましょう! Consolasはプログラミング用のClearTypeに最適化された見やすい素敵フォントです。勿論、スラッシュドゼロ。サイズは私は9で使ってます。
Ctrl+F5押す度にアウトプットウィンドウが立ち上がるのが猛烈にウザいので、「ビルド開始時に出力ウィンドウを表示」のチェックは外しておく。
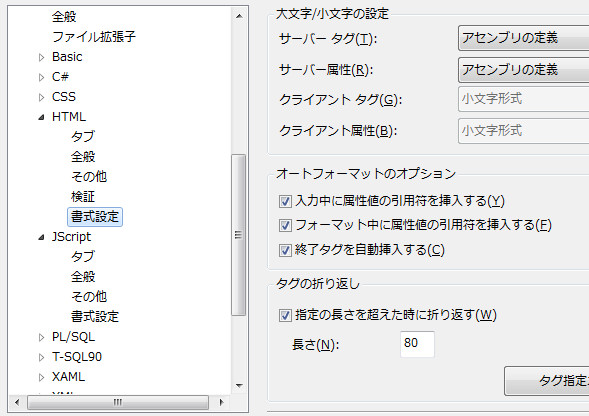
HTMLでの属性の引用符自動挿入はチェックつけといたほうが幸せ気分。
入力候補の、このTabかEnterのみで確定させるってのはチェックを外す。だってメソッド書くときは「(」で確定させたいし、オブジェクトを開くときは「.」で確定させたいもの。例えばdocument.getElementByIdは「doc -> Enter -> . -> get -> Enter -> (」じゃなくて「doc -> . -> get -> (」というように、スムーズに入力したい。一々Enterを挟むのは流れを止めてしまう。
まとめ
IDEを知ってて使わない、というのは個人の好き好きなのですが、単純に知らないというのは勿体無いな、と。特に初心者ほどIDEを必要とすると思います。初心者がプログラミング始めるなら、導入がメモ帳とブラウザだけで開発出来るJavaScriptお薦め!って台詞は、あまりよろしくないんじゃないかなー。初心者ほど些細なスペルミスや構文ミスでつまづく上に、目を皿のようにしてみても原因が分からない。たとえ導入までの敷居が若干高くなろうとも、親切にエラー箇所に波線を敷いてくれるIDEこそ必要なんじゃないかな。あと、デバッガ。ビジュアルに変数が動き変わることほど分かりやすいものもないでしょう。
IDEもEclipseのプラグインとか色々ありますが、Visual Studioの強力なjQuery対応度は何にも代え難いんじゃないでしょうか。導入もオールインワンなので何も考えなくてもいい簡単さですし。是非一度、試してみてもらえればいいなあ。
ついでですが、冒頭動画のlinq.jsは便利なJavaScriptライブラリ(無名関数を多用して関数型言語的にコレクション操作を可能にする)でいて、更にVisual Studioの入力補完に最適化してあるので使ってみてください、と宣伝。いや、作者私なので。ごほごほ。jQueryプラグインとして動作するバージョンも同梱してあります。
それと、勿論Visual Studioは有料版のほうが高機能な面もあります。JavaScript開発のみだとあまり差はないのですが、WindowsScriptHostをJavaScriptで書いてもデバッグ出来るとか無料版に比べて大したことない利点があるにはあります。C#でSilverlightなどもごりごり書きたい、とかになれば断然、有料版のほうが輝いてきます。
Ultimateは100万オーバーで無理なので、Professional買いましょう、私は買います。(メインはC#の人間なので。JSの人は正直Expressでイイと思うよ……)。まだ発売されてないのでこれから買います。「アップグレード」ですが、Express(無料版)からのアップグレードも認められているという意味不明仕様なので(誰が倍額する通常版買うんでしょうかね……)皆様も是非、上のリンクからamazonで買ってくれれば、ごほごほ。
DynamicJson ver 1.2.0.0
- 2010-05-21
DynamicJsonをver1.2.0.0に更新しました。おうぁぁぁぁ。Dynamicのまま配列をばらせないことに気づいた!foreachで列挙出来るのはいいけれど、Linqで、例えばSelectManyに渡せないぢゃん!ヤバいヤバい。バグではないけど、そんなんじゃ使い物にならない。ということでその辺のを修正しました。
何言ってるのかよくわからないですね、なわけで例を。
// page1から5までを取得して平らにする(で、古い順に並び替える)
var wc = new WebClient();
var statuses = Enumerable.Range(1, 5)
.Select(i =>
wc.DownloadString("http://twitter.com/statuses/user_timeline/neuecc.json?page=" + i))
.SelectMany(s => (dynamic[])DynamicJson.Parse(s))
.OrderBy(j => j.id);
foreach (var status in statuses)
{
Console.WriteLine(status.text);
}
neueccさん(私だ、私)の投稿を取得するわけですが、一回に20件しか取得出来ないので(countを指定すれば200件まで取れますけど)、複数ページ分取得して結合することにします。そういう場合はforでグルグル?ご冗談を、Modern C#(そんな定義ない)ではLINQを使います。
1ページのJSONは[{text:nantoka},{text:kantoka}] といった形に配列にデータが入った形で取得出来ます。それが5ページ分。[[{},{}],[{},{}]]といった感じなので、これを真平らにしてやりましょう。[{},{},{},{}]といった風に。それがSelectManyです。SelectManyは微妙にわかりにくいけれど、Linqの中でもかなり重要なんですよー。図解 SelectMany - NyaRuRuの日記なども参考に。
