DynamicJson - C# 4.0のdynamicでスムーズにJSONを扱うライブラリ
- 2010-04-30
C#4.0の新機能といったらdynamic。外部から来る型が決まってないデータを取り扱うときは楽かしら。とはいえ、実際に適用出来る範囲はそんなに多くはないようです。例えばXMLをdynamicで扱えたら少し素敵かも、と一瞬思いつつもElementsもDescendantsも出来なくてAttributeの取得出来ないXMLは、実際あんまり便利じゃなかったりする。ただ、ちょうどジャストフィットするものがあります。それは、JSONですよ、JSON。というわけで、dynamicでJSONを扱えるライブラリを書いてみました。ライブラリといっても300行程度のクラス一個です。
使い方は非常にシンプルで直感的。まずは、文字列JSONの読み込みの例を。DynamicJson.Parseメソッド一発です。
// Parse (from JsonString to DynamicJson)
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
var r1 = json.foo; // "json" - dynamic(string)
var r2 = json.bar; // 100 - dynamic(double)
var r3 = json.nest.foobar; // true - dynamic(bool)
var r4 = json["nest"]["foobar"]; // インデクサでのアクセスも可
// 定義されてるかチェック
var b1 = json.IsDefined("foo"); // true
var b2 = json.IsDefined("foooo"); // false
Parseしたら、あとはJavaScriptと同じ感じにプロパティ名をドット打つだけで値が取り出せます。dynamicとJSONは相性が良いですね、JavaScriptと全く同じ感覚です。注意点としては、存在しないプロパティ名を読むと例外が出ます。Dictionaryみたいなものだと思ってください。さすがにそれだと使いにくいところもあるので、IsDefinedメソッドであるかないかチェック出来ます。dynamicなため、IntelliSenseには出てこないということは注意してください。もう一つ気をつけなきゃいけないのは、数字は全てdoubleです。JSONでは数値類は全部一緒くたにNumberなので、適宜自分でキャストしてください。
オブジェクトからJSON文字列への変換
dynamicとは関係ないのですが、JSON文字列へのシリアライズも可能です。こちらもDynamicJson.Serializeメソッド一発。
// Serialize (from Object to JsonString)
var obj = new
{
Name = "Foo",
Age = 30,
Address = new
{
Country = "Japan",
City = "Tokyo"
},
Like = new[] { "Microsoft", "Xbox" }
};
// {"Name":"Foo","Age":30,"Address":{"Country":"Japan","City":"Tokyo"},"Like":["Microsoft","Xbox"]}
var jsonStringFromObj = DynamicJson.Serialize(obj);
匿名型でサクッとJSONを作り上げられます。非常にお手軽。DataContractJsonSerializerはちょっと大仰すぎなのよねえ、という時にはこれでサクサクッと作ってやってください。匿名型だけじゃなく、普通のオブジェクトでも大丈夫です(その場合はパブリックプロパティからKeyとValueを生成します)。
JSONオブジェクトの再編集・作成
生成したDynamicJsonは可変です。自由に編集して再シリアライズとか出来ます。
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
// 追加、編集、削除が出来ます
json.Arr = new string[] { "NOR", "XOR" }; // Add
json.foo = 5000; // Replace
json.Delete("bar"); // Delete
// DynamicJsonから文字列へのシリアライズはToStringを呼ぶだけ
var reJson = json.ToString(); // {"foo":5000,"nest":{"foobar":true},"Arr":["NOR","XOR"]}
// 配列はちょっと特殊で、foreachなので扱いたい場合はobject[]にキャストしてください
Console.WriteLine(json.Arr[1]); // XOR
foreach (var item in (object[])json.Arr)
Console.WriteLine(item); // NOR XOR
// 新しく作成することも出来ます
dynamic root = new DynamicJson(); // ルートのコンテナ
root.obj = new { }; // 空のオブジェクトの追加は匿名型をどうぞ
root.obj.str = "aaa";
root.obj.@bool = true; // C#の予約語と被る場合は@を先頭につけるとアクセス出来るよ!
root.array = new[] { 1, 200 }; // 配列の追加
root.obj2 = new { str2 = "bbbb", ar = new object[] { "foobar", null, 100 } }; // オブジェクトの追加と初期化
// {"obj":{"str":"aaa","bool":true},"array":[1,200],"obj2":{"str2":"bbbb","ar":["foobar",null,100]}}
Console.WriteLine(root.ToString());
追加は存在しないプロパティ名に直接突っ込めばOK。編集はそのまま上書き。型名とか関係ないので、元から入っているものの型に合わせる必要はありません。削除はDeleteメソッドを呼べば出来ます。配列はちょっと扱いが特殊でして、foreachしたかったりLinqメソッド使いたい場合はobject[]にキャストする必要があります。この辺は仕様です。諸事情によりIEnumerableじゃないんです。ごめんなさい。ちなみにobjectってものなあ、intが欲しいんすよ、っていう時は.Cast
一から新しいDynamicJsonオブジェクトを作成することも出来ます。普通にnewするだけ。注意点としては、変数はdynamicで受けてください。varで受けても何の嬉しいこともありませんので。あとは、普通にぽこぽこ足すだけ。オブジェクトを作る場合は空の匿名型でやります。決してDynamicJsonを足したりしないでください、がっかりなことになりますので。
実装の裏側
300行のクラス一個、ということで、勿論自前でパーサー書いてるわけがありません。ていうか、その手のは自分で書きたくないんだよね、ソートアルゴリズムとかもそうだけど、こういうのはちゃんと検証されてるものを使うべき。(そしてそもそも、ちゃんとしたのが書けるかというと、書けません……)。で、何を使っているかというと先日の記事でLinq to Jsonとか言ってたように、JsonReaderWriterFactoryを使用しています。
ようするに、ただのJsonReaderWriterFactoryのラッパーです。内部ではJSONの構造をXMLとして保持していて、書き出しの際にJsonReaderWriterFactoryを通しています。ただですね、Readerのほうは使い易くてJsonReaderWriterFactoryお薦め!なのですが、Writerのほうは結構厳しいです。ルールに則って書いたXMLを通すとJSONになる、という仕組みなのですが、ルールに則ってないと即弾かれるということでもあって、かなり面倒くさいです。
// 例えばこんなDynamicJSONは
dynamic root = new DynamicJson();
root.Hoge = "aiueo";
root.Arr = new[] { "A", "BC", "D" };
// 内部ではこんなコードに変換されています
new XElement("root", new XAttribute("type", "object"),
new XElement("Hoge", new XAttribute("type", "string"), "aiueo"),
new XElement("Arr", new XAttribute("type", "array"),
new XElement("item", new XAttribute("type", "string"), "A",
new XElement("item", new XAttribute("type", "string"), "BC",
new XElement("item", new XAttribute("type", "string"), "D")))));
このXElementを素で書いていくのは地獄でしょう。DynamicJsonはこの変換を自動で行います。dynamicでラッピングすることで、煩わしい部分を完全に包み隠すことができました。ここまで簡略化出来ると、DSLの域です。C#は大変素晴らしいデスネ。いや、マジで。
まとめ
クラス一個なので、csファイルをコピペって使ってもいいですし(その場合は追加でSystem.Runtime.Serializationの参照を)、DLLを参照設定に加えても、どちらでもお好きな方をどうぞ。数あるJSONライブラリの中でも、使いやすさはトップクラスなのではないでしょうか(自画自賛)。いや、これは、単純にdynamicの威力の賜物ですね。これを作るまではdynamicについて割と勘違いしていたところもあったのですが、なんというか、DSL向けだと思います。で、DSL指向で行くなら全部プロパティだけで組まないとダメですねえ。IntelliSenseが動かないのでメソッドを使うのは今ひとつ。そういう意味で、IsDefinedじゃなくて.property? とかって感じに、末尾に?をつけるとかどうかな!とか考えてみたんですが、コンパイル通らないのでダメでした、残念。「.あいうえお」なら行けるので、日本語プログラミングDSLが待たれるところです。嘘。
static void Main()
{
var publicTL = new WebClient().DownloadString(@"http://twitter.com/statuses/public_timeline.json");
var statuses = DynamicJson.Parse(publicTL);
foreach (var status in (dynamic[])statuses)
{
Console.WriteLine(status.user.screen_name);
Console.WriteLine(status.text);
}
}
最後に例として、Twitterのpublic_timeline.jsonを引っこ抜くコードを。凄まじく簡潔です。C#はどこをどう見てもLightWeightですね、本当にありがとうございました。
C#とLinq to JsonとTwitterのChirpUserStreamsとReactive Extensions
- 2010-04-29
何か盛り沢山になったのでタイトルも盛り沢山にしてみました。SEO(笑)
