CIや実機でUnityのユニットテストを実行してSlackに通知するなどする
- 2019-05-06
前回(?)CircleCIでUnityをテスト/ビルドする、或いは.unitypackageを作るまででは、ユニットテストに関する部分がうまく行ってなくて放置でした。放置でいっかな、と思ってたんですが、改めてユニットテストをCIでがっつり実行したい、というかIL2CPPのテストをがっつしやりたい。という切実な要望が私の中で発生したので(N回目)、改めて取り組んでみました。
さて、オフィシャルな(?)ユニットテストのコマンドラインの実行の口は、Writing and executing tests in Unity Test Runnerの最後の方のRunning from the command lineの節に書いてありました(コマンドライン引数のほうのマニュアルにはリンクすら張ってなかったので気づかなかった……!)。つまり、こんなふうにやればいい、と。
Unity.exe -runTests -testResults C:\temp\results.xml -testPlatform StandaloneWindows64
そうすると、テストが失敗しても正常終了して(?) results.xml に結果が入ってるからそっち見ればOK、と。んー、いや、何か違うような。「Run all in player」で出てくるGUI画面も意味不明だし、Editor上のTest Runnerはいい感じなのだけれど、ビルドしてのテストだとイマイチ感がめっちゃ否めない。
と、いうわけで、なんとなく見えてきたのは、テストはUnity Test Runnerでそのまま書きたいしエディタ上でPlay Modeテストもしたい。それをそのままCIや実機でテストできるように、表示やパイプラインだけをいい具合に処理するビルドを作る何かを用意すればいいんじゃないか、と。
RuntimeUnitTestToolkit v2
ちょうどUnity Test Runnerがイマイチだった頃に作った俺々テストフレームワークがありました。ので、それを元にして、Unity Test RunnerのCLI/GUIのフロントエンドとして機能するようにリニューアルしました。コード的には全面書き換えですね……!
Unity Test RunnerのPlayModeで動くテストがあれば、それだけで他に何もする必要はありません。例えばこんなやつがあるとして

メニューのほうで適当にターゲットフレームワークとかIL2CPPがどうのとかを設定してもらって

BuildUnitTestを押すと、こんなような結果が得られます。

比較的ヒューマンリーダブルなログ!WindowsでもIL2CPPビルドができるようになったのがとっても捗るところで、検証用の小さめプロジェクトなら1分あればコード編集からチェックまで行けるので、リフレクションのキワイ部分をごりごり突いてもなんとかなる!昔のiOSでビルドして動かしてをやってたのは本当に死ぬほど辛かった……。
これはHeadless(CUI)でビルドしたものですが、GUIでのビルドも可能です。

イケてる画面かどうかでは微妙ですが、機能的には十二分です。Headlessだと上から下まで全部のテストを実行しちゃいますが、GUIだとピンポイントで実行するテストを選べるので(ただしメソッド単位ではなくクラス単位)、テストプロジェクトが大きくなっている場合はこっちのほうが便利ですね。
さて、Headlessでビルドしたものは、もちろんCIでそのまま実行できます。

これはNGが出ている例ですが、ちゃんと真っ赤にCIのパイプラインが止まるようになってます。止まればもちろんCIの通知設定で、Slackでもなんでもどこにでもサクッと飛ばせます。実に正しい普通で普遍なやり方でいいじゃないですか。はい。というわけでやりたかったことが完璧にできてるのでめでたしめでたし。
Linux ContainerとUnity
相変わらずCircleCIで色々トライしているのですが、Linuxコンテナ + Unityでの限界、というかUnityのLinux対応が後手に回ってる影響をくらってビミョーという現実がやっと見えてきました。まず、そもそもにLinux + IL2CPPはまだサポートされてないので、CI上でIL2CPPビルドしたものを実行してテスト、みたいなのはその時点でできない。残念。しゃーないのでWindows + IL2CPPビルドを作って、実行だけ手元でやるのでもいっか、と思ったらそもそもLinuxでIL2CPPビルドができない。なるほど、そりゃそうか、って気もしますが悲しみはある。
と、いうわけで、コンテナベースでやるとどうしてもLinuxの上でのパターンが中心になってしまうので、Unityだと結構厳しいところはありますよねえ、という。
さて、CircleCIの場合は(有料プランでは)Mac VMも使えるので、多少コンフィグの書き方も変わってきますが(マシンセットアップ部分が面倒くさくなる!)、動かせなくもないんちゃうんちゃうんといったところです。或いはAzure DevOpsなどを使えばWindowsマシンが使えるので、こちらもUnityのインストールなどのセットアップは必要ですが、安心感はありますね。どちらにせよWindowsでしかビルドできないもの(Hololensとか)もあるので、ちょっとちゃんと考えてみるのはいいのかなあ、と思ってます。
何れにせよ、VMでやるんだったらそりゃ普通にできますよね、という当たり前の結論に戻ってくるのが世の中きびすぃ。とりあえず私的にはIL2CPPビルドが実行できればいいので、Linux + IL2CPP対応をどうかどうか……。
RandomFixtureKit
ユニットテスト用にもう一個、RandomFixtureKitというライブラリを作りました。こちらは .NET Core用とUnity用の両対応です。
なにかというと、オブジェクトにランダムで適当な値を自動で詰め込むという代物です。当然リフレクションの塊で、これのIL2CPP対応に、先のRuntimeUnitTestToolkitが役に立ちました。

APIも単純でFixtureFactory.Createで取り出すだけ。
// get single value
var value = FixtureFactory.Create<Foo>();
// get array
var values = FixtureFactory.CreateMany<Bar>();
// get temporal value(you can use this values to use invoke target method)
var (x, y, z) = FixtureFactory.Create<(int, string, short)>();
テスト書いていてダミーのデータを延々と書くの面倒くせー、という局面はめっちゃあって、別に賢い名前なんて必要なくて(例えばAddressにはそれっぽい住所、Nameにはそれっぽい人名を入れてくれるとか)、全然ランダム英数でもいいから詰めてくれればそれでいいの!というところにピッタリはまります。
実用的には、私はシリアライザの入れ替えとか(なぜか)よくやるんですが、旧シリアライザと新シリアライザで互換性なくて壊れたりしないように、相互に値を詰めたりとかして、同一の結果が得られることを確認したりします。そのときに、dllをなめて対象になる数百の型を取って、RandomFixtureKitを使って、適当な値を詰めた上で、一致を比較するユニットテストを用意するとかやったりします。
面白い機能としては、ランダムな値ではなくて、エッジケースになり得る値だけを詰めるモードを用意しています。
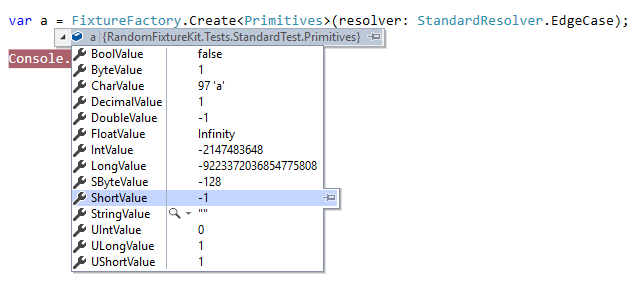
たとえばintだったらint.MinValue, MaxValue, 0, -1, 1を。コレクションだったらnull, 長さ0, 長さ1, 長さ9の中からランダムで詰める、といったものですね。
こういうキワいデータが入ったときにー、みたいなことは想定しなきゃいけないし、テストも書いておかなきゃなのは分かってるけれど、毎回データ変えて流すのクソ面倒くさいんですよね(私はシリアライザを(なぜか)よく書くので、本当にこういうデータをいっぱい用意する必要が実際ある)。ので、CreateManyで1000個ぐらい作って流し込んでチェックすれば、多少はケースが埋まった状態になるでしょうというあれそれです。使ってみると意外と便利ですよ。
ところで
ゴールデンウィークの最終日なのですが、ほとんど何もやってない!始まる前は、MessagePack-CSharpやMagicOnionのタスクを潰しつつ、Pure C#のHTTP/2 Clientを作ってMagicOnionを強化するぜ、とか息巻いていたのですが全然できてない。副産物というか横道にそれたユニットテスト関連を仕上げて終わりとか、なんと虚しい……。
できなかった理由の半分はSwitchでCelesteを遊び始めたらめちゃくちゃハマって延々とやり続けちゃったせいなのですが、まぁそれはそれで面白いゲームをたっぷり楽しめたということで有意義なのでよしということにしておきます。
MagicOnionは6月4日に勉強会をやります。というわけで、やる気もかなりあるし、アップデートネタも溜まっているんですが、実際にアップデートはできてないので(Issueのヘンジはちゃんとやってます!)、GWでガッと手を入れておきたかったんですが、うーん、まぁ明けてからやりまうす。色々良い感じになっていると思います。いやほんと。
True Cloud Native Batch Workflow for .NET with MicroBatchFramework
- 2019-04-24
AWS .NET Developer User Group 勉強会 #1にて、先日リリースしたMicroBatchFrameworkについて、話してきました。
タイトルが英語的に怪しいですが、まぁいいでしょう(よくない)
MicroBatchFrameworkの概要については、リリース時にCygames Engineers' BlogにてMicroBatchFramework – クラウドネイティブ時代のC#バッチフレームワークとして書かせていただきました。そう、最近はそっち(どっち)に書いてしまうのでこっち(あっち)に書かれなくなる傾向が!リポジトリの置き場としても、Cysharpオーガナイゼーション中心になってきています。これは会社としてメンテナンス体制とかもしっかり整えていくぞ、の現れなので基本的にはいいことです。
ちなみにCysharp、ページ下段にお問い合わせフォームが(ついに)付きました。興味ある方は応募していただいてもよろしくてよ?ビジネスのお問い合わせも歓迎です。別にゲームに限らずで.NET Coreの支援とかでもいいですよ。ただしオールドレガシーWindows案件はやりません。
クラウドネイティブ
これはセッションで口頭で言いましたが、バズワードだから付けてます。という側面は大いにあります。世の中マーケティングなのでしょーがないね。そもそも私はそういうのに乗っかるの、好きです。
そんな中身のないクラウドネイティブですが(真面目な定義はCNCFのDefinitionにちゃんとあります)、まぁコンテナ化です。ベンダー中立な。というのをコンテナ化ビリティの高さという表現に落としました。.NET Coreは結構いい線言ってると思いますよ。実際。
さて、そんなクラウドネイティブなふいんきのところでの、理想のバッチ処理ってなんやねん。というのを考えて、逆算でアプリケーション側で埋めるべきものを埋めるために作ったのがMicroBatchFrameworkです。インフラ側の欠けてるところはそのうちクラウド事業者が埋めてくれるか、現状でも全然実用レベルで回避はどうとでもなるでしょう。
私としてはC#が快適にかければなんだっていいんですが、なんだっていいというだけではなくC#としての自由の追求に関しては相当ラディカルなのですが、でも、それって割とクラウドネイティブの定義(ちゃんとしたほうの)通りなんですよね。別にコンテナに夢見てるわけじゃなくて、意外と堅実に正しく定義どおりのことやってるわけです。まー、FaaSのオーケストレーターは私の理想からベクトル真逆だし、FaaSのランタイムの重さ(実行が遅いという意味ではなくてシステムとしてのヘヴィさ)も受け入れ難いんで、世の中の正しい進化について正面から向かい合うのが結局一番ということで。
ところでMicroBatchFrameworkのウェブホスティング機能(MicroBatchFramework.WebHosting)はSwaggerによる実行可能なドキュメント生成、のほかに、HTTPをトリガーにする待ち受けという側面もあります。GCP Cloud Runの実行のためにはそういうの必要ですからね。毎回コンテナ起動みたいな夢見たモデルだけじゃなくて、割とちゃんと現実に即して機能は用意してます。意外と。割とちゃんと。そもそも、その辺は実用主義なので。
MicroBatchFrameworkはいい具合のバランス感覚で作れていると思うので、実際良いと思います。というわけで、是非試していただければですね。
CircleCIでUnityをテスト/ビルドする、或いは.unitypackageを作るまで
- 2019-04-08
死ぬほどお久しぶりです!別にインターネット的には沈黙してるわけじゃなくTwitterにもいるし、会社(Cysharp)関連で露出あるかもないかもというわけで、決して沈黙していたわけでもないはずですが、しかしブログは完全に放置していました、あらあら。
C#的にも色々やっていて、CloudStructuresのv2を@xin9leさんとともにリリースしたり、多分、今日に詳細を書くつもりですがMicroBatchFrameworkというライブラリをリリースしたり、Ulidというライブラリをリリースしてたり、まぁ色々やってます。ちゃんと。実際。今月はそのMicroBatchFramework関連で、AWS .NET Developer User Group 勉強会 #1に登壇しますし。リブートしたMagicOnionも来月勉強会開催予定だったりで、めっちゃやる気です。
さて、そんなやる気に満ち溢れている私なのですが(実際Cysharpもいい感じに動き出せているので!お問い合わせフォームないけどお問い合わせ絶賛募集中!)、ブログは放置。よくないね。というわけで表題の件について。
目的と目標
CIの有効性について未だに言う必要なんてなにもないわけですが、しかし、.unitypackageを手作業で作っていたのです。今まで。私は。UniRxとかMessagePack-CSharpの。そして死ぬほど面倒くさいがゆえに更新もリリースも億劫になるという泥沼にハマったのです。やる気が満ち溢れている時は手作業でもやれるけれど、やる気が低下している時でも継続してリリースできなければならないし、そのためにCIはきっちりセットアップしておかなければならないのです。という真理にようやく至りました。なんで今さらなのかというと、私がアプリケーション書くマンであることと、CIとかそういうのは全部、部下に丸投げして自分は一切手を付けてこなかったマンだからです。しかし会社のこともあるので、いい加減にそれで済まなくなってきたので(今更やっとようやく)真面目に勉強しだしたのですね……!
