Chaining Assertion ver 1.1.0.1
- 2011-02-28
リリースから、意外にも色々と反響を頂き、ありがとうございました。そんなわけで、意見を考慮した結果、メソッド増えました。当初のスタンスは、シンプルにIsのみでやる、というところだったので、現在結果的に4x2つある、という状況は理想的には望ましくないのですが、現実的にはしょうがないかな、といった感です。以下が、Chaining Assertionの全拡張メソッド。
Is
IsNot
IsNull
IsNotNull
IsInstanceOf
IsNotInstanceOf
IsSameReferenceAs
IsNotSameReferenceAs
IsNotはまんまで、AreNotEqualです。IsSameReferenceAsはAreSameで、参照比較。メソッド名長いね!ただ、私はAreSameという名前は曖昧で何がSameなのか(値がSameとも取れるじゃないか!)よく分からず嫌いだったので、Referenceをメソッド名に入れるのは確定でした。その上で、IsReferenceEqualsにするかで悩みましたが、ここはAreSameであることを想起させるためにも、Sameを名前に含めることにしました。
拡張のジレンマ
最も多く使う部分のみに絞って最少のものを提供する。という思想がありました。だからNotもSameも頻度的には下がるから不要で、それらが使いたい場合はAssert.AreSameといったものを使えばいい、と。従来のものを完全に置き換えるものじゃなく、要点を絞って、処方を出す。
でもまあ、Isのみにこだわりすぎるのって、逆に良くないよね、と。事実妥協してIsNull/IsNotNullは入れていたわけだし、もう少し妥協したっていいのではないかと。と、たがが外れた結果、増量しすぎた……。これだけ増えると、Isだけで済むんだよ!簡単だよ!強力だよ!という文句に説得力に欠けていってしまう。
なので、このまま拡張し続ける気はありません。メソッドが増えると、学習コストの増加とIntelliSense汚染が出てきてしまうので、便利メソッドを増やすのは、ないかな、と。特にStringやCollection周りには、Isのような汎用的なものではなく、もっと特化的なものがあれば「便利」なのは違いないのですが、でも、それ本当に便利かな、って。ラムダ式を使えば十分代替出来る、Linq to Objectsを使えば十分代替出来る。なら、それでいいよね、と。
例えば seq.All(pred).Is(true) が失敗する時、これだとどの値がfalseになったのか分からない。判定をLinq to ObjectsのAllに任せているから。これがもし、 seq.IsAll(pred) といったような、専用メソッドが用意されていれば、細かいエラーメッセージを出すことが出来て便利なのは間違いない。
でもAllだけ?他のは?Allだけ特別扱いする理由もない。じゃあ全部のLinq to Objectsを実装するか、といったらありえない!実装の手間・俺々実装によるバグ混入の可能性、そしてIntelliSense爆発。学習コストの増大(まあ、IsXxxでXxxをLinq to Objectsのものと同一にする、という原則を貫けば増大はしませんが)。
// ソート済みであるかどうかのチェック(NUnitのIsOrderedにあたるもの)を、Linq to Objectsで
var array = new[] { 1, 5, 10, 100 };
array.Is(array.OrderBy(x => x));
Linq to Objectsの汎用性の高さ!既存の仕組みに乗っかれる場合は、全力で乗っかりたい。DynamicJsonもそうで、扱いづらいJsonReaderWriterFactoryにdynamicの皮を被せているだけにすぎない、という。
まとめ
Assert.Hogeよりも圧倒的に書きやすく美しく短くなるというほかに、圧倒的に読みやすくなります。読みやすさはメンテナンス性の向上に繋がる。一生懸命テストを書いたはいいものの、面倒くさくてメンテ放置になって、ゴミの山になってしまった。という経験が、私はある(えー)。そんなわけで、書きやすさは何より大事だし、読みやすさまで手に入るなら僥倖だし、かつ、学習コストも最小限。という売り文句なので、是非試してみてもらえればと思います。
// 今回追加された細々としたもの
// Not Assertion
"foobar".IsNot("fooooooo"); // Assert.AreNotEqual
new[] { "a", "z", "x" }.IsNot("a", "x", "z"); /// CollectionAssert.AreNotEqual
// ReferenceEqual Assertion
var tuple = Tuple.Create("foo");
tuple.IsSameReferenceAs(tuple); // Assert.AreSame
tuple.IsNotSameReferenceAs(Tuple.Create("foo")); // Assert.AreNotSame
// Type Assertion
"foobar".IsInstanceOf<string>(); // Assert.IsInstanceOfType
(999).IsNotInstanceOf<double>(); // Assert.IsNotInstanceOfType
ようするところ、AssertThatを更に凝縮したような感じです。また、 Assert.That(array, Is.All.GreaterThan(0)) なんてのは array.All(x => x >= 0).Is(true) のほうがずっと良くない?って。思うわけです(但し、Assert.Thatはエラーメッセージがずっと親切)。なお、Is.All.GreaterThanは、一見IntelliSenseが効いて書きやすそうに見えるけれど、無駄な連鎖によりイライラさせられるだけで別に全然書きやすくない。連鎖において、一つ一つの処理に重みがないものは、どうかなあ。ただのシンタックス遊びだよ、こんなの(ラムダ式のないJavaでの苦肉の策だというのなら分かる)。
それと、基本的にオブジェクトへの拡張メソッドというのは、影響範囲が広すぎて禁忌に近いわけですが、ユニットテストという範囲が限定されている状況なので、許容できるのではないかな、と思っています。しかし8つはなぁ、多すぎかなあ……。今も、これで良かったのか相当悩んでます。InstanceOfは不要だったかも、typeof書きたくなかったというだけじゃ理由としてアレだし、メソッド増やすほどの価値はあったのか、多分、ないよね、うぐぐ。でも、これでほぼ全てがチェーンで書けるようになりました。それはそれでヨシと思うことにします。
メソッドチェーン形式のテスト記述ライブラリ
- 2011-02-24
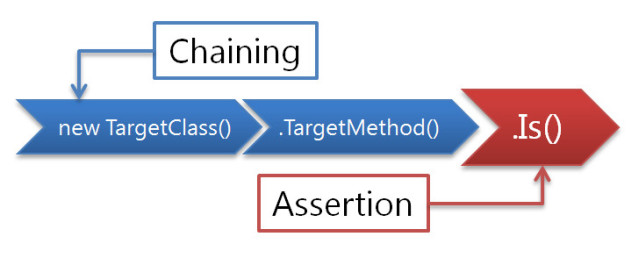
昨日の今日で特に更新はないのですが、せっかく画像作ったので再解説。命名は見たとおりに、メソッドチェーンで切らさずアサーションが書ける!ということから付けました。テストを、限りなくシンプルに素早く迷いなく書けるようにしたかった。その答えが、メソッドチェーンで最後に値を取ることです。
// 全てIs一つでメソッドチェーンで流るまま!
