Introduction to the pragmatic IL via C#
- 2017-12-04
この記事はC# Advent Calendar 2017のための記事になります。12/1はmasanori_mslさんの【C#】処理の委譲で迷った話でした。そしてこの記事は12/2、のはずが今は12/4、つまり……。すみません。
ところでですが、私は今年の自身のテーマとして、「Extreme C#」を掲げています。C#で極限まで性能を出していく、ということを主題にして様々なものを公開してきました。その中でもILを書く技術というのは、どうしても欠かせないものです。実際、私が近年制作したライブラリはほとんどIL生成を含んでいます。
例えば、シリアライザ - ZeroFormatter, MessagePack for C#, Utf8Json。RPC - PhotonWire, MagicOnion。DI - MicroResolver。これらから、実際に使われた例と、そして実地でしか知り得ないTipsを紹介します。
この記事によって、IL書きが決して黒魔術ではなく、ごく当たり前の選択肢、になるのは行き過ぎにしても、必要な時に抵抗なく選べるようになってくれれば幸いです。
動的生成の本質
IL書けるのは凄いとか、黒魔術とか、そんなイメージがなくもないと思うんですが、とはいえ別に漠然とILを書いても、別に速いコードになるわけではありません。そして、最初のイメージとして浮かぶのは「リフレクションを高速にするもの」だと思いますが、本質的にはそうではありません。じゃあ何かっていうと、私は「生成時の最適なコード分岐の抽象化」というイメージで捉えています。
具体例としてUtf8Jsonのシリアライズを見てみましょう。
namespace ConsoleApp26
{
// こんなどうでもいいクラスがあるとして
public class Person
{
public int Age { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
}
class Program
{
static void Main(string[] args)
{
// これで生成したシリアライザが作られる(or 取り出される)
var serializer = DynamicObjectResolver.Default.GetFormatter<Person>();
// 生成型名:Utf8Json.Formatters.ConsoleApp26_PersonFormatter1
Console.WriteLine(serializer.GetType().FullName);
// まぁこんな風にシリアライズする
var writer = new JsonWriter();
serializer.Serialize(ref writer, new Person(), BuiltinResolver.Instance);
Console.WriteLine(writer.ToString()); // {"Age":0,"FirstName":null,"LastName":null}
}
}
}
Utf8Jsonのシリアライザ生成は、DynamicObjectResolverのGetFormatterで行われています(普段はこれより高レベルなAPI、JsonSerializer.Serializeに隠れて裏で行われているので、露出はしていません)。シリアライザの生成ってどういうことかというと、概ねこんな感じです。
// このインターフェイスは公開
public interface IJsonFormatter<T> : IJsonFormatter
{
void Serialize(ref JsonWriter writer, T value, IJsonFormatterResolver formatterResolver);
T Deserialize(ref JsonReader reader, IJsonFormatterResolver formatterResolver);
}
// この型が動的に生成された
public class ConsoleApp26_PersonFormatter1
{
public void Serialize(ref JsonWriter writer, T value, IJsonFormatterResolver formatterResolver)
{
// この中身をIL直書きで埋め込み
}
// Deserialize...
}
よし、じゃあいっちょその生成部分見りゃあいいってことっすね、と見に行くときっとわけわかんなくて挫折する(DynamicObjectResolver.cs#L734-L1389)と思うのでお薦めしません(あばー)。この記事を最後まで読んでくれれば分かるようになりますよ!
さて、ILを埋め込むというのは、そもそも普通のC#で書けるということなのです。動的生成というのは、汎用化/抽象化なので、Personが来たときにはこういうコードを生成しよう、というのは素のC#で書けます。IL直書きは別にマジックでもなんでもなく、原則C#で書けること以上のことはできませんから。
public class ConsoleApp26_PersonFormatter1 : IJsonFormatter<Person>
{
// writerで手書きするならこんなもんですよね、的な。
public void Serialize(ref JsonWriter writer, Person value, IJsonFormatterResolver formatterResolver)
{
if(value == null)
{
writer.WriteNull();
return;
}
// なんとなく挙動のイメージは伝わるでしょう(伝わりますよね?)
writer.WriteBeginObject(); // {
writer.WritePropertyName("Age"); // "Age":
writer.WriteInt32(value.Age);
writer.WriteValueSeparator(); // ,
writer.WritePropertyName("FirstName"); // "FirstName":
writer.WriteString(value.FirstName);
writer.WriteValueSeparator(); // ,
writer.WritePropertyName("LastName"); // "LastName":
writer.WriteString(value.LastName);
writer.WriteEndObject(); // }
}
}
素朴に考えると、上のようなコードになるでしょう。 value.Age などの部分が、IL生成をしない汎用的なコードだとリフレクションが必要なものですが、IL生成によってそれを避ける、つまり「リフレクションを高速にするもの」状態です。また、高速化のポイントとしてはルックアップを最小に抑える、というのが挙げられます。プロパティ単位でアクセサーを生成していると、プロパティ名で辞書引き(文字列の辞書引きは比較的コストの高い処理です!)ではなく、型単位で全てまとまったものを生成することで、より高速なコードが得られます。
「普通は」このぐらいのコードが出来ると満足してしまうところですが、真の魔術師になりたいなら、もっとアグレッシブに行きましょう。Utf8Jsonの最新版のコード生成はこうなっています。
public class ConsoleApp26_PersonFormatter1 : IJsonFormatter<Person>
{
// プロパティ名は変わらないので、予めエンコード済みのキャッシュを持つ
byte[][] stringByteKeys;
public ConsoleApp26_PersonFormatter1()
{
stringByteKeys = new byte[][]
{
// Ageは一番最初なので{も含めて埋め込む。それ以外は二番目なので,も含めて埋め込む
JsonWriter.GetEncodedPropertyNameWithBeginObject("Age"), // {"Age":
JsonWriter.GetEncodedPropertyNameWithPrefixValueSeparator("FirstName"), // ,"FirstName":
JsonWriter.GetEncodedPropertyNameWithPrefixValueSeparator("LastName") // ,"LasttName":
};
}
public void Serialize(ref JsonWriter writer, Person value, IJsonFormatterResolver formatterResolver)
{
if (value == null)
{
writer.WriteNull();
return;
}
// byte[]の長さが7だと「生成時」に知ってるので、長さに最適化したバイトコピーを使う
// 32Bit環境か64Bit環境なのかも、「生成時」に知っているので、その環境向けのコードを吐く
UnsafeMemory64.WriteRaw7(ref writer, this.stringByteKeys[0]);
writer.WriteInt32(value.Age);
UnsafeMemory64.WriteRaw13(ref writer, this.stringByteKeys[1]);
writer.WriteString(value.FirstName);
UnsafeMemory64.WriteRaw12(ref writer, this.stringByteKeys[2]);
writer.WriteString(value.LastName);
writer.WriteEndObject();
}
}
初期化タイミングでキャッシュ出来るものは徹底的にキャッシュしよう、ですね。このぐらいまでなら手書きでもやってやれなくもないですが、そのbyte[]の長さに決め打たれたバイトコピーのメソッドを使う、というのは実質やれない、の領域です。また、「実行時」にしか知り得ない32Bitか64Bitという情報も含めて埋め込んでいけるのは実行時コード生成にだけ可能な芸当です(まぁif(IntPtr.Size == 4)ぐらいの分岐はJITで消えますが)。
さて、JSONのシリアライズはオプションによって様々に変更させることが求められます。例えば、「nullの場合は出力しない、名前をスネークケースにする」というオプション(DynamicObjectResolver.ExcludeNullSnakeCase)の場合、このようなコードを生成します。
public class ConsoleApp26_PersonFormatter1 : IJsonFormatter<Person>
{
byte[][] stringByteKeys;
public ConsoleApp26_PersonFormatter1()
{
// snake_caseのものをキャッシュ。nullかどうかで先頭が変わるので{や,は埋めこまない
stringByteKeys = new byte[][]
{
JsonWriter.GetEncodedPropertyName("age"),
JsonWriter.GetEncodedPropertyName("first_name"),
JsonWriter.GetEncodedPropertyName("last_name")
};
}
public void Serialize(ref JsonWriter writer, Person value, IJsonFormatterResolver formatterResolver)
{
if (value == null)
{
writer.WriteNull();
return;
}
writer.WriteBeginObject(); // {
var first = true;
// structはnullチェックなし
// if (value.Age != null)
{
if (!first)
{
writer.WriteValueSeparator();
}
else
{
first = false;
}
UnsafeMemory64.WriteRaw6(ref writer, this.stringByteKeys[0]);
writer.WriteInt32(value.Age);
}
if (value.FirstName != null)
{
if (!first)
{
writer.WriteValueSeparator();
}
else
{
first = false;
}
UnsafeMemory64.WriteRaw13(ref writer, this.stringByteKeys[1]);
writer.WriteString(value.FirstName);
}
if (value.LastName != null)
{
if (!first)
{
writer.WriteValueSeparator();
}
else
{
first = false;
}
UnsafeMemory64.WriteRaw12(ref writer, this.stringByteKeys[2]);
writer.WriteString(value.LastName);
}
writer.WriteEndObject(); // }
}
}
処理が多くなりましたね!そう、Defaultに比べるとExcludeNullは、条件分岐が増えることと、JSONとしてのプロパティの出力順番が不定のため、キャッシュのアグレッシブ度も下げざるを得ないため、実行速度が若干低下します。
今回別にJSONの解説をしたいわけではなくて、大事なのは、オプションによって最高速なコードは変わっていくということです。そこを共通化してオプションによってコード分岐させたりせずに、オプション毎に最適化されたコードを生成することが肝要です。とはいえ、徹底的にオプション毎にコード生成を分けるのは生成部分が肥大化するため、記述には大いに苦痛を伴うでしょう。それをありえないほどクソ丁寧に徹頭徹尾やってるからMessagePack for C#やUtf8Jsonはデタラメに高速なのです。
また、事前生成ではオプション毎の最適なコードの生成は事実上不可能(全ての組み合わせを用意することは出来ない!)ので、その点でもあらゆるパターンの最適化コードを作れる動的生成は有利です。もちろん、通常アプリケーションで使うオプションは固定なので、そのオプションに絞った生成をすればいい、とうのは回答の一つではありますが(実際、UnityのAOT環境であるIL2CPP向けのUtf8Json, MessagePack for C#では単一オプションでの生成を行う)。
ともあれ、IL生成とかなんとかいっても、環境固定・対象固定であれば、C#で書けるコードが動的に生成されている、というだけの話です。C#で見ると、まぁちょっと面倒くさいことやってるな、程度の話で、別に特別に複雑なことはやってないんですよね。
というわけで、コード生成をしたいと思ったら、考える順番として、必ず、C#だとどういうコードになるか、を想像して、いや、実際に書くところから始めましょう。それが出来上がれば、あとはILに起こすだけです。その起こすだけ、というのが難しそう!っていう話なのですが、実は現代はツールが充実しているので、以外と難しくありません!というわけで、本題に入っていきましょう。
動的生成の手段
それなりに色々あるので、何使えばいいのーガイド最新版。
CodeDom。今はRoslyn(C#実装のC#コンパイラ)があるので、レガシー互換したいとかの余程の謎事情がない限りは不要かな。特に、動的生成したい、という目的で選ぶ必要性はあまりないでしょう。
AssemblyBuilder。動的にアセンブリを生成します。アセンブリを生成するということは、動的にモジュールを作り、動的に型を作り、動的にメソッドを作ります。つまりなんでも出来ます。コードの埋め込みはIL手書き。今回の話のメイン。NuGetではSystem.Reflection.Emit。
DynamicMethod。こちらは動的にデリゲートを作るというもの。コードの埋め込みはIL手書き。NuGetではSystem.Reflection.Emit.Lightweightということで、Lightweightエディションです。LCG(Lightweight CodeGen)と言われることもある。型そのものを作るAssemblyBuilderよりも出来ることが圧倒的に限られてしまうので、Lightweightに済ませたい局面以外では不要、と言いたいところなのですが、実はLCGでしか出来ないこともあるので、現実的にはAssemblyBuilderと併用していくことになります。
LCGでしか出来ないことというのは、private変数への外側からのアクセスです。AssemblyBuilderでは、本当に外側からC#を書いた時のような制限がかかりますが、LCGではその辺を無視することが可能です。動的生成ではリフレクション系を扱うことが多いはずで、privateへもアクセスしたいというのは多くの場合要件に含まれるでしょう。
ExpressionTree。できることはLCGと同じ(最終的にデリゲート生成ではLCGを通して作られているので)。ただし定義されているExpression以上のことはできないのと、正直いってIL書くのに慣れると、ExpressionTreeのほうが冗長で面倒くさいので、最近の私は使いません。特に.NET 4から足されたループなど「文」系の構文をExpressionTreeで書くのはかなりダルいので、無理して拘る必要はないでしょう。
ただしExpressionTreeによるCompileはXamarin iOSなどのAOT環境(動的コード生成不可)でも動くデリゲートが生成できます。何故なら、AOT環境の場合はExpressionTree専用のインタプリタで動かすデリゲートを生成するからです。もちろん、インタプリタになるので低速ですが、互換性維持的に楽なので、その点ではLCGではなくExpressionTreeを選ぶという選択肢はアリです。
Microsoft.CodeAnalysis.CSharp(Roslyn)。C#コンパイラ、ということでILを書かずとも、文字列としてのC#コードを書けばそこから実行時に使えるコードを生成できます。ILの知識も不要だしC#コンパイラの最適化も受けれるのでいいね!って話なのですが、あんま使われてないし、実際私もあまり使う気にはなれません。何故かというと、標準入りせず(5年前の.NET 4.5からは、コアフレームワーク標準入りという概念はなくなって、新規ライブラリはNuGetによる提供が主体になったため)、かなり大仰なパッケージを入れる必要があるため、依存関係にそれを仕込みたくないというのが一つ。もう一つは、割と面倒くさい。ソースコードをポンと放り投げれば出来上がり、というほどではなく、参照関係をかっちりかき集めてこなきゃいけないので、想像よりも遥かに手間がかかるんですね。一度テンプレートコードみたいなのを作ってしまえばいいといえばいいんですが……。また、初回生成時コストがかなり高いのが、初回のみなので無視できると言い張るにしても若干厳しいところもある。
と、いうわけでこの記事ではAssemblyBuilderとDynamicMethodを中心に扱っていきます。
動的生成のためのツール
よし、じゃあ早速書いていくぜ、の前にツールです。はやる気持ちは抑えて、何はともあれツールです。ツールがあると理解がめちゃくちゃ早まりますし、ハマりどころもなくなってめちゃくちゃ楽になります。とにかく現代はツールがめちゃくちゃ充実しています。別にildasmとニラメッコしたり、デバッグシンポルを入れるのに四苦八苦したりする必要はありません。シンプルに書いて、ひたすらツールに突っ込むのがとにかく近道です。
DnSpy。最強の.NET逆コンパイラ。DynamicAssemblyで生成したコードなら、そのまま中身確認どころかステップ実行のデバッグができる。ヤバい。もうこれで何も怖くない。残念ながらDynamicMethodにたいしてのデバッグは出来ないので、それだけのためにもDynamicAssembly中心にしたい(が、DynamicMethodのプライベートアクセスの機能は重要なので頑張って両対応させるのが、一手間でも最終的には一番いい)。
ILSpy。みんな大好き定番.NET逆コンパイラ。DynamicAssemblyならDLLとして出力することが可能なので、それを流し込めば生成した結果がC#コードとして見れる。IL手書きは、たいてい一発でうまくいかなくてC#として解析できない腐ったILを作ってしまったりするのですが、それはそれで、生成されたILを見ることができるので間違っている場所を探し出すことができます。アセンブリのリロードがDnSpyと違ってサクサクできるので、未だにDnSpyよりもこちらのほうが出番ずっと多し。なお、この生成コードをDLLとして出力して確認する、というデバッグ手法はコード生成がめちゃくちゃ楽になるので、絶対欠かせません(で、DynamicMethodだとそれができないので頑張って両対応させるのが一番)。
LINQPad。LINQPadの何がいいかというと、ILタブがあるところ。C#で書いたコードがどういうILに変換されるかは、LINQPadでミニマムなコードを書いて確認するのが一番手っ取り早い。いわばカンニングです。別にILの全てを知らなきゃIL手書きできないわけじゃないんです、普通にC#で書いて、書き写してくだけでいいんですよ。いやほんと。それを繰り返していくうちに、そのうち覚えていくでしょうしね。そう、別にミニマムなコードだけじゃなく、「コード生成をしたいと思ったら、考える順番として、必ず、C#だとどういうコードになるか、を想像して、いや、実際に書くところから始めましょう」と言いましたが、そのコード全体をLINQPadに通してILタブを見れば、それが生成すべきコードの答えです!汎用的にするため、ある程度は自分で展開しなきゃいけないんですが、「答え」が存在しているのといないのとでは、難易度は桁違いに変わります。
LINQPadSpy。別に必ず必要でもないんですが、これはいわばC# to C#です。どういうことかというと、LINQPadの生成結果をILSpyに流したものがその場で確認できます。C# to C#って同じ結果だろ?と言いたいところなのですが、C#コンパイラもまたコンパイル時コード生成するので、全然異なるコードになってたりするんですね。例えばC#のswitch文のコンパイラ最適化についてという記事では、switchが二分探索に化ける例を紹介しました。そういうのをサクッと確認できるようになります。このINQPadSpyは私がForkしてLINQPad 5に対応させたものになります。
PEVerify。Visual Studioを入れればついてきます(ildasm.exeとかsn.exeとかと同じ場所にある、例えば "C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.7 Tools\x64\PEVerify.exe" )。これの何がいいかというと、IL手書きに間違ったコード生成はつきもの、なんですが、 その場合にどこがどう間違ってるか教えてくれます。その場所に関してはILSpyで確認できるので、ILSpyとPEVerifyを合わせれば、修正が圧倒的なスピードでできます。これないと、ひたすら気合で探していくことになりますからね。ちなみにunsafeコードがあると、その部分はダメだと指摘が来ますが、別にそれはそのままでいいので、ノイズになるのは諦めましょう。
Ildasm。99%、ILSpyがあれば不要な代物。ILSpyのほうが使いやすく、見やすいですからね。ただ、たまーに残り1%の部分でIldasmでしか表示できないものがあったりします。例えば.data領域に詰まった文字列定数のbytearrayなんかは、ILSpyだと見る術がありませんが、Ildasm経由で逆コンパイル結果を出力すると、そこの部分も見れたりします。別に見れると何があるというわけでもないですが、正しい理解のために、信頼できる無加工の生の出力をしてくれる、という性質は貴重なものがあります。めったに使いませんが。
ILの基礎
よし、じゃあ早速書くぞ、って話なのですが、まあ待ってください。まずは基礎の基礎ぐらいは軽く頭に入れておきましょう。ぶっちゃけ何も知らなくてもLINQPadで吐いたコードをカンニングコピペでなんとかなるといえばなんとかなる(ほんと!)んですが、さすがに少しぐらいは知ってたほうがエラー対処も容易になるので、覚えておきましょう。
C#コンパイラの仕事はILを作ることです。で、ILはスタックマシンとして解釈され実行されます。どういうことかというと、Stackに命令をPushしたりPopしたりして計算するそうな。
まぁ、LINQPadでふんいきを見てみましょう。

足し算は、Ldarg_0, Ldarg_1(引数ロード)がStackへPush。Add(足し算)がその詰まれた2つをPopして加算して、計算結果をPush。Ret(return)で、その最後の一つの値を返してStackを空に。というのが基本の流れです。
ところでLINQPadを使う場合の注意事項として、右下に最適化ボタンがあるので、必ずONにしておきましょう。

最適化がONじゃないとnop(何もしない命令、デバッガがこれで止まるようになるのでデバッグビルドで必要だけどリリースビルドでは不要)が大量に埋め込まれるので、見にくくなるためです。
さて、このldargやretがOpCodeという代物で、今のとこ226種類あります。ええ、via C#なのでC#で確認してみましょう。LINQPadで以下のコードを打ちます。
typeof(OpCodes).GetFields().Select(x => x.GetValue(null)).OfType<OpCode>().Dump();

とりあえずNameとStackBehaviourPopとStackBehaviourPushに注目。StackBehaviourPopが幾つ取り出すか、StackBehaviourPushが幾つ詰むか。ldarg.0(0番目の引数をロードする)はPop0, Push1。add(足し算)はPop1_pop1(Pop2じゃないんですね)で、Push1。二個消費して、一個返すということ。。
と、いうイメージで、一個のStackにPushしたりPopしたりして結果を作る。メソッドは大抵最後にreturnで戻り値を返すわけですが、その場合はStackに一個だけ値を残しておいて、OpCodes.Retを叩けばおk、と。
というわけで実際のIL生成としてDynamicMethodにした場合は、こうなります。さっきの足し算コードに、+ 99を追加というのにしましょう。
// (int x, int y) => x + y + 99
var dm = new DynamicMethod("Sum99", typeof(int), new[] { typeof(int), typeof(int) });
var il = dm.GetILGenerator();
// 引数0と引数1を詰んで加算、更に+99してreturn。
il.Emit(OpCodes.Ldarg_0); // [x]
il.Emit(OpCodes.Ldarg_1); // [x, y]
il.Emit(OpCodes.Add); // [(x + y)]
il.Emit(OpCodes.Ldc_I4, 99); // [(x + y), 99]
il.Emit(OpCodes.Add); // [(x + y + 99)]
il.Emit(OpCodes.Ret); // []
// そしてCreateDelegateでFuncを作る
var sum = (Func<int, int, int>)dm.CreateDelegate(typeof(Func<int, int, int>));
// 129
Console.WriteLine(sum(10, 20));
AssemblyBuilderもDynamicMethodも基本の流れは一緒です。 GetILGenerator でILGeneratorを取得して、EmitでOpCodeの埋め込み。そして最後にCreateTypeかCreateDelegateする。Emitメソッドは引数にOpCodeと、パラメータを受け取ります。パラメータは定数であったりメソッド呼び出しであればMethodInfoなど様々。全然タイプセーフじゃないので間違ったパラメータ突っ込んじゃうことは多数ですが頑張って慣れましょう。なお、こういうのは完全に頭に叩き込んでおいてソラで手書きする必要は全くありません。基本はLINQPadで書いてカンニングコピペです。
もう少し基礎知識を続けます、習うより慣れろ、ではあるものの、ある程度OpCodeの種類も知っておいたほうが良いでしょう。大雑把に解説しておきます。
読み込む系 - ldarg., ldloc., ldc.i4.*, ldfld, ldsfld, など。ldはロードで、それぞれargは引数(argument)、locはローカル変数(local)、i4は整数(4byte integer)、fldはフィールド、sfldはスタティックフィールド、の読み込みをします。つまりPop0, Push1。長いILを書いてる時に(正しくはLINQPadからコピペって書き写している時に)スタティックとそうでないやつの書き間違いを起こすことが稀によくある。よくあるミスなのでエラーになった時はその辺を真っ先に疑います。
ldargaやldfldaなど、最後にaがついてるやつがいますが、これはaddressだけ読むもので、参照系を扱う場合に使い分けが必要です。よくわからない場合は逆コンパイル結果を見ればOK。これもまた長いILを打ってるとたまに間違えて、死ぬ場合多数。
また、.0, .1, .2, .3 や .s というのが後者についてるものがありますが(ldc.i4.1, ldc.i4.sなど)、これは最適化です。i4だと-1 ~ 8までは引数不要でそのOpCode自体が数字も示して読み込めますよ、と。sはshort formで、これまた最適化で、1バイト以内に収まるものはこちらを使ったほうが良い、という扱いです。
面倒な場合は全部Ldc_I4でいいじゃん、ってところなのですが、何も考えずとも最適に扱えるよう、こういう拡張メソッドを用意しておくのは賢いやりかたです。
public static void EmitLdc_I4(this ILGenerator il, int value)
{
switch (value)
{
case -1:
il.Emit(OpCodes.Ldc_I4_M1);
break;
case 0:
il.Emit(OpCodes.Ldc_I4_0);
break;
case 1:
il.Emit(OpCodes.Ldc_I4_1);
break;
case 2:
il.Emit(OpCodes.Ldc_I4_2);
break;
case 3:
il.Emit(OpCodes.Ldc_I4_3);
break;
case 4:
il.Emit(OpCodes.Ldc_I4_4);
break;
case 5:
il.Emit(OpCodes.Ldc_I4_5);
break;
case 6:
il.Emit(OpCodes.Ldc_I4_6);
break;
case 7:
il.Emit(OpCodes.Ldc_I4_7);
break;
case 8:
il.Emit(OpCodes.Ldc_I4_8);
break;
default:
if (value >= -128 && value <= 127)
{
il.Emit(OpCodes.Ldc_I4_S, (sbyte)value);
}
else
{
il.Emit(OpCodes.Ldc_I4, value);
}
break;
}
Ldc_I4に限らず、慣れてきたら幾つか予め容易しておくと色々はかどります。この辺のユーティリティが勢揃いフルセットなのがSigilなのですが、これはこれでToo Muchなきらいもあるし、ツール類から流したりコピペったりする分には素のほうがやりやすかったりなので、むしろ最初のうちは素のままやっていったほうが良いでしょう。Sigilの検証などは一見良さそうなのですが、素で書いてILSpy/ILVerifyに流したほうが結局情報豊富だったりしますしね。
なお、Utf8JsonのILGeneratorExtensionsを参考までに。基本的には素朴にやれるものしか定義していません。
代入する系 - stloc, starg, stfld, stsfld, など。stはストアということで代入、まんまですね。スタックへの挙動はPop1, Push0です。そりゃそーだ。
算術演算系 - add, sub, mul, div, など。まぁこれはまんまですね。二項演算子なので、みんなPop1_pop1, Push1です
分岐系 - br, brtrue, beq, bgt, ble, bne, blt, など。brはbranchで、ようするところif + gotoです。C#でifで書いたものは、全てbr*に変換されています。値をPopして、それを元にしてジャンプするかどうかを決めます。beqはbranch equal, bneはbranch not equal, bleはbranch less than equal, bltはbranch less than, bgeはbranch greater than equal, bgtはbranch greater thanと、3文字で圧縮されると呪文のようでわかりにくくあるんですが、概ねそういうことですね。switchもありますが、C#のswitchとは異なることに注意。C#のswitchはコンパイラが場合によって二分探索に置き換えたりしますが、OpCodeのswitchは[0..]のジャンプテーブル(goto先が詰まってる)しかありません。
その他 - callはメソッド呼ぶ。Pop数は引数によりけりなので不定(Varpop)。callvirtというものもあって、違いはcallvirtが仮想メソッド呼び出し(インターフェース経由とかの場合)、callが直呼び出しということで、よくわかんなかったらcallvirtに倒しときゃとりあえず安全、という雑な言い方もできますが、例によって出し分け拡張メソッドを作っておくと、何も考えなくてラクかもしれません。
public static void EmitCall(this ILGenerator il, MethodInfo methodInfo)
{
if (methodInfo.IsFinal || !methodInfo.IsVirtual)
{
il.Emit(OpCodes.Call, methodInfo);
}
else
{
il.Emit(OpCodes.Callvirt, methodInfo);
}
}
こうやってIL眺めてると、高速なのはきっとCallのほうなんだろうなぁ、みたいなイメージが湧いてきます。取っ掛かりは、そういう雑なイメージからでいいんですよ。
retはreturn。voidのメソッドであってもメソッドの最後は必ずretでしめます。
dup。これはスタックの値を複製する。例えば連続してインスタンスのプロパティに代入する場合なんかに、インスタンスをdupしたりします。ようはオブジェクト初期化子なんかそうですね。

スタックの状態を書くと、
newobj(myclass)
dup(myclass, myclass)
ldc.i4(myclass, myclass, 15)
callvirt(myclass)
dup(myclass, myclass)
ldstr(myclass, myclass, "HogeHoge")
callvirt(myclass)
ret()
と、いうわけです。dupは何かとよく出てくるんですが、スタックの状況によって増えるものが違うんで混乱の原因ではありますね。まぁ、大抵はインスタンスのはずです。手書きの際に条件分岐などでdupすべきスタックの状態がグチャグチャでよくわからん!ってなる場合は、ローカル変数を作ってしまって、それをロードする、という形で逃げる手も割と良い手段です。LINQPadからのカンニングコピペは基本ですが、時に自分の意志で逸脱できるようになれば上級者!
AssemblyBuilderことはじめ
というわけで本編。AssemblyBuilderを始めましょう。習うより慣れろ、ということでまずやってみましょう。注意点としては、まずは.NET Coreや.NET Standardじゃなく、.NET Frameworkで作ってみてください(Linux環境下の人はmonoで!)。理由は、.NET Coreではアセンブリの保存ができないため、デバッグ難易度が跳ね上がるからです。
const string ModuleName = "FooBar";
// .NET 4.5から。それ以前ではAppDomain.CurrentDomain.DefineDynamicAssemblyをかわりに使う
// AssemblyBuilderAccessは.NET Coreでは現状Runしか使えないが、デバッグに超便利なので少なくともデバッグ用にだけはRunAndSaveの口を確保しておきたい
// 一つのAssemblyに複数ModuleをDefineすることが可能ですが、何かと混乱を招くので、わかりやすさのためにも1:1にしておくと良い
var assemblyBuilder = AssemblyBuilder.DefineDynamicAssembly(new AssemblyName(ModuleName), AssemblyBuilderAccess.RunAndSave);
// 基本的にはmoduleBuilderをstatic変数などに保持しておいて、必要な際に都度DefineTypeで動的に型定義していく
var moduleBuilder = assemblyBuilder.DefineDynamicModule(ModuleName, ModuleName + ".dll"); // RunAndSaveの場合、ここでファイル名を指定しておく
// Foo型を定義
var typeBuilder = moduleBuilder.DefineType("Foo", TypeAttributes.Public);
// Foo型からSumインスタンスメソッドを定義
var sum = typeBuilder.DefineMethod("Sum", MethodAttributes.Public, typeof(int), new[] { typeof(int), typeof(int) });
// そしてメソッドの中身をEmit
var il = sum.GetILGenerator();
il.Emit(OpCodes.Ldarg_1); // インスタンスメソッドの場合、arg0がthisになる
il.Emit(OpCodes.Ldarg_2);
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Ret);
// CreateTypeで型を実体化する
var fooType = typeBuilder.CreateType(); // これで「型」のできあがり
var instance = Activator.CreateInstance(fooType); // まぁ大抵は?生成したインスタンスをキャッシュするのでしょう
var result = fooType.GetMethod("Sum").Invoke(instance, new object[] { 10, 20 });
Console.WriteLine(result); // 30, ちゃんとSumが呼べてる。
// 保存する時はDefineDynamicModuleの時に指定したのと同じ名前で吐くのが安全のために良い
#if DEBUG
assemblyBuilder.Save(ModuleName + ".dll");
#endif
これでFooBarモジュールにSumメソッドを持つFoo型ができました。DefineDynamicAssembly -> DefineDynamicModuleは定形なので、こんなもんだと思ってください。ここで作るAssemblyBuilder/ModuleBuilderはアプリケーション中でずっと使いまわします(さすがに一つの型毎にAssembly生成してたら過剰すぎるので!)。
DefineTypeにより型定義、このDefineTypeはスレッドセーフなので安心して(?)グローバルに保存しているModuleBuilderから呼び出せます(ただしmonoでは非スレッドセーフなので、mono環境での実行を意識するならDefineTypeにlockかけましょう、例えばUnityとかね……)。
型を定義したら次はメソッド、ということでDefineMethod。Defineには他にDefineField, DefineConstructor, DefinePropertyなどあります。そして中身の記述のためILGeneratorを取り出し、Emit。最後にCreateTypeしてできあがり、です。
ここまでで通常は終わりですが、デバッグ時はSaveを呼んで、中身を確認すると色々と楽になれます。今回はFooBar.dllができたので、ILSpyで開いてみましょう。

問題なし、と。まぁ問題ない場合は問題なしでいいんですが、たいてい問題アリなので(特に長いコード書いてくと本当に辛い!)、こうして見れるのめちゃくちゃ大事です。
或いはdnSpyを使うという手もあります。dnSpyの場合はそのままステップ実行までできます!やり方は簡単で、Startボタンを押して、exeを指定。

あとは、Invokeしているところに止めて、F11連打してくと、Sumの呼び出しまでステップ実行で降りていけます。そうなるとロードしたインメモリアセンブリも表示されていて中身丸見えに。

