C#から使うMicrosoft Ajax MinifierでのJavaScriptコード圧縮
- 2010-09-09
いつのまにか独立してCodePlex入りしているMicrosoft Ajax Minifier。その名の通り、Microsoft謹製のJavaScript/CSSの圧縮/整形ツールです。発表からすぐに、GoogleのClosure Compilerが出てしまったのですっかり影も薄く、ていうか名前悪いよね、Ajax関係ないじゃん……。CodePlexのプロジェクトページも何だか活気ない寂れた感じで、あーあ、といった趣。良いツールなんですけどねえ。
コマンドライン版とDLL版が用意されていて、コマンドラインの、単体で実行可能なexeの解説は【ハウツー】Microsoft Ajax MinifierでJavaScriptを縮小化しようで解説されているので、DLL版の使い方を簡単に解説します。
C#が使える人ならばDLL版のほうが遥かに使いやすかったりして。設定をダラダラと引数を連ねるのではなく、オブジェクト初期化子とenumで出来るので、そう、IntelliSenseが効くわけです。ヘルプ要らずで書けるのは快適。Visual Studioは偉大だなぁ。コマンドライン, PowerShellを捨て、VSのConsoleApplicationを常に立ち上げよう。実際、ちょっとしたテキスト処理とかC#で書いちゃうんですよねえ、私。Linqが楽だから。
Minifierオブジェクトを作ってMinifyJavaScript(CSSの場合はMinifyStyleSheet)メソッドを実行するだけなので、コード見たほうが早いかな。例としてlinq.jsをlinq.min.jsに圧縮します。そして、解析されたWarningをコンソールに表示します。ただの圧縮だけでなく、このコード分析機能が実にありがたい。
using System;
using System.IO;
using Microsoft.Ajax.Utilities;
class Program
{
static void Main(string[] args)
{
var minifier = new Minifier
{
WarningLevel = 3, // 最大4。4はウザいのが多いので3がいいね。
FileName = "linq.js" // エラー表示用に使うだけなので、なくてもいい
};
var settings = new CodeSettings // CSSの場合はCSSSettings
{
LocalRenaming = LocalRenaming.CrunchAll,
OutputMode = OutputMode.SingleLine, // MultiLineにすると整形
IndentSize = 4, // SingleLineの時は意味なし
CollapseToLiteral = true,
CombineDuplicateLiterals = true
// その他いろいろ(それぞれの意味はIntelliSenseのsummaryを読めば分かるね!)
};
var load = System.IO.File.ReadAllText(@"linq.js"); // 読み込み
// 最後の引数はグローバル領域に何の変数が定義されてるか指定するもの
// 別になくても構わないんだけど、warningに出るので多少は指定しておく
var result = minifier.MinifyJavaScript(load, settings, "Enumerable", "Enumerator", "JSON", "console", "$", "jQuery");
// Warningで発見されたエラーはErrorsに格納されてる
foreach (var item in minifier.Errors)
{
Console.WriteLine(item);
}
File.WriteAllText("linq.min.js", result); // 書き出し
Console.WriteLine();
Console.WriteLine("Original:" + new FileInfo("linq.js").Length / 1024 + "KB");
Console.WriteLine("Minified:" + new FileInfo("linq.min.js").Length / 1024 + "KB");
}
}
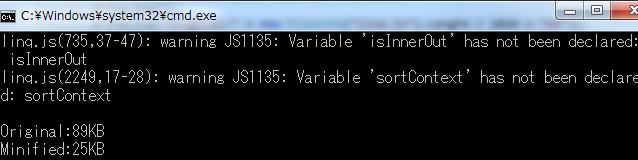
二つエラー出てますね。変数がvarで宣言されてないそうです。つまり、コードがその行通ると変数がグローバルに置かれてしまいます。確認したら、OrderBy実行したらsortContextという変数がグローバルに飛んでしまってました。ええ、つまりバグと言っていいです。……。あうあう、すみません、直します。これからは必ずAjax Minifierの分析を通してから公開しよう。どうでもよくどうでもよくないんですがlinq.jsもアップデートすべきことが結構溜まってるので近いうちには……。
というわけで、Ajax Minifierの偉大さが分かりました。素晴らしい!みんな使おう!DLLの形になっているので、T4 Templateと混ぜたりなどもしやすく、夢が膨らむ。minifyだけでなく、JSのパーサーとして抽象構文木を取り出したりなども出来ます。
WebでGUIでサクッと実行できる環境とかあるといいと思うんですよね。それこそDLLになっているので、Silverlightならすぐ作れるわけですし。誰か作ればいいのに。いや、お前が作れよって話なんですが。Ajax Minifierが出てすぐの頃に作ろうとしてお蔵入りしちゃったんだよね、ふーみぅ。そうそう、あと、VSと統合されて欲しい!このWarningは大変強力なので、その場でVSのエラー一覧に表示して欲しいぐらい。今のVSのエラー表示はWarningLevelで言うところの1ぐらいで警告出してくれて、それはそれで良い感じなんですが、やっぱこう、もっとビシッと言って欲しいわけですよ。
ワンクリックで整形/圧縮してくれるのとエラー一覧表示が出来るようなVisual Studio拡張を誰か作って欲しいなあ。いやー、本気で欲しいので、とりあえず私も自分で作ってみようと思い、VS2010 SDKは入れてみた。気力が折れてなければ来月ぐらいには公開、したい、です、予定は未定のやるやる詐欺ですががが。
TwitterTLtoHTML ver.0.2.0.0
- 2010-09-02
TwitterのBasic認証の有効期限が8月いっぱいだったのですよね。それは知っていて動かなくなるのも知っておきながら、実際に動かなくなるまで放置していたという酷い有様。結果的に自分で困ってました(普通に今も使っていたので)。というわけで、TwitterTL to HTMLをOAuth対応にしました。認証時のアプリケーション名がTL to HTMLなのですが、これは「Twitter」という単語名をアプリケーション名に入れられないためです。面倒くさいねえ。
OAuth認証は@ugaya40さんのOAuthAccessを利用しています。XboxInfoTwitでは自前のものを使っていたのですが、どうしょうもなく酷いので自分で作り直すかライブラリを使うか、でズルズル悩んで締切りを迎えたのでライブラリ利用に決定ー。使いやすくて良いと思います。
T4による不変オブジェクト生成のためのテンプレート
- 2010-08-30
不変欲しい!const欲しい!readonlyをローカル変数にもつけたい!という要望をたまに見かけるこの頃。もし、そういった再代入不可というマークがローカル変数に導入されるとしたら、readonlyの使い回しだけは勘弁です。何故って、ローカル変数なんて大抵は再代入しないので、readonly推奨ということになるでしょう、そのうちreadonly付けろreadonly付けろというreadonly厨が出てくるのは目に見えています。
良いことなら付ければいいじゃない、というのはもっともですが、Uglyですよ、視覚的に。readonly var hoge = 3 だなんて、見たくはない。頻繁に使うほうがオプションで醜く面倒くさいってのは、良くないことです。let hoge = 3 といったように、let、もしくはその他のキーワード(valとか?)を導入するならば、いいかな、とは思いますが。
それに、ただ単にマークしただけじゃあ不変を保証するわけでもない……。例えばListなんてClearしてAddRangeしたのと再代入とは、どう違うの?的な。難しいねえ。そんなimmutableの分類に関してはufcppさんのimmutableという記事が、コメント欄含め参考になりました。
そうはいっても、そんなにガチに捉えなくても、不変にしたいシチュエーションはいっぱいあります。実はオブジェクト指向ってしっくりきすぎるんです! 不変オブジェクトのすゝめ。 - Bug Catharsis。おお、すすめられたい。ところでしかし、こういう時にいつも疑問に思っているのは、生成どうすればいいのだろう、ということ。今のところ現実解としてあるのはreadonly、つまり、コンストラクタに渡すしかないのですが……
public Hoge(int a, int b, int c, string d, string e, DateTime f, .....
破綻してる。こんなクソ長いコンストラクタ見かけたら殺していいと思う。全くもって酷い。さて、どうしましょう。こういう場合はビルダーを使いましょう、とはEffective Javaが言ってますので(私、この本あんま好きじゃないんだよねー、とかはどうでもいいんですがー)とりあえずストレートに従ってみます。
// あまり行数使うのもアレなので短くしますが、実際は10行ぐらいあると思ってください
Hoge hoge = new HogeBuilder()
.Age(10)
.Name("hogehoge")
.Build();
まあ、悪くない、ですって?いえいえ、これはBuilder作るの面倒くさいし、第一Java臭い。メソッドチェーンだからモダンで素敵、と脳が直結してる人は考えが一歩足らない。むしろ古臭い。最近は流れるようなインターフェイスとかも割と懐疑的で、私は。頂くのはアイディアだけであって、書き方に関しては、各言語にきっちり馴染ませるべき。先頭の大文字小文字だけ整えて移植だとか、愚かな話。というわけで、C#ならオブジェクト初期化子を使おう。
var hoge = new HogeBuilder
{
Age = 10,
Name = "hogehoge"
}.Build();
// 暗黙的な型変換を使えばBuildメソッドも不要になる(私はvarのほうが好みですが)
Hoge hoge = new HogeBuilder
{
Age = 10,
Name = "hogehoge"
};
ええ、これなら悪くない。オブジェクト初期化子は大変素晴らしい(本当にそろそろModern C# Designをですね……)。ビルダーを作る手間もJava方式に比べ大幅に軽減されます(set専用の自動プロパティを用意するだけ)。それにIntelliSenseのサポートも効きます。
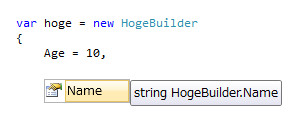
未代入のもののみリストアップしてくれる(Ctrl+Space押しだと全部出てきたりする、バグですかね、困った困った)。そういえばで、これは、不変である匿名型の記法とも似ています。余分なのは.Build()だけで、書く手間的にはそんな変わらない。
前説が長ったらしくなりました。本題は「匿名型のような楽な記法で不変型を生成したい」が目標です。C#の現在の記法では、それは無い。欲しいなあ。名前付き引数使えば似たような雰囲気になると言えばなるんですが、アレ使うと「省略可」な雰囲気が出てダメ。ビルダーで作りたいのは、原則「省略不可」なので。
なければ作ればいいじゃない、オブジェクト初期化子を使って.Buildで生成させるビルダーを作れば似たような感じになる。あとは、手動でそれ定義するの非常に面倒なので、そう、T4で自動生成しちゃえばいいぢゃない。
以下コード。例によってパブリックドメインで。別にブログにベタ貼りなコードは自明でいいんじゃないかって気もするんですが、宣言は一応しておいたほうがいいのかなー、と。
<#@ assembly Name="System.Core.dll" #>
<#@ import namespace="System.Linq" #>
<#@ import namespace="System.Collections.Generic" #>
<#@ import namespace="System.Text.RegularExpressions" #>
<#@ output extension="Generated.cs" #>
<#
// 設定:クラス名はそのまま文字列で入力
// クラスの持つ変数は、コンストラクタに書くみたいにdeffinesに
// "string hoge","int huga" といった形で並べてください
// usingとnamespaceは、直下の出力部を直に弄ってください
// partial classなので、これをベースにメソッドを足す場合は別ファイルにpartialで定義することを推奨します
// Code Contractsに関わる部分は(ContractVerification属性とContract.EndContractBlock())は、
// 対象がWindows Phone 7などContractが入っていない環境下では削除してください(通常の.NET 4環境では放置で大丈夫)
var className = "Person";
var deffines = new DeffineList {
"string name",
"DateTime birth",
"string address"
};
#>
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Diagnostics.Contracts;
namespace Neue.Test
{
[DebuggerDisplay(@"<#= deffines.DebuggerDisplay #>", Type = "<#= className #>")]
public partial class <#= className #> : IEquatable<<#= className #>>
{
<# foreach(var x in deffines) {#>
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly <#= x.TypeName #> <#= x.FieldName #>;
public <#= x.TypeName #> <#= x.PropName #> { get { return <#= x.FieldName #>; } }
<# } #>
private <#= className #>(<#= deffines.Constructor #>)
{
<# foreach(var x in deffines) {#>
this.<#= x.FieldName #> = <#= x.FieldName #>;
<# } #>
}
[ContractVerification(false)]
public static implicit operator Person(Builder builder)
{
return builder.Build();
}
public bool Equals(<#= className #> other)
{
if (other == null || GetType() != other.GetType()) return false;
if (ReferenceEquals(this, other)) return true;
return EqualityComparer<<#= deffines.First().TypeName #>>.Default.Equals(<#= deffines.First().FieldName #>, other.<#= deffines.First().FieldName #>)
<# foreach(var x in deffines.Skip(1)) {#>
&& EqualityComparer<<#= x.TypeName #>>.Default.Equals(<#= x.FieldName #>, other.<#= x.FieldName #>)
<# } #>
;
}
public override bool Equals(object obj)
{
var other = obj as <#= className #>;
return (other != null) ? Equals(other) : false;
}
public override int GetHashCode()
{
var hash = 0xf937b6f;
<# foreach(var x in deffines) {#>
hash = (-1521134295 * hash) + EqualityComparer<<#= x.TypeName #>>.Default.GetHashCode(<#= x.FieldName #>);
<# } #>
return hash;
}
public override string ToString()
{
return "{ " + "<#= deffines.First().PropName #> = " + <#= deffines.First().FieldName #> +
<# foreach(var x in deffines.Skip(1)) {#>
", <#= x.PropName #> = " + <#= x.FieldName #> +
<# } #>
" }";
}
public class Builder
{
<# foreach(var x in deffines) {#>
public <#= x.TypeName #> <#= x.PropName #> { private get; set; }
<# } #>
public <#= className #> Build()
{
<# foreach(var x in deffines) {#>
if ((object)<#= x.PropName #> == null) throw new ArgumentNullException("<#= x.PropName #>");
<# } #>
Contract.EndContractBlock();
return new <#= className #>(<#= string.Join(", ", deffines.Select(d => d.PropName)) #>);
}
}
}
}
<#+
class Deffine
{
public string TypeName, FieldName, PropName;
public Deffine(string constructorParam)
{
var split = constructorParam.Split(' ');
this.TypeName = split.First();
this.FieldName = Regex.Replace(split.Last(), "^(.)", m => m.Groups[1].Value.ToLower());
this.PropName = Regex.Replace(FieldName, "^(.)", m => m.Groups[1].Value.ToUpper());
}
}
class DeffineList : IEnumerable<Deffine>
{
private List<Deffine> list = new List<Deffine>();
public void Add(string constructorParam)
{
list.Add(new Deffine(constructorParam));
}
public string DebuggerDisplay
{
get
{
return "\\{ " + string.Join(", ", list.Select(d =>
string.Format("{0} = {{{1}}}", d.PropName, d.FieldName))) + " }";
}
}
public string Constructor
{
get { return string.Join(", ", list.Select(d => d.TypeName + " " + d.FieldName)); }
}
public IEnumerator<Deffine> GetEnumerator()
{
return list.GetEnumerator();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
#>
以下のようなのが出力されます(長いねー)
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Diagnostics.Contracts;
namespace Neue.Test
{
[DebuggerDisplay(@"\{ Name = {name}, Birth = {birth}, Address = {address} }", Type = "Person")]
public partial class Person : IEquatable<Person>
{
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly string name;
public string Name { get { return name; } }
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly DateTime birth;
public DateTime Birth { get { return birth; } }
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly string address;
public string Address { get { return address; } }
private Person(string name, DateTime birth, string address)
{
this.name = name;
this.birth = birth;
this.address = address;
}
[ContractVerification(false)]
public static implicit operator Person(Builder builder)
{
return builder.Build();
}
public bool Equals(Person other)
{
if (other == null || GetType() != other.GetType()) return false;
if (ReferenceEquals(this, other)) return true;
return EqualityComparer<string>.Default.Equals(name, other.name)
&& EqualityComparer<DateTime>.Default.Equals(birth, other.birth)
&& EqualityComparer<string>.Default.Equals(address, other.address)
;
}
public override bool Equals(object obj)
{
var other = obj as Person;
return (other != null) ? Equals(other) : false;
}
public override int GetHashCode()
{
var hash = 0xf937b6f;
hash = (-1521134295 * hash) + EqualityComparer<string>.Default.GetHashCode(name);
hash = (-1521134295 * hash) + EqualityComparer<DateTime>.Default.GetHashCode(birth);
hash = (-1521134295 * hash) + EqualityComparer<string>.Default.GetHashCode(address);
return hash;
}
public override string ToString()
{
return "{ " + "Name = " + name +
", Birth = " + birth +
", Address = " + address +
" }";
}
public class Builder
{
public string Name { private get; set; }
public DateTime Birth { private get; set; }
public string Address { private get; set; }
public Person Build()
{
if ((object)Name == null) throw new ArgumentNullException("Name");
if ((object)Birth == null) throw new ArgumentNullException("Birth");
if ((object)Address == null) throw new ArgumentNullException("Address");
Contract.EndContractBlock();
return new Person(Name, Birth, Address);
}
}
}
}
これで、どれだけ引数の多いクラスであろうとも、簡単な記述でイミュータブルオブジェクトを生成させることが出来ます。しかも、普通にクラス作るよりも楽なぐらいです、.ttをコピペって、先頭の方に、コンストラクタに並べる型を書くだけ。後は全部自動生成任せ。もし積極的に使うなら、Generated.csのほうを消して.ttのみにした状態で、ファイル→テンプレートのエクスポートで項目のエクスポートをすると使い回しやすくて素敵と思われます、項目名はImmutableObjectとかで。
// 書くときはこんな風にやります
var person1 = new Person.Builder
{
Name = "hoge",
Birth = new DateTime(1999, 12, 12),
Address = "Tokyo"
}.Build();
// 暗黙的な型変換も実装されているので、.Buildメソッドの省略も可
Person person2 = new Person.Builder
{
Name = "hoge",
Birth = new DateTime(1999, 12, 12),
Address = "Tokyo"
};
// 参照ではなく、全てのフィールドの値の同値性で比較される
Console.WriteLine(person1.Equals(person2)); // true
匿名型の再現なので、EqualsやGetHashCodeもオーバーライドされて、フィールドの値で比較を行うようになっています。この辺はもう手動だと書いてられないですよね。ReSharperなどを入れて生成をお任せする、という手はありますが。
==はオーバーライドされていません。これもまた匿名型の再現なので……。Tupleもされてないですしね。これは、フィールドをreadonlyで統一しようと「変更可能」な可能性が含まれるので==は不適切、というガイドライン的なもの(と解釈しました)に従った結果です。変更可能云々は、下の方で解説します。
Code Contracts
更に、Code Contractsを入れれば、値の未代入に対するコンパイラからの静的チェックまで得られます!下記画像のは、Addressが未入力で、通常は実行時に例外が飛ぶことで検出するしかないですが、Code Contractsが静的チェックで実行前にnullだと警告してくれています。
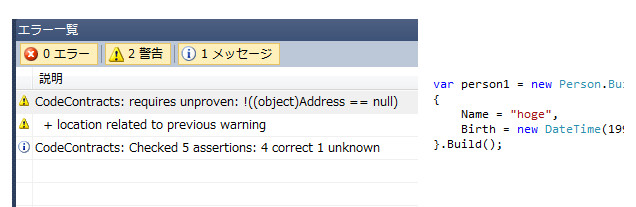
ビルダーの欠点は未代入の検出が実行時まで出来なかったりすること。インターフェイスで細工することで、順番を規定したり、必ず代入しなければならないものを定義し終えるまでは.BuildメソッドがIntelliSenseに出てこないようにする。などが出来ますが、手間がかかりすぎて理想論に留まっている気がします。
簡単であることってのはとても大事で、過剰な手間暇や複雑な設計だったりってのは、必ず無理が生じます。手間がかかること、複雑であることは、それ自体が良くない性質の一つであり、メリットがよほど上回らない限りは机上の空論にすぎない。
今回、Code Contractsのパワーにより、シンプルなオブジェクト初期化子を使ったビルダーでも未代入の静的チェックをかませる、という素敵機構が実現しました。残念ながらCode Contractsは要求環境が厳しいです。アドインを入れてない/入れられない(Express)場合はどうなるのか、というと、.NET 4にクラス群は入っているので、コンパイル通らないということはありません。普通にArgumentNullExceptionがthrowされるという形になります。
私が考えるに、.NET 4でクラスが入ったのって、Code Contractsのインストールの有無に関係なくコードが共有出来るように、という配慮でしかない予感。ExpressでContractクラスを使う意味は、あまりなさそうですね。Windows Phone 7環境など、Contractクラスそのものがないような場合では、T4のBuilderクラスBuildメソッドのContract.EndContractBlock();の一行とimplict operatorのContractVerification属性を削除してください。自分で好きに簡単に書き換えられるのもT4の良さです。
今回はnullチェックしかしていないので、つまり値型の未代入には無効です。何とかして入れたいとは思ったんですが、例えば対策として値型をNullableにするにせよType情報が必要で、そのためにはAssembly参照が必要で、と設定への手間が増えてしまうので今回は止めました(このT4はただ文字列を展開しているだけで、完全にリフレクション未使用)
Code Contractsに関しては、事前条件のnullチェックにしか使っていなくて真価の1%も発揮されていないので、詳しくはとある契約の備忘目録。契約による設計(Design by Contract)で信頼性の高いソフトウェアを構築しよう。 - Bug Catharsisなどなどを。不変オブジェクトに関してもそうだけれど、zeclさんの記事は素晴らしいです。
Code Contracts自体は、メソッド本体の上の方で、コントラクトの記述が膨れ上がるのは好きでないかも。従来型の、if-then-throwでの引数チェックも、5行を超えるぐらいになるとウンザリしますね。ご丁寧に{で改行して、if-then-throwの一個のチェックに4行も使って、それが5個ぐらい連なって20行も使いやがったりするコードを見ると発狂します。そういう場合に限ってメソッド本体は一行で他のメソッド呼んでるだけで、更にその、他のメソッドの行頭にも大量の引数チェックがあったりすると、死ねと言いたくなる。コードは視覚的に、横領域の節約も少しは大事だけど、縦も大事なんだよ、分かってよね……。メソッド本体が1000行とか書く人じゃなく、100行超えたら罰金(キリッ とか言ってる人だけど、それならガード句が10行超えたら罰金だよこっちとしては。
話が脱線した。つまるところ、コントラクトはライブラリレベルで頑張るよりも、言語側でのサポートが必要な概念ですね、ということで。実際rewriterとか、ライブラリレベル超えて無茶しやがって、の領域に踏み込んでいますし<Code Contracts。
プラスアルファ
partial classで生成されるので(デフォルトではクラス名.Generated.cs)、別ファイルにクラスを作ることで、フィールドの増減などでT4を後で修正しても、影響を受けることなくメソッドを追加することができます。
// Person.csという形で別ファイルで追加
using System;
namespace Neue.Test
{
public partial class Person
{
public int GetAge(DateTime target)
{
return (target.Year - birth.Year);
}
}
}
それと、nullチェックだけじゃなくきっちりBuildに前提条件入れたい(もしくはnullを許容したい)場合は、T4のBuildメソッドの部分に直に条件を書いてしまうか、それも何だか不自然に感じる場合は生成後のファイルをT4と切り離してしまうのも良いかもですね。自由なので好きにどうぞですます。
で、本当に不変なの?