Math.Pow(5, 2).Is(25);
"foobar".Is(s => s.StartsWith("foo") && s.EndsWith("bar"));
Enumerable.Range(1, 5).Is(1, 2, 3, 4, 5);
Assert.AreEqualの最大の問題は、どっちがactualでどっちがexpectedだか悩んでしまうこと。一秒でも引っかかったら「気持よくない」のです。テストはリズム。リズムを崩す要素は極限まで潰さなければならない。Chaining Assertionならば、引数として与えるのはexpectedだけなので、全く悩む必要がなくなる。些細なことですが、しかし、大きなことです。
また、この手のメソッドチェーン式のものでよく見られるのが「流れるようなインターフェイス」を名乗って、自然言語のようにチェーンで書けるようにする、などというものがありますが、滑稽です。EqualTo().Within().And()だの.Should().Not.Be.Null()だの、馬鹿げてる。ラムダ式なら一発だし、そちらのほうが遥かに分かりやすい。DSLは分かりやすく書きやすくすることを目指すものであって、形式主義に陥ることじゃない。自然言語風流れるようなインターフェイスは二度とDSLを名乗るべきではない。
もう一つの問題は、無駄に沢山あるアサート関数。覚えるのは面倒。特に、コレクション関連。ぶっちゃけ全然扱いやすくなく、そして、私達にはずっとずっと扱いやすいLinq to Objectsがあるじゃないか。というわけで、コレクションのテストをしたい時は、Linq to Objectsで結果まで絞ってIsで書くという手法を推奨します。
new[]{1, 3, 7, 8}.Contains(8).Is(true);
new[]{1, 3, 7, 8}.Count(i => i % 2 != 0).Is(3);
new[]{1, 3, 7, 8}.Any().Is(true);
new[]{1, 3, 7, 8}.All(i => i < 5).Is(false);
ね、このほうがずっと書きやすいし柔軟に書ける。
非同期のテスト
非同期のテストは難しい。結果が返ってくるのが非同期なのでテストを抜けてしまうので。ではどうするか、答えは、Rx使えば余裕です。例として以下のコードは今こそこそと作ってるWP7アプリ用のテストです。
[TestMethod]
public void Search()
{
// SearchLyricはWebRequestのBeginGetResponseで非同期に問い合わせるもの
// 結果はIObservableを返す非同期なものなので、ToEnumerableして同期的に待機する
var song = new Song { Artist = "吉幾三", Title = "俺ら東京さ行ぐだ" };
var array = song.SearchLyric().ToEnumerable().ToArray();
array.Count().Is(1);
array.First().Title.Is("俺ら東京さ行ぐだ 吉幾三");
array.First().Url.Is("http://music.goo.ne.jp/lyric/LYRUTND1127/index.html");
}
FirstとかToEnumerableで、非同期をサクッとブロックして同期的に待機してしまえば簡単に値を確保できてしまいます。とまあ、そんなわけで非同期処理は全部Rxで行うよう統一すると、こういうところで物凄く楽になるわけですね、素晴らしい。だからもう非同期プログラミングにRx無しとか全方位でありえないわけです。
といっても、Rxなんて使ってないし!という場合は、こんなものが。例は恣意的すぎますが
[TestMethod]
public void SpinUntilTest()
{
int number = 0;
// 非同期処理をしてるとする
ThreadPool.QueueUserWorkItem(_ =>
{
Thread.Sleep(3000); // 重たい処理をしてるとする
number = 1000;
});
// 指定条件が成立するまで待機
SpinWait.SpinUntil(() => number != 0, 10000); // Timeout = 10秒
number.Is(1000);
}
Pxチームの記事 SpinWait.SpinUntil for unit testing で見たのですが、SpinWait.SpinUntilが結構使えそうです。Thread.Sleepでタイムアウトいっぱいまで待つとか、手動でManualResetEventを設定する、などなどに比べると遥かにサクッと書けて良さそう。ていうかSpinWait.SpinUntilなんて初めて知りましたよ、本当にhidden gems!