最近話題のTwitterのChirpUserStreamsを使ってみましょー。ChirpUserStreamsとは、自分のタイムラインのあらゆる情報がストリームAPIによりリアルタイムで取得出来る、というもの。これを扱うには、まずはストリームをIEnumerable化します。そのまま扱うよりも、一度IEnumerable化すると非常に触りやすくなる、というのがLinq時代の鉄則です。C#でのストリームAPIの取得方法は以前にも記事にしましたが、かなり汚かったのでリライト。WebClient愛してる。
public static IEnumerable<XElement> ConnectChirpStream(string username, string password)
{
const string StreamApiURL = "http://chirpstream.twitter.com/2b/user.json";
var wc = new WebClient() { Credentials = new NetworkCredential(username, password) };
using (var stream = wc.OpenRead(StreamApiURL))
using (var reader = new StreamReader(stream))
{
var query = reader.EnumerateLines() // 1行に1JSONなのです
.Where(s => !string.IsNullOrEmpty(s)) // 空文字が来るので除去
.Select(s => // 文字列JSONからXElementへ変換
{
using (var jsonReader = JsonReaderWriterFactory.CreateJsonReader(Encoding.Default.GetBytes(s), XmlDictionaryReaderQuotas.Max))
return XElement.Load(jsonReader);
});
foreach (var item in query) yield return item; // 無限列挙
}
}
// StreamReaderの補助用拡張メソッド(あると大変便利)
public static IEnumerable<string> EnumerateLines(this StreamReader streamReader)
{
while (!streamReader.EndOfStream)
{
yield return streamReader.ReadLine();
}
}
中々シンプルに書けます。C#もLLと比べても全然引けを取らないでしょう(誰に言ってる)。ChirpUserStreamsはJSONでしか取れないのですが、StreamAPIではXmlよりもJSONのほうが使い易いので、JSONだけでも全然問題ありません。とはいえ、C#でJSONはちょっと扱いにくいんだよねー?と思いきや、意外に普通に標準ライブラリだけで何とかなりました。
参照設定にSystem.Runtime.Serializationを加えます(注:VS2008ではSystem.ServiceModel.Webを参照設定に加えてください)。この参照で通常使うのはDataContractJsonSerializerだと思いますが、もう一つ、JsonReaderWriterFactoryというクラスが用意されていて、このReaderはJSONをXmlReaderとして扱うことが出来ます。この図式は以前のLinq to HtmlのためのSGMLReader利用法と同じです。そのままXElementに流しこめば、JSONをXmlとして扱って、Linq to Jsonが成り立ちます。
さて、StreamAPIなのでEndOfStreamは来ない。繋ぎっぱなし、つまりはConnectChirpStreamメソッドは無限リストになります。この中には色々な情報が混ぜこぜになって来ます。投稿した、という他にも、誰かをフォローした、何かをふぁぼった、何かをリツイートした、などなどなどなど。クライアントソフト作るなら、当然どの情報も漏れ無く扱いたいわけですが、どうしましょう?foreachでグルッと回して、ifで分ける、しか、ない、かもですね? しかしそれは敗北です。退化です。foreachを使ったら負けだと思っている。
ところで突然に、今のところ思うReactive Extensions for .NET (Rx)を使うメリットは3つ。「複雑になりがちな複数イベントの合成」「同じく複雑になりがちな非同期処理のLinq化」そして、「列挙の分配」。従来型のLinqでは、一回の列挙には一個の処理しか挟めませんでした。例えば、MaxとCountを同時に取得する方法はなかった。MaxとCountを別々に二度列挙するか、または旧態依然なやり方、つまりforeachでグルグルと回してMaxとCountを手動で計算するかしかなかった。それはIEnumerableがPullモデルなためで、PushモデルのIObservableならば、出来ないこともない。
では、Rxでこのストリームを分配してみましょう。
static void Main(string[] args)
{
// IEnumerableをIObservableに変換し、Publish(Connectするまで列挙されない(ので分配が可能になる))
var connecter = ConnectChirpStream("username", "password")
.ToObservable()
.Publish();
// 1件目は必ず自分のフレンドのIDリストが来るらしいっぽいのでまるっと保存
HashSet<int> friendList;
connecter.Take(1).Subscribe(x => friendList = new HashSet<int>(
x.Element("friends").Elements().Select(id => (int)id)));
// どんなのが来るのかよく分からないのでモニタ用にテキストにまるっと保存
var sw = new StreamWriter("streamLog.txt") { AutoFlush = true };
connecter.Subscribe(x => sw.WriteLine(x));
// userがあるなら普通の投稿(ってことにしておく)
connecter.Where(x => x.Element("user") != null)
.Select(x => new
{
Text = x.Element("text").Value,
Name = x.Element("user").Element("screen_name").Value
})
.Subscribe(a => Console.WriteLine(a.Name + ":" + a.Text));
// favoriteとかretweetは "event":"favorite" というJSONが来る
var events = connecter.Where(x => x.Element("event") != null);
// favoriteの場合の処理
events.Where(x => x.Element("event").Value == "favorite")
.Subscribe(x => Console.WriteLine(x)); // favorite用の何か処理
// retweetの場合の処理
events.Where(x => x.Element("event").Value == "retweet")
.Subscribe(x => Console.WriteLine(x)); // retweet用の何か処理
// 同期か非同期かは、ToObservableの引数で変わる。デフォルトは同期
// Scheduler.ThreadPoolを引数に入れるとThreadPoolで非同期になる
connecter.Connect(); // 列挙開始
}
ID一覧取得、テキスト保存、投稿時処理、Fav時処理、リツイート時処理の5つへの分配が非常にスマートに出来ました。ToObservable、Publish、Connect。たったこれだけで一つストリームを複数に分配することが出来ます。普通にそれぞれをWhereだのSelectだの、独立してLinqでコネコネ出来ました。で、何が嬉しいかっていうと、それぞれが完全に独立していて見やすいってのは勿論あります。あと、部品化されてるので外部に分割しやすくなるんですね、物凄く。組み合わせたりもしやすいし。
結論
Rxヤバい。というわけで、みんなRx触ろう! .NET Framework 4.0ではRxで使うIObservableとIObserverインターフェイスが搭載されています。インターフェイスだけでどうすんだよボケ、っていうと、実際のところどうにもなりませんね、たはー。それでもインターフェイスだけ先行搭載ということは、RxはDevLabs内だけで終わる実験的プロジェクトではなく、必ず標準搭載するから安心しろよ!というメッセージだと受け取ることにしました。きっと.NET Framework 4.0 SP1には標準搭載されます。される、と、いいなあ。ちなみにRxは初期の頃と結構変わってますし、まだ変わるかも。でも、だからこそ、それに付き合うのも楽しいってものですよ?
ああ、あと、ChirpUserStreamsもヤバいですね。リアルタイムでゴリゴリ迫ってくる感覚は素敵というか、なんか別次元のメディアになった感じでもあります。今、新規にTwitterクライアント作るならStreamAPI完全対応すれば差別化出来て良いですね!私は作りませんが。ただ、ストリームAPIとRxは相性良いと思うので、ストリームAPI時代の到来と同時にRx時代も到来!する、かなあ?
ToDo
linq.jsがようやく一段落したので、Rxの紹介もまたやっていきたいですねー(すみません、かなり長いこと放置していて)。ToObservableによる列挙の分配は中々に強烈なので、linq.jsとRxJSを橋渡しするようなコードというかJSというかも用意したいなあ(軽く作ってみたんですが、RxJSでもPublishで分配出来て中々に威力ありそうでした)。うーん、考えてみるとやることはいっぱいあるねえ。適当に待っていてください。
linq.js ver 2.0 / jquery.linq.js - Linq for jQuery
- 2010-04-23
無駄に1280x720なので、文字が小さくて見えない場合はフルスクリーンにするかYouTubeに飛んでそちらで大きめで見てください。というわけで、動画です。linq.js + Visual Studio 2010で補完でウハウハでjQueryプラグインで世界系です。ここ最近、RxJS、JSINQとJavaScript系の話が続く中で、ふと、乗るしかない このビックウェーブに、という妄念が勢いづいてlinq.jsをver.2.0に更新しました。
内部コードを全面的に変更し、丸っきり別物になりました。破壊的な変更も沢山あります。名前空間がE、もしくはLinq.EnumerableだったのがEnumerableになり、幾つかのメソッドを廃止、廃止した以上にメソッドを大量追加。そして、WindowsScriptHostに対応しました。その他色々細かい変更事項の詳細は下の方で。あ、そうそう、名前空間はEnumerableを占有するので、prototype.jsとは被るため一緒に使えません。
今回の最大のポイントは、jquery.linq.jsという、jQueryのプラグイン化したlinq.jsを追加です。基本機能は完全に同一ですが、jQueryプラグイン版のみの特徴として、jQueryとEnumerableとの相互変換用のメソッドが定義されています。呼び出しは$.Enumerableを使います(グローバル名前空間は一つも汚しません)。
Linqとは?
