第一回UniRx勉強会を開催しました+スライドまとめ
- 2015-06-20
と、いうわけかでUniRx勉強会を開催しました。当日の模様はtogetterまとめで。登録が150人ほど、生憎の雨天でしたが130人以上来てくださってめっちゃ嬉しかったですね。慣れないというかはぢめての主催+司会でその辺アレだったのですが、会場をお貸し下さったgloopsさんの手厚い協力のお陰で、なんとか成立させることができ、ほんとうに感謝です。
私の発表資料は「History & Practices for UniRx UniRxの歴史、或いは開発(中)タイトルの用例と落とし穴の回避法」になります。
あまりUniRx固有、という感じでもなく、また凄い話、でもなんでもない地味な内容なのですけれど、ちょっとはまると嫌だなー、けどはまりがちなポイントを説明してみた、といった感。地味すぎてトリとしてはなんともいえない感じでしたね、うむむむ。ちなみにReal World UniRxというのは、Real World Haskell―実戦で学ぶ関数型言語プログラミングという本が名前的には元ネタです。Real World、現実世界で使われるUniRx。というわけで要約すれば事例求む、みたいな。
はじめてのUniRx
toRisouPさんの発表です。
資料的価値が非常に高く、わかりやすい。めっちゃ読みこむと良いと思います、スゴクイイ!Cold/Hotとか大事なんですがむつかしいところですしねー。
若輩エンジニアから見たUniRxを利用したゲーム開発
gloopsの森永さんの発表です。
toRisouPさんのが中級者向けでしたので、こちらが初心者向けでしたね。UniRxがどういう風に自分の中で浸透というか理解が進んでいくか、というのがstep by stepで紹介されていて、伝わりやすいと思います。あと、全然紹介していなかったObservableTriggerまわりの応用が完璧に書かれていてすばら。
Interactive UI with UniRx
トライフォートの岩下さんのセッションです。
UniRxって基本的にスクリプティング領域の技術なので、とにかく地味!なのですが、このセッションは地味どころかDemo含め、めっちゃ伝わるし美しさ、手触りが伝わって凄かった。実際本日一番の感動でしたにゃ。
「ずいぶんとダサいライティングを使っているのね」〜UniRxを用いた物理ベースライティング制御〜
ユニティ・テクノロジーズ・ジャパンの名雪さんのLTです。
色々なものへのReactiveな入力/出力ができるんじゃもん!と言ってはいるし興味はかなりあるのだけれど、自分でやったことが全くない領域で、それが実際になされてる様を目にするとオオーッってなりました。
その他
そういえば、ブログに書いてなかったんですがちょっと前に「Observable Everywhere - Rxの原則とUniRxにみるデータソースの見つけ方」という発表をしていました。
これ、自分的には結構良い内容だなー、と思っているので見たことないかたは是非目を通してもらえると。
まとめ
第一回、というわけなんですがかなり密度濃い内容になったのでは!?懇親会でも、自分の思っていたよりもずっと遥かに使い出している、注目している、という声をいただき嬉しかったですねー。もっとドンドン良くしていかなければ、と気が引き締まります。次回がいつになるかは完全不明(というか当分後かな?)ですが、やっていきたいなー、と思いましたです。
NotifyPropertyChangedGenerator - RoslynによるVS2015時代の変更通知プロパティの書き方
- 2015-06-13
半月前にIntroduction to NotifyPropertyChangedGeneratorというタイトルでセッションしてきました。
コードはGitHubで公開しているのと、NuGetでインストールもできます。
なにかというとVS2015のRoslynでのAnalyzerです。AnalyzerというとStyle Copに毛の生えたようなもの、をイメージしてしまうかもなのですが、全くそれだけじゃなく、真価はコードジェネレーターのほうにあると思っています。コンパイラでのエラーや警告も出せて、自然にVSやプロジェクトと統合されることから、Compiler Extension + Code Generatorとして私は捉えています。その例としてのINotifyPropertyChangedの生成となります。
POMO
Plain Old MVVM Object(笑)を定着させたいという意図は特にないのですが、割と語感が気に入ったので使ってみまふ。まぁとはいえ、やっぱ変更通知プロパティ程度で基底クラスを継承させるのは、そんなによろしいことではない、という認識はあるかなぁ、と。そのためのアプローチとして、こういったものが現実解にはなってくると思います、VS2015時代では。
さて、ちょうどufcppさんが【Roslynメタプログラミング】ValueChangedGaneratorを公開されました。アプローチが異なるわけですが、結構好みも出てくるかな、と思います。特に違いはpartialで外部ファイルに隔離 or 同一ファイル内で成形、は根本的に違うかもです。私はあまりpartialって好きではなくて、というのも結構迷子になるんですよね。いや、partial自体は素晴らしい機構でT4生成の時などに捗るんですが、このINotifyPropertyChanged程度のものでファイル分離されると、ファイル数が膨大になって、ちょっと……。また、プロパティのようなコードで触るものが外のファイルにあるのも、綺麗にはなるものの見通しは低下してしまうのではないかなあ、と。まぁ、この辺は良し悪しというかは好みかなー、といった感ですね。
色々なアプローチが考えられると思うので、色々試してみるのが良いと思います、Analyzer、可能性あって面白いです。ぜひ触ってみてくださいな。
UniRxでの空呼び出し検出、或いはRoslynによるCode Aware Libraries時代の到来について
- 2015-05-11
UniRx - Reactive Extensions for Unity用に、メソッド呼んだだけで何も処理してないIObservable<T>があったらWarningを出すAnalyzerを作ってみました。
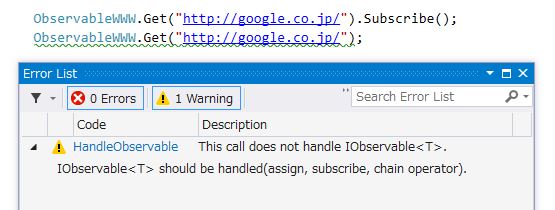
AnalyzerはVisual Studio 2015からの機能です。というわけでVisual Studio 2015 RCが必要です。あとは、NuGetからAnalyzerが入れられるようになっているので
- Install-Package UniRxAnalyzer
でOK。Unityのプロジェクトであっても問題なく使えます(ただしVSTUのcsproj自動生成でAnalyzerタグは吹っ飛ぶので、生成をフックして復元する必要はあります、フック方法の詳細はみんな大好き Boo.Lang を SATSUGAI する方法を参照のこと)。もし、他にこういうAnalyzerがあったら便利なのになー、とかってアイディアあったら気楽に言ってください!作りますので!
現在のうちの会社(グラニ)のプロジェクトはRxが土台から、ありとあらゆる全てで使われているので、ちょっとした呼び出しのつもりでやってたら何もおこらなくて(Susbcribe漏れ)クソが!となるシチュエーションが少なくなかったので、こういうAnalyzerが必需品だったのでした。
ようするにC# 5.0のTaskでawaitしてないと警告が出るのと同じ話なのですが、そういうのが言語組み込みキーワードでなくても自由に、(VS2015で動かせるなら)簡単にプロジェクト単位で追加出来る、というのがミソです。こういったライブラリとアナライザーの組み合わせは、Code Aware Librariesという言葉でまとめられます。.NET Compiler Platform ("Roslyn"): Analyzers and the Rise of Code-Aware Libraries。従来はライブラリのみの提供でしたが、そこにAnalyzerも組み合わせて、Best Practiceを一体化して伝えていくような世界観が広がっています。
例えば、私はLightNodeというWebAPIフレームワークを作っていますが、これは引数の型に幾つかの制約があります。また、メソッドのオーバーロードを許していなかったりします。それらは実行時のウォームアップのタイミングでフェイルファストとして気づかせるようにしていますが、それよりも前のタイミング、コードを書いている最中にリアルタイムで警告できれば、より良いでしょう。なので、Analyzerを同梱すれば、より良い形、より良いライブラリの有り様になります。
DiagnosticAnalyzerの作り方 Part2
以前にVS2015のRoslynでCode Analyzerを自作する(ついでにUnityコードも解析する)とVS2015+RoslynによるCodeRefactoringProviderの作り方と活用法という記事を書きましたが、基本的にはそれらと同じです、アタリマエですが。↑の記事はCTPの頃のもので、若干インターフェイスが変わっちゃっていますが、少し修正するだけでほぼほぼ同じかな。
今回作ったのはCode Analyzerで、Fixは含めていないのでcsファイル一個だけで済んでいます。
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class HandleObservableAnalyzer : DiagnosticAnalyzer
{
public const string DiagnosticId = "HandleObservable";
internal const string Title = "IObservable<T> does not handled.";
internal const string MessageFormat = "This call does not handle IObservable<T>.";
internal const string Description = "IObservable<T> should be handled(assign, subscribe, chain operator).";
internal const string Category = "Usage";
internal static DiagnosticDescriptor Rule = new DiagnosticDescriptor(DiagnosticId, Title, MessageFormat, Category, DiagnosticSeverity.Warning, isEnabledByDefault: true, description: Description);
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics { get { return ImmutableArray.Create(Rule); } }
public override void Initialize(AnalysisContext context)
{
context.RegisterSyntaxNodeAction(AnalyzeMethodDeclaration, SyntaxKind.MethodDeclaration);
}
private static void AnalyzeMethodDeclaration(SyntaxNodeAnalysisContext context)
{
var invocationExpressions = context.Node
.DescendantNodes(descendIntoChildren: x => !(x is InvocationExpressionSyntax))
.OfType<InvocationExpressionSyntax>();
foreach (var expr in invocationExpressions)
{
var type = context.SemanticModel.GetTypeInfo(expr).Type;
// UniRx.IObservable? System.IObservable?
if (new[] { type }.Concat(type.AllInterfaces).Any(x => x.Name == "IObservable"))
{
// Okay => x = M(), var x = M(), return M(), from x in M()
if (expr.Parent.IsKind(SyntaxKind.SimpleAssignmentExpression)) continue;
if (expr.Parent.IsKind(SyntaxKind.EqualsValueClause) && expr.Parent.Parent.IsKind(SyntaxKind.VariableDeclarator)) continue;
if (expr.Parent.IsKind(SyntaxKind.ReturnStatement)) continue;
if (expr.Parent.IsKind(SyntaxKind.FromClause)) continue;
// Okay => M().M()
if (expr.DescendantNodes().OfType<InvocationExpressionSyntax>().Any()) continue;
// Report Warning
var diagnostic = Diagnostic.Create(Rule, expr.GetLocation());
context.ReportDiagnostic(diagnostic);
}
}
}
}
戦略的には、メソッド呼び出し、つまりInvocationExpressionを拾いだして、そこからローカル変数代入/フィールド代入/return/LINQクエリ構文/メソッド呼び出しで使われていなければダメ扱いにする、という流れ。コード自体は行数も少なくて難しくはないのですけれど、戦略を決定するまでは割と悩みました。SyntaxTree自体も大量のメソッドがあり、SemanticModelも絡めると、色々な手段が取れそうでいて取れなさそうで、相当悩ましい。最終的にはかなり単純な手法に落ち着きましたが、直線距離で到達できるようになるまでには、かなり慣れが必要そうです。あと、最初作った時はクエリ構文のチェックを見落としてたりとか(さすがにこれを最初から気づくのは無理)、必要なケースを全て洗い出すのはそこそこ大変かな、といった感はあります。
DescendantNodesのdescendIntoChildrenという引数が中々面白くて、これは子孫ノードの探索を打ち切る条件を指定できます。これの何がいいって、例えばメソッド Observable.Range().Where().Select() があった場合、最上位のInvocationExpressionはObservable.Range().Where().Select()なのですが、その子孫に Observable.Range().Where() や Observable.Range() がいます。ふつーのDescendantNodesだとそれら全部を列挙してしまうんですが、今回は欲しいのは最上位だけなので、descendIntoChildrenで条件フィルタを足しています。
以前には紹介していない、ユニットテストのやり方も紹介しましょう。といっても、テンプレートに最初からTestプロジェクトと、便利クラス群が同梱されています。Analyzerだけの場合は基底クラスをDiagnosticVerifierに変えて……
namespace UniRxAnalyzer.Test
{
[TestClass]
public class HandleObservableAnalyzerTest : DiagnosticVerifier
{
protected override DiagnosticAnalyzer GetCSharpDiagnosticAnalyzer()
{
return new UniRxAnalyzer.HandleObservableAnalyzer();
}
[TestMethod]
public void UnHandle()
{
var source = @"
using System;
class Test
{
IObservable<int> GetObservable() => null;
void Hoge()
{
GetObservable();
}
}";
var expected = new DiagnosticResult
{
Id = UniRxAnalyzer.HandleObservableAnalyzer.DiagnosticId,
Message = "This call does not handle IObservable<T>.",
Severity = DiagnosticSeverity.Warning,
Locations = new[]
{
new DiagnosticResultLocation("Test0.cs", 10, 9)
}
};
this.VerifyCSharpDiagnostic(source, expected);
}
}
}
ようするにVerifyCSharpDiagnosticにテスト用のC#コードと、期待するDiagnosticResultを渡すだけです、実に簡単。もしエラーじゃなくOKの場合はsourceだけをVerifyCSharpDiagnosticに渡せば、そういうことになります。
まとめ
Analyzer、かなりイイです。実際。とにかくとりあえず触ってみませう。現状リファレンスとかは特にないですが、まぁLINQ to XML辺りがわかっていればSyntaxVisualizerとIntelliSenseを頼りになんとか作り上げられるでしょう!メソッド名を見ながらカンを働かせましょう。大丈夫大丈夫。また、GitHubには既にお手本となるAnalyzerが出回っているので、それを参照にすればかなりいけます。代表的なところではNR6Pack, StyleCopAnalyzers, Code Crackerなどがあります。
では、よきRoslynライフを!
LightNode 1.2.0 - Swagger統合によるAPIのデバッグ実行
- 2015-04-19
グラニのC#フレームワークの過去と未来、現代的なASP.NETライブラリの選び方という記事で、スライドと補足は先に上げましたが、以前に弊社で行った勉強会「Build Insider MEETUP with Grani 第1回」のレポートがBuild Insiderに上がっています。「using CSharp;」な企業を支える技術方針とベスト.NETライブラリ記事によるレポートは、さくさく読めるし、スライドで欠けていた部分も補完できていーんじゃないでしょーか。まる。
さて、で、基本的にAPIサーバーはOWINで行くんですが、API開発はとにかくふつーのウェブよりも開発がしにくい!の欠点を、前回LightNode 1.0、或いはWeb APIでのGlimpseの使い方はGlimpseフル統合で補おうとしました。それはそれでいいんですが、もう一つ足りない。それはともかく根本的にそもそも実行しづらい。さすがにモバイルのエミュレーターなりUnityのEditorなりから毎度実行は効率悪すぎてありえないし、POSTMANやFiddlerで叩くのも面倒くせえ。
そこでSwagger。とはなにか、というのは見てもらえれば。
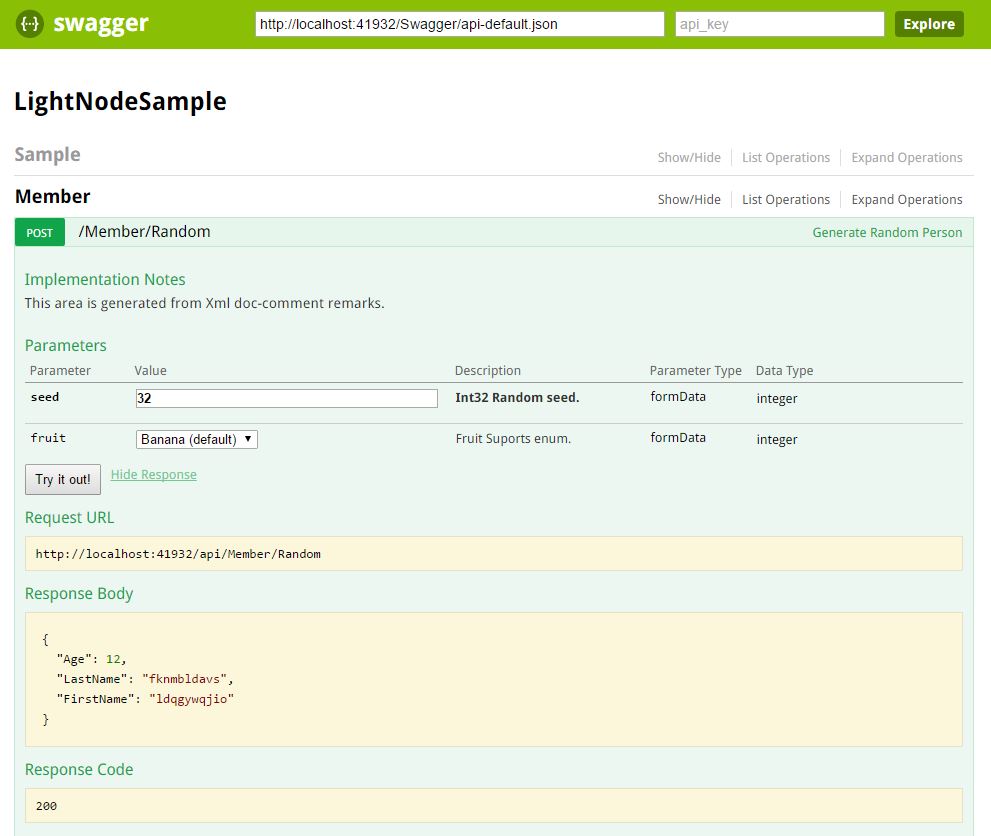
実行機付きのAPIのヘルプ・ドキュメントです。ヘルプ/ドキュメントはどうでもいいんですが、この実行機がかなり使いやすくいい!パラメータ入力してTry it out!でOK。認証が必要な場合も、右上にapi_keyというのが見えてますが、ちょっとindex.htmlを書き換えてこのapi_keyの部分を好きに都合のいい形態に変えてしまえば、機能します。実に便利。
SwaggerはAzureのAPI Appsでも利用されるようになったので、今後.NETでも目にする機会はちょっとずつ増えていくのではないでしょうか?ASP.NET Web APIで利用する方法はみそせんせーのSwagger を使った ASP.NET Web API のドキュメント生成を参照すれば良いでしょふ。
さて、LightNode(ってここではじめて解説しますが、私の作っているOwin上で動くMicro REST/RPCフレームワークです)では、Swagger統合はMiddlewareとして実装してあります。
- PM> Install-Package LightNode.Swagger
ルートをapiと別系統にswaggerとして切ってもらって、
// 今のところPOSTしかサポートしてないのでPostを有効にしてね
app.Map("/api", builder =>
{
builder.UseLightNode(new LightNodeOptions(AcceptVerbs.Get | AcceptVerbs.Post, new JilContentFormatter(), new GZipJilContentFormatter())
{
ParameterEnumAllowsFieldNameParse = true, // Enumを文字列で並べたいならこれをONにして
// 下2つはSwagger前提で使うならエラー表示的に便利
ErrorHandlingPolicy = ErrorHandlingPolicy.ReturnInternalServerErrorIncludeErrorDetails,
OperationMissingHandlingPolicy = OperationMissingHandlingPolicy.ReturnErrorStatusCodeIncludeErrorDetails
});
});
// こっちでSwaggerを有効にする
app.Map("/swagger", builder =>
{
// XMLコメントから引っ張ってくるばあい(オプション)はパスを指定してください
// メソッドに付与されているsummary, remarks, paramを情報として使います
var xmlName = "LightNode.Sample.GlimpseUse.xml";
var xmlPath = System.AppDomain.CurrentDomain.BaseDirectory + "\\bin\\" + xmlName; // もしくは HttpContext.Current.Server.MapPath("~/bin/" + xmlName);
// LightNode側のAPIのbasePathを指定
builder.UseLightNodeSwagger(new Swagger.SwaggerOptions("LightNodeSample", "/api")
{
XmlDocumentPath = xmlPath,
IsEmitEnumAsString = true // Enumを文字列で並べたいならtrueに
});
});
といった感じです。ちょっとややこしーですが、基本的にはUseLightNodeSwaggerだけでOK、ということで。これで、例えば http://localhost:41932/Swagger/ にアクセスすればSwaggerの画面が出てきます。Swagger-UI自体はdllに埋め込まれています。また、定義ファイル(JSON)はapi-default.jsonにアクセスすることで、直接取得できます。
もしOwinをIISでホストしている場合、IISのStaticFileハンドラーが邪魔してうまくホストできない場合があります。その場合、StaticFileハンドラーを殺してください。Owinでやる場合は、とにかくOwinに寄せたほうがいいですね(StaticFile系はMicrosoft.Owin.StaticFiles使いましょう)
<system.webServer>
<handlers>
<remove name="StaticFile" />
<!-- もしGlimpseもホストする場合はGlimpseのを先に書いといて -->
<add name="Glimpse" path="glimpse.axd" verb="GET" type="Glimpse.AspNet.HttpHandler, Glimpse.AspNet" preCondition="integratedMode" />
<add name="OWIN" path="*" verb="*" type="Microsoft.Owin.Host.SystemWeb.OwinHttpHandler" />
</handlers>
</system.webServer>
もし、例えば最初に例に出しましたが、認証情報を付与するとかでindex.htmlを埋め込みのではなくカスタムのを使いたい場合、OptionのResolveCustomResourceをハンドリングすればできます。例えばこんな感じに、別の埋め込みリソースから取り出したものに差し替えたり。
app.Map("/swagger", builder =>
{
builder.UseLightNodeSwagger(new LightNode.Swagger.SwaggerOptions("MySample", "/api")
{
ResolveCustomResource = (filePath, loadedEmbeddedBytes) =>
{
if (filePath == "index.html")
{
using (var resourceStream = typeof(Startup).Assembly.GetManifestResourceStream("MySample.Swagger.index.html"))
using (var ms = new MemoryStream())
{
resourceStream.CopyTo(ms);
return ms.ToArray();
}
}
return loadedEmbeddedBytes;
}
});
});
当然、index以外でもハンドリングできます。
まとめ
GlimpseとSwaggerがあわさって最強に見える!あとはもともとあるクライアント自動生成もあるので、三種の神器コンプリート。実際、これでAPI開発の苦痛に思えるところがかなり取り除かれたのではないかなー、って思ってます。これを全部自分で用意するのはそれはそれは大変なので、Owinで良かったし、組み合わせに関しても、.NETでOSSを使うってこういうことですよね?という例になればよいかな。
UniRx 4.8 - 軽量イベントフックとuGUI連携によるデータバインディング
- 2015-04-13
UniRx(Reactive Extensions for Unity)のVer 4.8が昨日、AssetStoreにリリースされました。UniRxとはなにか、というと、巷で流行りのReactive Programming、の.NET実装のReactive Extensions、のUnity実装で、私が去年ぐらいからチマチマと作っています。実際のところ細かいリリースは何度も行っているんで(差分はGitHubのReleasesに書いてあります)、開発/アップデートはかなりアクティブな状態でした。その間に、Google PlayやiOSのAppStoreでもチラホラと使用しているタイトルがあったりと(ありがとうございます!!!)、案外存外しっかりRealWorldしていました。GitHubのStarも順調に伸びていて、まぁまぁメジャーになってきた気はします。
その間に、いくつか素晴らしいプレゼン資料も作っていただきました!@torisoupさんの未来のプログラミング技術をUnityで -UniRx-は、分かりやすく魅力を感じさせてくれる内容になっていて、とても素晴らしいです。読むべし読むべし。toRisouPさんはQiitaでも多くの記事を書いてくださっていて、(私がgdgd書くよりも)はるかに分かりやすくていいですね!
