JavaScriptエディタとしてのVisual Studioの使い方入門
- 2010-05-24
linq.jsってデバッグしにくいかも……。いや、やり方が分かればむしろやりやすいぐらい。という解説を動画で。HDなので文字が見えない場合はフルスクリーンなどなどでどうぞ。中身の見えないEnumerableは、デバッガで止めてウォッチウィンドウでToArrayすれば見えます。ウォッチウィンドウ内でメソッドチェーンを繋げて表示出来るというのは、ループが抽象化されているLinqならではの利点。sortしようが何しようが、immutableなので元シーケンスに影響を与えません。ラムダ式もどきでインタラクティブに条件を変えて確認出来たりするのも楽ちん。
ところで、JavaScript開発でもIDE無しは考えられません。デバッグというだけならFirebugもアリではありますが、入力補完や整形が可能な高機能エディタと密接に結びついている、という点でIDEに軍配があがるんじゃないかと私は思っています。動画中ではVisual Studioの無料版、Visual Web Developerを使っています。Visual Studioというと、何か敷居が高く感じられるかもしれませんが、使う部分を絞ってみれば、超高性能なHTML/JavaScriptエディタとして使えちゃいます。有料版の最高級エディションは170万円ですからね(MSDNという何でも使えるライセンスがセットなので比較は不公平ですが)、機能限定版とはいえ、その実力は推して知るべし、です(機能限定部分は、主にC#でのASP.NET開発部分に絡むものなのでJavaScript周りでは全く関係ありません)。
VSを使うと何が嬉しいのでしょう?JavaScriptでの強力な入力補完、自動整形、使いやすいデバッガ、リアルタイムエラー通知。そしてこっそり地味に大切なことですが、jQueryの完璧な日本語ドキュメント付き入力補完が同梱されています。と、嬉しいことはいっぱいあるのですが、ASP.NETの開発用ではあるので、JS開発には不要なメニューが多くて戸惑う部分も多いのは事実。分かれば不要部分はスルーするだけなので簡単なのですが、そこまでが大変かもしれない。なので、JavaScript開発で使うVisualStudio、という観点に絞って、何が必要で不要なのかを解説していきます。
インストール
何はともあれまずはインストール。Microsoft Visual Studio ExpressからVisual Web Developerを選び、リンク先のWeb Platform Installerとかいうのをダウンロード&実行。
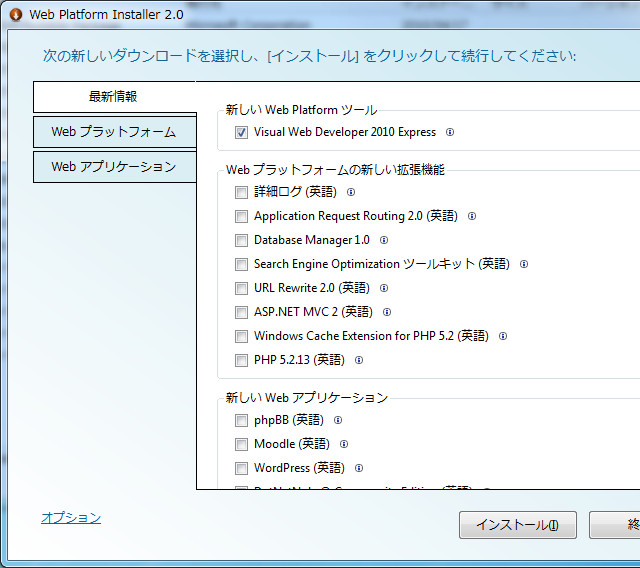
PHPとかWordPressとか色々ありますがどうでもいいので、Visual Web Developer 2010 Expressだけ入れましょう。クリックして指示に従って適当に待つだけ、10分ぐらいあれば終わるはず。10分は短くはないですが、インストール自体は非常に簡単です。
プロジェクト作成
実行すると初回起動時はイニシャライズが若干長いですが、それを超えれば新しいプロジェクトと新しいWebサイトの違いが分からねえええええ。で、ここは新しいWebサイトです。プロジェクトのほうはC#でASP.NETが基本なので関係ありません。スタートページから、もしくはファイル→新規作成→Webサイト。
![]()
更に項目があって分からねえ、けどここはASP.NET空のウェブサイトを選びます。次にソリューションエクスプローラーウィンドウを見ます(なければ表示→ソリューションエクスプローラー)。web.configとかいうゴミがありますが、それはスルーしておきましょう(消してもいいですが復活します)。空なので、ルートを右クリックして新しい項目の追加。
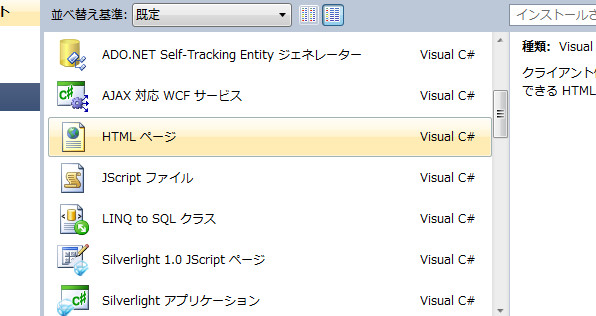
いっぱいあると思いますが、ほとんど関係ありません、ノイズです。真ん中ぐらいにあるHTMLページかJScriptファイルを選びましょう。あとは、エディタでガリガリと書いたら、Ctrl+F5を押せば簡易サーバーが立ち上がり、ブラウザ上に現在編集中のHTMLが表示されます。
以上が基本です。手順は簡単なので一度覚えればすんなり行くはずです。最初は如何せんHTML/JS用としてはダミー項目が多いのがやや難点。なお、保存時はデフォルトではMy DocumentのVS2010のWebSites下にHTMLとかが、Projects下に.slnファイル(プロジェクトを束ねている設定とかが書かれたファイル)が置かれています。以後プロジェクトをVSで開くときは.slnのほうをダブルクリック、もしくはスタートページの最近使ったプロジェクトから。
では、Visual Studioを使ってJavaScriptを書いて嬉しい!機能を幾つか挙げていきます。
エラー表示
小括弧が、波括弧が、足らなかったり足しすぎだったりを見落とすことは割とあります。そして起こる実行時エラー。こんなのコンパイルエラーで弾かれてくれ、あばばばば。と思うときはいっぱいあります。そこでVisual Studioのリアルタイムエラー検出。
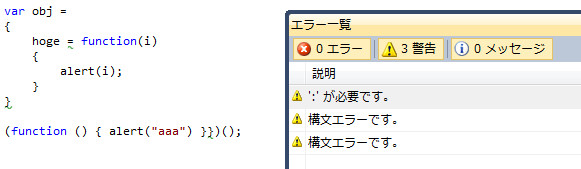
hoge = functionではなくhoge : function。下のは波括弧が一個多い。というのを、リアルタイムで検出してくれて、疑わしいところには波線を敷いてくれます。エラー一覧にも表示されるので、このウィンドウは常時表示させておくと書くのが楽になります。私は縦置きにしてエディタの左側にサイドバーとして常時表示。カラムはカテゴリと説明だけにしています。
エラー通知のためのコード走査はバックグラウンドで定期的に動いているようですが、任意に発動させたい場合はCtrl + Shift + Jで行えます。修正結果が正しいのかとっとと確認したいんだよ馬鹿やろー、って時に便利。というか普通に押しまくります、私は。
コードフォーマット
コード整形は大事な機能だと思っています。手動でスペース入れていくとか面倒くさいし。かといって整形が汚いコードは萎えます。

ショートカットはCtrl+K、で、Ctrlを押しながら続けてD。微妙に覚えにくいショートカット。ちなみに選択範囲のコメント化はCtrl+K, Cで、非コメント化はCtrl+K, U。ようするに整形系はCtrl+K始まりで、DはDocumentFormat、CはComment、UはUncommentの意味になるようです。フォーマットのルール(改行をどこに入れるか、とか)は設定で変えられます。
デバッグ
当然のようにブレークポイントの設定、ステップイン、ステップアウトなどのデバッグをサポートしています。

F9でブレークポイントを設定してF5でデバッグ実行。が基本です。ローカルウィンドウで変数の値表示、そして便利なのがウォッチウィンドウで、見たい値を好きに記述出来ます。式も書けるので平気で副作用かませます。で、デバッガで良いのはthisが見れるところですねー。JavaScriptはthisが不定で、いったいこの中のthisは何を指しているんだ!と悩んでしまうわけですが、そんなものデバッガで見れば一発で分かりますね、はは。考えるより前にとりあえずデバッグ実行。
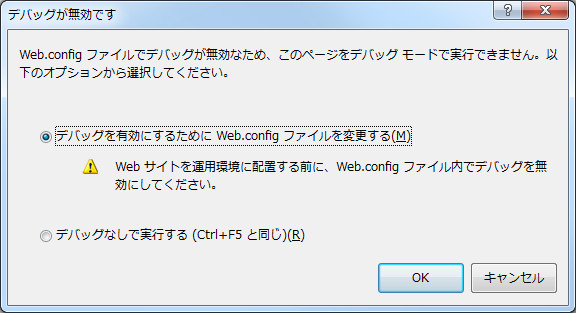
さて、そんなデバッグですが、初回時には何やら怪しげなダイアログが上がります。ここはYESで。そして、デバッグ出来ましたか?出来なかった人も多いかもしれません。実は、IEじゃないとデバッガ動かないのです。というわけで、ソリューションエクスプローラーからプロジェクトのルート部分を右クリックしてブラウザの選択を選ぶ。
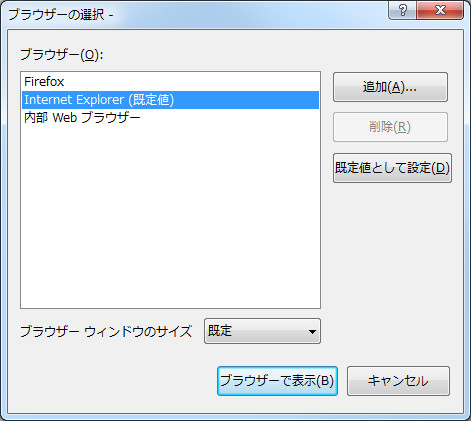
IEをデフォルトにしてください。一度設定すれば、以降はこの設定が継続されます。IEとか冗談じゃない。と思うかもしれませんが、えーと、IEで常に書くことで、IEで動かないスクリプトを書くことを避けられるのです、とかいうどうでもいい効用はあります。でもまあ、Firefox拡張とかChrome拡張を書くのにはデバッガが使えなくなるも同然なのは不便ですね。その時はデバッグは当然ブラウザ固有のデバッガを使い(デバッガを使わないと言う選択肢はないよ!)、エディタとしてだけに使えばいいぢゃない。
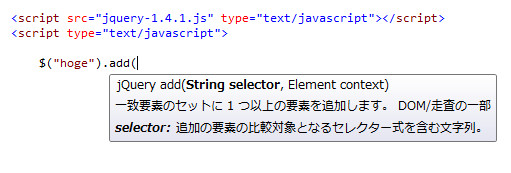
入力補完/日本語jQuery
入力補完(IntelliSense)は素敵。ローカル変数があればそれが出てくる。もう変数名打ち間違えで動かない、とかない。ドットを打てば、補完候補に文字列であればreplaceとか、配列であればjoinとか、DOMであればappendChildとか出てくる。メソッド名を暗記する必要もなければ、打ち間違えることもない。
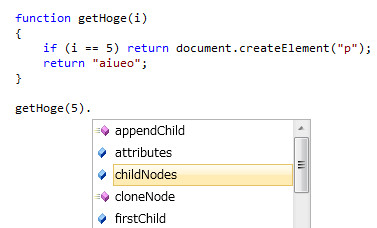
補完は割と賢くて、関数では引数を見て(というか裏でインタプリタ走ってるんですね、きっと)、ちゃんと返す値を判別してくれます。
ところでですが、最初の釣り画像にあるjQueryの日本語化ドキュメントはどこにあるのでしょうか?
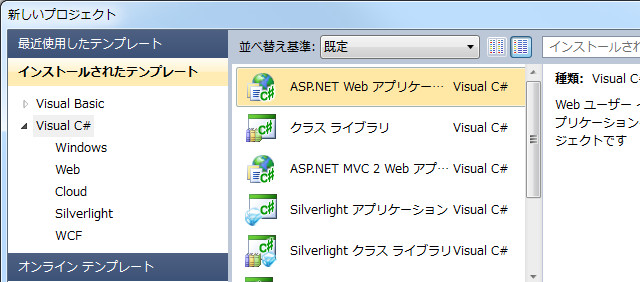
ファイル→新規作成→プロジェクトからASP.NET Webアプリケーションを選びます。すると、Scriptsフォルダの下にjquery-1.4.1-vsdoc.jsとかいうものが!こいつを、コピペって頂いてしまいましょう。ASP.NET Web Application自体はどうでもいいので破棄です、破棄。でもせっかくなので、Default.aspxを開いてCtrl+F5で実行してみてください。出来た!ウェブアプリが出来た!そう、C#+ASP.NETは驚くほど簡単にウェブアプリが作れるんです。あとは安レンタルサーバーさえ普及してくれれば……。
vsdocについて
-vsdoc自体は<script src>で読み込む必要はありませんし、実際にサーバーにアップロードする必要もありません。仕組みとしてはhoge.jsとhoge-vsdoc.jsが同じ階層にあると、VisualStudioの入力補完解析はhoge-vsdoc.jsを見に行く、といった感じになっています。なので、jquery-1.4.1.jsだけを読み込めばOKです。
HTMLファイルに記述する場合はscript srcで読み込めて補完が効くのは分かるけど、単独JSファイルの場合は読み込みの依存関係をどう指定すればよいでしょうか。答えは、ファイルの先頭にreference pathを記載します。
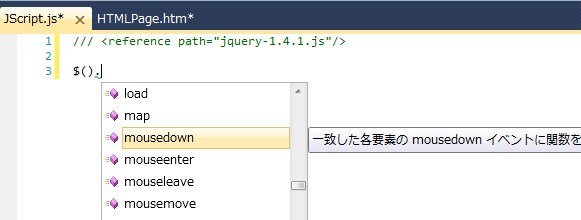
これで、JScript1.jsという単独JSファイルでもjQueryの補完が効かせられるようになりました。reference pathというのはVSだけで効果のあるタグで、ブラウザの解釈上はコメントに過ぎないので、ブラウザ表示時に問題が出ることもありません。
なお、このreference pathというのを覚えている必要はありません。refと記述してTabを二回押すとこのタグが展開されるはずです。コードスニペットというコード挿入の仕組みに予め用意されているわけです。なお、コードスニペットは、この他にもfor->Tab x2でforが展開されたりなど色々あって便利です(自分で作成することも出来る)。
その他設定など
その他、好みもありますが設定など。ツール→オプションから。
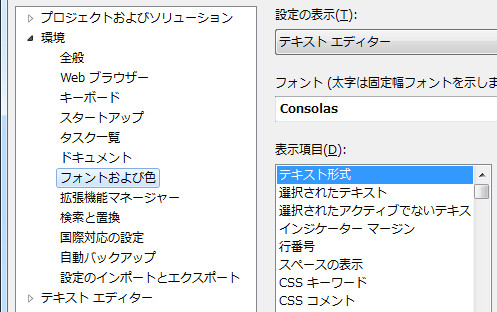
何はともかくフォントの変更。MSゴシックとかありえん。フォントをConsolasにしましょう! Consolasはプログラミング用のClearTypeに最適化された見やすい素敵フォントです。勿論、スラッシュドゼロ。サイズは私は9で使ってます。
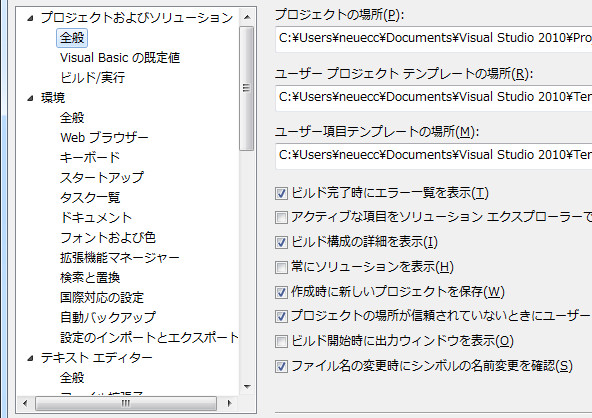
Ctrl+F5押す度にアウトプットウィンドウが立ち上がるのが猛烈にウザいので、「ビルド開始時に出力ウィンドウを表示」のチェックは外しておく。
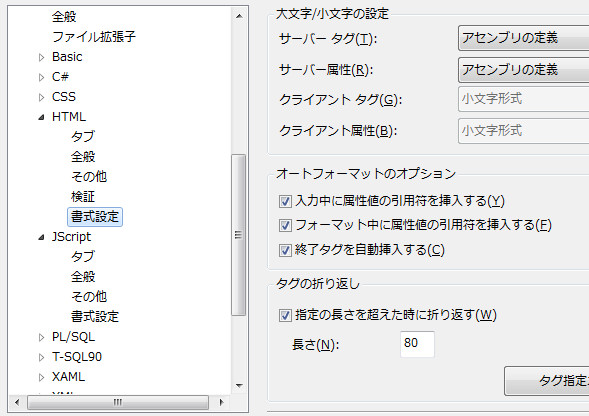
HTMLでの属性の引用符自動挿入はチェックつけといたほうが幸せ気分。
入力候補の、このTabかEnterのみで確定させるってのはチェックを外す。だってメソッド書くときは「(」で確定させたいし、オブジェクトを開くときは「.」で確定させたいもの。例えばdocument.getElementByIdは「doc -> Enter -> . -> get -> Enter -> (」じゃなくて「doc -> . -> get -> (」というように、スムーズに入力したい。一々Enterを挟むのは流れを止めてしまう。
まとめ
IDEを知ってて使わない、というのは個人の好き好きなのですが、単純に知らないというのは勿体無いな、と。特に初心者ほどIDEを必要とすると思います。初心者がプログラミング始めるなら、導入がメモ帳とブラウザだけで開発出来るJavaScriptお薦め!って台詞は、あまりよろしくないんじゃないかなー。初心者ほど些細なスペルミスや構文ミスでつまづく上に、目を皿のようにしてみても原因が分からない。たとえ導入までの敷居が若干高くなろうとも、親切にエラー箇所に波線を敷いてくれるIDEこそ必要なんじゃないかな。あと、デバッガ。ビジュアルに変数が動き変わることほど分かりやすいものもないでしょう。
IDEもEclipseのプラグインとか色々ありますが、Visual Studioの強力なjQuery対応度は何にも代え難いんじゃないでしょうか。導入もオールインワンなので何も考えなくてもいい簡単さですし。是非一度、試してみてもらえればいいなあ。
ついでですが、冒頭動画のlinq.jsは便利なJavaScriptライブラリ(無名関数を多用して関数型言語的にコレクション操作を可能にする)でいて、更にVisual Studioの入力補完に最適化してあるので使ってみてください、と宣伝。いや、作者私なので。ごほごほ。jQueryプラグインとして動作するバージョンも同梱してあります。
それと、勿論Visual Studioは有料版のほうが高機能な面もあります。JavaScript開発のみだとあまり差はないのですが、WindowsScriptHostをJavaScriptで書いてもデバッグ出来るとか無料版に比べて大したことない利点があるにはあります。C#でSilverlightなどもごりごり書きたい、とかになれば断然、有料版のほうが輝いてきます。
Ultimateは100万オーバーで無理なので、Professional買いましょう、私は買います。(メインはC#の人間なので。JSの人は正直Expressでイイと思うよ……)。まだ発売されてないのでこれから買います。「アップグレード」ですが、Express(無料版)からのアップグレードも認められているという意味不明仕様なので(誰が倍額する通常版買うんでしょうかね……)皆様も是非、上のリンクからamazonで買ってくれれば、ごほごほ。
DynamicJson ver 1.2.0.0
- 2010-05-21
DynamicJsonをver1.2.0.0に更新しました。おうぁぁぁぁ。Dynamicのまま配列をばらせないことに気づいた!foreachで列挙出来るのはいいけれど、Linqで、例えばSelectManyに渡せないぢゃん!ヤバいヤバい。バグではないけど、そんなんじゃ使い物にならない。ということでその辺のを修正しました。
何言ってるのかよくわからないですね、なわけで例を。
// page1から5までを取得して平らにする(で、古い順に並び替える)
var wc = new WebClient();
var statuses = Enumerable.Range(1, 5)
.Select(i =>
wc.DownloadString("http://twitter.com/statuses/user_timeline/neuecc.json?page=" + i))
.SelectMany(s => (dynamic[])DynamicJson.Parse(s))
.OrderBy(j => j.id);
foreach (var status in statuses)
{
Console.WriteLine(status.text);
}
neueccさん(私だ、私)の投稿を取得するわけですが、一回に20件しか取得出来ないので(countを指定すれば200件まで取れますけど)、複数ページ分取得して結合することにします。そういう場合はforでグルグル?ご冗談を、Modern C#(そんな定義ない)ではLINQを使います。
1ページのJSONは[{text:nantoka},{text:kantoka}] といった形に配列にデータが入った形で取得出来ます。それが5ページ分。[[{},{}],[{},{}]]といった感じなので、これを真平らにしてやりましょう。[{},{},{},{}]といった風に。それがSelectManyです。SelectManyは微妙にわかりにくいけれど、Linqの中でもかなり重要なんですよー。図解 SelectMany - NyaRuRuの日記なども参考に。
さて、この「.SelectMany(s => (dynamic[])DynamicJson.Parse(s))」って部分が、前は出来なかったのです、とほほほ。IEnumerable<T>を実装していれば(IEnumerable<dynamic>)で済んだのだけどなあ。そうすれば配列に変換しなくても済むので効率的にも良いし。Dynamic Viewと結果ビューが共存出来さえすれば……。
というわけですが、今回の修正で無事、出来るようになりました。配列変換は気にくわないけどしょうがない。IEnumerableを実装しているけれどDynamic Viewが使えるやり方募集中です。方法あったら誰か教えてくださいお願いします。
あと、キャストついでに、読み取り専用プロパティに対しても値をセットしようとして例外出るのを修正しました。これは、まあ、バグですね。仕様とか言ったら怒る。ていうかすみません。
linq.js ver 2.1.0.0 - ToDictionary, Share, Let, MemoizeAll
- 2010-05-18
CodePlex - linq.js - LINQ for JavaScript
linq.jsを2.0から2.1に更新しました。今回はただのメソッド追加というだけじゃなく、1.*の時から続いてる微妙コードを完全抹殺の一掃で書き換えた結果、内部的にはかなり大きな変更が入りました。その影響で挙動が変わってるところも割とあります。
まず、OrderByのロジックを変更しました。これで動作はC#完全準拠です(多分)。前のはかなりアレだったのでずっと書きなおしたいと思ってたのですが、やっと果たせました。従来と比べるとThenByを複数個繋げた時の挙動が変わってくる(今まではOrderByのみ安定ソートで、ThenBy以降は非安定ソートだったのが、今回からは幾つ繋げても安定ソートになります)ので、複雑なソートをやろうとしていた場合は違う結果が出る可能性はなきにしもあらず、ですが、基本的には変化なしと見て良いと思います。
ちなみにJavaScriptのArray.sortは破壊的だし、安定である保証もないので、linq.jsのOrderBy使うのは素敵な選択だと思いますよ!非破壊的で安定で並び替え項目を簡単に複数連結出来る(ThenBy)という、実に強力な機能を提供しています。代償は、ちょっと処理効率は重いかもですね、例によってそういうのは気にしたら負けだと思っている。
他に関係あるところで大きな変更はToLookup。戻り値を、今まではJSのオブジェクトだったのですが、今回からはlinq.jsの独自クラスのLookupになります。すみませんが、破壊的変更です、前と互換性ありません。変えた理由はJSのオブジェクトを使うとキーが文字列以外使えないため。そのことはわかっていて、でもまあいっかー、と思っていたのですがGroupByとか内部でToLookupを使ってるメソッドの挙動が怪しいことになってる(という報告を貰って気づいた)ので、ちゃんとした文字列以外でもキーに使えるLookupを作らないとダメだなー、と。
GroupByでのcompareSelector
そんなわけで、GroupByのキーが全部文字列に変換されてしまう、というアレゲなバグが修正されました。あと、オーバーロードを足して、compareKey指定も出来るようにしました。何のこっちゃ?というと、例えばDateもオブジェクトも参照の比較です。