何をもってどこまでを不変というのかはむつかしいところですが、Equalsが、GetHashCodeが変化するなら、可変かしら? 単純に全ての含まれる型のゲッターが常に同一の値を返さなければ不変ではない、でも良いですが。冒頭でも言いましたが、そう見るとreadonlyだけでは不変を厳密には保証しきれていません。匿名型で例を出すと
class MyClass
{
public int i;
public override int GetHashCode()
{
return i;
}
}
static void Main(string[] args)
{
var anon = new { MC = new MyClass { i = 100 } };
var hashCode1 = anon.GetHashCode();
anon.MC.i = 1000; // 変更
var hashCode2 = anon.GetHashCode();
Console.WriteLine(hashCode1 == hashCode2); // false
Console.WriteLine(hashCode1);
Console.WriteLine(hashCode2);
}
参照しているMyClassのインスタンスの中身が変化可能で、それが変化してしまえば、違う値になってしまいます。厳密に不変であるためには、中のクラス全てが不変でなければなりません。これは今の言語仕様的には制限かけるのは無理かなー、といったところ。T4なのでリフレクションで全部バラして、参照している型が本当の意味で不変なのかどうか検証して、可変の型を含む場合はジェネレートしない、という形でチェックかけるのは原理的には可能かもしれません、が、やはり色々無理があるかなあ。
まとめ
プログラミングの楽しさの源は、書きやすく見た目が美しいことです。私はLinq to Objects/Linq to Xmlでプログラミングを学んだようなものなので、Linqの成し遂げたこと(究極のIntelliSenseフレンドリーなモデル・使いづらいDOMの大破壊)というのが、設計の理想と思っているところが相当あります。C#は言語そのものが素晴らしいお手本。匿名型素晴らしいよ(一年ぐらい前は匿名型も可変ならいいのに、とか口走っていた時期があった気がしますが忘れた、いやまあ、可変だと楽なシチュエーションってのもそれなりにいっぱいあるんですよね)。
T4の標準搭載はC#にとって非常に大きい。T4標準搭載によって、出来る事の幅がもう一段階広がった気がします。partial class素晴らしい。自動生成って素敵。T4はただのテキストテンプレートじゃなくて「VSと密接に結びついていて」「なおかつ標準搭載」「もはやC#の一部といってもいい」ことが、全く違った価値をもたらしていると思います。自動生成前提のパターンを作っても/使ってもいいんだよ、と。言語的に足らない部分の迂回策が、また一つ加わった。
見た目上若干Uglyになっても自動生成でなんとかする、というのはJava + Eclipseもそうですが、それと違うのはpartialでUglyな部分を隔離出来る(隔離によって自動生成の修正が容易になることも見逃せない)ことと、自動生成部分をユーザーが簡単に書けること、ですね。Eclipseの自動生成のプラグインを書くのは敷居が高すぎですが、T4を書く、書くまではしなくても修正する、というのは相当容易でしょう。
最近本当にT4好きですねー。色々と弄ってしまいます。こーどじぇねれーと素晴らしい。あとは、T4自体のUglyさが少し軽減されればな、といったところでしょうか。テンプレートエンジンとしてRazorに切り替えられたりを望みたいなあ。
Reactive ExtensionsのFromEventをT4 Templateで自動生成する
- 2010-08-19
Rxで面倒くさいのが、毎回書かなければならないFromEvent。F#ならイベントがファーストクラスで、そのままストリーム処理に流せるという素敵仕様なのですが、残念ながらC#のeventはかなり雁字搦めな感があります。しかし、そこは豊富な周辺環境で何とか出来てしまうのがC#というものです。F#では form.MouseMove |> Event.filter と書けますが、 form.MouseMoveAsObservable().Where と書けるならば、似たようなものですよね?
というわけで、T4です。FromEventを自動生成しましょう!と、いうネタは散々既出で海外のサイトにも幾つかあるし、日本にもid:kettlerさんがFromEventが面倒なので自動生成させてみた2として既に書かれているのですが、私も書いてみました。書くにあたってid:kettlerさんのコードを大変参考にさせていただきました、ありがとうございます。
私の書いたもののメリットですが、リフレクションを使用しないFromEventで生成しているため、実行コストが最小に抑えられています。リフレクションを使わないFromEventは書くのが面倒でダルいのですが、その辺自動生成の威力発揮ということで。それと、命名規則をGetEventではなくEventAsObservableという形にしています。これは、サフィックスのほうがIntelliSenseに優しいため。
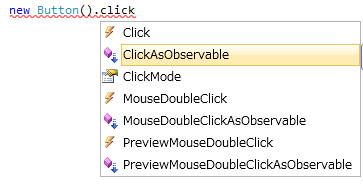
んね?この命名規則は、RxJSのほうで公式に採用されているものなので(例えばrx.jQuery.jsのanimateAsObservable)、俺々規則というわけじゃないので普通に従っていいと思われます。
以下コード。利用改変その他ご自由にどうぞ、パブリックドメインで。
<#@ assembly Name="System.Core.dll" #>
<#@ assembly Name="System.Windows.Forms.dll" #>
<#@ assembly Name="C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.0\Profile\Client\System.Xaml.dll" #>
<#@ assembly Name="C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.0\Profile\Client\PresentationCore.dll" #>
<#@ assembly Name="C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.0\Profile\Client\PresentationFramework.dll" #>
<#@ import namespace="System.Linq" #>
<#@ import namespace="System.Collections.Generic" #>
<#@ import namespace="System.Text.RegularExpressions" #>
<#@ import namespace="System.Reflection" #>
<#
// 設定:ここに生成したいクラス(のTypeをFullNameで)を足してください(以下の4つは例)
// クラスによってはassemblyの増減が必要です、WPF/Silverlightなどはフルパス直書きしてください
var types = new[] {
typeof(System.Collections.ObjectModel.ObservableCollection<>),
typeof(System.Windows.Forms.Button),
typeof(System.Windows.Controls.Primitives.TextBoxBase),
typeof(System.Windows.Controls.Primitives.ButtonBase)
};
#>
using System.Linq;
using System.Collections.Generic;
<# foreach(var x in GenerateTemplates(types)) {#>
namespace <#= x.Namespace #>
{
<# foreach(var ct in x.ClassTemplates) {#>
internal static class <#= ct.Classname #>EventExtensions
{
<# foreach(var ev in ct.EventTemplates) {#>
public static IObservable<IEvent<<#= ev.Args #>>> <#= ev.Name #>AsObservable<#= ct.GenericArgs #>(this <#= ct.Classname #><#= ct.GenericArgs #> source)
{
return Observable.FromEvent<<#= ev.Handler + (ev.IsGeneric ? "<" + ev.Args + ">" : "") #>, <#= ev.Args #>>(
h => <#= ev.IsGeneric ? "h" : "new " + ev.Handler + "(h)" #>,
h => source.<#= ev.Name #> += h,
h => source.<#= ev.Name #> -= h);
}
<# } #>
}
<# }#>
}
<# }#>
<#+
IEnumerable<T> TraverseNode<T>(T root, Func<T, T> selector)
{
var current = root;
while (current != null)
{
yield return current;
current = selector(current);
}
}
IEnumerable<ObservableTemplate> GenerateTemplates(Type[] types)
{
return types.SelectMany(t => TraverseNode(t, x => x.BaseType))
.Distinct()
.GroupBy(t => t.Namespace)
.Select(g => new ObservableTemplate
{
Namespace = g.Key,
ClassTemplates = g.Select(t => new ClassTemplate(t))
.Where(t => t.EventTemplates.Any())
.ToArray()
})
.Where(a => a.ClassTemplates.Any())
.OrderBy(a => a.Namespace);
}
class ObservableTemplate
{
public string Namespace;
public ClassTemplate[] ClassTemplates;
}
class ClassTemplate
{
public string Classname, GenericArgs;
public EventTemplate[] EventTemplates;
public ClassTemplate(Type type)
{
Classname = Regex.Replace(type.Name, "`.*$", "");
GenericArgs = type.IsGenericType
? "<" + string.Join(",", type.GetGenericArguments().Select((_, i) => "T" + (i + 1))) + ">"
: "";
EventTemplates = type.GetEvents(BindingFlags.Public | BindingFlags.InvokeMethod | BindingFlags.DeclaredOnly | BindingFlags.Instance)
.Select(ei => new { EventInfo = ei, Args = ei.EventHandlerType.GetMethod("Invoke").GetParameters().Last().ParameterType })
.Where(a => a.Args == typeof(EventArgs) || a.Args.IsSubclassOf(typeof(EventArgs)))
.Select(a => new EventTemplate
{
Name = a.EventInfo.Name,
Handler = Regex.Replace(a.EventInfo.EventHandlerType.FullName, "`.*$", ""),
Args = a.Args.FullName,
IsGeneric = a.EventInfo.EventHandlerType.IsGenericType
})
.ToArray();
}
}
class EventTemplate
{
public string Name, Args, Handler;
public bool IsGeneric;
}
#>
// こんなのが生成されます
namespace System.Collections.ObjectModel
{
internal static class ObservableCollectionEventExtensions
{
public static IObservable<IEvent<System.Collections.Specialized.NotifyCollectionChangedEventArgs>> CollectionChangedAsObservable<T1>(this ObservableCollection<T1> source)
{
return Observable.FromEvent<System.Collections.Specialized.NotifyCollectionChangedEventHandler, System.Collections.Specialized.NotifyCollectionChangedEventArgs>(
h => new System.Collections.Specialized.NotifyCollectionChangedEventHandler(h),
h => source.CollectionChanged += h,
h => source.CollectionChanged -= h);
}
}
}
namespace System.ComponentModel
{
internal static class ComponentEventExtensions
{
public static IObservable<IEvent<System.EventArgs>> DisposedAsObservable(this Component source)
{
return Observable.FromEvent<System.EventHandler, System.EventArgs>(
h => new System.EventHandler(h),
h => source.Disposed += h,
h => source.Disposed -= h);
}
}
// 以下略
使い方ですが、RxGenerator.ttとか、名前はなんでもいいのですがコピペって、上の方のvar typesに設定したい型を並べてください。一緒に並べたものの場合は、全て継承関係を見て重複を省くようになっています。WPFとかSilverlightのクラスから生成する場合は、assembly Nameに直にDLLのパスを書いてやってくださいな。コード的には、例によってLinq大活躍というかLinqなかったら死ぬというか。リフレクションxLINQxT4は鉄板すぎる。
一つ難点があって、名前空間をそのクラスの属している空間にきっちりと分けたせいで、例えばWPFのbutton.ClickAsObservableはSystem.Windows.Controls.Primitivesをusingしないと出てこないという、微妙に分かりづらいことになっちゃっています……。これ普通にHogeHogeExtensionsとかいう任意の名前空間にフラットに配置したほうが良かったのかなあ。ちょっと悩ましいところ。
T4の書き方
漠然と書いてると汚いんですよね、T4。読みにくくてダメだし読みにくいということは書きにくいということでダメだ。というわけで、今回からは書き方を変えました。ASP.NETのRepeater的というかデータバインド的にというかで、入れ物クラスを作って、パブリックフィールド(自動プロパティじゃないのって?そんな大袈裟なものは要りません)を参照させるという形にしました。foreachや閉じカッコ("}")は一行にする。<% %>で囲まれる範囲を最小限に抑えることで、ある程度の可読性が確保出来ているんじゃないかと思います。
といったようなアイディアは
よく訓練されたT4使いは 「何を元に作るか」 「何を作るか」 だけを考える。
何を元に作るかはきっと from ... select になるでしょう。 何を作るかの中では <#=o.Property#> で値を出力する事ができます。
csproj.user を作るための T4 テンプレート
からです。「何を元に作るか」 「何を作るか」 。聞いてみれば当たり前のようだけれど、本当にコロンブスの卵というか(前も同じこと書いた気がする)、脳みそガツーンと叩かれた感じで、うぉぉぉぉぉ、と叫んで納得でした。はい。それと、T4は書きやすいと言っても書きにくい(?)ので、囲む範囲を最小にするってことは、普通のコードでじっくり書いてからT4に移植しやすいってことでもあるんですね。
まとめ
最近F#勉強中なのです。Expert F# 2.0買ったので。と思ったらプログラミングF#が翻訳されて発売されるだとー!もうすぐ。あと一週間後。くぉ、英語にひいこらしながら読んでいるというのにー。
F#すげーなー、と知れば知るほど確かに思うわけですが、しかし何故か同時に、C#への期待感もまた高まっていきます。必ずや「良さ」を吟味して取り込んでくれるという信頼感があります、C#には。そしてまた、ライブラリレベルで強烈に何とか出来る地力がある、例えばイベントをストリームに見立てた処理には、Reactive Extensionsが登場してC#でも実現出来ちゃったり。Scalaと対比され緩やかに死んでいくJavaと比べると、F#と対比しても元気に対抗していくC#の頼もしさといったらない。
といっても、F#も全然まだ表面ぐらいしか見えてないし、突っつけば突っつくほど応えてくれる奥の深い言語な感じなので、今の程度の知識で比較してどうこうってのはないです。Java7のクロージャにたいし、Javaにそんなものはいらない、とか頑な態度を取っている人を見るとみっともないな、と思うわけですが、いつか私もC#に拘泥してC#にそんなものはいらない、的なことを言い出すようだと嫌だなー、とかってのは思ってます。進化を受け入れられなくなったら、終わり。
マルチパラダイム言語の勝利→C++/CLI大勝利ですか?→いやそれは多分違う。的なこともあるので何もかもを受け入れろ、ひたすら取り込んで鈍重な恐竜になれ(最後に絶滅する)、とは言いません。この辺のバランス感覚が、きっと言語設計にとって難しいことであり、そして今のC#は外から見れば恐竜のようにラムダ式だのdynamicだのを取り入れてるように見えるでしょうが、決してそうではなく、素晴らしいバランスに立っています。機能の追加が恐竜への道になっていない。むしろ追加によって過去の機能を互換性を保ちつつ捨てているんですよね、例えば、もうdelegateというキーワードは書くどころか目にすることもほとんどない←なのでC#を学習する場合、C#1.0->2.0->3.0->4.0という順番を辿るのは良くなくて、最新のものから降りていったほうがいい。
何が言いたいかっていったらC#愛してるってことですな。うはは。5.0にも当然期待していますし、Anders Hejlsbergの手腕には絶対的に信頼を寄せています。4.0は言語的な飛躍はあまりなかっただけに、5.0は凄いことになるに違いない。
linq.jsやRxJSのベンチマーク
- 2010-08-11
どうも、定期的linq.js - LINQ for JavaScript宣伝の会がやってまいりました。最近はページビューも絶好調、なのだけどDL数はそこまで伸びない(でも同種のライブラリよりもDL数多かったりするので需要が限界値と思われる)などなどな近況ですがこんばんわ。乱立するLinqのJavaScript実装……。などと言うほどに乱立はしてないし、そもそも2009/04に最後発で私が出したのが最後で、それ以降の新顔は見かけないのですが(しいて言えばRxJS)、ちょうどjLinqを実装した人が、ベンチ結果がボロボロだった、作り直してるという記事を出したので、ほぅほぅとそのベンチマークを見て、ちょっと改良して色々なLinq実装で比較してみました。
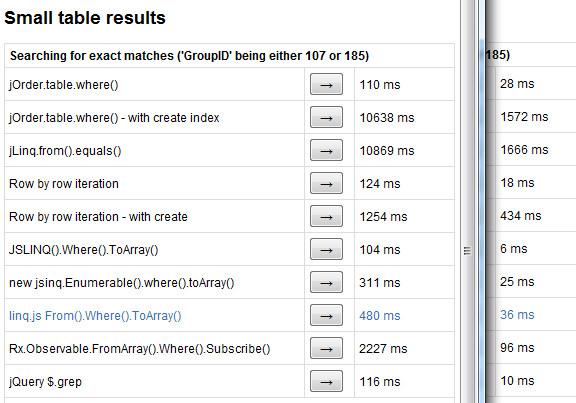
左のがIE8、重ねて後ろ側のがChrome。この画像は77件のJSONをGroupIDが107か185のもののみをフィルタして配列を返すという処理を1000回試行したもの。毎度思いますが、V8恐ろしく速い。そりゃnode.jsとか普通に現実的な話ですよね、大変素晴らしい。
jOrderについて
このベンチマークは、もとはjOrderという、Linq……ではなくてSQL風のもので(SQLっぽいのは結構いっぱいあります)、巨大なJSONを効率よく抽出するために、先にインデックス的なのを作ってそれから処理すれば速くなるよ!というライブラリが先々月ぐらいに出来たばっからしいのですが、それがjLinqと比較してこれだけ速いぜ!とやっていたようです。結果見る限りはjLinqクソ遅くてjOrderクソ速くて凄ー、となったのですが、なんかどーにも胡散臭さが拭えないわけですよ、ベンチ詐欺に片足突っ込んでいるというか。
jOrderは初回にインデックスっぽいものを作成するので、二回目以降の抽出は爆速、というのがウリ(っぽい)ようで、ベンチは確かに速い。で、その初回のインデックス生成は何時やってるんでしょうか?このベンチのソースを見ると、ボタンを押してからじゃなくて、ページのロード時にやってますね……。あの、それも立派なコストなのですが、無視ですか?無視ですか?そりゃあ試行回数を1000でベンチ取るならば無視出来るほどに小さいかもですね?でも、Test Cycles 1とか用意しているわけですが、どうなんでしょうね、インデックス作成時間を無視するのは、ちょっと卑怯すぎやしませんか?そもそも対象にひぢょーに遅いjLinq「だけ」を選んでいるというところがやらしい。
というわけで、オリジナルのベンチにはないのですがwith create indexというボタン押してからインデックスを作成する項目を足しました。1000回の試行では、コンセプトに乗っ取るなら1回のインデックス作成にすべきなんでしょうが、普通に1000回インデックス作成に走るのでクソ遅いです。あ、いや、別にアンチキャンペーン張ろうってわけじゃあないんですが、単純に面倒なので……。インデックス作成コストは試行回数1にすれば分かる。
ベンチ結果を見ると、まず、インデックス的なものの作成には非常にコストがかかってる。そして、わざわざコストをかけて生成したところで、Small table(77件のJSON)では、フィルタリングに関してはjQueryの$.grep、つまりは何も手をかけてないシンプルなフィルタリングと同じ速度でしかなくて、あまり意味が無い。Large table(1000件のJSON)ではそれなりな効果が出ているようですが、インデックス作成コストをペイするまでの試行回数を考えると、やはりあまり意味がなさそうな……。コンセプトは面白いんですが、それ止まりかなあ。機能的には、このインデックス生成一点勝負なところがあるので、他のLinq系ライブラリのような多機能なクエリ手段があるわけでもないし。
その他のライブラリについて
どれも似たり寄ったりで同じことが出来ますが、処理内容は全然違います。linq.jsは遅延評価であることと、列挙終了時にDisposeすることを中心に据えているので、シンプルにフィルタするだけのもの(jQueryの$.grepとか)よりも遥かに遅くなっています。JSINQも同じく遅延評価で、実装も大体似てます。なので、計測結果もほぼ同じですが、linq.jsのほうが遅い。これは、jsinqはDisposeがないため、その分の速度差が出ています(それ以外にも、単純にlinq.jsのほうが色々処理挟んでて遅め)。
LINQ to JavaScript(JSLINQ)はLINQの名を冠していますが、即時評価で、中身はただの配列のラッパーです。その分だけ単純な実装になっているので、単純なことをこなすには速い。jQueryの$.grepも同じく、普通に配列をグルッとループ回してifで弾いて、新しい配列にpushして、新しい配列を返すもの。というわけで、両者はほとんど同じ速度です。ただ、若干jQueryのほうが速いようで。これは、JSLINQはthis.itemsという形で対象の配列にアクセスしていて、それが速度差になってる模様。var items = this.itemsと列挙の前に置いてやれば、jQueryとほぼ同じ速度になる。1000回の試行だと20msecぐらいの差にはなるようですね。これが気にするほどかは、どうでしょう……。私は全く気にしません。
残念なことにめっちゃ遅いjLinqは、うーん、中はevalだらけだそうで、それが響いたそうです。と、作者が言ってるのでそうなのでしょう(適当)。RxJSも割と遅いんですが、これはしょうがないね!C#でもToObservableで変換かけたものの速度は割と遅くなるし。構造的に中間にいっぱい処理が入るので、そういうものだということで。
速度ねえ……
jLinqはさすがにアレゲなのですが、それ以外は別に普通に使う範囲ではそんな致命的に低速ってわけでもないんで、あまり気にしなくても良くね?と、かなり思ってます。linq.jsは速度を犠牲にして遅延評価だのDisposeだの入れてるわけですが、勿論、犠牲にしたなりのメリットはある(表現できる幅がとっても広がる)し。その辺はトレードオフ。配列をSelectしてToArrayするだけ、とかWhereしてToArrayするだけならば、、どうせjQueryも一緒に使うでしょ?的に考えて、jQueryの$.map, $.grepを使えば精神衛生上良いかもしれません。これは、C#で言うところのArray.ConvertAllは化石メソッドだけど、SelectしてToArrayならばConvertAllのほうが高効率なんだぜ(内心はどうでもいーんだけど)、といったようなノリで補えば良いでしょう。
それにしても、何でjQueryは$.eachの引数がmapやgrepと逆(eachだけindexが第一引数で値が第二引数)なんですかね。これ、統一してたほうが良いし、だいたいがして値が第一引数のほうが使いやすいのに。もう今更変えられない、ということなのかしらん。
そういえばで、せっかくなので「表現できる幅」の例として、ベンチには第一ソートキーにCurrency、それが重複してた場合の第二ソートキーにTotalを指定してみた例(OrderBy.ThenBy)とか(linq.js無しで書くとちょびっと面倒だよ!)、GroupIDでグルーピングした後にTotal値を合計といった集計演算(これもlinq.js無しだと面倒だよ!)とかを入れておいたので、良ければ見といてください。はい。まあ、別にこの辺はeager evaluationでも出来るというかソートもグルーピングも一度バッファに貯めちゃってるんですけどね!
