2013年を振り返る
- 2013-12-30
振り返るシリーズ第三弾。毎年、30日に振り返っているので、今年も30日で。ちなみに12/30は私の誕生日でして、ついに30歳を迎えてしまった……。20代さようなら、いや、別にいいんですが、C#er若くない人サイドに入ったな!という感じなわけでして、新陳代謝がほげもげとか。
2011年はMVP受賞、2012年はgloopsへの入社と退社(在籍期間たったの10ヶ月だった!)、というわけですが、では今年のメイントピックは、やはり当然グラニ a.k.a.謎社の始動です。2012年末の段階では
今はニート。ではなく、謎社にいます。謎社ってなんだよというか伏せる意味は特にないんですが、まぁまだ伏せておきます。実際のとこ出来たばかりの会社でして、だいたいほぼほぼ創立メンバーとして働いてます。そして現在のところPHPが95%でC#が5%といったところですが(私もPHP書いてますよ!毎日吐き気が!)、直近の目標はC#比率を高めることです(笑)
来年は変化というよりは進化、↑で書いたとおりにゲームを、じゃあなくて会社を前身させるのに全力で突き進む、というわっかりやすい目標があるんで、そのとーりに邁進しましょう。C#といったら謎社!みたいな、C#を使う人が憧れるぐらいな立ち位置の会社にできればいいなと思っています。
という話を立てていたわけですが、どうでしょう?かなりの部分で達成出来たのではないかと思います。会社は信じられないぐらいの成功を果たしていますし(※別に私の力ではなくてメンバー全員の力の賜物です)、当初PHPで書かれていたプログラムは、100%、C#へのリプレイスを果たしました。ボロ一軒家(リリース前は会社=一軒家にすし詰めで開発してた)でPHP書いてる時から、こういったヴィジョンを描いていたし、1年のうちに実現しきったのは、相当やった方だと年の末ぐらいは自画自賛させてくださいな。
といっても、まだ「C#を使う人が憧れるぐらいな立ち位置の会社」になれているかといったら、知名度であったり、そしてまだまだ実績も足りていないので、全然、目指す水準には満たしていないです。まだ、やっと0→1に、スタート地点に立ったばかり。ここからは1→100にしていかなければならない。また、外向きだけではなく、内側もまた全然整備しきれてないので、働く人がここで働くことに満足できる状態を作れなきゃとか、やることは山積み。
C#
今年のブログ内容は一気に非同期に傾いています。というのも会社で本格的にasyncを導入して使いまくり始めたこともあって、実践的に地雷を踏みまくってノウハウが溜まったからです。こういう実践的な話は、リファレンス情報だけではどうしても足りないわけで、両方が必要なのです。よく、C#はMSDNに情報がいっぱいあって、こんなに充実している言語、他にないよ!何が不満なの!?というけれど、半分合ってて、実態としては全然あってない。あくまで実践的な情報が重要度では第一、リファレンスは補完するもの。だから不満に感じるのは当然です。Microsoftとしては、そういう不足はコードレシピで補いたいようだけれど、それじゃ補えないというか、結局こういうのってリファレンス側に近い情報であって、欠落を埋められるわけがない。
じゃあ誰が埋めるのか、埋められるのかって、それは私達自身だけでしょう。自らの知見から来る情報がネットに溢れるといいな、と思っていますし、そのためにもまず自分たちがやっていきます。特に.NET界隈は実地的な話がなくて。海外とのレベル格差も酷い。圧倒的に日本はレベルが低い、ように見えてしまう。実際は優れた人は表に出てこないとか、絶対量が違うからとか、幾らでも言い分もあるし、確かにそうなのでしょう。でも、やっぱり、見えなければ意味がないし、その結果が、これ。C#という言語の他言語に比べた地位の低さ。例えばですよ、AWSは沢山の実地的な話が溢れてる。かたやAzureは、ただのリファレンス情報が垂れ流されているだけ。こういうの地味にきっついし差として現れるんだよね。C#も同じようなものですよ、現状。残念ながら。
というわけで超積極的に、情報は出していきたいのですにぇ。
さて、個人的には相変わらず小さなライブラリは作りまくってました。NuGetの登録数も36になりました。そういえばAsyncOAuthも今年からですね、おかげ様でOAuthライブラリといったらこれだよね!ぐらいに受け入れてもらえたようで、色々なところで使われているようです。謎社自身でもがしがし使ってます。
今年もう一つ、注力していたのはCloudStructuresというRedisクライアントですね。C# + Redis、しかもC# 5.0推奨というハードルの高さすぎてあまり使われてる感はないですが、これは謎社でハイパー使ってます。
AsyncOAuthやCloudStructuresは、謎社でのPHP→C#移行で絶対必要になるパーツという目算だったので先行して仕上げていました。その路線に乗っかって、来年育てていくのはLightNodeですね。こういう技術、必要になってから調べ始めているのでは遅く、でもあまり長いスパンで見ていてもしょうがない。研究開発機関ではないのだから。というわけで、今のところ、半歩先ぐらいを見据えて動いています。
ハイパー放置状態のlinq.jsを毎年何とかするする詐欺は、来年こそ、は……。
会社
今では当たり前のようにC#の企業ですが、当初はPHPでした。6/8時点で講演した.NET最先端技術によるハイパフォーマンスウェブアプリケーションは、はてブ300以上、現時点でViewsが33500と、.NET系にしてはクリティカルヒットを飛ばしましたが、スライドの冒頭で紹介したとおり、この時点ではPHPだったのです。実際にリプレースが完了したのは7/16日。深夜メンテナンス時間を挟んで朝に一気に切り替え。若干のトラブルはあったものの無事完了。
今年最大のハイライトであり、というか私自身も今のところ生きてて一番のハイライトですね。出来てまもない会社だから、体力も人員もない、でも凄い上り調子だからアプリを止めるとかありえないどころか育てなければならない。そんな中でリソース分散してPHPとC#を並走させて、統合、そして切り替え。まず、やるって決定が常識的に考えてありえないほど無茶苦茶だし、実際にやりきったのも凄いなぁと自画自賛Part2。やれるはずっていう机上の空論と、実際にやりきるってのは、違いはないけど必要な体力と精神力が全然違いますね、もうほんとヤバかった、特に精神的に……。
これに関しては、メンバーに恵まれました。出来たばかりの先行き不明な会社の、しょぼいホームページに、たった二行で求人情報が書かれててmailtoで送れ、というような状況で、素晴らしい人が次々と来てくれたのは信じられない話で。ほんと感謝の念に尽きません。
逆に今のほうが求人に苦戦しているのがアレ。あ、そんなわけでWe're Awaitingということで積極的に採用はしているのでいつでも歓迎ですよ - 求人ページ ← 未だにサイトしょぼい
職種はCTOなのですけれど、CTO論をぶったりは、しません特に。色々なところにボーダーがあって、そこを超えそうになったら発言するようにしているのと、つまり超えない時は何もやってないように見えて実際何もやってない!こたぁない。って感じですかね(テキトー)。まぁ、かくあるべきみたいなものはあります、私の中で、ちゃんと。どんぐらい全うしてるかというと、うーん、70点?
技術的な方向性はシンプルに最先端のC#、なわけですけれど、それが良いことなのかどーか。勿論、良いことです。でも必ずしも良いことと言えるわけじゃあない。じゃあ良いことに変えればいいだけです。こんなの単純な話で、よーは会社として保守的にならないことがバリューを産み出せるようになりゃあいいだけです。逆に、何も産み出せないならNGでしょうね。そうならないように何が出来るかを行動していくべきでしょう。
ゲーム
Super Hexagon最高!これに尽きる。マジ最高。これはヤヴァい。Windows Phoneの最大の欠点はSuper Hexagonがプレイできないことと断言していい。絶対無理ー、と思ったHYPER HEXAGONESTをクリアした瞬間とか、ゲームの達成感の全てが詰まってた。超興奮。数年ぶりにゲームの面白さを思い出させてくれたマスターピース。
というわけで、今年は圧倒的に超えられない壁にSuper Hexagonが存在しているのですが、次点としてはGAMELOFTのモバイル用レースゲーム、Asphalt 8かな。グラフィックのケレン味が実にモバイル向けで、スマートフォン向けゲームとしては現時点で最高のグラフィック品質。ゲームのほうも大味、じゃなくてダイナミックで楽しい。通信対戦もあるしね。
そしてWindows Store App版もある!しかもWindows Phone 8版もある!しかもWindows Store App - Windows Phone 8間での通信対戦が可能!(iPhone-AndroidとかiPhone-WP8とかは対戦不可)。そんなわけで社内Windowsクラスタで話題騒然、Surface持っているならマストバイ、とか微妙な盛り上がりを見せました。ていうか社内で普通にWindows Phone 8の実機が集まるところがまずアレ。
本とか映画とか漫画とかアニメとか
見てない!ゲームと同じく、この辺りも年々見なくなっていってますが今年は特に一番見てない気がする、忙しさのせいかな(言い訳)。引っ越しして、実家に預けていた本とか漫画を全部回収したのだけど、あー、学生の頃は、いっぱい読んでるわけでもないけれどまぁまぁ読んでたなぁ、とか寂しくなったりはしたりして。
来年
ここ数年は、毎年ジェットコースター状態で目まぐるしく変化していて。けれど、大きな目標からはブレないで、年々近づけている気がします。一番最初に若くない人サイドに入ったとか、新陳代謝とか言いましたが、来年はそういうことが起こる状態を作っていきたいですね。C#が、若い人がこぞって使うような言語になってればいい、と。そのためにできること。人がすぐに思い浮かべられる、メジャーなアプリケーションの創出と、C#による圧倒的な成果、C#だからこその強さ、というのを現実に示していくこと。雇用の創出、の連鎖。
というわけで、来年も引き続きご期待くださいだし、よろしくお願いします。
LightNode - Owinで構築するMicro RPC/REST Framework
- 2013-12-23
LightNodeというMicro RPC/REST FrameworkをOwinで作りました。というわけで、LightNodeについて……の前に、そもそもOwinって何?という感じだと思いますので、作成物を通してOwinが開くC#によるウェブ開発の未来について、もしくはOne ASP.NETというヴィジョンが見せる世界についてお伝えしようかな、と。これはOne ASP.NET Advent Calendar 2013への記事ですしね!ちなみに副題は「OWINでハイパー俺々フレームワーク作成」。きゃうん。
LightNode
バージョンはまだ0.1です。急ぎで作ったので、そう完成度高くないです。とはいえ十分動きますし、これは来年育てていきたいと思っているフレームワークです。やる気は、かなりあります。半年後ぐらいには実用になってるかなあ、と。ソースコードとか課題管理はGitHubで。
例によってインストールはNuGetから。
- Install-Package LightNode.Server
細かいパッケージが実はいっぱいあったりして……。
- Install-Package LightNode.Client.PCL.T4
- Install-Package LightNode.Formatter.JsonNet
- Install-Package LightNode.Formatter.ProtoBuf
- Install-Package LightNode.Formatter.MsgPack
LightNodeが提供するのはサーバーサイドフレームワーク(競合はASP.NET Web APIです)と、クライアントサイドのAPIアクセスコード自動生成(WCFがやっているような!)、両方です。クライアントサイドの生成は、Unity3Dへのコード生成が最初のターゲットだったはずなんですが時間的な都合上、今はPCLだけ、です。まあ近いうちにはUnityのは出します、あとTypeScript用のも。
目標はクライアントサイドからサーバーサイドまで全てC#で統一されることによる生産性の超拡張を具現化すること。クライアントがUnityでサーバーがOwinで全部C#、みたいな、ね。両方C#で作り上げられることによるメリットを最大限引き出すことを目指しています。また、JSONオンリーではなくMessagePackやProtocol Buffersでのやり取りも可能なように、パフォーマンスを最大限追求します。また、そのうえで他言語との通信も捨てない、というわけでHTTPでRESTなでほげもげは捨てず、他言語からもサーバーへは自由にアクセス可能です。
逆にRESTfulでビューティフォーなURL設計とかは優先度ゼロなので完全に捨てています。
Lightweight as a Server
LightNodeは超絶Lightweightなフレームワークです。何がLightweightかというと、パフォーマンスと実装の簡単さ、両方を指して言ってます。特に実装の手間はほとんどないぐらい非常に軽量です、ASP.NET Web APIとか超重量級ですからね(それはさすがにいいすぎ)。
サーバーはOwin上に構築されていますので、まずOwinMiddlewareのセットアップが必要です。コンフィグだけは少し書いて下さい。SelfHostでもIISでもいいので、どちらかのOwinホストパッケージをNuGetで引っ張ってきて、スタートアップクラスでUseLightNodeする。
// OwinのStartup
public class Startup
{
public void Configuration(Owin.IAppBuilder app)
{
// 受けつけるVerbを決めたりデフォのTypeFormatter(複数も当然できる)設定したり
app.UseLightNode(new LightNodeOptions(
AcceptVerbs.Get | AcceptVerbs.Post,
new JavaScriptContentTypeFormatter()));
}
}
準備はこれだけ。で、実際にAPIはどうやって作るかというと、LightNodeContractを継承したクラスのパブリックメソッドが、自動的にAPIとして公開されます。
// LightNodeContractを実装すると全てのpublicメソッドがAPIになる
// URLは {ClassName}/{MethodName} で固定
// この場合だと例えば http://localhost/My/Echo?x=test
public class My : LightNodeContract
{
// 戻り値は↑で設定したContentTypeFormatterでシリアライズされて渡る
public string Echo(string x)
{
return x;
}
// 今時なのでasyncもサポートしてるよ!戻り値はvoid, T, Task, Task<T>が使えます、ようは全部。
// パラメータのほうは配列、Nullable、オプション引数あたりはOK
public Task<int> Sum(int x, int? y, int z = 1000)
{
return Task.Run(() => x + y.Value + z);
}
}
これで、「http://localhost/My/Echo?str=hoge」で叩けるってことになります。URLは {ClassName}/{MethodName} の形式で完全に統一されて、カスタマイズの余地はありません。
サーバー側は基本的にこれだけです。単純!地味!
必要最小限のラインってどこかなぁ、というのを考えた時、ここになるかな、と。ルーティングやパラメータのバインディング、レスポンスへの戻り値の書き込みなどはフレームワークがやってくれなきゃ死ぬけれど、それ以上はない。これだけでも割と十分便利に使える、の限界ラインを狙って、極力、機能を削ぎ落とす形で取捨選択しています。ちょっと不便、なぐらいで存外良かったりするのですよ、ちょっと便利、のために色々なものが引っ張られるより100倍良いでしょう?
あと私は「設定より規約」って嫌いなんですよね。別にXML Hellがいいとは言わないですが、あのやり方はLL向けかなあ、という気が相当してまして、C#でそれをやっても嬉しいところってあんまないんじゃないかって思います。属性とか型をどういう活かすか、のほうがいいとオモイマス。
Lightweight as a Client
純粋(?)なRESTって、C#でも、他のどの言語でも、決して扱いやすいわけじゃない。だからラップしたHogeClientを作りますよね。そして、そうした特化したRestClientの作成って、結構難しい。使いやすいClientって中々作れるものじゃあないです。手間がかかるうえに使いにくいものが出来上がるなら、絶望的です。だからサーバーAPIとクライアント、自分たちで両方を作る時、もんのすごく苦労してしまう。どこもLightweightじゃない。こんなことならSOAPでVisual Studioで自動生成してくれてるののほうが100億倍Lightweightだったよー、とかね、それはそれで事実です。
そこでLightNodeは真のLightweightを提供します。自動生成するからコストゼロで完璧なClient SDKが手渡されます。
// 中身はHttpClientなので当然全部async
// メソッドは全て
// client.{ClassName}.{MethodName}Async({parameter}) で生成されます
var client = new LightNodeClient("http://localhost");
await client.Me.EchoAsync("test");
var sum = await client.Me.SumAsync(1, 10, 100);
C#クライアントにとって、自然な操作感でサーバーサイドへとアクセスし、戻り値を受け取ることが出来ます(複雑なオブジェクトは内部のシリアライザを通して自動変換されます)。クライアント側にとってはRPCのように、サーバーを意識せず透過的にやり取り可能なこと、を目指しました。
この自動生成コードは、HttpClientを使ったRestClientとしては、割とイイ感じに出力するので、そういったのの参考にもどうぞ多分。REST APIはこういった形にラップされてるのが使いやすいと思ってるんですね、私は。インターフェイスの明示的実装の活用例。手作業だと面倒でサボッてしまいがちなCancellationTokenも受け取り可能になってたり、その辺は機械生成ならではの徹底さです。
ちなみに現状は実装時間的都合でまだPOSTにしか対応してない(次のアップデートでGETにも対応させます……)。
Micro RPC/REST Framework
Micro RPC FrameworkないしMicro REST Frameworkというのは造語です。ググッてもさして検索結果には出てきません。とはいえ、言わんとすることは分かるのではないでしょうかしらん。ヘヴィ級ORMのEntity Frameworkに対する、機能最小限でコンパクトなDapper。みたいなものです。徹底的に削ぎ落としたREST Framework。対極にあるのはUltra Super HeavyなFramework、って何?というと、ASP.NET Web APIかな。そう、ASP.NET Web APIって、別にLightweightじゃないよね?と、ずっと思っていて。ずっとしっくりこなくて。
というか既存のRESTなフレームワークってどれもLightweightに思えない。何が自分の求めているものなのかなあってずっと考えていたのだけれど(その間、会う人会う人にWeb APIってしっくりこないんです!と吹っかけて回ってた、どうもご迷惑おかけしました)、RPCだ!って至りまして。一周回ってRPC、これはアリだ、と。
REST vs SOAP, REST vs RPC, REST vs WCF
そもそも対立軸がオカシイ。そして、その結果、orになるんだよね、どちらを選びますか?って。それ以外がないの。なんでそう極端な対立になってしまうの?でも、しかし、それはある意味正しい。だって何かを作るには、この世にあるものから選ぶしかないのだから。ヘヴィなSOAPが嫌ならRESTしかなく、ヘヴィなRPCが嫌ならRESTしかなく、ヘヴィなWCFが嫌ならREST(ASP.NET Web API)しかない。
でも、本来は選択肢もっとあって良かったはずなんだよね。どうして中間がなかったんだろうね。そんなにRESTfulは素晴らしく輝かしい未来だったのかな。あまりにも、SOAPが、WCFが辛すぎて反動で極端に振れるしかなかったのかな。
RESTful
どうでもいい。だからLightNodeはGETとPOSTしかありません。
XML/JSON/XXX-RPC
doudemoii。入/出力がフォーマットに固定されるのが世の中的に厳しい。XMLは今どきアリエナイといわれてもshoganai感じになってきてしまっているし、その他のバイナリ形式もJavaScriptで扱いにくくなったりして絶望感ある。JSON最強はありますけど、それはそれで、一部クライアントとはMsgPackとかProtobufとかで高速省スペースな通信したいって欲求には応えられない。仕様もあってないようなものだし、それらに従っていいこと、あまりない。
Language Interoperability
LightNodeはかなりC#に依存というか、むしろ尻尾から先頭までC#で一気通貫して通せることをメリットの一つとしています。とはいえ(広義の)RESTなので、HTTPでGETかPOSTでアドレス叩けば結果帰ってきます。他の言語からも叩けるって物凄く大事なので、いくら一気通貫、C#で大統一理論を正義にしていても、大事にしてあげたいです。JavaScript無視するとか自殺行為ですしね(TypeScriptコードの生成は将来的に作りたいものの一つです)。
仕様は、URLは{ClassName}/{MethodName}、パラメータはGETはクエリストリング、POSTはx-www-form-urlencodedで送ります。そのためということもあって、基本的にパラメータの型には制限があって、基本型(intとかstringとかDateTimeとか)のnullableとarray、それとオプション引数までにしか対応していません。複雑な型はダメ。
ダメな理由としては、あと、それ許可するとメソッドや引数がAPIドキュメントの代わりにならないんですよね。何を渡すことが許されるているのか、のシンプルさが消える。せっかくC#側で作ることの良さ、型があること、を消してしまうほうがmottainai、トレードオフとしてナシという判断です。そしてそのほうが言語間Interoperabilityにも有利ですし。
レスポンスのほうは自由です。何でもありです。基本的にbodyに書かれるだけなので、シリアライズ可能なものならなんでもOK。シリアライザも自由に選べます。こういった形式が自由なのは、パフォーマンスのためです。C#でガリガリに速くしたいなら、やっぱProtobufやMsgPackだろう、と(バイナリだから単純に高速省スペースとかいうのはただの幻想なのでWCFをそういう目では見ないようにしましょう)。でもJSONで吐けないのはそれはそれでありえないわけで、自由に選べる、かつ共存できるように(拡張子やContent-Typeで識別します)しています。
RPC風であり、REST風な中間点がこれかなあ、と。これなら俺々仕様っぽさは特になくRESTといって納得できるレベルに収まってるかと。そのうえで、クライアント側的にはRPC風に使えるのでシームレス感が相当ある。APIの構造がC#に引っ張られて、他言語からキモチワルイ感を醸しだしてしまう可能性はあるのですが(但しメソッド名のcamel,Pascalは自由でどちらでも通るようになってます)、こればっかりはshoganaiかなあ。
そもそもREST的な公開されてるほげもげって各言語、どの言語でも決して使いやすくはないような。だからSDKでラップしたものを使うでしょう?言語中立で万歳、みたいな理想世界がない以上は、プライマリの言語での使いやすさ+セカンダリ以降でも可能な限り使いやすさを維持できる構造、にするのがベターかなあ、って。思ってます。
Why Code Generation? Why not Dynamic Proxy?