alert(new Date(2000, 1, 1) == new Date(2000, 1, 1)); // false
alert({ a: 0} == { a: 0 }); // false
JavaScriptではどちらもfalse。別のオブジェクトだから。C#だとどちらもtrue、匿名型もDateTimeも、値が比較されます。そんなわけでJavaScriptで値で比較したい場合はJSONにでもシリアライズして文字列にして比較すればいいんじゃね?とか適当なことを言ってみたりはしますが、実際Linqだと参照比較のみだと困るシーン多いんですねえ。そんなわけで、GroupBy/ToLookup、その他多数のメソッドに比較キー選択関数を追加しました。例を一つ。
var objects = [
{ Date: new Date(2000, 1, 1), Id: 1 },
{ Date: new Date(2010, 5, 5), Id: 2 },
{ Date: new Date(2000, 1, 1), Id: 3 }
]
// [0] date:Feb 1 2000 ids:"1"
// [1] date:Jun 5 2010 ids:"2"
// [2] date:Feb 1 2000 ids:"3"
var test = Enumerable.From(objects)
.GroupBy("$.Date", "$.Id",
function (key, group) { return { date: key, ids: group.ToString(',')} })
.ToArray();
キーにDateを指定し、日付でグルーピングしたいと思いました(この程度の指定で関数書くのは面倒くさいし視認性もアレなので、文字列指定は非常に便利です)。しかし、それだけだと、参照比較なので同じ日付でも別物として扱われてしまうのでグルーピングされません。$.Date.toString()として文字列化すれば同一日時でまとめられるけれど、Keyが文字列になってしまう。後で取り出す際にKeyはDateのまま保っていて欲しい、といった場合にどうすればいいか、というと、ここで今回新設した第四引数のcompareSelectorの出番です。
// [0] date:Feb 1 2000 ids:"1,3"
// [1] date:Jun 5 2010 ids:"2"
var test2 = Enumerable.From(objects)
.GroupBy("$.Date", "$.Id",
function (key, group) { return { date: key, ids: group.ToString(',')} },
function (key) { return key.toString() })
.ToArray();
比較はキー(この場合$.Date)をtoStringで値化したもので行う、と指定することで、思い通りにグループ化されました。なお、C#でもこういうシーン、割とありますよね。C#の場合はIEqualityComparerを指定するのですが、わざわざ外部にクラス作るのは大変どうかと思う。といった時はAnonymousComparerを使えばlinq.jsと同じようにラムダ式でちゃちゃっと同値比較出来ます。
なお、今回からGroupByの第三引数(resultSelector)が未指定の場合はGroupingクラスが列挙されるように変更されました。GroupingはEnumerableを継承しているので全てのLinqメソッドが使えます。その他に、.Key()でキーが取り出しできるというクラスです。
Lookup
LookupはGroupByの親戚です。むしろGroupByは実はToLookupしたあと即座に列挙してるだけなのだよ、ナンダッテー。で、何かというとMultiDictionaryとかMultiMapとか言われてるような、一つのキーに複数個の要素が入った辞書です。そして、immutableです。不変です。変更出来ません。
var list = [
{ Name: "temp", Ext: "xls" },
{ Name: "temp2", Ext: "xLS" },
{ Name: "temp", Ext: "pdf" },
{ Name: "temp", Ext: "jpg" },
{ Name: "temp2", Ext: "PdF" }
];
var lookup = Enumerable.From(list).ToLookup("$.Ext", "$.Name", "$.toLowerCase()");
var xls = lookup.Get("XlS"); // toLowerCaseが適用されるため大文字小文字無視で取得可
var concat = xls.ToString("-"); // temp-temp2 <- lookupのGetの戻り値はEnumerable
var zero = lookup.Get("ZZZ").Count(); // 0 <- Getで無いKeyを指定するとEnumerable.Emptyが返る
// ToEnumerableでEnumerableに変換、その場合はGroupingクラスが渡る
// Groupingは普通のLinqと同じメソッド群+.Key()でキー取得
lookup.ToEnumerable().ForEach(function (g)
{
// xls:temp-temp2, pdf:temp-temp2, jpg:temp
alert(g.Key() + ":" + g.ToString("-"));
});
ToLookup時に第三引数を指定すると、戻り値であるLookupにもその比較関数が有効になり続けます。今回はtoLowerCaseを指定したので、大文字小文字無視でグルーピングされたし、Getによる取得も大文字小文字無視になりました。なお、GroupByでもそうですが、キーは文字列以外でも何でもOKです(compareSelectorを利用する場合はその結果が数字か文字列か日付、そうでない場合はそれそのものが数字か文字列か日付を使う方が速度的に無難です、後で詳しく述べますが)。
Dictionary
Lookupは内部でDictionaryを使うためDictionaryも作成、で、せっかく作ったのだから公開しますか、といった感じにToDictionaryが追加されました。ToObjectと違い、文字列以外をキーに指定出来るのが特徴です。
// 従来は
var cls = function (a, b)
{
this.a = a;
this.b = b;
}
var instanceA = new cls("a", 100);
var instanceB = new cls("b", 2000);
// オブジェクトを辞書がわりに使うのは文字列しか入れられなかった
var hash = {};
hash[instanceA] = "zzz";
hash[instanceB] = "huga";
alert(hash[instanceA]); // "huga" ([Object object]がキーになって上書きされる)
// linq.jsのDictionaryを使う場合……
// new Dictionaryはできないので、新規空辞書作成はこれで代用(という裏技)
// 第三引数を指定するとハッシュ値算出+同値比較にその関数を使う
// 第三引数が不要の場合はToDictionary()でおk
var dict = Enumerable.Empty().ToDictionary("", "",
function (x) { return x.a + x.b });
dict.Add(instanceA, "zzz");
dict.Add(instanceB, "huga");
alert(dict.Get(instanceA)); // zzz
alert(dict.Get(instanceB)); // huga
// ...といったように、オブジェクト(文字列含め、boolでも何でも)をキーに出来る。
// ToEnumerableで列挙も可能、From(obj)と同じく.Key .Valueで取り出し
dict.ToEnumerable().ForEach(function (kvp)
{
alert(kvp.Key.a + ":" + kvp.Value);
});
空のDictionaryを作りたい場合は、空のEnumerableをToDictionaryして生成します。微妙に裏技的でアレですが、まあ、こういう風に空から使うのはオマケみたいなものなので。というかToDictionaryメソッド自体がオマケです。DictionaryはLookupに必要だから作っただけで、当初は外部には出さないつもりでした。
第三引数を指定しないとオブジェクトを格納する場合は線形探索になるので、格納量が多くなると重くなります(toStringした結果をハッシュ値に使うので、Dateの場合は値でバラつくので大丈夫です、普通のオブジェクトの場合のみ)。第三引数を指定するとハッシュ値の算出にそれを使うため、格納量が増えても比較的軽量になります(ハッシュ衝突時はベタにチェイン法で探索してます)。なお、第三引数はハッシュ関数、ではあるのですが、それだけじゃなくて同値比較にも利用します。GetHashCodeとEqualsが混ざったようなものなので、ようするにAnonymousComparerのデフォルト実装と同じです。
勿論、ハッシュ関数と同値比較関数は別々の方が柔軟性が高いんですが(特にJavaScriptはハッシュ関数がないから重要性は高いよね!)、別々に設定って面倒くさいしぃー、結局一緒にするシーンのほうが割と多くない?と思っているためこのようなことになっています。というだけじゃなくて、もしequalsとgetHashCodeを共に渡すようにするなら{getHashCode:function(), equals:function()} といった感じのオブジェクト渡しにすると思うんですが、私はIntelliSenseの効かない、こういうオブジェクト渡しが好きではないので……。
メソッドはIDictionaryを模しているためAdd, Remove, Contains, Clear、それにインデクサが使えないのでGet, Set、EnumerableではないかわりにToEnumerableでKeyValuePairの列挙に変換。Addは重複した場合は例外ではなく上書き、Getは存在しない要素を取得しようとした場合は例外ではなくundefinedを返します。この辺はC#流ではなく、JavaScript風に、ということで。
GroupingはEnumerableを継承しているのに、DictionaryとLookupは継承していないのでToEnumerableで変換が必要です。C#準拠にするなら、Groupingと同じく継承すべきなのですが、あえて対応を分けた理由は、Groupingはそのまま列挙するのが主用途ですが、LookupやDictionaryはそのまま使うのがほとんどなので、IntelliSenseに優しくしたいと思ったのからです。90近いメソッドが並ぶと、本来使いたいGetとかが見えなくなってしまうので。
なお、Dictionaryの列挙順は、キーが挿入された順番になります。不定ではありません。JavaのLinkedHashMapみたいな感じです(C#だとOrderedDictionary、Genericsじゃないけど)。順序保持の理由は、DictionaryはLookupで使う->LookupはGroupByで使う->GroupByの取り出し順は最初にキーが見つかった順番でなければならない(MSDNにそう記載がある)。といった理由からです。ちなみにですが、GroupByが順番通りに来るってのは経験則では知ってたのですがMSDNに記載があったのは見落としていて、むしろ不定だと考えるべきじゃないか、とかTwitterでデマ吹いてたんですが即座にツッコミを頂いて大変助かりました、毎回ありがとうございます。
Share, Let, MemoizeAll
そして3つの新メソッド。これらはReactive Extensionsに含まれるSystem.Interactive.dllのEnumerableに対する拡張メソッドから移植しています。
// Shareはenumeratorを共有する
// 一つの列挙終了後に再度呼び出すと、以前中断されたところから列挙される
var share = Enumerable.Range(1, 10).Share();
var array = share.Take(4).ToArray(); // [1,2,3,4]
var arrayRest = share.ToArray(); // [5,6,7,8,9,10]
// 例えば、これだと二度列挙してしまうことになる!
// 1,1,2,3とアラートが出る
var range = Enumerable.Range(1, 3).Do("alert($)")
var car = range.First(); // 1
var cdr = range.Skip(1).ToArray(); // [2,3]
// Shareを使えば無駄がなくなる(アラートは1,2,3)
var share = range.Share();
var car = share.First(); // 1
var cdr = share.ToArray(); // [2,3]
Shareは、列挙の「再開」が出来ると捉えると良いかもしれません。ちなみに、再開が出来るというのは列挙完了までDispose(終了処理)しないということに等しいのには、少しだけ注意が必要かもしれません。
// Letの関数の引数は自分自身
// [1,2], [2,3], [3,4], [4,5]
Enumerable.Range(1, 5).Let(function (e)
{
return e.Zip(e.Skip(1), "x,y=>[x,y]");
});
// 上のLetはこれと等しい
var range = Enumerable.Range(1, 3);
range.Zip(range.Skip(1), "x,y=>[x,y]");
// 余談:Pairwiseは↑と同じ結果です、一つ先の自分との結合
Enumerable.Range(1, 5).Pairwise("x,y=>[x,y]");
Letは、Enumerableを受け取ってEnumerableを返す関数を渡します。何のこっちゃですが、外部変数に置かなくても、メソッドチェーンを切らさずに自分自身が使えるということになります。使い道は主に自分自身との結合を取りたい場合、とか。なお、何も対処せずそのまま結合すると二度列挙が回ることには注意が必要かもしれません。
// MemoizeAllは、そこを一度通過したものはキャッシュされる
var memo = Enumerable.Range(1, 3)
.Do("alert($)")
.MemoizeAll();
memo.ToArray(); // 一度目の列挙なのでDoでalertが出る
memo.ToArray(); // 二度目の列挙はキャッシュからなのでDoを通過しない
// Letと組み合わせて、自己結合の列挙を一度のみにする
Enumerable.Range(1, 5)
.MemoizeAll()
.Let(function (e) { return e.Zip(e.Skip(1), "x,y=>[x,y]") });
MemoizeAllはメモ化です。二度三度列挙するものは、一度.ToArray()とかして配列に置いたりすることが少なくなかったのですが、MemoizeAllはその辺を遅延評価のままやってくれます。使いかっては良さそう。ただし、これもShareと同じく列挙完了まで例外が起ころうが何だろうがDispose(終了処理)しないのは注意が必要かもしれません。素のJavaScriptではリソース管理は滅多にないので関係ないですが、例えばメモ化が威力を発揮しそうな(linq.jsではWSHで、C#だったら普通にやりますよね)ファイル読み込みに使おうとすると、ちょっと怖い。ていうか私はそういう場合は素直にToArrayします。
この3つは「注意が必要かもしれません」ばかりですね!ただ、MemoizeAll->Let->Zipで自分自身と結合するのは便利度鉄板かと思われます。便利すぎる。
まとめ
Dictionaryの導入は地味に影響範囲が大きいです。集合演算系メソッドもみんなDictionary利用に変えたので。なんでかというと、ええと、そう、今まではバグっておりました……。trueと"true"区別しないとか。Enumerable.From(["true",true]).Distinct()の結果が["true"]になってました。ほんとすみません。今回から、そういう怪しい挙動は潰れたと思います。いや、Dictionaryがバグッてたら元も子もないのですが多分大丈夫だと思います思いたい。
とにかく一年前の私はアホだな、と。来年も同じこと思ってそうですが。
Share, MemoizeAll, LetのRx移植三点セットは遊んでる分には面白いんですが、使いどころは難しいですね。ちなみに、MemoizeAllということで、RxにはAllじゃないMemoizeもあるのですが、かなり挙動が胡散臭いので私としては採用見送りだし、C#でも使う気はしません。内部の動きを相当意識してコントロールしないと暴走するってのが嫌。
VS2010のJavaScript用IntelliSenseは本当に強化されましたねー。ということで、VS2010ならDictionaryやLookupでIntelliSenseが動作するのですが、VS2008では動作しません。完全にVS2010用に調整してたら2008では動かないシーンも幾つか出てきてしまった……。まあでも、2010は素敵なのでみんな2010使えばいいと思うよ。私はまだExpressですががが。一般パッケージ販売まだー?(6月です)
そういえば、2.0は公開からひと月でDL数100到達。本当にありがとうございます。そろそろ実例サンプルも作っていきたいのですがネタがな。Google Waveって結局どうなんでしょうかね。ソーシャルアプリは何か肌に合わない雰囲気なのでスルーで、Waveに乗り込むぜ、とか思ってたんですが思ってただけで乗り込む以前に触ってもいないという有様。HTML5は、ええと、基本はC#っ子なのでSilverlight押しだから。うー、じゃあChrome拡張辺りで……。いやでもHTML5かな、よくわからないけれど。
今のところ最優先事項はlinq.javaなんですけどね、忘れてない忘れてない。というか、linq.js 2.0も今回のOrderByのロジック変更も、linq.javaで書いてあったのを持ってきただけだったりして。もうほんと、とっとと出したいです。出してスッキリして次に行きたい。
そんなわけで、この2.1でlinq.jsはようやくスタート地点に立てたぜ、という感じなので使ってやってください。
C# DynamicObjectの基本と細かい部分について
- 2010-05-06
DynamicJsonをver.1.1に更新しました。ver.1.0の公開以降に理解したDynamicObjectについての諸々を反映させてあります。具体的には、IsDefinedやDeleteといったメソッド名を書かずに、それらが呼び出せるようにし、また、foreach時にキャストが不要になりました。DynamicはIntelliSenseが効かないので、メソッド名を書かせたら負け。大まかに分けて「プロパティ」「名前付きメソッド」「名前無しメソッド」「キャスト」の4つをうまいこと振り分けて、不自然ではなく使えるようにすれば、DynamicObjectとして良い設計となるのではないかな、と思っています。
というわけで、今回は微妙にはまったDynamicObjectの挙動の色々について書きますが、その前に1.1の更新事項を。DynamicJson自体については、ver1.0のリリース時の記事を参照ください。
// ただの入れ物クラスなのであまり気にしないで。
public class FooBar
{
public string foo { get; set; }
public int bar { get; set; }
}
// こんなJSONがあったとするとする
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