まとめ
テストのないコードはレガシーコード。と、名著が言ってるので
Chaining Assertionで苦痛を和らげて、素敵なテスト生活を送りましょう。
XboxInfoTwit - ver.2.3.0.3
- 2011-02-24
Xbox.comの認証周りが変わってログイン出来なくなってしまってたのですが、それを修正しました。朝っぱらに急ぎで対応したので、あまりテストしてません。マズいところあったら後で直します。
Chaining Assertion for MSTest
- 2011-02-23
MSTest用の拡張メソッド集をCodePlexと、そしてNuGet(idはChainingAssertionです)にリリースしました。ライブラリといってもたった数百行(うち300行が自動生成)の、csファイル一つです。NuGet経由でも.csが一個配置されるだけという軽量軽快さ。中心となるのはIsというTへの拡張メソッドで、これはAssert.EqualとAssert.IsTrue(pred)とCollectionAsert.AreEqualを、一つのメソッドだけで表現します。単純なものですが、それだけなのに驚くほどテストが書きやすくなります。まずは例を。
// 全てのオブジェクトに.Isという拡張メソッドが追加されていて、3つのオーバーロードがあります
// Assert.AreEqualと等しい
Math.Pow(5, 2).Is(25);
// 条件式によるAssert.IsTrueをラムダ式で
"foobar".Is(s => s.StartsWith("foo") && s.EndsWith("bar"));
// コレクションの等値比較は可変長引数でダイレクトに書ける
Enumerable.Range(1, 5).Is(1, 2, 3, 4, 5);
以前どこかで見たような?はい。ベースはテストを簡単にするほんの少しの拡張メソッドで書いたものです。それを元に若干ブラッシュアップしています。ラムダ式によるAssert時のエラーメッセージが、非常に分かりやすくなりました。
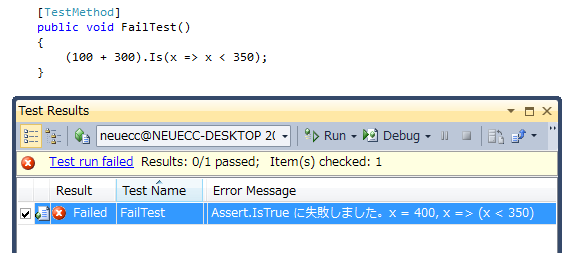
前はFuncだったのですが、Expressionで受けるようにしたので、情報が取れるようになったらからです。それと渡ってくる値に関しても表示。これで、情報が足りなくてイライラってのがなくなって、かなり書きやすくなりました。
ところでnullに関してはIsNullとIsNotNullというメソッドに分けました。あまり増やしたくはないので、入れるか悩んだんですけどね。x => x == null でもいいのだし。
TestCase/Run
以前書いた時もNUnit風のTestCaseの再現を試みていたのですが、今回は抜本的に作り替えてリベンジしました。再現度(それっぽい度)は相当上がっています。といっても、目的は再現度を上げることじゃあないですね、大丈夫です、これにより、遥かに使いやすく実用的になりました。
[TestClass]
public class UnitTest
{
public TestContext TestContext { get; set; }
[TestMethod]
[TestCase(1, 2, 3)]
[TestCase(10, 20, 30)]
[TestCase(100, 200, 300)]
public void TestMethod2()
{
TestContext.Run((int x, int y, int z) =>
{
(x + y).Is(z);
(x + y + z).Is(i => i < 1000);
});
}
}
TestContextへの拡張メソッドにRunというのが仕込んであって、それとTestCase属性が連動して、パラメータ指定のテストが行えるようになっています。TestCaseSource属性もありますよ?
[TestMethod]
[TestCaseSource("toaruSource")]
public void TestTestCaseSource()
{
TestContext.Run((int x, int y, string z) =>
{
string.Concat(x, y).Is(z);
});
}
public static object[] toaruSource = new[]
{
new object[] {1, 1, "11"},
new object[] {5, 3, "53"},
new object[] {9, 4, "94"}
};
何でTestContextへの拡張メソッドという形をとっているかというと、TestContextから実行中クラス名とメソッド名が簡単に取れるから、です。この二つさえ分かれば、あとはリフレクション+LINQでやり放題ですからねー。クラス名が取れるTestContext.FullyQualifiedTestClassNameは、どうやらVS2010からの追加なようで、ナイス追加。VS2008からTest周りは何も進化しなくてNUnitと比べるとアレもコレも、な感じなわけですが、地味に改良はされていたんですね。いや、誰が嬉しいんだよって話ですが、私は大変嬉しかったです。
テストケースとして分けられないので、非常にオマケ的ではあるんですが、大変お手軽なので無いよりは嬉しいかな、と。
まとめ
Assert.HogeHogeの楽しくなさは異常。本当にダルい。かといって、英語的表現を目指した流れるようなインターフェイスは爆笑ものの滑稽さ。ああいうのをDSLと言うのは止めましょうぜってぐらいの。まあ、そんなわけで、これを使うと結構快適に書けます。Isの一つ一つは馬鹿みたいに単純なたった一行のメソッドなんですが、それだけなのに、全然違うんですよね。
というわけでまあ、楽しいテスト生活を!あと、最近は自動化テストなPexや、それと絡むCodeContractsを触っているので、それらについて近いうちに書けたらと思っています。
Rx FromEvent再訪(と、コードスニペット)
- 2011-02-18
最近の私ときたらFromAsyncでキャッキャウフフしすぎだが、Asyncの前にEventを忘れているのではないか、と。というわけで、FromEventについて、「また」見直してみましょう!延々と最初の一歩からひたすら足踏みで前進していないせいな気はその通りで、いい加減飽きた次に進めということだけれど、まあそれはそのうち。私的にはFromEventはとうに既知の話だと思い込んで進めているのであまり話に出していなかっただけなのですが、初期に出したっきりで、特にここ数カ月で(WP7出たりAsync CTP出たり昇格したり)でRxが注目を浴びるのが多くなってはじめましてな場合は、そんな昔の記事なんて知らないよねですよねー(Blogの形式は過去記事へのポインタの無さが辛い)。なわけなので定期再び。
「Rxの原理再解説」や「時間軸という抽象で見るRx」、というネタをやりたいのですが、長くなるのと絵書いたり動画撮ったり色々準備がという感じで中々書き進められていないので、先にFromEvent再訪を。
4オーバーロード
FromEventはイベントをReactive Sequenceに変換するもの。これはオーバーロードが4つあります。
// ただのEventHandlerを登録する場合はハンドラの+-を書くだけ
// 例はWPFのWindowクラスのActivatedイベント
Observable.FromEvent(h => this.Activated += h, h => this.Activated -= h);
使う機会は少ないかな? 実際はEventHandler/EventArgsだけのものなどは少ないわけで。
// WPFのButtonなどり
Observable.FromEvent<RoutedEventArgs>(button1, "Click");
これはサンプルなどで最も目にすることが多いかもで、文字列でイベントを登録するもの。記述は短くなるのですが、動作的にはイベント登録時にリフレクションで取ってくることになるので、あまり推奨はしない。じゃあどうすればいいか、というと
// 第一引数conversionはRoutedEventHandlerに変換するためのもの、とにかく記述量大すぎ!
