RxJS用IntelliSense生成プログラム(と、VisualStudioのJavaScript用vsdocの書き方)
- 2010-03-26
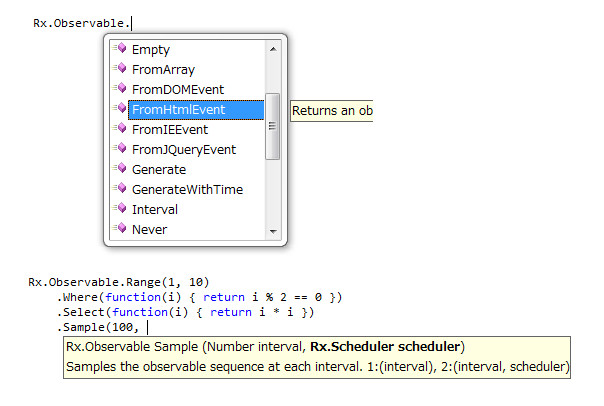
先日、Reactive Extensions for JavaScript(RxJS)の記事を書いたわけですが、触っていて困るのは、どのメソッドが使えるの?ということ。リファレンスもない中で、C#版の記憶を頼りに手打ちでメソッド名を探るなんて、無理。ましてやそんな状況じゃあ人に薦められないよ!というわけで、必要なのはIntelliSense(入力補完)です。rx.jsはある。rx-vsdoc.jsはない。ないものは、作ればいいぢゃない。そこで諦めてメソッド全部暗記してやるぜ、とか思うのはどうかしてる。諦めたら試合終了ですよ。楽するために手間を掛けるのです<プログラマの三大美徳。というわけで、作りました。
- RxVSDocGenerator.zip (source and binary)
vsdocファイルをそのまま配布するのはライセンスの問題が出そうなので、生成プログラムを配布します。手作業じゃなく自動生成で作ったので(面倒くさくて手作業なんてやってられるか!)。Rxをインストールしたフォルダ(デフォルトだとProgramFiles\Microsoft Reactive Extensions)のScriptSharpフォルダの下のRxJS.dllとRxJS.xmlを、生成プログラムと同じ階層に置いて実行すると、rx-vsdoc.jsが生成されます。
利用するにはvsdoc対応パッチをあてたVisualStudio 2008 SP1(VS2010はパッチをあてなくても対応しています)を用意して、rx.jsと同じ階層に置くだけです。HTMLで使う場合はscript src="rx.js"で読み込むだけ、独立したjsファイルで補完を使う場合は、行頭に/// <reference path="rx.js" />と記述すれば補完が読み込まれます。この辺は、以前に最もタメになる「初心者用言語」はVisualStudio(言語?)という記事を書いたときに補完愛してる愛してる愛してると連呼しながら解説してました。jQueryのドットで補完効かせながらのメソッドチェーンは気持ちイイんだって!
折角作ったので海外の人にも利用してもらおうと、また、標準でvsdocも同梱して欲しいと訴えるためにもとRxの公式フォーラムでスレ立てたけど、奇怪英語(機械翻訳英語)が恥ずかしいです……。ニュアンスをミジンコほどにも伝えられた気がしません。英語読めない書けないプログラマなんて小学生までだよねー、とかいう自己啓発系ブログ記事は山のようにあるわけですが、ふん、どうせ英語読めませんよ書けませんよ、ぐぐる先生による機械翻訳さえ超進化してくれれば小学生でも生きていけるもん!(ちなみに私はヤフー翻訳派です)
MIX10の発表によるとMicrosoftはAjax関連はjQueryに一本化する、ということで、C#erもますますJavaScriptを書かなければならないシーンは増えていきそうなので、せっかくなのでJavaScript用のvsdocの書き方を解説します。ついでに、LinqまみれなRxVSDocGeneratorのコードの解説も若干します。Mono.Cecil.dll使ってたりするんですよー(モジュールの参照用にしか使っていないので些かオーバースペック)。
C#と比較するJavaScriptの構造
JavaScriptは割とヒネクレた書き方が幾らでも出来るわけですが、VisualStudioの入力補完は、素の状態だと素直に書かないとついてきてくれません。というわけで素直に書きましょう。素直に書けば素直なIntelliSenseが手に入ります。以下、10秒でわかるC#とJavaScriptとの構造比較。
// 名前空間、もしくは静的クラス
Rx = {}
Rx.Disposable = {}
// クラス(コンストラクタ)
Rx.Observable = function(){ }
// 継承
Rx.AsyncSubject.prototype = new Rx.Observable;
// 静的フィールド
Rx.Disposable.Empty = null;
// インスタンスフィールド
Rx.GroupedObservable.prototype.Key = null;
// 静的メソッド
Rx.Observable.Range = function(start, count, scheduler){ }
// インスタンスメソッド
Rx.Observable.prototype.Select = function(selector){ }
ヒネクレたことさえしなければ、JavaScriptはシンプルです。オブジェクトとファンクションしか存在しない。シンプルさ故の制限を回避するために、また、幾らでも回避可能なためバッドノウハウのようなヒネクレた手段が大量に溢れていて、シンプルさとは無縁の奇怪な代物と成り果てていますが(JSはシンプルだよ、初心者にお薦め!というそばからクロージャがどうのapplyがどうのと言うのはどうなのよ、勿論、その柔軟さもまたJSの魅力の一つだとは思いますが、それをシンプルとは言わない)、素直に見れば、シンプルです。
そしてまあ、C#と割と似てます。構文似てるし。単一継承だし。prototypeに後からメソッドを足せるのは拡張メソッドのよう。違いは、privateはないしプロパティはないしインターフェイスはないしオーバーロードもない(但し引数は省略可能)、いつでも簡単に全てが変更可能(不注意に扱えばすぐ構造をぶっ壊せる←だからライブラリの衝突の問題がある)。といった問題は、若干ヒネクレればある程度は回避可能です、privateとか。でも、素直に書いた方が良いと思います。JavaScriptにprivateはない。と、割り切ってしまうと非常に楽になれます。良いか悪いかはともかく。
ただ、素直に書こうと、素のJavaScriptでは、補完は簡単に限界がきます。例えば以下のコード。
var func = function(bool) {
return (bool) ? "string" : [4, 5, 2, 3, 1];
}
var b = Math.random() < 0.5; // true or false