また、@Grabacr07さんのUniRx とか ReactiveProperty とかは、今回紹介するuGUI連携についての話が、分かりやすく綺麗に紹介されているので、こちらも必読です。必読。
UniRxの最初の発表は2014/04/19のUniRx - Reactive Extensions for Unityというところで、発端は非同期処理の解消、という一面からスタートしていたのですが、すぐにUnityの発する色々なイベント処理をRxで行おうという、本来の、でありつつも応用的なところが盛んに試されるようになったのは素晴らしいことだなぁ、と思っています。これはゲームプログラミングの持つ複雑さが、Reactive Programmingの使い道を無数に産むという、相性の良さがあるのかしらん。非同期だけじゃない、データバインドだけじゃないRealなReactive Programmingがここにあり、プログラミングを、C#の可能性を、パラダイムシフトを大いに楽しめる環境です。是非楽しんでください。もちろん、実用性もありますしね!
当然(?)フリーです。
ObservableTriggers
UniRx 4.8から、MonoBehaviourのイベントハンドリング手法をObservableTriggersという概念に全面移行しました。どういうことかというと、まず、ObservableMonoBehaviourは廃止です:) Obsoleteはつけていないし、動作はしますが、非推奨になりました。その代わりとなるのがObservableTriggersです。まず利用例を。
using UniRx;
using UniRx.Triggers; // この名前空間以下にTriggerは入ってるのでusingしときましょう
public class MyComponent : MonoBehaviour
{
void Start()
{
// AddComponentでTriggerを付与する
var trigger = this.gameObject.AddComponent<ObservableUpdateTrigger>();
// すると*Event*AsObservableが使えるようになる
trigger.UpdateAsObservable()
.SampleFrame(30)
.Subscribe(x => Debug.Log(x), () => Debug.Log("destroy"));
// 3秒後に自殺:)
GameObject.Destroy(this, 3f);
}
}
Triggerは対象GameObjectがDestroyされると、OnCompletedを流してイベント発火を終了します。
ObservableMonoBehaviourを継承するのではなく、AddComponentで必要なイベントのためのTriggerを与えてください。そうすれば、そのイベントがRxで取り扱えるようになります。標準では ObservableAnimatorTrigger, ObservableCollision2DTrigger, ObservableCollisionTrigger, ObservableDestroyTrigger, ObservableEnableTrigger, ObservableFixedUpdateTrigger, ObservableUpdateTrigger, ObservableLastUpdateTrigger, ObservableMouseTrigger, ObservableTrigger2DTrigger, ObservableTriggerTrigger, ObservableVisibleTrigger, ObservableTransformChangedTrigger, ObservableRectTransformTrigger, ObservableCanvasGroupChangedTrigger, ObservableStateMachineTrigger, ObservableEventTrigger を用意してあります。「ほぼ」全部です。4.6から追加された新しいイベント(OnTransformChildrenChangedとか)も網羅しています。(とはいえ全部ではないので、足りなくて必要なものがあったら自分で追加するか、私にリクエストください、単純にあまり需要なさそうだと勝手に判断したものはオミットしちゃっているので……)
また、AddComponentが面倒くさい!ので、GameObject/Componentに対して、UniRx.Triggersをusingしている場合は、XxxAsObservableメソッドを直接拡張メソッドから呼べて、するとTriggerが自動付与されるようになっています。
using UniRx;
using UniRx.Triggers; // 必ずこのusingが必要です
public class DragAndDropOnce : MonoBehaviour
{
void Start()
{
// OnMouseDownAsObservableが生えてる
this.OnMouseDownAsObservable()
.SelectMany(_ => this.UpdateAsObservable()) // UpdateAsObservableが生えてる
.TakeUntil(this.OnMouseUpAsObservable()) // OnMouseUpAsObservableが生えてる
.Select(_ => Input.mousePosition)
.Subscribe(x => Debug.Log(x));
}
}
なので、通常使う場合は、Triggerに関しては意識する必要はありません。(ObservableEventTrigger(uGUI用)とObservableStateMachineTrigger(Animation用)だけは自動付与がないので、これらの場合だけ自分で意識的に付与する必要があります)
ObservableMonoBehaviourは継承が必要だったり(基底クラスが強制される!)、baseメソッドの呼び出しが必須だったり、空イベントの呼び出しが必ず含まれるパフォーマンス低下などなど、決して使い勝手の良いものではありませんでした。というか使い勝手は最悪でした。なんで当初からObservableTriggerのようなやり方じゃなかったか、というと……、まぁ、単純に私のUnityへの理解不足です、すびばせん。ObservableTriggerは、Unityのコンポーネント指向を活かしつつ、Rxによってイベントを自然に外側で取り出せるようになっているので、圧倒的に便利な形になったのではないかなと思います。
uGUI
uGUIのイベントがUniRxでパーフェクトにハンドリングできます!この辺の話は前述のスライドUniRx とか ReactiveProperty とかに綺麗にまとまっているのですが、例えばボタンとかが
// インスペクタから貼っつけるとか
public Button MyButton;
// こんな感じで取る(onClick.AsObservable もしくは OnClickAsObservable)
MyButton.onClick.AsObservable().Subscribe(_ => Debug.Log("clicked"));
ほぅ……。普通だ。どうでも良さそうだ。と、いう具合にuGUIのEvent + AsObservableでイベントハンドリングができるようになっています。もう少し例を出すと
// ビューからのコントロールはインスペクタでペタペタ貼り付ける
public Toggle MyToggle;
public InputField MyInput;
public Text MyText;
public Slider MySlider;
// Startとかで宣言的にUIを記述していきましょう
void Start()
{
// チェックボックスのオン/オフでボタンの有効/非有効が切り替わるようにします
// OnValueChangedAsObservableは.onValueChanged.AsObservableのヘルパーで、単純に省略が楽という他に、
// 初期値(最初のisOnの値)がSubscribe時に流れていきます
// また、SubscribeToInteractableはUniRxのヘルパーで、 x => .interactable = x を省略できます
MyToggle.OnValueChangedAsObservable().SubscribeToInteractable(MyButton);
// 入力文字は1秒後にテキストラベルに反映されます
MyInput.OnValueChangeAsObservable()
.Where(x => x != null)
.Delay(TimeSpan.FromSeconds(1))
.SubscribeToText(MyText); // SubscribeToTextを使うと簡単に紐付けできます
// SubscribeToTextの人間の読める形に変換したい場合用ヘルパ
MySlider.OnValueChangedAsObservable()
.SubscribeToText(MyText, x => Math.Round(x, 2).ToString());
}
こんな風になります。uGUIの標準コントロールに関しては直接EventAsObservableできるように拡張されてます。ともあれ、uGUIのイベントハンドリングはスクリプトで行いましょう。uGUI標準のAddHandlerなどはやりづらいですが、UniRxはそれを簡単に行える仕組みが用意してあります。uGUIのチュートリアルや解説本では、インスペクタのイベントの部分をクリックしてメソッドと紐付けてー、などとやるかもしれませんが、あのやり方は最低最悪なので忘れましょう。スクリプトレスでイベント設定できるとか幻想なんで、少なくともRxを使おうとしているようなプログラマなら、一切見なかったことにしましょう。100億パーセントどうでもいい次元の話なので無視しておきましょう。やりづらいだけです。
unityEvent.AsObservableのかわりに、全てのUnityコントロールにはUnityEventAsObservableが定義されています。ButtonのonClickの場合は違いはないのですが、一部の値が流れるものに関しては違いがあって、コントロールに直接生えているものは初期値が流れるようになっています。この初期値が流れる、という性質は非常に重要です。と、いうのも、今回のようにUIを宣言的に記述した場合、初期値が流れないと、初期値を設定して回らなければならなくて全体の構築が狂ってしまうからです。と、いうわけで、基本的にはコントロールに生えているAsObservableを使いましょう。
ReactiveProperty
UniRx 4.8からReactivePropertyという特別な型が用意されています(あとReactiveCollectionとReactiveDictionary)。これは何かというと、通知可能なプロパティ。なんのこっちゃ。うーん、イベントと値がセットになった型。うーん、なんのこっちゃ……。
// 変更通知付きなモデル
public class Enemy
{
// HPは変更あったら通知して他のところでなんか変化を起こすよね?
public ReactiveProperty<long> CurrentHp { get; private set; }
// 死んだら通知起こすよね?
public ReadOnlyReactiveProperty<bool> IsDead { get; private set; }
public Enemy(int initialHp)
{
// 宣言的に記述していく。
// ReactivePropertyはそれ自体がIObservable<T>なので、Rxでチェーン可能で、更にそれをReactivePropertyに変換も可能
// 死んだかどうかというのはHPが0以下になったら、で表現できる
CurrentHp = new ReactiveProperty<long>(initialHp);
IsDead = CurrentHp.Select(x => x <= 0).ToReadOnlyReactiveProperty();
}
}
// こんなふうにして使う
// ボタンクリックしたらHPが99減ってくとする(実際はなんかCollision受けたら減るとか色々)
// ReactivePropertyの値は.Valueで取り出せる)
MyButton.OnClickAsObservable().Subscribe(_ => enemy.CurrentHp.Value -= 99);
// その変更を受けてUIに変更を戻す
enemy.CurrentHp.SubscribeToText(MyText); // とりあえず現在HPをTextに表示
// もし死んだらボタンクリックできないようにする
enemy.IsDead.Select(isDead => !isDead).SubscribeToInteractable(MyButton);
今まではイベント+普通の値で表現していたものが、プロパティ一個で表現できるようになります。また、イベント自体の取り扱いもRxなので合成可能になっていて、取り回しが向上します。というわけで、めちゃくちゃ便利。実際便利。通知が必要な値は片っ端からReactivePropertyにしましょう、それで幸せになれます!
更にReactivePropertyはInspectorで利便性が向上しています。
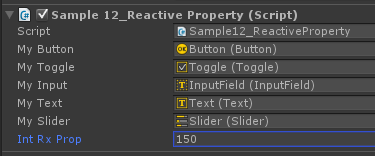
IntRxPropのところ、インスペクタに値を表示しているのですが、これの値をインスペクタで変更すると、紐付けていたイベント(.Subscribeしているもの)への通知も飛んでいきます。地味に捗る神機能。注意点としては、ジェネリックの型はインスペクタに表示できないという制限を引き継いでいるので、インスペクタに表示したいReactiveProeprtyは、専用のReactivePropertyを使いましょう。例えばIntReactivePropertyやBoolReactiveProperty、Vector2ReactivePropertyなどが標準では用意されています。EnumをReactiveProeprtyとして表示したい、というシチュエーションも多いと思います。その場合はSpecializedなReactivePropertyを定義していきましょう。例えば
// こんなEnumがあるとして
public enum Fruit
{
Apple, Grape
}
// こういう特化したReactiveProeprtyを作ればOK
[Serializable]
public class FruitReactiveProperty : ReactiveProperty<Fruit>
{
public FruitReactiveProperty()
{
}
public FruitReactiveProperty(Fruit initialValue)
:base(initialValue)
{
}
}
// また、InspectorDisplayDrawerにたいしてCustomPropertyDrawerを指定するとインスペクタでの表示が向上/イベント通知が可能になるので
// 特化ReactiveProeprtyの作成とワンセットで行いましょう
// ExtendInspectorDisplayDrawer自体は一個あればそれで大丈夫です
[UnityEditor.CustomPropertyDrawer(typeof(FruitReactiveProperty))]
[UnityEditor.CustomPropertyDrawer(typeof(YourSpecializedReactiveProperty2))] // 他、沢山ここにtypeofを追加していく
public class ExtendInspectorDisplayDrawer : InspectorDisplayDrawer
{
}
といった感じに拡張することで、より便利になっていきます。
MV(R)P
これらのUIの作り方を指して、Model-View-(Reactive)Presenterパターンというものを提唱します。
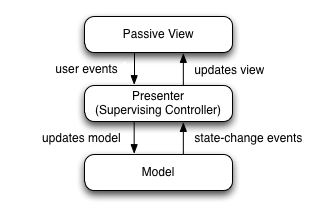
なぜMVPか、なんでMVVMではないか。まず、Unityはバインディングエンジンを持っていません。一般的にMVVMはViewとViewModelの間をバインディングエンジンが受け持ちます。なので、素の状態ではそもそもMVVMはできません。じゃあバインディングエンジンを作るか、となると、そんなレイヤーを挟むのは複雑になるしパフォーマンスも低下するし、デメリットがメリットを上回るバインディングエンジンを作るのは難しい。バインディングは誰かが動的レイヤーを引き受けなければならなくて(例えばName直書きなINotifyPropertyChangedであったり)、ピュアC#の世界とは相性が悪い。それをWPFではXAMLに押し付けているが、動的コード生成高速化の手段が取れないUnityでは、無理して実現する価値はない。
そんなわけで、MVVMはやらない。やらないとなると、バインディング機構が存在しない都合上、どこかで、だれかが、Vを知る必要がある(じゃなきゃViewのUpdateがかけれない)。というわけでVMは存在できず、Presenterを立てる。Model自体はPresenterにも依存しないし、Viewは知らない。ただしViewまで伝搬するため通知は可能でなければならない。それらをRxが繋ぎます。従来のMVPはステートの複雑化や伝搬に困難があったが、Observableはバインディングのようにシンプルに通知を行うことができるし、Viewへの適用もバインディングであるかのように綺麗に見せることができる。Rxを介すことによって、アプリケーションを作る上での問題が解消する。しかもレイヤー的にはないに等しく薄いので、一切のデメリットはない。
再度、コードと当てはめてみましょう。
// Presenter(Canvasのルートだったり、Prefabやパーツ分割単位のルート)
public class ReactivePresenter : MonoBehaviour
{
// PresenterはViewのコンポーネントを知っている(さわれる)
public Button MyButton;
public Toggle MyToggle;
// ModelからのState-Change-EventsはReactivePropertyによって伝搬される
// Modelの変更は基本的に自身が上層に通知可能であり、それはReactiveProeprtyで表現される
Enemy enemy = new Enemy(1000);
void Start()
{
// Viewからのuser eventsはRxによって伝搬され、Modelにまでリアクティブに浸透していく
MyButton.OnClickAsObservable().Subscribe(_ => enemy.CurrentHp.Value -= 99);
MyToggle.OnValueChangedAsObservable().SubscribeToInteractable(MyButton);
// Modelからの伝搬もまた、Presenterを介してRxによってViewのUpdateをかける
enemy.CurrentHp.SubscribeToText(MyText);
enemy.IsDead.Where(isDead => isDead == true)
.Subscribe(_ =>
{
MyToggle.interactable = MyButton.interactable = false;
});
}
}
この場合、ViewとPresenterの紐付けはUnityのインスペクタでやります、ぴっ、ぴっ、ぴっってドラッグアンドドロップですねん。ふつーの(?)MVPだと、このViewをIViewとしてモックと差し替え可能にしたりもしたりしなかったりですが、そこまでやってもメリットゼロなんでそんなことはやらないでダイレクトにViewの実体とひもづける形でOK。
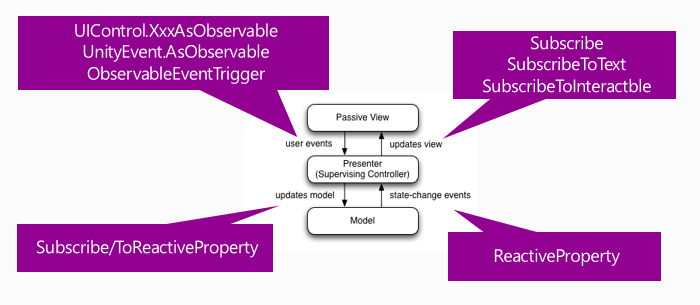
それぞれの伝搬ポイントにUniRxのメソッドやクラスが用意されているので、全てをシームレスに、Reactiveにつなぎ合わせることが可能です。UniRxならね。これの何が嬉しいかというと、見通しが良く、コード量が減ります。それがもう単純に嬉しい。また、イベントの関連付けはスクリプト側に寄っているので、インスペクタがカオティックにならずに済みます。かなりUnity(+Rx)の現実に沿った作り方なのではないかなー、と思うのですがどうでしょう?この辺は意見大募集中といったところです。
カスタムトリガーを作ろう
そんな風にアプリケーションを作っていくと、イベントはRx的に発動させるのが都合が良い、ということがわかってきます。実際そう。で、SubjectやReactivePropertyなどを駆使することによりModelをRx的に作っていくのは可能なのですが、ViewからのイベントをRx的に流すためにはどうすればいいのか。標準ではTriggerが用意されてますが、それだけじゃ足りない、例えばロングタップ作りたいとかジェスチャー作りたいとか……。という場合はTriggerを自作します。作り方は、ObservableTriggerBaseを継承して……
public class ObservableLongPointerDownTrigger : ObservableTriggerBase, IPointerDownHandler, IPointerUpHandler
{
public float IntervalSecond = 1f;
Subject<Unit> onLongPointerDown;
float? raiseTime;
void Update()
{
if (raiseTime != null && raiseTime <= Time.realtimeSinceStartup)
{
if (onLongPointerDown != null) onLongPointerDown.OnNext(Unit.Default);
raiseTime = null;
}
}
void IPointerDownHandler.OnPointerDown(PointerEventData eventData)
{
raiseTime = Time.realtimeSinceStartup + IntervalSecond;
}
void IPointerUpHandler.OnPointerUp(PointerEventData eventData)
{
raiseTime = null;
}
public IObservable<Unit> OnLongPointerDownAsObservable()
{
return onLongPointerDown ?? (onLongPointerDown = new Subject<Unit>());
}
protected override void RaiseOnCompletedOnDestroy()
{
if (onLongPointerDown != null)
{
onLongPointerDown.OnCompleted();
}
}
}
こんな感じ、これで他のTriggerと同じノリ、OnPointerDownAsObservableでタップを拾えるように、OnLongPointerDownAsObservableでロングタップを拾えるようになります。Subjectでイベント通知することと、RaiseOnCompletedOnDestroyのところでOnCompletedを発行するのが原則です。こういう形でイベントを拡張すると、よりスムーズにRxで全てが繋がっていきます!