耳タコなぐらい繰り返していますが、C#知らない人やこのサイトを始めて訪れた人にも使って欲しいんです!ということで、Linqとは何かを紹介します。簡単に言うと、そのふざけたforをぶち殺す。ための代物。Linq導入以降、当社比100%でfor, foreachの出番はなくなりました。ifも半減。ネスト量激減。えー、forー?forなんて使うの小学生までだよねー。
Linq(to Objects)とは?便利コレクション処理ライブラリです。語弊は、大いにある。あるのだけど、言い切るぐらいでいいと思うことにしている近頃。具体的には、mapやfilterやreduceが使えます。非破壊的なsortができます。Shuffle(ランダムに並びかえ)やDistinct(重複除去)などがあります。流れるようにメソッドチェーンで記述出来ます。index付きのforeachが書けます。DOMに対しても同じようにforeachやmapを適用できます。遅延評価が基本になっているので、幾つmapやfilterを繋げても、ムダの無い列挙が可能になっています。また、無限リストが扱えます。JavaScriptでプログラミングするにあたって不足しまくるコレクション処理を大幅に下支えするのが、linq.jsです。
Linqの世界、jQueryの世界
100億の言葉より1の実例。
// こんな感じ(1から10個、偶数のみを二乗したのをアラートに出す)
$.Enumerable.Range(1, 10)
.Where("$%2==0") // 他言語でfilterとか言われているもの
.Select("$*$") // 他言語でmapとか言われているもの
.ForEach("alert($)");
// Linq側はTojQueryでjQueryオブジェクトに変換
$.Enumerable.Range(1, 10)
.Select(function (i) { return $("<option>").text(i) })
.TojQuery()
.appendTo("#select1");
// jQueryオブジェクト側はtoEnumerableでLinqに変換
var sum = $("#select1").children()
.toEnumerable()
.Select("parseInt($.text())")
.Sum(); // 55
シームレスに結合されているようであまり統合されてはいません。お互い、コレクション操作中心であったり、連鎖で操作するという形なので、融け合うことはできません。toEnumerableに関しても、jQuery世界とは切り離された、Linqの世界へと移行するだけ。とはいえ、toEnumerableとTojQueryにより、チェーンを切らさずに相互変換して、スムーズに世界を切り替えられるというのは、中々に楽しい。
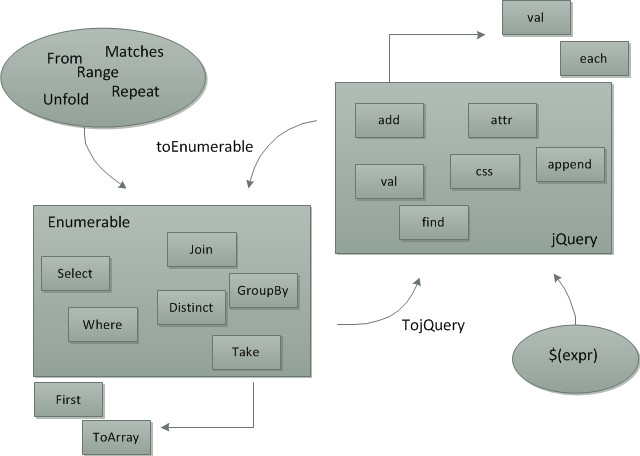
図にするとこんな感じ。jQueryの世界はメソッド名小文字、Linqの世界はメソッド名大文字、というので自分の今居る世界が分かります。Linqは世界系。世界に囚われると逃げ出すことは出来ないのです!いくらもがいても(Select)もがいても(Where)変わらない。鏡の中に逃げこむか(tojQuery)、鏡を割ってしまうか(ToArray)、どちらにせよ、代償を払うわけですね? 意味不明。そんな感じで非常に楽しいです。
IDE Lover
linq.jsの特徴として、入力補完サポートを徹底的に行っているという点があります。なぜなら、私自身がIDE大好きっ子、入力補完大好きっ子だから。テキストエディタで書いているとか言う人は、そのエディタは窓から投げ捨ててIDE使おうぜ! どんな感じで書けるかというと、動画を見てください、一番上の。今回は無料のVisual Web Developer 2010 Expressを使っています。インストールも拍子抜けするぐらい簡単ですよ!超お薦め。HTML/JSエディタとして使うポイントは、「Webサイトを作成」から「空のASP.NETウェブサイト」を選ぶことです。詳しくはまた後日にでも。
linq.js ver.2.0.0.0
では、本体の更新事項の方もご紹介。jquery.linq.jsも、この2.0から作られているので以下の事項は当てはまります。まず、名前空間を大々的に弄りました。Linq名前空間は全面的に廃止、Enumerableのみに。また、ショートカットとして用意していたEも廃止。それとLinq.ObjectとLinq.Enumerableは統合されて、Enumerableになりました。
次に廃止ですが、いっぱいあります。ToJSONの廃止、ちゃんと出力可能なのかを保証出来ないのでやめた。JSONは専用ライブラリ使ってください。ToTableの廃止、明らかに不要で邪魔臭かったから。なんでこんなもの搭載したのかすら謎。TraceFの廃止、というか、今までのTraceFをTraceとし、TraceFを消滅させました。TraceFはconsole.logに書き込んでいたのですが、IE8からはIEでも使えるようなので、F(Firebug)じゃなくていいかな、と。あと元のTraceはdocument.writeだったので、それは意味ねーだろ、ということで。あとは、RangeDownToの廃止。かわりにRangeToをマイナス方向への移動に対応させました。これは、ToなんだからUpとDownを区別するほうがオカシイってことにやっと気づいたからです、しょぼーん。
次に名前変更の類。ZipWithの名称をZipに変更(.NET 4.0と名前を合わせるため)。Sliceの名称をBufferWithCountに変更(Rxと名前を合わせるため)。Makeの名称をReturnに変更(Rxと名前を合わせるため)。Timesの名称をGenerateに変更(Rxと名前を合わせるため、RxのGenerateは基本Unfoldですが)。
新メソッドとしてMaxBy, MinBy, Alternate, TakeExceptLast, PartitionBy, Catch, Finallyを追加しました。MaxByとMinByはそのまんま。Alternateは一個毎に値を挟み込みます。TakeExceptLastは最後のn個(引数を省いた場合は1個)を除いて列挙します(Skipの逆バージョンみたいなもの)。PartitionByはGroupByの特殊系みたいな。CatchとFinallyはエラーハンドリング用。いつもなら、ここで例を出すところなのですが今回は省略、詳しくはリファレンスのほうで。
それと、OfTypeの追加。JavaScriptは型がゆるふわだからCastもOfTypeもイラナイし!と思ってたんですが、そしてCastは実際いらないのですが、OfTypeは翌々考えてみると型がゆるふわだからこそ、フィルタリングするために超絶必要じゃないか!ということに気づきました。ので追加。そして、これでCast以外は.NETのLinq演算子の全てを搭載ということになりました。
Windows Script Host
最後に、Enumerable.FromをJScriptのEnumeratorに対応させました(linq.jsのEnumeratorじゃなくて組み込みの方ね)。これにより、Windows Script Hostやエディタマクロでlinqが使えるようになりました。Linq for WSH!えー、WSH?WSHなんて使うの小学生までだよねー。今はPowerShellっすよ。と思うかもしれませんが違います。WSHならばJavaScriptで強烈に補完効かせながらガリガリ書けるのです。しかもLinqが使える。むしろPowerShellの時代は終わったね、WSH復権の時よ来たれ!だからそろそろアップデートかけて.NET Frameworkのライブラリが全面的に使えるようになって欲すぃ(今は、極一部のは使えないことはないのですが相当微妙)。では実例など少し。
// フォルダ下のフォルダ名とファイル名を取得する
var dir = WScript.CreateObject("Scripting.FileSystemObject").GetFolder("C:\\");
// 通常の場合
var itemNames = [];
for (var e = new Enumerator(dir.SubFolders); !e.atEnd(); e.moveNext())
{
itemNames.push(e.item().Name);
}
for (var e = new Enumerator(dir.Files); !e.atEnd(); e.moveNext())
{
itemNames.push(e.item().Name);
}
// linq.js
var itemNames2 = Enumerable.From(dir.SubFolders)
.Concat(dir.Files)
.Select("$.Name")
.ToArray();
WSHでJScriptを使う場合の最大の欠点は、foreachがないこと、でしょうか。生のEnumeratorを回すのは苦痛でしかない。しかし、linq.jsを用いればFrom.ForEachで簡単に列挙できます。それだけでなく、Linqの多様なメソッドを用いて自然なコレクション操作が可能です。上記例では、Concatでファイル一覧とサブフォルダ一覧を連結することで、名前の取り出しを共通化することができました。
WSHに関して詳しくはウェブで、じゃなくて後日、と言いたいのですが(既に記事がかなり長いので)、そんなこと言ってるといつまでたっても書かなさそうなので、簡単に説明を。WSH(WindowsScriptHost)とはWindows用のスクリプト環境で、自動化など、非常に強力で大抵のことが出来ます。で、標準ではVBScriptと、JScriptで書けます。つまりJavaScriptで書ける。つまりlinq.jsが読み込める。つまりLinqがWSHでも使える。WSHで扱うあらゆるコレクションに対して、Linqを適用させることが可能です。WSHだけでなく、Windows上でJScriptを用いるもの、例えばWindowsのデスクトップガジェットなどでも利用することが出来ます。
ライブラリを用いる場合は、wsfファイルで記述すると良いかもです。中身は簡単なXMLで、下のような感じに。
<job id="Main">
<script language="JScript" src="linq.js"></script>
<script language="JScript">
function EnumerateLines(filePath)
{
return Enumerable.RepeatWithFinalize(
function () { return WScript.CreateObject("Scripting.FileSystemObject").OpenTextFile(filePath) },
function (ts) { ts.Close() })
.TakeWhile(function (ts) { return !ts.AtEndOfStream })
.Select(function (ts) { return ts.ReadLine() });
}
EnumerateLines("C:\\test.txt").Take(10).ForEach(function (s)
{
WScript.Echo(s);
});
</script>
</job>
そうそう、自動Closeも含めたリソース管理も出来ます。ストリームなどにはRepeatWithFinalizeを使ってLinq化することで、Closeまで一本にまとめあげられます。といったような複雑なことが必要なくても、E.From(collection).ForEach()がふつーに便利です。というか、こんな単純なことすら素の状態じゃ出来ないJScriptに絶望した!でもそれがいい。JScript可愛いよJScript。
エディタマクロ
WSHによるJavaScript実行はEmEditorやサクラエディタ、Meryなど様々なテキストエディタで利用できます。せっかくなのでちょっと実用的なものを、と思って電卓を作ってみました。EmEditor用マクロです。選択範囲内の一行を計算し、その行の右側に出力します。ちゃちゃっと計算出来て便利。計算し直しを頻繁にする時は、新規ファイルを開いてまっさらなものに数式を書いて、Ctrl+A -> マクロ実行を繰り返すと良い感じ。