さて、この「.SelectMany(s => (dynamic[])DynamicJson.Parse(s))」って部分が、前は出来なかったのです、とほほほ。IEnumerable<T>を実装していれば(IEnumerable<dynamic>)で済んだのだけどなあ。そうすれば配列に変換しなくても済むので効率的にも良いし。Dynamic Viewと結果ビューが共存出来さえすれば……。
というわけですが、今回の修正で無事、出来るようになりました。配列変換は気にくわないけどしょうがない。IEnumerableを実装しているけれどDynamic Viewが使えるやり方募集中です。方法あったら誰か教えてくださいお願いします。
あと、キャストついでに、読み取り専用プロパティに対しても値をセットしようとして例外出るのを修正しました。これは、まあ、バグですね。仕様とか言ったら怒る。ていうかすみません。
linq.js ver 2.1.0.0 - ToDictionary, Share, Let, MemoizeAll
- 2010-05-18
CodePlex - linq.js - LINQ for JavaScript
linq.jsを2.0から2.1に更新しました。今回はただのメソッド追加というだけじゃなく、1.*の時から続いてる微妙コードを完全抹殺の一掃で書き換えた結果、内部的にはかなり大きな変更が入りました。その影響で挙動が変わってるところも割とあります。
まず、OrderByのロジックを変更しました。これで動作はC#完全準拠です(多分)。前のはかなりアレだったのでずっと書きなおしたいと思ってたのですが、やっと果たせました。従来と比べるとThenByを複数個繋げた時の挙動が変わってくる(今まではOrderByのみ安定ソートで、ThenBy以降は非安定ソートだったのが、今回からは幾つ繋げても安定ソートになります)ので、複雑なソートをやろうとしていた場合は違う結果が出る可能性はなきにしもあらず、ですが、基本的には変化なしと見て良いと思います。
ちなみにJavaScriptのArray.sortは破壊的だし、安定である保証もないので、linq.jsのOrderBy使うのは素敵な選択だと思いますよ!非破壊的で安定で並び替え項目を簡単に複数連結出来る(ThenBy)という、実に強力な機能を提供しています。代償は、ちょっと処理効率は重いかもですね、例によってそういうのは気にしたら負けだと思っている。
他に関係あるところで大きな変更はToLookup。戻り値を、今まではJSのオブジェクトだったのですが、今回からはlinq.jsの独自クラスのLookupになります。すみませんが、破壊的変更です、前と互換性ありません。変えた理由はJSのオブジェクトを使うとキーが文字列以外使えないため。そのことはわかっていて、でもまあいっかー、と思っていたのですがGroupByとか内部でToLookupを使ってるメソッドの挙動が怪しいことになってる(という報告を貰って気づいた)ので、ちゃんとした文字列以外でもキーに使えるLookupを作らないとダメだなー、と。
GroupByでのcompareSelector
そんなわけで、GroupByのキーが全部文字列に変換されてしまう、というアレゲなバグが修正されました。あと、オーバーロードを足して、compareKey指定も出来るようにしました。何のこっちゃ?というと、例えばDateもオブジェクトも参照の比較です。
alert(new Date(2000, 1, 1) == new Date(2000, 1, 1)); // false
alert({ a: 0} == { a: 0 }); // false
JavaScriptではどちらもfalse。別のオブジェクトだから。C#だとどちらもtrue、匿名型もDateTimeも、値が比較されます。そんなわけでJavaScriptで値で比較したい場合はJSONにでもシリアライズして文字列にして比較すればいいんじゃね?とか適当なことを言ってみたりはしますが、実際Linqだと参照比較のみだと困るシーン多いんですねえ。そんなわけで、GroupBy/ToLookup、その他多数のメソッドに比較キー選択関数を追加しました。例を一つ。
var objects = [
{ Date: new Date(2000, 1, 1), Id: 1 },
{ Date: new Date(2010, 5, 5), Id: 2 },
{ Date: new Date(2000, 1, 1), Id: 3 }
]
// [0] date:Feb 1 2000 ids:"1"
// [1] date:Jun 5 2010 ids:"2"
// [2] date:Feb 1 2000 ids:"3"
var test = Enumerable.From(objects)
.GroupBy("$.Date", "$.Id",
function (key, group) { return { date: key, ids: group.ToString(',')} })
.ToArray();
キーにDateを指定し、日付でグルーピングしたいと思いました(この程度の指定で関数書くのは面倒くさいし視認性もアレなので、文字列指定は非常に便利です)。しかし、それだけだと、参照比較なので同じ日付でも別物として扱われてしまうのでグルーピングされません。$.Date.toString()として文字列化すれば同一日時でまとめられるけれど、Keyが文字列になってしまう。後で取り出す際にKeyはDateのまま保っていて欲しい、といった場合にどうすればいいか、というと、ここで今回新設した第四引数のcompareSelectorの出番です。