まとめ
JSINQは良く出来てると思うのよ。ほんと(私はただのLinqマニアなので、基本的に他の実装は割と読んでますですよ)。ベンチ的にもlinq.jsより速いし(Disposeないからね、でもDispose使うシーンがそもそもあんまないという)、文字列クエリ式も(使わないけど)使えるし。じゃあ、JSINQじゃなくてlinq.jsがイイ!というような押しは、そこまであるかないか、どうなんでしょうね。1.メソッドの数が全然違う 2.ラムダ式的な文字列セレクターが使える 3.Dispose対応 4.RxJSにも対応 5.jQueryにも対応 6.WSHにも対応 7.VS用IntelliSense完備。ふむ、結構ありますね。というわけでlinq.jsお薦め。冒頭でも言いましたが最近のCodePlex上でのページビュー/ダウンロード数を見ると、競合のlinq移植ライブラリの中でもトップなんですよ、えへへ。まあ、4DL/dayとかいうショボい戦いなのですが。
jLinqの人が、パフォーマンス改善のついでにLinqという名前をやめてブランディングやり直すって言ってますが、きっと正しいと思う。「Linq」という名前がつく限りは「.NETの~」という印象が避けられないし、そのせいで敬遠されるというのは、間違いなくある。jLinqは、中身全然Linqじゃない独特な感じのなので、名前変えるのは、きっと良い選択。
linq.jsは100% Linqなので名前がどうこうってのはないですが、しかし、RxJSもそうなのだけど、.NET以外の人にも使って欲しいなって気持ちはとてもあります。やれる限りは頑張ってるつもりなんですが、中々どうして。JavaScriptエディタとしてのVisual Studioの使い方入門は100ブクマまであとちょい!な感じで、そういうとこに混ぜて宣伝とかいうセコい策を取ってはいるものの(いや、別にそういうつもりでやったわけでもないですが)色々と難すぃー。海外へも少しは知名度伸ばせたようなのだけど、そこでも基本的には.NET圏のみって雰囲気で、どうしたものかしらん。
つまるところ、そろそろ御託はどうでもいいから、RealWorldな実例出せよって話ですね!
テストを簡単にするほんの少しの拡張メソッド
- 2010-08-02
テストドリブンしてますか?私は勿論してません。え……。別に赤が緑になっても嬉しくないし。コード先でテスト後のほうが書きやすくていいなあ。でもそうなると、テスト書かなくなってしまって、溜まるともっと書かなくなってしまっての悪循環。
そんな普段あまりテスト書かないクソッタレな人間なわけですが(レガシーコード殺害ガイドが泣いている)、普段テスト書かないだけに書こうとすると単純なものですらイライライライラしてしまって大変よくない。しかし、それはそもそもテストツールが悪いんじゃね?という気だってする。言い訳じゃなく、ふつーにバッチイですよ、テストコード。こんなの書くのはそりゃ苦痛ってものです。
Before
例えば、こういうどうでもいいクラスがあったとします。
public class MyClass
{
public string GetString(string unya)
{
return (unya == "unya") ? null : "hoge";
}
public IEnumerable<int> GetEnumerable()
{
yield return 1;
yield return 2;
yield return 3;
}
}
ウィザードで生成されたのをベースに書くとこうなる(MSTestを使っています)
[TestMethod()]
public void GetStringTest()
{
MyClass target = new MyClass();
string unya = "unya";
string expected = null;
string actual;
actual = target.GetString(unya);
Assert.AreEqual(expected, actual);
expected = "hoge";
actual = target.GetString("aaaaa");
Assert.AreEqual(expected, actual);
}
[TestMethod()]
public void GetEnumerableTest()
{
MyClass target = new MyClass();
IEnumerable<int> expected = new[] { 1, 2, 3 };
IEnumerable<int> actual;
actual = target.GetEnumerable();
CollectionAssert.AreEqual(expected.ToArray(), actual.ToArray());
}
何だこりゃ。超面倒くさい。むしろテストがレガシーすぎて死にたい。CollectionAssertはIEnumerableに対応してないし。泣きたい。こんなの書いてられない。吐き気がする。
After
JavaScriptのQUnitは、大抵EqualとDeepEqualで済む簡単さで、それがテストへの面倒くささを大いに下げてる。見習いたい。シンプルイズベスト。ごてごてしたAssert関数なんて悪しき伝統にすぎないのではなかろうか?と思ったので、もうアサート関数なんてIsだけでいいぢゃん、ついでにactualの後ろに拡張メソッドでそのままexpected書けると楽ぢゃん、と開き直ることにしました。
[TestMethod()]
public void GetStringTest()
{
// 1. 全オブジェクトに対して拡張メソッドIsが定義されててAssert.AreEqualされる
// 2. ラムダ式も使えるので、andやorや複雑な比較などはラムダ式でまかなえる
// 3. nullはIs()で(本当はIs(null)でやりたかったのだけど、都合上断念)
new MyClass().GetString("aaaaa").Is("hoge");
new MyClass().GetString("aaaaa").Is(s => s.StartsWith("h") && s.EndsWith("e"));
new MyClass().GetString("unya").Is();
}
[TestMethod()]
public void GetEnumerableTest()
{
// 対象がIEnumerableの場合はCollectionAssert.Equalsで比較されます
// 可変長配列を受け入れることが出来るので直書き可
new MyClass().GetEnumerable().Is(1, 2, 3);
}
すんごく、すっきり。メソッドはIsだけ、ですがそれなりのオーバーロードが仕込まれているので、ほとんどのことが一つだけで表現出来ます。IsNullはIs()でいいし(表現的には分かりにくくて嫌なのですが、Is(null)だとオーバーロードの解決ができなくてIs((型)null)と書かなくて面倒くさいので、泣く泣く引数無しをIsNullとしました)し、IsTrueはIs(true)でいい。複雑な条件で比較したいときはラムダ式を渡せばいい。Is.EqualTo().Within().And() とか、全然分かりやすくないよね。流れるようなインターフェイスは悪くないけれど、別に自然言語的である必要なんて全然なくて、ラムダ一発で済ませられるならそちらのほうがずっと良い。.Should().Not.Be.Null()なんてまで来ると、もう馬鹿かと思った。
大事なのはシンプルに気持良く書けることであって、形式主義に陥っちゃいけないのさあ。
コレクション比較もIsだけですませます。IEnumerableを渡すことも出来るし、可変長引数による値の直書きも出来る。なお、Isのみなのでコレクション同士の参照比較はありません。コレクションだったら有無をいわさず要素比較にします。だって、別に参照比較したいシーンなんてほとんどないでしょ?そういう例外的な状況は素直にAssert.AreEqual使えばいい。また、CollectionAssertには色々なメソッドがありますが、それ全部Linqで前処理すればいいよね?例えばCollectionAsert.IsEmptyはAny().Is(false)で済ませられるので不要。他のも大体はLinqで何とかできるので大概不要です。
ところで、このぐらいだとウィザードが冗長というだけで
Assert.AreEqual(new MyClass().GetString("aaaaa"), "hoge");
って書けるじゃないかって突っ込みは、そのとおり。でも、少し長くなると、引数に押し込めるの大変になってきますよね。そうなると
var expected = "hoge";
var actual = new MyClass().GetString("aaaaa")
Assert.AreEqual(expected, actual);
といった具合に、変数名が必要になって大変かったるい。ので、余計な一時変数なしで流し込める方が圧倒的に楽です。そもそもに、Assert.AreEqualだと、毎回どっちがactualでどっちがexpectedだか悩むのがイライラしてしまって良くない。まあ、逆でもいいんですが。よくないんですが。
パラメータ違いのテストケース
ついでに面倒くさいのは、パラメータが違うだけにすぎない、同じようなAssertの量産。テストなんてとっとと書いてナンボなので大体コピペで取り回しちゃうわけですが、どう考えてもクソ対応です本当にありがとうございました。そういうことやると、テストの書き直しが出来なくなって身重になってしまって良くない。コードはサクッと書き直せるべきだし、テストもサクッと書き直せるべきだ。といったわけで、NUnitには属性を足すだけでパラメータ違いのテストを実行出来るそうですがMSTestにはなさそう。うーん、でも、Linqがあれば何でも出来るよ?Linq万能神理論。ということで、Linqをベースにしてパラメータ違いを渡せるクラスを書いてみました。
// コレクション初期化子を使ってパラメータを生成します
new Test.Case<int, int, int>
{
{1, 2, 3},
{100, 200, 500},
{10000, 20, 30}
}
.Select(t => t.Item1 + t.Item2 + t.Item3)
.Is(6, 800, 10050);
複数の値はTupleに突っ込めばいい。あとはSelectでactualを作って、最後にIsの可変長引数使って期待値と比較させれば出来上がり。Tupleは、C#には匿名型があるため、あまり活用のシーンがないのですが、こういうところでは便利。このTest.Caseは7引数のTupleまで対応しています(それ以上?そもそも標準のTupleの限界がそれまでなので)。使い方はnewしてコレクション初期化子でパラメータを並べるだけ。
つまるところTest.CaseクラスはただのTupleCollectionです。Tupleの配列を作るには、普通だと new[]{Tuple.Create, Tuple.Create...} と書かなければならず、死ぬほど面倒。そこで出てくるのがコレクション初期化子。これなら複数引数を受け入れるのが楽に記述できる。というわけで、コレクション初期化子を使いたいがためだけに、クラスを立てました。唯一の難点はnewしなければならない、つまりジェネリクスの型引数を書かなければならない、ということでしょうか。
そうそう、コレクション初期化子のおさらいをすると、IEnumerable<T>かつAddメソッド(名前で決め打ちされてる)があると呼び出せます。複数引数時も、波括弧で要素をくくることで対応できます(Dictionaryなどで使えるね)。
ソースコード
長々と長々してましたがソースを。Test.CaseのTupleの量産が面倒なのでT4 Templateにしました。Test.ttとかって名前にしてテストプロジェクトに突っ込んでください。中は完全に固定だから、取り回すなら生成後のTest.csを使っていくと良いかもですね。ご利用はご自由にどうぞ。パブリックドメインで。
<#@ assembly Name="System.Core.dll" #>
<#@ import namespace="System.Linq" #>
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
namespace Microsoft.VisualStudio.TestTools.UnitTesting
{
public static class Test
{
// extensions
/// <summary>IsNull</summary>
public static void Is<T>(this T value)
{
Assert.IsNull(value);
}
public static void Is<T>(this T actual, T expected, string message = "")
{
Assert.AreEqual(expected, actual, message);
}
public static void Is<T>(this T actual, Func<T, bool> expected, string message = "")
{
Assert.IsTrue(expected(actual), message);
}
public static void Is<T>(this IEnumerable<T> actual, IEnumerable<T> expected, string message = "")
{
CollectionAssert.AreEqual(expected.ToArray(), actual.ToArray(), message);
}
public static void Is<T>(this IEnumerable<T> actual, params T[] expected)
{
Is(actual, expected.AsEnumerable());
}
public static void Is<T>(this IEnumerable<T> actual, IEnumerable<Func<T, bool>> expected)
{
var count = 0;
foreach (var cond in actual.Zip(expected, (v, pred) => pred(v)))
{
Assert.IsTrue(cond, "Index = " + count++);
}
}
public static void Is<T>(this IEnumerable<T> actual, params Func<T, bool>[] expected)
{
Is(actual, expected.AsEnumerable());
}
// generator
<#
for(var i = 1; i < 8; i++)
{
#>
public class Case<#= MakeT(i) #> : IEnumerable<Tuple<#= MakeT(i) #>>
{
List<Tuple<#= MakeT(i) #>> tuples = new List<Tuple<#= MakeT(i) #>>();
public void Add(<#= MakeArgs(i) #>)
{
tuples.Add(Tuple.Create(<#= MakeParams(i) #>));
}
public IEnumerator<Tuple<#= MakeT(i) #>> GetEnumerator() { return tuples.GetEnumerator(); }
IEnumerator IEnumerable.GetEnumerator() { return GetEnumerator(); }
}
<#
}
#>
}
}
<#+
string MakeT(int count)
{
return "<" + String.Join(", ", Enumerable.Range(1, count).Select(i => "T" + i)) + ">";
}
string MakeArgs(int count)
{
return String.Join(", ", Enumerable.Range(1, count).Select(i => "T" + i + " item" + i));
}
string MakeParams(int count)
{
return String.Join(", ", Enumerable.Range(1, count).Select(i => "item" + i));
}
#>
オプション引数のお陰で、こういうちょっとしたのが書くの楽になりましたね(C#4.0 からの新機能)。あとは、可変長引数が配列だけじゃなくてIEnumerableも受け付けてくれれば、AsEnumerableで渡すだけの余計なオーバーロードを作らないで済むんだよね。C# 5.0に期待しますか。
まとめ
テストのないコードはレガシーコード。と、名著が言ってる(1/4ぐらいしかまだ読んでませんが!)のでテストは書いたほうがいいっす。
でも、コード書きってのは気持良くなければならない。気持ち良ければ自然に書くんです。書かない、抵抗感があるってのは、環境が悪いんです。「テスト書きは苦痛だけど良いことだから、赤が緑に変わると嬉しいから書こうぜ!」とかありえない。そんな自己啓発っぽいのは無理。というわけで、拡張メソッドで環境を変えて、気持よく生きましょうー。
JsUnit(非常にイマイチ)もそうだったんだけど、Java由来(xUnitはSmalltalkのー、とかって話は分かってます)のライブラリとかは、Java的な思考に引き摺られすぎ。もっと言語に合わせたしなやかなAPIってものがあると思うんですよね。MSTestはVS2010で、色々刷新してLinqや拡張メソッドを生かしたものを用意すべきだったと思います。C#2.0的なコードは読むのも書くのも、もう苦痛。レガシーコードとは何か?C#2.0的なコードです。いやほんと。生理的な問題で。
追記
ここで例として出したものを、より洗練させてライブラリとしてまとめました。Chaining Assertion for MSTest よければこちらもどうぞ。
Reactive Extensions入門 + メソッド早見解説表
- 2010-07-28
Silverlight Toolkitに密かに隠された宝石"System.Reactive.dll"が発見されてから1年。Reactive FrameworkからReactive Extensionsに名前が変わりDevLabsでプロジェクトサイトが公開され、何度となく派手にAPIが消滅したり追加されたりしながら、JavaScript版まで登場して、ここまで来ました。IObservable<T>とIObserver<T>インターフェイスは.NET Framework 4に搭載されたことで、将来的なSP1での標準搭載は間違いなさそう。Windows Phone 7にはベータ版の開発キットに搭載されているように、間違いなく標準搭載されそう。
現在はAPIもかなり安定したし、Windows Phone 7の登場も迫っている。学ぶならまさに今こそベスト!そんなわけで、Rxの機能の簡単な紹介と導入コード、重要そうなエッセンス紹介、そして(ほぼ)全メソッド一行紹介をします。明日から、いや、今日からRxを使いましょう。
その前にRxとは何ぞや?ですが、Linq to EventsもしくはLinq to Asynchronus。イベントや非同期処理をLinqっぽく扱えます。
Rxの出来る事
まずReactive Extensions for .NET (Rx)からインストール。そして、System.CoreEx、System.Reactiveを参照に加え(Rxにはもう一つ、System.Interactiveが含まれていて、これはEnumerableの拡張メソッド群になります)れば準備は終了。
// Rxの出来る事その1. イベントのLinq化
var button = new Button(); // WPFのButton
Observable.FromEvent<RoutedEventArgs>(button, "Click")
.Subscribe(ev => Debug.WriteLine(ev.EventArgs));
// Rxの出来る事その2. 非同期のLinq化
Func<int, int> func = i => i * 100; // intを100倍する関数
Observable.FromAsyncPattern<int, int>(func.BeginInvoke, func.EndInvoke)
.Invoke(5) // Invokeで非同期関数実行開始(Invokeは任意のタイミングで可)
.Subscribe(i => Debug.WriteLine(i)); // 500
// Rxの出来る事その3. 時間のLinq化
Observable.Timer(TimeSpan.Zero, TimeSpan.FromSeconds(5))
.Subscribe(l => Debug.WriteLine(l)); // 5秒毎に発火
// Rxの出来る事その4. Pull型のPush型への変換
var source = new[] { 1, 10, 100, 1000 };
source.ToObservable()
.Subscribe(i => Debug.WriteLine(i));
それぞれ一行でIObservable<T>に変換出来ます。あとは、LinqなのでSelectやWhereなどお馴染みのメソッドが、お馴染みなように使えます。そして最後にSubscribe。これは、まあ、foreachのようなものとでも捉えてもらえれば(今はね!)。
イベントをLinq化して何が嬉しいの?
合成出来るのが嬉しいよ!クリックしてクリックイベントが発動する、程度なら別にうまみはありません。でも、イベントは切り目をつけられないものも多数あります。例えばドラッグアンドドロップは「マウスダウン→マウスムーブ→マウスアップ」の連続的なイベント。従来は各関数の「外」で状態管理する変数を持ってやりくりしていましたが、Rxならば、スムーズにこれらを結合して一本の「ドラッグアンドドロップ」ストリームとして作り上げることが出来ます。逆に言えば、ただたんにイベントをLinq化しても嬉しいことはあまりありません。合成して初めて真価を発揮します。そのためには合成系のメソッド(SelectMany, Merge, Zip, CombineLatest, Join)を知る必要がある、のですがまだ当サイトのブログでは記事書いてません。予定は未定じゃなくて近日中には必ず紹介します……。
非同期をLinq化して何が嬉しいの?
それはもう自明で、単純にBeginInvoke/EndInvokeで待ち合わせるのは面倒くさいから。たった一行でラッピング出来る事の素晴らしさ!でも、同期的に書いてBackgroundWorkerで動かせばいいぢゃない。というのは、一面としては正しい。正しくないのは、Silverlightや、JavaScriptは非同期APIしか用意されていません。なので、クラウド時代のモダンなウェブアプリケーションでは、非同期と付き合うより道はないのです。
RxではBeginXxx/EndXxxという形で.NETの各メソッドにある非同期のパターンが簡単にラップ出来るようになっています。ジェネリクスの型として、引数と戻り値の型を指定して、あとはBeginInvokeとEndInvokeを渡すだけ。あの面倒くさい非同期処理がこんなにも簡単に!それだけで嬉しくありませんか?
Pull型をPush型に変えると何が嬉しいの?
分配出来るようになります。え?具体的には、C#とLinq to JsonとTwitterのChirpUserStreamsとReactive Extensionsという記事で紹介しました。そもそもPullとPushって何?という場合はメソッド探訪第7回:IEnumerable vs IObservableをどうぞ。
Rxを使うのに覚えておきたい大切な3つのこと
あまり深く考えなくても使えるけれど、少しポイントを押さえると、驚くほど簡単に見えてくる。「HotとColdの概念を掴むこと」「Schedulerが実行スレッドを決定すること」「Subjectでテストする」。この3つ。まあ、後の二つは実際のとここじつけみたいなもので、本当に大事なのはHotとColdです。あまりにも大事なのだけど、それに関して書くには余白が狭すぎる。ではなくて、以前にメソッド探訪第7回:IEnumerable vs IObservableとして書いたのでそちらで。とりあえず、ColdはSubscribeしたら即座に実行される、HotはSubscribeしても何もしないでイベント待ち。ぐらいの感覚でOKです。
Scheduler
Schedulerを使うと「いつ」「どこで」実行するかを決定することが出来ます。Rx内部でのメソッド実行は大抵このSchedulerの上に乗っかっています。
// 大抵の生成メソッドはISchedulerを受けるオーバーロードを持つ
// それに対してSchedulerを渡すと、実行スレッドを決定出来る
Observable.Range(1, 10, Scheduler.CurrentThread);
Observable.Interval(TimeSpan.FromSeconds(1), Scheduler.ThreadPool);
基本的には引数に渡すだけ。「いつ」「どこで」ですが、「いつ」に関してはRxの各メソッドが受け持つので、基本的には「どのスレッドで」実行するかを決めることになります。なお、当然デフォルト値もあるわけですが、RangeはCurrentThreadでTimerはThreadPoolだったりと、各メソッドによって若干違ったりすることに注意(但しTimerでCurrentThreadを選ぶと完全にブロックされてTimerというかSleepになるので、挙動として当然といえば当然のこと)
生成メソッドに渡す以外に、まだ使う場所があります。
// WPFでbutton1というボタンとtextBlock1というtextBlockがあるとする
Observable.FromEvent<RoutedEventArgs>(button1, "Click")
.ObserveOn(Scheduler.ThreadPool) // 重い処理をUIスレッドでするのを避けるためThreadPoolへ対比
.Do(_ => Thread.Sleep(3000)) // 猛烈に重い処理をすることをシミュレート
.ObserveOnDispatcher() // Dispatcherに戻す
.Subscribe(_ => textBlock1.Text = "clickした"); // UIスレッドのものを触るのでThreadPool上からだと例外
UIスレッドのコントロールに他のスレッドから触れると例外が発生します。でも、重たい処理をUIスレッド上でやろうものなら、フリーズしてしまいます。なので、重たい処理は別スレッドに退避し、コントロールの部品を弄る時だけUIスレッドに戻したい。という場合に、ObserveOnを使うことで簡単に実行スレッドのコントロールが可能になります。もうDispatcher.BeginInvokeとはサヨナラ!
Subjectって何?
SubjectはIObservableでありIObserverでもあるもの。というだけではさっぱり分かりません。これは、イベントのRxネイティブ表現です。なので、C#におけるeventと対比させてみると理解しやすいはず。eventはそのクラス内部からはデリゲートとして実行出来ますが、外からだと追加/削除しか出来ませんよね?Subjectはこれを再現するために、外側へはIObservableとして登録のみ出来るようにし、内部からのみ登録されたものへ実行(OnNext/OnError/OnCompleted)して値を渡します。なお、ただキャストしただけでは、外からダウンキャストすればイベントを直接実行出来るということになってしまうので、Subjectを外に公開する時は AsObservableメソッド(IObservableでラップする)を使って隠蔽します。
どんな時に使うかというとRx専用のクラスを作るとき、もしくはObservableの拡張メソッドを作る時、に有効活用出来るはずです。もしくは、メソッドを試すときの擬似的なイベント代わりに使うと非常に便利です。
// Buttonのイベントをイメージ
var buttonA = new Subject<int>();
var buttonB = new Subject<int>();
// Zipの動きを確認してみる……
buttonA.Zip(buttonB, (a, b) => new { a, b })
.Subscribe(a => Console.WriteLine(a));
buttonA.OnNext(1); // ボタンClickをイメージ
buttonA.OnNext(2); // Subscribeへ値が届くのはいつ?
buttonB.OnNext(10); // デバッグのステップ実行で一行ずつ確認
buttonA.OnCompleted(); // 片方が完了したら
buttonB.OnNext(3); // もう片方にClickが入ったときZipはどういう挙動する?
動きがよくわからないメソッドも、この方法で大体何とか分かります。Subjectには他に非同期実行を表現したAsyncSubjectなど、幾つか亜種があるのでそちらも見ると、Rxのメソッドの動きがよりイメージしやすくなります。例えばFromAsyncPatternは中ではAsyncSubjectを使っているので、AsyncSubjectの動き(OnCompletedの前後でHotとColdが切り替わる、OnNextはOnCompletedが来るまで配信されず、OnCompleted後に最後の値をキャッシュしてColdとして配信し続ける)を丁寧に確認することで、FromAsyncPatternの挙動の理解が簡単になります。
メソッド分類早見表
決して全部というわけではなく、幾つか飛ばしていますが簡単に各メソッドを分類して紹介。
生成系メソッド雑多分類
イベント(hot)
FromEvent - 文字列で与える以外のやり方もありますよ
非同期系(hot/cold)
Start - ToAsync().Invoke()の省略形
ToAsync - 拡張メソッドとしてじゃなくそのまま使うのが型推論効いて素敵
FromAsyncPattern - ToAsyncも結局これの省略形なだけだったりする
ForkJoin - 非同期処理が全て完了するのを待ち合わせて結果をまとめて返す
Enumerableっぽいの系(cold)
Range - いつもの
Return - ようするにRepeat(element, 1)
Repeat - 無限リピートもあるよ
ToObservable - pull to push
Generate - ようするにUnfold(と言われても困る?)