func(b).toUpperCase();
func(b).sort(); // どちらかで必ずエラー
引数の型が自由なら、戻り値の型もまた自由。じゃあどうするの?というと、どうにもなりません。戻り値の型はなるべく統一しましょう、IntelliSenseに優しくするために。これもまた素直の一つでしょうか、さてはて。
vsdoc.js入門
素直に素直に、と言ったところで何処かで破綻する。だいたい、JavaScriptの言語としての柔軟さを生かさないでどうする!という話は尤もなこと。そこで、VisualStudioはJavaScriptの入力補完に気の利いた仕組みを用意しています。ファイル名-vsdoc.jsが同階層にある場合、vsdoc.jsの構造を利用して入力補完を行います。なので、オリジナルに手を加える事なく補完を利用することが出来ますし、また、オリジナルが補完生成し辛い構造をしていても問題はありません。最終的にユーザーが利用するPublicの構造というのは、上で書いた素直なJavaScriptで再現出来るわけなので、それで構築すればいいだけです。勿論、別箇に構造を作成するというのは手間が増えるので、可能な限りは素直な構造にしておいたほうが無難です。
「IntelliSenseに候補が出ないものは存在しないに等しい」。これは.NETのクラスライブラリ設計という本に書かれている言葉なのですが(神本なので未読の人は絶対購入しましょう)、候補を出しさえしなければ、利用者にとって存在しないようなものに見えます。実際はpublicであっても、補完候補から削ってしまえばprivateに見える。擬似的なprivateの表現としては、中々スマートではないですか?
そんなvsdocですが、ちゃんとしたドキュメントが今ひとつ見あたらないので、jQuery用のvsdocを参考にすると良いでしょう。色々な属性が用意されているようですが、実際の入力補完に利用されるものは少ししかありません。optional属性なんて、オーバーロード的なものの表現に使えるのでは?と期待をかけたのですがそんなことはなくて、IntelliSense用には動作しませんでした。よって、summary, param, returnsだけ抑えておけば良いです。
var sum = function(x, y) {
/// <summary>足し算</summary>
/// <param type='Number' name='x'>引数1</param>
/// <param type='Number' name='y'>引数2</param>
/// <returns type='Number'></returns>
}
Rx.Disposable.Empty = new IDisposable;
C#と違ってfunctionの「下」にドキュメントコメントを書きます。また、ドキュメントコメントを使う場合は、関数本体はあってもなくても無視されるので、不要です。なお、ドキュメントコメントは-vsdoc.jsだけで有効なわけではなく、普通のjsファイルでも有効です。summary, paramは面倒くさかったら書かなくてもそんなに害はなさそうですが(但し引数違いのオーバーロードがある場合はsummaryで伝えてあげると使う人に優しい)、returns typeだけは欠かさず書いておきたい。これを書いておくと戻り値の型がVisualStudioに認識されるので、IntelliSenseを途絶さず利用できます。
制限事項としては関数のみにドキュメントコメントを埋め込むことが出来ます。vsdocを作る際にフィールドの型も認識させたい場合は、ダミーの変数を与えてあげればOK。
ジェネレータの解説
と、いった基本を抑えておけば、どんなライブラリに対してもvsdocを作れるね!じゃあ、rx-vsdoc.jsも手作業で作ろうか。と、思った時もありました。構造自体はjs自体をダンプでなんとかなる(と、いいなあ)だろうし、summaryやparamは諦めるとしてreturns typeだけを手作業で書くなら、どうせほとんどRx.Observableなので手間もそんなでもない。けど、rx.jsは難読化されていて引数の名前がイミフ、例えばRx.Observable.Range(k0, l0, m0)というんじゃ苦しい……。やっぱsummaryもparamも必要。でもどうすれば……?
そこで、インストールディレクトリを見てみるとScriptSharpなんてフォルダがあるんですよ。そう、RxJSはScript#でC#コードから生成されたJavaScriptライブラリだったのだよ、ナンダッテー!そして、ScriptSharp用のRxJS.dllには当然、完全なクラス構造と、引数の名前と型が保存されているし、更にはsummary用のxmlも用意されていた。つまり、ここからrx-vsdoc.jsを生成すればいいわけです。
というわけでリフレクション。型情報を取るため、早速Assembly.LoadFrom("RxJS.dll").GetTypes()とすると、落ちる。はあ、ScriptSharpのdllに依存してるのでそっちもないとダメなのね。というわけでScriptSharpのdllを幾つか参照に加えると、なんかうまく動かせない。ScriptSharpのdllはmscorlibの代替となってる(JSに変換可能なもののみに制限を加えてる?)から、一緒には動かせないとかそんな感じなのかなー、よくわからないけどとにかく動かせない、諦める。南無。無念。
そもそもLoadするからダメなわけで、Loadしなくていいよ、型情報だけ取れればそれでいいんだって。でも標準ライブラリには、それを可能にするのはないっぽい。けど、Monoにはあった。Cecil - Mono。参照も書き換えも出来るようですが、今回は参照のみで。色々出来そうなので、いつかもう少し触ってみたいですね。私は今回はじめてMono.Cecil.dllを使ったのですが、リファレンスの類も見てない(あるのか知らない)し、チュートリアルの類も見てない(ていうか日本語の情報がない)。でも、IntelliSenseでドット打ってれば何とかなりました。しっかりした構造とちゃんとしたメソッド名とIntelliSenseがあれば、リファレンスがなくても問題なく使えるわけです。すばらしきこのせかい!