#include = "linq.js"
with (document.Selection)
{
Enumerable
.RangeTo(GetTopPointY(eePosLogical), GetBottomPointY(eePosLogical))
.Select(function($i)
{
var $line = document.GetLine($i);
try { eval($line) } catch ($e) { } // SetVariableToGlobal
var $expr = $line.split("=")[0].replace(/^ +| +$/g, "");
try { var $result = eval($expr) } catch ($e) { }
return { PointY: $i, Result: $result, Line: $expr }
})
.Where(function(a) { return a.Result !== undefined })
.ForEach(function(a)
{
SetActivePoint(eePosLogical, 1, a.PointY, false)
SelectLine(); Delete();
document.writeln(a.Line + " = " + a.Result);
SelectLine(); UnIndent(); StartOfLine();
});
}
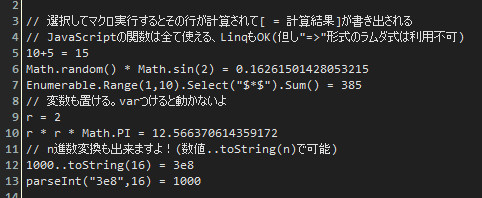
一行のうち=の左側をevalして、戻り値を返すものは出力、evalに失敗したものはスルー。ということなので、JavaScriptのMath関数は全部使えます。Select内の変数が$iとか、$始まりなのは変数定義による名前の衝突を避けるためです。慣れないマクロ書きなので色々酷い箇所も多いとは思いますが、なんとなく伝わるでしょうか? テキストエディタのマクロは、一行ずつの配列として、一行に対して操作をかけることが多いので、RangeToで範囲を作って、行ごとに適当に変形(Select)させて例外条件を省いて(Where)、処理(ForEach)。煩雑になりがちな行番号管理などを、流れるように簡単に記述出来ます。
なお、EmEditorは先頭に#includeを記述するだけでライブラリ読み込みが出来ますが、インクルード機能のないエディタでは以下のようなコードを先頭に置くことでライブラリが読み込めます。
eval(new ActiveXObject("Scripting.FileSystemObject").OpenTextFile("linq.js").ReadAll().replace(/^・ソ/,""));
ようするに、丸ごとテキストとして読み込んでevalです。/^・ソ/はUTF-8のBOM対策(適当すぎる)。一応、Meryでlinq.jsが動くのは確認しました。電卓マクロは動きません(eePosLogicalとかがEmEditorにしかないので、まあ、その辺は当然だししょうがないわなあ)
まとめ
今回のリニューアルは大変気合が入ってます。コード全部作り替えたぐらいには。最初はjQueryプラグインだけ足せばいいや、とか思ってたのですが、破壊的変更をかけるなら中途半端はいくない、と思い、やれるのは今だけということで徹底的に作り替えました。
ちなみに、ちっとも気にしてないパフォーマンスは悪化しました。ver.1.xがそれでもまだシンプルな構造だったのに比べ、今回は一回の呼び出し階層がかなり深くなった影響があります。列挙終了後にRepeatWithFinalizeとFinallyでしか使ってないDisposeのために階層駆け上がるし(これほんと入れようか悩んだんですけど、WSHだけでなく、将来的にはJavaScriptでもきっちりリソース管理でCloseって機会も増えそうなので入れました)。しかし遅いといっても、ベンチ取るとChromeなら爆速で誤差範囲に収まってしまうのですよ!Google Chrome、恐ろしい子。Firefoxだと?聞くな。いえいえ、JSINQよりは速かったですよ?←何だこの対抗心は
jQueryのおともに。WSHのおともに。エディタマクロのおともに。調度良い感じの隙間にピタリはまるようになっております。JavaScriptにおいてコレクションライブラリはニッチ需要だし、WSH用ライブラリなんて完全隙間産業なわけですが、むしろだからこそ、幾分か価値があるかな?合計83メソッドと、大充実なので、きっと要求に答えられると思います。
linq.jsをjQueryと一緒に使う
- 2010-04-15
linq.jsとjQueryを一緒に使うとするとどうなるのかな、という今まで微妙に避けてきた話。実用的なことを考えるなら避けて通れないのですが、実用的なことなんて考えたこともなかった!今まで!すみません。というわけで、少し考えてみます。あ、Linq to Xml(linq.xml.js)はボツの方向で行きます。RxJSを見習って、jQueryと仲良くやる方向で考えるつもりです。割とイイ線行ってたかなあ、とは思うんですが、クロスブラウザ対応の面倒くささが半端なくて実装しきる気力が持ちそうにないのと、やっぱセレクタ操作が冗長になりすぎてダメだったかなあ、なんて思ってます。
```javascript var p_arr = from p_ele in $("p") where "hoge" in p_ele.classes select p_elefor(var p in p_arr){ p.toggleClass("hilight"); }
こんな風なことができるのかと思ったがそんなわけはなく。<br /> <a href="http://d.hatena.ne.jp/beta_magnus/20100412/1271070326">Linq.js - 人生がベータ版</a> </blockquote> お試しありがとうございます。この例は、出来るといえば出来るし、出来ないといえば出来ないです。まず、クエリ構文では書けなくて、というのはともかくメソッド構文で実際にlinq.jsで組んでみるとこうなります。 ```javascript E.From($("p")) // 内包するDOM要素を列挙 .Select("jQuery($)") // 単一要素のjQueryオブジェクトにラップ .Where(function (q) { return q.attr("class") == "hoge" }) .ForEach(function (q) { q.toggleClass("hilight") }); // jQueryで同じような形にするならこうでしょうか $("p.hoge").each(function () { var q = $(this); q.toggleClass("hilight"); });FromでjQueryの選択された要素を列挙に変換します。jQueryの列挙はjQueryオブジェクトではなく、DOM要素をそのまま返すので(これは.eachで回した時も一緒ですね)、jQueryのメソッドを使いたい時は再度ラップしてあげます。ただまあ、単純なフィルタリングなら、jQueryのセレクタで書いたほうが当然すっきり仕上がりますね。更にまあ、そもそもeachする必要はなく、
// jQuery自体が集合を扱うので一行で書けるんですよね…… $("p.hoge").toggleClass("hilight");となってしまうわけで、DOMから選択してDOMに作用を加える、という一連のjQueryチェーンで綺麗に成り立っている場合に、linq.jsを挟む余地はありません。jQuery自体が集合を含有しているので、jQueryだけで綺麗に完結しちゃうんですね。そしてlinq.jsは、それ自体はクロスブラウザ対応だったりのDOM操作は一切持っていないので、その辺はjQueryにお任せします。そうなると、どうしても出番が限られてくるという。
じゃあ無価値なのかといえば勿論そんなことはなくて、DOMをDOMのまま扱って抽出して作用を加えるのではなく、そこからテキストだったり数値を抽出する、というシーンでは生き生きとします。DOMの選択、フィルタリングまではjQueryのセレクタで行ったらlinq.jsに渡す。数値だったら集計系のメソッドが使えるし、他にもテーブル内の文字をキーにして複数テーブルの結合(join)、なんかも簡単に出来ます。
ところで、 E.From($("selector")).Select("jQuery($)") というのは定型文になるので、jQuery自体に拡張してしまいます。こんなんでもプラグインって呼んでいいですか?(プラグインとしての部分は一行でも、繋がってる先はある意味ヘビー級なので)
// これでjQueryオブジェクトからtoEnumerable()を呼ぶとlinqが使える jQuery.fn.toEnumerable = function () { return E.From(this).Select("jQuery($)"); } // 例えば、input要素の数値を合計する、とか var sum = $("input").toEnumerable() .Select("parseInt($.val())") .Sum();割と便利。かな?具体例に乏しくて非常に説得力に欠ける感じですが、良ければ使ってやってください。
Linq to ObjectsをJavaScriptに実装する方法
- 2010-04-11
JavaScriptでLINQを使おう - 複雑な検索処理を簡潔に記述する「JSINQ」という記事が出ました。私はlinq.jsという、同種のJavaScriptへのLINQ移植ライブラリを作成している人間のため、JSINQの人気っぷりに思わず嫉妬してしまった(笑)のですが、そういう感情は抜いておいてこの紹介記事は、今ひとつよろしくない。
まず頂けないのが、列挙の方法。
// 生のenumeratorを取り出して列挙するですって!?
while (enumerator.moveNext()) {
var name = enumerator.current();
document.write(name + '<br>');
}
// eachが用意されているというのに!
result.each(function(name) { document.write(name + "<br />") });
C#でもJavaでも、きっと他の言語でも、反復子をwhileループで回すなんて原始的なことは普通やりませんよね? foreachに渡しますよね? そんなわけでJSINQにはeachメソッドが用意されているのですが紹介記事は普通にスルー。「enumeratorでの列挙とeachでの列挙二つ紹介する」「enumeratorのみ紹介する」「eachのみ紹介する」の三択で、スペースの都合上一つしか紹介出来ないなら、eachのほうを紹介すべきでしょう。いやまあ、例が一個だったらしょうがないなあ、どうせJSINQのチュートリアルの上のほうから抜き取っただけだろうしー、と思うのですが、三個もenumerator取り出しの例を出されるとさすがにオイオイオイオイ、と突っ込みたくなる。
もうひとつは、文字列によるクエリ構文を推しすぎ。JSINQの最大の特徴でもある部分なのでJSINQの紹介としては正しいのですが(JSINQのプロジェクトページでもそれをフィーチャーしてますしね)、LINQの紹介として見ると大変頂けない。.NETを知らない人(JavaScriptのライブラリなので、基本はJavaScriptの人が見るでしょう)がLinqを誤解してしまう要因になりうるので、こういった紹介は割とキツい。
LINQとはLanguage Integrated Query(統合言語クエリ)であり、言語に統合されていてこそLinqなのです。文字列で与えたらSQLと一緒。LinqはしばしばSQLっぽく記述するもの、と誤認されているようですが、違います。文字列で与えていたSQL(こんな風にね、と最近作ったDbExecutorというSQL実行簡易補助ライブラリをどさくさに紛れて紹介してみる)とは全く別物なのです。詳細は説明すると長くなるので省いちゃいます(え?)。理屈はともかく、言語に統合されていない状態でのSQLは書きやすいとはいえないわけですよ?