Using - 無限リピートリソース管理付き
Timer系(cold)
Timer - 実はcold
Interval - Timer(period, period)の省略形なだけだったり
GenerateWithTime - 引数地獄
空っぽ系(cold)
Empty - OnCompletedだけ発動
Throw - OnErrorだけ発動
Never - 本当に何もしない
その他
Defer - 生成の遅延
Create - 自作したい場合に(戻り値はDispose時の実行関数を返す)
CreateWithDisposable - 同じく、ただし戻り値はIDisposableを返す
こうしてみるとColdばかりで、Hotなのってイベントだけ?的だったりしますねー。では、IObservableの拡張メソッドも。
合成系
SelectMany - Enumerableと同じ感じですが、Rxでは合成のように機能する
Zip - 左右のイベントが揃ったらイベント発行(揃うまでQueueでキャッシュしてる)
CombineLatest - 最新のキャッシュと結合することで毎回イベント発行
Merge - Y字みたいなイメージで、左右の線を一本に連結
Join(Plan/And/Then) - Joinパターンとかいう奴らしいですが、Zipの強化版みたいな
Concat - 末尾に接続
StartWith - 最初に接続
時間系
Delay - 値を一定時間遅延させる、coldに使うと微妙なことになるので注意
Sample - 一定時間毎に、通過していた最新の値だけを出す
Throttle - 一定時間、値が通過していなければ、その時の最新の値を出す
TimeInterval - 値と前回の時間との差分を包んだオブジェクトを返す
RemoveTimeInterval - 包んだオブジェクトを削除して値のみに戻す
Timestamp - 値と通過した時間で包んだオブジェクトを返す
RemoveTimestamp - 包んだオブジェクトを削除して値のみに戻す
Timeout - 一定時間値が来なければTimeoutExceptionを出す
Connectable系(ColdをHotに変換する、細部挙動はSubjectでイメージするといい)
Publish - Subjectを使ったもの(引数によってはBehaviorSubject)
Prune - AsyncSubjectを使ったもの
Replay - ReplaySubjectを使ったもの
Enumerableに変換系(Push to Pull、使い道わかりません)
Next - MoveNext後に同期的にブロックして値が来るまで待機
Latest - 値を一つキャッシュするNext(キャッシュが切れると待機)
MostRecent - ブロックなしでキャッシュを返し続ける
例外ハンドリング系
OnErrorResumeNext - 例外来たら握りつぶして予備シーケンスへ移す
Catch - 対象例外が来たら握りつぶして次へ
Finally - 例外などで止まっても最後に必ず実行するのがOnCompletedとの違い
実行スレッド変更系
SubscribeOn - メソッド全体の実行スレッドを変える
ObserveOn - 以降に流れる値の実行スレッドを変える
クエリ系
Select - 射影(SelectManyはこっちじゃないのって話ももも)
Where - フィルタリング
Scan - Aggregateの経過も列挙するバージョン、一つ過去の値を持てるというのが重要
Scan0 - seed含む
GroupBy - グルーピング、なのだけどIGroupedObservableは扱いが少し面倒かなあ
BufferWithCount - 個数分だけListにまとめる
BufferWithTime - 一定時間内の分だけListにまとめる
BufferWithTimeOrCount - そのまんま、上二つが合わさったの
DistinctUntilChanged - 連続して同じ値が来た場合は流さない
すっとばす系
Skip - N個飛ばす
SkipWhile - 条件に引っかかる間は飛ばす
SkipLast - 最後N個を飛ばす(Lastを除いたTakeという趣向)
SkipUntil - 右辺のOnNextを察知する「まで」は飛ばす
Take - N個取る
TakeWhile - 条件に引っかかる間は取る
TakeLast - 最後N個だけを取る
TakeUntil - 右辺のOnNextを察知する「まで」は取る
Aggregate系
AggregateとかAllとかSumとかEnumerableにもある色々 - 値が確定したとき一つだけ流れてくる
変換系
ToEnumerable - 同期的にブロックしてIEnumerableに変換する、Hotだと一生戻ってこない
ToQbservable - IQueryableのデュアルらしい、完全にイミフすぎてヤバい
Start - ListなんだけどObservableという微妙な状態のものに変換する
その他
Materiallize - OnNext,OnError,OnCompletedをNotificationにマテリア化
Dematerialize - マテリア化解除
Repeat - OnCompletedが来ると最初から繰り返し
Let - 一時変数いらず
Switch - SelectMany書かなくていいよ的なの
AsObservable - IObservableにラップ、Subjectと合わせてどうぞ
疲れた。間違ってるとかこれが足りない(いやまあ、実際幾つか出してないです)とか突っ込み希望。
JavaScript版もあります
RxJSというJavaScript版のReactive Extensionsもあったりします。ダウンロードは.NET版と同じところから。何が出来るかというと、若干、というかかなりメソッドが少なくなってはいるものの、大体.NETと同じことが出来ます。SchedulerにTimeout(JavaScriptにはスレッドはないけどsetTimeoutがあるので、それ使って実行を遅らせるというもの)があったりと、相違も面白い。
JavaScriptは、まずAjaxが非同期だし、イベントだらけなのでRxが大変効果を発揮する。強力なはず、なのですが注目度はそんなに高くない。うむむ?jQueryと融合出来るバインディングも用意されていたりと、かなりイケてると思うのですがー。日本だとJSDeferredがあるね、アレの高機能だけど重い版とかとでも思ってもらえれば。
ところでObservableがあるということはEnumerableもありますか?というと、もちろんありますよ!linq.js - LINQ for JavaScriptとかいうライブラリを使えばいいらしいです!最近Twitterの英語圏でも話題沸騰(で、ちょっと浮かれすぎて頭がフワフワタイムだった)。RxJSと相互に接続できるようになっていたり、jQueryプラグインになるバージョンもあったりと、jQuery - linq.js - RxJSでJavaScriptとは思えない素敵コードが書けます。
JavaScriptはIEnumerableとIObservableが両方そなわり最強に見える。
Over the Language
Linqとは何ぞや。というと、一般にはLinq=クエリ構文=SQLみたいなの、という解釈が依然として主流のようで幾分か残念。これに対する異論は何度か唱えているけれど、では実際何をLinqと指すのだろう。公式の見解はともあれ勝手に考えると、対象をデータソースとみなし、Whereでフィルタリングし、Selectで射影するスタイルならば、それはLinqではないだろうか。
Linq to ObjectsはIEnumerableが、Linq to XmlではXElementが、Linq to SqlではExpression Treeが、Reactive ExtensionsにはIObservableの実装が必要であり、それぞれ中身は全く違う。昔はExpression Treeを弄ること、QueryProviderを実装することがLinq to Hogeの条件だと考えていたところがあったのだけど、今は、Linqの世界(共通のAPIでの操作)に乗っていれば、それはLinqなのだと思っている。
だからLinqは言語にも.NET Frameworkにも依存していない。Linqとは考え方にすぎない。例えば、Linq to Objectsはクロージャさえあればどの言語でも成り立つ(そう……JavaScriptでもね?)。むしろ重要なのは「Language INtegrated」なことであり、表面的なスタイル(SQLライクなシンタックス!)は全く重要ではない。言語に統合されていれば、異物感なく自然に扱え、IDEやデバッガなど言語に用意されているツールのサポートが得られる。(例えば……JavaScriptでガリガリと入力補完効かせてみたりね?)
言語を超えて共有される、より高い次元の抽象化としてのLinq。私はそんな世界に魅せられています。RxはLinqにおけるデータソースの概念をイベントや非同期にまで拡張(まさにExtension)して、更なる可能性を見せてくれました。次なる世界はDryad? まだまだLinqは熱い!
まとめ
ていうか改めてHaskellは偉大。でも、取っ付きやすさは大事。難しげなことを簡単なものとして甘く包んで掲示したLinqは、凄い。Rxも、取っ付きづらいFunctional Reactive Programmingを、Linqというお馴染みの土台に乗せたことで理解までの敷居を相当緩和させた。素晴らしい仕事です。
難しいことが簡単に出来る、というのがLinqのキモで、Rxも同じ。難しかったこと(イベントの合成/非同期)が簡単にできる。それが大事だし、その事をちゃんと伝えていきたいなあ。そして、Realworldでの実践例も。そのためにはアプリケーション書かなければ。アプリケーション、書きたいです……。書きます。
そういえばついでに、Rx一周年ということで、大体一年分の記事が溜まった(そしてロクに書いてないことが判明した)のと、少し前にlinq.jsのRT祭りがあった熱に浮かされて、応募するだけならタダ理論により10月期のMicrosoft MVPに応募しちゃったりなんかしました。恥ずかしぃー。分野にLinqがあれば!とか意味不明なことを思ったのですが、当然無いのでC#です、応募文句は、linq.js作った(DL数累計たった1000)と、Rx紹介書いてる、の二つだけって無理ですね明らかに。これから割と詳細に活動内容を書いて、送らなきゃいけないのですが、オール空白状態。応募したことに泣きたくなってきたよ、とほほ。
Windows Phone 7 + Reactive ExtensionsによるXml取得
- 2010-07-19
Windows Phone 7にはReactive Extensionsが標準搭載されていたりするのだよ!なんだってー!と、いうわけで、Real World Rx。じゃないですけれど、Rxを使って非同期処理をゴニョゴニョとしてみましょう。ネットワークからデータ取って何とかする、というと一昔前はRSSリーダーがサンプルの主役でしたが、最近だとTwitterリーダーなのでしょうね。というわけで、Twitterリーダーにします。といっても、ぶっちゃけただたんにデータ取ってリストボックスにバインドするだけです。そしてGUI部分はSilverlightを使用してWindows Phone 7でTwitterアプリケーションを構築 - @ITのものを丸ごと使います。手抜き!というわけで、差分としてはRxを使うか否かといったところしかありません。
なお、別に全然Windows Phone 7ならでは!なことはやらないので、WPFでもSilverlightでも同じように書けます。ちょっとしたRxのサンプルとしてどうぞ。今回は出たばかりのWindows Phone Developer Tools Betaを使います。Windows Phone用のBlendがついていたりと盛り沢山。
Xmlを読み込む
とりあえずLinq to XmlなのでXElement.Load(string uri)ですね。違います。そのオーバーロードはSilverlightでは使えないのであった。えー。なんでー。とはまあ、つまり、同期系APIの搭載はほとんどなくて、全部非同期系で操作するよう強要されているわけです。XElement.Loadは同期でネットワークからXMLを引っ張ってくる→ダウンロード時間中はUI固まる→許すまじ!ということのようで。みんな大好きBackgroundWorkerたん使えばいいぢゃない、みたいなのは通用しないそうだ。
MSDNにお聞きすれば方法 : LINQ to XML で任意の URI の場所から XML ファイルを読み込むとあります。ネットワークからデータを取ってくるときはWebClient/HttpWebRequest使えというお話。
では、とりあえず、MainPage.xamlにペタペタと書いて、MessageBox.Showで確認していくという原始人な手段を取っていきましょう。XElementの利用にはSystem.Xml.Linqの参照が別途必要です。
public MainPage()
{
InitializeComponent();
var wc = new WebClient();
wc.OpenReadCompleted += (sender, e) =>
{
var elem = XElement.Load(e.Result); // e.ResultにStreamが入ってる
MessageBox.Show(elem.ToString()); // 確認
};
wc.OpenReadAsync(new Uri("http://twitter.com/statuses/public_timeline.xml")); // 非同期読み込み呼び出し開始
}
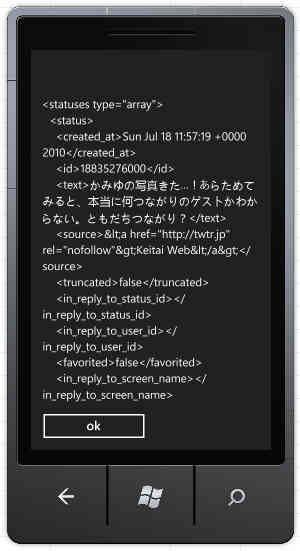
別に難しいこともなくすんなりと表示されました。簡単なことが簡単に書けるって素晴らしい。で、WebClientのプロパティをマジマジと見ているとAllowReadStreamBufferingなんてものが。trueの場合はメモリにバッファリングされる。うーん、せっかくなので完全ストリーミングでやりたいなあ。これfalseならバッファリングなしってことですよね?じゃあ、バッファリング無しにしてみますか。
var wc = new WebClient();
wc.AllowReadStreamBuffering = false; // デフォはtrueでバッファリングあり、今回はfalseに変更
wc.OpenReadCompleted += (sender, e) =>
{
try
{
var elem = XElement.Load(e.Result); // ここで例外出るよ!
}
catch (Exception ex)
{
// Read is not supporeted on the main thread when buffering is disabled.
MessageBox.Show(ex.ToString());
}
};
例外で死にました。徹底して同期的にネットワーク絡みの処理が入るのは許しません、というわけですね、なるほど。じゃあ別スレッドでやるよ、ということでとりあえずThreadPoolに突っ込んでみた。
wc.OpenReadCompleted += (sender, e) =>
{
ThreadPool.QueueUserWorkItem(_ =>
{
try
{
var elem = XElement.Load(e.Result);
MessageBox.Show(elem.ToString()); // 今度はここで例外!
}
catch(Exception ex)
{
// Invalid cross-thread access.
Debug.WriteLine(ex.ToString());
}
});
};
読み込みは出来たけど、今度はMessageBox.Showのところで、Invalid Cross Thread Accessで死んだ。そっか、MessageBoxもUIスレッドなのか。うーむ、世の中難しいね!というわけで、とりあえずDispatcher.BeginInvokeしますか。
wc.OpenReadCompleted += (sender, e) =>
{
ThreadPool.QueueUserWorkItem(_ =>
{
var elem = XElement.Load(e.Result);
Dispatcher.BeginInvoke(() => MessageBox.Show(elem.ToString()));
});
};
これで完全なストリームで非同期呼び出しでのXmlロードが出来たわけですね。これは面倒くさいし、Invoke系の入れ子が酷いことになってますよ、うわぁぁ。
Rxを使う
というわけで、非Rxでやると大変なのがよく分かりました。そこでRxの出番です。標準搭載されているので、参照設定を開きMicrosoft.Phone.ReactiveとSystem.Observableを加えるだけで準備完了。
var wc = new WebClient { AllowReadStreamBuffering = false };
Observable.FromEvent<OpenReadCompletedEventArgs>(wc, "OpenReadCompleted")
.ObserveOn(Scheduler.ThreadPool) // ThreadPoolで動かすようにする
.Select(e => XElement.Load(e.EventArgs.Result))
.ObserveOnDispatcher() // UIスレッドに戻す
.Subscribe(x => MessageBox.Show(x.ToString()));
wc.OpenReadAsync(new Uri("http://twitter.com/statuses/public_timeline.xml"));
非常にすっきり。Rxについて説明は、必要か否か若干悩むところですが説明しますと、イベントをLinq化します。今回はOpenReadCompletedイベントをLinqにしました。Linq化すると何が嬉しいって、ネストがなくなることです。非常に見やすい。更にRxの豊富なメソッド群を使えば普通ではやりにくいことがいとも簡単に出来ます。今回はObserveOnを使って、どのスレッドで実行するかを設定しました。驚くほど簡単に、分かりやすく。メソッドの流れそのままです。
FromAsyncPattern
WebClientだけじゃなく、ついでなのでHttpWebRequestでもやってみましょう。(HttpWebRequest)WebRequest.Create()死ね、といつも言ってる私ですが、SilverlightにはWebRequest.CreateHttpでHttpWebRequestが作れるじゃありませんか。何ともホッコリとします。微妙にこの辺、破綻した気がしますがむしろ見なかったことにしよう。
var req = WebRequest.CreateHttp("http://twitter.com/statuses/public_timeline.xml");
req.AllowReadStreamBuffering = false;
req.BeginGetResponse(ar =>
{
using (var res = req.EndGetResponse(ar))
using (var stream = res.GetResponseStream())
{
var x = XElement.Load(res.GetResponseStream());
Dispatcher.BeginInvoke(() => MessageBox.Show(x.ToString()));
}
}, null);
非同期しかないのでBeginXxx-EndXxxを使うのですが、まあ、結構面倒くさい。そこで、ここでもまたRxの出番。BeginXxx-EndXxx、つまりAPM(Asynchronus Programming Model:非同期プログラミングモデル)の形式の非同期メソッドをラップするFromAsyncPatternが使えます。
var req = HttpWebRequest.CreateHttp("http://twitter.com/statuses/public_timeline.xml");
req.AllowReadStreamBuffering = false;
Observable.FromAsyncPattern<WebResponse>(req.BeginGetResponse, req.EndGetResponse)
.Invoke() // 非同期実行開始(Invoke()じゃなくて()でもOKです、ただのDelegateなので)
.Select(res => XElement.Load(res.GetResponseStream()))
.ObserveOnDispatcher()
.Subscribe(x => MessageBox.Show(x.ToString()));
ラップは簡単で型として戻り値を指定してBeginXxxとEndXxxを渡すだけ。あとはそのまま流れるように書けてしまいます。普通だと面倒くさいはずのHttpWebRequestのほうがWebClientよりも素直に書けてしまう不思議!FromAsyncPatter、恐ろしい子。WebClient+FromEventは先にイベントを設定してURLで発動でしたが、こちらはURLを指定してから実行開始という、より「同期的」と同じように書ける感じがあって好き。WebClient使うのやめて、みんなHttpWebRequest使おうぜ!(ふつーのアプリのほうでは逆のこと言ってるのですががが)
ところで、非同期処理の実行開始タイミングはInvokeした瞬間であって、Subscribeした時ではありません。どーなってるかというと、ぶっちゃけRxは実行結果をキャッシュしてます。細かい話はまた後日ちゃんと紹介するときにでも。
バインドする
GUIはScottGu氏のサンプルを丸々頂いてしまいます。リロードボタンを押したらPublicTLを呼ぶだけ、みたいなのに簡略化してしまいました。
<Grid x:Name="LayoutRoot" Background="Transparent">
<Grid.RowDefinitions>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
</Grid.RowDefinitions>
<Button Grid.Row="0" Height="72" Width="200" Content="Reload" Name="Reload"></Button>
<ListBox Grid.Row="1" Name="TweetList" DataContext="{Binding}">
<ListBox.ItemTemplate>
<DataTemplate>
<StackPanel Orientation="Horizontal">
<Image Source="{Binding Image}" Height="73" Width="73" VerticalAlignment="Top" />
<StackPanel Width="350">
<TextBlock Text="{Binding Name}" Foreground="Red" />
<TextBlock Text="{Binding Text}" TextWrapping="Wrap" />
</StackPanel>
</StackPanel>
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
</Grid>
あとは、ボタンへのイベント設定と、Twitterのクラスを作る必要があります。
public class TwitterStatus
{
public long Id { get; set; }
public string Text { get; set; }
public string Name { get; set; }
public string Image { get; set; }
public TwitterStatus(XElement element)
{
Id = (long)element.Element("id");
Text = (string)element.Element("text");
Name = (string)element.Element("user").Element("screen_name");
Image = (string)element.Element("user").Element("profile_image_url");
}
}
public partial class MainPage : PhoneApplicationPage
{
public MainPage()
{
InitializeComponent();
Reload.Click += new RoutedEventHandler(Reload_Click); // XAMLに書いてもいいんですけど。
}
void Reload_Click(object sender, RoutedEventArgs e)
{
var req = HttpWebRequest.CreateHttp("http://twitter.com/statuses/public_timeline.xml");
req.AllowReadStreamBuffering = false;
Observable.FromAsyncPattern<WebResponse>(req.BeginGetResponse, req.EndGetResponse)
.Invoke()
.Select(res => XElement.Load(res.GetResponseStream()))
.Select(x => x.Descendants("status").Select(xe => new TwitterStatus(xe)))
.ObserveOnDispatcher()
.Subscribe(ts => TweetList.ItemsSource = ts);
}
}
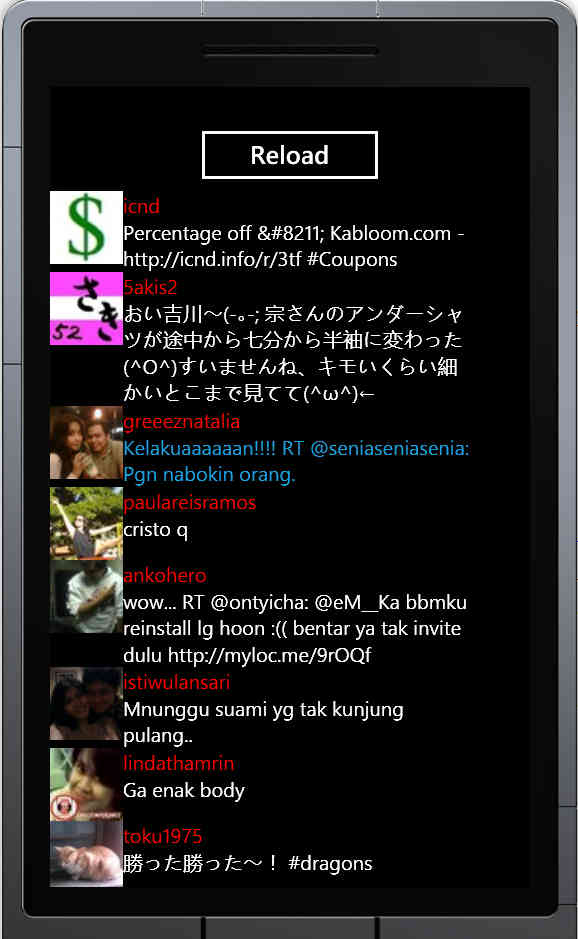
実行するとこんな具合に表示されます。簡単ですねー。ただ、これだとリロードで20件しか表示されないので、リロードしたら継ぎ足されるように変更しましょう。
イベントを合成する
継ぎ足しの改善、のついでに、一定時間毎に更新も加えよう。基本は一定時間毎に更新だけど、リロードボタンしたら任意のタイミングでリロード。きっとよくあるパターン。Reload.Click+=でハンドラ足すのはやめて、その部分もFromEventでObservable化してしまいましょう。そして一定時間毎のイベント発動はObservable.Timerで。
// 30秒毎もしくはリロードボタンクリックでPublicTimeLineを更新
Observable.Merge(
Observable.Timer(TimeSpan.Zero, TimeSpan.FromSeconds(30), Scheduler.NewThread).Select(_ => (object)_),
Observable.FromEvent<RoutedEventArgs>(Reload, "Click").Select(_ => (object)_))
.SelectMany(_ =>
{
var req = HttpWebRequest.CreateHttp("http://twitter.com/statuses/public_timeline.xml");
req.AllowReadStreamBuffering = false;
return Observable.FromAsyncPattern<WebResponse>(req.BeginGetResponse, req.EndGetResponse)();
})
.Select(res => XStreamingReader.Load(res.GetResponseStream()))
.SelectMany(x => x
.Descendants("status")
.Select(xe => new TwitterStatus(xe))
.Reverse()) // 古い順にする
.Scan((before, current) => before.Id > current.Id ? before : current) // 最後に通した記事よりも古ければ通さない(で、同じ記事を返す)
.DistinctUntilChanged(t => t.Id) // 同じ記事が連続して来た場合は何もしないでreturn
.ObserveOnDispatcher()
.Subscribe(t => TweetList.Items.Insert(0, t)); // Insertだって...