で、CIにはCircleCIを使います。なんでCircleCIなのかというと、一つはUnity Cloud Buildだとunitypackageを作れない(多分)というのが一つ。もう一つは、私が.NET CoreのCIもCircleCIに寄せているので、統一して扱えるといいよねというところです。また、Linuxの他にMacでのビルドもできるので(有料プラン)、iOSに、とかも可能になってくるかもしれませんしね。あと、単純にCircleCIが昨今のCIサービスで王者なので、長いものに巻かれろ理論でもある。でも私自身も最近使っていてかなり気に入ってるので、実際良いかと良いかと。コンテナベースで記述するのがとても小気味よいわけです、モダンっぽいし。
ゴールは
- リポジトリの一部ソース郡から.unitypackageを作る
- EditorでUnitTestを行う
- IL2CPP/Windowsでビルドする(↑のUnitTestのIL2CPP版を吐く)
となります。普通はAndroidやiOSビルドがしたいって話だと思うのですが、私はライブラリAuthorなので、まずそっちの要求のほうが先ということで(そのうちやりたいですけどね!)。Editorテストだけじゃなくて、IL2CPPで動作するか不安度もあるので、そっちのexeも吐ければ嬉しい。できればIL2CPPビルドのものも、ヘッドレスで起動して結果レポーティングまでやれればいいん&ちょっと作りこめばそこまで行けそうですが、とりあえずのゴールはビルドして生成物を保存するところまでにしておきましょう。そこまで書いてると記事長くなるし。
認証を通してUnityをCircleCI上で動かす
CircleCIということでコンテナで動かすんですが、まぁUnityのイメージを持ってきてbatchmodeで起動して成果を取り出すという、それだけの話です。適当にUnityのコマンドライン引数とにらめっこすれば良い、と。
コンテナイメージに関しては、幸い誰か(gablerouxさん)がgableroux/unity3d/tagsに公開してくれていて、綺麗にタグを振ってくれています。コンテナの良いところっていっぱいあると思いますが、コンテナレジストリが良い具合に抽象化されたファイル置き場として機能するのも素敵なとこですねえ。また、こうして公開してくれていれば、社内CIのUnityインストール管理とかしないで済むのも良いところです。大変よろしい。
で、Unityの実態は /opt/Unity/Editor/Unity にあるので、それを適当に -batchmode で叩けばいいんでしょって話ですが、しかし最大の関門はライセンス認証。それに関してはイメージを公開してくれているgablerouxさんのGabLeRoux/unity3d-ci-exampleや、そして日本語ではCircleCIでUnityのTest&Buildを雰囲気理解で走らせたに、手取り足取り乗っているので、基本的にはその通りに動かせば大丈夫です。
ただ、ちょっと情報が古いっぽくて、今のUnityだともう少し手順を簡単にできるので(というのを試行錯誤してたら苦戦してしまった!)、少しシンプルになったものを以下に載せます。
まず、ローカル上でライセンスファイルを作る必要があります。これはdockerイメージ上で行います。また、ここで使うイメージはCIで実際に使うイメージと同じバージョンでなければなりません。バージョン変わったらライセンス作り直しってことですね、しょーがない。そのうちここも自動化したくなるかもですが、今は手動でやりましょう。
docker run -it gableroux/unity3d:2018.3.11f1 bash
cd /opt/Unity/Editor
./Unity -quit -batchmode -nographics -logFile -createManualActivationFile
cat Unity_v2018.3.11f1.alf
イメージを落としてきて、 -quit -batchmode -nographics -logFile -createManualActivationFile でUnityを叩くと Unity_v***.alf という中身はXMLの、ライセンスファイルの元(まだuseridもpasswordも入力してないので、テンプレみたいなものです)が生成されます。こいつを、とりあえず手元(ホスト側)に持ってきます。docker cpでコンテナ->ホストにファイルを移動させてもいいんですが、まぁ1ファイルだけなのでcatしてコピペして適当に保存でもOK。
次にhttps://license.unity3d.com/manualを開いて、上記のalfファイルを上げると Unity_v2018.x.ulf ファイルがもらえます。これが実体です。生成過程でUnityのサイトにログインしているはずで、そのuserid/passwordが元になって、ライセンスファイルの実体が生成されました。中身はXMLです。
で、これは大事な情報なのでCircleCI上のEnvironment Variablesで秘匿しよう、という話になるんですが、改行の入った長いXMLなので、そのまんま中身をコピペるとファイルが、たいていどこか壊れて認証通らなくなります(散々通らないでなんでかなぁ、と悩みました!)。とはいえファイルそのものをリポジトリに上げるのはよろしくないので、CircleCIでUnityのTest&Buildを雰囲気理解で走らせたにあるとおり、暗号化したものをリポジトリに追加して、Environment VariablesにはKeyを追加しましょう。
openssl aes-256-cbc -e -in ./Unity_v2018.x.ulf -out ./Unity_v2018.x.ulf-cipher -k ${CIPHER_KEY}
${CIPHER_KEY}は、適当な文字列に置き換えてもらって、そしてこれをCircleCI上のEnvironment Variablesにも設定します。ファイルの置き場所は、とりあえず私は .circleci/Unity_v2018.x.ulf-cipher に置きました、CIでしか使わないものなので。
またはマルチラインキーの場合は base64を使うことが推奨されているようです => Encoding Multi-Line Environment Variables。こちらのほうが良さそうですね。
あとは .circleci/config.ymlを書くだけ、ということで、最小の構成はこんな感じになります。
version: 2.1
executors:
unity:
docker:
# https://hub.docker.com/r/gableroux/unity3d/tags
- image: gableroux/unity3d:2018.3.11f1
jobs:
build-test:
executor: unity
steps:
- checkout
- run: openssl aes-256-cbc -d -in .circleci/Unity_v2018.x.ulf-cipher -k ${CIPHER_KEY} >> .circleci/Unity_v2018.x.ulf
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -logFile -manualLicenseFile .circleci/Unity_v2018.x.ulf || exit 0
workflows:
version: 2
build:
jobs:
- build-test
-nographicsにすることでそのまま叩けるのと、-manualLicenseFileでライセンスファイルを渡してやるだけです。 認証する際の || exit 0 がお洒落ポイントで、認証が正常に済んでもexit code 1が返ってくるという謎仕様なので、とりあえずこのステップは強制的に正常終了扱いにしてあげることで、なんとかなります。なんか変ですが、まぁそんなものです。世の中。
まぁしかしGabLeRoux/unity3d-ci-exampleの(無駄に)複雑な例に比べれば随分すっきりしたのではないでしょうか。いやまぁ、Unityのイメージ作ってもらってるので感謝ではあるのですけれど、しかしサンプルが複雑なのは頂けないかなあ。私はサンプルは限りなくシンプルにすべき主義者なので。
.unitypackageを作る
バッチモードでは -executeMethod により特定のstatic methodが叩けるので、それでunitypackageを作るコードを用意します。 今回は Editor/PackageExport.cs に以下のようなファイルを。
using System;
using System.IO;
using System.Linq;
using UnityEditor;
using UnityEngine;
// namespaceがあると動かなさそうなので、グローバル名前空間に置く
public static class PackageExport
{
// メソッドはstaticでなければならない
[MenuItem("Tools/Export Unitypackage")]
public static void Export()
{
// configure
var root = "Scripts/CISample";
var exportPath = "./CISample.unitypackage";
var path = Path.Combine(Application.dataPath, root);
var assets = Directory.EnumerateFiles(path, "*", SearchOption.AllDirectories)
.Where(x => Path.GetExtension(x) == ".cs")
.Select(x => "Assets" + x.Replace(Application.dataPath, "").Replace(@"\", "/"))
.ToArray();
UnityEngine.Debug.Log("Export below files" + Environment.NewLine + string.Join(Environment.NewLine, assets));
AssetDatabase.ExportPackage(
assets,
exportPath,
ExportPackageOptions.Default);
UnityEngine.Debug.Log("Export complete: " + Path.GetFullPath(exportPath));
}
}
ちょっとassetsを取るところが長くなってしまっているのですが、.cs以外をフィルタするコードを入れています。たまに割と入れたくないものが混ざっていたりするので。あとは、CIではライセンス認証のあとに、これを叩くコマンドと、artifactに保存するコマンドを載せれば良いでしょう。
version: 2.1
executors:
unity:
docker:
# https://hub.docker.com/r/gableroux/unity3d/tags
- image: gableroux/unity3d:2018.3.11f1
jobs:
build-test:
executor: unity
steps:
- checkout
- run: openssl aes-256-cbc -d -in .circleci/Unity_v2018.x.ulf-cipher -k ${CIPHER_KEY} >> .circleci/Unity_v2018.x.ulf
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -logFile -manualLicenseFile .circleci/Unity_v2018.x.ulf || exit 0
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -executeMethod PackageExport.Export
- store_artifacts:
path: ./CISample.unitypackage
destination: ./CISample.unitypackage
workflows:
version: 2
build:
jobs:
- build-test
完璧です!
コマンドに関しては普通にWindowsのUnity.exeで試してから挑むのがいいわけですが、一つWindowsには難点があって、ログが標準出力ではなく %USERPROFILE%\AppData\Local\Unity\Editor\Editor.log にしか吐かれないということです。というわけで、Editor.logを開いてにらめっこしながらコマンドを作り込みましょう。めんどくせ。
EditorでUnitTestを行う
基本的に -runEditorTests をつけるだけなのですが、注意点としては -quit は外しましょう。ついてると正常に動きません(はまった)。
version: 2.1
executors:
unity:
docker:
# https://hub.docker.com/r/gableroux/unity3d/tags
- image: gableroux/unity3d:2018.3.11f1
jobs:
build-test:
executor: unity
steps:
- checkout
- run: openssl aes-256-cbc -d -in .circleci/Unity_v2018.x.ulf-cipher -k ${CIPHER_KEY} >> .circleci/Unity_v2018.x.ulf
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -logFile -manualLicenseFile .circleci/Unity_v2018.x.ulf || exit 0
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -executeMethod PackageExport.Export
- store_artifacts:
path: ./CISample.unitypackage
destination: ./CISample.unitypackage
- run: /opt/Unity/Editor/Unity -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -runEditorTests -editorTestsResultFile ./test-results/results.xml
- store_test_results:
path: test_results
workflows:
version: 2
build:
jobs:
- build-test
editorTestsResultFile で指定し、store_test_resultsに格納することでCircleCI上でテスト結果を見ることができます。
と、思ったんですが、なんかテスト周りは全体的にうまく動かせてないんで後でまた調べて修正します……。或いは教えてくださいです。
IL2CPP/Windowsでビルドする
なぜWindowsかというと、私がWindowsを使っているからというだけなので、その他のビルドが欲しい場合はそれぞれのビルドをしてあげると良いんじゃないかと思います!
いい加減コンフィグも長くなってきましたが、-buildWindows64Playerでビルドして、zipで固めてぽんということです。
version: 2.1
executors:
unity:
docker:
# https://hub.docker.com/r/gableroux/unity3d/tags
- image: gableroux/unity3d:2018.3.11f1
jobs:
build-test:
executor: unity
steps:
- checkout
- run: openssl aes-256-cbc -d -in .circleci/Unity_v2018.x.ulf-cipher -k ${CIPHER_KEY} >> .circleci/Unity_v2018.x.ulf
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -logFile -manualLicenseFile .circleci/Unity_v2018.x.ulf || exit 0
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -executeMethod PackageExport.Export
- store_artifacts:
path: ./CISample.unitypackage
destination: ./CISample.unitypackage
- run: /opt/Unity/Editor/Unity -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -runEditorTests -editorTestsResultFile ./test-results/results.xml
- store_test_results:
path: test_results
- run: /opt/Unity/Editor/Unity -quit -batchmode -nographics -silent-crashes -noUpm -logFile -projectPath . -buildWindows64Player ./bin-win64/CISample.exe
- run: apt-get update
- run: apt-get install zip -y
- run: zip -r CISampleWin64Binary.zip ./bin-win64
- store_artifacts:
path: ./CISampleWin64Binary.zip
destination: ./CISampleWin64Binary.zip
workflows:
version: 2
build:
jobs:
- build-test
これで一旦は希望のものは全てできました!

以上な感じが最終結果になります。
CircleCIでUnityビルドはプロダクトで使えるか
今回の例のようなライブラリ程度だと、リソースもほとんどないしリポジトリも全然小さいんでいいんですが、実プロダクトで使えるかというと、どうでしょう。まずリポジトリのサイズの問題で、次にビルド時間の問題で。クソデカい&高級マシンでも焼き上がり1時間は普通とか、そういう世界ですものね。常識的に考えてこれをクラウドでやるのは難しそう。オンプレのCircleCI Enterpriseだったら行けそうな気もしますが、どうでしょうねえ。しかしJenkinsマンやるよりは、こちらのほうが夢があるのと、実際うまくクラスタを組めば、ばかばかコンテナ立ち上げて同時並列でー、というビルドキュー長蛇列で待ちぼうけも軽減できたりで、良い未来は感じます。試してみたさはあります、あまりJenkinsに戻りたくもないし。
一回構築してみれば、ymlもそこそこシンプルだし、(ライセンス認証以外は)ymlコピペで済むので、Unity Cloud Build使わなくてもいいかなー、色々自由にできるし。っていうのはあります。というわけで、是非一緒にUnityでCircleCI道を突き進んでみましょう:) 今回はAndroidビルドやiOSビルドという面倒くさいところには一切手を付けてませんが、まぁほとんどビルドできてるわけで、やりゃあできるでしょう。いや、でもiOSとか死ぬほど面倒くさ(そう)なので、そのへんよしなにやってくれつつマシンパワーもそこそこ用意してくれるUnity Cloud Buildは偉い。
ところでこのブログ、ymlのシンタックスハイライトがない模様。やべー。このブログのメンテこそが一番最重要な気がしてきた。
2018年を振り返る
- 2018-12-30
毎年恒例ということで、今年も振り返ります。だいたい30日に書いてるのですが、理由は12月30日は私の誕生日なので色々ちょうどよいかな、と。いよいよ35歳なので、例のあれ、35年定年説になりました。そのへんどうでもいい外れ値をひた走ってるので一般論はあんま関係ないんですが、体力は落ちてる実感ありますね!肥ったし。文章はどんどんてきとーになってくし。
と、いうわけで、今年は客観的には激動の年です。会社辞めて会社作って会社作って。私生活でも色々あり、イベントが多くて中々どうして落ち着かなかった年です。そのため成果という点では不完全燃焼が否めないですね、どうしても集中しきれないし時間も上手く捻出できないし。GitHubの草生やしで考えれば、もう全然すっかすっか。その中でUniRx.AsyncやMagicOnion2など、今年もちゃんと大きめの成果を出せたのは、意地です。特にUniRx.Asyncの開発はしんどかった……(MagicOnion2のほうはCysharpとしての時間を使えたので良かったんですが、UniRx.Asyncの開発のための時間捻出はめっちゃ厳しかった)。まぁ、ダラダラ草生やすことをKPIにするよりは、一発ホームランをKPIにしたほうがエンジニアの脳トレ的にも随分かいいんじゃないでしょーか?
ここ数年は毎年、C#を書く技量が向上してていいわー、と言い続けてるんですが、今年も随分と向上しました!特に大きかったのはUniRx.Asyncの開発で、これのためにasync/awaitやTask周りの生態系を全部自前実装したので、曖昧な理解だった、ということに気づいてすらいなかったものも、全て完全に理解したので、私自身の能力の向上としてかなり大きいですね。車輪の再発明は良いものです。
きちんと最前線のC#を書けている自信がありますし、対外的な証明もできているので、能力的な意味では老害とはまだ遠そうでいいんじゃないでしょーか。色々な言語に手を出して成長、ってのも悪くはないでしょうが、一つの言語を集中的に深掘りするというのもまた成長の道かと思います。中途半端な深掘りだと言語固有の話になって応用がー、みたいなところがなくもないのですが、徹底的に深掘りすりゃあ、逆に言語固有じゃなくなって、応用が効いてくる領域に入るのです。もしなんとなく成長の限界を感じて他の言語やったほうがいいかな、とか思うのだとしたら、多分、全然深掘りが足りないじゃないかしら?と、思ったりね、します。実に上から目線ですが!