ライフサイクル管理
で、全部がRxになると、イベントをSubscribeしたのをどこで解除すればいーんですかー、って話になってきたりこなかったりする。基本的にTrigger系は自身が死んだ時に終了するからいいんですが、それ意外のもの、例えばObservable.TimerやObservable.EveryUpdateは自動的に止まらないので、自分で登録解除する必要があります。そのためのヘルパーとして、IDisposable.AddToがUniRxには用意されています。また、CompositeDisposableがSubscriptionの管理に使えます。
// CompositeDisposableはList<IDisposable>のようなもので、複数のIDisposableが管理できます
CompositeDisposable disposables = new CompositeDisposable(); // これをfieldにおいておいて
void Start()
{
Observable.EveryUpdate().Subscribe(x => Debug.Log(x)).AddTo(disposables); // AddToで詰める
}
void OnTriggerEnter(Collider other)
{
// .Clear() => 中の全てのdisposableのDisposeが呼ばれて、Listが空になります
// .Dispose() => 中の全てのdisposableのDisposeが呼ばれて、以降はAddされたら即対象をDisposeするようになります
disposables.Clear();
}
よくあるシチュエーションとして、Destroyした瞬間に解除したい、というのがあると思います。その場合AddTo(gameObject/component)が使えます。
void Start()
{
// 自分が消滅したらDispose
Observable.IntervalFrame(30).Subscribe(x => Debug.Log(x)).AddTo(this);
}
DisposeじゃなくてOnCompletedを出して欲しい、という場合にはTakeWhile, TakeUntil, TakeUntilDestroy, TakeUntilDisable辺りが使えます。
Observable.IntervalFrame(30).TakeUntilDisable(this)
.Subscribe(x => Debug.Log(x), () => Debug.Log("completed!"));
イベントを「繰り返す」場合に、Repeatが通常使われますが、実は危険です。源流がOnCompletedを発行すると無限ループ化するからです。ObservableTriggersが終了するとOnCompletedを発行するため、安易なRepeatの使用は無限ループ行きとなります。それを避けるには、RepeatUntilDestroy(gameObject/component), RepeatUntilDisable(gameObject/component), RepeatSafeが使えます。RepeatUntilDestroyとかは文字通りなんですが、RepeatSafeは連続してOnCompltedが発行された場合はRepeatを取りやめるという、無限ループ禁止機構のついたRepeatです。ベンリ。
最後に、ObserveEveryValueChangedを紹介します。これは、ラムダ式で指定した値を変更のあった時にだけ通知するという、つまり変更通知のない値を変更通知付きに変換するという魔法のような(実際ベンリ!)機能です(実際は毎フレーム監視してるんで、ポーリングによる擬似的なPull→Push変換)
// watch position change
this.transform.ObserveEveryValueChanged(x => x.position).Subscribe(x => Debug.Log(x));
これは監視対象がGameObjectの場合はDestroy時にOnCompletedを発行して監視を止めます。通常のC#クラス(POCO)の場合は、GCされた時に、同様にOnCompletedを発行して監視を止めるようになっています(内部的にはWeakReferenceを用いて実装されています)。ただのポーリングなので多用すぎるとアレですが、お手軽でベンリには違いないので適宜どうぞ。
パフォーマンス
パフォーマンスの話は一口で言うには結構難しいところです。まずいうと、RxとLINQを関連付けてLINQだからパフォーマンスがー、というのは微妙にあてはまりません。RxはPush型、最初のタイミングでパイプラインを構築し、それを(大抵の場合)かなり長い期間(最長でObjectが消滅するまで)購読する形になります。つまり、ライフサイクルが非常に長い。だから、パイプライン構築のためのオブジェクト(のGC)のコストというのは、そんなでもないと思ってもらっていいでしょふ。Updateの度に頻繁に数千構築/解体を繰り返すようなものではない、ということですねん。パイプラインに流れる値に関しては、その頻度と書きよう次第ですけれど。また、Rxのメソッドも軽いメソッドと重いメソッドがあるので、それ次第という面もあります。とはいえそこまで気にするほどではないかなー、と。
全体的にRxを適用すると、アプリケーションはPushベースで構築されることになるので、頻繁な問い合わせ処理(Pullベース)が消え、つまり更新駆動の最小限の差分処理だけが走るので、逆にパフォーマンスは上がる、という見方もできなくもないですが、まぁさすがにそれは都合の良すぎる捉え方でしょう:) ともあれ、そういったアプリケーション構築手法の変革もあるので、そこのところも含めて評価しなければなりません。
単純なコルーチンの代替、非同期通信処理の代替レベルでなら、実質ない、と言っても過言ではないところなので、それぐらいならばもうまるっきり気にせず、ですね。また、今まではObservableMonoBehaviourが不要な場合にも空イベントを回していて、それが若干の消費があったのですが、今回からは軽量なTriggerベースで必要なものにしかイベントを付与しないスタイルになったので、全体的にはかなり取り回しよくなってきたんじゃないかなー、と思います。
まだまだ全然パフォーマンスチューニングできる領域は沢山あるので、都度行っていくつもりです(分かりやすく効果の出るところでいえばWhere.Where.Whereチェーンは1個のWhereにできたり、かなり多用されるWhere.Selectチェーンも1個のWhereSelectチェーンにまとめあげられたり、などなど)
LINQ to GameObject
あと、これはUniRxとは関係ないのですがLINQ to GameObjectもアップデートしてます。
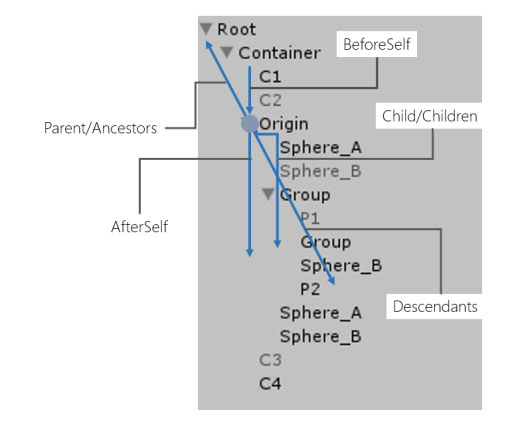
メインはLINQ風メソッドでtransformを自在に辿れるってところで、それはLINQ to GameObjectによるUnityでのLINQの活用を読んでいたたきたいのですが、もう一つの機能に、階層上の任意の位置にGameObjectをAddしたりMoveしたりするメソッドもあります。今回のアップデートで、これがuGUIのRectTransformに対応しました!uGUIはヒエラルキーの位置を表示情報としてかなり大事に扱うため、それのコントロールが容易になるLINQ to GameObjectは役立つはずです。
まとめ
今回のObservableTrigger、uGUI連携、そしてLifetime管理といった機能によって、より様々なところに導入しやすくなった、より使いやすくなったのではないでしょうか!
直近では4/16 18:30~の歌舞伎座.tech#7「Reactive Extensions」で「Observable Everywhere - UniRxによるUnityでのReactive Programming」と題して発表を行います。こちらはニコ生での放送もあるようなので、見るといいんじゃないかなー、ということで!
Microsoft MVP for .NET(C#)を再々々々受賞しました
- 2015-04-02
今年も受賞で、5年目です。実は今年から受賞分野がC#が.NETに統合されたので、エキスパタイズとしてはfor .NETになります。
会社は第一段階が終わり、といった感じで、それに付随する活動内容としても総まとめみたいなものが多かったかな、といったところでしょうか。今年はまた次の段階の始まりということで、より新しい勝負が必要になってきています。今、私が主に力を入れているのはUnityと、そのReactive Extensions実装のUniRxで、特にUniRxはかなりヒットさせられたとは思います。が、まだまだ兆しといったところなので、確固たるものにしなければならない。また、それを基盤にして、C#の強さというのを、ただの今までの.NETコミュニティにだけに留まらず、幅広い世界に届ける、伝えていきたいし、幸いにして私はそれが出来る立場にいると思っています。
より力強く、Real World C#というのを示し続けてきます。そんなわけで引き続き、今年もよろしくお願いします。
グラニのC#フレームワークの過去と未来、現代的なASP.NETライブラリの選び方
- 2015-03-25
Build Insider MEETUP with Graniというイベントで、グラニのC#フレームワーク(というほどのものはない!)の今までとこれからってのを話しました。
そのうちBuild Insiderで文字起こしとか公開されると思います。
2015年の今、どういうライブラリを選んだか、とかNLog大脱却、とかって話が見どころですかね。うちの考えるモダンなやり方、みたいな感じです。
実際、EventSourceやSemantic Logging Application Blockは良いと思いますので、触ってみるといいですね。少なくとも、イマドキにハイパーヒューマンリーダブル非構造化テキストログはないかなぁ、といったところです。
スライドにしたら判別不能になったOWINのStartup部分も置いておきます、参考までに。
// 開発環境用Startup(本番では使わないミドルウェア/設定込み)
public class Startup
{
public void Configuration(IAppBuilder app)
{
app = new ProfilingAppBuilder(app); // 内製Glimpse表示用AppBuilderラッパー(Middlewareトラッカー)
app.EnableGlimpse(); // Glimpse.LightNdoe同梱ユーティリティ
app.Use<GlobalLoggingMiddleware>(); // 内製ロギングミドルウェア
app.Use<ShowErrorMiddleware>(); // 内製例外時表示ミドルウェア
app.Map("/api", builder =>
{
var option = new LightNodeOptions(AcceptVerbs.Get | AcceptVerbs.Post,
new LightNode.Formatter.Jil.JilContentFormatter(),
new LightNode.Formatter.Jil.GZipJilContentFormatter())
{
OperationCoordinatorFactory = new GlimpseProfilingOperationCoordinatorFactory(),
ErrorHandlingPolicy = ErrorHandlingPolicy.ThrowException,
OperationMissingHandlingPolicy = OperationMissingHandlingPolicy.ThrowException,
};
builder.UseLightNode(option);
});
// Indexはデバッグ画面に回す
app.MapWhen(x => x.Request.Path.Value == "/" || x.Request.Path.Value.StartsWith("/DebugMenu"), builder =>
{
builder.UseFileServer(new FileServerOptions()
{
EnableDefaultFiles = true,
EnableDirectoryBrowsing = false,
FileSystem = new PhysicalFileSystem(@".\DebugMenu"),
});
});
// それ以外は全部404
app.MapWhen(x => !x.Request.Path.Value.StartsWith("/Glimpse.axd", StringComparison.InvariantCultureIgnoreCase), builder =>
{
builder.Run(ctx =>
{
ctx.Response.StatusCode = 404;
return Grani.Threading.TaskEx.Empty;
});
});
}
}
インデックスでアクセスすると表示するページはGlimpse.axdと、シングル全画面ページで表示できるローンチ部分へのリンクを貼っつけてあります。
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Debug Index</title>
</head>
<body>
APIのデバッグ<br />
<p>
<a href="../../Glimpse.axd?n=glimpse_redirect_popup">Glimpse Launch</a>
</p>
<p>
<a href="../../glimpse.axd">Glimpse Config</a>
</p>
</body>
</html>
まぁ、こういうのあると、Glimpseへのアクセスが近くで非常に便利です。
あと最後に、OWINでやるならこーいうのどうでしょう、というWeb.config。Owin Middlewareと機能重複して鬱陶しいからHttpModule丸ごと消そうぜ、という過激派な案ですにゃ。
<?xml version="1.0" encoding="utf-8"?>
<!-- OWIN向けウェブコン -->
<!-- Glimpse系のはリリース時にはxsltでまるっと消す -->
<configuration>
<configSections>
<section name="glimpse" type="Glimpse.Core.Configuration.Section, Glimpse.Core" />
</configSections>
<connectionStrings configSource="<!-- 接続文字列は外部に回す(DebugとReleaseでxsltで変換して別参照見るように) -->" />
<appSettings>
<!-- なんかここに書いたり外部ファイルとmergeしたり:) -->
</appSettings>
<system.web>
<!-- system.web配下のは片っ端から消してしまう -->
<httpModules>
<clear />
<add name="Glimpse" type="Glimpse.AspNet.HttpModule, Glimpse.AspNet" />
</httpModules>
<httpHandlers>
<clear />
<add path="glimpse.axd" verb="GET" type="Glimpse.AspNet.HttpHandler, Glimpse.AspNet" />
</httpHandlers>
<roleManager>
<providers>
<clear />
</providers>
</roleManager>
<customErrors mode="Off" />
<trace enabled="false" />
<sessionState mode="Off" />
<httpRuntime targetFramework="4.5" requestPathInvalidCharacters="" />
<globalization culture="ja-jp" uiCulture="ja-jp" />
<!-- リリース時にxsltでfalseにする -->
<compilation debug="true" />
</system.web>
<system.webServer>
<validation validateIntegratedModeConfiguration="false" />
<globalModules>
<clear />
</globalModules>
<modules>
<!-- モジュールも全消し -->
<remove name="OutputCache" />
<remove name="Session" />
<remove name="UrlRoutingModule-4.0" />
<!-- 以下デフォで読まれるモジュール名が延々と続く(system.webServer下は一括clearが使えなくて辛い)... -->
<add name="Glimpse" type="Glimpse.AspNet.HttpModule, Glimpse.AspNet" preCondition="integratedMode" />
</modules>
<handlers>
<add name="Glimpse" path="glimpse.axd" verb="GET" type="Glimpse.AspNet.HttpHandler, Glimpse.AspNet" preCondition="integratedMode" />
</handlers>
</system.webServer>
<!-- おまじない(笑)セクション -->
<system.net>
<connectionManagement>
<add address="*" maxconnection="1024" />
</connectionManagement>
<settings>
<servicePointManager expect100Continue="false" useNagleAlgorithm="false" />
</settings>
</system.net>
<!-- WebServiceでやるならPersistResultsで(当然このセクションもリリースでは消す) -->
<glimpse defaultRuntimePolicy="PersistResults" endpointBaseUri="~/Glimpse.axd">
<tabs>
<ignoredTypes>
<add type="Glimpse.AspNet.Tab.Cache, Glimpse.AspNet" />
<add type="Glimpse.AspNet.Tab.Routes, Glimpse.AspNet" />
<add type="Glimpse.AspNet.Tab.Session, Glimpse.AspNet" />
<add type="Glimpse.Core.Tab.Trace, Glimpse.Core" />
</ignoredTypes>
</tabs>
<runtimePolicies>
<ignoredTypes>
<add type="Glimpse.Core.Policy.ControlCookiePolicy, Glimpse.Core" />
<add type="Glimpse.Core.Policy.StatusCodePolicy, Glimpse.Core" />
<add type="Glimpse.Core.Policy.AjaxPolicy, Glimpse.Core" />
<add type="Glimpse.AspNet.Policy.LocalPolicy, Glimpse.AspNet" />
<add type="Glimpse.Core.Tab.Trace, Glimpse.Core" />
</ignoredTypes>
</runtimePolicies>
</glimpse>
</configuration>
Web API的なサービスでもGlimpse使えるよ!ってのはもっと知ってほしいかしらん。その辺はLightNode 1.0、或いはWeb APIでのGlimpseの使い方で詳しく解説しています。
LightNode 1.0、或いはWeb APIでのGlimpseの使い方
- 2015-02-16
こないだ、RedisクライアントのCloudStructuresを1.0にしたばかりですが、今回は大昔に作った自作Web APIフレームワークのLightNodeを1.0にしました。なんでドタバタやってるのかというと、.NET XRE(ASP.NET vNext)を様子見してたんですが、そろそろ今年一年どうしていくかの態度を決めなければならなくて、結論としては、OWINで行くことにしたからです。ちゃんちゃん。その辺の理由なんかは後ほど。
さて、Glimpseです。なにはなくともGlimpseです。イマドキでC#でウェブ作るんなら、まずはGlimpse入れましょう。絶対必須です。使ったことないんなら今すぐ使ってください。圧倒的なVisual Profiling!ボトルネックが一目瞭然。コンフィグも一覧されるので、普段気にしていなかったところも丸見え。データアクセスが何やってるかも一発で分かる。ちなみに、競合としては昔あったMiniProfilerは窓から投げ捨てましょう。ASP.NET開発はもはやGlimpse以前と以後で分けられると言っても過言ではない。
で、LightNode 1.0です。変更点はGlimpseにフル対応させたことで、ついでに細かいとこ直しまくりました、と。ともあれGlimpse対応が全てです。
で、作ってる間にGlimpseをWeb API(ASP.NET Web APIとは言ってない)系で使ったり、Owinと合わせて使ったりすることのノウハウも溜まったので、LightNodeの話というかは、そっちのことを放出したいな、というのがこの記事の趣旨ですね!