Mono.Cecil
型情報を取ってくるだけなら簡単で、というかSystem.Reflectionと大して変わりません。
var rxjsTypes = AssemblyFactory.GetAssembly("RxJS.dll")
.MainModule.Types.Cast<TypeDefinition>()
TypeDefinition, MethodDefinition, ParameterDefinitionといったのが個の要素。そして、対応するコレクションHogeCollectionが用意されています。HogeCollectionは残念ながらジェネリックではないため、Linqに流すためにはCastが必要になります。今回はParameterDefinitionCollectionのSelectを多用することが多かったので、Cast無しで使えるよう拡張メソッドを定義しちゃいました。
static IEnumerable<T> Select<T>(this ParameterDefinitionCollection source, Func<ParameterDefinition, T> selector)
{
return source.Cast<ParameterDefinition>().Select(selector);
}
この手のレガシーなコレクションに対するアドホックな対応は、例えば正規表現のMatchCollectionなんかにも使えそうです(と、いった発想の元ネタはAchiralから)
テンプレート置換
必要なJSの構造は上のほうで書いた通り決まったパターンがあるので、雛形を元に置換するのが楽。テンプレートエンジン、なんていう大仰なものは必要ないけれど、string.Formatでも{5}とか出てくると引数の管理が面倒だし、順番の変更にも弱い。なので簡易置換用の拡張メソッドを用意してみました。
static string TemplateReplace(this string template, object replacement)
{
var dict = replacement.GetType().GetProperties()
.ToDictionary(pi => pi.Name, pi => pi.GetValue(replacement, null).ToString());
return Regex.Replace(template,
"{(" + string.Join("|", dict.Select(kvp => Regex.Escape(kvp.Key)).ToArray()) + ")}",
m => dict[m.Groups[1].Value]);
}
オブジェクトを渡すと、{プロパティ名}の部分をプロパティの値に置換します。オブジェクトなのでクラスインスタンスでもいいのですが、匿名型も使えます。例えば
const string classTemplate = @"
{FullName} = function({Parameters})
{
/// <summary>{Summary}</summary>
{Param}
}";
var r = classTemplate.TemplateReplace(new
{
FullName = "Rx.Notification",
Parameters = "kind",
Summary = "Represents a notification to an observer.",
Param = " /// <param type='String' name='kind'></param>"
});
Console.WriteLine(r);
割と便利。たった9行なので、ちょっと気の利いた置換が欲しいなあ、って時にササッとコピペして取り出せるのが魅力です。最近、コピペに優しいプログラミングをよく考えてる。というのはともかくとして、実際どんな風に使っているかというと、
var classes = rxjsTypes
.Where(t => t.Constructors.Count > 0)
.Select(t => new
{
t.FullName,
Parameters = t.Constructors.Cast<MethodDefinition>()
.Select(m => m.Parameters)
.MaxBy(p => p.Count)
.Select(p => p.Name)
.ToJoinedString(", "),
Summary = summaries[t.FullName] + " " + t.Constructors.Cast<MethodDefinition>()
.OrderBy(m => m.Parameters.Count)
.Select(m => m.Parameters.Select(p => p.Name).ToJoinedString(", "))
.Select((s, i) => string.Format("{0}:({1})", i + 1, s))
.ToJoinedString(", "),
Param = t.Constructors.Cast<MethodDefinition>()
.MaxBy(m => m.Parameters.Count)
.Parameters
.Select(p => string.Format(Template.Param, p.ParameterType.ToJSName(), p.Name))
.ToJoinedString(Environment.NewLine),
})
.Select(a => Template.Class.TemplateReplace(a));
前段階で匿名型を生成して、最後のSelectで置換をかけてます。Select二段にしないでもいんじゃね?というとYESですが、このほうが見やすいと思うので。それにしてもリフレクションなわけで、Linqと非常に相性が良い。というか、Linqなしだと大量のforループとifで涙を流すことになりそう。なので、昔はリフレクションって結構敷居が高かったのですが、今はもうLinqでサクサクとWhereで切って捨ててSelectで繋げて繋げて、って出来るので書く分には楽チンです。これがLinq以前のC#2.0だったら、考えたくないなあ。
出力
クラス、継承、オブジェクト、メソッド、プロパティは全部バラバラに抽出しています。そして、全部IEnumerable<string>で止めています。最後にそれらをまとめて、テキストとして出力。
var vsdoc = Enumerable.Repeat(string.Format(Template.Object, RootNamespace), 1)
.Concat(classes)
.Concat(inheritance)
.Concat(objects)
.Concat(methods)
.Concat(properties)
.ToJoinedString(Environment.NewLine);
File.WriteAllText("rx-vsdoc.js", vsdoc, Encoding.UTF8);
せっかくクエリ遅延評価にさせているので、書き出しも一度stringに貯めないでストリームで書きだせば高効率ですねー。でも、一度文字列に出した方が書くの楽なので。せいぜい1000行程度なので、ケチッても意味ないですな。