なので、dnSpyを使っていくならSaveしなくても大丈夫です。ただ、そもそもILが腐っている場合にILSpyならSaveして腐ったILを見ることができますがdnSpyでは無理なので、ILのデバッグ的には腐ったILを修正していくフェーズのほうが多いので、できればSave可能な環境を作ったほうが良いでしょう。
でも最終成果物は.NET StandardなのでSaveできないんです!って場合は、というかもう今からライブラリ作る人はみんなそうだと思うんですが、そういう人はメインライブラリは.NET Standardで作って、それとは別に.NET Frameworkのコンソールアプリを作って、プロジェクト参照でライブラリを引っ張り、コンパイラシンボルで.NET Frameworkからの参照のときのみSaveの口を開けておく、みたいなやり方で確保するのがオススメです。例えばUtf8JsonはこんなAssemblyBuilder用のヘルパーを使っています。
using System.Reflection;
using System.Reflection.Emit;
namespace Utf8Json.Internal.Emit
{
internal class DynamicAssembly
{
#if NET45 || NET47
readonly string moduleName;
#endif
readonly AssemblyBuilder assemblyBuilder;
readonly ModuleBuilder moduleBuilder;
public ModuleBuilder ModuleBuilder { get { return moduleBuilder; } }
public DynamicAssembly(string moduleName)
{
#if NET45 || NET47
this.moduleName = moduleName;
this.assemblyBuilder = System.AppDomain.CurrentDomain.DefineDynamicAssembly(new AssemblyName(moduleName), AssemblyBuilderAccess.RunAndSave);
this.moduleBuilder = assemblyBuilder.DefineDynamicModule(moduleName, moduleName + ".dll");
#else
#if NETSTANDARD
this.assemblyBuilder = AssemblyBuilder.DefineDynamicAssembly(new AssemblyName(moduleName), AssemblyBuilderAccess.Run);
#else
this.assemblyBuilder = System.AppDomain.CurrentDomain.DefineDynamicAssembly(new AssemblyName(moduleName), AssemblyBuilderAccess.Run);
#endif
this.moduleBuilder = assemblyBuilder.DefineDynamicModule(moduleName);
#endif
}
#if NET45 || NET47
public AssemblyBuilder Save()
{
assemblyBuilder.Save(moduleName + ".dll");
return assemblyBuilder;
}
#endif
}
}
PEVerifyことはじめ
最初のうちどころか、慣れてきても、大抵はEmitには失敗します。どっか間違えます。例えばスタックにあまったものが存在している場合
var il = sum.GetILGenerator();
il.Emit(OpCodes.Ldarg_1);
il.Emit(OpCodes.Ldarg_2);
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Ldc_I4, 999); // 一個余計なものを足す
il.Emit(OpCodes.Ret);
これは、Sumを呼んだ時に実行時エラーとして「System.InvalidProgramException: JIT コンパイラで内部的な制限が発生しました。」がでます。この「JIT コンパイラで内部的な制限が発生しました。」はもう悲すぃぐらいに付き合うことになるでしょう。こいつの倒し方ですが、まぁようするにどこでエラーが起きたかを突き止めていくということ。で、役に立つ(?)のが、スタックをとりあえず空にしてダミーでreturnする方。
// こういうヘルパーメソッド用意しておくと便利
public static void EmitPop(this ILGenerator il, int count)
{
for (int i = 0; i < count; i++)
{
il.Emit(OpCodes.Pop);
}
}
// で、こういうふうにしてひたすら探る
var il = sum.GetILGenerator();
il.Emit(OpCodes.Ldarg_1);
il.Emit(OpCodes.Ldarg_2);
il.EmitPop(2); // 二個消す(いくつPopすれば分からない場合も多いけど、そのときは1, 2, 3...と適当にPop数を増やして例外が起きないように探ればOK)
il.Emit(OpCodes.Ldc_I4_1);
il.Emit(OpCodes.Ret);
// --- ここまでは大丈夫だった --
/*
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Ldc_I4, 999); // 一個余計なものを足す
il.Emit(OpCodes.Ret);
*/
Popとダミーのリターンで、どこまでのEmitは大丈夫で、どこからがダメなのかを探していきます。このやり方で9割ぐらいは最終的に見つかります。例えばldargとldarg_Sの間違いとかはサクッと見つかりますね。残り1割は、しょうがないケースなので頑張ろう。
この原始的なやり方は最後の最後まで役に立ちます。が、もう少し楽をしたいので、PEVerifyを使いましょう。PEVerifyによって95%ぐらいのエラーを一撃必殺で見抜くことができます。アセンブリのSaveとセット販売で用意しておくとデバッグが捗ります。
// ようはこういうヘルパーメソッドを用意しておく
static void Verify(params AssemblyBuilder[] builders)
{
var path = @"C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.6.1 Tools\x64\PEVerify.exe";
foreach (var targetDll in builders)
{
var psi = new ProcessStartInfo(path, targetDll.GetName().Name + ".dll")
{
CreateNoWindow = true,
WindowStyle = ProcessWindowStyle.Hidden,
RedirectStandardOutput = true,
RedirectStandardError = true,
UseShellExecute = false
};
var p = Process.Start(psi);
var data = p.StandardOutput.ReadToEnd();
Console.WriteLine(data);
}
}
// Invokeタイミングで死ぬのでDLLの生成自体は可能。SaveしてVerifyを通すようにしておきましょう。
try
{
var result = fooType.GetMethod("Sum").Invoke(instance, new object[] { 10, 20 });
Console.WriteLine(result); // ↑のとこで例外を吐く
}
finally
{
assemblyBuilder.Save(ModuleName + ".dll");
Verify(assemblyBuilder);
}
PEVerifyによって、例えばこういうメッセージが得られます。
[IL]: エラー:[FooBar.dll : Foo::Sum][オフセット 0x00000008] スタックに含めることができるのは、戻り値だけです。
ILSpyでDLLをIL Viewにして見てみると

オフセットはIL_0008に対応していて、retのあたりがダメなんだ、ということが分かります。で、まぁメッセージとニラメッコして、なんとなくスタックの数がおかしいんだろうなあ、と辺りをつけましょう。
さて、もう一個よくみる例外が「共通言語ランタイムが無効なプログラムを検出しました。」です。これもようするところ間違えたILをEmitしてるってことなんですが。例えばこういうコードをEmitしてPEVerifyにかけましょう。
var il = sum.GetILGenerator();
il.Emit(OpCodes.Ldarg_1);
// il.Emit(OpCodes.Ldarg_2); // スタック足りなくしてみる
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Ret);
こういう結果が得られます!
[IL]: エラー:[FooBar.dll : Foo::Sum][オフセット 0x00000001] スタックのアンダーフロー
腐ったILを生成すると、ILSpyのC#ビューがウンともスンとも言わなくなります。

が、ILビューは生きているので頑張りましょう。

オフセット0x00000001、つまりaddのところでスタック足りてませんよ、っていうことでした。OK。まぁこのぐらい短いとどうってことないですが、長いILだとスタックの数がオカシイのは分かるけど、どのへんイジりゃあいいんだこれ、って混乱したりしなかったりしますが、場所さえ突き止められれば、あとは気合でなんとでもなります。問題なし。
DynamicMethodことはじめ
DynamicMethodは、ようするところAssemblyBuilderからDefineAssembly/DefineModule/DefineTypeを抜いたものです。デリゲート生成しかできませんが、AssemblyBuilderをstaticなどっかに保存しておく、とか別に大したことないといえば大したことないけど、面倒っちゃあ面倒なので、いーんじゃないでしょうか。それと、大事なことが一つ。DynamicMethodならプライベートな変数やメソッドにアクセスできます。
// こんな型があるとして、ぷらいべーとなフィールドを高速に書き換えれるアクセサを用意してみましょう
public class Person
{
int age; // private field!
public Person(int age)
{
this.age = age;
}
public int GetAge()
{
return age;
}
}
// DefineMethodとほぼ同等に戻り値、引数の型を並べて作る
// ただしDynamicMethodだけの要素として、ModuleとSkipVisibilityに注意!
var dynamicMethod = new DynamicMethod("SetAge", null, new[] { typeof(Person), typeof(int) }, m: typeof(Person).Module, skipVisibility: true);
// ILGeneratorに関してはDefineMethodとかわりなし
var il = dynamicMethod.GetILGenerator();
il.Emit(OpCodes.Ldarg_0); // staticメソッドなので0はじまり
il.Emit(OpCodes.Ldarg_1);
il.Emit(OpCodes.Stfld, typeof(Person).GetField("age", BindingFlags.NonPublic | BindingFlags.Instance));
il.Emit(OpCodes.Ret);
// 最後にCreateDelegateでデリゲートを作る
var setAge = (Action<Person, int>)dynamicMethod.CreateDelegate(typeof(Action<Person, int>));
var person = new Person(10);
setAge(person, 999);
Console.WriteLine(person.GetAge()); // 999
よくあるゲッターへのアクセサ/セッターへのアクセサ、です。汎用的なものにすると引数/戻り値がobject型にならざるを得なくて、ボクシングが避けられずエクストリームなパフォーマンス追求には使えないんですが、カジュアル用途でやってくには十分以上に便利でしょう。
DynamicMethodの注目点はm:とskipVisibility:です。これを指定しておくとプライベート変数へのアクセスが可能になるほか、実はパフォーマンス的にも有利なので、別にプライベートへのアクセスがなくても、必ず指定するようにしておくと良いでしょう。
キャッシュが型単位だったり、インターフェイス単位で使う、などの場合にDynamicMethodだとやりづらくはあるんですが、コンストラクタにデリゲートを渡して、各メソッドはそれを移譲して呼び出すだけの入れ物型を用意してあげれば、DynamicMethodでも型付きのものとほぼ同様のことが可能です。DynamicAssemblyでのコンストラクタでキャッシュ用のフィールドを初期化する、といったケース(Utf8Jsonではエンコード済みのプロパティ名とか)も、同じようにコンストラクタで渡してあげれば良いでしょう。
例えばUtf8Jsonでは、基本はDynamicAssemblyで生成したシリアライザを使いますが、AllowPrivateオプションのシリアライザを使う場合は、DynamicMethod経由で生成し、以下の入れ物を通して型をキャッシュしています。
internal delegate void AnonymousJsonSerializeAction<T>(byte[][] stringByteKeysField, object[] customFormatters, ref JsonWriter writer, T value, IJsonFormatterResolver resolver);
internal delegate T AnonymousJsonDeserializeFunc<T>(object[] customFormatters, ref JsonReader reader, IJsonFormatterResolver resolver);
internal class DynamicMethodAnonymousFormatter<T> : IJsonFormatter<T>
{
readonly byte[][] stringByteKeysField;
readonly object[] serializeCustomFormatters;
readonly object[] deserializeCustomFormatters;
readonly AnonymousJsonSerializeAction<T> serialize;
readonly AnonymousJsonDeserializeFunc<T> deserialize;
public DynamicMethodAnonymousFormatter(byte[][] stringByteKeysField, object[] serializeCustomFormatters, object[] deserializeCustomFormatters, AnonymousJsonSerializeAction<T> serialize, AnonymousJsonDeserializeFunc<T> deserialize)
{
this.stringByteKeysField = stringByteKeysField;
this.serializeCustomFormatters = serializeCustomFormatters;
this.deserializeCustomFormatters = deserializeCustomFormatters;
this.serialize = serialize;
this.deserialize = deserialize;
}
public void Serialize(ref JsonWriter writer, T value, IJsonFormatterResolver formatterResolver)
{
if (serialize == null) throw new InvalidOperationException(this.GetType().Name + " does not support Serialize.");
serialize(stringByteKeysField, serializeCustomFormatters, ref writer, value, formatterResolver);
}
public T Deserialize(ref JsonReader reader, IJsonFormatterResolver formatterResolver)
{
if (deserialize == null) throw new InvalidOperationException(this.GetType().Name + " does not support Deserialize.");
return deserialize(deserializeCustomFormatters, ref reader, formatterResolver);
}
}
DynamicMethodの困った点は、Saveできないこと。dnSpyでのステップ実行もできません。これはデバッガビリティが恐ろしく落ちます。特に解決策という解決策もないんですが、しいていえばILGeneratorからの流れはDynamicAssemblyと変わらないので、Emit部分をメソッドで分けて、生成部分を共通化してやると良いでしょう。
その際の注意点は、引数の順番がズレること。これは、ArgumentFieldという構造体を用意して、Ldargなどはそれ経由で呼ぶようにして解決しました。
internal struct ArgumentField
{
readonly int i;
readonly bool @ref;
readonly ILGenerator il;
public ArgumentField(ILGenerator il, int i, bool @ref = false)
{
this.il = il;
this.i = i;
this.@ref = @ref;
}
public ArgumentField(ILGenerator il, int i, Type type)
{
this.il = il;
this.i = i;
this.@ref = (type.IsClass || type.IsInterface || type.IsAbstract) ? false : true;
}
public void EmitLoad()
{
if (@ref)
{
il.EmitLdarga(i);
}
else
{
il.EmitLdarg(i);
}
}
public void EmitStore()
{
il.EmitStarg(i);
}
}
もう一つは、インスタンスの呼び出し/インスタンスフィールドの呼び出しができないこと(DynamicMethodはインスタンスが存在しませんからね!)。そこでフィールドキャッシュのLoadなどは、Actionで外から渡すようにして、両者が共通でない部分は外出しするようにしました。正直言って、手間だし、ややグチャグチャしてしまうところもあるのですが、やる価値はあります。SaveなしでIL手書きと戦うのは本当にキツいので……。
ILGeneratorことはじめ
基本、今まで見た通りEmitするだけなんですが、まだループや分岐に関しては説明していないですね!で、ILにはそれらへの気の利いた文法はありません。全部labelとgotoで実現するものと思いましょう。そして、ループや分岐が絡むと途端にIL書く気が失せます。というのも、複雑怪奇になるので。例えばこんな単純なループですら……

なんかもう嫌な感じでいっぱいです。ああ、ああ……。といっても書かなきゃいけない局面もいっぱいあるんで、書きましょう。
まず、forはないものと思って、この手のイメージコードを作る場合は全部gotoに直します。それがILに近くなるので。近いほうがイメージもしやすい。
var i = 0;
goto FOR_CONDITION;
FOR_BODY:
if (i == 50) goto FOR_END;
FOR_CONTINUE: // 今回は使いませんが
i += 1;
FOR_CONDITION:
if (i < 100)
{
goto FOR_BODY;
}
FOR_END:
Console.WriteLine("End");
なるほど古き良きgoto。既に帰りたい感じですが、更にこれをEmitに直します。まぁ基本はLINQPadのコピペなのですが、LabelのDefineが必要です!
const string ModuleName = "FooBar";
var assemblyBuilder = AssemblyBuilder.DefineDynamicAssembly(new AssemblyName(ModuleName), AssemblyBuilderAccess.RunAndSave);
var moduleBuilder = assemblyBuilder.DefineDynamicModule(ModuleName, ModuleName + ".dll");
var typeBuilder = moduleBuilder.DefineType("Foo", TypeAttributes.Public);
var methodBuilder = typeBuilder.DefineMethod("For", MethodAttributes.Public, null, Type.EmptyTypes);
// -- ここから --
ILGenerator il = methodBuilder.GetILGenerator();
// gotoの行き先をあらかじめDefineLabelで持つ
var forBodyLabel = il.DefineLabel();
var forContinueLabel = il.DefineLabel();
var forConditionLabel = il.DefineLabel();
var forEndLabel = il.DefineLabel();
// ローカル変数を宣言する
var iLocal = il.DeclareLocal(typeof(int));
il.Emit(OpCodes.Ldc_I4_0);
il.Emit(OpCodes.Stloc, iLocal); // i = 0;
il.Emit(OpCodes.Br, forConditionLabel); // goto FOR_CONDITION;
// MarkLabelでラベルの位置を確定させる
il.MarkLabel(forBodyLabel); // FOR_BODY:
il.Emit(OpCodes.Ldloc, iLocal);
il.Emit(OpCodes.Ldc_I4, 50);
il.Emit(OpCodes.Beq, forEndLabel); // if(i == 50) goto FOR_END;
il.MarkLabel(forContinueLabel);
il.Emit(OpCodes.Ldloc, iLocal);
il.Emit(OpCodes.Ldc_I4_1);
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Stloc, iLocal); // i += 1;
il.MarkLabel(forConditionLabel); // FOR_CONDTION:
il.Emit(OpCodes.Ldloc, iLocal);
il.Emit(OpCodes.Ldc_I4, 100);
il.Emit(OpCodes.Blt, forBodyLabel); // if(i < 100) goto FOR_BODY;
il.MarkLabel(forEndLabel); // FOR_END:
il.EmitWriteLine("End"); // Stfld, Call WriteLine
il.Emit(OpCodes.Ret);
// -- ここまで --
var t = typeBuilder.CreateType();
dynamic instance = Activator.CreateInstance(t);
try
{
instance.For(); // 実行確認
}
finally
{
assemblyBuilder.Save(ModuleName + ".dll");
Verify(assemblyBuilder);
}
DefineLabelで予め宣言する、MarkLabelでラベル位置を決める、分岐系OpCodeでLabelを指定する。ということになります。まぁ、全部gotoなんだって思えば別になんてことない話ではあるんですが、だいぶ見辛くなりました。ただの、ほぼ空のfor文ですら!また、分岐はBeq_SなどがLINQPadなどの解析結果に出ると思うのですが、これはジャンプ先が近ければ_Sが使えて、遠ければ実行時エラーになります。埋め込み量がわかっている場合は_Sでいいんですが、動的生成の都合上、長さわからない場合っていうのも少なくなかったりするので、安全側に倒すなら、とりあえず_Sナシでやるってのは手だと思っています。ちょっとね、怖いんですよね。
ちなみに私はこれを書き写すにあたって、二回ミスってPEVerifyのお世話になりました(笑)。ちょっと長くなったり分岐入ると、やっぱミスってしまうんですよねぇ。で、これ、PEVerifyなしで探れって言われると、たかだかfor文一つだけでしかなくても、めっちゃ辛いわけです。実際の生成コードだとこれの比じゃなく長くなりますから、いやはや、大変な話です……。
キャッシュの手法
生成したコードは再利用するためにどこかに保持する必要があります。ああ、Dictionaryの出番だね。その通りですが、その通りではありません。Dictionaryのルックアップコストはタダではない!GetHashCodeとEqualsを呼び出すわけですが、例えばStringがキーなら、GetHashCodeで一回全舐めして、Equalsでやはり全舐めするわけです。おお……(もちろん、文字列の長さが長ければ長いほどコストは嵩む)。とはいえ、通常はTypeをキーにすると思うので、ルックアップのコストはそこまで高くはないので、構わないっちゃあ構わないでしょう。
が、もしTypeなら、ジェネリクスを有効に使うと、より高速なルックアップが可能です。MessagePack for C#やUtf8JsonではResolverという形で、生成した型をキャッシュ/取得する機構を全面採用しています。
internal sealed class DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal : IJsonFormatterResolver
{
public static readonly IJsonFormatterResolver Instance = new DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal();
static readonly Func<string, string> nameMutator = StringMutator.Original;
static readonly bool excludeNull = false;
const string ModuleName = "Utf8Json.Resolvers.DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal";
static readonly DynamicAssembly assembly;
static DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal()
{
assembly = new DynamicAssembly(ModuleName);
}
DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal()
{
}
// DynamicObjectResolverAllowPrivateFalseExcludeNullFalseNameMutateOriginal.Instance.GetFormatter<T>で取得する
public IJsonFormatter<T> GetFormatter<T>()
{
// 中身は型キャッシュのフィールドを取りに行くだけ
return FormatterCache<T>.formatter;
}
// 型キャッシュ
static class FormatterCache<T>
{
public static readonly IJsonFormatter<T> formatter;
// 静的コンストラクタはスレッドセーフが保証される
static FormatterCache()
{
// ここでILのEmitしてIJsonFormatter<T>を一度だけ生成している
formatter = (IJsonFormatter<T>)DynamicObjectTypeBuilder.BuildFormatterToAssembly<T>(assembly, Instance, nameMutator, excludeNull);
}
}
}
難点はアンロードできないことと、動的に生成しづらい(できないわけではない, ただしそれで生成した型もアンロード不可能)になりますが、大抵この手のライブラリの生成データはアプリケーションの生存期間でずっと生き続けるので、あまり問題にはならないでしょう。
その他Tips
C#コンパイラがコード生成するもの(yield returnやawaitなど)をIL生成でやるのは、無理です。が、そういうのが必要なのだという場合は、ヘルパーメソッドを作ってあげて、それを呼ぶ形にしてあの手この手でIL手書き部分を減らしてあげましょう。
unsafeをIL手書きで書くのは地獄の一里塚です。しかし、やらなければならない時はあります(実際MessagePack for C#やUtf8Jsonはunsafeが含まれてる)。そして、何気にfixedのコードもまた、コンパイラ生成だったりします。LINQPadで見てみましょう。

fixed(byte* p = xs) のコードは生成量が多くてうげー、って感じなので、基本 fixed(byte* p = &xs[0]) のほうでいいでしょう(nullチェック?それは外側でしましょ)。若干ややこしいですが、こんな感じで。
// DeclareLocalの際にpinned: trueを指定する
var p = il.DeclareLocal(typeof(byte).MakePointerType(), pinned: true); // byte*
// begin fixed定型文
il.Emit(OpCodes.Ldarg_1); // staticメソッドじゃないので1で。
il.Emit(OpCodes.Ldc_I4_0);
il.Emit(OpCodes.Ldelema, typeof(byte));
il.Emit(OpCodes.Stloc, p); // byte* p = &xs[0];
// -- ここに好きにBodyをどうぞ--
// end fixed定型文
il.Emit(OpCodes.Ldc_I4_0);
il.Emit(OpCodes.Conv_U);
il.Emit(OpCodes.Stloc, p);
il.Emit(OpCodes.Ret);
このfixed含みのコードをPEVerifyにかけると
[IL]: エラー:[Foo::For][オフセット 0x00000007][address of Byte が見つかりました][unmanaged pointerS が必要です] スタックに予期しない型があります。
[IL]: エラー:[Foo::For][オフセット 0x0000000A][Native Int が見つかりました][unmanaged pointerS が必要です] スタックに予期しない型があります。
という2つのエラーメッセージが必ず出てしまいますが、これはもうそういうものだと思うことにしましょう、しょうがない……。
ニッチトピックスとしてはGeneric型の生成は、結構大変です。いや、大変でもないんですが、そのジェネリックとしてのTを使って、別の型で生成するのがむつかしいのです。IntelliSenseから出てこないし普通に書いてると辿りつけないんですが、TypeBuilder.GetMethod経由だとDefineGenericParametersとMakeGenericTypeからMethodInfoが取れる。って、何言ってるのか全く意味不明と思うんですが、いつか誰かがはまった時のヒントとして残しておきます。もしジェネリック型を生成して、なにかよくわからないけれど、どうにもならないことがあったら、思い出してください。はい。
まとめ
とにかくツールの使いこなしが全てです。徒手空拳でILGeneratorと戦うのは、そりゃあ大変な努力が必要ですが、きっちりとツールを使っていけば、超絶難易度の黒魔術、というほどではなく、まぁまぁ常識的な範囲に収まります。書くだけなら。読み解くのはやっぱ一苦労だし、人の書いたのを読めるかって言ったら、まぁ読めないんですが(自分の書いたのだって数日置いたら読めないぞ!)、その辺はアセンブラなんでしょうがないね。読みの難易度と書きの難易度は非対称だし、読みに比べると、書きのほうがずっと楽、ということです(なんせカンニングコピペというテクが使えますからね)。
というわけで、あまり恐れずに、自分の中のツールセットとして持っておくと、なんらかのフレームワーク的なレイヤーを作る際にやれることが大きく広がるんじゃないかと思います。
とはいえ、別に無闇に使うのはお薦めしません!必要ないところでは必要ないのままでいいし、場合によってはベタなリフレクションで構わない場合も多いでしょう。そこの辺の選択は冷静にやったほうがいいですね、麻疹にかかるのも大事ですが、IL書きは割と冗談じゃなく本人以外メンテ不能になるので。
さて、そんなわけで明日のAdvent Calendardは既に書いていただいているのですが@NumAniCloudさんのC#で実装!RPGのパッシブ効果の作り方を通じたオブジェクト指向のノウハウです。
Utf8Json - C#最速のJSONシリアライザ(for .NET Standard 2.0, Unity)
- 2017-09-29
Utf8Jsonという新しいC#用のJSONシリアライザを作りました。.NET Standard 2.0で作っているのでふつーの.NETでもXamarinでも概ね動くはずです(.NET 4.5版もあります)。また、Unity用にもちゃんと用意しています。Unityの場合はJsonUtilityと比較してどうよ、ってことなんですが、いいと思いますよ(あとで少しだけ説明します)
なんかバズって、一気に350 Star超えしました。GitHubのToday's Trending - C#で1位、全体で20位ぐらいになってたりました。
使い方を説明してもしょうがないので(ReadMe見てね)、ここではパフォーマンスに関する実装面での工夫について説明します。

赤枠で囲ったのがUtf8Jsonで、それより左側はバイナリシリアライザです。JSONでは最速。ウリは超高速性と、十分な拡張性。さすがにフォーマットの違いがあるのでMessagePack for C#には敵わないのですが(というか改めて見てもむしろデタラメに速すぎ……)、他のJSONシリアライザよりも勝っています。シリアライズに至ってはprotobuf-netより速いし。また、メモリアロケーションも非常に少ない(基本的にpayloadのサイズ分しか必要とせず、メモリプールに収まる範囲内では、ゼロアロケーションです)。
コンセプトの核はシンプルです。JSONをUTF8 byte[]に直接読み書きすることで、バイナリシリアライザであるかのように動作させる。それにより、従来あったString(UTF16)との相互変換のオーバーヘッドを消して、速度を圧倒的に向上させることができる。
このような試みは、corefxlabによりSpan<T>という、そろそろ標準に入りそうでまだ入ってない効率的な配列のスライスっぽい何か、の活用の一貫として研究されています。corefxlabのWikiにあるSystem.Text.Formattingの解説を見てみましょう。ToStringやFormattingを避け、直接UTF8として書き込むことにより、多くのアロケーションを避け、より高速に動作することを目指しています。残念ながらこれは未だ「early prototype, not complete, please don't try to use it in real world software」ではありますが。また、汎用的なJSONシリアライザとはまた別のものです。とはいえ、コンセプトの正しさ、目指さなければならない地点はどこにあるか、というのは分かると思います。Utf8Jsonは、実装した結果を持って、そこに到達しました。
C#自体としてもUTF8String Constantsなどの提案もありますが、実現するかも分からない遠い未来のことであり、UTF16のコストは払い続けなければならないでしょうね。null安全に関する話もそうですが、C#もレガシー言語と言わざるを得ない要素は色々と嵩んできてはいると思っています。Stringに関してはGoのほうがモダンでイケてるStrings, bytes, runes and characters in Goように見えますし、しかし言語の大元に組み込まれているもの(UTF16)を変えるというのは非常に難しいところでしょう。その中で、しかし現実は現実として、今、このC#で、いかに、どこまでやれるかというのが勝負だし、C#を戦場で勝ち残れる環境に引き上げていくことでもあります。
TextReader/Writerのオーバーヘッド
通常のJSONシリアライザはstringを返しますが、別にstringを返されても使い道はないので、その後更にbyte[]に変換するでしょう、多くの場合はEncoding.UTF8.GetBytesにより。或いはTextReader/WriterでStreamに書き込みするかの、二択です。そこに着目した場合、通常のJSONシリアライザにはオーバーヘッドが存在します。例えばUtf8JsonとJil(C#での高速なJSONシリアライザとしてJSON.NETのオルタナティブとしては最もメジャー)で見てみると
// Object to UTF8 byte[]
[Benchmark]
public byte[] Utf8JsonSerializer()
{
return Utf8Json.JsonSerializer.Serialize(obj1, jsonresolver);
}
// Object to String to UTF8 byte[]
[Benchmark]
public byte[] Jil()
{
return utf8.GetBytes(global::Jil.JSON.Serialize(obj1));
}
// Object to Stream with StreamWriter
[Benchmark]
public void JilTextWriter()
{
using (var ms = new MemoryStream())
using (var sw = new StreamWriter(ms, utf8))
{
global::Jil.JSON.Serialize(obj1, sw);
}
}
Obj -> String -> byte[]は明らかに無駄ステップで、Obj -> byte[]のほうが明らかに速そうだ、というのは単純明快でよくわかります。では Object -> Stream(with StreamWriter)はどうでしょう。ベンチマークで分かる通り、StreamWriterを介したものはStringからのbyte[]よりも、むしろ低速です。一見「ストリーミング」で良いかのように見えますが、それは見せかけだけのことで、実際には内部でバッファを"いい具合"に抱えてやりくりしているだけのことであり、更にそれによりStreamWriterへの書き込みそのものに多くのオーバーへッドが存在するからです。このことはそもそもJilのReadMeにも書かれていることです、が、しかし例えばASP.NET Core MVCのシリアライザを差し替えようとして、このような実装をついしてしまうでしょう。
// ASP.NET Core, OutputFormatter
public class JsonOutputFormatter : IOutputFormatter //, IApiResponseTypeMetadataProvider
{
const string ContentType = "application/json";
static readonly string[] SupportedContentTypes = new[] { ContentType };
public Task WriteAsync(OutputFormatterWriteContext context)
{
context.HttpContext.Response.ContentType = ContentType;
// Jil, normaly JSON Serializer requires serialize to Stream or byte[].
using (var writer = new StreamWriter(context.HttpContext.Response.Body))
{
Jil.JSON.Serialize(context.Object, writer, _options);
writer.Flush();
return Task.CompletedTask;
}
// Utf8Json
// Utf8Json.JsonSerializer.NonGeneric.Serialize(context.ObjectType, context.HttpContext.Response.Body, context.Object, resolver);
}
}
context.Response.BodyはStreamだから、普通にStreamWriter通して書きますよね?そのことにより謳い文句よりもずっと低速で、多くのメモリ消費をしてしまっているというのに!これが、Jilに差し替えても爆速だぜー、を達成できない理由です(とはいえさすがにもちろんJSON.NETよりは遥かに速い)。今も変わらず、JSONのシリアライゼーションは.NETのボトルネックであり続けているのです。
ついでじゃないですが、StreamWriterは初期化時(コンストラクタ)に、デフォルトでchar[1024] と byte[3075] という、かなりデカいバッファをいきなり確保します。referencesource/streamwriter.cs#L203-L204。これは普通にデカい。こういうのがストリームの代償なんですよね、あばー。
シリアライズの最適化
こんな感じで動いています、の図。