OwinでGlimpseを使う
Glimpse自体はOwinに対応していません。勿論、vNextへの対応も含めてSystem.Webへの依存を断ち切ろうとしたGlimpse v2の計画は随分前から始まっているんですが、Issueをずっと見ている限り、かなり進捗は悪く、難航しているようです。正直、いつ完了するか全く期待持てない感じで、残念ながら待っていても使えるようにはなりません。
しかし、そもそもGlimpseのシステムはただのHttpModuleとHttpHandlerで動いています。つまり、Microsoft.Owin.Host.SystemWebでホストしている限りは、Owinであろうと関係なく動きます。動くはずです。実際Glimpse.axdにアクセスすれば表示されるし、一見動いています。そしてGlimpseにはページ埋め込みの他、Standaloneでの起動が可能(Glimpse.axdでの右側)なのでそこから起動すると……
いくらOwinでページ作ってアクセスしても何も表示されません、データがHistoryに蓄積されません。これにめっちゃハマって以前は諦めたんですが、今回LightNodeをOwinに何が何でも対応させたくて改めて調べた結果、対策分かりました。原因としては、Glimpseはリクエストの完了をPostReleaseRequestStateで受け止めているんですが、Microsoft.Owin.Host.SystemWebでホストしてOwinによるリクエストハンドリングでは、完了してもPostReleaseRequestStateが呼ばれません。結果的にOwinでふつーにやってる限りではGlimpseでモニタできない。
対策としては、単純に手動でEndRequestを叩いてやればいいでしょう。Middlewareを作るなら
public Task Invoke(IDictionary<string, object> environment)
{
return next(environment).ContinueWith((_, state) =>
{
((state as HttpContext).Application["__GlimpseRuntime"] as IGlimpseRuntime).EndRequest();
}, System.Web.HttpContext.Current);
}
ということになります。このMiddlewareを真っ先に有効にしてやれば、全てのOwinパイプラインが完了した際にEndRequestが叩かれる、という構造が出来上がります。System.Webをガッツリ使ったMiddlewareなんて気持ち悪いって?いやいや、まぁいーんですよ、そもそもGlimpseがSystem.Webでしか現状動かないんだから、ガタガタ言うでない。
さて、LightNodeのGlimpse対応DLLにはこのMiddlewareを最初から同梱してあります。LightNodeでGlimpse対応のConfigurationを書く場合は、以下のようになります。
public void Configuration(Owin.IAppBuilder app)
{
app.EnableGlimpse();
app.MapWhen(x => !x.Request.Path.Value.StartsWith("/glimpse.axd", StringComparison.OrdinalIgnoreCase), x =>
{
x.UseLightNode(new LightNodeOptions()
{
OperationCoordinatorFactory = new GlimpseProfilingOperationCoordinatorFactory()
});
});
}
まずEnableGlimpse、これが先のEndRequestを手動で叩くものになってます。次にMapWhenで、Glimpse.axdだけOwinパイプラインから外してやることで、LightNodeと共存させられます!ついでに、LigthNodeでのGlimpseモニタリングを有効にする場合はGlimpseProfilingOperationCoordinatorFactoryをOptionに渡してあげれば全部完了。
LightNode+GlimpseによるWeb APIモニタリング
何ができるようになるの?何が嬉しいの?というと、勿論当然まずはTimelineへの表示。

フィルター(Before/After)とメソッド本体がTimeline上で見えるようになります。これは中身何もないですが、勿論DatabaseやRedis、Httpアクセスなどがあれば、それらもGlimpseは全部乗っけることができるし、それらをWeb APIでも見ることができる。圧倒的に捗る。
そしてもう一つがLightNodeタブ。
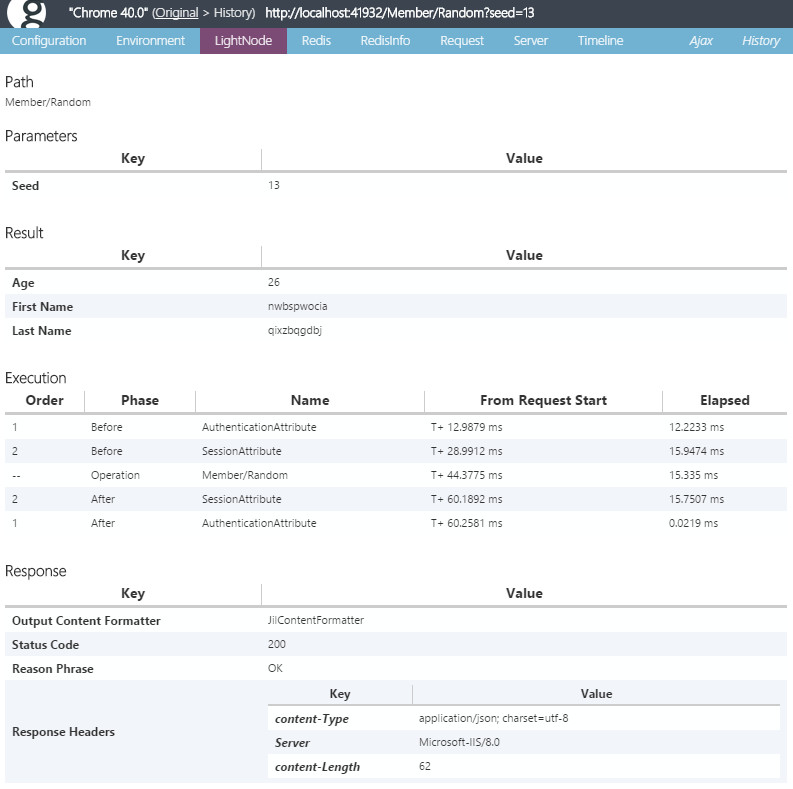
一回のリクエストのパラメータと、戻り値が表示されます。API開発の辛さって、戻り値が見えない(クライアント側でハンドリングして何か表示したりするも、領域的に見づらかったりする)のが結構あるなーって私は思っていて、それがこのLightNodeタブで解消されます。ちなみにもし例外があった場合は、ちゃんと例外を表示します。
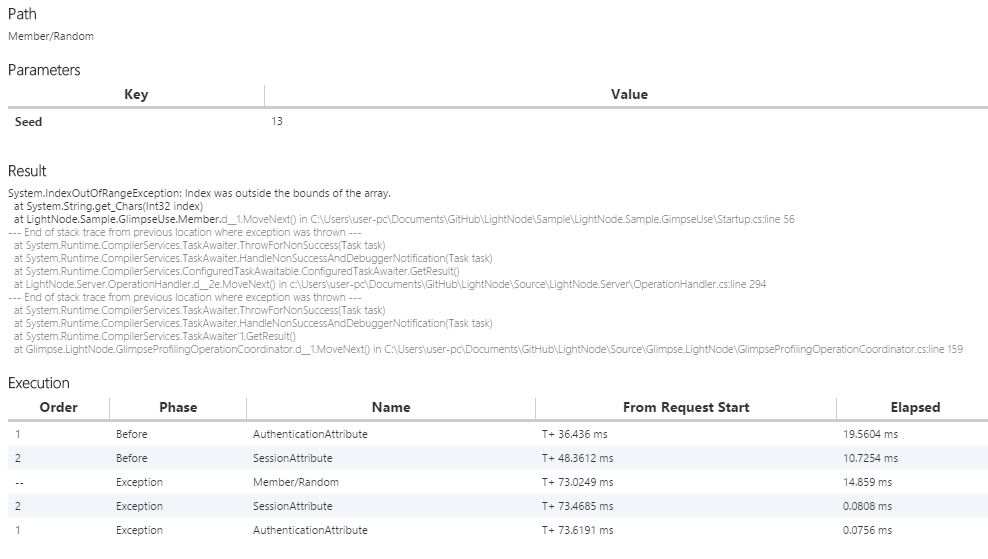
また、ExecutionのPhaseが以降はすべてExceptionになってるので、フィルターが遠ったパスも確認しやすいはずです。
Web APIのためのGlimpseコンフィグ
Web APIのためにGlimpseを使う場合、ふつーのWeb用のコンフィグだと些か不便なところがあるので、調整したほうがいいでしょう。私のお薦めは以下の感じです。
<!-- GlimpseはHUDディスプレイ表示のためなどでレスポンスを書き換えることがありますが、勿論APIには不都合です。
デフォルトはPersistResults(結果のHistory保存のみ)にしましょう -->
<glimpse defaultRuntimePolicy="PersistResults" endpointBaseUri="~/Glimpse.axd">
<tabs>
<ignoredTypes>
<!-- OWINで使うならこれらは不要でしょう、出てるだけ邪魔なので消します -->
<add type="Glimpse.AspNet.Tab.Cache, Glimpse.AspNet" />
<add type="Glimpse.AspNet.Tab.Routes, Glimpse.AspNet" />
<add type="Glimpse.AspNet.Tab.Session, Glimpse.AspNet" />
</ignoredTypes>
</tabs>
<runtimePolicies>
<ignoredTypes>
<!-- クライアントがクッキー使うとは限らないので、無視しましょう、そうしないとHistoryに表示されません -->
<add type="Glimpse.Core.Policy.ControlCookiePolicy, Glimpse.Core" />
<!-- 404とかもAPIならハンドリングして表示したい -->
<add type="Glimpse.Core.Policy.StatusCodePolicy, Glimpse.Core" />
<!-- Ajaxじゃないなら -->
<add type="Glimpse.Core.Policy.AjaxPolicy, Glimpse.Core" />
<!-- リモートで起動(APIならそのほうが多いよね?)でも有効にする -->
<add type="Glimpse.AspNet.Policy.LocalPolicy, Glimpse.AspNet" />
</ignoredTypes>
</runtimePolicies>
</glimpse>
defaultRuntimePolicyと、そして特にControlCookiePolicyが重要です。利用シチュエーションとしてStandalone Glimpseで起動してHistoryから結果を見る、という使い方になってくるはずなので(というかWeb APIだとそうしか方法ないし)、Cookieで選別されても不便すぎるかな、ブラウザからのAjaxならともかくモバイル機器から叩かれてる場合とかね。
さて、それは別として、様々なクライアントからのリクエストが混ざって判別できないというのも、それはそれで不便です。これを区別する手段は、あります。それは、クッキーです(笑) 判別用にクッキーでID振ってやるとわかりやすくていいでしょう。例えば以下の様な感じです。
var req = WebRequest.CreateHttp("http://localhost:41932/Member/Random?seed=13");
// "glimpseid" is Glimpse's client grouping key
req.CookieContainer = new CookieContainer();
req.CookieContainer.Add(new Uri("http://localhost:41932"), new Cookie("glimpseid", "UserId:4"));
glimpseidというのがキーなので、例えばそこにユーザーIDとか振っておくと見分けがついてすごく便利になります。
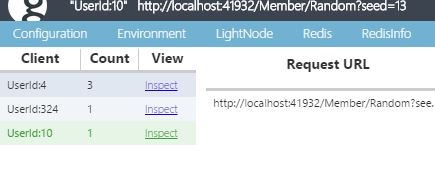
こんな感じです。これはデバッグビルド時のみといった形で、クライアントサイドで埋め込んであげたいですね。
LightNodeを使う利点
というわけでGlimpseとの連携が超強力なわけですが、LightNode自体はまず言っておくと、誰にでも薦めはしません。この手のフレームワークで何より大事なのが標準に乗っかることです。C#での大正義はASP.NET Web APIです、そこは揺るぎません。その上でLightNodeの利点は「シンプルなAPIがシンプルに作れる」「Glimpseによる強力なデバッグ支援」「クライアントコード自動生成」です。特に非公開のインターナルなWeb API層向けですね。反面お薦めしないのは、RESTfulにこだわりたい人です。LightNodeは設計思想として徹底的にRESTfulを無視してるんで、準拠するつもりは1ミリもありません。例えば、インターナルなAPIでRESTfulのために1つのURIを決めるのに3日議論するとか、凄まじく馬鹿げているわけで。LightNodeは悩みを与えません、そもそもメソッド書くしかできないという制約を与えているから。
凝ったルーティングもアホくさい。インターナルなWeb APIで、モバイル機器からのアクセスを前提にすると、クライアントサイドでのAPIライブラリを書くことになりますが、ルーティングが凝っていれば凝っているほど対応が面倒くさいだけ、という。嬉しさなんて0.1ミリもない。結局、ルールはある程度固定のほうが良いんですよ。さすがにパブリックAPIなら長いものに適当に巻かれて適当に誤魔化しますが。
というわけで、どういう人に薦めるかというと「とりあえずサクッとWeb API作りたい人」「モバイルクライアントからアクセスするインターナルなWeb APIを作りたい人」ですかねー。別にパブリックなのも作れないことはないですけど、別にそこまで違和感あるURLになるわけでもないですしね。
ちなみに、MVCとの共存は可能です。例えば
public void Configuration(IAppBuilder app)
{
app.Map("/api", x =>
{
x.UseLightNode();
});
}
といった感じにapi以下をLightNodeのパスってことにすればOK。それ以外のパスではASP.NET MVCが呼ばれます。ルートが変わるだけなので、他のコンフィグは不要です。あんまり細かくゴチャゴチャやると辛いだけなので、このぐらいにしておくのがいいですね。ちなみに、Owinで困るのはHttpModuleとの共存だったりします。実行順序もグチャグチャになるし(一応、少しはOwin側でコントロールかけられますが、辛いしね)同じようなものが複数箇所にあるというのは、普通にイけてない。これはMiddlewareのほうに寄せていきたいところ。脱HttpModule。
まとめ
あ、で、OWINな理由って言ってませんでしたっけ。なんかねー、XREは壮大すぎて危険な香りしかしないんですよ。少なくとも、今年の頭(今)に、今年に使う分のテクノロジーを仕込むには、賭けられないレベルで危なっかしい。Previewで遊びながら生暖かく見守るぐらいがちょうどいいです。まあ、アタリマエだろっていえばアタリマエ(ベータすら出てないものを実運用前提で使い出すとかマジキチである)ですけどね、だから別にXREがダメとかそういう話じゃないですよ。むしろXREはまだ評価できる段階ですらないし。
で、今は過渡期で宙ぶらりんなのが凄く困る話で、そのブリッジとしてOWINはアリかな、と。OWIN自体の未来は、まぁASP.NET 5はどうしてOWIN上に乗らなかったのかにあるように、Deadでしょう。しかし、今から来年の分(XREが実用になった世代)を仕込むには、System.Webへの依存の切り離しや、Owin的なパイプラインシステムへの適用は間違いなく重要。OWINならコーディングのノリもASP.NET 5と変わらないしコードの修正での移行も容易になる、最悪互換レイヤーを挟んで適用できるので、「今」の選択としては、消極的にアリです。
ASP.NET Web APIは、うーん、ASP.NET MVCとの統合が見えてる今、改めて選びたくない感半端ないんだよねぇ。GlimpseはASP.NET Web API対応しないの?というと、そういう話もあるにはあったようですが、色々難航していて、PullRequestで物凄く時間かけて(70レス以上!一年近く!)、それでも結局取り込まれてないんですよ。ここまで来るともはやGlimpse v2でのvNext対応でMVC統合されてるんだからそれでいいじゃん、に落ち着きそうで、恐らくもう動きはないでしょう。とか、そういう周辺のエコシステムの動きも今のASP.NET Web APIは鈍化させる状況にあるわけで、あんまポジティブにはなれないなぁ。とはいえ、現状のスタンダードなWeb API構築フレームワークとして消極的にアリ、と言わざるをえないけれど。ちなみにNancyは個人的には全くナシです、あれのどこがいいのかさっぱりわからない。
Glimpseの拡張は、ちょうど社内用拡張も全部書き換えたりして、ここ数日でめちゃくちゃ書きまくったんで、完全に極めた!うぉぉぉぉ、というわけで拡張ガイダンスはいつかそのうち書くかもしれませんし、多分書きません。つーかGlimpseちゃんと日本の世の中で使われてます?大丈夫かなー、さすがにGlimpseは圧倒的に良いので標準レベルで使われなければならないと思うのですけれど。
あー、で、LightNodeは、まあ良く出来てますよ、用途の絞り方というか課題設定が明確で、実装もきっちりしてありますし。うん、私は好きですけど(そりゃそうだ)、人に薦めるかといったら、Microsoftの方針がOwin的なオープンの流れから、やっぱり大Microsoft的なところに一瞬で戻ったりしてるんで(Hanselmanには少し幻滅している)、まぁ長いものには巻かれておきましょう。
CloudStructures 1.0 - StackExchange.Redis対応、RedisInfoタブ(Glimpse)
- 2015-02-06
CloudStructures、というRedisライブラリを以前に作ってたわけなのですが(CloudStructures - ローカルとクラウドのデータ構造を透過的に表現するC# + Redisライブラリ)、2013年末にGlimpseプラグインを追加してから一切音沙汰がなかった。私お得意の作るだけ作って放置パターンか!と思いきや、ここにきて突然の大更新。APIも破壊的大変更祭り。バージョンもどどーんと上げて1.0。ほぅ……。
- GitHub - neuecc/CloudStructures
- NuGet - CloudStructures
一番大きいのが、ベースにしてるライブラリがBookSleeveからStackExchange.Redisになりました。StackExchange.RedisはBookSleeveの後継で、そしてAzure Redis Cacheのドキュメントでもマニュアルに使用されているなど、今どきの.NETにおけるRedisクライアントのデファクトの位置にあると言ってよいでしょう。当然、移行する必要があったんですが腰が重くて……。
APIを変えた理由は、以前は「ローカルとクラウドのデータ構造を透過的に表現」というのに拘ってIAsyncCollection的に見せるのに気を配ってたんですが、Redis本来のコマンド表現と乖離があって、かなり使いづらかったんでやめたほうがいーな、と。メソッド名が変わっただけで使い方は一緒なんですが、とりあえずRedisのコマンド名が露出するようになりました。ま、このほうが全然イイですね。抽象化なんて幻想だわさ、特に名前の。
CloudStructuresの必要性
こんな得体のしれない野良ライブラリなんて使いたくねーよ、StackExchange.Redisを生で使えばいいじゃん。と、思う気持ちは至極当然でまっとうな感覚だと思います。私もそう思う。そして、単純なStringGet/Setぐらいしか使わないならそれでOKです、本当にただのキャッシュストアとして使うだけならば。しかし、本気でRedisを使い倒す、本気でRedisの様々なデータ構造を活用していこうとすると、StackExchange.Redisを生で使うのは限界が来ます。戻り値のオブジェクトへのマッピングすらないので、そこら中にSeiralize/Deserializeしなければならなくなる。ADO.NETのDbDataReaderを生で使うようなもので、そうなったら普通はなんかラップするよね?ADO.NETにはDapperのようなMicro ORMからEntity FrameworkのようなフルセットのORMまである。StackExchange.Redisが生ADO.NETを志向するならば(これは作者も言明していて、付随機能は足さない方針のようです)ならば、そこにO/R(Object/Redis)マッパーが必要なのは自然のことで、それがCloudStructuresです。
CloudStructuresが提供するのは自動シリアライズ/デシリアライズ、キーからの分散コネクション(シャーディング)、コマンドのロギング、Web.configからの接続管理、そしてGlimpse用の各種可視化プロファイラーです。元々、というか今もCloudStructuresはうちの会社でかなりヘヴィに使ってて(このことは何度か記事でも推してます、技評のグラニがC#にこだわる理由とか)、コマンドのロギングとかは執拗に拘ってます。今回はそうした長い利用経験から、やっぱイケてない部分も沢山あったので徹底的に見直しました。
シャーディングは、StackExchange.RedisはそもそもConnectionMultiplexerという形で内部で複数の台への接続を抱えられるんですが、これはどちらかというと障害耐性的な機能(Master/Slaveや障害検知時の自動昇格など)が主なので、Memcached的なクライアントサイドでの分散はBookSleeveの時と変わらず持っていません。なので引き続きシャーディングはCloudStructures側の機能として提供しています。
そもそもRedisが必要かどうかだと、んー、私としては規模に関わらず絶対に入れたほうがいいと思ってます。RDBMSの不得意なところを綺麗に補完できるので、RDBMSだけで頑張るよりも、ちょっとしたとこに使ってやると物凄く楽になると思います。導入もAzure Redis CacheやAWSのElastiCache for Redisのようにマネージドのキャッシュサービスが用意されているので、特にクラウド環境ならば簡単に導入できますしね。
使い方の基本
RedisSettingsまたはRedisGroupを保持して、各データ構造用のクラスをキー付きで作って、メソッド(全部async)を呼ぶ、です。
// 設定はスタティックに保持しといてください
public static class RedisServer
{
public static readonly RedisSettings Default = new RedisSettings("127.0.0.1");
}
// こんなクラスがあるとして
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
// RedisStringという型を作って... (RedisSettings.Default.String<Person>("key")でも作れます)
var redis = new RedisString<Person>(RedisServer.Default, "test-string-key");
// コマンドをがしがし呼ぶ、何があるかはIntelliSenseで分かる
await redis.Set(new Person { Name = "John", Age = 34 });
// 取得もそのまま呼ぶ
var copy = await redis.Get();
// Listも同じ感じ
var list = new RedisList<Person>(RedisServer.Default, "test-list-key");
await list.LeftPush(new[] { new Person { Name = "Tom" }, new Person { Name = "Mary" } });
var persons = await list.Range(0, 10);
難しいところはなく、割と直感的。StackExchange.Redisのままだと、特にListが辛かったりするんで、相当楽になれるかな。
メソッド名は基本的にStackExchange.Redisのメソッド名からデータ構造名のプリフィックスとAsyncサフィックスを抜いたものになってます。例えばSetAddAsync()はRedisSet.Add()になります。SetAddなんて最悪ですからね、そのまんま扱いたくない名前。Asyncをつけるかどうかはちょっと悩ましかったんですが、まぁ全部Asyncだしいっか、と思ったんで抜いちゃいました。
他の特徴としては全てのセット系のメソッドにRedisExpiryという引数を足してます。これは、SetのついでにExpireを足すって奴ですね。標準だとStringSetぐらいにしかないんですが、元々Redisは個別にExpireを呼べば自由につけれるので、自動でセットでつけてくれるような仕組みにしました。なんだかんだでExpireはつける必要があったりして、今までは毎回Task.WhenAllでまとめててたりしてたんですがすっごく面倒だったので、これで相当楽になれる、かな?