全部rxjsTypesをルートにして生成しているので、クエリ構文を使って巨大な一塊にしてみたら面白かったかな、なんて思いますが若干悪趣味な気もするのでやめておきます。そもそも、このドットだらけ、Selectだらけの時点で若干どうよ、といった趣が漂っているのは間違いない。いやいや、ドット素敵です。Linq素敵なんだって、本当に。こういうの書いてるとC#2.0と3.0は別物だろ常識的に考えて、と思わなくもない。セミコロン率は物凄く低くなりましたね……。あと、LinqとSQLを関連付けるのはそろそろやめようぜー、的な思いがふと過ぎったり。Twitterのpublic検索でlinqをキーワードに毎日眺めてるんですが、今でも割とそういう印象持ってる人多いんだなー、と。だからどうしたとかどうなるってこともないですが。
まとめ
IntelliSenseでLinqはより楽しくなる。メソッドチェインはIntelliSenseでより楽しくなる。そして、VisualStudioはJavaScriptエディタとしても優秀なので皆VisualStudio使おう!インストールが面倒?Microsoft Visual Studio 2008 Express EditionからWeb インストールをクリックするだけでオールインワンでダウンロード含めて10分ぐらいで全部やってくれる。時間がかかるというのは正しいですが、意外と面倒くさくはないんです。それと、このExpress Editionは無料です。
入力補完だけじゃなく、コード整形やデバッガ(開発環境と完全統合されているためFirebugよりもずっと使いやすい)などもあるし、ある程度は裏でインタプリタをぶん回して変数名間違いなどのエラーを補足してくれるので、IDE無しでJavaScript書くなんて、そんな苦労、しなくてもいいんだよ……。
Reactive Extensions for JavaScript
- 2010-03-18
MIX10終了しましたねー。何はともかく皆してIE9の話題ばかりで、ああ、InternetExplorerは愛されてるなあ(色々な意味で)、などというのを横目に、私にとっての最大のニュースはReactive Extensions for JavaScript(RxJS)です。Reactive Extensions(Rx)はこのサイトでもカテゴリーを作ってメソッド探訪なんてやってるぐらいに注目していたわけで、当然MIX10でJavaScript版出すという話を聞いた時からwktkが止まらなかったわけですが、全く期待を裏切らなかった!というか、こいつはヤバいですよ?
Reactive Extensionsとは何ぞや、というと、LinqというC#の関数型言語みたいなリスト処理ライブラリ(語弊ありまくり)のイベントとか非同期版です。イベントや非同期処理にたいしてmapとかfilterとかfoldとか、お馴染みなリスト操作関数が使えちゃうという、その発想はなかったわ、なライブラリです。C#版は去年の夏ぐらいにプレビュー版が出て、いまも精力的に開発が続いているのですが、今回はJavaScript移植版が出た、という話です。イベント(onclick!onclick!)や非同期(XMLHttpRequest!)ってのは、勿論C#でも大事なのですが、JavaScriptなんてそれが主役というぐらいなわけなので、C#版よりもインパクトは大きいです。何よりも、C#は言語やライブラリが強力なので別にRx使わなくてもって感じなのですが、JavaScriptは違う。あまりにも貧弱。なので、優れたイベント/非同期処理ライブラリの重要度はC#の比ではなく高い。
RxJSの面白いところはjQueryに対抗するものではなく、むしろ協調動作するように作られていることです。DOM操作はjQuery、イベントや非同期処理はRxJS、二つの強力なライブラリを組み合わせることで、JavaScriptプログラミングは次のパラダイムへ向かおうとしています。御託は、もういいですね、とりあえずサンプルを。
マウスをクリックして四角形を掴んで、マウスを動かして、放すという、ごく普通のドラッグアンドドロップ。素の JavaScriptではどうやって実装しますか?グローバルに状態管理用のオブジェクトを置いて、オフセット用の変数置いて、マウスの状態を監視して、うーん、考えたくない。あまり綺麗に出来そうにない。それがRxJSを使ってみると――
var O = Rx.Observable; // using
$(function()
{
var doc = $(document);
var area = $("#dragArea");
O.FromJQueryEvent(area, "mousedown")
.Select(function(e)
{
var offset = $(e.target).offset();
return { X: e.pageX - offset.left, Y: e.pageY - offset.top }
})
.SelectMany(function(offset)
{
return O.FromJQueryEvent(doc, "mousemove")
.TakeUntil(O.FromJQueryEvent(doc, "mouseup"))
.Select(function(e) { return { X: e.pageX - offset.X, Y: e.pageY - offset.Y }; })
})
.Subscribe(function(a) { area.css({ left: a.X, top: a.Y }) });
});
状態管理変数は使いませんし、全て一連のメソッドチェーンだけで完結します。以下解説。
Rx.Observable.FromJQueryEventは、イベントをRxオブジェクトに変換します。これはjQueryの$などと同じものだと思ってください。FromJQueryEventと同様の動作をするものにFromHtmlEventというものがあります。ほとんど同様ですが、jQueryオブジェクトを使う場合はFromJQueryEvent、getElementByIdなどで得られたネイティブの要素を使う場合はFromHtmlEventを使いましょう。基本的には、クロスブラウザ回りの面倒事を任せられるjQueryとの併用がお薦めです。
Rxオブジェクトに変換後は、多数のメソッドをjQueryのようにチェーンさせて記述していきます。どれだけ多数かというと、ここに並べてみます。
Subscribe, Select, Let, MergeObservable, Concat, Merge, Catch, OnErrorResumeNext, Zip, CombineLatest, Switch, TakeUntil, SkipUntil, Scan1, Scan, Finally, Do, Where, Take, GroupBy, TakeWhile, SkipWhile, Skip, SelectMany, TimeInterval, RemoveInterval, Timestamp, RemoveTimestamp, Materialize, Dematerialize, AsObservable, Delay, Throttle, Timeout, Sample, Repeat, Retry, BufferWithTime, BufferWithCount, StartWith, DistinctUntilChanged, Publish, Prune, Replay