お仕事
先に仕事の話を考えると、株式会社グラニを退任しました。私だけではなく皆バラバラになっているので(もちろんマイネットさんのほうで引き続きタイトル開発にあたっているメンバーもいます)、グラニという会社の始まりから終わりまで、ですね。結末として、悪くはない(退職時の未払いなどももちろんありませんし、エンジニアメンバーは他社に転職した人も、みな良いところに移れているので、グラニという会社が経験としてもキャリアとしても、良いものを提供できたのではないかなー、と思ってます、まぁ役員としてはこれが最後の仕事の成果という形になるのでそう思わせてください……!)ですが、もちろん、最良ではない、です。
CTOとしてどうだったかというと、会社として一点突破な凡百じゃない他にない個性を作れたし、悪くないところまで突き進めた、という点ではよくやれてはいますが(別に「素で」やってるわけじゃなくて割としっかり戦略組んでやっての結果なのでそれなりに大変なんですよ!)、最良のエンディングではないという結果をもって、ベストじゃあないでしょうね。実際反省点はめちゃくちゃ多いです。世の中、結果が全てで、一般論のハンマーを叩き返すには結果を出していかなきゃいけないので、今回の5年間の結果では一般論に反逆はできないんで、次はもっとうまくやる。という決意もあります。
退任後にはNew World, Inc.を設立しました。設立じゃない道も模索していたのですが、うまくまとまらなかったので、とりあえずやったことないしやってみっか、と。なんで株式会社なのかというと、とりあえず作ってみたかったから、以外の理由はない、です。次の会社のスタートまでの間(4ヶ月ぐらい)は、この会社名義、といってもほぼ個人事業主として仕事していました。一応会社としてのビジネスプランも考えてはいたのですが、時間的なものもあって結局ほとんど個人事業主的な働き方に終始しました。
こちらは死ぬほど反省点ありますね……。あまり表明するのもアレですが、多分、まぁ、請負で作業するの自分には向いてないんだとは思います……。それ以外にも単純にスキル不足があって、自分が組んできた環境ではなく自由度もそう高くない中でのパフォーマンスチューニング、みたいなことをするための手札があんまなかったですね。こういうスキルって、多分テクニカルサポート(それも高額なプレミア契約の)の人が持つスキルなんでしょうけれど、明らかに自分の手札にはなかったのを自覚しました。ここはもう能力不足だし、あったほうがいいのは間違いないんで、来年は伸ばしていこうかな、とは思ってます。
グラニでのトラブルシューティングは、徹夜で張り付いて空いてそうな時間にサーバー一時的に止まるの強行でダンプ取ったり、本番環境データベース相当のをコピーして好きに実験したり、既に豊富に用意しているモニタリング系システムにクエリ書いたり追加したり、そもそも根本からライブラリを自作のものを開発して取り替えたりと、権限に甘えきったことやってたんで、まぁ世の中そんなイージーモードなわけないぞ、と。そりゃそうだ。会社としてはイージーモードな世界を作るのが大事で、個人スキルとしてはハードモードな世界でやりきれる能力をつけるのが大事。両面から頑張っていきたい。
そして、株式会社Cysharpを設立しました。設立に関する話は←の記事と、Social Game Infoでのインタビューを読んでいただければなのですが、まず、この座組のインパクトはめっちゃあったかな、と!社名もそうですが!大きなことがやれそうな予感があります。来年はそうした予感を実現していくという、チャレンジの年です。会社としてもそれなりな規模にはしていきたいと思っているので、そのへんもやっていければ。
引き続きゲーム関連で勝負をかけるわけですけれど、ゲーム関連から攻めるのがC#にとって一番、あるいは唯一芽があるから、というのも大きくて。私はインターネットで育ってきたので、ウェブに話題が少ない言語や環境って嫌なんですよね、だからエンタープライズで採用伸びてるとか世界的には数字は良いんだとか、そういうの興味なくて。目の前のインターネットの世界で話題になり誰もが使う言語、であって欲しい。C#が。誰もが使い、話題にし、エコシステムが形成され、若い人がどんどん使う。そこへ向かうには、ゲームやUnityと絡めていくことが唯一の道だと思っています(個人的にはXamarinでは無理でしょう、と思ってるので)。そしてそこに対して貢献したいのです。それはMicrosoftやUnityの「外の人」だからこそできることでもある。
C#
UniTask(UniRx.Async)のリリースによるコンセプト実証と大規模アップデートによる真の実用化。これはNew Worldとして動き出してちょい過ぎぐらいから作成に着手しました。私の中でこれのリリースには大きな意味があって、New World, Incとしての名刺、つまるところ私自身の自信が欲しかったのです。特にUnity関連においてUniRxは前の世代の話なので、今の世代で絶対の自信を持って薦められるものが欲しかった。そういうものがあると自分にも自信ができるんで、交渉も強気に迫れますからね。
UniTaskはUnityに最適化したasync/await生態系の再発明です。これやりきれる人って世の中いないんで、成果として世の中に存在するのはめっちゃレアなんじゃないでしょーか。と思える程度にはいい感じだと思います。しかし例によってまだバグや機能改善がかなり残っているのに、いったん放置が始まっていて、これは本当に私の悪癖ですね……。来年の抱負は放置しない、です。ほんと。ほんと。
もう一個がMagicOnion v2のリリースで、これはグラニでのやり残したことの一つの消化、という意味合いもあります(技術的にはもう一つやり残したことありますけれど、「まともな」UIライブラリの作成とプラクティスの構築とか)。そして、Cysharpで掲げる「C#大統一理論」のキーパーツですね。応用事例をどんどん作っていきたいます。
また、MagicOnionはリポジトリをCysharp/MagicOnionに移しています。これはメンテしっかりやっていくぞ、の現れですね!他にUniRxやMessagePack for C#などもorgnaization(Cysharpじゃなくて中立的組織)に移したいなあ、とは思ってます。そうした継続的メンテナンス体制を作って、永く行き続けていくものになっていければいいなあ、と。まあカウボーイエンジニアから会社経営者になったわけで、そのへんも世の中によりよい形を、ということで。
パフォーマンスの追求は引き続きやっていきたいテーマで、一旦のまとめをCEDEC 2018で最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭すると題して講演しました。こういうのってどのへんまでDeepでDopeに書けばいいのか難しくて、浅瀬ちゃぷちゃぷなんちゃうんちゃうんな思いと戦いつつ、実体験ベースってのもあり良いちゃあ良かったんじゃないでしょうか。
Unity ECSはもっと力入れてやりたかったんですが、ほとんど出来なかったですね。LTドリブン開発だー、と思ったけれどロクにできずMemory Management of C# with Unity Native Collectionsでお茶濁しした程度だったので……。物理エンジンと絡めて、やりたいネタが2年ぐらい前からあって、ECSの登場でまさに最適なプラットフォーム!これでちゃりんちゃりんする!と考えてたのに何も実装できず一年が終わるとは……。来年こそリベンジします。
漫画/音楽/ゲーム/その他…
今年感動したゲームはDetroit: Become Human一択ですねえ、もう全く悩まず。映像も音楽もシナリオもシステムも、あらゆる点で監督(デヴィッド・ケイジ)の神経質そうな(ほんと!)目が行き届いていて、完璧。ただの雰囲気ゲーにならずゲームとしてもちゃんと面白く仕上がっているので、非の打ち所がない(リプレイが面倒くさくてエンディングコンプがダルい問題はありますが、一周+αの体験だけで十分価値あるんで良いんじゃないでしょーか)。
漫画はうめざわしゅん - えれほんがとても良くて、三話(+1)入った短編集で二話目は無料で読めます。とにかくまぁ漫画が上手い。まぁあと古いですが今年読んだんで内田 春菊 - 目を閉じて抱いても。全然古くないというかむしろ今の時代のほうが共感できるんちゃうんちゃうん、と(といっても1994-2000だとそこまで古くもないのかー、いや、古いかー)。
音楽は、今年まぁまぁケンドリック・ラマーの記事を目にしたから(来日で一悶着あったからかしらん)、というわけでもないですが最新作のDAMN、ではなくてその前のTo Pimp A butterflyをよく聞いてました。特に一曲目のWesley's Theory。もともとこれ作曲してるFlying Lotusが好きというのもありますが、Flying Lotusの手掛けた中でも傑作と思ふ。アルバム全編を貫くストーリーも重たく、比喩も強烈で、言葉の強さを心底叩き込んでくる。そりゃ心震えますよ!
映画は、これも古いですがNetflixで見たニコラス・ウィンディング・レフン - ドライヴが良かった。映像美とバイオレンス!まぁーもうとにかく最高に格好良い。こりゃすげえ、と思わず監督の大ファンになって初期作のプッシャー三部作、これはまぁまぁだったんですが、最新作のネオン・デーモンが……。設定も良い。映像も良い。プロットも悪くない。映画としてはつまらない。というしょっぱい代物に……。脚本と構成が悪いんかなー、もう少しうまくやりゃあ、めっちゃ良くなったはずなのに感で超もったいない……。設定と映像は本当に好みなだけに、あうあうって感じ。何れにせよ次回作あったら見るよ!と思ったら、来年(2019)にAmazon Prime VideoのシリーズとしてToo Old to Die Youngというドラマを撮ってるそうで。日本に来るのかな、Netflixだったら絶対来るはずだけどAmazon Prime Videoだとどうなんでしょ。
Hajime Kinoko写真集「Perfect Red」は、写真集はもちろん、個展とショーも見に行きましたが、圧倒的な空間で。ショーだと、人間の表現として、静と動の中間のような世界なんですよね。例えば、静が彫刻、動がバレエのようなものだったりだとすると、その間。ほとんど止まっているのだけれど、手の動き、顔の表情、そして縄が皮膚に言葉を与えていて。表現としては未成熟というかアングラ感が拭えないですが(決して悪いことではなくそれはそれでいいんですが)、もっと表に出れば出るほど洗練されていくのでは、というわけで来年も見たいですね。
来年は
とにもかくにもCysharpをしっかり始動させます。会社の理念がC#とOSSを中心に、というのもあるので、技術のコミュニティ貢献も引き続き、ですね。そしてメンテやIssueを放置しないという抱負は、ただの意気込みじゃなくて組織的な解決となるよう、具体的に動いていきます。
技術的には、今年は色々な言い訳がありますが、チャレンジがなかったなー、というのは否めないです。UniRx.AsyncもMagicOnion2も延長線上ですから。時間がない中で一定の成果を出すことが必須という状況下だったのでしゃーなし、という言い訳もありますが、来年こそは今までの延長線上にない別のことも手掛けたい、と毎年言ってますが、今年も思います。とりあえずとにかくUnity ECSは絶対やりますから……!
ともあれ、Cysharpの活動にご期待下さい。人も募集ちゅ(します、そろそろ)。です。そろそろお問い合わせフォームぐらいはつけたい。
MagicOnion v1 -> v2リブート, gRPCによる.NET Core/Unity用ネットワークエンジン
- 2018-12-28
先にCygames Engineers' BlogでMagicOnion – C#による .NET Core/Unity 用のリアルタイム通信フレームワークとしてリリースを出しましたが、改めまして、MagicOnionというフレームワークを正式公開しました。
MagicOnionはAPI通信系とリアルタイム通信系を一つのフレームワークで賄う、というコンセプトを元に、前職のグラニで「黒騎士と白の魔王」の開発において必要に迫られて捻り出されたものでした。
で、今更気づいたのがMagicOnionって正式リリースしてなかったんですよね、このブログでも↑のような形でしか触れていなくて、公式ドキュメントも貧弱な謎フレームワークだったという。今回Ver2って言ってますが、その前はVer0.5でしたし。まぁここでは便宜的にv1と呼びます。
何故に正式リリースまで行かなかったかというと、リアルタイム通信部分が微妙だったから。↑のp.39-40で説明していますが、Unary + ServerStreamingという構成で組んだのが、かなり開発的に辛かったんですね。時間的問題もあり強行するしかなかったんですが、ちゃんと自分が納得いく代案を出せない限りは、大々的には出していけないなあ、と。
その後すったもんだがあったりなかったりで、プレーンなgRPCでリアルタイム通信を組む機会があって、↑の時に考えていたDuplexStreaming一本で、コマンドの違いをProtobufのoneofで吸収する、という案でやってみたのですが、すぐに気づきましたね、これ無理だと。UnaryはRPCなのですが、Duplex一本はRPCじゃないんで、ただたんにoneofをswitchしてメソッド呼び出す、だけじゃ全然機能足りてない、と。
ただまぁコネクション的にはDuplex一本案は間違ってなさそうだったので、その中で手触りの良いRPCを組むにはどうすればいいか……。と、そこでMagicOnionをリブートさせるのが一番手っ取り早いじゃん、というわけで着手したりしなかったりしたりしたのでした。その間にCysharpの設立の話とかもあり、事業の中心に据えるものとしても丁度良かったという思惑もあります。
早速(?)Qiitaでも何件か紹介記事書いてもらいました。
- Unity+MagicOnionで超絶手軽にリアルタイム通信を実装してみた
- MagicOnion v2を使ってUnity IL2CPPでgRPC通信をする
- Docker を利用して MagicOnion & .Net Core の開発環境を整える
v1 -> v2
Unary系(API通信系)はほとんど変わっていません。それは、v1の時点で十分に高い完成度があって、あんま手を加える余地はなかったからですね。ただしフィルターだけ戻り値をTaskからValueTaskに変えています。これはフィルターの実行はメソッド実行前に同期的にフック(ヘッダから値取り出してみるとか)するだけ、みたいなものも多いので、TaskよりValueTaskのほうが効率的に実行できるからですね。
元々フィルターを重ねることによるオーバーヘッドを極小にするため、純粋にメソッド呼び出しが一個増えるだけになるように構成してあったのですが、更により効率的に動作するようになったと思います。
SwaggerのUIを更新するのと、HttpGatewayの処理を効率化するのが課題として残っているので、それは次のアップデートでやっていきます。
また、Unity向けにはコードジェネレート時にインターフェイス定義でTaskをIObservableに変換していたのですが、今のUnityは.NET 4.xも使えるということで、インターフェイスはそのまま使ってもらうようにしています。Taskのままで。
StreamingHub
の、導入に伴って、v1でリアルタイム通信系をやるための補助機構である StreamingContextRepository を廃止しました。StreamingContextRepositoryは、まぁ、正直微妙と思っていたのでなくせて良かったかな。決して機能してないわけではないのですけれど。
代わりのコネクションを束ねる仕組みはGroupという概念を持ってきました。これはASP.NETのWebsocketライブラリであるASP.NET Core SignalRにあるものを、再解釈して実装しています。
MagicOnionのGroupの面白いところは、裏側の実装を変えられることで、デフォルトはImmutableArrayGroupという、MORPGのようなルームに入って少人数で頻繁にやり取りするようなグルーピングに最適化された実装になっています。もう一種類はConcurrentDictionaryGroupという、こちらはMMORPGやグローバルチャットのような、多人数が頻繁に出入りするようなグルーピングのための実装です。更に、RedisGroupというバックエンドにRedisのPubSubを置いて複数サーバー間でグループを共有するシステムも用意しています、これはチャットや、全体通知などに有効でしょう。
また、GroupにはInMemoryStorage[T]というプロパティが用意されていて、グループ内各メンバーに紐付いた値をセットできるようにしています。これは、通信のブロードキャスト用グループの他に、値の管理のためにConcurrentDictionary[ConnectionId, T]のようなものを用意してデータを保持したりが手間で面倒くさいんで、いっそグループ自体にその機能持ってたほうが便利で最高に楽じゃん、という話で、実際多分これめちゃくちゃ便利です。
まとめ
というわけで、リブートしました!最初チョロいと思ってたんですが、割とそんなことはなくて、この形にまとめあげるまではそれなりに大変でした……。の甲斐もあって、今回のMagicOnionはかなり自信を持って推進できます。以前はそもそもgRPC本体をフォークして魔改造したり、というのもあったのですが、今は公式ビルドを使えるようになったのでUnity向けにも良い具合になってきています。
MagicOnion2の内容は、(v1を)実際に使ってリリースした後の反省点が盛り込まれているので、そういう点で二周目の強みがあります。最初からこの形で出すのは絶対にできないであろうものなので、しっかりと経験が活かされています。実プロダクトで使って初めて見えるものっていっぱいありますからねー。とはいえv1はv1で大きな役割を果たしたと思いますし、まぁあと自分で言うのもアレですが「黒騎士と白の魔王」が証明したこと(gRPCがUnityでいけるんだぞ、という)ってメチャクチャ大きかったなあ、と。
CysharpとしてもMagicOnion、使っていきますし、ほんと是非是非使ってみてもらえると嬉しいです。コードジェネレーターもついにWin/Mac/Linux対応しましたので(まだ微妙にバグいのですが年内か、年明け早々にはなんとかします)、ガッツリと使っていけるのではないかとです。
UniTask(UniRx.Async)から見るasync/awaitの未来
- 2018-12-25
C# Advent Calendar 2018大遅刻会です。間に合った。間に合ってない。ごめんなさい……。今回ネタとして、改めてコード生成に関して、去年は「動的」な手法を解説した - Introduction to the pragmatic IL via C#ので、現代的な「静的」な手法について説明してみよう、と考えていたのですが、そういえばもう一つ大遅刻がありました。
7月にUniTask - Unity + async/awaitの完全でハイパフォーマンスな統合という記事を出して、リリースしたUniTaskですが、その後もちょこちょこと更新をしていて、内部実装含め当初よりもかなり機能強化されています。といった諸々を含めて、Unity 非同期完全に理解した勉強会で話してきました。