今のクライアントコードは、T4によるソースコード生成になっています。正直ダサい。クライアント側はソースコード生成よりも、共通のインターフェイスに対して動的コード生成でProxy作ってやるほうが手軽に扱えていいのよね。どういうイメージかと言いますと、例えば
// こういうインターフェイスがサーバー側とクライアント側が共に参照するDLLに定義してあって
public interface IHoge
{
int Sum(int x, int y);
}
// サーバー側は↑のインターフェイスを実装する
public class HogeContract : IHoge
{
public int Sum(int x, int y)
{
return x + y;
}
}
// クライアント側は↓のような形で使える
// Createの戻り値がIHogeになってて、その実装は動的生成されたもの、という感じ
var sum = LightNodeClient.Create<IHoge>("http://localhost").Sum(10, 20);
実にスッキリしていいですね!クライアントサイドのIHogeの実装は、動的コード生成により実行時に挿入されるので一切、手を加える必要はありません。ちなみに実装方法はAssemblyBuilderを使ってひたすらILゴリゴリです。ExpressionTreeのCompileToMethodは静的メソッドしか作れないので、↑のイメージのようなインスタンスメソッドへの生成は気合入れて書くしかないのですねえ、やれやれ……。
でも、今回はソースコード生成にしました。それはIL書くのが面倒だから、ではなくて(実際面倒だからってのはちょっとありますが!)、理由はそれなりに幾つかあります。
まず、インターフェイスの戻り値=クライアントにとっての戻り値、じゃあなくなってます。具体的にはTaskです。非同期以降の世界ではクライアント側の型はTask以外はありえないんです。ここで、じゃあインターフェイス側もTaskを強要すればいい、ってのは、それは不便なのでナシですしねえ。クライアント側のメソッド名はXxxAsyncにしたいとかってのもありますし、やっぱ、現代においてはインターフェイスをきっちり一致させるというのは難しい。
あと、Unity。まあ、何度か名前↑で出しているようにUnityはかなりターゲットなわけですが、UnityのC#ってバージョン古いのですよね、Taskなんてないんですよ……。そんなわけで各プラットフォーム毎に全然違う生成したほうがいいってことになってしまいますよねえ、と。C#以外にTypeScriptなんかもターゲットにしたいですしね。
そして最後に、AssemblyBuilderはフル.NET Frameworkにしかない。WinRTやPhone、当然PCLにはない。ないないないないなので、手間隙かけてIL書いてもあんま嬉しくなれない。
そんなわけで、ソースコード生成を手法に選んでいます。
とはいえ、提供手段がT4であることが良いかどうかはビミョイところですね。こういうの自体は、別に割とあるパターンではあるのですけど、例えばPetaPocoやORM LiteなどMicro ORM系はEFなどのヘヴィーなデザイナの代わりとしてT4を用いているし、 T4 MVCとかもあるし、……、うーん、そのぐらいか。あんまないね。
あと今の実装はdllをロードしてそれを解析するんですが、ロードしたあとそのまんまアセンブリ掴みっぱなしで解放されないから、解放するにはVS再起動しないといけないとかいうクソ仕様とかも残ってるので、何とかしなきゃ度は相当高いです。誰か解決策教えてください。
Performance
機能面では最小な上に(劣る、とは言いません)、わざわざ新しく作る以上、パフォーマンスで負けていたら馬鹿みたいな話です。というわけで結果。
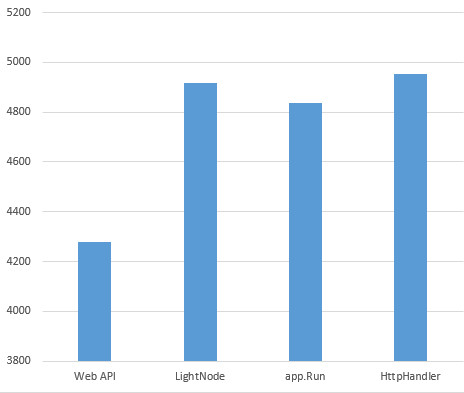
OWIN上のWeb API、OWIN上のLightNode、OWIN上の生app.Run、あとふつーにIISでホストする生HttpHandlerの4つでテキトーに測ってみました。Nancyは加えようと思ったんですがちょっと動かなくて調べる時間がなかったので(この記事はAdvent Calendar的にギリギリで書き上げているのです!)いったんナシ。
んで、速いです。というかほっとんど生HttpHandlerと変わらない速度出せてます。そりゃ機能少ないんだから当たり前……、ではないです。機能が少ない=速い、に直接結びつくほど世の中、甘くはありません!この手のものを作るにあたって速度を稼ぐポイントは幾つかあって、しっかりポイント抑えたコード生成(&キャッシュ)をしつつ、余計な要素を足さないことで最速になります。そりゃそーだ。ともあれ、これ以上は速くならないという限界ラインを突いてます。これより先はどう頑張っても誤差範囲は超えないでしょう、というか生Handler近辺の時点で、もう大して変えられんです。
その辺の実装のコツのお話はまた次回にでも。(ただEnum周りのマッピング処理が現在ゴミなのでEnum入れると遅いです、これは次回までに改善します)
Owin
ASP.NET Web APIがOwin対応とか、そういうのどーでもいーんだよね。だってIISにホストするでしょ?SelfHostとか別になくてもいいレベルでしょ?プロダクション環境では使わないでしょ?というわけで、あるものを使うという点では、別に今はOwin対応とかドウデモイイレベルの話です。皆が今Owinにさして興味持てなかったり使い道に想像沸かないとしても、そりゃそうだ、です。だってIISでいいんですもの。
Owinの利点はMiddlewareを組み合わせられること。けれど現状は、多様なMiddlewareは、特にはない。できたてほやほやみたいなものだから。むしろASP.NET Web APIやASP.NET MVCレベルでのコンポーネントのほうがあるし、将来的にもきっとそうでしょう。つまり、Middlewareも利点だー!と声高に言ってもshoganaiところがある。
でも、それでも、そこに未来はある。Owinは誰もが簡単にMiddlewareを作れる。小さなちょっとしたユーティリティから、大きいフレームワークまで。ついに始まった自由の世界。多様なMiddlewareは、今は、特にはない。でも、作ればいい、必ず彩り豊かになる。そうなればASP.NET Web APIのOwin対応なども、意味がでてくる。
そしてパフォーマンスですら手に入る。ああ、パフォーマンスは大事だ、そう、本当は大事でなかったとしても、とにかくキャッチーだからね。今までのASP.NETコアランタイム、System.Webがヘヴィだとしたら、それを完全にバイパスして直繋ぎしたら。発表されたHelios IIS Owin Web Server Hostは驚異的なパフォーマンスを見せている。なるほど、すごく魅力的に見える。なにより、Microsoftは本気なんだなって気がする。Helios自体はまだαだけど、今はSystem.Webにホストしてもらって、Heliosが完成したらそっちでホストすればいい。そこが選べるのもOwinのいいところだ。ああ!素晴らしいじゃないか、Owin!
Create Your Own Framework
俺々フレームワークは悪。常識です。常識。かといって、何もかも作らないわけにはいきません。何を作り、作らないか、その見極めが戦略として非常に大事。自分の戦略でもそうだし会社だったらなお大事。
さて、今回は作ったわけですけれど、その理由は単純にないから。ないものは作る。当たり前だよにぇ。といっても何もかもを満たすものなんて存在しないので、妥協できるかどうかのラインを見定めるってことではあるのだけれど。妥協ラインですが、C#の場合って、Microsoftで完結するものなら凄く整ってるんですよね、妥協OKというかむしろ完璧すぎるぐらいに。でも、今回の需要はMicrosoftの外側、Unityとか他のクライアント系のとか、それらと一気通貫に繋がって欲しいって需要なのです。Microsoftの中で完結してそれ以外とは疎結合、じゃなくて、繋がれる範囲は可能な限り全開に密結合して欲しいってのがリクエスト。そういうのって、未来永劫Microsoftから出てくることはない。絶対に。だから、作るって結論になる。
あともう一つはどのぐらいのクオリティで作れるか。作ったはいいけどクソクオリティだったら不幸になるだけだからね!そして、C#の場合はVisual Studioとの統合具合もかなり大事。だから、MVCフレームワークなどだと、単純に作業量が超絶多くて全体のクオリティを保つのは非常に大変なうえに、ASP.NET MVCはVS統合が進んでてサクサクViewとControllerを相互に移動出来たりコンパイルエラーがくっついてたり、そういうところまで面倒見るのは不可能に近い。だから、部分的に良い物を作れたとしても全体的には超えるのって凄く難しいから、俺々フレームワークは、あまり良い選択肢にはなれなさそう(でもNancyとか頑張って欲しい!)。
Service系のフレームワークだとViewとかとの面倒みなくていいしVS統合もそんなに気を配らなくていい(WCFぐらいパーフェクトな統合があればそりゃ素敵だけど、WCFは統合されてはいても他に問題だらけなので除外)、最小限の機能のラインが見えていて、かなり満たしやすい。性能だって少し頑張れば既存のものを抜くのも簡単。そんなわけで作るのはアリだ、のラインに個人的には達しました。
Owin EcoSystem
Service系ならば、そもそもHTTPに乗らなくてもいいじゃない?特にパフォーマンス優先なら!という選択もありますね。それを選ばないのは、エコシステム。サーバー側には沢山のノウハウやシステムがあり、何もしなくても最高のInteroperabilityがある。通信関連ではHTTPったら最強ね。っていうのは揺るがない。よほどパフォーマンス優先な根幹的な何かを作るのでなければ。
そして、Owinもまた理由になります。今までの俺々フレームワークの最大の欠点は、全て自前で作るしかなかったことです。でもOwinがあれば違う。認証?他のMiddlewareで。パフォーマンスモニタ系?例えばGlimpseは最高のモニタライブラリだけど、俺々フレームワークで、こういうのが一切使えなくなるって、痛手というか、それだけでありえないレベルになりますよね。でも、Owinならば、GlimpseがOwinに対応すればそれだけで乗っかることが出来る(そして実際、現在対応作業中のようです)。New Relicのような監視ツールなどもそう、俺々フレームワークであっても、そういうのにフルに乗っかっていけるってのが、今までと違うところだし、だから、作ってもOKの許容ラインに達しやすくなったと思いますですよ。
私も、LightNodeのようなフレームワークレベルのものだけじゃなく、他のフレームワークで使える小さなMiddlewareをこっそり作って公開してたりします。一つはOwinRequestScopeContextで、HttpContext.CurrentのようなものをOwin上で使えるようにするもの。もう一つはRedisSessionで、その名の通り、裏側がRedisのセッションストアです。RedisのHash構造に格納していて、リクエスト開始時に全部のデータを読み込み、リクエスト実行中のアクセスは全てインメモリで完結さえ、リクエスト終了時に変更があったもの差分だけを書き出す(RedisのHash構造だからこそ可能)ようにしています。実はこれの原型は既に謎社で実稼働していて、沢山のアクセスを捌いている実績アリだったりして。
今後RubyのRackにある便利Middlewareが移植されたりとかもするんじゃないでしょうか、むしろ良さそーな発想のものは自分達で移植してみるのもいいかもしれません。Owinが出たことで、自分達で作ることが、独善じゃなく発展の道になった。
One ASP.NET。You。使うだけじゃなく作る。それがこれからのASP.NETの未来だと思います。
Related Works
WCF。なんのかんのいってWCF。は偉いねえ、壮大だねえ、とか。LightNodeはWCFのABCからBindingを抜いたようなイメージでいいですよ。で、やっぱWCFとかの、その手の抽象化は辛い!何か被せて共通化して出来た気がするのは誰も満足させられないパターン。
rpcoder。Aimingさんの、独自IDL(Interface Definition Language)からUnity用のC#コードとかを吐き出すもの。LightNodeとの違いは、IDLかどうか、かしらん。LightNodeはIDLじゃなくてサーバーサイドの実装そのものが定義になるので、そういった外部定義不要なので、手間削減と、実装との乖離が絶対にないってとこかしらん。
似たようなというか定義という点ではRAMLとかね、まぁRAMLは最悪かなぁって思うのですけれど。RESTfulの呪縛に囚われて極北まで行くとそうなるのかねえ。どうぞ素敵なモデリングをしてください。ほんとdoudemoii。
Google Cloud Endpoints。サーバーの実装があって、そこからiOSやAndroid用のコードを生成するってもの。いいですねー、これですよこれ。Cloud Endpointsの正式リリースはついこないだですが、(特に)モバイル向けのバックエンドはこういうのがベストだと本当に思いますし、RPCの時代というかそういったようなものの時代への揺り戻しというか、再び多様性の時代が来たかな、と、健全で素敵です。
ServiceStack。これは、WCF Alternativeの中では一番メジャーな選択肢、ではあるのだけど、正直、なんか、この人のAPIセンスは……。辛い。正直ナシです。ちなみにv4から有料化しました。
Finagle。Twitter製の、Scalaでできた非同期でプラガブルなRPCフレームワーク。非同期なので全部Future(C#のTaskみたいなもの)。Relatedといったけど特に直接的な影響はないけど、オサレでモダンなフレームワークがRPC、というところだけちょっと強調とか。
DuoVia.Http。Owinで動くLightweightのService Libraryということで、LightNodeに一番近い先行実装ですね!クライアント側はプロキシによる動的生成なので非同期なし。サーバー側がrefやoutに対応させたりとか多機能を狙いすぎて、実行速度が引っ張られてたりとか、ちょっと違うかな、と。
ASP.NET Web API。まぁ、散々腐しましたけれど、実際ふつーに選ぶのならASP.NET Web APIが最初の選択肢だと思います。悪くないですよむしろイイですよ。そもそもLightNodeの実装にあたっては50分で掴み取る ASP.NET Web API パターン&テクニックとかOne ASP.NET, OWIN & Katanaとかガン見してたので味噌先生には頭が上がらないのでWeb APIいいんじゃないでしょうか(適当)。真面目な話、ASP.NET Web APIが一番参考にしてるのは間違いないですので、話の流れ(?)で色々腐しましたが、良いと思いますよ、本当。
Conclusion
One ASP.NETと言いつつも別にフィーチャーされないYou!の部分を推してみました。人昔前は、こういった俺々フレームワークが乱立しないのが.NETの良さ、と言われていた、こともありました。ありました。過去の話です。世界の進化は速く、Microsoftだけが一手に全ての需要を引き受けられるわけがない。それぞれの需要に合わせて、時に組み合わせて、時に自分で作り上げることができる。そういった世界の幕開けがOwinです。まだまだMiddlewareは足りていないので、「組み立てる」にはならないでしょう、けれどそれを解決するためにも、自分達で作り、公開していきましょう?それがOpenな世界だし、これからのC#コミュニティのあるべき姿だと思っています。
(いつもやるやる詐欺で毎回言ってる気がしますが)LightNodeはコンセプトだけじゃなく、真面目に育てていきたいと思っています。そもそも、会社として、この辺の通信が来年は重要課題になってくるなあ、というのがあって考えてたものなので、諸々色々で半年後ぐらいには十分な完成度で掲示できるかなあ、って思いますですよ。勿論、皆さん今から使ってくれたら嬉しいですにぇ。
また、コンセプト語るには実装がなきゃ、と相当思っていまして。かつて人々は「パターン」「契約による設計」などアイデアに名前をつけて論じたけれど、 このごろの新しいアイデアはフレームワークやプログラミング言語、データベースエンジンなどを通じて表現されるようになった。 今は書籍ではなく実装が思想を表現する手段になっていると、Eric Evans(DDD本の人)は語った。そんなわけで、というわけではないですけれど、私は私の思想はコードで表現していきたいと思っているし、そもそもそうしてきた。linq.js(LINQが言語を超えることを)もChaining Assertion(流れるようなインターフェイスや英語的なるものの馬鹿らしさを)もReactiveProperty(全てが繋がるイメージを)もそうです。ライブラリは思想の塊なのです、言葉に出されていなければそこに思想はない?そんなことはなく、ずっと流暢に語ってくれるはず。
そしてC#の強さの証明は、会社の結果で表現していきます。実証されなければ何の意味もないし、何の説得力もない。誰に?というと、日本に、世界に。というわけで、引き続き来年の諸々にもご期待ください!