流れるようにメソッド足しまくるの楽しい!楽しすぎて色々足しすぎて悪ノリしている感が否めません、とほほ。解説しますと、まず一行目のMerge。これは複数本のイベントを一本に統一します。統一するためには型が同じでなければならないのですが、今回はTimer(long)と、Click(RoutedEventArgs)なのでそのままでは合成出来ません。どちらも発火タイミングが必要なだけでlongもRoutedEventArgsも不必要なため、Objectにキャストしてやって合流させました。
こういう場合、Linq to Objectsなら.Cast<object>()なんですよね。Castないんですか?というと、一応あるにはあるんですが、実質無いようなもので。というわけで、今のところキャストしたければ.Select(=>(object))を使うしかありません。多分。もっとマシなやり方がある場合は教えてください。
続いてSelectMany。TimerもしくはClickは発火のタイミングだけで、後ろに流すのはFromAsyncPatternのデータ。こういった、最初のイベントは発火タイミングにだけ使って、実際に流すものは他のイベントに摩り替える(例えばマウスクリックで発動させて、あとはマウスムーブを使うとか)というのは定型文に近い感じでよく使うことになるんじゃないかと思います。SelectMany大事。
XMLの読み込み部は、せっかくなので、こないだ作ったバッファに貯めこむことなくXmlを読み込めるXStreamingReaderを使います。こんな風に、XMLを読み取ってクラスに変換する程度ならXElement.Loadで丸々全体のツリーを作るのも勿体無い。XStreamingReaderなら完全ストリーミングでクラスに変換出来ますよー。という実例。
その下は更にもう一個SelectMany。こっちはLinq to Objectsのものと同じ意味で、IEnumerableを平たくしています。で、ScanしたDistinctUntilChangedして(解説が面倒になってきた)先頭にInsert(ちょっとダサい)。これで古いものから上に足される = 新しい順番に表示される、という形になりました。XAML側のListBoxを直に触ってInsertとか、明らかにダサい感じなのですが、まあ今回はただのサンプルなので見逃してください。
RxのMergeに関しては、後日他のイベント合流系メソッド(CombineLatest, Zip, And/Then/Plan/Join)と一緒に紹介したいと思っています。合流系大事。
まとめ
驚くほどSilverlightで開発簡単。っぽいような印象。C#書ける人ならすぐにとっかかれますねー。素晴らしい開発環境だと思います。そして私は同時に、Silverlight全然分かってないや、という現実を改めて突きつけられて参ってます。XAMLあんま書けない。Blend使えない。MVVM分からない。モバイル開発云々の前に、基本的な技量が全然欠けているということが良く分かったし、それはそれで良い収穫でした。この秋なのか冬なのかの発売までには、ある程度は技術を身につけておきたいところです。
そしてそれよりなにより開発機欲すぃです。エミュレータの起動も速いし悪くないのですが、やっぱ実機ですよ、実機!配ってくれぇー。
XStreamingReader - Linq to Xml形式でのストリーミングXml読み込み
- 2010-07-16
CodePlex : XStreamingReader - Streaming for Linq to Xml
1クラスライブラリシリーズ。もしくはストリーミングをIEnumerableに変換していこうシリーズ。またはシンプルだけど小粒でピリッと隙間にぴったりはまるシリーズ(を、目指したい)。といったわけで、100行程度ではあるのですが、表題の機能を持つコードをCodePlexに公開しました。それとおまけとして、XMLファイルからC#クラス自動生成T4 Templateも同梱。
Linq to Xml風にXmlを読み込めるけれど、ツリーを構築せずストリームで、完全遅延評価で実行します。Linq to Xmlには、書き込み用にXStreamingElementというものがあるため、それと対比した読み込み用という位置付けのつもりです。メモリの厳しいモバイル機器や、巨大なXMLを読み込む際に使えるんじゃないかと思っています。
利用例
ぶっちゃけまるっきりXElementと同じです。例としてYahoo!天気情報のRSSから京都と東京を取り出し。
// XElement
var kyoto = XElement.Load(@"http://rss.weather.yahoo.co.jp/rss/days/6100.xml")
.Descendants("item")
.Select(x => new
{
Title = (string)x.Element("title"),
Description = (string)x.Element("description"),
PubDate = (DateTime)x.Element("pubDate")
})
.Where(a => !a.Title.StartsWith("[PR]")) // itemが広告の場合は除外
.ToArray();
// XStreamingReader
var tokyo = XStreamingReader.Load(@"http://rss.weather.yahoo.co.jp/rss/days/4410.xml")
.Descendants("item")
.Select(x => new
{
Title = (string)x.Element("title"),
Description = (string)x.Element("description"),
PubDate = (DateTime)x.Element("pubDate")
})
.Where(a => !a.Title.StartsWith("[PR]")) // itemが広告の場合は除外
.ToArray();
Load/Parseで生成し、ElementsやDescendantsで抽出。あとは、IEnumerable<XElement>となっているので、SelectしたりWhereしたり。完全にLinq to Xmlと同じAPIです。同じすぎてこれだけだと利点がさっぱり見えませんが、100%遅延評価+ストリーミング読み込みで逐次生成という違いがあります。詳しくは次のセクションで。
バックグラウンド
Androidでは性能のためにDOMじゃなくてSAXでXML扱うんだ。という話を良く聞いて、確かにただデータ取るためだけにDOM構築ってのは嫌だし、そりゃ避けたい。対象がDOMなら素直にそう思いますが、しかし、もしそれがLinq to Xmlならどうだろう?Windows Phone 7だったらLinq to Xml使うに決まってるよ、と言いたいのですが、これってDOMと同じく、すぐに(LoadなりParseなりした直後)ツリーを構築しています。Elements()なりDescendants()なりの戻り値がIEnumerableなため、遅延評価かと思ってしまうわけですが、遅延評価されるのはツリーの探索が、というだけであって、構築自体は即時でされています。
DOMに比べて軽量(という謳い文句)であることと、非常に軽々と書けるため抵抗感がないわけですが、考えてみれば Load.Descendants.Select みたいな、API叩いて何らかのクラスなり匿名型なりに変換するという程度の、しかしよくある定型作業は、わざわざツリー作る必要はなくストリーミングで取れるし、それならばストリーミングで取るべきではある。しかし、今時XmlReaderを直で触るなんて、時代への逆行のようなことはやりたくない。
ストリームはIEnumerableに変換するのがLinq以降のC#の常識。というのを日々連呼しているので、今回はXmlReaderをIEnumerable<T>に変換しなければなりません。しかし、困ったのが、<T>のTを何にすればいいのか、ということ。ファイル読み込みなら一行のString。データベースなら、IDataRecord(DbExecutorというライブラリとしてCodePlexに公開しています)を用いましたが、XmlReaderだと適当なのが見当たらない。XmlReaderを直接渡すのは危なっかしいし、そもそも渡したところで面倒くさいことにかわりなくてダメだ。何か適切なコンテナが……。
と、考えたり考えなかったりで、Twitterでもにょもにょと言っていたら
@neuecc Linq to Xml を使うにしても XmlReaderからReadSubtreeで切り出した断片に対してかなー、XML全体をオンメモリさせる必然性がなければStreamから読んで処理した端からGCに捨てて貰えるようにしておきたいだけだけど
http://twitter.com/kazuk/status/18193188205
うぉ!うぉぉぉぉぉ!なるほど、断片をXElementに変換してそれを渡せば、操作しやすいし感覚的にもXElement.Loadなどと変わらないしでベストだ!言われてみればそりゃそうだよねー、ですが全然頭になかった、まさにコロンブスの卵。こういうことがサラッと出てくることこそが、凄さだよね。
と、感嘆しつつ、それそのまま頂き、というわけで、TをXElementにするという形で解決しました。
public IEnumerable<XElement> Descendants(XName name)
{
using (var reader = readerFactory())
{
while (reader.ReadToFollowing(name.LocalName, name.NamespaceName))
{
yield return XElement.Load(reader.ReadSubtree());
}
}
}
Descendantsの実装はこんな感じで、断片から都度XElement生成しているという、それだけの単純明快な代物です。そのため挙動はXElement.Load.Descendantsと完全同一というわけじゃありません。例えばサブツリー中に同名の要素がある場合、XElementでDescendantsの場合はサブツリー中の要素も列挙しますが、XStreamingReaderではトップ要素のものだけが拾われます。
他に注意点としては、それぞれのXElementは完全に独立しているため、ParentやNextNodeなどは全てnullです。よってAncestorsで先祖と比較しながらの複雑な抽出、などといったことも出来ません。TwitterのAPIのような、ウェブサービスとして用意されているXMLなら素直な構造なので問題はありませんが、SGMLReaderでLinq to HTMLなどといった場合は、結構複雑なクエリで抽出することになるため使えないでしょう。その場合は素直にXElement.Loadを使うのが良いと思います。
おまけ(Xml→自動クラス生成)
Xmlから人力でClass作るのって定型作業で面倒だよねー。ということで、自動生成するT4 Templateも同梱しました。プロパティ定義だけではなく(ちゃんとPascalCaseに直します)、コンストラクタにXElementを投げるとマッピングもしてくれます。つまりは、XStreamingReaderの仕様に合わせたものです。
.ttの上の方にある3つの項目を適当に書き換えると
string XmlString = new WebClient().DownloadString("http://twitter.com/statuses/public_timeline.xml");
const string DescendantsName = "status"; // select class root
const string Namespace = "Twitter"; // namespace
namespace Twitter
{
public class Status
{
public string CreatedAt { get; set; }
public string Id { get; set; }
// snip...
public User User { get; set; }
public string Geo { get; set; }
public Status(XElement element)
{
this.CreatedAt = (string)element.Element("created_at");
this.Id = (string)element.Element("id");
this.User = new User(element.Element("user"));
this.Geo = (string)element.Element("geo");
}
}
public class User
{
public string Id { get; set; }
public string Name { get; set; }
public string ScreenName { get; set; }
// snip...
public string FollowRequestSent { get; set; }
public User(XElement element)
{
this.Id = (string)element.Element("id");
this.Name = (string)element.Element("name");
this.ScreenName = (string)element.Element("screen_name");
this.FollowRequestSent = (string)element.Element("follow_request_sent");
}
}
}
こんなのが生成されます。型は全部stringになるので、手動で直してください。半自動生成。T4で生成→新しいクラスファイル作って生成結果をコピペ→型を直す。みたいな使い方をイメージしています。完全自動生成じゃないと変更に対する自動追随ってのが出来ないので、自動生成する意味が半減。しかし、型かあ、スキーマないと無理ですな。まあ、ウェブサービスのAPIなどは基本的には固定で変化がないでしょうから、ある程度は手間を省けるんじゃないかと思われます。
まとめ
断片とはいえ、XElement作るのは無駄じゃないの?というと、無駄ではあります。抽出したらすぐ用済みでポイなわけなので、純粋にパフォーマンスの観点から言えばXmlReaderを直で触ったほうが良いに決まっています。しかし、さすがにそこまで来ると無視して良いと思うわけです。例えばLinqで一時的な匿名型は使わないって?ああ、むしろLinqなんてやめて全部forループにでもします?言いだいたらキリがない。
今回で大事なのは、ストリーミング化しても、決して使いやすさは損なわれていないということです。ツリー構築型と全く同じように快適に書ける。それが何より大切。「性能のために書きやすさが犠牲になるぐらいなら性能なんていらない!」と、現実は言えなくても心では言ってしまいます。ユーザー視点だと逆ですが……。ただ、中長期的には、スパゲティコードは開発者を幸せにしない→機能追加速度低下/洗練が鈍る→ユーザーも不幸せになる、のループが回るので綺麗さは重要。勿論、そこが性能上本当にボトルネックになっているならば気合入れて叩く必要がありますが、気分的に、もしくはマイクロベンチマーク的にちょっと性能Downな程度でパフォーマンスチューニングとか言い出すのならシバいてよし。
といったわけかで、私なりにWindows Phone 7プログラミングへの準備を進めています。これで、準備になってる?……だと?ご冗談を。ですね、はい、すみません。開発キットのベータ版が出たので、次回はWindows Phone 7で何か作ろう紹介でも書く予定は未定。
IEnumerableのCastを抹殺するためのT4 Templateの使い方
- 2010-07-07
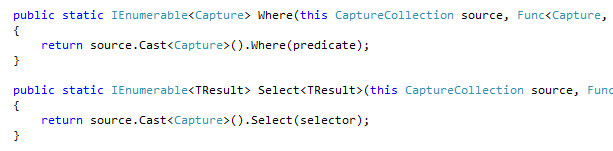
.NET Framework 1.0の負の遺産、HogeCollection。それらの大半はIEnumerable<T>を実装していない、つまるところ一々Cast<T>しなければLinqが使えない。ほんとどうしょうもない。大抵のHogeCollectionは実質Obsoleteみたいなもので、滅多に使わないのだけれど、ただ一つ、RegexのMatchCollectionだけは頻繁に使うわけで、Castにイラつかされるので殺害したい。RegexにはMatchCollection、GroupCollection、CaptureCollectionという恐怖の連鎖が待っているので余計に殺したい。(ところで全く本題とは関係ないのですが、Captureは今ひとつ使い道がわからな……)
// わざとらしい例ですが
var q = Regex.Matches("aag0 hag5 zag2", @"(.)ag(\d)")
.Cast<Match>()
.SelectMany(m => m.Groups.Cast<Group>().Skip(1).Select(g => g.Value))
.ToArray(); // a0h5z2
おお、何というCast地獄!つーか.NET 4でBCL書き直したとか言うんなら、その辺も少し融通聞かせてIEnumerable<T>にしてくれてもさー。あ、要望出さないのが悪いとかなのでしょうか……。それなら自己責任ですね、ちゃんと出していかないと。なのはともかく、自己責任ならば自己責任なりに、文句だけ言っててもしょうがないので自前で何とかしましょう。
ようするに.Cast<Hoge>()を自動で挟めばいいわけですよね。んー、ぴこーん!T4でジェネレートすればいいんじゃね?というわけで、T4 Templateを使ってみました。実際のところT4試してみたかったんだけどネタがなかったので、ネタが出てきて万歳!が本音だったりはします。
何もないところからテンプレートじゃあ作りようもないので、ひとまず完成系を書いてみる。
public static class MatchCollectionExtensions
{
public static IEnumerable<TResult> Select<TResult>(this MatchCollection source, Func<Match, TResult> selector)
{
return source.Cast<Match>().Select(selector);
}
// Where, Aggregate, ....
}
こんな形。グッとイメージしやすくなります。型引数のTSourceを消して、Castを挟んで……。やるべき事が大体見えてきました。まずは、Enumerableの拡張メソッドの抽出を。
var extMethods = typeof(Enumerable)
.GetMethods()
.Where(mi => Attribute.IsDefined(mi, typeof(ExtensionAttribute)));
特にBindingFlagsは設定しませんが、ExtensionAttributeが指定されているものがあれば拡張メソッド、という判定で問題なく取り出すことが出来ます。続いて戻り値を抽出。
var returnType = extMethods
.Select(mi => mi.ReturnType)
.Select(mi => Regex.Replace(mi.Name, "`.*$", "")
+ (mi.IsGenericType ? ("<" + string.Join(", ", mi.GetGenericArguments().Select(t => t.Name)) + ">") : ""));
IEnumerable<T>のNameはIEnumerable1になっているので1を正規表現で削除。そして引数を並べる。ただまあ、これだけだとジェネリック引数がネストしたものに対応出来ていなかったりTSourceが除去できてなかったりダメなのですが、それはそれ(最終的なコードは下記の実例のほうを見てください)。
といったわけで、相変わらずリフレクション+Linqは鉄板ですね。というかLinqなしのリフレクションとかやりたくない……。こんな感じにポチポチと素材集めをしたら、T4化します。
<#@ template language="C#" #>
<#@ output extension="cs" #>
<#@ assembly Name="System.Core.dll" #>
<#@ import namespace="System" #>
<#@ import namespace="System.Collections.Generic" #>
<#@ import namespace="System.Linq" #>
<#@ import namespace="System.Text" #>
<#@ import namespace="System.Runtime.CompilerServices" #>
<#@ import namespace="System.Text.RegularExpressions" #>
<#@ import namespace="System.Reflection" #>
<#
var target = new Dictionary<string, string>
{
{"MatchCollection", "Match"},
{"GroupCollection", "Group"},
{"CaptureCollection", "Capture"}
};
#>
<#
var ignoreMethods = new HashSet<string>
{
"Max", "Min", "Average", "Sum", "Zip", "OfType", "Cast",
"Join", "GroupJoin", "ThenBy", "ThenByDescending", "LongCount"
};
#>
using System;
using System.Collections.Generic;
using System.Linq;
namespace System.Text.RegularExpressions
{
<#
foreach (var kvp in target)
{
#>
public static class <#= kvp.Key.Replace(".","") #>Extensions
{
<#
foreach (var methodInfo in typeof(Enumerable).GetMethods().Where(mi => Attribute.IsDefined(mi, typeof(ExtensionAttribute))))
{
if(ignoreMethods.Contains(methodInfo.Name)) continue;
#>
public static <#= MakeReturnType(methodInfo, kvp.Value) #> <#= methodInfo.Name #><#= MakeGenericArguments(methodInfo) #>(this <#= kvp.Key #> source<#= MakeParameters(methodInfo, kvp.Value) #>)
{
return source.Cast<<#= kvp.Value #>>().<#= MakeMethodBody(methodInfo) #>;
}
<#}#>
}
<#}#>
}
<#+
const string TSource = "TSource";
static string ConstructTypeString(Type type, string castType)
{
var result = type.Name.Contains(TSource)
? type.Name.Replace(TSource, castType)
: Regex.Replace(type.Name, "`.*$", "");
if (type.IsGenericType)
{
result += string.Format("<{0}>", string.Join(", ", type.GetGenericArguments().Select(t => ConstructTypeString(t, castType))));
}
return result;
}
static string MakeReturnType(MethodInfo info, string castType)
{
return ConstructTypeString(info.ReturnType, castType);
}
static string MakeGenericArguments(MethodInfo info)
{
var types = info.GetGenericArguments().Select(t => t.Name).Where(s => s != TSource);
return types.Any() ? string.Format("<{0}>", string.Join(", ", types)) : "";
}
static string MakeParameters(MethodInfo info, string castType)
{
var param = info.GetParameters()
.Skip(1)
.Select(pi => new { pi.Name, ParameterType = ConstructTypeString(pi.ParameterType, castType) });
return param.Any()
? ", " + string.Join(", ", param.Select(a => a.ParameterType + " " + a.Name))
: "";
}
static string MakeMethodBody(MethodInfo info)
{
var args = info.GetParameters().Skip(1).Select(pi => pi.Name);
return string.Format("{0}({1})", info.Name, args.Any() ? string.Join(", ", args) : "");
}
#>
上のほうの、ディクショナリ(target)の初期化子を弄ることで対象の型を増減できます。namespaceはテンプレートに埋め込みなので変える場合は適当に変えてください。ハッシュセット(ignoreMethods)はその名の通り、除外したい拡張メソッドを指定します。今回はMax,Minなどと、Zip,Join,GroupJoin(これらは若干弄らないと対応出来ないので見送り)を除外しています。あとLongCountも外してます、理由はRxのSystem.InteractiveがLongCountで競合するから(多分、Rxチームのミスだと思うのでそのうち直ると思います)。
どんなクラスにも対応出来る(はず)ので、もしキャストが必要なウザいHogeCollectionがあったら、このテンプレートを使ってみると良いかもしれません。WinFormsのControl.ControlCollectionとかWPFのUIElementCollectionとか(そういうのは、元よりごった煮で詰め込むの前提なので、UIElementでSelect出来ても嬉しくはないかなー)。ともあれ、利用はご自由にどうぞ。
こんな感じに、MatchCollection, GroupCollection, CaptureCollectionだと合計1100行ぐらいのコードが生成されます。これで、CastいらずにLinqが書けるようになりました。メデタシメデタシ。
T4 Template
T4 Templateはかなり良いですね。VisualStudioと密接に動作して、生成出来ないようならエラーですぐ知らせてくれるのが嬉しい。これ大事。超大事。それがないと書けません。C#もそうだけれど、とりあえず書く→コンパイラエラー→直す、をリアルタイムで繰り返せるのは素晴らしい。現代のプログラミング環境はこうでないと、な良さに溢れてます。アドインを入れれば入力補完やシンタックスハイライトも付いてくるので非常に快適。
T4 Templateは標準搭載の機能だし実に強力なので、積極的に使っていきたいものです。MSDNだとコード生成とテキスト テンプレート辺りかな。例によって、読んでもさっぱり意味がわかりません(笑) 今のところオフィシャルだとこんなドキュメントしかないのかなあ、少し厳しめ。いやまあ、T4自体は構文がシンプルなので、ただ書くだけならサンプル改変で何とかなる、というか、私もサンプル改変以上の機能は知らないのですががが。
Rx(Reactive Extensions)を自前簡易再実装する
- 2010-07-05
という表題でUstreamやりました。Reactive Extensions for .NET (Rx)のSelect, Where, ToObservable, FromEventを実装することで、挙動を知ろうという企画。結果?酷いものです!
