C#で原始的にSQLを扱うお話
- 2010-04-05
世の中はLinq to SQLだのLinq to Entitiesだのを羨ましいなあ、と指を加えて眺めている昨今ですがこんばんわ。Linq好きーな私ですがこのサイトではObjectsとXmlしか扱っていないのは、単純に私が触った事ないから、です。あうあう。そんな私ですが、SQLを(大変嫌々ながら)触らなければならなかったりする場合もないわけじゃないのですが、アレですね、思うのはパラメータ。あれにadd。add。するのが大変美しくない。もっと格好良く、一発で決めようぜ。と思って色々悩んだんですが、どうにも上手く行きそうにない。やけくそになってビルダー+コレクション初期化子を考えてみました。
var cmd = new SqlCommand();
cmd.CommandText = @"select * from Foo where Bar > @Hoge and Tako = @Ika";
cmd.Parameters.AddRange(new SqlParameterBuilder
{
{"@Hoge", "2"}
{"@Ika", "たこやき"}
}.ToArray());
分かりづらくなってるだけで、普通にadd, addでいいですね。ダメだこりゃ。ボツ。ちなみに実装は超単純。
public class SqlParameterBuilder : IEnumerable<SqlParameter>
{
List<SqlParameter> parameters = new List<SqlParameter>();
public SqlParameterBuilder Add(string parameterName, object value)
{
parameters.Add(new SqlParameter(parameterName, value));
return this;
}
public IEnumerator<SqlParameter> GetEnumerator()
{
return parameters.GetEnumerator();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
コレクション初期化子の復習をしますと、IEnumerableかつAddメソッドが実装されているクラスに対してコレクション初期化子が使えます。Addは名前で決め打ちされています。メソッド名はAddじゃなくてAppendがいいなー、とか思ってもダメです。コレクション初期化子を使いたい場合はAddです。何でこんなヘンテコなことになってるのか、の理由は2008-02-08 - 当面C#と.NETな記録の記事を参照に。Addが複数引数を取る場合は{{},{}}って書けますが、IntelliSenseの補助がないので割と不便だったりしますねえ。
関数渡し
whileでEndまで読んで、ってのは嫌いです。Stream系のは全部yield returnでライン毎に返す拡張メソッドを定義しますね、私は。というわけで、SQLのDataReaderもStreamと同じ図式なので、同じ感じにしましょー。
var command = new SqlCommand();
command.CommandText = @"select hogehogehoge";
var result = command.EnumerateAll(dr => new
{
AA = dr.GetString(0),
BB = dr.GetInt32(1)
});
いい感じに見えないでしょうかどうでしょうか?といっても、これは以前書いたものの使い回しだったりしますが、その以前書いたコードとやらは若干反省してます。以下、書き直したコード。
public static IEnumerable<T> EnumerateAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
yield return selector(reader);
}
}
}
public static T[] ReadAll<T>(this IDbCommand command, Func<IDataReader, T> selector)
{
return command.EnumerateAll(selector).ToArray();
}
そう、以前は無理やりEnumerable.Repeatで無限リピートさせておりましたが、あのテクニックはyield returnが使えない(別関数に分けない場合)時のためのテクニックであって、yield returnが使えるなら素直にwhileループを回して書いた方がマシなのです。どうにも、まずLinqで書いたらどうなるのか、というのが頭に最初に浮かんでしまってフツーの書き方を忘れてしまいがちなのですが、大事なのはシンプルに表現すること、です。何故Linqを使うのか、そのほうがシンプルに書けるから。whileのほうがシンプルになるなら、そちらを選ぼう。弁解のために言っておくと、あれはreturn IEnumerableとyield returnの挙動の違いの例のために書いたわけですががが。あと、yieldが言語によってサポートされてるからってのもありますね。C#1.0のように自前でEnumerator用意して書かなきゃならないのならば、Linqで生成したほうが良いわけで。
マッピング
GetInt32(1)とか列を意識してオブジェクトに詰めるのがダルい。定形作業だし列がズれたら修正面倒だし殺したい。こんなの人間のやる作業じゃない。つーわけで、入れ物に詰めるのぐらいは自動化しよう。ああ、Linq to Sql使いたいなあ。
// このクラスにデータベースから値を入れるとして
class MyClass
{
public int IntProp { get; set; }
public string StrProp { get; set; }
}
static void Main(string[] args)
{
// プロパティ名と対比させて自動詰め込み
var command = new SqlCommand();
command.CommandText = @"
select
hoge as IntProp,
huga as StrProp
from NantokaTable";
var result = command.Map<MyClass>();
}
public static T[] Map<T>(this IDbCommand command) where T : new()
{
Dictionary<string, PropertyInfo> properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
列名とプロパティ名を摺り合わせているだけで、非常に単純なものです。気になるreaderのFieldCountとかGetNameの処理効率ですが、実行した時点で一行のキャッシュが生成されて、そこから取ってくる感じになるので重たくはないっぽいです。たぶん。ちゃんと追っかけたわけじゃないので全然断言は出来ませんが。あとは辞書生成のコストですかね。Type毎で固定なら毎回辞書作らなくてもキャッシュ出来るじゃん、という。静的コンストラクタを使えば、実現できます。
public static class Extensions
{
public static T[] Map<T>(this IDbCommand command) where T : new()
{
return SqlMapper<T>.Map(command);
}
private static class SqlMapper<T> where T : new()
{
static readonly Dictionary<string, PropertyInfo> properties;
static SqlMapper()
{
properties = typeof(T)
.GetProperties(BindingFlags.Public | BindingFlags.Instance)
.ToDictionary(pi => pi.Name);
}
public static T[] Map(IDbCommand command)
{
return command.ReadAll(dr =>
{
var result = new T();
for (int i = 0; i < dr.FieldCount; i++)
{
if (dr.IsDBNull(i)) continue;
properties[dr.GetName(i)].SetValue(result, dr[i], null);
}
return result;
});
}
}
}
割とスマート。ジェネリック静的クラスには直接拡張メソッドは定義出来ないので、入れ子のprivateな静的クラスを挟んでいます。 と、こんな感じにSQLを触っていると非常に原始人っぽい。先日のテンプレート置換と同じく、コピペに優しい小粒でピリッと役立ち、なメソッドの作成を志してる感じです。まあ実際は自分だけが使うUtilなんて許されるわけもなく普通に地味にドロドロと(ああ、胃が……)。
そういえばであまり関係ないのですが、SQL文ってどこに置くべきなんでしょうかね。外部ファイルにしておいて読み込み、などというのは個人的にはどうかなー、と思っていて。どうせ呼び出し部分と1:1になるなら、↑のようにハードコードでも別によくないかしらん、そのほうがソースコード上の距離が近いこともあって分かりやすくなる。とか、どうなんでしょうかねえ。再コンパイルが不要になるといって、どうせSQLに変更入ったらコードのほうも変更入れないとマズい可能性が高そう、とか。
追記
マッパーはSystem.Data.LinqにあるDataContext.ExecuteQuery(TResult) メソッド そのものですね、たはは、シラナカッタヨ。↑のほうが超単純実装+キャッシュなので速いとは思いますが、どうでもいい差ですな。全く同じものだと悔しいので、outer joinとかでNullが混じる場合もすんなり使えるように、IsDBNullを足してスキップするようにしました。まあSQLでcoalesceで明示的にやったほうが良いとは思いますが。EnumerateAllのほうは普通に使えると思うのでぜひぜひ。
RxJS用IntelliSense生成プログラム(と、VisualStudioのJavaScript用vsdocの書き方)
- 2010-03-26
先日、Reactive Extensions for JavaScript(RxJS)の記事を書いたわけですが、触っていて困るのは、どのメソッドが使えるの?ということ。リファレンスもない中で、C#版の記憶を頼りに手打ちでメソッド名を探るなんて、無理。ましてやそんな状況じゃあ人に薦められないよ!というわけで、必要なのはIntelliSense(入力補完)です。rx.jsはある。rx-vsdoc.jsはない。ないものは、作ればいいぢゃない。そこで諦めてメソッド全部暗記してやるぜ、とか思うのはどうかしてる。諦めたら試合終了ですよ。楽するために手間を掛けるのです<プログラマの三大美徳。というわけで、作りました。
- RxVSDocGenerator.zip (source and binary)
vsdocファイルをそのまま配布するのはライセンスの問題が出そうなので、生成プログラムを配布します。手作業じゃなく自動生成で作ったので(面倒くさくて手作業なんてやってられるか!)。Rxをインストールしたフォルダ(デフォルトだとProgramFiles\Microsoft Reactive Extensions)のScriptSharpフォルダの下のRxJS.dllとRxJS.xmlを、生成プログラムと同じ階層に置いて実行すると、rx-vsdoc.jsが生成されます。
利用するにはvsdoc対応パッチをあてたVisualStudio 2008 SP1(VS2010はパッチをあてなくても対応しています)を用意して、rx.jsと同じ階層に置くだけです。HTMLで使う場合はscript src="rx.js"で読み込むだけ、独立したjsファイルで補完を使う場合は、行頭に/// <reference path="rx.js" />と記述すれば補完が読み込まれます。この辺は、以前に最もタメになる「初心者用言語」はVisualStudio(言語?)という記事を書いたときに補完愛してる愛してる愛してると連呼しながら解説してました。jQueryのドットで補完効かせながらのメソッドチェーンは気持ちイイんだって!
折角作ったので海外の人にも利用してもらおうと、また、標準でvsdocも同梱して欲しいと訴えるためにもとRxの公式フォーラムでスレ立てたけど、奇怪英語(機械翻訳英語)が恥ずかしいです……。ニュアンスをミジンコほどにも伝えられた気がしません。英語読めない書けないプログラマなんて小学生までだよねー、とかいう自己啓発系ブログ記事は山のようにあるわけですが、ふん、どうせ英語読めませんよ書けませんよ、ぐぐる先生による機械翻訳さえ超進化してくれれば小学生でも生きていけるもん!(ちなみに私はヤフー翻訳派です)
MIX10の発表によるとMicrosoftはAjax関連はjQueryに一本化する、ということで、C#erもますますJavaScriptを書かなければならないシーンは増えていきそうなので、せっかくなのでJavaScript用のvsdocの書き方を解説します。ついでに、LinqまみれなRxVSDocGeneratorのコードの解説も若干します。Mono.Cecil.dll使ってたりするんですよー(モジュールの参照用にしか使っていないので些かオーバースペック)。
C#と比較するJavaScriptの構造
JavaScriptは割とヒネクレた書き方が幾らでも出来るわけですが、VisualStudioの入力補完は、素の状態だと素直に書かないとついてきてくれません。というわけで素直に書きましょう。素直に書けば素直なIntelliSenseが手に入ります。以下、10秒でわかるC#とJavaScriptとの構造比較。
// 名前空間、もしくは静的クラス
Rx = {}
Rx.Disposable = {}
// クラス(コンストラクタ)
Rx.Observable = function(){ }
// 継承
Rx.AsyncSubject.prototype = new Rx.Observable;
// 静的フィールド
Rx.Disposable.Empty = null;
// インスタンスフィールド
Rx.GroupedObservable.prototype.Key = null;
// 静的メソッド
Rx.Observable.Range = function(start, count, scheduler){ }
// インスタンスメソッド
Rx.Observable.prototype.Select = function(selector){ }
ヒネクレたことさえしなければ、JavaScriptはシンプルです。オブジェクトとファンクションしか存在しない。シンプルさ故の制限を回避するために、また、幾らでも回避可能なためバッドノウハウのようなヒネクレた手段が大量に溢れていて、シンプルさとは無縁の奇怪な代物と成り果てていますが(JSはシンプルだよ、初心者にお薦め!というそばからクロージャがどうのapplyがどうのと言うのはどうなのよ、勿論、その柔軟さもまたJSの魅力の一つだとは思いますが、それをシンプルとは言わない)、素直に見れば、シンプルです。
そしてまあ、C#と割と似てます。構文似てるし。単一継承だし。prototypeに後からメソッドを足せるのは拡張メソッドのよう。違いは、privateはないしプロパティはないしインターフェイスはないしオーバーロードもない(但し引数は省略可能)、いつでも簡単に全てが変更可能(不注意に扱えばすぐ構造をぶっ壊せる←だからライブラリの衝突の問題がある)。といった問題は、若干ヒネクレればある程度は回避可能です、privateとか。でも、素直に書いた方が良いと思います。JavaScriptにprivateはない。と、割り切ってしまうと非常に楽になれます。良いか悪いかはともかく。
ただ、素直に書こうと、素のJavaScriptでは、補完は簡単に限界がきます。例えば以下のコード。
var func = function(bool) {
return (bool) ? "string" : [4, 5, 2, 3, 1];
}
var b = Math.random() < 0.5; // true or false
func(b).toUpperCase();
func(b).sort(); // どちらかで必ずエラー
引数の型が自由なら、戻り値の型もまた自由。じゃあどうするの?というと、どうにもなりません。戻り値の型はなるべく統一しましょう、IntelliSenseに優しくするために。これもまた素直の一つでしょうか、さてはて。
vsdoc.js入門
素直に素直に、と言ったところで何処かで破綻する。だいたい、JavaScriptの言語としての柔軟さを生かさないでどうする!という話は尤もなこと。そこで、VisualStudioはJavaScriptの入力補完に気の利いた仕組みを用意しています。ファイル名-vsdoc.jsが同階層にある場合、vsdoc.jsの構造を利用して入力補完を行います。なので、オリジナルに手を加える事なく補完を利用することが出来ますし、また、オリジナルが補完生成し辛い構造をしていても問題はありません。最終的にユーザーが利用するPublicの構造というのは、上で書いた素直なJavaScriptで再現出来るわけなので、それで構築すればいいだけです。勿論、別箇に構造を作成するというのは手間が増えるので、可能な限りは素直な構造にしておいたほうが無難です。
「IntelliSenseに候補が出ないものは存在しないに等しい」。これは.NETのクラスライブラリ設計という本に書かれている言葉なのですが(神本なので未読の人は絶対購入しましょう)、候補を出しさえしなければ、利用者にとって存在しないようなものに見えます。実際はpublicであっても、補完候補から削ってしまえばprivateに見える。擬似的なprivateの表現としては、中々スマートではないですか?