An Internal of LINQ to Objects
- 2013-12-16
というタイトルで、大阪で開催された第3回 LINQ勉強会で発表してきました。
大阪は初めてですね!というか、東京以外で発表しに行くのは初めてです。大阪遠い。
レベル感は、まぁもうLINQも初出から10年も経つわけだし(経ってない)、もはや初心者向けもないだろうということで、LINQ to ObjectsのDeep Diveなネタを突っ込んでおきました。こんなにまとまってる資料は世界にもないですよ!なんで知ってるかというと、linq.jsの実装で延々と何回も書いてるからです、はい。いいことです。そのぐらいにはパーフェクトな実装ということで。ver.3の完成は、も、もう少し、ま、まだ……。ごめんなさい。近いうちには、またベータ出すよ!←いい加減完成させろ
口頭で捕捉した内容としては、yield returnで書くメソッドは引数チェック用のと分離させよう、というところ。これ、メンドーくさかったらやらなくていいです。実際メンドウクサイですしね。コアライブラリっぽい位置づけのものだったらがっつしやるのも良いとは思いますが、普段からやるのはカッタルイでしょう。と、いっても、LINQ以降はあまり生でyield return使うこともないでしょうけれど。
イテレータの話とかは、実際doudemoiiんですが、気になる人は、これはそもそもC#の言語仕様書に書いてあります。言語仕様書はVSインストールディレクトリの
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC#\Specifications\1041\CSharp Language Specification.docx
にあるので(日本語訳されてるよ!)、読んだことない人は眺めてみると楽しいんではかと思います。
非同期時代のLINQ
- 2013-12-04
この記事はC# Advent Calendar 2013の4日目となります。2012年はMemcachedTranscoder - C#のMemcached用シリアライザライブラリというクソニッチな記事で誰得でした(しかもその後、私自身もMemcached使ってないし)。その前、2011年はModern C# Programming Style Guide、うーん、もう2年前ですかぁ、Modernじゃないですねえ。2011年の時点ではC# 5.0はCTPでしたが、もう2013年、当然のようにC# 5.0 async/awaitを使いまくる時代です。変化は非常に大きくプログラミングスタイルも大きく変わりますが、特にコレクションの、LINQの取り扱いに癖があります。今回は、非同期時代においてLINQをどう使いこなしていくかを見ていきましょう。
Selectは非同期時代のForEach
これ超大事。これさえ掴んでもらえれば十二分です。さて、まず単純に、Selectで値を取り出す場合。
// こんな同期版と非同期版のメソッドがあるとする
static string GetName(int id)
{
return "HogeHoge:" + id;
}
static async Task<string> GetNameAsync(int id)
{
await Task.Delay(TimeSpan.FromMilliseconds(100)); // 適当に待機
return "HogeHoge:" + id;
}
// 以後idsと出てきたらこれのこと指してるとします
var ids = Enumerable.Range(1, 10);
// 同期バージョン
var names1 = ids.Select(x => new { Id = x, Name = GetName(x) }).ToArray();
// 非同期バージョン
var names2 = await Task.WhenAll(ids.Select(async x => new { Id = x, Name = await GetNameAsync(x) }));
ラムダ内でasyncを書き、結果はIEnumerable<Task<T>>となるので、配列に戻してやるためにTask.WhenAllとセットで使っていくのが基本となります。Task.WhenAllで包むのはあまりにも頻出なので、以下の様な拡張メソッドを定義するといいでしょう。
// こういう拡張メソッドを定義しておけば
public static class TaskEnumerableExtensions
{
public static Task WhenAll(this IEnumerable<Task> tasks)
{
return Task.WhenAll(tasks);
}
public static Task<T[]> WhenAll<T>(this IEnumerable<Task<T>> tasks)
{
return Task.WhenAll(tasks);
}
}
// スッキリ書ける
var names2 = await ids.Select(async x => new { Id = x, Name = await GetNameAsync(x) }).WhenAll();
では、foreachは?
// 同期
foreach (var id in ids)
{
Console.WriteLine(GetName(id));
}
// 非同期
foreach (var id in ids)
{
Console.WriteLine(await GetNameAsync(id));
}
そりゃそーだ。……。おっと、しかしせっかく非同期なのに毎回待機してループしてたらMottaiなくない?GetNameAsyncは一回100ミリ秒かかっているから、100*10で1秒もかかってしまうんだ!ではどうするか、そこでSelectです。
// 同期(idsがList<int>だとする)
ids.ForEach(id =>
{
Console.WriteLine(GetName(id));
});
// 非同期
await ids.Select(async id =>
{
Console.WriteLine(await GetNameAsync(id));
})
.WhenAll();
ForEachの位置にSelect。ラムダ式中では戻り値を返していませんが、asyncなので、Taskを返していることになります(Task<T>ではなく)。同期ではvoidとなりLINQで扱えませんが、非同期におけるvoidのTaskは、Selectを通ります。あとはWhenAllで待機してやれば出来上がり。これは全て同時に走るので100msで完了します。10倍の高速化!
ただし、この場合処理順序は保証されません、同時に走っているので。例えばとある時はこうなりました。
HogeHoge:1
HogeHoge:10
HogeHoge:8
HogeHoge:7
HogeHoge:4
HogeHoge:2
HogeHoge:6
HogeHoge:3
HogeHoge:9
HogeHoge:5
処理順序を保証したいなら?WhenAll後に処理ループを回せばいいぢゃない。
// こうすれば全て並列でデータを取得したあと、取得順のままループを回せる
var data = await ids.Select(async id => new { Id = id, Name = await GetNameAsync(id) }).WhenAll();
foreach (var item in data)
{
Console.WriteLine(item.Name);
}
一旦、一気に詰めた(100ms)後に、再度回す(0ms)。これはアリです。そんなわけで、非同期時代のデータの処理方法は三択です。逐次await, ForEach代わりのSelect, 一気に配列に詰める。どれがイイということはないです、場合によって選べばいいでしょう。
ただ言えるのは、超大事なのは、Selectがキーであるということ、ForEachのような役割を担うこと。しっかり覚えてください。
非同期とLINQ、そしてプリロードについて
さて、SelectだけではただのForEachでLINQじゃない。LINQといったらWhereしてGroupByして、ほげ、もげ……。そんなわけでWhereしてみましょう?
// 非同期の ラムダ式 をデリゲート型 'System.Func<int,int,bool>' に変換できません。
// 非同期の ラムダ式 は void、Task、または Task<T> を返しますが、
// いずれも 'System.Func<int,int,bool>' に変換することができません。
ids.Where(async x =>
{
var name = await GetNameAsync(x);
return name.StartsWith("Hoge");
});
おお、コンパイルエラー!無慈悲なんでなんで?というのも、asyncを使うと何をどうやってもTask<bool>しか返せなくて、つまりFunc<T,Task<bool>>となってしまい、Whereの求めるFunc<T,bool>に合致させることは、できま、せん。
Whereだけじゃありません。ラムダ式を求めるものは、みんな詰みます。また、Selectで一度Task<T>が流れると、以降のパイプラインは全てasyncが強いられ、結果として……
// asyncでSelect後はTask<T>になるので以降ラムダ式は全てasyncが強いられる
// これはコンパイル通ってしまいますがkeySelectorにTaskを渡していることになるので
// 実行時エラーで死にます
ids.Select(async id => new { Id = id, Name = await GetNameAsync(id) })
.OrderBy(async x => (await x).Id)
.ToArray();
Selectがパイプラインにならず、むしろ出口(ForEach)になっている。自由はない。
ではどうするか。ここは、一度、配列に詰めましょう。
// とある非同期メソッドのあるClassがあるとして
var models = Enumerable.Range(1, 10).Select(x => new ToaruClass());
// 以降の処理で使う非同期系のメソッドなり何かを、全てawaitで実体化して匿名型に詰める
var preload = await models
.Select(async model => new
{
model,
a = await model.GetAsyncA(),
b = await model.GetAsyncB(),
c = await model.GetAsyncC()
})
.WhenAll();
// そうして読み取ったもので処理して、(必要なら)最後に戻す
preload.Where(x => x.a == 100 && x.b == 20).Select(x => x.model);
概念的にはプリロード。というのが近いと思います。最初に非同期なデータを全て取得しまえば、扱えるし、ちゃんと並列でデータ取ってこれる。LINQの美徳である無限リストが取り扱えるような遅延実行の性質は消えてしまいますが、それはshoganai。それに、LINQにも完全な遅延実行と、非ストリーミングな遅延実行の二種類があります。非ストリーミングとは、例えばOrderBy。これは並び替えのために、実行された瞬間に全要素を一度蓄えます。例えばGroupBy。これもグルーピングのために、実行された瞬間に全要素を舐めます。非同期LINQもまた、それらと同種だと思えば、少しは納得いきませんか?現実的な妥協としては、このラインはアリだと私は思っています。分かりやすいしパフォーマンスもいい。
AsyncEnumerableの幻想、或いはRxとの邂逅
それでも妥協したくないならば、次へ行きましょう。まだ手はあります、良いかどうかは別としてね。注:ここから先は上級トピックなので適当に読み飛ばしていいです
そう、例えばWhereAsyncのようにして、Func<T,bool>じゃなくFunc<T,Task<bool>>を受け入れてくれるオーバーロードがあれば、いいんじゃない?って思ってみたり。こんな風な?
public static class AsyncEnumerable
{
// エラー:asyncとyield returnは併用できないよ
public static async IEnumerable<T> WhereAsync<T>(this IEnumerable<T> source, Func<T, Task<bool>> predicate)
{
using (var e = source.GetEnumerator())
{
while (e.MoveNext())
{
if (await predicate(e.Current))
{
yield return e.Current;
}
}
}
}
}
ただ、問題の本質はそんなことじゃあない。別にyield returnが使えなければ手書きで作ればいいわけで。そして作ってみれば、本質的な問題がどこにあるのか気づくことができます。
class WhereAsyncEnumerable<T> : IEnumerable<T>, IEnumerator<T>
{
IEnumerable<T> source;
Func<T, Task<bool>> predicate;
T current = default(T);
IEnumerator<T> enumerator;
public WhereAsyncEnumerable(IEnumerable<T> source, Func<T, Task<bool>> predicate)
{
this.source = source;
this.predicate = predicate;
}
public IEnumerator<T> GetEnumerator()
{
return this;
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
public T Current
{
get { return current; }
}
object System.Collections.IEnumerator.Current
{
get { return Current; }
}
public void Reset()
{
throw new NotSupportedException();
}
public void Dispose()
{
}
// ↑まではdoudemoii
// MoveNextが本題
public bool MoveNext()
{
if (enumerator == null) enumerator = source.GetEnumerator();
while (enumerator.MoveNext())
{
// MoveNextはasyncじゃないのでawaitできないからコンパイルエラー
if (await predicate(enumerator.Current))
{
current = enumerator.Current;
return true;
}
}
return false;
}
}
MoveNextだけ見てもらえればいいのですが、predicateを使うのはMoveNextなわけです。ここがasyncじゃないと、AsyncなLINQは成立しません。さて、もしMoveNextがasyncだと?
public async Task<bool> MoveNext()
{
// ここで取得するenumeratorのMoveNextも
// 全て同一のインターフェイスであることが前提条件なのでTask<bool>とする
if (enumerator == null) enumerator = source.GetEnumerator();
while (await enumerator.MoveNext())
{
if (await predicate(enumerator.Current))
{
current = enumerator.Current;
return true;
}
}
return false;
}
これは機能します。MoveNextをasyncにするということは連鎖的に全てのMoveNextがasync。それが上から下まで統一されれば、このLINQは機能します。ただ、それってつまり、IEnumerator<T>を捨てるということ。MoveNextがasyncなのは、似て非なるものにすぎない。当然LINQっぽい何かもまた、全て、このasyncなMoveNextを前提にしたものが別途用意されなければならない。そして、それが、Ix-Async。
Ix-Asyncのインターフェイスは、上で出したasyncなMoveNextを持ちます。
public interface IAsyncEnumerable<out T>
{
IAsyncEnumerator<T> GetEnumerator();
}
public interface IAsyncEnumerator<out T> : IDisposable
{
T Current { get; }
Task<bool> MoveNext(CancellationToken cancellationToken);
}
そして当然、各演算子はIAsyncEnumerableを求めます。
public static IAsyncEnumerable<TSource> Where<TSource>(this IAsyncEnumerable<TSource> source, Func<TSource, bool> predicate);
これの何が便利?IEnumerable<T>からIAsyncEnumerable<T>へはToAsyncEnumerableで変換できはするけれど……、求めているのはIEnumerable<Task<T>>の取り扱いであったりpredicateにTaskを投げ込めたりすることであり、何だかどうにもなく、これじゃない感が否めない。
そもそも、LINQ to Objectsから完全に逸脱した新しいものなら、既にあるじゃない?非同期をLINQで扱うなら、Reactive Extensionsが。
Reactive Extensionsと非同期LINQ
ではRxで扱ってみましょう。の前に、まず、predicateにTaskは投げ込めません。なのでその前処理でロードするのは変わりません。ただ、そのまま続けてLINQ的に処理可能なのが違うところです。
await ids.ToObservable()
.SelectMany(async x => new
{
Id = x,
Name = await GetNameAsync(x)
})
.Where(x => x.Name.StartsWith("Hoge"))
.ForEachAsync(x =>
{
Console.WriteLine(x);
});
おお、LINQだ?勿論、Where以外にも何でもアリです。RxならLINQ to Objects以上の山のようなメソッドを繋げまわることが可能です。ところで、ここで出てきているのはSelectMany。LINQ to ObjectsでのSelectの役割を、Rxの場合はSelectManyが担っています。asyncにおいてForEachはSelectでRxでSelectはSelectMany……。混乱してきました?
なお、これの結果は順不同です。もしシーケンスの順序どおりにしたい場合はSelect + Concatを代わりに使います。
await ids.ToObservable()
.Select(async x => new
{
Id = x,
Name = await GetNameAsync(x)
})
.Concat()
.Where(x => x.Name.StartsWith("Hoge"))
.ForEachAsync(x =>
{
Console.WriteLine(x);
});
ソーナンダー?ちなみにSelectManyはSelect + Mergeに等しい。
await ids.ToObservable()
.Select(async x => new
{
Id = x,
Name = await GetNameAsync(x)
})
.Merge()
.Where(x => x.Name.StartsWith("Hoge"))
.ForEachAsync(x =>
{
Console.WriteLine(x);
});
この辺のことがしっくりくればRxマスター。つまり、やっぱRxムズカシイデスネ。とはいえ、見たとおり、Rx(2.0)からは、asyncとかなり統合されて、シームレスに取り扱うことが可能になっています。対立じゃなくて協調。自然に共存できます。ただし、単品でもわけわからないものが合わさって更なるカオス!強烈強力!
まとめ
後半のAsyncEnumerableだのIx-AsyncだのRxだのは、割とdoudemoii話です、覚えなくていいです。特にIx-Asyncはただの思考実験なだけで実用性ゼロなので本気でdoudemoiiです。Rxは便利なので覚えてくれてもいいのですが……。
大事なのは、async + Selectです。SelectはForEachなんだー、というのがティンとくれば、勝ったも同然。そして、プリロード的な使い方。そこさえ覚えれば非同期でシーケンス処理も大丈夫。
asyncって新しいので、今まで出来たことが意外と出来なくてはまったりします。でも、それも、どういう障壁があって、どう対処すればいいのか分かっていればなんてことはない話です。乗り越えた先には、間違いなく素晴らしい未来が待っているので、是非C# 5.0の非同期、使いこなしてください。
GlimpseによるRedis入出力の可視化とタイムライン表示
- 2013-11-15
空前のGlimpseブーム!Glimpse最高!これ入れてないASP.NET開発はレガシー!というわけで、グラニ a.k.a. 謎社でも激しく使用を開始しています。さて、ではGlimpseとは何ぞやか、という話は今回は、しません(!)。それは誰かがしてくれます(チラッ。今回は本題のRedis周りのGlimpse拡張について。
CloudStructures 0.6
グラニではRedisライブラリとしてBookSleeve + CloudStructuresを利用しています。RedisやBookSleeveについては、C#のRedisライブラリ「BookSleeve」の利用法を読んでね!何故BookSleeveだけじゃないのかというと、BookSleeveだけだと使いづらいからです。例えるなら、BookSleeveはRedisドライバであり、ADO.NETみたいなもの。CloudStructuresはO/R(Object/Redis)マッパーであり、Dapperのようなもの。といった関係性で捉えてもらえればあってます。で、CloudStructuresは私謹製です。
今回Glimpseと連携させて使いやすくログ吐きするのに若干足りてなかったので、出力用のインターフェイス ICommandTracer を破壊的変更かけてがっつし変えちゃってます。というわけでバージョン0.6に更新。破壊的変更、ま、まだ0.xだし……。0.xとはいえ、CloudStructuresはグラニのプロダクション環境下で激しく使われてます。もんのすごい量のメッセージを捌いている(BookSleeve開発元のStackOverflowよりも遥かに捌いているはず)、秒間で数万とか数十万とかのクエリ数を、なので実績は十二分にあると言えるでしょう。
今回からリポジトリにCloudStructures.Demo.Mvcというプロジェクトを入れているので、実環境でどういう風に使えばいいのかとか、Glimpseでどう表示されるのかが分かるようになってますので、使う時は参考にどうぞ。
Glimpseによる表示
今回からCloudStructuresによるRedisアクセスを可視化できるように、Glimpseプラグインが別途インストールできるようになりました。NuGet上で Glimpse.CloudStructures.Redisから入れればおk。インストール後、Glimpseを有効にし、ICommandTracerにGlimpse.CloudStructures.Redis.RedisProfilerを渡してやると(Web.configからの設定の仕方などはCloudStructures.Demo.Mvcを見て下さい)、以下のようになります。
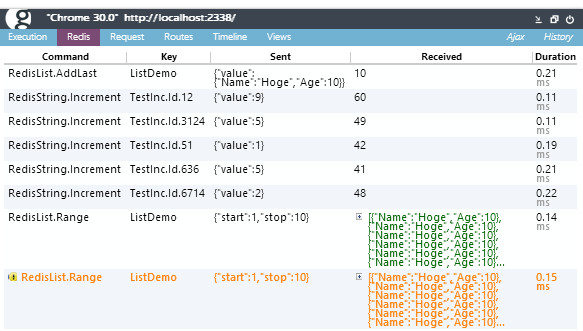
Redisタブが追加され、Redisで、どのコマンドでどのキーで実行したか、何を送って何を受け取れたか、かかった時間。それらが一覧表示されます。また、重複コマンド・キーで発行した場合は警告表記になります(一番下のオレンジの)
とにかく、通信が全部見える。中身含めて。圧倒的に捗ります。これがないなんて、盲目で歩いているに等しかった。ありえない。もう、戻れない。見えるっては、いいことですねぇ、ほんと。
更に、Glimpse標準のTimelineタブに統合されていて、これが超絶最高です。
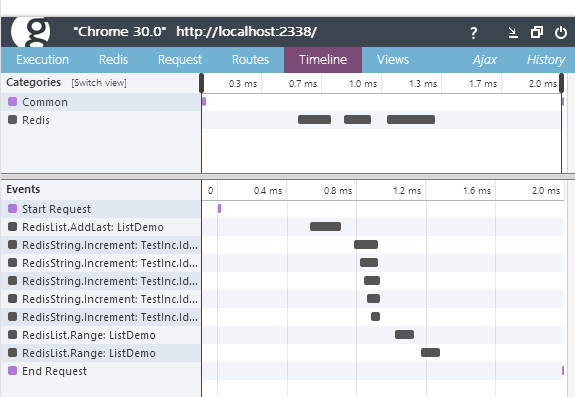
5つ連なってる部分、これは非同期に並列アクセスされています。コードは
var ids = new[] { 12, 3124, 51, 636, 6714 };
var rand = new Random();
await Task.WhenAll(ids.Select(async x =>
{
await RedisGroups.Demo.String<int>("TestInc.Id." + x).Increment(rand.Next(1, 10));
}).ToArray());
のようになっているわけですが、これ、もし同期アクセスだったら、同時に動くことなく、この分だけタイムラインが右に長くなるわけです。可視化されることで全て非同期!全てパイプライン!効率的に、高速に、というのがとてもわかりやすく見えます。実際、グラニではこういった一気に叩いてWhenAllというパターンを多用して高速なレスポンスを実現しています。ここまでASP.NET MVCの非同期コントローラーを死ぬほど使い倒している企業は、世界でも稀なのではないか、というレベルで非同期祭りやってます。(そして時に地雷踏みつつ前進してます)。
Glimpseについてもうちょっとだけ
実際のところGlimpse、ただ入れただけだとあんまり嬉しいことはないでしょう。色々なサーバーの情報が見えると言ったって、そんなの一度だけ見れば十分だしー、で終わってしまったり。ただ情報がありゃあいいってものじゃなくて、何の情報が必要か、が大事。でも、Glimpseってカスタマイズが容易なんですね。だから、その会社にとって、そのアプリケーションにとって大事な情報を流しこむことができる。大事な情報を流しこむようにすることで「頻繁に使うものではない」から「頻繁に使うもの」に変える。そうすることで、手放せないものとなります。