9月!更新内容の告知もしてなければ、この発表のフォローアップもしてない!最近はこうした文章仕事がめっちゃ遅延するようになってしまいました、めっちゃよくない傾向です。来年はこの辺もなんとかしていきたい。
と、いうわけで、予定を変えてUniRx.Asyncについて、というか、それだとUnity Advent Calendarに書けよって話になるので、UniRx.Asyncは独自のTask生態系を作っている、これは.NET Core 2.1からのValueTaskの拡張であるIValueTaskSourceに繋がる話なので、その辺を絡めながら見ていってもらえると思います。
Incremental Compilerが不要に
告知が遅延しまくっている間にUnity 2018.3が本格リリースされて、標準でC# 7.xに対応したため、最初のリリース時の注釈のような別途Incremental Compiler(preview)を入れる必要がなくなりました。Incremental Compiler、悪くはないのですが、やっぱpreviewで怪しい動きもしていたため、標準まんまで行けるのは相当嬉しいです。というわけで今まで敬遠していた人も早速試しましょう。
new Progress[T] is Evil
これは普通の.NETにも言える話なのですが、C#のasync/awaitの世界観では進捗状況はIProgress[T]で通知していくということになっています(別にAction[T]でよくね?そっちのほうが速いし、説はある)。進捗はReport(T value)メソッドで通知していくことになりますが、こいつは必ずSynchronizationContext.Post経由で値を送ります。これがどういうことかというと、Unityだとfloatを使う、つまりIProgress[float]で表現する場合が多いはずですが、なんと、ボックス化します。(If T is a value type, it will get boxed here.)じゃねーよボケが。アホか。これはオプションで回避不能なので、new Progress[T]は地雷だと思って「絶対に」使わないようにしましょう。
代わりにUniRx.AsyncではProgress.Createを用意しました。これはSynchronizationContextを使いません。もしSyncContext経由で同期したいならマニュアルでやってくれ。Unityの場合、進捗が取れるシチュエーションはメインスレッド上のはずなので、ほとんどのケースでは不要なはずです。
こういった、あらゆる箇所での.NET標準の余計なお世話を観察し、Unityに適した形に置き直していくことをUniRx.Asyncではやってるので、async/await使うならUniRx.Asyncを使ったほうがいいのです。標準のも、今の時代で設計するならこうはなってないと思うんですけどね、まぁ時代が時代なのでshoganai。
コルーチンの置き換えとして
コルーチン、或いはRxでできた処理は、改めて全部精査して、全てasync/awaitで実装できるようにしました。
Add UniTask.WaitUntil
Add UniTask.WaitWhile
Add UniTask.WaitUntilValueChanged
Add UniTask.WaitUntilValueChangedWithIsDestroyed
Add UniTask.SwitchToThreadPool
Add UniTask.SwitchToTaskPool
Add UniTask.SwitchToMainThread
Add UniTask.SwitchToSynchronizationContext
Add UniTask.Yield
Add UniTask.Run
Add UniTask.Lazy
Add UniTask.Void
Add UniTask.ConfigureAwait
Add UniTask.DelayFrame
Add UniTask.Delay(..., bool ignoreTimeScale = false, ...) parameter
概ね名前からイメージ付くでしょう、イメージ通りの挙動をします。こんだけ用意しておきゃほとんど困らないはず(逆に言えば、標準のasync/awaitには何もありません)
ちなみにSwitchTo***は、最初のVisual Studio Async CTP(お試しエディション)に搭載されていたメソッドで、すぐに廃止されました。というのも、async/awaitが自動でスレッド(SynchronizationContext)をコントロールするというデザインになったからですね。あまりにも最初期すぎる話なのでこの辺の話が残っているものも少ないのですが、ちゃんと岩永さんのブログには残っていたので大変素晴らしい。
UniRx.Asyncでは不要なオーバーヘッドを避けるため(そもそも特にUnityだとメインスレッド張り付きの場合のほうが多い)、自動でSynchronizationContextを切り替えることはせず、必要な場合に手動で変更してもらうというデザインを取っています。というか、今からasync/await作り直すなら絶対こうなったと思うんだけどなぁ、どうなんでしょうねぇ。ちょっとSynchronizationContextに夢見すぎだった時代&Windows Phone 7(うわー)とかの要請が強すぎたせいっていう時代背景は感じます。
Everything is awaitable
考えられるありとあらゆるものをawait可能にしました。AsyncOperationだけじゃなくてWWWやJobHandle(そう、C# Job Systemもawaitできます!)、そしてReactivePropertyやReactiveCommand、uGUI Events(button.OnClickAsyncなど)からMonoBehaviour Eventsまで。
さて、AsyncOpeartionなど長さ1の非同期処理がawait可能なら、そらそーだ、って話なのですが、イベントがawait可能ってどういうこっちゃ、というところはあります。
// ようするところこんな風に待てる
async UniTask TripleClick(CancellationToken token)
{
await button.OnClickAsync(token);
await button.OnClickAsync(token);
await button.OnClickAsync(token);
Debug.Log("Three times clicked");
}
コレに関してはスライドに書いておきましたが、「複雑なイベントの合成」をする際に、Rxよりも可読性良く書ける可能性があります。
Rxは「複雑なイベントハンドリング」を簡単にするものじゃなかったの!?という答えは、YesでもありNoでもありで、複雑なものは複雑で、難しいものは難しいままです。イベントハンドリングは手続き的に記述出来ない(イベントコールバックが飛び飛びになる)ため、コールバックを集約させて合成できるRxが、素のままでやるより効果的だったわけですが、async/awaitはイベントコールバックを手続き的に記述できるため、C#のネイティブのコントロールフロー(for, if, whileなど)や自然な変数の保持が可能になります。これは関数合成で無理やり実現するよりも、可読性良く実現できる可能性が高いです。
単純なものをasync/awaitで記述するのは、それはそれで効率やキャンセルに関する対応を考慮しなければならなくて、正しく処理するのは地味に難易度が高かったりするので、基本的にはRxで、困ったときの必殺技として手段を知っている、ぐらいの心持ちが良いでしょう
async UniTask TripleClick(CancellationToken token)
{
// 都度OnClick/token渡しするよりも最初にHandlerを取得するほうが高効率
using (var handler = button.GetAsyncClickEventHandler(token))
{
await handler.OnClickAsync();
await handler.OnClickAsync();
await handler.OnClickAsync();
Debug.Log("Three times clicked");
}
}
↑こういう色々なことを考えるのが面倒くさい。
Exception/Cancellationの扱いをより強固に
UniTaskでは未処理の例外はUniTaskScheduler.UnobservedTaskExceptionによって設定されている未処理例外ハンドラによって処理されます(デフォルトはロギング)。これは、UniTaskVoid、或いはUniTask.Forgetを呼び出している場合は即時に、そうでない場合はUniTaskがGCされた時に未処理例外ハンドラを呼びます。
async/awaitが持つべきステータスは「正常な場合」「エラーの場合」「キャンセルの場合」の3つがあります。しかし、async/awaitならびにC#の伝搬システムは、正常系は戻り値、異常系は例外の二択しかないため、「キャンセルの場合」の表現としてawaitされた元にはOperationCanceledExceptionが投げられます。よって、例外の中で、OperationCanceledExceptionは「特別な例外」です。デフォルトではこの例外が検出されて未処理の場合は、未処理例外ハンドラを無視します。何もしません。キャンセルは定形の処理だと判断して、無視します。
また、例外を使うためパフォーマンス上の懸念もあります。そこで、UniTask.SuppressCancellationThrowを使うことで、対象のUniTaskが例外の発生源であれば(throw済みで上の階層に伝搬されたものではない)、例外の送出ではなく、Tupleでの戻り値としてキャンセルを受け取り、例外発生のコストを抑えることができます。これはイベントハンドリングなどの場合に有用です、が、正しく使うことは内部をかなりのレベルで理解していないといけないため、ぶっちゃけムズい。ただたんにSuppressCancellationThrowを使うだけでパフォーマンスOKというわけにはいかんのだ。というわけで、どうしてもパフォーマンス的に困ったときのための逃げ道、ぐらいに思っておいてください。
UniTaskTracker
とはいえなんのかんのでTaskがリークしてしまったり、想像以上に多く起動してしまっていたりもあるでしょう。UnityのEditor拡張でトラッキングウィンドウを用意したので、すべて追跡できます。
こういうのRxにも欲しいわー。そうですね、なんか実装方法は考えてみようかとは思いますが一ミリも期待しないで待たないでください。
IValueTaskSourceでWhenAllを進化させる
.NET CoreのC#はTaskとValueTaskに分かれているわけですが、面倒くせーから全てValueTaskでいーじゃん、というわけにはいきません(なお、私の意見は全部ValueTaskでいいと思ってます、というのも使い分けなんて実アプリ開発でできるわけないから)。そうはいかない一番大きな理由はWhenAllで、このTaskで最も使われる演算子であろうWhenAllは、Taskしか受け取らないので、Taskへの変換が必要になってきます。せっかくValueTaskなのにモッタイナイ。じゃあValueTask用のWhenAllを作ればいいじゃん、というとそれも無理で、Task.WhenAllはTaskのinternalなメソッドに依存して最適化が施されているので、外部からはどうしても非効率的なWhenAllしか作れない仕様になっています(クソですね!)。
が、しかし、そもそもWhenAllってあんま効率的じゃなくないっすか?というのがある。と、いうのも、配列を受け取るAPIでも、まず保守的にコピーしてるんですよね。可変長引数でWhenAll(new[]{ foo, bar, baz })みたいに渡してもコピーされてるとか馬鹿らしい!あと、WhenAllの利用シーンでもう一つ多いのが WhenAll(source.Select(x => x.FooAsync()))のような、元ソース起点に非同期メソッドを呼んで、それを全部待つ、みたいなシチュエーション。なんかねー、別に配列作んなくてもいいじゃん、みたいな気になるんですよね。
と、そこでIValueTaskSourceの出番で、Task(ValueTaskですが)の中身を完全に自分の実装に置き換えることができるようになった、のがIValueTaskSourceです。よって、真に効率的なValueTaskに最適化されたうえで↑のような事情を鑑みたWhenAll作れるじゃん、って。思ったわけですよ。
そこでMagicOnionでは(UniRx.Asyncじゃないのかよって、IValueTaskSourceはUnityの話じゃないですから!)ReservedWhenAllPromiseというカスタムなWhenAllを用意してみました。
var promise = new WhenAllPromise(source.Length);
foreach (var item in source)
{
promise.Add(item.FooAsync());
}
await promise.AsValueTask();
のように書けます。つまり何かと言うと、WhenAllに必要なのは「個数」で、個数が最初から確定しているなら、それを渡せばいいし、WhenAll自体の駆動に配列は必要ないので、随時Addしてあげてもいいわけです。これで、一切配列を使わない効率的なWhenAllが実装できました。めでたし。
他にも型が異なるTaskをawaitするのにValueTupleで受け取りたい、というのをTask.WhenAllを介さずにその個数に最適化したWhenAllを用意するとか、やりたい放題にめっちゃ最適化できるわけです。
と、いうのも踏まえて、(サーバーサイドC#における)アプリケーションのTaskの定義はValueTaskで統一しちゃっていいと思うし、そのかわりに幾つかの最適化したValueTask用のWhenAllを用意しましょう。というのが良い未来なんじゃないかなー、って思ってます。(このValueTask用のWhenAllのバリエーションはCysharpとして作ったらOSSで公開するので、こちらは期待して待っててください!)
まとめ
UniRx.AsyncナシでUnityにasync/awaitを持ち込んで使いこなすのはかなりの無理ゲーなので、よほどUnity以外で使い込んできた経験がある、とかでなければ、素直に使って頂ければと思います。また、そうでなくてもUnity向けに完全に作り直しているUniTaskの存在価値というのは、スライドのほうで十分理解してもらえてるのではとも思っています。
別にCLRの実装は至高のものだ!ってこたぁ全然なくて、時代とかもあるんで、後の世に作り直されるこたぁ往々にめっちゃある。Microsoftのハイパーエンジニアが練りに練ったものだろうがなんだろうが、永遠に輝き続けるコードなんてあんまなく、時代が経ちゃあどれだけ丁寧に作られたものでも滅びるんです。人間もプログラムも老化には逆らえない(WPFなんて何年前のUIフレームワークなんでしょう!)。というわけで、あんまり脳みそ固くせず、自分の意志で時々に見直して考えてみるといいんじゃないでしょうか。(古の)Microsoftよりも(現代の観点では)私のほうが正しい、とか自信持って言っておきましょう。
さて、UniRx.Asyncは(UniRxも)まだまだ完成しきってるとは言えない、のにドキュメント放置、更新放置で例によって半年ぐらい来てしまったのですが、その間は株式会社Cysharpを設立しましたであったり、MagicOnionのリブートであったり、結構わたわたしてしまったところがありなのですが、ようやく諸々落ち着いてきたので、また腰据えて改善に取り組んでいきたいと思います。まぁドキュメントが全然足りないんですけど(UniRx.Asyncの機能は、かなり膨大なのです……)。
C#的にも、自分でTaskの全域を見つめ直して作り直すという経験を通して得られたものも多かったので、今回の記事もそうですが、Unity関係なくasync/awaitを使っていく上で使える話は色々出せていければというところですね。ではまた次回の更新の時まで!次こそはすぐブログ書きますから!
株式会社Cysharpを設立しました
- 2018-10-31

株式会社Cygames、技術開発子会社を立ち上げ 株式会社Cysharp設立のお知らせ
Cygamesさんと共に、新しくCysharpという会社を立ち上げました。今年の5月に、創業期より参加し6年ほど取締役CTOを務めていた株式会社グラニを退任し、6月からNew Worldという会社を作っていたのですが、今後の活動は基本的にCysharpに集約していきます。
社名の通り、C#を全力でやる会社です。分かりやすい!という出落ちな社名が一周回って気に入ってます。
単一言語にフォーカスするのは勿論リスキーなのですが、自分達の働きがC#をレガシーにしない、むしろ常に最前線に押し上げていく。雇用も需要も作る。世の中のスタンダードをC#にする。という妄想、ではなくて覚悟でやっていくので、つまりは大丈夫にしていくのです。C#自体の発展が滞ってしまえばオシマイなのですが、そこもまた世界が盛り上がっているなら投資は続きます。逆に盛り下がれば、より危なさが増していくので、「業界全体やコミュニティの発展」が大事なわけで、そこを強く意識しながら動いていきたいですね。
もう一つは会社として多様性の確保をどこでやるのか。そもそもグラニの時からC#全振りで多様性のかけらもなかったのですが、無数にあるスタートアップは総体として多様性があればいいと考えてます。テクノロジーを固定して、当たるスタートアップもあれば外れるスタートアップもある。小さな企業がマイクロサービスだの多様性だので採用技術を分散させるのは、中途半端で力を集中させられないだけで、失敗する可能性を上げるだけです。
さて、Cysharpなのですが、親会社であるCygamesさんがかなり大きな企業で、会社を支えるモバイルゲームの部門もあれば、先月発表されたPS4向けのProject AwakeningのようなAAAゲームを内製ゲームエンジンで制作する部門もあれば、Cygames Researchのようなアカデミックに近い研究開発部門もある。大きな企業ならではの自社内での多様性、その中の一つとしてCysharpを考えれば、何も違和感はないでしょう。
私自身としても、個人、あるいは小さいところでやっていくのにはスケールに限界があり、もとより技術にフォーカスした会社を成立させるのはかなり厳しいと考えていたのですが(ミドルウェアで成立させている会社は本当に凄い!)、そしてせめてそれ自体が市場での価値があるものなら、プロダクトベースでやってやれないこともないのですが、「C#」を主軸にしてどうこうっていう、それ自体で大きな価値、大きな影響を作っていくのはかなり難しい。
そういうこともあったりなかったりで(中略)Cygamesさんと共にやっていくことになりました。こうした組み方であれば、言語にフォーカスするというのは、大きなシナジーを産めるはずです!