RedisExpiryはTimeSpanかDateTimeから暗黙的変換で生成されるので、明示的に作る必要はありません。
var list = new RedisList<int>(settings);
await list.LeftPush(1, expiry: TimeSpan.FromSeconds(30));
await list.LeftPush(10, expiry: DateTime.Now.AddDays(1));
こんな感じ。これは、StackExchange.RedisがRedisKey(stringかbyte[]から暗黙的に変換可能)やRedisValue(基本型に暗黙的/明示的に変換可能)な仕組みなので、それに似せてみました。違和感なく繋がるのではないかな。
コンフィグ
Web.configかapp.cofingから設定情報を引っ張ってこれます。トランスフォームとかもあるので、なんのかんのでWeb.configは重宝しますからねー、あると嬉しいんじゃないでしょうか。
<configSections>
<section name="cloudStructures" type="CloudStructures.CloudStructuresConfigurationSection, CloudStructures" />
</configSections>
<cloudStructures>
<redis>
<group name="Cache">
<!-- Simple Grouping(key sharding) -->
<add connectionString="127.0.0.1,allowAdmin=true" db="0" />
<add connectionString="127.0.0.1,allowAdmin=true" db="1" />
</group>
<group name="Session">
<!-- Full option -->
<add connectionString="127.0.0.1,allowAdmin=true" db="2" valueConverter="CloudStructures.GZipJsonRedisValueConverter, CloudStructures" commandTracer="Glimpse.CloudStructures.Redis.GlimpseRedisCommandTracer, Glimpse.CloudStructures.Redis" />
</group>
</redis>
</cloudStructures>
こんな感じに定義して、
public static class RedisGroups
{
// load from web.config
static Dictionary<string, RedisGroup> configDict = CloudStructures.CloudStructuresConfigurationSection
.GetSection()
.ToRedisGroups()
.ToDictionary(x => x.GroupName);
// setup group
public static readonly RedisGroup Cache = configDict["Cache"];
public static readonly RedisGroup Session = configDict["Session"];
static RedisGroups()
{
// 後述しますがGlimpseのRedisInfoを有効にする場合はここで登録する
Glimpse.CloudStructures.Redis.RedisInfoTab.RegisiterConnection(new[] { Cache, Session });
}
}
こんな風にstatic変数に詰めてやると楽に扱えます。
シリアライズ
CloudStructuresは基本型(int, double, string, etc)はそのまま格納し、オブジェクトはシリアライザを通します。シリアライザとして標準ではJSONシリアライザのJilを使っています。理由は、速いから。JilはJSON.NETと違って、JsonReader/Writerも提供しないし、複雑なカスタムオプションもフォールバックもありません(多少の(特にDateTime周りの)オプションはありますが)。単純にJSONをシリアライズ/デシリアライズする、もしくはdynamicで受け取る。それだけです。まぁ、CloudStructuresの用途には全然合ってる。
以前はprotobuf-netを使っていたんですが、今後はやめようと思ってます。理由は、DataMemberをつけて回るのが面倒だから、ではなくて、空配列/空文字列/nullのハンドリングが凄く大変だったり(ネストしたオブジェクトの空配列がデシリアライズしたらnullになってた、とかね……これは正直ヤバすぎた)、バージョニング(特にEnumの!)が辛かったり、型がないとデシリアライズできないのでちょっとしたDumpすらできなかったりと、実運用上クリティカルすぎる案件が多くてそろそろもう無理。
かわりに、ではないですが圧縮することを提案します。CloudStructuresは標準でGZipJsonRedisValueConverterというものも用意していまして、それに差し替えることでJSONをGZipで圧縮して格納/展開します。圧縮は、特にデカい配列を突っ込んだりするときに物凄く効きます。めちゃくちゃ容量縮みます。protobufにせよmsgpackにせよ、シリアライザは圧縮、ではないんで、バイナリフォーマットとして小さくはなっても、配列にたいしてめちゃくちゃ縮むとかそういうことは起こり得ません(勿論、別にmsgpack+GZipとか併用するのは構わないけれど)。
圧縮の欠点は圧縮なんで、圧縮/解凍にそれなりにパフォーマンスを取られること。と、いうわけでCloudStructuresではLZ4で圧縮するものも用意しました。LZ4はfastest compression algorithmということで、GZipと比べて数倍、圧縮/解凍が速い、です(ただしサイズ自体はGZipよりは縮まない)。この手の用途ではかなり適しているかなー、と。LZ4のライブラリはLZ4 for .NETを用いてます。
- NuGet - CloudStructures.LZ4
インストールはNuGetから入れてもらった後に、LZ4JsonRedisValueConverterに差し替えるだけ。
ふつーはそのまま生JSON、気にしたいけど色々入れたくない人はGZip、エクストリームに頑張ってみたい人はLZ4を選べばいいと思います。更にもっとやりたい人はObjectRedisValueConverterBaseを継承して、自作のRedisValueConverterを作ってみてくださいな。
Glimpseプラグイン
もはやASP.NET開発でGlimpseは絶対に欠かせません。使わないのはありえないレベル。あ、MiniProfilerはもういらないので投げ捨てましょう。というわけでCloudStructuresはGlimpse用のプラグインをしっかり用意してあります。相当気合入れて作りこんであるので、これのためにもRedis使うならCloudStructuresで触るべき、と言えます。マジで。
- NuGet - Glimpse.CloudStructures.Redis
インストールはNuGetから本体とは別に。それとGlimpseを使う場合は、commandTracerにGlimpseRedisCommandTracerを渡しておいてあげてください。またRedisInfoで情報を出す場合、接続文字列でallowAdminをtrueにしておく必要があります。
<add connectionString="127.0.0.1,allowAdmin=true" db="0" commandTracer="Glimpse.CloudStructures.Redis.GlimpseRedisCommandTracer, Glimpse.CloudStructures.Redis" />
まず、Timeline。
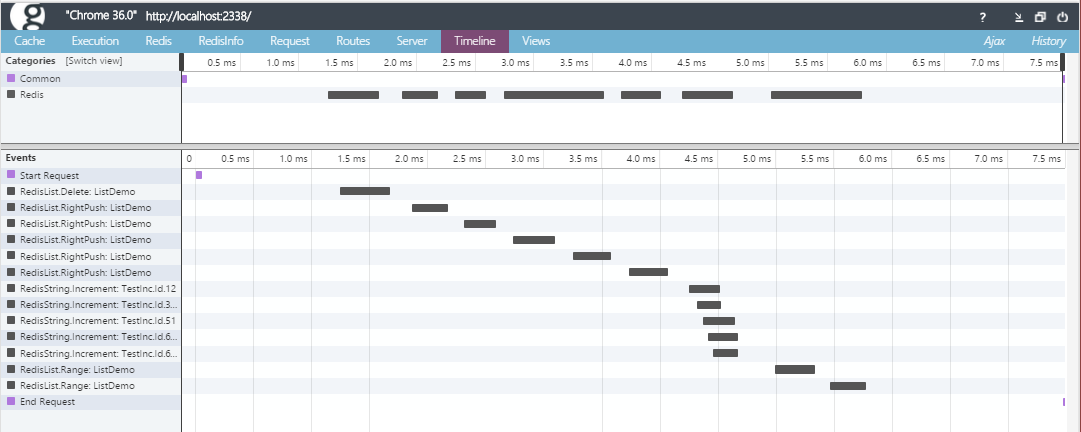
コマンドの並列実行具合がしっかりタイムラインで確認できます。
Redisタブ。
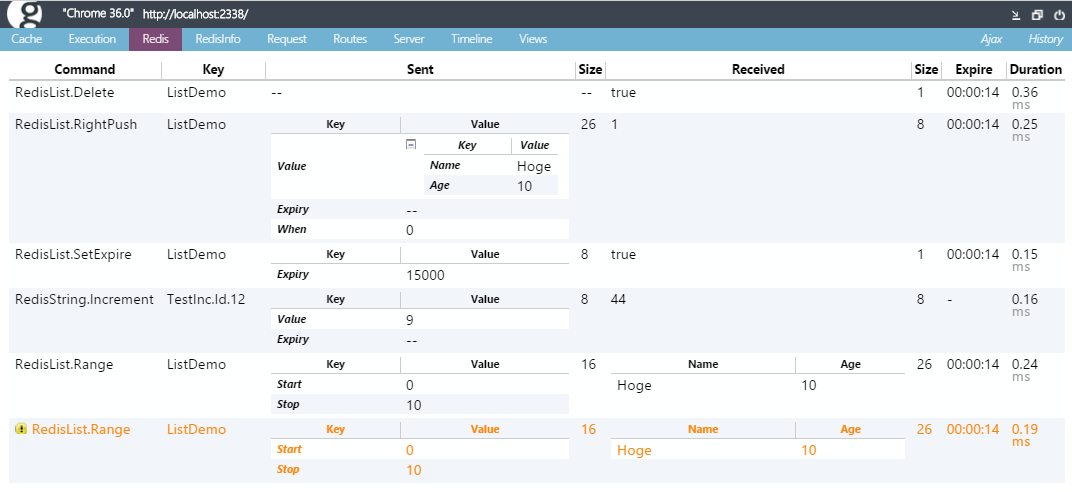
コマンド名、キー名、送受信オブジェクトのダンプとサイズ、Expire時間と処理にかかった時間、そしてキーとコマンドで重複して発行してたら警告。これを見れば一回のページリクエストの中でどうRedisを使ったかが完全に分かるようになってます。不足してる情報は一切なし、とにかく全部出せる仕組みにしました。
最後にRedisInfoタブ。RedisInfoタブを使うには、最初に言ったallowAdmin=trueにすることと、もう一つ、最初に情報表示に使うRedisGroupを登録しておく必要があります。
Glimpse.CloudStructures.Redis.RedisInfoTab.RegisiterConnection(new[] { Cache, Session });
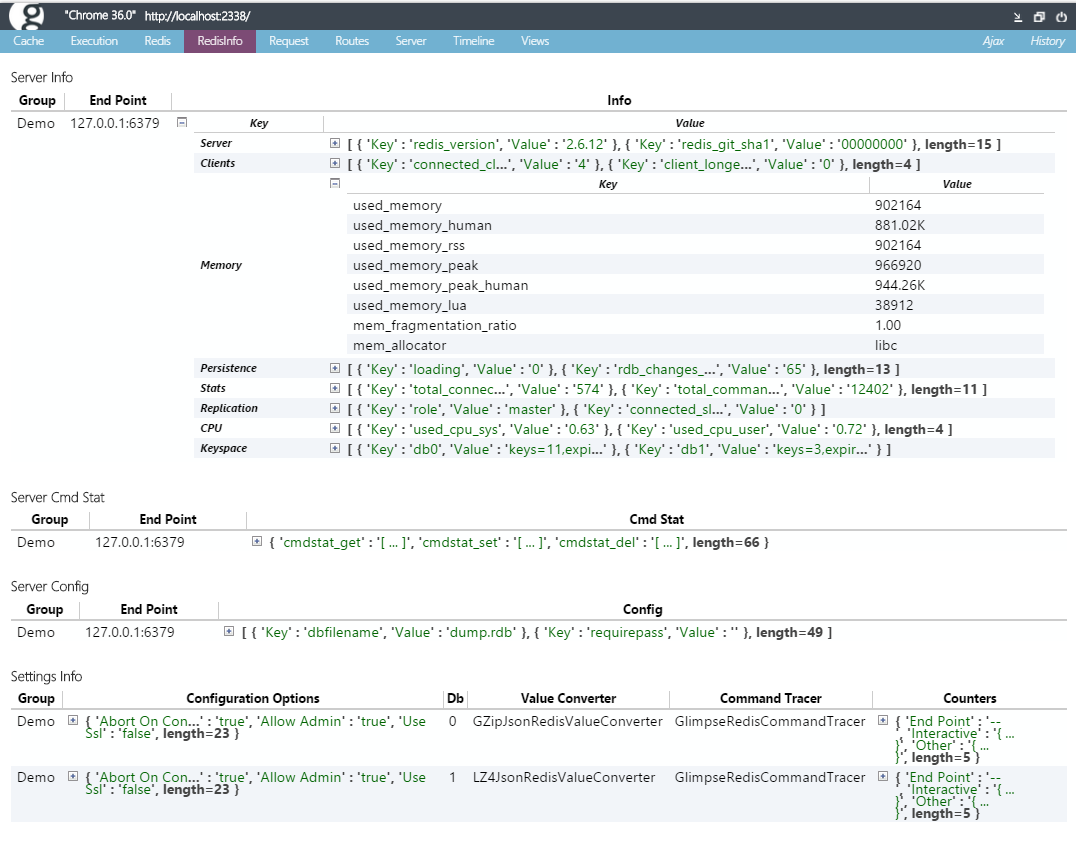
ServerInfoからCmdStat、コンフィグ、クライアント側のコンフィグやコネクションの状態を全部表示します。全部。全部。出せそうな情報は全部収集してきてます。こういうの何気に結構地味に相当大事だったりしますのよ、特にRedisサーバーの情報やコンフィグなんて普段は見ないですからね、こうして超絶カジュアルに見れるっての、かなりありがたい。
まとめ
そんなわけで凄く良くなったんで、かなりお薦めデス。ネーミングが直球なものしか付けないことの多い私にしては、CloudStructuresってライブラリ名はかなりカッコイイという点でもお薦めですね!
問題は旧CloudStructuresとの互換性が、かなり無いので既に使ってる場合は移行が大変ってことデスネ。うちはどうしたんだって?移行してないよ!どーしようかなぁ、うーん、そこはちょっとかなり悩ましい……。
まぁCloudStructuresを使うかどうかはともかくとして、RedisはC#界隈でももっとばんばん使われて欲すぃですねー、そして使うならStringGet/Setだけじゃもったいない。
Open on GitHub - Visual StudioからGitHubのページを開くVS拡張
- 2015-01-14
を、作りました。
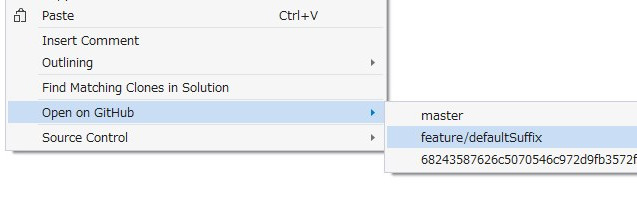
機能は見たまんま?です。ソースコード上で右クリックすると「Open on GitHub」メニューが出るので、そこからmasterかbranchかrevisionを選ぶと、該当のGitHubのブロブページが開きます。便利。
インストールはVisual Studio Galleryからどうぞ。例によってソースコードはGitHubで公開しています。
How to make VSIX
VS拡張はドキュメントがあるんだかないんだか、一応あるんですけど、どうも取っ付きが悪いのが難点。今回はWalkthrough: Adding a Submenu to a Menuをベースに弄ってます。といってもやることは簡単なので、そんな大したことはないですが。
まず、メニュー系は全部vsctというクソ書きづらいXMLを弄って作っていきます。テンプレートは「Visual Studio Package」でウィザードで「Menu Command」を選んどくといいでしょふ、というかそれ以外だと詰む。で、vsctのうち
<Group guid="guidOpenOnGitHubCmdSet" id="ContextMenuGroup" priority="0x0600">
<Parent guid="guidSHLMainMenu" id="IDM_VS_CTXT_CODEWIN" />
</Group>
Parentを「guidSHLMainMenu, IDM_VS_CTXT_CODEWIN」にするとエディタのコンテキストメニューに出てきます。あとはまぁ、適当にどうぞ。OpenOnGitHub.vsctとOpenOnGitHubPackage.csが全て。分かれば難しくない、分かるまでがダルい。
と、ここまでが普通の感じなんですがVSCT(Visual Studio Command Table)は闇が深くて、IDM_VS_CTXT_CODEWINだとcshtmlとかjsonとかcssでは出てきません!これは別のParentを設定する必要があります。しかも、そのGUIDとかはノーヒント……。既存の拡張を観て研究してもいいんですが、本質的にはUsing EnableVSIPLogging to identify menus and commands with VS 2005 + SP1の記事にある、レジストリ弄ってEnableVSIPLoggingをオンにして、直接対象ウィンドウのGUIDとCmdIdを取得するほうがいいかと思われます。取得したIDとかの使い方はOpenOnGitHub.vsctに載ってるので興味ある人は見てくださいな。
あと、Gitの解析にlibgit2を使っているんですが、VSIXでネイティブバイナリを同梱するためにcsprojに
<Content Include="NativeBinaries\amd64\git2-91fa31f.dll">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
<IncludeInVSIX>true</IncludeInVSIX>
</Content>
といったようにIncludeInVSIXをつけなきゃいけないとか、VSIX自体の署名を切らないといけない(テンプレートから作ると入ってるのでカットする)とか、細かいのをこなしていけば出来上がり!
最近のWindowsでGit
SourceTreeがゴミクズすぎて困る。ので、最近はVSのGit使ってたりします。割といいです。
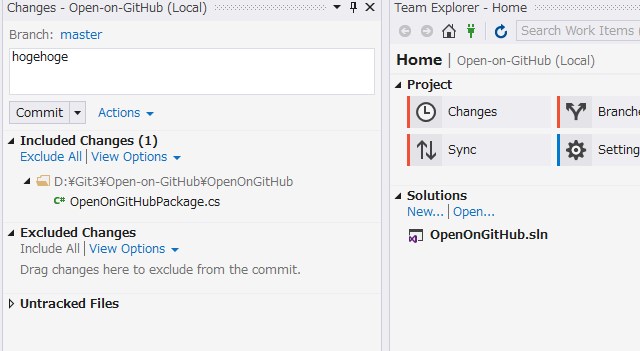
コミットウィンドウが切り離せることに気付いてから、切り離して使ってます。そうするとまぁまぁコミットしやすい。Commit and Syncはなんのかんのいってベンリだし、SourceTreeよりもPushPullも気持ち早い。DiffとかがVS上で行えるのはサイキョーなので、あとはツリー表示さえあれば完璧だなぁ。ともあれ、VSのGit、いいです。見直しましょう。とにかくSourceTreeは使っててストレスで禿げるのでメインVS、サブSourceTreeぐらいの感じが今のとこ一番いい。
まとめ
ともあれOpen on GitHubはマジベンリ。うちの会社はGitHubでリポジトリ管理してるんですが、いっつも社内チャットに貼り付けるURLとか探してくるのひぢょーにダルくて、ずっと欲しかったのよね。やっと重い腰を上げて作りました。ほんとベンリ。もっと早くに作っておけば良かった。
2014年を振り返る
- 2014-12-30
振り返るシリーズ第三弾。12/30日にやってるのは誕生日なので、まぁ今年もそれで、と。今年はグラニ設立2年目になったわけですが、去年のまとめでは
ここ数年は、毎年ジェットコースター状態で目まぐるしく変化していて。けれど、大きな目標からはブレないで、年々近づけている気がします。一番最初に若くない人サイドに入ったとか、新陳代謝とか言いましたが、来年はそういうことが起こる状態を作っていきたいですね。C#が、若い人がこぞって使うような言語になってればいい、と。そのためにできること。人がすぐに思い浮かべられる、メジャーなアプリケーションの創出と、C#による圧倒的な成果、C#だからこその強さ、というのを現実に示していくこと。雇用の創出、の連鎖。
なるほど。達成度でいうと、今年は残念ながら弱いかなぁ、うむむむ。そこに向けて突き進んでいるというのは変わらないのですが、来年に向けての準備といった感になってしまったかも。あとは、どちらかというと一年目の総まとめみたいな感じ。一番大きなセッションはAWS Summit Tokyo 2014での発表、AWS + Windows(C#)で構築する.NET最先端技術によるハイパフォーマンスウェブアプリケーション開発実践かな?一端の成果を示したうえで、次のステップへ、といったような。
C#
今年は大分記事数少なめになってしまってます!過去最小かも。かわりにライブラリは過去最多で作ったかもしれません。
去年に引き続き、前半はLightNodeの作成続き。OWIN上に作られたMicro RPC/REST フレームワーク。コンセプトはいいと思うし実装もかなりいいと思うし、既にプロダクションに突っ込んで稼働してるんで、ちゃんと使えるし作って良かったとは思ってます。ASP.NET MVC 6でAction FilterがOWIN風デリゲートチェーンになってるのなんかはLightNodeでは最初からそうしてるし、絶対そのほうがいいでしょドヤァ、言ったとおりでしょ!といった先見の明もある!が、しかし、コミット止まって完全に息切れしてますね(笑)
というのも、うーん、まぁ去年後半から今年前半にかけてはOWINへの傾倒もあったのですけれど、ASP.NET vNextがね……。アレによって完全にOWIN無価値になりましたから。思想的/コードのふいんき的な面では親しいところがあるので、今やるならOWINベースで書くのは良いと思ってます。そうすればvNextへの「移植」が容易になりますから。でも、移植なんですよね、そのまま持ってく(一応互換レイヤーで持ってけますが)わけではないところからして、萎える……かなりOne ASP.NET(笑)感があって、割と嫌な気分ですねー。誰かマジに来日するScott Hanselmanに突っ込んでくださいよ(私は行きません)。とはいえ良くなってる面も理解できるんで、来年は気持ちを切り替えてvNextやりますよ、はい。ちなみにLightNode自体は、vNextベースで、ちょっと違う形で生まれ変わるはずです、という計画があります、やるやる詐欺。
RespClientというPowerShell向けのRedisクライアント/コマンドレットも今年作りました。これはまぁ、たまに私自身も便利にツカッテマス。メンテはguitarrapc先生に譲りました。Redisは相変わらずモリモリ使ってまして、素晴らしいKVSだと思います。来年はやはりこれも放置気味なCloudStructuresをStackExchange.Redisに対応させないと、という……。
そして今年最大の気合の入れ方でリリースしたのがUniRx - ReactiveExtensions for Unity。絶対に必要になる、と、こそこそ作ってたんですが、実際良いもの、欠かせないものになったと思ってます。そして、成功した!と言ってもいいかなー。uFrameに同梱されるようになったとか、海外でも反響あったうえに、国内でもじわじわ話題になりだしていて、かなりいい感じです。来年もがんがん更新していきたい(ちなみに現在AssetStoreでアップデート申請中!)。また、UnityコミュニティとC#コミュニティには若干の断絶がありますが、そこも埋められたらな、といったところですね。
ちなみにUnity関連では、他にLINQ to GameObjectという小品もリリースしたりしたり。
LINQ to BigQueryというGoogle BigQuery用のライブラリも結構な大物でした、と作るの大変だった(というか面倒だった)度合い的に。BigQueryは、正直、凄い。.NETの人もAzureの人も、とりあえず使うべき。うちの会社も基本AWSですが、BigQueryだけはBigQuery。BigQueryに突っ込むためのロギング周りについても一家言できたのですが、その辺はEtwStreamという作りかけの謎プロジェクトがあるので、それが完成した時にでも、お話しましょう(実際作りきりたいとはオモッテマス)
今年はUniRx(Rx), LINQ to BigQuery(Queryable), LINQ to GameObject(LINQ to XML)を通して、改めてLINQとは何ぞやか、というのを掲示できたのも良かったかと思います。口で説明するよりモノで黙らせたほうが早いというアレソレ。
会社
いいところは、今年も非常に強力なメンバーが多くJOINしてくれた!人は会社の原動力ですからね、うちを選んでくれたことに大変感謝です。「C#」では本当に、類を見ないほど力のある会社となっているのではないかな、と。より能力を発揮してもらうような環境を作りたいですね。
さて、今年はやけにCTOの役割とは!みたいなテーマが盛り上がったところですが、私の場合どうかしらん。広告塔代わりであったり求人面であったりなんかは、十二分すぎるほど果たせたとは思います。技術選定なんかも適度に先駆的に、的確だった。少なくとも失敗はない。合間合間にガッと作ってるライブラリ郡も(会社でコソッと作る時間も少し持ってますが、基本的には家で仕上げてますよ)、戦略的に根幹をなすようにしたりで、よくやれたんじゃないかなー。
とはいえ反省点は多かったり。割と勢いだけで突っ走れた1年目と違って2年目は中々むつかしく。特に時間が細切れになるのは避けられなくて、どうも集中しきれず成果としてはかなりイマイチ。この辺は受け入れつつ細切れでも効率的に作業できるよう自分を律するしかないですかね、といった感。そんなわけで自社のプログラムにがっつり関われたかというとかなりそうでもないのが、もにょもにょ。かなり良くない。総論するとどーも歯切れ悪い感じ。来年はドヤッ!といえるようにならないとかな。
ゲーム
PS4やXbox Oneも買ったのですが、うーん。結局やっぱりあんまプレイしてないのよねー。ただまぁPS4>超えられない壁>Xbox Oneというのは痛感しました、これはキビシイ……。Kinect2も割とガッカリ系。そんなわけでvvvvvvのiOS移植が一番楽しんだのかも。
音楽
今年中頃からはずっと大森靖子聞いてましたね、ライブにも行ったし……。YouTube動画だと弾き語りの大森靖子 LIVE @ TIF2013とバンド編成の大森靖子&THEピンクトカレフ@ZeppDiverCityあたりがお薦め。エキセントリックな情報とかインターネット時代の戦略とか、うーん、まぁ、パンクですよ、パンク(適当)。
来年
テーマは「クライアントサイドとサーバーサイドをC#で統一することのメリットの実証」「さらにリアルタイムネットワークもC#で統一」「のためのヒットアプリケーションの創出」です。指向はあんま変わってないんですが、より具体的に。来年は動く年かな、といったところなので是非期待してください。
Unityのコルーチンの分解、或いはUniRxのMainThreadDispatcherについて
- 2014-12-18
この記事はUnity Advent Calendar 2014のための記事になります。昨日はkomiyakさんのUnity を使いはじめたばかりの頃の自分に伝えたい、Unity の基本 【2014年版】でした。いやー、これはまとまってて嬉しい情報です。ところでカレンダー的には穴開けちゃってます(遅刻遅延!)、すみません……。
さて、今回の内容ですが、私の作っているUniRxというReactive Programming(バズワード of 2014!)のためのライブラリを、最近ありがたいことに結構使ってみたーという声を聞くので、Rxの世界とUnityの世界を繋ぐ根幹である、MainThreadDispatcherと、その前準備に必要なコルーチンについて書きます。
Coroutine Revisited
コルーチンとはなんぞや。なんて今更ですって!はい。とりあえず、Unityは基本的にシングルスレッドで動いています。少なくともスクリプト部分に関しては。Unityのコルーチンは、IEnumeratorでyield returnすると、その次の処理を次フレーム(もしくは一定秒数/完了後などなど)に回します。あくまでシングルスレッド、ということですね。挙動について。簡単な確認用スクリプトを貼っつけて見てみると……
void Start()
{
Debug.Log("begin-start:" + Time.frameCount);
StartCoroutine(MyCoroutine());
Debug.Log("end-start" + Time.frameCount);
}
IEnumerator MyCoroutine()
{
Debug.Log("start-coroutine:" + Time.frameCount);
yield return null;
Debug.Log("after-yield-null:" + Time.frameCount);
yield return new WaitForSeconds(3);
Debug.Log("end-coroutine:" + Time.frameCount);
}
呼ばれる順番とframeCountを考えてみようクイズ!意外と引っかかるかもしれません。答えのほうですが……
begin-start:1
start-coroutine:1
end-start:1
after-yield-null:2
end-coroutine:168
となります。最後の秒数のフレームカウントはどうでもいいとして、start-coroutineが呼ばれるのはend-startの前ってのがちょっとだけヘーってとこかしら。IEnumerator自体はUnity固有の機能でもなく、むしろC#の標準機能で、通常は戻り値を持ってイテレータを生成するのに使います(Pythonでいうところのジェネレータ)
// 偶数のシーケンスを生成
IEnumerable<int> EvenSequence(int from, int to)
{
for (int i = from; i <= to; i++)
{
if (i % 2 == 0)
{
yield return i;
}
}
}
void Run()
{
var seq = EvenSequence(1, 10);
// シーケンスはforeachで消費可能
foreach (var item in seq)
{
Debug.Log(item);
}
// あるいはEnumeratorを取得し回す(foreachは↓のコードを生成する)
// Unityでのコルーチンでの利用され方はこっちのイメージのほうが近い
using (var e = seq.GetEnumerator())
{
while (e.MoveNext())
{
Debug.Log(e.Current);
}
}
}
Unityのコルーチンとしてのイテレータの活用法は、戻り値を原則使わず(宣言がIEnumerator)、yield returnとyield returnの間に副作用を起こすために使うということですね。これはこれで中々ナイスアイディアだとは思ってます。
言語システムとしてはC#そのままなので、誰かがIEnumeratorを消費しているということになります。もちろん、それはStartCoroutineで、呼んだ瞬間にまずはMoveNext、その後はUpdateに相当するようなタイミングで毎フレームMoveNextを呼び続けているようなイメージ。
擬似的にMonoBehaviourで再現すると
public class CoroutineConsumer : MonoBehaviour
{
public IEnumerator TargetCoroutine; // 何か外からセットしといて
void Update()
{
if (TargetCoroutine.MoveNext())
{
var current = TargetCoroutine.Current;
// 基本的にCurrent自体はそんな意味を持たないで次フレームに回すだけ
if (current == null)
{
// next frame
}
// ただしもし固有の何かが返された時はちょっとした別の挙動する
if (current is WaitForSeconds)
{
// なんか適当に秒数待つ(ThreadをSleepするんじゃなく挙動的には次フレームへ)
}
else if (current is WWW)
{
// isDoneになってるまで適当に待つ(ThreadをSleepするんじゃなく挙動的には次フレームへ)
}
// 以下略
}
}
}
こんな感じでしょうか!yield returnで返す値が具体的にUnityのゲームループにおいてどこに差し込まれるかは、UnityのマニュアルのScript Lifecycle Flowchartの図を見るのが分かりやすい。
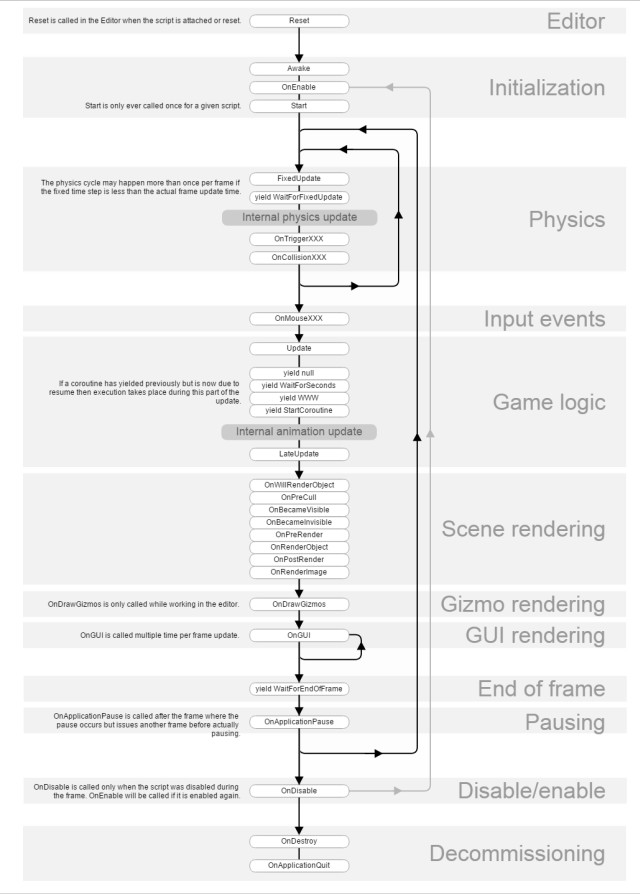
nullが先頭でWaitForEndOfFrameは末尾なのね、とか。yield returnで返して意味を持つ値はYieldInstruction、ということになっているはずではあるんですが、実際のとこWWWはYieldInstructionじゃないし、YieldInstruction自体はカスタマイズ不能で自分で書けるわけじゃないんで(イマイチすぎる……)なんだかなぁー。Lifecycle Flowchartに書かれていない中でyield可能なのはAsyncOperationかな?