何も一気に全部を知る必要はないので、あまり圧倒されずに、少しずつ学んでいければいいかな? 私もちょいちょいとブログ記事で紹介していきたいと思っています(やるやる詐欺ばかりですが……)。そうそう、ソースコードが圧縮されていて実際の名称は不明なのでRxオブジェクトと呼んでますが、それであってるかは今のところ謎です。C#ではIObservableなので、IObservableでいいかな、という気はしますが。
イベント as リスト
もう少しFromJQueryEventの動きを考えますか。イベントが発生すると、後ろのメソッドにイベントオブジェクトが渡されます。再度クリックすると、またイベントが発生しイベントオブジェクトが渡されます。再度(以下略)。つまりは、[event, event, event...]。終りのない配列。無限リスト。まるでイテレータのような……。そう、ObserverパターンとIteratorパターンは同じなのだよ、ナンダッテー!よく分からない?確かに。こういう時は他の人の言葉を借りてしまおう。最近Scalaの入門記事が注目を集めました。「神は言われた。「リストあれ。」」。そうです、イベントもまた、Rxの手にかかればリストになってしまうのです。Rxは関数型言語のリスト操作のようにイベントを高階関数で処理できます。それがもたらす世界、想像するとワクワクしませんか?なお、JavaScriptで配列やDOMに対してリスト操作を行うライブラリとしてlinq.jsというがありますのでよろしくお願いします←宣伝(作ってるの私なので)。
ドラッグアンドドロップの構造
mousedownでイベントが発動しても、本当に必要なイベントはdownじゃなくてmove。なので、downはイベント発動とオフセット算出にだけ使って、実際に後ろに流す情報は別のところから得ます。そこで、mousedownとmousemoveを合流させなければなりません。シーケンス(Rxによりリストのような何かになっているので、Sequenceが言葉として適切な気がします)の結合はMergeやCombineLatest、Zipなど、用途に応じて色々あるのですが、ここは一(mousedown)から多(mousemove)の状態を作ることが可能なSelectManyを使用します。SelectManyに渡す高階関数の戻り値(Rxオブジェクト)が、更に平たくされて後ろのメソッドに渡されていくことになります。
TakeUntilは、「~まで取得する」。引数のイベントが発動されるまでシーケンスを流し、発動されたら一切流さなくなる。つまりFrom(mousemove).TakeUntil(mouseup)は、mouseupされるまでmousemoveイベントを発行するということ。驚くほど簡単にドラッグアンドドロップの構造が記述出来てしまいました。これはヤバい。Rxヤバい。簡潔すぎるだろ常識的に考えて。
Selectは多くの関数型言語やRubyなどで言うところのmapで、要素を変形して返すもの。ここではeventからclientX, clientYだけのオブジェクトを作っています。mapがあるということは、勿論filterもあります(メソッド名はWhere)。この辺はlinq.jsの解説がそのまんま適用出来ます。何故かというと、Observerパターン(RxJS)とIteratorパターン(linq.js)は(以下略)。
Subscribe
シーケンスを変形していったら、最後に登録してやる必要があります。それがSubscribe。Subscribeを呼んで、初めてイベント(mousedownなど)に関連付けられます(addEventListenerです、ようするに)。このSubscribeは感覚的にはforeachのようなもので、無名関数の第一引数に今までに変形させた変数が入っているので、それを取り出して何らかのアクションを取る。今回はstyleを弄って四角形の座標を変更してやりました。
addEventListenerということは、デタッチもあるの?というと、ありますあります。Subscribeの戻り値はvoidではなく、IDisposableオブジェクトというものになっています。この戻り値のIDisposableオブジェクトを取っておけば、デタッチさせたい時にDisposeメソッドを呼んでデタッチさせられます。
Rx.Observable
Rxオブジェクトのメソッド一覧は書きましたが、Rx.ObservableにはFromHogeHoge以外にも色々なメソッドがあるよ。イベントだけじゃなく、あらゆる方向からRxオブジェクトを作り出す驚異のメソッド群はこれだ!
Amb, Catch, Concat, Create, CreateWithDisposable, Defer, Empty, FromArray, FromDOMEvent, FromHtmlEvent, FromIEEvent, FromJQueryEvent, Generate, GenerateWithTime, Interval, Merge, Never, OnErrorResumeNext, Range, Repeat, Return, Start, Throw, Timer, ToAsync, Using, XmlHttpRequest
いっぱいありますねー。名前から想像つくものからつかないものまで。XmlHttpRequestとか興味をひくところです。そう、Rxはイベントだけではなく、非同期通信までリストに変換し統一的な操作を可能にしてしまうわけです。こっちも重要なので、後日サンプル書きます。
結論
jQueryあるからRxJSなんてイラね、というわけじゃあないんですよ!ふたり揃ってプリキュア。最初の方にも書きましたが、jQueryのDOM操作は素晴らしいのでおまかせでいいです。イベントや非同期処理はjQueryだけじゃ足りないところがあります。そこはRxJSで補います。ついでに通常のリスト操作(配列やDOM Elements)は全然足りてません。prototype.jsはあんなにイけてたのに、jQueryになってからリスト処理がシンドいですね。そこはlinq.jsです(宣伝しつこい)。これでもうJavaScriptに死角はなくなった……、勝った、HTML5時代バンザイ!(でも私はC# + Silverlight4に期待をかけるけどね)
参考リンク
Rxチームの一員であるJeffrey van Goghによる、Rxをインストールしたディレクトリに置いてある、TimeFilesサンプルの解説。forループがダサいのでlinq.jsを使って書き直してTwitterに流したんですが、そうしたらJeffrey van Goghに言及してもらった!。これは嬉しい。
{kind=link}
Matthew PodwysockiによるRxJSの解説シリーズ。From(mousemove).TakeUntil(mouseup)のネタ元はここだったりして。最高にクール!