基本的にゲーム領域での技術開発を中心に行っていきますが、今までどおりに「業界全体の技術やコミュニティの発展に貢献してまいります」、というわけで、ゲームに限らず色々なところで使えるテクノロジーを発信し続けられると考えています。ゲーム業界が魅力的なのは、技術的にハイエンドであり、そこで培われる技術は広い目であらゆるところで役立つからです。実際、グラニでの成果は世界レベルで大きな影響を与えられたと思っていますが、よりスケールアップして、日本はもとより、世界でも大きい存在感を出せるようにしていければと考えています。
なので引き続き、開発した成果はOSSとして出していきますので、その辺はもろもろ安心してください。
会社としての究極的な目標は「C#大統一理論で世界征服」です。クライアントサイドとサーバーサイドに分けて、クライアントサイドでは(Unityの)C#スクリプティングで究極のパフォーマンスを目指す。サーバーサイドではLinux上で動く(さよならWindows Server).NET Coreにフォーカスして、C#でのコンテナベースでの次世代アーキテクチャの確立と実証。でやっていきます。そして両方そなわり最強に見える。
とりあえずまずはMagicOnionをリブートします:)
まだ積極的な採用までは行きませんが、「C#の可能性を切り開いていく」ことに共感し、本気でコミットしていく覚悟があるなら(ちなみにCLR至上主義みたいなのは私は好きではないです、それは可能性を狭めていることなので。UnityもCLRもそれぞれ共に良いと考えて、特性を引き出せる人が望ましいですね)、是非、私の方まで直接言って頂ければというところです。
ちなみにオフィスは渋谷/神泉ですので(Cygamesさんのフロアです)、お近くの方は是非是非。
Memory Management of C# with Unity Native Collections
- 2018-10-23
と、題してECS完全に理解した勉強会で登壇してきました。
ECSは今後力を入れていきたい分野で、LTドリブン開発ということで、登壇するからにはやってこにゃ!という意気込みだったのですが諸々が諸々で色々間に合わずだったので、ややお茶を濁した展開になってしまいました。なむ。それは別として、これ自体は結構いい話なんじゃないかとは思います。
制約には必ず理由があるはずで、UnityやECSが持つ制約(それは時にC#らしくない、という難癖に繋がる)も、その理由をちゃんと紐解けば合理的な判断に見えるはずです。そこを示していきたいな、というのが今回の発表の流れです。時間的都合もあってECS成分が薄くなってしまいましたが、意味や繋がりは分かってもらえたはずです。私はCoreCLRのアプローチもUnityのアプローチも、どっちもいいと思ってるしどっちも面白く感じられているので、両者を見ながらC#の可能性を広げていきたいですね。
まるでC++というか原始時代に回帰してると言えなくもないんですが、表面のレイヤーはmanagedなC#であることに変わりないし、なるべくその表面のレイヤーを増やす努力は続いていると思われます!ただ、一昔前では、そこC++がー、とかそこはランタイムがー、で賄っていた部分がC#で実装するものとして表に出てきたんですね。これ自体はいいことなのですが、故に、使いこなすための知識としては、回帰してます。(Spanはunsafeまみれじゃないぞ、と言いたいかもしれませんが、Unsafe.***はunsafeマークのついてない実質unsafeなので、むしろより悪質です)。
時代は変わっていくし、C#らしさも変わっていくわけなので、そこは「面白く思うこと」が何より大事だし、変わったものには素直に従って深く追求していく姿勢が大事。乗り遅れず、最前線でやっていきましょう!
最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
- 2018-08-25
と、題しまして、CEDEC 2018にて講演してきました。
今回、事前情報で事務局による誤記が漏れたり、当日のスポンサードの表記から分かる通り、縁がありこのセッションは某社にスポンサードいただきました。公募で落ちてしまい話したくても話せないというパターンも少なくない中で、このような形で枠を得られたのは、申し訳なさもありますが、同時に幸運でもありますので、いつになく気合を入れて仕上げてきました!(ほんと)。難易度はそこまで高いわけじゃない(実際、中辛で設定しました)ので、もっとdopeな話を聞きたい人には物足りなさもあるかもですが、C#というテーマだとあまり語られることのない、目新しい領域の話ですので、新鮮に聞いていただけた方も多いのではないかと思います。
会場も満員御礼で立ち見からの入場規制まで行きましたし、反響も資料は多くリツイートされましたし、反応もかなり良いようなので、かなり満足度高いセッションということでいいのではないでしょうか(多分!)。
謎のChapter4, 5, 6は勿論、最初から存在しない……!次回にご期待下さい。また来年。
Chapter 4: async/await Hackに関しては、来月9/15に行われる「Unity 非同期完全に理解した勉強会」にて話させていただく「Deep Dive UniRx.Async(UniTask)」に内容含まれますので、そちらに乞うご期待。ぜひ参加どうぞどうぞ、と言いたいところなのですがめちょくちょ埋まってしまっているので、ぜひ生放送のほうを見てください。
C#元年を始めよう
去年Uniteにて発表したC#大統一理論がかなりインパクトあったというのもあり、また、その波及効果なのかはさておき、最近手応えを感じ始めてきところでもあります。なのでまぁ、諦めたくないんですね、ここで踏み込んでいけばまだまだ行けるはずなんだ、という。
というわけかで、これは自分自身へのスローガンでもあり、あらゆる方向からアプローチしていこう、と。最初の方で冗談めいて言ってるトライアングル論法は、割と真面目な話でもあり、UniRxの強化(async/await, UniTask)は、よりサーバーサイドC#との親和性を高めていくことにも実は繋がっているのです。実は。
全方位で武器を磨き示すことによって、多くの人が合理的な判断としてC#を選択していく。そんな時代が作れるんじゃないか、始まるんじゃないか。そんな期待と、そのために色々やっていくぞ、という宣言なわけです。ほんと。
こういうの昔もなんかあったなー、と思い出すものがありまして、2012年にgloopsを辞めてからグラニが表に出る前の謎の空白期間があったのですが、その頃のような心境です。何か大きなことを仕込んでいて、やってやるぞ!という、あれそれです。
というわけで、外から見て私が何やってるかは完全に謎だとは思いますが、今後の私の活動にも期待しておいてくださいな。
UniTask - Unity + async/awaitの完全でハイパフォーマンスな統合
- 2018-07-12
Unityでasync/await使えてハッピー。が、しかしまだ大々的に使われだしてはいないようです。理由の一つとして、Unityが標準でサポートする気が全くなさそう。少なくとも、Unityがフレームワークとしてasync/awaitには何一つ対応していない。async/awaitという道具立てだけじゃあ何もできないのです、フレームワークとして何らかのサポートがなければ機能しないわけですが、なんと、何もない……。
何もないことの理由はわからないでもないです。パフォーマンス面で不満/不安もありそうですし、マルチスレッドはC# Job System使ってくれというのは理にかなっている(私もそちらが良いと思います、つまりTaskのマルチスレッドな機能は原則使わない)。とはいえ、async/awaitは便利なので、このまま、便利だけど性能は微妙だから控えようみたいな扱い(あ、それ知ってる、LINQだ)になるのは嫌なのよね。まぁLINQは局所的なので使わないのは簡単なのだけど(実際、最近は私もあまりLINQ書いてないぞ!遅いからね!)、async/awaitは割と上位に伝搬していって汚染気味になるので、そもそも一度どこかで使うと使わない、という選択肢が割と取りづらいので、ならいっそむしろ超究極パフォーマンスのasync/awaitを提供すればそれで全部解決なのである。
という長ったらしい前置きにより、つまり超究極パフォーマンスのUnityのasync/await統合を提供するライブラリを作りました。場所は(面倒くさいので)UniRxに同梱です。というわけでなんと久しぶりにUniRxも更新しました……!(主にReactivePropertyが高速になりました、よかったよかった。PRとかIssueのチェックはこれからやります、いや、まず重い腰を上げたというのが何より大事なのですよ!)
GitHub/UniRx と、アセットストアに既に上がっています。
UniTask
何ができるか、について。
// この名前空間はasync有効化と拡張メソッドの有効化に必須です
using UniRx.Async;
// UniTask<T>をasyncの戻り値にできます、これはより軽量なTask<T>の置き換えです
// ゼロ(or 少しの)アロケーションと高速な実行速度を実現する、Unityに最適化された代物です
async UniTask<string> DemoAsync()
{
// Unityの非同期オブジェクトをそのまま待てる
var asset = await Resources.LoadAsync<TextAsset>("foo");
// .ConfigureAwaitでプログレスのコールバックを仕込んだりも可能
await SceneManager.LoadSceneAsync("scene2").ConfigureAwait(new Progress<float>(x => Debug.Log(x)));
// 100フレーム待つなどフレームベースの待機(フレームベースで計算しつつTimeSpanも渡せます)
// (次の更新でフレーム数での待機はDelayFrameに名前変えます)
await UniTask.Delay(100); // be careful, arg is not millisecond, is frame count
// yield return WaitForEndOfFrameのような、あるいはObserveOnみたいな
await UniTask.Yield(PlayerLoopTiming.PostLateUpdate);
// もちろんマルチスレッドで動作する普通のTaskも待てる(ちゃんとメインスレッドに戻ってきます)
await Task.Run(() => 100);
// IEnumeratorなコルーチンも待てる
await ToaruCoroutineEnumerator();
// こんなようなUnityWebRequestの非同期Get
async UniTask<string> GetTextAsync(UnityWebRequest req)
{
var op = await req.SendWebRequest();
return op.downloadHandler.text;
}
var task1 = GetTextAsync(UnityWebRequest.Get("http://google.com"));
var task2 = GetTextAsync(UnityWebRequest.Get("http://bing.com"));
var task3 = GetTextAsync(UnityWebRequest.Get("http://yahoo.com"));
// 並列実行して待機、みたいなのも簡単に書ける。そして戻り値も簡単に受け取れる(これ実際使うと嬉しい)
var (google, bing, yahoo) = await UniTask.WhenAll(task1, task2, task3);
// タイムアウトも簡単にハンドリング
await GetTextAsync(UnityWebRequest.Get("http://unity.com")).Timeout(TimeSpan.FromMilliseconds(300));
// 戻り値はUniTask<string>の場合はstringを、他にUniTask(戻り値なし)、UniTaskVoid(Fire and Forget)もあります
return (asset as TextAsset)?.text ?? throw new InvalidOperationException("Asset not found");
}
提供している機能は多岐にわたるのですが、
- Unityの非同期オブジェクトをawaitできるように拡張(最速で動くように細心の注意を払って対応させています)
- コルーチンやUniRxで出来るフレームベースのawaitサポート(Delay, Yield)
- 戻り値をTupleで受け取れるWhenAll, どれが返ってきたかをindexで受け取れるWhenAny, 便利なTimeout
- 標準のTaskよりも高速でアロケーションの少ないUniTask[T], UniTask, UniTaskVoid
となっています。で、何が出来るのかと言うと、ようはコルーチンの完全な置き換えが可能です。async/awaitがあります、っていう道具立てだけだと、何もかもが足りないんですね。ちゃんと機能するようにフレームワーク側でサポートさせてあげるのは必須なのですが、前述の理由(?)どおり、Unityはサポートする気が1ミリもなさそうなので、代わりに必要だと思える全てを提供しました。
Taskを投げ捨てよ
目の付け所がいかれているので、Taskを投げ捨てることにしました。Taskってなんなの?というと、asyncにする場合戻り値がTaskで強要される、という型。そして究極パフォーマンスの実現として、このTaskがそもそも邪魔。なんでかっていうと、歴史的経緯によりそもそもTaskは図体がデカいのです。異様に高機能なのは(TaskSchedulerがどうだのLongRunningがどうだの)、ただたんなる名残(或いは負の遺産)でしかない。アドホックな対応を繰り返すことにより(言語/.NET Frameworkのバージョンアップの度に)コードパス的に小さくはなっていったのですが(async/awaitするためだけには不要な機能がてんこ盛りなのだ!)、もういっそ全部いらねーよ、という気にはなる。
そこでC# 7.0です。C# 7.0からasyncの戻り値を任意の型に変更することが可能になりました。詳しくは言語仕様のAsync Task Types in C#に書いてありますが、Builderを実装することにより、なんとかなります。
というわけで、UniRx.Asyncでは軽量のTaskであるUniTaskと、そのためのBuilderを完全自前実装して、Unityに最適化されたasync/awaitを実現しました。
代わりにC# 7.0が必須のため、現状ではIncremental Compilerを導入する必要があります(現状のUnity 2017/2018はC# 6.0のため)

Incremental Compilerではなくても、恐らくUnity 2018の近いバージョンではC#のバージョン上がりそうな気配なので、先取りするのは悪くないでしょう。
PlayerLoop
UniRx.AsyncはUniRxに依存していません。そのため、GitHubのreleasesページではUniRxを含まないパッケージも提供しています。併せて使ったほうがお得なのは事実ですが、なしでも十分に機能します。
さて、UniRxではMainThreadDispatcherというシングルトンのMonoBehaviourにMicroCoroutine(というイテレータを中央管理するもの)を駆動してもらっていましたが、今回スタンドアロンで動作させるため、別の手段を取りました。それがPlayerLoopです(詳しくはテラシュールブログの解説が分かりやすい)。
これをベースにUpdateループをフックして、await側に戻す処理を仕掛けています。
Multithreading
掲げたのはNo Task, No SynchronizationContext。何故かというと、そもそもUnityの非同期って、C++のエンジン側で駆動されていて、C#のスクリプティングレイヤーに戻ってくる際には既にメインスレッドで動くんですよね。例えば AsyncOperation.completed += action とか。コルーチンのyield retunもそうですね、PlayerLoop側で処理されている。ようするに、本来SynchronizationContextすら不要なのです、全てメインスレッドで動作するので。
通常のC#はスレッドベースで、Windows FormsやWPF, ASP.NETなど諸々の事情を吸収するために存在していたわけですが、Unityだけで考えるなら完全に不要です。他のものにはないフレーム毎に駆動することと、本体がC#ではなくC++側にあるということが大きな大きな違いです。async/awaitやTask自体は汎用的にする必要があるため、それらの吸収層が必要(SynchronizationContext)なわけですが、当然ながらオーバーヘッドなので、取り除けるなら取り除いたほうが良いでしょう。そのために、UniTaskの独自実装も含めて、全てのコードパスを慎重に検討し、不要なものを消し去りました。
UniTaskはどちらかというとJavaScript的(シングルスレッドのための非同期の入れ物)に近いです。Taskは、そうした非同期の入れ物に加えてマルチスレッドのためなどなど、とにかく色々なものが詰まりすぎていて、あまりよろしくはない。非同期とマルチスレッドは違います。明確に分けたほうが良いでしょうし、UnityではC# JobSystemを使ったほうが良いので、カジュアルな用途以外(まぁラクですからね)ではマルチスレッドとしてのTaskの出番は少なくなるでしょう。
嬉しいこととして、スレッドを使わないのでWebGLでもasync/awaitが完全に動作します。
Rx vs Coroutine vs async/await
もう結論が出ていて、async/await一本でOK、です。まずRxには複数の側面があって、代表的にはイベントと非同期。そのうち非同期はasync/awaitのほうがハンドリングが用意です。そしてコルーチンによるフレームベースの処理に関してはUniTask.DelayやYieldが解決しました。ので、コルーチン→出番減る, async/await → 非同期, Rx → イベント処理 というように分離されていくと思われます。
C# Standard vs Unity
正直なところ私は別にUnityがC#スタンダードに添わなくてもいいと思ってるんですよね。繰り返しましが、Unityの本体はC++の実行エンジンのほうで、C#はスクリプティングレイヤーなので。C#側が主張するよりも、C++に寄り添うことを第一に考えたほうが、よい結果がもたらされると思っています。よりC#に、というならPure C#ゲームエンジンでないとならないですが、商業的にはほぼ全滅であることを考えると、Unityぐらいの按配が実際ちょうどいいのだろうな、と。理想もいいんですが、ビジネスとしての成功がないと全く意味がないので。
と、いうわけで、C# JobSystemは大歓迎だしBurst Compilerは最高 of 最高なわけですが(そしてECSなんてそもそもオブジェクト指向ですらなくなる)、さて、Task。UniTaskの有用性や存在意義については、よくわかってもらえたと思います!そのうえで、それを分かったうえでもノンスタンダードな選択を取るべきなのか論は、それ自体は発生して然りです。
まぁ、まずUnityだとそもそもC# 7.0が来たら片っ端からValueTask(という、TとTaskのユニオンがC# 7.0から追加された)に置き換え祭りは発生するでしょう。実際async祭りで組むと、「同期で動くTask」がどうしても多く発生してしまい、無駄なアロケーション感半端ないので、ValueTask主体のほうがよい。
更にその上で.NET Core 2.1ではValueTaskにIValueTaskSourceという仕掛けが用意されて、これは何かと言うと、やっぱりasync/awaitの駆動においてTaskを無視するための仕組みです(現状はSystem.IO.Pipelinesというこれまたつい先週ぐらいに出た機能のみ対応)。そう、別にUnityだけじゃなくて通常の.NETでもTaskはオーバーヘッドと認識されているのだ……。
つまりなんというか、そう、そもそもC#本流ですら割と迷走しているのだ……。存在すると思っているStandardなんてもはやないのだ……。てわけで、別にUniTask、いいんじゃない?とか思ってしまいますがどうでしょう。どうでしょうね、それはさすがにポジショントークすぎにしても。
ようはポリシーとして、asyncで宣言した際に、TaskにするかValueTaskにするかUniTaskにするかを迫られます。逆に言えばそれだけです。あれ、意外と人畜無害。そう、意外と人畜無害なのです。よし、なら、とりまやってみるか。いいんじゃないかな?別に最悪、一括置換で戻したり進めたり割と容易なので。あと、ちなみに、UniTaskがUnityでデファクトスタンダードになれば、尚更迷う必要性はなくなるので、むしろ是非みんなでデファクトスタンダードまで持っていきましょう:)
まとめ
非同期革命の幕開け!そもそもこれぐらいやらないと世論は動かない、というのもあるので、フルセットでどーんと凄い(っぽい)(実際凄い)のを掲示することにはめちゃくちゃ意味があります。UniTaskが流行っても流行らなくても、この掲示にはめちゃくちゃ意味があるでしょう。UniRx.Asyncが何を実現したかを理解することは非常に重要です、教科書に出ますよ!