Shift+Alt+F10はお友達。それにしたってぐだぐだ。想像以上に頭が真っ白。セッションやライブコーディングしてる人は凄いね、と実感する。プレゼンどころか人と話すのも苦手です、な私には敷居が高かった。とにかく説明ができない。デバッガで動かせば分かりやすいよねー、なんてやる前は思ってたんですが、人がデバッガ動かしてるの見ててもさっぱり分かりやすくないよ!ということに途中で気づいて青ざめる。
まあ、こういうのも経験積まないとダメよね、と考えると、リスクゼロ(見てくれた人には申し訳ないですが)で練習出来るので、これからもネタがあればやっていきたいとは思います。反省は活かして。ネタはあまりないのでリクエストあればお願いします。Ustreamの高画質配信については、去年に書いた高画質配信するためのまとめ記事が自分で役に立ったぜ、経験が活きたな、的な。私自身の環境はちょっと、というかかなり変わったのですが、配信の基本的部分に関しては今も昔も(といっても1年前か)変わってなかったね。
さて、そんなUstreamはともかくとして、Rxの基本的な拡張メソッド「Select, Where」と、基本的な生成メソッド「ToObservable, FromEvent」を自前で実装してみる/デバッガで追ってみましょう。自分の手で動かして追うと理解しやすくなります。なので、以下に出すソースはコピペでもいいので、実際にVisualStudio上で動かしてもらえればと思います。
IEnumerableで考える
IObservableの拡張メソッド実装、の前に復習を兼ねてIEnumerableの拡張メソッドを実装してみましょう。
public static IEnumerable<TR> Select<T, TR>(IEnumerable<T> source, Func<T, TR> selector)
{
foreach (var item in source)
{
yield return selector(item);
}
}
恐ろしく簡単です。こんなにも簡単に書けるのは、yield returnのお陰。裏では、コンパイラが自動で対応するIEnumerable, IEnumeratorを生成してくれます。もしこれを教科書通りに自前で書くとしたら
public static IEnumerable<TR> Select<T, TR>(IEnumerable<T> source, Func<T, TR> selector)
{
return new SelectEnumerable<TR>(); // 本当は引数も必要ですが省略
}
class SelectEnumerable<T> : IEnumerable<T>
{
public IEnumerator<T> GetEnumerator()
{
return new SelectEnumerator<T>();
}
// 以下略
// IEnumerator IEnumerable.GetEnumerator()
}
class SelectEnumerator<T> : IEnumerator<T>
{
// Current, Dispose, MoveNextが必要ですが略
}
ああ、長い。やってられない。こんなものがオブジェクト指向だなどと言うならば、クソったれだと唾を吐きたくなる。そこで、AnonymousHogeパターンを用いれば……
public static IEnumerable<TR> Select<T, TR>(this IEnumerable<T> source, Func<T, TR> selector)
{
return new AnonymousEnumerable<TR>(() =>
{
var enumerator = source.GetEnumerator();
return new AnonymousEnumerator<TR>(
() => enumerator.MoveNext(),
() => selector(enumerator.Current),
() => enumerator.Dispose()
);
});
}
驚くほどスッキリ。デザインパターンの本はC#でラムダ式全開でやり直すと、考え方はともかく、コードは全然違った内容になるんじゃないかなあ、とか思いつつ。この突然出てきたAnonymousEnumerableに関しては.NET Reactive Framework メソッド探訪第二回:AnonymousEnumerableを参照にどうぞ。去年の9月ですか……。AnonymousObservableも紹介する、といって10ヶ月後にようやく果たせている辺りが、やるやる詐欺すぎて本当にごめんなさい。
簡単に説明すれば、コンストラクタにラムダ式で各メソッドの本体を与えてあげることで、その場でクラスを作ることが出来るという代物です。クロージャによる変数キャプチャにより、引数を渡し回す必要もないため非常にすっきり書く事ができます。
これってようするにJavaの無名クラスでしょ?と言うと、その通り。おお、Java、大勝利。なんてこたぁーない。大は小を兼ねない、むしろこれは、小は大を兼ねる事の証明。
AnonymousObservable
IObservableはIEnumerableのようなコンパイラサポートはないので、自前で書かなければなりません。が、普通に書くと面倒なので、AnonymousObservableを使って書くことにしましょう。
public class AnonymousObservable<T> : IObservable<T>
{
Func<IObserver<T>, IDisposable> subscribe;
public AnonymousObservable(Func<IObserver<T>, IDisposable> subscribe)
{
this.subscribe = subscribe;
}
public IDisposable Subscribe(IObserver<T> observer)
{
return subscribe(observer);
}
}
public class AnonymousObserver<T> : IObserver<T>
{
Action<T> onNext;
Action<Exception> onError;
Action onCompleted;
public AnonymousObserver(Action<T> onNext, Action<Exception> onError, Action onCompleted)
{
this.onNext = onNext;
this.onError = onError;
this.onCompleted = onCompleted;
}
public void OnCompleted()
{
onCompleted();
}
public void OnError(Exception error)
{
onError(error);
}
public void OnNext(T value)
{
onNext(value);
}
}
public class AnonymousDisposable : IDisposable
{
Action dispose;
bool isDisposed = false;
public AnonymousDisposable(Action dispose)
{
this.dispose = dispose;
}
public void Dispose()
{
if (!isDisposed)
{
isDisposed = true;
dispose();
}
}
}
そのまま書き出すだけなので、難しいことは何一つありませんが、面倒くさい……。なお、今回はRx抜きでの実装のためこうして自前で定義していますが、RxにはObservable.Create/CreateWithDisposable、Observer.Create、Disposable.Createというメソッドが用意されていて、それらは今回定義したAnonymousHogeと同一です。new ではなくCreateメソッドで生成するため型推論が効くのが嬉しい。
Observable.Select/Where
下準備が済んだので実装していきましょう。まずはSelect。
public static IObservable<R> Select<T, TR>(this IObservable<T> source, Func<T, TR> selector)
{
return new AnonymousObservable<TR>(observer => source.Subscribe(
new AnonymousObserver<T>(
t => observer.OnNext(selector(t)),
observer.OnError,
observer.OnCompleted)));
}
Enumerableと似ているようで非常に分かりにくい。AnonymousObservableの引数のラムダ式は、Subscribeされた時に実行されるもの。というわけで、突然出てきているかのような引数のobserverは、Subscribeによって一つ後ろのメソッドチェーンから渡されるものとなります。
Observable.Range(1, 10) // これがsource
.Select(i => i * i)
.Subscribe(i => Console.WriteLine(i)); // これがobserver
こんな前後関係の図式になっています。ドットの一つ前のメソッドがsource、一つ後ろのメソッドがobserver。 最終的な目的としては元ソースからOnNext->OnNext->OnNextと値を伝搬させる必要があるわけですが、元ソースは末端どころか次に渡す先すら知りません。そのため、まず最初(Subscribeされた時)にsource.Subscribeの連鎖で元ソースまで遡ってやる必要がある、というわけです。非常に説明しづらいのでデバッガで追ってみてください。
public static IObservable<T> Where<T>(this IObservable<T> source, Func<T, bool> predicate)
{
return new AnonymousObservable<T>(observer => source.Subscribe(
new AnonymousObserver<T>(
t => { if (predicate(t)) observer.OnNext(t); },
observer.OnError,
observer.OnCompleted)));
}
WhereはSelectのOnNext部分が違うだけのもの。コピペ量産体制。
ToObservable
Selectなどと同じくreturn new AnonymousObservableですが、もうSubscribeはしません(そもそもIObservable sourceがないので出来ないですが)。ここからは、末端から伝達されてきたobserverに対して値をPushしてやります。
public static IObservable<T> ToObservable<T>(this IEnumerable<T> source)
{
return new AnonymousObservable<T>(observer =>
{
var isErrorOccured = false;
try
{
foreach (var item in source)
{
observer.OnNext(item);
}
}
catch (Exception e)
{
isErrorOccured = true;
observer.OnError(e);
}
if (!isErrorOccured) observer.OnCompleted();
return new AnonymousDisposable(() => { });
});
}
Subscribeされると即座にforeachが回ってOnNext呼びまくる。ToObservableはHot or ColdのうちColdで、Subscribeされるとすぐに値が列挙されるわけです。Coldってのは、なんてことはなく、ようはすぐforeachされるからってだけの話でした。
戻り値のIDisposableは、FromEventではイベントのデタッチなどの処理がありますが、ToObservableでは何もする必要がないので何も無し。
FromEvent徹底解剖
Coldだけでは、別にEnumerbaleと全然変わらなくて全く面白くないので、Hot Observableも見てみます。Hotの代表格はFromEvent。そんなFromEventには4つのオーバーロードがあります。せっかくなので、細かく徹底的に見てみましょう。
public class EventSample
{
public event EventHandler BlankEH;
public event EventHandler<SampleEventArgs> GenericEH;
public event SampleEventHandler SampleEH;
}
public class SampleEventArgs : EventArgs { }
public delegate void SampleEventHandler(object sender, SampleEventArgs e);
static void Main(string[] args)
{
var sample = new EventSample();
// 1. EventHandlerに対応するもの
Observable.FromEvent(
h => sample.BlankEH += h, h => sample.BlankEH -= h);
// 2. EventHandler<EventArgs>に対応するもの
Observable.FromEvent<SampleEventArgs>(
h => sample.GenericEH += h, h => sample.GenericEH -= h);
// 3. 独自EventHandlerに対応するもの
Observable.FromEvent<SampleEventHandler, SampleEventArgs>(
h => new SampleEventHandler(h),
h => sample.SampleEH += h, h => sample.SampleEH -= h);
// 4. リフレクション
Observable.FromEvent<SampleEventArgs>(sample, "GenericEH");
Observable.FromEvent<SampleEventArgs>(sample, "SampleEH");
}
FromEventと言ったら文字列で渡して―― という感じだったりですが、むしろそれのほうが例外的なショートカットで、基本はeventをadd/removeする関数を渡します。3つもありますが、基本的には三番目、conversionが必要なものが最も多く出番があるでしょうか。ただのEventHandlerなんて普通は使わないし、ジェネリクスのEventHandlerもほとんど見かけないしで、どうせみんな独自のEventHandlerなんでしょ、みたいな。もしEventHandler<T>で統一されていれば、こんな面倒くさいconversionなんて必要なかったのに!もしくは、みんなAction<object, TEventArgs>で良かった。名前付きデリゲートの氾濫の弊害がこんなところにも……。
実際のとこ文字列渡しで良いよねー、と思います。リフレクションのコストはどうせ最初の一回だけだし。リファクタリング効かないといっても、別にイベントの名前なんて変更しないっしょっていうか、フレームワークに用意されてるイベントは固定だし、って話ですし。
FromEventの作成
そんなわけで、今回は3引数のFromEventを作ります。FromEventの戻り値はIEventなので、IEventの定義も一緒に。
public interface IEvent<TEventArgs> where TEventArgs : EventArgs
{
object Sender { get; }
TEventArgs EventArgs { get; }
}
public class AnonymousEvent<TEventArgs> : IEvent<TEventArgs> where TEventArgs : EventArgs
{
readonly object sender;
readonly TEventArgs eventArgs;
public AnonymousEvent(object sender, TEventArgs eventArgs)
{
this.sender = sender;
this.eventArgs = eventArgs;
}
public object Sender
{
get { return sender; }
}
public TEventArgs EventArgs
{
get { return eventArgs; }
}
}
public static IObservable<IEvent<TEventArgs>> FromEvent<TDelegate, TEventArgs>(
Func<EventHandler<TEventArgs>, TDelegate> conversion,
Action<TDelegate> addHandler,
Action<TDelegate> removeHandler) where TEventArgs : EventArgs
{
return new AnonymousObservable<IEvent<TEventArgs>>(observer =>
{
var handler = conversion((sender, e) =>
{
observer.OnNext(new AnonymousEvent<TEventArgs>(sender, e));
});
addHandler(handler);
return new AnonymousDisposable(() => removeHandler(handler));
});
}
感覚的にはToObservableの時と一緒。Subscribeされたら実行される関数を書く。Subscribe時に実際に実行されるのはaddHandlerだけ。つまりイベント登録。そしてイベントが発火した場合は、conversionのところのラムダ式に書いたものが呼び出される、つまり次のobserverに対してOnNextでIEventを送る。そして、DisposeされたらremoveHandlerの実行。
これが、Hotなわけですね。つまりSubscribeだけではOnNextが呼ばれず、もう一段階、奥から実行される。
// 実行例としてObservableCollectionなどを用意。
var collection = new ObservableCollection<int>();
var collectionChanged = Observable.FromEvent<NotifyCollectionChangedEventHandler, NotifyCollectionChangedEventArgs>(
h => new NotifyCollectionChangedEventHandler(h),
h => collection.CollectionChanged += h,
h => collection.CollectionChanged -= h)
.Select(e => (int)e.EventArgs.NewItems[0]);
// attach
collectionChanged.Subscribe(new AnonymousObserver<int>(i => Console.WriteLine(i), e => { }, () => { }));
collectionChanged.Subscribe(new AnonymousObserver<int>(i => Console.WriteLine(i * i), e => { }, () => { }));
collection.Add(100); // 100, 10000
collection.Add(200); // 200, 40000
利用時は大体こんな感じになります。いたって普通。
まとめ
というわけで実装を見ていきましたが、意外と簡単です。リフレクタでToObservable見たけどこんな簡単じゃなかったぞ!と言われると、そうですね、実際のRxはScheduler(カレントスレッドで実行するかスレッドプールで実行するか、などなどが選べる)が絡むので実装はもう少し、というかもうかなり複雑です。だからこそ惑わされてしまうというわけで、基本的な骨格部分にのみ絞ってみれば十二分にシンプル、というのを掴むのが肝要じゃないかと思います。
次回は前回予告の通りに、後回しにしちゃってるけれど結合周りを紹介できればいいなあ。あと、FromAsyncか、Timer周辺か、Schedulerか……。RxJSもちゃんと例を出したいし、例を出したいといえば、そう、メソッド紹介だけじゃなく実例も出していきたいなあ、だし。うーん。まあ、ボチボチとやっていきます。最近ほんとRxの知名度・注目度が高まってるような気がしてます。ぐぐる検索で私のへっぽこ記事が上位に出てしまうという現状なので、申し訳ない、じゃなくて、それ相応の責任を果たすという方向で頑張りたいと思います。つまりは記事をちゃんと充実させよう。
linq.js ver.2.2.0.0 - 配列最適化, QUnitテスト, RxJSバインディング
- 2010-06-29
CodePlex - linq.js - LINQ for JavaScript
linq.jsをver 2.2に更新しました。変更事項は、メソッドの追加、配列ラッピング時の動作最適化、ユニットテストのQUnitへの移行、RxJSバインディング追加の4つです(あと、若干のバグフィックスと、RxJS用vsdoc生成プログラムの同梱)。まずは、追加した二つのメソッドについて。
var seq = Enumerable.From([1, 5, 10, 4, 3, 2, 99]);
// TakeFromLastは末尾からn個の値を取得する
var r1 = seq.TakeFromLast(3).ToArray(); // [3, 2, 99]
// 2.0から追加されているTakeExceptLast(末尾からn個を除く)と対になっています
var r2 = seq.TakeExceptLast(3).ToArray(); // [1, 5, 10, 4]
// ToJSONはjson文字列化します(列挙をJSON化なので必ず配列の形になります)
// JSON.stringifyによるJSON化のため、
// ネイティブJSON対応ブラウザ(IE8以降, Firefox, Chrome, Opera...)
// もしくはjson2.jsをインポートしていないと動作しません
var objs = [{ hoge: "huga" }, { tako: 3}];
var json = Enumerable.From(objs).ToJSON(); // [{"hoge":"huga"},{"tako":3}]
TakeFromLast/TakeExceptLastはRxからの移植です(Rxについては後でまた少し書きます)。RxではTakeLast, SkipLastという名前ですが、諸般の都合により名前は異なります。より説明的なので悪くはないかな、と。
もう一つはToJSONの復活。ver 1.xにはあったのですが、2.xでばっさり削ってたました。復活といっても、実装は大きく違います。1.xでは自前でシリアライズしていたのですが、今回はJSON.stringifyに丸投げしています。と、いうのも、IE8やそれ以外のブラウザはJSONのネイティブ実装があるので、それに投げた方が速いし安全。ネイティブ実装はjson2.jsと互換性があるので、IE6とかネイティブ実装に対応していないブラウザに対しては、json2.jsを読み込んでおくことでToJSONは動作します。
json2.jsはネイティブ実装がある場合は上書きせずネイティブ実装を優先するようになっているので、JSON使う場合は何も考えずとりあえず読み込んでおくといいですね。
配列ラップ時の最適化
Any, Count, ElementAt, ElementAtOrDefault, First, FirstOrDefault, Last, LastOrDefault, Skip, SequenceEqual, TakeExceptLast, TakeFromLast, Reverse, ToString。
Enumerable.From(array)の直後に、以上のメソッドを呼んだ際は最適化された挙動を取るように変更しました。各メソッドに共通するのは、lengthが使えるメソッドということです。Linqは基本的に長さの情報を持っていない(無限リストとか扱えるから)ため、例えばCountだったら最後まで列挙して長さを取っていました。しかし、lengthが分かっているのならば、Countはlengthに置き換えられるし、Reverseは[length - 1]から逆順に列挙すればいい。ElementAt(n)はまんま[n]だしLastは[length - 1]だし、などなど、lengthを使うことで計算量が大幅に低減されます。
C#でも同様のことをやっている(ということは以前にLinqとCountの効率という記事で書いてあったりはする)のですが、今になってようやく再現。先の記事にあるように、C#では中でisやasを使ってIEnumerableの型を調べて分岐させてますが、linq.jsでは Enumerable.FromでEnumerableを生成する際に、今まではEnumerableを返していたところを、ArrayEnumerable(継承して配列用にメソッドをオーバーライドしたもの)を返す、という形を取っています。
これが嬉しいかどうかというと、そこまで気にするほどではありません。C#では array.Last() のように使えますが、linq.jsではわざわざ Enumerable.From(array).Last() と、ラップしなきゃいけませんから、それならarray[array.length - 1]でいいよ、という。ちなみに当然ですがFrom(array).Where().Count()とか、他のLinqメソッドを挟むと、ArrayEnumerableじゃなくEnumerableになるため最適化的なものは消滅します。
でもまあ、意味はあるといえばあります。配列を包んだだけのEnumerableは割と色々なところで出てきます。例えばGroupJoin。これのresultSelectorの引数のEnumerableは、配列をラップしただけです。又は、ToLookup。Lookupを生成後、Getで取得した際の戻り値のEnumerableは配列を包んだだけです。GroupByの列挙(Grouping)もそう。特にGroupingで、グループの個数を使うってシーンは多いように思います。そこで今まではCount()で全件列挙が廻っていたのが、一度も列挙せずに値が取れるというのは精神衛生上喜ばしい。
パフォーマンス?