// 逆コンパイル結果のイメージ。
public sealed class PersonFormatter : IJsonFormatter<Person>
{
// 実質シングルトンになるので永久にキャッシュ
private readonly byte[][] stringByteKeys;
public PersonFormatter()
{
// プロパティ名は"{", ":", ","を引っ付けた上で事前生成してキャッシュ
this.stringByteKeys = new byte[][]
{
JsonWriter.GetEncodedPropertyNameWithBeginObject("Age"), // {\"Age\":
JsonWriter.GetEncodedPropertyNameWithPrefixValueSeparator("Name") // ,\"Name\":
};
}
public sealed Serialize(ref JsonWriter writer, Person person, IJsonFormatterResolver jsonFormatterResolver)
{
if (person == null) { writer.WriteNull(); return; }
// WriteRawXはメモリコピーの特化版(生成時にx32/x64とsrcの長さが分かってるので、特化して生成する)
UnsafeMemory64.WriteRaw7(ref writer, this.stringByteKeys[0]);
writer.WriteInt32(person.Age); // itoaで直接書き込むことによりToString + UTF8エンコードを避ける
UnsafeMemory64.WriteRaw8(ref writer, this.stringByteKeys[1]);
writer.WriteString(person.Name);
writer.WriteEndObject();
}
// public unsafe Person Deserialize(ref JsonReader reader, IJsonFormatterResolver jsonFormatterResolver)
}
この場合だと処理ステップ的には5ブロック分です。JSONのシリアライズが(バイナリに比べて)遅くなってしまう要因は色々あるのですが、各プロパティ名の書き込みには最適化の余地があります。一つに、名前は固定なので、事前にエンコードしておきましょう。更に、区切り記号":"や連結","、ヘッダ"{"の出現位置は決まっているので、名前にくっつけて一体化してしまいます。パフォーマンス向上の基本原則は呼び出し回数を抑えること、なので一体化には大いに意味があります。あとは、ターゲットがbyte[]なので、メモリコピーするだけです。
そして、更にメモリコピーの最適化の問題に入ります。C#におけるコピーの手法として、Array.Copy、を卒業した人はBuffer.BlockCopyを使い出します。これはプリミティブ型のコピーでは、Array.Copyより高速という謳い文句で、概ね実際そうなのですが、小さいサイズのコピーの場合は話が少々違ってきます。そして、プロパティ名は通常、かなり小さい(普通は10バイト以下、多くても30バイト以下でしょう)。
そしてそもそもBuffer.BlockCopyには無駄があります。coreclrに改善PRが出されているので、それを見るのが分かりやすいですが、Buffer.BlockCopyはランタイムのネイティブのC++コードの呼び出しになりますが、型のチェックと汎用的な型による処理が入っているんですね。というのも、Buffer.BlockCopyはプリミティブ型全てがコピーできる代物だから。でも、利用用途の9割はbyte[]のコピーのはずで、より最適なコードが叩き込めるはずです。というわけで、2016年の2月に、これは入りました。それ以前のものに関しては南無、という話です。それとCore CLRの話なのでCoreじゃないCLRにどの程度反映されているかは謎です(多分、反映されてない気がする)。
とはいえどちらにせよ使いません。unsafeが許されるなら.NET 4.6から追加されたBuffer.MemoryCopyのほうが高速だからです。じゃあそれでOKかというと、やはりそんなことはなくて、GitHubのcoreclr上で何度か最適化PRが出されていて、現在の最新のPRはOptimize Buffer.MemoryCopy #9786です。中身を説明すると、ある程度のThreshold(x64では2048)までは、SSE2が使える環境なら64バイト単位(RyuJITがそうする)、そうじゃなければ8バイト単位でC#のunsafeで普通にコピーするという代物です。なるほどunsafeで普通にコピー。それが速い。そうなのか。
で、さらにILGeneratorによる実行時動的生成なので、コピー元の長さも知っているので、分岐も消せるんですね、直接埋め込んでしまえば。と、いうわけで、UnsafeMemory.csには31バイトまでの最適化メソッドがあります。コード生成時に長さを判定して、31バイト以下なら専用メソッドを直接呼ぶコード、それ以上はBuffer.MemoryCopyを使うコードを生成。これが真の最速コピー。
なお、ILにはCpblk命令がありますが(C#からは直接呼べない)、結局コレはランタイムがどう処理するかって話でしかなくて別に特にマジックもなく、むしろあまり使われないせいで最適化の手が回ってない説すらあるんで、夢は持たないでおきましょう。どうしても使いたければ現在はNuGetからSystem.Runtime.CompilerServices.Unsafeを落としてくれば使うこと自体は簡単にできます。
itoa/atoi, dtoa/atod
itoaというと古き良き香りって話で、まぁ実際古き良き話なのですが、integer to ascii、ということで数字をUTF8 byte[]に変換するなら、これが使えます。UTF8は数字はascii同様ですからね。コレの何が良いかというと、ToStringしなくて済みます。ToStringは何気にコストなのです!(ようするにInteger to UTF16だから)。更に加えてbyte[]にしたければUTF16 -> UTF8へのエンコードまで必要です。絶対避けたい話ですよね、ということで数字の書き込みはitoaを実装することにしましょう。また、その逆 atoi も大事。atoiのほうは、普通だと byte[] -> String -> int.Parse という処理順になって無駄があるんで、そこ直接 byte[] -> int に変換かけれたほうが有利になります。
itoaは割と素朴に実装するだけなのでいいんですが、dtoaは問題です。doubleはねー、大変なんですよ……!ここがバイナリシリアライザと大きな違いで、バイナリシリアライザはdoubleでもサクッと高速に変換できるんですが、doubleをテキストに変換する/テキストからdoubleに変換するのは割と大仕事で、性能面に差が出てきてしまうところPart1です(Part2は文字列で、文字列はエスケープが必要になって全走査かける必要があるからめちゃくちゃネックになる)。
んで、dtoaをどうするかなんですが、モダンでイケてるアルゴリズムとしてGrisu2というのがあって(論文は2004年と比較的新しいですね)、それのC++実装としてgoogle/double-conversionがあるので(Grisu3かも、別にバージョン(?)違いは性能向上ってよりは機能面での違いってふいんきではある、ふぃっしゅ数みたいなもんですよ←違います)、今回はそれをPure C#として移植しました。これでまぁ、概ねOKでしょう。
なお、dtoaのアルゴリズムの比較はC++の高速なJSONライブラリであるRapidJSONの作者が、それのために色々アルゴリズムを比較しているdtoa-benchmarkが割と詳しい、です。RapidJSONの作者さんはテンセント勤務。うーん、中国強い。実際、C#もGitHub見てると中国語しか説明ない謎ライブラリ、でも強そう、あと英語圏でも無名そうなのにStarいっぱいついてる、みたいな中華圏ローカルでも規模めっちゃデカいし出来も凄いんです感がとてもあって、めっちゃ面白い。時代は中国。
この辺のことをSpanベースの標準サポートでやりたいのがcorefxlab/System.Text.Primitiveなんですが、まぁまだ作りかけって感じですね。実際、大事なところは TODO:そのうちやる、みたいになってるし。この辺はSpanがそもそもまだリリースされてない → Utf8Stringが全然固まってない、で、その後にくる課題だと思うんで、完成するまで先は長そうです。Utf8Jsonはcorefxlabがやりたかったことがかなり詰まってるんですよねえ。そういう意味でも未来のライブラリです。実際、JSONシリアライザとしては世代が一つ先のものと言えるでしょう。
デシリアライズの最適化
デシリアライズの最適化、に関してはMessagePack for C#におけるオートマトンベースの文字列探索によるデシリアライズ速度の高速化で説明したオートマトンによる検索をIL生成で埋め込んでいます。

やってることは以前に書いた通りなので詳しいのはそれ読んでほしいんですが、文字列にデコードしてハッシュテーブルでマッチングするんじゃなくて、バイト列をそのまま使って、かつlong単位でバイト列を切り取ってオートマトン探索をマッチする定数ごとコード生成時に埋め込む、という割と大掛かりな代物 。大掛かりではあるんですが、コード的にもコピペして持ってきただけなので新規の手間は全然かかってません!なお、もちろん、Stringにデコードしたりとかせずに、更にエスケープされているまんまでスライスを作ってそれでオートマトンに通してます。とにかく無駄処理は徹底的に省く。テキストフォーマットだと、その辺に特にシビアにならなきゃいけなくて、性能を気にする場合はバイナリシリアライザよりも難易度がかなり高い……。
Mutable Struct Reader/Writer
Mutable Struct is Evil!というのは過去のこと、というわけではないですが、考えなしにとりあえず否定するのは時代遅れの腐った脳みそです。と、いうわけでUtf8Jsonの最もプリミティブな部位、JSONを読み書きするJsonReader/JsonWriterは状態を持つ構造体です。例えばJsonReaderはbyte[]とint offsetを保持し、読み込みのたびにoffsetが進みます。
これは、値渡しをしてはいけないことを意味します。また、ローカル変数に入れるのも禁止です。コピー禁止、徹底的に。というわけで、型毎のシリアライザ、IJsonFormatterの定義はこうなっています。
public interface IJsonFormatter<T> : IJsonFormatter
{
void Serialize(ref JsonWriter writer, T value, IJsonFormatterResolver formatterResolver);
T Deserialize(ref JsonReader reader, IJsonFormatterResolver formatterResolver);
}
ちなみに、値渡しの禁止はC# 7.2のref-like typesによって、コンパイラによる制御がかけられる、といいなあ、というのが詳しくはcsharp-7.2/span-safety.mdをどうぞでref周りには色々と手が入る予定があるんですが、残念ながら禁止はできなさそうです(ref-likeであってref-onlyではない、みたいな)。なので自己責任で気をつけてください、という話になります。csharp-7.2/Readonly referencesあたりは少し助けになりますが、それでも完全ではないですね。ref周りの強化はまだ続いてくので、今後に注視していきたいところ。
また、JsonReader/Writerはあまり気の利いたステートを持ちません。中身は byte[] bufferとint offset しか持ちません。なので、例えばJSON.NETはStartArrayすると、EndArrayまではWriteValueに対して","を自動でつけてくれるとかしてくれますが、そういうのは一切してくれません。100%マニュアル管理です。これは、↑で出たプロパティ名に"{"とか":"とか","がくっついてるなどなど、最適化のために内部ステートをガン無視した投下を行うで、管理しようがないからってのが理由になりますね。あとは、もちろん不要なステート管理は性能上の無駄なので、そうじゃなくても最初から捨てる気でした。
いえいえ、別にだからといって読み書きしづらいわけじゃないですよ?むしろReadに関しては、かなりやりやすいと思います。例えばList[int]のデシリアライザを作るとして
public List<int> Deserialize(ref JsonReader reader, IJsonFormatterResolver formatterResolver)
{
if (reader.ReadIsNull()) return null;
var list = new List<int>();
var count = 0; // 外部変数で状態管理(JsonReaderは状態を持たない)
while (reader.ReadIsInArray(ref count))
{
list.Add(reader.ReadInt32()); // Int32で読む
}
return list;
}
と、結構端的に書けます。JSON.NETだとwhile(Read())してTokenをswitchして...とやらなきゃいけないので、むしろこっちのほうが書きやすいとすら言えるでしょう。このAPIスタイルはMessagePack for C#のMessagePackBinaryを踏襲したものです。前方から、型が確定の状態で読み進めていくのにやりやすいAPIと思っています(ただしTokenを使ったdynamicな処理しようとするとReadを忘れるというミス率高し、つい数時間前にもそのミスによるバグレポを直した)。ただし、一般的なAPIスタイルではない、という自覚はあります。まぁ、ハナからMutable Structで一般的じゃないので、いいじゃないですか。つーかXmlReader辺りから続く、10年物の骨董品みたいなAPIスタイルをいつまでも有難がってるほうがおかしい。
Unity/コードジェネレーター
Unityには標準でJsonUtilityがあって、それは十分に高速でイケてるんですが、幾つか難点が。一つはUnityのシリアライズ対応に従わなければならないところがあって、nullableダメとか配列がルートにできないとかDictionaryがダメとか(当然他のコレクションもダメ、配列とListだけ)nullのハンドリングがビミョウどころかヤバい(中身が空のインスタンスが生成される、classなのにdefault(struct)みたいな処理がされる)とか、厳しいところもあります。それを乗り越えれば高速でいいんですが。
もう一つは、ターゲットがstringなので、File I/OやNetwork I/Oが相手の場合はUTF8変換が必要になりますよね(もちろんその分のアロケーションは存在する)
ってことで、Utf8Jsonを使うと直接byte[]に変換出来て真のゼロアロケーションを達成出来る!おまけにどんな型でも自在にシリアライズ可能!その上で十二分に高速!まぁ高速性に関しては、JsonUtilityとbyte[]変換分を加算した上で、いい勝負ってぐらいですね。勝てるケースもありますが微妙な判定のケースもあるので、どっこい、ぐらいです。さすがに、JsonUtilityはシリアライズ対象に制約があるということは、UnityのC++エンジンの内部に都合がよい形で、C++でガリガリッと処理しているということだと思うんで(なので制約がキツいのは受け入れてあげるべきと思ってます、しょーがないじゃん、世の中なんでもトレードオフですよ)、Pure C#レイヤーだけでいい勝負できてることのほうがむしろ凄いことです。いや実際。
PC版の場合は、ILGeneratorによる動的コード生成も動くので、そのまんまJsonUtilityを置き換えれるといっても過言ではないです。が、iOS/AndroidなどIL2CPPの場合は勿論動きません。……。てわけで、例によってコマンドラインアプリケーションとしてコードジェネレーターを用意してあって、動的コード生成のかわりに事前生成したのに差し替えられるようになってます。ビルド時のフックなりUnityのPre/Post処理などに入れるなりして動かせば、そこまで面倒って感じではないと思います、最初のセットアップさえ完了すれば。
そして、MessagePack for C#などの場合はWindowsでしか動かなかったコードジェネレーターが、今回からwin/mac/linuxで動くようになりました……!おめでとうおめでとう。.NET CoreによるC#でのクロスプラットフォームアプリケーションの成果物なので、みんなクロスプラットフォームでちょっとした小物作る場合はGoだけじゃなくてC#も使いましょう。
てわけでUnity用にはUtf8Json/relasesページにして.unitypackageと、コードジェネレーターのzipが置いてあります。
ちなみにstringが欲しい場合は出来上がったbyte[]をGetString、しなくてもToJsonStringメソッドが映えてるのでそちらを使うことで、stringへの変換もできます。その場合はobject -> byte -> string(utf16)という変換パスになるので、byte[]に比べると速度が落ちてしまいますが、この辺は最優先のターゲットとしてどちらを優先するか、というところなのでしょうがないとこです。
テキスト(JSON) vs バイナリ
JSON最強理論はあるのですが(実際Utf8Jsonはprotobuf-netより速いし)、それでも私は使い分けすべきと思ってます。というのも、バイナリ(MessagePack for C#)は鬼のように速いし、これはもうフォーマットの違いがさすがに決定的で、Utf8Jsonをそこまで高速化するのは絶対不可能です。テキストをほぼバイナリであるかのようにあつかって処理はしてますが、やっぱ限界はあります、特にdoubleとか文字列(エスケープ)とかのネックっぷりがキツい。それとどうしてもペイロードがデカくなるので、デカいってのは純粋に読み書きのコストが増大してパフォーマンス的には(比較すると)不利になりますからね。
とはいえ、MesssagePackだけでOKかというと、そうじゃあないんですよね。公開API作るならJSONじゃなきゃだし、Web用もJavaScriptで読めるJSONじゃなきゃ基本ダメ。モバイルや別言語との通信だったらMessagePackでもOKではありますが、しかしJSONのほうがやりやすい場合も多いでしょう。
というわけで、JSONじゃなきゃダメなシチュエーションは当然あるので、そこはUtf8Json。それ以外(いっぱいありますよね?Redisに保存するものとか)だったら、MessagePack for C#。という風な使い分けが良いと思ってます。また、MessagePack for C#のほうが多機能(Unionサポートなど、これはJsonだとInvalidなオレオレJSONが出来上がるのでサポートする気はない)なので、C#で完結する処理ではMessagePack for C#のほうが便利です。
多少の機能性に違いはあれど、原則出力形式が違うこと以外は、Utf8JsonとMessagePack for C#に大きな差はありません。protobuf等の場合使い勝手が悪くてJSONを選ぶ、ということもありましたが、MessagePack for C#の場合は違います。なので、普通に使い分けしてください。これがC#におけるシリアライザに関してのファイナルアンサーです。完全に決着ついた。もう一切悩む必要はない。
まとめ
Utf8Jsonの公開効果によってMessagePack for C#の知名度もつられて上昇しMsgPack-Cliのスター数を遥かに抜いてった。この辺は意図してることで、同じようなものを連発して、相互に認知度高めていくのは基本っちゃあ基本ですね。もう一つブーストさせたかったので、想定通りの結果でよきかなよきかな。
目的のもう一個は最適なテキストプロトコル処理を作ることで、以前にC#の高速なMySQLのドライバを書いてるよという話を書きましたが、進捗ダメです!じゃなくて、別に諦めたわけでも放置したわけでもなくて、MySQLって基本はテキストプロトコルで、そこに対して最速の処理をあてたかったんですね。んで、私自身、最速バイナリ処理の技法は持ってたんですが、最速テキスト処理の技法がなくて、MySQLにたいして研究からやってるのあんま効率良くなかった。比較対象もないし、処理通すのにMySQL叩くのも面倒なうえにピュアな処理じゃないし。そこで、JSONはめっちゃ都合よくて、サクッと手元で完結するし比較対象はいっぱいあるし、おまけに完成すれば絶対に需要がある。更にはシリアライザのアーキテクチャ自体はMessagePack for C#で完成しているので、かなりの部分を流用できる。いいことづくめじゃん。というのが、作ろうとした発端でした。というわけでMySQLドライバは諦めてないというか、むしろここが出発点なのでmattekudasai……!
それとMagicOnion(gRPCの上に構築したMessagePackを使うC# RPC)のα版からの脱出も諦めてません。んで、今もHTTP/1 Gatewayはあるんですが、どちらかというとSwaggerを動かすためだけの開発用で、プロダクションに使えるレベルのものではないんですね。grpc-gatewayとかgrpc-webレベルのものになれば、HTTP/1のいわゆるREST APIみたいなものもMagicOnionで書きおこせるようになる。そのためには納得がいくレベルの高速さと拡張性を備えたJSONシリアライザが必要で(JSON.NETは拡張性はOKだけど性能がダメ、Jilは性能はまぁ良いとしても拡張性がダメ。MagicOnionはただシリアライズ-デシリアライズしてるだけじゃなくて、MessagePack for C#が微妙にメタい処理を挟んで高性能を実現するような設計になってるので)、なんと悲しいことに空席で存在してなかった。Utf8Jsonならそれを満たせます。メデタシメデタシ。実際ほんと困ってたので出来てよかった。この辺、シリアライザを自分で用意できると融通が効きまくって最高に良い。出来ることの幅がかなり広がる。
と、いうわけで、かなり良いライブラリに仕上がったと思うので(特に、基礎レベルの出来はMessagePack for C#で証明済みというか、沢山issueを貰って改善してった歴史があった積み重ねが乗っかってる)、ぜひぜひ使ってみてくださいな。
MessagePack for C#におけるオートマトンベースの文字列探索によるデシリアライズ速度の高速化
- 2017-08-28
MessagePack for C# 1.6.0出しました。目玉機能というか、かなり気合い入れて実装したのは文字列キー(Map)時のデシリアライズ速度の高速化です。なんと前バージョンに比べて2.5倍も速くなっています!!!

他のシリアライザと比較してみましょう。

IntKey, StringKey, Typeless_IntKey, Typeless_StringKeyがMessagePack for C#です。MessagePack for C#はどのオプションにおいても、デシリアライズのプロセスにおいてメモリを一切消費しません。(56Bはデシリアライズ後の戻り値のサイズのみです)
JSONの二種はStringからとbyte[]からStreamReaderの2つの計測を入れてます。これは、通常byte[]でデータは届くので、計測的にはそこも入れないとダメですよね、ということで。StreamReader通すとオーバーヘッドがデカくなりすぎて(UTF8デコードが必要というのもある)、どうしてもかなり速度が落ちてしまうんですよね。なので、JSONは、バイナリ系に比べると現実的なケースではかなり遅くなりがちなのは避けられません。見慣れないHyperionはAkka.NETのためのシリアライザでWireのForkです。この辺はシリアライザマニアしか知らないものなのでどうでもいいでしょう(
さて、MessagePack for C#の数字キー(Array)が一番速いです。文字列キーの3倍速い、ただしこれは数字キーのケースがヤバいぐらいむしろ速すぎなんで、別に文字列キーが遅いわけじゃあないというのは、他と比べれば分かるでしょう(文字列キー時ですらprotobuf-netより高速!)。数字キーのほうが高速になるのは、原理を考えると当然の話で、数字キーはMessagePackのArray、文字列キーはMapを使ってシリアライズするのですが、デシリアライズ時にArrayの場合は read array length, for(array length) { binary decode } という感じのデシリアライズを試みます。Mapの場合は read map length, for(map length) { decode key, lookup by key, binary decode } という具合に、キーのデコードと、どのメンバーに対してデシリアライズすればいいのかのルックアップの、2つの余計なコストがかかってくるので、どうしても遅くなってしまいます。
とはいえ、文字列キーは中々に有用で、コントラクトレス(属性つけなくていお手軽エディション)やJSONの気楽な置き換え、より固い他言語との相互通信やバージョニング耐性、より自己記述的なスキーマあたりのメリットがあり、割と使われてます。実際、結構使われているっぽいです。もともと数字キーはエクストリームにチューニングされていて激速だったんですが、文字列キーはそれほどでもなかったので、文字列キーのデシリアライズ速度の高速化が急務でした。
最終的にはオートマトンベースの文字列探索をIL生成時インライン化で埋め込むことにより高速化を達成したのですが(インライン化が効果あるのはMicroResolver - C#最速のDIコンテナライブラリと、最速を支えるメタプログラミングテクニックの実装時に分かっていたので、そのアイディアを転用してます)、とりあえずそこに至るまでのステップを見ていきましょうでしょう。
文字列のデコードを避ける
素朴な実装、MessagePack for C#のついこないだまで(前の前のバージョン)の実装では、文字列キーをStringにデコードしていました。そこから引っ張ってくる、という。
// 文字列をキーにしたDictionaryをキャッシュとして持つというのはあるあよくある。
static Dictionary<string, TValue> cache = new Dictionary<string, TValue>();
// ネットワークからデータが来る場合はUTF8Stringのbyte[]の場合が非常に多い
// で、キャッシュからデータを引くためにstringにデコードしなければらない
var key = Encoding.UTF8.GetString(bytes, offset, count);
var v1 = d1[key];
// この場合、keyは無駄 of 無駄で、デコードなしに辞書が引けたら
// デコードコストがなくなってパフォーマンスも良くなる&一時ゴミを作らないので全面的にハッピー
ということです。シチュエーションとして、なくはないんじゃないでしょうか?実際具体的なところとしては、MessagePack for C#の文字列キーオブジェクトのデコードでは、このケースにとても当てはまります。Fooというプロパティがあったら Dictionary<string, MemberInfo> にTryGetValue("Foo")でMemberInfoを取り出す。みたいな感じです。
public class MyClassFormatter : IMessagePackFormatter<MyClass>
{
Dictionary<string, int> jumpTable;
public MyClassFormatter()
{
// MyProperty1, 2, 3の3つのプロパティのあるクラスのためのプロパティ名 -> ジャンプ番号のテーブル
jumpTable = new Dictionary<string, int>(3)
{
{ "MyProperty1", 0 },
{ "MyProperty2", 1 },
{ "MyProperty3", 2 },
};
}
public MyClass Deserialize(byte[] bytes, int offset, IFormatterResolver formatterResolver, out int readSize)
{
// ---省略
// 中では Encoding.UTF8.GetString(bytes, offset, count)
var key = MessagePackBinary.ReadString(bytes, offset, out readSize);
if (!jumpTable.TryGetValue(key, out var jumpNo)) jumpNo = -1;
// 以下それ使ってデシリアライズ...
switch (jumpNo)
{
case 0:
break;
default:
break;
}
}
}
ちなみにswitch(string)はC#のswitch文のコンパイラ最適化についてに書きましたが、コンパイラがバイナリサーチに変換するだけなので、そこまで夢ある速度は出ません(こういうケースでバイナリサーチとハッシュテーブル、どっちが速いかは微妙なラインというかむしろハッシュテーブルのほうが速い)。あとIL生成でそれやるのは面倒なので、現実的な実装では辞書引きが落とし所になります。
とはいえまぁ、そのデコードって無駄なんですよね。byte[]で届いてくるのを、辞書から引くためだけにデコードしてる。byte[]のまま比較すればデコードコストはかからないのに!
そこで、byte[]のまま辞書引きができるようなEqualityComparerを実装しましょう。そうすると
// 別に辞書のKeyとして引くだけなら、 byte[]そのもので構わないので、こうする。
Dictionary<ArraySegment<byte>, TValue> d2;
// そのためにはArraySegment<byte>のEqualityComparerが必要
d2 = new Dictionary<ArraySegment<byte>, TValue>(new ByteArraySegmentEqualityComparer());
// すると、byte[] + offset + countだけでキーを引ける。
var v2 = d2[new ArraySegment<byte>(bytes, offset, count)];
ハッピーっぽい。さて、実はこれ、ようするにC#で入る入る詐欺中のUTF8Stringです。Dictionary<UTF8String>で持てばデコード不要でマッチできますよね、という。しかし、残念ながらUTF8Stringの実装は中途半端な状態で、ぶっちけ使いものにならないレベルなので、存在は無視しておきましょう(少なくとも辞書のキーとして使うにはGetHashCodeのコードが仮すぎて話にならないんで、絶対にやめるべき、ていうかいくら仮でもあの実装はない)。いつか正式に入った時は、そちらを使えば大丈夫ということになるとは思います。まぁ、まだ当分は先ですね。
ByteArraySegmentEqualityComparerを実装する
Dictionaryの仕組みとしてはGetHashCodeでオブジェクトが入ってる可能性がありそうな連結リストを引いて、その後にEqualsで正確な比較をする。という感じになっています。二段構え。なので、Equalsをオーバーライドする時は必ずGetHashCodeもオーバーライドしなければならない、の理由はその辺この辺ということです。
public class ByteArraySegmentEqualityComparer : IEqualityComparer<ArraySegment<byte>>
{
public int GetHashCode(ArraySegment<byte> obj)
{
throw new NotImplementedException();
}
public bool Equals(ArraySegment<byte> x, ArraySegment<byte> y)
{
throw new NotImplementedException();
}
}
さて、GetHashCodeはどうしましょう。アルゴリズムは色々ありますが、素朴に実装するならFNV1-a Hashというのがよく使われます。
public int GetHashCode(ArraySegment<byte> obj)
{
var x = obj.Array;
var offset = obj.Offset;
var count = obj.Count;
uint hash = 0;
if (x != null)
{
var max = offset + count;
hash = 2166136261;
for (int i = offset; i < max; i++)
{
hash = unchecked((x[i] ^ hash) * 16777619);
}
}
return unchecked((int)hash);
}
先に出たswitch(string)の中でのハッシュコード算出でもこのアルゴリズムが使われています(つまりC#コンパイラの中にこれの生成コードが埋まってます)。
素朴にそれを実装してもいいんですが、見た通り、なんか別にそんな速くなさそうなんですよね、見た通り!ハッシュコード算出のアルゴリズムは実は色々あるんですが、もっと良いのはないのか、ということで色々と調べて試して回ったのですが、最終的にFarmHashが良さそうでした。これは一応Googleで実装され使われているという謳い文句になっていて、できたのが2014年と比較的新しめです。詳細はその前身のCityHashのスライドを読んで下さい。
一応特性としては特に文字列に対してイケてるっていうのと、短めの文字列にたいしても最適化されているというのが、良いところです。
何故なら、今回のターゲットは文字列、そしてメンバー名は通常4~12あたりが最も多いからです。実際にFarmHashのコードの一部を引いてくると、こんな感じです。
static unsafe ulong Hash64(byte* s, uint len)
{
if (len <= 16)
{
if (len >= 8)
{
ulong mul = k2 + len * 2;
ulong a = Fetch64(s) + k2;
ulong b = Fetch64(s + len - 8);
ulong c = Rotate64(b, 37) * mul + a;
ulong d = (Rotate64(a, 25) + b) * mul;
return HashLen16(c, d, mul); // 中身はMurmurっぽいの(^ * mulを4回ぐらいやる)
}
// if(len >= 4, len > 0)
}
// if(len <= 32, 64, 128...)
}
と、文字列の長さ毎に、算出コードに細かい分岐が入っていて、なんかいい感じです。Fetch64というのはlongで引っ張ってくるとこなので、8~16文字の時の処理は Fetch, Fetch, Rotate, Rotate, MulMul。まぁ、細かい話はおいておいて、FNV1-aより計算回数は少なそうです。
そんなFarmHash、使いたければFarmhash.SharpというC#移植があるので、それを使えばいいでしょう。ただ、MessagePack for C#の場合は微妙にそれではダメだったので(Farmhash.SharpはOffsetが0から前提だった……)、自分で必要な分だけ移植しました。そのバージョンはMessagePack.Internal.FarmHashの中にInternalという名に反してpublicで置いてあるので、MessagePack for C#を引っ張ってくれば使えます。
GetHashCodeについてはそのぐらいにしておいて、Equalsについてですが、ようはmemcmp。なのですがC#にはありません。最近だとSystem.Memoryに入っているReadOnlySpanを使ってSequenceEqualを使うと、それっぽい実装が入っているので割と良いのですが、まだpreviewなので自前実装にしておきましょう。ここは素朴にループ回してもよいのですが、unsafeにしてlong単位で引っ張ってやったほうが高速といえば高速です。
public unsafe class ByteArraySegmentEqualityComparer : IEqualityComparer<ArraySegment<byte>>
{
static readonly bool Is64Bit = sizeof(IntPtr) == 8;
public int GetHashCode(ArraySegment<byte> obj)
{
// 特に文字列が前提のシナリオでFarmHashは高速
if (Is64Bit)
{
return unchecked((int)MessagePack.Internal.FarmHash.Hash64(obj.Array, obj.Offset, obj.Count));
}
else
{
return unchecked((int)MessagePack.Internal.FarmHash.Hash32(obj.Array, obj.Offset, obj.Count));
}
}
public unsafe bool Equals(ArraySegment<byte> left, ArraySegment<byte> right)
{
var xs = left.Array;
var xsOffset = left.Offset;
var xsCount = left.Count;
var ys = right.Array;
var ysOffset = right.Offset;
var ysCount = right.Count;
if (xs == null || ys == null || xsCount != ysCount)
{
return false;
}
fixed (byte* px = xs)
fixed (byte* py = ys)
{
var x = px + xsOffset;
var y = py + ysOffset;
var length = xsCount;
var loooCount = length / 8;
// 8byte毎に比較
for (var i = 0; i < loooCount; i++, x += 8, y += 8)
{
if (*(long*)x != *(long*)y)
{
return false;
}
}
// あまったら4byte比較
if ((length & 4) != 0)
{
if (*(int*)x != *(int*)y)
{
return false;
}
x += 4;
y += 4;
}
// あまったら2byte比較
if ((length & 2) != 0)
{
if (*(short*)x != *(short*)y)
{
return false;
}
x += 2;
y += 2;
}
// 最後1byte比較
if ((length & 1) != 0)
{
if (*x != *y)
{
return false;
}
}
return true;
}
}
}
まぁこんなもんでしょう。これらのコードはMessagePack.Internal.ByteArrayComparerに埋まっているので、internalだけどpublicなので、MessagePack for C#を入れてもらえればコピペせずとも使えます。
実際、これでStringデコードしてくるよりも高速になりました!素晴らしい!終了!
オートマトンによる文字列探索
と思って、実際実装もしたんですが、そしてまぁ確かに速くはなったんですが、しかし満足行くほど速くはならなかったのです。いや、別に遅くはないんですが、それでもなんというかすっごく不満。もっと速くできるだろうという感じで。
んで、こうしてGetHashCodeとEqualsを全部手実装して思ったのは、GetHashCodeを消し去りたい。しょーがないんですが、Equals含めるとこれbyte[]を二度読みしてることになってるわけで。DictionaryはO(1)かもしれんがbyte[n]に対して、O(n * 2)じゃん、的な。しかもデシリアライズって全プロパティを見るので、クラス単位でDictionaryを作ると、というか作るわけですが、普通は一個か二個はハッシュテーブルの原理的に衝突します。衝突するので、Equalsはもう少し何度か呼ばれることになる。なんかもういけてない!ていうかそれがIntKeyに対しての速度が出ない要因なわけです。
これをなんとかするための案として出てきたのがオートマトンで探索かけること。これはもともとJilの最適化トリックで言及されていたので、いつかやりたいなあ、と前々から思っていたので、今しかないかな、と。ついでにオートマトン化して探索を埋め込めるようになると、IL的なインライン化もより進められるので一石二鳥。MicroResolverの実装時にILインライン化が効果あったのは分かっていたので、もはややはりやるしかない。
具体的にはこんなイメージです。
"MyProperty1"という文字列はUTF8だと"77 121 80 114 111 112 101 114 116 121 49"というbyte[]。で、それを1byteずつ比較するのはアレなので、long(8 byte)単位で取り出すと"8243118316933118285, 3242356"になる(8byteに足りない部分は0埋めします、UTF8文字列前提ならその処理でもコンフリクトはなく大丈夫、多分……)。で、それで分岐かけた探索に変換する、と。オートマトンといいつつも、一方向の割と単純なツリー(ようするところトライ木)ではある。
これによって、long単位でのFetch二回と、比較二回だけでメンバー検索処理が済む!実際にジェネレートされるコードは以下のような感じです。