それと、UniRx全然更新していなくてごめんなさい、があります。ごめんなさい。今回、ReactivePropertyのパフォーマンス向上を(ようやく)入れたり、今後はちゃんと面倒みていくのでまたよろしくおねがいします。
Open Collective/UniRxというところで寄付/スポンサー募集もはじめたので、よければ個人/企業で入れてくれると嬉しいですね……!今ならUniRxのGitHubページのファーストビューにロゴが出るので、特に企業などはアピールポイントです……!
Microsoft MVP for Visual Studio and Development Technologies(C#)を再々々々々々々受賞しました
- 2018-07-02
新規は毎月で、更新は7月に統一という周期らしく、全然忘れていたのですが、当日はインターネット的にはそわそわした空気を感じたりなかったりはします。変わらず、Visual Studio and Development Technologies、つまりC#を受賞しました。

↑このリングに一個足されます(後日発送)
去年はMessagePack for C#やUtf8Jsonといった、世界的にもヤバいレベルのライブラリの作成(とその実装詳細の紹介)が、最も直接的な成果ですね。私が担っているのはOSSと、実践的で先鋭的なC#、その実証と共有というところであり、世界的に見ても成果を示せているという自信もあり、またMVPはその客観的な証明と考えています。偉そう!まぁ実際成果はえらい。
毎年、今までの延長線じゃない何かをやりたいんだ!と言いつつ、手癖のバリエーション勝負になってる気がしなくもないのがどうなのよ、と思うところもあるのですが、まぁそれはそれでしつこく繰り返すことで、ちゃんと深化しているので、よしとはしておきましょう。近年は C# x 無限大のパフォーマンス、を勝負の軸にしているのですが、結構意義はあると思います。
4月の退職エントリでは、これから何をやっていくのか模索中、という感だったのですが、結果的に今は、割とちゃんと会社を立てて、その名義で仕事を受けています。New World, Inc. ← 未だに何もデザインされていない。UnityやgRPC関連でのアドバイスとかやっていますので、興味あればお問い合わせくだしあ。
去年よりも上を、去年よりも上を、とハードルは無限に高くなっていくので、個人にせよ会社にせよ、世界にインパクトを残していける何かをやっていこう、というのが目標ですね。手元でも一つ二つ、仕込んでいるのがあるのできっと近いうちにお見せ出来ると思います。願わくばそれでチャリンチャリンできるといいんですが(笑)、まぁできなくてもそれはそれですねん。
Rx.NETの近況、或いはUniRxの近況(?)
- 2018-05-07
あまり長々とした記事ばかりではなく、サラッと流したのも書きましょう!というかリハビリです、リハビリ。ハイパー無職タイムが発動しつつあることもあり、ダラけようと思えば無限にダラけてしまえるのです。なんだかやっぱ一瞬、緊張の糸が途切れた感はどうしてもあります、どうしても。GitHubのグラフもかなり白くなってしまっていますからねー、いやはや。その辺はそろそろモードを切り替えないと、というタイミングです。色々と考えてはいるんですけどね。やることが多すぎると逆にフリーズするというあるああるあるです。
dotnet/reactive
GitHubのリポジトリが Reactive-Extensions/Rx.NET から dotnet/reactive に引越ししました(リダイレクトされます)。これ、ただ単に引っ越したというだけではなく、今回からついにRx.NETがコミュニティ主導による開発に引き渡された、という意味合いを持ちます。これ凄く大きなことでめちゃくちゃ大事なのですよ。
何故かというと、経緯は issues/466 Become an official dotnet repo?のディスカッションにありますが、Rx.NET自体が、ずっとRx v2以降長らくRx.NETの開発をほぼ一人でリードしてきた Bart J.F. De Smet氏(MicrosoftのPrincipal Software Development Engineer, 直近ではBingやコルタナの裏側の分散サービス基盤をRxで実装、とか)によって開発の主導権は握られていました。これは別に悪いことではないですよ!(ほぼ)オリジナルのAuthorですし、実装力も高いですし、学生時代(MS MVP時代)のブログなんかはもう10年前とかの記事ばかりですが今でも珠玉のものばかりですし、私のリスペクトするエンジニアの一人です。んで、まぁそれはいいんですが、かなり昔(4年も前)にRx v3の計画を発表していて(Cloud-scale Event Processing using Rx)、その中心が「Reactor」という上記コルタナの裏側で作られたシステムを元にしてRxを見つめ直すという、多分に野心的なシステムで、なんと結局パブリックにするといって未だにパブリックにされていない!
その辺ののらりくらりっぷりは、以前に私の書いた各言語に広まったRx(Reactive Extensions、ReactiveX)の現状・これからという記事で悲観的に説明しましたが、やはり想像通りに、そんな野心的なビジョンがあるせいで、Rx.NETの開発はほとんど止まっちゃいました。その後の進捗としてはRx.NETをGitHub上でコミュニティを加えて開発していく、という話があり、実際にコミュニティの手によりv3もリリースされましたが、UWPや.NET Standardへ対応するといった、リリースマネージャーを引き受けただけであり、Rx.NETを発展させていく、という点では依然としてコミュニティの手には渡っていない状況が続いていました。
とはいえ、RxJavaやRxSwiftは次々と進化を遂げていて、Rx.NETは元祖ではあるが、ただ単に元祖であるというだけで、すっかり先端ではなくなった現状が間違いなくあり、また、もはや決して看過されるべきではない時期が来ている。壮大なビジョンやオリジナル著者へのリスペクトも大事ですが、何よりも重要なのは止まらない成長なのだ。と、突きつけられたのが件のissueで、まぁ概ね開発の主導も移されました。
こういうの、パイオニアってだけじゃ追いつかれ追い抜かれちゃうから、現代では元祖であること、そのこと自体には価値はないのですよね。良くも悪くも目の前にあるモノの出来が全てで。元祖だとか、10年先を行っていただとか、それは立派なことで尊敬されるべきことですが、ようするにただの勲章なのです。勲章を誇りだしたら老害ですから、一番よくない価値観でもある。(C#は昔からー、とかWPF/XAMLはー、とかMVVMはずっと前にー、とかRxはー、とか言うのはダサいところは結構あります、C#が格好良かった(まだ過去形ではない)のは、実践的な形に落とし込んだ先端を走り続けていたことでしょう)。
さて、開発の主導が渡されたからといって、じゃあ誰が開発していけるの?という話ですが、まずはRxJavaに追いつこうぜ、というところで、現在RxJavaのプロジェクトリードであるakarnokd氏が(RxJavaのコミット数2位、2015年以降だと1位)入って、オペレーターの追加やRxJavaによって成熟された最適化が始まっています。外部の風強い……。
議論の場もreactivex/slackのrxnetチャンネルに移り、活発にやり取りされています。そんなわけで、そう遠くなくRx.NETの時は動き出しそうです。めでたしめでたし。
UniRxの近況?
まぁ、ぶっちけるとRx.NETにおける Bart先生と同じような状況ですね!やりたいこともあるし将来のビジョンもあり、やる気もあるはずなのだけど、手が止まっている、みたいな。ダメじゃん!ダメですね……。
ではなくて、ええと、まぁ私もNew World, Inc.という会社をこないだ立ち上げまして、とりあえず何かお金に変えていかなければならないのです!別に有料にしたりはしませんが、寄付ぐらいは入れたいかなー、とか、思っているのですけれど、だったらプロジェクトはアクティブじゃないとダメですよねアタリマエですよね、ということで、いよいよついにちゃんとガチでやってきます。ほんと。これはほんと。人は霞じゃ生きていけないのでチャリンチャリンも大事。私はよくチャリンチャリンビジネスと言ってます。
それとは別にRx.NET本体をUnity(.NET 4.6/IL2CPP)対応させるというのもあります。これは、Rx.NET側からの要請もあって、手伝っていきたいことですね。とはいえ、UniRxはUnityにフィットさせるために手を加えているものも多いので、コンパイル通してランタイムエラー潰しただけだと、ぶっちけイマイチなところがかなり出てくるので、単純移植はそこまで価値あるかというと、そうでもないかな。というわけで、どちらにせよRxJavaに追いつけプロジェクトのほうが優先なわけで、そちらが落ち着いたら、UniRx側で得た知見などを少しずつフィードバックしていこうかなとは思ってますが、だいぶ遠い未来にはなりそうなので、そういう面でもUniRxは安心して使ってほしいですね。更新もします、しますから……!
実際まあ、Unityもasync/await入ってRxとどう使い分けるとかそもそも使い分けないとか、色々あるわけで、で、私はその答えを持っているので(async/await自体もC#7までの機能をフルに使って色々ごにょったりしたことあるので、私、めちゃくちゃ詳しいんです!)、ライブラリ実装という技術面でも、こうした文章での解説でも、出せていけたらなーという感じですねー。
とにかくダラダラ生きないためにも今年は色々やっていきますよです。
株式会社グラニを退任します
- 2018-04-02
創業期より参加し、取締役CTOを務めている株式会社グラニを退任します(今日、ではなく正確にはもう少し残りますが)。
マイネットさんのプレスリリースより、グラニのスマートフォンゲーム事業に関する買収と協業に向けた基本合意のお知らせ、グラニのスマートフォンゲーム「黒騎士と白の魔王」の配信権を買取。4月よりマイネットグループが提供・運営を持ちまして、タイトルならびにグラニのメンバーはマイネットグループへと参画しますが、私は移らず、そのまま退任という形になります。開発チームそのものはマイネットさんへ引き続きジョインしますので、ゲーム自体の運営は問題なく続いていきます。その点はご安心ください。
私の次は決まっていないので、とりあえずGitHubにレジュメを公開しています。
- GitHub - neuecc/Resume
また、個人会社として New World, Inc. を設立しました(正確にはまだ設立しきってなくて準備中なのでfoundedはちょっと嘘です)。
社是は「新世界の創造」です。次のプロダクトにご期待下さい。とはいうものの、まぁ、まだ基本的にはただの個人事業主です。
技術顧問/社外CTO/スポットでの短期の初期技術支援から中期ぐらいまでの恒久的支援、.NET向けのSDK制作などカスタムな一品物の制作(+サポート)、C#全般の教育やパフォーマンスチューニング、ライブラリ導入支援(UniRx、MessagePack for C#, Utf8Json, MagicOnionなど)、サーバーサイドのロギングや解析などモニタリング設計、ネットワーク関連やgRPC、Roslyn(C#コンパイラ)を使ったLintやコードジェネレーターの開発、その他特にメタプログラミングが必要な基盤技術開発など、スタンダードな.NETからUnityのほうまで、私に任せていただくことが最適な領域は数多くあると思いますので、上記レジュメとあわせて、ご興味ある方はお声がけください。
更に言うと、まだ動き出してもいないので、条件によってはフルコミットな参画もなくはないので、まずは気楽にご相談からでどうぞ。
グラニを振り返り
2012年からなので、私のキャリアの中では最も長く働いたところとなります。5年間で技術トレンドも変わり、主に携わったソーシャルゲーム業界も、ウェブからネイティブへとシフトしていったわけですが、トレンドが移ってもなお、最初から最後までグラニは技術的に独特な存在感を放ち続けられた、と思っています。当初より、凡百な会社には絶対にしないという意志で、開発の方向性の意思決定や、露出のコントロールをしてきたのですが、そこはしっかり達成できたでしょう。
CTOの役割って色々あって、マネージャー色の強い形であるとか(いわゆるVPoEがいない場合はそれを兼ねて、どちらかというとそちらが強め)、あるいは技術専任の最高系なのか。私が掲げていたのは、上記の通りグラニを凡百の会社にしないこと、であったので、技術色強めでやる以外の選択はなかったです。もちろん、私より優れた技術的な人間が入ってきてそこに任せるのが適任であるという結論が正しければ譲るべきとは思いますが(ありがちなのは人に任せないことによるCTOが技術の限界値となりボトルネック化する)、結果的に最後まで私より技術+露出という面で優れた人間が入ってこなかったので(別に潰したり引き立てなかったりということはなく、客観的にね)、延々と前線にいたのは正当化されるでしょう、多分きっと。
私の理想の目的は別に前線で強いコードを書き続けること、ではなくて凡百の会社にしないこと、にあるので、必要なら技術開発を主導すべきだし、必要なら引いて広報に回るべきだし(雑誌連載持ってきたりインタビュー持ってきたり、登壇などもそうですが)、という観点で評価すれば、めちゃくちゃよくやったと自画自賛します。はい。
ただし、そこに注力した分だけ、他で劣ったところも少なからずあります(教育とかはてんでダメだし、もう少しチーム全体の成長も望むならマネジメント力を磨くか、それのできる人間を採れるべきだった)。何もかもが優れてる、何もかも良かったと言うことはできないので、トータルバランスとして、アリだったかナシだったかが問われます。これの答えは私が出せる話ではないですが、私は最初から最後までグラニにいてエンジニアの全員を採用してきましたが、皆がグラニでの経験はプラスになったと思ってもらえれば、何よりだと考えています。
神獄のヴァルハラゲート
前半のハイライトは、「神獄のヴァルハラゲート」のリリース、そしてC#への移行です。
最初はPHPで開発されていました。なんでやねん、というところですが、まぁ色々理由はあるのですけれど、PHPで開発したほうが早く確実にリリースできそうだった、というのがあります。グラニは、gloopsのとあるゲームの開発チームが独立した形で設立されたので、技術的なバックボーンはC#(gloopsは当時唯一C#(ASP.NET Web Forms)でソーシャルゲームを開発、かつモバゲープラットフォーム上でトップのデベロッパーという中々凄い会社でした)にあるのですが、C#でソーシャルゲームを開発するのって、ライブラリが足りなすぎて難易度が結構高いのです。そこをgloopsは当時のCTOがフレームワークを作り上げてカバーしていたわけですが、一から、短期勝負でやっていくのなら、そこを再開発するよりかは、ライブラリも知見も豊富にあるPHPを選択するのは、全くおかしくない決定でした。
と、いうと私がそうしたチョイスをしたように見えますが、実際のところはジョインが諸事情で一ヶ月ほど遅れていて、既にPHPである程度作られていた後だったので、そりゃPHPでやるべきでしょう、みたいな。でもやっぱり結果的に正解でした。何より優先すべきはプロダクトの素早い成功でしたし(会社として収入がないので、一軒家にすし詰めになって無給で働いていたのです!)、成功したあとならなんだって出来ると思っていたので、素早く呑んでPHPを書きましたとも。
幸い、リリース初日にして成功を確信できたので、すぐさまC#移行のプロジェクトがスタート。まだ設立したばかりで、一本しかない状況でいきなり移植(しかもPHP側も成功を波に乗せるためどんどん追加開発していかなければならない)というのも、正直狂った判断としか言いようがないのですが、決断は遅れれば遅れるほど致命的になるので、ここはもうやりきれることを信じて即決。社長も信頼してくれて、全面的に任せてくれたというのも大きな支援でしたね。
そして何より、まだC#でやれるかも分かっていない状況なのに誘って入ってくれた人、設立されたばかりの怪しい会社にまともな応募ページもないようなホームページから応募してきてくれて入ってくれた人、強力なメンバーに恵まれました。これが一番の成功の理由で、本当に本当に感謝しています。(WebArchivesに残ってた当時のホームページ、こんな一文とmailtoしか書かれていないようなところから応募してくれたのは実際凄い、勿論私のTwitterとかBlogを見てくれていて情報をある程度は知ってはるとはいえ)
gloops時代での経験、そしてPHPでのヴァルハラゲートを経て組んだ設計は、ウェブソーシャルゲーム時代における一つの総決算でした。技術的にも成果としても他社の先を行き、C#の強さを証明する大きな事例の一つにもなれたでしょう(実際、今もC#を軸に組んでる他社さんにある程度は影響を与えられているようです)。
また、技術的にオープンに発信をし続けることで、「業界をリードする企業となること」「C#を強くアピールすること」「C#でトップの企業であると認知されること」を推進できたと考えています。それによる会社の技術的ブランドの向上は、内向けにも(所属することへの誇り・明確な方向性・技術的挑戦) 外向けにも(知名度・採用力)大きくプラスになりましたし、CTOとして何をすべきか、の答え、一例でもあると思います。
黒騎士と白の魔王
後半のハイライトは「黒騎士と白の魔王」のリリース、の間に幾つかのタイトルのリリースはありますが、大きく動いたのはここです。
の前に、その間で一番大きなものがUniRxの公開です。業界全体がネイティブシフト(今となっては懐かしい言葉の気もしますが、ウェブソーシャルゲームからiOS/Androidアプリへの移行のこと)する中で、グラニも当然ネイティブゲーム開発に乗り出すのは当然で、かつUnityを選ぶのも必然(C#だから!)。かといって既に名だたるメーカーも参入し、市場が形成されている中で、ただたんにゲーム作りました、だけじゃあ技術的に一ミリも目立てない。私自身も(Microsoft .NETの)C#業界ではそれなりの知名度があっても、Unityでの実績はゼロで、知名度は全くない。当然ヒットするゲームは作っていくつもりでしたが、それだけじゃあ、ヴァルハラゲートで達成したことは達成できないことは明白でした。何か、グラニならではの強み、まさにC#力を活かして、他社にはできない唯一のことをやらなければならない。その中で産まれたのが「C#大統一理論(サーバーとクライアントをC#で統一して活かす)」と「UniRx」でした。
UniRxは、結果的にかなりメジャー級のヒットになり、グラニが「黒騎士と白の魔王」のリリースまで沈黙していた間の技術的アピールも埋めることができたし、黒騎士の技術基盤という意味でも大きな柱になりました(良くも悪くも!)。
技術的な広報は、アピールしなくなると、どれだけ今まで目立っていてもすぐに存在感が消えることは前職の頃から分かっていたことなので、とはいえ開発に期間が空くと出すものがないから消えてしまうわけで、どうやって開発と開発の間を埋めていくかは大きな課題で、変化球的な対応ですが、(狙っていたこととはいえ)上手くいって助かりました。なんというか、メジャー級の商品(例えばコカコーラとか)が巨額の資金を投じてでも延々とCMなどプロモーションをやり続ける理由がよくわかります。多分、何もしなければコカコーラレベルのものですら埋没していってしまうのでしょう。それを考えれば「〇〇の技術で凄い会社」みたいなブランドなんて、続けなければ秒速で吹き飛びます。
「黒騎士と白の魔王」の開発は結構時間がかかりましたが、終わってみれば、最近の他社比較でそこまで大きく開発期間がズレたわけでもなく、また、よりゲームの造りが重厚になっていく時代をきちんとキャッチアップできていました(例えば、黒騎士はキャラがかなりヌルヌル動くのですが、開発当時の時期の感覚では、ほとんど一枚絵でエフェクトだけ飾っておけば良い、的なところもなきにしもあらずで、ちゃんと二年先のトレンドを抑えてあった)。その甲斐もあり、チャートアクションも悪くなく、自社オリジナルIPとしては十分なヒットにできました。