このArrayへの最適化は勿論パフォーマンスのためなのですが、じゃあ全体的にlinq.jsのパフォーマンスはどうなの?というと、遅いよ!少し列挙するだけで山のように関数呼び出しが間に入りますから、速そうな要素が一つもない。ただ、遅さがクリティカルに影響するほどのものかは、場合によりけりなので分かりません。遅い遅いと言っても、jQueryでセレクタ使って抽出してDOM弄りするのとどちらが重いかといったら、(データ量にもよりますが)圧倒的にDOM弄りですよね?的な。
JavaScriptは、どうでもいいようなレベルの高速化記事がはてブなんかにも良く上がってくるんですが、つまらない目先に囚われず、全体を見てボトルネックをしっかり掴んでそこを直すべきだと思うんですよね。「1万回の要素追加で9msの高速化」とか、意味無いだろそれ絶対と思うのですが……。
ただ、アプリケーションとライブラリだと話は別で、ライブラリならば1msでも速いにこしたことはないのは事実です。linq.jsは仕組み的には遅いの確定なのはしょうがないとしても、もう少しぐらいは、速度に気を使って努力すべきな気はとてもします。今後の課題。
コードスニペット
無名関数書くのに、毎回function(x) { return って書くの、面倒くさいですよね。ということで、Visual Studio用のコードスニペットを同梱しました。func1->Tab->Tabで、linq.jsで頻繁に使う一行の無名関数 function(x){ return /* キャレットここ */ } を生成してくれます。これは激しく便利で、C#の快適さの3割ぐらいを占めていると言っても過言ではないぐらいに便利なのですが、動画じゃないと伝わらないー、けれど動画撮ってる体力的余裕がないので省略。
func0, func1, func2, action0, action1, action2を定義しています。0だの1だのは引数の数。funcはreturn付き、actionはreturn無しのスニペットです。また、Enumerable.RangeとEnumerable.Fromにもスニペットを用意しました。erange, efromで展開されます。jQueryプラグイン版の場合はjqrange, jqfromになります。
インストールは、Visual Studio 2010でツール→コードスニペットマネージャーを開いてインポートでsnipetts/.snippetを全部インポート。
binding for RxJS
RxJS -Reactive Extensions for JavaScriptと接続出来るようになりました。ToObservableとToEnumerableです(jQuery版のTojQueryとtoEnumerableと同じ感覚)。
// enumerable sequence to observable
var source = Enumerable.Range(1, 10)
.Shuffle()
.ToObservable()
.Publish();
source.Where(function (x) { return x % 2 == 0 })
.Subscribe(function (x) { document.writeln("Even:" + x + "<br>") });
source.Where(function (x) { return x % 2 != 0 })
.Subscribe(function (x) { document.writeln("Odd:" + x + "<br>") });
source.Connect();
// observable to enumerable
var subject = new Rx.ReplaySubject();
subject.OnNext("I");
subject.OnNext(4);
subject.OnNext("B");
subject.OnNext(2);
subject.OnNext("M");
var result = subject.ToEnumerable()
.OfType(String)
.Select(function (x) { return x.charCodeAt() - 1 })
.Select(function (x) { return String.fromCharCode(x) })
.ToString("-");
alert(result); // H-A-L
ToObservableでは、こないだ例に出したPublishによる分配を。ToEnumerableは、例が全然浮かばなかったので適当にOnNextを発火させた奴をEnumerable化出来ますねー、と。なお、cold限定です。hotに対して適用すると空シーケンスが返ってくるだけです(ちなみにC#版のRxでhotに対してToEnumerableするとスレッドをロックして無限待機になる)
それと、RxVSDocGeneratorの最新版を同梱してあります。以前に公開していたのは、RxJSのバージョンアップと同時に動かなくなっちゃってたのよね。というわけで、修正したうえで同梱商法してみました。
プレースホルダの拡張
無名関数のプレースホルダが少し拡張されました。今までは引数が一つの時のみ$が使えたのですが、今回から二引数目は$$、三引数目は$$$、四引数目は$$$$が使えるようになりました。
// 連続した重複がある場合最初の値だけを取る
// (RxのDistinctUntilChangedをlinq.jsでやる場合)
// 1, 5, 4, 3, 4
Enumerable.From([1, 1, 5, 4, 4, 3, 4, 4])
.PartitionBy("", "", "key,group=>group.First()")
// $$でニ引数目も指定出来るようになった
Enumerable.From([1, 1, 5, 4, 4, 3, 4, 4])
.PartitionBy("", "", "$$.First()")
便利といえば便利ですが、あまりやりすぎると見た目がヤバくなるので適度に抑えながらでどうぞ。なお、以前からある機能ですが""は"x=>x"の省略形です。PartitionByでは、それぞれkeySelectorとelementSelector。
入門QUnit
今までlinq.jsのユニットテストはJSUnitを使用していたんですが、相当使いにくくてやってられなかったため、QUnitに移しました。QUnitはjQueryの作者、John Resigの作成したテストフレームワークで、流石としか言いようがない出来です。物凄く書きやすい。JSUnitだとテストが書きづらくて、だから苦痛でしかなかった。テストドリブンとか言うなら、まずはテストが書きやすい環境じゃないとダメだ。
JSUnitのダメな点―― 導入が非常に面倒。大量のファイルを抱えたテスト実行環境が必要だし、クエリストリングでファイル名を渡さなければならなかったり、しかも素ではFirefox3で動かなかったりと(Firefox側のオプションを調整)下準備が大変。面倒くささには面倒くささなりのメリット(Java系の開発環境との連携とかあるらしいけど知らない)があるようですが、俺はただテスト書いて実行したいだけなんだよ!というには些か重たすぎる。一方、QUnitはCSSとJSとHTMLだけで済む。
また、JSUnitはアサーションのメソッドが微妙。大量にあるんだけど、逆に何が何だか分からない。assertObjectEqualsとかassertArrayEqualsとか。ArrayEqualsはオブジェクトの配列を値比較してくれない上に、それならせめて失敗してくれればいいものの成功として出されるから役に立たなかったり、ね……。QUnitは基本、equal(参照比較)とdeepEqual(値比較)だけという分かりやすさ。deepEqualはしっかりオブジェクト/配列をバラして再帰的に比較してくれるという信頼感があります。
テスト結果画面の分かりやすさもQUnitに軍配が上がる。というかJSUnitは致命的に分かりづらい。一つのテスト関数の中に複数のアサートを入れると、どれが失敗したか分からないという有様。なのでJSUnitではtestHoge1, testHoge2といった形にせざるを得ないのだけど、大変面倒。更に、JSUnitのテスト実行は遅くて数百件あるとイライラする。
そもそもJSUnitはコードベースが古いし最近更新されてるかも微妙(GitHubに移って開発は進んでるようですが)。というわけで今からJavaScriptでユニットテストやるならQUnitがいいよ!残念ながらか、ネットを見ると古い紹介記事ばかりが見当たるので、ていうかオフィシャルのドキュメントまで古かったりしてアレゲなので、簡単に解説します。と、思ってたのですが、一月程前に素晴らしいQUnitの記事が出ていました。なので基本無用なのですが、文章を書いてしまってあったので(これ書いてたのは4月頃なのです)出します、とほほ。
まず、QUnit - jQuery JavaScript LibraryのUsing QUnitのところにあるqunit.jsとqunit.cssを落とし、下記のテンプレHTMLは自前で作る。ファイル名はなんでもいいんですが、私はtestrunner.htmとでもしておきました。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>linq.js test</title>
<link href="qunit.css" rel="stylesheet" type="text/css" />
<script src="qunit.js" type="text/javascript"></script>
<!-- テストに必要な外部ライブラリは好きに読み込む -->
<script src="linq.js" type="text/javascript"></script>
<!-- ここにテスト直書きもアリだし -->
<script type="text/javascript">
test("Range", function()
{
deepEqual(Enumerable.Range(1, 3).ToArray(), [1, 2, 3]);
});
// 自動的にロード後に実行されるので、これも問題なく動く
test("hoge", function ()
{
var h2 = document.getElementsByTagName("h2");
equal(h2.length, 2);
});
</script>
<!-- 外部jsファイルにして読み込むのもアリ -->
<script src="testEnumerable.js" type="text/javascript"></script>
<script src="testProjection.js" type="text/javascript"></script>
</head>
<body>
<h1 id="qunit-header">linq.js test</h1>
<h2 id="qunit-banner"></h2>
<h2 id="qunit-userAgent"></h2>
<ol id="qunit-tests"></ol>
</body>
</html>
実行用のHTMLにqunit.jsとqunit.cssを読み込み、body以下の4行を記述すれば準備は完了(bodyの4行はid決め打ちで面倒だし、どうせ空なので、qunit.js側で動的に生成してくれてもいいような気がする、というか昔はそうだった気がするけどjQuery依存をなくした際になくしたのかしらん)。
あとは、test("テスト名", 実行される関数) を書いていけばいいだけ。そうそう、test関数はHTMLが全てロードされてから実行が始まるので、jQuery読み込んでjQuery.readyで囲む必要とかは特にありません。testProjection.jsは大体↓のような感じ。
/// <reference path="testrunner.htm"/>
module("Projection");
test("Select", function ()
{
actual = Enumerable.Range(1, 10).Select("i=>i*10").ToArray();
deepEqual(actual, [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]);
actual = Enumerable.Range(1, 10).Select("i,index=>i*10+index").ToArray();
deepEqual(actual,[10, 21, 32, 43, 54, 65, 76, 87, 98, 109]);
});
reference pathはVisualStudio用のパスなのであんま気にせずにー。詳細はJavaScriptエディタとしてのVisual Studioの使い方入門のほうで。読み込み元のHTMLを指定しておくとIntelliSenseが効いて、書くのが楽になります。
actual(実行結果)は私は別変数で受けてますが、当然、直書きでも構いません。アサーション関数は、基本は(actual, expected(期待する結果), message(省略可能)) の順番になっています。
equal(1, "1"); // okay - 参照比較(==)
notEqual
strictEqual(1, "1"); // failed - 厳密な比較(===)
notStrictEqual
deepEqual([1], [1]); // okay - 値比較
notDeepEqual
ok(1 == "1"); // okay - boolean
ok(1 !== "1"); // okay - notの場合は!で
基本的に使う関数はこれらだけです。ドキュメントへの記載はないのですが、以前にあったequalsとsameはequalとdeepEqualに置き換わっています。後方互換性のためにequals/sameは残っていますが、notと対称が取れるという点で、equal/deepEqualを使ったほうが良いんじゃないかと思います。
非同期テストとかは、またそのうちに。
まとめ
linq.js ver.2出したときには、もう当分更新することなんてないよなあ、なんて思っていたのですが、普通にポコポコと見つかったり。でもさすがに、もうないと思いたい。C#との挙動互換性も、私の知る限りでは今回の配列最適化が最後で、やり残しはない。そして今回がラストだー、とばかりに思いつく要素を全部突っ込んでやりました。
そんなわけなので、使ってやってください。私がVisualStudio使いなのでVS関連の補助が多めですが、別にVS必須というわけじゃなくプラスアルファ的なもの(入力補完ドキュメントだのコードスニペットだの)でしかないので、エディタ書きでも何ら問題なく使える、かな、きっと。
Reactive Extensions for .NET (Rx) メソッド探訪第7回:IEnumerable vs IObservable
- 2010-06-24
物凄く期間を開けてしまいましたが、Reactive Extensions for .NET (Rx)紹介を再開していきます。もはやRxってなんだっけ?という感じなので、今回は最も基本である、IObservableについて扱います。ボケーッとしている間にIQbservable(IQueryableのデュアル)とか出てきてて置いてかれちゃってるし。
そんなこんなで、IObservableはIEnumerableのデュアルなんだよ、とか言われてもぶっちゃけさっぱり分かりません。なので、その辺のことはスルーして普通にコードで対比させながら見ていくことにします。
// IEnumerable (RunはForEachです、ようするに)
Enumerable.Range(1, 10)
.Where(i => i % 2 == 0)
.Select(i => i * 2)
.Run(Console.WriteLine, () => Console.WriteLine("completed!"));
// IObservable
Observable.Range(1, 10)
.Where(i => i % 2 == 0)
.Select(i => i * 2)
.Subscribe(Console.WriteLine, () => Console.WriteLine("completed!"));
ボタンを押して確認する、までもなく同じ結果です。1から10までを偶数だけ通して二倍して出力。見た目は同じですが、中身は丸っきり違います。見た目が一緒すぎて言葉で表現出来ないので図に表してみました。
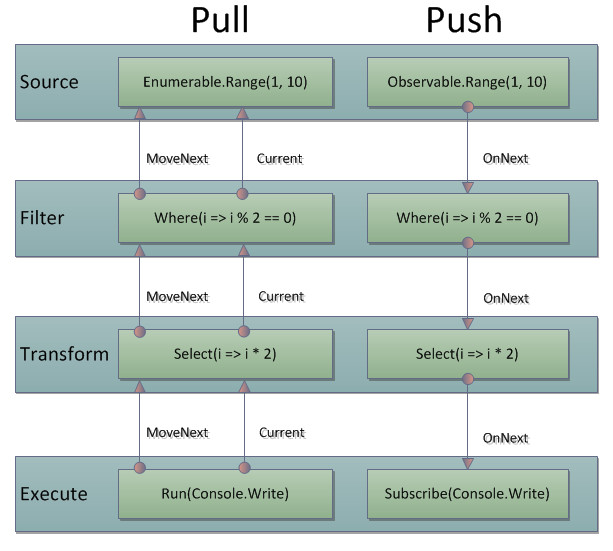
何という下手っぴな図、さっぱり伝わらん。……。というのはおいておいて、矢印の向きに注目。IEnumerableの連鎖は、列挙を消費する時にIEnumeratorの伝搬に変わります。Run->Select->Where->RangeとMoveNextが駆け上がったら、今度はRange->Where->Select->RunとCurrentが降りていきます。末尾(Run)が値を要求(MoveNext)して値(Current)を取り出すという連鎖。末端から根元の値を引っ張ってくる(Pull)ようなイメージ。
IObservableは、根元自体が値を押し出していく(Push)ようなイメージ。こちらはIObserverの連鎖になっていて、根元からOnNextで値を伝えていきます。
Pushのメリット
Observable.Rangeのような、もしくはEunmerableに対してToObservableした時のような、普通のPull型シーケンスをPush型に変換することのメリットは?イベントや非同期など、他の形式から生成されたIObservableと連携出来る、というのは当然一番の話ですが、もう一つ、要素を分配出来るようになります。
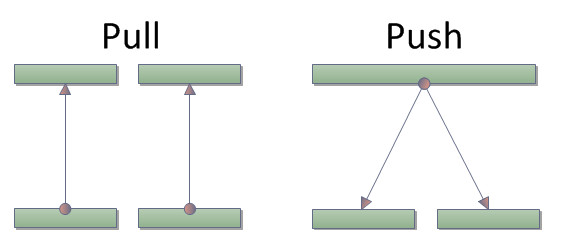
このイミフな図の言わんとしていることが伝わる、わけはないので説明。Pull型はソースと1対1の関係である必要があるため、複数の列挙の消費者(RunだったりCountだったりSumだったりLastだったり)がいる場合、接続した回数だけ列挙が最初から回ることになります。かたやPush型は、1対多の関係を持つことが出来るため、一度の列挙で全ての消費者に値を配分することが可能です。
Hot vs Cold
同じように見えるIObservableにも、HotとColdという性質があります。それはyield returnで作る遅延評価のIEnumerableと、配列のように既に値が生成済みのIEnumerableとの違い、のようなものかもしれません。
var seq = Observable.Range(1, 5)
.Do(i => Console.WriteLine("source -> " + i));
button1.Click += (sender, e) =>
seq.Subscribe(i => Console.WriteLine("button1 -> " + i));
button2.Click += (sender, e) =>
seq.Subscribe(i => Console.WriteLine("button2 -> " + i));
Doは、列挙に通ったものを取り出しつつも素通しします。つまり、 Select(i => { action(i); return i; }) です。今回は列挙がその箇所を通ったかどうかを書き出しています。余談ですが、IEnumerableならNyaRuRuさんの作成されたAchiralにはHookというメソッドがあって、細かい列挙中のモニタリングが出来るようになっています。
実行結果を見てみると、ボタンを押す=Subsribeを繋げると、即座に列挙が開始されていて、これだとIEnumerableのforeachと何も変わません。よって、このIObservableはColdです。もう値は生成され終わっているので。Subscribeの度に即座に全ての値をPushします。
ではHotは?
// FromEvent(canvas,"MouseMove")は手軽ですが、丁寧にこう書くほうが理想的かしら
Func<IObservable<Point>> GetMouseMovePosition = () =>
Observable.FromEvent<MouseEventHandler, MouseEventArgs>(
h => (sender, e) => h(sender, e),
h => canvas.MouseMove += h,
h => canvas.MouseMove -= h)
.Select(e => e.EventArgs.GetPosition(canvas));
// ICollection<IDisposable>です。
var disposables = new CompositeDisposable();
evenButton.Click += (sender, e) =>
{
disposables.Add(
GetMouseMovePosition()
.Where(p => p.X % 2 == 0 && p.Y % 2 == 0)
.Subscribe(p => Console.WriteLine("Even -> " + p.X + ":" + p.Y)));
};
oddButton.Click += (sender, e) =>
{
disposables.Add(
GetMouseMovePosition()
.Where(p => p.X % 2 != 0 && p.Y % 2 != 0)
.Subscribe(p => Console.WriteLine("Odd -> " + p.X + ":" + p.Y)));
};
disposeButton.Click += (sender, e) =>
{
// Disposeでイベントのデタッチ + 再登録不可
// Clearでイベントのデタッチ + 再登録可
disposables.Clear();
};
例えばマウスイベント。クリックの度にOnNextに値を送る、ムーブの度に値を送るといったイベントをIObservable化するFromEventはHot。無限リスト状態になっているものは、接続しただけでは値が送られてこないとも言えるので、幾つでもSubscribeすることが出来ます。サンプルでは、ボタンをクリックすればしただけ、右側のログ表示に同内容のものが連続して表示されるのが確認出来ます。
両者が混ざったような挙動をするIObservableもあります(例えばReplaySubject)ので、HotなのかColdなのか両方なのか。というのを意識してみると理解が深まるかもしれません。また、メソッドの動作確認などの際にHotとColdを区別せずにいると、思わぬ挙動で混乱するかもしれないので注意。というか、私はよくやります……。Observable.Rangeばかりで確認していてイミフ!と思ったら、FromEventでチェックしたら何て分かりやすいこと!というのが何度も。
CompositeDisposable
本題と離れますがTips。イベントのデタッチが簡単なのもRxのメリットの一つです。さて、複数イベントをデタッチする場合はどうしましょうか?List<IDisposable>に格納してforeachで列挙してDispose、というのも悪くないですが、そういう用途で使うためのCompositeDisposableというICollection<IDisposable>なクラスが用意されているので、そちらを使ったほうがよりスマートに書けます。
上のSilverlightのHotのサンプルコードでは、ボタンを押す(=Subscribeする=イベントを登録する)度にCompositeDisposableにAdd。そしてDisposeAllボタンでまとめてデタッチしています。
var subject = new Subject<int>();
var d1 = subject.Subscribe(i => Console.WriteLine(i));
var d2 = subject.Subscribe(i => Console.WriteLine(i * i));
using (new CompositeDisposable(d1, d2))
{
subject.OnNext(2); // 2, 4
subject.OnNext(3); // 3, 9
}
subject.OnNext(2); // usingを抜けデタッチ済みなので何も起こらない
List<IDisposable>に対するCompositeDisposableのメリットは、Disposeで解除出来るということ。つまり、using構文に放りこむことが可能です。多段Usingよりも綺麗に見えるのでお薦め。
上の例にコソッと出したSubjectクラスはPush型シーケンスの大本で、OnNextやOnCompletedを後続に送ることが出来ます。イベントのラップじゃなく、Rxネイティブなクラスを作る場合に使います。Subjectはちゃんと詳しく書かなきゃいけない大事なクラスの一つなので、また次にでもきっちり紹介する予定は未定。
列挙の分配
Pushのメリットとして分配可能なことを挙げたのに、Coldなので分配出来ません。以上終了。で終わるわけは当然ないわけで、Cold to Hot変換メソッドが使えます。Publishです。Publishの戻り値はIConnectableObservable。
public interface IConnectableObservable<out T> : IObservable<T>
{
IDisposable Connect();
}
IObservableなのでメソッドチェインを繋げることが出来ます。そして、Subscribeしても列挙は始まりません。Connectを呼んだ時に、一度だけ列挙することが出来ます(二度以降Connectを呼んでも何もしない)
私はダムの堰止をイメージしています。何もしないとドバドバと水が流れてしまうのでPublishで一時的に止めて、Connectで放水。放水後は空っぽ。みたいな。
Max/Sumなど集計系
インターフェイスを挙げただけじゃよく分からないので実例を。SumやMaxといった集計系メソッドと合わせて使ってみます。そこら中にモニタリング用のDoが入っていてコードが若干分かりづらいですが、実行結果で、どのタイミングで値が通過するのかを確認してみてください。
var source = Enumerable.Range(1, 5)
.Do(i => Console.WriteLine("Source -> " + i));
enumerableButton.Click += (sender, e) =>
{
var sum = source.Sum();
var max = source.Max();
var all = source.All(i => i < 3);
Console.WriteLine("sum = " + sum);
Console.WriteLine("max = " + max);
Console.WriteLine("all = " + all);
};
observableButton.Click += (sender, e) =>
{
var connectable = source.ToObservable().Publish();
connectable.Subscribe(_ => { }, () => Console.WriteLine("OnCompleted"));
var sum = default(int);
connectable
.Do(i => Console.WriteLine("BeforeSum -> " + i))
.Sum()
.Do(i => Console.WriteLine("AfterSum -> " + i))
.Subscribe(i => sum = i);
var max = default(int);
connectable
.Do(i => Console.WriteLine("BeforeMax -> " + i))
.Max()
.Do(i => Console.WriteLine("AfterMax -> " + i))
.Subscribe(i => max = i);
var all = default(bool);
connectable
.Do(i => Console.WriteLine("BeforeAll -> " + i))
.All(i => i < 3)
.Do(b => Console.WriteLine("AfterAll -> " + b))
.Subscribe(b => all = b);
connectable.Connect();
Console.WriteLine("sum = " + sum);
Console.WriteLine("max = " + max);
Console.WriteLine("all = " + all);
};
値が確定した時、Allならば全ての列挙が完了した(OnCompletedを受信する)か、条件がfalseのものが見つかったときに、1つだけSubscribeに値が届きます。SumやMaxは、全ての列挙が完了しないと算出出来ないので、全て完了したとき。こういった結果の確定するタイミングは、Enumerableでの場合と変わりません。
このような動作(戻り値が長さ1のIObservable)をするものには、 Aggreagte, Count, Any... 、ようするにIEnumerableにもあって戻り値がIEnumerableじゃないメソッドは全てそうです。全部似たりよったりなので具体的な紹介は省きます。
Pushのデメリット
IObservable便利すぎてIEnumerableいらなくネ? と、言いたいところですが、例えばこれら集計系メソッドは全て長さ1のIObservableになります。Sumの場合、欲しいのはintであってIObservableではありません。長さ1のIObservableは、いつConnectされるか分からないのでSubscribeで外の値に受け渡してやらなければならないわけですが、見た目が美しくなく宣言も冗長になる。
また、集計するのに複数回列挙は確かに格好悪いな!よし、そういう場合はRx使おう。と思った場合はとりあえず待った。ただの配列からの列挙程度の場合は、ふつーに複数回列挙したほうがPublishで分岐させるよりも遥かに速かったりします。元ソースが複雑にLinqで繋いであって重たかったり、ファイルやネットワーク経由だったりで複数呼び出しを避けたい、副作用があって複数回呼びだすと内容が変化している、という場合はRxです。が、一旦ToListしてキャッシュすれば済むシーンならば、キャッシュした方が分かりやすく速い場合が多かったりします。
Publishの具体的な使い処としては、以前に、TwitterのStreamAPIをRxを使って分配するという記事で紹介しました。
まとめ
PullとPushは、むしろ動作的にはPushのほうが素直で分かりやすい雰囲気。難解だと思って避けていたそこのアナタ、さあ、Rxを使おう! しかしColdとHotは大いなる罠。初見ではきっとつまづく。この区別は本当に大事。Rxが難解っぽいとしたら、Cold/Hotのせい。挙動がまるっと変わるんだもの。でも、ゆっくり紐解けば全然大丈夫。さあ、Rxを使おう!Publishや集計系はそんなには使わないかもですが、覚えておくと便利な時も割とある。さあ、Rxを(ry
個人的にRxの特色・使いどころは「イベントの合成」「タイマー・ネットワーク・スレッドなど非同期処理の一元化」「シーケンスの分配」の3つだと思っているのですが、このブログでは、延々とシーケンス分配という、3つの中で一番どうでもいい機能しか紹介していない!という酷い事実に気がつきました。そんなんじゃRxのポテンシャルを全然伝えられない。
というわけで、次回はタイマー辺りを紹介したいと思います予定は未定。というか計画ではObservableの合流周りとMarble Diagramについてを書く予定。Rxの知名度も徐々に上がってきているようなので、しっかり紹介していきたいですし、他の人も書いて欲すぃ。
Linq雑話
- 2010-06-08
ここ数日Twitterで見た/出したLinqネタまとめ。私の広くない観測範囲(@neuecc)での話ですが。
SelectManyとクエリ構文でUsing
ネタ元、コード元はCode, code and more code.: SelectMany; combining IDisposable and LINQから。
static void Main(string[] args)
{
var firstLines =
from path in new[] { "foo.txt", "bar.txt" }
from stream in File.OpenRead(path)
from reader in new StreamReader(stream)
select path + "\t" + reader.ReadLine();
}
public static IEnumerable<TResult> SelectMany<TSource, TDisposable, TResult>(
this IEnumerable<TSource> source,
Func<TSource, TDisposable> disposableSelector,
Func<TSource, TDisposable, TResult> resultSelector) where TDisposable : IDisposable
{
foreach (var item in source)
{
using (var disposableItem = disposableSelector(item))
yield return resultSelector(item, disposableItem);
}
}
自前定義の拡張メソッドはメソッド構文だけのものと思っていませんでしたか?私はそう思っていました。でも、クエリ構文でも同名のものがあれば拡張メソッドが使用されるんです、というお話。それを利用してusingのネストをクエリ構文で華麗に表現してやったぜー、というサンプルで、確かにこれはクール!素晴らしすぎる。
でも、クエリ構文使いたいかというと、そんなことはなく変わらずメソッド構文派です、私は。クエリ構文自体は悪いとは思わないし、良さがあるのも分かるんですが、他の拡張メソッドに繋げる時に前後にカッコで括ると途端に書き/読みにくくなることと、拡張性の乏しさが如何ともし難い。クエリ構文とメソッド構文のちゃんぽんになるぐらいなら、メソッド構文だけで書いたほうが美しいよね、と思ってしまう。あと、クエリ構文の存在が「LINQ = SQLみたいなの」という図式を産んでしまっているくさいのも、憎んでしまいますね……。
ラムダ式の引数の名前とシャッフルについて
お馴染み感溢れるOrderByでのシャッフル。
var rand = new Random();
var shuffle = Enumerable.Range(1, 10).OrderBy(_ => rand.Next());
それはそれとして、ラムダ式の引数の名前どうする?というお話が。私は、引数を使わない場合は _ を、使う場合は型の1~2文字(i(Int32)とかs(String)とかa(AnonymousType)とか、考えるの面倒なときはx、配列系はarかxs)という自分ルールを敷いています。以前にラムダ式の引数の名前という記事を書いたのですが、その時から変わっていません。ですが、最近ネットで見かけるコードでは全部_でまかなう例もよく見るね、と。Scalaでは匿名関数の引数として_が使える(プレースホルダ構文って言うんですね、名前知らなかった)ようなので、_をダメとは言い辛いのですけど、私はちょち苦手(linq.jsで$をゴリゴリ使ってるくせに、って話ではあるけど) 。
C#にもプレースホルダ構文みたいなの欲しいね、というのは、若干ある。プロパティの「value」とか最初からそこにある良く分からない変数、みたいなのはあるし。ただ、IntelliSenseとの兼ね合いもあるし、そういうのが入れられるか、入って本当に幸せになれるのかどうかの判断は保留。短絡的に欲しい!って言うのは簡単だけど、それの及ぼす影響となると分からないものだ。
それともう一つ。OrderByの引数は比較関数ではなくキーセレクターにすぎないのでちゃんとシャッフルされる、とか言ったりなどした私ですが、そうじゃなくてシャッフルの精度はランダムの範囲に影響されるね(実際上は問題ないとしても)、という話が。完全に頭から抜け落ちていて、かつ、全くもってその通りで恥ずかしかったりしたのですが確認できてよかったです、感謝。
OrderByのComparison
全然使わないけどOrderByの第二引数。
class MyClass
{
public int Hoge { get; set; }
public int Fuga { get; set; }
}
static void Main(string[] args)
{
var array = new[] { new MyClass(), new MyClass() };
// コンパイルは通るけど例外出る
var ordered = array.OrderBy(x => x).ToArray();
// 上のはこれに等しい(当然、例外出る)
array.OrderBy(x => x, Comparer<MyClass>.Default);
// AnonymousComparerを使えばComparisonを使った比較が出来る
array.OrderBy(x => x, (x, y) => x.Fuga - y.Hoge);
}
OrderByついでですが、キーセレクターは制約かかってないので別にIComparableじゃなくても動いたりします。そういう時はComparer<T>.Defaultが指定されることになって、例外出て死ぬだけです。意味ナイネ。
DescendingとThenByがあるので滅多に使わないであろう第二引数はIComparer。一々クラス作ってnewですってよ、C#らしくないですね。Comparisonじゃないなんて!大変ウザい。そんな人のためのAnonymousComparer。ラムダ式でIEqualityComparer/IComparerを作ることが出来ます。また、Linq標準演算子への拡張メソッドとしてOrderBy/ThenByのオーバーロードとしてComparisonが使えるようになります。便利ですね!是非使ってください、という宣伝。
Empty -> Sum
Empty.Sum()は0。言われてみれば当たり前といえば当たり前なのですが……。
// SumはAggregateで表現出来る
var sum = Enumerable.Range(1, 10).Aggregate((x, y) => x + y); // 55
// でもEmptyで例外出るから表現出来ない(キリッ
sum = Enumerable.Empty<int>().Sum(); // 0
sum = Enumerable.Empty<int>().Aggregate((x, y) => x + y); // 例外
// 実はseed与えればおk
sum = Enumerable.Empty<int>().Aggregate(0, (x, y) => x + y); // 0
SumやMax, Minなどは全てAggregateで表現出来ます。でも、Sumは空シーケンスの時はゼロ出すけど(MaxやAverageは例外)Aggregateを使うと例外が出てしまうので表現出来ない、とか言ったのですが0を最初に与えとけばいいよね、という話が。ぬお、そうでした!