これはグラニで実際に使っているタブですが、Log, PlatformAPI, Redis, SQL Explainは弊社が独自に作成したタブです。以前にHttp, SQL, Redisのロギングと分析・可視化についてという記事を書きましたが、そこで、外部へのアクセスをフックする仕組みは作ってあったので、それぞれでGlimpseにデータ流すように変えただけです。これによりRedis, Http, SQLの全てがタブで全て見えるし、Timelineにも出てくるのでボトルネックが一目瞭然に。過度な通信なども一発で分かる。
SQL Explainはリクエスト中で発行された全てのSQLに対してexplainを発行し結果を表示しています(うちはMySQLを使っているのでexplainです、SQL Serverならそれ用のコマンド打てば同様以上のことが当然可能です)。これにより、将来ボトルネックになるクエリが早期発見できます。
explainとか面倒だから全てに律儀に打ったりしないし、*ms以上遅いクエリは警告するとかやったって、開発環境のデータ量だと無意味だったりするでしょう。だから、全てのクエリに対して自動でexplainをかけてやって、怪しそうなもの(using filesortとか)は最初から警告してあげる。これで、クソクエリの早期撲滅が可能となります。
ちなみにMiniProfilerとの使い分けですが、うちではむしろもうMiniProfilerイラナクね?の方向で進んでます。ちょっとまだGlimpse、足りてないところもあるのですが、割と直ぐに解決しそうだし、むしろMiniProfiler動かしてるとHistoryが汚れるのでGlimpseにとって邪魔なのですよね。
まとめ
といったように、グラニではより開発しやすい環境を作ることに全力を注いでいます。なんと今だとアプリケーションエンジニア・インフラエンジニア・フロントエンドエンジニアを募集中だそうですよ!←求人広告記事ダッタノカー、イヤソンナコトナイデスケドネ。なんか敷居高杉と思われてるかもですが、アプリエンジニアに関しては割とそんなことなく、基準は最低限LINQ to Objects知ってる程度からなので気楽にどうぞ。最近、オフィスを六本木ヒルズに移転しまして、ハードウェア環境も充実しているので、そちらの面でも開発しやすいかな、と。モニタも27インチ(2560x1440)をトリプルですしドリンク無料飲み放題ですし。
ソフトウェア側も良さそうならどんどんバシバシ変えてます。Glimpseも最初は導入されてませんでしたが、後から入れていますしね。ASP.NET MVCも早速5へ。この辺の姿勢は初期の文化が大事だと思っているので、絶対緩めないのを信条にしています。
なお、Glimpseの導入や独自タブの作成、ならびにGlimpse.CloudStructures.Redisの作成は、私がやったわけではありません!私がやったのはSQL Explainタブの作成とICommandTracerの改変、Glimpse.CloudStructures.Redisを社外に出せるよう依存部分の除去しただけでして。そんなわけで皆で一岩となって改革してるんですよー、とっても刺激的でいい職場です。私にとっても。←ヤッパリ求人広告記事ダッタノカー、イヤソンナコトナイデスヨ。
.NETのコレクション概要とImmutable Collectionsについて
- 2013-10-31
先週の土曜日に、「プログラミング .NET Framework 第4版 」座談会でOverview of the .NET Collection Framework and Immutable Collectionsとして、コレクションフレームワークとImmutable Collectionsについて話してきました。
案外コレクションについてまとまった話って、ない(or .NET 4.5からReadOnly系が入ってきて、話が更新されているもの)ので、資料として役に立つのではないかと思います。
Collection Framework
前半部分ですが、これのジューヨーなところはILinqable<T>、じゃなくて(スライド資料では出てないのでナンノコッチャですが)、ReadOnly系の取り扱いですね。MutableとReadOnlyが枝分かれしている理由とか対処方法とか、が伝えたかった点です。いやあ、コレクション作る時は両方実装しよう!とかしょうもないですねえ、shoganaiのですねぇ……。
IEnumerable<T>とIReadOnlyCollection<T>の差異は実体化されていない「可能性がある」かどうか。で、なのでメソッドの引数などで内部で実体化されてるのを前提にほげもげしたい場合は、IReadOnlyCollection<T>を受け取るほうが望ましいといえば望ましいのですが、汎用的にIEnumerableのままで……という場合は、以下のようなメソッドを用意しとくといいでしょう。
/// <summary>
/// sourceが遅延状態の場合、実体化して返し、既に実体化されている場合は何もせずそれ自身を返します。
/// </summary>
/// <param name="source">対象のシーケンス。</param>
/// <param name="nullToEmpty">trueの場合、sourceがnull時は空シーケンスを返します。falseの場合はArgumentNullExceptionを吐きます。</param>
public static IEnumerable<T> Materialize<T>(this IEnumerable<T> source, bool nullToEmpty = true)
{
if (nullToEmpty && source == null)
{
return Enumerable.Empty<T>();
}
else
{
if (source == null) throw new ArgumentNullException("sourceがnullです");
}
if (source is ICollection<T>)
{
return source;
}
if (source is IReadOnlyCollection<T>)
{
return source;
}
return source.ToArray();
}
こんなのを作って、冒頭で呼べば、二度読みなどもOKに。
public static void Hoge<T>(IEnumerable<T> source)
{
source = source.Materialize(); // ここで実体化する
// あとは好きに書けばいいのではないでせうか
}
どうでしょ。また、二度読みなら列挙したらキャッシュして、再度読む時はそっから読んでくれればいいのに!というリクエストあるかと思います。それは一般的にはメモ化(Memoization)といいます。というわけで、シーケンスに実装してみましょう。
public static IEnumerable<T> Memoize<T>(this IEnumerable<T> source)
{
if (source == null) throw new ArgumentNullException("sourceがnull");
return new MemoizedEnumerable<T>(source);
}
class MemoizedEnumerable<T> : IEnumerable<T>, IDisposable
{
readonly IEnumerable<T> source;
readonly List<T> cache = new List<T>();
bool cacheComplete = false;
IEnumerator<T> enumerator;
public MemoizedEnumerable(IEnumerable<T> source)
{
this.source = source;
}
public IEnumerator<T> GetEnumerator()
{
if (enumerator == null) enumerator = source.GetEnumerator();
return new Enumerator(this);
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
public void Dispose()
{
if (enumerator != null) enumerator.Dispose();
}
class Enumerator : IEnumerator<T>
{
readonly MemoizedEnumerable<T> enumerable;
int index = 0;
public Enumerator(MemoizedEnumerable<T> enumerable)
{
this.enumerable = enumerable;
}
public T Current { get; private set; }
public void Dispose()
{
}
object System.Collections.IEnumerator.Current
{
get { return Current; }
}
public bool MoveNext()
{
if (index < enumerable.cache.Count)
{
Current = enumerable.cache[index];
index++;
return true;
}
if (enumerable.cacheComplete) return false;
if (enumerable.enumerator.MoveNext())
{
Current = enumerable.enumerator.Current;
enumerable.cache.Add(Current);
index++;
return true;
}
enumerable.cacheComplete = true;
enumerable.enumerator.Dispose();
return false;
}
public void Reset()
{
throw new NotSupportedException("Resetは産廃");
}
}
}
こうしておけば、
// hoge:xが出力されるのは1回だけ
var seq = Enumerable.Range(1, 5)
.Select(x =>
{
Console.WriteLine("hoge:" + x);
return x;
})
.Memoize();
// なんど
foreach (var item in seq.Zip(seq, (x, y) => new { x, y }).Take(4))
{
Console.WriteLine(item);
}
// ぐるぐるしても一度だけ
foreach (var item in seq.Zip(seq, (x, y) => new { x, y }))
{
Console.WriteLine(item);
}
といった感じ。Materializeより合理的といえば合理的だし、そうでないといえばそうでない感じです。私はMaterializeのほうが好み。というのもMemoizeは完了していないEnumeratorを保持しなければいけない関係上、Disposeの扱いがビミョーなんですよ、そこが結構引っかかるので。
あと、IEnumerable<T>ですが、スレッドセーフではない。そう、IEnumerable<T>にはスレッドセーフの保証は実はない。というのを逆手に取ってる(まぁ、それはあんまりなので気になる人はlockかけたりしましょう)。ちなみにReadOnlyCollectionだってラップ元のシーケンスが変更されたらスレッドセーフじゃない。そして、スレッドセーフ性が完璧に保証されているのがImmutable Collections。という話につながったりつながらなかったり。
Immutable Collections
Immutable Collectionsは実装状況が.NET Framework Blogで随時触れられていて、リリース時のImmutable collections ready for prime timeを読めば、なんなのかっては分かるのではかと。その上で私が今回で割と酸っぱく言いたかったのは、ReadOnly「ではない」ってことです。そして結論はアリキタリに使い分けよう、という話でした。
セッション後の話とかTwitterで、バージョニングされたコレクションって捉えるといいんじゃないの?と意見頂いたのですが、なるほどしっくりきそうです。
スピーカー予定
今後ですが、大阪です!12/14、第3回 LINQ勉強会で発表する予定なので、関西圏の人は是非是非どうぞ。セッションタイトルは「An Internal of LINQ to Objects」を予定しています。これを聞けばLINQ to ObjectsのDeep Diveの部分は全部OK、といった内容にするつもりです。もう初心者向けってこともないので、完全に上級者がターゲットで。
asyncの落とし穴Part3, async voidを避けるべき100億の理由
- 2013-10-10
だいぶ前から時間経ってしまいましたが、非同期の落とし穴シリーズPart3。ちなみにまだ沢山ネタはあるんだから!どこいっても非同期は死にますからね!
async void vs async Task
自分で書く場合は、必ずasync Taskで書くべき、というのは非同期のベストプラクティスで散々言われていることなのですけれど、理由としては、まず、voidだと、終了を待てないから。voidだと、その中の処理が軽かろうと重かろうと、終了を感知できない。例外が発生しても分からない。投げっぱなし。これがTaskになっていれば、awaitで終了待ちできる。例外を受け取ることができる。await Task.WhenAllで複数同時に走らせたのを待つことができる。はい、async Taskで書かない理由のほうがない。
んじゃあ何でasync voidが存在するかというと、イベントがvoidだから。はい。button_clickとか非同期対応させるにはvoidしかない。それだけです。なので、自分で書く時は必ずasync Taskで。async voidにするのはイベントだけ。これ絶対。
ASP.NET + async voidで死ぬ
それでもasync voidをうっかり使っちゃうとどうなるでしょう?終了を待てないだけとか、そんなんならいいんですよ、でも、ASP.NETでasync void使うと死にます。文字通りに死にます。アプリケーションが。じゃあ、ASP.NET MVCで試してみましょうか。WebForms?しらね。
public async void Sinu()
{
await Task.Delay(TimeSpan.FromSeconds(1));
}
public ActionResult Index()
{
Sinu();
return View();
}
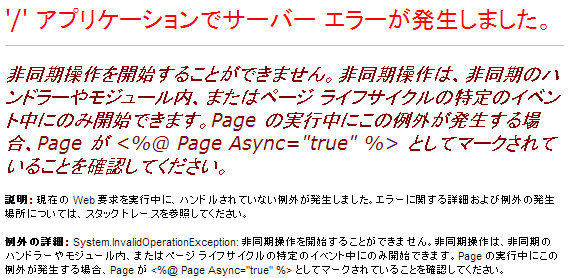
死にました!警告一切ないのに!って、ああ、そうですね、async="true"にしないとですね、まぁそれはないのですけれど、はい、Task<ActionResult>を返しましょう。そうすればいいんでしょ?
public async void Sinu()
{
await Task.Delay(TimeSpan.FromSeconds(1));
}
public async Task<ActionResult> Index()
{
Sinu();
return View();
}

はい、死にました!非同期操作が保留中に非同期のモジュールとハンドラーが完了しちゃいましたか、しょーがないですね。しょーがない、のか……?
で、これの性質の悪いところは、メソッド呼び出しの中に一個でもasync voidがあると詰みます。
// こんなクソクラスがあるとして
public class KusoClass
{
public async void Sinu()
{
await Task.Delay(TimeSpan.FromSeconds(1)); // 1じゃなく5ね。
}
}
// この一見大丈夫そうなメソッドを
public async Task Suteki()
{
// ここでは大丈夫
await Task.Delay(TimeSpan.FromSeconds(1));
// これを実行したことにより……
new KusoClass().Sinu();
// ここも実行されるし
await Task.Delay(TimeSpan.FromSeconds(1));
}
// このアクションから呼び出してみると
public async Task<ActionResult> Index()
{
// これを呼び出してちゃんと待機して
await Suteki();
// ここも実行されるのだけれど
await Task.Delay(TimeSpan.FromSeconds(1));
return View();
}
死にます。ただし、上で5秒待機を1秒待機に変えれば、動きます。なぜかというと、KusoClass.Sinuを実行のあとに2秒待機があってViewを返してるので、Viewを返すまでの間にKusoClass.Sinuの実行が完了するから。そう、View返すまでに完了してればセーフ。してなければ死亡。まあ、ようするに、死ぬってことですね結局やっぱり。何故かたまに死ぬ、とかいう状況に陥ると、むしろ検出しづらくて厄介極まりないので、死ぬなら潔く死ねって感じ。検出されずそのまま本番環境に投下されてしまったら……!あ、やった人がいるとかいないとかいるらしい気がしますが気のせい。
呼び出し階層の奥底にasync voidが眠ってたら死ぬとか、どーせいという話です。どーにもならんです。なので、共通ライブラリとか絶対async void使っちゃダメ。あるだけで死んでしまうのですから。
FireAndForget
さて、投げっぱなしの非同期メソッドを使いたい場合、どうすればいいんでしょう?
public async Task ToaruAsyncMethod()
{
await Task.Delay(TimeSpan.FromSeconds(1));
Debug.WriteLine("hoge");
}
public async Task<ActionResult> Index()
{
// 待機することなく投げっぱなしにしたいのだけど警告が出る!
ToaruAsyncMethod();
return View();
}
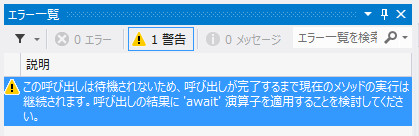
あー、警告ウザす警告ウザす。その場合、しょうがなく変数で受けたりします。
public async Task<ActionResult> Index()
{
// 警告抑制のため
var _ = ToaruAsyncMethod();
return View();
}
はたしてそれでいーのか。いやよくない。それに、やっぱこれだと例外発生した時に捉えられないですしね。TaskScheduler.UnobservedTaskExceptionに登録しておけば大丈夫ですけれど(&これは登録必須ですが!)。というわけで、以下の様なものを用意しましょう。
// こんな拡張メソッドを用意すると
public static class TaskEx
{
// ロガーはここではNLogを使うとします
private static readonly NLog.Logger logger = NLog.LogManager.GetCurrentClassLogger();
/// <summary>
/// 投げっぱなしにする場合は、これを呼ぶことでコンパイラの警告の抑制と、例外発生時のロギングを行います。
/// </summary>
public static void FireAndForget(this Task task)
{
task.ContinueWith(x =>
{
logger.ErrorException("TaskUnhandled", x.Exception);
}, TaskContinuationOptions.OnlyOnFaulted);
}
}
// こんな投げっぱなしにしたい非同期メソッドを呼んでも
public async Task ToaruAsyncMethod()
{
await Task.Delay(TimeSpan.FromSeconds(1)).ConfigureAwait(false);
Debug.WriteLine("hoge");
throw new Exception();
}
public ActionResult Index()
{
ToaruAsyncMethod().FireAndForget(); // こうすれば警告抑制&例外ロギングができる
return View();
}
いいんじゃないでしょうか?
ところで、ToaruAsyncMethodに.ConfigureAwait(false)をつけてるのは理由があって、これつけないと死にます。理由は、覚えてますか?asyncの落とし穴Part2, SynchronizationContextの向こう側に書きましたが、リクエストが終了してHttpContextが消滅した状態でawaitが完了するとNullReferenceExceptionが発生するためです。
そして、これで発生するNullReferenceExceptionは、FireAndForget拡張メソッドを「通りません」。こうなると、例外が発生したことはUnobservedTaskExceptionでしか観測できないし、しかも、そうなるとスタックトレースも死んでいるため、どこで発生したのか全く分かりません。Oh...。
たとえFireAndForgetで警告が抑制できたとしても、非同期の投げっぱなしは細心の注意を払って、呼び出しているメソッド階層の奥底まで大丈夫であるという状態が確認できていて、ようやく使うことができるのです。うげぇぇ。それを考えると、ちゃんと警告してくれるのはありがたいね、って思うのでした。
まとめ
voidはまぢで死ぬ。投げっぱなしも基本死ぬ。
では何故、我々は非同期を多用するのか。それはハイパフォーマンスの実現には欠かせないからです。それだけじゃなく、asyncでしか実現できないイディオムも山のようにあるので。いや、こんなの全然マシですよ、大袈裟に書きましたがasync void使わないとか当たり前なのでそこ守れば大丈夫なんですよ(棒)。じゃあ何でasync voidなんてあるんだよとか言われると、イベント機構があるからしょうがないじゃん(ボソボソ)、とか悲しい顔にならざるを得ない。
というわけで、弊社は非同期でゴリゴリ地雷踏みたいエンジニアを大募集してます。ほんと。
謎社が一周年を迎えました。
- 2013-09-30

まあ、迎えたのは9/19なので、10日以上経っちゃってるんですが。ほげ。というわけかで、謎社あらため株式会社グラニは、設立一年を迎えました。前職を退職したのが10/20なので、私にとっては一年、まだ経ってません。はい。今の役職は取締役CTOなのですが、実は設立時には居なかったんですねえ。ジョインしたのは若干遅れてます。その間シンガポールにいたりほげもげ……。
ともあれ今は、当面は地下に潜伏していますが、必ず浮上しますのでしばしお待ちくだしあ。
gloopsを退職しました。 - 2012/10/20
なんで謎社かというと、退職後から表に出るまでは、ちょっとだけ内緒ということで、その間Twitterでずっと謎社って言ってたのが残ってるだけですね。Twilog @neuecc/謎社 古い順。googleで謎社で検索しても一位がグラニになってたりするので、それはそれで何となく定着してるのでヨシとしませうか。
一年の成果
謎々潜伏期間中に思い描いてたこと、あります。
C#といったら謎社!みたいな、C#を使う人が憧れるぐらいな立ち位置の会社にできればいいなと思っています
2012年を振り返る。 - 2012/12/30
これには、まず、会社が成功してなきゃダメです。その点でいうと、最初のタイトル(1/25に出しました)神獄のヴァルハラゲートは大躍進を遂げ、3度のテレビCM(今も放送してます)、GREE Platform Award2013年上半期総合大賞受賞など、業界では2013年を代表するタイトルとなれたと思います。
というわけで、会社は成功した(勿論、まだまだこれから更に発展していきますよ!)。技術的にはどうでしょう。実は最初のリリース時はPHPだったのですが、これは7月にC#に完全リプレースしていて、今は100% C#, ASP.NET MVCで動いています。技術に関しては、一部はリリース前にBuild Insider Offlineというイベントで.NET最先端技術によるハイパフォーマンスウェブアプリケーションとして発表しましたが(.NET系にしては珍しくはてブ300超えて割とヒット)、使用テクノロジ・アーキテクチャに関しては、間違いなく最先端を走っていると思います。エクストリームWebFormsやエクストリームDataSetに比べると、ちゃんと技術を外に語れるのがいいですにぇ。
また、.NETでのフルAWS環境で超高トラフィックを捌いているのですが、これは結構珍しいところかもです。.NETというだけじゃなく、この業界だと、データベースはFusion-ioのようなハイパーなドライブを詰んだオンプレミス環境であることも多いのですが、Fusion-ioは甘え、クラウドでも十分やれる。むしろこれからはそれがスタンダード。完全クラウドでやれる、という証明をしていく、というわけでAWS ゲーム業界事例 株式会社グラニ様などでも紹介されています。
NewRelicやSumo Logicなど、日本では(特に.NETでは)マイナーなサービスでも、良いと思ったら柔軟にガンガン導入していっています。特にSumoLogicはWindows+日本語環境だと文字化けとかもありましたが、弊社からのフィードバックで解消していっているなど(つまりうち以外誰も使ってないのかいな……)我々が次代のスタンダードを作っていく、という気概でやっていってます。
と、たった一年の企業にしては相当やったと思うのですが、しかし、「憧れるぐらいな立ち位置」には、まだまだ全然。土台は出来たと思うので、ここからはしっかり発展させていかなきゃな、と。
We're Hiring
というわけで、何を言いたいかというとコレです(笑)。超採用中です。グラニ/採用情報が、非常に古臭いページで、しかもmailtoでしか応募できないというハードルの高さでアレなのですが、かなり!真面目に!募集してます。ページはそのうちまともになるので、むしろ応募人数が少ないmailtoのうちのほうが採用確立高いかもですよ!?