しかし技術的に大成功かというと、何とも言い難いところはいっぱいあります。特にUnity側での、初期の技術決定のほとんどは失敗で、これはもう単純に開発経験のなさが大きく響いていて、終盤までダメージを与え続けることにりました。UIに関しても当時はNGUI vs uGUI(まだベータだった)で、これからの開発期間を考えると先行してuGUIを採用して進めるべき、という決断は正しかったと思うのですが、当時はまだベータ故にuGUI自体の未完成さと合わせた手間取るところの多さ+それ故に、uGUIを更に抽象化した巨大なUIフレームワークの開発を推進し、その独自UIフレームワークが目も当てられない大失敗で、開発効率でも性能面でも、そして技術蓄積という面でも大きなマイナスという、最初から特大の技術的負債を抱えるという有様は決して肯定はできません。
なのでCTOとしての技術的采配という面では、良い選択を取れてきていません。これはかなり悔いが残るところで、ちゃんと埋めたいと思っています。
代わりの挽回として、土壇場になってのシリアライザの置換(MessagPack for C#の開発)とネットワークフレームワークのgRPCへの全移行(MagicOnionの開発)を主導しました。これをリリース半年前に決定してやっているので、ヴァルハラゲートのC#移行と並ぶ、クレイジーな決断でした。いやほんと。全く検証とかしてないしね。
結果的にやりきって成功だったので良かったねという話ですが、失敗したらもうなんというかかんというか。そこを強権的に自己責任(とはいえダメージは会社全体に及ぶ)で選択できるのがCTOだし、自分でやりきるのもまたCTOなんじゃないでしょうか、という例です。万人にお薦めはしませんが、自分/自分のチームに自信を持てるなら、冒険的なこと、やるのはいいことです。多分。別に博打を打ったわけじゃあなく、私は自分自身の能力と、グラニのメンバーの能力を鑑みて、全然やれると踏んでいたので。結果成功しましたが、振り返ると成功理由の一つは人に任せっぱにするんじゃなくて自分も大事なところを噛むこと、ですかねえ。UIフレームワーク開発は投げっぱに近かったので、結果振り返ると博打で、博打はどっちに転ぶか分からないので良い判断ではなかった。
gRPCの事例が(非ゲームで)最近は増えてきましたが、ストリーミングも含めて黒騎士ほど使い倒しているところは少ないようです。その点でも技術的な優位性を世に示すことが出来ました。また、MessagPack for C#はC#最速のシリアライザとしてUniRxに継ぐヒットを飛ばし、世界的にも大きな貢献を果たしました。
グラニを技術的に特異な(しかし優れた)立ち位置として認知させるだけの技術開発は出来たと思っていますし、とはいえ、ただたんに技術で遊ぶわけではなく、ちゃんとゲームの成功に結びつくよう導入できました。この辺のバランスを上手く取って開発を推進出来たという点では、大きな成果を残せたのでないかな。
これから
口幅ったいことを言えばグラニは「C#の大本山」みたいになれましたし、実際、この先にC#大統一理論的に、めちゃくちゃやれる企業がどれだけ出てくるだろうか。ということを考えると、幸い技術的な情報は積極的に公開していったので、芽吹いていってくれたら嬉しいなあ、って。めっちゃ思います。まだまだやり残したこともやれることもあるので!
私自身は幸い、現在も色々とお声掛け頂いています。ちょっとばかし煮え切らない姿勢でいて申し訳なさもあるのですが、皆さんからお話を伺いながら、何をしていこうか固めている最中です。
グラニでの5年間で、大きな成長を果たせました。良い経営陣、良い同僚に恵まれて、私が好き放題やるのを支えてもらっちゃいました。本当に、良い経験ができ、良い実績が残せ、楽しかったです。願わくば次のキャリアでも同じような、より大きな挑戦をしていきたいところです。
ReactivePropertySlim詳解
- 2018-01-18
ReactiveProperty v4.1.0 をリリースしましたということで、Pull Requestしたコードをリリースして頂きました。ReactivePropertyはオリジナルは私が作ったのですが、数年前からokazukiさんがメインに開発/リリースしてもらっています。
今回はReactivePropertySlimという新クラスが追加されました!名前の通り、軽量なReactivePropertyで、これはもともと社内で(Unityの)ReactivePropertyを大量に使っていて、改善のやり玉に上がっていて、その中で施された/施した施策を移植してきたという代物になります。当初そんな乗り気じゃなかったんですが、同僚に書き換えてもらったのを見て、ようやくやる気が上がったという、最低ですね、はい。
無印との違いは
- フィールド数を最小限にしてアロケーションを抑えた(無印はバリデーション系などのためにSubjectやLazyの保持がかなりある)
- 内部で使ってるSubjectをやめて完全自前管理&Subscription(IDisposable)自体を連結リストのノード自身にすることで、複数Subscribeでのアロケーションをなくした
- 変更通知の実行をスケジューラー経由で行わず直接する(無印はデフォルトでDispatcher経由になるけれど、パフォーマンス上の問題と、厄介な挙動を時折示していた)
- バリデーション系のメソッドを除去
- ReactivePropertySlimからObservable Sourceを受けとる機能/コンストラクタを削除(ReadOnlyReactivePropertySlimのみがその機能を持つ)
もともとReactivePropertyはViewModelでのViewへのバインディング用を主に考えて機能を足していったため、Modelで使う分には不適切な重さがあるな、と考えていました。なので今回、一掃して、2018年エディションとして再デザインしました。基本的な箇所の設計は2011年と6年前のものなので、今視点で見ると考慮が甘い部分も割とあったのですよね。
パフォーマンスを見てみましょう。


上がコンストラクタ+3つSubscribeした場合。下がValueへの代入を3回した場合。Subscribeの高速化と生成時も含めた省メモリは意図通りなのですが、Valueの代入のほうがインパクト大きいですね。こっちは想定外。これはScheduler経由をなくした効果だと思われるけれど、かなりの差がでてて、あらあら、という感じ……(ちなみにSchedulerはImmediate指定してるのでSchedulerの中では最速ではあるはず)。
生成/Subscribeの高速化は起動時間(Unityだとシーン初期化だとか、WPFでもWindow作ったりとか)に影響あるので、短いにこしたこたぁないですねん。いいことです。
ReactiveProperty/Subject分解
Slim、について考える前に、改めてReactivePropertyについて見てみましょう。
// 最小のReactivePropertyはSubjectのラッパーというイメージ
public class MinimumReactiveProperty<T> : IObservable<T>
{
readonly Subject<T> subject = new Subject<T>();
T latestValue;
public T Value
{
get
{
return latestValue;
}
set
{
// 値の設定で通知
latestValue = value;
subject.OnNext(value);
}
}
public IDisposable Subscribe(IObserver<T> observer)
{
return subject.Subscribe(observer);
}
}
これ以上ないってぐらいシンプルで、まぁいいじゃんって話で、2011年は不満はなかったんですが、今視点で見るとちょっと引っかかるところがあったりします。
というわけで、Subjectを展開してみます。
public class MinimumReactiveProperty<T> : IObservable<T>
{
// Subjectの内部のobserverのリスト
IObserver<T>[] data;
public T Value
{
set
{
// subject.OnNext(value);
for (var i = 0; i < data.Length; i++)
{
data[i].OnNext(value);
}
}
}
public IDisposable Subscribe(IObserver<T> observer)
{
// observerの追加のたびに新しい配列に詰め直し(ImmutableArray)
var newData = new IObserver<T>[data.Length + 1];
Array.Copy(data, newData, data.Length);
newData[data.Length] = value;
data = newData; // (代入時、実際にはThreadsafeのための挙動も入ります)
// 購読解除のためのIDisposableの生成
return new Subscription(this, observer);
}
}
Subjectは内部でIObserverをImmutableArrayとして保持しています。なのでSubscribeがある度に、新規配列を生成してコピーしてます。古いやつはゴミ行き!これは一見無駄に見えますが、別に悪い話ではなくて、一点目はスレッドセーフになること(しやすいこと、実際には代入前後にThreadSafeを確保する処理は必要)。二点目は、OnNextが最速になること。C#において列挙は、配列をその配列の長さでforで回すのが最速です。通常、この手のイベント処理は、購読が初回の一回で、その後に大量の配信があるという構成になるのが普通なので、OnNext側の性能を最大限にするというのは全然アリです。
また、こう見ると、Subjectではなく生のevent構文を使ったほうが安価に見えるかもしれませんが、実はC#のeventも似たような実装になっているためMulticastDelegate.CompibeImplぶっちゃけ同じです(この辺は特にイベント専用のマジックとかなく、割と実装されたまんまに実行されます)。
そして、最後に購読解除のためのSubscriptionを作って返す。これは必要コストですよねshoganai。
で、まぁ、OnNextの性能を最大限にするとはいえImmutableArrayは生成コストがちょっと高いよねー、と思ってました。また、Subscriptionを都度生成しなきゃいけないのも必要コストとはいえ勿体無くて、気になるものは気になる。うーむ。
それらを何とかするアイディアとして、必要コストとして絶対に存在するSubscriptionを線形リストのノードにすることで、最小限の生成に抑えました。
// 別添えでLinkedList本体は作らず、ReactivePropertySlim自体をLinkedListにする(節約)
internal interface IObserverLinkedList<T>
{
void UnsubscribeNode(ObserverNode<T> node);
}
// LinkedListNode自体がSubscriptionになる(節約)
internal sealed class ObserverNode<T> : IObserver<T>, IDisposable
{
readonly IObserver<T> observer;
IObserverLinkedList<T> list;
public ObserverNode<T> Previous { get; internal set; }
public ObserverNode<T> Next { get; internal set; }
public ObserverNode(IObserverLinkedList<T> list, IObserver<T> observer)
{
this.list = list;
this.observer = observer;
}
public void OnNext(T value)
{
observer.OnNext(value);
}
public void OnError(Exception error)
{
observer.OnError(error);
}
public void OnCompleted()
{
observer.OnCompleted();
}
public void Dispose()
{
var sourceList = Interlocked.Exchange(ref list, null);
if (sourceList != null)
{
sourceList.UnsubscribeNode(this);
sourceList = null;
}
}
}
// というのを使って実装すると
public class ReactivePropertySlim<T> : IReactiveProperty<T>, IReadOnlyReactiveProperty<T>, IObserverLinkedList<T>
{
// LinkedListでいうFirstとLastを保持(ReactivePropertySlim自体がLinkedList本体になる)
ObserverNode<T> root;
ObserverNode<T> last;
public T Value
{
set
{
this.latestValue = value;
// LinkedListを辿ってObserverを発火
var node = root;
while (node != null)
{
node.OnNext(value);
node = node.Next;
}
this.PropertyChanged?.Invoke(this, SingletonPropertyChangedEventArgs.Value);
}
}
public IDisposable Subscribe(IObserver<T> observer)
{
// 線形リストのノードを作って、自身でノードを管理する
var next = new ObserverNode<T>(this, observer);
if (root == null)
{
root = last = next;
}
else
{
last.Next = next;
next.Previous = last;
last = next;
}
return next; // ノード自体がSubscription
}
// SubscriptionのDisposeでLinkedListを張り替える
void IObserverLinkedList<T>.UnsubscribeNode(ObserverNode<T> node)
{
if (node == root)
{
root = node.Next;
}
if (node == last)
{
last = node.Previous;
}
if (node.Previous != null)
{
node.Previous.Next = node.Next;
}
if (node.Next != null)
{
node.Next.Previous = node.Previous;
}
}
}
良い所は、生成において無駄が全くない。同居できるものは徹底的に同居させることで、もうこれ以上は削れないでしょう。多分。悪い所は、線形リストの列挙は、配列列挙よりも明らかに遅いので、通知のパフォーマンスの低下がある。まあこのへんは購読料にもよりけりなので、なんとも言い難いところですね。(それとReactiveProperty, ReactivePropertySlim比較だと、スケジューラー経由を削ったことによってそれどころじゃないパフォーマンス向上を果たした)。
悪い所は、スレッドセーフじゃないです。うーん、Subscriptionの解除側ぐらいはスレッドセーフにしたほうがいいかなあ。ここちょっと悩ましい所で、考えさせてください。
***Slim
***Slimという命名は、ManualResetEventとManualResetEventSlimの関係性にならって付けています。ManualResetEventは、通常Slim版しか使わないです。
と、いうわけで、ReactivePropertySlimも、Model専用での推奨というかは、ViewModel側でも支障がなければ積極的に使ったほうが幸せになれると思っています。機能的には、バリデーションが必要なところだけ、無印を使うのがいいと考えています。
機能的に低下した所は他に、ToReactivePropertySlimがありません。これは、Sourceから流れてくるのとValueへのセットの二通りで値が変化する(Mergeされてる)のが気持ち悪いというか、使いみちあるのそれ?みたいに思ったからです。ない、とはいわないまでも、存在がおかしい。のでいっそ消しました。かわりにToReadOnlyReactivePropertySlimがあります。値の変化はSourceからのみ。このほうが自然でしょふ。
UniRx
Unityは元々ほとんどシングルスレッドなので、スレッドセーフじゃなくても概ね問題はないし、ゴミにたいして敏感な環境でもあるので、むしろReactiveProeprty(無印)をSlim版に変えたいと思ってます(今の無印版の命名をどうしようか問題はある、どうしよう)。が、破壊的変更になるので、どうしようか……。でも明らかにSlimのほうがいいし、デフォで使ってもらうべきなので、まぁ、多分、変えます。近いうち(ほんとか?)に。
あとToReactivePropertyでReadOnlyReactivePropertyを返すようにするかも。前述のように普通のToReactivePropertyがなくなるので、そっちのほうが自然にまとまった感じでいいんじゃないかなー、とか。
ところでちなみに.NET版のReactivePropertyよりもUniRxのReactivePropertyのほうが元々スリムなので、冒頭のベンチマークほどのOnNext(Valueへの代入)の性能差は出ませんので、そこは安心してください。
まとめ
パフォーマンス向上の原則はオブジェクトを作らない!オブジェクトを作らないためには、機能を一つのクラスに詰める!機能は分けない!まぁ、分けないことによって使い勝手が悪くなるのは最悪なので、パブリックAPIは適切な分割と集約をきっちり意識して、プライベートAPIは、性能を意識して、あえて統合する、というのもアリ(必ずしも性能が最重要案件ではないというか、最適化は後回しでいい場合が多いので、別に全てをそうしろとはいいませんよ)。ということで。
ReactivePropertySlimはSlimの名前の通り、小さくはあるんですが、大きく作るよりも、小さく作るほうが存外難しく、そして価値あるものです。実装自体は見た通り簡単なもので、別に複雑なアルゴリズムやコーディングが入っているわけでもないですが、アイディアが大事ということで。言われてみれば、そうですねー、っていう話ではあるのだけれど、そこに気づいて実装まで回せるかというのは全然難易度が違うんですよね。ともあれ、中々良い仕上がりになったと思うので、是非試してみてください(機能的には無印と一緒ですが!)。
2017年を振り返る
- 2017-12-31
毎年恒例ということにしているので、今年も振り返ってみます。
まず、「黒騎士と白の魔王」がリリースされました。開発2年分の成果が結実ということで、まずはメデタシ。セールス的にも一定の足跡を残せています。昨今モバイルゲームもシブい状況になってきてはいますが、その中でキャラ物ではないノンIPのオリジナルタイトルでこのレベルに達せているものがどれだけあるか、ということを考えると、自分達でいうのもアレですが、実際やりますな、みたいなのは、ありますね!