var arrayJson = DynamicJson.Parse(@"[1,10,200,300]");
var objectJson = DynamicJson.Parse(@"{""foo"":""json"",""bar"":100}");
// .プロパティ名()はIsDefined("プロパティ名")と同じになります
var b1_1 = json.IsDefined("foo"); // true
var b2_1 = json.IsDefined("foooo"); // false
var b1_2 = json.foo(); // true
var b2_2 = json.foooo(); // false;
// .("プロパティ名")はDelete("プロパティ名")と同じになります
json.Delete("foo");
json("bar");
// キャストはDeserialize<T>()と同じになります
var array1 = arrayJson.Deserialize<int[]>();
var array2 = (int[])arrayJson; // array1と一緒
int[] array3 = arrayJson; // こう書いてもDeserialize呼び出しと同じだったりする
// 配列だけではなく、パブリックプロパティ名で対応を取るマッピングも可能です
var foobar1 = objectJson.Deserialize<FooBar>();
var foobar2 = (FooBar)objectJson;
FooBar foobar3 = objectJson;
// 勿論、配列+オブジェクトでも可。Linqに繋げる時はキャストで囲みましょう(asはダメ)
var objectJsonList = DynamicJson.Parse(@"[{""bar"":50},{""bar"":100}]");
var barSum = ((FooBar[])objectJsonList).Select(fb => fb.bar).Sum(); // 150
var hoge = objectJsonList as FooBar[]; // これはnullになる、asとキャストは挙動が違う
// array状態のDynamicJsonにforeachはdynamicが渡る
// 中の型が分かっている場合は、varではなく型名指定するといいかも
// ちなみに、数字はdynamicのままだと全てdoubleです
foreach (int item in arrayJson)
{
Console.WriteLine(item); // 1, 10, 200, 300
}
// オブジェクト状態のDynamicJsonへのforeachはKeyValuePair
// .Key、.Valueなのは分かってる、というならdynamicで受けると楽かも
foreach (KeyValuePair<string, object> item in objectJson)
{
Console.WriteLine(item.Key + ":" + item.Value); // foo:json, bar:100
}
foreachを自然に使えるようにしたのと、IsDefined、Remove、DeserializeをDynamicとして自然に呼び出せるようにした、というのが更新内容になります。IsDefined("name")が.name()で自然なのか?というと、どうなんでしょうねー、という感じですが、しかしDynamicはIntelliSenseが効かないのです!なので、多少ややこしくても、こうして使える方が便利だと思われます。
ところで、キャストとasの関係は、DynamicObjectだとより正確に意識する必要が出てきます。キャストとasは例外が飛ぶかnullになるかの違いしかない、と思っていたりしたのは私なのですが、そんなことはなくて、asはユーザ定義の変換演算子を呼ばないという性質があります。DynamicObjectでもそれが反映されているため、キャストするとTryConvertが呼ばれるのですが、asは純粋にそのクラスの継承関係しか見ません。
DynamicObjectとは
では本題。まずは基本から。型宣言がdynamicの場合に、挙動が変わるオブジェクトの作成方法は、DynamicObjectを継承して、挙動を変えたいメソッド(Tryなんたら)をオーバーライドするだけです。
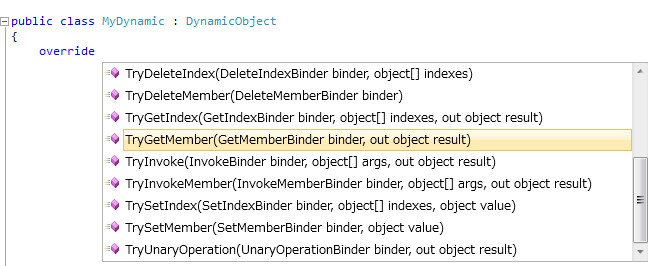
override->スペースでIntelliSenseに候補が出てきますね、素敵。Try何とかかんとかの第一引数はbinderですが、とりあえずbinder.Nameだけで何とかなります。成否はboolで返し(falseの場合は、呼び出しを解決するため更に連鎖が重なったりする)、trueの場合はresultにセットした値が呼び出し元に返る。といった仕組みになっています。
呼び出しの解決
簡単な例、ということで呼び出し名を返す、というだけの単純なTryInvokeMemberを定義してみます。
// MyDynamic:DynamicObjectのオーバーライド、メソッド呼び出し名を文字列としてそのまま返す、引数がある場合はfalse
public override bool TryInvokeMember(InvokeMemberBinder binder, object[] args, out object result)
{
result = binder.Name;
return (args.Length > 0) ? false : true;
}
dynamic d = new MyDynamic();
var t1 = d.Hoge(); // Hoge - dynamic(string)
var t2 = d.ToString(); // ToStringにはならない、MyDynamicのToStringが呼ばれる
さて、この場合本来あるメソッドであるToStringやEquals、その他自分で定義したメソッドがあれば、それらを呼んだ場合はどちらが優先されるでしょうか、というと、定義されたメソッドが優先です。なので、TryInvokeMemberにだけ挙動を定義しておくと、どうやっても呼べないメソッドが出てきます。例えばDynamicJsonで言えば、プロパティ名がToStringのJSONに対してToString()で定義されているか確認は出来ません。そのための回避策として、TryInvokeMemberはIsDefinedの簡易記法としています。IsDefined("ToString")ならば問題なく呼べますので。
引き続いて、TryInvokeMemberがfalseの場合も見てみます。
public override bool TryGetMember(GetMemberBinder binder, out object result)
{
result = new MyDynamic();
return true;
}
public override bool TryInvoke(InvokeBinder binder, object[] args, out object result)
{
result = ((string)args[0]).ToUpper();
return true;
}
dynamic d = new MyDynamic();
var t = d.Hoge("aaa"); // AAA(InvokeMemberが失敗したらGetMemberが呼ばれ、それのTryInvokeが呼ばれる)
d.Hoge("aaa")は、まずTryInvokeMemberが呼ばれます。今回は引数がある場合はfalseとしているので、失敗します。すると、呼び出しの解決のためTryGetMemberが呼ばれます。ここでtrueの場合は、引数を持ってTryInvokeが呼ばれます。TryInvokeはd("aaa")のような、メソッド名なしでの関数呼び出しです。C#にはない記法となるので、TryInvokeMemberからの失敗の連鎖でTryGetMemberでDynamicObject以外を返すと、TryInvokeに失敗という形で例外が出ます。
ややこしいですね!この失敗の連鎖はDynamicJsonではオブジェクトがネストしている際の呼び出しの解決に利用しています。
var json = DynamicJson.Parse(@"{""tes"":10,""nest"":{""a"":0}");
json.nest(); // これはjson.IsDefined("nest")
json.nest("a"); // これはjson.nest.Delete("a")
json.nest("a")は、まずTryInvokeMemberが呼んでいます。これは原則IsDefinedと等しいのですが、引数がある場合はfalseにしています。そのためTryGetMemberが呼ばれて.nestを取得。そして、TryInvoke(これはDeleteに等しい)を呼ぶという流れになっています。真面目にDynamicObjectを使って構造を作る場合、呼び出し解決順序などを意識する必要は、間違いなくあります。ややこしいですけどねー。
DynamicObjectとforeach
DynamicObjectがIEnumerableならば、foreachはそれを呼びます。ていうかforeach可能なものはIEnumerableにするでしょ常識的に考えて。と、言いたいのですが世の中そうもいかなかったりします。
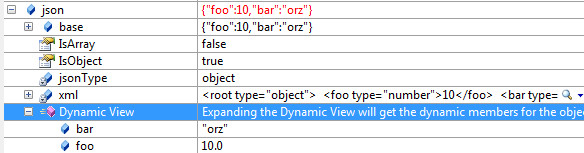
Dynamicの変数はデバッガで見るとDynamic Viewというものが用意されていて、展開すると全てのプロパティ名と値を表示してくれます(これに対応させるにはGetDynamicMemberNamesをオーバーライドする必要がある、DynamicObject作るなら必須!)。大変便利なのですが、これ、クラスがIEnumerableを実装している場合はIEnumerableの結果ビューに置き換わってしまい、Dynamic Viewがなくなってしまいます。
Dynamic Viewがないと非常に不便極まりないので、DynamicJsonではIEnumerableの実装は断念しました。しかし、foreachでそのまま呼べないのは不便だ。どうする?となって思い浮かんだのは、IEnumerableじゃなくてもGetEnumeratorがあればforeachって呼ばれるんだよねー、普通のクラスは。という仕様がC#にはあるので、Dynamicでも行けるかな?と思いきやそんなことはなく、呼ばれませんでした。じゃあ、かわりにforeach時に何が呼ばれていたか、というと、TryConvertが呼ばれます。
public override bool TryConvert(ConvertBinder binder, out object result)
{
// foreachで呼ばれた時はbinder.TypeがIEnumerable
if (binder.Type == typeof(IEnumerable))
{
result = Enumerable.Range(1, 10); // resultはIEnumerableとIEnumerator、どちらでも可
return true;
}
// 通常のキャストは適当に分岐させるか、キャストの演算子オーバーロードでもどちらでもいい
// 演算子オーバーロードがある場合は、そちらが優先されます
result = (binder.Type == typeof(string)) ? "hogehoge" : null;
return true;
}
dynamic d = new MyDynamic();
foreach (var item in d)
{
Console.WriteLine(item); // 1,2,3,4,5,6,7,8,9,10
}
var ie = (IEnumerable)d; // これは失敗する、インターフェイスへの明示的型変換は不可!
C#ではインターフェイスの演算子オーバーロードは定義出来ないし、Dynamicでも呼び出しは不可能になっています。が、foreach呼び出し時のみ、TryConvertにTypeがIEnumerableとして渡るようになっているので、そこでtrueを返せば、IEnumerableではないDynamicObjectでもforeachで列挙出来ます。
正直なところ、セコいハックに過ぎないです。本当はデバッガでDynamic Viewと結果ビューが共存できればいいんですよ、ていうか出来るべき。あと、Dynamic Viewは今のところ値がnullのものは表示しないようになっているのですが、これも不便な仕様ですね、改善して欲しいところ。とはいえ、IEnumerableじゃないから不便になってる!ということは無いと思われます。どちらにせよIEnumerableじゃなくてもdynamicはキャストしないと拡張メソッドが呼べない(つまりそのままではLinqが使えない)ため、利用感は犠牲にしていません。
そういえばExpandoObjectはIEnumerableなのにdynamic viewが出るので、何か方法はあるかもしれませんね。
まとめ
dynamicは当初思っていたよりも、遥かに使いがいのある仕組みでした。dynamicはDSL。だと思います。そして、DSLとして便利に使わせるならば、メソッド名で呼ばせるのは厳禁。用意された機構を上手く使ってIntelliSenseレスでも快適に操作出来るようにしなければならない。というか、それで操作出来ないならば普通にC#で組んでIntelliSense効かせた方がずっと良い。
と、まあ、そんなわけでDynamicJsonは400行程度の小さいコードですが、割と色々考えて作ってありますので、是非使ってみてください。お手製ライブラリにありがちなJSON解析の出来が怪しい、といった問題を、解析部を.NET FrameworkのJsonReaderWriterFactoryに丸投げしているため避けられている、というのも大きな利点かと思われます。
ソースコード本体は、ArrayとObjectを一つのクラスに統合しているため、各メソッド行頭でifで分ける、というのが若干怪しいのですが(オブジェクト指向的にはポリモーフィズム、ていうかDynamicならその辺考えずに分けても問題ない、だろうけど400行のコードですからねえ、分割したほうが手間かつ分かりにくくなるだろうしで、まだリファクタリングの出番ではない、と思いますです、これ以上規模が膨れるなら別ですが)、全体的にはDynamicObjectの機能を満遍なく使っているので、参考になるかと思います。あと、JSON書き出し時のLinq to XmlでのXML組み立て部分は若干トリッキーなものの、割とよく出来ているかな? Deserializeはもう少し気合入れて実装し直さないとダメな感じですがががが。
DynamicJson - C# 4.0のdynamicでスムーズにJSONを扱うライブラリ
- 2010-04-30
C#4.0の新機能といったらdynamic。外部から来る型が決まってないデータを取り扱うときは楽かしら。とはいえ、実際に適用出来る範囲はそんなに多くはないようです。例えばXMLをdynamicで扱えたら少し素敵かも、と一瞬思いつつもElementsもDescendantsも出来なくてAttributeの取得出来ないXMLは、実際あんまり便利じゃなかったりする。ただ、ちょうどジャストフィットするものがあります。それは、JSONですよ、JSON。というわけで、dynamicでJSONを扱えるライブラリを書いてみました。ライブラリといっても300行程度のクラス一個です。
使い方は非常にシンプルで直感的。まずは、文字列JSONの読み込みの例を。DynamicJson.Parseメソッド一発です。
// Parse (from JsonString to DynamicJson)
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
var r1 = json.foo; // "json" - dynamic(string)
var r2 = json.bar; // 100 - dynamic(double)
var r3 = json.nest.foobar; // true - dynamic(bool)
var r4 = json["nest"]["foobar"]; // インデクサでのアクセスも可
// 定義されてるかチェック
var b1 = json.IsDefined("foo"); // true
var b2 = json.IsDefined("foooo"); // false
Parseしたら、あとはJavaScriptと同じ感じにプロパティ名をドット打つだけで値が取り出せます。dynamicとJSONは相性が良いですね、JavaScriptと全く同じ感覚です。注意点としては、存在しないプロパティ名を読むと例外が出ます。Dictionaryみたいなものだと思ってください。さすがにそれだと使いにくいところもあるので、IsDefinedメソッドであるかないかチェック出来ます。dynamicなため、IntelliSenseには出てこないということは注意してください。もう一つ気をつけなきゃいけないのは、数字は全てdoubleです。JSONでは数値類は全部一緒くたにNumberなので、適宜自分でキャストしてください。
オブジェクトからJSON文字列への変換
dynamicとは関係ないのですが、JSON文字列へのシリアライズも可能です。こちらもDynamicJson.Serializeメソッド一発。
// Serialize (from Object to JsonString)
var obj = new
{
Name = "Foo",
Age = 30,
Address = new
{
Country = "Japan",
City = "Tokyo"
},
Like = new[] { "Microsoft", "Xbox" }
};
// {"Name":"Foo","Age":30,"Address":{"Country":"Japan","City":"Tokyo"},"Like":["Microsoft","Xbox"]}
var jsonStringFromObj = DynamicJson.Serialize(obj);
匿名型でサクッとJSONを作り上げられます。非常にお手軽。DataContractJsonSerializerはちょっと大仰すぎなのよねえ、という時にはこれでサクサクッと作ってやってください。匿名型だけじゃなく、普通のオブジェクトでも大丈夫です(その場合はパブリックプロパティからKeyとValueを生成します)。
JSONオブジェクトの再編集・作成
生成したDynamicJsonは可変です。自由に編集して再シリアライズとか出来ます。
var json = DynamicJson.Parse(@"{""foo"":""json"", ""bar"":100, ""nest"":{ ""foobar"":true } }");
// 追加、編集、削除が出来ます
json.Arr = new string[] { "NOR", "XOR" }; // Add
json.foo = 5000; // Replace
json.Delete("bar"); // Delete
// DynamicJsonから文字列へのシリアライズはToStringを呼ぶだけ
var reJson = json.ToString(); // {"foo":5000,"nest":{"foobar":true},"Arr":["NOR","XOR"]}
// 配列はちょっと特殊で、foreachなので扱いたい場合はobject[]にキャストしてください
Console.WriteLine(json.Arr[1]); // XOR
foreach (var item in (object[])json.Arr)
Console.WriteLine(item); // NOR XOR
// 新しく作成することも出来ます
dynamic root = new DynamicJson(); // ルートのコンテナ
root.obj = new { }; // 空のオブジェクトの追加は匿名型をどうぞ
root.obj.str = "aaa";
root.obj.@bool = true; // C#の予約語と被る場合は@を先頭につけるとアクセス出来るよ!