現在どのぐらい人数がいるかというと、会社全体で既に50人ぐらい、エンジニアも20人弱います。小規模な会社、というフェーズは超えてます。会社自体も↑のように割と成功しているので、色々とは安心してください。
開発環境はかなり充実していて、トリプルディスプレイが出力できない開発PCなんて許さん!とかショボい椅子は嫌だ!とかWindows 8じゃなきゃ嫌だ!とか当然VS2012!Fakesの使えないVisual StudioなんてありえないからPremium以上!とか、こんなにやれてる会社は中々ないでしょう。
コードは、つい7月にリリースしたものがソースコードの全てで過去の遺産が一切ない状態なので、100%、C# 5.0 + .NET 4.5 + ASP.NET MVC 4という、最先端のフレームワークが存分に利用できます。これは、常にアップデートしていく、という意思が固いので、今後も古いもので書かなきゃいけない……みたいな状況は絶対作りません。これはもう宣言。誓って。
技術的にも凄まじいasync祭り(Webでここまでやってるのは世界でも稀でしょう)とか、良くも悪くも先端を突っ走るし地雷は自分で踏んで自分で処理して、「我々が道を作る」覚悟で、技術的に業界をリードする会社であろうとしています。そうじゃなきゃ「C#を使う人が憧れるぐらいな立ち位置」にはなれませんから。なので、技術的な発信に関しては、私に限らず、皆がアクティブに行っていきたいと思っています。なお、私含めてMicrosoft MVPは3人在籍しています。
C#といったら謎社にする。といった気概のある方は、是非とも応募してみて下さい。らんぷの巣窟にC#で殴りこみをかけれるとか謎社にしか出来ない面白いポジションですし、.NET世界に篭もらずに、C#を業界のスタンダードへと導けるのは我々だけ!というぐらいな勢いがありますよ。
(注意:但し、我々はサービスを提供している会社です。技術あってのサービス、サービスあっての技術。両輪なので、多少の偏りはいいんですが、片方がゼロの場合は良い物は作れないので、お断るかもしれません)
とかなんとかだと、ハードル高すぎ、な感がするかもですが、そんなにそんなでもないので、気になるなぁと思った人は現時点での何らかの懸念(技術的に、とかスキルセットが合わないかも、とか)は抜きにして、来てもらえると嬉しいですね。ウェブ系以外でも全然OKですし。C#が全てに通用することを現実世界での成功でもって証明する!ことも掲げているので、ウェブ以外であっても、アリアリなのです。
MySQL + Dapperによる高負荷時のバグで死んだ話
- 2013-08-06
今回はMySQLとDapperを組み合わせると死ぬ、という超極少数にしか該当しない話ですよ!というわけで、まぁ読み物としてどーぞ。ちなみに割とクリティカルなので、その組み合わせで何かやろうという人は気をつけたほうがいいです。
観測
何が起こるかの観測からはじめましょう。まず、NuGetからMySQL.DataとDapperをインストールして、以下の簡単なコードを走らせ、ません。コード書いて待機で。
using Dapper;
using MySql.Data.MySqlClient;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
class Program
{
static void Main(string[] args)
{
// スレッドプールを先に伸びるように
ThreadPool.SetMinThreads(200, 200);
var count = 0;
// とりあえず200並列で実行する
Parallel.For(0, 10000, new ParallelOptions { MaxDegreeOfParallelism = 200 }, () =>
{
var conn = new MySqlConnection("せつぞくもじれーつ,Max Pool Size=1000");
conn.Open();
return conn;
}, (x, state, conn) =>
{
System.Console.WriteLine(Interlocked.Increment(ref count));
// ↑や↓にグチャグチャありますが、実態はこの一行だけです
conn.Query<long>("select 1", buffered: false).First();
return conn;
}, conn =>
{
conn.Dispose();
});
}
}
Parallelなのは高負荷じゃないとイマイチ分からないので、そのシミュレートね。これも別にそこまで高負荷ってわけでもないですが、まぁこんなんでいいのです(原因分かってて逆算して書いてるので)。接続文字列は、とりあえず200並列に耐えられるようにMaxPoolSizeだけ大きめに設定しておきます。さて、そしてPowerShellを立ち上げ、とりあえず以下のスクリプトを走らせておきます。
while ($true) {Get-NetTCPConnection | group state -NoElement; sleep 1}
で、上のC#コードを実行。すると、実行は、遅いです。Parallelなので速いのか遅いのかわからないかもですが、まあぶっちけ凄く遅いです。正常状態ならサクッと終わるのですが、↑のはかなりもたついてます。で、運が良ければ以下の例外にも遭遇するでしょう。時には完走するかもしれませんが。
ハンドルされていない例外: System.AggregateException: 1 つ以上のエラーが発生しました。
---> MySql.Data.MySqlClient.MySqlException: Unable to connect to any of the specified MySQL hosts.
---> System.Net.Sockets.SocketException: そのようなホストは不明です。
よくわからないけどSocketExceptionで死にますね!!!さて、PowerShellのほうはどうなっていたか、というと、
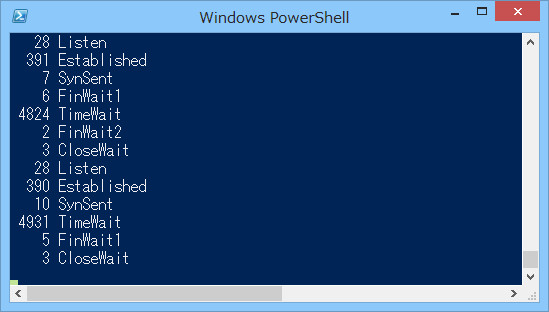
ぎゃー、TIME_WAIT祭だー。って、Parallelだからそうなったんじゃないかって?いえいえ、所詮200並列ですし、ある程度はOpen/Close繰り返されるとはいえ、4000個もコネクション作ったりなんてしないです。ていうかそもそもコネクションプールあるんだから、そんなに繋ぐわけないでしょーが。
つまり、どういうことだってばよ?シンプルな例にしましょうか。
using (var conn = new MySqlConnection("せつぞくもじれーつ"))
{
conn.Open();
for (int i = 0; i < 100; i++)
{
conn.Query<long>("select 1", buffered: false).First();
}
}
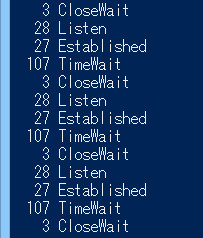
はい。100のループで100のTIME_WAITが発生しています。つまり、1クエリにつき1TIME_WAITです。ほへ……?ということは、低負荷時はそれでも生きてられるかもですが、高負荷時は、最初の例で見たように、山のようなTIME_WAITに見舞われます。そしてsocketは枯渇する。そして死ぬ。
何故こうなるのか
何故、の前にどの組み合わせでなるか、というと、現時点での最新のDapper(1.13)で、Queryをbuffered:falseで、FirstなどReaderの列挙を完了させないもの(ToListとかなら大丈夫)で確定させると詰みます。じゃあまあ、原因にDeepDive。
キーになるコードは、Dapperのこのメソッドです。
private static IEnumerable<T> QueryInternal<T>(this IDbConnection cnn, string sql, object param, IDbTransaction transaction, int? commandTimeout, CommandType? commandType)
{
var identity = new Identity(sql, commandType, cnn, typeof(T), param == null ? null : param.GetType(), null);
var info = GetCacheInfo(identity);
IDbCommand cmd = null;
IDataReader reader = null;
bool wasClosed = cnn.State == ConnectionState.Closed;
try
{
cmd = SetupCommand(cnn, transaction, sql, info.ParamReader, param, commandTimeout, commandType);
if (wasClosed) cnn.Open();
reader = cmd.ExecuteReader(wasClosed ? CommandBehavior.CloseConnection : CommandBehavior.Default);
wasClosed = false; // *if* the connection was closed and we got this far, then we now have a reader
// with the CloseConnection flag, so the reader will deal with the connection; we
// still need something in the "finally" to ensure that broken SQL still results
// in the connection closing itself
var tuple = info.Deserializer;
int hash = GetColumnHash(reader);
if (tuple.Func == null || tuple.Hash != hash)
{
tuple = info.Deserializer = new DeserializerState(hash, GetDeserializer(typeof(T), reader, 0, -1, false));
SetQueryCache(identity, info);
}
var func = tuple.Func;
while (reader.Read())
{
yield return (T)func(reader);
}
// happy path; close the reader cleanly - no
// need for "Cancel" etc
reader.Dispose();
reader = null;
}
finally
{
if (reader != null)
{
if (!reader.IsClosed) try { cmd.Cancel(); }
catch { /* don't spoil the existing exception */ }
reader.Dispose();
}
if (wasClosed) cnn.Close();
if (cmd != null) cmd.Dispose();
}
}
色々ありますが、while(reader.Read())以下の部分だけを見ればOKです。ToListなら大丈夫でFirstだとダメな理由もここにあります。ToListの場合、Readerが全て読むので、コード上にコメントでhappy pathと書いてある、reader.Disposeが呼ばれます、そしてfinallyでは何もしない。逆にFirstの場合は、最初のyield returnで打ち切られてfinallyへ向かうので、cmd.Cancel()が呼ばれた後に、reader.Disposeが呼ばれます。
そう、ここです。reader.Disposeの前にcmd.Cancelが呼ばれる、というのが、非常にマズい。少なくともMySQL Connectorにおいては。MySQL ConnectorのCommmand.Cancelの実装を見てみましょう。あ、MySQL Connectorのソースコードはちゃんと公開されています、Download Connector/NetのSelect PlatformでSource Codeを選べば落とせます。zipで。リポジトリは、多分公開されてない、残念ながら……。
さて、Command.Cancelは以下のメソッドを呼び出します。
public void CancelQuery(int timeout)
{
MySqlConnectionStringBuilder cb = new MySqlConnectionStringBuilder(Settings.ConnectionString);
cb.Pooling = false;
cb.AutoEnlist = false;
cb.ConnectionTimeout = (uint)timeout;
using (MySqlConnection c = new MySqlConnection(cb.ConnectionString))
{
c.isKillQueryConnection = true;
c.Open();
string commandText = "KILL QUERY " + ServerThread;
MySqlCommand cmd = new MySqlCommand(commandText, c);
cmd.CommandTimeout = timeout;
cmd.ExecuteNonQuery();
}
}
どういうことか。「新しいコネクションをコネクションプーリングなしで新規生成して」「KILL QUERY実行して」「コネクションを閉じる」。KILL QUERYはどうでもいいんですが、新しいコネクションをプーリングなしで作って閉じるということがどういう結果をもたらすか。一回のクエリ毎に↑のが実行されるとどうなるか。まず、遅くなる。そりゃ遅いわな、1クエリ毎に1接続&切断してるんだもの。そして、1クエリ = 1TIME_WAIT。完全にコードは書かれたとおりに動いて書かれるとおりの結果しか出てこない。素晴らしい。泣ける。
どうすればいいのか
これ、1.12 ~ 1.13の間に加えられた変更が原因です。具体的にはIssue 106で、SQL ServerだとTimeoutException出るから、reader閉じる前にcommandのCancel呼んで欲しいんだよねー、というパッチが受け入れられたのでした。その結果、MySQLだと死ぬことに。
なので、1.12を使えば問題は起こりません。もしくは1.13だったら、手動でソースコードに修正を加えればいいでしょう。もともとDapperはソースコードが1ファイルなので、NuGet経由ではなく、最新のコードをファイルで持ってくれば、編集は楽です。
ちなみに、この件はDapperのForumでは報告済みです。一ヶ月前に。そして返事はありません。みょーん。まあ、あと究極的にはSQL ServerをとるかMySQLをとるか、になるので、どうなんでしょうね、あんま期待は持たないほうがいい気もします。
おまけ、MySQL Connectorのコネクションプールについて
MySQL Connectorのコードは結構素朴なので、読みやすいです(MSのSqlServerのに比べると遥かに!)。というわけで、つらつら読んでみるといいんじゃないでしょーか。参考になったりゲッソリしたり色々です。
というわけでコネクションプールとかがどうなってるかの説明しませう。そしてそれぞれが接続文字列のオプションでどう弄れるのかについて。接続文字列でのオプションの設定は結構重要ですからね、失敗してると死にますから。何度か死にましたから……。接続文字列のリファレンスはこちらConnector/Net Connection String Options Reference。古いもの(日本語訳されてる!)だけを参照すると時々痛い目に会うので適度に注意。
さて、まず、MySqlConnectionをnewすること自体は全然軽くて(ただの入れ物なので)じゅーよーなメソッドはOpenとCloseです。OpenするとコネクションプールからDriver(これが本当の実態でプールするもの)を取り出します。CloseするとコネクションプールにDriverを戻します。これが基本的なこと。ちなみにプールはQueueです、なのでDriverは先入れ先出しで循環してます。
プールということは、一度生成したコネクションはいつ消えるの?というと、Closeする時です。Close時にExpireしているかチェックし、してれば消滅、してなければプールへ。基準時間は 「接続が最初に作られた時」です。そのExpireの時間はどこで設定するの?というと接続文字列のConnection Lifetime。ちなみにデフォルトは0で、Close時には消滅しません。 なお、コネクションの最大プール数も接続文字列で指定できて、そのMax Pool Sizeのデフォは100です。
実際のところ、Close時以外にもコネクションが消える時があります。3分に一回、アイドル状態の接続がチェックされて(Timerで別スレッドで常に巡回されてる)、その時に、3分以上、プールに溜まったままのコネクションはお掃除されます。基準時間は「接続がプールに戻された時」です。Connection Lifetimeと基準が違うんですね。
Open/Closeを繰り返すことのロスは、上記のようにプールから取り出したり戻したり程度なので、かなり小さいです(一応、取り出したりする際にプールをlockしますが、全然小さいので無視できるでしょう)。あと、一応Open時にサーバーが生きてるかPingを飛ばします(この動作はビミョーだと思うんですけどねえ)。プールのlockよりも、コスト的にはこっちのほうが大きいかもですね。
あと他に接続文字列だと、Connection TimeoutとDefaultCommandTimeoutを弄っておくと幸せになれるでしょふ。
DefaultCommandTimeoutで設定できるコマンドタイムアウトはExecuteNonQueryやExecuteReaderで最初のレスポンスが戻ってくるまでの時間ではかられます。だから、ExecuteReaderでも、例えば数億件のデータがあって凄く時間がかかるものでも、反応はかえって来てるのでそこでのTimeout判定は入りません。レコード数よりも、純粋なSQLの内容(馬鹿でかいデータにlikeで検索とかは引っかかりますよね)のためのものです。
Connection Timeoutは、実はコネクションをOpenにする時、だけに関連してるわけじゃあなかったりします。streamからReadする際の時間でもConnectionStringsのConnect Timeoutで判定があります。この値を流用されるのイマイチ納得いかない気がしなくもないですが、まあそんなもんですかねえ。なので結果セットを読み込んでる最中でもネットワークの調子が悪くて止まると、タイムアウト判定が来ます。Raedの単位はデータセット全て、ではなく1行分とか、そういう特定バイト数ごとになるので、巨大データを読み取るのに時間がかかるので死ぬ、とかにはなりません。一応参考までにってとこですかね。
まとめ
このDapperで死ぬ問題、プロダクション環境化で発覚したんですよね!!!分かってみると割と単純なのですが、しかし条件が変則的で突き止めるのに手間取って泣きたかった……。低負荷だと割と動いちゃうというか、そこそこの負荷でも割と耐え切れちゃう(IIS偉い)ので、全然気づかず。なんか分からないけど超高負荷の時に落ちる!とか、ね。ワケワカラナカッタ。まず疑うのは自分のコードのほうだしねえ。
まぁ、解決してほんと良かったです、はい。解決しなかったら首吊るしかなかったですもの、思い出すだけでハイパーお通夜。冗談抜きに今までの人生で一番精神的に苦しかった……。そんな感じで若干トラブルもありましたが、それを除けばDapperはパワフルでかなり満足しています。少々、上モノを被せているので、その辺のものはそのうち紹介しましょうかしらん。
Http, SQL, Redisのロギングと分析・可視化について
- 2013-07-30
改善は計測から。何がどれだけの回数通信されているか、どれだけ時間がかかっているのか、というのは言うまでもなく重要な情報です。障害対策でも大事ですしね。が、じゃあどうやって取るの、というとパッとでてくるでしょうか?そして、それ、実際に取っていますか?存外、困った話なのですねー。TraceをONにすると内部情報が沢山出てきますが、それはそれで情報過多すぎるし、欲しいのはそれじゃないんだよ、みたいな。
Grani←「謎社」で検索一位取ったので、ちょっと英語表記の検索ランキングをあげようとしている――では自前で中間を乗っ取ってやる形で統一していて、使用している通信周り、Http, RDBMS, Redisは全てログ取りして分析可能な状態にしています。
HTTP
HttpClient(HttpClientについてはHttpClient詳解を読んでね)には、DelegatingHandlerが用意されているので、その前後でStopwatchを動かしてやるだけで済みます。
public class TraceHandler : DelegatingHandler
{
static readonly Logger httpLogger = NLog.LogManager.GetLogger("Http");
public TraceHandler()
: base(new HttpClientHandler())
{
}
public TraceHandler(HttpMessageHandler innerHandler)
: base(innerHandler)
{
}
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, System.Threading.CancellationToken cancellationToken)
{
var sw = Stopwatch.StartNew();
// SendAsyncの前後を挟むだけ
var result = await base.SendAsync(request, cancellationToken);
sw.Stop();
httpLogger.Trace(Newtonsoft.Json.JsonConvert.SerializeObject(new
{
date = DateTime.Now,
command = request.Method,
key = request.RequestUri,
ms = sw.ElapsedMilliseconds
}, Newtonsoft.Json.Formatting.None));
return result;
}
}
// 使う時はこんな感じにコンストラクタへ突っ込む
var client = new HttpClient(new TraceHandler());
// {"date":"2013-07-30T21:29:03.2314858+09:00","command":{"Method":"GET"},"key":"http://www.google.co.jp/","ms":129}
client.GetAsync("http://google.co.jp/").Wait();
なお、StreamをReadする時間は含まれていないので、あくまで向こうが反応を返した速度だけの記録になりますが、それでも十分でしょう。 Loggerは別にConsole.WriteLineでもTraceでも何でもいいのですが、弊社では基本的にNLogを使っています。フォーマットは、Http, Sql, Redisと統一するためにdate, command, key, msにしていますが、この辺もお好みで。
なお、DelegatingHandlerは連鎖して多段に組み合わせることが可能です。実際AsyncOAuthと合わせて使うと
var client = new HttpClient(
new TraceHandler(
new OAuthMessageHandler("key", "secret")));
といった感じになります。AsyncOAuthはHttpClientの拡張性がそのまま活かせるのが強い。
SQL
全てのデータベース通信は最終的にはADO.NETのDbCommandを通ります、というわけで、そこをフックしてしまえばいいのです。というのがMiniProfilerで、以下のように使います。
var conn = new ProfiledDbConnection(new SqlConnection("connectionString"), MiniProfiler.Current);
MiniProfilerはASP.NET MVCでの開発に超絶必須な拡張なわけで、当然、弊社でも使っています。さて、これはこれでいいのですけれど、MiniProfiler.Currentは割とヘヴィなので、そのまま本番に投入するわけもいかずで、単純にトレースするだけのがあるといいんだよねー。なので、ここは、MiniProfiler.Current = IDbProfilerを作りましょう。
なお、DbCommandをフックするProfiledDbConnectionに関してはそのまま使わせてもらいます。ただたんに移譲してるだけなんですが、DbCommandやDbTransactionや、とか、関連するもの全てを作って回らなければならなくて、自作するのカッタルイですから。ありものがあるならありものを使おう。ちなみに、MiniProfilerにはSimpleProfiledConnectionという、もっとシンプルな、本当に本当に移譲しただけのものもあるのですけれど、これはIDbConnectionがベースになってるので実質使えません。ProfiledDbConnectionのベースはDbConnection。IDbConnectionとDbConnectionの差異はかなり大きいので(*AsyncもDb...のほうだし)、実用的にはDbConnectionが基底と考えてしまっていいかな。