// [0] date:Feb 1 2000 ids:"1,3"
// [1] date:Jun 5 2010 ids:"2"
var test2 = Enumerable.From(objects)
.GroupBy("$.Date", "$.Id",
function (key, group) { return { date: key, ids: group.ToString(',')} },
function (key) { return key.toString() })
.ToArray();
比較はキー(この場合$.Date)をtoStringで値化したもので行う、と指定することで、思い通りにグループ化されました。なお、C#でもこういうシーン、割とありますよね。C#の場合はIEqualityComparerを指定するのですが、わざわざ外部にクラス作るのは大変どうかと思う。といった時はAnonymousComparerを使えばlinq.jsと同じようにラムダ式でちゃちゃっと同値比較出来ます。
なお、今回からGroupByの第三引数(resultSelector)が未指定の場合はGroupingクラスが列挙されるように変更されました。GroupingはEnumerableを継承しているので全てのLinqメソッドが使えます。その他に、.Key()でキーが取り出しできるというクラスです。
Lookup
LookupはGroupByの親戚です。むしろGroupByは実はToLookupしたあと即座に列挙してるだけなのだよ、ナンダッテー。で、何かというとMultiDictionaryとかMultiMapとか言われてるような、一つのキーに複数個の要素が入った辞書です。そして、immutableです。不変です。変更出来ません。
var list = [
{ Name: "temp", Ext: "xls" },
{ Name: "temp2", Ext: "xLS" },
{ Name: "temp", Ext: "pdf" },
{ Name: "temp", Ext: "jpg" },
{ Name: "temp2", Ext: "PdF" }
];
var lookup = Enumerable.From(list).ToLookup("$.Ext", "$.Name", "$.toLowerCase()");
var xls = lookup.Get("XlS"); // toLowerCaseが適用されるため大文字小文字無視で取得可
var concat = xls.ToString("-"); // temp-temp2 <- lookupのGetの戻り値はEnumerable
var zero = lookup.Get("ZZZ").Count(); // 0 <- Getで無いKeyを指定するとEnumerable.Emptyが返る
// ToEnumerableでEnumerableに変換、その場合はGroupingクラスが渡る
// Groupingは普通のLinqと同じメソッド群+.Key()でキー取得
lookup.ToEnumerable().ForEach(function (g)
{
// xls:temp-temp2, pdf:temp-temp2, jpg:temp
alert(g.Key() + ":" + g.ToString("-"));
});
ToLookup時に第三引数を指定すると、戻り値であるLookupにもその比較関数が有効になり続けます。今回はtoLowerCaseを指定したので、大文字小文字無視でグルーピングされたし、Getによる取得も大文字小文字無視になりました。なお、GroupByでもそうですが、キーは文字列以外でも何でもOKです(compareSelectorを利用する場合はその結果が数字か文字列か日付、そうでない場合はそれそのものが数字か文字列か日付を使う方が速度的に無難です、後で詳しく述べますが)。
Dictionary
Lookupは内部でDictionaryを使うためDictionaryも作成、で、せっかく作ったのだから公開しますか、といった感じにToDictionaryが追加されました。ToObjectと違い、文字列以外をキーに指定出来るのが特徴です。
// 従来は
var cls = function (a, b)
{
this.a = a;
this.b = b;
}
var instanceA = new cls("a", 100);
var instanceB = new cls("b", 2000);
// オブジェクトを辞書がわりに使うのは文字列しか入れられなかった
var hash = {};
hash[instanceA] = "zzz";
hash[instanceB] = "huga";
alert(hash[instanceA]); // "huga" ([Object object]がキーになって上書きされる)
// linq.jsのDictionaryを使う場合……
// new Dictionaryはできないので、新規空辞書作成はこれで代用(という裏技)
// 第三引数を指定するとハッシュ値算出+同値比較にその関数を使う