定数は実行時に生成されて埋め込まれるので、実行マシンのエンディアンの影響は受けません。メンバー数が多くなっている場合は、そこは二分検索コードを生成してILで埋め込みます。実際のシチュエーションだと、最初の8byteのところに集中するので、そこが二分検索、あとは普通は一本道なのでひたすらlongで取り出して比較、ですね。通常メンバ名は16文字以下なので、1回の二分検索と1回の比較で済むはずです。仮に多くなっても文字数 / 8の比較程度なので、そこまで大きくはならないでしょう。
完全に手書きじゃ無理な最適化ということで、いい感じです。さて、mpc.exe(事前コード生成)による生成は、ここまでの対応はしていないので、Unityだとここまで速くはなってないです、しょぼん(ただDictionary likeなオートマトン検索は行います、インライン化されないということなんで、いうてそこそこ悪くはないです)。事前生成で定数を埋め込むことに日和ってるので、まぁ別にLittleEndianだしいいじゃん、に倒してもいいかもしれないし、いくないかもしれないしでなんともかんともというところ。
まとめ
オートマトン化のIL実装は結構苦戦して、今回の土日は延々と試行錯誤してました。土曜だけで終わらせるはずが……。まぁ、結果としてできてよかった。
というわけでエクストリーム高速化されました。ここまで徹底的にやってるシリアライザは存在しないので、そりゃ速いよね。性能面では文句ないわけですが、機能面でも既に他を凌駕しています。目標は性能面でも機能面でも究極のシリアライザを作る、ということになってきたので以下ロードマップとか、私の考えているシリアライザの機能とはこういうのです、というラインナップ。
- Generics - 普通の。最初から実装済み。
- NonGenerics - フレームワークから要求されることが多い。最初から実装済み。
- Dynamic - Dynamicで受け取れるデシリアライズ、Ver 1.2.0から実装済み。
- Object Serialize - シリアライズ時はObject型を具象型でシリアライズする必要がある。Ver 1.5.0から実装済み(実はつい最近ようやく!)
- Union(Polymorphism, Surrogate, Oneof) - 複数型がぶら下がるシリアライズ。最初から実装済み。
- Configuration - Resolverで概ね賄えるけれど、一部のプリミティブが最適化のためオミットされるので、そこの調整が必要。
- Extensibility - 拡張性。Resolverにより最初から実装済み。Ver 1.3.0から MessagePackFormatterAttribute により簡易的な拡張も可能。
- Compression - 圧縮。LZ4で最初から実装済み。
- Stream - ストリーミングデシリアライズ。Ver 1.3.3から限定サポート(readStrict:trueでサイズ計算して必要な分だけStreamから読み取れる)。
- Async - 現状だとむしろ遅くなるのでやる気あんまなし、System.IO.Pipelinesが来たら考える。ただStream APIに関しては入れてもいいかも入れよう。
- Reader/Writer - Primitive API(MessagePackBinary)として最初から実装済み。ちょいちょいAPIは足していて、あらゆるユースケースに対応できる状態に整備されたはず。
- JSON - JSONとの相互変換。ToJson, FromJsonがVer 1.3.1から実装済み。
- Private - プライベートフィールドへのアクセス。コード生成的にひとひねり必要なのでまだ未実装。
- Circular reference - 循環参照。ID振って色々やる俺々拡張実装が必要で一手間なので当分未実装。
- IDL(Schema) - MessagePack自体に存在しないのでないが、C#クラス定義がそれになるような形で最初から実装済み。
- Pre Code Generation - シリアライザ事前生成。最初から実装済み。ただしWindowsのみでMacはまだ未対応。
- Typeless(self-describing) - 型がバイナリに埋まってるBinaryFormatter的なもの。ver 1.4.0から実装済み。
- Overwrite(Merge) - デシリアライズ時に生成せず上書き、Protobufにはある。現在実装中。
- Deferred - デシリアライズを遅延する。FlatBuffersやZeroFormatterのそれ。コンセプト実装中。
Overwriteは結構面白いと思っていて、例えばUnityだとMonoBehaviourに直接デシリアライズを投げ込むとかが可能になります。デシリアライズのための中間オブジェクトを作らなくて済むのでメモリ節約度がかなり上がるので、普通のAPI通信だと大したことないんですが、リアルタイム通信で頻度が多いようだと、かなりいけてるかなー、と思います。構造体を使うといっても、レスポンス型が大きい場合は構造体は逆に不利ですからね(巨大な構造体はコピーコストが嵩むので)。
DeferredはZeroFormatterアゲイン。アゲインってなんだよって感じですが。なんですかね。
とはいえ、やってると本当にキリがないので、ちょっと一端は実装は後回しにしたいので、もう少し先になります。というのも、UniRx(放置中!)とかMagicOnion(放置中!)とか、先にやるべきことがアリアリなので……!現実逃避してる場合ではない……!
C#のベンチマークドリブンで同一プロジェクトの性能向上を比較する方法
- 2017-08-20
ある日のこと、MessagePack for C#のTypeless Serializerがふつーのと比べて10倍遅いぞ、というIssueが来た。なるほど遅い。Typelessはあんま乗り気じゃなくて、そもそも実装も私はコンセプト出しただけでフィニッシュまでやったのは他の人で私はプルリクマージしただけだしぃ、とかいうダサい言い訳がなくもないのですが、本筋のラインで使われるものでないとはいえ、実装が乗ってるものが遅いってのは頂けない。直しましょう直しましょう。
速くするのは、コード見りゃあどの辺がネックで手癖だけで何をどうやりゃよくて、どの程度速くなるかはイメージできるんで割とどうでもいいんですが(実際それで8倍高速化した)、とはいえ経過は計測して見ていきたいよね。ってことで、Before, Afterをどう調べていきましょうか、というのが本題。
基本的にはBenchmarkDotNetを使っていきます。詳しい使い方はC#でTypeをキーにしたDictionaryのパフォーマンス比較と最速コードの実装で紹介しているので、そちらを見てくださいね、というわけでベンチマークをセットアップ。
class Program
{
static void Main(string[] args)
{
var switcher = new BenchmarkSwitcher(new[]
{
typeof(TypelessSerializeBenchmark),
typeof(TypelessDeserializeBenchmark),
});
switcher.Run(args);
}
}
internal class BenchmarkConfig : ManualConfig
{
public BenchmarkConfig()
{
Add(MarkdownExporter.GitHub);
Add(MemoryDiagnoser.Default);
// ダルいのでShortRunどころか1回, 1回でやる
Add(Job.ShortRun.With(BenchmarkDotNet.Environments.Platform.X64).WithWarmupCount(1).WithTargetCount(1));
}
}
[Config(typeof(BenchmarkConfig))]
public class TypelessSerializeBenchmark
{
private TypelessPrimitiveType TestTypelessComplexType = new TypelessPrimitiveType("John", new TypelessPrimitiveType("John", null));
[Benchmark]
public byte[] Serialize()
{
return MessagePackSerializer.Serialize(TestTypelessComplexType, TypelessContractlessStandardResolver.Instance);
}
}
// Deserializeも同じようなコードなので省略。
ベンチマークコードは本体のライブラリからプロジェクト参照によって繋がっています。こんな感じ。

というわけで、これでコード書き換えてけば、グングンとパフォーマンスが向上してくことは分かるんですが、これだと値をメモらなきゃダメじゃん。Before, Afterを同列に比較したいじゃん、という至極当然の欲求が生まれるのであった。そうじゃないと面倒くさいし。
2つのアセンブリ参照
古いバージョンをReleaseビルドでビルドしちゃって、そちらはDLLとして参照しちゃいましょう。とやると、うまくいきません。

同一アセンブリ名のものは2つ参照できないからです。ということで、どうするかといったら、まぁプロジェクトは自分自身で持ってるので、ここはシンプルにアセンブリ名だけ変えたものをビルドしましょう。

これを参照してやれば、一旦はOK。
extern alias
2つ、同じMessagePackライブラリが参照できたわけですが、今度はコード上でそれを使い分けられなければなりません。そのままでは出し分けできないので(同一ネームスペース、同一クラス名ですからね!)、次にaliasを設定します。

対象アセンブリのプロパティで、Aliasesのところに任意のエイリアスをつけます。今回は1_4_4にはoldmsgpack, プロジェクト参照している最新のものにはnewmsgpackとつけてみました。
あとはコード上で、extern aliasとoldmsgpack::といった::によるフル修飾で、共存した指定が可能です。
// 最上段でextern aliasを指定
extern alias oldmsgpack;
extern alias newmsgpack;
[Config(typeof(BenchmarkConfig))]
public class TypelessSerializeBenchmark
{
private TypelessPrimitiveType TestTypelessComplexType = new TypelessPrimitiveType("John", new TypelessPrimitiveType("John", null));
[Benchmark]
public byte[] OldSerialize()
{
// フル修飾で書かなきゃいけないのがダルい
return oldmsgpack::MessagePack.MessagePackSerializer.Serialize(TestTypelessComplexType, oldmsgpack::MessagePack.Resolvers.TypelessContractlessStandardResolver.Instance);
}
[Benchmark(Baseline = true)]
public byte[] NewSerialize()
{
return newmsgpack::MessagePack.MessagePackSerializer.Serialize(TestTypelessComplexType, newmsgpack::MessagePack.Resolvers.TypelessContractlessStandardResolver.Instance);
}
}
これで完成。実行すれば

最終的に、以前と比較して9倍ほど速くなりました。実際には、何度か実行していって、速くなったことを確認しながらやっています。
クソ遅かったのね!って話なのですが、Typelessは実際クソ遅かったのですが、それ以外の普通のは普通にちゃんと速かったので、一応、大丈夫です、はい、あくまでTypelessだけです、すみません……。
まとめ
ある程度完成している状態になっているならば、ベンチマークドリブンデベロップメントは割とかなり効果的ですね。改善はまずは計測から、とかいっても、結局、その数値が速いのか遅いのかの肌感覚がないとクソほども役に立たないわけですが(ただたんに漠然と眺めるだけの計測には本当に何の意味もないし、数値についての肌感覚を持っているかいないかの経験値は、ツールが充実している今でもなお重要だと思います。肌感覚に繋げていくことを意識して、経験を積みましょう)、さすがにBefore, Afterだととてもわかりやすくて、導入としてもいい感じです。
MessagePack for C#は、昨日ver 1.5.0を出しまして、最速モード(Object-Array)以外の部分(Object-Map)でも性能的にかなり向上したのと、object型のシリアライズがみんなの想像する通りのシリアライズをしてくれるようにようやくなりまして、本気で死角なし、になりました。Typelessの性能向上は次のアップデート。それと、もう一つ大型の機能追加(とても役に立ちます!特にUnityで!)を予定しているので、まだまだ良くなっていきますので期待しといてください。
C#の高速なMySQLのドライバを書こうかという話、或いはパフォーマンス向上のためのアプローチについて
- 2017-08-07
割とずっと公式のC# MySQL Driverは性能的にビミョいのではと思っていて、それがSQL Serverと比較してもパフォーマンス面で足を引っ張るなー、と思っていたんですが、いよいよもって最近はシリアライザも延々と書いてたりで、その手の処理に自信もあるし、いっちょやったるかと思い至ったのであった。つまり、データベースドライバをシリアライゼーションの問題として捉えたわけです。あと会社のプログラム(黒騎士と白の魔王)のサーバー側の性能的にもう少し飛躍させたくて、ボトルネックはいっぱいあるんですが、根本から変えれればそれなりにコスパもいいのでは、みたいな。