root.array = new[] { 1, 200 }; // 配列の追加
root.obj2 = new { str2 = "bbbb", ar = new object[] { "foobar", null, 100 } }; // オブジェクトの追加と初期化
// {"obj":{"str":"aaa","bool":true},"array":[1,200],"obj2":{"str2":"bbbb","ar":["foobar",null,100]}}
Console.WriteLine(root.ToString());
追加は存在しないプロパティ名に直接突っ込めばOK。編集はそのまま上書き。型名とか関係ないので、元から入っているものの型に合わせる必要はありません。削除はDeleteメソッドを呼べば出来ます。配列はちょっと扱いが特殊でして、foreachしたかったりLinqメソッド使いたい場合はobject[]にキャストする必要があります。この辺は仕様です。諸事情によりIEnumerableじゃないんです。ごめんなさい。ちなみにobjectってものなあ、intが欲しいんすよ、っていう時は.Cast
一から新しいDynamicJsonオブジェクトを作成することも出来ます。普通にnewするだけ。注意点としては、変数はdynamicで受けてください。varで受けても何の嬉しいこともありませんので。あとは、普通にぽこぽこ足すだけ。オブジェクトを作る場合は空の匿名型でやります。決してDynamicJsonを足したりしないでください、がっかりなことになりますので。
実装の裏側
300行のクラス一個、ということで、勿論自前でパーサー書いてるわけがありません。ていうか、その手のは自分で書きたくないんだよね、ソートアルゴリズムとかもそうだけど、こういうのはちゃんと検証されてるものを使うべき。(そしてそもそも、ちゃんとしたのが書けるかというと、書けません……)。で、何を使っているかというと先日の記事でLinq to Jsonとか言ってたように、JsonReaderWriterFactoryを使用しています。
ようするに、ただのJsonReaderWriterFactoryのラッパーです。内部ではJSONの構造をXMLとして保持していて、書き出しの際にJsonReaderWriterFactoryを通しています。ただですね、Readerのほうは使い易くてJsonReaderWriterFactoryお薦め!なのですが、Writerのほうは結構厳しいです。ルールに則って書いたXMLを通すとJSONになる、という仕組みなのですが、ルールに則ってないと即弾かれるということでもあって、かなり面倒くさいです。
// 例えばこんなDynamicJSONは
dynamic root = new DynamicJson();
root.Hoge = "aiueo";
root.Arr = new[] { "A", "BC", "D" };
// 内部ではこんなコードに変換されています
new XElement("root", new XAttribute("type", "object"),
new XElement("Hoge", new XAttribute("type", "string"), "aiueo"),
new XElement("Arr", new XAttribute("type", "array"),
new XElement("item", new XAttribute("type", "string"), "A",
new XElement("item", new XAttribute("type", "string"), "BC",
new XElement("item", new XAttribute("type", "string"), "D")))));
このXElementを素で書いていくのは地獄でしょう。DynamicJsonはこの変換を自動で行います。dynamicでラッピングすることで、煩わしい部分を完全に包み隠すことができました。ここまで簡略化出来ると、DSLの域です。C#は大変素晴らしいデスネ。いや、マジで。
まとめ
クラス一個なので、csファイルをコピペって使ってもいいですし(その場合は追加でSystem.Runtime.Serializationの参照を)、DLLを参照設定に加えても、どちらでもお好きな方をどうぞ。数あるJSONライブラリの中でも、使いやすさはトップクラスなのではないでしょうか(自画自賛)。いや、これは、単純にdynamicの威力の賜物ですね。これを作るまではdynamicについて割と勘違いしていたところもあったのですが、なんというか、DSL向けだと思います。で、DSL指向で行くなら全部プロパティだけで組まないとダメですねえ。IntelliSenseが動かないのでメソッドを使うのは今ひとつ。そういう意味で、IsDefinedじゃなくて.property? とかって感じに、末尾に?をつけるとかどうかな!とか考えてみたんですが、コンパイル通らないのでダメでした、残念。「.あいうえお」なら行けるので、日本語プログラミングDSLが待たれるところです。嘘。
static void Main()
{
var publicTL = new WebClient().DownloadString(@"http://twitter.com/statuses/public_timeline.json");
var statuses = DynamicJson.Parse(publicTL);
foreach (var status in (dynamic[])statuses)
{
Console.WriteLine(status.user.screen_name);
Console.WriteLine(status.text);
}
}
最後に例として、Twitterのpublic_timeline.jsonを引っこ抜くコードを。凄まじく簡潔です。C#はどこをどう見てもLightWeightですね、本当にありがとうございました。
C#とLinq to JsonとTwitterのChirpUserStreamsとReactive Extensions
- 2010-04-29
何か盛り沢山になったのでタイトルも盛り沢山にしてみました。SEO(笑)
最近話題のTwitterのChirpUserStreamsを使ってみましょー。ChirpUserStreamsとは、自分のタイムラインのあらゆる情報がストリームAPIによりリアルタイムで取得出来る、というもの。これを扱うには、まずはストリームをIEnumerable化します。そのまま扱うよりも、一度IEnumerable化すると非常に触りやすくなる、というのがLinq時代の鉄則です。C#でのストリームAPIの取得方法は以前にも記事にしましたが、かなり汚かったのでリライト。WebClient愛してる。
public static IEnumerable<XElement> ConnectChirpStream(string username, string password)
{
const string StreamApiURL = "http://chirpstream.twitter.com/2b/user.json";
var wc = new WebClient() { Credentials = new NetworkCredential(username, password) };
using (var stream = wc.OpenRead(StreamApiURL))
using (var reader = new StreamReader(stream))
{
var query = reader.EnumerateLines() // 1行に1JSONなのです
.Where(s => !string.IsNullOrEmpty(s)) // 空文字が来るので除去
.Select(s => // 文字列JSONからXElementへ変換
{
using (var jsonReader = JsonReaderWriterFactory.CreateJsonReader(Encoding.Default.GetBytes(s), XmlDictionaryReaderQuotas.Max))
return XElement.Load(jsonReader);
});
foreach (var item in query) yield return item; // 無限列挙
}
}
// StreamReaderの補助用拡張メソッド(あると大変便利)
public static IEnumerable<string> EnumerateLines(this StreamReader streamReader)
{
while (!streamReader.EndOfStream)
{
yield return streamReader.ReadLine();
}
}
中々シンプルに書けます。C#もLLと比べても全然引けを取らないでしょう(誰に言ってる)。ChirpUserStreamsはJSONでしか取れないのですが、StreamAPIではXmlよりもJSONのほうが使い易いので、JSONだけでも全然問題ありません。とはいえ、C#でJSONはちょっと扱いにくいんだよねー?と思いきや、意外に普通に標準ライブラリだけで何とかなりました。
参照設定にSystem.Runtime.Serializationを加えます(注:VS2008ではSystem.ServiceModel.Webを参照設定に加えてください)。この参照で通常使うのはDataContractJsonSerializerだと思いますが、もう一つ、JsonReaderWriterFactoryというクラスが用意されていて、このReaderはJSONをXmlReaderとして扱うことが出来ます。この図式は以前のLinq to HtmlのためのSGMLReader利用法と同じです。そのままXElementに流しこめば、JSONをXmlとして扱って、Linq to Jsonが成り立ちます。
さて、StreamAPIなのでEndOfStreamは来ない。繋ぎっぱなし、つまりはConnectChirpStreamメソッドは無限リストになります。この中には色々な情報が混ぜこぜになって来ます。投稿した、という他にも、誰かをフォローした、何かをふぁぼった、何かをリツイートした、などなどなどなど。クライアントソフト作るなら、当然どの情報も漏れ無く扱いたいわけですが、どうしましょう?foreachでグルッと回して、ifで分ける、しか、ない、かもですね? しかしそれは敗北です。退化です。foreachを使ったら負けだと思っている。
ところで突然に、今のところ思うReactive Extensions for .NET (Rx)を使うメリットは3つ。「複雑になりがちな複数イベントの合成」「同じく複雑になりがちな非同期処理のLinq化」そして、「列挙の分配」。従来型のLinqでは、一回の列挙には一個の処理しか挟めませんでした。例えば、MaxとCountを同時に取得する方法はなかった。MaxとCountを別々に二度列挙するか、または旧態依然なやり方、つまりforeachでグルグルと回してMaxとCountを手動で計算するかしかなかった。それはIEnumerableがPullモデルなためで、PushモデルのIObservableならば、出来ないこともない。
では、Rxでこのストリームを分配してみましょう。
static void Main(string[] args)
{
// IEnumerableをIObservableに変換し、Publish(Connectするまで列挙されない(ので分配が可能になる))
var connecter = ConnectChirpStream("username", "password")
.ToObservable()
.Publish();
// 1件目は必ず自分のフレンドのIDリストが来るらしいっぽいのでまるっと保存
HashSet<int> friendList;
connecter.Take(1).Subscribe(x => friendList = new HashSet<int>(
x.Element("friends").Elements().Select(id => (int)id)));
// どんなのが来るのかよく分からないのでモニタ用にテキストにまるっと保存
var sw = new StreamWriter("streamLog.txt") { AutoFlush = true };
connecter.Subscribe(x => sw.WriteLine(x));
// userがあるなら普通の投稿(ってことにしておく)
connecter.Where(x => x.Element("user") != null)
.Select(x => new
{
Text = x.Element("text").Value,
Name = x.Element("user").Element("screen_name").Value
})
.Subscribe(a => Console.WriteLine(a.Name + ":" + a.Text));
// favoriteとかretweetは "event":"favorite" というJSONが来る
var events = connecter.Where(x => x.Element("event") != null);
// favoriteの場合の処理
events.Where(x => x.Element("event").Value == "favorite")
.Subscribe(x => Console.WriteLine(x)); // favorite用の何か処理
// retweetの場合の処理
events.Where(x => x.Element("event").Value == "retweet")
.Subscribe(x => Console.WriteLine(x)); // retweet用の何か処理
// 同期か非同期かは、ToObservableの引数で変わる。デフォルトは同期
// Scheduler.ThreadPoolを引数に入れるとThreadPoolで非同期になる
connecter.Connect(); // 列挙開始
}
ID一覧取得、テキスト保存、投稿時処理、Fav時処理、リツイート時処理の5つへの分配が非常にスマートに出来ました。ToObservable、Publish、Connect。たったこれだけで一つストリームを複数に分配することが出来ます。普通にそれぞれをWhereだのSelectだの、独立してLinqでコネコネ出来ました。で、何が嬉しいかっていうと、それぞれが完全に独立していて見やすいってのは勿論あります。あと、部品化されてるので外部に分割しやすくなるんですね、物凄く。組み合わせたりもしやすいし。
結論
Rxヤバい。というわけで、みんなRx触ろう! .NET Framework 4.0ではRxで使うIObservableとIObserverインターフェイスが搭載されています。インターフェイスだけでどうすんだよボケ、っていうと、実際のところどうにもなりませんね、たはー。それでもインターフェイスだけ先行搭載ということは、RxはDevLabs内だけで終わる実験的プロジェクトではなく、必ず標準搭載するから安心しろよ!というメッセージだと受け取ることにしました。きっと.NET Framework 4.0 SP1には標準搭載されます。される、と、いいなあ。ちなみにRxは初期の頃と結構変わってますし、まだ変わるかも。でも、だからこそ、それに付き合うのも楽しいってものですよ?
ああ、あと、ChirpUserStreamsもヤバいですね。リアルタイムでゴリゴリ迫ってくる感覚は素敵というか、なんか別次元のメディアになった感じでもあります。今、新規にTwitterクライアント作るならStreamAPI完全対応すれば差別化出来て良いですね!私は作りませんが。ただ、ストリームAPIとRxは相性良いと思うので、ストリームAPI時代の到来と同時にRx時代も到来!する、かなあ?
ToDo
linq.jsがようやく一段落したので、Rxの紹介もまたやっていきたいですねー(すみません、かなり長いこと放置していて)。ToObservableによる列挙の分配は中々に強烈なので、linq.jsとRxJSを橋渡しするようなコードというかJSというかも用意したいなあ(軽く作ってみたんですが、RxJSでもPublishで分配出来て中々に威力ありそうでした)。うーん、考えてみるとやることはいっぱいあるねえ。適当に待っていてください。
linq.js ver 2.0 / jquery.linq.js - Linq for jQuery
- 2010-04-23
無駄に1280x720なので、文字が小さくて見えない場合はフルスクリーンにするかYouTubeに飛んでそちらで大きめで見てください。というわけで、動画です。linq.js + Visual Studio 2010で補完でウハウハでjQueryプラグインで世界系です。ここ最近、RxJS、JSINQとJavaScript系の話が続く中で、ふと、乗るしかない このビックウェーブに、という妄念が勢いづいてlinq.jsをver.2.0に更新しました。
内部コードを全面的に変更し、丸っきり別物になりました。破壊的な変更も沢山あります。名前空間がE、もしくはLinq.EnumerableだったのがEnumerableになり、幾つかのメソッドを廃止、廃止した以上にメソッドを大量追加。そして、WindowsScriptHostに対応しました。その他色々細かい変更事項の詳細は下の方で。あ、そうそう、名前空間はEnumerableを占有するので、prototype.jsとは被るため一緒に使えません。
今回の最大のポイントは、jquery.linq.jsという、jQueryのプラグイン化したlinq.jsを追加です。基本機能は完全に同一ですが、jQueryプラグイン版のみの特徴として、jQueryとEnumerableとの相互変換用のメソッドが定義されています。呼び出しは$.Enumerableを使います(グローバル名前空間は一つも汚しません)。
Linqとは?
耳タコなぐらい繰り返していますが、C#知らない人やこのサイトを始めて訪れた人にも使って欲しいんです!ということで、Linqとは何かを紹介します。簡単に言うと、そのふざけたforをぶち殺す。ための代物。Linq導入以降、当社比100%でfor, foreachの出番はなくなりました。ifも半減。ネスト量激減。えー、forー?forなんて使うの小学生までだよねー。
Linq(to Objects)とは?便利コレクション処理ライブラリです。語弊は、大いにある。あるのだけど、言い切るぐらいでいいと思うことにしている近頃。具体的には、mapやfilterやreduceが使えます。非破壊的なsortができます。Shuffle(ランダムに並びかえ)やDistinct(重複除去)などがあります。流れるようにメソッドチェーンで記述出来ます。index付きのforeachが書けます。DOMに対しても同じようにforeachやmapを適用できます。遅延評価が基本になっているので、幾つmapやfilterを繋げても、ムダの無い列挙が可能になっています。また、無限リストが扱えます。JavaScriptでプログラミングするにあたって不足しまくるコレクション処理を大幅に下支えするのが、linq.jsです。
Linqの世界、jQueryの世界
100億の言葉より1の実例。
// こんな感じ(1から10個、偶数のみを二乗したのをアラートに出す)
$.Enumerable.Range(1, 10)
.Where("$%2==0") // 他言語でfilterとか言われているもの
.Select("$*$") // 他言語でmapとか言われているもの
.ForEach("alert($)");
// Linq側はTojQueryでjQueryオブジェクトに変換
$.Enumerable.Range(1, 10)
.Select(function (i) { return $("<option>").text(i) })
.TojQuery()
.appendTo("#select1");
// jQueryオブジェクト側はtoEnumerableでLinqに変換
var sum = $("#select1").children()
.toEnumerable()
.Select("parseInt($.text())")
.Sum(); // 55
シームレスに結合されているようであまり統合されてはいません。お互い、コレクション操作中心であったり、連鎖で操作するという形なので、融け合うことはできません。toEnumerableに関しても、jQuery世界とは切り離された、Linqの世界へと移行するだけ。とはいえ、toEnumerableとTojQueryにより、チェーンを切らさずに相互変換して、スムーズに世界を切り替えられるというのは、中々に楽しい。
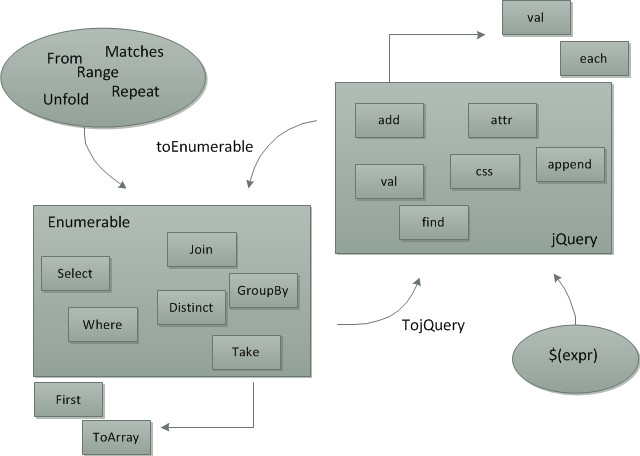
図にするとこんな感じ。jQueryの世界はメソッド名小文字、Linqの世界はメソッド名大文字、というので自分の今居る世界が分かります。Linqは世界系。世界に囚われると逃げ出すことは出来ないのです!いくらもがいても(Select)もがいても(Where)変わらない。鏡の中に逃げこむか(tojQuery)、鏡を割ってしまうか(ToArray)、どちらにせよ、代償を払うわけですね? 意味不明。そんな感じで非常に楽しいです。
IDE Lover
linq.jsの特徴として、入力補完サポートを徹底的に行っているという点があります。なぜなら、私自身がIDE大好きっ子、入力補完大好きっ子だから。テキストエディタで書いているとか言う人は、そのエディタは窓から投げ捨ててIDE使おうぜ! どんな感じで書けるかというと、動画を見てください、一番上の。今回は無料のVisual Web Developer 2010 Expressを使っています。インストールも拍子抜けするぐらい簡単ですよ!超お薦め。HTML/JSエディタとして使うポイントは、「Webサイトを作成」から「空のASP.NETウェブサイト」を選ぶことです。詳しくはまた後日にでも。
linq.js ver.2.0.0.0
では、本体の更新事項の方もご紹介。jquery.linq.jsも、この2.0から作られているので以下の事項は当てはまります。まず、名前空間を大々的に弄りました。Linq名前空間は全面的に廃止、Enumerableのみに。また、ショートカットとして用意していたEも廃止。それとLinq.ObjectとLinq.Enumerableは統合されて、Enumerableになりました。
次に廃止ですが、いっぱいあります。ToJSONの廃止、ちゃんと出力可能なのかを保証出来ないのでやめた。JSONは専用ライブラリ使ってください。ToTableの廃止、明らかに不要で邪魔臭かったから。なんでこんなもの搭載したのかすら謎。TraceFの廃止、というか、今までのTraceFをTraceとし、TraceFを消滅させました。TraceFはconsole.logに書き込んでいたのですが、IE8からはIEでも使えるようなので、F(Firebug)じゃなくていいかな、と。あと元のTraceはdocument.writeだったので、それは意味ねーだろ、ということで。あとは、RangeDownToの廃止。かわりにRangeToをマイナス方向への移動に対応させました。これは、ToなんだからUpとDownを区別するほうがオカシイってことにやっと気づいたからです、しょぼーん。
次に名前変更の類。ZipWithの名称をZipに変更(.NET 4.0と名前を合わせるため)。Sliceの名称をBufferWithCountに変更(Rxと名前を合わせるため)。Makeの名称をReturnに変更(Rxと名前を合わせるため)。Timesの名称をGenerateに変更(Rxと名前を合わせるため、RxのGenerateは基本Unfoldですが)。
新メソッドとしてMaxBy, MinBy, Alternate, TakeExceptLast, PartitionBy, Catch, Finallyを追加しました。MaxByとMinByはそのまんま。Alternateは一個毎に値を挟み込みます。TakeExceptLastは最後のn個(引数を省いた場合は1個)を除いて列挙します(Skipの逆バージョンみたいなもの)。PartitionByはGroupByの特殊系みたいな。CatchとFinallyはエラーハンドリング用。いつもなら、ここで例を出すところなのですが今回は省略、詳しくはリファレンスのほうで。
それと、OfTypeの追加。JavaScriptは型がゆるふわだからCastもOfTypeもイラナイし!と思ってたんですが、そしてCastは実際いらないのですが、OfTypeは翌々考えてみると型がゆるふわだからこそ、フィルタリングするために超絶必要じゃないか!ということに気づきました。ので追加。そして、これでCast以外は.NETのLinq演算子の全てを搭載ということになりました。
Windows Script Host
最後に、Enumerable.FromをJScriptのEnumeratorに対応させました(linq.jsのEnumeratorじゃなくて組み込みの方ね)。これにより、Windows Script Hostやエディタマクロでlinqが使えるようになりました。Linq for WSH!えー、WSH?WSHなんて使うの小学生までだよねー。今はPowerShellっすよ。と思うかもしれませんが違います。WSHならばJavaScriptで強烈に補完効かせながらガリガリ書けるのです。しかもLinqが使える。むしろPowerShellの時代は終わったね、WSH復権の時よ来たれ!だからそろそろアップデートかけて.NET Frameworkのライブラリが全面的に使えるようになって欲すぃ(今は、極一部のは使えないことはないのですが相当微妙)。では実例など少し。
// フォルダ下のフォルダ名とファイル名を取得する
var dir = WScript.CreateObject("Scripting.FileSystemObject").GetFolder("C:\\");
// 通常の場合
var itemNames = [];
for (var e = new Enumerator(dir.SubFolders); !e.atEnd(); e.moveNext())
{
itemNames.push(e.item().Name);
}
for (var e = new Enumerator(dir.Files); !e.atEnd(); e.moveNext())
{
itemNames.push(e.item().Name);
}
// linq.js
var itemNames2 = Enumerable.From(dir.SubFolders)
.Concat(dir.Files)
.Select("$.Name")
.ToArray();
WSHでJScriptを使う場合の最大の欠点は、foreachがないこと、でしょうか。生のEnumeratorを回すのは苦痛でしかない。しかし、linq.jsを用いればFrom.ForEachで簡単に列挙できます。それだけでなく、Linqの多様なメソッドを用いて自然なコレクション操作が可能です。上記例では、Concatでファイル一覧とサブフォルダ一覧を連結することで、名前の取り出しを共通化することができました。