var elements = document.getElementsByTagName('a');
var enumerable = new jsinq.Enumerable(elements);
var query = new jsinq.Query(' \
from e in $0 \
where e.href.indexOf("google.co.jp") > -1 \
select e \
');
query.setValue(0, enumerable);
var result = query.execute();
var enumerator = result.getEnumerator();
while (enumerator.moveNext()) {
var e = enumerator.current();
document.write(e.text + ': ' + e.href + '<br>');
}
改行のために末尾に\を入れなければならない、不恰好なプレースホルダ、クエリコンパイルの必要性(executeメソッドの実行でメソッドチェーン形式に変換されます、面白いことにこの点まで.NET Frameworkの忠実な再現となっています(クエリ構文はメソッド構文の糖衣構文にすぎない))。というわけで、到底書きやすいとは言えません。この例を見て、長げーよ馬鹿、意味ねー、アホじゃねーの?普通にfor回した方が百億倍マシだろ、と思った人もいるでしょう。その通りです。素直に便利かも……とか思ったなら、物事はもう少し冷静に見るようにしてください。しかしメソッド構文(jQueryのようにメソッドチェーンで書く方法)ならこう書けます。
var elements = document.getElementsByTagName('a');
new jsinq.Enumerable(elements)
.where(function(e) { return e.href.indexOf("google.co.jp") > -1 })
.each(function(e) { document.write(e.text + ": " + e.href + "<br>") });
これなら納得で、割と使えるかもって感じではないでしょうか? JSINQにおける文字列によるクエリ構文は、人を釣るためのただの餌です。そんな餌で俺様が釣られクマー。jSINQをJavaScriptライブラリとして使うのならば、メソッド構文のほうをお薦めします。クエリ構文はネタ、もしくはただの技術誇示にすぎません。よくやるなー、って感じで素晴らしいとは思いますが、実用性は皆無です。JSINQ自体はLinqの移植として割と良く出来ているので(何だこの上から目線)、文字列クエリ構文で試してみて使えないなー、と思ってしまった、もしくは紹介を見て文字列クエリ構文とかこのライブラリダメだろ、と思った人は、その辺は誤解なくどうぞ。
linq.js
LinqのJavaScript実装は他にもあります。一つは、ええと、私の作成しているlinq.jsです。売り文句はJSINQと同じくSystem.Enumerableとの完全なるAPI互換。.NET4までの範囲を全てカバーしています。更にその上に、Achiral, Ruby, Haskellなどから参考にした大量のメソッドが追加されていることと、Visual Studioで使う場合にはIntelliSenseが動作するファイルがあること、などなど「実用的に使う」ことを強く意識して作っています。手前味噌なのでアレですが、他のどのライブラリよりも使える度は高いと思っています。
- linq.js - LINQ for JavaScript Library - プロジェクトページ
- 紹介と簡単なチュートリアル
- 入力補完に対応させたのでVSでの利用法紹介
- ブログ記事のlinq.jsカテゴリ(最後の更新が去年の9月、がーん)
更新が微妙に止まっているのですが、WindowsScriptHostで快適に使えるような追加ライブラリを作成中(と、9月に言ったっきり絶賛作業休止中、すみません、でもやる気はあるので遠くないうちに必ず出します)。あと、Reactive Extensions for JavaScriptという、これまた.NET発のJavaScript移植ライブラリが出ているので、それとの協調動作も考えています。
Linqを自分で実装する
では本題。実際にLinqをJavaScriptで実装してみましょう。C#でSelectを実装してみたことはありますか? 何のことはなく、たった1行で出来ちゃうんですよね。そんなわけで、実際のところ別に難しいことはありません。勿論、全てのAPIを網羅するのは面倒くさいですが、基本的な原理を掴んでおくとグッと利用法が広がるはずです。まずは、一番単純な、Array.prototypeに生やす方法を考えてみます。例としてmapとforEachを実装してみましょう。
Array.prototype.map = function(selector) {
var result = [];
for (var i = 0; i < this.length; i++)
result.push(selector(this[i]));
return result;
}
Array.prototype.forEach = function(action) {
for (var i = 0; i < this.length; i++)
action(this[i], i); // with index
}
var array = [1, 2, 3, 4, 5, 6, 7, 8, 9];
array.map(function(i) { return { Single: i, Double: i * 2} })
.forEach(function(a) { alert(a.Single + ":" + a.Double) });
配列を変形してforeach。非常に単純な代物ですが、単純が故にmapやfilterは便利ですよね、かなり多用します。C#における匿名型は、JavaScriptではそのままハッシュを返すことで実現されます。さて、このやり方には問題が二つあります。一つはビルトインオブジェクトのprototypeを拡張する、微妙なお行儀の悪さ。そこで、arrayを独自オブジェクトにくるんでやりましょう。
function Enumerable(array) {
this.source = array;
}
Enumerable.prototype.map = function(selector) {
var result = [];
for (var i = 0; i < this.source.length; i++)
result.push(selector(this.source[i]));
return new Enumerable(result);
}
Enumerable.prototype.filter = function(predicate) {
var result = [];
for (var i = 0; i < this.source.length; i++)
if (predicate(this.source[i])) result.push(this.source[i]);
return new Enumerable(result);
}
Enumerable.prototype.reduce = function(func) {
var result = this.source[0];
for (var i = 1; i < this.source.length; i++)
result = func(result, this.source[i]);
return result;
}
var array = [1, 2, 3, 4, 5, 6];
var sum = new Enumerable(array)
.filter(function(i) { return i % 2 == 0 })
.map(function(i) { return i * i })
.reduce(function(x, y) { return x + y });
alert(sum); // 56
配列を一旦包まなくてはならないのが煩わしいのですが、メソッドチェーンのコンボを決めて、気持ちよく列挙することが出来ます。この例ではFirefoxのfilter, map, reduceを再定義してみました(thisObjectの辺りはスルーしてますしreduceの引数なんかも違いますが)。1から6の配列のうち偶数のみを二乗して足し合わせる。答えは56。さて、しかしこの方式にも問題があります。Arrayのprototype拡張が抱えているもう一つの問題と同じですが、メソッドの一つ一つを通る度に無駄な中間配列を生成してしまっています。メソッドチェーンの形になっていると隠蔽されてしまうのですが、冷静に眺めてみればこういうことです。
var array = [1, 2, 3, 4, 5, 6];
var _array = [];
for (var i = 0; i < array.length; i++) {
if (array[i] % 2 == 0) _array.push(array[i]);
}
var __array = [];
for (var i = 0; i < _array.length; i++) {
__array.push(_array[i] * _array[i]);
}
var sum = __array[0];
for (var i = 1; i < __array.length; i++) {
sum += __array[i];
}
さすがに、これはあまりのアホさと無駄さに死ね!と言いたくなりませんか?まあ、この程度は大したコストではないのも確かですし、これこそが富豪的プログラミングだ!といえば、そうだし、その辺はそんなに否定しません。些細なパフォーマンスチューニングにはあまり興味ありません。が、しかし、根本的な問題として、これだと無限リストが扱えません。無限リストとは無限に続くもの、例えば [0,1,2,...,9999,10000,...] 。そんなの使わないって?いやいや、使いこなすと存外便利ですよ? そんなわけで、富豪とか云々を抜きにしても、ただのArrayラッパーは却下です。即時評価なfilterやmapなんて使いたくありません。.NET FrameworkのLinq to Objectsは遅延評価なので、無限リストも扱えますし中間配列といった無駄は出てきません。では遅延評価のリスト処理をどう実装しましょうか。無限リストを作る方法は色々あるでしょうが、ここはLinqの移植なのでC#でのやり方と同じくイテレータパターンを用います。
IEnumerable = function(moveNext) {
this.getEnumerator = function() {
return { current: null, moveNext: moveNext }
}
}
// Generator
Enumerable =
{
toInfinity: function(from) {
if (from === undefined) from = 0;
return new IEnumerable(function() {
this.current = from++;
return true;
});
}
}
// select as map
IEnumerable.prototype.select = function(selector) {
var source = this;
var enumerator = null;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
if (enumerator.moveNext()) {
this.current = selector(enumerator.current);
return true;
}
return false;
});
}
// 無限に2倍するリスト[0, 1, 4, 9, 16,...