そんなvsdocですが、ちゃんとしたドキュメントが今ひとつ見あたらないので、jQuery用のvsdocを参考にすると良いでしょう。色々な属性が用意されているようですが、実際の入力補完に利用されるものは少ししかありません。optional属性なんて、オーバーロード的なものの表現に使えるのでは?と期待をかけたのですがそんなことはなくて、IntelliSense用には動作しませんでした。よって、summary, param, returnsだけ抑えておけば良いです。
var sum = function(x, y) {
/// <summary>足し算</summary>
/// <param type='Number' name='x'>引数1</param>
/// <param type='Number' name='y'>引数2</param>
/// <returns type='Number'></returns>
}
Rx.Disposable.Empty = new IDisposable;
C#と違ってfunctionの「下」にドキュメントコメントを書きます。また、ドキュメントコメントを使う場合は、関数本体はあってもなくても無視されるので、不要です。なお、ドキュメントコメントは-vsdoc.jsだけで有効なわけではなく、普通のjsファイルでも有効です。summary, paramは面倒くさかったら書かなくてもそんなに害はなさそうですが(但し引数違いのオーバーロードがある場合はsummaryで伝えてあげると使う人に優しい)、returns typeだけは欠かさず書いておきたい。これを書いておくと戻り値の型がVisualStudioに認識されるので、IntelliSenseを途絶さず利用できます。
制限事項としては関数のみにドキュメントコメントを埋め込むことが出来ます。vsdocを作る際にフィールドの型も認識させたい場合は、ダミーの変数を与えてあげればOK。
ジェネレータの解説
と、いった基本を抑えておけば、どんなライブラリに対してもvsdocを作れるね!じゃあ、rx-vsdoc.jsも手作業で作ろうか。と、思った時もありました。構造自体はjs自体をダンプでなんとかなる(と、いいなあ)だろうし、summaryやparamは諦めるとしてreturns typeだけを手作業で書くなら、どうせほとんどRx.Observableなので手間もそんなでもない。けど、rx.jsは難読化されていて引数の名前がイミフ、例えばRx.Observable.Range(k0, l0, m0)というんじゃ苦しい……。やっぱsummaryもparamも必要。でもどうすれば……?
そこで、インストールディレクトリを見てみるとScriptSharpなんてフォルダがあるんですよ。そう、RxJSはScript#でC#コードから生成されたJavaScriptライブラリだったのだよ、ナンダッテー!そして、ScriptSharp用のRxJS.dllには当然、完全なクラス構造と、引数の名前と型が保存されているし、更にはsummary用のxmlも用意されていた。つまり、ここからrx-vsdoc.jsを生成すればいいわけです。
というわけでリフレクション。型情報を取るため、早速Assembly.LoadFrom("RxJS.dll").GetTypes()とすると、落ちる。はあ、ScriptSharpのdllに依存してるのでそっちもないとダメなのね。というわけでScriptSharpのdllを幾つか参照に加えると、なんかうまく動かせない。ScriptSharpのdllはmscorlibの代替となってる(JSに変換可能なもののみに制限を加えてる?)から、一緒には動かせないとかそんな感じなのかなー、よくわからないけどとにかく動かせない、諦める。南無。無念。
そもそもLoadするからダメなわけで、Loadしなくていいよ、型情報だけ取れればそれでいいんだって。でも標準ライブラリには、それを可能にするのはないっぽい。けど、Monoにはあった。Cecil - Mono。参照も書き換えも出来るようですが、今回は参照のみで。色々出来そうなので、いつかもう少し触ってみたいですね。私は今回はじめてMono.Cecil.dllを使ったのですが、リファレンスの類も見てない(あるのか知らない)し、チュートリアルの類も見てない(ていうか日本語の情報がない)。でも、IntelliSenseでドット打ってれば何とかなりました。しっかりした構造とちゃんとしたメソッド名とIntelliSenseがあれば、リファレンスがなくても問題なく使えるわけです。すばらしきこのせかい!
Mono.Cecil
型情報を取ってくるだけなら簡単で、というかSystem.Reflectionと大して変わりません。
var rxjsTypes = AssemblyFactory.GetAssembly("RxJS.dll")
.MainModule.Types.Cast<TypeDefinition>()
TypeDefinition, MethodDefinition, ParameterDefinitionといったのが個の要素。そして、対応するコレクションHogeCollectionが用意されています。HogeCollectionは残念ながらジェネリックではないため、Linqに流すためにはCastが必要になります。今回はParameterDefinitionCollectionのSelectを多用することが多かったので、Cast無しで使えるよう拡張メソッドを定義しちゃいました。
static IEnumerable<T> Select<T>(this ParameterDefinitionCollection source, Func<ParameterDefinition, T> selector)
{
return source.Cast<ParameterDefinition>().Select(selector);
}
この手のレガシーなコレクションに対するアドホックな対応は、例えば正規表現のMatchCollectionなんかにも使えそうです(と、いった発想の元ネタはAchiralから)
テンプレート置換
必要なJSの構造は上のほうで書いた通り決まったパターンがあるので、雛形を元に置換するのが楽。テンプレートエンジン、なんていう大仰なものは必要ないけれど、string.Formatでも{5}とか出てくると引数の管理が面倒だし、順番の変更にも弱い。なので簡易置換用の拡張メソッドを用意してみました。
static string TemplateReplace(this string template, object replacement)
{
var dict = replacement.GetType().GetProperties()
.ToDictionary(pi => pi.Name, pi => pi.GetValue(replacement, null).ToString());
return Regex.Replace(template,
"{(" + string.Join("|", dict.Select(kvp => Regex.Escape(kvp.Key)).ToArray()) + ")}",
m => dict[m.Groups[1].Value]);
}
オブジェクトを渡すと、{プロパティ名}の部分をプロパティの値に置換します。オブジェクトなのでクラスインスタンスでもいいのですが、匿名型も使えます。例えば
const string classTemplate = @"
{FullName} = function({Parameters})
{
/// <summary>{Summary}</summary>
{Param}
}";
var r = classTemplate.TemplateReplace(new
{
FullName = "Rx.Notification",
Parameters = "kind",
Summary = "Represents a notification to an observer.",
Param = " /// <param type='String' name='kind'></param>"
});
Console.WriteLine(r);
割と便利。たった9行なので、ちょっと気の利いた置換が欲しいなあ、って時にササッとコピペして取り出せるのが魅力です。最近、コピペに優しいプログラミングをよく考えてる。というのはともかくとして、実際どんな風に使っているかというと、
var classes = rxjsTypes
.Where(t => t.Constructors.Count > 0)
.Select(t => new
{
t.FullName,
Parameters = t.Constructors.Cast<MethodDefinition>()
.Select(m => m.Parameters)
.MaxBy(p => p.Count)
.Select(p => p.Name)
.ToJoinedString(", "),
Summary = summaries[t.FullName] + " " + t.Constructors.Cast<MethodDefinition>()
.OrderBy(m => m.Parameters.Count)
.Select(m => m.Parameters.Select(p => p.Name).ToJoinedString(", "))
.Select((s, i) => string.Format("{0}:({1})", i + 1, s))
.ToJoinedString(", "),
Param = t.Constructors.Cast<MethodDefinition>()
.MaxBy(m => m.Parameters.Count)
.Parameters
.Select(p => string.Format(Template.Param, p.ParameterType.ToJSName(), p.Name))
.ToJoinedString(Environment.NewLine),
})
.Select(a => Template.Class.TemplateReplace(a));
前段階で匿名型を生成して、最後のSelectで置換をかけてます。Select二段にしないでもいんじゃね?というとYESですが、このほうが見やすいと思うので。それにしてもリフレクションなわけで、Linqと非常に相性が良い。というか、Linqなしだと大量のforループとifで涙を流すことになりそう。なので、昔はリフレクションって結構敷居が高かったのですが、今はもうLinqでサクサクとWhereで切って捨ててSelectで繋げて繋げて、って出来るので書く分には楽チンです。これがLinq以前のC#2.0だったら、考えたくないなあ。
出力
クラス、継承、オブジェクト、メソッド、プロパティは全部バラバラに抽出しています。そして、全部IEnumerable<string>で止めています。最後にそれらをまとめて、テキストとして出力。
var vsdoc = Enumerable.Repeat(string.Format(Template.Object, RootNamespace), 1)
.Concat(classes)
.Concat(inheritance)
.Concat(objects)
.Concat(methods)
.Concat(properties)
.ToJoinedString(Environment.NewLine);
File.WriteAllText("rx-vsdoc.js", vsdoc, Encoding.UTF8);
せっかくクエリ遅延評価にさせているので、書き出しも一度stringに貯めないでストリームで書きだせば高効率ですねー。でも、一度文字列に出した方が書くの楽なので。せいぜい1000行程度なので、ケチッても意味ないですな。
全部rxjsTypesをルートにして生成しているので、クエリ構文を使って巨大な一塊にしてみたら面白かったかな、なんて思いますが若干悪趣味な気もするのでやめておきます。そもそも、このドットだらけ、Selectだらけの時点で若干どうよ、といった趣が漂っているのは間違いない。いやいや、ドット素敵です。Linq素敵なんだって、本当に。こういうの書いてるとC#2.0と3.0は別物だろ常識的に考えて、と思わなくもない。セミコロン率は物凄く低くなりましたね……。あと、LinqとSQLを関連付けるのはそろそろやめようぜー、的な思いがふと過ぎったり。Twitterのpublic検索でlinqをキーワードに毎日眺めてるんですが、今でも割とそういう印象持ってる人多いんだなー、と。だからどうしたとかどうなるってこともないですが。
まとめ
IntelliSenseでLinqはより楽しくなる。メソッドチェインはIntelliSenseでより楽しくなる。そして、VisualStudioはJavaScriptエディタとしても優秀なので皆VisualStudio使おう!インストールが面倒?Microsoft Visual Studio 2008 Express EditionからWeb インストールをクリックするだけでオールインワンでダウンロード含めて10分ぐらいで全部やってくれる。時間がかかるというのは正しいですが、意外と面倒くさくはないんです。それと、このExpress Editionは無料です。
入力補完だけじゃなく、コード整形やデバッガ(開発環境と完全統合されているためFirebugよりもずっと使いやすい)などもあるし、ある程度は裏でインタプリタをぶん回して変数名間違いなどのエラーを補足してくれるので、IDE無しでJavaScript書くなんて、そんな苦労、しなくてもいいんだよ……。
Reactive Extensions for JavaScript
- 2010-03-18
MIX10終了しましたねー。何はともかく皆してIE9の話題ばかりで、ああ、InternetExplorerは愛されてるなあ(色々な意味で)、などというのを横目に、私にとっての最大のニュースはReactive Extensions for JavaScript(RxJS)です。Reactive Extensions(Rx)はこのサイトでもカテゴリーを作ってメソッド探訪なんてやってるぐらいに注目していたわけで、当然MIX10でJavaScript版出すという話を聞いた時からwktkが止まらなかったわけですが、全く期待を裏切らなかった!というか、こいつはヤバいですよ?