WSHに関して詳しくはウェブで、じゃなくて後日、と言いたいのですが(既に記事がかなり長いので)、そんなこと言ってるといつまでたっても書かなさそうなので、簡単に説明を。WSH(WindowsScriptHost)とはWindows用のスクリプト環境で、自動化など、非常に強力で大抵のことが出来ます。で、標準ではVBScriptと、JScriptで書けます。つまりJavaScriptで書ける。つまりlinq.jsが読み込める。つまりLinqがWSHでも使える。WSHで扱うあらゆるコレクションに対して、Linqを適用させることが可能です。WSHだけでなく、Windows上でJScriptを用いるもの、例えばWindowsのデスクトップガジェットなどでも利用することが出来ます。
ライブラリを用いる場合は、wsfファイルで記述すると良いかもです。中身は簡単なXMLで、下のような感じに。
<job id="Main">
<script language="JScript" src="linq.js"></script>
<script language="JScript">
function EnumerateLines(filePath)
{
return Enumerable.RepeatWithFinalize(
function () { return WScript.CreateObject("Scripting.FileSystemObject").OpenTextFile(filePath) },
function (ts) { ts.Close() })
.TakeWhile(function (ts) { return !ts.AtEndOfStream })
.Select(function (ts) { return ts.ReadLine() });
}
EnumerateLines("C:\\test.txt").Take(10).ForEach(function (s)
{
WScript.Echo(s);
});
</script>
</job>
そうそう、自動Closeも含めたリソース管理も出来ます。ストリームなどにはRepeatWithFinalizeを使ってLinq化することで、Closeまで一本にまとめあげられます。といったような複雑なことが必要なくても、E.From(collection).ForEach()がふつーに便利です。というか、こんな単純なことすら素の状態じゃ出来ないJScriptに絶望した!でもそれがいい。JScript可愛いよJScript。
エディタマクロ
WSHによるJavaScript実行はEmEditorやサクラエディタ、Meryなど様々なテキストエディタで利用できます。せっかくなのでちょっと実用的なものを、と思って電卓を作ってみました。EmEditor用マクロです。選択範囲内の一行を計算し、その行の右側に出力します。ちゃちゃっと計算出来て便利。計算し直しを頻繁にする時は、新規ファイルを開いてまっさらなものに数式を書いて、Ctrl+A -> マクロ実行を繰り返すと良い感じ。
#include = "linq.js"
with (document.Selection)
{
Enumerable
.RangeTo(GetTopPointY(eePosLogical), GetBottomPointY(eePosLogical))
.Select(function($i)
{
var $line = document.GetLine($i);
try { eval($line) } catch ($e) { } // SetVariableToGlobal
var $expr = $line.split("=")[0].replace(/^ +| +$/g, "");
try { var $result = eval($expr) } catch ($e) { }
return { PointY: $i, Result: $result, Line: $expr }
})
.Where(function(a) { return a.Result !== undefined })
.ForEach(function(a)
{
SetActivePoint(eePosLogical, 1, a.PointY, false)
SelectLine(); Delete();
document.writeln(a.Line + " = " + a.Result);
SelectLine(); UnIndent(); StartOfLine();
});
}
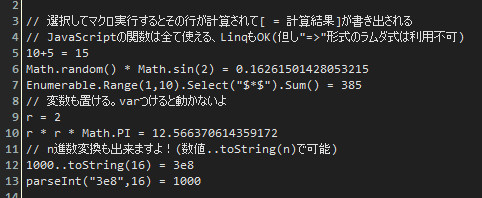
一行のうち=の左側をevalして、戻り値を返すものは出力、evalに失敗したものはスルー。ということなので、JavaScriptのMath関数は全部使えます。Select内の変数が$iとか、$始まりなのは変数定義による名前の衝突を避けるためです。慣れないマクロ書きなので色々酷い箇所も多いとは思いますが、なんとなく伝わるでしょうか? テキストエディタのマクロは、一行ずつの配列として、一行に対して操作をかけることが多いので、RangeToで範囲を作って、行ごとに適当に変形(Select)させて例外条件を省いて(Where)、処理(ForEach)。煩雑になりがちな行番号管理などを、流れるように簡単に記述出来ます。
なお、EmEditorは先頭に#includeを記述するだけでライブラリ読み込みが出来ますが、インクルード機能のないエディタでは以下のようなコードを先頭に置くことでライブラリが読み込めます。
eval(new ActiveXObject("Scripting.FileSystemObject").OpenTextFile("linq.js").ReadAll().replace(/^・ソ/,""));
ようするに、丸ごとテキストとして読み込んでevalです。/^・ソ/はUTF-8のBOM対策(適当すぎる)。一応、Meryでlinq.jsが動くのは確認しました。電卓マクロは動きません(eePosLogicalとかがEmEditorにしかないので、まあ、その辺は当然だししょうがないわなあ)
まとめ
今回のリニューアルは大変気合が入ってます。コード全部作り替えたぐらいには。最初はjQueryプラグインだけ足せばいいや、とか思ってたのですが、破壊的変更をかけるなら中途半端はいくない、と思い、やれるのは今だけということで徹底的に作り替えました。
ちなみに、ちっとも気にしてないパフォーマンスは悪化しました。ver.1.xがそれでもまだシンプルな構造だったのに比べ、今回は一回の呼び出し階層がかなり深くなった影響があります。列挙終了後にRepeatWithFinalizeとFinallyでしか使ってないDisposeのために階層駆け上がるし(これほんと入れようか悩んだんですけど、WSHだけでなく、将来的にはJavaScriptでもきっちりリソース管理でCloseって機会も増えそうなので入れました)。しかし遅いといっても、ベンチ取るとChromeなら爆速で誤差範囲に収まってしまうのですよ!Google Chrome、恐ろしい子。Firefoxだと?聞くな。いえいえ、JSINQよりは速かったですよ?←何だこの対抗心は
jQueryのおともに。WSHのおともに。エディタマクロのおともに。調度良い感じの隙間にピタリはまるようになっております。JavaScriptにおいてコレクションライブラリはニッチ需要だし、WSH用ライブラリなんて完全隙間産業なわけですが、むしろだからこそ、幾分か価値があるかな?合計83メソッドと、大充実なので、きっと要求に答えられると思います。
linq.jsをjQueryと一緒に使う
- 2010-04-15
linq.jsとjQueryを一緒に使うとするとどうなるのかな、という今まで微妙に避けてきた話。実用的なことを考えるなら避けて通れないのですが、実用的なことなんて考えたこともなかった!今まで!すみません。というわけで、少し考えてみます。あ、Linq to Xml(linq.xml.js)はボツの方向で行きます。RxJSを見習って、jQueryと仲良くやる方向で考えるつもりです。割とイイ線行ってたかなあ、とは思うんですが、クロスブラウザ対応の面倒くささが半端なくて実装しきる気力が持ちそうにないのと、やっぱセレクタ操作が冗長になりすぎてダメだったかなあ、なんて思ってます。
```javascript var p_arr = from p_ele in $("p") where "hoge" in p_ele.classes select p_elefor(var p in p_arr){ p.toggleClass("hilight"); }
こんな風なことができるのかと思ったがそんなわけはなく。<br /> <a href="http://d.hatena.ne.jp/beta_magnus/20100412/1271070326">Linq.js - 人生がベータ版</a> </blockquote> お試しありがとうございます。この例は、出来るといえば出来るし、出来ないといえば出来ないです。まず、クエリ構文では書けなくて、というのはともかくメソッド構文で実際にlinq.jsで組んでみるとこうなります。 ```javascript E.From($("p")) // 内包するDOM要素を列挙 .Select("jQuery($)") // 単一要素のjQueryオブジェクトにラップ .Where(function (q) { return q.attr("class") == "hoge" }) .ForEach(function (q) { q.toggleClass("hilight") }); // jQueryで同じような形にするならこうでしょうか $("p.hoge").each(function () { var q = $(this); q.toggleClass("hilight"); });FromでjQueryの選択された要素を列挙に変換します。jQueryの列挙はjQueryオブジェクトではなく、DOM要素をそのまま返すので(これは.eachで回した時も一緒ですね)、jQueryのメソッドを使いたい時は再度ラップしてあげます。ただまあ、単純なフィルタリングなら、jQueryのセレクタで書いたほうが当然すっきり仕上がりますね。更にまあ、そもそもeachする必要はなく、
// jQuery自体が集合を扱うので一行で書けるんですよね…… $("p.hoge").toggleClass("hilight");となってしまうわけで、DOMから選択してDOMに作用を加える、という一連のjQueryチェーンで綺麗に成り立っている場合に、linq.jsを挟む余地はありません。jQuery自体が集合を含有しているので、jQueryだけで綺麗に完結しちゃうんですね。そしてlinq.jsは、それ自体はクロスブラウザ対応だったりのDOM操作は一切持っていないので、その辺はjQueryにお任せします。そうなると、どうしても出番が限られてくるという。
じゃあ無価値なのかといえば勿論そんなことはなくて、DOMをDOMのまま扱って抽出して作用を加えるのではなく、そこからテキストだったり数値を抽出する、というシーンでは生き生きとします。DOMの選択、フィルタリングまではjQueryのセレクタで行ったらlinq.jsに渡す。数値だったら集計系のメソッドが使えるし、他にもテーブル内の文字をキーにして複数テーブルの結合(join)、なんかも簡単に出来ます。
ところで、 E.From($("selector")).Select("jQuery($)") というのは定型文になるので、jQuery自体に拡張してしまいます。こんなんでもプラグインって呼んでいいですか?(プラグインとしての部分は一行でも、繋がってる先はある意味ヘビー級なので)
// これでjQueryオブジェクトからtoEnumerable()を呼ぶとlinqが使える jQuery.fn.toEnumerable = function () { return E.From(this).Select("jQuery($)"); } // 例えば、input要素の数値を合計する、とか var sum = $("input").toEnumerable() .Select("parseInt($.val())") .Sum();割と便利。かな?具体例に乏しくて非常に説得力に欠ける感じですが、良ければ使ってやってください。
Linq to ObjectsをJavaScriptに実装する方法
- 2010-04-11
JavaScriptでLINQを使おう - 複雑な検索処理を簡潔に記述する「JSINQ」という記事が出ました。私はlinq.jsという、同種のJavaScriptへのLINQ移植ライブラリを作成している人間のため、JSINQの人気っぷりに思わず嫉妬してしまった(笑)のですが、そういう感情は抜いておいてこの紹介記事は、今ひとつよろしくない。
まず頂けないのが、列挙の方法。
// 生のenumeratorを取り出して列挙するですって!?
while (enumerator.moveNext()) {
var name = enumerator.current();
document.write(name + '<br>');
}
// eachが用意されているというのに!
result.each(function(name) { document.write(name + "<br />") });
C#でもJavaでも、きっと他の言語でも、反復子をwhileループで回すなんて原始的なことは普通やりませんよね? foreachに渡しますよね? そんなわけでJSINQにはeachメソッドが用意されているのですが紹介記事は普通にスルー。「enumeratorでの列挙とeachでの列挙二つ紹介する」「enumeratorのみ紹介する」「eachのみ紹介する」の三択で、スペースの都合上一つしか紹介出来ないなら、eachのほうを紹介すべきでしょう。いやまあ、例が一個だったらしょうがないなあ、どうせJSINQのチュートリアルの上のほうから抜き取っただけだろうしー、と思うのですが、三個もenumerator取り出しの例を出されるとさすがにオイオイオイオイ、と突っ込みたくなる。
もうひとつは、文字列によるクエリ構文を推しすぎ。JSINQの最大の特徴でもある部分なのでJSINQの紹介としては正しいのですが(JSINQのプロジェクトページでもそれをフィーチャーしてますしね)、LINQの紹介として見ると大変頂けない。.NETを知らない人(JavaScriptのライブラリなので、基本はJavaScriptの人が見るでしょう)がLinqを誤解してしまう要因になりうるので、こういった紹介は割とキツい。
LINQとはLanguage Integrated Query(統合言語クエリ)であり、言語に統合されていてこそLinqなのです。文字列で与えたらSQLと一緒。LinqはしばしばSQLっぽく記述するもの、と誤認されているようですが、違います。文字列で与えていたSQL(こんな風にね、と最近作ったDbExecutorというSQL実行簡易補助ライブラリをどさくさに紛れて紹介してみる)とは全く別物なのです。詳細は説明すると長くなるので省いちゃいます(え?)。理屈はともかく、言語に統合されていない状態でのSQLは書きやすいとはいえないわけですよ?
var elements = document.getElementsByTagName('a');
var enumerable = new jsinq.Enumerable(elements);
var query = new jsinq.Query(' \
from e in $0 \
where e.href.indexOf("google.co.jp") > -1 \
select e \
');
query.setValue(0, enumerable);
var result = query.execute();
var enumerator = result.getEnumerator();
while (enumerator.moveNext()) {
var e = enumerator.current();
document.write(e.text + ': ' + e.href + '<br>');
}
改行のために末尾に\を入れなければならない、不恰好なプレースホルダ、クエリコンパイルの必要性(executeメソッドの実行でメソッドチェーン形式に変換されます、面白いことにこの点まで.NET Frameworkの忠実な再現となっています(クエリ構文はメソッド構文の糖衣構文にすぎない))。というわけで、到底書きやすいとは言えません。この例を見て、長げーよ馬鹿、意味ねー、アホじゃねーの?普通にfor回した方が百億倍マシだろ、と思った人もいるでしょう。その通りです。素直に便利かも……とか思ったなら、物事はもう少し冷静に見るようにしてください。しかしメソッド構文(jQueryのようにメソッドチェーンで書く方法)ならこう書けます。
var elements = document.getElementsByTagName('a');
new jsinq.Enumerable(elements)
.where(function(e) { return e.href.indexOf("google.co.jp") > -1 })
.each(function(e) { document.write(e.text + ": " + e.href + "<br>") });
これなら納得で、割と使えるかもって感じではないでしょうか? JSINQにおける文字列によるクエリ構文は、人を釣るためのただの餌です。そんな餌で俺様が釣られクマー。jSINQをJavaScriptライブラリとして使うのならば、メソッド構文のほうをお薦めします。クエリ構文はネタ、もしくはただの技術誇示にすぎません。よくやるなー、って感じで素晴らしいとは思いますが、実用性は皆無です。JSINQ自体はLinqの移植として割と良く出来ているので(何だこの上から目線)、文字列クエリ構文で試してみて使えないなー、と思ってしまった、もしくは紹介を見て文字列クエリ構文とかこのライブラリダメだろ、と思った人は、その辺は誤解なくどうぞ。
linq.js
LinqのJavaScript実装は他にもあります。一つは、ええと、私の作成しているlinq.jsです。売り文句はJSINQと同じくSystem.Enumerableとの完全なるAPI互換。.NET4までの範囲を全てカバーしています。更にその上に、Achiral, Ruby, Haskellなどから参考にした大量のメソッドが追加されていることと、Visual Studioで使う場合にはIntelliSenseが動作するファイルがあること、などなど「実用的に使う」ことを強く意識して作っています。手前味噌なのでアレですが、他のどのライブラリよりも使える度は高いと思っています。
- linq.js - LINQ for JavaScript Library - プロジェクトページ
- 紹介と簡単なチュートリアル
- 入力補完に対応させたのでVSでの利用法紹介
- ブログ記事のlinq.jsカテゴリ(最後の更新が去年の9月、がーん)
更新が微妙に止まっているのですが、WindowsScriptHostで快適に使えるような追加ライブラリを作成中(と、9月に言ったっきり絶賛作業休止中、すみません、でもやる気はあるので遠くないうちに必ず出します)。あと、Reactive Extensions for JavaScriptという、これまた.NET発のJavaScript移植ライブラリが出ているので、それとの協調動作も考えています。
Linqを自分で実装する
では本題。実際にLinqをJavaScriptで実装してみましょう。C#でSelectを実装してみたことはありますか? 何のことはなく、たった1行で出来ちゃうんですよね。そんなわけで、実際のところ別に難しいことはありません。勿論、全てのAPIを網羅するのは面倒くさいですが、基本的な原理を掴んでおくとグッと利用法が広がるはずです。まずは、一番単純な、Array.prototypeに生やす方法を考えてみます。例としてmapとforEachを実装してみましょう。
Array.prototype.map = function(selector) {
var result = [];
for (var i = 0; i < this.length; i++)
result.push(selector(this[i]));
return result;
}
Array.prototype.forEach = function(action) {
for (var i = 0; i < this.length; i++)
action(this[i], i); // with index
}
var array = [1, 2, 3, 4, 5, 6, 7, 8, 9];
array.map(function(i) { return { Single: i, Double: i * 2} })
.forEach(function(a) { alert(a.Single + ":" + a.Double) });
配列を変形してforeach。非常に単純な代物ですが、単純が故にmapやfilterは便利ですよね、かなり多用します。C#における匿名型は、JavaScriptではそのままハッシュを返すことで実現されます。さて、このやり方には問題が二つあります。一つはビルトインオブジェクトのprototypeを拡張する、微妙なお行儀の悪さ。そこで、arrayを独自オブジェクトにくるんでやりましょう。
function Enumerable(array) {
this.source = array;
}
Enumerable.prototype.map = function(selector) {
var result = [];
for (var i = 0; i < this.source.length; i++)
result.push(selector(this.source[i]));
return new Enumerable(result);
}
Enumerable.prototype.filter = function(predicate) {
var result = [];
for (var i = 0; i < this.source.length; i++)
if (predicate(this.source[i])) result.push(this.source[i]);
return new Enumerable(result);
}
Enumerable.prototype.reduce = function(func) {
var result = this.source[0];
for (var i = 1; i < this.source.length; i++)
result = func(result, this.source[i]);
return result;
}
var array = [1, 2, 3, 4, 5, 6];
var sum = new Enumerable(array)
.filter(function(i) { return i % 2 == 0 })
.map(function(i) { return i * i })
.reduce(function(x, y) { return x + y });
alert(sum); // 56
配列を一旦包まなくてはならないのが煩わしいのですが、メソッドチェーンのコンボを決めて、気持ちよく列挙することが出来ます。この例ではFirefoxのfilter, map, reduceを再定義してみました(thisObjectの辺りはスルーしてますしreduceの引数なんかも違いますが)。1から6の配列のうち偶数のみを二乗して足し合わせる。答えは56。さて、しかしこの方式にも問題があります。Arrayのprototype拡張が抱えているもう一つの問題と同じですが、メソッドの一つ一つを通る度に無駄な中間配列を生成してしまっています。メソッドチェーンの形になっていると隠蔽されてしまうのですが、冷静に眺めてみればこういうことです。
var array = [1, 2, 3, 4, 5, 6];
var _array = [];
for (var i = 0; i < array.length; i++) {
if (array[i] % 2 == 0) _array.push(array[i]);
}
var __array = [];
for (var i = 0; i < _array.length; i++) {
__array.push(_array[i] * _array[i]);
}
var sum = __array[0];
for (var i = 1; i < __array.length; i++) {
sum += __array[i];
}
さすがに、これはあまりのアホさと無駄さに死ね!と言いたくなりませんか?まあ、この程度は大したコストではないのも確かですし、これこそが富豪的プログラミングだ!といえば、そうだし、その辺はそんなに否定しません。些細なパフォーマンスチューニングにはあまり興味ありません。が、しかし、根本的な問題として、これだと無限リストが扱えません。無限リストとは無限に続くもの、例えば [0,1,2,...,9999,10000,...] 。そんなの使わないって?いやいや、使いこなすと存外便利ですよ? そんなわけで、富豪とか云々を抜きにしても、ただのArrayラッパーは却下です。即時評価なfilterやmapなんて使いたくありません。.NET FrameworkのLinq to Objectsは遅延評価なので、無限リストも扱えますし中間配列といった無駄は出てきません。では遅延評価のリスト処理をどう実装しましょうか。無限リストを作る方法は色々あるでしょうが、ここはLinqの移植なのでC#でのやり方と同じくイテレータパターンを用います。
IEnumerable = function(moveNext) {
this.getEnumerator = function() {
return { current: null, moveNext: moveNext }
}
}
// Generator
Enumerable =
{
toInfinity: function(from) {
if (from === undefined) from = 0;
return new IEnumerable(function() {
this.current = from++;
return true;
});
}
}
// select as map
IEnumerable.prototype.select = function(selector) {
var source = this;
var enumerator = null;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
if (enumerator.moveNext()) {
this.current = selector(enumerator.current);
return true;
}
return false;
});
}
// 無限に2倍するリスト[0, 1, 4, 9, 16,...