中間結果としては、コスパがいいというには微妙な感じというか、Mean下がってなくてダメじゃんという形になって、割と想定と外れてしまってアチャー感が相当否めなくて困ったのですが(ほんとにね!)、まぁそこはおいおいなんとかするとして(します)、メモリ確保だけは確実にめちゃくちゃ減らしました。1/70も減ってるのだから相当中々だと思いたい、ということで、スタート地点としては上等じゃないでしょふか。
↑のベンチマークはBenchmarkDotNetで出していまして、使い方はこないだ別ブログに書いた C#でTypeをキーにしたDictionaryのパフォーマンス比較と最速コードの実装 ので、そちらを参照のことこと。
まだふいんき程度ですが、コードも公開しています。
まだα版とすらいえない状態なので、そこはおいおい。
性能向上のためのアプローチ
競合として、公式のMySQL Connectorと非公式のAsync MySQL Connectorというのがあります。非公式のは、名前空間どころか名前まで被せてきて紛らわしさ超絶大なので、この非公式のやつのやり方は好きじゃありません。
それはさておき、まず非同期の扱いについてなんですが、別に非同期にしたからFastなわけでもありません。だいたいどうせASP.NETの時点でスレッドいっぱいぶちまけてるんちゃうんちゃうん?みたいなところもあるし。むしろ同期に比べてオーバーヘッドが多くなりがち(実装を頑張る必要大!)なので、素朴にやるとむしろ性能低下に繋がります。
さて、で、パフォーマンスを意識したうえで、どう実装していけば良いのか、ですが、MySqlSharpでは以下のものを方針としています。
- 同期と非同期は別物でどちらかがどちらかのラッパーだと遅い。両方、個別の実装を提供し、最適化する必要がある
- 禁忌のMutableなStructをReaderとして用意することでGCメモリ確保を低減する
- テキストプロトコルにおいて数値変換に文字列変換+パースのコストを直接変換処理を書くことでなくす
- ADO.NET抽象を避けて、プリミティブなMySQL APIを提供する。ADO.NETをはそのラッパーとする
- 特化したDapper的なMicro ORMを用意する、それは上記プリミティブMySQL APIを叩く
- Npgsql 3.2のようなプリペアドステートメントの活用を目指す
といったメニューになっていまして、実装したものもあれば妄想の段階のものもあります。
Mutable Struct Reader
structはMutableにしちゃいけない、というのが世間の常識で実際そうなのですが、最近のC#はstruct絡みが延々と強化され続けていて(まだ続いてます - C# Language Design Notes for Jul 5, 2017によるとC# 7.2でrefなんとかが大量投下される)、structについて真剣に考え、活用しなければならない時が来ています。
ところでMySQLのプロトコルはバイナリストリームは、更にPacketという単位で切り分けられて届くようになっています。これを素朴に実装すると
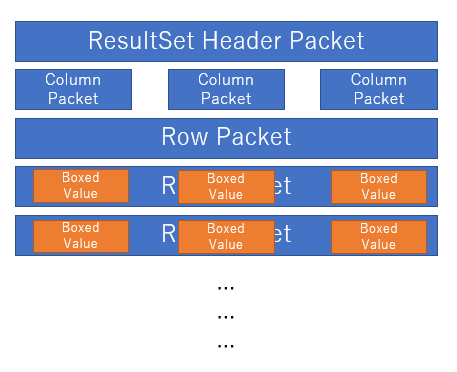
Packet単位にクラスを作っちゃって、無駄一時オブジェクトがボコボコできちゃうんですね。
// ふつーのパターンだとこういう風にネストしていくようにする
using (var packetReader = new PacketReader())
using (var protocolReader = new ProtocolReader(packetReader))
{
var set = protocolReader.ReadTextResultSet();
}
かといって、Packet単位で区切って扱えるようにしないと実装できなかったりなので、悩ましいところです。そこで解決策として Mutable Struct Reader を投下しました。
// MySqlSharpはこういうパターンを作った
var reader = new PacketReader(); // struct but mutable, has reading(offset) state
var set = ProtocolReader.ReadTextResultSet(ref reader); // (ref PacketReader)
PacketReaderはstructでbyte[]とoffsetを抱えていて、Readするとoffsetが進んでいく。というよくあるXxxReader。しかしstruct。それを触って実際にオブジェクトを組み立てる高レベルなリーダーはstaticメソッド、そしてrefで渡して回る(structなのでうかつに変数に入れたりするとコピーされて内部のoffsetが進まない!)。
奇妙なようでいて、実際見かけないやり方で些か奇妙ではあるのですが、この組み合わせは、意外と良かったですね、APIの触り心地もそこまで悪くないですし。もちろんノーアロケーションですし。というわけで、いつになくrefだらけになっています。時代はref。
数値変換を文字列変換を介さず直接行う
クエリ結果の行データは、MySQLは通常テキストプロトコルで行われています(サーバーサイドプリペアドステートメント時のみバイナリプロトコル)。どういうことかというと、1999は "1999" という形で受け取ります。実際にはbyte[]の"1999" ですね。これをintに変換する場合、素朴に書くとこうなります(実際、MySQL Connectorはこう実装されてます)
// 一度、文字列に変換してからint.Parse
int.Parse(Encoding.UTF8.GetString(binary));
これにより一時文字列を作るというゴミ製造が発生します、ついでにint.Parseだって文字列を解析するのでタダな操作じゃない。んで、UTF8で、文字数の長さもわかっている状態で、中身が数字なのが確定しているのだから、直接変換できるんじゃないか、というのがMySqlSharpで導入したNumberConverterです。
const byte Minus = 45;
public static Int32 ToInt32(byte[] bytes, int offset, int count)
{
// Min: -2147483648
// Max: 2147483647
// Digits: 10
if (bytes[offset] != Minus)
{
switch (count)
{
case 1:
return (System.Int32)(((Int32)(bytes[offset] - Zero)));
case 2:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 10) + ((Int32)(bytes[offset + 1] - Zero)));
case 3:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 100) + ((Int32)(bytes[offset + 1] - Zero) * 10) + ((Int32)(bytes[offset + 2] - Zero)));
// snip case 4..9
case 10:
return (System.Int32)(((Int32)(bytes[offset] - Zero) * 1000000000) + ((Int32)(bytes[offset + 1] - Zero) * 100000000) + ((Int32)(bytes[offset + 2] - Zero) * 10000000) + ((Int32)(bytes[offset + 3] - Zero) * 1000000) + ((Int32)(bytes[offset + 4] - Zero) * 100000) + ((Int32)(bytes[offset + 5] - Zero) * 10000) + ((Int32)(bytes[offset + 6] - Zero) * 1000) + ((Int32)(bytes[offset + 7] - Zero) * 100) + ((Int32)(bytes[offset + 8] - Zero) * 10) + ((Int32)(bytes[offset + 9] - Zero)));
default:
throw new ArgumentException("Int32 out of range count");
}
}
else
{
// snip... * -1
}
}
ASCIIコードでベタにやってくるので、じゃあベタに45引けば数字作れますよね、という。UTF-8以外のエンコーディングのときどーすんねん?というと
- 対応しない
- そん時は int.Parse(Encoding.UTF8.GetString(binary)) を使う
のどっちかでいいかな、と。今のところ面倒なので対応しない、が有力。
Primitive API for MySQL
MySQL Protocolには本来、もっと色々なコマンドがあります。COM_QUIT, COM_QUERY, COM_PING, などなど。まぁ、そうじゃなくても、COM_QUERYを流すのにADO.NET抽象を被せる必要はなくダイレクトに投下できればいいんじゃない?とは思わなくもない?
// Driver Direct
var driver = new MySqlDriver(option);
driver.Open();
var reader = driver.Query("selct 1"); // COM_QUERY
while (reader.Read())
{
var v = reader.GetInt32(0);
}
// you can use other native APIs
driver.Ping(); // COM_PING
driver.Statistics(); // COM_STATISTICS
// ADO.NET Wrapper
var conn = new MySqlConnection("connStr");
conn.Open();
var cmd = conn.CreateCommand();
cmd.CommandText = "select 1";
var reader = cmd.ExecuteReader();
while (reader.Read())
{
var v = reader.GetInt32(0);
}
APIはADO.NETに似せるようにしてはいますが、余計な中間オブジェクトも一切なく直接叩けるのでオーバーヘッドがなくなります。もちろん、実用的にはADO.NETを挟まないと色々な周辺ツールが使えなくなるので、殆どの場合はADO.NET抽象経由になるとは思いますが。
とはいえ、DapperのようなORMをMySqlSharp専用で作ることにより、直接MySqlSharpのPrimitive APIを叩いて更なるパフォーマンスのブーストが可能です。理屈上は。まだ未実装なので知らんけど。恐らくいけてる想定です、脳内では。
まとめ
実装は、むしろMySQL公式からドキュメントが消滅している - Chapter 14 MySQL Client/Server Protocolせいで、Web Archivesから拾ってきたり謎クローンから拾ってきたりMariaDBのから拾ってきたりと、とにかく参照が面倒で、それが一番捗らないところですね。もはやほんとどういうこっちゃ。
MySQLには最近X-Protocolという新しいプロトコルが搭載されていて、こちらを通すと明らかに良好な気配が見えます。これはProtocol Buffersでやり取りするため、各言語のドライバのシリアライゼーションの出来不出来に、性能が左右されなくなるというのも良いところですね。
が、Amazon AuroraではX-Protocolは使えないし、あまり使えるようになる気配も見えないので、あえて書く意味は、それなりにあるんじゃないかしらん。ちゃんと完成すればね……!それと.NET CoreなどLinux環境下などでも.NET使ってくぞー、みたいな流れだと、当然データベースはMySQL(やPostgreSQL)のほうが多くなるだろう、というのは自然なことですが、そこでDBなども含めたトータルなパフォーマンスでは.NET、遅いっすね!ってなるのはめっちゃ悔しいじゃないですか。でも実際そうなるでしょう。だから、高速なMySQLドライバーというのは、これからの時代に必要なもののはずなのです。
公開しないほうがお蔵入りになる可能性が高いので、公開しました。あとは私の頑張りにご期待下さい。
C#におけるTypeをキーにした非ジェネリック関数の最適化法
- 2017-07-11
MicroResolver 2.3.3!というわけで、例によってバージョンがデタラメになるんですが、アップデートしてました。MicroResolverとその解説については以前のブログ記事 MicroResolver - C#最速のDIコンテナライブラリと、最速を支えるメタプログラミングテクニック をどうぞ。そして、オフィシャルな(?)ベンチマーク結果でも、それなりに勝利を収めています。
|Container|Singleton|Transient|Combined|Complex|Property|Generics|IEnumerable|
|:------------|------------:|------------:|-----------:|----------:|:------------|----------:|--------------:|
|No|61
53|68
62|83
103|90
82|119
99|73
79|177
139|
|abioc 0.6.0|27
37|31
57|48
84|63
72|
|
|741
506
|
|Autofac 4.6.0|749
623|707
554|1950
1832|6510
6472|6527
6417|1949
1563|7715
5635|
|DryIoc 2.10.4|29
42|38
63|55
80|62
70|82
92|50
84|259
184|
|Grace 6.2.1|27
38|35
58|49
82|67
75|87
94|46
77|265
194|
|Mef2 1.0.30.0|239
167|254
174|332
256|528
317|1188
680|261
429|1345
758|
|MicroResolver 2.3.3|31
37|35
59|58
77|92
86|43
66|
|285
203|
|Ninject 3.2.2.0|5192
3216|16735
11856|44930
30318|131301*
84559*|112654*
76631*|48775
27198|102856*
68908*|
|SimpleInjector 4.0.8|66
68|77
70|103
103|129
105|212
146|75
82|795
451|
|Unity 4.0.1|2517
1375|3761
1962|10161
5372|27963
16013|29064
16150|
|43685
23347|
前回の結果はジェネリック版だったのですが、やっぱ物言いがつきまして、非ジェネリック版でやれよ、という話になりました。で、2.0.0は非ジェネリック版で負けちゃってたのです。うーん、そこそこ気を使ってたはずなんですが、負けちゃった。ジェネリック版なら勝ってるんだぜ!とか主張するのは激ダサなので、なんとかして、非ジェネリック版の最適化を進めました。そして、なんとか幾つかのものは勝利を収めました。いや、普通に幾つかのでは負けてるじゃん、って話もありますが、概ね高水準だし、そこは許してください(?)、ジェネリック版なら勝ってるし(ダサい)。理論上、何やればこれ以上に縮められるかは分かってはいるんですけどねー。
というわけで今回は非ジェネリック関数の最適化法について、です。まず、MicroResolverは(ZeroFormtterやMessagePack for C#もそうですが)ジェネリック版を全てのベースにしています。
// というクラスが生成される
public class ObjectResolver_Generated1
{
// というコードが生成される
public override T Resolve<T>()
{
return Cache<T>.factory(); // Func<T>.Invoke()
}
}
Tを元にしてデリゲートを探して、それをInvokeする。その最速系がジェネリックタイプキャッシングだという話でした。非ジェネリックの場合は、Typeをハッシュキーにして、デリゲートを探さなければなりません。ここでMicroResolverの初期の実装ではオレオレハッシュテーブルを作って対処しました。
// こんな構造体を定義しておいて
struct HashTuple
{
public Type type;
public Func<object> factory;
}
// これがハッシュテーブルの中身、基本的に固定配列が最強です
private HashTuple[][] table;
// Resolve<T> は、つまりFunc<T> なわけですが、これはFuncの共変を使って直接 Func<object> に変換できます
// ExpressionTree経由で上からデリゲートを生成して変換する、という手が一般に使われますが、
// それは関数呼び出しが一つ増えるオーバーヘッドですからね!
// というわけで、MicroResolverのRegister<T>のTにはclass制約がかかってます
table[hash][index] = new Func<object>(Resolve<T>);
// で実際に呼び出すばやい
public object Resolve(Type type)
{
var hashCode = type.GetHashCode();
var buckets = table[hashCode % table.Length];
// チェイン法によるハッシュテーブルの配列は、拡縮を考えなくていいので連結リストではなく固定サイズの配列
// 当然これがループ的には最速だし、ついでに.Lengthで回せるので配列の境界チェックも削れる
for (int i = 0; i < buckets.Length; i++)
{
if (buckets[i].type == type)
{
return buckets[i].factory();
}
}
throw new MicroResolverException("Type was not dound, Type: " + type.FullName);
}
理屈的には全く良さそうです!しかし、この実装では「遅くて」他のDIライブラリに対してベンチマークで敗北したのです。敗北!許せない!というわけで、ここから更に改善していきましょう。限界まで最適化されているように見えて、まだまだ余地があるのです。目を皿のようにして改善ポイントを探してみましょう!
非ジェネリック関数はジェネリック関数のラップではない
当たり前ですが、ラップにしたらラップしているという点でのオーバーヘッドがかかり、遅くなります。↑のコードはラップではないように見えて、ラップだったのです。どーいうことかというと
// new Func<object>(Resolve<T>) で生成したデリゲートは、こういう呼ばれ順序になる
object Resolve(Type type) => T Resolve() => Cache<T>.factory()
// そう、短縮できますよね、こういう風に
object Resolve(Type type) => Cache<T>.factory()
// つまりこういう風に、生のデリゲートを直接登録しちゃえばよかったのです
table[hash][index] = (Func<object>)Cache<T>.factory();
// ちなみにExpressionTreeで生成する場合は、もっと呼ばれる段数が多くなるので、理屈として一番遅いですね
object Resolve(Type type) => (object)Resolve() => T Resolve() => Cache<T>.factory()
これはもう先入観として非ジェネリックはジェネリックのラップで作らなきゃいけない、と思いこんでいたせいで、全体のコード生成のパスを見渡してみれば、直接渡してあげても良かったんですね。これで、ジェネリック版も非ジェネリック版も、どちらもどちらかのラップではない、ネイティブなスピードを手に入れることができました。
ちなみにジェネリック版が非ジェネリック版のラップの場合は、Typeのルックアップのコストがどちらも必ずかかってしまうので(ジェネリック版がネイティブなスピードにならない)、とても良くないパターンです。
ハッシュテーブルを最適化する
一件、このケースに特化した最速なハッシュテーブルに見えて、既にアルゴリズム的に遅かったのです。剰余が。modulo is too slow。
// これがゲロ遅い
var buckets = table[hashCode % table.Length];
// こうすれば良い(ただしテーブルサイズは2のべき乗である必要があります!)
var buckets = table[hashCode & (table.Length - 1)];
// もちろんテーブルサイズは固定なので、予め -1 したのは変数に持っておきましょう
var buckets = table[hashCode & tableLengthMinusOne];
割と純粋なデータ構造とアルゴリズムのお話ですが、ハッシュテーブルのサイズはどうするのが高速なのか問題、で、テーブルサイズが2のべき乗の場合にはビット演算を使って、低速な剰余を避けることが可能です。ハッシュテーブルに関しては「英語版の」ほうのWikipediaが例によって詳しいです - Hash table - Wikipedia。
.NETのDictionaryはテーブルサイズとして素数を使っています、そのため剰余が避けられません。今回の最初の実装も.NETのものを参考に作っていたので剰余をそのまんま剰余で残してしまったんですねえ。ただし2のべき乗のほうも弱点はあって、ハッシュ関数が悪い場合に、偏りが生じやすくなるとのこと。素数のほうがそれを避けやすい。ので、一般の実装としてやるなら.NETのDictionaryが素数を使うのは最適なチョイスとも思えます。ただ、今回はTypeのGetHashCode、はそれなりにしっかり分散されてるもの(だと思われる)なので、2のべき乗をチョイスするのが効果的といえるでしょう。この辺を弄れるのも、汎用コレクションを使わない利点ですね。まぁ、エクストリームなパフォーマンスを求めるなら、という話ですが。
あとは衝突しなければしないほど高速(衝突したらforループ回る回数が多くなる)なので、テーブルに対するload factorは相当余裕のある感じの設定にしました。かなりスカスカ。まぁ、別にちょっと余計なぐらいでもいいでしょう。
TypeがKeyで、Value側がジェネリックで自由に変更可能な、汎用な固定サイズハッシュテーブルの実装はFixedTypeKeyHashtable.csに置いておきますんで、使えるケースがありそうな人は是非どうぞ。ハヤイデス。Keyは別にType以外にしてもいいんですが、汎用にするとIEqualityComaprer経由で呼ばなきゃいけなくてオーバーヘッドがあるので、もしKeyを他のに変えたければ、そこだけ変えた特化実装を別途用意するのが良いでしょう。Value側は気にする必要はないんですけどね。あと、KeyのGetHashCodeの性質には注意したほうがいいかもです(上述の通り、素数ではないので性質に影響されやすい)
まとめ
どちらの対策も同じように効果絶大でした。どっちも普通だったらそこまで大したことないようなことなんですけどね、マイクロベンチマークで超極小の差を競い合ってる状況では、この差が死ぬほどでかい。というわけで、もう完全に限界の領域。とはいえ、まだまだIoC Performance的には、Singletonには明確に改善の余地があって、事前に生成済みインスタンスを渡してあげるオーバーロードを用意して、その場合は直接埋め込んじゃえばいいとか、そういうこともできます。これは幾つかのDIライブラリがやってますね。役に立たないとは言わないけれど、基本的にはベンチマークハックっぽくて好きくないですが、まぁ、まぁ。
非ジェネリックに関しては type == type を削る余地が残ってます(信頼性は若干犠牲にしますが、事実上問題にならない)。どうやって、というと、登録すべきTypeが全部既知なんですよね、コード生成時に。つまり、非ジェネリック版ももっとアグレッシブにコード生成する余地があり、ハッシュテーブルのルックアップ部分まで含めてコード生成すれば、より改善され(る余地があ)るということです。擬似コードでいえば
// こういうコードを生成する
object Resolve(Type type)
{
var hashCode = type.GetHashCode();
switch(hashCode)
{
case 341414141:
// もしハッシュコードが同一のものがあった場合は、生成時に追加でifを入れる
// ただし通常そんなことは起こらない + 同一ハッシュコードの別タイプが来るケースはほぼない、のでtypeの真の同一値比較を省く
return new Transient1(); // この中でインライン生成する
case 643634533:
return HogeSingleton.Value; // シングルトンは値をそのままルックアップするだけ
// 以下、型は全て既知でハッシュコードも全部知っているので、羅列する
}
}
ってコードを作ればいいわけです。こういうのは、まさに動的コード生成の強みを120%活かすって感じで面白くはあります。
ただしintの数値がバラバラの場合は「C#コンパイラが」二分探索コードを作るので - C#のswitch文のコンパイラ最適化について - Grani Engineering Blog、IL生成でこれやるのはかなり骨の折れる仕事です。しかも、二分探索と高速化したハッシュテーブルでは、かなりいい勝負が出来ている状態なので、あえてここまでやるのはちょっと、ってとこもあります。でも、生成部分まで完全にインライン化するのは効果大なので、やればきっと速くなりそうです(でも生成コードサイズはクソデカくなりそうだ)。このアプローチはabiocというIoCライブラリが取っていて、なので実際に最速のパフォーマンスを出せているわけですね。abiocのコード生成はIL EmitではなくRoslynを使っているので、こういった「C#コンパイラ」がやる仕事を簡単に記述できます。アプローチとして面白いやりかたです。
というわけで(?)理論値に挑んだわけですが、どうでしょう。速いコードって実は難しいコードではなくて、コードパスが短いコードが速くなるわけです、どうしても、そりゃそうだ、と。複雑なことをどうやって短い命令数のコード(短いコードという意味ではない)で表現するか。実行時にのみ知りうる情報を使ったコード生成技術を駆使することで、最短のパスを作り込んでいく。そういうことなんですね。
そのうえで、超基本的なアルゴリズムの話が残ってたりするところがあったりで、コンピューターの世界はモダンになったようで、実はあまり変わってないね、という側面もあったりで面白い感じです。
C#は簡単に遅いコードが書ける言語だし、正直割と痛感しているところもあるのですが、とはいえかなりの部分で高速に仕上げる余地が残っている言語でもあります(テンプレートメタプログラミングはできませんが!)。ILを自由に弄れる技術が身につくと「理論上存在する想像する最高のコード」に到れる道のりがグッと広がるので、ぜひぜひ習得してみるのも面白いかと思います。
MicroResolver - C#最速のDIコンテナライブラリと、最速を支えるメタプログラミングテクニック
- 2017-07-09
MicroResolver、というDIコンテナを作りました。Microといいつつ、フルフルではないですがそれなりにフルセットな機能もあります。DIの意義とか使い方とかは割とどうでもいい話なので、何をやったら最速にできるのかってところを中心に説明しますので、DIに興味ない人もどうぞ。
- GitHub - neuecc/MicroResolver
- Install-Package MicroResolver
例によってインストールはNuGetからで、.NET 4.6 から .NET Standard 1.4 で使えます。
DIコンテナはIoC Performanceという、存在するDIライブラリは全部突っ込んだ総合ベンチマークがあるので、そこで好成績を出せれば勝ったといえるでしょう。
|Container|Singleton|Transient|Combined|Complex|
|:------------|------------:|------------:|-----------:|----------:|
|No|53
50|58
51|71
73|87
67|
|abioc 0.6.0|46
47|67
55|72
66|86
65|
|Autofac 4.6.0|562
477|545
488|1408
1252|4726
4350|
|DryIoc 2.10.4|49
37|47
47|62
60|69
57|
|fFastInjector 1.0.1|21
27|61
52|145
108|373
223|
|Mef2 1.0.30.0|187
119|199
133|274
159|447
266|
|MicroResolver 2.0.0|26
33|31
39|50
55|72
63|
|Ninject 3.2.2.0|3978
2444|12567
7963|34620
19315|95859*
60936*|
|SimpleInjector 4.0.8|58
44|82
59|93
76|109
80|
|Unity 4.0.1|1992
1042|2745
1523|7161
3843|19892
10586|
てわけで、TransientとCombinedで勝ってます。フル結果はでっかいのでこちら。ただし、これはジェネリクス版に書き換えて比較しているので、ノンジェネリクスで統一している場合は若干異なる結果になります。つまり、MicroResolverにやや有利になってます。その辺どうしていきましょうかってのは要議論。
使い方イメージ
高速化の説明の前に、さすがに簡単な使い方がわからないとイメージつかないと思うので、使い方の方を軽く。
// Create a new container
var resolver = ObjectResolver.Create();
// Register interface->type map, default is transient(instantiate every request)
resolver.Register<IUserRepository, SqlUserRepository>();
// You can configure lifestyle - Transient, Singleton or Scoped
resolver.Register<ILogger, MailLogger>(Lifestyle.Singleton);
// Compile and Verify container(this is required step)
resolver.Compile();
// Get instance from container
var userRepository = resolver.Resolve<IUserRepository>();
var logger = resolver.Resolve<ILogger>();
というわけで、ObjectResolver.Create でコンテナを作って、そこにRegisterでインターフェイス-具象型の関連をマップしていって、Compileで検証とコード生成。あとはResolveで取り出せる。みたいなイメージです。普通のDIコンテナです。APIは私が一番触り心地が楽なように、かつ、一般的なものとは外れないように選んでいきました。Bind().To()とかいうような Fluent Syntax でやらせるやつは最低の触り心地なので、ナイですね。ナイ。まじでナイ。
IL生成時インライン化
単発のパフォーマンスは普通に動的コード生成やれば普通に出るのでいいんですが、少し複雑な依存関係を解決する、ネストの深い生成時にパフォーマンスの違いが大きく現れます。↑のベンチマークも、見方がわからないと漠然と速いとか遅いとかしかわからないと思うんですが、ぶっちゃけSingletonはどうでもよくて(というのも、別にDI使う時にSingletonで生成するものってあんま多くないよね?)大事なのはTransientとCombined、あるいはComplexです。Transientは単発の生成、Combinedは依存関係のある複数生成、ComplexはCombinedよりも多くの複数生成になってます。ようはこういうことです。
// こんなクラスが色々あるとして
public class ForPropertyInjection : IForPropertyInjection
{
[Inject]
public void OnCreate()
{
}
}
public class ForConstructorInjection : IForConsturctorInjection
{
[Inject]
public IForFieldInjection MyField;
}
public class ComplexType : IComplexType
{
[Inject]
public IForPropertyInjection MyProperty { get; set; }
public ComplexType(IForConsturctorInjection instance1)
{
}
[Inject]
public void Initialize()
{
}
}
// このComplexTypeをどのようにライブラリは生成するか想像しましょう?
var v = resolver.Resolve<IComplexType>();
で、最初に、私はこういう実装にしたんですね。
static IComplexType ResolveComplexType(IObjectResolver resolver)
{
var a = resolver.Resolve<IForConsturctorInjection>();
var b = resolver.Resolve<IForPropertyInjection>();
var result = new ComplexType(a);
result.MyProperty = b;
result.Initialize();
return result;
}
まぁ別におかしくはない、素直なコード生成の実装だったんですが、これでベンチマーク走らせたら見事に負けたんですね。負けた!マジか!どういうことだ!ってことでよーく考えたんですが、中で多段にResolve<T>してるとこがネックっぽい。それなりに、というかかなり気を使って単発Resolve速度は上げてるんですが、とはいえ、多段呼び出しは多段呼び出しで、恐らくそれのせいで負けてるわけです。というか、もはやここを削る以外にやれることないし。というわけで、考えた手法はインライン化です、依存を解決した生成コードは全部フラットにインライン化してIL埋め込みます。
static ComplexType ResolveComposite()
{
var a = new ForConstructorInjection();
a.MyField = new ForFieldInjection();
var b = new ForPropertyInjection();
b.OnCreate();
var result = new ComplexType(a);
result.MyProperty = b;
result.Initialize();
return result;
}
↑のようなイメージのコードが型毎に生成されてます。これの効果は絶大で、Transientでは勝ってるのにCombinedでは負けたー、という状況もなくなり、他をきちんとなぎ倒せるようになりました。めでたしめでたし。実装的にもIL Emitの分割点を適切に切って足すだけなので、実はそんな難しくない。コスパ良い。
Dynamic Generic Type Caching
コード生成ってようするにデリゲートを作ることなんですが、それを型で分類してキャッシュするわけですが、それをどうやって保持して取り出しましょうか、という問題が古くからあります。普通はDictionary<Type, T>とか、ConcurrentDictionary<Type, T>とか使うんですが、ジェネリクスを活用すればもう少し速くできるんですね。ようするに
static Cache<T>
{
// ここに保持すればいいんじゃもん
public Func<T> factory;
}
こういうことです。これは別に珍しくなく、 EqualityComparer<T>.Default とかで割と日常的に使ってるはずです。しかしコンテナって複数作ったりするので、staticクラスにはできないんですよねー、ということで困ってしまうわけですが、私はこういうふうに解決しました。まず、これがObjectResolver(コンテナ)のシグネチャ(一部)です。
public abstract class ObjectResolver
{
public abstract T Resolve<T>();
}
で、ObjectResolver.Createで新しいコンテナを作成する際に、こういう型を動的生成しています(とにかくなんでも生成するのです!)
public class ObjectResolver_Generated1 : ObjectResolver
{
public override T Resolve<T>()
{
// 余計なものが一切ない超絶シンプルなコードパスにまで落とし込んでいるので、当然最強に速い
return Cache<T>.factory();
}
Cache<T>
{
// IL生成時インライン化のとこで説明したコードがここに代入されてる
public Func<T> factory;
}
}
さすがにもはや文句のつけようもなく、これ以上速くするのは難しいでしょう。しいていえばTransientとSingletonが共通化されているので(Singletonの場合はfactory()を呼ぶと中でLazy.Valueを返すようになってる)、もしSingletonなら.Valueで取れたほうが速くなります。ただ、そうなるとTransientとSingletonで分岐コード書かなきゃいけなくなって、Transientの速度が犠牲になるんですよね。明らかにTransientを優先すべきなので、分岐なしのTransientを最速にする実装にしています。
ところで、これやるとコンテナを解放することはできません。作った型は消せません。あと、やっぱコンテナ生成速度はそれなりに犠牲になってます。ただまぁ、コンテナ山のように作ることって普通ないと思うんで(生成速度が遅いといっても、ユニットテストとかでテストメソッド毎に作るぐらいなら別に許せるレベルですよ)いいでしょう。山のように作らなければ、解放できないことによるメモリ云々カンヌンも大したことないはずなので。
非ジェネリック用の特化ハッシュテーブル
いくらジェネリクスを最速にしても、フレームワークから使われる時って object Resolve(Type type) を要求することが多いんですよね。なので、そっちのほうも最適化してやらなきゃいけません。んで、デザインとしてMicroResolverは事前Compileで、以後追加はない、完全に中身が固定化されるという仕様にしたので、マルチスレッドは考えなくていい。つまりConcurrentDictionaryはサヨナラ。そしてDictionaryも、さようなら。エクストリームな領域では汎用コンテナを使ったら負けです。中身が完全に固定されていて追加がない状態なら、固定配列を使ってもう少しパフォーマンスを稼げるはずだし、実装も簡単。
// こんな構造体を定義しておいて
struct HashTuple
{
public Type type;
public Func<object> factory;
}
// これがハッシュテーブルの中身、基本的に固定配列が最強です
private HashTuple[][] table;
// Register<T> は、つまりFunc<T> なわけですが、これはFuncの共変を使って直接 Func<object> に変換できます
// ExpressionTree経由で上からデリゲートを生成して変換する、という手が一般に使われますが、
// それは関数呼び出しが一つ増えるオーバーヘッドですからね!
// というわけで、MicroResolverのRegister<T>のTにはclass制約がかかってます
table[hash][index] = new Func<object>(Resolve<T>);
// で実際に呼び出すばやい
public object Resolve(Type type)
{
var hashCode = type.GetHashCode();
var buckets = table[hashCode % table.Length];
// チェイン法によるハッシュテーブルの配列は、拡縮を考えなくていいので連結リストではなく固定サイズの配列
// 当然これがループ的には最速だし、ついでに.Lengthで回せるので配列の境界チェックも削れる
for (int i = 0; i < buckets.Length; i++)
{
if (buckets[i].type == type)
{
return buckets[i].factory();
}
}
throw new MicroResolverException("Type was not dound, Type: " + type.FullName);
}
実装は別に難しくなくて、難しいのは汎用コンテナを捨てる、という決断だけですね。捨ててもいいんだ、という発想を持てること。が何気に大事です。当たり前ですが一般論はDictionaryを使えってことですが、使わないという選択を完全に捨て去ってしまうのは間違いです。そこの塩梅を持てるようになると、一歩ステップアップできるんじゃないでしょうか?杓子定規の綺麗事ばかり言ってると人間進歩しないですしね。むしろ世の中の本質は汚いところにある。
さて、とはいえ、ジェネリック版が優先で、非ジェネリックはサブなんですが、実装によっては非ジェネリックを優先で、ジェネリックはフォールバックにする実装もあります。というか普通はそっちです。ので、ベンチマークではどっち優先のものかで差が出ちゃうんですよね。今回私が計測したのはジェネリック優先のベンチマークにしましたが、非ジェネリック優先のベンチマークだと、そのものが非ジェネリック優先で作られたものに負けてしまったりします。きわどい勝負をしてるので、むつかしいところですね。
DIとしての機能
一応DIとしてはちゃんと機能あって、コンストラクタインジェクション、プロパティインジェクション、フィールドインジェクション、メソッドインジェクションをサポートしてます。インジェクト対象は明示的に[Inject]をつけてください。かわりに、プライベートでも問答無用で差し込めます。
public class MyType : IMyType
{
// field injection
[Inject]
public IInjectTarget PublicField;
[Inject]
IInjectTarget PrivateField;
// property injection
[Inject]
public IInjectTarget PublicProperty { get; set; }
[Inject]
IInjectTarget PrivateProperty { get; set; }
// constructor injection
// if not marked [Inject], the constructor with the most parameters is used.
[Inject]
public MyType(IInjectTarget x, IInjectTarget y, IInjectTarget z)
{
}
// method injection
[Inject]
public void Initialize1()
{
}
[Inject]
public void Initialize2()
{
}
}
// and resolve it
var v = resolver.Resolve<IMyType>();
お行儀が良いのはコンストラクタインジェクションで、お行儀が一番悪いのはプライベートフィールドインジェクションなんですが、ぶっちけコンストラクタインジェクションに拘る必要はないでしょうね。プライベートフィールドインジェクションとかするとDIコンテナ以外から生成できないじゃん!とかいうけど、どうせDIコンテナ使ったらアプリケーション全体でDIコンテナ依存するので、コンストラクタインジェクションならDIコンテナなしでもDependency Injection Patternとしてキレイにおさまるからいいよね、とかクソどうでもいいので無視でいいでしょう。むしろライブラリ使うんなら諦めてライブラリと心中するぐらいの覚悟のほうが、いい結果残せるでしょう。
まぁプライベートフィールドインジェクションすると警告出て(未初期化のフィールドを触ってます的なあれそれ)ウザかったりもしますが。
そういう意味ではService Locator is an Anti-Patternもどうでもよくて、Service Locatorの何が悪い(どうせキレイに作ってもなんらかのライブラリに依存するんだから、Service Locatorなしでメンテナンスビリティ云々とかないでしょふし、どうせそもそも深い依存関係をDIコンテナから生成するならコンストラクタで依存を表明とか実質ないんでどうでもよろし)。ってのはありますね。でも普通にService Locatorでやるよりも依存のトップからMicroResolverでResolveしたほうがパフォーマンスが良いので、そういう観点から適当に判断しましょう:)
まぁあと、RegisterCollectionで登録しておくと T[]とかで取り出したりできます。大事大事。
// Register type -> many types
resolver.RegisterCollection<IMyType>(typeof(T1), typeof(T2), typeof(T3));
resolver.Compile();
// can resolve by IEnumerbale<T> or T[] or IReadOnlyList<T>.
resolver.Resolve<IEnumerable<IMyType>>();
resolver.Resolve<IMyType[]>();
resolver.Resolve<IReadOnlyList<IMyType>>();
// can resolve other type's inject target.
public class AnotherType
{
public AnotherType(IMyType[] targets)
{
}
}
Lifetime.Scopedとかもありますが、その辺はReadMe見てください。この辺までカバーしておけば、別にパフォーマンス特化で機能犠牲、ってわけでもなく、ちゃんとDIライブラリとしての機能は満たしているといえるでしょう。実際満たしてる。
まとめ
テストのための設計、というのがすごく好きじゃなくて、テスタビリティのためにシンプルなプロダクトの設計を、大なり小なり歪めるでしょうね。そして、どうしてもDependency Injection Patternのようになっていくわけですが、ライブラリなしでそのパターンやると、相当キツいってのが間違いなくあるんですねー。ライブラリのチョイスとか利用ってものすごく大事だと思っていて、何も考えずテスト最高!とかいってるのはあまりにもお花畑なんで、一歩引いて考えたい、と。とはいえ、さすがに無策なのはそれはそれでしょーもないんで、改めてDIパターンとは、サービスロケーターとは、そしてDIライブラリとは、っていうところから見つめ直してみました。
DIライブラリのパフォーマンスは、まぁそこまで大事ではないと思います、少なくともシリアライザよりは。なので、さすがにベンチマークであからさまに遅いのは正直使う気起きなくなると思いますが(Ninject!)、そこそこのなら別にいいんじゃないかと。SimpleInjectorは速度と機能、そしてコミュニティの成熟度からバランスは良さそうだなーって印象ありますね。AutofacやUnity(DIライブラリの)は、基幹的な設計が(パフォーマンス的な意味で)古いというところもあってベンチ結果は一歩遅いんですが、とはいえこれがネックになるかどうかでいうと、なんともってところです。とはいえあえて古臭いものを使いたいかって話はある。
DIライブラリ全体の印象としては、雨後の筍のように山のようにあるだけに、上位のものはみんなかなりパフォーマンス的に競っていて、それぞれ良いアプローチをしていて、「ランキング一位を目指す」的なプログラミング芸としては中々楽しかった!それじゃただの趣味プロですね。いい加減さすがにC#メタプログラミングは極めた感ある。というか2~3日腰据えて書いただけで一位取れちゃうってのもどうなのかね、うーん。
まぁ、それなりにいい感じにまとまってるとは思うんで、MicroResolverも、よければ使ってみてくださいな。ちなみにUnity(ゲームエンジン)版はありません(今回の目的がハナからベンチマークで一位を取る、というところにフォーカスしてるんでIL生成芸以外のことはやる気なし)
Microsoft MVP for Visual Studio and Development Technologies(C#)を再々々々々々受賞しました
- 2017-07-02
今年の受賞で、7年目です。今回から周期がズレていて、全体で7月に統一ということらしいのですが(私は前は4月でした)、正直忘れていたりしなかったりもなかったんで反応遅れてましたが受賞してました。変わらずの Visual Studio and Development Technologies という長いやつで、ようするにC#です。
私の主な活動は、OSSと、実践的で先鋭的なC#というところで、その領域では他の誰よりも結果を出せているでしょう。特にOSS面では、今までがある意味、ただ作るだけに近かったものが、近年では、より戦略的に世界に向けて使わせる・流行らせるということを明確な意思を持ってやってますし、成果も出ていると思います。毎年更新とはいえ、毎年同じように変わらずにいてもしょうがないので、より新しく、意味ある結果を残していければいいと考えています。逆に言えば、何も変わりなくなれば、死んだみたいなものなので辞めどきでしょう。幸い、まだ死んではいないようですし、常に新しい成果で客観的にそうであると納得させられなければ意味がないので、MVPの更新という目は一つの実証ではありますが、それよりも厳しい目で律していきたいです。
私自身、まだ表現したいことは沢山あるので、次の期では、今までの延長線上とは違う、また別の何かを見せられればというところです。何れにせよ、絶対の安泰なんてない世界だとは思ってるので、より踏み込んで示していきたいので、よろしくお願いします。
MessagePack for C# 1.4.1 - JSONサポート強化, dynamic対応, Typelessシリアライズなど
- 2017-06-30
めちゃくちゃ久々ですが、この間、何も書いてないわけではなかったです!会社ブログのほうに、Unite 2017 Tokyo講演「「黒騎士と白の魔王」にみるC#で統一したサーバー/クライアント開発と現実的なUniRx使いこなし術」、リアルタイム通信におけるC# - async-awaitによるサーバーサイドゲームループ、MessagePack for C#に見るC#でのバイナリの読み方と最適化法と三本書いてました。
また、Unite 2017とAWS Summit 2017という大きめの会場での発表もしていました。
Uniteはクライアントサイド中心に、AWS Summitではサーバーサイド中心にという形で用意していたのですが、特にUniteのほうは幅広く扱いすぎて散漫になってしまって、割と反省しています。どちらのセッションもコード成分が少なめになってしまったのも如何ともし難いところで、どこかでもう少しコードコードしたものをしたい気は割としています。
MessagePack for C# 1.4.1
さて、本題。MessagePack for C#の1.4.1をリリースしました。ちなみに表記する際 MessagePack-CSharp と呼ぶべきか MessagePack for C# と呼ぶべきかが悩ましいですね。1.0.0の時から、特に機能追加でのアナウンスをしていなかったので、一挙紹介したいと思います。かなり強化されています……!
JSONサポート
もともとToJsonだけだったのですが(MessagePackBinaryをJSON形式に変換、バイナリなので中身がわかりにくいmsgpackの中身を解析するのに便利)、FromJsonが追加されています。
// JSON文字列をMessagePackバイナリ(byte[])に変換
var msgpackBin = MessagePackSerializer.FromJson(@"{""hoge"":""foo"",""huga"":2000}");
// byte[]は送信するなり保存するなり、MessagePackとしてDeserializeするなりお好きなように。
// {"hoge":"foo","huga":2000}
Console.WriteLine(MessagePackSerializer.ToJson(msgpackBin));
FromJson、便利なの?というと、んー、まぁあんまり使うことはないかなー、とは思いますが、(互換的な意味/ブラウザからだから)JSONで受けて、内部的にはMsgPackで流す、みたいなシナリオもなくはないんですよね。そういうところではいいんじゃないでしょうか。また、後述するdynamicと組み合わせると以外と便利かもしれません。
Dynamicデシリアライズ
XMLだと、構造を見て、手でマップしていくということが割とあったのですが、JSONではXMLにおける属性など複雑な要素がないぶんだけ、そのままストレートにデシリアライズでマッピングするだけで事足りることがほとんどになった気がします。ましてやMessagePackはバイナリなので、手付けで対応つけるのもやりにくいでしょう。とはいえ、C#的な構造に1:1でマッピング出来ないような構造がこないとも限らず、簡単に、動的に弄れる機構があれば、かなり有意義なのは間違いないでしょう。MessagePack for C#は、標準でdynamicで受けることで、動的オブジェクトとして操作できるようになります。
// こんなデータがあったとして
var bin = MessagePackSerializer.Serialize(new Dictionary<object, object>
{
{ "Name" , "foobar" },
{ "Arguments", new object[]{ 1, 100.424, "hugahuga" } },
});
// dynamicでデシリアライズ!
var d = MessagePackSerializer.Deserialize<dynamic>(bin);
// インデクサを使って動的に辿って取り出せる
Console.WriteLine(d["Name"]); // foobar
Console.WriteLine(d["Arguments"][1]); // 100.424
Console.WriteLine(d["Arguments"][2]); // hugahuga
// データ構造はToJsonで確認しておけばよろし
// {"Name":"foobar","Arguments":[1,100.424,"hugahuga"]}
Console.WriteLine(MessagePackSerializer.ToJson(bin));
ちなみにFromJsonとDeserialize<dynamic>を組み合わせれば、MessagePack for C#だけで簡易的なJSON解析・値の取得が可能になります。
// FromJsonとDeserialize<dynamic>を組み合わせてDynamicJsonになる
var d = MessagePackSerializer.Deserialize<dynamic>(MessagePackSerializer.FromJson(@"{""hoge"":""foo"",""huga"":2000}"));
Console.WriteLine(d["hoge"]); // foo
Console.WriteLine(d["huga"]); // 2000
性能的には、まぁわざわざmsgpackのbyte[]を介しているので、超速い!ってわけじゃないんですが、そもそもMessagePack for C#の速度が他の数倍速いということもあって、普通にかなりの速度が出ます。
なお、dynamicデシリアライズの正確な実体は PrimitiveObjectResolver で、StandardResolverの最後のフォールバックとして組み込まれています。
Typelessシリアライズ
Typelessって何?ってことですが、BinaryFormatterみたいなものです。普通の(?)シリアライザは、デシリアライズ時に<T>だの引数にTypeだのと、とにかく型を要求します。何故かと言うと、どの型に変換すればいいのかわからないから。でもBinaryFormatterは違います、APIを見てください、Typeを要求していないのです!
public object Deserialize(Stream serializationStream);
それなのにobjectで返されたほうには、ちゃんとシリアライズした時の型で帰ってくる。すごいね!便利だね!その理由は……、.NETの型がバイナリに埋まってるから。バイナリに埋まってるので、その情報を元にデシリアライズしているのです。というわけで、そんなTypelessで処理できるバージョンが実装されました。
// .Typeless経由でトップレベルのTypelessSerializerが使える
var bin = MessagePackSerializer.Typeless.Serialize(new MyClass() { Hoge = 100 });
// ちゃんとMyClass.Hoge = 100 でデシリアライズされてる
var mc = MessagePackSerializer.Typeless.Deserialize(bin);
// こんな風に、型名が先頭にシリアライズされてる。
// Dump結果はMapのように見えますが、実際はMsgPackの拡張領域(100)を使い、型を埋めている
// {"$type":"ConsoleApp73.MyClass, ConsoleApp73","Hoge":100}
Console.WriteLine(MessagePackSerializer.ToJson(bin));
実装的には TypelessContractlessStandardResolver 経由でシリアライズされているので、普通のシリアライズと混ぜることができます。どういうことかというと、object[]とかでも問答無用にきちんとシリアライズ/デシリアライズできます。
// こんな型があったとして
public class RpcInfo
{
public string MethodName { get; set; }
public object[] Arguments { get; set; }
}
// ----
var info = new RpcInfo
{
MethodName = "Hoge/Huga",
Arguments = new object[] { "foo", 100, new MyClass() }
};
// RpcInfoとしてシリアライズ
var bin = MessagePackSerializer.Serialize<RpcInfo>(info, TypelessContractlessStandardResolver.Instance);
// (object[] Arguments)が正しく復元されている
var info2 = MessagePackSerializer.Deserialize<RpcInfo>(bin, TypelessContractlessStandardResolver.Instance);
こういう、ふつーだと出来ないことが色々できる感じで夢広がりますね。前述のPrimitiveObjectResolverでも、まぁまぁ賄えるのですが、独自型とかを入れると扱いが厄介になってしまうので、そういう点でこちらの TypelessResolver のほうがイケテル度は高いです。
ところで、型を埋め込み、任意の型でデシリアライズできる場合には脆弱性が出る可能性があります。詳しくはBreaking .NET Through Serializationという資料を読んでほしいのですが(この資料は大変素晴らしいのでC#書く人は絶対読んだほうがいいですよ)、中には酷いクラスがあって、例えば System.CodeDom.Compiler.TempFileCollection はデストラクタでFile.Delete が走ります。基本的にインターネットの外からやってくるものに絶対の安全はありません。MessagePackはバイナリだからといって、別に不正データが投げつけられないわけではないので、TempFileCollection を型情報として埋めて、File.Deleteの対象をデシリアライズさせるものを投げつければ、ファイルをボロボロに削除されちゃうでしょう。
MessagePack for C#ではそれなりの安全性(最もキケンな[Serializable]のルールには従わない、↑で挙げられてるようなヤベークラスはそもそもデシリアライズできないようにしている)はありますが、絶対の保証がある、と言い切れるかというとなんともというところです。まぁ、シリアライザを作るってことは、表面上に見えるよりも、もっと色々なことを考えて作ってるんですよ、ということで。
標準Resolverから外しているように、Typeless自体がオススメかどうかというと微妙なのですが(型を埋め込む都合上バイナリサイズも膨らむし、他言語との互換性も消滅する)、欲しいシチュエーションというのは間違いなく存在するので、そういう時に覚えていてもらえれば嬉しいです。
Stream API
基本的にMessagePack for C#はbyte[]レベルで動作します。byte[]を直接読み、byte[]に直接書く。それにより、あらゆるオーバーヘッドを削減しているんですが、既存フレームワークなどにシリアライザ拡張を仕込む場合、Streamを引数に取るケースが多いんですね、というか普通そうですよね。そんな場合、高レベルAPI(MessagePackSerializer.Serialize/Deserialize)にはStreamオーバーロードが用意されているのですが、プリミティブなAPI(MessagePackBinary)には、ありませんでした。
さすがにそれはやりづらいねー、ってのはわかるー、ので、新しくMessagePackBinaryのWrite/ReadにStreamを受け取るオーバーロードが用意されました。最終的にbyte[]に読み取って/書き込んでから処理するのですが、そこのところを内部のメモリープールを通したりして、なるべくオーバーヘッドが少なくなるようにしています。
また、新たに MessagePackSerializer.Deserialize(Straem stream, bool readStrict) というオーバーロードが高レベルAPIに登場しました。readStrictがtrueの場合、Streamから読み取る範囲が、きっちりMessagePackのブロック分だけになります。デフォルトはfalseです。falseの場合はStreamを最後まで呼んで、そのbyte[]ブロックを処理します。そのため、Streamに連続的にMessagePackのバイナリが詰まっていた場合に処理できなかったんですね、これがreadStrictなら、正しくDeserializeを連発するだけでも動作させられます。
using (var ms = new MemoryStream())
{
// Streamに連続的に書き込む
MessagePackSerializer.Serialize(ms, new[] { 1, 10, 100, 1000 });
MessagePackSerializer.Serialize(ms, new[] { 1000, 100, 10, 1 });
ms.Position = 0;
// readStrict: trueで正しく順番にデシリアライズできる
var a1 = MessagePackSerializer.Deserialize<int[]>(ms, readStrict: true); // [1, 10, 100, 1000]
var a2 = MessagePackSerializer.Deserialize<int[]>(ms, readStrict: true); // [1000, 100, 10, 1]
}
じゃあtrueがデフォルトのほうがいいじゃん!ってことなんですが、パフォーマンス的にはfalseのほうがいいのです。というのも正確にMessagePackのブロック範囲を読み取るために、先にブロック範囲を解析する必要があるので……。これは、MessagePack for C#がbyte[]レベルで動作しているため、正しくストリーミングで読み書きできるわけじゃないからです。その辺のトレードオフは承知の上でbyte[]レベルを基本に敷いています。ストリーミングでやるから単純にロスなしでパフォーマンス良いんだぜ!じゃないところが世の中の現実的なところ、ということで。
Resolverによる拡張
MessagePack for C#の拡張ポイントは IFormatterResolver のみです。なんたらオプションとかなんたらセッティングスとかなく、どのリゾルバーを使うか。それだけの単純明快な仕様になっています。そして、それだけで十分すぎるほど機能するのです!なんでそうなのかというと、本質的にシリアライザって、ある型にたいしてどういうbyte[]を書く/読むか、ってことの連続にすぎないんですね。なので MessagePack for C# ではそこだけに注目して、ある型にたいしてどういうbyte[]を書く/読むか、を定義することがシリアライザの最小の実装としました。それがIMessagePackFormatter<T>で、Tに対してSerializeとDeserializeを定義します。組み込みで126個用意されてるようです、凄い、地道な作業です……。