もしイテレータの挙動について更に詳しく知りたい人は、私の以前書いたスライドAn Internal of LINQ to Objectsの14Pを参照してくださいな。
UniRx.FromCoroutine
というわけかで(一旦)コルーチンの話はおしまい。ここからはUniRxの話。UniRxについてはneue cc - A Beginners Guide to Reactive Extensions with UniRxあたりをどうぞ。UniRxはFromCoroutineメソッドにより、コルーチンをUniRxの基盤インターフェースであるIObservable<T>に変換します。
// こんなのがあるとして
IEnumerator CoroutineA()
{
Debug.Log("a start");
yield return new WaitForSeconds(1);
Debug.Log("a end");
}
// こんなふうに使える
Observable.FromCoroutine(CoroutineA)
.Subscribe(_ => Debug.Log("complete"));
// 戻り値のあるバージョンがあるとして
IEnumerator CoroutineB(IObserver<int> observer)
{
observer.OnNext(100);
yield return new WaitForSeconds(2);
observer.OnNext(200);
observer.OnCompleted();
}
// こんなふうに合成もできる
var coroutineA = Observable.FromCoroutine(CoroutineA);
var coroutineB = Observable.FromCoroutine<int>(observer => CoroutineB(observer));
// Aが終わった後にBの起動、Subscribeには100, 200が送られてくる
var subscription = coroutineA.SelectMany(coroutineB).Subscribe(x => Debug.Log(x));
// Subscribeの戻り値からDisposeを呼ぶとキャンセル可能
// subscription.Dispose();
IObservable<T>になっていると何がいいかというと、合成可能になるところです。Aが終わった後にBを実行する、Bが失敗したらCを実行する、などなど。また、戻り値を返すことができるようになります。そして、コルーチンに限らず、あらゆるイベント、あらゆる非同期がIObservable<T>になるので、全てをシームレスに繋ぎ合わせることができる。そこが他のライブラリや手法と一線を画すRxの強みなんです、が、長くなるのでここでは触れません:)
また、MonoBehaviour.StartCoroutineを呼ばなくてもコルーチンが起動しています。これは結構大きな利点だと思っていて、というのも、コルーチンを使うためだけにMonoBehaviourにする必要がなくなる。やはり普通のC#クラスのほうが取り回しが良いので、MonoBehaviourにする必要がないものはしないほうがいい。けれど、コルーチンは使いたい。そうした欲求に応えてくれます。
更にFromCoroutine経由にするとEditor内部では通常は動かせないコルーチンを動かすことができます!(これについては後で説明します)
といった応用例はそのうちやるということで、とりあえずFromCoroutineの中身を見て行きましょう。
// Func<IEnumerator>はメソッド宣言的には「IEnumerator Hoge()」になる
public static IObservable<Unit> FromCoroutine(Func<IEnumerator> coroutine, bool publishEveryYield = false)
{
return FromCoroutine<Unit>((observer, cancellationToken) => WrapEnumerator(coroutine(), observer, cancellationToken, publishEveryYield));
}
// ↑のはWrapEnumeratorを介してこれになっている
public static IObservable<T> FromCoroutine<T>(Func<IObserver<T>, CancellationToken, IEnumerator> coroutine)
{
return Observable.Create<T>(observer =>
{
var cancel = new BooleanDisposable();
MainThreadDispatcher.SendStartCoroutine(coroutine(observer, new CancellationToken(cancel)));
return cancel;
});
}
// WrapEnumeratorの中身は(オェェェェ
static IEnumerator WrapEnumerator(IEnumerator enumerator, IObserver<Unit> observer, CancellationToken cancellationToken, bool publishEveryYield)
{
var hasNext = default(bool);
var raisedError = false;
do
{
try
{
hasNext = enumerator.MoveNext();
}
catch (Exception ex)
{
try
{
raisedError = true;
observer.OnError(ex);
}
finally
{
var d = enumerator as IDisposable;
if (d != null)
{
d.Dispose();
}
}
yield break;
}
if (hasNext && publishEveryYield)
{
try
{
observer.OnNext(Unit.Default);
}
catch
{
var d = enumerator as IDisposable;
if (d != null)
{
d.Dispose();
}
throw;
}
}
if (hasNext)
{
yield return enumerator.Current; // yield inner YieldInstruction
}
} while (hasNext && !cancellationToken.IsCancellationRequested);
try
{
if (!raisedError && !cancellationToken.IsCancellationRequested)
{
observer.OnNext(Unit.Default); // last one
observer.OnCompleted();
}
}
finally
{
var d = enumerator as IDisposable;
if (d != null)
{
d.Dispose();
}
}
}
WrapEnumeratorの中身が長くてオェェェって感じなんですが何やってるかというと、元のコルーチンを分解して、Rx的に都合のいい形に再構築したコルーチンに変換してます。都合のいい形とは「キャンセル可能」「終了時(もしくは各yield時)にObserver.OnNextを呼ぶ」「全ての完了時にObserver.OnCompletedを呼ぶ」「エラー発生時にObserver.OnErrorを呼ぶ」を満たしているもの。コルーチン自体がC#の標準機能のままで、なにも特別なことをしていないなら、別に自分で回す(enumerator.MoveNextを手で呼ぶ)ことも、何も問題はない、わけです。
そんなラップしたコルーチンを動かしているのがMainThreadDispatcher.SendStartCoroutine。今のMainThreadDispatcher.csは諸事情あって奇々怪々なんですが、SendStartCoroutineのとこだけ取り出すと
public sealed class MainThreadDispatcher : MonoBehaviour
{
// 中略
/// <summary>ThreadSafe StartCoroutine.</summary>
public static void SendStartCoroutine(IEnumerator routine)
{
#if UNITY_EDITOR
if (!Application.isPlaying) { EditorThreadDispatcher.Instance.PseudoStartCoroutine(routine); return; }
#endif
if (mainThreadToken != null)
{
StartCoroutine(routine);
}
else
{
Instance.queueWorker.Enqueue(() => Instance.StartCoroutine_Auto(routine));
}
}
new public static Coroutine StartCoroutine(IEnumerator routine)
{
#if UNITY_EDITOR
if (!Application.isPlaying) { EditorThreadDispatcher.Instance.PseudoStartCoroutine(routine); return null; }
#endif
return Instance.StartCoroutine_Auto(routine);
}
}
if UNITY_EDITORのところは後で説明するのでスルーしてもらうとして、基本的にはInstance.StartCoroutine_Autoです。ようはMainThreadDispatcherとは、シングルトンのMonoBehaviourであり、FromCoroutineはそいつからコルーチンを起動しているだけなのであった。なんだー、単純。汚れ仕事(コルーチンの起動、MonoBehaviourであること)をMainThreadDispatcherにだけ押し付けることにより、それ以外の部分が平和に浄化される!
コルーチンの起動が一極集中して、それで実行効率とか大丈夫なの?というと存外大丈夫っぽいので大丈夫。実際、私の会社ではこないだ一本iOS向けにゲームをリリースしましたがちゃんと動いてます。しかしそうなるとStartCoroutineはMonoBehaviourのインスタンスメソッドではなく、静的メソッドであって欲しかった……。
その他、SendStartCoroutineはスレッドセーフ(他スレッドから呼ばれた場合はキューに突っ込んでメインスレッドに戻ってから起動する)なのと、UnityEditorからの起動を可能にしています(EditorThreadDispatcher.Instance.PseudoStartCoroutine経由で起動する)。なので、普通にStartCoroutineを呼ぶ以上のメリットを提供できているかな、と。
UnityEditorでコルーチンを実行する
Editorでコルーチンを動かせないのは存外不便です。WWWも動かせないし……。UniRxではFromCoroutine経由で実行すると、内部でMainThreadDispatcher.SendStartCoroutine経由になることにより、Editorで実行できます。使い方は本当にFromCoroutineしてSubscribeするだけ、と、通常時のフローとまるっきり一緒です。ここで毎回エディターの時は、通常の時は、と書き分けるのはカッタルイですからね。汚れ仕事はMainThreadDispatcherが一手に引き受けています。そんな汚れ仕事はこんな感じの実装です。
class EditorThreadDispatcher
{
// 中略
ThreadSafeQueueWorker editorQueueWorker= new ThreadSafeQueueWorker();
EditorThreadDispatcher()
{
UnityEditor.EditorApplication.update += Update;
}
// 中略
void Update()
{
editorQueueWorker.ExecuteAll(x => Debug.LogException(x));
}
// 中略
public void PseudoStartCoroutine(IEnumerator routine)
{
editorQueueWorker.Enqueue(() => ConsumeEnumerator(routine));
}
void ConsumeEnumerator(IEnumerator routine)
{
if (routine.MoveNext())
{
var current = routine.Current;
if (current == null)
{
goto ENQUEUE;
}
var type = current.GetType();
if (type == typeof(WWW))
{
var www = (WWW)current;
editorQueueWorker.Enqueue(() => ConsumeEnumerator(UnwrapWaitWWW(www, routine)));
return;
}
else if (type == typeof(WaitForSeconds))
{
var waitForSeconds = (WaitForSeconds)current;
var accessor = typeof(WaitForSeconds).GetField("m_Seconds", BindingFlags.Instance | BindingFlags.GetField | BindingFlags.NonPublic);
var second = (float)accessor.GetValue(waitForSeconds);
editorQueueWorker.Enqueue(() => ConsumeEnumerator(UnwrapWaitForSeconds(second, routine)));
return;
}
else if (type == typeof(Coroutine))
{
Debug.Log("Can't wait coroutine on UnityEditor");
goto ENQUEUE;
}
ENQUEUE:
editorQueueWorker.Enqueue(() => ConsumeEnumerator(routine)); // next update
}
}
IEnumerator UnwrapWaitWWW(WWW www, IEnumerator continuation)
{
while (!www.isDone)
{
yield return null;
}
ConsumeEnumerator(continuation);
}
IEnumerator UnwrapWaitForSeconds(float second, IEnumerator continuation)
{
var startTime = DateTimeOffset.UtcNow;
while (true)
{
yield return null;
var elapsed = (DateTimeOffset.UtcNow - startTime).TotalSeconds;
if (elapsed >= second)
{
break;
}
};
ConsumeEnumerator(continuation);
}
}
ようは、UnityEditor.EditorApplication.updateでジョブキューを回しています。コルーチン(Enumerator)を手動で分解して、EditorApplication.updateに都合の良い形に再編しています。yield return nullがあったらキューに突っ込んで次のupdateに回すことで、擬似的にStartCorotineを再現。WaitForSecondsだったらリフレクションで内部の秒数を取ってきて(ひどぅい)ぐるぐるループを展開。などなど。
仕組み的には単純、なんですが結構効果的で便利かな、と。ユーザーは全くそれを意識する必要がないというのが一番いいトコですね。
ちなみにアセットストアからダウンロードできるバージョンでは、まだこの仕組みは入ってません(すびばせん!)。GitHubの最新コードか、あとは、ええと、近いうちにアップデート申請しますので来年には使えるようになっているはずです。。。
まとめ
コルーチンをコルーチンたらしめているのは消費者であるStartCoroutineであって、IEnumerator自体はただのイテレータにすぎない。なので、分解も可能だし、他の形式に展開することもできる。
UniRx経由でコルーチンを実行すると「色々なものと合成できる」「(複数の)戻り値を扱える」「キャンセルが容易」「MonoBehaviourが不要」「スレッドセーフ」「エディターでも実行可能」になる。いいことづくめっぽい!Reactive Programmingの力!そんな感じに、UniRxはなるべくシームレスにRxの世界とUnityの世界を繋げるような仕組みを用意しています。是非ダウンロードして、色々遊んでみてください。
VS2015+RoslynによるCodeRefactoringProviderの作り方と活用法
- 2014-12-08
この記事はC# Advent Calendar 2014のための記事になります。私は去年のAdvent Calendarでは非同期時代のLINQというものを書いていました、うん、中々良い記事であった(自分で言う)。今年のテーマはRoslynです。
先月にVS2015のRoslynでCode Analyzerを自作する(ついでにUnityコードも解析する)という記事を書きましたが、VS2015 PreviewではRoslynで作る拡張にもう一つ、Code Refactoringがあります。こちらも簡単に作れて、中々ベンリなので(前にVS2015のRoslynは以前から後退して「あんま大したことはできない」と言いましたが、それはそれでかなり役立ちです)、是非作っていきましょう。Code Analyzerと同じく非常に簡単に作れるのと、テンプレートがよくできていてちゃんとガイドになってるので、すんなり入れるかと思います。なお、こちらはCode Analyzerと違いNuGet配布やプロジェクト単位での参照は不可能、VSIXのみ。そこはちょっと残念……。
Code Refactoring
下準備としてはCode Analyzerの時と同じくVisual Studio 2015 Previewのインストールの他に、Visual Studio 2015 Preview SDKと.NET Compiler Platform SDK Templates、そして.NET Compiler Platform Syntax Visualizerを入れてください。
さて、まずテンプレートのVisual C#→Extensibilityから「Code Refactoring(VSIX)」を選びます。とりあえずこのテンプレート(がサンプルになってます)をCtrl+F5で実行しましょう。これで立ち上がるVSは通常のVSに影響を及ぼさず自作拡張がインストールされる特殊なインスタンスになってます(devenv.exeを引数「/rootsuffix Roslyn」で立ち上げてる、のがDebugのとこで確認できる)。というわけで、このテンプレートの拡張によりクラス名をCtrl+.することにより
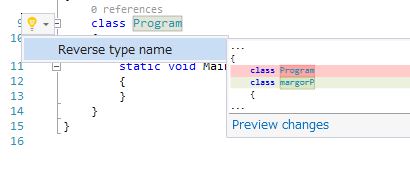
クラス名が逆になる、という(実にどうでもいい)機能拡張が追加されました!と、いうわけで、Code RefactoringはCode Analyzerと同じく「Light Bulb」によるCode Actionが実装可能になります。Code AnalyzerはDiagnosticが起点でしたが、こちらは、指し示された位置を起点にコードの削除/追加/変更を行えるという感じ。「リファクタリング」というとコード修正のイメージが個人的には強いんですが、RoslynのCode Refactoringはどちらかというと「コード生成」に使えるな、という印象です。例えばプロパティを選択してCode RefactoringでINotifyPropertyChangedのコードに展開してしまうとか。大量に作る場合、一個一個コードスニペットで作るより、そっちのほうが速く作れそうですよね?など、色々使い手はあるでしょふ。結構可能性を感じるし、良い機能だと思っています(それR#で今までも出来たよ!とかそれEclipseで既に!とか言いたいことはあるかもしれませんが!)
ただまあ、Code Refactoringって名前は好きじゃない。けれど、じゃあ何がいいかっていうと、なんでしょうねぇ。Code Generate、ジェネレートだけじゃないから、まぁCode Actionかなぁ。AnalyzerもCode Actionだから区別付かなくて嫌だって可能性もあるか、うーん、うーん、ま、いっか……。
ArgumentNullExceptionProvider
サンプルコードがたった1ファイルのように、作るのはとても簡単です。CodeRefactoringProviderを継承してComputeRefactoringsAsyncを実装する、だけ。適当にシンタックスツリーを探索して、もしLight Bulbを出したければcontext.RegisterRefactoringにCodeActionを追加する、と。
というわけで早速何か一個作ってみましょう。実用的なのがいいなぁ、ということでnullチェック、if(hoge == null) throw new ArgumetNullException(); というクソ面倒くさい恒例のアレを自動生成しよう!絶対使うし、あるとめちゃくちゃ捗りますものね!
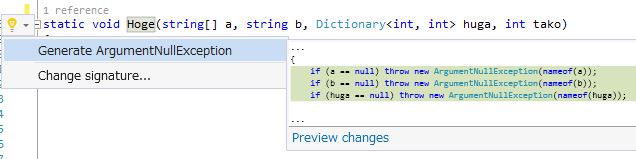
上の画像のが完成品です。便利そう!便利そう!