// 第三引数が不要の場合はToDictionary()でおk
var dict = Enumerable.Empty().ToDictionary("", "",
function (x) { return x.a + x.b });
dict.Add(instanceA, "zzz");
dict.Add(instanceB, "huga");
alert(dict.Get(instanceA)); // zzz
alert(dict.Get(instanceB)); // huga
// ...といったように、オブジェクト(文字列含め、boolでも何でも)をキーに出来る。
// ToEnumerableで列挙も可能、From(obj)と同じく.Key .Valueで取り出し
dict.ToEnumerable().ForEach(function (kvp)
{
alert(kvp.Key.a + ":" + kvp.Value);
});
空のDictionaryを作りたい場合は、空のEnumerableをToDictionaryして生成します。微妙に裏技的でアレですが、まあ、こういう風に空から使うのはオマケみたいなものなので。というかToDictionaryメソッド自体がオマケです。DictionaryはLookupに必要だから作っただけで、当初は外部には出さないつもりでした。
第三引数を指定しないとオブジェクトを格納する場合は線形探索になるので、格納量が多くなると重くなります(toStringした結果をハッシュ値に使うので、Dateの場合は値でバラつくので大丈夫です、普通のオブジェクトの場合のみ)。第三引数を指定するとハッシュ値の算出にそれを使うため、格納量が増えても比較的軽量になります(ハッシュ衝突時はベタにチェイン法で探索してます)。なお、第三引数はハッシュ関数、ではあるのですが、それだけじゃなくて同値比較にも利用します。GetHashCodeとEqualsが混ざったようなものなので、ようするにAnonymousComparerのデフォルト実装と同じです。
勿論、ハッシュ関数と同値比較関数は別々の方が柔軟性が高いんですが(特にJavaScriptはハッシュ関数がないから重要性は高いよね!)、別々に設定って面倒くさいしぃー、結局一緒にするシーンのほうが割と多くない?と思っているためこのようなことになっています。というだけじゃなくて、もしequalsとgetHashCodeを共に渡すようにするなら{getHashCode:function(), equals:function()} といった感じのオブジェクト渡しにすると思うんですが、私はIntelliSenseの効かない、こういうオブジェクト渡しが好きではないので……。
メソッドはIDictionaryを模しているためAdd, Remove, Contains, Clear、それにインデクサが使えないのでGet, Set、EnumerableではないかわりにToEnumerableでKeyValuePairの列挙に変換。Addは重複した場合は例外ではなく上書き、Getは存在しない要素を取得しようとした場合は例外ではなくundefinedを返します。この辺はC#流ではなく、JavaScript風に、ということで。
GroupingはEnumerableを継承しているのに、DictionaryとLookupは継承していないのでToEnumerableで変換が必要です。C#準拠にするなら、Groupingと同じく継承すべきなのですが、あえて対応を分けた理由は、Groupingはそのまま列挙するのが主用途ですが、LookupやDictionaryはそのまま使うのがほとんどなので、IntelliSenseに優しくしたいと思ったのからです。90近いメソッドが並ぶと、本来使いたいGetとかが見えなくなってしまうので。
なお、Dictionaryの列挙順は、キーが挿入された順番になります。不定ではありません。JavaのLinkedHashMapみたいな感じです(C#だとOrderedDictionary、Genericsじゃないけど)。順序保持の理由は、DictionaryはLookupで使う->LookupはGroupByで使う->GroupByの取り出し順は最初にキーが見つかった順番でなければならない(MSDNにそう記載がある)。といった理由からです。ちなみにですが、GroupByが順番通りに来るってのは経験則では知ってたのですがMSDNに記載があったのは見落としていて、むしろ不定だと考えるべきじゃないか、とかTwitterでデマ吹いてたんですが即座にツッコミを頂いて大変助かりました、毎回ありがとうございます。
Share, Let, MemoizeAll
そして3つの新メソッド。これらはReactive Extensionsに含まれるSystem.Interactive.dllのEnumerableに対する拡張メソッドから移植しています。
// Shareはenumeratorを共有する
// 一つの列挙終了後に再度呼び出すと、以前中断されたところから列挙される
var share = Enumerable.Range(1, 10).Share();
var array = share.Take(4).ToArray(); // [1,2,3,4]
var arrayRest = share.ToArray(); // [5,6,7,8,9,10]
// 例えば、これだと二度列挙してしまうことになる!