Enumerable.toInfinity().select(function(i) { return i * 2 });
LinqはIEnumerableオブジェクトの連鎖で成り立っています。また、return thisでメソッドチェーンをするわけではありません。selectを見てください。メソッドが呼ばれた時点では何も実行せずに、クロージャにより環境を保持した新しいIEnumerableを生成し、それを返しています。ではいつ実行されるのかというと、getEnumerator()が呼ばれ、それで取得されたenumeratorオブジェクトのmoveNext()を呼んだ時です。
さて、しかしこのままではgetEnumeratr()で反復子を取得しての列挙しか出来なくて不便なので、forEachなどを定義してやる必要があります。また、無限リストが本当に無限のままでは困るので、停止させるものが必要です。というわけで、代表的なものを幾つか紹介します。
IEnumerable = function(moveNext) {
this.getEnumerator = function() {
return { current: null, moveNext: moveNext }
}
}
// Generator
Enumerable =
{
from: function(array) {
return Enumerable.repeat(array)
.take(array.length)
.select(function(ar, i) { return ar[i] });
},
toInfinity: function(from) {
if (from === undefined) from = 0;
return new IEnumerable(function() {
this.current = from++;
return true;
});
},
repeat: function(element) {
return new IEnumerable(function() {
this.current = element;
return true;
});
}
}
// select as map
IEnumerable.prototype.select = function(selector) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
if (enumerator.moveNext()) {
this.current = selector(enumerator.current, ++index);
return true;
}
return false;
});
}
// where as filter
IEnumerable.prototype.where = function(predicate) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
while (enumerator.moveNext()) {
if (predicate(enumerator.current, ++index)) {
this.current = enumerator.current;
return true;
}
}
return false;
});
}
IEnumerable.prototype.take = function(count) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
while (++index < count && enumerator.moveNext()) {
this.current = enumerator.current;
return true;
}
return false;
});
}
IEnumerable.prototype.toArray = function() {
var result = [];
var enumerator = this.getEnumerator();
while (enumerator.moveNext()) {
result.push(enumerator.current);
}
return result;
}
// 利用例
// こんな配列があったとして
var array = [1232, 421, 1, 2, 3412, 42, 4, 2, 45];
// 偶数のもののみ二倍した新しい配列を生成
var array2 = Enumerable.from(array)
.where(function(i) { return i % 2 == 0 })
.select(function(i) { return i * 2 })
.toArray();
// 1-100の配列を作成
var array3 = Enumerable.toInfinity(1).take(100).toArray();
// ""のみの長さ100の配列を作成
var array4 = Enumerable.repeat("").take(100).toArray();
生成用メソッドとして、配列を反復子に変換するfrom, 無限にインクリメントした整数を返すtoInfinity, 無限に同一要素を繰り返すrepeatを定義しました。メソッドチェーン用として関数を要素に適用させるselect, 関数でフィルタリングするwhere, 指定個数取得するtake。そしてメソッドチェーンを打ちきって通常使えるオブジェクトに変換するものとして、配列に変換するtoArrayを定義。
fromがrepeatとtakeとselectの組み合わせで出来ているというのが、面白いところです。所謂Fill(配列の初期化)も、repeat->take->toArrayで出来てしまいます。小さなパーツを組み合わせてあらゆることを出来るようにするのがLinqの魅力です。
速度?これが速いと思いますか?そうですねえ、見るからに、xxxですね。しかし、私はミリセカンド単位でのパフォーマンスチューニングにはあまり興味がありません。はいはい、富豪的富豪的。実際のとこGoogle Chrome使えばIE6の1000倍速くなるんだぜ!(数値は適当)。って感じなので、JavaScript側での最適化は、あまり……。とくにLinqではDOM操作とか重たいことをやるんではなくて、純粋に、連鎖の分だけ関数呼び出しが増えるって程度でしかないので、この程度のことでムダムダムダムダー、と言ってもしょうがない気がします。なので、そんなことは気にしないことにします。
ラムダ式もどき
function(x,y,...){return ...}は、長い。Firefoxならfunction() ... で書けるけれど、それでも長い。というわけで、linq.jsでは文字列でラムダ式風に記述出来るようにしています。
var CreateLambda = function(expression) {
if (expression.indexOf("=>") == -1) {
return new Function("$", "return " + expression);
}
else {
var expr = expression.match(/^[(\s]*([^()]*?)[)\s]*=>(.*)/);
return new Function(expr[1], "return " + expr[2]);
}
}
var lambda = CreateLambda("i=>i*i");
var r = lambda(3); // 9
E.Range(1,10).Where("$%2==0").Select("$*$") // linq.jsではこんな感じで書ける
「引数=>式」で文字列を与えます。引数が一つ以下の場合は=>を省略出来ると同時に、$が引数の値として使えるようになっています(Scalaの_とかこんな感じ、なはず)。実装は見た通り非常に単純で文字列分解してnew Functionに渡して関数作ってるだけ。これの難点は、クロージャにならないので、変数のキャプチャが出来ないことです。まあ、そういう時は諦めて無名関数作ってください。
まとめ
filterやmapやreduceが使えて、distinct(重複除去、いわゆるuniq)が使えて、遅延評価だったり、selectやwhereを何段もポコポコと追加出来るわけです。linq.jsはシンプルなライブラリです。派手な機能は一切ありません。ただ列挙して処理するメソッドしかありません。DOMなど一切触りません(DOMの列挙自体は可能なので、DOMノードを流してフィルタリングしたり加工したり、というのは有益でしょう)。ただ、それ故に、使い道は無限大です。
微妙に更新止まってます、が、やる気はあります!まずはWSH対応から!と言いたいのですが、現在は何故かJava移植の制作を進めています。Javaにも素晴らしいLinq to Objectsの世界を、忠実移植で。というわけなのですが、これも先月ぐらいからやるやる詐欺中。中身は完全に出来上がっていて現在テストとJavaDoc書き中。今月中にはリリースしたい、ですね。先月も同じこと言ってましたが、まあ、着々と鈍足ながらも進んでいるので、近いうちにはお見せできるはずです。
ともあれ、Linq to Objectsは大変素晴らしいので、C#な人はガンガン使って欲しいし、JavaScriptの人はlinq.jsを試して欲しいし、Javaな人はもう少し待ってください。私は、ええと、このサイトのC#カテゴリのほとんどがLinq絡みです、ひたすらに使い倒して、有用な使い方を紹介していけたらと思っています。
ParseOrDefault
- 2010-04-09
match があれば TryParse いらないんじゃないか - 予定は未定Blog版という記事を見て、outとかrefは確かにしょっぱい。そういえばF#はTryParseはTuple返しで、おまけに let success, value = int.TryParse "123" という自然な多値返しが出来てCOOLなんだよねー。などと思ってC#でTuple返しにしたものを書いたりしたのですが、どうもしっくりこなくて延々と弄っているうちに明後日の方向へ。
さて、で、「数値に変換できるなら変換して返し、できないなら -1 を返す」というシチュエーションは大変多くて、それにoutを使って組み上げるのは、とてもかったるい、大変避けたい。かといってStringへの拡張メソッドを大量に生やすのも、IntelliSense的な観点からして抑えたい(それにしてもT4 Template使って生成ってのは面白いですね)。なので、汎用的に使えることは捨てて、上述のシチュエーション、変換出来るなら変換して、出来ないなら指定したデフォルト値を返すことにのみ絞って、拡張メソッドにしました。Stringに生やすのは抵抗感があるって場合はUtil.ParseOrDefaultとかにしてもいいと思います。
using System;
static class Program
{
static void Main(string[] args)
{
// 例えばURLのクエリストリングのパースをしたい時とかありますよね!
// num=100にint.Parse(num)はnum=hugaが来たら死ぬのでデフォでは0にしたいとか
var r1 = "100".ParseOrDefault(int.TryParse, -1); // 100
var r2 = "huga".ParseOrDefault(int.TryParse, -1); // -1
// 勿論、int.Parse以外でも何でもいけます
var r3 = "2000/12/12".ParseOrDefault(DateTime.TryParse, DateTime.Now);
// デフォルト値を省く時は型の明記が必要
var r4 = "2000/12/12".ParseOrDefault<DateTime>(DateTime.TryParse);
}
}
public static class StringExtensions
{
public delegate bool TryParse<T>(string input, out T value);
public static T ParseOrDefault<T>(this string input, TryParse<T> tryParse)
{
return input.ParseOrDefault(tryParse, default(T));
}
public static T ParseOrDefault<T>(this string input, TryParse<T> tryParse, T defaultValue)
{
T value;
return tryParse(input, out value) ? value : defaultValue;
}
}
out付きの汎用Funcはデフォルトでは定義されていません。なので、自前で定義する必要があります。この辺の話は@takeshikさんのスライドわんくま東京#38 LT 「Func<> と ref / out 小咄」が詳しいのでどうぞ。こんなデリゲートは単体では使うことは滅多にないでしょうから、static classの中に閉じ込めておくことで名前空間を汚しません(笑)
引数にT defaultValueを要求することで、型推論が働いてTryParseを渡す際に明示的な型付けが不要になります。C#の型推論(と言っていいのかな?)がScalaやF#に比べて弱いのは事実なので、ここは、C#でも自然な形で扱えるような誘導、設計が大事です。型を書いたら負けだと思っている、みたいな。まあ、どんなに頑張っても負けるときは負けるので、その時は潔く書くことにします。
ちなみに、ParseOrDefaultは最初はこんな形でした。酷過ぎる。私は骨の髄まで関数型言語脳ならぬLinq脳なので、とにかくまず無理矢理にでもLinqで処理する方法を考えて、出来上がってふと冷静に眺めると、普通に書けよ馬鹿、ということに気付いて普通に書き直すというサイクルを取ってます。馬鹿すぎる。DbExecutorで紹介したyield returnで一個のみの列挙を返すというのを、やたら使って見ちゃったりするところが麻疹。Repeat(value,1) と Repeat(value,int.MaxValue)があればLinqは何でも記述出来るんです病。
DbExecutor - Linqで操作しやすいSQL実行ライブラリ
- 2010-04-07
前回の記事を書いたところ、ついったで素敵な突っ込みを頂けたので、それを元にもう少し練り直してライブラリ化し、CodePlexに公開しました。ライブラリといってもAnonymousComparerと同じく単純なものですので、ソースコード一本のみ。ご自由にお使いください。例によってCodePlexでの英語がヤバい(小学生レベル、とりあえず何でもforつけておけばいいだろ、的な)ですね、世の中厳しい。
Linq to Sqlと名乗りたいところなのですが、本物がありますから名乗れないー。以前はIQueryableじゃないものをLinq to Hogeって言うのはどうよ、なんて思っていたのですが、考えてみるとLinq to XmlもXMLをIEnumerableベースに処理しやすいような構造を持たせたクラス群にすぎず、別にIQueryableは関係ない。Rxもそうで、あれはIEnumerableでもIQueryableでもなく完全に独立している、けれど、Linq to Events。ようするにLinq的な操作が出来ればLinqなわけです。というわけで、これはSqlをIEnumerableベースで処理出来るようにしたLinq to DB。でも本当に超絶薄いラッパーにすぎないのであんまカッコつけた名前付けるのも恥ずかしくDbExecutorという極々普通の名前に落ち着きました。「Linqで操作しやすい」とかいう釣りタイトルをつけてますが、ただたんにIEnumerable返すというだけです。SQL周りは真剣に追いかけると無限泥沼になる気がする(Entity Framework、そして更にその次へと……?)。追いかけてみたいですが、まあ、まずは、一歩目から。
何で作ったかと言うと、SQLを扱っていて嫌なusing地獄を殺したかったから。
using (var conn = new SqlConnection("connectionString"))
using (var cmd = conn.CreateCommand())
{
conn.Open();
cmd.CommandText = "select ....";
using (var reader = cmd.ExecuteReader())
{
foreach (IDataRecord item in reader)
{
ちょっとクエリ呼びたいだけなのに、普通にこの量、このネスト。こんなんだからLLの人に馬鹿にされてしまうんだよ。で、ふと思ったのは、この図式ってもしかしてWebRequestと同じですか?