Reactive Extensionsとは何ぞや、というと、LinqというC#の関数型言語みたいなリスト処理ライブラリ(語弊ありまくり)のイベントとか非同期版です。イベントや非同期処理にたいしてmapとかfilterとかfoldとか、お馴染みなリスト操作関数が使えちゃうという、その発想はなかったわ、なライブラリです。C#版は去年の夏ぐらいにプレビュー版が出て、いまも精力的に開発が続いているのですが、今回はJavaScript移植版が出た、という話です。イベント(onclick!onclick!)や非同期(XMLHttpRequest!)ってのは、勿論C#でも大事なのですが、JavaScriptなんてそれが主役というぐらいなわけなので、C#版よりもインパクトは大きいです。何よりも、C#は言語やライブラリが強力なので別にRx使わなくてもって感じなのですが、JavaScriptは違う。あまりにも貧弱。なので、優れたイベント/非同期処理ライブラリの重要度はC#の比ではなく高い。
RxJSの面白いところはjQueryに対抗するものではなく、むしろ協調動作するように作られていることです。DOM操作はjQuery、イベントや非同期処理はRxJS、二つの強力なライブラリを組み合わせることで、JavaScriptプログラミングは次のパラダイムへ向かおうとしています。御託は、もういいですね、とりあえずサンプルを。
マウスをクリックして四角形を掴んで、マウスを動かして、放すという、ごく普通のドラッグアンドドロップ。素の JavaScriptではどうやって実装しますか?グローバルに状態管理用のオブジェクトを置いて、オフセット用の変数置いて、マウスの状態を監視して、うーん、考えたくない。あまり綺麗に出来そうにない。それがRxJSを使ってみると――
var O = Rx.Observable; // using
$(function()
{
var doc = $(document);
var area = $("#dragArea");
O.FromJQueryEvent(area, "mousedown")
.Select(function(e)
{
var offset = $(e.target).offset();
return { X: e.pageX - offset.left, Y: e.pageY - offset.top }
})
.SelectMany(function(offset)
{
return O.FromJQueryEvent(doc, "mousemove")
.TakeUntil(O.FromJQueryEvent(doc, "mouseup"))
.Select(function(e) { return { X: e.pageX - offset.X, Y: e.pageY - offset.Y }; })
})
.Subscribe(function(a) { area.css({ left: a.X, top: a.Y }) });
});
状態管理変数は使いませんし、全て一連のメソッドチェーンだけで完結します。以下解説。
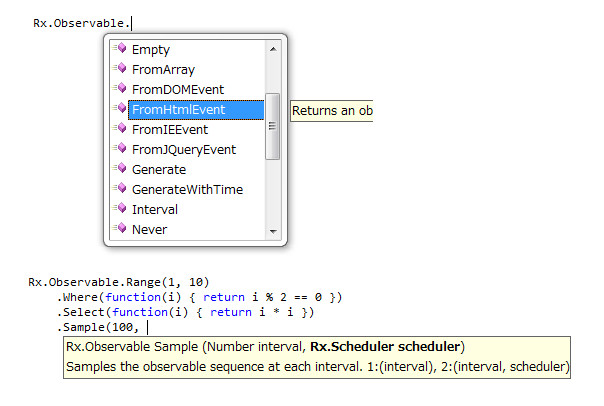
Rx.Observable.FromJQueryEventは、イベントをRxオブジェクトに変換します。これはjQueryの$などと同じものだと思ってください。FromJQueryEventと同様の動作をするものにFromHtmlEventというものがあります。ほとんど同様ですが、jQueryオブジェクトを使う場合はFromJQueryEvent、getElementByIdなどで得られたネイティブの要素を使う場合はFromHtmlEventを使いましょう。基本的には、クロスブラウザ回りの面倒事を任せられるjQueryとの併用がお薦めです。
Rxオブジェクトに変換後は、多数のメソッドをjQueryのようにチェーンさせて記述していきます。どれだけ多数かというと、ここに並べてみます。
Subscribe, Select, Let, MergeObservable, Concat, Merge, Catch, OnErrorResumeNext, Zip, CombineLatest, Switch, TakeUntil, SkipUntil, Scan1, Scan, Finally, Do, Where, Take, GroupBy, TakeWhile, SkipWhile, Skip, SelectMany, TimeInterval, RemoveInterval, Timestamp, RemoveTimestamp, Materialize, Dematerialize, AsObservable, Delay, Throttle, Timeout, Sample, Repeat, Retry, BufferWithTime, BufferWithCount, StartWith, DistinctUntilChanged, Publish, Prune, Replay
何も一気に全部を知る必要はないので、あまり圧倒されずに、少しずつ学んでいければいいかな? 私もちょいちょいとブログ記事で紹介していきたいと思っています(やるやる詐欺ばかりですが……)。そうそう、ソースコードが圧縮されていて実際の名称は不明なのでRxオブジェクトと呼んでますが、それであってるかは今のところ謎です。C#ではIObservableなので、IObservableでいいかな、という気はしますが。
イベント as リスト
もう少しFromJQueryEventの動きを考えますか。イベントが発生すると、後ろのメソッドにイベントオブジェクトが渡されます。再度クリックすると、またイベントが発生しイベントオブジェクトが渡されます。再度(以下略)。つまりは、[event, event, event...]。終りのない配列。無限リスト。まるでイテレータのような……。そう、ObserverパターンとIteratorパターンは同じなのだよ、ナンダッテー!よく分からない?確かに。こういう時は他の人の言葉を借りてしまおう。最近Scalaの入門記事が注目を集めました。「神は言われた。「リストあれ。」」。そうです、イベントもまた、Rxの手にかかればリストになってしまうのです。Rxは関数型言語のリスト操作のようにイベントを高階関数で処理できます。それがもたらす世界、想像するとワクワクしませんか?なお、JavaScriptで配列やDOMに対してリスト操作を行うライブラリとしてlinq.jsというがありますのでよろしくお願いします←宣伝(作ってるの私なので)。
ドラッグアンドドロップの構造
mousedownでイベントが発動しても、本当に必要なイベントはdownじゃなくてmove。なので、downはイベント発動とオフセット算出にだけ使って、実際に後ろに流す情報は別のところから得ます。そこで、mousedownとmousemoveを合流させなければなりません。シーケンス(Rxによりリストのような何かになっているので、Sequenceが言葉として適切な気がします)の結合はMergeやCombineLatest、Zipなど、用途に応じて色々あるのですが、ここは一(mousedown)から多(mousemove)の状態を作ることが可能なSelectManyを使用します。SelectManyに渡す高階関数の戻り値(Rxオブジェクト)が、更に平たくされて後ろのメソッドに渡されていくことになります。
TakeUntilは、「~まで取得する」。引数のイベントが発動されるまでシーケンスを流し、発動されたら一切流さなくなる。つまりFrom(mousemove).TakeUntil(mouseup)は、mouseupされるまでmousemoveイベントを発行するということ。驚くほど簡単にドラッグアンドドロップの構造が記述出来てしまいました。これはヤバい。Rxヤバい。簡潔すぎるだろ常識的に考えて。
Selectは多くの関数型言語やRubyなどで言うところのmapで、要素を変形して返すもの。ここではeventからclientX, clientYだけのオブジェクトを作っています。mapがあるということは、勿論filterもあります(メソッド名はWhere)。この辺はlinq.jsの解説がそのまんま適用出来ます。何故かというと、Observerパターン(RxJS)とIteratorパターン(linq.js)は(以下略)。
Subscribe
シーケンスを変形していったら、最後に登録してやる必要があります。それがSubscribe。Subscribeを呼んで、初めてイベント(mousedownなど)に関連付けられます(addEventListenerです、ようするに)。このSubscribeは感覚的にはforeachのようなもので、無名関数の第一引数に今までに変形させた変数が入っているので、それを取り出して何らかのアクションを取る。今回はstyleを弄って四角形の座標を変更してやりました。
addEventListenerということは、デタッチもあるの?というと、ありますあります。Subscribeの戻り値はvoidではなく、IDisposableオブジェクトというものになっています。この戻り値のIDisposableオブジェクトを取っておけば、デタッチさせたい時にDisposeメソッドを呼んでデタッチさせられます。
Rx.Observable
Rxオブジェクトのメソッド一覧は書きましたが、Rx.ObservableにはFromHogeHoge以外にも色々なメソッドがあるよ。イベントだけじゃなく、あらゆる方向からRxオブジェクトを作り出す驚異のメソッド群はこれだ!
Amb, Catch, Concat, Create, CreateWithDisposable, Defer, Empty, FromArray, FromDOMEvent, FromHtmlEvent, FromIEEvent, FromJQueryEvent, Generate, GenerateWithTime, Interval, Merge, Never, OnErrorResumeNext, Range, Repeat, Return, Start, Throw, Timer, ToAsync, Using, XmlHttpRequest
いっぱいありますねー。名前から想像つくものからつかないものまで。XmlHttpRequestとか興味をひくところです。そう、Rxはイベントだけではなく、非同期通信までリストに変換し統一的な操作を可能にしてしまうわけです。こっちも重要なので、後日サンプル書きます。
結論
jQueryあるからRxJSなんてイラね、というわけじゃあないんですよ!ふたり揃ってプリキュア。最初の方にも書きましたが、jQueryのDOM操作は素晴らしいのでおまかせでいいです。イベントや非同期処理はjQueryだけじゃ足りないところがあります。そこはRxJSで補います。ついでに通常のリスト操作(配列やDOM Elements)は全然足りてません。prototype.jsはあんなにイけてたのに、jQueryになってからリスト処理がシンドいですね。そこはlinq.jsです(宣伝しつこい)。これでもうJavaScriptに死角はなくなった……、勝った、HTML5時代バンザイ!(でも私はC# + Silverlight4に期待をかけるけどね)
参考リンク
Rxチームの一員であるJeffrey van Goghによる、Rxをインストールしたディレクトリに置いてある、TimeFilesサンプルの解説。forループがダサいのでlinq.jsを使って書き直してTwitterに流したんですが、そうしたらJeffrey van Goghに言及してもらった!。これは嬉しい。
{kind=link}
Matthew PodwysockiによるRxJSの解説シリーズ。From(mousemove).TakeUntil(mouseup)のネタ元はここだったりして。最高にクール!