public class TraceDbProfiler : IDbProfiler
{
static readonly Logger sqlLogger = NLog.LogManager.GetLogger("Sql");
public bool IsActive
{
get { return true; }
}
public void OnError(System.Data.IDbCommand profiledDbCommand, ExecuteType executeType, System.Exception exception)
{
// 何も記録しない
}
// 大事なのは↓の3つ
Stopwatch stopwatch;
string commandText;
// コマンドが開始された時に呼ばれる(ExecuteReaderとかExecuteNonQueryとか)
public void ExecuteStart(System.Data.IDbCommand profiledDbCommand, ExecuteType executeType)
{
stopwatch = Stopwatch.StartNew();
}
// コマンドが完了された時に呼ばれる
public void ExecuteFinish(System.Data.IDbCommand profiledDbCommand, ExecuteType executeType, System.Data.Common.DbDataReader reader)
{
commandText = profiledDbCommand.CommandText;
if (executeType != ExecuteType.Reader)
{
stopwatch.Stop();
sqlLogger.Trace(Newtonsoft.Json.JsonConvert.SerializeObject(new
{
date = DateTime.Now,
command = executeType,
key = commandText,
ms = stopwatch.ElapsedMilliseconds
}, Newtonsoft.Json.Formatting.None));
}
}
// Readerが完了した時に呼ばれる
public void ReaderFinish(System.Data.IDataReader reader)
{
stopwatch.Stop();
sqlLogger.Trace(Newtonsoft.Json.JsonConvert.SerializeObject(new
{
date = DateTime.Now,
command = ExecuteType.Reader,
key = commandText,
ms = stopwatch.ElapsedMilliseconds
}, Newtonsoft.Json.Formatting.None));
}
}
これで、
{"date":"2013-07-15T18:24:17.4465207+09:00","command":"Reader","key":"select * from hogemoge where id = @id","ms":6}
のようなデータが取れます。パラメータの値も展開したい!とかいう場合は自由にcommandのとこから引っ張れば良いでしょう。更に、MiniProfiler.Currentと共存したいような場合は、合成するIDbProfilerを用意すればなんとかなる。Time的には若干ずれますが、そこまで問題でもないかしらん。
public class CompositeDbProfiler : IDbProfiler
{
readonly IDbProfiler[] profilers;
public CompositeDbProfiler(params IDbProfiler[] dbProfilers)
{
this.profilers = dbProfilers;
}
public void ExecuteFinish(IDbCommand profiledDbCommand, ExecuteType executeType, DbDataReader reader)
{
foreach (var item in profilers)
{
if (item != null && item.IsActive)
{
item.ExecuteFinish(profiledDbCommand, executeType, reader);
}
}
}
public void ExecuteStart(IDbCommand profiledDbCommand, ExecuteType executeType)
{
foreach (var item in profilers)
{
if (item != null && item.IsActive)
{
item.ExecuteStart(profiledDbCommand, executeType);
}
}
}
public bool IsActive
{
get
{
return true;
}
}
public void OnError(IDbCommand profiledDbCommand, ExecuteType executeType, Exception exception)
{
foreach (var item in profilers)
{
if (item != null && item.IsActive)
{
item.OnError(profiledDbCommand, executeType, exception);
}
}
}
public void ReaderFinish(IDataReader reader)
{
foreach (var item in profilers)
{
if (item != null && item.IsActive)
{
item.ReaderFinish(reader);
}
}
}
}
といったものを用意しておけば、
var profiler = new CompositeDbProfiler(
StackExchange.Profiling.MiniProfiler.Current,
new TraceDbProfiler());
var conn = new ProfiledDbConnection(new SqlConnection("connectionString"), profiler);
と、書けます。
SumoLogicによる分析
データ取るのはいいんだけど、それどーすんのー?って話なわけですが、以前にASP.NETでの定期的なモニタリング手法に少し出しましたけれど、弊社ではSumo Logicを利用しています。例えば、SQLで採取したログに以下のようクエリが発行できます。
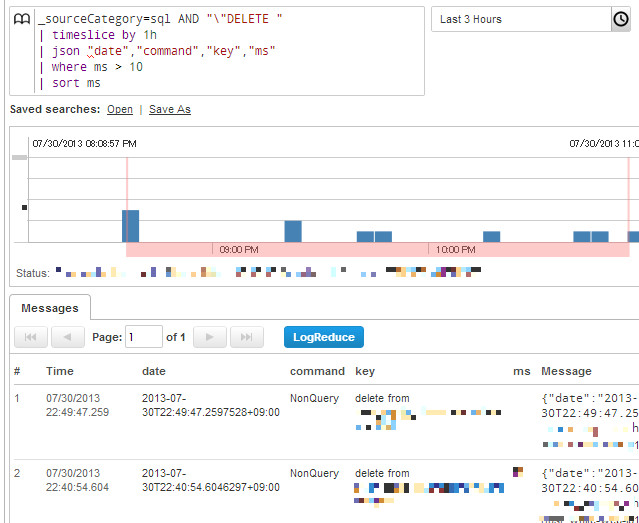
これは10ミリ秒よりかかったDELETE文を集計、ですね。Sumoは結構柔軟なクエリで、ログのパースもできるんですが、最初からJSONで吐き出しておけばjsonコマンドだけでパースできるので非常に楽ちん。で、パース後は10msより上なら ms > 10 といった形でクエリ書けます。
問題があった時の分析に使ってもいいし、別途グラフ化も可能(棒でも円でも色々)されるので、幾つか作成してダッシュボードに置いてもいいし、閾値を設定してアラートメールを飛ばしてもいい。slow_logも良いし当然併用しますが、それとは別に持っておくと、柔軟に処理できて素敵かと思われます。
Redis
弊社ではキャッシュ層もMemcachedではなく、全てRedisを用いています。Redisに関しては、C#のRedisライブラリ「BookSleeve」の利用法を読んでもらいたいのですが、ともあれ、BookSleeveと、その上に被せているお手製ライブラリのCloudStructuresを使用しています。
実質的に開発者が触るのはCloudStructuresだけです。というわけで、CloudStructuresに用意してあるモニター用のものを使いましょう。というかそのために用意しました。まず、ICommandTracerを実装します。
public class RedisProfiler : ICommandTracer
{
static readonly Logger redisLogger = NLog.LogManager.GetLogger("Redis");
Stopwatch stopwatch;
string command;
string key;
public void CommandStart(string command, string key)
{
this.command = command;
this.key = key;
stopwatch = Stopwatch.StartNew();
}
public void CommandFinish()
{
stopwatch.Stop();
redisLogger.Trace(Newtonsoft.Json.JsonConvert.SerializeObject(new
{
date = DateTime.Now,
command = command,
key = key,
ms = stopwatch.ElapsedMilliseconds
}, Newtonsoft.Json.Formatting.None));
// NewRelic使うなら以下のも。後で解説します。
var ms = (long)System.Math.Round(stopwatch.Elapsed.TotalMilliseconds);
NewRelic.Api.Agent.NewRelic.RecordResponseTimeMetric("Custom/Redis", ms);
}
}
何らかのRedisへの通信が走る際にCommandStartとCommandFinishが呼ばれるようになってます。そして、RedisSettingsに渡してあげれば
// tracerFactoryにFuncを渡すか、.configに書くかのどちらかで指定できます
var settings = new RedisSettings("127.0.0.1", tracerFactory: () => new RedisProfiler());
// {"date":"2013-07-30T22:41:34.2669518+09:00","command":"RedisString.TryGet","key":"hogekey","ms":18}
var value = await new RedisString<string>(settings, "hogekey").GetValueOrDefault();
みたいになります。
CloudStructuresは、既に実アプリケーションに投下していて、凄まじい数のメッセージを捌いているので、割と安心して使っていいと思いますですよ。ServiceStack.Redisはショッパイけど、BookSleeveはプリミティブすぎて辛ぽよ、な方々にフィットするはずです。実際、C# 5.0と合わせた際のBookSleeveの破壊力は凄まじいので、是非試してみて欲しいですね。
New Relicによるグラフ化
Sumo Logicはいいんですけど、しかし、もう少し身近なところにも観測データを置いておきたい。そして見やすく。弊社ではモニタリングにNew Relicを採用していますが、そこに、そもそもSQLやHttpのカジュアルな監視は置いてあるんですね。なので、Redis情報も統合してあげればいい、というのが↑のNewRelicのAPIを叩いているものです。ただたんにNuGetからNewRelicのライブラリを持ってきて呼ぶだけの簡単さ。それだけで、以下の様なグラフが!
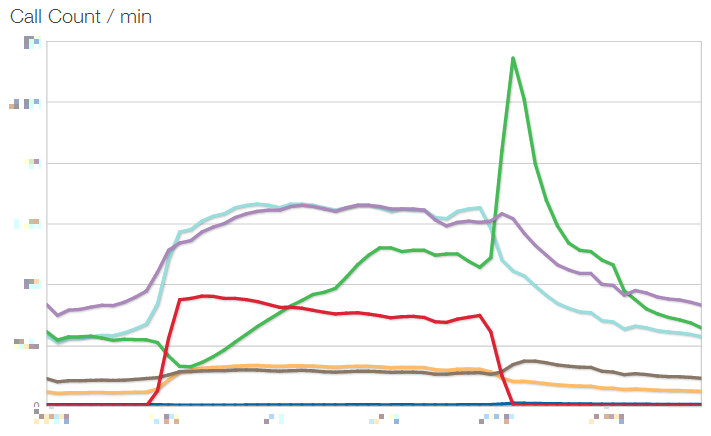
これはCall Countですが、他にAverageのResponse Timeなどもグラフ化してカスタムダッシュボードに置いています。
線が6本ありますが、これは用途によってRedisの台を分けているからです。例えばRedis.Cache, Redis.Session、のように。NewRelicのAPIを叩く際に、Custom/Redis/Cache、Custon/Redis/Sessionのようなキーのつけ方をすることで、個別に記録されます(それぞれのSettingsに個別のICommandTracerを渡しています)。ダッシュボードの表示時にCustom/Redis/*にするだけでひとまとめに表示できるから便利。
今のところ、Redisは全台平等に分散ではなく、グループ分け+負荷の高いものは複数台で構成しています。キャッシュ用途の台はファイルへのセーブなしで、完全インメモリ(Memcachedに近い)にしているなど、個別チューニングも入っています。
一番カジュアルに確認できるNew Relic、詳細な情報や解析クエリはSumo Logic。見る口が複数あるのは全然いいことです。
レスポンスタイム
HttpContextのTimestampに最初の時間が入っているので、Application_EndRequestで捕まえて差分を取ればかかった時間がサクッと。
protected void Application_EndRequest()
{
var context = HttpContext.Current;
if (context != null)
{
var responseTime = (DateTime.Now - context.Timestamp);
// 解析するにあたってクエリストリングは邪魔なのでkeyには含めずの形で
logger.Trace(Newtonsoft.Json.JsonConvert.SerializeObject(new
{
date = DateTime.Now,
command = this.Request.Url.GetComponents(UriComponents.Path, UriFormat.Unescaped),
key = this.Request.Url.GetComponents(UriComponents.Query, UriFormat.Unescaped),
ms = (long)responseTime.TotalMilliseconds
}, Newtonsoft.Json.Formatting.None));
}
}
取れますね。
まとめ
改善は計測から!足元を疎かにして改善もクソもないのです。そして、存外、当たり前のようで、当たり前にはできないのね。また、データは取るだけじゃなく、大事なのは開発メンバーの誰もが見れる場所にあるということ。いつでも。常に。そうじゃないと数字って相対的に比較するものだし、肌感覚が養えないから。
弊社では、簡易なリアルタイムな表示はMiniProfilerとビュー統合のログ表示。実アプリケーションでは片っ端から収集し、NewRelicとSumoLogicに流しこんで簡単に集計・可視化できる体制を整えています。実際、C#移行を果たしてからの弊社のアプリケーションは業界最速、といってよいほどの速度を叩きだしています。基礎設計からガチガチにパフォーマンスを意識しているから、というのはもちろんあるのですが(そしてC# 5.0の非同期がそれを可能にした!)、現在自分が作っているものがどのぐらいのパフォーマンスなのか、を常に意識できる状態に置けたことも一因ではないかな、と考えています。(ただし、.NET最先端技術によるハイパフォーマンスウェブアプリケーションで述べましたが、そのためには開発環境も本番と等しいぐらいのネットワーク環境にしてないとダメですよ!)
私は今年は、言語や設計などの小さな優劣の話よりも、実際に現実に成功させることに重きを置いてます。C#で素晴らしい成果が出せる、その証明を果たしていくフェーズにある。成果は出せるに決まってるでしょ、と、仮に理屈では分かっていても、しかしモデルケースがなければ誰もついてこない。だから、そのための先陣を切っていきたい。勿論、同時に、成果物はどんどん公開していきます。C#が皆さんのこれからの選択肢の一番に上がってくれるといいし、また、C#といったらグラニ、となれるよう頑張ります。
ASP.NETでの定期的なモニタリング手法
- 2013-07-20
cron的な定期実行といったら、タスクスケジューラ使え。完。なわけですが、それとは別にして、アプリケーションサーバー内部からしか分からない情報を定期的に吐き出したいようなシチュエーションにどうしましょうか?例えばスレッドプールの情報!かなり古いのですがHow To 情報: カスタム カウンタを使った ASP.NET スレッド プールの監視方法なんて、まずレジストリに登録して、そこから定期的に無限ループ+Thread.Sleep(ダセぇ)で出力という、なんともトホホな感じ。いや、これトホホでしょう。というわけで、もっとモダンにいきましょう。
IHttpModuleとInit, Dispose
カスタム HTTP モジュールを作成および登録するということで、IHttpModuleを作成することで、ASP.NETパイプライン上での各イベント時に実行されるものを追加していくことができます。Global.asax.csに直書きでもいいですが、こっちのほうが分離されてる感はありますにぇ。さて、通常はapplication.BeginRequest+=とか、イベント登録するんですが、Application_Startイベントに相当するものは……ありません。はい。ただしかわりにInitメソッドがあります。普段はイベント登録しますが、ここでメソッド実行すれば、それApplication_Startに等しいよねー、と思っていた時もありました。
public class CountModule : IHttpModule
{
public static int Count = 0;
public void Init(HttpApplication context)
{
Interlocked.Increment(ref Count);
}
}
これ、ブレークポイントを張って様子みたり、Countの値を表示して見たりするとわかりますが、何度も呼ばれます。何度も何度も。どーいうことかというと、Application_StartとInitは等しくないです。ASP.NET Runtimeは複数のアプリケーションプールを作り、それごとにInitは呼ばれてるんですね。じゃあ、どうするか、というと……
public class CallOnceModule : IHttpModule
{
static int initializedModuleCount;
public void Init(HttpApplication context)
{
var count = Interlocked.Increment(ref initializedModuleCount);
if (count != 1) return;
// ここに本体書く
}
public void Dispose()
{
var count = Interlocked.Decrement(ref initializedModuleCount);
if (count == 0)
{
// ここに本体書く
}
}
}
Initが呼ばれた回数を取れば、正しく1回になります。ちなみに属性を張るだけで、Application_Startっぽく呼び出されるメソッドを作れるWebActivatorも、似たような感じの仕組みです。
Timer
IHttpModuleの話はこのぐらいにして、本体の話にいきましょう。定期的に、例えば1分間隔に、とかは、Timer使えばいいんですよ、Timer。あ、Timerは幾つかありますが、System.Threading.Timerのほうね。
/// <summary>
/// 1分間隔でThreadInfoをログ取りするモジュール
/// </summary>
public class ThreadInfoLoggingModule : IHttpModule
{
static NLog.Logger logger = NLog.LogManager.GetLogger("ThreadInfo");
static NLog.Logger classLogger = NLog.LogManager.GetCurrentClassLogger();
static int initializedModuleCount;
static Timer timer;
public void Init(HttpApplication context)
{
var count = Interlocked.Increment(ref initializedModuleCount);
if (count != 1) return;
timer = new Timer(_ =>
{
try
{
var date = DateTime.Now;
int availableWorkerThreads, availableCompletionPortThreads;
ThreadPool.GetAvailableThreads(out availableWorkerThreads, out availableCompletionPortThreads);
int maxWorkerThreads, maxCompletionPortThreads;
ThreadPool.GetMaxThreads(out maxWorkerThreads, out maxCompletionPortThreads);
using (var sw = new System.IO.StringWriter())
using (var jw = new Newtonsoft.Json.JsonTextWriter(sw))
{
jw.Formatting = Newtonsoft.Json.Formatting.None;
jw.WriteStartObject(); // {
jw.WritePropertyName("date");
jw.WriteValue(date);
jw.WritePropertyName("availableWorkerThreads");
jw.WriteValue(availableWorkerThreads);
jw.WritePropertyName("availableCompletionPortThreads");
jw.WriteValue(availableCompletionPortThreads);
jw.WritePropertyName("maxWorkerThreads");
jw.WriteValue(maxWorkerThreads);
jw.WritePropertyName("maxCompletionPortThreads");
jw.WriteValue(maxCompletionPortThreads);
jw.WriteEndObject(); // }
jw.Flush();
var message = sw.ToString();
logger.Trace(message);
}
}
catch (Exception ex)
{
classLogger.ErrorException("ThreadInfoLogging encounts error", ex);
}
}, null, TimeSpan.FromMinutes(1), TimeSpan.FromMinutes(1));
}
public void Dispose()
{
var count = Interlocked.Decrement(ref initializedModuleCount);
if (count == 0)
{
var target = Interlocked.Exchange(ref timer, null);
if (target != null)
{
target.Dispose();
}
}
}
}
なにをやっているか。よーするに、Timerで1分置きにロガーでJSONを吐き出してます。ロガーは謎社ではNLogを使ってます。というかこのModuleでは謎社のプロダクション環境で動いてるものです。なお、JsonTextWriter使ってるところは、別に普通にSerializeで構いませんですよ、なんとなく手書きしちゃっただけなので。
というわけで、これでThreadPoolの情報が取れました。やったね!あとはJSONなので好きな様にゴリゴリすればいいんですが、賢く解析したいなら、とりあえず謎社ではSumo Logicを使っています。Next Generation Log Management & Analyticsということで、集計ツールと解析ウェブアプリをワンセットで提供してくれてます。
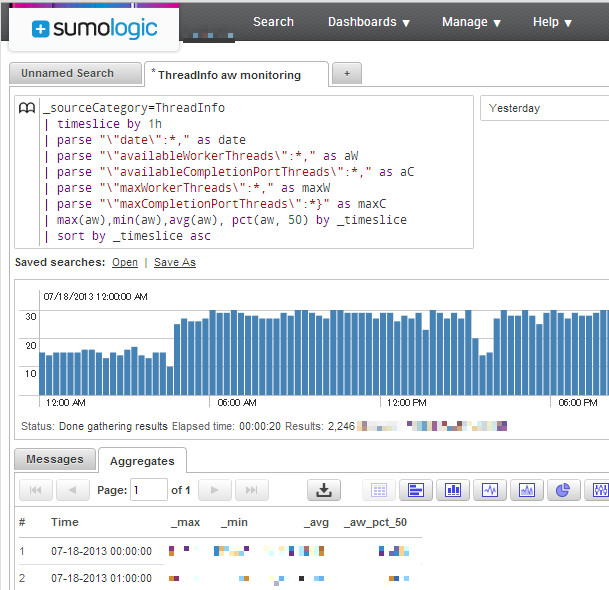
独自のクエリ言語でガッと解析してグラフ化できてる、ってのは伝わるでしょうか?ふいんきね。便利そう、とか思ってもらえれば。クエリと可視化、更に閾値による通知など、色々できちゃいます。こいつぁイイね?←ちなみに、私はまだ全然クエリ書けないので、これは謎社の誇るPowerShellマスターが用意してくれました。
(ここではparseが手書きチックですが、実際にJSONをSumoでパースする際はJsonコマンドが用意されているので、それを使えばもっと綺麗にparseできます)
BookSleeveのMonitor
ついでに、謎社ではRedisを多用しているんですが、RedisライブラリであるBookSleeveは、GetCountersというメソッドで、それぞれのRedisConnectionの情報を吐き出すことができます。これを1分置きに、ThreadInfoと同様に吐き出すようにしてます。
/// <summary>
/// 1分間隔でRedis(BookSleeve)のCounterをログ取りするモジュール