// 1,1,2,3とアラートが出る
var range = Enumerable.Range(1, 3).Do("alert($)")
var car = range.First(); // 1
var cdr = range.Skip(1).ToArray(); // [2,3]
// Shareを使えば無駄がなくなる(アラートは1,2,3)
var share = range.Share();
var car = share.First(); // 1
var cdr = share.ToArray(); // [2,3]
Shareは、列挙の「再開」が出来ると捉えると良いかもしれません。ちなみに、再開が出来るというのは列挙完了までDispose(終了処理)しないということに等しいのには、少しだけ注意が必要かもしれません。
// Letの関数の引数は自分自身
// [1,2], [2,3], [3,4], [4,5]
Enumerable.Range(1, 5).Let(function (e)
{
return e.Zip(e.Skip(1), "x,y=>[x,y]");
});
// 上のLetはこれと等しい
var range = Enumerable.Range(1, 3);
range.Zip(range.Skip(1), "x,y=>[x,y]");
// 余談:Pairwiseは↑と同じ結果です、一つ先の自分との結合
Enumerable.Range(1, 5).Pairwise("x,y=>[x,y]");
Letは、Enumerableを受け取ってEnumerableを返す関数を渡します。何のこっちゃですが、外部変数に置かなくても、メソッドチェーンを切らさずに自分自身が使えるということになります。使い道は主に自分自身との結合を取りたい場合、とか。なお、何も対処せずそのまま結合すると二度列挙が回ることには注意が必要かもしれません。
// MemoizeAllは、そこを一度通過したものはキャッシュされる
var memo = Enumerable.Range(1, 3)
.Do("alert($)")
.MemoizeAll();
memo.ToArray(); // 一度目の列挙なのでDoでalertが出る
memo.ToArray(); // 二度目の列挙はキャッシュからなのでDoを通過しない
// Letと組み合わせて、自己結合の列挙を一度のみにする
Enumerable.Range(1, 5)
.MemoizeAll()
.Let(function (e) { return e.Zip(e.Skip(1), "x,y=>[x,y]") });
MemoizeAllはメモ化です。二度三度列挙するものは、一度.ToArray()とかして配列に置いたりすることが少なくなかったのですが、MemoizeAllはその辺を遅延評価のままやってくれます。使いかっては良さそう。ただし、これもShareと同じく列挙完了まで例外が起ころうが何だろうがDispose(終了処理)しないのは注意が必要かもしれません。素のJavaScriptではリソース管理は滅多にないので関係ないですが、例えばメモ化が威力を発揮しそうな(linq.jsではWSHで、C#だったら普通にやりますよね)ファイル読み込みに使おうとすると、ちょっと怖い。ていうか私はそういう場合は素直にToArrayします。
この3つは「注意が必要かもしれません」ばかりですね!ただ、MemoizeAll->Let->Zipで自分自身と結合するのは便利度鉄板かと思われます。便利すぎる。
まとめ
Dictionaryの導入は地味に影響範囲が大きいです。集合演算系メソッドもみんなDictionary利用に変えたので。なんでかというと、ええと、そう、今まではバグっておりました……。trueと"true"区別しないとか。Enumerable.From(["true",true]).Distinct()の結果が["true"]になってました。ほんとすみません。今回から、そういう怪しい挙動は潰れたと思います。いや、Dictionaryがバグッてたら元も子もないのですが多分大丈夫だと思います思いたい。
とにかく一年前の私はアホだな、と。来年も同じこと思ってそうですが。
Share, MemoizeAll, LetのRx移植三点セットは遊んでる分には面白いんですが、使いどころは難しいですね。ちなみに、MemoizeAllということで、RxにはAllじゃないMemoizeもあるのですが、かなり挙動が胡散臭いので私としては採用見送りだし、C#でも使う気はしません。内部の動きを相当意識してコントロールしないと暴走するってのが嫌。
VS2010のJavaScript用IntelliSenseは本当に強化されましたねー。ということで、VS2010ならDictionaryやLookupでIntelliSenseが動作するのですが、VS2008では動作しません。完全にVS2010用に調整してたら2008では動かないシーンも幾つか出てきてしまった……。まあでも、2010は素敵なのでみんな2010使えばいいと思うよ。私はまだExpressですががが。一般パッケージ販売まだー?(6月です)
そういえば、2.0は公開からひと月でDL数100到達。本当にありがとうございます。そろそろ実例サンプルも作っていきたいのですがネタがな。Google Waveって結局どうなんでしょうかね。ソーシャルアプリは何か肌に合わない雰囲気なのでスルーで、Waveに乗り込むぜ、とか思ってたんですが思ってただけで乗り込む以前に触ってもいないという有様。HTML5は、ええと、基本はC#っ子なのでSilverlight押しだから。うー、じゃあChrome拡張辺りで……。いやでもHTML5かな、よくわからないけれど。