はてなダイアリー to HTML
- 2010-03-09
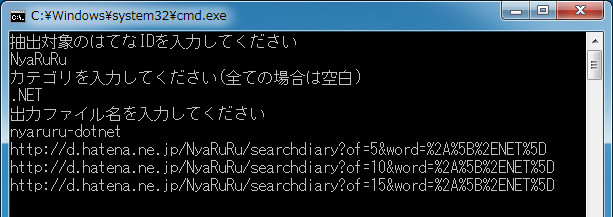
はてなダイアリーの記事を根こそぎ取得してローカルHTMLに保存するアプリケーションです。過去ログを全部取得して昇順に並び替えます。カテゴリ指定も可。 本文抽出アルゴリズムだなんて高尚なことはせず、HTMLをそのまま切り出しているだけのはてなダイアリー完全特化なぶんだけ、デザインやsyntax-highlightなどもそのままで見ることができます。上の画像はNyaRuRuの日記(勝手に貼ってすみません)の.NETカテゴリーを抽出しているところ。私がC#やLinqを覚えられたのはNyaRuRuさんの日記のお陰といっても過言ではなく、しかも読み返す度に新しい発見があって本当に素晴らしい。ので、度々読み返しているのですが、はてな重い。重い。なら全部ぶっこぬけばいいぢゃない。というのが作った理由でして……。
あと、最近こそこそごそごそとC++も勉強中なので、 [C++] - Cry’s Diaryや [C++] - Faith and Brave - C++で遊ぼうを読むと、(大体は全く分からないのですが)勉強になります。なお、Permalinkは相対パスになってしまい使えないのですが、日付の部分は絶対パスなので、コメント見たくなったりPermalinkを取りたくなったら日付から辿れます。
こうしてHTMLを自炊(?)すると、電子ブックリーダー欲しくなりますね。それと、リーダーはやっぱブラウザが載ってないとダメよねー。PDF(と独自形式?)だけ見れても嬉しくぁない。そんなに本には興味ない。HTMLが見たいのです。Twitterのログが見たいのです。2chまとめサイトが見たいのです。海外の技術書は結構PDFで買える感じなのでそれはそれで気になるところですが――。
以下ソースコード。↑のzipにも同梱してありますが。コンパイルにはSGMLReaderが必要です。
static class Program
{
static IEnumerable<T> Unfold<T>(T seed, Func<T, T> func)
{
for (var value = seed; ; value = func(value))
{
yield return value;
}
}
const string HatenaUrl = "http://d.hatena.ne.jp";
static void Main()
{
Thread.GetDomain().UnhandledException += (sender, e) =>
{
Console.WriteLine(e.ExceptionObject);
Console.ReadLine();
};
Console.WriteLine("抽出対象のはてなIDを入力してください");
var id = Console.ReadLine();
Console.WriteLine("カテゴリを入力してください(全ての場合は空白)");
var word = Console.ReadLine();
Console.WriteLine("出力ファイル名を入力してください");
var fileName = Console.ReadLine();
// 抽出クエリ!
var root = XElement.Load(new SgmlReader { Href = HatenaUrl + "/" + id + ((word == "") ? "" : "/searchdiary?word=*[" + Uri.EscapeDataString(word) + "]") });
var contents = Unfold(root,
x =>
{
var prev = x.Element("head").Elements("link")
.FirstOrDefault(e => e.Attribute("rel") != null && e.Attribute("rel").Value == "prev");
if (prev == null) return null;
retry:
try
{
var url = HatenaUrl + prev.Attribute("href").Value;
Console.WriteLine(url); // こういうの挟むのビミョーではある
return XElement.Load(new SgmlReader { Href = url });
}
catch (WebException) // タイムアウトするので
{
Console.WriteLine("Timeout at " + DateTime.Now.ToString() + " wait 15 seconds...");
Thread.Sleep(TimeSpan.FromSeconds(15)); // とりあえず15秒待つ
goto retry; // 何となくGOTO使いたい人
}
})
.TakeWhile(x => x != null)
.SelectMany(x => x
.Descendants("div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "day"))
.TakeWhile(e => !Regex.IsMatch(e.Value, @"^「\*\[.+\]」に一致する記事はありませんでした。検索語を変えて再度検索してみてください。$")) // 間違ったカテゴリ入力した時対策
.Reverse(); // 古いのから順に見たいので
// style抽出
var styles = root.Element("head").Elements("link")
.Where(e => e.Attribute("rel").Value == "stylesheet")
.Select(e => { e.SetAttributeValue("href", HatenaUrl + e.Attribute("href").Value); return e; }) // 副作用ダサい
.Concat(root.Element("head").Elements("style"));
// HTML組み立て!
var html = new XStreamingElement("html", // まあ、Reverseでバッファに貯めるので焼け石に水ですけどね、XStreamingElement
new XStreamingElement("head", styles),
new XStreamingElement("body",
// new XElement("div", new XAttribute("class", "hatena-body"), サイドバーとか邪魔なので無視
// new XElement("div", new XAttribute("class", "main"),
new XStreamingElement("div", new XAttribute("id", "days"),
contents)));
// 保存
var path = Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().FullName), fileName + ".html");
var xws = new XmlWriterSettings { Indent = true, CheckCharacters = false }; // 不正な文字のあるサイトを書き出すと落ちるので防止
using (var xw = XmlWriter.Create(path, xws))
{
html.Save(xw);
}
}
}
try-catchが出るとゴチャついて嫌。なのだけど、しょうがないか。それと Unfoldはどうしたものかねえ。極力、標準演算子のみで済ませたいんですが、今回はちょっと使わざるを得なかったと思っています。次のページのURLを得るには、取得したHTMLから解析しなければならない。下流で解析し取得した次のURLは、上流に渡さなきゃいけない。のですが、通常は下から上に渡せないのがLinqなのよね。そんな場合、外部変数を介して渡すか、Unfoldか、場合によってはScanなんかを使うかになるわけで、とにかく外部変数は避けたかったのでUnfoldを使いました。
HTMLへの書き出し部分では物珍しい XStreamingElementを使ってみました。今回はただ単に書き出すだけなので、通常のXElementのようにメモリ内にツリーを保持する必要はないし、相当大きいXmlを扱うため効率も気になってくるところ。そこで遅延ストリーム書き込みを可能にするXStreamingElementの出番です。詳しくは 方法: 大きな XML ドキュメントのストリーミング変換を実行する をどうぞ。とはいっても、このプログラムでは反転させるためReverseでバッファに全て溜め込んでいるので、まあ……。XStreamingElementって言いたいだけちゃうんか、みたいな。
デザインはdiv class=hatena-bodyとdiv class=mainを抜いているので(不必要なサイドバーの描画を除去するため)、この二つに依存するCSSが書かれているサイトの場合はデザインが崩れることがあります。ちなみにneuecc clipはこの二つどころか、その他にもwrapperを置いているというデタラメなCSS構造をしているため、デザインは保存出来ません。全くもって酷い。もっとスクレイピングに優しいHTMLを書かないとダメですな。
HTMLへの書き出し部分ははまりどころでした。最初Save(fileName)で保存していたんですが、特定のサイトの特定の部分で落ちてしまって困りました。具体的には 2008-07-23 - Faith and Brave - C++で遊ぼう で(例に出してすみません)、Protocol Bufferによる出力結果がInvalidXmlCharに引っかかってアウト、のようです。回避する方法は、XmlWriterSettingsのCheckCharactersをfalseに設定したXmlWriterを生成して書き出せばOK。
XboxInfoTwit - ver.2.2.0.0
- 2010-03-06
今回の更新は、HTMLをXMLに変換するライブラリをTidy.NetからSGMLReaderに変更しました。数日前にSGMLReaderでLinq to Html最高なんてエントリーを上げていたので、早速実戦投入というわけです。内部コードが割と変わったため、ver2.1系列から2.2へとアップ。利用者的にはぶっちゃけどうでもいい話です。すみません。
ユーザーに関係ある変更点は、先日発売されたばかりのBioShock2で実績が取得出来てなかったので、それを直しました。私はBioShock2でしか確認していないのですが、「カルドセプト」や「のーふぇいと!」も実績が取得出来ないという報告が上がっていたので、今回の修正によって取得出来るようになった、かもしれません。分かりません。カルドセプトやのーふぇいと!を持っている方は実績取れたよー、と教えていただけると助かります。一応Twitter検索で追っかけてはいるんですけど、最近投稿量が多くて(認証者数は1400行きました、ありがとうございます)全然目を通せていなかったりして。
追記:「カルドセプト」、「のーふぇいと!」ともに実績取得出来ているようです。確認していただいた方、ありがとうございました。
C#でスクレイピング:HTMLパース(Linq to Html)のためのSGMLReader利用法
- 2010-03-02
Linq to XmlがあるならLinq to Htmlもあればいいのに!と思った皆様こんばんは。まあ、DOMでしょ?ツリーでしょ?XHTMLならそのままXDocument.Loadで行けるよね?XDocument.Parseで行けるよね? ええ、ええ、行けますとも。XHTMLなら、ね、ValidなXHTMLならね。世の中のXHTML詐称の99.99%がそのまま解析出来るわけがなく普通に落ちてくれるので、XDocumentにそのまま流しこむことは出来ないわけです(もちろん、うちのサイトも詐称ですよ!ていうかこのサイトのHTMLは酷すぎるのでそのうち何とかしたい……)。
そこでHtmlを整形してXmlに変換するツールの出番なわけですが、まず名前が上がるのがTidy、の.NET移植であるTidy.NETで、これは論外。とにかく面倒くさい上に、パースしきれてなくてXDocumentに流すと平然と落ちたりする。おまけにXDocumentに入れるには文字列にしてから入れる必要があって二度手間感がある、などなど全くお薦めできません。XboxInfoTwitはTidy使ってますが、後悔してますよ……。
次にHtml Agility Packで、これは中々良いです。Linq to Xml風で大変使いやすい。のですが、あくまで風味であって、なんで本物のLinq to Xmlが目の前にあるのに、それっぽく模したものを覚えなきゃいけないの?二度手間で面倒くさいよ。
そこで、第三の選択としてSGMLReaderを使うという方法を提案します。SGML Reader自体は古くからあるのですが、日本語での情報はあまりないみたいだしLinq to Xmlと組み合わせたスクレイピング用途、に至っては皆無のようなので、ここで紹介しましょう。とりあえず例を。
// たったこれだけのメソッドを用意しておけば
static XDocument ParseHtml(TextReader reader)
{
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower })
{
sgmlReader.InputStream = reader; // ↑の初期化子にくっつけても構いません
return XDocument.Load(sgmlReader);
}
}
static void Main(string[] args)
{
using (var stream = new WebClient().OpenRead("http://www.bing.com/search?cc=jp&q=linq"))
using (var sr = new StreamReader(stream, Encoding.UTF8))
{
var xml = ParseHtml(sr); // これだけでHtml to Xml完了。あとはLinq to Xmlで操作。
XNamespace ns = "http://www.w3.org/1999/xhtml";
foreach (var item in xml.Descendants(ns + "h3"))
{
Console.WriteLine(item.Value); // bingでlinqを検索した結果のタイトルを列挙
}
}
}
見たとおり、信じられないほど簡単です。SgmlReaderはXmlReaderを継承しているため、XDocument.Load(xmlReader)にそのまま流し込めます。また、SgmlReader自体もDocTypeとInputStreamを設定するだけという超簡単設計になっているため、楽にHtml to Xmlが実現。HtmlはXDocumentになってしまえさえすれば、あとは慣れ親しんだLinq to Xmlの操作で抽出していけます。
例では、BingでLinqを検索した結果の検索結果見出し部分を抽出しています。見出しはh3で囲まれているので、Descendants(ns + "h3")。以上。超簡単。C#のスクレイピングの簡単さはRubyも超えたね!