string html;
var req = (HttpWebRequest)WebRequest.Create("http://google.co.jp");
using (var res = req.GetResponse())
using (var stream = res.GetResponseStream())
using (var sr = new StreamReader(stream))
{
html = sr.ReadToEnd();
}
ちょっとWebからデータを取得したいだけなのに狂ったようにusingを重ねなければならない!そしてもう一つ嫌なのが、変数に渡す際に、usingのスコープが絡むので場合によっては外で定義しなければならないこと。string html;だってさ。嫌だ嫌だ。別にvarが使えないから嫌だと言っているわけじゃなくて(半分はそうなのですが)、代入位置と宣言が離れるのは可読性が落ちます。あとは、単純に不恰好ですしね。そんなWebRequestですが、WebClientという簡単に使えるものが用意されているので、普段はこっちを使うわけです。
var html = new WebClient().DownloadString("http://google.co.jp");
素晴らしい! 私はWebClientが好きです。簡単なのは良いこと、を体現していますから。ネット上のサンプルがやたらとWebRequestを使うものばかりなことを嘆きます。WebRequestとWebClientでCookie認証をする方法とかいう記事を書いたりと、必死に普及に励んだりしていますが中々どうして焼け石に水、ていうか確かに少し凝ったことをやろうとすると面倒くさいのは否めませんね……。
というわけかで、偉大なるWebClientを見習って、SqlConnectionの一連の流れを抹殺するラッパーを作ってみました。プリミティブなAPIなんて触りたくないっす。プリミティブなものは魅力どころか穢れたものに見えてしまうので、可能な限り隠蔽してやりたいのです。本当は生のSQLだって触りたくないんですけどね……。さて、目標は、簡単に使えることと、usingが極力表に出ないようにすること。とりあえず利用例から。PersonTableというAgeとFirstNameとLastNameが格納されてるテーブルからデータを引っ張ってきます。
// ただの入れ物
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
static class Program
{
static void Main(string[] args)
{
// 実行→即Closeの場合静的メソッドを用いる(Regexと同じ感覚で)
var maxAge = DbExecutor.ExecuteScalar<int>(new SqlConnection("ConnectionString"),
@"select max(Age) from PersonTable");
// 接続を維持して複数回実行する場合はインスタンス生成で
using (var executor = new DbExecutor(new SqlConnection("ConnectionString")))
{
// 列名とプロパティ名を対比させてマッピング
// パラメータはstring.Format的に@p0, @p1などに対して適用される
var persons = executor.ExecuteQuery<Person>(@"
select
FirstName + ' ' + LastName as Name,
Age
from PersonTable
where Age < @p0 and FirstName = @p1"
, 20, "Osakana").ToList(); // 遅延評価なのでusingを抜ける前にリスト化などどうぞ
// ExecuteReadはIEnumerable<IDataRecord>で一行ずつ取得できる
var persons2 = executor.ExecuteRead(@"select * from PersonTable")
.Select(dr => new
{
Age = dr.GetInt32(0),
FirstName = dr.GetString(1),
LastName = dr.GetString(2)
});
}
}
}
といった感じに、処理用のラッパーにDB接続を渡して実行します。メソッドはExecuteScalar, ExecuteNonQuery, ExecuteRead, ExecuteQueryの4つ。ScalarとNonQueryは普通のと同じ、Readは一行毎に列挙、Queryはオブジェクトへのマッピングが出来ます。4つのメソッドの引数は全て同じで、string query, params object[] parametersになります。パラメータは@p0, @p1, といったように「@p順番」に対して適用されます。
実行して即座にコネクションを閉じたい場合は静的メソッドを、接続を維持したまま複数実行した場合はインスタンスを生成してください。DbExecutor自体がIDisposableで、Dispose時に中のコネクションに対しDisposeを呼びます。なお、トランザクション関連のメソッドはありませんが、それはTransactionScopeを使ってくださいな。
スコープと遅延評価
同じ処理はメソッドに括り出す!Don't Repeat Yourself!コピペ禁止!ではあるものの、スコープが絡むと結構難しい。usingは難敵です。以下、実装の一部。
// 実装(一部抜粋)
public class DbExecutor : IDisposable
{
// usingを共通化させたいんだけど、普通に値返すとスコープ抜けちゃう
// →IEnumerableで包んでしまえばいいぢゃない!
private IEnumerable<DbCommand> UsingCommand(string query, object[] parameters)
{
using (var cmd = dbConnection.CreateCommand())
{
if (dbConnection.State != ConnectionState.Open) dbConnection.Open();
cmd.CommandText = query;
foreach (var p in parameters.Select((v, i) => CreateParameter(cmd, "@p" + i, v)))
{
cmd.Parameters.Add(p);
}
yield return cmd;
}
}
// UsingCommand().First().ExecuteScalar()だとusingを抜けてから実行になるのでダメなのですよー
public T ExecuteScalar<T>(string query, params object[] parameters)
{
return UsingCommand(query, parameters).Select(c => (T)c.ExecuteScalar()).First();
}
public IEnumerable<IDataRecord> ExecuteRead(string query, params object[] parameters)
{
return UsingCommand(query, parameters).SelectMany(c => c.EnumerateAll());
}
}
public static class IDbCommandExtensions
{
public static IEnumerable<IDataRecord> EnumerateAll(this IDbCommand command)
{
using (var reader = command.ExecuteReader())
{
while (reader.Read()) yield return reader;
}
}
}
UsingCommandメソッドが苦心の跡です。ExecuteScalarとExecuteReadの処理(DbCommand取ってパラメータ足す)を共通化したかったのですが、usingが難敵で。ExecuteScalarはTを返すから即時実行、これをusingで一部括り出すのは簡単なのですが、問題はExecuteRead。IEnumerableを返すから遅延実行で、これに対してusing(cmd){return cmd}なんて関数を使ってしまうと、実行時に即座にusingのスコープを抜けてしまってusingが無効になってしまう(どころかDispose済みになってしまうので実効時エラー)。
じゃあどうすればいいか、というと、usingに括り出した部分も遅延評価してしまえばいい。そこで要素一つのみでyield returnする。そして、即時評価のものはSelect->First、遅延評価のものはSelectManyを使うことで、無事Usingを共通化出来ました。おお、Linqは何と素晴らしいのでしょうか!何かと言うと、つまりは、Linq to Objectsの用途はリスト処理だけじゃないんですね。IEnumerableはインフラ。そして、Reactive Extensionsに入っているEnumerableEx.Return(これはEnumerable.Repeat(elem,1)に等しい)の意味合いがジワジワくる。Returnは明らかにHaskell由来の命名で、モナドが(以下略、もしくはナンダッテー)
で、まあ、利用時は結局データベースとの接続やトランザクションとの兼ね合いもあるので、接続の状態自体は割と意識してないとダメですね。適当なところでToListとでもしておいてください。この辺も含有した上での解決策は課題ですね、今はうまいやり方が全然思いつかない。
SQLiteで使う
勿論、SqlServer以外でも使えます。System.Data.SQLiteで試しましたが、問題なく動きました。というわけで、Hello, SQLite。SQLiteをインストールしたら参照設定にSystem.Data.SQLiteを加えて
var builder = new SQLiteConnectionStringBuilder { DataSource = "test.db" };
using (var executor = new DbExecutor(new SQLiteConnection(builder.ConnectionString)))
{
var existsTable = executor.ExecuteRead(@"select * from sqlite_master where type='table' and name = @p0", "test")
.Any();
if (!existsTable)
{
executor.ExecuteNonQuery(@"create table test (Age, Name)");
executor.ExecuteNonQuery(@"insert into test values(10,'hoge')");
executor.ExecuteNonQuery(@"insert into test values(20,'tako')");
executor.ExecuteNonQuery(@"insert into test values(30,'ika')");
}
executor.ExecuteRead(@"select * from test where Age >= @p0", 20)
.Select(dr => new { Age = dr.GetInt32(0), Name = dr.GetString(1) })
.ToList()
.ForEach(a => Console.WriteLine(a.Name + ":" + a.Age));
}
existsTableのクエリはテーブルがあるかないかを調べるもので、一行帰ってくるならテーブルが存在する、何も帰ってこない時はテーブルが存在しない。というわけで、それAny()で、ですね。IEnumerableベースで扱えると、こういうことが非常に楽です。