Enumerable.toInfinity().select(function(i) { return i * 2 });
LinqはIEnumerableオブジェクトの連鎖で成り立っています。また、return thisでメソッドチェーンをするわけではありません。selectを見てください。メソッドが呼ばれた時点では何も実行せずに、クロージャにより環境を保持した新しいIEnumerableを生成し、それを返しています。ではいつ実行されるのかというと、getEnumerator()が呼ばれ、それで取得されたenumeratorオブジェクトのmoveNext()を呼んだ時です。
さて、しかしこのままではgetEnumeratr()で反復子を取得しての列挙しか出来なくて不便なので、forEachなどを定義してやる必要があります。また、無限リストが本当に無限のままでは困るので、停止させるものが必要です。というわけで、代表的なものを幾つか紹介します。
IEnumerable = function(moveNext) {
this.getEnumerator = function() {
return { current: null, moveNext: moveNext }
}
}
// Generator
Enumerable =
{
from: function(array) {
return Enumerable.repeat(array)
.take(array.length)
.select(function(ar, i) { return ar[i] });
},
toInfinity: function(from) {
if (from === undefined) from = 0;
return new IEnumerable(function() {
this.current = from++;
return true;
});
},
repeat: function(element) {
return new IEnumerable(function() {
this.current = element;
return true;
});
}
}
// select as map
IEnumerable.prototype.select = function(selector) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
if (enumerator.moveNext()) {
this.current = selector(enumerator.current, ++index);
return true;
}
return false;
});
}
// where as filter
IEnumerable.prototype.where = function(predicate) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
while (enumerator.moveNext()) {
if (predicate(enumerator.current, ++index)) {
this.current = enumerator.current;
return true;
}
}
return false;
});
}
IEnumerable.prototype.take = function(count) {
var source = this;
var enumerator = null;
var index = -1;
return new IEnumerable(function() {
if (enumerator == null) enumerator = source.getEnumerator();
while (++index < count && enumerator.moveNext()) {
this.current = enumerator.current;
return true;
}
return false;
});
}
IEnumerable.prototype.toArray = function() {
var result = [];
var enumerator = this.getEnumerator();
while (enumerator.moveNext()) {
result.push(enumerator.current);
}
return result;
}
// 利用例
// こんな配列があったとして
var array = [1232, 421, 1, 2, 3412, 42, 4, 2, 45];
// 偶数のもののみ二倍した新しい配列を生成
var array2 = Enumerable.from(array)
.where(function(i) { return i % 2 == 0 })
.select(function(i) { return i * 2 })
.toArray();
// 1-100の配列を作成
var array3 = Enumerable.toInfinity(1).take(100).toArray();
// ""のみの長さ100の配列を作成
var array4 = Enumerable.repeat("").take(100).toArray();
生成用メソッドとして、配列を反復子に変換するfrom, 無限にインクリメントした整数を返すtoInfinity, 無限に同一要素を繰り返すrepeatを定義しました。メソッドチェーン用として関数を要素に適用させるselect, 関数でフィルタリングするwhere, 指定個数取得するtake。そしてメソッドチェーンを打ちきって通常使えるオブジェクトに変換するものとして、配列に変換するtoArrayを定義。
fromがrepeatとtakeとselectの組み合わせで出来ているというのが、面白いところです。所謂Fill(配列の初期化)も、repeat->take->toArrayで出来てしまいます。小さなパーツを組み合わせてあらゆることを出来るようにするのがLinqの魅力です。
速度?これが速いと思いますか?そうですねえ、見るからに、xxxですね。しかし、私はミリセカンド単位でのパフォーマンスチューニングにはあまり興味がありません。はいはい、富豪的富豪的。実際のとこGoogle Chrome使えばIE6の1000倍速くなるんだぜ!(数値は適当)。って感じなので、JavaScript側での最適化は、あまり……。とくにLinqではDOM操作とか重たいことをやるんではなくて、純粋に、連鎖の分だけ関数呼び出しが増えるって程度でしかないので、この程度のことでムダムダムダムダー、と言ってもしょうがない気がします。なので、そんなことは気にしないことにします。
ラムダ式もどき
function(x,y,...){return ...}は、長い。Firefoxならfunction() ... で書けるけれど、それでも長い。というわけで、linq.jsでは文字列でラムダ式風に記述出来るようにしています。
var CreateLambda = function(expression) {
if (expression.indexOf("=>") == -1) {
return new Function("$", "return " + expression);
}
else {
var expr = expression.match(/^[(\s]*([^()]*?)[)\s]*=>(.*)/);
return new Function(expr[1], "return " + expr[2]);
}
}
var lambda = CreateLambda("i=>i*i");
var r = lambda(3); // 9
E.Range(1,10).Where("$%2==0").Select("$*$") // linq.jsではこんな感じで書ける
「引数=>式」で文字列を与えます。引数が一つ以下の場合は=>を省略出来ると同時に、$が引数の値として使えるようになっています(Scalaの_とかこんな感じ、なはず)。実装は見た通り非常に単純で文字列分解してnew Functionに渡して関数作ってるだけ。これの難点は、クロージャにならないので、変数のキャプチャが出来ないことです。まあ、そういう時は諦めて無名関数作ってください。
まとめ
filterやmapやreduceが使えて、distinct(重複除去、いわゆるuniq)が使えて、遅延評価だったり、selectやwhereを何段もポコポコと追加出来るわけです。linq.jsはシンプルなライブラリです。派手な機能は一切ありません。ただ列挙して処理するメソッドしかありません。DOMなど一切触りません(DOMの列挙自体は可能なので、DOMノードを流してフィルタリングしたり加工したり、というのは有益でしょう)。ただ、それ故に、使い道は無限大です。
微妙に更新止まってます、が、やる気はあります!まずはWSH対応から!と言いたいのですが、現在は何故かJava移植の制作を進めています。Javaにも素晴らしいLinq to Objectsの世界を、忠実移植で。というわけなのですが、これも先月ぐらいからやるやる詐欺中。中身は完全に出来上がっていて現在テストとJavaDoc書き中。今月中にはリリースしたい、ですね。先月も同じこと言ってましたが、まあ、着々と鈍足ながらも進んでいるので、近いうちにはお見せできるはずです。
ともあれ、Linq to Objectsは大変素晴らしいので、C#な人はガンガン使って欲しいし、JavaScriptの人はlinq.jsを試して欲しいし、Javaな人はもう少し待ってください。私は、ええと、このサイトのC#カテゴリのほとんどがLinq絡みです、ひたすらに使い倒して、有用な使い方を紹介していけたらと思っています。
ParseOrDefault
- 2010-04-09
match があれば TryParse いらないんじゃないか - 予定は未定Blog版という記事を見て、outとかrefは確かにしょっぱい。そういえばF#はTryParseはTuple返しで、おまけに let success, value = int.TryParse "123" という自然な多値返しが出来てCOOLなんだよねー。などと思ってC#でTuple返しにしたものを書いたりしたのですが、どうもしっくりこなくて延々と弄っているうちに明後日の方向へ。
さて、で、「数値に変換できるなら変換して返し、できないなら -1 を返す」というシチュエーションは大変多くて、それにoutを使って組み上げるのは、とてもかったるい、大変避けたい。かといってStringへの拡張メソッドを大量に生やすのも、IntelliSense的な観点からして抑えたい(それにしてもT4 Template使って生成ってのは面白いですね)。なので、汎用的に使えることは捨てて、上述のシチュエーション、変換出来るなら変換して、出来ないなら指定したデフォルト値を返すことにのみ絞って、拡張メソッドにしました。Stringに生やすのは抵抗感があるって場合はUtil.ParseOrDefaultとかにしてもいいと思います。
using System;
static class Program
{
static void Main(string[] args)
{
// 例えばURLのクエリストリングのパースをしたい時とかありますよね!
// num=100にint.Parse(num)はnum=hugaが来たら死ぬのでデフォでは0にしたいとか
var r1 = "100".ParseOrDefault(int.TryParse, -1); // 100
var r2 = "huga".ParseOrDefault(int.TryParse, -1); // -1
// 勿論、int.Parse以外でも何でもいけます
var r3 = "2000/12/12".ParseOrDefault(DateTime.TryParse, DateTime.Now);
// デフォルト値を省く時は型の明記が必要
var r4 = "2000/12/12".ParseOrDefault<DateTime>(DateTime.TryParse);
}
}
public static class StringExtensions
{
public delegate bool TryParse<T>(string input, out T value);
public static T ParseOrDefault<T>(this string input, TryParse<T> tryParse)
{
return input.ParseOrDefault(tryParse, default(T));
}
public static T ParseOrDefault<T>(this string input, TryParse<T> tryParse, T defaultValue)
{
T value;
return tryParse(input, out value) ? value : defaultValue;
}
}
out付きの汎用Funcはデフォルトでは定義されていません。なので、自前で定義する必要があります。この辺の話は@takeshikさんのスライドわんくま東京#38 LT 「Func<> と ref / out 小咄」が詳しいのでどうぞ。こんなデリゲートは単体では使うことは滅多にないでしょうから、static classの中に閉じ込めておくことで名前空間を汚しません(笑)
引数にT defaultValueを要求することで、型推論が働いてTryParseを渡す際に明示的な型付けが不要になります。C#の型推論(と言っていいのかな?)がScalaやF#に比べて弱いのは事実なので、ここは、C#でも自然な形で扱えるような誘導、設計が大事です。型を書いたら負けだと思っている、みたいな。まあ、どんなに頑張っても負けるときは負けるので、その時は潔く書くことにします。
ちなみに、ParseOrDefaultは最初はこんな形でした。酷過ぎる。私は骨の髄まで関数型言語脳ならぬLinq脳なので、とにかくまず無理矢理にでもLinqで処理する方法を考えて、出来上がってふと冷静に眺めると、普通に書けよ馬鹿、ということに気付いて普通に書き直すというサイクルを取ってます。馬鹿すぎる。DbExecutorで紹介したyield returnで一個のみの列挙を返すというのを、やたら使って見ちゃったりするところが麻疹。Repeat(value,1) と Repeat(value,int.MaxValue)があればLinqは何でも記述出来るんです病。
DbExecutor - Linqで操作しやすいSQL実行ライブラリ
- 2010-04-07
前回の記事を書いたところ、ついったで素敵な突っ込みを頂けたので、それを元にもう少し練り直してライブラリ化し、CodePlexに公開しました。ライブラリといってもAnonymousComparerと同じく単純なものですので、ソースコード一本のみ。ご自由にお使いください。例によってCodePlexでの英語がヤバい(小学生レベル、とりあえず何でもforつけておけばいいだろ、的な)ですね、世の中厳しい。
Linq to Sqlと名乗りたいところなのですが、本物がありますから名乗れないー。以前はIQueryableじゃないものをLinq to Hogeって言うのはどうよ、なんて思っていたのですが、考えてみるとLinq to XmlもXMLをIEnumerableベースに処理しやすいような構造を持たせたクラス群にすぎず、別にIQueryableは関係ない。Rxもそうで、あれはIEnumerableでもIQueryableでもなく完全に独立している、けれど、Linq to Events。ようするにLinq的な操作が出来ればLinqなわけです。というわけで、これはSqlをIEnumerableベースで処理出来るようにしたLinq to DB。でも本当に超絶薄いラッパーにすぎないのであんまカッコつけた名前付けるのも恥ずかしくDbExecutorという極々普通の名前に落ち着きました。「Linqで操作しやすい」とかいう釣りタイトルをつけてますが、ただたんにIEnumerable返すというだけです。SQL周りは真剣に追いかけると無限泥沼になる気がする(Entity Framework、そして更にその次へと……?)。追いかけてみたいですが、まあ、まずは、一歩目から。
何で作ったかと言うと、SQLを扱っていて嫌なusing地獄を殺したかったから。
using (var conn = new SqlConnection("connectionString"))
using (var cmd = conn.CreateCommand())
{
conn.Open();
cmd.CommandText = "select ....";
using (var reader = cmd.ExecuteReader())
{
foreach (IDataRecord item in reader)
{
ちょっとクエリ呼びたいだけなのに、普通にこの量、このネスト。こんなんだからLLの人に馬鹿にされてしまうんだよ。で、ふと思ったのは、この図式ってもしかしてWebRequestと同じですか?
string html;
var req = (HttpWebRequest)WebRequest.Create("http://google.co.jp");
using (var res = req.GetResponse())
using (var stream = res.GetResponseStream())
using (var sr = new StreamReader(stream))
{
html = sr.ReadToEnd();
}
ちょっとWebからデータを取得したいだけなのに狂ったようにusingを重ねなければならない!そしてもう一つ嫌なのが、変数に渡す際に、usingのスコープが絡むので場合によっては外で定義しなければならないこと。string html;だってさ。嫌だ嫌だ。別にvarが使えないから嫌だと言っているわけじゃなくて(半分はそうなのですが)、代入位置と宣言が離れるのは可読性が落ちます。あとは、単純に不恰好ですしね。そんなWebRequestですが、WebClientという簡単に使えるものが用意されているので、普段はこっちを使うわけです。
var html = new WebClient().DownloadString("http://google.co.jp");
素晴らしい! 私はWebClientが好きです。簡単なのは良いこと、を体現していますから。ネット上のサンプルがやたらとWebRequestを使うものばかりなことを嘆きます。WebRequestとWebClientでCookie認証をする方法とかいう記事を書いたりと、必死に普及に励んだりしていますが中々どうして焼け石に水、ていうか確かに少し凝ったことをやろうとすると面倒くさいのは否めませんね……。
というわけかで、偉大なるWebClientを見習って、SqlConnectionの一連の流れを抹殺するラッパーを作ってみました。プリミティブなAPIなんて触りたくないっす。プリミティブなものは魅力どころか穢れたものに見えてしまうので、可能な限り隠蔽してやりたいのです。本当は生のSQLだって触りたくないんですけどね……。さて、目標は、簡単に使えることと、usingが極力表に出ないようにすること。とりあえず利用例から。PersonTableというAgeとFirstNameとLastNameが格納されてるテーブルからデータを引っ張ってきます。
// ただの入れ物
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
static class Program
{
static void Main(string[] args)
{
// 実行→即Closeの場合静的メソッドを用いる(Regexと同じ感覚で)
var maxAge = DbExecutor.ExecuteScalar<int>(new SqlConnection("ConnectionString"),
@"select max(Age) from PersonTable");
// 接続を維持して複数回実行する場合はインスタンス生成で
using (var executor = new DbExecutor(new SqlConnection("ConnectionString")))
{
// 列名とプロパティ名を対比させてマッピング
// パラメータはstring.Format的に@p0, @p1などに対して適用される
var persons = executor.ExecuteQuery<Person>(@"
select
FirstName + ' ' + LastName as Name,
Age
from PersonTable
where Age < @p0 and FirstName = @p1"
, 20, "Osakana").ToList(); // 遅延評価なのでusingを抜ける前にリスト化などどうぞ
// ExecuteReadはIEnumerable<IDataRecord>で一行ずつ取得できる
var persons2 = executor.ExecuteRead(@"select * from PersonTable")
.Select(dr => new
{
Age = dr.GetInt32(0),
FirstName = dr.GetString(1),
LastName = dr.GetString(2)
});
}
}
}
といった感じに、処理用のラッパーにDB接続を渡して実行します。メソッドはExecuteScalar, ExecuteNonQuery, ExecuteRead, ExecuteQueryの4つ。ScalarとNonQueryは普通のと同じ、Readは一行毎に列挙、Queryはオブジェクトへのマッピングが出来ます。4つのメソッドの引数は全て同じで、string query, params object[] parametersになります。パラメータは@p0, @p1, といったように「@p順番」に対して適用されます。
実行して即座にコネクションを閉じたい場合は静的メソッドを、接続を維持したまま複数実行した場合はインスタンスを生成してください。DbExecutor自体がIDisposableで、Dispose時に中のコネクションに対しDisposeを呼びます。なお、トランザクション関連のメソッドはありませんが、それはTransactionScopeを使ってくださいな。
スコープと遅延評価
同じ処理はメソッドに括り出す!Don't Repeat Yourself!コピペ禁止!ではあるものの、スコープが絡むと結構難しい。usingは難敵です。以下、実装の一部。
// 実装(一部抜粋)
public class DbExecutor : IDisposable
{
// usingを共通化させたいんだけど、普通に値返すとスコープ抜けちゃう
// →IEnumerableで包んでしまえばいいぢゃない!
private IEnumerable<DbCommand> UsingCommand(string query, object[] parameters)
{
using (var cmd = dbConnection.CreateCommand())
{
if (dbConnection.State != ConnectionState.Open) dbConnection.Open();
cmd.CommandText = query;
foreach (var p in parameters.Select((v, i) => CreateParameter(cmd, "@p" + i, v)))
{
cmd.Parameters.Add(p);
}
yield return cmd;
}
}
// UsingCommand().First().ExecuteScalar()だとusingを抜けてから実行になるのでダメなのですよー
public T ExecuteScalar<T>(string query, params object[] parameters)
{
return UsingCommand(query, parameters).Select(c => (T)c.ExecuteScalar()).First();
}
public IEnumerable<IDataRecord> ExecuteRead(string query, params object[] parameters)
{
return UsingCommand(query, parameters).SelectMany(c => c.EnumerateAll());
}
}
public static class IDbCommandExtensions
{
public static IEnumerable<IDataRecord> EnumerateAll(this IDbCommand command)
{
using (var reader = command.ExecuteReader())
{
while (reader.Read()) yield return reader;
}
}
}
UsingCommandメソッドが苦心の跡です。ExecuteScalarとExecuteReadの処理(DbCommand取ってパラメータ足す)を共通化したかったのですが、usingが難敵で。ExecuteScalarはTを返すから即時実行、これをusingで一部括り出すのは簡単なのですが、問題はExecuteRead。IEnumerableを返すから遅延実行で、これに対してusing(cmd){return cmd}なんて関数を使ってしまうと、実行時に即座にusingのスコープを抜けてしまってusingが無効になってしまう(どころかDispose済みになってしまうので実効時エラー)。
じゃあどうすればいいか、というと、usingに括り出した部分も遅延評価してしまえばいい。そこで要素一つのみでyield returnする。そして、即時評価のものはSelect->First、遅延評価のものはSelectManyを使うことで、無事Usingを共通化出来ました。おお、Linqは何と素晴らしいのでしょうか!何かと言うと、つまりは、Linq to Objectsの用途はリスト処理だけじゃないんですね。IEnumerableはインフラ。そして、Reactive Extensionsに入っているEnumerableEx.Return(これはEnumerable.Repeat(elem,1)に等しい)の意味合いがジワジワくる。Returnは明らかにHaskell由来の命名で、モナドが(以下略、もしくはナンダッテー)
で、まあ、利用時は結局データベースとの接続やトランザクションとの兼ね合いもあるので、接続の状態自体は割と意識してないとダメですね。適当なところでToListとでもしておいてください。この辺も含有した上での解決策は課題ですね、今はうまいやり方が全然思いつかない。
SQLiteで使う