残る問題は、日本語を扱う際はエンコーディング周りの設定が面倒くさい(間違ったエンコーディングだと文字化けする)、ということなのですが、そのWebClientのエンコーディング問題は、.NET Framework 4.0から修正された System.Net.WebClient は、HTTP ヘッダーから Encoding を自動的に認識してほしい | Microsoft Connect らしいです。素晴らしい!提案して頂いたbiacさんに感謝。
追記(2014/3/26)
いつのバージョンからか、TimeoutでWebExceptionが出るようになってたかもしれません。これはdtdを読みに行こうとしているのが原因のようなので、 IgnoreDtd = true を足してやれば回避できます。
using (var sgmlReader = new SgmlReader { DocType = "HTML", CaseFolding = CaseFolding.ToLower, IgnoreDtd = true })
ということです。
追記(より簡単に)
上の記事を書いてから気づいたのですが、HrefプロパティにURLを指定するだけで、中でStream類を作って自動的にHtmlだと判別してくれるようです。更には、エンコーディングもContentTypeを見て自動調整してくれます(詳しくはSgmlParser.csのOpenメソッドを参照)。よって、もっとずっと簡単に書けます。
static void Main(string[] args)
{
XDocument xml;
using (var sgml = new SgmlReader() { Href = "http://www.xbox.com/ja-JP/games/calendar.aspx" })
{
xml = XDocument.Load(sgml); // たった3行でHtml to Xml
}
// Xboxの発売スケジュールからタイトルと発売日を抜き出してみる
var ns = xml.Root.Name.Namespace;
var query = xml.Descendants(ns + "table")
.Last()
.Descendants(ns + "tr")
.Skip(1) // テーブル一行目は項目説明なので飛ばす
.Select(e => e.Elements(ns + "td").ToList())
.Select(es => new
{
Title = es.First().Value,
ReleaseDate = es.Last().Value
});
// 書き出し
foreach (var item in query)
{
Console.WriteLine(item.Title + " - " + item.ReleaseDate);
}
}
usingの辺りが若干鬱陶しいので、最初の例のようにメソッドに切り出してもいいかもしれません(CaseFolding.ToLowerも付けたいし)。Loadし終わったらストリームはもう不要です。XDocumentはメモリ内に全部構築するタイプのもので、実質XmlDocument(DOMツリー)の代替となっています。抽出時のXml名前空間ですが、サイトによってついていたりついていなかったりするので、var ns = xml.Root.Name.Namespaceとしておくと、全てのサイトに対応出来ます。
抽出のテクニック
上の例は Xbox.com | Xbox ゲームソフト 発売スケジュールからタイトルと発売日を抽出するというものです。定期的にページを監視して、更新されたらTwitterに投稿するXbox発売予定BOTとか作れますね!Xmlで取れるAPIさえあれば……なんてことはなくなりました!これからは 全てのサイトが易々とスクレイピング可能な代物として浮き上がってきますな。
ただし、元がHTMLのものはAPIとして用意されているXMLと違って、抽出に優しくない構造をしています。 Descendants一発でOk、というわけにもいかないので若干の慣れは必要かもしれません。今回の例の抽出コードが何やってるかよくわからない、という人はHTMLソースと見比べてみてください。目的のTableに辿り着くにも、いくつかの方法があります。決め打ち成分が入ってしまうのはどうにもならないのですが、何を決め打ちにするのがスッキリ書けるのか、となると色々です。今回はTableがLastである、という点を使いましたが、他の方法を考えてみると
var case2 = xml.Descendants(ns + "div")
.Where(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1")
.SelectMany(e => e.Descendants(ns + "tr"));
var case3 = xml.Descendants(ns + "table")
.First(x => x.Ancestors().Any(e => e.Attribute("class") != null && e.Attribute("class").Value == "XbcWpFreeForm1"))
.Descendants(ns + "tr");
目的のTableを囲むdivのclassが XbcWpFreeForm1であり、XbcWpFreeForm1が適用されているdivは一つしかない、ということに着目するとこうなります。case2は、divを全て列挙して探し出す方法。First(predicate)ではなくWhere.SelectManyにすることで、目的のTableが複数個ある場合でも対応出来ます。case3はTableに絞った上で、そのTableの上位階層(Ancestors)にXbcWpFreeForm1が含まれるかを探し当てる方法。Last、という決め打ちが難しい(場合により変動するケース)場合には有効でしょう。この、上位階層(Ancestors)や下位階層(Descendants)の要素に特異な要素はないか(Any)、と探す手法は、ターゲット自体に特徴がなく抽出し難い場合に活用出来ます。
そもそもDescendantsなんて富豪すぎて許せん、実行効率命!という人はElement("body").Element("div")....とトップから掘っていってもいいわけですが、さすがにElementの連続はダルいのでXPathを使うのもよいでしょう。Linq to XmlでのXPathの利用法は、以前neue cc - そしてXPathに戻るに書きました。XPathは、複雑なことを書こうとすると暗号めいた感じになるから余りすきじゃないですね。私は多少冗長なぐらいでもLinqで書くのが好きだなあ。
何故C#には(Javaの)Collections.sortに相当するものがないのか
- 2010-02-25
Java は Collections.sort があるのに .NET は List 自身が Sort メソッドを持っているのはなぜ?
だそうです。あまり疑問でもないです。だってIListはSortないし。比較するならIList - ListでありList
そして何故かスレッドの話は迷走していて不思議。パフォーマンス? んー……。勝手な印象論ですみませんが、1さん(名前を出すのもアレなので1さん、ということにさせてください)はJavaのCollections.sortの性能を勘違いしているんじゃないかな? 配列のコピーを問題にしてるようだけど、Javaの方式はコピー、してますよ。もっとも最初の方の発言(効率は重要じゃない)と後ろの発言(コピーが嫌)が矛盾していますが。ともかく、実際のSunの実装を見てみましょう。
public static <T extends Comparable<? super T>> void sort(List<T> list) {
Object[] a = list.toArray();
Arrays.sort(a);
ListIterator<T> i = list.listIterator();
for (int j=0; j<a.length; j++) {
i.next();
i.set((T)a[j]);
}
}
toArrayしてコピー。それをsortして、forで詰め替え。C#で同じような外部Sort関数を書くのならば以下のようになります。厳密には違いますが、それは最後に述べます。
static void Sort<T>(IList<T> list)
{
T[] array = new T[list.Count];
list.CopyTo(array, 0);
Array.Sort(array); // List<T>のSortもArray.Sortを利用しています
for (int i = 0; i < array.Length; i++)
{
list[i] = array[i];
}
}
forで詰め替えている様は、マジマジと見ると微妙。実際、このコードには問題があります。クイズだと思って、どこが問題なのか考えてみてください、答えは最後に述べます。
List<T>のSortは、内部に配列を持っているため、CopyToとforでの詰め替えが不要です。パフォーマンスで言えば理想的な形になっているわけです。 ゲッタとセッタ経由でソートの入れ替えすればいいぢゃん、というのはそうですね、違います。配列のほうが速いし!というのもそうでしょうが、それ以前にListインターフェイスの実装は自由です。例えばLinkedListのゲッタを考えてみたらどうでしょう。getの度に前(もしくは後ろ)から走査があるため、パフォーマンスが悲惨な事になるのは容易に想像出来ます。ListはArrayListだけじゃないので、ゲッタ/セッタに頼るのは無理がある。汎用的に、Listインターフェイスならば何でも受け入れるという設計にする以上、コピーを作るのは不可避です。
というわけで、パフォーマンス云々を言うならば、内部を知っているListクラスがSortを持つのはベストな選択でしょう。そして利便性を考えてもベストな選択。ならばいったい何処に不満があるのでしょうか?
Javaのほうが優れているのは、「自前でIListを実装したクラス」を破壊的ソートするのに、クラスにSortメソッドを用意したくない。といったところでしょうか。Sortの実装自体は通常はArray.Sortを呼ぶだけなので簡単なので別に手間でもないのですけどね……。というか、この手の基本アルゴリズムを自前実装したのを使うのは悪です(勉強用に、なら当然すべきで悪なのは自前実装の妄信です)。
ようするところ、Sortメソッドを自前で用意したくないけど破壊的ソートが欲しい、ということになる。ふーむ、個人的にはなくてもいいかな。非破壊的なソートがLinqのOrderByを使うことで可能なので、破壊的のほうを欲しいとはあまり思わない。
ListIterator
では本題。何でC#には破壊的ソートをしてくれる外部関数がないの?というと、インターフェイスの都合上、不可能だから。が理由だと私は考えています(そもそも必要性薄いから、が最大の理由だと思いますがそれはそれとして)。Javaのsortと私の書いたC#のSortを見比べてください。大きな違いがあります。それは、forでソートした配列をリストに詰め直している部分。
i.set((T)a[j]); // Java
list[i] = array[i]; // C#
C#の場合、listがLinkedListのようなものだった場合は悲惨なことになります。それに比べて、JavaではListIteratorを用いているため、配列と同じ処理効率で値をセット出来ます。C#には、このJavaのListIteratorに相当するものがないので、全てのIListに対して問題なく性能を発揮する破壊的ソート関数を作成することは不可能です。
「LinkedListのようなもの」という歯切れの悪い言い方をしたのは、.NETのLinkedList
ただ、IListのインデクサは取得にコストがかからないことを期待、してもいいとは思います。そんなのを一々気にしてたら何も作れない。それにちゃんと、.NETのLinkedListはIListじゃないしね。ね。というわけで上のほうで出したクイズは、問題があるかないかは何とも言えない微妙ラインです。んーと、つまりはfor(int i;i < hoge.length(); i++)の問題点はどこだー!みたいな話で、基本的にはhoge.length()なんてコストがかからないのを期待して問題ないし、コストがかかるんならそのクソクラスが悪い、みたいな。
ついでに個人的な意見ですがListインターフェイスにListIteratorはそこまで必要ではない。普通のIteratorと機能がかなり被る割には、使う機会はとても少ない。おまけに、ListIteratorのsetってoptionalで、実装されていることが保証されてない。この手の、実装しなくてもいいインターフェイスって撲滅した方がいいと思うんですけどねー。私は怖くて呼べません。
とはいえ、保証されないインターフェイスを完全に撲滅など出来はしません。例えばList(Java)/IList(C#)のAddは実行出来ることが保証されていない。JavaならArrays.asList(1, 2, 3).add(4)を、C#なら(array as IList
まとまってませんが、結論としては疑問に思ったらソース読むのが手っ取り早い、とかそんなところで。Javaの良いところはC#に比べてフレームワークのコードへのアクセスが簡単なところですね。C#は部分的にはコードは公開されていて大変タメになるのですが、色々と面倒くさいし、公開されてない範囲も少なくないし……。.NET Reflectorのお世話になりまくってイリーガルな気分を味わうのはもう嫌ぽ。嘘。リフレクタ大好きですがそれはそれ。
Re:Scheduled
- 2010-02-18
Windows7杯では、無事グランプリを逃して部門賞に落ち着いたりした昨今ですがこんばんわ。長らくBlog放置、ついでにゲームも放置中という有様なので、改めてスケジュールを考えなおさないとな、というところに来てたりします。今年はまずはlinq.jsのWSH対応をやるぞ!とか言ってた気がしますがちっともやってませんし。で、代わりに何をやっているかというと、何故かここ一ヶ月は延々とLinqのJava移植をやっていたりします。どうしてこうなった……。予定なんて立てるだけ無駄ってことですな。
そんなわけで、今週中、無理でも来週中にはリリースするつもり、です。もう実装は出来上がっているのですがテストを一切書いてないので、テスト書きとJavaDoc書きと、あと事前条件の例外送出(これも一切書いてない)が残っているので、やらないといけない。実装はやる気満々にノリノリで書けたんですが、残ったこれらをやるのはモチベーションが全然上がらない。ダルぃ。シュタゲやりたい(やれよ)
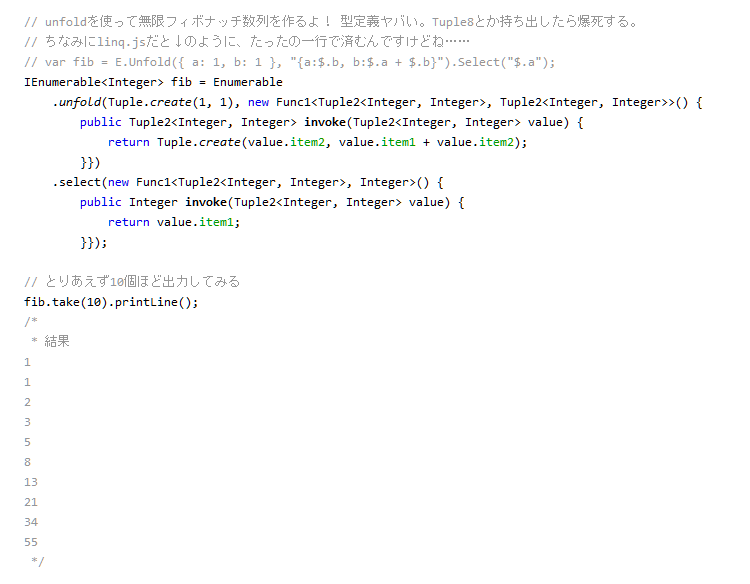
進捗は例によってneuecc on Twitterでgyazoで画像張りながら、Javaに文句つけながらやってます。スタンダードにwhere-selectとか(NetBeansの赤線は解決しました)、正規表現がスッキリ!とかは、まぁまぁ悪くないと思うのですが、左外部結合で記述がカオスなどは何とも言えないネタ感が。作者の私がメソッドのシグネチャを合わせられなくて苦労したぐらいなので、一体誰が使えるんだよ、という。Join系は鬼門です。あと、匿名型の代わりにTupleを使うのですが、型定義が地獄になるのもねえ。 定番の無限フィボナッチなんかも書いたけど、Tupleの型定義のクドささえなければ見れるのだけど、現状だと少し厳しい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
// static importと合わせるとLLっぽく見えて素敵、的な何か
for (int i : range(5, 10)) {
System.out.println(i);
}
// 10以上のもののうち重複なしで二倍にしてリストに格納する的な何か
int[] array = {3, 13, 51, 2, 1, 51, 67, 32, 13, 9};
ArrayList<Integer> list = Enumerable.from(array)
.where(Predicates.greaterEqual(10))
.distinct()
.select(Functions.multiply(2))
.toList(); // [26,102,134,64]
Java7のクロージャと型推論に期待しつつ、今のうちに出来ることはやっておく、的な何か。期待しないで期待して待っててください。多分、思われているよりかはマトモに使える代物だと思います。移植なんて誰もが考えるし、LinqのJava実装なんて当然幾つかあるんですが、どれも全然徹底してない(中途半端にSQLには対応してる)ので、今一つなんですね(JavaScriptの時も同じこと思ったわけだけど……)。ひたすら愚直にLinq to Objectsだけを忠実移植したものは初になると思います。いやまあ、何で誰もやらないかっていうと誰得としか言いようがないから、ってのもありますが。私は、割と普通なLinq好きーなのでそんなのちっとも気にしない!