はてなダイアリー to HTML
- 2010-03-09
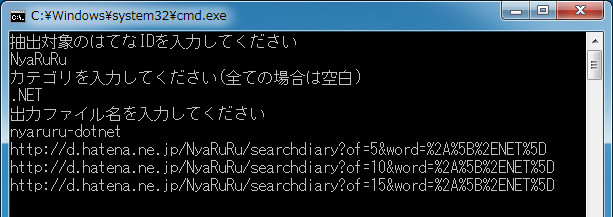
はてなダイアリーの記事を根こそぎ取得してローカルHTMLに保存するアプリケーションです。過去ログを全部取得して昇順に並び替えます。カテゴリ指定も可。 本文抽出アルゴリズムだなんて高尚なことはせず、HTMLをそのまま切り出しているだけのはてなダイアリー完全特化なぶんだけ、デザインやsyntax-highlightなどもそのままで見ることができます。上の画像はNyaRuRuの日記(勝手に貼ってすみません)の.NETカテゴリーを抽出しているところ。私がC#やLinqを覚えられたのはNyaRuRuさんの日記のお陰といっても過言ではなく、しかも読み返す度に新しい発見があって本当に素晴らしい。ので、度々読み返しているのですが、はてな重い。重い。なら全部ぶっこぬけばいいぢゃない。というのが作った理由でして……。
あと、最近こそこそごそごそとC++も勉強中なので、 [C++] - Cry’s Diaryや [C++] - Faith and Brave - C++で遊ぼうを読むと、(大体は全く分からないのですが)勉強になります。なお、Permalinkは相対パスになってしまい使えないのですが、日付の部分は絶対パスなので、コメント見たくなったりPermalinkを取りたくなったら日付から辿れます。
こうしてHTMLを自炊(?)すると、電子ブックリーダー欲しくなりますね。それと、リーダーはやっぱブラウザが載ってないとダメよねー。PDF(と独自形式?)だけ見れても嬉しくぁない。そんなに本には興味ない。HTMLが見たいのです。Twitterのログが見たいのです。2chまとめサイトが見たいのです。海外の技術書は結構PDFで買える感じなのでそれはそれで気になるところですが――。
以下ソースコード。↑のzipにも同梱してありますが。コンパイルにはSGMLReaderが必要です。
static class Program
{
static IEnumerable<T> Unfold<T>(T seed, Func<T, T> func)
{
for (var value = seed; ; value = func(value))
{
yield return value;
}
}
const string HatenaUrl = "http://d.hatena.ne.jp";
static void Main()
{
Thread.GetDomain().UnhandledException += (sender, e) =>
{
Console.WriteLine(e.ExceptionObject);
Console.ReadLine();
};
Console.WriteLine("抽出対象のはてなIDを入力してください");
var id = Console.ReadLine();
Console.WriteLine("カテゴリを入力してください(全ての場合は空白)");
var word = Console.ReadLine();
Console.WriteLine("出力ファイル名を入力してください");
var fileName = Console.ReadLine();
// 抽出クエリ!
var root = XElement.Load(new SgmlReader { Href = HatenaUrl + "/" + id + ((word == "") ? "" : "/searchdiary?word=*[" + Uri.EscapeDataString(word) + "]") });
var contents = Unfold(root,
x =>
{
var prev = x.Element("head").Elements("link")
.FirstOrDefault(e => e.Attribute("rel") != null && e.Attribute("rel").Value == "prev");
if (prev == null) return null;
retry:
try
{
var url = HatenaUrl + prev.Attribute("href").Value;
Console.WriteLine(url); // こういうの挟むのビミョーではある
return XElement.Load(new SgmlReader { Href = url });
}
catch (WebException) // タイムアウトするので
{
Console.WriteLine("Timeout at " + DateTime.Now.ToString() + " wait 15 seconds...");
Thread.Sleep(TimeSpan.FromSeconds(15)); // とりあえず15秒待つ
goto retry; // 何となくGOTO使いたい人
}
})
.TakeWhile(x => x != null)
.SelectMany(x => x
.Descendants("div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "day"))
.TakeWhile(e => !Regex.IsMatch(e.Value, @"^「\*\[.+\]」に一致する記事はありませんでした。検索語を変えて再度検索してみてください。$")) // 間違ったカテゴリ入力した時対策
.Reverse(); // 古いのから順に見たいので
// style抽出
var styles = root.Element("head").Elements("link")
.Where(e => e.Attribute("rel").Value == "stylesheet")
.Select(e => { e.SetAttributeValue("href", HatenaUrl + e.Attribute("href").Value); return e; }) // 副作用ダサい
.Concat(root.Element("head").Elements("style"));
// HTML組み立て!