Observable.FromEvent<RoutedEventHandler, RoutedEventArgs>(
h => h.Invoke, h => button1.Click += h, h => button1.Click -= h);
ハンドラの+-を自前で書くわけですが、EventArgsと一対一の俺々EventHandlerへの変換関数も必要になっています。これはnew RoutedEventHandler() などとしなくても、 Invoke と書くだけで良いようです。最後のオーバーロードは
// EventHandler<T>利用のものって本当に少ないんですよね、こちらを標準にして欲しかった
Observable.FromEvent<TouchEventArgs>(h => button1.TouchDown += h, h => button1.TouchDown -= h);
EventHandler<T>のものはスッキリ書けます。
コードスニペット
conversionが必要なFromEvent面倒くさい。それにしても面倒くさい。WPFのINotifyPropertyChangedほどじゃないけれど、やはり面倒くさい。ジェネリックじゃない俺々EventHandlerどもは爆発しろ!デリゲートはEventHandler<T>とFuncとActionがあれば他は原則不要(ref付きが必要とか、そういう特殊なのが欲しい時に初めて自前定義すればよろし)。と、嘆いてもしょうがない。何とかしなければ。以前はT4でガガガガッと自動生成してしまう方法を紹介しましたが、少し大仰な感があります。もう少しライトウェイトに、今度は、コードスニペットでいきましょう。
// 普通に使うもの
Observable.FromEvent<$EventHandler$, $EventArgs$>(h => h.Invoke, h => $event$ += h, h => $event$ -= h)
// 拡張メソッドとして定義する場合のもの
public static IObservable<IEvent<$EventArgs$>> $eventName$AsObservable(this $TargetType$ target)
{
return Observable.FromEvent<$EventHandler$, $EventArgs$>(
h => h.Invoke, h => target.$eventName$ += h, h => target.$eventName$ -= h);
}
この二つです。二つ目の拡張メソッドのものは、ええと、大体の場合は長ったらしくて面倒なので拡張メソッドに退避させるわけですが、それを書きやすくするためのものです。利用時はこんな形。
class Program
{
static void Main(string[] args)
{
var c = new ObservableCollection<int>();
var obs1 = Observable.FromEvent<NotifyCollectionChangedEventHandler, NotifyCollectionChangedEventArgs>(h => h.Invoke, h => c.CollectionChanged += h, h => c.CollectionChanged -= h);
var obs2 = c.CollectionChangedAsObservable();
}
}
public static class EventExtensions
{
public static IObservable<IEvent<NotifyCollectionChangedEventArgs>> CollectionChangedAsObservable<T>(this ObservableCollection<T> target)
{
return Observable.FromEvent<NotifyCollectionChangedEventHandler, NotifyCollectionChangedEventArgs>(
h => h.Invoke, h => target.CollectionChanged += h, h => target.CollectionChanged -= h);
}
}
rxevent -> TabTab か、 rxeventdef -> TabTab というだけで、この面倒くさい(長い!)定義が簡単に書けます。おっと、スニペットファイルはXMLなのでこれだけじゃ動きませんね。ベタ張りだと長いので、ダウンロードはneuecc / RxSnippet / source – Bitbucketの二つからどうぞ。そうしたら、ツール->コードスニペットマネージャーで追加してやってください。
今回、スニペットはSnippet Designerで作成しました。Visual Studioと統合されているので非常に書きやすくてGood。コンパイルがしっかり通る、万全な雛形をコード上で作ったら右クリックしてExport As Snippet。スニペットエディタ上に移ったら、置換用変数を選択してMake Replacement。それだけで出来上がり。あとはプロパティのDescriptionとShortcutを書くだけ。楽すぎる。もうスニペットを手書きとか馬鹿らしくてやってられません。これだけ楽だと、ちょっとした面倒事を片っ端からスニペット化していけるというものですねん。
アタッチ、デタッチのタイミングを考えよう
Rxで意外と困るのが、いつアタッチされているのか、デタッチされているのか、よくわからなかったりします。慣れると分かってくるのですが、最初は存外厳しい。そういう時は悩まずに、デバッガを使おう!