標準Linq以外のメソッド類はlinq.jsにあるのは大体入れた。linq.jsのRangeDownToはアホだったので削った。RangeTo(0,-10)でいいわけですよね、Toなのだから。DownToとかアホすぎた、といったような反省も若干活かしてます。それとRxのCatchとかFinallyも入れた。良さそうなのは何でもいれますよー。というわけでもないのですけどね、ちょっと便利、程度だと躊躇います。入力補完に大量にメソッドが出るってのはあんまり嬉しいものでもないですから、なるべく厳選して。
デスクトップヒストリー
- 2010-02-07
以前に応募した、Windows 7杯 自作PCの祭典 2009ですが、部門賞「勝手にオレが一番!部門」で無事受賞することが出来ました。部門賞の5台の中から、一般投票でグランプリを決めるので、是非とも私に投票してやってくださいー。あと2/13に秋葉原のリナカフェで当日一般投票&結果発表があるそうなので、そちらも是非どうぞ。あ、私の応募記事ですが→neue cc - デスクトップシアター for Windows 7杯になります。発表会場ではパネルに写真を飾るそうなので、もう少し良い写真を撮っておけば良かったなあ。昔は壁紙を揃えたりカッコつけた照明にしたりしてたんですが、今回は応募締め切りギリギリで必死に写真撮って記事書いて、ってやってたので余裕がありませんでした。若干後悔。
私的には、定格パフォーマンス部門の人のLevel 10が自作PC本体の魅力としてはカッコイイ!ですね。写真の構図が憎い。 あと、バカPC部門の冷蔵庫PCはナイスですな。リザーブタンク=ペットボトルは最高のアイディアだと思います。それにしても、かなり大掛かりに加工してあって、凄いなあ。まさに自作PC、という凄さでは一番ですね。他は、んー、特別賞のマルチタッチ賞が該当なしなのはしょうがないかな。Windows7杯なので、Win7の追加機能であるマルチタッチを!というのは分からないでもないけれど、自作PCでマルチタッチを生かすっていうのは難しいよ。一体何をどうすればいいんだ、という。
写真で振り返る机上写真の歴史
写真が残ってなかったりするのがあるのが悔しいなあ。とか思いつつも、残ってるものを探してきました。ローカルHDDに見つからなくても、Web上に残ってたりして助かりました。やっててよかったWebサイト。といっても、やはり残ってないのも多いのね。残念。

2002年です。VAIOなので自作PCじゃないよ! これは何と言うか、懐かしいね。非常に懐かしい。CRTモニタはともかく、MDデッキとかMIDI音源(YAMAHAのMU2000)とかポータブルCDプレイヤーとか、今じゃあすっかり廃れたものが映っていて泣ける。マウスはIntelliMouse Explorerの、たぶん初代かな。

飛んで2006年です。4年も飛んじゃうのが痛い、こうなるまでにも過程があったんですが……。2002年の写真を見て思いっきり懐かしめたので、もっと残ってると良かったのだけど。既にXbox360だものねえ(画面のものはPGR3)。時代飛びすぎ。この頃はCRT信者でモニタを22インチCRETにしてトランスコーダーで写していましたね。液晶なんて残像!残像!あんなもんクソだ使えねー。CRT解像度最強だし。とか言ってた気がしますが、なかったことにしましょう。ちなみに2chスピーカーはこの頃のほうが良いの使ってました。PIEGAのアルミニュウム筐体のスピーカーでして、音もデザインもとても気に入ってました。サラウンド環境は7.1ch。マウスはMX1000かな、これは。多ボタンマウス信者の始まりである。

2007年の8月。いつのまにやら全モニターが液晶になってる。やっぱ液晶だとスタイリッシュな感じになりますなー。大きさは全部WUXGA(1920x1200)。サラウンドは、センタースピーカーなしの6.1chという若干変則的な形を取っていました。デスクトップシアターだとセンタースピーカーの置き場に困るんですよねー。この問題を解決させられなくてずーっと悩んでいました。ま、この頃はセンタースピーカーは左右スピーカーの中央で聞けるのならなくても問題ない。一人で椅子に座って聞くデスクトップシアターではファントム再生(左右のスピーカーでセンタースピーカーの音を仮想的に作る)でも問題ない。むしろ、そのほうが音の統一感が出ていい。とか言っていましたが、なかったことにしましょう。マウスは恐らくMX-R。キーボードはHappyHackingKeyboardですなー。デザインは最高に好き。でも、今は日本語配列のRealForceになりました。

2007年の11月。これはデスクトップシアターの薦めという記事で書いた時のもの。スピーカーを小型スピーカーに変更したことで、9.1ch環境になりました。スペース的にも大型スピーカーを廃したことで余裕が出て正解だったと思っています。センタースピーカーも、(モニタ土台のほうの)デスク下に配置することで解決。PIEGAのスピーカーとの決別と、それによる2ch再生力の低下に悩んだんですが、それは今ではSTAXで聴くからいいもん、という方向で解決(?)しました。

2008年の11月。こりゃまたえらく簡素になったねー、というわけですが、これは引越しして一人暮らしを始めた時の写真です。モニタとかデュアルでいいっすよ、とか思って色々と整理したはずなんですが、やっぱりデュアルでは不満になったので結局、買い揃えていくことになったという。なんだかなー。ともかく、新生活のフレッシュさを感じたり感じなかったりして、ちょっと思い出深い。涙ちょちょぎれます。で、まあ、私は家にいる時は、このデスク左にちょっと映ってるベッドで寝てるか、椅子に座ってるかの二択しかありません。NEETになりたいなあ。職場なんて行きたくないでござる。

2009年の2月。これはneue cc - 解像度6000オーバーという記事で書いたもので、メインモニタがついに30インチになりました記念。メインモニタとあわせて左右のモニタも新調しました。ちなみに、せっかくの縦回転ですが、今の環境だと縦が塞がっているので出来ないんですよねえ……。トレードオフといえばそうなのですけど、この頃がちょっと懐かしい。

2010年の1月。これがneue cc - デスクトップシアター for Windows 7杯の写真で、今の環境です。9.1chなのですが、AVアンプを変えたので全方位を横一列に取り囲んでの9.1chじゃなくて、フロント上部に2台設置しての9.1chという環境に変わりました。このハイトスピーカーの置き方は最近出たドルビープロロジックIIzという規格によるもので、徐々に増えて行くんじゃないかと思っています。まあ、あとは再びクアドラプルモディスプレイ環境に戻ったり、ノートPCがあるから5画面だよ、といった感じであったり、今までの集大成的なものになっています。
といったわけで、駆け足で振り返ってみました。やっぱ2002-2006の間の写真がないのが痛い。絶対後悔するので、写真はちゃんと残しておきましょう、まる。ブログにアップしておけば、サルベージも容易でいいね!ていうか、実際2002年の写真以外はローカルに残ってなくて全部ウェブから引っ張ってきたのですが……。やっててよかったWebサイト。あと、写真がちっとも上達しないのが酷い。むむむ。
AnonymousComparer - ver.1.2.0.0
- 2010-02-04
AnonymousComparerを再度バージョンアップしました。ダウンロードは上記リンク先、CodePlexからどうぞ。バグがなければ、これで最後だと思います。いやもう内容的には出尽くしたかな、と。更新内容はIComparer<T>を作成可能にしました。また、OrderByでIComparer<T>を利用するものへ、拡張メソッドを追加しました。
// こんなシーケンスがあるとして、IComparer<T>を使用してその場で自由に比較を指定したい
var seq = new[] { 1, 2, 3 };
// IComparer<T>を作る
var comparer = AnonymousComparer.Create<int>((x, y) => y - x);
seq.OrderBy(x => x, comparer);
// OrderBy/ThenByに拡張メソッドが追加されているので、型推論が効いたまま書けます
// List.Sort(Comparison)みたいなイメージですかね
seq.OrderBy(x => x, (x, y) => y - x); // 3, 2, 1
seq.OrderByDescending(x => x, (x, y) => y - x); // 1, 2, 3
LinqにはDescendingが用意されているので、あまり使い道はなさそうですね。私もOrderByのICompare<T>オーバーロードを使いたいと思ったシチュエーションが今までにありませんし……。第一引数がkeySelectorなので、それで十分用を足せちゃうのですよね。それにしても、DescendingでIComparerを指定した場合の結果は紛らわしくていかんですな。
さて、更新内容はもう一つあって、むしろこっちのほうが重要なのですが、compareKeySelectorを利用したオーバーロード(Linq演算子への拡張メソッドは全部それです)で、シーケンスにnullが含まれている場合にnullで落ちるのを修正しました。今回からはヌルぽで落ちません。どういうこっちゃ、というと説明しづらいのでコードで。
class MyClass
{
public int MyProperty { get; set; }
public override string ToString()
{
return "Prop = " + MyProperty;
}
}
static void Main()
{
var array = new[]
{
new MyClass{MyProperty=1},
null,
new MyClass{MyProperty=2},
null,
new MyClass{MyProperty=1}
};
var r1 = array.Count(); // 5
var r2 = array.Distinct().Count(); // 4 (nullが重複として消える)
foreach (var item in array.Distinct(mc => mc.MyProperty))
{
Console.WriteLine((item == null) ? "ヌルぽ" : item.ToString());
}
// 出力結果は
// Prop = 1
// ヌルぽ
// Prop = 2
}
といった感じです。分かったような分からないような?