var html = new XStreamingElement("html", // まあ、Reverseでバッファに貯めるので焼け石に水ですけどね、XStreamingElement
new XStreamingElement("head", styles),
new XStreamingElement("body",
// new XElement("div", new XAttribute("class", "hatena-body"), サイドバーとか邪魔なので無視
// new XElement("div", new XAttribute("class", "main"),
new XStreamingElement("div", new XAttribute("id", "days"),
contents)));
// 保存
var path = Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().FullName), fileName + ".html");
var xws = new XmlWriterSettings { Indent = true, CheckCharacters = false }; // 不正な文字のあるサイトを書き出すと落ちるので防止
using (var xw = XmlWriter.Create(path, xws))
{
html.Save(xw);
}
}
}
try-catchが出るとゴチャついて嫌。なのだけど、しょうがないか。それと Unfoldはどうしたものかねえ。極力、標準演算子のみで済ませたいんですが、今回はちょっと使わざるを得なかったと思っています。次のページのURLを得るには、取得したHTMLから解析しなければならない。下流で解析し取得した次のURLは、上流に渡さなきゃいけない。のですが、通常は下から上に渡せないのがLinqなのよね。そんな場合、外部変数を介して渡すか、Unfoldか、場合によってはScanなんかを使うかになるわけで、とにかく外部変数は避けたかったのでUnfoldを使いました。
HTMLへの書き出し部分では物珍しい XStreamingElementを使ってみました。今回はただ単に書き出すだけなので、通常のXElementのようにメモリ内にツリーを保持する必要はないし、相当大きいXmlを扱うため効率も気になってくるところ。そこで遅延ストリーム書き込みを可能にするXStreamingElementの出番です。詳しくは 方法: 大きな XML ドキュメントのストリーミング変換を実行する をどうぞ。とはいっても、このプログラムでは反転させるためReverseでバッファに全て溜め込んでいるので、まあ……。XStreamingElementって言いたいだけちゃうんか、みたいな。
デザインはdiv class=hatena-bodyとdiv class=mainを抜いているので(不必要なサイドバーの描画を除去するため)、この二つに依存するCSSが書かれているサイトの場合はデザインが崩れることがあります。ちなみにneuecc clipはこの二つどころか、その他にもwrapperを置いているというデタラメなCSS構造をしているため、デザインは保存出来ません。全くもって酷い。もっとスクレイピングに優しいHTMLを書かないとダメですな。
HTMLへの書き出し部分ははまりどころでした。最初Save(fileName)で保存していたんですが、特定のサイトの特定の部分で落ちてしまって困りました。具体的には 2008-07-23 - Faith and Brave - C++で遊ぼう で(例に出してすみません)、Protocol Bufferによる出力結果がInvalidXmlCharに引っかかってアウト、のようです。回避する方法は、XmlWriterSettingsのCheckCharactersをfalseに設定したXmlWriterを生成して書き出せばOK。
XboxInfoTwit - ver.2.2.0.0
- 2010-03-06
今回の更新は、HTMLをXMLに変換するライブラリをTidy.NetからSGMLReaderに変更しました。数日前にSGMLReaderでLinq to Html最高なんてエントリーを上げていたので、早速実戦投入というわけです。内部コードが割と変わったため、ver2.1系列から2.2へとアップ。利用者的にはぶっちゃけどうでもいい話です。すみません。
ユーザーに関係ある変更点は、先日発売されたばかりのBioShock2で実績が取得出来てなかったので、それを直しました。私はBioShock2でしか確認していないのですが、「カルドセプト」や「のーふぇいと!」も実績が取得出来ないという報告が上がっていたので、今回の修正によって取得出来るようになった、かもしれません。分かりません。カルドセプトやのーふぇいと!を持っている方は実績取れたよー、と教えていただけると助かります。一応Twitter検索で追っかけてはいるんですけど、最近投稿量が多くて(認証者数は1400行きました、ありがとうございます)全然目を通せていなかったりして。
追記:「カルドセプト」、「のーふぇいと!」ともに実績取得出来ているようです。確認していただいた方、ありがとうございました。
C#でスクレイピング:HTMLパース(Linq to Html)のためのSGMLReader利用法
- 2010-03-02
Linq to XmlがあるならLinq to Htmlもあればいいのに!と思った皆様こんばんは。まあ、DOMでしょ?ツリーでしょ?XHTMLならそのままXDocument.Loadで行けるよね?XDocument.Parseで行けるよね? ええ、ええ、行けますとも。XHTMLなら、ね、ValidなXHTMLならね。世の中のXHTML詐称の99.99%がそのまま解析出来るわけがなく普通に落ちてくれるので、XDocumentにそのまま流しこむことは出来ないわけです(もちろん、うちのサイトも詐称ですよ!ていうかこのサイトのHTMLは酷すぎるのでそのうち何とかしたい……)。
そこでHtmlを整形してXmlに変換するツールの出番なわけですが、まず名前が上がるのがTidy、の.NET移植であるTidy.NETで、これは論外。とにかく面倒くさい上に、パースしきれてなくてXDocumentに流すと平然と落ちたりする。おまけにXDocumentに入れるには文字列にしてから入れる必要があって二度手間感がある、などなど全くお薦めできません。XboxInfoTwitはTidy使ってますが、後悔してますよ……。
次にHtml Agility Packで、これは中々良いです。Linq to Xml風で大変使いやすい。のですが、あくまで風味であって、なんで本物のLinq to Xmlが目の前にあるのに、それっぽく模したものを覚えなきゃいけないの?二度手間で面倒くさいよ。
そこで、第三の選択としてSGMLReaderを使うという方法を提案します。SGML Reader自体は古くからあるのですが、日本語での情報はあまりないみたいだしLinq to Xmlと組み合わせたスクレイピング用途、に至っては皆無のようなので、ここで紹介しましょう。とりあえず例を。
// たったこれだけのメソッドを用意しておけば
static XDocument ParseHtml(TextReader reader)
{
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower })
{
sgmlReader.InputStream = reader; // ↑の初期化子にくっつけても構いません
return XDocument.Load(sgmlReader);
}
}
static void Main(string[] args)
{
using (var stream = new WebClient().OpenRead("http://www.bing.com/search?cc=jp&q=linq"))
using (var sr = new StreamReader(stream, Encoding.UTF8))
{
var xml = ParseHtml(sr); // これだけでHtml to Xml完了。あとはLinq to Xmlで操作。
XNamespace ns = "http://www.w3.org/1999/xhtml";
foreach (var item in xml.Descendants(ns + "h3"))
{
Console.WriteLine(item.Value); // bingでlinqを検索した結果のタイトルを列挙
}
}
}
見たとおり、信じられないほど簡単です。SgmlReaderはXmlReaderを継承しているため、XDocument.Load(xmlReader)にそのまま流し込めます。また、SgmlReader自体もDocTypeとInputStreamを設定するだけという超簡単設計になっているため、楽にHtml to Xmlが実現。HtmlはXDocumentになってしまえさえすれば、あとは慣れ親しんだLinq to Xmlの操作で抽出していけます。
例では、BingでLinqを検索した結果の検索結果見出し部分を抽出しています。見出しはh3で囲まれているので、Descendants(ns + "h3")。以上。超簡単。C#のスクレイピングの簡単さはRubyも超えたね!