さて、まずはLight Bulbをどこで出したいか。メソッドの引数で出すんで、引数を選択してたらそれは対象にしたいかなぁ?あと、一々選択するのも面倒だから、メソッド名でも出しましょうか。ふむ、とりあえず実装が簡単そうなメソッド名だけで行きましょう。何事も作る時は単純なところから広げていくのが一番、特に初めてのものはね。
// ArgumentNullExceptionProviderという名前でプロジェクト作ったらクラス名が酷いことに、その辺はちゃんと調整しましょふ
[ExportCodeRefactoringProvider(ArgumentNullExceptionProviderCodeRefactoringProvider.RefactoringId, LanguageNames.CSharp), Shared]
internal class ArgumentNullExceptionProviderCodeRefactoringProvider : CodeRefactoringProvider
{
public const string RefactoringId = "ArgumentNullExceptionProvider";
public sealed override async Task ComputeRefactoringsAsync(CodeRefactoringContext context)
{
// とりあえずコード全体を取る(これはほとんど定形)
var root = await context.Document.GetSyntaxRootAsync(context.CancellationToken).ConfigureAwait(false);
// SemanticModel(コードをテキストとしてではなく意味を持ったモデルとして取るようにするもの、これもほぼ必須)
var model = await context.Document.GetSemanticModelAsync(context.CancellationToken).ConfigureAwait(false);
// context.Spanが選択位置、ということで選択位置のコードを取る(この辺もほぼ定形かな)
// もし選択範囲に含まれてるものから一部のものを取り出す、とかならroot.DescendantNodes(context.Span).OfType<XxxSyntax>() という手とか色々
var node = root.FindNode(context.Span);
// メソッド定義じゃなかったら無視
var methodDecl = node as MethodDeclarationSyntax;
if (methodDecl == null) return;
// コード生成作る
var action = CodeAction.Create("Generate ArgumentNullException", c => GenerateArgumentNullException(context.Document, model, root, methodDecl, c));
// とりあえず追加
context.RegisterRefactoring(action);
}
async Task<Document> GenerateArgumentNullException(Document document, SemanticModel model, SyntaxNode root, MethodDeclarationSyntax methodDecl, CancellationToken cancellationToken)
{
// あとで書く:)
return document;
}
}
まずはこんなとこですね、ようはサンプルからClassDeclarationSyntaxをMethodDeclarationSyntaxに変えただけ + CodeActionを作るところの引数にSemanticModelとrootのSyntaxNodeを足してあります。この辺はほとんど定形で必要になってくるので、とりあえず覚えておくといいでしょう。さて、一旦こいつで実行してみて、ちゃんとLight Bulbが思ったところに出るか確認してから次に行きましょー。続いて本題のコード生成部分。
Task<Document> GenerateArgumentNullException(Document document, SemanticModel model, SyntaxNode root, MethodDeclarationSyntax methodDecl, CancellationToken cancellationToken)
{
// 引数はParameterListから取れる。
// この辺はVSでMethodDeclarationSyntaxをF12で飛んで、metadataからそれっぽいのを探しだすといいんじゃないかな?
// ドキュメントがなくてもVisual StudioとIntelliSenseがあれば、なんとなく作れてしまうのがC#のいいところだからね!
var parameterList = methodDecl.ParameterList;
// ただのType(TypeSyntax)はコード上のテキスト以上の意味を持たない、
// そこからstructかclassか、など型としての情報を取るにはSemanticModelから照合する必要がある
var targets = parameterList.Parameters
.Where(x =>
{
var typeSymbol = model.GetTypeInfo(x.Type).Type;
return typeSymbol != null && typeSymbol.IsReferenceType;
});
// C#コードを手組みするのは(Trivia対応とか入れると)死ぬほど面倒なのでParseする
var statements = targets.Select(x =>
{
var name = x.Identifier.Text;
// String Interpolationベンリ(ただし文法はまだ変更される模様……)
return SyntaxFactory.ParseStatement("if (\{name} == null) throw new ArgumentNullException(nameof(\{name}));");
}).ToArray();
// 追加、メソッドBodyはBody以下なのでそこの先頭に(AddStatementsだと一番下に置かれてしまうのでダメ、nullチェックは「先頭」にしたい)
var newBody = methodDecl.Body.WithStatements(methodDecl.Body.Statements.InsertRange(0, statements));
// 入れ替え
var newRoot = root.ReplaceNode(methodDecl.Body, newBody);
var newDocument = document.WithSyntaxRoot(newRoot);
return Task.FromResult(newDocument);
}
SemanticModelがキーです。SyntaxTreeから取ってきただけのものは、何の情報も持ってません、ほんとただのコード上の字面だけです。今回で言うとnullチェックしたいのは参照型だけですが、それを識別することが出来ません。そこからTypeInfoを取り出すことができるのがSemanticModelになります。例えば「Dictionary」から「System.Collections.Generic.Dictionary」といったフルネームを取り出したりなど、とかくコード操作するには重要です。今回はこれでIsReferenceTypeを引き出しています。
あとは、コードの手組みは辛すぎるのでSyntaxFactory.ParseXxxを活用して済ませちゃうのは楽です。その後は、rootからReplaceと、documentから丸っと差し替えなどは定形ですね。あ、そうそう、あとnameofはC# 6.0の新機能です。ベンリベンリ。
では、実際使ってみると……。
// これが
static void Hoge(string[] a, string b, Dictionary<int, int> huga, int tako)
{
}
// こうなる、あ、れ……?
static void Hoge(string[] a, string b, Dictionary<int, int> huga, int tako)
{
if (a == null) throw new ArgumentNullException(nameof(a));if (b == null) throw new ArgumentNullException(nameof(b));if (huga == null) throw new ArgumentNullException(nameof(huga));}
はい。ちゃんと機能するコードができてはいます。が、なんじゃこりゃーーーーー。なんでかっていうとTrivia(空白とか改行)が一切考慮されてないから、なんですね。Code Refactoringを作る上でメンドウクサイのは、こうしたTriviaへの考慮です。置換なら既存のTriviaをそのまま使えるんですが、コード追加系だと、自分でTrivia入れたり削ったりの調整しないと見れたもんじゃなくなります。というわけで、こっから先が地獄……。まぁ、頑張りましょう。さすがにそのままだと使えないので、調整しましょう。
まずは改行です。改行は結構簡単で、(大抵の場合)TrailingTrivia(後方のTrivia(空白や改行など))にCRLFを仕込むだけ。
// statementsのところをこう変更すると
var statements = targets.Select(x =>
{
var name = x.Identifier.Text;
var statement = SyntaxFactory.ParseStatement("if (\{name} == null) throw new ArgumentNullException(nameof(\{name}));");
// TrailingTriviaは行末、というわけで改行を仕込む
return statement.WithTrailingTrivia(SyntaxFactory.CarriageReturnLineFeed);
})
.ToArray();
// 置換結果はこうなります、だいぶ良くなった!
static void Hoge(string[] a, string b, Dictionary<int, int> huga, int tako)
{
if (a == null) throw new ArgumentNullException(nameof(a));
if (b == null) throw new ArgumentNullException(nameof(b));
if (huga == null) throw new ArgumentNullException(nameof(huga));
}
だいぶいい線いってますね!このぐらいできれば、あとは実行後にCtrl+K, D(ドキュメントフォーマット)押してね、で済むんで全然妥協ラインです。が、もう少し完璧にしたいならインデントも挟みましょうか。インデントの量は直前の{から引っ張ってきて調整してみましょふ。
// WithLeadingTriviaの追加
var statements = targets.Select(x =>
{
var name = x.Identifier.Text;
var statement = SyntaxFactory.ParseStatement("if (\{name} == null) throw new ArgumentNullException(nameof(\{name}));");
// LeadingTriviaに「{」のとこのインデント + 4つ分の空白を入れる
return statement
.WithLeadingTrivia(methodDecl.Body.OpenBraceToken.LeadingTrivia.Add(SyntaxFactory.Whitespace(" ")))
.WithTrailingTrivia(SyntaxFactory.CarriageReturnLineFeed);
})
.ToArray();
// 置換結果はこうなります、完璧!
static void Hoge(string[] a, string b, Dictionary<int, int> huga, int tako)
{
if (a == null) throw new ArgumentNullException(nameof(a));
if (b == null) throw new ArgumentNullException(nameof(b));
if (huga == null) throw new ArgumentNullException(nameof(huga));
}
こんなところですね。さて、勿論このコードはOpenBraceTokenが改行された位置にあることを前提にしているので、後ろに{を入れるスタイルのコードには適用できません。また、空白4つをインデントとして使うというのが決め打ちされています。また、なんども実行しても大丈夫なように既にthrow new ArgumentNullExceptionが記述されてる引数は無視したいよねえ、などなど、完璧を求めるとキリがありません。キリがないということは、適当なところでやめておくのが無難ということです、適度な妥協大事!
フォーマットする
とはいえ、フォーマットはもう少しきちんとやりたいところです。実は簡単にやる手段が用意されていて、.WithAdditionalAnnotations(Formatter.Annotation) を呼ぶことで、その部分だけフォーマットがかかります。正確にはフォーマットが可能になるタイミングでフォーマットがかかるようになります、どういうことかというと、例えばインデントのフォーマットは前後のコード情報がなければかけることは出来ません。このコード例でいうとif()...は前後空白もない完全一行だけなのでフォーマットもなにもできない。なのでAnnotationのついたコード片がフォーマット可能なドキュメントにくっついたタイミングで自動でかかるようになります。AnnotationはRoslynの構文木内でのみ使われるオプション情報とでも思ってもらえれば。
var statements = targetParameters
.Select(x =>
{
var name = x.Identifier.Text;
var statement = SyntaxFactory.ParseStatement("if (\{name} == null) throw new ArgumentNullException(nameof(\{name}));");
// Formatter.Annotationつけてフォーマット
return statement
.WithTrailingTrivia(SyntaxFactory.CarriageReturnLineFeed)
.WithAdditionalAnnotations(Formatter.Annotation);
})
.ToArray();
これは簡単でイイですね!!!なのでTriviaの付与は、最低限のCRLFぐらいを部分的に入れるだけでOK。これは、これからもめちゃくちゃ多用するのではかと思われます。他にAnnotationにはSimplifier.Annotationなどが用意されてます。
フルコード
最初に妥協した(?)引数を選択してたらそれも対象に、ってコードも入れましょうか。というのを含めたフルコードは以下になります。
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CodeActions;
using Microsoft.CodeAnalysis.CodeRefactorings;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Formatting;
using System.Collections.Generic;
using System.Composition;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
namespace Grani.RoslynTools
{
[ExportCodeRefactoringProvider(GenerateArgumentNullExceptionCodeRefactoringProvider.RefactoringId, LanguageNames.CSharp), Shared]
internal class GenerateArgumentNullExceptionCodeRefactoringProvider : CodeRefactoringProvider
{
public const string RefactoringId = "GenerateArgumentNullException";
public sealed override async Task ComputeRefactoringsAsync(CodeRefactoringContext context)
{
// とりあえずコード全体を取る(これはほとんど定形)
var root = await context.Document.GetSyntaxRootAsync(context.CancellationToken).ConfigureAwait(false);
// SemanticModel(コードをテキストとしてではなく意味を持ったモデルとして取るようにするもの、これもほぼ必須)
var model = await context.Document.GetSemanticModelAsync(context.CancellationToken).ConfigureAwait(false);
// context.Spanが選択位置、ということで選択位置のコードを取る(この辺もほぼ定形かな)
var node = root.FindNode(context.Span);
// パラメータリストの場合はそれだけ、クラス名だったらその定義の全部の引数を取る
MethodDeclarationSyntax methodDecl;
IEnumerable<ParameterSyntax> selectedParameters;
if (node is MethodDeclarationSyntax)
{
methodDecl = (MethodDeclarationSyntax)node;
selectedParameters = methodDecl.ParameterList.Parameters;
}
else
{
// 単品選択のばやい(名前の部分選択でParameterSyntax、型の部分選択でParentがParameterSyntax)
if (node is ParameterSyntax || node.Parent is ParameterSyntax)
{
var targetParameter = (node as ParameterSyntax) ?? (node.Parent as ParameterSyntax);
// 親方向にMethodDeclarationSyntaxを探す
methodDecl = targetParameter.Ancestors().OfType<MethodDeclarationSyntax>().FirstOrDefault();
selectedParameters = new[] { targetParameter };
}
else
{
// 選択範囲から取り出すばやい
var parameters = root.DescendantNodes(context.Span).OfType<ParameterSyntax>().ToArray();
if (parameters.Length == 0) return;
methodDecl = parameters[0].Ancestors().OfType<MethodDeclarationSyntax>().FirstOrDefault();
selectedParameters = parameters;
}
}
if (methodDecl == null) return;
// ただのType(TypeSyntax)はコード上のテキスト以上の意味を持たない、
// そこからstructかclassか、など型としての情報を取るにはSemanticModelから照合する必要がある
var replaceTargets = selectedParameters
.Where(x =>
{
var typeSymbol = model.GetTypeInfo(x.Type).Type;
// ジェネリック型で型引数がclassでstructでもない場合はIsXxxが両方false、これはif(xxx == null)の対象にする
return typeSymbol != null && typeSymbol.IsReferenceType || (!typeSymbol.IsReferenceType && !typeSymbol.IsValueType);
})
.ToArray();
if (replaceTargets.Length == 0) return;
// コード生成作る(nameof利用の有無で2つ作ってみたり)
var action1 = CodeAction.Create("Generate ArgumentNullException", c => GenerateArgumentNullException(context.Document, root, methodDecl, replaceTargets, true, c));
var action2 = CodeAction.Create("Generate ArgumentNullException(unuse nameof)", c => GenerateArgumentNullException(context.Document, root, methodDecl, replaceTargets, false, c));
// 追加
context.RegisterRefactoring(action1);
context.RegisterRefactoring(action2);
}
Task<Document> GenerateArgumentNullException(Document document, SyntaxNode root, MethodDeclarationSyntax methodDecl, ParameterSyntax[] targetParameters, bool useNameof, CancellationToken cancellationToken)
{
// nameof版と非nameof版を用意
var template = (useNameof)
? "if ({0} == null) throw new ArgumentNullException(nameof({0}));"
: "if ({0} == null) throw new ArgumentNullException(\"{0}\");";
var statements = targetParameters
.Select(x =>
{
// C#コードを手組みするのは(Trivia対応とか入れると)死ぬほど面倒なのでParseする
var name = x.Identifier.Text;
var statement = SyntaxFactory.ParseStatement(string.Format(template, name));
// Formatter.Annotationつけてフォーマット
return statement
.WithTrailingTrivia(SyntaxFactory.CarriageReturnLineFeed)
.WithAdditionalAnnotations(Formatter.Annotation);
})
.ToArray();
// 追加
var newBody = methodDecl.Body.WithStatements(methodDecl.Body.Statements.InsertRange(0, statements));
// 入れ替え
var newRoot = root.ReplaceNode(methodDecl.Body, newBody);
var newDocument = document.WithSyntaxRoot(newRoot);
return Task.FromResult(newDocument);
}
}
}
まずLight Bulbを出すためのチェックがFindNodeだけでは済まなくなるので、root.DescendantNodes(context.Span)が活躍します。あとは、もう、色々もしゃもしゃと。とにかくコーナーケース探していくとかなり面倒くさかったり。例えば、引数の型の部分を選択した時と、名前の部分を選択した時の対処、などなど……。しょうがないけれどね。
それと、もしメソッドの中に参照型の引数がなかったらLight Bulbを出さないようにするため、replaceTargetsの生成をRegisterRefactoringの前に変更しています。それと、ジェネリックな型引数の場合で制約がついてない状態も生成対象に含めるよう微調整。といったような、この辺の細かい調整はある程度出来上がってからやってくのが良いでしょうねー。
Portable?
ところで、CodeRefactoringにせよAnalyzerにせよ、テンプレートではコア部分はPCLで生成されています。ということは、実は、System.IOとか使えない。これ、ちょっと色々な邪道な操作したい時に不便なんですよ……。ていうかVisual Studio前提なんだからPCLである必要ないじゃん!いみわからない、なんでもPCLって言っておけばいいってもんでもないでしょう!あー、もう私はPCL大嫌いだよぅー。しかもPCLで生成されたプロジェクトは普通のプロジェクトタイプには簡単には戻せないんですよ、うわぁ……。
まあcsprojを手で書き換えればできます。やりかたは
<!-- こいつを消す -->
<ProjectTypeGuids>{786C830F-07A1-408B-BD7F-6EE04809D6DB};{FAE04EC0-301F-11D3-BF4B-00C04F79EFBC}</ProjectTypeGuids>
<!-- こいつを消す -->
<TargetFrameworkProfile>Profile7</TargetFrameworkProfile>
<!-- こいつを消して -->
<Import Project="$(MSBuildExtensionsPath32)\Microsoft\Portable\$(TargetFrameworkVersion)\Microsoft.Portable.CSharp.targets" />
<!-- かわりにこれを追加 -->
<Import Project="$(MSBuildToolsPath)\Microsoft.CSharp.targets" />
なんだかなぁー。
ビルトイン拡張
VS2015ではビルトインで幾つかCode Refactoringが入っています。が、ノーヒント(Ctrl+.を押すまではLight Bulbが出ない)なので、宝探し状態です!例えばプロパティを選択すると「Generate Constructor」が出てきたり。まぁ、これはそのうちリストが公開されるでしょう。
まとめ
拡張を作るのは簡単!うーん、んー、簡単?まぁ簡単!少なくとも今までよりは比較的遥かに簡単カジュアルに作れるようになりました。こうした自動生成って、一般的なものだけではなく、プロジェクト固有で必要になるものもあると思います。例えばうちの会社ではシリアライザにprotobuf-netを使っているので、クラスのプロパティの各属性にDataMemberをつけて回る必要がある。ちゃんとOrderの順番を連番にして。でも手作業は面倒、そこで、CodeRefactoring。
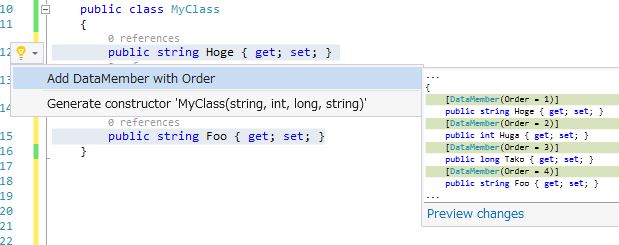
こんな風にプロパティを選択してCtrl+.でほいっと生成できる。このコードはちゃんと属性の振り直しとかも配慮してある(場合によって追加、場合によって置き換え、とかのコードを書くのはやっぱり結構面倒!フルコードはneuecc/AddDataMemberWithOrderCodeRefactoringProvider.csに置いておきます、使いたい方 もしくは CodeRefactoring作りの参考にどうぞ)
こうしたプロジェクト固有の必要な自動生成のためのコードがサクッと作れるようになったのは地味に革命的かなぁ、なんて思ってます。どんどん活用されていくといいですね、少なくともうちの会社(グラニ)では社内用に皆で色々作って配布していこうかなあと計画しています(ところでグラニはまだまだアクティブにエンジニアの求人してます!最先端のC#に興味のある方は是非是非どうぞ、「今から」VS2015を使い倒しましょう)。
AnalyzerもCode Refactoringも、すっごくミニマムな仕様に落ち着いていて、限りなく削っていった形なんだろうなぁ、と想像します。すごく小さくて、でも、すごく使い手がある。いい落とし所だと思ってます。あとはもう活用するもしないも全て自分達次第。とにかくまずは、是非触ってみてください。可能性を感じましょう。
kpm wrapでVS2015 Previewでもcsprojをkprojで参照する
- 2014-12-03
この記事は土壇場駆け込みで爆誕したASP.NET Advent Calendar 2014の3日目の記事です。昨日はASP.NET Web API で Jil JSON Serializer を使ってみるでした。Jilいいよね、うん、使われるようになるといいと思ってます。
さて、次のASP.NET(ASP.NET 5/vNext)は、もうみんな薄々気付いていると思いますが、Web APIとかOwinとかは結局vNextにおいて……。口には出せなくても!絶対にオフィシャルにアナウンスされることはなくても!ふむ、まぁ、その辺は置いておきましょう、はい。そんな不穏なことはね!ね!というわけでそんなことは全く関係なく今回はkpm wrapの話です。何それ、というと、多分、今の間しか使うことはないと思います。いや、むしろ今の間だからこそ直接使う人はそんないないと思います。つまり、誰にとっても全く役に立たないお話。
失われたプロジェクト参照
なんとASP.NET 5(旧vNext、ちなみにMVCは6なので割と紛らわしいネーミングじゃ)のプロジェクトでは、csprojが参照できません。へー、どーいうことなのー?というとこーいうことです。
参照設定でプロジェクト選んでも参照できない!何がnot supportedだよ、クソが!じゃあどうするか、というと、ASP.NET 5 Class Libraryという新設されたK専用のクラスライブラリプロジェクトを選べば作れる。ほぅ……、そんなポータブルじゃなさすぎるクラスライブラリ作ってたまるか、何が嬉しくてクラスライブラリをウェブ専用(っぽく)しなきゃならんのだ!