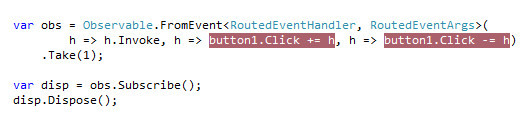
こういったように、アタッチのラムダ式、デタッチのラムダ式にそれぞれ縄を張れば、いつ呼ばれるのか一目瞭然です。悩むよりも手を動かしたほうがずっと早い。
ところでRxのいいところは、イベントのデタッチが恐ろしく簡単になったことです。そのお陰で今まであまりやらなかった、そもそも考えすらしなかった、アタッチとデタッチを繰り返すようなイベント処理の書き方が発想として自然に浮かび上がるようになった。少し簡単に書けるようになった、という程度じゃあそんな意味がない。Rxのように極限まで簡単に書けるようになると、スタイルが一変して突然変異が発生する。ある意味これもまた、パラダイムシフトです。オブジェクト指向から関数型へ?いえいえ、C#から、Linqへ。
まとめ
2/11にRx v1.0.2856.0 releaseとしてアップデートが来てました。大量更新ですよ大量更新!正式入りしたから更新ペースがゆったりになるかと思いきや、その逆で加速しやがった!ちなみに破壊的変更も例によって平然とかけてきて、Drainというメソッドが消滅しました(笑) 何の躊躇いもないですね、すげー。
代わりに、Christmas Releaseの時に消滅してWP7と互換がなくなった!と騒いだPruneとReplayは復活しました(なんだってー)。というわけで、再びWP7との互換は十分保たれたという形ですね、ヨカッタヨカッタ。そんなわけで、常に見張ってないと分からないエキサイティングさが魅力のRx、是非是非使っていきましょう。
実践 F# 関数型プログラミング入門
- 2011-02-14
共著者の一人であるいげ太さんから献本のお誘いを受け、実践F#を献本頂きました。発売前に頂いたのですが、もう発売日をとっくに過ぎている事実!ど、同時期に書評が並ぶよりもずらしたほうがいいから、分散したんだよ(違います単純に遅れただけです、げふんげふん)
NuGetの辺りでも出しましたが、F#スクリプトは活用し始めています。いいですね、F#。普通に実用に投下できてしまいます、今すぐで、C#とかち合わない領域で。勿論、それだけで留めておくのはモッタイナイところですが、とりあえずの一歩として。実用で使いながら徐々に適用領域を増やせるという、なだらかな学習曲線を描けるって最高ぢゃないですか。
F#を学ぶ動機
最近流行りだから教養的に覚えておきたいとか、イベントがファーストクラスとか非同期ワークフローが良さそうなので知っておきたいとか、私はそんな動機ドリブンのつもりでしたが、そういう動機だと実に弱いんですね!そんな動機から発したもので完走出来たものは今まで一つもありません(おっと、積み本の山が……)。もっと具体的に甘受できる現金なメリットがないと駄目なんだ。そんな情けない人間は私だけではない、はず、はず。
というわけで、実際、動機付けが一番難しいのではないかと思います、「実践」するには。F#の場合「それC#で」という誘惑から逃れるのは難しく、正面から向かわないとでしょう。この図式と対比させられるJava-Scala間では、「それJavaで」とは口が裂けても言えなくて(Java……ダメな子)、学ぶことがそのままJVMの資産を活かしてアプリケーションを書けるというモチベーションに繋がりますが、C#は割とよく出来る子だから。そんなわけかないかですが、本書では、冒頭1章でF#手厚く説明されています。言語の歴史を振り返って、パラダイムを見て、F#とはどういう流れから生まれてきた言語なのか。丁寧だとは思います。
並列計算。マルチパラダイム。うーん、それだけだと請求力に欠けるよね、何故ならF#が関数型ベースのマルチパラダイム言語であるように、C#はオブジェクト指向型ベースのマルチパラダイム言語だから。
などとやらしくgdgdとしててもまあ何も始まらない。いいからコード書こうぜ!といった流れで2章で環境導入の解説(この解説は非常に役立ちでした、F# Interactiveのディレクティブ一覧や、__SOURCE_DIRECTORY__でパスが取れるとか、F#のソースコードの所在とか)で、あとは書く!と。なんとも雑念に満ちたまま読み始めたわけですが、読み始めるとグイグイ引きこまれました。なんというか、学ぶのに楽しい言語なんですよね、F#。
それと、Visual Studioに統合されたF# Interactiveがとんでもなく便利で。こいつは凄い。私、今までREPLって別にどうでもいいものと思っていたのですよ。コマンドプロンプトみたいな画面で一行一行打っていくの。REPLは動作が確認しやすくてイイとかいう話を耳にしては、なにそれ、そもそもメチャクチャ打ちづらいぢゃん、イラネーヨって。でもVSに統合されたF# Interactiveは、IDEのエディタで書くこと(シンタックスハイライト, 補完, リアルタイムエラー通知)とREPLの軽快さが合体していて、最強すぎる。しかもその軽快さで書いたコードはスクリプトとして単独ファイルで実行可能、だと……!F#スクリプト(fsx)素晴らしい。C#で心の底から欲しいと思っていたものが、ここにあったんだ……!
と、読み始めてたら、普通に楽しい言語だし、並列や言語解析といった大変なところに入らなくても実用的だしで、かなりはまってます。F#いいよF#。始める前に考えてた動機だとかなんて幻でしかなく、始めたら自然に心の奥から沸き上がってくるものこそ継続されるものだと、何だか感じ入ってしまったり。
パイプライン演算子
F#といったらパイプライン演算子。パイプラインは文化。と、いうわけかで、実際、私がよく目にしているF#のコードというのは基本|>で繋ぐ、という形であり、それが実にイイなー。などという憧憬はあるのでF#を書くとなったらとりあえずまずはパイプライン演算子の学習から入ったりなどしたりする。
このパイプライン演算子、書くだけならスッと頭に入るけれど、どうしてそう動くのかが今一つしっくりこなかった、こともありました。関数の定義自体は物凄くシンプルでたった一行で。
// |>は中置換なのとinlineなので正確には一緒ではないですが、その辺は本を参照ください!
let pipe x f = f x
おー、すんごくシンプル。シンプルすぎて逆にさっぱり分からない。型も良くわからない。困ったときはじっくり人間型推論に取り組んでみますと、まず、変数名はpipeであり、二引数を持つから関数。
pipe : x? -> f? -> return?
まだ型は分からないので?としておきます。右辺を見るとf x。つまりfは一引数を持つので関数。
x? -> (f_arg? -> f_ret?) -> return?
fの第一引数はxの型であり、fの戻り値が関数全体の戻り値の型となるので
x? -> (x? -> return?) -> return?