スクロールバーの長さがものがたる。
IFormatterResolver は何かというと、その IMessagePackFormatter を取り出す機構です。
// IntFormatterが出てくる
var intFormatter = resolver.GetFormatter<int>();
で、それがどこで使われているかというと、IMessagePackFormatterです。IMessagePackFormatterを取り出すIFormatterResolverはIMessagePackFormatterで使われる、というわけわからん感じですが、どういうことかというと、例えばオブジェクトをシリアライズする場合。
[MessagePackObject]
public class SampleModel
{
[Key(0)]
public int Id{ get; set; }
[Key(1)]
public Person User { get; set; }
[Key(2)]
public DateTime CurrentTime { get; set; }
}
public sealed class SampleModelFormatter : IMessagePackFormatter<SampleModel>
{
public int Serialize(ref byte[] bytes, int offset, SampleModel value, IFormatterResolver formatterResolver)
{
if (value == null)
{
return MessagePackBinary.WriteNil(ref bytes, offset);
}
var startOffset = offset;
offset += MessagePackBinary.WriteFixedArrayHeaderUnsafe(ref bytes, offset, 3);
// formatterResolver経由で各型のシリアライザを取得している
offset += formatterResolver.GetFormatter<int>().Serialize(ref bytes, offset, value.Id, formatterResolver);
offset += formatterResolver.GetFormatter<Person>().Serialize(ref bytes, offset, value.User, formatterResolver);
offset += formatterResolver.GetFormatter<DateTime>().Serialize(ref bytes, offset, value.CurrentTime, formatterResolver);
return offset - startOffset;
}
}
オブジェクトのシリアライズが代表的ですが、型はネストするんですね、ネストした各プロパティの型の子シリアライザを取得するためにformatterResolverが使われます。このformatterResolverはシリアライズの際のトップレベルから渡され続けて、それにより挙動がカスタマイズできます。
// デフォルト:Contract(属性付与)が必要なResolver
MessagePackSerializer.Serialize(model, MessagePack.Resolvers.StandardResolver.Instance);
// 無指定で全てのpublic型をシリアライズなJSON.NETライクにカジュアルに使えるResolver
MessagePackSerializer.Serialize(model, MessagePack.Resolvers.ContractlessStandardResolver.Instance);
Resolverは大量に用意されているのですが、大きく分けて、他のと混ぜて使うためのものと、トップレベルで渡されることを想定した複合の二種があります。例えば単独だとDateTimeには組み込みで二種類あります。
// DateTimeFormatter, MsgPackのTimestampの仕様でシリアライズ/デシリアライズする。UTCになる。
var formatterA = BuiltinResolver.Instance.GetFormatter<DateTime>();
// DateTime.ToBinaryで.NETに特化した仕様でシリアライズ/デシリアライズする。DateTimeKindが保持される。
var formatterB = NativeDateTimeResolver.Instance.GetFormatter<DateTime>();
では、NativeDateTimeResolverを使いたい、という場合には、使いたいResolverを先に持ってけばいい、と。
// StandardResolverによる解決の前にNativeDateTimeResolverで解決させる
MessagePack.Resolvers.CompositeResolver.RegisterAndSetAsDefault(
NativeDateTimeResolver.Instance,
StandardResolver.Instance);
CompositeResolverは組み込みのお手軽にResolverのカスタムチェーンを作れる代物ですが、CompositeResolverにこだわらず、自分でResolverを作ってしまうのも良いです(むしろ割とそちらのほうがオススメ、ReadMeに書かれているものをコピペすれば、別に難しくはありません)。ちなみにStandardResolverは以下のような単発Resolverの混合品になっています。
// StandardResolverの解決順序
static readonly IFormatterResolver[] resolvers = new[]
{
BuiltinResolver.Instance, // Try Builtin
AttributeFormatterResolver.Instance, // Try use [MessagePackFormatter]
DynamicEnumResolver.Instance, // Try Enum
DynamicGenericResolver.Instance, // Try Array, Tuple, Collection
DynamicUnionResolver.Instance, // Try Union(Interface)
DynamicObjectResolver.Instance, // Try Object
PrimitiveObjectResolver.Instance // finally, try primitive resolver
};
ここから足したり引いたりして、オレオレStandardResolverを作っても良いわけです。それがMessagePack for C#のシリアライズ動作のカスタマイズになっています。なお、リゾルバーの解決チェーンはTの解決時に一回だけ走るようになっていて、そこで確定したら(ジェネリクスの利用法のハックにより)C#レベルでキャッシュされるので、超高速に取り出すような構造にしています。毎回、解決のチェーンを回したり、TypeをキーにしてDictionaryから引っ張る、とかやってたりしたら遅いですからね。
こういった仕組みだけで、ここまで徹底的に過激にやってる例は他にないんですが、めちゃくちゃ機能するので、世の中は見習うといいでしょう。
MessagePackFormatterAttribute
基本的にオブジェクトのシリアライズは、IMessagePackFormatterにより提供される外部シリアライザ経由で実行されます。通常は、属性付与により動的にシリアライザが生成されますが、全く別個のカスタマイズされた挙動をさせたい場合もなくはないでしょう、その際にはカスタムResolverを作って、通常利用するResolverの先頭に差し込んで貰う、というのも面倒くさいので、クラスに対して1:1で固有のシリアライザを紐付けられる属性を追加しました。
// この属性で渡したTypeがシリアライザとして使われる
[MessagePackFormatter(typeof(CustomObjectFormatter))]
public class CustomObject
{
string internalId;
public CustomObject()
{
this.internalId = Guid.NewGuid().ToString();
}
// ネストしたクラスの中にシリアライザがあるので、プライベートフィールドのシリアライズも可能
// みたいな自由なカスタマイズができるようになる
class CustomObjectFormatter : IMessagePackFormatter<CustomObject>
{
public int Serialize(ref byte[] bytes, int offset, CustomObject value, IFormatterResolver formatterResolver)
{
return formatterResolver.GetFormatterWithVerify<string>().Serialize(ref bytes, offset, value.internalId, formatterResolver);
}
public CustomObject Deserialize(byte[] bytes, int offset, IFormatterResolver formatterResolver, out int readSize)
{
var id = formatterResolver.GetFormatterWithVerify<string>().Deserialize(bytes, offset, formatterResolver, out readSize);
return new CustomObject { internalId = id };
}
}
}
このシリアライザの選択もResolverによって提供されていて、AttributeFormatterResolverがこの解決を行ってくれる代物になっています。なので、「MessagePackFormatterAttributeを無視したい」という場合はAttributeFormatterResolverを抜いたリゾルバーを渡せばいい、ということになります。また、それを無視した、更に別の挙動に変えたい場合は、「その前」にその型に適合するResolverを用意しておけばいいわけですね。シリアライザの挙動のカスタマイズは全てリゾルバーで解決可能、な問題になるように全体的なAPIを調整してあるのは、優れた点だと思っています。
DataContract対応
今まで独自属性(MessagePackObjectAttributeやKeyAttribute)のみだったのですが、DataContractAttributeにも対応しました。
[DataContract]
public class Sample1
{
[DataMember(Order = 0)]
public int Foo { get; set; }
[DataMember(Order = 1)]
public int Bar { get; set; }
}
Orderをint key, Nameをstring key代わりにできます。DataContractを使うことのメリットは、共有したい型のプロジェクトをMessagePack for C#の参照のないプレーンなプロジェクトにできることです。デメリットはAnalyzerの解析対象外になることと、mpc.exeによるコードジェネレート対象外になること。また、UnionやSerializationConstructorなどの、より強力なMessagePack for C#の機能は使えません。なので、できればMessagePack for C#を参照したほうがオススメです。
強い署名
すとぅろんぐねーむさいんど、好きですか?私は嫌いです。今の世の中に全く見合ってないレガシーなシステムだと思っています。しかし、.NETの世界は残念ながら強い署名と共に生きていくしかないのです。それは.NET Core時代であっても。CorefxのStrong Name Signingというドキュメントが最新の見解になりますが、もうこれが存在する理由は、互換性のためしょうがなく維持する必要があり、そして、署名されたものが存在すれば、そこからは署名の負の連鎖が繋がっているという、そういう荒涼とした世界だけです。
というわけで現状、NuGetでは署名したのが配られています。
性能改善
地道に出来るとこはやってますねん。特にオブジェクトをMapでシリアライズする場合(ContractlessResolverやKey(string)など)の性能を向上してます。これはJSONリプレイス的な意味で、かなり使われる形式なので、ちゃんと手を打ちたかったので。具体的にどんな形になったかというと
// こんなよくあるものがあるとして
[MessagePackObject(keyAsPropertyName: true)]
public class SampleModel
{
public int Age { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
}
// Beforeのサンプル
public sealed class SampleModelFormatter : IMessagePackFormatter<SampleModel>
{
public int Serialize(ref byte[] bytes, int offset, SampleModel value, IFormatterResolver formatterResolver)
{
if (value == null)
{
return MessagePackBinary.WriteNil(ref bytes, offset);
}
var startOffset = offset;
// 個数3が固定なので、コード生成時に15以下は判定なし(FixedMapHeaderUnsafe)で書き込み
offset += MessagePackBinary.WriteFixedMapHeaderUnsafe(ref bytes, offset, 3);
// {"プロパティ名":値} を書き込んでいく
offset += MessagePackBinary.WriteString(ref bytes, offset, "Age");
offset += MessagePackBinary.WriteInt32(ref bytes, offset, value.Age);
offset += MessagePackBinary.WriteString(ref bytes, offset, "FirstName");
offset += MessagePackBinary.WriteString(ref bytes, offset, value.FirstName);
offset += MessagePackBinary.WriteString(ref bytes, offset, "LastName");
offset += MessagePackBinary.WriteString(ref bytes, offset, value.LastName);
return offset - startOffset;
}
}
Beforeはせやな、って感じの、わりとストレートな実装でした。しいていえば、Mapのヘッダーサイズだけは最適化しています(コード生成時に判定できるので15以下ならFixed、それ以上なら内部で個数判定してフォーマットを決めるWriteMapHeaderを使ったコードを生成する)。
Afterは、というと
// Afterのサンプル
public sealed class SampleModelFormatter : IMessagePackFormatter<SampleModel>
{
// プロパティ名のバイト列は固定なので、事前に変換しておく
readonly byte[][] stringByteKeys = new byte[][]
{
global::System.Text.Encoding.UTF8.GetBytes("Age"),
global::System.Text.Encoding.UTF8.GetBytes("FirstName"),
global::System.Text.Encoding.UTF8.GetBytes("LastName"),
};
public int Serialize(ref byte[] bytes, int offset, SampleModel value, IFormatterResolver formatterResolver)
{
if (value == null)
{
return MessagePackBinary.WriteNil(ref bytes, offset);
}
var startOffset = offset;
offset += MessagePackBinary.WriteFixedMapHeaderUnsafe(ref bytes, offset, 3);
// 文字列のバイナリです、ということでそのままシーケンシャルに書いていく
// コード生成なら、生成時点で順番を固定で確定できるので、Dictionary<string, byte[]>みたいな辞書参照コストがかかるようなこともしない
offset += MessagePackBinary.WriteStringBytes(ref bytes, offset, stringByteKeys[0]);
offset += MessagePackBinary.WriteInt32(ref bytes, offset, value.Age);
offset += MessagePackBinary.WriteStringBytes(ref bytes, offset, stringByteKeys[1]);
offset += MessagePackBinary.WriteString(ref bytes, offset, value.FirstName);
offset += MessagePackBinary.WriteStringBytes(ref bytes, offset, stringByteKeys[2]);
offset += MessagePackBinary.WriteString(ref bytes, offset, value.LastName);
return offset - startOffset;
}
// deserialize...
}
プロパティ名は常に固定なのだから、事前に変換して持っておけばいいでしょ、という単純なお話でした。Beforeは毎回UTF8.GetBytesしていたわけですが、Afterではそのコストがゼロになっています。これはさすがに誰がどう見ても明らかにafterのほうが速い。実際に実装する時は、こういうようなコンセプトコードを書いた上で、動的生成のためILを打ち込みます。今回は変更量も大したことなかったので、割とサクッと書けました。よかったですね。
こういうのって、言われるとそりゃそーだってところだし難しい話でもなんでもない単純なことなんですが、割と見逃しちゃうところだったりします。コロンブスの卵的な。実装的にも(特にIL書く量が増えて)面倒くさいし。そういう部分を徹底的に精査して最適化を埋め込みまくってるのが、MessagePack for C#の速さの秘訣です。地道で、徹底的な改善こそが全て。近道なんてないのです。
Mapの場合、デシリアライズ速度も改善可能なんですが、アイディアはありつつちょっと具体的な実装がないのでまだ保留中。理屈的にはロスを減らせるんですが、せっかく実装しても、それが実際速いかどうかが別問題だったりで難しいんですよねえ。
まとめ
MessagePack for C#は既に黒騎士と白の魔王で全面的(Unityクライアント-gRPCサーバー間の通信と、サーバーサイドでのRedisへのシリアライズデータ格納)に使われているため、バグも概ね取り除かれていて、プロダクション環境で安心して使わえるレベルになっています。機能面でも、シリアライザに要求される幅広いシナリオに、ほとんど対応できるレベルになっています。というか、むしろ機能面でここまで揃ってるシリアライザも実際ないですね。JSON, Typeless, dynamic、そして拡張性。最強っぽい。細かいできることはまだ色々残っていますが(循環参照のサポートが一番大きいかな)、普通に使う限りは全く不便しないはずです。Unity向けにはコードジェネレータの利便性を高める(Macサポートとか)ってのがだいぶ優先度高めで未だに抜本的には手が出てません……。
ASP.NET Core MVCサポートも、私が適当に書いたものよりも、Using MessagePack with ASP.NET Core MVCといったちゃんとした(ちゃんとした!)実装を用意してもらったりなど、採用してもらっていってるかなー、と思います。それ以外にDatadogSharpという私が現在書いているDatadog APM用のクライアントの通信もMessagePack for C#を用いています。SignalRにMsgPack Protocolを採用するという話もあるんですが、それは強い署名がなかったので敗退したんですが、署名もしたしStream APIも入れたんで、機会あればもう少し粘りたいかな、といったところですね。
ところで、今日(今日!)のGTMF 2017 OSAKAにて株式会社CRI・ミドルウェアさんと共に「「黒騎士と白の魔王」の CRIWARE 活用事例」というセッションを行います。大阪です。実はこの記事、東京-大阪の新幹線の中で書いてるんですねー。また、同じ内容を7/14のGTMF 2017 TOKYOでも行いますので是非是非よろよろしくお願いします。懇親会などでもふらついていますので、よければ捕まえてやってください。
C# 7.0 custom task-like の正しいフレームワークでの利用法
- 2017-04-06
例年、この頃はMVP更新が云々とかなのですが、今年からシステムが変わって更新時期に変動があるんで何もありませんが、一応まだ継続しています。それはともかくとしてVisual Studio 2017が出ました。会社でも全プロジェクトがVS2017に移行完了を果たして、代わり映えしないようで、タプル記法のデコンストラクションとか工夫すると結構便利だな、とか使い始めると色々発見があります。タプル記法やデコンストラクションの工夫に関しては、弊社エンジニアリングブログのC# 7.0 が使えるようになったので ValueTuple を活用してみたをどうぞ。
そんな中で、私がはよ来てくれ……と願っていたC# 7.0の新機能は、task-likeです。Proposal: arbitrary task-like types returned from async methodsで延々と議論されていたようですが、これは何かというと、asyncでTask以外の型が返せるようになります。もともとC# 7.0からValueTaskが入って、async ValueTask<T> を返せるようになる必要があったついでに搭載されたみたいなものですが、色々何か出来そうですよね!?
というわけで、早速有効に使えるシチュエーションを用意しました。というか早速投下しています。
task-likeがない場合の苦痛
現在、私はMagicOnionというgRPCをベースにしたフレームワークを作っています。シリアライザはこないだ公開したエクストリーム速くて軽量なMessagePack for C#です。と、そういう細かいことはどうでもいいとして、MagicOnionではこんな風に書きます。
// 定義を用意して
public interface IMyFirstSerivce : IService<IMyFirstSerivce>
{
UnaryResult<int> Sum(int x, int y);
}
public class MyFirstSerivce : ServiceBase<IMyFirstSerivce>, IMyFirstSerivce
{
// これがサーバーで呼び出される実装になる
public UnaryResult<int> Sum(int x, int y)
{
var sum = x + y;
return UnaryResult(x + y);
}
}
static async Task Run()
{
var channel = new Channel("localhost:1111", ChannelCredentials.Insecure);
// インターフェースで動的にクライアントを自動生成する
var client = MagicOnionClient.Create<IMyFirstSerivce>(channel);
// 自然な感じでサーバー - クライアント通信で受け取れる
var result = await client.Sum(10, 20);
Console.WriteLine(result);
}
まぁまぁ自然な感じでいいじゃん?ってところですが、面倒くさいのは UnaryResult<T> を返さなければならないところ。そのため UnaryResuylt() というヘルパー関数を読んで包んだのをリターンする羽目になってます。これが地味に面倒くさい。return x + y; って書きたいじゃん、って。
で、MagicOnionがUnaryResultを強制するには理由があって、多くの場合は戻り値そのものだけで良いんですが、場合によってはレスポンスヘッダを取りたいとかステータスコードを取りたいとか、そういうのに対応する必要があるんですね。
// awaitしない
var response = client.Sum(10, 20);
// headerを取るとか
var header = await response.ResponseHeadersAsync;
// statusを取るとかしたかったりする
var trailer = response.GetStatus();
// 結果を取る場合。 await response はこれのショートカットでしかなかったりする
var result = await response.ResponseAsync;
APIの触り心地に関してはものすごく考えたんですが、最終的にこの辺が妥協点になってくるかな、と。しょうがないね。さて、ではasyncになるとどうでしょう?
public interface IMyFirstSerivce : IService<IMyFirstSerivce>
{
Task<UnaryResult<string>> EchoAsync(string message);
}
public class MyFirstSerivce : ServiceBase<IMyFirstSerivce>, IMyFirstSerivce
{
// サーバー側の書き味は普通、なんですが……
public async Task<UnaryResult<string>> EchoAsync(string message)
{
await Task.Delay(TimeSpan.FromSeconds(10));
return UnaryResult(message);
}
}
static async Task Run()
{
var channel = new Channel("localhost:1111", ChannelCredentials.Insecure);
var client = MagicOnionClient.Create<IMyFirstSerivce>(channel);
// await await !!!
var result = await await client.EchoAsync("hogehoge");
// というのも、await一発でUnaryResultの取得になる
var response = await client.EchoAsync("takotako");
// ようするにこれのショートカットはawait awaitになってしまうのだ……
var result2 = await response.ResponseAsync;
}
注目はawait awaitです。なんと、await awaitという世にも奇っ怪な記述が合法として出てくるのであった、最悪……。
task-likeがある場合
そこでC# 7.0 task-likeですよ!
// SyncもAsyncも共にUnaryResultとして定義
public interface IMyFirstSerivce : IService<IMyFirstSerivce>
{
UnaryResult<int> SumAsync(int x, int y);
UnaryResult<string> EchoAsync(string message);
}
public class MyFirstSerivce : ServiceBase<IMyFirstSerivce>, IMyFirstSerivce
{
public async UnaryResult<int> SumAsync(int x, int y)
{
// UnaryResult()で囲む必要なし!やったー!
return x + y;
}
public async UnaryResult<string> EchoAsync(string message)
{
// 勿論awaitする場合も普通に
await Task.Delay(TimeSpan.FromSeconds(3));
return message;
}
}
static async Task Run()
{
var channel = new Channel("localhost:1111", ChannelCredentials.Insecure);
var client = MagicOnionClient.Create<IMyFirstSerivce>(channel);
// 自然に扱える!
var result1 = await client.SumAsync(1, 100);
var result2 = await client.EchoAsync("hogehoge");
}
UnaryResult()でのラップもawait awaitも不要です。非常に綺麗にすっきりと扱えるようになりました。あってヨカッタtask-like。かなり有意義に使えてると思いますです。
これは何をやっているかというと、async UnaryResult の場合に独自のコード生成が入って、UnaryResult()の呼び出しを自動で行ってくれるようになってます。UnaryResult()でのラップやawait awaitもダルいのですが、地味に辛いのがTask<UnaryResult<T>>という、ジェネリクスが二階層になっているところですね。継承の連鎖が悪で少ないに越したことはないのと同様に、ジェネリクスのネストも、書き味的にも読み味的にも、少ないに越したことはないのです(ところでかんすーがたげんごの人は型をネストさせまくることの可読性低下にあまりにも無頓着すぎる気がとってもしてます、よくないね)。
警告を無視する
ところで、asyncでawaitなしだと警告がでます。CS1998 Async method lacks 'await' operators and will run synchronously というあれ。お薦めは、ガン無視することです。プロジェクト設定のほうで1998は警告「しない」にしちゃうのがいいでしょう。

ずっと会社でasyncまみれになってン年間過ごして思ったのは、この警告いらないわ。別に。抵抗感あるかもとは思いますが、それでもなお無視したほうが幸せ度上がると思います。
task-likeの作り方
適当にやりました。いや、だってよくわからんし。なんで適当にAsyncTaskMethodBuilderに丸投げです。まぁこれはValueTaskのtask-likeと一緒です。ノリが同じなのでそれで動くと思ってたし、実際それで動いた。超絶手間なくtask-like対応できたわー。
// 対象の型にAsyncMethodBuilder属性をつける
[AsyncMethodBuilder(typeof(AsyncUnaryResultMethodBuilder<>))]
public struct UnaryResult<TResponse>
{
}
// こちらがその中身。基本AsyncTaskMethodBuilderに丸投げです。
public struct AsyncUnaryResultMethodBuilder<T>
{
private AsyncTaskMethodBuilder<T> methodBuilder;
private T result;
private bool haveResult;
private bool useBuilder;
public static AsyncUnaryResultMethodBuilder<T> Create()
{
return new AsyncUnaryResultMethodBuilder<T>() { methodBuilder = AsyncTaskMethodBuilder<T>.Create() };
}
public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine
{
methodBuilder.Start(ref stateMachine);
}
public void SetStateMachine(IAsyncStateMachine stateMachine)
{
methodBuilder.SetStateMachine(stateMachine);
}
public void SetResult(T result)
{
if (useBuilder)
{
methodBuilder.SetResult(result);
}
else
{
this.result = result;
haveResult = true;
}
}
public void SetException(Exception exception)
{
methodBuilder.SetException(exception);
}
public UnaryResult<T> Task
{
get
{
if (haveResult)
{
return new UnaryResult<T>(result);
}
else
{
useBuilder = true;
return new UnaryResult<T>(methodBuilder.Task);
}
}
}
public void AwaitOnCompleted<TAwaiter, TStateMachine>(ref TAwaiter awaiter, ref TStateMachine stateMachine)
where TAwaiter : INotifyCompletion
where TStateMachine : IAsyncStateMachine
{
useBuilder = true;
methodBuilder.AwaitOnCompleted(ref awaiter, ref stateMachine);
}
[SecuritySafeCritical]
public void AwaitUnsafeOnCompleted<TAwaiter, TStateMachine>(ref TAwaiter awaiter, ref TStateMachine stateMachine)
where TAwaiter : ICriticalNotifyCompletion
where TStateMachine : IAsyncStateMachine
{
useBuilder = true;
methodBuilder.AwaitUnsafeOnCompleted(ref awaiter, ref stateMachine);
}
}
まぁ細かいことはいいんです、どうでも。
まとめ
C# 7.0は良い。というかMagicOnionはもはやC# 7.0が前提みたいな新世代フレームワークと化してますとかかんとか。MagicOnionは現在CM放送中(!)の黒騎士と白の魔王でも全面採用しています。黒騎士ではHTTP/1 Web APIはほぼ使われてないのです。クライアント-サーバー間もサーバー-サーバー間も全てgRPC。時代はHTTP/2。圧倒的な次世代。gRPCも、Unityでも動くようにgRPCにかなりの魔改造を施したカスタム仕様で、かなりアグレッシブな感じです。
その一端はUnite 2017でお話するつもりなので是非是非来てくださいな。もちろん、UniteはUnityのイベントなのでクライアントサイド中心の話なのでサーバー側(gRPC/MagicOnion)の話は少なめになりますが、近いうちに他のイベントでサーバー側でもお話できればな、と思ってます。ちょうど5月6月はクラウド系の大規模カンファレンスがラッシュでありますしね。
C#(.NET, .NET Core, Unity, Xamarin)用の新しい高速なMessagePack実装
- 2017-03-13
と、いうものを作りました。MessagePackのC#版です。以前に作ったZeroFormatterのコードをベースに、バイナリの読み書きをMsgPackのフォーマットに差し替えたものになります。MsgPackのライブラリはすでにあるじゃん(MsgPack-Cli)!ってことなんですが、パフォーマンスにかなり差があります。

JSON.NET(スタンダードで、豊富なAPIを持ってる)に対するJil(スピード特化、APIは必要十分はあるけれどJSON.NETほどではない)のようなものと思ってください。とはいえ、生のまま使っても問題は出ない(デフォルトのままで最高速が出るようにチューニングしてある)でしょうし、カスタマイズの口自体も十分用意してあります!詳しくは「拡張」の項で説明しますが、既に私自身が他のライブラリへの対応・インメモリデータベースの内部構造・RPCのシリアライゼーションフォーマットとして応用アプリケーションを作りまくっていて、それの要求に十分応えられるだけの拡張性があります。
今回のコードは、未来のアーキテクチャで実装された、C#のシリアライザ設計を一歩前進させる、隙のない代物になっています。というのは大げさでもなく、現代最先端のC#の設計技術を投下してあるので、世代的に今までのものとは、一つ二つ先を行ってます。C#でJSON以外のフォーマットのシリアライザを使おうと考えたら、もうこれ一択で悩まなくていいですよ。いや、ZeroFormatterとは悩んでください。
そう、ZeroFormatterは?というと、性能特性にクセがあるので、汎用フォーマットとしてはMsgPackのほうがずっと使いやすい、ですね。もちろん、無限大高速な性質はハマるシチュエーションではすごくハマると思いますよ!別にオワコンじゃないです!しかし、FlatBuffersが主流にはならないのと同じように、ハマるシチュエーションをきちんと考えたほうが良いかな、といったところはやっぱあります。使い勝手は工夫しましたが、どうしても、これ系のバイナリ形式そのもののクセは存在しちゃうので。
ところで、詳しくは圧縮の項で説明しますが、LZ4を内蔵したことにより、パフォーマンスを比較的維持したまま、更にファイルサイズを縮めることを可能にしています。これは、ただたんに出来上がったものを上からLZ4で圧縮しているのではなくて、MessagePack + LZ4のパイプラインを一体化して、LZ4のネイティブAPIを効率よく叩くことによって実現しています。また、lz4自体のオプションもシリアライザと併用して使うのに最適になるように調整してあります(コードもメモリプールを使って圧縮のために使う辞書のアロケーションをなくしたりなどの改造を入れてる)
Unity向けには、更にunsafeな拡張をONにしるとVector3[](など)のシリアライズがJsonUtilityの20倍高速化される拡張機能なども設けてます。これは超強力で、Meshなどの巨大データや大量の位置データのやり取りなどに役立つはずです。C#マジおせーからC++で書こうぜ、に最後の最後はなるにしても、それまでの遊び幅は大幅に拡張されるでしょう。
使いかた
Unity版はサイトのReleasesページから、.NETはNuGet経由で入れてもらうのがいいでしょふ。
APIのノリは完全に一緒で、静的関数のSerializeかDeserializeを呼ぶだけです。ただし対象クラスへの特別なマークが必要です。
// 属性をつけるのは「必須」です、これは堅牢性を高めるためです
[MessagePackObject]
public class MyClass
{
// Keyは配列のindexとして扱います、これはバージョニングで重要です
// Key名はIntかStringが選べて、Intの場合はArrayで、Stringの場合はMapでシリアライズされます
[Key(0)]
public int Age { get; set; }
[Key(1)]
public string FirstName { get; set; }
[Key(2)]
public string LastName { get; set; }
// publicメンバーで不要なフィールドは明示的に[IgnoreMember]を付与する必要があります
[IgnoreMember]
public string FullName { get { return FirstName + LastName; } }
}
class Program
{
static void Main(string[] args)
{
var mc = new MyClass
{
Age = 99,
FirstName = "hoge",
LastName = "huga",
};
// 基本的に Serialize/Deserialize を呼ぶだけの直感的で単純なAPIが全てです
var bytes = MessagePackSerializer.Serialize(mc);
var mc2 = MessagePackSerializer.Deserialize<MyClass>(bytes);
// ToJsonメソッドによってバイナリを簡単に読みやすいJSON文字列に変換できます
// これはデバッグ用途などで非常に役に立つでしょう!
var json = MessagePackSerializer.ToJson(bytes);
Console.WriteLine(json); // [99,"hoge","huga"]
}
}
属性をつけるのが「必須」なのは煩わしいところですが、これは堅牢性を高めるためです。MsgPack-Cliとの機能面での最大の差はオブジェクトシリアライズの扱いで、MsgPack-CliはデフォルトでArray、かつ、何もマークしていないものもシリアライズ可能です。これは、プロパティが増えた時の挙動(バージョニング)が極めて危険で、全くよろしくない。そのため、そもそも必須扱いにしてプログラム実行時の限りなく早いタイミングで気づけるようにしています。
かわりにこの煩わしさは、Visual StudioのAnalyzerによってある程度緩和できるようにしています。

また、気楽にやりたい場合は、[MessagePackContract(keyAsPropertyName = true)]にすると、プロパティへの属性付けは不要で、プロパティ名をキーとして扱いMap形式でシリアライズします。JSONライクで手軽ですが、シリアライズ/デシリアライズにかかる時間と、バイナリサイズは肥大化します。ただしKeyに名前がついてるとデバッグ時の楽さはあがるのと、遅くなるといっても依然高速なので、「アリ」な選択ではあるでしょう。
後述しますが引数にFormatterResolverを渡すことによってシリアライザの挙動がカスタマイズできて、標準で用意している ContractlessStandardResolver を渡すと(あるいはSetDefaultResolverでデフォルト挙動を差し替えることも可能)、[MessagePackObject]属性の付与も不要になります。
MessagePackSerializer.Serialize(mc, MessagePack.Resolvers.ContractlessStandardResolver.Instance);
この場合もキー名を文字列としてMapでシリアライズします。Mapを使うので、バージョニングに対する不安もありません。このオプションを合わせた場合が、最もお気楽に使える、 JSON.NETとの互換性というか使用感は変わらない感じになるんじゃないかと思います。また、この場合は匿名型もシリアライズできます(デシリアライズはできない)。
と、色々ありますが、お薦めは明示的にMessagePackObjectをつけて、KeyをIntにすることです。ようするにデフォルトのままが最も最高の効率で最もお薦め、ということです!まぁContractlessStandardResolverも悪くはないです、特に後述するLZ4圧縮と組み合わせれば配列など気になるデッカいデータを処理する時にはきちんとキーを縮められるので、全然良いかなとは。
パフォーマンス/最適化
細かい機能は置いといて、まずパフォーマンスについて詳しく見ていきましょう!