/// </summary>
public class RedisCounterLoggingModule : IHttpModule
{
static NLog.Logger logger = NLog.LogManager.GetLogger("RedisCounter");
static NLog.Logger classLogger = NLog.LogManager.GetCurrentClassLogger();
static int initializedModuleCount;
static Timer timer;
public void Init(HttpApplication context)
{
var count = Interlocked.Increment(ref initializedModuleCount);
if (count != 1) return;
timer = new Timer(_ =>
{
try
{
var date = DateTime.Now;
// ここは謎社Internalな部分なのでテキトーにスルーしてくださいな
var query = Grani.Core.GlobalConfig.RedisGroupDictionary
.SelectMany(x => x.Value.Settings, (x, settings) => new { x.Value.GroupName, settings });
foreach (var item in query)
{
var connection = item.settings.GetConnection();
var counters = connection.GetCounters();
using (var sw = new System.IO.StringWriter())
using (var jw = new Newtonsoft.Json.JsonTextWriter(sw))
{
jw.Formatting = Newtonsoft.Json.Formatting.None;
jw.WriteStartObject(); // {
jw.WritePropertyName("date");
jw.WriteValue(date);
jw.WritePropertyName("GroupName");
jw.WriteValue(item.GroupName);
jw.WritePropertyName("Host");
jw.WriteValue(item.settings.Host + ":" + item.settings.Port);
jw.WritePropertyName("Db");
jw.WriteValue(item.settings.Db);
jw.WritePropertyName("MessagesSent");
jw.WriteValue(counters.MessagesSent);
jw.WritePropertyName("MessagesReceived");
jw.WriteValue(counters.MessagesReceived);
jw.WritePropertyName("MessagesCancelled");
jw.WriteValue(counters.MessagesCancelled);
jw.WritePropertyName("Timeouts");
jw.WriteValue(counters.Timeouts);
jw.WritePropertyName("QueueJumpers");
jw.WriteValue(counters.QueueJumpers);
jw.WritePropertyName("Ping");
jw.WriteValue(counters.Ping);
jw.WritePropertyName("SentQueue");
jw.WriteValue(counters.SentQueue);
jw.WritePropertyName("UnsentQueue");
jw.WriteValue(counters.UnsentQueue);
jw.WritePropertyName("ErrorMessages");
jw.WriteValue(counters.ErrorMessages);
jw.WritePropertyName("SyncCallbacks");
jw.WriteValue(counters.SyncCallbacks);
jw.WritePropertyName("AsyncCallbacks");
jw.WriteValue(counters.AsyncCallbacks);
jw.WritePropertyName("SyncCallbacksInProgress");
jw.WriteValue(counters.SyncCallbacksInProgress);
jw.WritePropertyName("AsyncCallbacksInProgress");
jw.WriteValue(counters.AsyncCallbacksInProgress);
jw.WritePropertyName("LastSentMillisecondsAgo");
jw.WriteValue(counters.LastSentMillisecondsAgo);
jw.WritePropertyName("LastKeepAliveMillisecondsAgo");
jw.WriteValue(counters.LastKeepAliveMillisecondsAgo);
jw.WritePropertyName("KeepAliveSeconds");
jw.WriteValue(counters.KeepAliveSeconds);
jw.WritePropertyName("State");
jw.WriteValue(counters.State.ToString());
jw.WriteEndObject(); // }
jw.Flush();
var message = sw.ToString();
logger.Trace(message);
}
}
}
catch (Exception ex)
{
classLogger.ErrorException("RedisCounterLogging encounts error", ex);
}
}, null, TimeSpan.FromMinutes(1), TimeSpan.FromMinutes(1));
}
public void Dispose()
{
var count = Interlocked.Decrement(ref initializedModuleCount);
if (count == 0)
{
var target = Interlocked.Exchange(ref timer, null);
if (target != null)
{
target.Dispose();
}
}
}
}
RedisGroupとかコネクション管理はBookSleeveの上に被せてるCloudStructuresによるものです(プロダクション環境でヘヴィに使ってますよ!)。CloudStructuresの使い方とかもまたそのうち。
まとめ
とまぁ、そんなふうにして色々データ取ってます。改善の基本はデータ取りから。色々なところからデータ取ってチェック取れるような体制を整えています。次回は、SQLやHttp、Redisの実行時間をどう取得するかについてお話しましょふ。たぶんね。きっと。
ところで、プロダクション環境下で――と書いているように、謎社のアプリケーションは完全にC#に移行しました。結果ですが、最先端環境で練り上げたC#によるウェブアプリケーションは、超絶速い。しかも、完全にAWSクラウドに乗っけての話ですからね、オンプレミスでのスペシャルなマシンやFusion-ioなDBでやってるわけじゃなく、成果出せてる。
Sumo LogicやNew Relicなど外部サービスの活用やRedisの使い倒しかた、非同期処理の塊、などなど、次世代のC#ウェブアプリケーションのスタンダードというものを示せたのではないかな、と思っています。詳しい話はそのうちまたどこかで発表したいとは思うので待っててください。
C#で扱うRedisのLuaスクリプティング
- 2013-07-10
Redis 2.6からLuaスクリプティングが使えるようになりました。コマンドはEVALです。というわけでC#のRedisライブラリ、BookSleeveで、試してみましょう。RedisやBookSleeveに関しては、以前に私がBuildInsiderで書いたC#のRedisライブラリ「BookSleeve」の利用法を参照ください。
BookSleeveは当然NuGet経由で入れるとして、Windows版のRedisバイナリもNuGetで配布されています。手軽に試してみるなら、Install-Package Redis-64が良いのではないでしょーか。現在の最新は2.6.12.1ということで、Evalにも対応しています。インストールするとpackages\Redis-64.2.6.12.1\toolsにredis-server.exeが転がっているので、それを起動すれば、とりあえず127.0.0.1:6379で動きます。
多重アクセスの検出
HelloWorld!ということで、多重アクセス検知のスクリプトでも書いてみます。ルールとしては、X秒以内にY回アクセスしてきた人間はZ秒アク禁にする。という感じですね。DOSアタック対策的な。LUAスクリプティングを使わないと、キーを2つ用意したりしなけりゃいけなかったり複数コマンド打ったりしたりとか、若干面倒だったり効率悪いのですが、スクリプティング使えば一発で済ませられます。
public static class RedisExtensions
{
public static async Task<bool> DetectAttack(this RedisConnection redis, int db, string key, int limitCount = 10, int durationSecond = 1, int bannedSecond = 300)
{
var result = await redis.Scripting.Eval(db, @"
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local count = redis.call('incr', key)
if(count >= limit) then
local banSec = tonumber(ARGV[3])
redis.call('EXPIRE', key, banSec)
return true
else
local expireSec = tonumber(ARGV[2])
redis.call('EXPIRE', key, expireSec)
return false
end", new[] { key }, new object[] { limitCount, durationSecond, bannedSecond }).ConfigureAwait(false);
// Lua->Redisはtrueの時に1を、falseの時にnullを返す
return (result == null) ? false
: ((long)result == 1) ? true
: false;
}
}
こんな感じですね。基本的にはEvalメソッドでスクリプトを渡すだけです、あとKEYS配列とARGV配列を必要ならば。戻り値の扱いなどに若干のクセがありますので、その辺はRedisのEVALのドキュメントを読んでおくといいでしょう。
スクリプトは、まずincrを呼んでカウントを取る。そのカウントが指定数を超えてたらExpireの時間をBanの時間(デフォは300秒=5分)引き伸ばす。超えてなければ、Expireの時間を指定間隔(デフォは1秒)だけ伸ばす。もし1秒以内に連続でアクセスがあれば、Incrのカウントが増えていく。1秒以上経過すればExpireされているので、countは0スタートになる。といった感じです。
利用する場合はこんな具合。
var redis = new RedisConnection("127.0.0.1");
await redis.Open();
var v = await redis.DetectAttack(0, "hogehoge");
Console.WriteLine(v); // false
for (int i = 0; i < 15; i++)
{
var v2 = await redis.DetectAttack(0, "hogehoge");
Console.WriteLine(v2); // false,false,...,true,true
}
いい具合ですにぇ?
EVALSHA
BookSleeveのEvalは、正確にはEVALSHAです(更に正しくはデフォルトの、引数のuseCacheがtrueの場合)。
EVALSHAは、事前にスクリプトのSHA1を算出し、初回に登録しておくことで、コマンドの転送をSHA1の転送だけで済ませます。スクリプトを毎回投げていたらコマンド転送に時間がかかるので、それの節約です。この辺をBookSleeveは何も意識しなくても、やってくれるのが非常に楽ちん。素晴らしい。
Increment/DecrementLimit
せっかくなので、もう一つ例を。RedisのIncrementやDecrementはアトミックな操作で非常に使いやすいのですが、上限や下限を設けたい場合があります。例えば、HPは0以下になって欲しくないし、最大HPを超えて回復されても困る、みたいな。それも当然、Luaスクリプティングを使えば簡単に実現可能です。
public static async Task<long> IncrementWithLimit(this RedisConnection redis, int db, string key, long value, long maxLimit)
{
var result = await redis.Scripting.Eval(db, @"
local inc = tonumber(ARGV[1])
local max = tonumber(ARGV[2])
local x = redis.call('incrby', KEYS[1], inc)
if(x > max) then
redis.call('set', KEYS[1], max)
x = max
end
return x", new[] { key }, new object[] { value, maxLimit }).ConfigureAwait(false);
return (long)result;
}
incrbyの結果が指定の値を超えていたら、setで固定する、といった感じです、単純単純。使うときはこんな具合。
var redis = new RedisConnection("127.0.0.1");
await redis.Open();
var v1 = await redis.IncrementWithLimit(0, "hoge", 40, maxLimit: 100);
var v2 = await redis.IncrementWithLimit(0, "hoge", 40, maxLimit: 100);
var v3 = await redis.IncrementWithLimit(0, "hoge", 40, maxLimit: 100);
// 40->80->100
Console.WriteLine(v1 + "->" + v2 + "->" + v3);
楽ちん、これは捗る。
まとめ
というわけで、RedisいいよRedis。いやほんと色々な面で使ってて嬉しいことが多いです。RDBMSだけで頑張ると非常に辛ぽよ、Redisがあるだけで何かと楽になれますので、一家に一台は置いておきたい。
Luaスクリプティングは複数コマンド間で戻り値が扱えるため、利用範囲がグッと広がります。そしてスクリプティング中の動作もまたアトミックである、というのが嬉しい点です(C#コード上で複数コマンドを扱うと、そこの保証がないというのが大きな違い)。と同時に注意しなければならないのは、アトミックなので、スクリプト実行中は完全にブロックされてます。ので、あまりヘヴィなことをLuaスクリプティングでやるのは避けたほうがいいのではないかなー、と思われます。
asyncの落とし穴Part2, SynchronizationContextの向こう側
- 2013-07-02
非同期QUIZの時間がやってきました!前回はデッドロックについてでしたが、今回はヌルポについて扱いましょう。まずは以下のコードの何が問題なのかを当ててください。ASP.NET MVCです。あ、.NET 4.5ね。
public class HomeController : Controller
{
async Task DoAsync()
{
await Task.Delay(TimeSpan.FromSeconds(3));
}
public ActionResult Index()
{
DoAsync();
return View();
}
}
どこがダメで、どうすれば改善されるのかはすぐ分かると思います。「なにが起こるのか」「なぜ起こるのか」について、考えてみてください。おわり。
さて、で、Ctrl+F5で実行すると、このコードは何の問題もなくふとぅーに動きます。一見何の問題もない。実際何の問題もない。オシマイ。
というのもアレなので、何が起こっているのか観測します。まず、Global.asax.csに以下のコードを。
protected void Application_Start()
{
// ルーターの登録とか標準のものがこの辺に
Trace.Listeners.Add(new TextWriterTraceListener(@"D:\log.txt"));
Trace.AutoFlush = true;
System.Threading.Tasks.TaskScheduler.UnobservedTaskException += (sender, e) =>
{
Trace.WriteLine(e.Exception);
};
}
で、本体はこんな風に。
public class HomeController : Controller
{
async Task DoAsync()
{
Trace.WriteLine("start"); // 何か開始処理があるのだとする
await Task.Delay(TimeSpan.FromSeconds(3)); // 何か非同期処理してるとする
Trace.WriteLine("end"); // 何か後処理があるのだとする
}
public ActionResult Index()
{
GC.Collect(); // GC自然発生待ちダルいので発動しちゃう
var _ = DoAsync(); // 非同期処理を"待たない"
return View();
}
}
D:\log.txtは、まぁどこに吐いてもいいんですが、ちゃんと書き込み権限があるところに。んでは、実行しましょう。log.txtは、初回はまず、「start」と書かれます。つまり、endまで到達してないことが確認できます。二回目のアクセスではGC.Collectが走り、それによりUnobservedTaskExceptionが実行されます。で、log.txtには以下のものが書き込まれます。
System.AggregateException: タスクの例外が、タスクの待機によっても、タスクの Exception プロパティへのアクセスによっても監視されませんでした。その結果、監視されていない例外がファイナライザー スレッドによって再スローされました。 ---> System.NullReferenceException: オブジェクト参照がオブジェクト インスタンスに設定されていません。
場所 System.Web.ThreadContext.AssociateWithCurrentThread(Boolean setImpersonationContext)
場所 System.Web.HttpApplication.OnThreadEnterPrivate(Boolean setImpersonationContext)
場所 System.Web.HttpApplication.System.Web.Util.ISyncContext.Enter()
場所 System.Web.Util.SynchronizationHelper.SafeWrapCallback(Action action)
場所 System.Web.Util.SynchronizationHelper.<>c__DisplayClass9.<QueueAsynchronous>b__7(Task _)
場所 System.Threading.Tasks.ContinuationTaskFromTask.InnerInvoke()
場所 System.Threading.Tasks.Task.Execute()
--- 内部例外スタック トレースの終わり ---
---> (内部例外 #0) System.NullReferenceException: オブジェクト参照がオブジェクト インスタンスに設定されていません。
場所 System.Web.ThreadContext.AssociateWithCurrentThread(Boolean setImpersonationContext)
場所 System.Web.HttpApplication.OnThreadEnterPrivate(Boolean setImpersonationContext)
場所 System.Web.HttpApplication.System.Web.Util.ISyncContext.Enter()
場所 System.Web.Util.SynchronizationHelper.SafeWrapCallback(Action action)
場所 System.Web.Util.SynchronizationHelper.<>c__DisplayClass9.<QueueAsynchronous>b__7(Task _)
場所 System.Threading.Tasks.ContinuationTaskFromTask.InnerInvoke()
場所 System.Threading.Tasks.Task.Execute()<---
おぅ!例外が発生していた!ぬるり!ぬるり!
GC.Collectを実行している理由は、Taskに溜まった未処理例外は、GCが走ったタイミングでUnobservedTaskExceptionに渡されるので、それを待つ時間を短縮しているだけです。GC.Collectを明示的に実行しなくても、長く動かしてればそのうち発生します。
というわけで、何が起こるのか、というと、await Task.Delayのところでヌルリが発生します。↑の例外情報からは、どこで発生していたのかの情報が一切出てこないので(さすがにこれなんとかして欲しいですけどねぇ……)、いざ発生するとなると場所を突き止めるのに割と苦労します、というか虱潰ししかないので結構大変です。そもそもUnobservedTaskExceptionをモニタしてなければ、発生していたことにすら気づけません。
なぜ起こるのか、というと、awaitによってPOSTする先のContextが消滅しているからです。非同期処理を待たなかったことによって、Viewの表示まで全て完了してContextが消滅する。その後で、DoAsync内のawaitが完了し、続行しようとPOSTを開始する、と、しかしContextは消滅していてなにもなーい。ので、ぬるり。
では、解決方法は、というと、例によってasyncで統一するか
public class HomeController : Controller
{
async Task DoAsync()
{
Trace.WriteLine("start"); // 何か開始処理があるのだとする
await Task.Delay(TimeSpan.FromSeconds(3)); // 何か非同期処理してるとする
Trace.WriteLine("end"); // 何か後処理があるのだとする
}
public async Task<ActionResult> Index()
{
GC.Collect();
await DoAsync(); // awaitする
return View();
}
}
もしくはConfigureAwait(false)でContextを維持しないこと。
public class HomeController : Controller
{
async Task DoAsync()
{
Trace.WriteLine("start"); // 何か開始処理があるのだとする
await Task.Delay(TimeSpan.FromSeconds(3)).ConfigureAwait(false); // ConfigureAwait(false)する
Trace.WriteLine("end"); // 何か後処理があるのだとする
}
public ActionResult Index()
{
GC.Collect();
var _ = DoAsync(); // 非同期処理を"待たない"
return View();
}
}
です。
そもそも、何故非同期処理を"待たない"のか。例えば、アクセスログを取るために記録するだけだとか、別に完了を待つ必要がないものだったりするなら、待たないことでレスポンスは速くなる。待つ必要ないのなら、待たなくてもいいぢゃない。それはそうです。
なので、待たないなら待たないでいいのですが、中身について用心しないと、ヌルりで死んでしまいます。これは、同期的に待つ時もそうですね。待つなら待つでいいですけれど、中身について用心しないと、デッドロックで死んでしまいます。待っても死亡、待たなくても死亡、ホント非同期は地獄だぜ!