ver.2.1.0.1
- 2010-01-28
Jewel Questで「未知のエラー」が発生する件を修正しました。言い訳がましいですが、これXbox.comのバグですよ! Netflixの時もなんじゃこりゃ、と思ったんですが、今回は"Insert translated text here"です。明らかにオイオイオイオイしっかりやれよ、って感じにアレなメッセージが浮かび上がってます。

こんなのがステータス画面のソースを開くと確認出来ます。いやまあ、だから何だって話ではあるのですけど。イレギュラーなことやってるのはコッチですからね……。
さて、ところで今回の不具合は1月上旬に報告を貰ったのに対処したのが1月ギリギリってどういうことよ、すみません本当にゴメンナサイ。不具合情報の報告は大変ありがたいのですけど、ちゃんとそのありがたさに応えなきゃダメですね、私。特に今回は確認も修正も全く難しくないところなので、しっかりしろよ、というお話でして。今後はしっかり対応していきます。
ただ、既知の不具合である、一部の人がログイン段階でコケるという件は全く手付かずです。いやー、自分のとこに環境ないとさっぱり分からん。あ、あとカルドセプトでステータスが反映されない件も放置中です、すみません。気が向いたら、というかソフト入手したらそのうち……。
AnonymousComparer - ver.1.1.0.0
- 2010-01-26
AnonymousComparerをバージョンアップしました。ダウンロードは上記リンク先、CodePlexからどうぞ。更新内容はCreateのオーバーロードに追加して、IEqualityComparerの完全模写を可能にしました。今まではキー選択だけだったのですが、今回からはEqualsとGetHashCodeを個別に指定することが可能です。
var myClassComparer = AnonymousComparer.Create<MyClass>(
(x, y) => x.MyProperty == y.MyProperty, // Equals
obj => obj.MyProperty.GetHashCode()); // GetHashCode
こんな感じに指定します。全くもってそのままです。Equalsとかをラムダ式で指定するというだけです。型推論は効きませんので指定してやってください。なお、使い方自体は全然変わってませんので、普通の使い方は初回リリース時の記事を参照ください。
以下オマケ。
// ランダムでtrueかfalse返すComparer
var rand = new Random();
var randomComparer = AnonymousComparer.Create<MyClass>(
(_, __) => rand.Next(0, 2) == 0, _ => 0);
// 間引くのに使えるぜ!
var mabiita = list.Distinct(randomComparer).ToArray();
// とか思ったけど、最初の一つ目は必ず選択されるのよね(Distinctなので当然……)
// といった、特殊な間引き方をしたい人はどうぞ(いません)
// 普通にやるならWhereでランダムにフィルタリングするのを選びます
色々と用途が考えられるようで、そもそもEqualityComparer自体があまり使う状況ってないので、使い道が考えられない微妙な感じが素敵です。まあ、AnonymousComparer自体はふつーに使う分にはふつーに便利ですので、Linqのお供にどうぞ。もう一つ、今度は役に立つ例でも。
class MyClass
{
public int Prop1 { get; set; }
public string Prop2 { get; set; }
public string Prop3 { get; set; }
}
static void Main()
{
var array = new[]
{
new MyClass{Prop1=30, Prop2="hoge", Prop3="huga"},
new MyClass{Prop1=100, Prop2="foo", Prop3="bar"},
new MyClass{Prop1=100, Prop2="hoge", Prop3="mos"},
new MyClass{Prop1=30, Prop2="hoge", Prop3="mos"}
};
// Prop1とProp2が一致するのだけ省きたい!といった複数キー指定は匿名型を作る
array.Distinct(mc => new { mc.Prop1, mc.Prop2 });
}
複数キーで比較したい時は、匿名型を作るのが手っ取り早いです。こういった用途に匿名型を使うというテクニックは、Linqの他のところでも結構出てくるので覚えておくと便利です。富豪的?気にしない気にしない。
日常雑話
- 2010-01-24
扁桃炎で水曜日にダウンしてから(扁桃炎って40度も熱出るんだねー、インフルエンザかと思っちゃったよ)本当にダウンしっぱなしで、ここ数日は寝て薬飲んで寝るだけの最低最悪でした。今も全然治ってないので最悪です。そんな時でも人は働かなきゃ行けないんですね、社畜! NEETになりたいよう。さて、そんなわけなのですが、そろそろやることがいっぱいつまってきてしまっているので整理します。だらだら生きてるとだらだらネット見てTwitterやって過ごすだけになってしまうのです。それは私です。
- XboxInfoTwitでJewel Questをプレイ中の人がいると「未知のエラー」で死ぬ件を修正する
これは原因まで掴めているし、そもそもこの件については、わざわざ教えてもらったというのに半月スルーしていたという最低な有様なのでとっとと直しなさい、という話なので直します。体調が悪い時にやるとポカミスやりそうなので、体調治ったら真っ先にアップデートかけますので。
- OS再インストールする
物凄くグチャグチャなので、ずーっと再インストールしようと思っていたのですが延ばし延ばしにしすぎました。どうでもいい話なのですけど、とっととする、とここに書けばいい加減にやる気を出す気がしてきました。気のせいです。
- Rxの記事書く
ネタは結構いっぱいあるのですが、Forumが活況すぎてそっち追うのにいっぱいいっぱい。あとRx自体が実に難しくて、私の能力的に結構いっぱいいっぱいです。あと英語のせいで脳みそが知恵熱でオーバーヒートしてます。私のTOEICのスコア舐めるなよ(受けた事ないので知らないけど、多分想像を絶するほど低い)。扁桃炎になったのもそれのせい(違)。とりあえず、近いうちにIObservableの連鎖についてきっちり書きたいと思ってます。
- Ajax MinifierにGUIつけたの作る
Ajax Minifierとかみんな憶えてないでしょ。便利なMS製のJavaScript圧縮/解析ソフトです。CUIのみなのでGUIを提供したいと思ったのです。半分作ってあって、一応動くのはあります。ただ全然GUIになってません。Ajax Minifierが告知されてすぐに作り出して、そしてすぐに放置したというダメ人間。完成させたいです。GoogleがClosure Toolsとか出しちゃったしもういっかー、とか思ってません。Microsoft大好きっ子なのでAjax Minifier使うぜ。ていうかネーミングが悪いよね。Ajaxあんま関係ないし。
- linq.js WSH拡張作る
作る。作る。本気本気。もう1月も終わりそうなのに何も手をつけてないけど本気。
- プログラミングHaskell読む
F#の本がamazonから届いてしまう前に読む(笑) ちなみに積み本はいっぱいあって、どうしたものかなー、って感じですねえ。レガシーコード改善ガイドとリファクタリングとEffective C#と初めてのRubyと、まあ、そんなのを積んでます。そんな量でもないか。まあとにかく、積み本は良くないのでちゃんと読めって話ですな。
- シュタインズゲートをプレイする
- アサシンクリード2クリアする
シュタゲ未プレイなのが許されるのは(ry それにしても最近積みゲー多すぎですね。ゲームへの欲望ってのは本当に確実になくなってますねえ。そんなにC#楽しいか!って話なのですが。C#楽しいよLinq可愛いよハァハァ。それがいいのか悪いのかはなんとも言えないですけど、ただでさえ視野狭窄な私なので、ゲームからインスピレーションを受けないと感性が完全に死ぬので切らしたくはないですねぇ。今後はバイオショック2とガクブル島(OBLIVION)とスプセルコンヴィクションかな、手を出すのは。XBLAのDarwinia+は出たら買うと思う。まさかNAIJはないでしょう……。オフィシャルで動画見れます→Darwinia+ Promotional Trailer Streaming。良い感じ。
と
いうわけでどうでもいいTODO?の列挙でした。もう少し先の方を見ると、一応コレ作りたいとかアレ作りたいとかいう計画もあるんですが、少しも手をつけてないうちは妄想でしかないので、現実的な目の前の課題をちゃんと片付けてから夢見なさい、ですね。薬飲んでも続く微熱と下痢が治ってくれさえすれば――。TODOを消化出来る、なんてことはないんですが、ここ数日の人生死んだ感がヤヴァかったので、ちょっとは心入れ替えてやるんじゃないかと思われます。
人生死んだ感が発生すると、何か美味しいものが食べたくなって、食べログで近場の店を漁るなどしてしまうのだけど、一人じゃ入れないな、しょぼーん。となるなど。そんな時は「孤独のグルメ」を胸に……。いや、ランチと夜は違うじゃないですか。考えてみると孤独のグルメはお昼が多かったような。とりあえず今は美味しいビーフシチューが食べたい気分なので夜に一人で言っても平気な感じにコースじゃなくてビーフシチューだけ食べて帰れるような店(そんな都合のいい店などない)を探すという無駄に時間費やしてます。寝ろ。
デスクトップシアター for Windows 7杯
- 2010-01-15

Windows 7杯 自作PCの祭典 2009応募の記事です。
応募対象は「勝手にオレが1番! 部門」で、コンセプトは「デスクトップシアター」。机周りと一台のPCに全ての機能を集約させることで、椅子から一歩も動くことなくゲーム、映画、インターネット、プログラミングなどあらゆることを快適に行うという引きこもり推奨システムです。実際、私は寝るとき以外は常に椅子の上にいます。
個室やワンルームの狭い空間を有効活用する、という点でもPCに全てを集約させるというのは合理的判断だと思います。その狭い部屋にテレビを入れる必要はあるのか?ディスプレイで全部まかなえばいいじゃない、ノートPCなんて捨てろ! 自作PCを組め!