オールスターで並べてみました。小さくて見えませんね、もう少し大きい図はGitHubのページにあるのでそちらを。とりあえず最強に速いです、ということで。
どんなケースが来ても、まぁ、速いデス。圧倒的に。で、速い理由というか他が遅い理由は無限大に説明できるんで、まぁいいでしょう。基本的にはZeroFormatterで行ったことがそのままあてはまってますが、それに加えてMessagePackの仕様に対する最適化と、ZeroFormatterよりも効率的なIL生成によって、なんか結果ZeroFormatterより速くなってしまってなんともかんとも……。
・一切無駄なオブジェクトを生成しない、最終的なbyte[]以外のアロケーションは一切なし
・シリアライズ時のbyte[]の拡張が必要な場合も、64K以下は効率的に内蔵の作業用メモリプールを使うためアロケーションなし
・Streamベースではなくbyte[]ベースのプリミティブAPIにより、Stream抽象による呼び出しオーバーヘッドを削減
・シリアライザのキャッシュ/ルックアップにジェネリクス型変数からの取り出しによるDictionary呼び出しコストを削減
・効率的なメモリプールの使用による作業領域のメモリ拡張の削減
・デリゲート経由ではなく直接、型をIL生成することによる余分な呼び出しコストの削減
・ILコード生成時にプリミティブに対する書き込み/読み込みは、プリミティブAPIを直接呼び出すコード生成によりメソッド呼び出しコスト削減
・ILコード生成時にMsgPackの固定範囲に収まっているキーは範囲分岐判定せず直接呼び出すコードを埋め込み
・コレクションのイテレートをIEnumerable抽象で扱わず、各コレクションそれぞれに対し個別に最適化
・プリミティブ配列に関しては更にジェネリクスも使わず各プリミティブ配列専用のビルトインシリアライザを用意
・ルックアップテーブル事前生成によるデシリアライズ時のタイプ判定コードを削除
・文字列など長さが必要な可変フォーマットに対するヒューリスティックな長さ判定によるコピーコスト削減
・全コードパスがジェネリクスで貫通していてボクシング一切なし
・IL生成ができない環境ではソースコード解析からの事前コード生成による対応
頭からつま先までギッチシと最適化してあるんで、これ以上の速いシリアライザを書くことは不可能でしょう。ってZeroFormatterの時にも言った気がするので説得力が微妙になくなってますが、今度の今度こそもうやれることは絶対にない、というレベルでありとあらゆる設計と技法を突っ込んだので、これがC#の性能限界でしょう、しかも今回はunsafeではなくてsafeなのです!(LZ4, Unityのunsafe拡張を除く)。unsafeがなくてもC#は速いんです。はい。これはMsgPackがBigEndianなのでunsafe使ってもうまみがあんまないから、非unsafeに倒してみたってところですんが。
IL生成がより効率的になったのは、ZeroFormatter以降に何故かILを書きまくる羽目になったせいか、私自身のIL書き能力が向上したことによる余裕によって、結構アグレッシブに生成時分岐で最適なコードを直接埋め込んでみたからです。やっただけ効果は出ますねえ、やはり。なるほど。
コレクションのイテレートに関しては、さすがに数多いので抽象化はしてるんですが、こんなジェネリクス型を用意しました。
public abstract class CollectionFormatterBase<TElement, TIntermediate, TEnumerator, TCollection> : IMessagePackFormatter<TCollection>
where TCollection : IEnumerable<TElement>
where TEnumerator : IEnumerator<TElement>
微妙に奇々怪々な内容になっていますが、これが最も速いコレクションのシリアライズ/デシリアライズをするために必要な抽象なのです。例えば、これなら各コレクション専用のstruct enumeratorを使うことができます。ただたんにIEnumerable<T>をforeachするだけじゃ遅くてやってられないのですよ。
というような細かいハックは沢山入ってるんですが、とはいえ基本的にはStreamを捨ててbyte[]ベースにしたというのが大きいですね。byte[]ベースなのストリーミングでのシリアライズ/デシリアライズができないのですが、例えば巨大配列のケースではプリミティブAPIと小シリアライザを使って対処するとか、逃げ口はそれなりに用意されてるので、超絶巨大な一個のオブジェクト、みたいなシチュエーションじゃなきゃ大概なんとかなるものです。
System.IO.Pipelinesが出たら、Pipelines版作ってもいいかな、とは思いますが。しかし、そっちがあればbyte[]版とかイラネー?っていうと、実際のところそんなこたぁなくて、In/Outがbyte[]で確定してる状況では、byte[]版のほうが良いでしょうね。System.IO.Pipelinesで作るとストリーミングでシリアライズ/デシリアライズできるので、その点は良くなると思うんですが、利用するフレームワークの口が大抵はbyteで空いてるんで、ほとんどのシチュエーションでbyte[]版のほうが良好ってことになりそうだとは思ってます。ので、別にそんな優先度も希望も高くは持ってません。XxxAsyncみたいな非同期APIも同じような話が言えて、細切れでawaitかけるような中身になってると、むしろ相当遅くなってしまいます。基本的にはガリッとバッファ確保してガッと書いて、ガッとFlushにしないとダメなのですよ。なので、まぁPipelines版は別ですが、ふつーの形で非同期APIを作る意味は全くないと思ってるんで、それはナシです。むしろそういうのがあると、そっちのほうが良いのかな、とユーザーに思わせてしまうのでAPI設計的に非常によろしくない。
ファイルサイズと圧縮
MessagePackのイケてるところは、型の表現力が非常に高いのに、バイナリサイズが小さくなるところ。一般的にオブジェクトへのシリアライズにはArrayフォーマットが使われて、これはProtoなどのTagで1バイト使用するより小さくなる。もちろん、Arrayを使うことはバージョニングに問題を抱えていないこともないですが、概ねNil埋めで大丈夫な範囲に収まるので許容できるのではないかと考えています。
が、それと圧縮は別問題で、やっぱ圧縮は圧縮で、かけると非常に縮むんですよね。でも当然圧縮は別途パフォーマンスロスを抱えてしまうわけで、と、そこでMessagePack for C#は最速を誇るlz4での圧縮を標準でサポートしました。LZ4は圧縮率はそこそこですが、圧縮/伸張が速い(特に伸張がヤバいぐらい速い)という特徴があります。これはMessagePackのユースケースにかなりハマるんじゃないでしょうか(圧縮率が重要なシチュエーションでは、lz4と同作者のZStandardというものがあって、これもバランス良くて素晴らしい)。
// 基本的に MessagePackSerializer のかわりに LZ4MessagePackSerialzier を呼ぶだけ
var bytes = LZ4MessagePackSerialzier.Serialize(mc);
var mc2 = LZ4MessagePackSerialzier.Deserialize<MyClass>(bytes);
// ToJsonメソッドによってバイナリを簡単に読みやすいJSON文字列に変換できます
// これはデバッグ用途などで非常に役に立つでしょう!
var json = LZ4MessagePackSerialzier.ToJson(bytes);
Console.WriteLine(json); // [99,"hoge","huga"]
んで、とにかく速い。ほとんど変わらないだけの圧縮/伸張速度なのにファイルサイズは激縮み!ただし、一応言っておくと圧縮はデータの内容によって全く効かないこともあれば、重複だらけデータなら効果はてきめんになったり(だからJSON+GZipで配列縮めると大量の同じような文字列キーが縮んでほぼ無視できるようになる)ということがあります。この試験データは重複多めなので、圧縮が効きやすいうえに効率も良いのでめっちゃ縮んでいるだけです。処理時間も複雑なデータであれば、このデータのようにあんま変わらない、などということはなく2倍ぐらいの差になるケースも出てきます(それでも他のシリアライザを単独で使うより速いというのが驚異的な話なのですが!)。この辺は相性とかモノ次第って面もありますが、実際リアルなデータ(現在開発中のゲーム)での色々寄せ集めて集合させた5Mぐらいのデータは800KBになりました、速度的にはx1.5がけぐらい。全然割に合います。
で、このLZ4圧縮はMsgPackで出来上がったデータに対して上からLZ4をかけてるわけではありません。まず、これ自体が正しいMsgPackデータになってます(なので他のMessagePackシリアライザにそのまま渡しても認識はできる、デシリアライズはできませんが、正しく実装されたシリアライザなら少なくとも(Bodyはbinaryですが)Dumpは可能)。MsgPackの仕様のExt領域を使って(TypeCode:99)、LZ4圧縮によるMsgPackという形でシリアライズしています。
なんでかというと、そもそもLZ4がbyte[]ブロックベースで動作する圧縮フォーマットなのです。(C#の)Streamとして使えるベンリAPIがあったりしますが、それはただのラッパーで、むしろかなり速度低下させる一因です。黙ってbyte[]ベースの最もプリミティブなLZ4のAPIを叩く。それが最高に速い。そして、つまりこれって今のMessagePack for C#の実装とめっちゃ相性が良い、こっちもbyte[]ベースですから。相性が良いのは良いとして、ただたんに左から右に流すだけだと、無駄なbyte[]コピーが発生しちゃうんですよね(最終サイズのbyte[]にリサイズするコストとかがどうしてもある)。どうせLZ4通すなら、別にその時点はただの中間地点なので、リサイズする必要はないんで、当然ノーリサイズでそのまま流す。リサイズするのはLZ4通した本当の最後の最後だけ。
それとLZ4の生デコンプレスAPIは、「復元後(圧縮前)のサイズを知っている」ことで、より効率的にデコンプレスできるようになっています。が、LZ4自身には復元後のサイズは埋まってません。なるほど。なるほど。なのでふつーに左から右に流すだけ圧縮だと、真の意味で効率的な復元は実現できません。そこでExt領域を使っている理由がでてきて、MessagePack for C#のLZ4統合では、復元後のサイズを先頭に埋め込んであります。それを使うことにより、真の最高速でのLZ4によるデコンプレスを実現してます。
なお、独断と偏見により64バイト以下はLZ4として圧縮せず素通しするようにしています。なので頻繁に送受信する軽量なデータは圧縮/伸張によるパフォーマンスの影響を一切受けません。これもExt領域を使った意味があって、素通しでもLZ4でも、そのまんまMsgPackとして扱えるんですね。どちらもValidなMsgPackなので、きっちり正しくクライアント側でハンドリングできるようになりました。
シリアライザの選択に悩まないと言いましたが、MessagePackSerializerを使うかLZ4MessagePackSerializerを使うかは、悩みますねえー。
イミュータブルオブジェクトへのデシリアライズ
デシリアライズ処理には通常publicなsetterを要求しますが、MessagePack C#はイミュータブルオブジェクトへのデシリアライズを可能にしています。これが出来ると、
[MessagePackObject]
public class Point
{
[Key(0)]
public int X { get; }
[Key(1)]
public int Y { get; }
public Point((int, int) p)
{
this.X = p.Item1;
this.Y = p.Item2;
}
[SerializationConstructor]
public Point(int x, int y)
{
this.X = x;
this.Y = y;
}
}
KeyがIntの場合は引数の位置で、Stringの場合は名前(大文字小文字無視)でマッチさせます。ある程度「気を利かせてくれる」とかではなく、明確に仕様として設け、コンフィグの口を持っているところは目新しいんじゃないかと。そして、これ、実際便利です。
Union
Union(インターフェイスのシリアライズ/ポリモーフィズム)は2要素の配列として表現しています。一つ目が識別キー。二つ目が中身。
// mark inheritance types
[MessagePack.Union(0, typeof(FooClass))]
[MessagePack.Union(1, typeof(BarClass))]
public interface IUnionSample
{
}
[MessagePackObject]
public class FooClass : IUnionSample
{
[Key(0)]
public int XYZ { get; set; }
}
[MessagePackObject]
public class BarClass : IUnionSample
{
[Key(0)]
public string OPQ { get; set; }
}
// ---
IUnionSample data = new FooClass() { XYZ = 999 };
// serialize interface.
var bin = MessagePackSerializer.Serialize(data);
// deserialize interface.
var reData = MessagePackSerializer.Deserialize<IUnionSample>(bin);
// use type-switch of C# 7.0
switch (reData)
{
case FooClass x:
Console.WriteLine(x.XYZ);
break;
case BarClass x:
Console.WriteLine(x.OPQ);
break;
default:
break;
}
これ、C# 7.0の型でswitchできるのと相性良いんですよね。便利で良くなったと思います。
拡張
今回、デフォルトでやたら拡張パッケージがあります。
Install-Package MessagePack.ImmutableCollection
Install-Package MessagePack.ReactiveProperty
Install-Package MessagePack.UnityShims
Install-Package MessagePack.AspNetCoreMvcFormatter
ImmutableCollectionやReactivePropertyをシリアライズ可能にするやつ。UnityShimsはUnityと相互通信する際のVector3とかとそのシリアライザ。AspNetCoreMvcFormatterはASP.NET Core MVC用のシリアライザ換装するやつです。
拡張を有効にする場合は、Resolverというものを使っていきます。こんな感じで。
// set extensions to default resolver.
MessagePack.Resolvers.CompositeResolver.RegisterAndSetAsDefault(
// enable extension packages first
ImmutableCollectionResolver.Instance,
ReactivePropertyResolver.Instance,
MessagePack.Unity.Extension.UnityBlitResolver.Instance,
MessagePack.Unity.UnityResolver.Instance,
// finaly use standard(default) resolver
StandardResolver.Instance);
);
この辺のは細かい使い方といったところなので、ReadMeを見てもらえれば、なのですが、MessagePack for C#ではコンフィグ/拡張ポイントをResolverに寄せているので、これの仕組みさえ理解してもらえれば全ての拡張の方法がわかります!逆に、これがちょっと初見だとむつかしめなので、もう少し優しい何かも用意したい気もしなくはないですが、多分、このままでいいんじゃないかな、とも思ってます。
for Unity
今回はZeroFormatterと違って、コードジェネレート不要です!なんですと!!!きっちりとUnityでちゃんと動作するILGenerationによって、ふつーの.NET版と変わらない動的コード生成/パフォーマンスでUnityでも動きます。IL2CPPじゃなければ。IL2CPPじゃなければ。PCでもAndroidでもどんとこい、なんですが、IL2CPPはダメです。IL2CPPの場合は、やっぱりコードジェネレートしてください、今回もコードジェネレーター同梱してあります(そして未だにWindowsでしか動作しません、なんとかしたい……)
更に今回はunsafeじゃありません!ほとんどのコードがsafeで動いてるのでソースコードべた配布。やったね。unsafe使わなくても結構速く出来るんですよ。とはいえ、LZ4がunsafeバリバリなので、LZ4使いたい場合はunsafeを有効にしてください。詳しいことはReadMeで。
ついでにunsafe時のスペシャルフィーチャーとして、エクストリーム高速なVector3[]シリアライザをUnity用に特別に用意しました。

JsonUtilityの20倍速い。これならMeshとかの大量の頂点を扱うものでも、そこそこなんとか戦えるんじゃないでしょうか。それ以上頑張りたかったらC++で、ですけれど、C#でもここまでなら頑張れる……!
なんで速いかというと、structの配列はメモリ上に一列に並ぶというC#の特性を利用して、まるっとそのままコピーしてるからです。Oh……。まぁ、アリでしょう。アリでしょう。なお、さすがにこれは正規のMessagePackの配列じゃなくなる(純粋なバイト列)ので、拡張フォーマットとしてマークして押し込んでます。MessagePackはこれが便利……なんか特化したの突っ込んでも仕様的にValidだと言い張れる。てわけで、アリでしょう。アリ。最高にクールな機能だと思ってます。
MsgPack-Cliとの互換性
あまり考えてない&こちらからサポートする気はあんまナイデス。互換性は基本的にあるんですが、微妙にありません!多分、普通に使ってる場合は非互換になります。C#の型をMsgPackとしてどう表現するか、というところで差異が出ちゃうんで、しょーがない。
Enumのシリアライズ/デシリアライズが、MessagePack for C#ではデフォルトはIntegerになります。文字列でのシリアライズ/デシリアライズのサポートは、Enumを文字列で扱うと明らかに遅くなるのでやる気nothing、と思ってたんですがまさかの1.0.0を投げた直後に要望が来たのでしょうがなく追加で入れることになったのであった。1.0.1スタートの理由、おうふおうふ。というわけでResolverを差し替えることによってEnumを文字列で扱う対応はできます。よかったね。なお、MsgPack-Cliは文字列になるほうがデフォです。なのでデフォのままだと、ここで互換性なくなります。
DateTimeの形式が互換性ありません。MessagePack for C#ではProposalで提唱されているTimestamp拡張を実装しています(ほぼほぼファイナルなんだと思うけど一向にマージされないので、早まったかな、どうなんだろう……)。これもResolverを自前で書けば解決可能なので適当にどうぞ。
あとはdecimalとかGuid辺りの扱いもちょっと違いますがResolverを自前で(以下略)
多言語間での通信
C#独自の型になると、なんというかよしなにハンドリングしてください状態になってしまうんですが、基本型だけ使ってる分には概ね大丈夫でしょう。ただしDateTimeだけは↑に書いたように、特殊なハンドリングしてるんで他の言語のサポート状況次第です。不安なら文字列にして送ったりUnixTimestampにして送ったりすればいいんじゃないでしょーか。DateTimeが互換の問題になるのは別にMsgPackに限らず、JSONでもよくあることですねー。故に標準で型としてサポートして欲しいし、↑のTimestamp拡張がAcceptされるのを待ち望んでいます。
あとは、オブジェクトはIntがキーのArrayかStringがキーのMapのどちらかです、ってことですね。これは他の言語も概ねその二択なので、問題なく相互変換できると思っています。
Protobufとの比較
Protocol Buffersと比較すると、MsgPackはダンプ耐性があるのが好みです。自己記述的で、スキーマと照らし合わせなくても良いため、デバッグとかで何かと捗ります(MessagePack for C#についてるJSONへのダンプ機能は超嬉しいはず、ていうか私が超嬉しい)。また、nullの扱いが明確なのも嬉しいところで、Protobufはそれがかなりのハマりどころで、色々と詰むんですが、MsgPackは完全にC#をシリアライズ/デシリアライズしても自然のまま扱えます。どういうことかというとこういうことです。
[ProtoContract]
public class Parent
{
[ProtoMember(1)]
public int Primitive { get; set; }
[ProtoMember(2)]
public Child Prop { get; set; }
[ProtoMember(3)]
public int[] Array { get; set; }
}
[ProtoContract]
public class Child
{
[ProtoMember(1)]
public int Number { get; set; }
}
using (var ms = new MemoryStream())
{
// nullをシリアライズすると
ProtoBuf.Serializer.Serialize<Parent>(ms, null);
ms.Position = 0;
var result = ProtoBuf.Serializer.Deserialize<Parent>(ms);
// なんとデシリアライズするとstructのように0埋めされたものになってデシリアライズする!これはヤバい。
Console.WriteLine(result != null); // True
Console.WriteLine(result.Primitive); // 0
Console.WriteLine(result.Prop); // null
Console.WriteLine(result.Array); // null
}
using (var ms = new MemoryStream())
{
// 空配列をシリアライズする
ProtoBuf.Serializer.Serialize<Parent>(ms, new Parent { Array = new int[0] });
ms.Position = 0;
var result = ProtoBuf.Serializer.Deserialize<Parent>(ms);
// nullになって帰ってくる!なんじゃそりゃ、マジでヤバい。
Console.WriteLine(result.Array == null); // True, null!
}
protobuf-netの問題というか、protobuf自体の型表現力的にしょーがないんですねー、protobufの表現力は実はかなり弱いのです……。なので、protobufを.protoからの生成じゃなく使う、つまり普通の汎用シリアライゼーションフォーマットとして使うのは激しくお薦めしません。実運用に入ると間違いなく問題になるはずです(というか実際グラニでは激しく問題になった!もう二度とprotobuf-netは使わん!)
かわりに、protobufはIDLやそのRPCフレームワークであるgRPCが強力で、多言語間での通信仕様として使うには、圧倒的に秀でていると思います。gRPCは最高ですよ。MsgPackはオブジェクトシリアライズの統一的仕様が存在しないので、言語間での通信仕様としては正直、かなり厳しいと思いますね。いや、別にJSONのように手で調整するなら構わないし、It's like JSONってのはそういうことだろっていうとそういうことなんですが、話が違うのはいかんせんバイナリだということ。JSONはテキストなので目で見て調整できたり、暗黙的にObjectはStringがKeyのMapですよね、で統一されてるんですが、MsgPackはバイナリなので調整辛いし、オブジェクトがArrayなのかMapなのかも統一感なかったりで、ちょっとショッパイと言わざるをえないです。
なので、gRPCとか言語超えたRPCではProtobufが圧倒的に優勢で、これは未来永劫変わらないでしょう。MsgPack-RPCやMsgPack-IDLはコケた、といっても過言ではないし、別に蘇ることもないと思うんで。
しかしバイナリ仕様としては非常に優れてるし、Dump可能なところも嬉しすぎるので、多言語間通信「以外」での局面では、最高のフォーマットだと思います。多言語間通信においても自社内とかの閉じたところなら調整はやりやすいので、決してダメというわけでもない、でしょうが、まぁそういう場合はIDL欲しくなるのがフツーなので、訴求力は弱くなっちゃてるでしょうねえ、現状で既に(MsgPackを「選ばない」理由としては至極真っ当だと思います)。RPCを捨てて、JSON-Schema的な純粋な仕様定義を再展開すればあるいは?とは、やっぱあんま思わないんで、ここはしゃーなしで諦めたほうがいいかしらん、外野の意見では。
MessagePack-RPC/gRPC
と、言っておきながらなんですが、MessagePack for C#を使ったRPCを作っています。MagicOnion - gRPC based HTTP/2 RPC Streaming Framework for .NET, .NET Core and Unity. ということで、通常gRPCはprotobufで通信するんですが、そのシリアライゼーションレイヤーをMessagePackに置き換えてます。なんでかっていうと、それによってIDL不要でRPCできるようにしてからです。IDLを使わない局面ではMsgPackは上で言った通り最高のフォーマットなので。
MagicOnionの特徴は、IDLを使わなくても、型安全で通信のスキーマがかっちり決まった状態になることです。何故か、というと、C#そのものがスキーマとして動くので。MagicOnionは Server C# - Client C# の通信フレームワークになっていて、多言語ではなく同言語間に限定することによって、MsgPackのウィークポイントを塞ぎつつ、素のgRPCよりも、よりC#の特色を活かした強力な機能と書きやすさを付与しています。パフォーマンスも文句なく良い、むしろ素のgRPCよりも良い(シリアライザの性能差で)
まだ開発中なので、今後に乞うご期待:) 実際にUnityで開発中のゲームはこのフレームワークを使ったものになっています。HTTP/1 APIは完全消滅。中々アグレッシブです。
まとめ
ZeroFormatterよりもResolver回り(拡張/オプション)のAPIが大幅に改善されてます。ふつーの利用時は関係ないんですが、フレームワークに組み込んだり、拡張する場合に、こちらのほうが圧倒的に良いです。性能特化のDIを用意したってことなんですが、まぁ相応に良いですねぇ。ちょっとDI嫌いは返上しよう……。ZeroFormatterにも後で移植しよう……。
改めてZeroFormatterとどっちがいーんですか!というと、特性に合わせて選んでくださいとしか言いようがありません。ZeroFormatterが効果アリ!なシチュエーションでピンポイントで使っていけば勿論それは効果アリ!ですが、ぶっちけ7割がた、MsgPackのほうが良いケースのほうが多いとは思っています。MsgPackは偉大なフォーマットですぞよ(ただしTimestampのフォーマットは早く決めて欲しい)。私の中でZeroFormatterのようなフォーマットが必要な理由が、MasterMemoryを作ったことにより、そっちのほうが上位の形で解消されてしまったというのがんががが……。
MsgPack-Cliとでは、まぁお好みで。アタリマエですが実績は無視できないファクターでしょう。ライブラリのメンテナーとして信頼できるかどうかも違いですね(私よりもずっと安定感あると思います!別に私もやらないわけじゃないんですが、ムラがあるんで)。それと私はSilverlightとかWindows Phoneとかサポートする気はないんで、その辺が必要な場合は必須ですね。
世の中、もう十分枯れきったと思っているところでも全然ゆるくて、手を加えられる余地はあるんだなぁ、というのは発見でした。シリアライザがここまで性能伸ばせるなんて、やってみるまで思いもしなかった。C#の良くないところに、ピーキーにチューニングされたライブラリが少ない(Javaのほうが遥かに多いのは事実でしょう!)ことがあり、それが諸々のパフォーマンステストや、そもそもの実績に影響を与えているのですよね。
結局、今までC#がその辺を「ゆるく考えていた」ことの積み重なりが、今の体たらくを招いていることの一因だとも思っています。別にMicrosoftだけではなくコミュニティ全体がね。吐気がするような継承の瓦礫の塔を築いたり、無駄にFunctionalであろうとしたり。私は、C#は好きな言語だから使っているというだけじゃなくて、「前線で戦える言語」だから使っているのです。何かの理想を追う言語ではなく、真に実践的な言語であるから全力で投資しているのです。常に戦場であり、他の言語なりフレームワークなりと戦っているフィールドであり、そこではフェアに評価されるべきであり、戦って死ね。と。C#を前線で戦わせるためにも、こうして一つ一つ、証明し続けていかなければならないでしょう。
UniRxを支えるユニットテスト - RuntimeUnitTestToolkit for Unity
- 2017-03-05
オープンなようなクローズドなような、ラウンドテーブルディスカッションのような、少人数のところでUnityのユニットテストについて話してきました。というか、UniRxのために作って、以降、私の作るUnity用の色々なので使いまわしてる自作のユニットテストフレームワークについて、ですね。
このフレームワークはずっとUniRxの中に埋まったまんまだったんですが、使える形でパッケージしたのを、今日GitHubに公開しました。unitypackageとしても置いてあるので、一応インポートはしやすいはずです。
とりあえず必要な機能しか入れてないんで、汎用テストフレームワークとしては足りない機能が普通に多いので、その辺も作ってからアセットストアに公開したいなぁ、と思ってはいたんですが、まぁそうなるといつまで経っても公開できなさそうなので、とりあえず現段階のもので公開、です。
.NETのテスト事情、或いはUnityでテストを書かないことについて
私はライブラリとしてはふつーの.NETと共通で動くものを作ることが多いんで、まぁそういう場合は大部分はふつーの.NETのユニットテストを書いたほうが遥かに書きやすいでしょう!つまりUnityでテストを書くコツはUnityで書かないということです!!!みもふたもない。

テストのメソッドを右クリックしてデバッグ実行で直接Visual Studioのデバッガでダイレクトにアタッチできたりとか、基本的に最高ですね。
さて、スライドにも書いたのですが、最近はxUnit.netを好んで使っています。MSTestはいい加減投げ捨てていいでしょう、というか投げ捨てるべきでしょう。NUnitは知らん。いらん。補助としてChainingAssertionは変わらず使ってるんですが、.NETCore対応を内部では作って使ってるんですが公開には至ってない……。
また、モックライブラリとしてはMicrosoft Fakes Frameworkのような大仰なものは「絶対に」使うべきではない、という思いが強くなってます。テストはただでさえ負債になりやすいのに(盲目的にテストは書くべき信仰してる人は、テストの負債化に関して全く言及しないのがポジショントークなのか脳みそお花畑なのか、頭悪そうですね)、大きな自動生成を伴うものは負債の連鎖を作りやすいなー、と。シンプルに作らないと、シンプルに投げ捨てることができない、というね。そして、投げ捨てるのは簡単ではなく、投げ捨てるのもまた技術なわけです。
RuntimeUnitTestToolkit
.NETでテスト書くからそれでOK、というわけは当然なくて、Unityだけでしか動かない部分もあるし、そもそもUnityでちゃんと動くかどうかの保証はない。更にはIL2CPPに通した場合はやっぱり別物の挙動というか動かなくなるケースは「非常に多い」ので、ちゃんとIL2CPPで動くことを保証しなければならない。そこで作ったのがRuntimeUnitTestToolkitです。Unityには標準でテストツールあるじゃん、って話ですが、あれは実機動作させられないので論外です。それで用が満たせりゃあ標準の使うわ。

テストが並べられて、ボタン押したら実行、ボタンが緑になったら成功、赤になったら失敗というシンプルなふいんきのものです。一個のシーンになってるので、ビルドして実機転送すればそのまま実機で動きます。
実際に自分で使うには、Releaseページからunitypackageを落としてきてインポート。で、UnitTest.sceneを開いて再生すればOK。簡単簡単。
テストの書き方ですが、基本的にはMonoBehaviourを継承したりもしないシンプルなクラスを用意します。
// make unit test on plain C# class
public class SampleGroup
{
// all public methods are automatically registered in test group
public void SumTest()
{
var x = int.Parse("100");
var y = int.Parse("200");
// using RuntimeUnitTestToolkit;
// 'Is' is Assertion method, same as Assert(actual, expected)
(x + y).Is(300);
}
// return type 'IEnumerator' is marked as async test method
public IEnumerator AsyncTest()
{
var testObject = new GameObject("Test");
// wait asynchronous coroutine(UniRx coroutine runnner)
yield return MainThreadDispatcher.StartCoroutine(MoveToRight(testObject));
// assrtion
testObject.transform.position.x.Is(60);
GameObject.Destroy(testObject);
}
IEnumerator MoveToRight(GameObject o)
{
for (int i = 0; i < 60; i++)
{
var p = o.transform.position;
p.x += 1;
o.transform.position = p;
yield return null;
}
}
}
属性とかは特に必要なく、戻り値voidのパブリックメソッドは強制的にテストメソッドとして認識します。また、戻り値IEnumertorのクラスは非同期テストメソッドとして認識してコルーチンとして動かすので、中でyieldとか他のコルーチンを動かしての待機とかも自由にできます。
さすがに定義だけでテストクラスを認識できないので、それとは別にテストローダーを書いてあげます。
public static class UnitTestLoader
{
[RuntimeInitializeOnLoadMethod(RuntimeInitializeLoadType.BeforeSceneLoad)]
public static void Register()
{
// setup created test class to RegisterAllMethods<T>
UnitTest.RegisterAllMethods<SampleGroup>();
// and add other classes
}
}
これで実行してやれば、書いたクラスが実行時にボタンとしてシーンに追加されます。