まあ、変数で受けたりしない限りは警告は出してくれますので(ウザいと思っていたアナタ!実に有益な警告ではないですか!)、不注意による死亡はある程度は避けられはします。
.NET 4.0 vs .NET 4.5
.NET 4.5だと、↑のような挙動ですが、.NET 4.0だとちょっと事情が違ったりします。async/awaitは利用したままで、ターゲットフレームワークのバージョンだけ4.0にしましょう。
<system.web>
<httpRuntime targetFramework="4.0" />
<compilation debug="true" targetFramework="4.0" />
</system.web>
で、Ctrl+F5で実行して、何度かブラウザをリロードしましょう。死んでます。IIS Expressが。完全に無反応になります。何故?Windowsのイベントビューアーを見ましょう。
ハンドルされない例外のため、プロセスが中止されました。というわけで、未処理例外が突き抜けてアプリケーションエラーとして記録されていくためです。プロダクション環境でもIISのラピッドフェール保護が発動して、デフォルトでは5分以内に5エラーでアプリケーションは停止します。これは実にクリティカル。
なんで.NET 4.0と4.5で挙動が違うのか、というと、Taskの未処理例外の扱いが4.0と4.5で変わったためです。この辺はPfxTeamのTask Exception Handling in .NET 4.5を参照にどーぞ。4.5のほうが安全っちゃー安全ですね。いずれにせよ、UnobservedTaskExceptionの例外ロギングは欠かさずやっておきましょう。
まとめ
非同期もいいんですけど、実際にマジでフルに使い出すと結構なんだかんだでハマりどころは多いですねぇ。幸い、デバッガビリティに関してはWindows 8.1 + Visual Studio 2013である程度改善するようで、待ち遠しいです。とはいえデッドロックだったりコンテキスト場外でヌルりだとかは、注意するしかない。
ASP.NET MVCのフィルターはやく非同期に対応してくださいー。ASP.NET MVC 5でも予定に入ってないようでどうなってんだゴルァ。Resultで待つしかなくて非常にヒヤヒヤします。EF6も非同期対応とか、そもそもMVC 5では.NET 4.5からのみだとか、どんどん非同期使われてくにつれ、死亡率も間違いなく上がってきますにゃ。
Micro-ORMとテーブルのクラス定義自動生成について
- 2013-06-30
謎社のデータアクセスはMicro-ORMでやっています。生SQL書いて、シンプルなPOCOにマッピングするだけの。ですが、そこで困るのはPOCOの作成。データベースの写しなだけのクラスですが、手で作るには、ひじょーに面倒。Entity Frameworkならドラッグアンドドロップで!DataSetですらホイホイと作れるのに、100%手作業とか嫌だよー、200テーブルを延々とクラス作るだけの刺身たんぽぽなんてしてたら死んじゃうよー。
というわけで、Micro-ORM使うなら避けては通れない定義。EFのクラス定義だけ流用しちゃうとか色々と逃げ道も考えられなくもないですが、もしくは数によっては手動で頑張ってしまうのも手ですが、ここは自動生成しましょうの会。
GetSchema
普通にSQLのクエリを書いてデータベースの情報を取ってくることも可能ですが、各データベースでそれぞれバラバラだったりするので、ここはADO.NETで用意されているGetSchemaを使いましょう。情報取得の部分が抽象化されていて、型無しDataTableとして受け取ることが可能です。
using (var conn = new MySqlConnection("接続文字列。MySQLでもなんでもいいよ。"))
{
conn.Open();
var schema = conn.GetSchema();
}
さて、schemaとやらをデバッガで見てみるとですね……
うおおお、これがDataTableか!な、なんだ、このデバッガビリティの低さは……。これはヤヴァい。マジキチ。RowsのKeyを辿るのも苦労するうえに、Valueが一覧で見れない。頑張ってもKeyだけ。なんだこりゃ。データの取得もLINQ to DataSet(笑)によって、普通に実に扱いづらい。話にならない。 クソが。というわけで、今時ならば型無しDataTableはdynamicで扱ったほうが楽です。ExpandoObjectに変換しましょう。
public static class DataTableExtensions
{
/// <summary>DataTableの各RowをExpandoObjectに変換します。</summary>
public static IEnumerable<dynamic> AsDynamic(this DataTable table)
{
return table.AsEnumerable().Select(x =>
{
IDictionary<string, object> dict = new ExpandoObject();
foreach (DataColumn column in x.Table.Columns)
{
var value = x[column];
if (value is System.DBNull) value = null;
dict.Add(column.ColumnName, value);
}
return (dynamic)dict;
});
}
}
こんなものを用意すると、 var schema = conn.GetSchema().AsDynamic() とするだけで
うおおおおおおお、超捗る!ちゃんと動的ビューでKeyとValueが見える!ExpandoObjectありがとう。DataTableは死ね。また、DBNullをフツーのnullに変換したりなどもしているので、データを触るのもかなり捗るといったところもあります。item.Field<string>("CollectionName")と書くよりも、item.CollectionNameって書きたいですから。
では、気を取り直してこれで解析していきましょう。まずは、件のCollectionNameを見てみますか。
// MetaDataCollections
// DataSourceInformation
// DataTypes
// Restrictions
// ReservedWords
// Databases
// Tables
// Columns
// Users
// Foreign Keys
// IndexColumns
// Indexes
// Foreign Key Columns
// UDF
// Views
// ViewColumns
// Procedure Parameters
// Procedures
// Triggers
foreach (var item in conn.GetSchema().AsDynamic())
{
Console.WriteLine(item.CollectionName);
}
MySQLでは以上のデータが取れるようです。この辺は使ってるデータベースによってかなり変わるので、適宜調べながら合わせてみてくださいな。というわけで、それっぽそうなTablesを見てみます。var tables = conn.GetSchema("Tables").AsDynamic(); とすれば
テーブル一覧が取れるようです。で、しかし、今回必要なのはTablesではありません。TablesはほんとーにTableのデータだけなので。今回必要なのは、Columnsです。
var columns = conn.GetSchema("Columns").AsDynamic()
.GroupBy(x => x.TABLE_NAME) // 全てのカラムが平らに列挙されてくるのでテーブル名でグルーピング
.Select(g => new
{
ClassName = g.Key, // クラス名はテーブル名(= グルーピングのキー)
Properties = g
.OrderBy(x => x.ORDINAL_POSITION) // どんな順序で来るか不明なので、カラム定義順にきちんと並び替え
.Select(x => new
{
Name = x.COLUMN_NAME,
Type = x.DATA_TYPE
})
.ToArray()
});
良い感じに作れてきました。さて、クラスを自動生成するのに必要なのは「クラス名」「プロパティ名」「プロパティの型」です。DATA_TYPEだとDBの生の型名、bigintとかvarcharとかC#のデータ型じゃないよー。なので、このまんまじゃダメです。
というわけで、マッピングを用意してあげます。といっても手動でやる必要はなくて、これはGetSchema("DataTypes")で取れます。
// 型名を決めるのに必要なのは
// TypeName(MySQLの型名), DataType(.NETの型名), IsUnsigned
var typeDictionary = conn.GetSchema("DataTypes").AsDynamic()
.ToDictionary(x =>
Tuple.Create((string)x.TypeName.ToLower(), (bool?)x.IsUnsigned ?? false),
x => (Type)Type.GetType(x.DataType));
// MySQLのtinyintはboolとして使われることが多いので、そちらにマッピングしちゃう(不要ならしなくていいです)
typeDictionary[Tuple.Create("tinyint", true)] = typeof(bool);
typeDictionary[Tuple.Create("tinyint", false)] = typeof(bool);
// nullableの場合を考慮する必要があるのでTypeDictionaryは生では使わない
Func<string, bool, bool, string> getTypeName = (dataType, isUnsigned, isNullable) =>
{
var type = typeDictionary[Tuple.Create(dataType.ToLower(), isUnsigned)];
return (isNullable && type.IsValueType)
? type.Name + "?" // 値型かつnull許可の時
: type.Name;
};
TypeName(MySQLの型名), DataType(.NETの型名), IsUnsigned。それにNullableへの対応を組み合わせれば、マッピングできると考えられます。GetSchemaからの情報だけだとNullable対応が苦しくなるので、外にメソッド立てています。
さて、この型定義辞書を使って変換すると、以下のようになります。
var columns = conn.GetSchema("Columns").AsDynamic()
.GroupBy(x => x.TABLE_NAME) // 全てのカラムが平らに列挙されてくるのでテーブル名でグルーピング
.Select(g => new
{
ClassName = g.Key, // クラス名はテーブル名(= グルーピングのキー)
Properties = g
.OrderBy(x => x.ORDINAL_POSITION) // どんな順序で来るか不明なので、カラム定義順にきちんと並び替え
.Select(x => new
{
Name = x.COLUMN_NAME,
// unsignedの判定はCOLUMN_TYPEから、nullableの判定はYES/NOで行われる
Type = getTypeName(x.DATA_TYPE, x.COLUMN_TYPE.Contains("unsigned"), x.IS_NULLABLE == "YES")
})
.ToArray()
});
これで完璧!さて、定義の抽出はできたので、次はテンプレート作りにいきましょうか。
T4
(テキストとしての)C#コード生成は、C#コード上で文字列を切った貼ったする、わけは勿論ありません。この手の作業するときはテンプレートエンジンを使うのが良いでしょう。最近だとRazorを使ったRazorEngineなどもあるのですが、RazorはあくまでHTML/XMLを出力するのに向いている構文で、C#コードを出力するような用途で使うのは、あまり向いていません。ここは素直にVisual Studio標準のT4 Templateを使うのが良いでしょう。あえてStringTemplate.NETとか、他のを選ぶ理由は、ないかなぁ。T4でいいですよ。
T4にはVisual Studioと連携して保存時にテンプレートが当てはまったテキストを出力するタイプと、ふつーのクラスとして、実行時に任意の変数をあてて、テキストを生成するもののニタイプが選べます。このブログでも何度か紹介してきたのは、全て前者でしたが、今回は後者のパターンを使います。
昔の名前は「前処理されたテキストテンプレート」でした。VS2012から名前変わって「ランタイムテキストテンプレート」になったようです。見つからなかったら検索ウィンドウにT4と入れると良いですよ。では、まず、TableGeneratorTemplate.ttとしてテンプレートを定義します。
<#@ template language="C#" #>
<#@ assembly name="System.Core" #>
<#@ import namespace="System.Linq" #>
<#@ import namespace="System.Text" #>
<#@ import namespace="System.Collections.Generic" #>
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
public class <#= ClassName #>
{
<# foreach(var x in Properties) {#>
public <#= x.Type #> <#= x.Name #> { get; set; }
<# } #>
public override string ToString()
{
return ""
<# foreach(var x in Properties) {#>
+ "<#= x.Name #> : " + <#= x.Name #> + "|"
<# } #>
;
}
}
テンプレートの記法としては、#=で囲むだけなので、まぁそう難しいものでもないです、読みづらさはかなりありますが。さて、このままだとClassNameとかPropertiesとかいうのは未定義でコンパイルもできないので、パーシャルクラスを作ります。クラス名はテンプレートと同名で。
public partial class TableGeneratorTemplate
{
public string ClassName { get; set; }
public IEnumerable<dynamic> Properties { get; set; }
public TableGeneratorTemplate(string className, IEnumerable<dynamic> properties)
{
this.ClassName = className;
this.Properties = properties;
}
}
これで、パラメータを渡せるようになりました。コンパイルエラーも出ません。というわけで実際に出力しましょう。テンプレートをnewして、TransformTextを呼ぶだけです。
// あ、ちなみにここまでのはConsoleApplicationでの話でした、はい。
// テーブル名.csにテンプレートを当てて全部出力
foreach (var item in columns)
{
var tt = new TableGeneratorTemplate(item.ClassName, item.Properties);
var text = tt.TransformText();
File.WriteAllText(item.ClassName + ".cs", text, Encoding.UTF8);
}
これで、以下の様なファイルがテーブル数だけ出力されます。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
public class aiueo_test_table
{
public Int64 id { get; set; }
public String name { get; set; }
public Int32 age { get; set; }
public DateTime? created { get; set; }
public DateTime? modified { get; set; }
public override string ToString()
{
return ""
+ "id : " + id + "|"
+ "name : " + name + "|"
+ "age : " + age + "|"
+ "created : " + created + "|"
+ "modified : " + modified + "|"
;
}
}
やったね!刺身たんぽぽさようなら!ちなみにただのプロパティの塊というだけじゃなく、ToStringも生成しておいてやると、実アプリでのデバッグの時に割と便利ですねー。
応用
GetSchemaで得られる情報は他にも沢山ありますので、Diffを取るプログラムを書けたり、あと、Index, IndexColumnsでインデックスの情報が取れます。インデックスで貼られているものはselectクエリーをほぼほぼ発行するはず、とみなせるので、selectクエリを発行するメソッドを自動生成しちゃったりとかは、実際に謎社ではしています。
つまり作業手順としては、どちらかというデータベースファーストになります。結局、コードとデータベースは違うので、データベース優先の定義・作業のほうが、どこまでいっても自然かな、と。(EF)コードファーストは私は幻想だと思っています。別に、SQL Server Management StudioなりHeidiSQLなどのツールでぽちぽち定義作るのは、そう面倒なわけでもない。そこからC#側のクラス定義も自動で生成できるのなら、むしろ、無理のあるコードでのデータベース表現をして回るよりも、結局、楽じゃない?DB定義をC#側から発行されて、どーのこーとか、なんてのに気を使わなくてもいいので、ずっと楽ちんだと思うんだ。原始的で全然スマートじゃないようで、実利はこっちにある。
まとめ
コードの詳細はMySQLなので、SQL Serverとかじゃ100%そのままは動かないかもですが、その辺は適宜調整してください、きっと似たようなのはあるはずなので。
あと、GetSchemaのDataTableで何が取れるのか、どんなフィールドがあるのかって、特にMySQLだとドキュメントゼロなのですが、そこでAsDynamicは本当に死ぬほど役に立ちました。Visual Studio上でのデバッガビリティを高めるの超大事。その辺がクソなのがDataTableの嫌なところですねえ。今時DataSetを使いまくってるレガシー会社とかあると悲しいですねえ。
ともあれ、dynamicはかなりデバッガビリティ高いので、活用してあげると良いです。dynamic、最近だと忘れ去られているC#の機能らしいので(笑)まあ、メインには使いませんけれど、あるとやっぱ便利なので、あって良かったなって、思いますよん。
AsyncOAuth ver.0.7.0 - HttpClient正式版対応とバグ修正
- 2013-06-24
HttpClientがRTMを迎えた、と思ったら、次バージョンのベータが出た、と、展開早くて追いつけないよ~な感じですが、とりあえず正式版のほうを要求する形で、AsyncOAuthも今回からBetaじゃなくなりました。
- AsyncOAuth - GitHub
- PM> Install-Package AsyncOAuth
AsyncOAuthについてはAsyncOAuth - C#用の全プラットフォーム対応の非同期OAuthライブラリを、HttpClientについてはHttpClient詳解、或いはAsyncOAuthのアップデートについてを参照ください。
今回のアップデートなのですが、PCL版HttpClientのRTM対応という他に、バグ修正が二点ほどあります。バグ的には、結構痛いところですね……。
OrderByと文字列について
バグ修正その一として、OAuthの認証シグネチャを作るのにパラメータを並び替える必用があるのですが、その並び順が特定条件の時に狂っていました。狂っている結果、正しく認証できないので、実行が必ず失敗します。特定条件というのは、パラメータ名が大文字始まりと小文字始まりが混在するときです。例えばhogeとHugaとか。本当はHuga-hogeにならなければならないのに、hoge-Hugaの順序になってしまっていたのでした。
なぜそうなったか、というと、OrderByをデフォルトで使っていたからです。
// charの配列をOrderByで並び替えると、ASCIIコード順 = 65:'A', 97:'a'
foreach (var item in new[] { 'a', 'A' }.OrderBy(x => x))
{
Console.WriteLine((int)item + ":" + (char)item);
}
// stringの配列をOrderByで並び替えると、良い感じ順 = "a", "A"
foreach (var item in new[] { "a", "A" }.OrderBy(x => x))
{
Console.WriteLine(item);
}
良い感じ順!というのはなにかというと、StringComparison/Comparer.CurrentCultureの順番です。ほぅ……。ありがたいような迷惑のような。で、今回はASCIIコードにきっちり従って欲しいので、
// 実際のコード。
// ところでrealmのところは!x.Key.Equals("realm", StringComparison.OrdinalIgnoreCase) って書くべき、次のバージョンで直します
var stringParameter = parameters
.Where(x => x.Key.ToLower() != "realm")
.Concat(queryParams)
.OrderBy(p => p.Key, StringComparer.Ordinal)
.ThenBy(p => p.Value, StringComparer.Ordinal)
.Select(p => p.Key.UrlEncode() + "=" + p.Value.UrlEncode())
.ToString("&");
といったように、StringComparer.OrdinalをOrderBy/ThenByに渡してあげることで解決しました。メデタシメデタシ。文字列の比較とか、言われてみれば基本中の基本っっっ!なのですけれど、完全に失念してました。テストでも、パラメータ小文字ばっかだったりして問題が中々表面化しないんですね、言い訳ですけれど……。しかし、幾つかのライブラリ見てみると、ほとんどがこれの対応できてなかったので私だけじゃないもん!みたいな、うう、情けないのでやめておきましょう。OAuthBase.csもissueには上がってましたがマージされてないんで、同様の問題抱えてるのですねえ。さすがにDotNetOpenAuthはきっちりできていました。
UriクラスとQueryとエスケープについて
バグ修正その2。GETにパラメータをくっつける、つまりクエリストリングとして並べた時に、日本語などURLエンコードが必要な物が混ざっている時に必ず認証に失敗しました。エンコード周りということで、お察しの通り二重エンコードが原因です。
これに関しては、私のUriクラスへの認識が甘々だったのがマズかったです。ぶっちけ、ただのstringを包んだだけの面倒臭い代物とか思ってたりとかしたりとか……。いや、さすがにそこまでではないんですが、まぁしかし甘々でした。こっちは↑のに比べても本当に初歩ミスすぎて穴掘って埋まりたいですぅー。相当恥ずかしい。
// クエリストリングつけたものを投げるとして
var uri = new Uri("http://google.co.jp/serach?q=つくば");
// QueryはURLエンコードされてる => ?q=%E3%81%A4%E3%81%8F%E3%81%B0
Console.WriteLine(uri.Query);
// URLエンコードされてるのを渡したとして
uri = new Uri("http://google.co.jp/serach?q=%E3%81%A4%E3%81%8F%E3%81%B0");
// ToString結果はURLデコードされたものがでてくる => http://google.co.jp/serach?q=つくば
Console.WriteLine(uri.ToString());
というわけで、Queryは常にURLエンコードされるし、ToStringは常にURLデコードされてる。この辺の認識がフワフワッとしてると、エンコードやデコード結果が非常にアレになっちゃうんですね……。
// 元データが欲しい時はOriginalString
Console.WriteLine(uri.OriginalString);
// エンコードされないで取るにはGetComponentsで指定してあげる
// ちなみにQueryは (UriComponents.Query | UriComponents.KeepDelimiter, UriFormat.Escaped) と等しい
var unescaped = uri.GetComponents(UriComponents.Query, UriFormat.Unescaped);
Console.WriteLine(unescaped); // q=つくば
GetComponents大事大事。
Next
今回からBetaを取ったということで、1.0に上げようかなあ、とか思ったんですが、↑のように手痛いバグが残っていたことが発覚したりなので、まだもう少し様子見といった感。さすがにもう大丈夫なはず!といくら思っても見つかっていくわけで、枯れてるって本当に大事ですねえ。AsyncOAuthも枯れたライブラリになるよう、頑張ります。今回のバグとかもユーザーが伝えてくれるお陰なので足を向けて寝られません。
私自身が使ってるのか?というと、答えは、使っています!こないだに.NET最先端技術によるハイパフォーマンスウェブアプリケーションというセッションを行ない、そこで言及したように、現在、某ソーシャルゲームをC#で再構築中です。で、GREEにせよMobageにせよ、ソーシャルゲームってOpenSocialの仕組みに乗っかっているのですが、その認証がOAuthなのです。というわけで、めっちゃくちゃヘヴィーに使っています。(認証の形態がちょっと違うので幾つかメソッドが足されているのと、Shift-JIS対応とかのためのカスタムバージョンだったりはしますが…… その辺はAsyncOAuth本体にも載せるか検討中)。実戦投下まであとちょっとってところですが、それできっちり動ききれば、十分に枯れた、といえるのではないかと思っています。その時までは0.xで。でも現状でもかなり大丈夫だとは思いますので、是非是非使ってください。