発端はlinq.jsでこの問題(というかC#と互換が取れてないこと)に気づいたことで、linq.jsではAggregateでやってるため、AggregateはScan.LastだからScan.LastOrDefault(0)にするー、なんて考えてたんですが、初項0で済むというシンプルさを完全に失念。標準演算子外のメソッドを大量に用意してあるので、そっち側で解決しちゃおうとしてしまう姿勢は、ちょっと頭硬直化しちゃってる、全くもってよろしくない。
シャッフルの話といい、Aggregateの話といい、最近はLinqに慣れすぎて逆に見方が定型的になりすぎていると実感したので、少し気を引き締めないと。あ、で、そんなこんなでlinq.jsの空シーケンスでのSumの問題は次のリリースで直します。他にもバグがあったり(MemoizeAllが少しマズい)、加えたいことが数点あったりするので、もう少し先になりますが。
世の中の主流はまだVS2005ですか?
開発言語としてのJavaとC#を10の視点から比較
共通点が多いが、今後は違いが大きくなるかも
しかし近年のC#はLINQ(Language Integrated Query:言語統合クエリ)プロジェクトが重視されています。これはクエリ、集合操作、変換、および型推測などのデータ指向機能の多くを直接的にC#言語に統合しようとするものです。今後は違いがさらに大きくなっていくかもしれません。
プログラマが知っておきたいJavaと.NETの違い (3/4) - @IT
Linqは、VS2008出たのは3年前だよね(プレビュー版から言えばどれだけ前なのかしら)。今後は違いが大きくなるかも、じゃなくて既に違いは大きすぎるような。そして10の比較というけれど、最大の違いはデリゲートの有無では?特に、匿名メソッド/ラムダ式の有無。A.R.N [ Top > 書庫 > Microsoftの「Delegate」について ]にある、Javaには無名クラスがあるからdelegateは不要、とは10年以上前のSunの言で、さすがに10年以上も前のを持ち出してどうこう言ってもしょうがないのですが(比較対象に匿名メソッドないし)、価値観は移り変わっていくものなのだと思わずにはいられない。匿名クラスで代用出来るって、いやまあ出来なくもないのは分かりますがUglyすぎ。今、クロージャなんて不要、とか言ったらフルボッコなはず。
言語面で見ると、Java5から進化の足を止めている(そしてJava7延期しすぎ)ように見えるJavaと、ひたすら貪欲に(無節操に)取り込み続けるC#。スタート時には似たようなものだったとして、今はもうコードの見た目からして全然似てるようには見えない。Java畑の人は、今でもC#はJavaに似たようなもの、という認識なのかしら。
確かに、古典的に書けば似てますが……。そして、他の言語を考えれば、やっぱ似てるといえば似てるのですが。しかし……。ふむ。そろそろModern C# Designが出版されるべき。 Bart De Smetが書くC# 4.0 Unleashed
には超期待。
.NET(C#)におけるシリアライザのパフォーマンス比較
- 2010-05-29
ちょっとしたログ解析(細々としたのを結合して全部で10万件ぐらい)に書き捨てコンソールアプリケーションを使って行っていたのですが(データ解析はC#でLinqでコリっと書くのが楽だと思うんです、出力するまでもなく色々な条件を書いておいてデバッガで確認とか出来るし)、実行の度に毎回読んでパースして整形して、などの初期化に時間がかかってどうにも宜しくない。そこで、データ丸ごとシリアライズしてしまえばいいんじゃね?と思い至り、とりあえずそれならバイナリが速いだろうとBinaryFormatterを使ってみたら異常に時間がかかってあらあら……。
というしょうもない用途から始まっているので状況としては非現実的な感じではありますが、標準/非標準問わず.NET上で実装されている各シリアライザで、割と巨大なオブジェクトをシリアライズ/デシリアライズした時間を計測しました。そんなヘンテコな状況のパフォーマンスなんてどうでもいー、という人は、各シリアライザの基本的な使いかたの参考にでもしてください(いやまあ、どれもnewしてSerializeメソッド呼ぶだけですが)。ソースは後で出しますが、具体的に計測に使ったオブジェクトはテスト用クラスが10万件含まれたListです。まずは結果のほうを。
Serialize BinaryFormatter
00:00:06.4701421
53MB
Serialize XmlSerializer
00:00:07.7035246
59MB
Serialize DataContractSerializer
00:00:02.1545153
149MB
Serialize DataContractSerializer Binary
00:00:01.4706517
78MB
Serialize DataContractJsonSerializer
00:00:02.6021908
47MB
Serialize DataContractJsonSerializer Binary
00:00:02.5019512
75MB
Serialize NetDataContractSerializer
00:00:09.1802584
183MB
Serialize NetDataContractSerializer Binary
00:00:08.1960399
99MB
Serialize Formatter`1 - Protocol Buffers
00:00:00.7043000
13MB
Serialize MsgPackFormatter - MessagePack
00:01:33.3844083
46MB
Serialize JsonSerializer - JSON.NET
00:00:07.4997295
38MB
Serialize JsonSerializer - JSON.NET BSON
00:00:11.7767353
44MB
Deserialize BinaryFormatter
00:00:59.1693980
Check => OK
Deserialize XmlSerializer
00:00:02.7073623
Check => NG
Deserialize DataContractSerializer
00:00:06.3459340
Check => OK
Deserialize DataContractSerializer Binary
00:00:03.5622500
Check => OK
Deserialize DataContractJsonSerializer
00:00:10.5392504
Check => OK
Deserialize DataContractJsonSerializer Binary
00:00:07.2658857
Check => OK
Deserialize NetDataContractSerializer
00:00:09.1020073
Check => OK
Deserialize NetDataContractSerializer Binary
00:00:07.4024345
Check => OK
Deserialize Formatter`1 - Protocol Buffers
00:00:00.9176016
Check => OK
Deserialize MsgPackFormatter - MessagePack
00:00:29.8292134
Check => OK
Deserialize JsonSerializer - JSON.NET
00:00:11.7517757
Check => OK
Deserialize JsonSerializer - JSON.NET BSON
00:00:12.0099519
Check => OK
対象シリアライザ、かかった時間、シリアライズ時は出力ファイルサイズ、デシリアライズ時は正しく復元できたかを表示しています。
.NET標準ライブラリからはBinaryFormatter, XmlSerializer, DataContractSerializerとそのバイナリ出力, DataContractJsonSerializerとそのバイナリ出力, NetDataContractSerializerとそのバイナリ出力。オープンソースライブラリからは、GoogleのProtocol Buffersの.NET移植protobuf-net、国産のMessagePackのC#実装、Json.NETのJSONシリアライズとBSON(Mong DBで使われているバイナリ形式のJSON)のシリアライズを出力しました。
BinaryFormatter遅くね?が発端であり裏付けるように、BinaryFormatterのデシリアライズが異常に遅い。他が数秒なのに1分かかってます。テスト用データの詳細は後で述べますが、どうもObjectの配列が含まれていると遅くなるようです。テストデータにはKeyValuePair[]を含んでいるので、それが引っかかって激遅に。シリアライザする対象によって速度が変化するのは分かりますが、幾らなんでも限度を超えた速度低下。バグじゃないかしら?と言いたい。DataContractSerializerでもバイナリが吐ける昨今、もはやObsoleteにしてもいい雰囲気すら漂う。
XmlSerializerが速い・サイズ少ないという感じですがデシリアライズでCheck => NGと表記されているように、シリアライズに失敗しています。テストデータにKeyValuePair[]が含まれているのですが、それがシリアライズ出来なくて空配列になってしまったため。Dictionaryがシリアライズ出来なかったりと、XmlSerializerは割と使いにくいところがあります。今だとガイドライン的にも、XmlのAttributeの設定とか出力するXMLを細かく制御するならXmlSerializer、そうでないならDataContractSerializerのほうを推奨、とのことです。
そのDataContractSerializerはファイルサイズが嵩んでいるのが難点。属性などを付与していないため、テストデータ中の自動プロパティが <_x003C_MyProperty1_x003E_k__BackingField>hoge1</_x003C_MyProperty1_x003E_k__BackingField> といったような、とんでもなく長ったらしいタグになってしまっているのが原因。DataMember属性で名前を振ってあげればマシになりますが、今回は属性未使用で計測としました。そんなDataContractSerializerですが、バイナリXMLとして保存するとファイルサイズが縮むので気になる場合はそちらを使えばいいのかも。パフォーマンスも良くなります。
DataContractJsonSerializerは、シリアライズ・デシリアライズの速度はXMLよりも劣っていますが、ファイルサイズに関しては(JSONなので当然とはいえ)比較にならないほど小さい。バイナリXMLよりも小さくて、中々優秀のようです。しかし、バイナリ化して保存すると逆にファイルサイズが膨らむという罠が。
NetDataContractSerializerはシリアライザ作る時に型指定がいらなかったりと利便性はちょびっと○。また、循環参照が含まれていても問題なくシリアライズ出来たりと、DataContractSerializer(素の状態だと循環参照が含まれると例外)とは若干毛色が違います。といった点から言っても、BinaryFormatterの後継はこれになるのでしょう。
Protocol Buffersは爆速な上に非常に縮んで素晴らしい!さすがGoogle。ということだけじゃなく、protobuf-netの実装も良いのでしょうね。APIも非常に練られていて使いやすいし、C#でのクラスから.protoファイルの生成とかも出来て大変便利。Silverlightで使えるし、Windows Phone 7でも動かせるよう調整中、とのことでかなり気に入りました。
MsgPackFormatterはシリアライズ、デシリアライズ共にかなり時間が……。これは、MessagePackが、というよりも、実装の方でオブジェクトグラフの生成に時間がかかってるようです。
JSON.NETは中々優秀な結果を出しています。しかし、Performance ComparisonでDataContractSerializerよりも速いぜ!と謳っていたけれど、そんなことはなく。こういうのは計測する内容によって変わってくるので一概にどうこう言えないんですねー、というのを知るなど。バイナリ化で逆にサイズが膨らむのはDataContractJsonSerializerと同様。なお、JSON.NETはAPIが正直使いにくくてどうにかならないのかねー、と思うので個人的には好きじゃありません。使いやすいAPI設計ってセンスが必要ですよね……。
コード
割と長ったらしいので、分割して。追試したい方はこちらに元ソース置いておくので使ってみてください。VS2010用。ライブラリ全部揃えるのも大変だと思うので、測定を省きたい項目はMainメソッドのリスト初期化子の部分で該当するものをコメントアウトすれば省けます。
[ProtoContract]
[Serializable]
public class TestClass : IEquatable<TestClass>
{
[ProtoMember(1)]
public string MyProperty1 { get; set; }
[ProtoMember(2)]
public int MyProperty2 { get; set; }
[ProtoMember(3)]
public DateTime MyProperty3 { get; set; }
[ProtoMember(4)]
public bool MyProperty4 { get; set; }
[ProtoMember(5)]
public KeyValuePair<string, string>[] MyProperty5 { get; set; }
public bool Equals(TestClass other)
{
return this.MyProperty1 == other.MyProperty1
&& this.MyProperty2 == other.MyProperty2
&& this.MyProperty3 == other.MyProperty3
&& this.MyProperty4 == other.MyProperty4
&& this.MyProperty5.SequenceEqual(other.MyProperty5);
}
public override int GetHashCode()
{
return this.MyProperty1.GetHashCode() + this.MyProperty2.GetHashCode();
}
}
これがテスト用クラスの中身です。string, int, DateTime, bool, KeyValuePair<string,string>[] とそこそこ満遍なく散りばめて、それとデシリアライズがちゃんと出来たか確認出来るようIEquatable<TestClass>を実装して値比較出来るようにしています。&&や||や三項演算子の:は前置にする派。綺麗に揃う感じが好き。属性はProtocol Buffersはつけないと動かないのでProtoMemberを指定していますが、それ以外は無指定です。指定した方が縮んだりとかありそうですが、私的には無指定の状態で調べたいなあ、と思ったのでなし。最適じゃない状態からのそれぞれのシリアライズ形式への生成、書き戻しの具合を見たいと思ったので。いや、単純に各実装で使う属性を調べるのが面倒だったという手抜きな理由もありますが。
public abstract class SerializerBenchmark
{
public static readonly List<TestClass> TestData;
static SerializerBenchmark()
{
TestData = Enumerable.Range(1, 100000)
.Select(i => new TestClass
{
MyProperty1 = "hoge" + i,
MyProperty2 = i,
MyProperty3 = new DateTime(1999, 12, 11).AddDays(i),
MyProperty4 = i % 2 == 0,
MyProperty5 = Enumerable.Range(1, 10)
.ToDictionary(x => x.ToString(), _ => i.ToString()).ToArray()
})
.ToList();
}
public static SerializerBenchmark<T> Create<T>(T serializer, Func<T, Action<Stream, Object>> serializeSelector, Func<T, Func<Stream, Object>> deserializeSelector, string optional = null)
{
return new SerializerBenchmark<T>(serializer, serializeSelector, deserializeSelector, optional);
}
public abstract void Serialize();
public abstract void Deserialize();
}
ベンチマークで重複コードのコピペ(ストップウォッチを前後に挟んだり)を省くために抽象クラスを作りました。このList<TestClass> TestDataが実際にシリアライズ/デシリアライズに使ったデータになります。Enumerable.Range(1, 100000)のToListで10万件のリスト生成。KeyValuePairの配列は、全て長さ10で、DictionaryのToArrayで作っています。
public class SerializerBenchmark<T> : SerializerBenchmark
{
private T serializer;
private string name;
Action<Stream, Object> serialize;
Func<Stream, Object> deserialize;
private string FileName { get { return name + ".temp"; } }
public SerializerBenchmark(T serializer, Func<T, Action<Stream, Object>> serializeSelector, Func<T, Func<Stream, Object>> deserializeSelector, string optional = null)
{
this.serializer = serializer;
this.name = serializer.GetType().Name + ((optional == null) ? "" : " " + optional);
this.serialize = serializeSelector(serializer);
this.deserialize = deserializeSelector(serializer);
}
private void Bench(string label, Action action)
{
GC.Collect();
Console.WriteLine(label + " " + name);
var sw = Stopwatch.StartNew();
action();
Console.WriteLine(sw.Elapsed);
}
private void OpenAndExecute(string path, Action<FileStream> action)
{
using (var fs = File.Open(path, FileMode.OpenOrCreate))
{
action(fs);
}
}
public override void Serialize()
{
Bench("Serialize", () => OpenAndExecute(FileName, fs => serialize(fs, TestData)));
Console.WriteLine(new FileInfo(FileName).Length / 1024 / 1024 + "MB");
}
public override void Deserialize()
{
List<TestClass> data = null;
Bench("Deserialize", () => OpenAndExecute(FileName, fs => data = (List<TestClass>)deserialize(fs)));
Console.Write("Check => ");
Console.WriteLine(TestData.SequenceEqual(data) ? "OK" : "NG");
}
}
こちらがベンチマークの中身。処理を共通化したかったのですが、各シリアライザがIFormatter(Serialize,Deserializeメソッドを持つインターフェイス)を実装している、なんてことは全くなくて共通化しようがなくてうぎゃー。せめてメソッド名が全てSerializeならdynamic使うという最終手段もあるけれど、DataContractSerializerのメソッド名はWriteObjectだし、ダメだこりゃ。
で、気づいたのがSerializeはAction<Stream, Object>、DeserializeはFunc<Stream, Object>だということ。というわけで、各メソッドそのものをコンストラクタで渡してあげる形にすることで共通化できた。めでたしめでたし。もはやFuncやActionのない世界は考えられませんね!え、Javaのことですか知りません。
Deserialize時には、正しくデシリアライズ出来たかのチェックを仕込んでいます。データがListなのでLinqのSequenceEqualで元データと値比較。Listの要素であるTestClassもIEquatableなので、全部値比較で確認。
static class Program
{
static void Main(string[] args)
{
var bench = new List<SerializerBenchmark>
{
SerializerBenchmark.Create(new BinaryFormatter(), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new XmlSerializer(typeof(List<TestClass>)), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new DataContractSerializer(typeof(List<TestClass>)), x => x.WriteObject, x => x.ReadObject),
SerializerBenchmark.Create(new DataContractSerializer(typeof(List<TestClass>)),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(new DataContractJsonSerializer(typeof(List<TestClass>)), x => x.WriteObject, x => x.ReadObject),
SerializerBenchmark.Create(new DataContractJsonSerializer(typeof(List<TestClass>)),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(new NetDataContractSerializer(), x => x.Serialize, x => x.Deserialize),
SerializerBenchmark.Create(new NetDataContractSerializer(),
x => (s, data) => XmlDictionaryWriter.CreateBinaryWriter(s).Using(xw => x.WriteObject(xw, data)),
x => s => XmlDictionaryReader.CreateBinaryReader(s,XmlDictionaryReaderQuotas.Max).Using(xr => x.ReadObject(xr)),
"Binary"),
SerializerBenchmark.Create(ProtoBuf.Serializer.CreateFormatter<List<TestClass>>(), x => x.Serialize, x => x.Deserialize, "- Protocol Buffers"),
SerializerBenchmark.Create(new MsgPackFormatter(), x => x.Serialize, x => x.Deserialize, "- MessagePack"),
SerializerBenchmark.Create(new JsonSerializer(),
x => (s, data) => new StreamWriter(s).Using(sw => new JsonTextWriter(sw).Using(tw=> x.Serialize(tw, data))),
x => s => new StreamReader(s).Using(sr => new JsonTextReader(sr).Using(tr=> x.Deserialize<List<TestClass>>(tr))),
"- JSON.NET"),
SerializerBenchmark.Create(new JsonSerializer(),
x => (s, data) => new BsonWriter(s).Using(bw => x.Serialize(bw, data)),
x => s => new BsonReader(s){ReadRootValueAsArray = true}.Using(br => x.Deserialize<List<TestClass>>(br)),
"- JSON.NET BSON")
};
bench.ForEach(b => b.Serialize());
Console.WriteLine();
bench.ForEach(b => b.Deserialize());
Console.ReadKey();
}
// IDisposable extensions
static void Using<T>(this T disposable, Action<T> action) where T : IDisposable
{
using (disposable) action(disposable);
}
static TR Using<T, TR>(this T disposable, Func<T, TR> func) where T : IDisposable
{
using (disposable) return func(disposable);
}
}
Listに突っ込んで、まとめてForEachで計測。でも何だかゴチャゴチャしててキタナイですね……。Listの最初の3つまでは良いんです。それぞれ一行で。SerializeとDeserialize登録するだけで。その次から想定外でして……。そう、Serializeは決して必ずしもAction<Stream, Object>じゃあなかった!例えばDataContractSerializerでバイナリXML化を行うには、WriteObjectにStreamじゃなくてXmlDictionaryWriterを渡さなきゃいけない。と、いうわけで、そういった特別対応が必要なメソッドには入れ子のラムダ式を作って処理しています。そのせいでゴチャゴチャと。もはや可読性の欠片もない。がくり。入れ子のラムダが出てくると読むのシンドイんですよね、可能な限り避けたいとは思ってるんですが……。
Using拡張メソッドは、using構文使うと式じゃなくて文になってラムダ式で書きづらくてウザいので無理やり式にするためのシロモノ。そのせいで入れ子が更に入れ子になって可読性落としてる気がする。何事もやりすぎはいけない。
まとめ
DataContractSerializer良いよね。XmlDictionaryWriter.CreateBinaryWriter突っ込めばバイナリ化も出来るし。あとprotobuf-netはこうして数字見ると本当に凄いね。と、いったことことぐらいしか言うことがなく。
それとは関係あったりなかったりで、Twitter素晴らしい。毎回思うけれど、やっぱTwitterは素晴らしい。もともとBinaryFormatterなんか遅くね?とTwitterに愚痴ったところからスタートして、色々な人にアドバイスを受けて最終的にこんな記事(斜め上なだけな気はする)になったわけで、Twitterなかったら「遅くね?以上終了」で終わってた。
私がTwitterをはじめたのはTwitterはじめましたとかいう記事で確認出来るところでは2008/01/04(CoD4について書いてますけど、CoD4のシングルはあんま好きじゃなかった、でもその後マルチプレイヤーにはまったので結局MW2買ってますね!)。しかも、この後も当分は何もポストしないままでいて、同年9月の三度目の正直とかいう記事でTwitter→はてダへの転送ツールを作ってからようやく始めてました。コードの一部が載ってますけど、postList.Addとかいうのが初々しいなあ。今だとforeach使ったら負け、.ToList()だろ常識的に考えて。ですね。あと、TrimStartの使い方を間違えてるという。1年半前の私のド素人っぷりが伺えて面白い。ていうか、考えてみると物凄く成長しましたね……。
そして今ではすっかりTwitter中毒です。あらあらうふふ。
アドバイス受けてばかりというのもアレですので、私でも応えられそうなのがTLに流れてきたり検索(キーワード「Linq」を割と頻繁に眺めてる)にかかった時は答えるようにしています。いや、あんましてないかも。積極的に答えるようにしていきたいなあ、と。そんなわけで、@neueccでTwitterやってるので気が向いたらフォローしてやってください。