最近では1920x1080のマルチメディア用途を狙った(ただのコスト削減流用という話でもある)16:9 HD液晶も数多いので、別に珍しいスタイルではないのですが、デスクトップシアターはただたんに表示させるだけ、ただたんに集約させただけではありません。スペースがないから妥協して集約させたのではなく、集約させたが故のメリットをハードウェア・ソフトウェア両面から徹底的に追求しました。
なお、画像はクリックすると原寸写真に遷移します。
構成パーツ
CPU : Intel Core i7 920
マザーボード : Asus P6T
メモリ : Corsair TR3X6G1600C8 2GB x 6
ビデオカード(メイン) : ELSA GLADIAC GTX 260 896MB(NVIDIA GeForce GTX 260)
ビデオカード(サブ) : LEADTEC WinFast PX8400 GS TDH Silent(NVIDIA GeForce 8400 GS)
SSD(メイン) : Intel SSDSA2MH08 X25-M 80GB x2 (RAID 0)
HDD(サブ) : SEAGATE ST31500341AS (1.5TB SATA300 7200) x2 (RAID 0)
光学ドライブ : Pioneer BD-ROM BDC-202
CPUクーラー : サイズ MUGEN∞2 無限2 SCMG-2100
ケース : CoolerMaster Sileo 500
電源 : CoolerMaster Silent Pro M600
センターモニタ : NEC LCD3090WQXi(BK)
サイドモニタ : SAMSUNG SyncMaster 2343BW x2
トップモニタ : DELL 2405FPW
HDMIキャプチャボード : Blackmagic Design: Intensity
AVアンプ : ONKYO TX-NA1007(B)
スピーカー : ECLIPSE TD307II x9
サブウーファー : ECLIPSE 316SW
Game Console:Xbox360 Elite
使用OS : Windows 7 Ultimate(64bit版)
PCケース内部

モノがある関係上、こんな角度からしか撮れなくてすみません。パーツよくわかりませんよね、これじゃあ。PC本体はあまり特筆すべき組み方でもなく、いたって普通です。メインドライブのSSDx2のRAID 0は体感ですら明らかに高速で非常に快適。プチフリ?そんなのありませんよ。みんなSSDにすればいいのさ。容量不足(160GB)は基本的にはそこまで深刻でもないのですが、HD動画キャプチャを行うので(主にXbox360の、1時間で数百GB行く)、大容量かつ高速なドライブが必要(未圧縮でキャプチャするため速度がないとコマ落ちします)。そのため、サブとして1.5TBのHDDをx2 RAID 0で用意。静音PCを狙ってHDDはスマートドライブに格納、また密閉度の高いケースを利用しました。CPU, Caseファンも平常時は低速回転させています。
かなり窒息度が高く、熱源も少なくないため温度モニタリングの状態は常に怪しげで不安度高し(平常時CPU温度55度前後)。そして絶望的な配線センス。次にPCを作るときは配線を魅せるようなのが作りたいかも。
PCケース外観

見た目はヘンテツもないわけで、実際のところ部屋の光の当たらない隅に置いてあるので、黒ければそれで良かったりします。なので、外観デザインは目立たないこと、ただそれだけを求めました。ついでに天板のサイズがぴったりだったので、ヘッドフォンアンプのSRM-600limitedを載せています。更にその上にオーディオインターフェイスとしてRME Fireface UCを設置。これは、明らかにオーバースペックでした。色々と反省。買う前は使いこなす構想があったのですが、今じゃあSTAXとAVアンプに音を送るだけの「聴き専」野郎ですよ! 許すまじ。時間に余裕ができたら、追々弄っていきたいです。
解説文

正面画像は一番上で使ったので、周囲を写して。4画面で9.1chサラウンドでXbox360しながらも同時に攻略サイトを見ながらTwitterに投稿しつつ動画キャプチャのモニタリングもしながらついでにUStreamで動画配信(以前にUstreamでFlash Media Encoderを使って高画質配信するためのまとめという記事を書いています)も出きれぅ(動画配信の状況は冒頭写真がそれです)。
やりすぎ。しかし圧倒的に便利。これこそ、まさに集約させたが故のメリットです。どれだけ過剰なやりすぎ要求にも答えてくれる、それが自作PC。
マルチメディア再生も当然、全てPCで行います。PCで動画を見ると解像度の差がTVで見るよりも、モロに出ますからね、持っててよかったBlu-rayドライブ。Xbox360好きーな私ですが、別にBlu-rayは否定しませんよ?(別にPS3も否定しませんが……買わないというだけで)。
DVDはTotal Media TheatreのSlimHDで再生しています。NVIDIA CUDAを利用した超解像による拡大処理で、Blu-rayに迫……りは全然しないのですが、まあ、何もしないスケーリング処理よりかは遥かにマシです。
音声はBD, DVD共に、PCではデコード処理は行わず生データのまま光出力でAVアンプに回してのサラウンド再生。ちなみに普通の2ch音楽の再生も、AVアンプでサラウンドエフェクトかけて聴いてたりします。音場がグッと広がって良いものです。普段はサラウンドで、しっかり聴きたいときはヘッドフォンで。そういう切り分けをすると、音楽がより楽しめます。
ベンチマーク
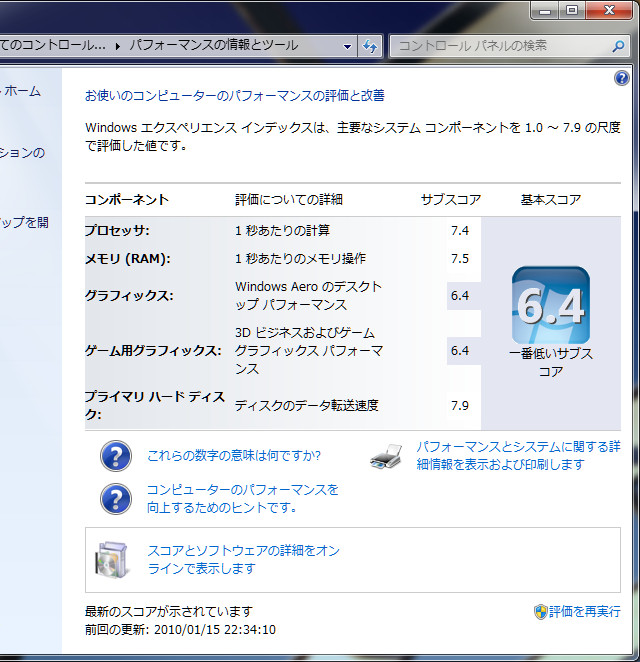
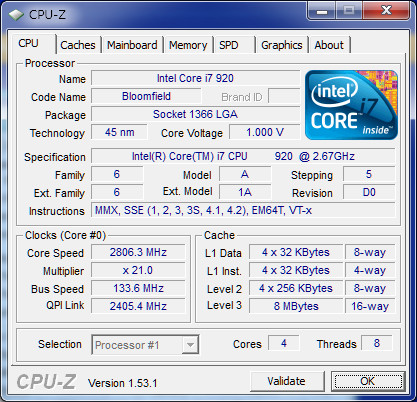
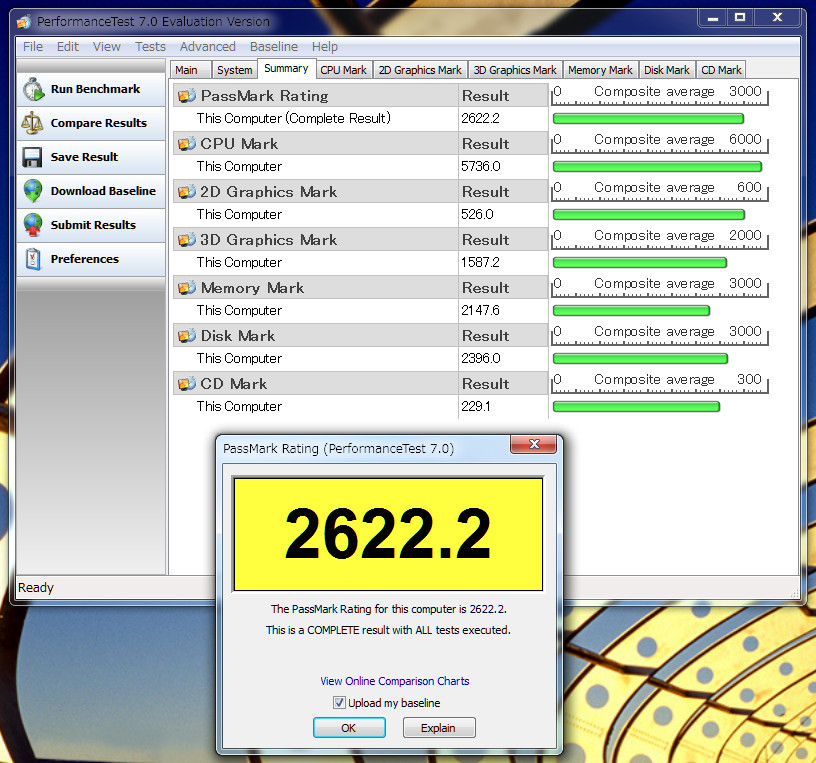

以上のようにコンテストの趣旨を履き違えたかのごとく、自作PC本体よりも周辺環境の拡充に力を注いでいるため、ベンチマーク結果はどうでもいいと思ってたりします。ただの飾りです。偉い人にはそれがわからんのです。
Windows 7を使って良かったと感じた点
いやー、いいOSですよ。画面綺麗だしメモリ大量に積めるし。メモリは7ではなく64bit OSの利点なわけですが。Win7は64bitのみの提供でも良かったんじゃないかしらん。ショートカットキーの充実(Winキー+矢印によるウィンドウサイズ変更とか)は最高に便利ですね!と、褒めたいのですが、この辺はAutoHotKeyによる自作スクリプトで解決していて使っていなかったり……。まあ、わざわざAutoHotKeyを導入しなくても使えるというのは良いことです。Windows標準搭載により、こういうことが出来ることの便利さが周知されるというのも素敵。この、偏狭のブログで幾ら布教させようとしても閑古鳥が泣くだけで虚しさがつどりますが、Microsoftが布教してくれたなら、それで満足です。さすがMicrosoft、(以下略)にしびれるあこがれるぅ。
あ、モニタの多さによるウィンドウ移動の大変さはAutoHotKeyの自作スクリプトで解決させました。 -> AutoHotKeyによるマウスカスタマイズとマルチディスプレイのためのスクリプト
デスクトップシアターはWindows OSとハードウェア(自作PC)とソフトウェアが全部噛みあってこそ成り立つもの。私はOSにもハードウェアにも貢献出来ませんが、一個人として、ソフトウェア側からの拡充に努めたいと思っています。AutoHotKeyスクリプトもそうだし、Xbox360の隣で常にPCが起動しているならPC側で、ネット経由でXbox360の状況をモニタリングすればいいぢゃない -> XboxInfoTwit とかもそう。
何にせよ、アホみたいに大量にソフトを起動してもメモリ余裕、OS大安定、動作軽快なわけでして、Windows 7の凄さ、良さというのを実感するところです。そういえば、Windows7といったらマルチタッチ対応も挙げられます。デスクトップシアターに有効活用できないかなあ、どうやったら上手く組み込めるかなあ、というのを考えています。まだまだ拡張の構想はあるので、来年は更にパワーアップしたもので応募してみたいですね!
更新履歴
2010/01/22 CPU-Zによるベンチマークの画像を張り忘れていました(画像自体のアップロードは行っていたのですがHTMLに張り忘れていた)。申し訳ありませんでした。
C#(.NET Framework)の文字列連結について
- 2010-01-07
一般に文字列を+=で連結するのは遅いと言われています。事実そのとおりで、多量の連結を+=で行うと死ぬほど時間がかかります。例えば、以下のようなコードで示されることが多いでしょう。
// ベンチマーク用関数(10万回実行)
Func<Action, TimeSpan> bench = action =>
{
var sw = Stopwatch.StartNew();
for (int i = 0; i < 100000; i++)
{
action();
}
return sw.Elapsed;
};
// StringBuilderの計測(最後のToStringを入れてませんが、あまり変わらないのでスルー)
var sb = new StringBuilder();
var sbTime = bench(() => sb.Append("hoge"));
// stringの+=での計測
var s = "";
var stringTime = bench(() => s += "hoge");
Console.WriteLine(sbTime); // 0.004sec
Console.WriteLine(stringTime); // 14.97sec
0.004secと15secでは話になりません(正確には、StringBuilderでは最後に文字列に変換するToStringを入れるべきですが、それでも1secは超えなくて差は歴然なので省略します)。ならば、文字列を連結する場合は、どのような時でもパフォーマンスのためにStringBuilderを使うべきでしょうか? 答えは違います。
// ILではひとつにまとまる
// IL_0001: ldstr "abcde"
var s = "a" + "b" + "c" + "d" + "e";
定数の連結はコンパイル時にひとまとめにされるので、StringBuilderを使うのは愚かな選択となります。この辺はILDASMで見ればわかるし、Reflectorでもひとまとめになって展開されているのが確認できます。では定数ではなく動的に値を返すものは?
static string Get()
{
return DateTime.Now.ToString();
}
static void Main(string[] args)
{
// IL_0031: call string [mscorlib]System.String::Concat(string[])
var s = Get() + Get() + Get() + Get() + Get();
}
ILを見ると、s += Get(); s += Get(); みたいな展開のされかたにはならず、String.Concat(string[])が呼ばれることになります。よって、速度を心配してStringBuilderを使う必要は全くありません。測定してみましょう。(ちなみにs+=Get()だとString.Concat(string,string)が大量に呼ばれることになるのが遅い理由)
// benchとGetは上で使ったのと同じものを流用
var sbTime = bench(() =>
{
var sb = new StringBuilder();
sb.Append(Get())
.Append(Get())
.Append(Get())
.Append(Get())
.Append(Get());
var s = sb.ToString();
});
var stringTime = bench(() =>
{
var s = Get() + Get() + Get() + Get() + Get();
});
Console.WriteLine(sbTime); // 0.65sec
Console.WriteLine(stringTime); // 0.64sec
速度はほとんど変わりません。StringBuilderとString.Concatでは処理の中身は結構違いますが、速度変わらないのならどっちでもいいよね。なら、記述しやすいほうを選ぶのが良いでしょう。妄信的にパフォーマンスのためにStringBuilder!とか思っている人は、少し考え直してみてください。そんなの当たり前だろ常識的に考えて、と思っていた時期が私にもありました……。世の中は存外StringBuilder神話に溢れているかもですよ? いやほんと。あとC#なら逐語的リテラル文字列もお忘れなく。