勿論、SqlServer以外でも使えます。System.Data.SQLiteで試しましたが、問題なく動きました。というわけで、Hello, SQLite。SQLiteをインストールしたら参照設定にSystem.Data.SQLiteを加えて
var builder = new SQLiteConnectionStringBuilder { DataSource = "test.db" };
using (var executor = new DbExecutor(new SQLiteConnection(builder.ConnectionString)))
{
var existsTable = executor.ExecuteRead(@"select * from sqlite_master where type='table' and name = @p0", "test")
.Any();
if (!existsTable)
{
executor.ExecuteNonQuery(@"create table test (Age, Name)");
executor.ExecuteNonQuery(@"insert into test values(10,'hoge')");
executor.ExecuteNonQuery(@"insert into test values(20,'tako')");
executor.ExecuteNonQuery(@"insert into test values(30,'ika')");
}
executor.ExecuteRead(@"select * from test where Age >= @p0", 20)
.Select(dr => new { Age = dr.GetInt32(0), Name = dr.GetString(1) })
.ToList()
.ForEach(a => Console.WriteLine(a.Name + ":" + a.Age));
}
existsTableのクエリはテーブルがあるかないかを調べるもので、一行帰ってくるならテーブルが存在する、何も帰ってこない時はテーブルが存在しない。というわけで、それAny()で、ですね。IEnumerableベースで扱えると、こういうことが非常に楽です。
それにしてもSystem.Data.SQLiteいいですね、初めて使ったんですが拍子抜けするぐらいに簡単に試せました。インストールしたら参照設定に加えるだけ、DataSourceに直にファイル名指定すれば、あれば読み込み、なければ生成してくれる。データベースは設定が面倒っちいですからねー、こう簡単に出来るのは嬉しいです。
おまけ
で、まあ、VS2008ならLinq to SQL/Entities使わないのー?って話であり、まあ、ねえ、確かに、ねえ。なので、ひっそりとVS2005バージョンも作ってみました(zipに同梱してあります)。内部的にも(当然)Linq未使用なので 、VS2008で対象フレームワークが.NET 2.0の場合でも、こちらなら使えます。内部でSelectとかSelectManyを再定義して、拡張メソッドの呼出じゃなくて普通の呼び出しに書き換えただけです。あまりの型推論の効かなさにイライラしました。もうC#2.0に戻るとか無理すぎるだろ常識的に考えて。
List<Person> persons = executor.ExecuteRead<Person>(@"select * from PersonTable", null,
delegate(IDataRecord dr)
{
Person p = new Person();
p.Age = dr.GetInt32(0);
p.Name = dr.GetString(1) + " " + dr.GetString(2);
return p;
});
ExecuteReadとExecuteQueryは、IEnumerableを返されても困ると思うので、Listを返すようにしています。ExecuteReadはSelectがないので、第三引数でConverterデリゲートを受けるようにして、Selectの代わりにしました。 使う分には、VS2008のものとさして変わらないと思います。
追記
初回リリース時の名前はDbExecuterだったんですが、DbExecutorに変更しました。stableとか言っておきながら4時間で撤回とか、殺されていいですね、ほんとすみませんすみません。あまりの恥ずかしさに穴掘って埋まりたいです……。まあ、executerでもよくね?と思わなくもなくもないのですが、実際問題ぐぐる先生の検索結果で大きな差があるので、むしろ変えるなら、たった4時間の今のうちしかない、と思ったので変更しちゃいました。しかし、ああ……。スペルは結構気をつけてるほうだと思ったんだけどなあー。
C#で原始的にSQLを扱うお話
- 2010-04-05
世の中はLinq to SQLだのLinq to Entitiesだのを羨ましいなあ、と指を加えて眺めている昨今ですがこんばんわ。Linq好きーな私ですがこのサイトではObjectsとXmlしか扱っていないのは、単純に私が触った事ないから、です。あうあう。そんな私ですが、SQLを(大変嫌々ながら)触らなければならなかったりする場合もないわけじゃないのですが、アレですね、思うのはパラメータ。あれにadd。add。するのが大変美しくない。もっと格好良く、一発で決めようぜ。と思って色々悩んだんですが、どうにも上手く行きそうにない。やけくそになってビルダー+コレクション初期化子を考えてみました。
var cmd = new SqlCommand();
cmd.CommandText = @"select * from Foo where Bar > @Hoge and Tako = @Ika";
cmd.Parameters.AddRange(new SqlParameterBuilder
{
{"@Hoge", "2"}
{"@Ika", "たこやき"}
}.ToArray());
分かりづらくなってるだけで、普通にadd, addでいいですね。ダメだこりゃ。ボツ。ちなみに実装は超単純。
public class SqlParameterBuilder : IEnumerable<SqlParameter>
{
List<SqlParameter> parameters = new List<SqlParameter>();
public SqlParameterBuilder Add(string parameterName, object value)
{
parameters.Add(new SqlParameter(parameterName, value));
return this;
}
public IEnumerator<SqlParameter> GetEnumerator()
{
return parameters.GetEnumerator();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
コレクション初期化子の復習をしますと、IEnumerableかつAddメソッドが実装されているクラスに対してコレクション初期化子が使えます。Addは名前で決め打ちされています。メソッド名はAddじゃなくてAppendがいいなー、とか思ってもダメです。コレクション初期化子を使いたい場合はAddです。何でこんなヘンテコなことになってるのか、の理由は2008-02-08 - 当面C#と.NETな記録の記事を参照に。Addが複数引数を取る場合は{{},{}}って書けますが、IntelliSenseの補助がないので割と不便だったりしますねえ。
関数渡し
whileでEndまで読んで、ってのは嫌いです。Stream系のは全部yield returnでライン毎に返す拡張メソッドを定義しますね、私は。というわけで、SQLのDataReaderもStreamと同じ図式なので、同じ感じにしましょー。
var command = new SqlCommand();
command.CommandText = @"select hogehogehoge";
var result = command.EnumerateAll(dr => new
{
AA = dr.GetString(0),
BB = dr.GetInt32(1)
});
いい感じに見えないでしょうかどうでしょうか?といっても、これは以前書いたものの使い回しだったりしますが、その以前書いたコードとやらは若干反省してます。以下、書き直したコード。
public static IEnumerable<T> EnumerateAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
yield return selector(reader);
}
}
}
public static T[] ReadAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
return command.EnumerateAll(selector).ToArray();
}
そう、以前は無理やりEnumerable.Repeatで無限リピートさせておりましたが、あのテクニックはyield returnが使えない(別関数に分けない場合)時のためのテクニックであって、yield returnが使えるなら素直にwhileループを回して書いた方がマシなのです。どうにも、まずLinqで書いたらどうなるのか、というのが頭に最初に浮かんでしまってフツーの書き方を忘れてしまいがちなのですが、大事なのはシンプルに表現すること、です。何故Linqを使うのか、そのほうがシンプルに書けるから。whileのほうがシンプルになるなら、そちらを選ぼう。弁解のために言っておくと、あれはreturn IEnumerableとyield returnの挙動の違いの例のために書いたわけですががが。あと、yieldが言語によってサポートされてるからってのもありますね。C#1.0のように自前でEnumerator用意して書かなきゃならないのならば、Linqで生成したほうが良いわけで。
マッピング
GetInt32(1)とか列を意識してオブジェクトに詰めるのがダルい。定形作業だし列がズれたら修正面倒だし殺したい。こんなの人間のやる作業じゃない。つーわけで、入れ物に詰めるのぐらいは自動化しよう。ああ、Linq to Sql使いたいなあ。
// このクラスにデータベースから値を入れるとして
class MyClass
{
public int IntProp { get; set; }
public string StrProp { get; set; }
}
static void Main(string[] args)
{
// プロパティ名と対比させて自動詰め込み
var command = new SqlCommand();
command.CommandText = @"
select
hoge as IntProp,
huga as StrProp
from NantokaTable";
var result = command.Map<MyClass>();
}
public static T[] Map<T>(this IDbCommand command) where T : new()
{
Dictionary<string, PropertyInfo> properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
列名とプロパティ名を摺り合わせているだけで、非常に単純なものです。気になるreaderのFieldCountとかGetNameの処理効率ですが、実行した時点で一行のキャッシュが生成されて、そこから取ってくる感じになるので重たくはないっぽいです。たぶん。ちゃんと追っかけたわけじゃないので全然断言は出来ませんが。あとは辞書生成のコストですかね。Type毎で固定なら毎回辞書作らなくてもキャッシュ出来るじゃん、という。静的コンストラクタを使えば、実現できます。
public static class Extensions
{
public static T[] Map<T>(this IDbCommand command) where T : new()
{
return SqlMapper<T>.Map(command);
}
private static class SqlMapper<T> where T : new()
{
static readonly Dictionary<string, PropertyInfo> properties;
static SqlMapper()
{
properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
}
public static T[] Map(IDbCommand command)
{
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
if (dr.IsDBNull(i)) continue;
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
}
}
割とスマート。ジェネリック静的クラスには直接拡張メソッドは定義出来ないので、入れ子のprivateな静的クラスを挟んでいます。 と、こんな感じにSQLを触っていると非常に原始人っぽい。先日のテンプレート置換と同じく、コピペに優しい小粒でピリッと役立ち、なメソッドの作成を志してる感じです。まあ実際は自分だけが使うUtilなんて許されるわけもなく普通に地味にドロドロと(ああ、胃が……)。
そういえばであまり関係ないのですが、SQL文ってどこに置くべきなんでしょうかね。外部ファイルにしておいて読み込み、などというのは個人的にはどうかなー、と思っていて。どうせ呼び出し部分と1:1になるなら、↑のようにハードコードでも別によくないかしらん、そのほうがソースコード上の距離が近いこともあって分かりやすくなる。とか、どうなんでしょうかねえ。再コンパイルが不要になるといって、どうせSQLに変更入ったらコードのほうも変更入れないとマズい可能性が高そう、とか。
追記
マッパーはSystem.Data.LinqにあるDataContext.ExecuteQuery(TResult) メソッド そのものですね、たはは、シラナカッタヨ。↑のほうが超単純実装+キャッシュなので速いとは思いますが、どうでもいい差ですな。全く同じものだと悔しいので、outer joinとかでNullが混じる場合もすんなり使えるように、IsDBNullを足してスキップするようにしました。まあSQLでcoalesceで明示的にやったほうが良いとは思いますが。EnumerateAllのほうは普通に使えると思うのでぜひぜひ。
RxJS用IntelliSense生成プログラム(と、VisualStudioのJavaScript用vsdocの書き方)
- 2010-03-26
先日、Reactive Extensions for JavaScript(RxJS)の記事を書いたわけですが、触っていて困るのは、どのメソッドが使えるの?ということ。リファレンスもない中で、C#版の記憶を頼りに手打ちでメソッド名を探るなんて、無理。ましてやそんな状況じゃあ人に薦められないよ!というわけで、必要なのはIntelliSense(入力補完)です。rx.jsはある。rx-vsdoc.jsはない。ないものは、作ればいいぢゃない。そこで諦めてメソッド全部暗記してやるぜ、とか思うのはどうかしてる。諦めたら試合終了ですよ。楽するために手間を掛けるのです<プログラマの三大美徳。というわけで、作りました。
- RxVSDocGenerator.zip (source and binary)
vsdocファイルをそのまま配布するのはライセンスの問題が出そうなので、生成プログラムを配布します。手作業じゃなく自動生成で作ったので(面倒くさくて手作業なんてやってられるか!)。Rxをインストールしたフォルダ(デフォルトだとProgramFiles\Microsoft Reactive Extensions)のScriptSharpフォルダの下のRxJS.dllとRxJS.xmlを、生成プログラムと同じ階層に置いて実行すると、rx-vsdoc.jsが生成されます。
利用するにはvsdoc対応パッチをあてたVisualStudio 2008 SP1(VS2010はパッチをあてなくても対応しています)を用意して、rx.jsと同じ階層に置くだけです。HTMLで使う場合はscript src="rx.js"で読み込むだけ、独立したjsファイルで補完を使う場合は、行頭に/// <reference path="rx.js" />と記述すれば補完が読み込まれます。この辺は、以前に最もタメになる「初心者用言語」はVisualStudio(言語?)という記事を書いたときに補完愛してる愛してる愛してると連呼しながら解説してました。jQueryのドットで補完効かせながらのメソッドチェーンは気持ちイイんだって!
折角作ったので海外の人にも利用してもらおうと、また、標準でvsdocも同梱して欲しいと訴えるためにもとRxの公式フォーラムでスレ立てたけど、奇怪英語(機械翻訳英語)が恥ずかしいです……。ニュアンスをミジンコほどにも伝えられた気がしません。英語読めない書けないプログラマなんて小学生までだよねー、とかいう自己啓発系ブログ記事は山のようにあるわけですが、ふん、どうせ英語読めませんよ書けませんよ、ぐぐる先生による機械翻訳さえ超進化してくれれば小学生でも生きていけるもん!(ちなみに私はヤフー翻訳派です)
MIX10の発表によるとMicrosoftはAjax関連はjQueryに一本化する、ということで、C#erもますますJavaScriptを書かなければならないシーンは増えていきそうなので、せっかくなのでJavaScript用のvsdocの書き方を解説します。ついでに、LinqまみれなRxVSDocGeneratorのコードの解説も若干します。Mono.Cecil.dll使ってたりするんですよー(モジュールの参照用にしか使っていないので些かオーバースペック)。
C#と比較するJavaScriptの構造
JavaScriptは割とヒネクレた書き方が幾らでも出来るわけですが、VisualStudioの入力補完は、素の状態だと素直に書かないとついてきてくれません。というわけで素直に書きましょう。素直に書けば素直なIntelliSenseが手に入ります。以下、10秒でわかるC#とJavaScriptとの構造比較。
// 名前空間、もしくは静的クラス
Rx = {}
Rx.Disposable = {}
// クラス(コンストラクタ)
Rx.Observable = function(){ }
// 継承
Rx.AsyncSubject.prototype = new Rx.Observable;
// 静的フィールド
Rx.Disposable.Empty = null;
// インスタンスフィールド
Rx.GroupedObservable.prototype.Key = null;
// 静的メソッド
Rx.Observable.Range = function(start, count, scheduler){ }
// インスタンスメソッド
Rx.Observable.prototype.Select = function(selector){ }
ヒネクレたことさえしなければ、JavaScriptはシンプルです。オブジェクトとファンクションしか存在しない。シンプルさ故の制限を回避するために、また、幾らでも回避可能なためバッドノウハウのようなヒネクレた手段が大量に溢れていて、シンプルさとは無縁の奇怪な代物と成り果てていますが(JSはシンプルだよ、初心者にお薦め!というそばからクロージャがどうのapplyがどうのと言うのはどうなのよ、勿論、その柔軟さもまたJSの魅力の一つだとは思いますが、それをシンプルとは言わない)、素直に見れば、シンプルです。
そしてまあ、C#と割と似てます。構文似てるし。単一継承だし。prototypeに後からメソッドを足せるのは拡張メソッドのよう。違いは、privateはないしプロパティはないしインターフェイスはないしオーバーロードもない(但し引数は省略可能)、いつでも簡単に全てが変更可能(不注意に扱えばすぐ構造をぶっ壊せる←だからライブラリの衝突の問題がある)。といった問題は、若干ヒネクレればある程度は回避可能です、privateとか。でも、素直に書いた方が良いと思います。JavaScriptにprivateはない。と、割り切ってしまうと非常に楽になれます。良いか悪いかはともかく。
ただ、素直に書こうと、素のJavaScriptでは、補完は簡単に限界がきます。例えば以下のコード。
var func = function(bool) {
return (bool) ? "string" : [4, 5, 2, 3, 1];
}
var b = Math.random() < 0.5; // true or false
func(b).toUpperCase();
func(b).sort(); // どちらかで必ずエラー
引数の型が自由なら、戻り値の型もまた自由。じゃあどうするの?というと、どうにもなりません。戻り値の型はなるべく統一しましょう、IntelliSenseに優しくするために。これもまた素直の一つでしょうか、さてはて。
vsdoc.js入門
素直に素直に、と言ったところで何処かで破綻する。だいたい、JavaScriptの言語としての柔軟さを生かさないでどうする!という話は尤もなこと。そこで、VisualStudioはJavaScriptの入力補完に気の利いた仕組みを用意しています。ファイル名-vsdoc.jsが同階層にある場合、vsdoc.jsの構造を利用して入力補完を行います。なので、オリジナルに手を加える事なく補完を利用することが出来ますし、また、オリジナルが補完生成し辛い構造をしていても問題はありません。最終的にユーザーが利用するPublicの構造というのは、上で書いた素直なJavaScriptで再現出来るわけなので、それで構築すればいいだけです。勿論、別箇に構造を作成するというのは手間が増えるので、可能な限りは素直な構造にしておいたほうが無難です。
「IntelliSenseに候補が出ないものは存在しないに等しい」。これは.NETのクラスライブラリ設計という本に書かれている言葉なのですが(神本なので未読の人は絶対購入しましょう)、候補を出しさえしなければ、利用者にとって存在しないようなものに見えます。実際はpublicであっても、補完候補から削ってしまえばprivateに見える。擬似的なprivateの表現としては、中々スマートではないですか?
そんなvsdocですが、ちゃんとしたドキュメントが今ひとつ見あたらないので、jQuery用のvsdocを参考にすると良いでしょう。色々な属性が用意されているようですが、実際の入力補完に利用されるものは少ししかありません。optional属性なんて、オーバーロード的なものの表現に使えるのでは?と期待をかけたのですがそんなことはなくて、IntelliSense用には動作しませんでした。よって、summary, param, returnsだけ抑えておけば良いです。
var sum = function(x, y) {
/// <summary>足し算</summary>
/// <param type='Number' name='x'>引数1</param>
/// <param type='Number' name='y'>引数2</param>
/// <returns type='Number'></returns>
}
Rx.Disposable.Empty = new IDisposable;
C#と違ってfunctionの「下」にドキュメントコメントを書きます。また、ドキュメントコメントを使う場合は、関数本体はあってもなくても無視されるので、不要です。なお、ドキュメントコメントは-vsdoc.jsだけで有効なわけではなく、普通のjsファイルでも有効です。summary, paramは面倒くさかったら書かなくてもそんなに害はなさそうですが(但し引数違いのオーバーロードがある場合はsummaryで伝えてあげると使う人に優しい)、returns typeだけは欠かさず書いておきたい。これを書いておくと戻り値の型がVisualStudioに認識されるので、IntelliSenseを途絶さず利用できます。
制限事項としては関数のみにドキュメントコメントを埋め込むことが出来ます。vsdocを作る際にフィールドの型も認識させたい場合は、ダミーの変数を与えてあげればOK。
ジェネレータの解説
と、いった基本を抑えておけば、どんなライブラリに対してもvsdocを作れるね!じゃあ、rx-vsdoc.jsも手作業で作ろうか。と、思った時もありました。構造自体はjs自体をダンプでなんとかなる(と、いいなあ)だろうし、summaryやparamは諦めるとしてreturns typeだけを手作業で書くなら、どうせほとんどRx.Observableなので手間もそんなでもない。けど、rx.jsは難読化されていて引数の名前がイミフ、例えばRx.Observable.Range(k0, l0, m0)というんじゃ苦しい……。やっぱsummaryもparamも必要。でもどうすれば……?
そこで、インストールディレクトリを見てみるとScriptSharpなんてフォルダがあるんですよ。そう、RxJSはScript#でC#コードから生成されたJavaScriptライブラリだったのだよ、ナンダッテー!そして、ScriptSharp用のRxJS.dllには当然、完全なクラス構造と、引数の名前と型が保存されているし、更にはsummary用のxmlも用意されていた。つまり、ここからrx-vsdoc.jsを生成すればいいわけです。
というわけでリフレクション。型情報を取るため、早速Assembly.LoadFrom("RxJS.dll").GetTypes()とすると、落ちる。はあ、ScriptSharpのdllに依存してるのでそっちもないとダメなのね。というわけでScriptSharpのdllを幾つか参照に加えると、なんかうまく動かせない。ScriptSharpのdllはmscorlibの代替となってる(JSに変換可能なもののみに制限を加えてる?)から、一緒には動かせないとかそんな感じなのかなー、よくわからないけどとにかく動かせない、諦める。南無。無念。
そもそもLoadするからダメなわけで、Loadしなくていいよ、型情報だけ取れればそれでいいんだって。でも標準ライブラリには、それを可能にするのはないっぽい。けど、Monoにはあった。Cecil - Mono。参照も書き換えも出来るようですが、今回は参照のみで。色々出来そうなので、いつかもう少し触ってみたいですね。私は今回はじめてMono.Cecil.dllを使ったのですが、リファレンスの類も見てない(あるのか知らない)し、チュートリアルの類も見てない(ていうか日本語の情報がない)。でも、IntelliSenseでドット打ってれば何とかなりました。しっかりした構造とちゃんとしたメソッド名とIntelliSenseがあれば、リファレンスがなくても問題なく使えるわけです。すばらしきこのせかい!