ある程度リフレクションでメソッドとかの認識をしているんですが、ちゃんとIL2CPPで動作するギリギリのリフレクション加減で仕上げつつ、書きやすい直感的にAPIに仕立てたというのが工夫ポイントですね!
with UniRx
UniRxは結構ユニットテスト向けだったりします。例えば何かアクションを加えてイベントが発行されることを確認したい、という場合に、IObservableとして公開されているならば
public IEnumerator WithUniRxTestA()
{
// subscribe event callback
var subscription = obj.SomeEventAsObservable().First().ToYieldInstruction();
// raise event
obj.RaiseEventSomething();
// check event raise complete
yield return subscription;
subscription.Result.Is();
}
と、サクッと書けたりします。あるいは、何か色々によって色々値が変わるということは
public IEnumerator UniRxTestB()
{
// monitor value changed
var subscription = obj.ObserveEveryValueChanged(x => x.someValue).Skip(1).First().ToYieldInstruction();
// do something
obj.DoSomething();
// wait complete
yield return subscription;
subscription.Result.Is();
}
と、ObserveEveryValueChangedで外側からサクッと値の監視が可能です。また、各種のObservableTriggerを突っ込むことによって、外側から内部の状態をサクッとモニタできます。あまり実際のプログラムでは使うことはないようなことも、ユニットテストなら派手に使っても構わないし、そういう時に楽ができるツールがUniRxには揃っています。外側からサクッとどうこうする手段がないと、インスペクタにユニットテスト用の特別な何かを仕込んでアサートとかいう、しょぼいテストフレームワーク(UnityのIntegration Test Frameworkのことですよ!)になってしまいがちですので。
まとめ
現状のUnityの単体テストツールは、必要な要件を全く満たしてなくて使えなさすぎですぅ。テストツールは結構大事で、とりあえずテスト大事、とりあえずテスト書くんだ、とかいってしょうもないツールを土台にやってるとボロボロに負債になるんで、ちゃんと自分の要件を意識して選択しないとダメですね。そこも把握できてなかったり、あとシンタックスも非常に大事で、Spec系がぶっちゃけ書き方違うだけで本質的に変わらないのに非常に感触が変わるのと同じで、そういうの大事にできない人はプログラミングの感性足りてないんで、小手先のテスト信仰とかしてないで、それ以前にまともな感性磨いたほうが良さそうですね。
とはいえ、Unity 5.6から良くなる気配を見せていて、少なくともその延長線上にはちゃんとした未来がありそうなだけの土台は作れてそうなので良かった。それ以前の(現在の)は本当にセンスなさすぎて、こいつらの感性の先に未来はなさそうだなー、と思ってたんで。
RuntimeUnitTestToolkitをオススメするかっていうと、実機で動かすのに困ってればいいんじゃないでしょうか!とはいえ、素朴すぎるってところはあるんで、もう少し作り込まないと使えないというケースは多そうってところです。私も、自分の作る程度の規模では困ってないんですが、会社のプロジェクトに入れると困るところは多く出てきそうだなー、という感じですね。足らないところを自分で補っていけるならというところです。
近況
ところでなんと今年に入ってブログ書いてなかった!はうう!というのは、書きかけのプロジェクトが多くてそれにあくせくあくせくだからんですねえ。公開まであともう一歩、というところまでに持ってけているのは MessagePack for C#(.NET, .NET Core, Unity, Xamarin) です。
ZeroFormatterあるじゃん、なのに何故、って話ですが、まぁそれは公開時にでも。とりあえず、エクストリーム速いです。それと、拡張性も重視して組んでいて、Unity用の特殊な拡張をアドオンとして有効化すると、例えばVector3[]のシリアライズ/デシリアライズがJsonUtilityの50倍高速化(50倍!)とか、色々強力で強烈になってます。乞うご期待。
それと会社ブログ - Grani Engineering Blog始めましたということで、そっちに幾つか記事書いてますね。C#のswitch文のコンパイラ最適化についてとか。あとgRPC化とか。
こちらも、シリアライザのMessagePack for C#化とか大工事を何度かしつつも、もうすぐとりあえずStableといえるとこまで持ってけそうです。
また、Unity用のインメモリ内蔵データベースとしてMasterMemoryというのも作っていて
これももうすぐ公開できそうかもかもといったところで、とりあえず色々あって大変大変。どれもUnityでのユニットテストには RuntimeUnitTestToolkit で動かしてるんで、私自身は超ヘビーに使いまくってますよ、です。
2016年を振り返る
- 2016-12-31
振り返る、のも五回目。今年は、ものすごくC#を書く技量が向上した気がします。いやほんと。私も結構歳とった感があるのですが(昨日誕生日で33歳でした!)、まだグッと成長できる切り口が残ってたんだなぁと思うと大変嬉しい話です。正直今年はあまり良いニュースはなかったのですが、自分のメインの軸で自己成長を実現できたというのは、次のステップ頑張ろうって気になれます。
C#
プログラミングって、ある程度はパターンがあって、このシチュエーションにはこれを当てはめて、こういう風に組み立てていけば勝てる、みたいな手札の多さが強さ(?)みたいなところがあると思ってるんですが、ここ2年ほど私自身のデッキは割と安定していたんですよね。言語やフレームワークのアップデートに従って組み替えたり、他のライブラリを見て手札を、アイディアを増やすというのは随時やっていってましたが、大きく変わるようなことはなかったなあ、と。言語がアップデートされると、そりゃ当然手法も大きく変わるんですが、良くも悪くもC#は安定期に入っていて、ぶっちけそんな変わってないし、次のC#も大して変わらないですしね。
って状況だったんですが、今年はガラッと書き方、考え方が変わりました。もちろん、使い続けている手札もいっぱいありますが、新規に入ってきた要素もとても多くて。そのお陰で、APIの表現力も大幅に上がりました。組み合わせの問題でもあるので、手札が多いと、やれることの幅やAPIの表現力が爆発的に上がっていくので非常に良いことです(逆に手札が少ない人の作るAPIは窮屈だったりするというのはありますね、そういうのみると慢心してる感じだなあ、とか思ったりはします)
変わった要因は2つあって、一つは、今年はパフォーマンスを極限まで追い求めたコードを色々書いたから。ブログを漁るとUnityでのボクシングの殺し方、或いはラムダ式における見えないnewの見極め方、Unityにおけるコルーチンの省メモリと高速化について、或いはUniRx 5.3.0でのその反映、UniRx 5.4.0 - Unity 5.4対応とまだまだ最適化と、UniRxの継続アップデートはいつも新しいことを考えたり、導入したりするきっかけになっています。UniRxも今年はGitHubで1000Star越えを果たしたり、スーパーマリオラン(5000万ダウンロード!)に採用されていたりと、一つの山を超えた感じはあります。
個人的にブレークスルーだったのはLINQ to GameObject 2.1 - 手書き列挙子による性能向上と追加系をより使いやすくで、改めてLINQ、そしてパフォーマンスとは、に関して見直すきっかけになりました。そしてZeroFormatter - C#の最速かつ無限大高速な .NET, .NET Core, Unity用シリアライザーで、集大成として結実しました。いやぁ、大変だった。ほんと大変だった、終わってみればあっさりって気もしなくもないんですが、いやぁ、大変だった……。シリアライザなんて枯れた群雄割拠な代物と思ってましたが、性能面でもまだまだ全然追求できる幅あったんだというのは驚きで。意外と世の中まだやれることは無限にある。C#もまだまだ限界は迎えてない。
性能は最大の機能だ、というのは勿論なのですけれど、究極的にそれを実現するためには新しいアイディアを大量に投下しなきゃいけなかった。今まで自分はいかにヌルいコードを書いてたんだ、と痛感させられました。また、そんな性能追求ギプスのお陰で沢山の手札を手に入れられて、それは視野の広がりをもたらして、ただたんに性能のために、というだけじゃなく書き方の広がりを手に入れられたと思ってます。
突き詰めてやることにはとても意義がある。逆に、そこまでしなければ手に入れられないものもある。手札を増やすのに他の言語に浮気するってのも悪いことではないですが、その前に目の前のことを突き詰めてみるってのもいいんじゃないのってのはとっても思います。nullがどうこうとか言ってる前にC#どんだけ書けるのよ、みたいな。みたいな?
技術的負債との付き合い方
技術的負債って、優秀なエンジニアがしっかり考えれば発生しない。わけではないんですよね。コードなんて誰が書いても、書いた瞬間から腐敗は始まっていて、アプリケーションとしてローンチする前から負債になっている場合すらある。そして、出来ないエンジニアの作る負債よりも、むしろ出来るエンジニアの作る負債のほうが痛かったりする。JavaScript界隈でよく聞くような、新しい技術をいっぱい取り入れました、でももう時代遅れです!みたいなのは典型ですが(これも普通よりちょっと出来るエンジニアぐらいのほうがハマりやすい罠)、そんなんじゃなくても、大なり小なり腐敗を抱えて生きてるわけです。
永遠に輝くコードなんて存在しないからこそ、むしろいかに捨てるかに腐心するほうが良い。もちろん、私の書くものだって例外じゃあなくて、ゴミは作ってしまうのね。別にゴミだと思って作るわけじゃなくても!ダメだと気づいたら、しょうがないので焼却する。これがね、自分の作ったコードなら躊躇なく捨てられる。捨てた際のカバーもなんとかできる、こともある(できないこともある、ひどぅぃ)。けれど他人の作ったものの扱いはとても難しい。そもそも他人の書いたものをジャッジするのが難しい!自分の書いたものを、あぁ、アイディア自体がゴミでダメですね、と切り捨てれても、他人のものを正しく判定するのはむつかしいんだなあ。いや、現在にたいしてダメか否かの判定は簡単ですけれど、未来の判定をするのがむつかしい。
自分の書いたものだと未来も見えるんですよね、このアイディアの延長線上に何があるか想像がつく、未来がないことが見えた時、やめましょう、投げ捨てましょう、になる。けれど、他人の未来はわからなくて、今はまだまだだけど、もう少しやってりゃあなんとかなるかもしれない……。とか思っちゃうわけです。期待して。或いは目をつむって。実際大抵はそんなことはなくて、ダメなもんはダメだったりするわけですが。
損切りするのが難しいのと一緒で、そりゃうまくできりゃあ良いんですが。というかうまくできなきゃあダメなんですが。傷口は 消毒で誤魔化してないで、腐食が進む前に切り落とさなきゃ本当にダメで。腐った土台のうえでいくら技巧を凝らしても、醜い延命策で、なんの解決にもなってないというか、むしろただの時間の浪費なんですよね。いやはや。
何れにせよ、奢った気持ちで書かれたものはダメですねぇ。「よくできているのにどうしょうもなくダメなプログラム」とは何ぞやか、というのを考え直すきっかけになりましたし、そうして考え直すことは自分の書き方の変化にも繋がりました。自分自身ね、そういうの書いちゃってたりやっぱしてしまうわけで。
お仕事
というわけで技術的負債の返却、じゃないですが、今年の後半は、意識的に、問題を技術で解決するというところにフォーカスしていました。結構ね、状況は余裕じゃないんですが、なんとかして解消しなければならない!
ZeroFormatterを起点に、まだ未完成のものでMagicOnion - gRPC based HTTP/2 RPC Streaming FrameworkとMasterMemory - Embedded Readonly In-Memory Document Databaseというのを用意しています。
現状をクソだというのはイージーなんですが、なんとか維持しつつも解決させるってのは結構難しくある。アイデアというのは複数の問題を一気に解決するものであるとはよく言ったものですが、実際、これらの導入によって抱えている問題をそれなりに解決できる。といいなぁ。
技術で技術を返却するってのは、良くも悪くもですね。特に、私自身がCTOという立場でそれやってるのは、結構キワキワだとは思ってます。意識して脳みその9割をコードに割くようにしてるのは、逆に他のことはあまり考えてないってことですからねぇ。正直、あんまいいことじゃあないし、来年も同じようにしたいとは思わないというか、すべきではないと思ってますが、現在の状況からすればこれが最善、かな。と選んでやってます。この辺はしゃーない。もう少しうまくやれりゃあいいのですけれど。
損切りのタイミングを逸したとか、自分で返却しなきゃいけないものを返却できなかったりとか、前期であまり良い決断ができてなかったというのはうーむ、といったところも多々ありつつ。対外的なプレゼンスに関してはよくやれたと思ってますし、その辺の人にはできないことをやってるとは思いますが、それだけでいいと言い切れない程度には歯切れの悪い年でした。
ゲームとか音楽とか
とんかつDJアゲ太郎だけはアニメ全部見ました:) それ以外はアニメもドラマも何もかも完走できてないというかロクに見ちゃいない。本も読んでなければ漫画も見てないんですが、うーん、何が良かったかなあ。本日のバーガーはテーマ的には良かった!色々なハンバーガーがあるし、あっていんだよ、という当たり前のような当たり前を認識できて。
ゲームは、うーん、オーディンスフィア レイヴスラシルは今年でしたか、良かった。あとスーパーマリオランはレート3000、ブラックコインコンプぐらいにはやりました。レートカンストはちょっと不毛感あるので、いったんそろそろいいかな感もありますが。
音楽は、水曜日のカンパネラをよく聴いてましたねー、ジパングと私を鬼ヶ島に連れてってが傑作で。あと、つい先日出た戸川純 with Vampillia / わたしが鳴こうホトトギスが良くてホクホク。
来年
年始暫くはひたすらシステムプログラミングですねー。好きでやってていいってことにも、限度が、頻度というものがあって、大げさ大掛かりなものを連続して作らなきゃいけないってのは正直シンドイ。ゆうて神経めっちゃ使うのよ。やるにしても、もう少し間隔あけながらやりたいよぅ、というのも自業自得なんでしょーがない。
というわけかで、去年の目標であったグラフィックプログラミングはちっとも前進しませんでした。今年はVRにもしっかり手を出したかったんですが、あまりやれてないですね、まぁそうしたグラフィックプログラミングも、VRも、あと最近興味あるのはディープラーニングも、ゲームをリリースするまではお預け。
というわけで、リリースしましょう、ってことですね!
ASP.NET Coreを利用してASP.NET Coreを利用しないMiddlewareの作り方
- 2016-12-25
今回の記事はASP.NET Advent Calendar 2016向けのものとなります。最終日!特に書くつもりもなかったのですが、たまたま表題のような機能を持つMiddlewareを作ったので、せっかくなので書いておくか、みたいなみたいな。
.NET 4.6でASP.NET Core
まぁ普通に.NET 4.6でASP.NET Coreのパッケージ入れるだけなんですが。別にASP.NET Coreは.NET Coreでしか動かせないわけではなくて、ちゃんと(?).NET 4.6でも動きます。如何せん.NET Coreがまだ環境として成熟してはいないので、強くLinuxで動かしたいという欲求がなければ、まだまだWindows/.NET 4.6で動かすほうが無難でしょう。Visual Studioのサポートも2015だとちょっとイマイチだとも思っていて、私的には本格的に作り出していくのはVisual Studio 2017待ちです。脱Windowsとして、Linuxでホスティングするというシナリオ自体にはかなり魅力的に思っていますし、ライブラリを作るのだったら今だと.NET Core対応は必須だと思いますけれど。
Hello Middleware
Middlewareとはなんぞやか、というと、ASP.NET公式のMiddlewareのドキュメントが見れば良いですね。

Httpのリクエストを受けつけて、レスポンスを返す。ASP.NET Core MVCなどのフレームワークも、Middlewareの一種(図で言うところのMiddleware3にあたる、パイプラインの終点に位置する)と見なせます。このパイプラインのチェーンによって、事前に認証を挟んだりロギングを仕込んだりルーティングしたりなど、機能をアプリケーションに足していくことができます。
考え方も、実質的なメソッドシグネチャもASP.NET Coreの前身のOWINと同一です。今ではOWIN自体の機能や周辺フレームワークは完全に整っていて、ASP.NET Coreで全て賄えるようになっているので、新しく作る場合はASP.NET Coreのことだけを考えればいいでしょう。逆に、OWINで構築したものをASP.NET Coreへ移行することはそう難しくないです
ASP.NET Coreのパッケージはいろいろあって、どれを参照すべきか悩ましいのですが、最小のコア部分となるのはMicrosoft.AspNetCore.Http.Abstractionsです。これさえあればMiddlewareが作れます。
では、パイプラインの各部にフックするだけの単純なMiddlewareを作りましょう!
public class HelloMiddleware
{
// RequestDelegate = Func<HttpContext, Task>
readonly RequestDelegate next;
public HelloMiddleware(RequestDelegate next)
{
this.next = next;
}
public async Task Invoke(HttpContext context)
{
try
{
Console.WriteLine("Before Next");
// パイプラインの「次」のミドルウェアを呼ぶ
// 条件を判定して「呼ばない」という選択を取ることもできる
await next.Invoke(context);
Console.WriteLine("After Next");
}
catch (Exception ex)
{
Console.WriteLine("Exception" + ex.ToString());
}
finally
{
Console.WriteLine("Finally");
}
}
}
注意点としては、完全に「規約ベース」です。コンストラクタの第一引数はRequestDelegateを持ち(その他のパラメータが必要な場合は第二引数以降に書く)、public Task Invoke(HttpContext context)メソッドを持つ必要があります。逆に、それを満たしていればどのような形になっていても構いません。
この規約ベースなところは賛否あるかなぁ、というところですが(私はどちらかというと否)、C#の言語機能としてはしょうがない面もあります。(自分でもこの手のフレームワークを何個か作った経験があるところから理解している上で)実装面の話をすると、この規約で最も大事なところは、コンストラクタの第一引数でRequestDelegateを受け入れるところにあります。そして、C#は具象型のコンストラクタの型の制約は入れられないんですよね。なので、MiddlewareBaseとか作ってもあんま意味がなくて、ならもう全部規約ベースで処理しちゃおうって気持ちは分かります。
Invokeのメソッドシグネチャをpublic Task Invoke(HttpContext context, RequestDelegate next)にすることで、そうしたコンストラクタの制約を受ける必要がなくなって、メソッドに対するインターフェイスでC#として綺麗な制約をかけることは可能になるんですが(私も、なので以前はそういうデザインを取っていた)、そうなるとパフォーマンス上の問題を抱えることになります。Invoke(HttpContext context, RequestDelegate next)というメソッドシグネチャだと実行時に"next"を解決していくことになるのですが、これやるとどうしても、nextを解決するための余計なオブジェクト(クロージャを作るかそれ用の管理オブジェクトを新しく作るか)が必要になりますし、呼び出し階層もその中間層を挟むため、どうしても一個深くなってしまいます。
ミドルウェアパイプラインは構築時にnextを解決することができるわけで、そうした実行時のコストを構築時に抑え込むことが原理上可能です。それが、コンストラクタでnextを受け入れることです。C#を活かした設計の美しさ vs パフォーマンス。このMiddlewareチェーンはASP.NET Coreにおける最も最下層のレイヤー。この局面ではパフォーマンスを選ぶべきでしょう。実に良いチョイスだと思います。
最後に、使いやすいように拡張メソッドを用意しましょう。拡張メソッドなのでnamespaceは浅めのところにおいておくと使いやすいので、その辺は適当に気をつけましょう:)
public static class HelloMiddlewareExtensions
{
public static IApplicationBuilder UseHello(this IApplicationBuilder builder)
{
// 規約ベースで実行時にnewされる。パラメータがある場合はparams object[] argsで。
return builder.UseMiddleware<HelloMiddleware>();
}
}
Middlewareを使う
作ったら使わないと動作確認もできません!というわけでホスティングなのですが、これもAspNetCoreのパッケージはいっぱいありすぎてよくわからなかったりしますが、「Microsoft.AspNetCore.Server.*」がサーバーを立てるためのライブラリになってます。IISならIISIntegration、Linuxで動かすならKestrel、コンソールアプリなどでのセルフホストならWebListenerを選べばOK。今回はMicrosoft.AspNetCore.Server.WebListenerで行きましょう。
class Program
{
static void Main(string[] args)
{
var webHost = new WebHostBuilder()
.UseWebListener() // ホスティングサーバーを決める
.UseStartup<Startup>() // サーバー起動時に呼ばれるクラスを指定
.UseUrls("http://localhost:54321") // 立ち上げるアドレスを指定
.Build();
webHost.Run();
}
}
public class Startup
{
// Configure(IApplicationBuilder app)というのも規約ベースで名前固定
public void Configure(IApplicationBuilder app)
{
// さっき作ったMiddlewareを使う
app.UseHello();
// この場で最下層の匿名Middleware(nextがない)を作る
app.Run(async ctx =>
{
var now = DateTime.Now.ToString();
Console.WriteLine("---------" + now + "----------");
await ctx.Response.WriteAsync(DateTime.Now.ToString());
});
}
}
例によって規約ベースなところが多いので、まぁ最初はコピペで行きましょう、しょーがない。これでブラウザでlocalhost:54321を叩いてもらえば、現在時刻が出力されるのと、コンソールにはパイプライン通ってますよーのログが出ます。

基本のHello Worldはこんなところでしょう、後は全部これの応用に過ぎません。
ASP.NET Coreを利用してASP.NET Coreを利用しない
さて、本題(?)。現在、私はMagicOnionというフレームワークを作っていて(まぁまぁ動いてますが、一応alpha段階)、謳い文句は「gRPC based HTTP/2 RPC Streaming Framework for .NET, .NET Core and Unity」。つまり……?gRPCというGoogleの作っている「A high performance, open-source universal RPC framework」を下回りで使います。つまり、ASP.NET Coreは使いません。さよならASP.NET Core……。
gRPCは(.NET以外では)非常に盛り上がりを見せていて、ググればいっぱい日本語でもお話が見つかるので、知らない方は適当に検索を。非常に良いものです。
gRPCはHTTP/2ベースで、しかもデータは基本的にはProtocol Buffersでやり取りされているので、従来のエコシステム(HTTP/1 + JSON)からのアクセスが使えません。そこでgrpc-gatewayというプロキシを間に挟むことで HTTP/1 + JSONで受けてHTTP/2 + Protobuf にルーティングします。それによりSwaggerなどの便利UIも使えて大変捗るという図式です。素晴らしい!
grpc-gatewayは素晴らしいんですが、Pure Windows環境で使うのは恐らく無理があるのと、MagicOnionではデータをZeroFormatterでやり取りするようにしているので、そのまま使えません。残念ながら。しかし、特にSwaggerが使いたいんで絶対にgrpc-gateway的なものは欲しい。と、いうわけで、用意しました。ASP.NET Coreを利用して(HTTP/1 + JSON)、ASP.NET Coreを利用しない(HTTP/2 + gRPC/MagicOnion/ZeroFormatter)。
public class MagicOnionHttpGatewayMiddleware
{
readonly RequestDelegate next;
// MagicOnionのHandler(キニシナイ)
readonly IDictionary<string, MethodHandler> handlers;
// gRPCのコネクション
readonly Channel channel;
public MagicOnionHttpGatewayMiddleware(RequestDelegate next, IReadOnlyList<MethodHandler> handlers, Channel channel)
{
this.next = next;
this.handlers = handlers.ToDictionary(x => "/" + x.ToString());
this.channel = channel;
}
public async Task Invoke(HttpContext httpContext)
{
try
{
var path = httpContext.Request.Path.Value;
// HttpContextのパスをgRPCのパスと適当に照合する
MethodHandler handler;
if (!handlers.TryGetValue(path, out handler))
{
await next(httpContext);
return;
}
// BodyにJSONがやってきてるということにする(実際はFormからの場合など分岐がいっぱいでもっと複雑ですが!)
string body;
using (var sr = new StreamReader(httpContext.Request.Body, Encoding.UTF8))
{
body = sr.ReadToEnd();
}
// JSON -> C# Object
var deserializedObject = Newtonsoft.Json.JsonConvert.DeserializeObject(body, handler.RequestType);
// C# Object -> ZeroFormatter
var requestObject = handler.BoxedSerialize(deserializedObject);
// gRPCのMethodをリクエストを動的に作る
var method = new Method<byte[], byte[]>(MethodType.Unary, handler.ServiceName, handler.MethodInfo.Name, MagicOnionMarshallers.ByteArrayMarshaller, MagicOnionMarshallers.ByteArrayMarshaller);
// gRPCで通信、レスポンスを受け取る(ZeroFormatter)
var rawResponse = await new DefaultCallInvoker(channel)
.AsyncUnaryCall(method, null, default(CallOptions), requestObject);
// ZeroFormatter -> C# Object
var obj = handler.BoxedDeserialize(rawResponse);
// C# Object -> JSON
var v = JsonConvert.SerializeObject(obj, new[] { new Newtonsoft.Json.Converters.StringEnumConverter() });
// で、HttpContext.Responseに書く。
httpContext.Response.ContentType = "application/json";
await httpContext.Response.WriteAsync(v);
}
catch (Exception ex)
{
// とりあえず例外はそのまんまドバーッと出しておいてみる
httpContext.Response.StatusCode = 500;
await httpContext.Response.WriteAsync(ex.ToString());
}
}
}
細かいところはどうでもいいんですが(あと一部端折ってます、実際はもう少し複雑なので)、基本的な流れはJSONをZeroFormatterに変換→内部で動いてるgRPCと通信→ZeroFormatterをJSONに変換。です。見事に左から右にデータを流すだけー、のお仕事、ですね!
MagicOnion本体は限界までボクシングが発生しないように、ラムダのキャプチャなどにも気を使って、ギチギチにパフォーマンスチューニングしてあるんですが、このGatewayはそんなに気を使ってません:) まぁ、もとより複数回の変換が走ってる、パフォーマンス最優先のレイヤーではないから、いっかな、という。どっちかというとデバッグ用途でSwaggerを使いたいがために用意したようなものです。本流の通信はこのレイヤーを通ることはないので。

ちゃんとgRPCでもSwagger使えてめっちゃ捗る。
What is MagicOnion?
gRPCは.protoを記述してサーバーコードの雛形とクライアントコードを生成します。私はこのIDL(Interface Definition Language)の層があまり好きじゃないんですね。そもそも、クライアントもサーバーも、ありとあらゆる層をC#で統一しているので、C#以外を考慮する必要がないというのもあるので。なので、C#自体をIDLとして使えるように調整したり、MVCフレームワークでいうフィルターが標準でないので、それを差し込めるようにしたり、gRPCは(int x, int y, int z)のような引数に並べるような書き方ができない(必ずRequestクラスを要求する!)ので、動的にそれを生成するようにしたりして、より自然にC#で使えるように、かつ、パフォーマンスも一切犠牲にしない(中間層が入ってるからオーバーヘッドと思いきや、むしろプリミティブ型が使えるようになったのでむしろ素のgRPCより速くなる)ようにしています。そもそもそしてUnityでも動作出来るような調整/カスタマイズなどなども込みで、ですね。
それ以外の話はZeroFormatterと謎RPCについて発表してきました。にて少し書いてあります。もう少し詳細な話は、完成した時に……。
まとめ
.NET Coreを本格的に(プロダクション環境で)使うということは、特に開発環境という点でまだ足りないところが多くて(project.json廃止とかゴタついたところもあるし)、VS2017待ちだと判断しています。しかし、ASP.NET Coreのフレームワーク面では十分完成していて、問題ないですね。なので、そちらから随時移行していきたいという気持ちでいます。
まぁ、とはいえ↑で書いたとおり、ほとんどASP.NET Core自体すら使わないんですが。うーん、そうですね、やっぱスタンダードな作り(JSON API)をクロスプラットフォームを紳士に取り組んでます、みたいなことやってる間に、世界は凄いスピードで回ってるんですよね。Microsoftは常に一歩遅いと思っていて、まぁ今回もやっぱそうですよね、という感じで、世間が成熟した頃にやっと乗り出すようなスピード感だと思ってます。ナデラでOSSでスピーディーなのかといったら、別に私はそう思ってないですね、スピードという点では相変わらずだなぁ、と。むしろ「正しくやろうとする」圧力の高さに自分で縛られてしまっている気すらします。スタンダードだからとJSONでコンフィグ頑張ろうとしてやっぱダメでした撤回、みたいな。そういうのあんま良くないし、その辺の束縛から自由になれた時が真のスタートなんじゃないかな。
ともあれ、私はgRPCにベットしてるんで、ASP.NET Core自体は割とどうでも良く思ってます、今のところ。でもそれはそれとして、当然(補助的に)使ってく必要はあるんで、そういう時にちょいちょいと出番はあるでしょう。
C#に置ける日付のシリアライズ、DateTimeとDateTimeOffsetの裏側について
- 2016-12-07
C# Advent Calendar 2016の記事になります。何気に毎年書いてるんですよねー。今年は、つい最近ZeroFormatterというC#で最速の(本当にね!)シリアライザを書いたので、その動的コード生成部分にフォーカスして、ILGenerator入門、にしようかと思ってました。ILGeneratorでIL手書き、というと、黒魔術!難しい!と思ってしまうけなのですが、実のところ別に、分かるとそれほど難しくはなくて(面倒くさい&デバッグしんどいというのはある)、しかし同時にILGeneratorで書いたから速かったり役に立ったり、というのもなかったりします。大事なのは、どういうコードを生成するのかと、全体でどう使わせるようなシステムに組み上げるのか、だったり。とはいえ、その理想的なシステムを組むための道具としてILGeneratorによるIL手書きが手元にあると、表現力の幅は広がるでしょう。
シリアライザ作って思ったのは、Jilは(実装が)大変良くできているし、SigilはIL生成において大いに役立つ素晴らしいライブラリだと思ってます。まぁ、そういうの作る時って依存避けたいので使わなかったけれどね……。
みたいなイイ話をしようと思っていたんですが、ちょっと路線変更でDateTimeについてということにします。えー。まぁいいじゃないですか、DateTimeだって深いですし、IL手書きなんかよりずっと馴染み深いではないですか。役立ち役立ち。
DateTimeとはなんぞやか
シリアライズの観点から言うと、ulongです。DateTimeとはulongのラッパー構造体というのが実体です。ulongとは、Ticksプロパティのことを指していて、なので例えばDayを取ろうとすれば内部的にはTicksから算出、AddHoursとすればhoursをTicksに変換した後に内部的なulongを足して、新しい構造体を返す。といった形に内部的にはなっています。それぞれのオペレーションは除算をちょっとやる程度なので、かなり軽量といってもいいでしょう。
つまり、DateTimeとはなんぞやかというのは、Ticksってなんやねん、という話でもある。
Ticksとは、100ナノセカンド精度での、0が0001/01/01 00:00:00から、最大が9999/12/31 23:59:59.999999までを指す。ほほー。
// 0001-01-01T00:00:00.0000000
new DateTime(ticks: 0).ToString("o");
// 0001-01-01T00:00:00.0000001
new DateTime(ticks: 1).ToString("o");
// 3155378975999999999
DateTime.MaxValue.Ticks
DateTimeにはもう一つ、Kindという情報も保持しています。KindはUtcかLocalか謎か(Unspecified)の三択。
public enum DateTimeKind
{
Unspecified = 0,
Utc = 1,
Local = 2
}
ふつーにDateTime.Nowで取得する値は、Localになっています、ので日本時間である+9:00された値が取れます。さて、このKindは内部的にはどこに保持されているかというと、Ticksと相乗りです!ulong、つまり8バイト、つまり64ビットのうち62ビットをTicksの表現に、残りの2ビットでKindを表現しています。なんでそういう構造になっているかといえば、まぁ節約ですね、メモリの節約。まー、コアライブラリなのでそういう気の使い方します、的な何か。
Ticksプロパティ、Kindプロパティはそれぞれ内部データを脱臭した値が出てくるので、そうしたTicks, Kindが相乗りした内部データを取りたい場合はToBinaryメソッドを使います。復元する場合は、FromBinaryです。
// Ticks + Kind(long, 8byte)
var dateData = DateTime.Now.ToBinary();
var now = DateTime.FromBinary(dateData);
これで8バイトでDateTimeの全てを表現できるので、これが最小かつ最速な手法になります。あまり使うこともないと思いますが。
さて、当然ZeroFormatterはそうしたToBinaryで保持してるんだよね!?というと、違います!seconds:long + nanos:intという12バイト使った表現(秒+ナノ秒)にしています。これはProtocol Buffersの表現を流用していて、うーん、一応クロスプラットフォーム的にはそのほうがいいかな、みたいな(でも今考えると別にTicksで何が悪い、って気はする……失敗した……)。そして、Kindは捨てています。シリアライズ時にToUniversalTimeでUTCに変換し、そのUTCの値のみシリアライズしています。
で、Kindは、私は捨てていいと思ってます。一応MSDNのDateTime、DateTimeOffset、TimeSpan、および TimeZoneInfo の使い分けというドキュメントにもありますが
DateTime データを保存または共有する際、UTC を使用する必要があり、DateTime 値の Kind プロパティを DateTimeKind.Utc に設定する必要があります。
UTCかLocalか、なんていうだけの二値はシリアライズに全く向いてないです。それだったらTimeZoneも保存しないと意味がない。アメリカで復元したらどうなんねん、みたいな。なのでシリアライズという観点で見るとKindはナンセンス極まりないです。これはDateTimeの設計が悪いって話でもあるんですが(後述するDateTimeOffsetがDateTimeのラッパーみたいな感じになってますけれど、本質的にはその逆であるべきだと思う)、その辺(初期の.NETのクラスはどうしても微妙にしょっぱいところがある)はshoganaiんで、受け入れるんだったらKindは無視。これが鉄板。
DateTimeOffset
Kindを無視するのはいいけれど、時差の保存は欲しいよね、という時の出番がDateTimeOffset。これは内部的には ulong(DateTime) + short(オフセット分) の2つの値で保持しています。まんま、DateTimeとOffset。DateTime.NowとDateTimeOffset.Nowって同じような値が帰ってくるし違いはなんなんやねん、というと、DateTimeOffsetはローカル時間といったKindじゃなくて、明確に内部的に+9時間というオフセットを持っているということです。
ZeroFormatterでシリアライズする際は、こちらはオフセットも保存していて、 seconds:long + nanos:int + minutes:short の14バイトの構成です。
ZeroFormatter上では明確にDateTimeとDateTimeOffsetは違うものとして取り扱ってるわけですが、よくあるDateTimeをToString("o")した場合って(んで、JSONなんかに乗せる場合って)
// 2016-12-07T03:19:23.7683110+09:00
DateTime.Now.ToString("o");
// 2016-12-07T03:19:23.7713117+09:00
DateTimeOffset.Now.ToString("o");
と、いうふうに、完全に一緒なわけです。というか、むしろこれはDateTimeの(文字列への)シリアライズをDateTimeOffsetとして表現している、とも言えます。まぁ、そのほうが実用上は親切ではある。が、これはDateTimeもDateTimeOffsetも区別してない(stringで表現)からっていうことであって、決してKindもシリアライズしているということではないということには注意。そして明確にDateTimeとしてDateTimeOffsetを違うものとして扱うなら(ZeroFormatterの場合)、良くも悪くもこういう表現はできないんだなぁ。不便だけどね。
基本的にDateTimeOffset、のほうが使われるべき正しい表現だと思うんですが、.NETのクラス設計上、DateTimeのほうが簡潔(だし内部構造的にもDateTimeOffsetはDateTime+αという形)で短い名前(名前超大事!)である以上、DateTimeの天下は揺るがないでしょう。残念なことにDateTimeOffsetの登場が.NET 2.0 SP1からだということもあるし。DateTimeOffsetがDateTimeで、DateTimeがLocalDateTimeだったら話は変わってくるでしょうけれど(そしてそんな構造だったらきっとLocalDateTimeは使われない)、まぁ変わらないものは変わらないです。まぁ保存用途ならUTCが良いと思うんで、現代的な意味では逆にDateTimeOffsetの出番はより減ってきたとも言える。データがクラウドに保存されて世界各国で共有されるとか当たり前なので、保存はUTC、表示時にToLocalTimeのほうが合理的。Kindって何やねん、と同じぐらいOffsetって何やねん、みたいな。
まぁLocalDateTime, ZonedDateTime, OffsetDateTimeという3種で表現というJava8方式が良いですよねということになる。
NodaTime
日付と時間に関しては、TimeZoneやCalendarなど、真面目に扱うとより泥沼街道を突っ走らなければならないわけですが、いっそ.NET標準のクラスを「使わない」という手もあります。NodaTimeは良い代替で、Javaの実質標準のJodaTime(後にJava8 Date API)の移植ではありますが、製作者がJon Skeet(Stackoverflow回答ランキング世界一位, Microsoft MVP, google, C# in Depth著者)なので、ありがちなJava移植おえー、みたいなのでは決してないのが一安心。
こういった標準クラスを置き換える野良ライブラリはシリアライズ出来ないのが難点で、そうしたシリアライズの表象でだけDateTime/DateTimeOffsetに置き換えるというのはよくあるパターンですが面倒くさくはある。シリアライザの拡張ポイントを利用してネイティブシリアライズ出来るようにするのが良い対応かなー、というのはあります。NodaTimeは標準でJson.NETに対応した拡張ライブラリが用意されているというところも、(当たり前ですが)わかってるなー度が高くていいですね。ZeroFormatterも拡張ポイントを持っているので、必要な分だけ手書きして対応させれば、まぁ、まぁ:)
まとめ
DateTimeOffsetも可愛い子ではある。時に使ってあげてください。というわけで、次のアドベントカレンダーは@Marimoiroさんです!