残る問題は、日本語を扱う際はエンコーディング周りの設定が面倒くさい(間違ったエンコーディングだと文字化けする)、ということなのですが、そのWebClientのエンコーディング問題は、.NET Framework 4.0から修正された System.Net.WebClient は、HTTP ヘッダーから Encoding を自動的に認識してほしい | Microsoft Connect らしいです。素晴らしい!提案して頂いたbiacさんに感謝。
追記(2014/3/26)
いつのバージョンからか、TimeoutでWebExceptionが出るようになってたかもしれません。これはdtdを読みに行こうとしているのが原因のようなので、 IgnoreDtd = true を足してやれば回避できます。
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower, IgnoreDtd = true })
ということです。
追記(より簡単に)
上の記事を書いてから気づいたのですが、HrefプロパティにURLを指定するだけで、中でStream類を作って自動的にHtmlだと判別してくれるようです。更には、エンコーディングもContentTypeを見て自動調整してくれます(詳しくはSgmlParser.csのOpenメソッドを参照)。よって、もっとずっと簡単に書けます。
static void Main(string[] args)
{
XDocument xml;
using (var sgml = new SgmlReader() { Href = "http://www.xbox.com/ja-JP/games/calendar.aspx" })
{
xml = XDocument.Load(sgml); // たった3行でHtml to Xml
}
// Xboxの発売スケジュールからタイトルと発売日を抜き出してみる
var ns = xml.Root.Name.Namespace;
var query = xml.Descendants(ns + "table")
.Last()
.Descendants(ns + "tr")
.Skip(1) // テーブル一行目は項目説明なので飛ばす
.Select(e => e.Elements(ns + "td").ToList())
.Select(es => new
{
Title = es.First().Value,
ReleaseDate = es.Last().Value
});
// 書き出し
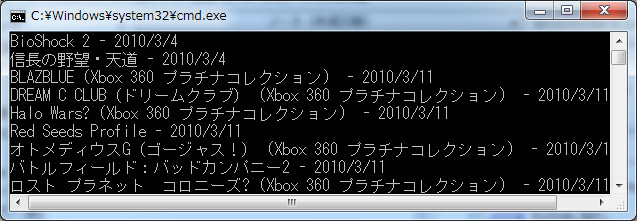
foreach (var item in query)
{
Console.WriteLine(item.Title + " - " + item.ReleaseDate);
}
}
usingの辺りが若干鬱陶しいので、最初の例のようにメソッドに切り出してもいいかもしれません(CaseFolding.ToLowerも付けたいし)。Loadし終わったらストリームはもう不要です。XDocumentはメモリ内に全部構築するタイプのもので、実質XmlDocument(DOMツリー)の代替となっています。抽出時のXml名前空間ですが、サイトによってついていたりついていなかったりするので、var ns = xml.Root.Name.Namespaceとしておくと、全てのサイトに対応出来ます。
抽出のテクニック
上の例は Xbox.com | Xbox ゲームソフト 発売スケジュールからタイトルと発売日を抽出するというものです。定期的にページを監視して、更新されたらTwitterに投稿するXbox発売予定BOTとか作れますね!Xmlで取れるAPIさえあれば……なんてことはなくなりました!これからは 全てのサイトが易々とスクレイピング可能な代物として浮き上がってきますな。
ただし、元がHTMLのものはAPIとして用意されているXMLと違って、抽出に優しくない構造をしています。 Descendants一発でOk、というわけにもいかないので若干の慣れは必要かもしれません。今回の例の抽出コードが何やってるかよくわからない、という人はHTMLソースと見比べてみてください。目的のTableに辿り着くにも、いくつかの方法があります。決め打ち成分が入ってしまうのはどうにもならないのですが、何を決め打ちにするのがスッキリ書けるのか、となると色々です。今回はTableがLastである、という点を使いましたが、他の方法を考えてみると
var case2 = xml.Descendants(ns + "div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1")
.SelectMany(e => e.Descendants(ns + "tr"));
var case3 = xml.Descendants(ns + "table")
.First(x => x.Ancestors().Any(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1"))
.Descendants(ns + "tr");
目的のTableを囲むdivのclassが XbcWpFreeForm1であり、XbcWpFreeForm1が適用されているdivは一つしかない、ということに着目するとこうなります。case2は、divを全て列挙して探し出す方法。First(predicate)ではなくWhere.SelectManyにすることで、目的のTableが複数個ある場合でも対応出来ます。case3はTableに絞った上で、そのTableの上位階層(Ancestors)にXbcWpFreeForm1が含まれるかを探し当てる方法。Last、という決め打ちが難しい(場合により変動するケース)場合には有効でしょう。この、上位階層(Ancestors)や下位階層(Descendants)の要素に特異な要素はないか(Any)、と探す手法は、ターゲット自体に特徴がなく抽出し難い場合に活用出来ます。
そもそもDescendantsなんて富豪すぎて許せん、実行効率命!という人はElement("body").Element("div")....とトップから掘っていってもいいわけですが、さすがにElementの連続はダルいのでXPathを使うのもよいでしょう。Linq to XmlでのXPathの利用法は、以前neue cc - そしてXPathに戻るに書きました。XPathは、複雑なことを書こうとすると暗号めいた感じになるから余りすきじゃないですね。私は多少冗長なぐらいでもLinqで書くのが好きだなあ。