Mono.Cecil
型情報を取ってくるだけなら簡単で、というかSystem.Reflectionと大して変わりません。
var rxjsTypes = AssemblyFactory.GetAssembly("RxJS.dll")
.MainModule.Types.Cast<TypeDefinition>()
TypeDefinition, MethodDefinition, ParameterDefinitionといったのが個の要素。そして、対応するコレクションHogeCollectionが用意されています。HogeCollectionは残念ながらジェネリックではないため、Linqに流すためにはCastが必要になります。今回はParameterDefinitionCollectionのSelectを多用することが多かったので、Cast無しで使えるよう拡張メソッドを定義しちゃいました。
static IEnumerable<T> Select<T>(this ParameterDefinitionCollection source, Func<ParameterDefinition, T> selector)
{
return source.Cast<ParameterDefinition>().Select(selector);
}
この手のレガシーなコレクションに対するアドホックな対応は、例えば正規表現のMatchCollectionなんかにも使えそうです(と、いった発想の元ネタはAchiralから)
テンプレート置換
必要なJSの構造は上のほうで書いた通り決まったパターンがあるので、雛形を元に置換するのが楽。テンプレートエンジン、なんていう大仰なものは必要ないけれど、string.Formatでも{5}とか出てくると引数の管理が面倒だし、順番の変更にも弱い。なので簡易置換用の拡張メソッドを用意してみました。
static string TemplateReplace(this string template, object replacement)
{
var dict = replacement.GetType().GetProperties()
.ToDictionary(pi => pi.Name, pi => pi.GetValue(replacement, null).ToString());
return Regex.Replace(template,
"{(" + string.Join("|", dict.Select(kvp => Regex.Escape(kvp.Key)).ToArray()) + ")}",
m => dict[m.Groups[1].Value]);
}
オブジェクトを渡すと、{プロパティ名}の部分をプロパティの値に置換します。オブジェクトなのでクラスインスタンスでもいいのですが、匿名型も使えます。例えば
const string classTemplate = @"
{FullName} = function({Parameters})
{
/// <summary>{Summary}</summary>
{Param}
}";
var r = classTemplate.TemplateReplace(new
{
FullName = "Rx.Notification",
Parameters = "kind",
Summary = "Represents a notification to an observer.",
Param = " /// <param type='String' name='kind'></param>"
});
Console.WriteLine(r);
割と便利。たった9行なので、ちょっと気の利いた置換が欲しいなあ、って時にササッとコピペして取り出せるのが魅力です。最近、コピペに優しいプログラミングをよく考えてる。というのはともかくとして、実際どんな風に使っているかというと、
var classes = rxjsTypes
.Where(t => t.Constructors.Count > 0)
.Select(t => new
{
t.FullName,
Parameters = t.Constructors.Cast<MethodDefinition>()
.Select(m => m.Parameters)
.MaxBy(p => p.Count)
.Select(p => p.Name)
.ToJoinedString(", "),
Summary = summaries[t.FullName] + " " + t.Constructors.Cast<MethodDefinition>()
.OrderBy(m => m.Parameters.Count)
.Select(m => m.Parameters.Select(p => p.Name).ToJoinedString(", "))
.Select((s, i) => string.Format("{0}:({1})", i + 1, s))
.ToJoinedString(", "),
Param = t.Constructors.Cast<MethodDefinition>()
.MaxBy(m => m.Parameters.Count)
.Parameters
.Select(p => string.Format(Template.Param, p.ParameterType.ToJSName(), p.Name))
.ToJoinedString(Environment.NewLine),
})
.Select(a => Template.Class.TemplateReplace(a));
前段階で匿名型を生成して、最後のSelectで置換をかけてます。Select二段にしないでもいんじゃね?というとYESですが、このほうが見やすいと思うので。それにしてもリフレクションなわけで、Linqと非常に相性が良い。というか、Linqなしだと大量のforループとifで涙を流すことになりそう。なので、昔はリフレクションって結構敷居が高かったのですが、今はもうLinqでサクサクとWhereで切って捨ててSelectで繋げて繋げて、って出来るので書く分には楽チンです。これがLinq以前のC#2.0だったら、考えたくないなあ。
出力
クラス、継承、オブジェクト、メソッド、プロパティは全部バラバラに抽出しています。そして、全部IEnumerable<string>で止めています。最後にそれらをまとめて、テキストとして出力。
var vsdoc = Enumerable.Repeat(string.Format(Template.Object, RootNamespace), 1)
.Concat(classes)
.Concat(inheritance)
.Concat(objects)
.Concat(methods)
.Concat(properties)
.ToJoinedString(Environment.NewLine);
File.WriteAllText("rx-vsdoc.js", vsdoc, Encoding.UTF8);
せっかくクエリ遅延評価にさせているので、書き出しも一度stringに貯めないでストリームで書きだせば高効率ですねー。でも、一度文字列に出した方が書くの楽なので。せいぜい1000行程度なので、ケチッても意味ないですな。
全部rxjsTypesをルートにして生成しているので、クエリ構文を使って巨大な一塊にしてみたら面白かったかな、なんて思いますが若干悪趣味な気もするのでやめておきます。そもそも、このドットだらけ、Selectだらけの時点で若干どうよ、といった趣が漂っているのは間違いない。いやいや、ドット素敵です。Linq素敵なんだって、本当に。こういうの書いてるとC#2.0と3.0は別物だろ常識的に考えて、と思わなくもない。セミコロン率は物凄く低くなりましたね……。あと、LinqとSQLを関連付けるのはそろそろやめようぜー、的な思いがふと過ぎったり。Twitterのpublic検索でlinqをキーワードに毎日眺めてるんですが、今でも割とそういう印象持ってる人多いんだなー、と。だからどうしたとかどうなるってこともないですが。
まとめ
IntelliSenseでLinqはより楽しくなる。メソッドチェインはIntelliSenseでより楽しくなる。そして、VisualStudioはJavaScriptエディタとしても優秀なので皆VisualStudio使おう!インストールが面倒?Microsoft Visual Studio 2008 Express EditionからWeb インストールをクリックするだけでオールインワンでダウンロード含めて10分ぐらいで全部やってくれる。時間がかかるというのは正しいですが、意外と面倒くさくはないんです。それと、このExpress Editionは無料です。
入力補完だけじゃなく、コード整形やデバッガ(開発環境と完全統合されているためFirebugよりもずっと使いやすい)などもあるし、ある程度は裏でインタプリタをぶん回して変数名間違いなどのエラーを補足してくれるので、IDE無しでJavaScript書くなんて、そんな苦労、しなくてもいいんだよ……。
Reactive Extensions for JavaScript
- 2010-03-18
MIX10終了しましたねー。何はともかく皆してIE9の話題ばかりで、ああ、InternetExplorerは愛されてるなあ(色々な意味で)、などというのを横目に、私にとっての最大のニュースはReactive Extensions for JavaScript(RxJS)です。Reactive Extensions(Rx)はこのサイトでもカテゴリーを作ってメソッド探訪なんてやってるぐらいに注目していたわけで、当然MIX10でJavaScript版出すという話を聞いた時からwktkが止まらなかったわけですが、全く期待を裏切らなかった!というか、こいつはヤバいですよ?
Reactive Extensionsとは何ぞや、というと、LinqというC#の関数型言語みたいなリスト処理ライブラリ(語弊ありまくり)のイベントとか非同期版です。イベントや非同期処理にたいしてmapとかfilterとかfoldとか、お馴染みなリスト操作関数が使えちゃうという、その発想はなかったわ、なライブラリです。C#版は去年の夏ぐらいにプレビュー版が出て、いまも精力的に開発が続いているのですが、今回はJavaScript移植版が出た、という話です。イベント(onclick!onclick!)や非同期(XMLHttpRequest!)ってのは、勿論C#でも大事なのですが、JavaScriptなんてそれが主役というぐらいなわけなので、C#版よりもインパクトは大きいです。何よりも、C#は言語やライブラリが強力なので別にRx使わなくてもって感じなのですが、JavaScriptは違う。あまりにも貧弱。なので、優れたイベント/非同期処理ライブラリの重要度はC#の比ではなく高い。
RxJSの面白いところはjQueryに対抗するものではなく、むしろ協調動作するように作られていることです。DOM操作はjQuery、イベントや非同期処理はRxJS、二つの強力なライブラリを組み合わせることで、JavaScriptプログラミングは次のパラダイムへ向かおうとしています。御託は、もういいですね、とりあえずサンプルを。
マウスをクリックして四角形を掴んで、マウスを動かして、放すという、ごく普通のドラッグアンドドロップ。素の JavaScriptではどうやって実装しますか?グローバルに状態管理用のオブジェクトを置いて、オフセット用の変数置いて、マウスの状態を監視して、うーん、考えたくない。あまり綺麗に出来そうにない。それがRxJSを使ってみると――
var O = Rx.Observable; // using
$(function()
{
var doc = $(document);
var area = $("#dragArea");
O.FromJQueryEvent(area, "mousedown")
.Select(function(e)
{
var offset = $(e.target).offset();
return { X: e.pageX - offset.left, Y: e.pageY - offset.top }
})
.SelectMany(function(offset)
{
return O.FromJQueryEvent(doc, "mousemove")
.TakeUntil(O.FromJQueryEvent(doc, "mouseup"))
.Select(function(e) { return { X: e.pageX - offset.X, Y: e.pageY - offset.Y }; })
})
.Subscribe(function(a) { area.css({ left: a.X, top: a.Y }) });
});
状態管理変数は使いませんし、全て一連のメソッドチェーンだけで完結します。以下解説。
Rx.Observable.FromJQueryEventは、イベントをRxオブジェクトに変換します。これはjQueryの$などと同じものだと思ってください。FromJQueryEventと同様の動作をするものにFromHtmlEventというものがあります。ほとんど同様ですが、jQueryオブジェクトを使う場合はFromJQueryEvent、getElementByIdなどで得られたネイティブの要素を使う場合はFromHtmlEventを使いましょう。基本的には、クロスブラウザ回りの面倒事を任せられるjQueryとの併用がお薦めです。
Rxオブジェクトに変換後は、多数のメソッドをjQueryのようにチェーンさせて記述していきます。どれだけ多数かというと、ここに並べてみます。
Subscribe, Select, Let, MergeObservable, Concat, Merge, Catch, OnErrorResumeNext, Zip, CombineLatest, Switch, TakeUntil, SkipUntil, Scan1, Scan, Finally, Do, Where, Take, GroupBy, TakeWhile, SkipWhile, Skip, SelectMany, TimeInterval, RemoveInterval, Timestamp, RemoveTimestamp, Materialize, Dematerialize, AsObservable, Delay, Throttle, Timeout, Sample, Repeat, Retry, BufferWithTime, BufferWithCount, StartWith, DistinctUntilChanged, Publish, Prune, Replay
何も一気に全部を知る必要はないので、あまり圧倒されずに、少しずつ学んでいければいいかな? 私もちょいちょいとブログ記事で紹介していきたいと思っています(やるやる詐欺ばかりですが……)。そうそう、ソースコードが圧縮されていて実際の名称は不明なのでRxオブジェクトと呼んでますが、それであってるかは今のところ謎です。C#ではIObservableなので、IObservableでいいかな、という気はしますが。
イベント as リスト
もう少しFromJQueryEventの動きを考えますか。イベントが発生すると、後ろのメソッドにイベントオブジェクトが渡されます。再度クリックすると、またイベントが発生しイベントオブジェクトが渡されます。再度(以下略)。つまりは、[event, event, event...]。終りのない配列。無限リスト。まるでイテレータのような……。そう、ObserverパターンとIteratorパターンは同じなのだよ、ナンダッテー!よく分からない?確かに。こういう時は他の人の言葉を借りてしまおう。最近Scalaの入門記事が注目を集めました。「神は言われた。「リストあれ。」」。そうです、イベントもまた、Rxの手にかかればリストになってしまうのです。Rxは関数型言語のリスト操作のようにイベントを高階関数で処理できます。それがもたらす世界、想像するとワクワクしませんか?なお、JavaScriptで配列やDOMに対してリスト操作を行うライブラリとしてlinq.jsというがありますのでよろしくお願いします←宣伝(作ってるの私なので)。
ドラッグアンドドロップの構造
mousedownでイベントが発動しても、本当に必要なイベントはdownじゃなくてmove。なので、downはイベント発動とオフセット算出にだけ使って、実際に後ろに流す情報は別のところから得ます。そこで、mousedownとmousemoveを合流させなければなりません。シーケンス(Rxによりリストのような何かになっているので、Sequenceが言葉として適切な気がします)の結合はMergeやCombineLatest、Zipなど、用途に応じて色々あるのですが、ここは一(mousedown)から多(mousemove)の状態を作ることが可能なSelectManyを使用します。SelectManyに渡す高階関数の戻り値(Rxオブジェクト)が、更に平たくされて後ろのメソッドに渡されていくことになります。
TakeUntilは、「~まで取得する」。引数のイベントが発動されるまでシーケンスを流し、発動されたら一切流さなくなる。つまりFrom(mousemove).TakeUntil(mouseup)は、mouseupされるまでmousemoveイベントを発行するということ。驚くほど簡単にドラッグアンドドロップの構造が記述出来てしまいました。これはヤバい。Rxヤバい。簡潔すぎるだろ常識的に考えて。
Selectは多くの関数型言語やRubyなどで言うところのmapで、要素を変形して返すもの。ここではeventからclientX, clientYだけのオブジェクトを作っています。mapがあるということは、勿論filterもあります(メソッド名はWhere)。この辺はlinq.jsの解説がそのまんま適用出来ます。何故かというと、Observerパターン(RxJS)とIteratorパターン(linq.js)は(以下略)。
Subscribe
シーケンスを変形していったら、最後に登録してやる必要があります。それがSubscribe。Subscribeを呼んで、初めてイベント(mousedownなど)に関連付けられます(addEventListenerです、ようするに)。このSubscribeは感覚的にはforeachのようなもので、無名関数の第一引数に今までに変形させた変数が入っているので、それを取り出して何らかのアクションを取る。今回はstyleを弄って四角形の座標を変更してやりました。
addEventListenerということは、デタッチもあるの?というと、ありますあります。Subscribeの戻り値はvoidではなく、IDisposableオブジェクトというものになっています。この戻り値のIDisposableオブジェクトを取っておけば、デタッチさせたい時にDisposeメソッドを呼んでデタッチさせられます。
Rx.Observable
Rxオブジェクトのメソッド一覧は書きましたが、Rx.ObservableにはFromHogeHoge以外にも色々なメソッドがあるよ。イベントだけじゃなく、あらゆる方向からRxオブジェクトを作り出す驚異のメソッド群はこれだ!
Amb, Catch, Concat, Create, CreateWithDisposable, Defer, Empty, FromArray, FromDOMEvent, FromHtmlEvent, FromIEEvent, FromJQueryEvent, Generate, GenerateWithTime, Interval, Merge, Never, OnErrorResumeNext, Range, Repeat, Return, Start, Throw, Timer, ToAsync, Using, XmlHttpRequest
いっぱいありますねー。名前から想像つくものからつかないものまで。XmlHttpRequestとか興味をひくところです。そう、Rxはイベントだけではなく、非同期通信までリストに変換し統一的な操作を可能にしてしまうわけです。こっちも重要なので、後日サンプル書きます。
結論
jQueryあるからRxJSなんてイラね、というわけじゃあないんですよ!ふたり揃ってプリキュア。最初の方にも書きましたが、jQueryのDOM操作は素晴らしいのでおまかせでいいです。イベントや非同期処理はjQueryだけじゃ足りないところがあります。そこはRxJSで補います。ついでに通常のリスト操作(配列やDOM Elements)は全然足りてません。prototype.jsはあんなにイけてたのに、jQueryになってからリスト処理がシンドいですね。そこはlinq.jsです(宣伝しつこい)。これでもうJavaScriptに死角はなくなった……、勝った、HTML5時代バンザイ!(でも私はC# + Silverlight4に期待をかけるけどね)
参考リンク
Rxチームの一員であるJeffrey van Goghによる、Rxをインストールしたディレクトリに置いてある、TimeFilesサンプルの解説。forループがダサいのでlinq.jsを使って書き直してTwitterに流したんですが、そうしたらJeffrey van Goghに言及してもらった!。これは嬉しい。
{kind=link}
Matthew PodwysockiによるRxJSの解説シリーズ。From(mousemove).TakeUntil(mouseup)のネタ元はここだったりして。最高にクール!
はてなダイアリー to HTML
- 2010-03-09
はてなダイアリーの記事を根こそぎ取得してローカルHTMLに保存するアプリケーションです。過去ログを全部取得して昇順に並び替えます。カテゴリ指定も可。 本文抽出アルゴリズムだなんて高尚なことはせず、HTMLをそのまま切り出しているだけのはてなダイアリー完全特化なぶんだけ、デザインやsyntax-highlightなどもそのままで見ることができます。上の画像はNyaRuRuの日記(勝手に貼ってすみません)の.NETカテゴリーを抽出しているところ。私がC#やLinqを覚えられたのはNyaRuRuさんの日記のお陰といっても過言ではなく、しかも読み返す度に新しい発見があって本当に素晴らしい。ので、度々読み返しているのですが、はてな重い。重い。なら全部ぶっこぬけばいいぢゃない。というのが作った理由でして……。
あと、最近こそこそごそごそとC++も勉強中なので、 [C++] - Cry’s Diaryや [C++] - Faith and Brave - C++で遊ぼうを読むと、(大体は全く分からないのですが)勉強になります。なお、Permalinkは相対パスになってしまい使えないのですが、日付の部分は絶対パスなので、コメント見たくなったりPermalinkを取りたくなったら日付から辿れます。
こうしてHTMLを自炊(?)すると、電子ブックリーダー欲しくなりますね。それと、リーダーはやっぱブラウザが載ってないとダメよねー。PDF(と独自形式?)だけ見れても嬉しくぁない。そんなに本には興味ない。HTMLが見たいのです。Twitterのログが見たいのです。2chまとめサイトが見たいのです。海外の技術書は結構PDFで買える感じなのでそれはそれで気になるところですが――。
以下ソースコード。↑のzipにも同梱してありますが。コンパイルにはSGMLReaderが必要です。
static class Program
{
static IEnumerable<T> Unfold<T>(T seed, Func<T, T> func)
{
for (var value = seed; ; value = func(value))
{
yield return value;
}
}
const string HatenaUrl = "http://d.hatena.ne.jp";
static void Main()
{
Thread.GetDomain().UnhandledException += (sender, e) =>
{
Console.WriteLine(e.ExceptionObject);
Console.ReadLine();
};
Console.WriteLine("抽出対象のはてなIDを入力してください");
var id = Console.ReadLine();
Console.WriteLine("カテゴリを入力してください(全ての場合は空白)");
var word = Console.ReadLine();
Console.WriteLine("出力ファイル名を入力してください");
var fileName = Console.ReadLine();
// 抽出クエリ!
var root = XElement.Load(new SgmlReader { Href = HatenaUrl + "/" + id + ((word == "") ? "" : "/searchdiary?word=*[" + Uri.EscapeDataString(word) + "]") });
var contents = Unfold(root,
x =>
{
var prev = x.Element("head").Elements("link")
.FirstOrDefault(e => e.Attribute("rel") != null && e.Attribute("rel").Value == "prev");
if (prev == null) return null;
retry:
try
{
var url = HatenaUrl + prev.Attribute("href").Value;
Console.WriteLine(url); // こういうの挟むのビミョーではある
return XElement.Load(new SgmlReader { Href = url });
}
catch (WebException) // タイムアウトするので
{
Console.WriteLine("Timeout at " + DateTime.Now.ToString() + " wait 15 seconds...");
Thread.Sleep(TimeSpan.FromSeconds(15)); // とりあえず15秒待つ
goto retry; // 何となくGOTO使いたい人
}
})
.TakeWhile(x => x != null)
.SelectMany(x => x
.Descendants("div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "day"))
.TakeWhile(e => !Regex.IsMatch(e.Value, @"^「\*\[.+\]」に一致する記事はありませんでした。検索語を変えて再度検索してみてください。$")) // 間違ったカテゴリ入力した時対策
.Reverse(); // 古いのから順に見たいので
// style抽出
var styles = root.Element("head").Elements("link")
.Where(e => e.Attribute("rel").Value == "stylesheet")
.Select(e => { e.SetAttributeValue("href", HatenaUrl + e.Attribute("href").Value); return e; }) // 副作用ダサい
.Concat(root.Element("head").Elements("style"));
// HTML組み立て!
var html = new XStreamingElement("html", // まあ、Reverseでバッファに貯めるので焼け石に水ですけどね、XStreamingElement
new XStreamingElement("head", styles),
new XStreamingElement("body",
// new XElement("div", new XAttribute("class", "hatena-body"), サイドバーとか邪魔なので無視
// new XElement("div", new XAttribute("class", "main"),
new XStreamingElement("div", new XAttribute("id", "days"),
contents)));
// 保存
var path = Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().FullName), fileName + ".html");
var xws = new XmlWriterSettings { Indent = true, CheckCharacters = false }; // 不正な文字のあるサイトを書き出すと落ちるので防止
using (var xw = XmlWriter.Create(path, xws))
{
html.Save(xw);
}
}
}
try-catchが出るとゴチャついて嫌。なのだけど、しょうがないか。それと Unfoldはどうしたものかねえ。極力、標準演算子のみで済ませたいんですが、今回はちょっと使わざるを得なかったと思っています。次のページのURLを得るには、取得したHTMLから解析しなければならない。下流で解析し取得した次のURLは、上流に渡さなきゃいけない。のですが、通常は下から上に渡せないのがLinqなのよね。そんな場合、外部変数を介して渡すか、Unfoldか、場合によってはScanなんかを使うかになるわけで、とにかく外部変数は避けたかったのでUnfoldを使いました。
HTMLへの書き出し部分では物珍しい XStreamingElementを使ってみました。今回はただ単に書き出すだけなので、通常のXElementのようにメモリ内にツリーを保持する必要はないし、相当大きいXmlを扱うため効率も気になってくるところ。そこで遅延ストリーム書き込みを可能にするXStreamingElementの出番です。詳しくは 方法: 大きな XML ドキュメントのストリーミング変換を実行する をどうぞ。とはいっても、このプログラムでは反転させるためReverseでバッファに全て溜め込んでいるので、まあ……。XStreamingElementって言いたいだけちゃうんか、みたいな。
デザインはdiv class=hatena-bodyとdiv class=mainを抜いているので(不必要なサイドバーの描画を除去するため)、この二つに依存するCSSが書かれているサイトの場合はデザインが崩れることがあります。ちなみにneuecc clipはこの二つどころか、その他にもwrapperを置いているというデタラメなCSS構造をしているため、デザインは保存出来ません。全くもって酷い。もっとスクレイピングに優しいHTMLを書かないとダメですな。
HTMLへの書き出し部分ははまりどころでした。最初Save(fileName)で保存していたんですが、特定のサイトの特定の部分で落ちてしまって困りました。具体的には 2008-07-23 - Faith and Brave - C++で遊ぼう で(例に出してすみません)、Protocol Bufferによる出力結果がInvalidXmlCharに引っかかってアウト、のようです。回避する方法は、XmlWriterSettingsのCheckCharactersをfalseに設定したXmlWriterを生成して書き出せばOK。