今のところ最優先事項はlinq.javaなんですけどね、忘れてない忘れてない。というか、linq.js 2.0も今回のOrderByのロジック変更も、linq.javaで書いてあったのを持ってきただけだったりして。もうほんと、とっとと出したいです。出してスッキリして次に行きたい。
そんなわけで、この2.1でlinq.jsはようやくスタート地点に立てたぜ、という感じなので使ってやってください。
C# DynamicObjectの基本と細かい部分について
- 2010-05-06
DynamicJsonをver.1.1に更新しました。ver.1.0の公開以降に理解したDynamicObjectについての諸々を反映させてあります。具体的には、IsDefinedやDeleteといったメソッド名を書かずに、それらが呼び出せるようにし、また、foreach時にキャストが不要になりました。DynamicはIntelliSenseが効かないので、メソッド名を書かせたら負け。大まかに分けて「プロパティ」「名前付きメソッド」「名前無しメソッド」「キャスト」の4つをうまいこと振り分けて、不自然ではなく使えるようにすれば、DynamicObjectとして良い設計となるのではないかな、と思っています。
というわけで、今回は微妙にはまったDynamicObjectの挙動の色々について書きますが、その前に1.1の更新事項を。DynamicJson自体については、ver1.0のリリース時の記事を参照ください。
// ただの入れ物クラスなのであまり気にしないで。
public class FooBar
{
public string foo { get; set; }
public int bar { get; set; }
}
// こんなJSONがあったとするとする
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
var arrayJson = DynamicJson.Parse(@"[1,10,200,300]");
var objectJson = DynamicJson.Parse(@"{""foo"":""json"",""bar"":100}");
// .プロパティ名()はIsDefined("プロパティ名")と同じになります
var b1_1 = json.IsDefined("foo"); // true
var b2_1 = json.IsDefined("foooo"); // false
var b1_2 = json.foo(); // true
var b2_2 = json.foooo(); // false;
// .("プロパティ名")はDelete("プロパティ名")と同じになります
json.Delete("foo");
json("bar");
// キャストはDeserialize<T>()と同じになります
var array1 = arrayJson.Deserialize<int[]>();
var array2 = (int[])arrayJson; // array1と一緒
int[] array3 = arrayJson; // こう書いてもDeserialize呼び出しと同じだったりする
// 配列だけではなく、パブリックプロパティ名で対応を取るマッピングも可能です
var foobar1 = objectJson.Deserialize<FooBar>();
var foobar2 = (FooBar)objectJson;
FooBar foobar3 = objectJson;
// 勿論、配列+オブジェクトでも可。Linqに繋げる時はキャストで囲みましょう(asはダメ)
var objectJsonList = DynamicJson.Parse(@"[{""bar"":50},{""bar"":100}]");
var barSum = ((FooBar[])objectJsonList).Select(fb => fb.bar).Sum(); // 150
var hoge = objectJsonList as FooBar[]; // これはnullになる、asとキャストは挙動が違う
// array状態のDynamicJsonにforeachはdynamicが渡る
// 中の型が分かっている場合は、varではなく型名指定するといいかも
// ちなみに、数字はdynamicのままだと全てdoubleです
foreach (int item in arrayJson)
{
Console.WriteLine(item); // 1, 10, 200, 300
}
// オブジェクト状態のDynamicJsonへのforeachはKeyValuePair
// .Key、.Valueなのは分かってる、というならdynamicで受けると楽かも
foreach (KeyValuePair<string, object> item in objectJson)
{
Console.WriteLine(item.Key + ":" + item.Value); // foo:json, bar:100
}
foreachを自然に使えるようにしたのと、IsDefined、Remove、DeserializeをDynamicとして自然に呼び出せるようにした、というのが更新内容になります。IsDefined("name")が.name()で自然なのか?というと、どうなんでしょうねー、という感じですが、しかしDynamicはIntelliSenseが効かないのです!なので、多少ややこしくても、こうして使える方が便利だと思われます。