これ以上は型を当てはめることが出来ず、また、特に矛盾なくジェネリクスで構成できそうなので
'a -> ('a -> 'b) -> 'b
となる('aがC#でいう<T>みたいなものということで)。なるるほど、あまりに短いスパッとした定義なので面食らいますが、分かってしまえばその短さ故に、これしかないかしらん、という当たり前のものとして頭に入る、といいんですがそこまではいきませんが、まあ使うときは感覚的にこう書けるー、程度でいいので大丈夫だ問題ない。
このパイプライン演算子をC#で定義すると
public static TR Pipe<T, TR>(this T obj, Func<T, TR> func)
{
return func(obj);
}
比較するとちょっと冗長すぎはします。とはいえ、この拡張メソッドは、これはこれでかなり有益で、例えばEncodingのGetBytesなどを流しこんだりがスムーズに出来ます。例えばbyte[]の辺りは変換後に別の関数を実行して更に別の、という形で入れ子になりがちで、かといって変数名を付ける必要性も薄くて今一つ綺麗に書けなくて困るところなのですが、パイプライン演算子(モドき)さえあれば、
// ハッシュ値計算
var md5 = "hogehogehugahuga"
.Pipe(Encoding.UTF8.GetBytes)
.Pipe(MD5.Create().ComputeHash)
.Pipe(BitConverter.ToString);
// B6-06-FC-CF-DC-99-6D-55-95-B8-B6-75-DB-EE-C8-AE
Console.WriteLine(md5); // Pipe(Console.WriteLine)でもいいですね
気持ちよく、また入れ子がないため分かりやすく書けます。そのためC#でも最近は結構使ってます。ただ、Tへの拡張メソッドという影響範囲の大きさは、相当な背徳を背負います。というかまあ、共同作業だと、使えないですね、やり過ぎ度が高くなりすぎてしまって。パイプはC#のカルチャーでは、ない。うぐぐ。F#なら
"hogehogehugahuga"
|> Encoding.UTF8.GetBytes
|> MD5.Create().ComputeHash
|> BitConverter.ToString
|> printfn "%s"
このようになりますね。「|>」という記号選びが実に絶妙。ちゃんと視覚的に意味の通じる記号となっているし、縦に並べた際の見た目が美しいのが素敵。美しいは分かりやすいに繋がる。
"hogehogehugahuga"
|> (Encoding.UTF8.GetBytes >> MD5.Create().ComputeHash >> BitConverter.ToString)
|> printfn "%s"
翌々眺めると、関数が並んでるなら合成(>>演算子)も有りですね!びゅーてぃほー。
LINQ
関数型言語といったら高階関数でもりもりコレクション処理であり、そしてそれはLinq to Objectsであり。F#ではSeq関数群をパイプライン演算子を使って組み上げていきます。
[10; 15; 30; 45;]
|> Seq.filter (fun x -> x % 2 = 0)
|> Seq.map (fun x -> x * x)
|> Seq.iter (printfn "%i")
filterはWhere、mapはSelect、iterは(Linq標準演算子にないけど)ForEachといったところでしょうか。
new[] { 10, 15, 30, 45 }
.Where(x => x % 2 == 0)
.Select(x => x * x)
.ForEach(Console.WriteLine); // 自前で拡張メソッド定義して用意する
比べると、|>はドットのような、メソッドチェーンのような位置付けで対比させられようです。違いは、パイプライン演算子のほうが自由。例えば、拡張メソッドとして事前にかっきりと定義しなくてもチェーン出来る。だから、F#にSeq.iterなどがもしなかったとしても、
[10; 15; 30; 45;]
|> (fun xs -> seq {for x in xs do if x % 2 = 0 then yield x * x })
|> (fun xs -> for x in xs do printfn "%i" x)
その場でサクサクッと書いたものを繋げられたり、yieldもその場で書けたり(まあこれは内包表記に近くC#だと別にクエリ式でもいいし、といった感じで意味はあまりないですが)実に素敵。しかし、自由には代償が必要で。何かといえば、補完に若干弱い。シーケンスの連鎖では、基本的には次に繰り出したいメソッドはSeqなわけで、一々Seq.などと打つまでもなくドットだけでIntelliSenseをポップアップさせて繋げていくほうが楽だし、ラムダ式の記法に関してもfunキーワードが不要な分スッキリする。
この辺は良し悪しではなくカルチャーの違いというか立ち位置の差というか。C#のほうがオブジェクト指向ライクなシンタックスになるし、F#のほうが関数型ライクなシンタックスだという。同じ処理を同じようにマルチパラダイムとして消化していても、優劣じゃない差異ってのがある。これは、私は面白いところだなーと思っていて。どちらのやり方も味わい深い。
最後に
C#単独で見た時よりも.NETの世界が更に広く見えるようになったと思います。あ、こんな世界は広かったんだって。今後は、ぽちぽちとF# Scriptを書きつつ、FParsecにも手を出したいなあといったところですね。
大して書けはしませんが、それなりに書き始めて使い出せている、歩き始められているのは間違いなく本書のお陰です。「こう書くと良いんだよ」という、誘導がうまい感じなのでするっと入れました。どうしてもC#風に考えてしまって、それがF#にそぐわなくてうまくいかなくて躓いたりするわけですが、そこで、ここはこうだよ、って教えてくれるので。ちょっとした疑問、何でオーバーロードで作らないの?とかの答えは、載っています。
それと最後にクドいけれど、Visual Studio統合のF# Interactiveは本当に凄い。C# 5.0のCompiler as a ServiceはこれをC#にも持ってきてくれることになる、のかなあ。
Linq to ObjectsとLinq to Xmlを.NET 2.0環境で使う方法
- 2011-02-09
LinqのないC#なんて信じられない。カレールゥのないカレーライスみたいなものです。しかし.NET Framework 2.0ときたら……。幸いなことに、開発はVisual Studio 2008以降で、ターゲットフレームワークを2.0に、とすることでvarやラムダ式は使うことが可能です。拡張メソッドも小細工をすることで利用可能になります。といったことは、C# 3.0 による .NET 2.0 アプリケーション開発 - XNA で LINQ を使おう - NyaRuRuの日記に書いてありますねん。あと足りないのはLinqを実現するEnumerableクラス。その辺のことはNyaRuRuさんの日記の追記のほうにもありますが、LINQBridgeを使うことで拡張メソッドのための小細工なども含めて、全部面倒見てくれます。つまり、Linq to Objectsを.NET 2.0で使いたければLINQBridge使えばいい。以上。
というだけで終わるのもアレなので、Linq to Objectsが使えるなら、Linq to Xmlも使いたいよね?Linq to Xmlの強力さを一度味わったら二度とXmlDocumentも使いたくないし生のXmlReader/Writerも使いたくないし。でも残念なことにLINQBridgeはto Objectsだけ。となれば自前再実装、は無理なので、そこは.NET Frameworkのオープンソース実装のMonoからソースコードをお借りすればいいんじゃなイカ?