さて、私個人としても、今年は大きな弾を幾つか出して、大きなインパクトを与えられたんじゃないかと思います。去年ではC#を書く技量が向上した、というのが実感としてありました。そして今年も引き続き、技量向上しました!と、はっきりと言い切れる、感じ取れるだけの成長は果たせています。人間どこででも、どこまでも成長できるし、完成したと思った瞬間に下り坂は始まるのでしょう。そして、成長を対外的にちゃんと証明し続けられている限りは、まだ下り坂、ではなさそうです。
というわけで、対外的には良い感じかな?対外的に、という言い方がアレですが、個人的なところだと、今年は前半は良かったんですが、後半の息切れ加減が酷くて、来年は気合い入れ直さないとなー、というところが結構あります。今年はCTOという職種が色々な意味で話題になる機会が、狭い世界では多かったわけですが、んー、スキャンダルはないんですが(笑)役割として全うできているかというと、反省として特に後半はダメかな。自己採点でほんと良くないんで、ごめんなさい&がんばります、です。
C#
今年の自身のテーマとして、C#で極限まで性能を出していく(Extreme C#)、ということを主題にして様々なものを公開してきました。目的は2つあって、繰り返すことで、本気で、正しく、自分の血肉にしようというのがまず一つ。外に出せるレベルの品質を担保し(面倒くさい汚れ/単調な仕事もきっちりこなして)、しつこく変奏を弾き続けることで、曖昧さが1ミリもない100%の自信と理屈の裏付けをしようということですね。まぁ別にえらいことはなく、何事も反復練習と経験です。
もう一つは自分のブランディングの再構築。もういい加減「LINQの人」的なブランドはさすがに古臭いし、いつまでも引きずっててもダサいし、何の役にも立たないところもある。というわけで、「パフォーマンスといったら」のブランドに変えよう、と。単発だとやっぱ弱いんで、2つ3つと呆れるぐらいにひたすら連発されれば、強固にイメージも上塗りされていくでしょう。きっと。
というわけかでブログを振り返る。ブログの記事数は年々減ってきているのですが、そのかわり一発一発が重めなので、その辺でカバー。でいいかしらん?
今年の第一弾はMessagePack for C#、C#(.NET, .NET Core, Unity, Xamarin)用の新しい高速なMessagePack実装でした。MessagePack for C#は、一気に知名度も得て、世界中で使われる最速のC#バイナリシリアライザとしてある程度の地位を確立できました。実際、今年一番の成果で、世界に貢献してて偉いですね!
誕生理由は、完全に黒騎士のため。これ完成してなかったらヤバかった……!元々、前年に作ったZeroFormatterを導入してたんですが、想定してたよりも性能面で機能しなかったというか、むしろ全然機能してなくて、マズいな、というのを感じてたのです(ZeroFormatterが悪いというかは黒騎士の用法とマッチしてなかった)。
とはいえ作っちゃったし入れちゃったんだし、そこはそのままにするしかないんじゃない?(開発時期的にも後期でリサーチとかしてる余裕ゼロだし)。と、常識的な判断をするところだったんですが、本能的にこのまま進めるべきではないと判断して、裏でコソコソ作り始めて最初にポソッと呟いたのが2017年2月13日。黒騎士のリリースが 2017年4月26日 なので本当に直前で(この辺は職権濫用というか私の立場がCTOだからやれたことですね、ほんと)。3月に完成したら、それを受けてMagicOnionのシリアライザもZeroFormatterからMessagePack for C#に差し替えました。
スケジュールもテストもクソもないんですが、まぁ最高のもの作りゃあ問答無用で良いから大丈夫でしょ、ぐらいの勢いはありました。一度シリアライザ作りきった経験(ZeroFormatter)と、それの導入と結果で黒騎士で求められる性能特性とかその他その他とかをしっかり把握出来てたんで、強くてニューゲームの気分で、絶対出来るという確信はあったし、その通りになったのでヨカッタネ(終わってみればそう言えるんであって、自信はあれど、作ってる最中のプレッシャーは普通にキツかったですよ)。
この辺の、技術判断は、自分自身でやるものに関してはあまりミスらないなぁ、という自信と実績はそこそこあります。ダメだと判断したらすぐに自分でリカバーすればいいということでもあり。ただ、大きなプロジェクトの責任者としての立ち位置だと、自分でやれるものもあれば、当然やれないものもあって、その場合の、人に任せること、判断するってことは、単純じゃないですね。そして、その辺のところで、失敗だ、といえるものもそれなりにあったのが(今年の判断で、というかここ数年での結果として下ったのが今年だ、ということですが)いささか悔いるところです。根気と眼力が問われるところで、とりあえず自分には両方が足りなかったし、今はどうなのかな、正直今も全然ではありそう。
そして引き続きでMagicOnionが正式リリースを迎えていない……!のが良くない。前からの傾向ですが、今年は特にとっちらかってしまった感は否めず……。MagicOnion自体は、gRPC(モバイルで/Unityで)いち早く実践投下したりの珍奇性と、そして今年は特に日本ではgRPCの知名度/採用率が飛躍的に上がったと思うのですが、それにいち早く手を付けていたりと、悪くない判断だったんじゃないでしょふか。実装的にもC# 7.0 custom task-like の正しいフレームワークでの利用法とか、面白く仕上がっていますしね。だから、ちゃんと完成させて正式リリースするんじゃもん……。
【Unite 2017 Tokyo】「黒騎士と白の魔王」にみるC#で統一したサーバー/クライアント開発と現実的なUniRx使いこなし術でクライアントサイドを、AWS Summitで「黒騎士と白の魔王」gRPCによるHTTP/2 - API, Streamingの実践としてサーバーサイドのセッションをしました。この2つは大きなイベントで、ちゃんと話せてこれたのはいい感じ。クライアントサイドをもう少し誇れる感じで言いたかったのですが、うーみぅ。
MicroResolver - C#最速のDIコンテナライブラリと、最速を支えるメタプログラミングテクニックは、突然のDI。なんでもいいからIL書き技術を磨く実験台が欲しかった説はある。素振り大事。総合ベンチマークがあって、1msを競う戦いができる環境ってのがヨカッタですね。色々学びあったし、実際ベンチ勝負で勝った。この辺で、C#で最速を叩き出すための勘所を、完全に掴みました。なぜ遅いのかが理解できて、どうすりゃ速くできるか知っている。そして、そのとおりに書くことができる。
そして自信をつけた私は、C#の高速なMySQLのドライバを書こうかという話、或いはパフォーマンス向上のためのアプローチについて、という、長年の懸念だったC#のMySQLドライバ遅い問題に手をいれるぜ、と思って始めたプロジェクト。未完!こういうやりかけ放置よくない。今年の放置っぷりは酷い。
MessagePack for C#におけるオートマトンベースの文字列探索によるデシリアライズ速度の高速化、これはいい話ですねー。ところでMessagePack for C#はめちゃくちゃ更新してましてNuGetのVersion Historyを見てもらえれば分かるんですが

今年58回も更新してるんですよ!58回!シリアライザは本当に大変なんです!JSON.NETが無限に更新し続ける理由がわかりましたよ、なにをそんなに更新する必用あるんだって話ですが、あるんですよ、ほんと。そしてprotobuf-netやJilやMsgPack-Cliに沢山issueが詰まれる理由もわかりましたよ。シリアライザは無限にバグるんです!いやー、シリアライザのメンテマンとか大変ですよぅー、私は二個抱えることになって本当に本当に本当に大変なのです、そりゃ他のことに中々手がつけられなくなるというのも分かってほすぃ。
というわけかで、二個抱えるうちのもう一個、Utf8Json - C#最速のJSONシリアライザ(for .NET Standard 2.0, Unity)の公開。これも世界的にかなりインパクトあってヨカッタ。Utf8JsonやMessagePack for C#の意義って、新しい時代のパフォーマンスのベースラインを示した、ヌルい眼前に実証をもって叩きつけたことにあると思ってます。C#はねー、やっぱ実装がヌルいものが多いです、というか、BCL含めて99%のものがヌルいです。それはしょうがないんですけどね、そういう時代じゃなかったからだし。でも時代は明らかに変わった、変わってている、その中で新しい基準が必要だし、その基準というものを私は作って、突きつけられたんじゃないかな、と。
もちろん、Utf8Json自体も「ちゃんと使える」JSONライブラリになってます。JSONってかなりフワフワなので、おしきかせの決め打ちフォーマットだけじゃなく、あらゆるJSONをちゃんとデシリアライズできるようにするカスタマイズ性が絶対に必要なんですね。そこをきちんと満たしつつ、超高性能も実現している、というのがもう一つのUtf8Jsonのキモです(一番の目玉はUtf8バイナリとみなして読み書きするってところですが)
最後に総決算としてIntroduction to the pragmatic IL via C#、ILの書き方を残しました。
お仕事
マジカル変化球で負債を返却する、というのを去年後半から今年前半にかけてやって、それを成立させました(黒騎士リリース)。中盤は成果のスポークスマンで、それもまぁ悪くないでしょう(Unite, AWS Summit講演)。この辺は考えていた既定路線でちゃんとハマっていたと思うんですが、後半も技術にフォーカスに脳みそを意識しすぎて、しかも出来たもの(Utf8Jsonとか)が会社のプロダクトとして直接役立ったかというと、役立ってないわけではないが凄い貢献するわけではない、ぐらいになったのがいくなかったですねえ。MySQLドライバをほっぽりだしてしまったのがロードマップ的にはまずかった(それの代替/副産物がUtf8Jsonなのですけれど)。
さすがに技術フォーカスすれば、してない時に比べると脳みそが回ってる度は高くなるとはいえ、リサーチやってるわけでもないんで、もちっとプロダクトの改善に目を向けたいし、積み残して放置気味な厄介なバグをちゃんと潰したいし、MagicOnionの正式リリースもしたい。マネジメントとまでは言わないですが、一区切りついたということもあるので、開発組織の方向付けとかもあるでしょう。
漫画/音楽/ゲーム/その他...
すっかりkindleで電子書籍中心になりました。iPhone * Plus(今はXですが)の、やや大きめサイズのスマフォのお陰で、漫画や小説の小さな文字がギリギリ読めるサイズ(欲を言えばもう少し大きい方がいい)で、いつでも手軽に開けるようになったのが大きい。iPadも持ってるのですが、やっぱスマフォでサクッとになりがちですね。なので、スマフォは大きめサイズのもの一択。もう小さいのには戻りたくない(ので、XでPlusからちょっと画面サイズ小さくなったのはなんとも言い難いところ)。
で、見直してみると凄い良かった、って思えるのがナカッタ。カモ。うーん、どういうこっちゃら。駆け込みでセンチメントの行方(12/21, センチメントの季節の新章)が出たのが良かった。変わらずとてもドキッと来る感じで。好き。
音楽はNUITOを今年知ったのです!最高……!2009年に出た唯一のアルバム、Unutellaめっちゃ聴いた(Apple Musicにもあります)!ライブ(去年から7年ぶりに再開したそうで)も行った!超良かった!Shobaleader One(スクエアプッシャーのバンド名義)の来日公演も行けたし、今年は中々に満喫したかもしれない。
ライブとか美術展とか演劇とか、一期一会で、基本、次はないよねー、と思う度が強くなったので(逃した後悔がそれなりにあったせいかも)、なるべく気になったら行くようにしたい。してる。しはじめた。VRDGも開催される毎に行ってましたが、毎回面白くてよきかなよきかな。来年はコンテンポラリーダンスを色々見ていきたいですねぇ。
ゲームはSwitchも買ったしPS4もそこそこ稼働させたしで色々買ってはみたものの、んー、ロクに最後までプレイしたものが、ない……!その中でいうとRUINERは良かったし最後までやりました。このビジュアルは最高。ゲーム的には、まぁそこそこまぁまぁだけど、とにかくビジュアルが最高。ゲーム的には年末に買ったばかりではあるんですが、BLUE REVOLVERは間違いなく面白い。良い。あとはみんな挙げますが実際NieR:Automataはヨカッタ。
来年は
今年は技術面では普通の(?)C#にフォーカスしすぎたきらいがありますね。Unityが手付かずで。ついでにUniRxも放置で(ひどぅぃ、あ、アセットストアにアップデート申請は年末のこないだ出したので来年頭には通ってそうです)。というわけで、Unityに再フォーカスしたい。
というのと、あとここ数年ずっと頭のなかにあったやりたいこと、をやる手法というのが年末の末の末にやっと見いだせて光が指したんで、技術的にそれを実装したいというのが密やかにあります。今までのお得意のプログラミング、とは違う領域になるので、そこをやりきるのがチャレンジでもありますねー。C#じゃゲロ遅いってことでC++かCompute Shaderでやるかなー、とも思ってるんで、C#と付き合って10年目にして脱C#かもしれないしそうじゃないかもしれない。まぁ部分的ってだけで、相変わらず技術のベースはC#であり続ける気がします。
ともあれ来年は来年で、新しい何かを示し続けよう、というのは絶対に変わらないものとしてあります。C#も客観的には正直しょっぱい情勢と言わざるをえないのですが、そこもちゃんと尽力していきましょう。そして、黒騎士リリース以後のグラニの技術にもご期待下さい。