ところで、キャストとasの関係は、DynamicObjectだとより正確に意識する必要が出てきます。キャストとasは例外が飛ぶかnullになるかの違いしかない、と思っていたりしたのは私なのですが、そんなことはなくて、asはユーザ定義の変換演算子を呼ばないという性質があります。DynamicObjectでもそれが反映されているため、キャストするとTryConvertが呼ばれるのですが、asは純粋にそのクラスの継承関係しか見ません。
DynamicObjectとは
では本題。まずは基本から。型宣言がdynamicの場合に、挙動が変わるオブジェクトの作成方法は、DynamicObjectを継承して、挙動を変えたいメソッド(Tryなんたら)をオーバーライドするだけです。
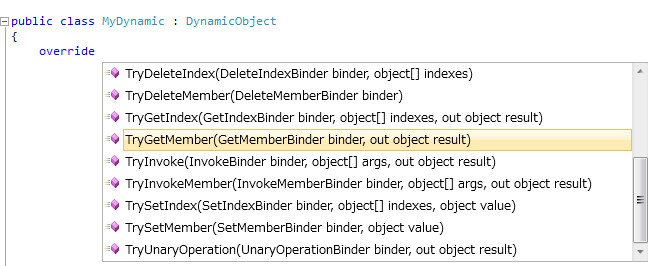
override->スペースでIntelliSenseに候補が出てきますね、素敵。Try何とかかんとかの第一引数はbinderですが、とりあえずbinder.Nameだけで何とかなります。成否はboolで返し(falseの場合は、呼び出しを解決するため更に連鎖が重なったりする)、trueの場合はresultにセットした値が呼び出し元に返る。といった仕組みになっています。
呼び出しの解決
簡単な例、ということで呼び出し名を返す、というだけの単純なTryInvokeMemberを定義してみます。
// MyDynamic:DynamicObjectのオーバーライド、メソッド呼び出し名を文字列としてそのまま返す、引数がある場合はfalse
public override bool TryInvokeMember(InvokeMemberBinder binder, object[] args, out object result)
{
result = binder.Name;
return (args.Length > 0) ? false : true;
}
dynamic d = new MyDynamic();
var t1 = d.Hoge(); // Hoge - dynamic(string)
var t2 = d.ToString(); // ToStringにはならない、MyDynamicのToStringが呼ばれる
さて、この場合本来あるメソッドであるToStringやEquals、その他自分で定義したメソッドがあれば、それらを呼んだ場合はどちらが優先されるでしょうか、というと、定義されたメソッドが優先です。なので、TryInvokeMemberにだけ挙動を定義しておくと、どうやっても呼べないメソッドが出てきます。例えばDynamicJsonで言えば、プロパティ名がToStringのJSONに対してToString()で定義されているか確認は出来ません。そのための回避策として、TryInvokeMemberはIsDefinedの簡易記法としています。IsDefined("ToString")ならば問題なく呼べますので。
引き続いて、TryInvokeMemberがfalseの場合も見てみます。
public override bool TryGetMember(GetMemberBinder binder, out object result)
{
result = new MyDynamic();
return true;
}
public override bool TryInvoke(InvokeBinder binder, object[] args, out object result)
{
result = ((string)args[0]).ToUpper();
return true;
}
dynamic d = new MyDynamic();
var t = d.Hoge("aaa"); // AAA(InvokeMemberが失敗したらGetMemberが呼ばれ、それのTryInvokeが呼ばれる)
d.Hoge("aaa")は、まずTryInvokeMemberが呼ばれます。今回は引数がある場合はfalseとしているので、失敗します。すると、呼び出しの解決のためTryGetMemberが呼ばれます。ここでtrueの場合は、引数を持ってTryInvokeが呼ばれます。TryInvokeはd("aaa")のような、メソッド名なしでの関数呼び出しです。C#にはない記法となるので、TryInvokeMemberからの失敗の連鎖でTryGetMemberでDynamicObject以外を返すと、TryInvokeに失敗という形で例外が出ます。
ややこしいですね!この失敗の連鎖はDynamicJsonではオブジェクトがネストしている際の呼び出しの解決に利用しています。
var json = DynamicJson.Parse(@"{""tes"":10,""nest"":{""a"":0}");
json.nest(); // これはjson.IsDefined("nest")
json.nest("a"); // これはjson.nest.Delete("a")
json.nest("a")は、まずTryInvokeMemberが呼んでいます。これは原則IsDefinedと等しいのですが、引数がある場合はfalseにしています。そのためTryGetMemberが呼ばれて.nestを取得。そして、TryInvoke(これはDeleteに等しい)を呼ぶという流れになっています。真面目にDynamicObjectを使って構造を作る場合、呼び出し解決順序などを意識する必要は、間違いなくあります。ややこしいですけどねー。
DynamicObjectとforeach