Monoのソースコードはmono/mono - GitHubで管理されています。私はGitじゃなくてMercurial派なのでGitは入れてないのでPullは出来ない、ので、普通にDownloadsからzipで落としました。クラスライブラリはmcs\class以下にあります。まずはEnumerableから行きましょう。
Linq to Objects
新規にクラスライブラリプロジェクトを立てて(プロジェクト名は何が良いでしょうかねえ、私はMono.Linqとしました)、ターゲットフレームワークを2.0に変更。そしてSystem.Core/System.Linqをフォルダごとドラッグアンドドロップでソリューションエクスプローラに突っ込む。そしてコンパイル!
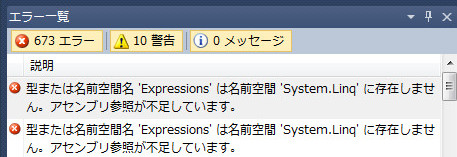
ふむ。華麗に673件のエラーが出てますね。どうやらExpressionsがないそうで。ふーむ、つまりQueryable関連ですねえ。Enumerableだけだと関係ないので削除してもいいんですが、せっかくなのでIQueryableも使えるようにしましょう!System.Core/System.Linq.ExpressionsもEnumerableと同じようにフォルダごとコピー。更にコンパイル!
するとまだまだ346件エラー。FuncがないとかExtensionAttributeがないとか。.NET 3.0で追加された拡張メソッド用の属性とかFuncがないわけですね。というわけで、それらも持ってきてやります。ExtensionAttributeはmcs/class/System.Core/System.Runtime.CompilerServicesにあります。Enumerableだけの場合はExtensionAttributeだけでいいのですが、Queryableも使う場合は他のクラスも必要になるので、ここもフォルダごとコピーしましょう。
もう一つの、FuncとActionはSystem.Core/SystemにFuncs.csとActions.csとして定義されているので、これらも持ってきます。なお、FuncとActionは#ifディレクティブにより.NET4以下の場合は4引数までのものしか使えないようになっていますが、.NET4からの16引数までのものも使いたければ、#ifディレクティブを削除すればOK。
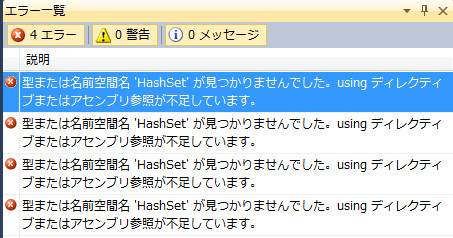
これでコンパイルするとエラーはたった4つになります!ってまだエラーあるんですか、あるんですねえ。HashSetがないとか。HashSetで、ああ、集合演算系が使ってるもんねえ、とティンと来たら話は早い。こいつはSystem.Core/System.Collections.Generic/HashSet.csにあります。みんなSystem.Core下にあるので捜すの楽でいいですね。
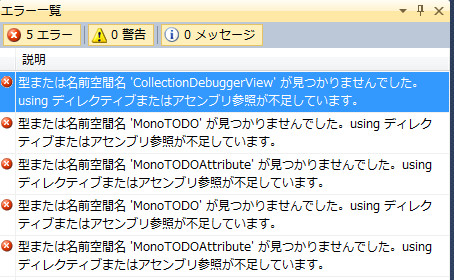
コンパイルしたらエラーが増えた!HashSet.csのエラーですね。CollectionDebuggerViewとMonoTODOという属性が無いそうだ。よくは分かりませんが、名前からして大したことはなさそうだしたったの5つなので、削除してしまっても問題なく動きます。ので削除してしまいましょう。と言いたいんですが、せっかくなのでこの二つの属性も拾ってきます。この二つはSystem.Coreにはないし、正直見たこともない属性なので何処にあるのか検討付きません。というわけで、まあ検索すれば一発です。
System.Data.Linq/src/DbLinq/MonoTODOAttribute.cs、って随分変なとこにありますね、とにかくこれと、corlib/System.Collections.Generic/CollectionDebuggerView.csを持ってくる。
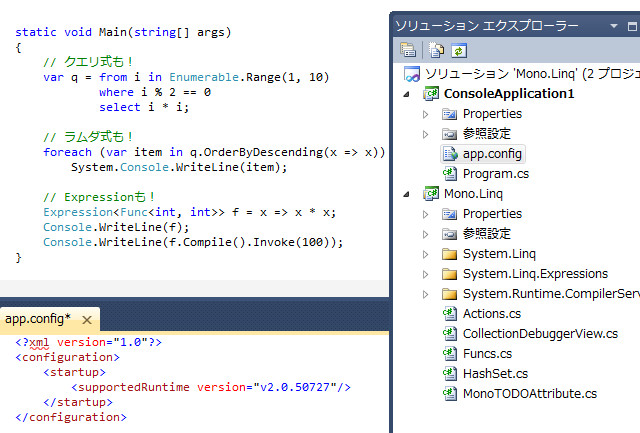
これで完成。コンパイル通る。動く。ターゲットフレームワーク2.0でもLinq!何も問題もなくLinq!ラムダもvarも拡張メソッドもある!うー、わっほい!C# 3.0で.NET Framework 2.0という奇妙な感覚が非常に素敵です。
Linq to Xml