別の道としてはNuGet経由でdllを渡すとか、そーいうアプローチが推奨されてて、それは一見良いように見えて全然よくないです。csprojを参照してソースコードと直にひっつくってのはすごく大事なんです。クラスライブラリもF12でソースにダイレクトに飛べる環境を作るのはめちゃくちゃ大事なんです。NuGetでdllで分離して理想的!だとかそんなお花畑理論に乗っかるきは毛頭ない。
kpm wrap
そんなわけでものすごく憤慨して、Kマジダメだわー、ありえないわー、センスないわー、ぐらいに思ってたりなかったりしたんですが、さすがに突っ込まれる。さすがに気づく。というわけで、最新のKRuntimeは、ちゃんとkprojでもcsprojを参照できるようになっています。また、一定の手順を踏めばVS2015でも参照が可能になります。さすがに次のバージョンのVS2015では(アルファ?ベータ?)対応してくると思うので、短い寿命のお話、或いはそういう風な仕組みになっているのねのお話。
まず、aspnet/HomeからDownload ZIPしてkvm.cmdを拾ってきます。こっから先はcmdで叩いていきます。まずkvm listすると1.0.0-beta1が入ってるのを確認できるはず。VS2015 Preview同梱がそれなんですね。というわけで、1.0.0-beta2を入れましょう。「kvm install latest」コマンドだと恐らく最新のmasterバージョンになってしまってよろしくないので、バージョン指定しましょう。MyGet - aspnetvnextを見るとバージョン確認できるので、そこから任意にバージョン指定でいれましょう。しかしそれでも404 NotFoundが返ってきてうまく入れられないことがあります!その場合は上のURLのところからKRE-CLR-x86のアイコンをクリックすれば生のnupkgが拾えるのでそいつを手で解凍して↓の場所に配置しましょう、nupkgをzipに変えるだけですがちゃんとNuGet.exeで展開してもいいです(どうでもいい)
あとは「%UserProfile%.kre\packages\」のbeta2のbinのとこにkpmが転がってるので、そいつでkpm wrapコマンドを叩けばOK。あとすると
kpm wrap "c:\ToaruWebApp\src\ToaruClassLibrary"
Wrapping project 'ToaruClassLibrary' for '.NETFramework,Version=v4.5'
Source c:\ToaruWebApp\src\ToaruClassLibrary\ToaruClassLibrary.csproj
Target c:\ToaruWebApp\wrap\ToaruClassLibrary\project.json
Adding bin paths for '.NETFramework,Version=v4.5'
Assembly: ../../src/ToaruClassLibrary/obj/{configuration}/ToaruClassLibrary.dll
Pdb: ../../src/ToaruClassLibrary/obj/{configuration}/ToaruClassLibrary.pdb
というありがたいメッセージによりラッピングが完了します。あとはGUIからAdd Referenceすれば……、まぁ当然not supportedと怒られます。が、project.jsonを手編集すればいけるようになります!dependenciesに
"ToaruClassLibrary": "1.0.0.0"
とでも足してやれば(ちゃんとIntelliSenseも効いてる)あら不思議、謎の空っぽいASP.NETライブラリが追加されてリファレンスにもきちんと追加されてコードでも参照できるようになる(ようになる時もある、なんかむしろあんまうまく行かないことのほうが多いので、なんか別の条件というか再現手順間違えてるかも……とりあえず動かなかったらしょーがないということで!)
仕組み?
wrapコマンドを実行するとglobal.jsonが
{
"sources": [
"src",
"test",
"wrap"
]
}
になってます。global.jsonについてはmiso_soup3 Blog - ASP.NET 5 について一部に詳しく書いてありますが、プロジェクトを探すためのルートですね。で、増えたのはwrapで、wrapフォルダにこの場合だとToaruClassLibraryというASP.NET 5クラスライブラリプロジェクトができています。wrapコマンドにより生成される実体はこいつで、こいつのproject.jsonは
{
"version": "1.0.0.0",
"frameworks": {
"net45": {
"wrappedProject": "../../src/ToaruClassLibrary/ToaruClassLibrary.csproj",
"bin": {
"assembly": "../../src/ToaruClassLibrary/obj/{configuration}/ToaruClassLibrary.dll",
"pdb": "../../src/ToaruClassLibrary/obj/{configuration}/ToaruClassLibrary.pdb"
}
}
}
}
何が何なのかは、十分想像できそうですね。
というわけで、KのウェブプロジェクトがASP.NET 5 クラスライブラリしか参照できないという原則に変化はありません。ただしkpm wrapコマンドを叩くことでcsprojのdllから参照を作ってくれます。まぁ、dllということでビルドしないと反映されないじゃん!とかありますが、とりあえず一応実用上は問題ないレベルにまではなっている、かな……?(もしSubModuleとかで参照されてる共通ライブラリのcsprojが更新されたとして、各自のローカルで明示的にそれをリビルドしないと変更反映されないことになって不便そうだなあ、とか辛そうな点は幾らでも探せますけね)
まとめ
まぁ、VS上だとすっごく不安定で、動いたり動かなかったりって感じなんで、現状あんま実用性はない、かな……。とりあえず、次のバージョンぐらいではcsprojの参照も行けるようになった、という確認が取れた、というだけで十二分です。ASP.NET 5は仕組みがやりすぎに複雑で、VSとの統合もうまくいってるんだかいってないんだか(例えばVS2015でついにできるようになったウォッチウィンドウ上でのラムダ式が何故かASP.NETプロジェクトでは効かない、とか)ってところですが、まぁリリース版にはその辺も解決されるでしょう、と思いたい!
さて、明日のASP.NET Advent Calendar 2014はDapperの話のようです。Dapperは私もヘヴィに使ってますからね!楽しみです(ついちょっと前まで埋まってなかったんですがギリギリ繋がったようでホッ)
VS2015のRoslynでCode Analyzerを自作する(ついでにUnityコードも解析する)
- 2014-11-20
Visual Studio 2015 Previewが発表されました!この中にはC# 6.0やRoslynも含まれていて、今から試すことができます。C#の言語機能は他の人が適当にまとめてくれるので私はノータッチということで、新機能であるRoslynで拡張を作っていきましょう。
Roslynによる拡張は、ン年前に最初のPreviewが出た時は、Visual Studioの解析エンジン自体がRoslynになるから簡単にアレもコレも出来るぜ!と夢いっぱいのこと言ってましたが、実のところ最終的に現在(VS2015 Preview)ではかなり萎んでしまいました。「Code Refactoring」と「Diagnostic with Code Fix」だけです。何ができるかは、まぁ名前から察しということで、あんま大したことはできないです。がっくし。とはいえ、しかし全然使いドコロはあるし簡単に作れはするので、とにかく見て行きましょう。
下準備としてVS2015 Previewのインストールの他に、Visual Studio 2015 Preview SDKと.NET Compiler Platform SDK Templates、そして.NET Compiler Platform Syntax Visualizerを入れてください。
Diagnostic with Code Fix
今回は「Diagnostic with Code Fix」を作ります。まずテンプレートのVisual C#→Extensibilityから「Diagnostic with Code Fix(NuGet + VSIX)」を選んでください。NuGet + VSIXというのが面白いところなんですが、とりあえずこのテンプレート(はサンプルになってます)をビルドしましょう(Testプロジェクトは無視していいです)。そして、ReferencesのAnalyzers(ここがVS2015から追加されたものです!)からAdd Analyzerを選び、さっきビルドしたdllを追加してみてください。
するとコード解析が追加されて、クラス名のところにQuick Fixが光るようになります。
サンプルコードのものはMakeUpperCaseということで、クラス名に小文字が含まれていたら警告を出す&全部大文字に修正するQuickFixが有効になります。
つまりDiagnostic with Code Fixは、よーするに今までもあったCode Analysis、FxCopです。ただし、Roslynによって自由に解析でき、追加できます。また、ReferencesのAnalyzersに追加できるということで、ユーザーのVisual Studio依存ではなく、プロジェクト内に直接含めることができます。追加/インストールはdllをNuGetで配ることが可能(だからVSIX + NuGetなんですね、もちろんVSIXでも配れます)。より気軽に、よりパワフルにコード解析が作れるようになったということで、地味に中々革命的に便利なのではないでしょうか?
このまま、そのサンプルコードのMakeUpperCaseの解説、をしてもつまらないので、続けて実用的(?)なものを一個作りました。
namespaceの修正
うちの会社ではUnityを使ってモバイルゲーム開発を行っていますが、LINQもガリガリ使います。その辺のことはLINQ to GameObjectによるUnityでのLINQの活用にも書いたのですが、困ったことに標準UnityではLINQ to Objectsを使うとAOTで死にます。Unity + iOSのAOTでの例外の発生パターンと対処法で書いたように対処事態は可能なんですが、最終的に標準LINQを置き換える独自実装をSystem.LinqExネームスペースに用意することになりました。で、それを使うには「using System.LinqEx;」する必要があります。「using System.Linq;」のかわりに。むしろ「using System.Linq;」はAOTで死ぬので禁止したいし、全面的に「using System.LinqEx;」して欲しい。すみやかに。どうやって……?
そこでDiagnostic with Code Fixなんですね。既存コードの全てに検査をかけることもできるし(ソリューションエクスプローラーから対象プロジェクトを右クリックしてAnalyze→Run Code Analysis)、書いてる側からリアルタイムに警告も出せるし、ワンポチでSystem.LinqExに置き換えてくれる。このぐらいなら全ファイルから「using System.Linq;」を置換すりゃあいいだけなんですが、リアルタイムに警告してくれるとうっかり忘れもなくなるし(CIで警告すればいいといえばいいけど、その前に自分で気づいて欲しいよね)、もっと複雑な要件でも、RoslynでSyntaxTreeを弄って置き換えるので、テキスト置換のような誤爆の可能性があったり、そもそも複雑で警告/置換不能、みたいなことがなくなるので、とても有益です。
というわけで「using System.Linq;」を見つけたら「using System.LinqEx;」に書き換える拡張を作りましょう!(うちの会社にとっては)実用的で有益で、かつ、はぢめての拡張のテーマとしてもシンプルで作りやすそうでちょうどいいですね!
DiagnosticAnalyzer
コード解析はDiagnosticAnalyzer、コード置換はCodeFixProviderが担当します。必要なファイルはこの2ファイルだけ(シンプル!)、コード置換が不要ならDiagnosticAnalyzerだけ用意すればOK。というわけで、以下がDiagnosticAnalyzerのコードです。
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Diagnostics;
using System.Collections.Immutable;
namespace UseLinqEx
{
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class UseLinqExAnalyzer : DiagnosticAnalyzer
{
// この辺はテンプレートのままに適当に書き換え
public const string DiagnosticId = "UseLinqEx";
internal const string Title = "System.Linq is unsafe in Unity. Must use System.LinqEx.";
internal const string MessageFormat = "System.Linq is unsafe in Unity. Must use System.LinqEx."; // 同じの書いてる(テキトウ)
internal const string Category = "Usage"; // Categoryの適切なのってナンダロウ
internal static DiagnosticDescriptor Rule = new DiagnosticDescriptor(DiagnosticId, Title, MessageFormat, Category, DiagnosticSeverity.Warning, isEnabledByDefault: true);
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics { get { return ImmutableArray.Create(Rule); } }
// namespaceを引っ掛ける
public override void Initialize(AnalysisContext context)
{
// なにをRegisterすればいいのか問題、テンプレではRegisterSymbolActionですが、
// SymbolActionにはなさそうだなー、と思ったら他のRegisterHogeを使いましょう
// ここではRegisterSyntaxNodeActionでSyntaxKind.UsingDirectiveを呼びます
// SyntaxKindの判定はRoslyn Syntax Visualizerに助けてもらいましょう
context.RegisterSyntaxNodeAction(Analyze, SyntaxKind.UsingDirective);
}
static void Analyze(SyntaxNodeAnalysisContext context)
{
// Nodeの中身はSyntaxKindで何を選んだかで変わるので適宜キャスト
var syntax = (UsingDirectiveSyntax)context.Node;
if (syntax.Name.NormalizeWhitespace().ToFullString() == "System.Linq")
{
var diagnostic = Diagnostic.Create(Rule, syntax.GetLocation());
context.ReportDiagnostic(diagnostic);
}
}
}
}
SupportedDiagnosticsより上のものは見た通りのコンフィグなので、まぁ見たとおりに適当に弄っておけばいいでしょう。コード本体はInitializeです。ここで、対象のノードの変更があったら起こすアクションを登録します。で、まずいきなり難しいのは、何をRegisterすればいいのか!ということだったりして。そこで手助けになるのがSyntax Visualizerです。入れましたか?入れましたよね?View -> Other Window -> Roslyn Syntax Visualizerを開くと、あとはエディタ上で選択している箇所のSyntaxTreeを表示してくれます。例えば、今回の対象であるusingの部分を選択すると「using System.Linq;」は……
と、いうわけで、たかがusingの一行ですが、めっちゃいっぱい入ってます。Node(でっかいの), Token(こまかいの), Trivia(どうでもいいの)というぐらいに覚えておけばいいでしょう(適当)。さて、というわけでusingの部分はUsingDirectiveであることが大判明しました。これ以外にもとにかくSyntaxTreeの操作は、何がどこに入ってて何を置換すればいいのかを見極める作業が必要なので、Syntax Visualizerはマストです。めっちゃ大事。めっちゃ助かる。超絶神ツール。
あとは、まぁ、見たまんまな感じで、これで警告は出してくれます。WarningじゃなくてErrorにしたいとか、Infoにしたいとかって場合はRuleからDiagnosticSeverityを変えればOK。
CodeFixProvider
続いてCodeFixProviderに行きましょう。まずはコード全体像を。
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CodeActions;
using Microsoft.CodeAnalysis.CodeFixes;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using System.Collections.Immutable;
using System.Composition;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
namespace UseLinqEx
{
[ExportCodeFixProvider("UseLinqExCodeFixProvider", LanguageNames.CSharp), Shared]
public class UseLinqExCodeFixProvider : CodeFixProvider
{
public sealed override ImmutableArray<string> GetFixableDiagnosticIds()
{
// このDiagnosticIdでAnalyzerと起動するCodeFixProviderが紐付けられてる
return ImmutableArray.Create(UseLinqExAnalyzer.DiagnosticId);
}
public sealed override FixAllProvider GetFixAllProvider()
{
return WellKnownFixAllProviders.BatchFixer;
}
public sealed override async Task ComputeFixesAsync(CodeFixContext context)
{
// ドキュメントのルート
var root = await context.Document.GetSyntaxRootAsync(context.CancellationToken).ConfigureAwait(false);
var diagnostic = context.Diagnostics.First(); // 警告だしてるとこ
var diagnosticSpan = diagnostic.Location.SourceSpan; // の、ソース上の位置みたいなの
// ↑を使って、目的のモノを見つける独自コードを書く!
// 何が何だか分からないので、ウォッチウィンドウで手探るに書きまくって探し当てるといいでしょふ
// "UsingDirectiveSyntax UsingDirective using System.Linq;" が見つかる
var usingDirective = root.FindNode(diagnosticSpan);
// で、作って登録する
var codeAction = CodeAction.Create("ReplaceTo System.LinqEx", c => ReplaceToLinqEx(context.Document, root, usingDirective, c));
context.RegisterFix(codeAction, diagnostic);
}
static Task<Document> ReplaceToLinqEx(Document document, SyntaxNode root, SyntaxNode usingDirective, CancellationToken cancellationToken)
{
// たんなるusingDirectiveでも、中にはキーワード・スペース、;や\r\nが含まれているので、
// 純粋に新しいusingを作って置換するだけだと、付加情報がうまく置換できない可能性が高い
// ので、(面倒くさくても)既存ノードからReplaceしていったほうが無難
var linqSyntax = usingDirective.DescendantNodes().OfType<IdentifierNameSyntax>().First(x => x.ToFullString() == "Linq");
var linqEx = usingDirective.ReplaceNode(linqSyntax, SyntaxFactory.IdentifierName("LinqEx"));
// ルートのほうにリプレースリプレース
var newRoot = root.ReplaceNode(usingDirective, linqEx);
var newDocument = document.WithSyntaxRoot(newRoot); // ルート差し替えでフィニッシュ
return Task.FromResult(newDocument);
}
}
}
ここでの作業は、変更対象のノードを見つけることと、差し替えることです。ノードを見つけるための下準備に関しては、とりあえずサンプルコードのまんま(diagnostic/diagnosticSpan)でいいかな、と。そこから先は独自に探し出す必要があります。今回はUsingDirectiveを見つけたかったんですが、幸いルートからのFindNode一発で済みました、楽ちん。あとは置換するだけです。
置換に関しては、コード上に書いたように、大きい単位で新しいSyntaxNodeを作って差し替える、のはやめたほうがいいです。そうするとトリビアを取りこぼす可能性が高く、うまく修正かけられなかったりします。面倒くさくても、置き換えたいものをピンポイントに絞って置換かけましょう。ノードを探索するにはLINQ to XMLスタイルでのDescendantsやAncestors、ChildNodesとかがあります。LINQ to SyntaxTreeってところで、この辺はまさにLINQ to XMLとは何であるのか。ツリー構造に対するLINQ的操作のリファレンスデザインだと捉えることができるって感じですね。
さて、置換といっても、Roslynのコードは全てイミュータブル(不変)なので、戻り値をうまく使ってルートに伝えていく必要があります。Replace一発では済まないのです。これは面倒くさいんですが、まぁ慣れればこんなものかなー、と思えるでしょう、多分きっと。
ともあれ、これで出来上がりました!ちなみにデバッグはVsixプロジェクトをデバッグ実行すれば、拡張ロード済みの新しいVSが立ち上がる&アタッチされているので、サクッとデバッグできます。これは相当楽だし助かる(いかんせん慣れないRoslynプログラムは試行錯誤しまくるので!)。また、生成物に関してはAnalyzersにdllを手配置もいいですが、ビルドプロジェクト自体に.nupkg生成が含まれているので、そいつを使ってもいいでせう。その辺のことはテンプレートに入ってるReadMe.txtに書いてあるので一回読んでおくといいかな。
Unityで使う
新しいVSが出ると拡張が対応してくれるか、が最大の懸念になるのですが、なんとVisual Studio Tools for Unity(VSTU/旧UnityVS)は初日から対応してくれました!まさにMicrosoft買収のお陰という感じで、非常に嬉しい。遠慮無くVisual Studio 2015 Preview Tools for Unityを入れましょう。VSTUについてはVisual Studio Tools for Unity(UnityVS) - Unity開発におけるVisual Studioのすすめを見てね。
基本的にはUnityのプロジェクトにも全く問題なくAnalyzerを追加できて解析できます。素晴らしい!んですが、問題が一点だけあります。それはVSTUはUnity側に何か変更があった時に.csprojを自動生成するんですが、その自動生成によってせっかく追加したAnalyzerも吹っ飛びます。Oh……。
という時のためにVSTUはProject File Generationという仕組みを用意してくれています。これによってプロジェクトとソリューションの自動生成をフックできます(ちなみに実例として、うちの会社ではソリューションにサーバーサイドとか色々なプロジェクトをぶら下げてるのでソリューション自動生成を抑制したり、Unityプロジェクト側にT4テンプレートを使った自動生成コードを入れているので、VSTUのcsprojの自動生成時に.ttファイルを復元してやったり、とか色々な処理を入れてます)
今回は自動生成で消滅するAnalyzerを復元してやる処理を書きましょう。Editor拡張として作るので、Editorフォルダ以下にProjectFileHook.csを追加し、以下のコードを追加。
using System.IO;
using System.Linq;
using System.Text;
using System.Xml.Linq;
using UnityEditor;
[InitializeOnLoad]
public class ProjectFileHook
{
// necessary for XLinq to save the xml project file in utf8
private class Utf8StringWriter : StringWriter
{
public override Encoding Encoding
{
get { return Encoding.UTF8; }
}
}
static ProjectFileHook()
{
SyntaxTree.VisualStudio.Unity.Bridge.ProjectFilesGenerator.ProjectFileGeneration += (string name, string content) =>
{
// ファイルがない場合はスルー(初回生成時)
if (!File.Exists(name)) return content;
// 現在のcsprojをnameから引っ張ってきてAnalyzerを探す
var currentContent = XDocument.Load(name);
var ns = currentContent.Root.Name.Namespace;
var analyzers = currentContent.Descendants(ns + "Analyzer").ToArray();
// content(VSTUが生成した新しいcsprojにAnalyzerを注入)
var newContent = XDocument.Parse(content);
newContent.Root.Add(new XElement(ns + "ItemGroup", analyzers));
// したのを返す
using (var sw = new Utf8StringWriter())
{
newContent.Save(sw);
return sw.ToString();
}
};
}
}
nameにファイルパス、contentにVSTUが生成した新しいcsprojのテキストが渡ってくるので、それを使ってモニョモニョ処理。csprojはXMLなので、LINQ to XML使ってゴソゴソするのが楽ちんでしょう。
これでUnityでもRoslynパワーを100%活かせます!やったね!
まとめ
あんだけ盛大に吹聴してたわりには、コード解析とリファクタリングだけかよ……、という感はなきにしも非ずですが、そのかわりすっごく簡単に作れる、追加できる仕組みを用意してくれたのは評価できます(えらそう)。かなり便利なので、早速是非是非遊んでみるといいんじゃないかな、とオモイマス。
ところで今回の例、CodeFixProviderはナシにしてAnalyzerだけにして、AnalyzerのレベルをWarningではなくDiagnosticSeverity.Errorにすることで、「LINQ禁止」を暗黙のルールじゃなくコンパイル不可能レベルで実現できます。拡張メソッドを明示的に呼び出せば回避できますが、ルールにプラスしてEnumerableの静的メソッドも殺せば、もう完全に死亡!恐ろしい恐ろしい。あ、勿論やらないでくださいね!