DynamicObjectがIEnumerableならば、foreachはそれを呼びます。ていうかforeach可能なものはIEnumerableにするでしょ常識的に考えて。と、言いたいのですが世の中そうもいかなかったりします。
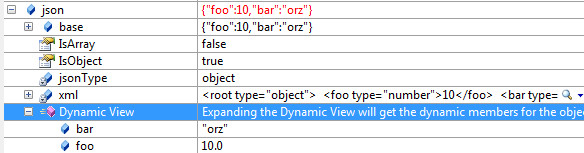
Dynamicの変数はデバッガで見るとDynamic Viewというものが用意されていて、展開すると全てのプロパティ名と値を表示してくれます(これに対応させるにはGetDynamicMemberNamesをオーバーライドする必要がある、DynamicObject作るなら必須!)。大変便利なのですが、これ、クラスがIEnumerableを実装している場合はIEnumerableの結果ビューに置き換わってしまい、Dynamic Viewがなくなってしまいます。
Dynamic Viewがないと非常に不便極まりないので、DynamicJsonではIEnumerableの実装は断念しました。しかし、foreachでそのまま呼べないのは不便だ。どうする?となって思い浮かんだのは、IEnumerableじゃなくてもGetEnumeratorがあればforeachって呼ばれるんだよねー、普通のクラスは。という仕様がC#にはあるので、Dynamicでも行けるかな?と思いきやそんなことはなく、呼ばれませんでした。じゃあ、かわりにforeach時に何が呼ばれていたか、というと、TryConvertが呼ばれます。
public override bool TryConvert(ConvertBinder binder, out object result)
{
// foreachで呼ばれた時はbinder.TypeがIEnumerable
if (binder.Type == typeof(IEnumerable))
{
result = Enumerable.Range(1, 10); // resultはIEnumerableとIEnumerator、どちらでも可
return true;
}
// 通常のキャストは適当に分岐させるか、キャストの演算子オーバーロードでもどちらでもいい
// 演算子オーバーロードがある場合は、そちらが優先されます
result = (binder.Type == typeof(string)) ? "hogehoge" : null;
return true;
}
dynamic d = new MyDynamic();
foreach (var item in d)
{
Console.WriteLine(item); // 1,2,3,4,5,6,7,8,9,10
}
var ie = (IEnumerable)d; // これは失敗する、インターフェイスへの明示的型変換は不可!
C#ではインターフェイスの演算子オーバーロードは定義出来ないし、Dynamicでも呼び出しは不可能になっています。が、foreach呼び出し時のみ、TryConvertにTypeがIEnumerableとして渡るようになっているので、そこでtrueを返せば、IEnumerableではないDynamicObjectでもforeachで列挙出来ます。
正直なところ、セコいハックに過ぎないです。本当はデバッガでDynamic Viewと結果ビューが共存できればいいんですよ、ていうか出来るべき。あと、Dynamic Viewは今のところ値がnullのものは表示しないようになっているのですが、これも不便な仕様ですね、改善して欲しいところ。とはいえ、IEnumerableじゃないから不便になってる!ということは無いと思われます。どちらにせよIEnumerableじゃなくてもdynamicはキャストしないと拡張メソッドが呼べない(つまりそのままではLinqが使えない)ため、利用感は犠牲にしていません。
そういえばExpandoObjectはIEnumerableなのにdynamic viewが出るので、何か方法はあるかもしれませんね。
まとめ
dynamicは当初思っていたよりも、遥かに使いがいのある仕組みでした。dynamicはDSL。だと思います。そして、DSLとして便利に使わせるならば、メソッド名で呼ばせるのは厳禁。用意された機構を上手く使ってIntelliSenseレスでも快適に操作出来るようにしなければならない。というか、それで操作出来ないならば普通にC#で組んでIntelliSense効かせた方がずっと良い。
と、まあ、そんなわけでDynamicJsonは400行程度の小さいコードですが、割と色々考えて作ってありますので、是非使ってみてください。お手製ライブラリにありがちなJSON解析の出来が怪しい、といった問題を、解析部を.NET FrameworkのJsonReaderWriterFactoryに丸投げしているため避けられている、というのも大きな利点かと思われます。
ソースコード本体は、ArrayとObjectを一つのクラスに統合しているため、各メソッド行頭でifで分ける、というのが若干怪しいのですが(オブジェクト指向的にはポリモーフィズム、ていうかDynamicならその辺考えずに分けても問題ない、だろうけど400行のコードですからねえ、分割したほうが手間かつ分かりにくくなるだろうしで、まだリファクタリングの出番ではない、と思いますです、これ以上規模が膨れるなら別ですが)、全体的にはDynamicObjectの機能を満遍なく使っているので、参考になるかと思います。あと、JSON書き出し時のLinq to XmlでのXML組み立て部分は若干トリッキーなものの、割とよく出来ているかな? Deserializeはもう少し気合入れて実装し直さないとダメな感じですがががが。