ではLinq to Xmlも用意しましょう。といっても、やることは同じようにmonoのコードから拝借するだけです。mcs/class/System.Xml.Linq下にあるSystem.Xml.Linq, System.Xml.Schema, System.Xml.XPathをフォルダごとコピー。そしてコンパイルすると!例によってエラー。
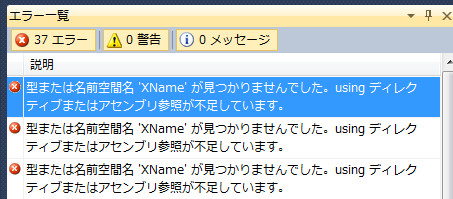
XNameが見つからないそうで。んー、あれ、XNameは普通にLinq to Xmlの一部では?と、いうわけでSystem.Xml.Linq/XName.csを見に行くと、あー、#if NET_2_0で.NET2.0環境下では全部消えてる!しょうがないので、ここではソースコードを直に編集して#ifディレクトブを除去しちゃいます。
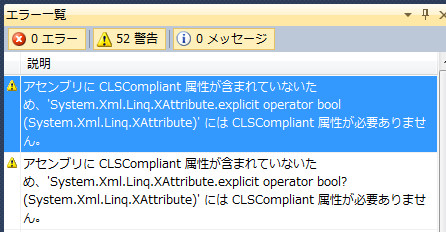
コンパイルは通りましたが警告ががが。CLSCompliantがついてないってさ。というわけで、Properties/AssemblyInfo.csにCLSCompliantを付けてやります。
[assembly: System.CLSCompliant(true)]
これで完成。Linq to Xmlが使えるようになりました!マジで!マジで。
ライセンス
ライセンスは大事。FAQ: Licensing - Monoで確認するところ、クラスライブラリはMIT X11 Licenseになるようです。かなり緩めのライセンスなので比較的自由に扱えるのではないかと思いますが、詳細はFAQならびにMIT X11 Licenseの条項を個々人でご確認ください。
まとめ
Linqがあれば.NET 2.0でも大丈夫。もう何も怖くない。まあ、実際.NET 2.0のプロジェクトを今からやるかといえば、これは最終手段であって、まずやることは全力で反対して.NET 4を採用させることでしょう。既存のプロジェクトに対する改修でLinqを突っ込むのは、うーん、そんなこと許されるんですか!許されるなら平気でやります!大抵は許されない気がしますが!
さて、.NET 4の人でもこれを用意する利点はあります。学習用に。シームレスにLinqの中へデバッグ実行で突入出来ます。挙動の理解にこれより最適なものはないでしょう。ソースコードを眺めるもよし、ですしね。それと、これを機にMonoに触れる、機会はWindowsな私だとあまりないのですが、ソースコードに触れてみるのも結構幸せ感です。mono独自のクラス(Mono.Xxx)も色々あって面白そう。
余談ですが、Windows Phone 7やSilverlightであのクラスがない!という状況もMonoの手を借りることで何とかなるケースも。(何とかならないケースは、依存がいっぱいで沢山ソースを持ってこなければならない場合。さすがにそう大量となるとどうかな、と)
.NETコードへデバッグ実行でステップインする方法
デバッグ実行といえば、Microsoftもソースコードを公開しています。.NET Framework Librariesで公開されてます。.NET 4をDownloadすれば、その中にあります。やたら階層が深くて迷ってしまいますが、EnumerableとQueryableは Source.Net\4.0\DEVDIV_TFS\Dev10\Releases\RTMRel\ndp\fx\src\Core\System\Linq にあります。Symbolをモニョッとすれば、Visual Studio内でもステップインでデバッグ出来ますねえ。というわけで、その解説もついでなので。
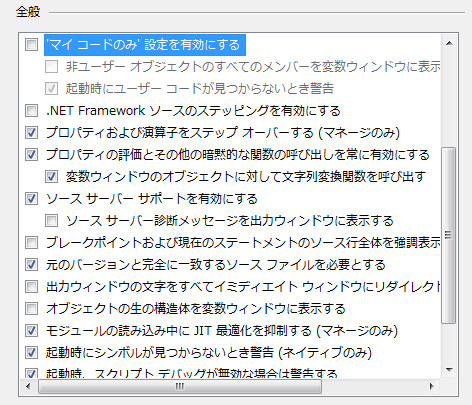
まず、オプション->デバッグ->全般で「マイコードのみ設定を有効にする」のチェックを外します。そして、「ソースサーバーサポートを有効にする」のチェックを入れます。この二つだけ(多分)。ちなみに、「.NET Frameworkソースのステッピングを有効にする」というなんともそれっぽいオプションは罠なので無視しておきましょう。
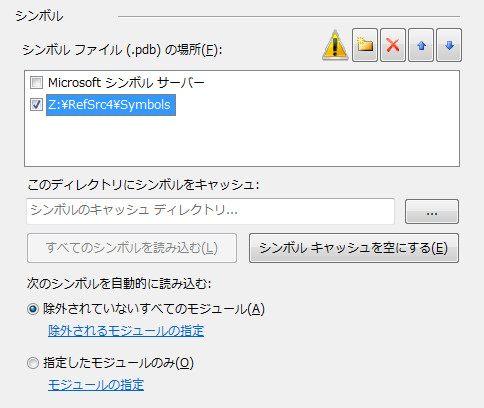
あとはデバッグ->シンボルでダウンロードした先のフォルダを指定すればOK。私はZ:\RefSrc4\Symbolsになってます。これで、F11でめくるめく.NET Frameworkの無限世界にステップインで帰ってこれなくなります!やり過ぎると普通に鬱陶しくなるので、その他のオプション類とかで適度に抑制しながらやりませう。