それにしてもSystem.Data.SQLiteいいですね、初めて使ったんですが拍子抜けするぐらいに簡単に試せました。インストールしたら参照設定に加えるだけ、DataSourceに直にファイル名指定すれば、あれば読み込み、なければ生成してくれる。データベースは設定が面倒っちいですからねー、こう簡単に出来るのは嬉しいです。
おまけ
で、まあ、VS2008ならLinq to SQL/Entities使わないのー?って話であり、まあ、ねえ、確かに、ねえ。なので、ひっそりとVS2005バージョンも作ってみました(zipに同梱してあります)。内部的にも(当然)Linq未使用なので 、VS2008で対象フレームワークが.NET 2.0の場合でも、こちらなら使えます。内部でSelectとかSelectManyを再定義して、拡張メソッドの呼出じゃなくて普通の呼び出しに書き換えただけです。あまりの型推論の効かなさにイライラしました。もうC#2.0に戻るとか無理すぎるだろ常識的に考えて。
List<Person> persons = executor.ExecuteRead<Person>(@"select * from PersonTable", null,
delegate(IDataRecord dr)
{
Person p = new Person();
p.Age = dr.GetInt32(0);
p.Name = dr.GetString(1) + " " + dr.GetString(2);
return p;
});
ExecuteReadとExecuteQueryは、IEnumerableを返されても困ると思うので、Listを返すようにしています。ExecuteReadはSelectがないので、第三引数でConverterデリゲートを受けるようにして、Selectの代わりにしました。 使う分には、VS2008のものとさして変わらないと思います。
追記
初回リリース時の名前はDbExecuterだったんですが、DbExecutorに変更しました。stableとか言っておきながら4時間で撤回とか、殺されていいですね、ほんとすみませんすみません。あまりの恥ずかしさに穴掘って埋まりたいです……。まあ、executerでもよくね?と思わなくもなくもないのですが、実際問題ぐぐる先生の検索結果で大きな差があるので、むしろ変えるなら、たった4時間の今のうちしかない、と思ったので変更しちゃいました。しかし、ああ……。スペルは結構気をつけてるほうだと思ったんだけどなあー。
C#で原始的にSQLを扱うお話
- 2010-04-05
世の中はLinq to SQLだのLinq to Entitiesだのを羨ましいなあ、と指を加えて眺めている昨今ですがこんばんわ。Linq好きーな私ですがこのサイトではObjectsとXmlしか扱っていないのは、単純に私が触った事ないから、です。あうあう。そんな私ですが、SQLを(大変嫌々ながら)触らなければならなかったりする場合もないわけじゃないのですが、アレですね、思うのはパラメータ。あれにadd。add。するのが大変美しくない。もっと格好良く、一発で決めようぜ。と思って色々悩んだんですが、どうにも上手く行きそうにない。やけくそになってビルダー+コレクション初期化子を考えてみました。
var cmd = new SqlCommand();
cmd.CommandText = @"select * from Foo where Bar > @Hoge and Tako = @Ika";
cmd.Parameters.AddRange(new SqlParameterBuilder
{
{"@Hoge", "2"}
{"@Ika", "たこやき"}
}.ToArray());
分かりづらくなってるだけで、普通にadd, addでいいですね。ダメだこりゃ。ボツ。ちなみに実装は超単純。
public class SqlParameterBuilder : IEnumerable<SqlParameter>
{
List<SqlParameter> parameters = new List<SqlParameter>();
public SqlParameterBuilder Add(string parameterName, object value)
{
parameters.Add(new SqlParameter(parameterName, value));
return this;
}
public IEnumerator<SqlParameter> GetEnumerator()
{
return parameters.GetEnumerator();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
コレクション初期化子の復習をしますと、IEnumerableかつAddメソッドが実装されているクラスに対してコレクション初期化子が使えます。Addは名前で決め打ちされています。メソッド名はAddじゃなくてAppendがいいなー、とか思ってもダメです。コレクション初期化子を使いたい場合はAddです。何でこんなヘンテコなことになってるのか、の理由は2008-02-08 - 当面C#と.NETな記録の記事を参照に。Addが複数引数を取る場合は{{},{}}って書けますが、IntelliSenseの補助がないので割と不便だったりしますねえ。
関数渡し
whileでEndまで読んで、ってのは嫌いです。Stream系のは全部yield returnでライン毎に返す拡張メソッドを定義しますね、私は。というわけで、SQLのDataReaderもStreamと同じ図式なので、同じ感じにしましょー。
var command = new SqlCommand();
command.CommandText = @"select hogehogehoge";
var result = command.EnumerateAll(dr => new
{
AA = dr.GetString(0),
BB = dr.GetInt32(1)
});
いい感じに見えないでしょうかどうでしょうか?といっても、これは以前書いたものの使い回しだったりしますが、その以前書いたコードとやらは若干反省してます。以下、書き直したコード。
public static IEnumerable<T> EnumerateAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
yield return selector(reader);
}
}
}
public static T[] ReadAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
return command.EnumerateAll(selector).ToArray();
}
そう、以前は無理やりEnumerable.Repeatで無限リピートさせておりましたが、あのテクニックはyield returnが使えない(別関数に分けない場合)時のためのテクニックであって、yield returnが使えるなら素直にwhileループを回して書いた方がマシなのです。どうにも、まずLinqで書いたらどうなるのか、というのが頭に最初に浮かんでしまってフツーの書き方を忘れてしまいがちなのですが、大事なのはシンプルに表現すること、です。何故Linqを使うのか、そのほうがシンプルに書けるから。whileのほうがシンプルになるなら、そちらを選ぼう。弁解のために言っておくと、あれはreturn IEnumerableとyield returnの挙動の違いの例のために書いたわけですががが。あと、yieldが言語によってサポートされてるからってのもありますね。C#1.0のように自前でEnumerator用意して書かなきゃならないのならば、Linqで生成したほうが良いわけで。
マッピング
GetInt32(1)とか列を意識してオブジェクトに詰めるのがダルい。定形作業だし列がズれたら修正面倒だし殺したい。こんなの人間のやる作業じゃない。つーわけで、入れ物に詰めるのぐらいは自動化しよう。ああ、Linq to Sql使いたいなあ。
// このクラスにデータベースから値を入れるとして
class MyClass
{
public int IntProp { get; set; }
public string StrProp { get; set; }
}
static void Main(string[] args)
{
// プロパティ名と対比させて自動詰め込み
var command = new SqlCommand();
command.CommandText = @"
select
hoge as IntProp,
huga as StrProp
from NantokaTable";
var result = command.Map<MyClass>();
}
public static T[] Map<T>(this IDbCommand command) where T : new()
{
Dictionary<string, PropertyInfo> properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
列名とプロパティ名を摺り合わせているだけで、非常に単純なものです。気になるreaderのFieldCountとかGetNameの処理効率ですが、実行した時点で一行のキャッシュが生成されて、そこから取ってくる感じになるので重たくはないっぽいです。たぶん。ちゃんと追っかけたわけじゃないので全然断言は出来ませんが。あとは辞書生成のコストですかね。Type毎で固定なら毎回辞書作らなくてもキャッシュ出来るじゃん、という。静的コンストラクタを使えば、実現できます。
public static class Extensions
{
public static T[] Map<T>(this IDbCommand command) where T : new()
{
return SqlMapper<T>.Map(command);
}
private static class SqlMapper<T> where T : new()
{
static readonly Dictionary<string, PropertyInfo> properties;
static SqlMapper()
{
properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
}
public static T[] Map(IDbCommand command)
{
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
if (dr.IsDBNull(i)) continue;
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
}
}
割とスマート。ジェネリック静的クラスには直接拡張メソッドは定義出来ないので、入れ子のprivateな静的クラスを挟んでいます。 と、こんな感じにSQLを触っていると非常に原始人っぽい。先日のテンプレート置換と同じく、コピペに優しい小粒でピリッと役立ち、なメソッドの作成を志してる感じです。まあ実際は自分だけが使うUtilなんて許されるわけもなく普通に地味にドロドロと(ああ、胃が……)。
そういえばであまり関係ないのですが、SQL文ってどこに置くべきなんでしょうかね。外部ファイルにしておいて読み込み、などというのは個人的にはどうかなー、と思っていて。どうせ呼び出し部分と1:1になるなら、↑のようにハードコードでも別によくないかしらん、そのほうがソースコード上の距離が近いこともあって分かりやすくなる。とか、どうなんでしょうかねえ。再コンパイルが不要になるといって、どうせSQLに変更入ったらコードのほうも変更入れないとマズい可能性が高そう、とか。
追記
マッパーはSystem.Data.LinqにあるDataContext.ExecuteQuery(TResult) メソッド そのものですね、たはは、シラナカッタヨ。↑のほうが超単純実装+キャッシュなので速いとは思いますが、どうでもいい差ですな。全く同じものだと悔しいので、outer joinとかでNullが混じる場合もすんなり使えるように、IsDBNullを足してスキップするようにしました。まあSQLでcoalesceで明示的にやったほうが良いとは思いますが。EnumerateAllのほうは普通に使えると思うのでぜひぜひ。